#destination file already exists wordpress
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has a 66 index score for customer satisfaction in the US.
Link
Get help for Plugin Installation, upload & uninstallation errors in your WordPress website. Call 8886061808 (US Toll free) to get urgent help for WordPress plugin issues.
#woocommerce installation failed#wordpress plugin install update failed#wordpress installation failed#destination file already exists wordpress#wordpress uninstall plugin hook#can't delete plugin wordpress#how to remove elementor from wordpress#delete wordpress plugin from cpanel#wordpress all plugins deactivated#how to activate wordpress plugin from cpanel#how to remove plugin from wordpress#uninstall wordpress plugin command line#Troubleshooting for wordpress plugin#wordpress plugin installation failed destination folder already exists
0 notes
Text
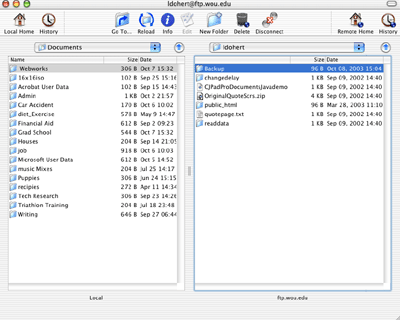
Ssh File Transfer For Mac

Mac Transfer To New Mac
Ssh File Transfer For Mac Os
Ssh File Transfer Mac To Linux
Secure Shell (SSH) is a cryptographic network protocol for operating network services securely over an unsecured network. Typical applications include remote command-line, login, and remote command execution, but any network service can be secured with SSH. SSH provides a secure channel over an unsecured network by using a client��server architecture, connecting an SSH client application. Mac Terminal SSH file transfer? Ask Question Asked 9 years, 1 month ago. Active 2 years, 8 months ago. Viewed 93k times 12. Is there a way to transfer files directly from a Mac to another using only Terminal? Perhaps using SSH? Mac ssh terminal. So far in this series of posts on ssh on macOS. Quick Introduction to ssh for Mac Admins; SSH Keys, Part 1: Host Verification; SSH Keys, Part 2: Client Verification; Transferring files with ssh (this post); SSH Tunnels (upcoming); Please consider supporting Scripting OS X by buying one of my books! In the previous posts we looked how to connect with ssh to a remote computer (host) and how to. WinSCP is a popular free SFTP and FTP client for Windows, a powerful file manager that will improve your productivity. It supports also Amazon S3, FTPS, SCP and WebDAV protocols. Power users can automate WinSCP using.NET assembly. It can act as a client for the SSH, Telnet, rlogin, and raw TCP computing protocols and as a serial console client. Version 0.63; WinSCP is a free open-source SFTP and FTP client for Windows. Its main function is to secure file transfer between a local and a remote computer. Beyond this, WinSCP offers scripting and basic file manager functionality.
Do you have a file on your Linux PC that needs to be transferred to your Linux server and you are not sure how to do this? This article teaches you how to copy files via SSH to your remote Linux server. It presents two methods for achieving this file transfer in a secure way. One based on the scp program and one based on the rsync program.
Background
Once you have your own Linux server up and running, you typically access it through SSH. SSH stands for Secure Socket Shell. SSH enables you to securely log in and access your Linux server over an unsecured network. Through SSH you can install, configure and update software on your Linux server, to name just a few common Linux server administration tasks.
While administering you Linux server, sooner or later you run into a situation where you have a file on your own Linux PC and you need to transfer this file to your Linux server. So you SSH-ed into your server and you are staring at your terminal screen, wondering how to go about this task. Unfortunately, you cannot directly transfer a file from your own PC to your remote Linux server through this active SSH terminal session. Luckily though, several methods exist that enable you to copy files via SSH. This article presents you with two of these methods. Namely, by using the scp and rsync programs.
System setup
A typical system setup consists of your Linux desktop PC, connected to your local network router, and a remote Linux server somewhere in the cloud. Instead of setting up a cloud server somewhere for this article (think Digital Ocean or Linode for example) , I decided on running a Linux server as a virtual machine (VM) on my laptop. Pes 2010 for mac os. Below you can find an illustration of the system setup:
My trusty Lenovo Thinkpad T450s serves as the Desktop PC. I run Debian 10 on this PC and its hostname is set to tinka. The Linux server VM also runs Debian 10 and its hostname is set to debianvm. I configured the same username on both the PC and the server. It is set to pragmalin. Refer to this article in case you would like to setup a similar Debian server as a virtual machine with VirtualBox.
Connecting to your server via SSH
While explaining the steps for copying files to the Debian server via SSH, I’ll occasionally SSH into the Debian server to verify that the files actually got transferred. Here follows a quick refresher that explains how you can log into your server via SSH.
The command from a Linux terminal on your PC to connect to your server is: ssh <username>@ip-address or ssh <username>@hostname. In my case the hostname of the Debian server VM is debianvm . My username on this server is set to pragmalin. This means that I can log into this server via SSH with the command:
ssh pragmalin@debianvm
To close the SSH connection, simply type the exit command:
SCP versus RSYNC
Before diving into the actual file copying via SSH, we should discuss the two commonly used programs for this, namely scp and rsync.
The SCP program
The scp program is a secure copy program. So basically a secure and remote version of the cp program that you locally use for copying files. Pretty much all Linux server distributions install the scp program by default, including Debian. Now, if the already installed scp program does all we need then why would we ever need another program for the same task? Read on and you’ll see that rsync does offer some benefits.
The RSYNC program
The rsync program is labeled as a fast, versatile and remote file-copying tool. But it is not just a plain file-copying tool. The rsync program features build-in synchronization functionality. This means that it only copies a file to the remote server if it is not already present. In contrast, the scp program blatantly overwrites the file. Furthermore, rsync can compress the files during the transfer. In other words, rsync is faster and uses less network bandwidth.
By default rsync does not communicate in a secure way. Luckily an easy fix exists for this. You can force rsync to use the SSH protocol by specifying the -e 'ssh' option when calling the program. Another minor disadvantage is that rsync is not installed by default on all Linux server distributions. Of course this is merely a one time inconvenience. You can simply install it with sudo apt install rsync. Just keep in mind that the rsync program needs to be installed on both sides. So both on your PC and your server.
When should you use scp and when rsync? They both work, so it partially comes down to personal preference. Personally, I use scp for small quick file transfers as its syntax strikes me as more intuitive. For large file transfers, I opt for rsync, because it is faster and uses less network bandwidth. For example when I need to restore a complete backup to one of my servers.

WordPress archive
For file copy via SSH testing purposes, this article uses the latest WordPress archive. WordPress is a hugely popular website content management system and runs on millions of websites, including the PragmaticLinux blog. We are not actually going to install WordPress, but just use the WordPress files for file copy example purposes.
Go ahead and download the latest WordPress archive from https://wordpress.org/latest.tar.gz. On my PC the file wordpress-5.4.2.tar.gz is now present in directory /home/pragmalin/Downloads/ Free mp3 to m4a converter for mac.
Copy a single file
Let’s start out with copying just a single file to the server via SSH. Open your terminal and go to the directory that holds to previously downloaded WordPress archive. Next, run either one of the following commands to copy the file to your remote server. Just replace the /home/pragmalin directory name with the name of your home directory on the server and replace the pragmalin@debianvm part with your username on the server and the hostname of the server, respectively:
scp wordpress-5.4.2.tar.gz pragmalin@debianvm:/home/pragmalin
rsync -e 'ssh' -avz wordpress-5.4.2.tar.gz pragmalin@debianvm:/home/pragmalin
If you now SSH into your server, you can verify the presence of the wordpress-5.4.2.tar.gz file in your user’s home directory. Both the scp and rsync commands have a similar structure. It is:
(COMMAND) (OPTIONAL ARGUMENTS) (SOURCE) (DESTINATION)
As you can see in this example, the scp program does not require any arguments. However, the rsync program does: -e 'ssh' -avz. For detailed information on the command options, you can refer to the program’s man-page. Alternatively, you can make use of the excellent explainshell.com website. Here are the links for an explanation of the previous two commands: scp and rsync.
Permissions
Note that you can only copy files to a directory where the username you specified has write permissions. That is the reason why I specified the home directory in this example. If you need to store the file in a directory where your user does not have write permissions, then you would have to connect to the server via SSH afterwards and move the file with the help of sudo mv.
Reverse transfer direction
You can copy the files via SSH in the other direction too. So from the server to your PC. You just need to swap the (SOURCE) and (DESTINATION) in the command. For example:
scp pragmalin@debianvm:/home/pragmalin/wordpress-5.4.2.tar.gz /home/pragmalin/Downloads
rsync -e 'ssh' -avz pragmalin@debianvm:/home/pragmalin/wordpress-5.4.2.tar.gz /home/pragmalin/Downloads
Copy all files in a directory
Another common operation is to copy all the files in a specific directory via SSH. We need a few files to try this out. Since we already downloaded the WordPress archive, we might all well extract its contents to get a bunch of files for testing purposes:
tar -xvf wordpress-5.4.2.tar.gz
The newly created wordpress subdirectory now holds the archive contents. To copy all the files in this directory to your remote server, run either one of the following commands. Just replace the /home/pragmalin directory name with the name of your home directory on the server and replace the pragmalin@debianvm part with your username on the server and the hostname of the server, respectively:
scp * pragmalin@debianvm:/home/pragmalin
rsync -e 'ssh' -avz --no-recursive * pragmalin@debianvm:/home/pragmalin
If you now SSH into your server, you can verify the presence of the files such as index.php, wp-config-sample.php, etc. in your user’s home directory.
Copy all files in a directory recursively
In the previous section just the files in a specific directory were copied. This did not include subdirectories. If you want to copy everything, so files and subdirectories, run either one of the following commands. Just replace the /home/pragmalin directory name with the name of your home directory on the server and replace the pragmalin@debianvm part with your username on the server and the hostname of the server, respectively:
scp -r * pragmalin@debianvm:/home/pragmalin
rsync -e 'ssh' -avz * pragmalin@debianvm:/home/pragmalin
The output of the command is a bit too long for a screenshot. However the following screenshot from the directory contents listing on the server show proof that the copy operation worked. You can verify the presence of the files such as index.php and wp-config-sample.php, but also all the directories such as wp-admin, wp-contents, etc. in your user’s home directory:
Wrap up
After working through this article, you now know about two programs (scp and rsync) that enable you to copy files via SSH. Both commands get the job done. The syntax of the rsync command is a bit more complicated so you might prefer scp. Keep in mind though that rsync uses less network bandwidth. As a result rsync is faster especially when transferring a large amount of data.
The syntax for both commands is not hard to understand. Nevertheless, it is complex enough that you probably won’t memorize them, unless used frequently. For this reason I recommend bookmarking this article. That way you can quickly reference this information when needed.
Connecting to every server. With an easy to use interface, connect to servers, enterprise file sharing and cloud storage. You can find connection profiles for popular hosting service providers.
Cryptomator. Client side encryption with Cryptomator interoperable vaults to secure your data on any server or cloud storage. Version 6
Filename Encryption File and directory names are encrypted, directory structures are obfuscated.
File Content Encryption Every file gets encrypted individually.
Secure and Trustworthy with Open Source No backdoors. No registration or account required.
Edit any file with your preferred editor. To edit files, a seamless integration with any external editor application makes it easy to change content quickly. Edit any text or binary file on the server in your preferred application.
Share files.
Web URL Quickly copy or open the corresponding HTTP URLs of a selected file in your web browser. Includes CDN and pre-signed URLs for S3.
Distribute your content in the cloud. Both Amazon CloudFront and Akamai content delivery networks (CDN) can be easily configured to distribute your files worldwide from edge locations. Connect to any server using FTP, SFTP or WebDAV and configure it as the origin of a new Amazon CloudFront CDN distribution.
Amazon CloudFront Manage custom origin, basic and streaming CloudFront distributions. Toggle deployment, define CNAMEs, distribution access logging and set the default index file.
First class bookmarking. Organize your bookmarks with drag and drop and quickly search using the filter field.
Mac Transfer To New Mac
Files Drag and drop bookmarks to the Finder.app and drop files onto bookmarks to upload.
Spotlight Spotlight Importer for bookmark files.
History History of visited servers with timestamp of last access.
Import Import Bookmarks from third-party applications.
Ssh File Transfer For Mac Os
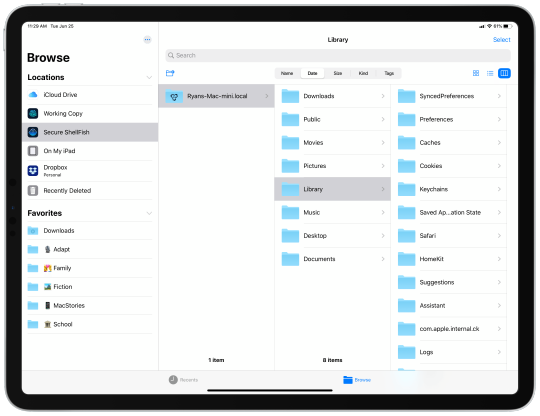
Browse with ease. Browse and move your files quickly in the browser with caching enabled for the best performance. Works with any character encoding for the correct display of Umlaute, Japanese and Chinese.
Quick Look
Quickly preview files with Quick Look. Press the space key to preview files like in Finder.app without explicitly downloading.
Accessible

The outline view of the browser allows to browse large folder structures efficiently. Cut & paste or drag & drop files to organize.
Transfer anything. Limit the number of concurrent transfers and filter files using a regular expression. Resume both interrupted download and uploads. Recursively transfer directories.
Download and Upload
Drag and drop to and from the browser to download and upload.
Synchronization
Synchronize local with remote directories (and vice versa) and get a preview of affected files before any action is taken.
Integration with system technologies. A native citizen of Mac OS X and Windows. Notification center, Gatekeeper and Retina resolution.
Keychain
All passwords are stored in the system Keychain as Internet passwords available also to third party applications. Certificates are validated using the trust settings in the Keychain.
Bonjour
Auto discovery of FTP & WebDAV services on the local network.
Finder
Use Cyberduck as default system wide protocol handler for FTP and SFTP. Open .inetloc files and .duck bookmark files from the Finder.
Notifications
Notifications in system tray (Windows) and the Notification Center (Mac).
Windows
Reads your proxy configuration from network settings. Encrypts passwords limiting access to your account.
We are open. Licensed under the GPL.
Come in. You can follow the daily development activity, have a look at the roadmap and grab the source code on GitHub. We contribute to other open source projects including OpenStack Swift Client Java Bindings, Rococoa Objective-C Wrapper and SSHJ.

International. Speaks your language.
Ssh File Transfer Mac To Linux
English, čeština, Nederlands, Suomi, Français, Deutsch, Italiano, 日本語, 한국어, Norsk, Slovenčina, Español, Português (do Brasil), Português (Europeu), 中文 (简体), 正體中文 (繁體), Русский, Svenska, Dansk, Język Polski, Magyar, Bahasa Indonesia, Català, Cymraeg, ภาษาไทย, Türkçe, Ivrit, Latviešu Valoda, Ελληνικά, Cрпски, ქართული ენა, Slovenščina, українська мова, Română, Hrvatski & Български език.
0 notes
Text
What to Expect from the Next Generation of Secure Web Gateways
After more than a century of technological innovation, since the first units rolled off Henry Ford’s assembly lines, automobiles and transportation bear little in common with the Model T era. This evolution will continue as society finds better ways to achieve the outcome of moving people from point A to point B.
While secure web gateways (SWGs) have operated on a far more compressed timetable, a similarly drastic evolution has taken place. SWGs are still largely focused on ensuring users are protected from unsafe or non-compliant corners of the internet, but the transition to a cloud- and the remote-working world has created new security challenges that the traditional SWG is no longer equipped to handle. It’s time for the next generation of SWGs that can empower users to thrive safely in an increasingly decentralized and dangerous world.
How We Got Here
The SWG actually started out as a URL filtering solution and enabled organizations to ensure that employees’ web browsing complied with corporate internet access policy.
URL filtering then transitioned to proxy servers sitting behind corporate firewalls. Since proxies terminate traffic coming from users and complete the connection to the desired websites, security experts quickly saw the potential to perform more thorough inspection than just comparing URLs to existing blacklists. By incorporating anti-virus and other security capabilities, the “secure web gateway” became a critical part of modern security architecture. However, the traditional SWG could only play this role if it was the chokepoint for all internet traffic, sitting at the edge of every corporate network perimeter and having remote users “hairpin” back through that network via VPN or MPLS links.
Next-Generation SWG
The transition to a cloud and remote-working world has put new burdens on the traditional perimeter-based SWG. Users can now directly access IT infrastructure and connected resources from virtually any location from a variety of different devices, and many of those resources no longer reside within the network perimeter on corporate servers.
This remarkable transformation also expands the requirements for data and threat protection, leaving security teams to grapple with a number of new sophisticated threats and compliance challenges. Unfortunately, traditional SWGs haven’t been able to keep pace with this evolving threat landscape.
Just about every major breach now involves sophisticated multi-level web components that can’t be stopped by a static engine. The traditional SWG approach has been to coordinate with other parts of the security infrastructure, including malware sandboxes. But as threats have become more advanced and complex, doing this has resulted in slowing down performance or letting threats get through. This is where Remote Browser Isolation (RBI) brings in a paradigm shift to advanced threat protection. When RBI is implemented as an integral component of SWG traffic inspection, and with the right technology like pixel mapping, it can deliver real-time, zero-day protection against ransomware, phishing attacks, and other advanced malware while not hindering the browsing experience.
Another issue revolves around the encrypted nature of the internet. The majority of web traffic and virtually all cloud applications use SSL or TLS to protect communications and data. Without the ability to decrypt, inspect, and re-encrypt traffic in a compliant, privacy-preserving manner, a traditional SWG is simply not able to cope with today’s world.
Finally, there is the question of cloud applications. While cloud applications operate on the same internet as traditional websites, they function in a fundamentally different way than traditional SWGs simply can’t understand. Cloud Access Security Brokers (CASBs) are designed to provide visibility and control over cloud applications, and if the SWG doesn’t have access to a comprehensive CASB application database and sophisticated CASB controls, it is effectively blind to the cloud.
What we need from Next-Gen SWGs

Fig. Next-Generation Secure Web Gateway Capabilities
A next-gen SWG should help simplify the implementation of Secure Access Service Edge (SASE) architecture and help accelerate secure cloud adoption. At the same time, it needs to provide advanced threat protection, unified data control, and efficiently enable a remote and distributed workforce.
Here are some of the use cases:
Enable a remote workforce with a direct-to-cloud architecture that delivers 99.999% availability – As countries and states slowly came out of the shelter-in-place orders, many organizations indicated that supporting a remote and distributed workforce will likely be the new norm. Keeping remote workers productive, data secured, and endpoints protected can be overwhelming at times. A next-gen SWG should provide organizations with the scalability and security to support today’s remote workforce and distributed digital ecosystem. A cloud-native architecture helps ensure availability, lower latency, and maintain user productivity from wherever your team is working. A true cloud-grade service should offer five nines (99.999%) availability consistently.
Reduce administrative complexity and lower cost – Today, with increased cloud adoption, more than eighty percent of traffic is destined for the internet. Backhauling internet traffic to a traditional “Hub and Spoke” architecture which requires expensive MPLS links can be very costly. Network slows to a halt as traffics spikes, and VPN for remote workers have proven to be ineffective. A next-gen SWG should support the SASE framework and provide a direct-to-cloud architecture that lowers the total operating costs by reducing the need for MPLS links. With a SaaS delivery model, next-gen SWG’s remove the need to deploy and maintain hardware infrastructure reducing hardware and operating costs. Per Gartner’s SASE report, organizations can “reduce complexity now on the network security side by moving to ideally one vendor for secure web gateway (SWG), cloud access security broker (CASB)…” By unifying CASB and SWG, organizations can benefit from unified policy and incident management, shared insights on business risk and threat database, and reduced administrative complexity.
Defend against known and unknown threats – As the web continues to grow and evolve, web-borne malware attacks grow and evolve as well. Ransomware, Phishing and other advanced web-based threats are putting users and endpoints at risk. A next-gen SWG should provide real-time Zero-day malware and advanced phishing protection via a layered approach that integrates dynamic threat intelligence for URL, IPs, and file-hashes and real-time protection against unknown threats with machine-learning and emulation-based sandboxing. A next-gen SWG should also include integrated Remote Browser Isolation to prevent unknown threats from ever reaching the endpoints. Furthermore, a next-gen SWG should provide the capability to decrypt, inspect, and re-encrypt SSL/TLS traffic so threats and sensitive data cannot hide in encrypted traffic. Lastly, a next-gen SWG should be XDR-integrated to improve SOC efficiencies. SOC teams have too much to deal with already and they shouldn’t settle for Siloed security tools.
Lockdown your data, not your business – More than 95% of companies today use cloud services, yet only 36% of companies can enforce data loss prevention (DLP) rules in the cloud at all. A next-gen SWG should offer a more effective way to enforce protection with built-in Data Loss Prevention templates and in-line data protection workflows to help organizations comply with regulations. Device-to-cloud data protection offers comprehensive data visibility and consistent controls across endpoints, users, clouds, and networks. When incidents do happen, administrators should be able to manage investigations, workflows, and reporting from a single console. Next-gen SWGs should also integrate user and entity behavior analytics (UEBA) to further protect business-sensitive data by detecting and separating normal users from malicious or compromised ones.
SWGs have clearly come a long way from just being URL filtering devices to the point where they are essential to furthering the safe and accelerated adoption of the cloud. But we need to push the proverbial envelope a lot further. Digital transformation demands nothing less.
from WordPress https://ift.tt/38lDpGR via Blogger https://ift.tt/3ir8Wf9
0 notes
Text
Continuous Deployments for WordPress Using GitHub Actions
Continuous Integration (CI) workflows are considered a best practice these days. As in, you work with your version control system (Git), and as you do, CI is doing work for you like running tests, sending notifications, and deploying code. That last part is called Continuous Deployment (CD). But shipping code to a production server often requires paid services. With GitHub Actions, Continuous Deployment is free for everyone. Let’s explore how to set that up.
DevOps is for everyone
As a front-end developer, continuous deployment workflows used to be exciting, but mysterious to me. I remember numerous times being scared to touch deployment configurations. I defaulted to the easy route instead — usually having someone else set it up and maintain it, or manual copying and pasting things in a worst-case scenario.
As soon as I understood the basics of rsync, CD finally became tangible to me. With the following GitHub Action workflow, you do not need to be a DevOps specialist; but you’ll still have the tools at hand to set up best practice deployment workflows.
The basics of a Continuous Deployment workflow
So what’s the deal, how does this work? It all starts with CI, which means that you commit code to a shared remote repository, like GitHub, and every push to it will run automated tasks on a remote server. Those tasks could include test and build processes, like linting, concatenation, minification and image optimization, among others.
CD also delivers code to a production website server. That may happen by copying the verified and built code and placing it on the server via FTP, SSH, or by shipping containers to an infrastructure. While every shared hosting package has FTP access, it’s rather unreliable and slow to send many files to a server. And while shipping application containers is a safe way to release complex applications, the infrastructure and setup can be rather complex as well. Deploying code via SSH though is fast, safe and flexible. Plus, it’s supported by many hosting packages.
How to deploy with rsync
An easy and efficient way to ship files to a server via SSH is rsync, a utility tool to sync files between a source and destination folder, drive or computer. It will only synchronize those files which have changed or don’t already exist at the destination. As it became a standard tool on popular Linux distributions, chances are high you don’t even need to install it.
The most basic operation is as easy as calling rsync SRC DEST to sync files from one directory to another one. However, there are a couple of options you want to consider:
-c compares file changes by checksum, not modification time
-h outputs numbers in a more human readable format
-a retains file attributes and permissions and recursively copies files and directories
-v shows status output
--delete deletes files from the destination that aren’t found in the source (anymore)
--exclude prevents syncing specified files like the .git directory and node_modules
And finally, you want to send the files to a remote server, which makes the full command look like this:
rsync -chav --delete --exclude /.git/ --exclude /node_modules/ ./ [email protected]:/mydir
You could run that command from your local computer to deploy to any live server. But how cool would it be if it was running in a controlled environment from a clean state? Right, that’s what you’re here for. Let’s move on with that.
Create a GitHub Actions workflow
With GitHub Actions you can configure workflows to run on any GitHub event. While there is a marketplace for GitHub Actions, we don’t need any of them but will build our own workflow.
To get started, go to the “Actions” tab of your repository and click “Set up a workflow yourself.” This will open the workflow editor with a .yaml template that will be committed to the .github/workflows directory of your repository.

When saved, the workflow checks out your repo code and runs some echo commands. name helps follow the status and results later. run contains the shell commands you want to run in each step.
Define a deployment trigger
Theoretically, every commit to the master branch should be production-ready. However, reality teaches you that you need to test results on the production server after deployment as well and you need to schedule that. We at bleech consider it a best practice to only deploy on workdays — except Fridays and only before 4:00 pm — to make sure we have time to roll back or fix issues during business hours if anything goes wrong.
An easy way to get manual-level control is to set up a branch just for triggering deployments. That way, you can specifically merge your master branch into it whenever you are ready. Call that branch production, let everyone on your team know pushes to that branch are only allowed from the master branch and tell them to do it like this:
git push origin master:production
Here’s how to change your workflow trigger to only run on pushes to that production branch:
name: Deployment on: push: branches: [ production ]
Build and verify the theme
I’ll assume you’re using Flynt, our WordPress starter theme, which comes with dependency management via Composer and npm as well as a preconfigured build process. If you’re using a different theme, the build process is likely to be similar, but might need adjustments. And if you’re checking in the built assets to your repository, you can skip all steps except the checkout command.
For our example, let’s make sure that node is executed in the required version and that dependencies are installed before building:
jobs: deploy: runs-on: ubuntu-latest steps: - uses: actions/checkout@v2 - uses: actions/[email protected] with: version: 12.x - name: Install dependencies run: | composer install -o npm install - name: Build run: npm run build
The Flynt build task finally requires, lints, compiles, and transpiles Sass and JavaScript files, then adds revisioning to assets to prevent browser cache issues. If anything in the build step fails, the workflow will stop executing and thus prevents you from deploying a broken release.
Configure server access and destination
For the rsync command to run successfully, GitHub needs access to SSH into your server. This can be accomplished by:
Generating a new SSH key (without a passphrase)
Adding the public key to your ~/.ssh/authorized_keys on the production server
Adding the private key as a secret with the name DEPLOY_KEY to the repository

The sync workflow step needs to save the key to a local file, adjust file permissions and pass the file to the rsync command. The destination has to point to your WordPress theme directory on the production server. It’s convenient to define it as a variable so you know what to change when reusing the workflow for future projects.
- name: Sync env: dest: '[email protected]:/mydir/wp-content/themes/mytheme’ run: | echo "$" > deploy_key chmod 600 ./deploy_key rsync -chav --delete \ -e 'ssh -i ./deploy_key -o StrictHostKeyChecking=no' \ --exclude /.git/ \ --exclude /.github/ \ --exclude /node_modules/ \ ./ $
Depending on your project structure, you might want to deploy plugins and other theme related files as well. To accomplish that, change the source and destination to the desired parent directory, make sure to check if the excluded files need an update, and check if any paths in the build process should be adjusted.
Put the pieces together
We’ve covered all necessary steps of the CD process. Now we need to run them in a sequence which should:
Trigger on each push to the production branch
Install dependencies
Build and verify the code
Send the result to a server via rsync
The complete GitHub workflow will look like this:
name: Deployment on: push: branches: [ production ] jobs: deploy: runs-on: ubuntu-latest steps: - uses: actions/checkout@v2 - uses: actions/[email protected] with: version: 12.x - name: Install dependencies run: | composer install -o npm install - name: Build run: npm run build - name: Sync env: dest: '[email protected]:/mydir/wp-content/themes/mytheme’ run: | echo "$" > deploy_key chmod 600 ./deploy_key rsync -chav --delete \ -e 'ssh -i ./deploy_key -o StrictHostKeyChecking=no' \ --exclude /.git/ \ --exclude /.github/ \ --exclude /node_modules/ \ ./ $
To test the workflow, commit the changes, pull them into your local repository and trigger the deployment by pushing your master branch to the production branch:
git push origin master:production
You can follow the status of the execution by going to the “Actions” tab in GitHub, then selecting the recent execution and clicking on the “deploy“ job. The green checkmarks indicate that everything went smoothly. If there are any issues, check the logs of the failed step to fix them.

Check the full report on GitHub
Congratulations! You’ve successfully deployed your WordPress theme to a server. The workflow file can easily be reused for future projects, making continuous deployment setups a breeze.
To further refine your deployment process, the following topics are worth considering:
Caching dependencies to speed up the GitHub workflow
Activating the WordPress maintenance mode while syncing files
Clearing the website cache of a plugin (like Cache Enabler) after the deployment
The post Continuous Deployments for WordPress Using GitHub Actions appeared first on CSS-Tricks.
Continuous Deployments for WordPress Using GitHub Actions published first on https://deskbysnafu.tumblr.com/
0 notes
Text
Smashing Podcast Episode 9 With Stéphanie Walter: How Can I Work With UI Frameworks?
Smashing Podcast Episode 9 With Stéphanie Walter: How Can I Work With UI Frameworks?
Drew McLellan
2020-02-11T05:00:00+00:002020-02-11T08:07:04+00:00
As a developer myself, one of the things that I like about UI frameworks is that they often come with default styling, but is that something that we should be relying on in projects? Simply using the default styling and trusting that whoever produced the framework has done a really good job in designing those components? Join me for today ’s podcast episode in which I soeak to UX Designer Stéphanie Walter about things we should be considering when building on a UI framework.
Show Notes
Stéphanie’s website
Stéphanie on Twitter
Weekly Update
“How To Create A Card Matching Game Using Angular And RxJS” by Anna Prenzel
“How To Create A Headless WordPress Site On The JAMstack” by Sarah Drasner
“Magic Flip Cards: Solving A Common Sizing Problem” by Dan Halliday
“Django Highlights: User Models And Authentication (Part 1)” by Philip Kiely
“How To Create Maps With React And Leaflet” by Shajia Abidi
Transcript
Drew McLellan: She’s a user centered designer and expert in mobile experience, who crossed delightful products and interfaces with a special focus on performance. She’s worked on projects for clients such as the University of Luxembourg, European Investment Bank, BMW and Microsoft to name but a few, and she helps those clients deliver successful projects to their audience all the way from strategy to the final product. She’s a Google Developer expert in product design and a passionate teacher sharing her knowledge in numerous blog posts, articles, workshops and conference presentations. So we know she’s an expert user experience designer, but did you know she once had a job fitting carpets with Sir Elton John? My Smashing friends, please welcome Stéphanie Walter. Hello Stéphanie, how are you?
Stéphanie Walter: Hi, I’m smashing and loved the introduction.
Drew: So I wanted to talk to you today about a particular issue and that’s the subject of using off-the-shelf user interface frameworks. Now you’re a user experience designer and you work with lots of different clients and your job is to help those clients create the best possible user experiences through crafting highly usable user interfaces. So the idea of being able to do that with an off-the-shelf set of tools seems like a bit of a stretch to me. Is the use of UI framework something you see a lot throughout your work?
Stéphanie: Yeah, it’s something I’ve seen a lot, especially in the last few years because I started working with an agency and now I work within the company. So in those super big IT tech teams and yeah, at the moment there’s a lot of framework UIs like the one that I’ve seen the most is Material-UI, basically Material design is a Google design kind of guidelines and thing, and Material-UI is the team from Angular, but also the team from React. They created their own framework using kind of the look and feel of the Material design from Google. But it has nothing to do with Google anymore. It’s just like they, I don’t know, I think they liked the look and feel. So at the moment, those are the two main UI framework I work with. And also there’s something called Ant Design, that’s grew quite popular.
Stéphanie: It’s a React framework. I don’t know if they have Angular too. I think it was made by a team in China. And it’s interesting because not only does it provide the components, everything in React, but if you go to their website you’ll also get the scratch files, which is actually quite interesting because then it kind of motivates or helps the designer build or shape the interface into the UI components used by that framework. So yeah, it’s something I’ve seen a lot, especially in big IT teams because most of the times those don’t have a designer. At the moment I’m basically UX team of one in a small team at a European investment bank. So it’s me as a UX designer. I work with a team of developers, business analysts, all the good people, but still is one designer for the whole project.
Stéphanie: Until I arrived there was no designer. So it’s kind of a solution implemented in a lot of companies, especially on internal products for instance. Where they usually say, okay, we don’t really need a designer for that. We just need something that works for our internal users and let’s just use a framework because it’s convenient for the developers. Most of the components are already there and since they don’t have designers in the team, then it’s kind of replacing, as to say, the role of a UI designer. Yeah, problem with that is that, okay, then you have the components, but the role of the UI designer is not just to decide about should the button be red, green, orange, blue, whatever. Usually the role of the UI designer is information architecture, understanding user needs. So everything that goes beyond the interface. So even if you have this kind of framework that kind of takes care of the whole UI, So visually what you see on the screen.
Stéphanie: You still need someone at some point to do the job of understanding what do we put on the screen, how is it going to behave? What happens when we click here? How does the user accomplish their goal? How do we go from point A to point B? Because we can use a model, we can use tabs, we can use all of the components. So that’s why it’s always kind of a little bit complex and tricky.
Drew: Is it possible, do you think be able to create a usable user interface using an off the shelf UI framework, or is it always going to be a bit of a compromise?
Stéphanie: I kind of hope so. I kind of hope so because otherwise I’m building not usable interfaces. So this answer is totally biased, but yeah, I think it is, but it also depends on the level of compromise you’re willing to do and there’s compromises on both sides. At the moment I’m compromising a lot of buttons for instance, because you have some really specific buttons in Material-UI, and I don’t really like the ripple effect on the button. I think it works great on mobile because on mobile you need a kind of a big feedback when user clicks on or touches the button. But then the steps is kind of ripple effect that goes all the way on the button. It’s a little bit overkill, especially when there’s a lot of button. But still we are going to keep this ripple effect because it would be super complex to remove it because this was built in to the React framework. And to have another hover effect on this button, something more subtle that will not be this kind of whooshy thing here. It would be super complex.
Stéphanie: So this is the kind of compromises you do. But on the meantime, I don’t compromise on specific things which is custom components. Where I was working before, the current client for a travel and airline company. And airline has some really, really super specific needs. The calendar for the airline for instance, you want to put prices, you want to put… if you don’t travel to this destination on a specific date, you don’t know when to put that, you have this departure and arrival and the basic calendar of most of those UI frameworks don’t provide these kind of things. So at some point you can say, okay, we will just use the calendar they have. And that’s it. You need to go beyond that. So most of the compromises are basically built on, do we use the basic component? Do we create a custom one that will fit the user needs? Or do we make a mix of the two? In the case of the calendar, for instance, we use the calendar grid, so we use the basic component and then we enhanced it with customization on top of that. So it was a lot of React development for that one.
Stéphanie: And yeah, so usually you do a lot of compromises.
Drew: So it sounds like using a user interface framework can get you a certain amount of the way there, but to really have a good user interface as a result of it, you need to do quite a bit of customization on top?
Stéphanie: Usually. Yeah.
Drew: Does that customization go beyond theming?
Stéphanie: Yeah, my developer wished it wouldn’t go beyond theming. Eugene If you listen to me. I think he would be super happy if we would just change a few colors on everything. But yes, at some point you need to go beyond the customization because first, like UI frameworks are like Lego tools is kind of a toolbox. So you have a lot of different components in the box, but this doesn’t build a page. You still need a header, you still need a footer. You still need extra content that was not in the framework. So sometimes you can tweak a component into what you needed. From what I understood, we are using the card component to build a modal windows, but the thing with the modal windows is that it doesn’t really behave like a card.
Stéphanie: You are kind of going a little bit beyond that. You need a background with obscurification. You need to trigger it on click while usually your card is already there in the interface. So we are using this card component because it has a lot of the things we need like the background, a header and a title at the top, some buttons at the bottom. So we have the structure and then we tweak it a little bit. But we end up with some conflict sometimes about semantics, HTML as well. Because for instance, I wanted to have buttons that didn’t have button shapes, so just like link button and the developer said, “Okay, so we use a link like your href link.” I said, “No, this is not a link. It’s a button. When they click it, it doesn’t open a new page. It clears everything that is into the form.”
Stéphanie: So it should be technically from a semantical point of view, it should be a button. “Yeah. But it doesn’t exist in the framework.” I say “So okay, I know so what do we do?” So usually you start discussing these little things and since I’m really annoying my developers with accessibility also, this is another extra layer of trying to make sure that we have the basic components that they work well with. But also that they are semantically like I don’t want to have buttons with gifs within gifs within gifs. Otherwise we’ll have issues in the end.
Drew: I guess starting a new project that’s going to use a UI framework, you probably need to start with some sort of user research.
Stéphanie: Yes.
Drew: Is that fair?
Stéphanie: You should. You need to. So yes, usually you can have all the components you want. You still need to know what do your users need on the pages, how are they going to navigate? You need to build a flow. So usually even before deciding on a framework, what we do is we go to our users, we talk to them, we try to understand their needs. So at the moment I’m quite lucky because the users are internally within the bank. So we do a lot of workshops with them and you have to imagine it’s a super complex interface. We are migrating from something that was built, I don’t know, I think 10 or even 15 years ago to something all new shiny using Material-UI React. So it’s quite a big change and you have to understand that during those 15 years, everyone who wanted something could go to the support and then they ask the IT team to implement it. So at the moment my interface is like 400 pages with tables, within tables, within tables, with other tables, and stuff that shouldn’t even be in tables.
Stéphanie: Like we have a lot of things that are just key value, key value, key value. So they build the table with two columns. I’m like, “Nope, maybe we can do something better with that.” So at the moment what we are doing is we did some user research to understand the different goals of the users. So what we identified is that what they do with the interface, they have some planification goals. They need to plan their work. So I want to know that this operation is going to go to this meeting, so I need that on that schedule, stuff like that. They want to monitor a thing, they want to report the data. So monitoring is just like looking at the data and making sure everything is fine. Reporting is being able to exploit the data, to do something with it they want to share and to kind of collaborate with colleagues and all of that we discovered by discussing directly with the users.
Stéphanie: And what we discovered is that actually some of the things we were planning on migrating at the end are some of the most important things on a daily basis for the user. So the planification user goal is one of the kind of biggest one at the moment. So we are really, really working on that. So yeah we do use the interview and now we are in the phase where at the moment we are super high level saying okay we need to build the shell, we need to understand navigation. But at the moment we didn’t really go through all of the data and this is now what we are going to do. And it’s interesting because we have a lot of tables and we said we can either go the kind of not smart way and just put the tables in the new interface and we’re done, or we can say, okay, let’s try to understand what those tables are, What do our users use this table for?
Stéphanie: And then maybe some of the tables could be displayed as data visualization and then to do that you need to understand the whole business So that the data makes sense. So if you have a nice framework and you say, okay, let’s use this chart… I think is called chart JS framework. You have a lot of things, you can have histogram, pie charts and graphs and everything, but at some point you still need a designer to help you decide. Okay, this data, does it make sense if we show it into a graph or it makes more sense to show it as a pie because we want to show part of the whole, or we want to compare evolution for one country in the last 10 years, then a histogram is more interesting. So based on what the user wants to do with the data, you are going to display them a whole other way.
Stéphanie: And usually it’s not a developer job to do that. Our developer, they’re super smart guy. I’m sorry, but I honestly work with guy developers, I wish I had some ladies, but no. None of them are women. So super smart guys but they are not super qualified to say, okay, this data should be displayed like that, that, that and that. So in the end you still need some designers go to talk to the users, understand what you can do with the data and this goes far beyond just saying, okay, this should be a tab bar or this should be a navigation on the left.
Drew: And after making those sorts of decisions based on talking to the users. Would you typically take the resulting prototypes or designs back to users to test them again to see if they understand your type of chart choice for example?
Stéphanie: Yeah, we did that a lot actually, which is really nice because then you don’t develop something until you know it’s going to be useful and usable. So it depends. If it’s quicker to actually develop the thing because they have already most of the components, what I usually do is I do really quick paper prototyping and then we develop the thing because it’s quick, even without the data. If it’s something complex, something really, really new that will take a lot of time to develop, then we say, okay, we design a few screens and we do some testing directly on the screen. So we have a tool it’s called InVision, where basically you put all of your design, you can create links between the different parts. The thing is it also depends what you want to test. If you want to test phones for instance, it’s a nightmare to test those in InVision because the people can’t really feel them and especially on mobile phone for example.
Stéphanie: So it’s always kind of being smart. What’s the fastest and cheapest way? Is it faster and cheaper to test only designs. Is this enough? For forms usually, not really because you have auto completes all of the heavy lifting you put in the front end who have actually the user fill a form so for forms, maybe it’s more efficient to actually build a form and test it. But for new things, yeah, we do a lot of designs. We go to the users. So at the moment we either do one-on-ones, but my users are really busy people. It’s a European investment bank so they don’t have that much time. So what we usually do is that if we come to one-on-one with the users, we do some small meetings, like more like focus groups. And it’s also interesting because then you have kind of a confrontation sometimes. Some people say, “Yeah, I think it works for me because I work like that and that,” and then there’ll be other people who are like, “Oh you work like that? Actually no, I do it like that and that.”
Stéphanie: So it’s also interesting to kind of have a few people in the room and to listen just to the conversation, taking notes and say, “Oh maybe then we could do that” and “This component would be better based on what I just heard.” And things like that.
Drew: If you’re working with a more general audience for your product. So perhaps not internal users like you have, but more the general public, are there inexpensive ways that designers can get that use of research in? Are there easier ways if you don’t know directly who your users are going to be?
Stéphanie: You should know who they are going to be otherwise it does the job of the marketing people before building the product. But yeah, we did some guerrilla user testing for instance, You can still use InVision for instance. So you can build some prototypes in InVision and then you can recruit the users through social media, for instance. I was working for a product that helped, what is the name, car dealerships mechanics who repair things and then to also inform the client about extra repairs, things like that. So we had already kind of a growing community on LinkedIn and Facebook. So what you can do is you can recruit those people. You can do remote testing, like we are having conversation in a tool like an online tool. You can do some screen sharing. So we did that for some project also.
Stéphanie: I would just give you one advice is test the tool before, because I was using, it was called appear.in. But I think they changed the name to Whereby or something, but it’s really in the browser who I said, okay, it’s nice because then the users don’t need to install anything but do users were not on a real computer. They were into VM, into a Citrix and they didn’t have microphones so what we ended up doing is like they used my tool to share the screen. They were clicking on the prototype and at the same time I had them over the phone, like a landline phone, to talk to them directly. So there’s always, this was a quite cheap because it was a wonderful day of recruiting, I think we had 10 users or something like that. Yeah, you can do a lot of things even if you can’t go face to face, I’ve done a lot of usability testing directly on Skype or things like that. So there’s always some cheap ways to do that.
Drew: When it comes to choosing a UI framework to work with, if that’s the route that you’re going, is that something that you would leave just to the developers or is that something that designers should get involved in too?
Stéphanie: For me, you should involve the whole team. Like the designers, the developers, maybe also architects if you have some, because how the framework is built might also influence these kind of things. Unfortunately, most of the time when they arrive on the project, the framework was already decided. No, actually it’s funny, either it’s already decided or they ask me to validate their choice of the framework, but I didn’t do any reviews or research. I have strictly no idea what’s in the project because they didn’t even show me their screens. They’re like, “Yeah, do your thing. We can use this framework.” I don’t know. Well, do we have a screen? So they ended up showing you a few screens, which was a Windows native app they wanted to migrate in the cloud. They said, “Yeah, we only need the buttons and mostly like forms and things like that.”
Stéphanie: But it’s really hard to say, “Yeah, go for this framework, we have all of the components we need.” Or like, “Don’t go if you don’t have a rough idea of what’s your content going to be, what is the navigation.” So I think you should still have kind of a global overview before choosing your frameworks unless you’re 100% sure you have all of the components. But I have a feeling that most of the time the framework choice is basically based on what technologies do developer like at the moment, do they have experience with a framework before that? We used Ant on some projects just because a few developers had experience with that and they really liked it and they were kind of efficient using Ant. And for the Material React UI it’s the same. It’s like because the developer already used it on previous projects, so they are efficient with it.
Drew: So really it’s got to be a balance between what the developers are comfortable with, what they know, what’s going to work with their technology stack and then what the requirements of the product are in terms of creating a good user interface. And you somehow need to balance the two of those to find the ideal framework for it.
Stéphanie: Yes. I have a kind of a specific requirement for some project, which is… I’m in Luxembourg, we have a lot of European institutions and things like that, so we have an extra accessibility requirement for some of those. And usually when the framework was decided, they didn’t really check about the accessibility of their framework and then they come back a few months after the beginning of the project saying, “Oh, just told us that there’s this new law and we should be accessible but we don’t know how to do that.” Like yeah, it’s a little bit too late. So for me, to choose a framework you need really to know all of the constraints at the beginning of the project and if accessibility is one of them you need to test your components and make sure that they are going to be accessible. But I am not a React or Angular developer, but I’m pretty sure that it’s super complex to turn a not accessible UI framework into something accessible. I guess it might be a little bit complex to rebuild all of the components, so things like that.
Drew: If you find yourself working on a project where that process hasn’t taken place and a UI framework has already been chosen, is there a danger that the user interface could start being influenced by the components that already exist within that framework rather than being driven by the needs of the user?
Stéphanie: It really, honestly, most of the projects I worked on, eventually you end up having a lot of trade offs, even if you really try to push. So it’s mostly about balance and discussing with the developers. So usually what I do is we do some wire frames, even quick paper wire frames, say okay, on this page we will need that and that and that component, the first thing I do is I ask the developer do we have that in our framework at the moment? What does it look like? And then we decide together, okay, this is a component that would do the job or okay this will not do the job. Do we tweak it? Like do we still keep the component but change it a little bit so that it does the job, or do we build something from scratch?
Stéphanie: And at the end of the day it will depend on the budget of course. So you ended up doing trade offs. Like I would be okay for small components that are almost never used if they’re not perfect and there’s kind of few issues. But for main navigation, main structure, things that you see all the time on the screen, for instance, this really needs to work. The user’s needs to understand how they work efficiently and yeah, it’s, as you said, finding a balance between the ideal experience you wish you would have if you didn’t have any framework and what you have at hand and the budget and also the timing. If we say, okay, for these sprints, the feature needs to be finished at the end of this sprint, and then they say, okay, but if you want your components we will never finish the feature at the end of this sprint then you start discussing, okay, do we finish this feature in the next screen, do we take more time to do it properly? And usually it really depends.
Stéphanie: The things that frustrate me the most is when I know that we use a crop fix component and they say to me like, Oh no, don’t worry. We will fix that later. And I knew that the later unfortunately might never happen. So depends on the team. But after a while you have the experience and you know, will this later arrive and or will it not? Yeah, it’s about compromises. When you are working with these kind of tools.
Drew: As a developer myself, one of the things that I like about UI frameworks is that they often come with default styling. So that means that I don’t necessarily need to have a designer maybe to help me with the look and feel of all the components. Is that something that we should be relying on in projects? Just the default styling and trusting that whoever produced the framework has done a really good job in designing those components? Or would you be styling those components yourself?
Stéphanie: I think it truly depends. The problem for instance with Material-UI is the look and feel of your a web app will be basically the configured Google products. So if you don’t actually change the font, change a few colors and kind of bring your own brand identity and do that, you’ll have a product that will just looked like any Google product, which could be a good thing because if your users are used to Google products it might help them understand it. So usually if you don’t have a designer in the team, do you have any choice? Like a lot of the different work I’ve seen, they come with custom themes so at least you can change the colors. I think you can change the fonts also pretty easily. But again, like if you change the colors and you’re not super good at design or even accessibility, maybe the colors you will use will clash, they might have contrast problems.
Stéphanie: For instance, I love orange, but it’s one of the most annoying color to work with because to have a real accessible orange, for instance, as a button with white text, it almost looks brownish. And if you want to have this really shiny orange, you need dark text on top of it to make it readable but it kind of makes your interface look like Halloween at the end of the day. Yeah, I see you laughing. But it’s true. So it’s always about these kind of compromises and say if you’re a developer and you want to use the framework as it is and you don’t have a designer, I think it’s still better than not having anything and building it from scratch and then it’s super complex to use. But the thing is, just because you have the components doesn’t mean you will build a great interface. It’s like Lego bricks. If you have the Lego bricks, okay it’s fine, but you can do a real nice spaceship or you can do something that isn’t holding together and will fall apart because you didn’t have really a plan.
Stéphanie: So design is kind of more than that. Design is about really understanding what’s going to be on the screen, how it will work. And I know some developers who actually have the capability to do that. So they are really good with usability guidelines and they understand a lot of design rules, for instance. So when it comes to choosing the components, they’re really good at that. And I know developers who have no idea what components to choose and choose the first one that does the job. But after a while it doesn’t work anymore. Like tabs for instance, we had an interface where some developers chose tabs. I think it makes sense at the beginning when you only have three items. But then there was 12 items on the screen and then you have the tabs that are three lines of tabs, and all of those are the same level one tabs, and there’s tabs within tabs. So they had the component, it looked nice because they use the framework, but it wasn’t really usable.
Stéphanie: And I had the same with like a modal windows for instance. Where they build the projects without a designer and after a while I think the client asked for more and more stuff into this modal. So they ended up with a screen with a table and when you click on add a row, you open a modal, and in this modal you have two tabs, and then in one of those tabs you even have another table and then they wanted to add an extra stuff into that, I was like, okay, maybe we can put a modal on top of a modal. And at some point the designer would reply, okay, if you have that much content in the modal, it should not be a modal window. It should be a page. So even if you have the component, you still need kind of an architect to do the plan and make sure that all of those components work well together.
Drew: So if as a designer, you’re being asked to change the styling of some components, would you just try and change all of the styling? Would you customize all of it or are there certain areas that you’d focus on?
Stéphanie: Colors I think because it’s the first thing you see, colors can actually bring you identity. If you have like a strong brand identity, at least having the colors of your product on the buttons or the icons and things like that, already helps you customize the framework. Fonts because I think it’s easy, if the framework is well-built, usually you change the whole font family in someplace and then it should kind of cascade on the rest of the site. So colors and fonts is I think two easy ways to quickly customize the framework. Icons is another nice way to bring personality, but it might be difficult because from what I’ve seen, most of the framework come with custom icons or Font Awesome or like a library already built in. So to replace those, first you need a lot of icons if you want to replace them all. So it might be a little bit complex. I have also seen frameworks that lets you choose which icon pack you want to use. like Font Awesome, Glyphicons and some of the other ones. So this is the kind of things you can quite easily customize.
Stéphanie: And then it’s about look and feel, for instance the header, usually you have different kinds of headers, footers. How do you navigate things like that. So there’s already a lot of small customization you can bring so that it doesn’t look Material-UI-ish, it more looks like your brand and then you can play around with border radius’s for instance. Whether you want completely rounded buttons, or you want square buttons or you want something in the middle like shadows also. So some small stuff that are kind of usually easy to customize because most of those frameworks have them in CSS variables. This is the kind of small things that you can customize without I think a lot of effort, except for these ripple effects. I hate that. I’m going to fight it. I kind of hope they change it eventually.
Drew: I guess things like that, that might seem obvious might seem just like a surface level effect, Do you think that would be easy to change and in this case it turns out it wasn’t easy to change? Is that just a case of speaking to your developers to find out what’s going to be easy to customize and what’s not going to be easy?
Stéphanie: Yeah, usually, especially if they’re used to work with the framework, they know what’s easy to change on it. It depends on the developer, I had discussion with one developer and I asked him if we can not have like uppercase buttons, because they are kind of a little bit hard to read, especially in the font we were using, he went into the documentation and say, I don’t know if we can customize it because I can’t see it in the API. I was like, what API? It’s like CSS class, CSS definition. You remove the uppercase from the CSS and it’s done. So he was like looking for an API to change just the font, how does the font look like. And I was like, yeah, but if there’s no API for that, I think you can change it in CSS.
Stéphanie: But then it’s complex because if you have to change this in like all of the CSS line. So it’s usually kind of a big discussion. It was the same… was like drop downs. So Material-UI, the React version we use, has some customized drop downs. So when you have a select box like form element, the select it opens these custom components and I don’t know why but we have a big problem with that on Internet Explorer. We are going to migrate to windows 10 and Edge. I’m looking forward to it, but we are still Internet Explorer 11 at the moment. And what’s happened is whenever you use or you open one of those components, it freezes the screen behind it and you have a scroll bar, so it kind of jumps around whenever you want to use one of those.
Stéphanie: And at some point we discuss with the developer, is the customizing of that worth the screen jumping around whenever users click on that. And it’s like, honestly for me, no, I prefer it not to jump and we use the select in the browser, then it will not look the same if our users have Edge and, no not Edge, IE. Or if some users are using Firefox, okay? So it will not look the same but it will be the native one and it will not make the page jump around every time someone clicks. So it’s this kind of discussion also, do we want to customize it but then it’s kind of clumsy or do we say, okay we are not going to customize it. We had the same debate with a scroll bar because we had another project we had drop-downs and they were 100 elements at some point in the drop downs. So there’s an auto complete but you can still scroll inside the drop down. And the developer said, yeah but this is looking really ugly on IE, the default scroll bar.
Stéphanie: And they investigated, they found JavaScript library that would let us have this really small little a scroll down you have on Mac and have it everywhere. Then we said, okay, is it worth investigating? We need to investigate, test it, put it everywhere, test all of the browsers. So we said we are going to do it, but only if it doesn’t damage the performance and if he doesn’t damage the rest of your experience, otherwise it’s perfectly normal that the browser element don’t look the same on any browsers. So at the end, don’t customize everything.
Drew: I guess it’s a collaborative team effort, then? Everyone needs to discuss and balance up again all the different performance factors, ease of customization and where that customization happens. So once you’ve got your UI framework in place, you’ve got all your components specified and built out and customized and styled to how you want them. I guess you need to document that in some way to maintain consistency?
Stéphanie: So at some point as a designer what we usually do, we already document them in our sketch files. So we have the working files with every single screen and everything. And in the sketch files we have really specific art boards where we put all of the different components. So that if another designer works on the project, they know that the components already exist and they can just drag and drop it in a new page and reuse it afterwards. So we have this system where we document the components also we document the use, like when do you use this component? When do you use that one? Where is this one working better? So all of the different states for instance, like inputs, we have I think 10 of those, like a focus with a placeholder, without a place holder, with content like arrows and things like that. So again, we bring consistency and then the development parts, it really depends on the kind of maturity of the communication of the team. So what we are currently building is basically a library of components and we are also building the tool around it.
Stéphanie: So my developer is currently building that and the idea is to build the component first in our kind of a sandbox, document it. Also he builds things where you can change the colors and if have a button for instance, you can change the icon, you can change the text to see if it will still work with longer text, smaller text, things like that. So we are building this sandbox and in the sandbox, you have a ‘Read me’ tab where you have documentation for how should this look, how should this component be used, when, how is it supposed to behave? Like auto complete for instance, seems to be something really, really easy, But if you start actually designing the flow of the auto complete, what happens when you put the focus in the field? Do you start auto completing or offering suggestion after one character after two, after three? If it’s after three, what happens in the meantime?
Stéphanie: So there’s a lot of different questions about that that we also document, which is really going super deep into that so that if this auto complete gets implemented on another project or gets used by another team, they know exactly how it’s supposed to work as well. So we kind of do the same. The two of us, so designers are documenting into the design tools and usually in the design tool we document the colors and shadows and gradients so that the developer don’t have to look around and try to remember exactly what the hexadecimal code for this button was and things like that. So in the end it’s kind of you have this UI framework that was super generic and you customized it, you made sure that the components you use are actually the ones that are going to help your user accomplish their goals.
Stéphanie: Everything you’ve customized is kind of starting to become your own little design system. So at the end you’re building a design system, but instead of building it from scratch, you’re basically building it using React, Material or, what was the other one? Ant or something like that. So it’s the same constraints.
Drew: Would you go back to user testing at this point after things have actually been built? Would you go back and test things with users again?
Stéphanie: We have tests, like real people testing, like regression testing and making sure that everything works. Like when you click it works, when you hover it works, stuff like that. But yes in the end, especially if we didn’t do a prototype, if we did the user testing in mockups, we want sometimes to test it again with the real users who have a feeling that everything is still working. So yeah, sometimes we go again into user testing at the end. We do that usually at the end of a few sprints where the features were implemented. So usually what happens is like we do the research, we design the feature into design tools, we do quick testing at the beginning, then it’s implemented, we do tests to make sure it works. And then again we go back to the users.
Stéphanie: And it’s also interesting because we are building a community with the users. So they’re actually quite eager to see that. The first testing was a little bit kind of a sneak peek, like, Oh, this is what it might look like. And then they are super curious about how it works and how it looks like at the end. So we go back usually in one-on-one testing for that or if we don’t have the time, we do just like panels and also we deploy it. So sometimes we do AB testing also sometimes if we don’t have time for the user testing one-on-ones, we deployed it and then we say, okay, it was deployed. If you have any feedback, please come back to us. Also if you see bugs, because sometimes we compete, the team missed a bug or something, so if we don’t have time for re testing it, we still try to find and manage to find some ways to gather feedback even after it’s deployed.
Drew: And over time, one of the things that might be a concern probably from a technical point of view is that you’ve built on top of a UI framework and then a new version of that framework comes out and things have changed. Is that a situation that you’ve experienced where a new version has come, your developers want to update but it might have implications on the design?
Stéphanie: Yeah. The thing is we have test environments, so they’re really quick and easy thing to do is like, okay, let’s put in your version in one of those secure environment and see what is broken. So from when designers most of the time when they do a new version they tell developers, is it going to break? Like is this new version something completely new and it’s not compatible with the old version? Or is this new version something that is just an announcement and you might not break that many things. So yeah, obviously sometimes when you put a new version it completely breaks, but this is again, then you have like testing stories and like technical investigation stories to decide if we are going to migrate or not. Also like from what I understand in some of the environment I worked on, they kind of encapsulated those in web components.
Stéphanie: So they’re already has kind of two different version of Angulars on some components, it was using one version on the other ones it was using the other one and from what I understood it works because then you only encapsulate what you need. So this apparently is also a solution is then you can use whatever version you want, but I’m not a developer but I feel at some point you’ll be like, okay, this component is using that version of Angular and this one, this and this maybe kind of becomes super hard to maintain. Do you know?
Drew: Yup.
Stéphanie: It does. Okay. So yeah, you make sure it still works, but I don’t have the feeling that Material-UI are like those frameworks, even bootstrap for instance, they don’t have any new version every year or something. It’s a long lifecycle and in the case of my tool, I think this tool will be here for the next year, so we have eventually to update. But if you’re building kind of a online tool, more like a B to B product. Most of the time you revise every three years or something. And usually there is a new technology. I was talking to a friend and they’re currently working on a project where they’re rebuilding and riffing on React. The first version was built three years ago with another technology. I really don’t remember the technology, but they say, okay, we are three years later, they’re already rebuilding it. And I think in like three years, they will re-rebuild it. So at some points if you’re in like in B to C products, I even wonder if you update your framework or if you are going to change the design and rebuild it anyway in a few years from scratch.
Drew: Is there anything else that we should be considering when building on a UI framework?
Stéphanie: I feel we covered a lot of things. Well, the thing is like, there’s always a way to do it quick, user research, talk to users or at least do usability testing. Make sure you don’t design or build in a silo and try to have other people at least look at what you’ve created to make sure that the components as a developer, that you used as a developer I really do wonder are going to do the job. And don’t ask the designer to put paint on top of the framework at the end of the project because it’s kind of already too late to do big infrastructure on changes. It might not work.
Drew: So at Smashing, we have books, we have conferences, and of course, we have Smashing Magazine, a website with loads of articles. We’re all about learning. So what is it that you’ve been learning lately?
Stéphanie: I’ve been taking online introduction to psychology class.
Drew: Tell us a bit about that.
Stéphanie: Last lesson was actually super interesting. We were talking about visual illusions and how they work with your brain. So it’s really super complex and there’s… Apparently not everyone agrees on the explanation of most of those illusions, but it’s interesting because I had a small psychology lesson, like I read books on cognitive sciences and things like that. So I already knew kind of the basics, but it’s interesting to see like all the different aspects of psychology. So the interesting part of this course is it’s an introduction but it explains to you kind have all the branches from say child development psychology to trauma psychology to intercultural psychology. So and then illusions and I think this week it’s actually about cognitive psychology and how to apply psychology to interfaces. So all of those really, really interesting topics. And it’s nice because it’s an online class, so I’m basically learning stuff on my couch with some tea, and yeah, that’s really, really cool.
Drew: Oh, that’s super interesting. If you, dear listener, would like to hear more from Stéphanie. You can follow her on Twitter where she’s @WalterStephanie, or find her on the web at stephaniewalter.design. Thanks for joining us today, Stéphanie. Do you have any parting words for us?
Stéphanie: Thanks for having me. It was a smashing experience.

(dm, ra, il)
0 notes
Text
How to discover and curate content with Scoop.it

If you’ve been around here for a while, you know we’re always talking about ways content curation can help businesses thrive.
Any industry and company size can benefit from strategic content curation.
It can help turn your employees into your biggest advocates and your sales representatives into top sellers.
Content curation can grow the impact of your email newsletters, your social media, blog, content hubs, and even get your eCommerce store to attract more customers.
That’s why in this guide, we’re sharing exactly how Scoop.it can help you see success with content curation across your entire company.
We’re taking you on a Scoop.it tour. Let’s dive in!
Add the content URL to your Scoop.it topic page of choice
If you regularly spend time catching up on industry news, reports, and expert thought pieces, you may be looking for an easy way to curate them across your networks.
Scoop.it topics make that super easy.
First, you’ll create one or more topic pages on topics you want to curate content on. These will be topics relevant to your products and services, as well as those your potential and existing customers and employees care about.
Then, inside of a relevant topic, you’ll simply paste a link from the piece of content you were just reading or watching.
After pasting the link and hitting the green arrow button, you’ll get a chance to:
Add your own insight
Add and select social channels to share this piece of content on
Enter edit mode to change description or image and add tags
Select whether to post now or at a later time and date
You can do this any time you come across a curated piece of content worth sharing, wherever you find it.
Available to: All Scoop.it users, including those on the free plan
Add new content with Scoop.it Bookmarklet
The above process is quite simple. But what if you could add the blog posts, videos, and other pieces of content to your Scoop.it topics even more easily?
Scoop.it Bookmarklet helps you do exactly that on the fly. You won’t even have to leave the piece of content you’re consuming!
To add the Bookmarklet to your browser, open the Scoop.it Bookmarklet page. Add it to your browser bookmarks. Then, copy the text in the textbox by clicking the button below:

Then, head to the new bookmark you just made. Select to edit it and replace the URL in it with the text you just copied:
Once you’ve done that, you’re ready to bookmark anywhere on the internet!
When you’re on a page you’d like to add to one of your Scoop.it topics, simply click that bookmark.
The below box will pop up. Under Destination, you’ll choose the Scoop.it topic you’re adding this piece to.
Then, you’ll see all the standard options to edit the piece you’re scooping: adding insights, social sharing, editing description and tags, and choosing when to publish.
Time = saved!

Available to: All Scoop.it users, including those on the free plan
Use the content suggestions engine from your Scoop.it topic page
Curating content you’re already consuming anyway is easy.
But what if you’re having an extremely busy week and you…
Don’t have time to catch up on industry news?
Don’t want to curate just any content you find because you don’t have time to make sure it’s good and on topic?
Don’t want to go without showing up on your main channels?
That’s when some help would come in handy.
In Scoop.it, this help lives at the top right corner of your topic pages.
Once you click Suggestions, you’ll see a search engine you can use to get as many recommendations as you need and refine the criteria to find the best ones.
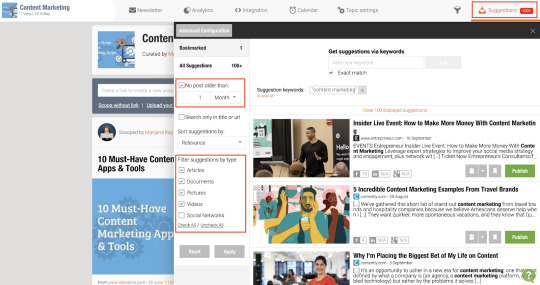
As you can see, you can choose:
If the content needs to match your exact search term
How old can the content be
Sorting by relevance or freshness
Filtering by format types including articles, documents, pictures, videos, and social networks
You can then publish the pieces you like (or schedule for later), bookmark for later, and even flag as irrelevant or discard altogether.
Available to: All Scoop.it users, including those on the free plan
Automatically curate from trusted sites with RSS feeds and sitemaps
Do you follow blogs and publications that always publish content that’s relevant and valuable to your audience?
If so, you can skip manual content curation altogether.
Instead of curating by adding URLs to your Scoop.it topics or using the Scoop.it Bookmarklet, you can add an RSS feed or a sitemap to your topic.
Then, Scoop.it will keep an eye on these sources and automatically add them to your Scoop.it topic when they go live.
It’s also easy to set up! In your Scoop.it topic of choice, click Settings, then Automatic Content Import:

Click a button to add an RSS feed, then enter the feed URL:

If you’re unsure of the RSS feed URL, here are two things you can do:
Type in the publication URL, including the https://, and add /feed to the end. This works for websites run on WordPress.
In case this doesn’t work, right click on the website’s page and choose Page Source. Then, use the search feature (Ctrl+F on a PC or Command+F on a Mac) and type in RSS. The feed’s URL is between the quotes after href=.
Once you’ve added all the sources you want to automatically add to your Scoop.it topic, you can manage them from the same page in your topic’s settings.

And just like that, your Scoop.it topic is already packed with content you already love and trust, even during the busiest of times. Magic!
Available to: Scoop.it users on Plus and Enterprise plans
Upload content that isn’t tied to a URL
Want to share an infographic, a graph, or even a research study in a PDF file, but you have them as a file rather than on a URL?
It’s easy and quick to do. Simply select Scoop without link or Upload your own document from your preferred Scoop.it topic page.
Then, add all the elements you want to share alongside this file or document.
Title and description are mandatory fields. These are great places to add attention-grabbing copy and make it clear what the content you’re scooping is about. It’s the same approach you’d use with a blog post you’re writing.
You can also add your own insight in a separate field, tag this scoop so you can easily find it later, and directly share it on social channels on the date and time you choose.
These options let you share images, free text, Microsoft Office files, and PDFs.

Available to: Scoop without link to Scoop.it Plus and Enterprise users, Upload your own document to Enterprise users
Use Scoop.it’s advanced suggestions engine
Do you want to get recommendations for content to curate, but in a more refined way?
Do you need them straight in your inbox instead of running a search every time?
Are you looking for content on the same topics, week after week?
You can automate all of this (and more) with the advanced suggestions engine on Scoop.it Enterprise.
All of your searches are available from this clean dashboard. You can use it to scoop these pieces of content to your Scoop.it topics and toggle between your saved searches from the menu on the left:
Adding new saved searches is easy. Simply click the New search on the left and enter your keywords:
One of the best advantages of the advanced suggestions engine is the specificity you can go into with your searches.
Inside any of your saved searches, you can click Edit and get extra specific on the conditions for the content suggestions you want to get.
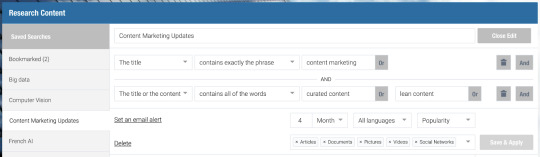
Here are the elements you can use:
Searching inside just the title, title and content, or domain
Containing or not containing some or all of the words you’ve entered
Modifiers for Boolean search: you can include or exclude results with AND and OR search parameters
Email alerts to automatically receive content that matches your search, and decide on the email frequency, content recency, language, and criteria
Filters for content format, such as articles, videos, and images
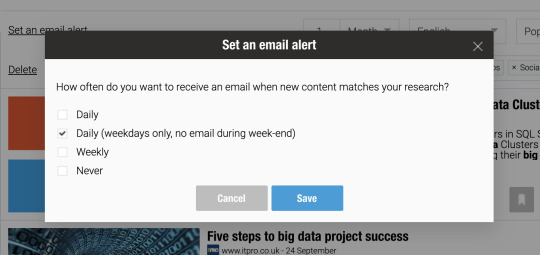
The best part? Once you set these searches and filters up, you don’t have to think about them again. Scoop.it does the work for you—all you need to do is view these searches, or your emails, regularly.
Available to: Scoop.it Enterprise users
Monitor content (your own or competitor’s) to never miss a thing
If you want to…
Track all the content sources you trust so you can curate fast
Monitor your competitor’s content, including their blog and social media
Keep an eye on all your content feeds, including your RSS feeds, social accounts, and YouTube channel
…you can do so from a single screen, in Scoop.it’s Content Monitoring.
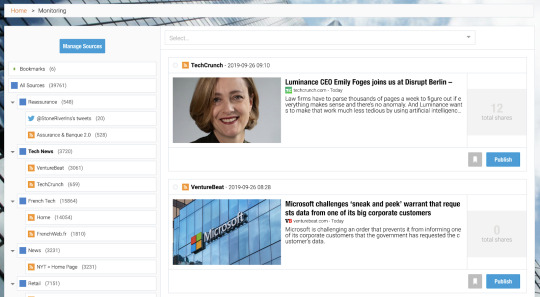
When you click Manage Sources inside your Content Monitoring dashboard, you can add as many sources as you want.
Scoop.it will give you the space to add special links such as Twitter lists and Facebook pages. You can even upload an OPML file with a list of sources if you have it.
Finally, once you’ve added all the sources you wanted to, you can organize them on the right-hand side by dragging and dropping them to the position you want. This way, they’ll be structured and easy to find when you’re working from your Content Monitoring dashboard.

Available to: Scoop.it Enterprise users
Get others in your company to suggest content for your Scoop.it topics
Once you’ve set up your Scoop.it account for success through suggestions, automated curation, and monitoring, there’s one thing left to do: getting your employees to contribute to your content curation.
In the past, you and your team may have used email or Slack messages to pass great content around.
Now, you can use Scoop.it to remove friction of emails and messages. Instead, all content goes directly into your designated Scoop.it topics.
This is what it looks like:
As you can see, instead of letting you scoop a post (with or without a link), this setup asks you to suggest it. When you’re setting up the roles in your Scoop.it Enterprise account, you can define who can scoop directly or add a suggestion.
This way, you can turn your team members and employees into your strongest content curation engine without adding more hurdles to the process.
All they need to do is add the piece of content to the relevant topic, and you’re good to go!
Available to: Scoop.it Enterprise users
Start curating content with Scoop.it now
You already knew content curation is a powerful strategy for your business, but you may have thought it’s time-consuming or hard to prioritize.
Now you know it doesn’t have to be that way. With the right tool, you can automate a huge part of the process, so you can focus on areas where you make the most impact.
Scoop.it will help you do just that. If this tour revealed a chance for you to succeed with curated content, make sure to get a free trial of Scoop.it or talk to us if you want a demo of Scoop.it Enterprise!
The post How to discover and curate content with Scoop.it appeared first on Scoop.it Blog.
How to discover and curate content with Scoop.it published first on https://improfitninja.weebly.com/
0 notes
Text
CS235 Project 5- Find Route in Map Solved
CS235 Project 5- Find Route in Map Solved
For this project you will design and implement two classes (City and RouteMap) to find a route, if one exists, from origin to destination city, given a particular map.
This project will build on ideas we have worked with already (reading input from a file, working with abstractions – i.e. a City and a RouteMap).
However this time you will be responsible for the design!
GitHub Classroom assignment…
View On WordPress
0 notes
Text
Doubts about sales slow the recovery of car production | Economy
Car registrations in the EU in March fell 55% and manufacturers are wary of how the market will react to the shaking of the coronavirus. Those doubts, added to those of the security measures and the suppliers, are holding back the return to vehicle production. Only three of the twelve Spanish assembly factories plan to do so on April 27, two weeks after the end of economic hibernation: Seat, Volkswagen and Mercedes. The rest will begin on May 4, except for the PSA and Renault plants, which have no date.
“We have the logistics chain ready and we are interested in producing now, but now there is no market to sell the cars and we cannot stake for stock,” says a spokesperson for PSA, the French group that controls the Peugeot, Citroën and Opel brands (among others) and which operates factories in Vigo, Zaragoza and Madrid. At Renault a similar reflection is repeated: “The problem is not that dealerships are opening, but that there is demand.”
No one knows for sure what the reaction of potential buyers will be, but the recession that threatens the world economy does not contribute to optimism in a sector that has already touched on 2020. With the Covid-19, all initial expectations have been ruined. And some more current, such as those of the consultancy PwC, predict that the European market will end this year by shrinking more than 30%. At the moment, dealers in half Europe are still closed. Germany has given good news: it will allow vendors to open as one of the measures to ease prolonged confinement until May 3.
Interestingly Volkswagen and Daimler (owner of Mercedes) are two of the groups that will begin to assemble vehicles sooner. Mercedes union sources, however, indicate that at the Vitoria plant the company has already announced that the production forecast for this year has fallen by 30,000 vehicles. And both Volkswagen plants in Pamplona and Seat in Martorell will pick up the idle pulse. Nissan, as Renault has done, will put its component and engine centers to work earlier, but manufacturing in Barcelona will start on May 4 and limited. He will only make the station wagons he makes for Mercedes. And it will be so because this May he had to make the last deliveries of that vehicle to the German group and now he must make up for lost time. At the moment, it will not manufacture anything else.
“Returning to business will not be easy and I don't think people will run to a dealership when this is over,” says Carlos Faubel, chairman of the Ford works council in Almussafes (Valencia). The American multinational has twice delayed the date of return to work. Now they work with the date of May 4, like Nissan and Iveco. Sources of the company also stress that 80% of its production – as it happens in the rest of the industry – is destined for export, but the main destination markets for cars made in Spain are affected by the crisis.
Auxiliary industry, ready
The automotive auxiliary industry says it is about to serve brands, but warns that it will be gradual. “The start curve of each company of automotive suppliers will not be homogeneous and will depend on the level of existing orders and the gradual opening of vehicle manufacturers in Spain and in Europe,” says José Portilla, CEO of the Sernauto association. Gestamp, the main Spanish group in the sector, says that it will open factories when manufacturers demand it.
“We depend on the market and suppliers,” says the spokesperson for the Volkswagen plant in Navarra. Its launch is an example of how companies are considering the return guaranteeing the security conditions agreed a week ago by employers and unions. It will begin on April 27 with a single shift of activity and on the third day it will stop again to analyze how the plan has worked and readjust the program. It will not be until May 5 that another shift will start, and then, between both working bands, an hour of inactivity will be set. The goal: avoid crowds.
Seat communicated yesterday to the works council to start the same day, but it will do so with a seventh part of the activity and it takes between six and eight weeks to reach normal production. For this reason, it has proposed a new temporary employment regulation file (ERTE) for that period. All brands will follow the same example.
Information about the coronavirus
– Here you can follow the last hour on the evolution of the pandemic
– This is how the coronavirus curve evolves in Spain and in each autonomy
– Questions and answers about coronavirus
– Guide to action against the disease
– In case of symptoms, these are the phones that have been enabled in each community
– Click here to subscribe to the daily pandemic newsletter
Due to the exceptional circumstances, EL PAÍS is offering all its digital content for free. Information regarding the coronavirus will remain open as long as the severity of the crisis persists.
Dozens of journalists work tirelessly to bring you the most rigorous coverage and fulfill their public service mission. If you want to support our journalism you can do it here for 1 Euro the first month (from June 10 euros). Subscribe to the facts.
Subscribe
The post Doubts about sales slow the recovery of car production | Economy appeared first on Cryptodictation.
from WordPress https://cryptodictation.com/2020/04/17/doubts-about-sales-slow-the-recovery-of-car-production-economy/
0 notes
Quote
Continuous Integration (CI) workflows are considered a best practice these days. As in, you work with your version control system (Git), and as you do, CI is doing work for you like running tests, sending notifications, and deploying code. That last part is called Continuous Deployment (CD). But shipping code to a production server often requires paid services. With GitHub Actions, Continuous Deployment is free for everyone. Let’s explore how to set that up. DevOps is for everyone As a front-end developer, continuous deployment workflows used to be exciting, but mysterious to me. I remember numerous times being scared to touch deployment configurations. I defaulted to the easy route instead — usually having someone else set it up and maintain it, or manual copying and pasting things in a worst-case scenario. As soon as I understood the basics of rsync, CD finally became tangible to me. With the following GitHub Action workflow, you do not need to be a DevOps specialist; but you’ll still have the tools at hand to set up best practice deployment workflows. The basics of a Continuous Deployment workflow So what’s the deal, how does this work? It all starts with CI, which means that you commit code to a shared remote repository, like GitHub, and every push to it will run automated tasks on a remote server. Those tasks could include test and build processes, like linting, concatenation, minification and image optimization, among others. CD also delivers code to a production website server. That may happen by copying the verified and built code and placing it on the server via FTP, SSH, or by shipping containers to an infrastructure. While every shared hosting package has FTP access, it’s rather unreliable and slow to send many files to a server. And while shipping application containers is a safe way to release complex applications, the infrastructure and setup can be rather complex as well. Deploying code via SSH though is fast, safe and flexible. Plus, it’s supported by many hosting packages. How to deploy with rsync An easy and efficient way to ship files to a server via SSH is rsync, a utility tool to sync files between a source and destination folder, drive or computer. It will only synchronize those files which have changed or don’t already exist at the destination. As it became a standard tool on popular Linux distributions, chances are high you don’t even need to install it. The most basic operation is as easy as calling rsync SRC DEST to sync files from one directory to another one. However, there are a couple of options you want to consider: -c compares file changes by checksum, not modification time -h outputs numbers in a more human readable format -a retains file attributes and permissions and recursively copies files and directories -v shows status output --delete deletes files from the destination that aren’t found in the source (anymore) --exclude prevents syncing specified files like the .git directory and node_modules And finally, you want to send the files to a remote server, which makes the full command look like this: rsync -chav --delete --exclude /.git/ --exclude /node_modules/ ./ [email protected]:/mydir You could run that command from your local computer to deploy to any live server. But how cool would it be if it was running in a controlled environment from a clean state? Right, that’s what you’re here for. Let’s move on with that. Create a GitHub Actions workflow With GitHub Actions you can configure workflows to run on any GitHub event. While there is a marketplace for GitHub Actions, we don’t need any of them but will build our own workflow. To get started, go to the “Actions” tab of your repository and click “Set up a workflow yourself.” This will open the workflow editor with a .yaml template that will be committed to the .github/workflows directory of your repository. When saved, the workflow checks out your repo code and runs some echo commands. name helps follow the status and results later. run contains the shell commands you want to run in each step. Define a deployment trigger Theoretically, every commit to the master branch should be production-ready. However, reality teaches you that you need to test results on the production server after deployment as well and you need to schedule that. We at bleech consider it a best practice to only deploy on workdays — except Fridays and only before 4:00 pm — to make sure we have time to roll back or fix issues during business hours if anything goes wrong. An easy way to get manual-level control is to set up a branch just for triggering deployments. That way, you can specifically merge your master branch into it whenever you are ready. Call that branch production, let everyone on your team know pushes to that branch are only allowed from the master branch and tell them to do it like this: git push origin master:production Here’s how to change your workflow trigger to only run on pushes to that production branch: name: Deployment on: push: branches: [ production ] Build and verify the theme I’ll assume you’re using Flynt, our WordPress starter theme, which comes with dependency management via Composer and npm as well as a preconfigured build process. If you’re using a different theme, the build process is likely to be similar, but might need adjustments. And if you’re checking in the built assets to your repository, you can skip all steps except the checkout command. For our example, let’s make sure that node is executed in the required version and that dependencies are installed before building: jobs: deploy: runs-on: ubuntu-latest steps: - uses: actions/checkout@v2 - uses: actions/[email protected] with: version: 12.x - name: Install dependencies run: | composer install -o npm install - name: Build run: npm run build The Flynt build task finally requires, lints, compiles, and transpiles Sass and JavaScript files, then adds revisioning to assets to prevent browser cache issues. If anything in the build step fails, the workflow will stop executing and thus prevents you from deploying a broken release. Configure server access and destination For the rsync command to run successfully, GitHub needs access to SSH into your server. This can be accomplished by: Generating a new SSH key (without a passphrase) Adding the public key to your ~/.ssh/authorized_keys on the production server Adding the private key as a secret with the name DEPLOY_KEY to the repository The sync workflow step needs to save the key to a local file, adjust file permissions and pass the file to the rsync command. The destination has to point to your WordPress theme directory on the production server. It’s convenient to define it as a variable so you know what to change when reusing the workflow for future projects. - name: Sync env: dest: '[email protected]:/mydir/wp-content/themes/mytheme’ run: | echo "$" > deploy_key chmod 600 ./deploy_key rsync -chav --delete \ -e 'ssh -i ./deploy_key -o StrictHostKeyChecking=no' \ --exclude /.git/ \ --exclude /.github/ \ --exclude /node_modules/ \ ./ $ Depending on your project structure, you might want to deploy plugins and other theme related files as well. To accomplish that, change the source and destination to the desired parent directory, make sure to check if the excluded files need an update, and check if any paths in the build process should be adjusted. Put the pieces together We’ve covered all necessary steps of the CD process. Now we need to run them in a sequence which should: Trigger on each push to the production branch Install dependencies Build and verify the code Send the result to a server via rsync The complete GitHub workflow will look like this: name: Deployment on: push: branches: [ production ] jobs: deploy: runs-on: ubuntu-latest steps: - uses: actions/checkout@v2 - uses: actions/[email protected] with: version: 12.x - name: Install dependencies run: | composer install -o npm install - name: Build run: npm run build - name: Sync env: dest: '[email protected]:/mydir/wp-content/themes/mytheme’ run: | echo "$" > deploy_key chmod 600 ./deploy_key rsync -chav --delete \ -e 'ssh -i ./deploy_key -o StrictHostKeyChecking=no' \ --exclude /.git/ \ --exclude /.github/ \ --exclude /node_modules/ \ ./ $ To test the workflow, commit the changes, pull them into your local repository and trigger the deployment by pushing your master branch to the production branch: git push origin master:production You can follow the status of the execution by going to the “Actions” tab in GitHub, then selecting the recent execution and clicking on the “deploy“ job. The green checkmarks indicate that everything went smoothly. If there are any issues, check the logs of the failed step to fix them. Check the full report on GitHub Congratulations! You’ve successfully deployed your WordPress theme to a server. The workflow file can easily be reused for future projects, making continuous deployment setups a breeze. To further refine your deployment process, the following topics are worth considering: Caching dependencies to speed up the GitHub workflow Activating the WordPress maintenance mode while syncing files Clearing the website cache of a plugin (like Cache Enabler) after the deployment
http://damianfallon.blogspot.com/2020/04/continuous-deployments-for-wordpress.html
0 notes
Text
Smashing Podcast Episode 11 With Eduardo Bouças: What Is Sourcebit?
About The Author
Drew is a director at edgeofmyseat.com, co-founder of Notist and lead developer for small content management system Perch. Prior to this, he was a Web Developer … More about Drew McLellan …
In this episode of the Smashing Podcast, we’re talking about an interesting open-source tool called Sourcebit. How can it help our content workflow with JAMstack sites? Drew McLellan speaks to developer Eduardo Bouças to find out.
In this episode of the Smashing Podcast, we’re talking about an interesting open-source tool called Sourcebit. How can it help our content workflow with JAMstack sites? I spoke to developer Eduardo Bouças to find out.
Show Notes
Weekly Update
Transcript
Drew McLellan: He’s a web developer, technologist, writer and occasional public speaker with a strong track record of working on open source projects. He works as a software engineer on the JAMstack site management platform, Stackbit, and develops open source tools such as Staticman, Speedtracker, and Sourcebit. So we know he’s an expert in the modern web platform. But did you know he’s deathly allergic to Wednesday? My Smashing friends please welcome Eduardo Boucas. Hi, Eduardo, how are you?
Eduardo Bouças: I’m Smashing.
Drew: I wanted to talk to you today about a tool that I know you’ve been working on called Sourcebit. I know you do a lot of work both at the day job Stackbit, and personally in your own time, around sort of tooling with sort of what we now call JAMstack sites. So before we talk about what Sourcebit does itself, perhaps you can tell us a bit about the sort of scenario with the JAMstack site that might lead to somebody needing a tool like Sourcebit.
Eduardo: Sure. So to go back in time a little bit when I started using a static site generator. My first encounter with a JAMstack was with Jekyll, as I’m sure many people are as well. And when I started using Jekyll for my site, the authoring experience was a bit cumbersome. So it involved manually editing Markdown files on my local machine and then pushing them to get repo and then the thing would get integrated and built. And that’s still a workflow that exists today and that many people use and it makes sense for a lot of people in a lot of organizations. But, first of all, it doesn’t scale very well if you have like a larger team and especially if you have people from less technical backgrounds who may not be comfortable with Markdown or with using Git or with that whole pushing to a GitHub repo workflow.
Eduardo: And so it makes a lot of sense, in my opinion to couple a static site generator with what is now these days called a headless or a decoupled CMS. So if you come from a more traditional web development background where you might use something like WordPress, a headless CMS is something that behaves in a very similar way. So you still have this interface where you can author your content, and you have a nice WYSIWYG editor and media management and everything.
Eduardo: But the output of such a platform is not a fully formatted HTML page. And instead, the content is exported in a way in a format that is agnostic of any technology or any tech stack. And so that content is, it’s possible to integrate that content with your static site generator. And that’s why I think it makes a lot of sense to couple a headless CMS with a static site generator because you kind of get the best of both worlds in the sense that you get the performance, the security and the simplicity of using a static site generator, but at the same time, you still get kind of a rich authoring experience by using a nice editorial interface.
Eduardo: And even though it makes a lot of sense to couple those two tools together, it’s not particularly straightforward to integrate them. Especially if you’re using a more traditional file based static site generator, such as Jekyll or Hugo, where everything has to live as a file. So how do you take that content that lives in this headless CMS? And how do you translate that into files that your static site generator can understand and process?
Eduardo: As you said, I’m super passionate about creating tools for developers and particularly creating tools that allows developers to use the JAMstack paradigm with as little friction as possible. And that’s where source that comes in. That’s why I’m super passionate about this project in particular. So the idea is, that Sourcebit allows you to connect to any API based data source such as a headless CMS, you sort of tell it where your content lives, you help it make some sense of the structure of your content. And then Sourcebit takes care of sucking all that content down and writing it into the files with the formats into location static site generator is expecting. So that’s kind of the idea behind Sourcebit.
Drew: So rather than having authors work directly with markdown files, that your static site generator turns to a site, you’ve got your authors working with another tool, a headless CMS, maybe something like Contentful or even WordPress, and then Sourcebit is the bit in between that gets that content from where it’s been authored, and translates it in a way into a format that the static site generator can turn into a static site?
Eduardo: Exactly, yeah. And the way that it could, kind of see two different ways of using the tool that can help developers. One is making Sourcebit part of your deployment routine. So if you’re using a hosting platform like Netlify, for example, and you configure your deploy commands to be a Hugo build, is it the build command for Hugo or something said, so the command that generates the static files for Hugo, you would also have another command as part of that routine. That would be something like Sourcebit fetch. And so at build time, Sourcebit will go pull all the other data, generate all the files that Hugo needs. And then the whole deployment will already use those files and deploy all the content that is coming from the CMS. So that’s kind of one possible use case for Sourcebit.
Eduardo: The other one is to use Sourcebit in a local development workflow. So you can run Sourcebit with something that we call the watch mode. And so Sourcebit keeps looking for changes in the remote data source, so in this case, headless CMS. And so whenever you publish an article or you change an entry into CMS Sourcebit will acknowledge that and it will regenerate all the files for you locally. And so what that means for a developer working locally is that you can have your CMS window next to your Jekyll or Hugo site, running locally, and then you can see changes happening in real time. You change something on the CMS and then you can see that change being reflected on the local side, which I find super useful. So those are kind of the two ways that you could get use Sourcebit.
Drew: So I guess for all that to work Sourcebit has to know about both the system that the content’s stored in and the way that the static site generator needs the files organized in the file system. How do those two things work?
Eduardo: Sourcebit is a plugin-based architecture. So the idea is that you’re going to have different types of plugins that will accomplish different tasks. We have something that we call the source plugins, which are solely responsible for connecting to a data source like Contentful, for example, and they will connect to that data source, they will pull content and they will normalize that content into a format that is kind of agnostic of data source such that if you want to connect multiple data sources, so you’re using WordPress and Contentful, and Sanity, for example, all the content from those data sources will be normalized into a format that is kind of standardized across the board. So the responsibility of the source plugins will be to just that, to connect to a data source, normalize the content and put them into a bucket of data.
Eduardo: And then you have another type of plugin which we call a target plugin. And the target plugin has no knowledge whatsoever about where the data is coming from, but it knows about a particular piece of software that is expecting that data for example, you might have a target plugin for Hugo a target plugin for Jekyll. So the target plug in will be responsible for writing that data into specific format and the specific locations that the static site generated is expecting.
Eduardo: And then you might have other types of plugins that don’t know about the source and don’t know about destination. They’re just responsible for kind of massaging the data and doing all sorts of transformations in between. So that’s kind of the way that the tool is organized. And I think the benefit of that approach is that each plugin is only concerned about a specific area. So if you are, let’s say that you’re maintaining the source plugin for Contentful, you don’t ever need to worry about what static site generators will be supported. You just worry about maintaining that specific plugin that we take care of making sure that it can be plugged in into any combination of static site generators or different outputs that you want to use.
Drew: So is it possible to have multiple sources running at once and use a Sourcebit more like a content aggregator to pull them from lots of different sources at once?
Eduardo: Yes, yes, it’s totally possible. And that’s why we kind of use that principle of normalizing the data, because you might have as many data sources as you want. And then when a plugin comes in to kind of transform that data, it doesn’t really care where the data comes from, everything is treated the same. So it’s totally possible to do that. You can configure as many source plugins as you want. And so it’ll pull data from as many places as you want.
Drew: Yeah, that could be quite interesting. Could you think of a corporate website might have a blog in there, it might have copy from marketing agency, it might have job openings coming from an HR system. And you could potentially configure Sourcebit to pull that into one location before generating the site, which is quite an exciting prospect, I think.
Eduardo: Yeah, yeah. And CMS is are just one possible data source that you might use this tool with. For example, one of my colleagues that started was creating a source plugin that pulls data from Reddit, for example. And that’s just one very simple example of one possible data source. So as you say, it could get quite interesting because you might be pulling data from a CMS, might be pulling data from Reddit, Twitter or an HR platform and it just all comes down together nicely. So, yeah, it’s a possible use case for it for sure.
Drew: What sort of plugins exist at the moment for different sources?
Eduardo: So we launched the first kind of public version of the tool last week. And we launched with a two source plugins and two target plugins. So the source plugins are for Contentful and Sanity. And the target plugins are for Jacqueline and Hugo. We will keep working on your plugins internally at Stackbit. But our goal is for the community to eventually take ownership of the tool as well like this is a fully open source MIT license project. And so we would love to see people creating their plugins and building stuff with Sourcebit that we haven’t even thought of. So, that’s the ultimate goal. We’ve been in touch with people from different CMS companies who are interested in building their plugins as well. So we’re in constant contact with them. So hopefully we’ll see a nice ecosystem of plugins somewhat soon.
Drew: How complex is it to develop a plugin if you’ve got a completely custom system that you know that you need to integrate with? Is it a very involved difficult task to develop plugin or is it easier than that?
Eduardo: I’m a bit biased to answer that. I like to think that it’s simple and I’ve tried my best to make the process simple and also very well documented. So we have one of the repositories that we make available is kind of a sample plugin, where we have a fully annotated source code for a plugin. So we have comments on every possible function that you might implement outlining the arguments that it receives, how you can use this function to get data from this etc. So hopefully that’ll be a very useful resource. We also have documentation pages where we kind of outline the anatomy of a plugin, like how it pulls data where it’s supposed to push that into. So hopefully, it’s a fairly straightforward process.
Eduardo: But different systems will present different challenges. So I’m sure there will be suggestions and feature requests from someone in the community saying, “I want to integrate with this system. So I kind of need a way of doing this.” And we’ll be more than happy to kind of accommodate those requests and kind of work with the community to make the plugin architecture better over time.
Drew: And it’s all written in, I presume is JavaScript node?
Eduardo: It is. It is.
Drew: I noticed that you mentioned earlier briefly that you can run Sourcebit with a watch flag, and it will help you to have a sort of live updating workflow. Is that something that needs to be implemented by the source plugin, or is that general system? Is it a polling mechanism or are you listening for sort of hooks and things from the source system?
Eduardo: The core application is very lean, and it’s not opinionated at all. So it’s up to each Source plugin to kind of implement that functionality. All the core application does on that front is it tells the plugin what are the kind of the options that the user asked for. So in the two plugins that we launched with, so we have one for Contentful, and one for Sanity, the way that the watch mode is implemented in each of them is very different. For example, in Contentful we have, as I mentioned, a polling mechanism in a regular interval of time, like poll for changes whereas for Sanity, we have like a running web socket that is constantly listening for changes and respond to the changes. But basically, the idea is that the source plugin implements its own listening mechanism and it’s responsible for telling the core application that I have new content please update yourself. That’s kind of the domain idea.
Drew: That sounds like quite a flexible system then that should cope with lots of different sources and different types of system.
Eduardo: Yes. I was just going to say like still on that topic of flexibility, one thing that I wanted to mention as well is Sourcebit is configured using a JavaScript file. So if something similar to what you would do with some like web pack, for example, although a bit simpler. And so you have the option to configure each of the plugins on that file manually. But we also offer this commandline interface, where basically each plugin is able to tell the core application the set of questions that it needs to ask the user in order to configure itself. So basically, when you run npx create-sourcebit, it can create everything from scratch for you.
Eduardo: So it pulls a list of all the available plugins to have the option to sit on a source plugin for Contentful and the target plugin for Jekyll, for example. And then based on the plugins that you choose, it then asks you a series of questions that will ultimately lead to a fully configured JavaScript file. So for example, for Contentful it’ll ask you for your credentials, like how do I access your Contentful account? And then it will actually pull all the content types from Contentful. And it’ll ask you okay, I found this content type called blog posts. What is this? Is this like a page? Is this a data object? And if it’s a page, where should I store this? What kind of fields should I use for the layout for the content?
Eduardo: I think it’s a very user friendly way of configuring the whole project. So hopefully, by the end of this configuration process, you can just run a command and you can pull the content straight away without having to mess around with JavaScript files.
Drew: So that configuration process answering those questions, then writes the JavaScript configuration file for you, which you can then presumably just commit into your source control and distribute to other developers on your project or into your build process for running live. You mentioned a third type of plugin distinct from the source and the target that works on data in this agnostic format in the middle. What sort of scenarios do you imagine that being used for?
Eduardo: We created a plugin that is responsible for transforming assets. So to give you an example, let’s say that I’m using Contentful, and you have images embedded as part of a blog post. And by default, if you just pull that data from Contentful, the images will be using a live URL from like Contentful CDN which is a totally viable option if that’s what you want to use. But you might want to instead, serve the images alongside the content. So have them in your repo and served from whatever service you’re using to serve to site as well. And so that plugin in specific, it will look for any assets that are using, it will pull those assets down, download them basically to your repo or to your local file system which it can then push.
Eduardo: And it will replace any URLs in your files that reference that remote URL, it’ll replace those with references to the local files instead. So basically, when you push the site, you push the content and the assets and everything will just work seamlessly. So, that’s one example of kind of a transformation plugin that is not pulling. It’s not specific to a data source and it’s not specific to a static site generator. It just transforms things in between.
Drew: You mentioned that there are target plugins for Jekyll and Hugo, are there any that you’re expecting to see in the near future?
Eduardo: Well, I’m a big fan of Eleventy. So I’m really hoping to see an Eleventy plugin coming out fairly soon. And then I guess there are some static site generators that already have their own kind of plugin ecosystem. So I’m curious to see if people will still find a need to have a source plugin for those types of static site generators. Like another possible way that you can use Sourcebit by the way, is if you’re using something like Next.js, so like any node based static site generator. You don’t necessarily need a target plugin, you can just require Sourcebit as an NPM module, and you can run the all the mechanisms for fetching data. You can just run those as in memory functions and get your content available as part of your Next.js pages. To answer your question, I guess for those we won’t see target plugins specifically, but we can already use Sourcebit in that way. In terms of next source plugins, I would expect to see Eleventy and maybe a few other kind of file based static site generators in the near future.
Drew: This is all quite exciting stuff, I think. Is it just you working on it in terms of development or is there a bigger team?
Eduardo: I’ve been kind of the main developer working on it, but it’s a team effort. So it’s something that a bunch of people at Stackbit identified as a problem. And we’ve been working together on kind of specification and the right way to approach this. I just happen to be the guy pressing the keys to make it happen.
Drew: And I guess Sourcebit actually can be very useful for Stackbit customers, which is Stackbits motivation for developing and contributing this but obviously, it’s going to be useful to a much wider audience than just Stackbit customers.
Eduardo: Yeah, we have big plans for Sourcebit internally. It’ll really help us achieve our mission in terms of making JAMstack, accessible to as many people as possible, but we wanted to make sure that we share this particular project with the community because we feel that it’ll help a lot of people regardless of whether they’re interested in using Stackbit or not. So that’s why it’s a fully open source project.
Drew: That’s great. Is there anything else you’d like to tell us about Sourcebit?
Eduardo: No. I would just love people to try it out. I’m sure we can share links to like the repo and stuff like that. There’s a YouTube video in the main repository, that shows how the experience is like when using Sourcebit with a headless CMS and a static site generator. So it kind of gives you an idea of what it’s like to use the CLI and the whole interactive setup process, and I would just love people to try it out. And get in touch if they think it could be improved or it’s terrible, or it’s great, or it’s helping them. So yeah, I would love to hear from people.
Drew: That’s great. We’ll link that all from the show notes, but also Sourcebit be found at github.com/stackbithq/sourcebit. So I’ve been learning all about Sourcebit today, what have you been learning about lately?
Eduardo: I’ve been super interested in learning about Serverless. And I’ve actually been trying to learn as much as possible about it for the past few months. It’s a concept that I’m super interested in. It’s one of those seismic changes in how you approach development. And I’m super interested in kind of the use cases that it has and kind of the different ways of rethinking how you build an application for Serverless. So that’s something that I’ve been trying to read about as much as possible and just playing around and trying, like side projects. Yeah, it’s an area I’m super passionate about.
Drew: It’s very interesting, isn’t it? Quite a shift in how you have to think about projects?
Eduardo: Definitely, definitely. There’s a metaphor, and I don’t want to ramble about Serverless here, which is that a metaphor that I think is really helpful is to think about Serverless as kind of using Uber as opposed to owning a car, like it forces you to, you still have a car, like the term Serverless maybe is a bit misleading because you still have a server, but if you have a car, you might just leave your stuff in the car because you know it’s going to be there the next day, whereas if you’re using at Uber, it forces you to rethink and to acknowledge that every day you’re going to get a new car with different people driving it, and it just have to adapt your way around that fact. So, that metaphor really helped me wrap my head around the whole Serverless paradigm.
Drew: Yes, I had not heard that before, that’s quite an interesting way of looking at it. If you, dear listener, would like to hear more from Eduardo, you can follow him on Twitter, where he’s @Eduardoboucas. And you can find his web development periodical build times at Eduardoboucas.com. Thanks for joining us today. Eduardo. Do you have any parting words?
Eduardo: No, not really. Just first of all, thank you so much for having me. It’s been a pleasure. And by the way that weird pronunciation for my last name, maybe I should say that it’s, if you want to find my Twitter handle and website the surname is B-O-U-C-A-S. Boucas is another weird Portuguese pronunciation if you want to find, it’s Eduardoboucas. So, yeah, thank you so much for having me. It’s been a pleasure.
Drew: Thank you so much.
(dm, ra, il)
Website Design & SEO Delray Beach by DBL07.co
Delray Beach SEO
source http://www.scpie.org/smashing-podcast-episode-11-with-eduardo-boucas-what-is-sourcebit/ source https://scpie.tumblr.com/post/612281392186998784
0 notes
Text
Smashing Podcast Episode 11 With Eduardo Bouças: What Is Sourcebit?
About The Author
Drew is a director at edgeofmyseat.com, co-founder of Notist and lead developer for small content management system Perch. Prior to this, he was a Web Developer … More about Drew McLellan …
In this episode of the Smashing Podcast, we’re talking about an interesting open-source tool called Sourcebit. How can it help our content workflow with JAMstack sites? Drew McLellan speaks to developer Eduardo Bouças to find out.
In this episode of the Smashing Podcast, we’re talking about an interesting open-source tool called Sourcebit. How can it help our content workflow with JAMstack sites? I spoke to developer Eduardo Bouças to find out.
Show Notes
Weekly Update
Transcript
Drew McLellan: He’s a web developer, technologist, writer and occasional public speaker with a strong track record of working on open source projects. He works as a software engineer on the JAMstack site management platform, Stackbit, and develops open source tools such as Staticman, Speedtracker, and Sourcebit. So we know he’s an expert in the modern web platform. But did you know he’s deathly allergic to Wednesday? My Smashing friends please welcome Eduardo Boucas. Hi, Eduardo, how are you?
Eduardo Bouças: I’m Smashing.
Drew: I wanted to talk to you today about a tool that I know you’ve been working on called Sourcebit. I know you do a lot of work both at the day job Stackbit, and personally in your own time, around sort of tooling with sort of what we now call JAMstack sites. So before we talk about what Sourcebit does itself, perhaps you can tell us a bit about the sort of scenario with the JAMstack site that might lead to somebody needing a tool like Sourcebit.
Eduardo: Sure. So to go back in time a little bit when I started using a static site generator. My first encounter with a JAMstack was with Jekyll, as I’m sure many people are as well. And when I started using Jekyll for my site, the authoring experience was a bit cumbersome. So it involved manually editing Markdown files on my local machine and then pushing them to get repo and then the thing would get integrated and built. And that’s still a workflow that exists today and that many people use and it makes sense for a lot of people in a lot of organizations. But, first of all, it doesn’t scale very well if you have like a larger team and especially if you have people from less technical backgrounds who may not be comfortable with Markdown or with using Git or with that whole pushing to a GitHub repo workflow.
Eduardo: And so it makes a lot of sense, in my opinion to couple a static site generator with what is now these days called a headless or a decoupled CMS. So if you come from a more traditional web development background where you might use something like WordPress, a headless CMS is something that behaves in a very similar way. So you still have this interface where you can author your content, and you have a nice WYSIWYG editor and media management and everything.
Eduardo: But the output of such a platform is not a fully formatted HTML page. And instead, the content is exported in a way in a format that is agnostic of any technology or any tech stack. And so that content is, it’s possible to integrate that content with your static site generator. And that’s why I think it makes a lot of sense to couple a headless CMS with a static site generator because you kind of get the best of both worlds in the sense that you get the performance, the security and the simplicity of using a static site generator, but at the same time, you still get kind of a rich authoring experience by using a nice editorial interface.
Eduardo: And even though it makes a lot of sense to couple those two tools together, it’s not particularly straightforward to integrate them. Especially if you’re using a more traditional file based static site generator, such as Jekyll or Hugo, where everything has to live as a file. So how do you take that content that lives in this headless CMS? And how do you translate that into files that your static site generator can understand and process?
Eduardo: As you said, I’m super passionate about creating tools for developers and particularly creating tools that allows developers to use the JAMstack paradigm with as little friction as possible. And that’s where source that comes in. That’s why I’m super passionate about this project in particular. So the idea is, that Sourcebit allows you to connect to any API based data source such as a headless CMS, you sort of tell it where your content lives, you help it make some sense of the structure of your content. And then Sourcebit takes care of sucking all that content down and writing it into the files with the formats into location static site generator is expecting. So that’s kind of the idea behind Sourcebit.
Drew: So rather than having authors work directly with markdown files, that your static site generator turns to a site, you’ve got your authors working with another tool, a headless CMS, maybe something like Contentful or even WordPress, and then Sourcebit is the bit in between that gets that content from where it’s been authored, and translates it in a way into a format that the static site generator can turn into a static site?
Eduardo: Exactly, yeah. And the way that it could, kind of see two different ways of using the tool that can help developers. One is making Sourcebit part of your deployment routine. So if you’re using a hosting platform like Netlify, for example, and you configure your deploy commands to be a Hugo build, is it the build command for Hugo or something said, so the command that generates the static files for Hugo, you would also have another command as part of that routine. That would be something like Sourcebit fetch. And so at build time, Sourcebit will go pull all the other data, generate all the files that Hugo needs. And then the whole deployment will already use those files and deploy all the content that is coming from the CMS. So that’s kind of one possible use case for Sourcebit.
Eduardo: The other one is to use Sourcebit in a local development workflow. So you can run Sourcebit with something that we call the watch mode. And so Sourcebit keeps looking for changes in the remote data source, so in this case, headless CMS. And so whenever you publish an article or you change an entry into CMS Sourcebit will acknowledge that and it will regenerate all the files for you locally. And so what that means for a developer working locally is that you can have your CMS window next to your Jekyll or Hugo site, running locally, and then you can see changes happening in real time. You change something on the CMS and then you can see that change being reflected on the local side, which I find super useful. So those are kind of the two ways that you could get use Sourcebit.
Drew: So I guess for all that to work Sourcebit has to know about both the system that the content’s stored in and the way that the static site generator needs the files organized in the file system. How do those two things work?
Eduardo: Sourcebit is a plugin-based architecture. So the idea is that you’re going to have different types of plugins that will accomplish different tasks. We have something that we call the source plugins, which are solely responsible for connecting to a data source like Contentful, for example, and they will connect to that data source, they will pull content and they will normalize that content into a format that is kind of agnostic of data source such that if you want to connect multiple data sources, so you’re using WordPress and Contentful, and Sanity, for example, all the content from those data sources will be normalized into a format that is kind of standardized across the board. So the responsibility of the source plugins will be to just that, to connect to a data source, normalize the content and put them into a bucket of data.
Eduardo: And then you have another type of plugin which we call a target plugin. And the target plugin has no knowledge whatsoever about where the data is coming from, but it knows about a particular piece of software that is expecting that data for example, you might have a target plugin for Hugo a target plugin for Jekyll. So the target plug in will be responsible for writing that data into specific format and the specific locations that the static site generated is expecting.
Eduardo: And then you might have other types of plugins that don’t know about the source and don’t know about destination. They’re just responsible for kind of massaging the data and doing all sorts of transformations in between. So that’s kind of the way that the tool is organized. And I think the benefit of that approach is that each plugin is only concerned about a specific area. So if you are, let’s say that you’re maintaining the source plugin for Contentful, you don’t ever need to worry about what static site generators will be supported. You just worry about maintaining that specific plugin that we take care of making sure that it can be plugged in into any combination of static site generators or different outputs that you want to use.
Drew: So is it possible to have multiple sources running at once and use a Sourcebit more like a content aggregator to pull them from lots of different sources at once?
Eduardo: Yes, yes, it’s totally possible. And that’s why we kind of use that principle of normalizing the data, because you might have as many data sources as you want. And then when a plugin comes in to kind of transform that data, it doesn’t really care where the data comes from, everything is treated the same. So it’s totally possible to do that. You can configure as many source plugins as you want. And so it’ll pull data from as many places as you want.
Drew: Yeah, that could be quite interesting. Could you think of a corporate website might have a blog in there, it might have copy from marketing agency, it might have job openings coming from an HR system. And you could potentially configure Sourcebit to pull that into one location before generating the site, which is quite an exciting prospect, I think.
Eduardo: Yeah, yeah. And CMS is are just one possible data source that you might use this tool with. For example, one of my colleagues that started was creating a source plugin that pulls data from Reddit, for example. And that’s just one very simple example of one possible data source. So as you say, it could get quite interesting because you might be pulling data from a CMS, might be pulling data from Reddit, Twitter or an HR platform and it just all comes down together nicely. So, yeah, it’s a possible use case for it for sure.
Drew: What sort of plugins exist at the moment for different sources?
Eduardo: So we launched the first kind of public version of the tool last week. And we launched with a two source plugins and two target plugins. So the source plugins are for Contentful and Sanity. And the target plugins are for Jacqueline and Hugo. We will keep working on your plugins internally at Stackbit. But our goal is for the community to eventually take ownership of the tool as well like this is a fully open source MIT license project. And so we would love to see people creating their plugins and building stuff with Sourcebit that we haven’t even thought of. So, that’s the ultimate goal. We’ve been in touch with people from different CMS companies who are interested in building their plugins as well. So we’re in constant contact with them. So hopefully we’ll see a nice ecosystem of plugins somewhat soon.
Drew: How complex is it to develop a plugin if you’ve got a completely custom system that you know that you need to integrate with? Is it a very involved difficult task to develop plugin or is it easier than that?
Eduardo: I’m a bit biased to answer that. I like to think that it’s simple and I’ve tried my best to make the process simple and also very well documented. So we have one of the repositories that we make available is kind of a sample plugin, where we have a fully annotated source code for a plugin. So we have comments on every possible function that you might implement outlining the arguments that it receives, how you can use this function to get data from this etc. So hopefully that’ll be a very useful resource. We also have documentation pages where we kind of outline the anatomy of a plugin, like how it pulls data where it’s supposed to push that into. So hopefully, it’s a fairly straightforward process.
Eduardo: But different systems will present different challenges. So I’m sure there will be suggestions and feature requests from someone in the community saying, “I want to integrate with this system. So I kind of need a way of doing this.” And we’ll be more than happy to kind of accommodate those requests and kind of work with the community to make the plugin architecture better over time.
Drew: And it’s all written in, I presume is JavaScript node?
Eduardo: It is. It is.
Drew: I noticed that you mentioned earlier briefly that you can run Sourcebit with a watch flag, and it will help you to have a sort of live updating workflow. Is that something that needs to be implemented by the source plugin, or is that general system? Is it a polling mechanism or are you listening for sort of hooks and things from the source system?
Eduardo: The core application is very lean, and it’s not opinionated at all. So it’s up to each Source plugin to kind of implement that functionality. All the core application does on that front is it tells the plugin what are the kind of the options that the user asked for. So in the two plugins that we launched with, so we have one for Contentful, and one for Sanity, the way that the watch mode is implemented in each of them is very different. For example, in Contentful we have, as I mentioned, a polling mechanism in a regular interval of time, like poll for changes whereas for Sanity, we have like a running web socket that is constantly listening for changes and respond to the changes. But basically, the idea is that the source plugin implements its own listening mechanism and it’s responsible for telling the core application that I have new content please update yourself. That’s kind of the domain idea.
Drew: That sounds like quite a flexible system then that should cope with lots of different sources and different types of system.
Eduardo: Yes. I was just going to say like still on that topic of flexibility, one thing that I wanted to mention as well is Sourcebit is configured using a JavaScript file. So if something similar to what you would do with some like web pack, for example, although a bit simpler. And so you have the option to configure each of the plugins on that file manually. But we also offer this commandline interface, where basically each plugin is able to tell the core application the set of questions that it needs to ask the user in order to configure itself. So basically, when you run npx create-sourcebit, it can create everything from scratch for you.
Eduardo: So it pulls a list of all the available plugins to have the option to sit on a source plugin for Contentful and the target plugin for Jekyll, for example. And then based on the plugins that you choose, it then asks you a series of questions that will ultimately lead to a fully configured JavaScript file. So for example, for Contentful it’ll ask you for your credentials, like how do I access your Contentful account? And then it will actually pull all the content types from Contentful. And it’ll ask you okay, I found this content type called blog posts. What is this? Is this like a page? Is this a data object? And if it’s a page, where should I store this? What kind of fields should I use for the layout for the content?
Eduardo: I think it’s a very user friendly way of configuring the whole project. So hopefully, by the end of this configuration process, you can just run a command and you can pull the content straight away without having to mess around with JavaScript files.
Drew: So that configuration process answering those questions, then writes the JavaScript configuration file for you, which you can then presumably just commit into your source control and distribute to other developers on your project or into your build process for running live. You mentioned a third type of plugin distinct from the source and the target that works on data in this agnostic format in the middle. What sort of scenarios do you imagine that being used for?
Eduardo: We created a plugin that is responsible for transforming assets. So to give you an example, let’s say that I’m using Contentful, and you have images embedded as part of a blog post. And by default, if you just pull that data from Contentful, the images will be using a live URL from like Contentful CDN which is a totally viable option if that’s what you want to use. But you might want to instead, serve the images alongside the content. So have them in your repo and served from whatever service you’re using to serve to site as well. And so that plugin in specific, it will look for any assets that are using, it will pull those assets down, download them basically to your repo or to your local file system which it can then push.
Eduardo: And it will replace any URLs in your files that reference that remote URL, it’ll replace those with references to the local files instead. So basically, when you push the site, you push the content and the assets and everything will just work seamlessly. So, that’s one example of kind of a transformation plugin that is not pulling. It’s not specific to a data source and it’s not specific to a static site generator. It just transforms things in between.
Drew: You mentioned that there are target plugins for Jekyll and Hugo, are there any that you’re expecting to see in the near future?
Eduardo: Well, I’m a big fan of Eleventy. So I’m really hoping to see an Eleventy plugin coming out fairly soon. And then I guess there are some static site generators that already have their own kind of plugin ecosystem. So I’m curious to see if people will still find a need to have a source plugin for those types of static site generators. Like another possible way that you can use Sourcebit by the way, is if you’re using something like Next.js, so like any node based static site generator. You don’t necessarily need a target plugin, you can just require Sourcebit as an NPM module, and you can run the all the mechanisms for fetching data. You can just run those as in memory functions and get your content available as part of your Next.js pages. To answer your question, I guess for those we won’t see target plugins specifically, but we can already use Sourcebit in that way. In terms of next source plugins, I would expect to see Eleventy and maybe a few other kind of file based static site generators in the near future.
Drew: This is all quite exciting stuff, I think. Is it just you working on it in terms of development or is there a bigger team?
Eduardo: I’ve been kind of the main developer working on it, but it’s a team effort. So it’s something that a bunch of people at Stackbit identified as a problem. And we’ve been working together on kind of specification and the right way to approach this. I just happen to be the guy pressing the keys to make it happen.
Drew: And I guess Sourcebit actually can be very useful for Stackbit customers, which is Stackbits motivation for developing and contributing this but obviously, it’s going to be useful to a much wider audience than just Stackbit customers.
Eduardo: Yeah, we have big plans for Sourcebit internally. It’ll really help us achieve our mission in terms of making JAMstack, accessible to as many people as possible, but we wanted to make sure that we share this particular project with the community because we feel that it’ll help a lot of people regardless of whether they’re interested in using Stackbit or not. So that’s why it’s a fully open source project.
Drew: That’s great. Is there anything else you’d like to tell us about Sourcebit?
Eduardo: No. I would just love people to try it out. I’m sure we can share links to like the repo and stuff like that. There’s a YouTube video in the main repository, that shows how the experience is like when using Sourcebit with a headless CMS and a static site generator. So it kind of gives you an idea of what it’s like to use the CLI and the whole interactive setup process, and I would just love people to try it out. And get in touch if they think it could be improved or it’s terrible, or it’s great, or it’s helping them. So yeah, I would love to hear from people.
Drew: That’s great. We’ll link that all from the show notes, but also Sourcebit be found at github.com/stackbithq/sourcebit. So I’ve been learning all about Sourcebit today, what have you been learning about lately?
Eduardo: I’ve been super interested in learning about Serverless. And I’ve actually been trying to learn as much as possible about it for the past few months. It’s a concept that I’m super interested in. It’s one of those seismic changes in how you approach development. And I’m super interested in kind of the use cases that it has and kind of the different ways of rethinking how you build an application for Serverless. So that’s something that I’ve been trying to read about as much as possible and just playing around and trying, like side projects. Yeah, it’s an area I’m super passionate about.
Drew: It’s very interesting, isn’t it? Quite a shift in how you have to think about projects?
Eduardo: Definitely, definitely. There’s a metaphor, and I don’t want to ramble about Serverless here, which is that a metaphor that I think is really helpful is to think about Serverless as kind of using Uber as opposed to owning a car, like it forces you to, you still have a car, like the term Serverless maybe is a bit misleading because you still have a server, but if you have a car, you might just leave your stuff in the car because you know it’s going to be there the next day, whereas if you’re using at Uber, it forces you to rethink and to acknowledge that every day you’re going to get a new car with different people driving it, and it just have to adapt your way around that fact. So, that metaphor really helped me wrap my head around the whole Serverless paradigm.
Drew: Yes, I had not heard that before, that’s quite an interesting way of looking at it. If you, dear listener, would like to hear more from Eduardo, you can follow him on Twitter, where he’s @Eduardoboucas. And you can find his web development periodical build times at Eduardoboucas.com. Thanks for joining us today. Eduardo. Do you have any parting words?
Eduardo: No, not really. Just first of all, thank you so much for having me. It’s been a pleasure. And by the way that weird pronunciation for my last name, maybe I should say that it’s, if you want to find my Twitter handle and website the surname is B-O-U-C-A-S. Boucas is another weird Portuguese pronunciation if you want to find, it’s Eduardoboucas. So, yeah, thank you so much for having me. It’s been a pleasure.
Drew: Thank you so much.
(dm, ra, il)
Website Design & SEO Delray Beach by DBL07.co
Delray Beach SEO
source http://www.scpie.org/smashing-podcast-episode-11-with-eduardo-boucas-what-is-sourcebit/ source https://scpie1.blogspot.com/2020/03/smashing-podcast-episode-11-with.html
0 notes
Text
Smashing Podcast Episode 11 With Eduardo Bouças: What Is Sourcebit?
About The Author
Drew is a director at edgeofmyseat.com, co-founder of Notist and lead developer for small content management system Perch. Prior to this, he was a Web Developer … More about Drew McLellan …
In this episode of the Smashing Podcast, we’re talking about an interesting open-source tool called Sourcebit. How can it help our content workflow with JAMstack sites? Drew McLellan speaks to developer Eduardo Bouças to find out.
In this episode of the Smashing Podcast, we’re talking about an interesting open-source tool called Sourcebit. How can it help our content workflow with JAMstack sites? I spoke to developer Eduardo Bouças to find out.
Show Notes
Weekly Update
Transcript
Drew McLellan: He’s a web developer, technologist, writer and occasional public speaker with a strong track record of working on open source projects. He works as a software engineer on the JAMstack site management platform, Stackbit, and develops open source tools such as Staticman, Speedtracker, and Sourcebit. So we know he’s an expert in the modern web platform. But did you know he’s deathly allergic to Wednesday? My Smashing friends please welcome Eduardo Boucas. Hi, Eduardo, how are you?
Eduardo Bouças: I’m Smashing.
Drew: I wanted to talk to you today about a tool that I know you’ve been working on called Sourcebit. I know you do a lot of work both at the day job Stackbit, and personally in your own time, around sort of tooling with sort of what we now call JAMstack sites. So before we talk about what Sourcebit does itself, perhaps you can tell us a bit about the sort of scenario with the JAMstack site that might lead to somebody needing a tool like Sourcebit.
Eduardo: Sure. So to go back in time a little bit when I started using a static site generator. My first encounter with a JAMstack was with Jekyll, as I’m sure many people are as well. And when I started using Jekyll for my site, the authoring experience was a bit cumbersome. So it involved manually editing Markdown files on my local machine and then pushing them to get repo and then the thing would get integrated and built. And that’s still a workflow that exists today and that many people use and it makes sense for a lot of people in a lot of organizations. But, first of all, it doesn’t scale very well if you have like a larger team and especially if you have people from less technical backgrounds who may not be comfortable with Markdown or with using Git or with that whole pushing to a GitHub repo workflow.
Eduardo: And so it makes a lot of sense, in my opinion to couple a static site generator with what is now these days called a headless or a decoupled CMS. So if you come from a more traditional web development background where you might use something like WordPress, a headless CMS is something that behaves in a very similar way. So you still have this interface where you can author your content, and you have a nice WYSIWYG editor and media management and everything.
Eduardo: But the output of such a platform is not a fully formatted HTML page. And instead, the content is exported in a way in a format that is agnostic of any technology or any tech stack. And so that content is, it’s possible to integrate that content with your static site generator. And that’s why I think it makes a lot of sense to couple a headless CMS with a static site generator because you kind of get the best of both worlds in the sense that you get the performance, the security and the simplicity of using a static site generator, but at the same time, you still get kind of a rich authoring experience by using a nice editorial interface.
Eduardo: And even though it makes a lot of sense to couple those two tools together, it’s not particularly straightforward to integrate them. Especially if you’re using a more traditional file based static site generator, such as Jekyll or Hugo, where everything has to live as a file. So how do you take that content that lives in this headless CMS? And how do you translate that into files that your static site generator can understand and process?
Eduardo: As you said, I’m super passionate about creating tools for developers and particularly creating tools that allows developers to use the JAMstack paradigm with as little friction as possible. And that’s where source that comes in. That’s why I’m super passionate about this project in particular. So the idea is, that Sourcebit allows you to connect to any API based data source such as a headless CMS, you sort of tell it where your content lives, you help it make some sense of the structure of your content. And then Sourcebit takes care of sucking all that content down and writing it into the files with the formats into location static site generator is expecting. So that’s kind of the idea behind Sourcebit.
Drew: So rather than having authors work directly with markdown files, that your static site generator turns to a site, you’ve got your authors working with another tool, a headless CMS, maybe something like Contentful or even WordPress, and then Sourcebit is the bit in between that gets that content from where it’s been authored, and translates it in a way into a format that the static site generator can turn into a static site?
Eduardo: Exactly, yeah. And the way that it could, kind of see two different ways of using the tool that can help developers. One is making Sourcebit part of your deployment routine. So if you’re using a hosting platform like Netlify, for example, and you configure your deploy commands to be a Hugo build, is it the build command for Hugo or something said, so the command that generates the static files for Hugo, you would also have another command as part of that routine. That would be something like Sourcebit fetch. And so at build time, Sourcebit will go pull all the other data, generate all the files that Hugo needs. And then the whole deployment will already use those files and deploy all the content that is coming from the CMS. So that’s kind of one possible use case for Sourcebit.
Eduardo: The other one is to use Sourcebit in a local development workflow. So you can run Sourcebit with something that we call the watch mode. And so Sourcebit keeps looking for changes in the remote data source, so in this case, headless CMS. And so whenever you publish an article or you change an entry into CMS Sourcebit will acknowledge that and it will regenerate all the files for you locally. And so what that means for a developer working locally is that you can have your CMS window next to your Jekyll or Hugo site, running locally, and then you can see changes happening in real time. You change something on the CMS and then you can see that change being reflected on the local side, which I find super useful. So those are kind of the two ways that you could get use Sourcebit.
Drew: So I guess for all that to work Sourcebit has to know about both the system that the content’s stored in and the way that the static site generator needs the files organized in the file system. How do those two things work?
Eduardo: Sourcebit is a plugin-based architecture. So the idea is that you’re going to have different types of plugins that will accomplish different tasks. We have something that we call the source plugins, which are solely responsible for connecting to a data source like Contentful, for example, and they will connect to that data source, they will pull content and they will normalize that content into a format that is kind of agnostic of data source such that if you want to connect multiple data sources, so you’re using WordPress and Contentful, and Sanity, for example, all the content from those data sources will be normalized into a format that is kind of standardized across the board. So the responsibility of the source plugins will be to just that, to connect to a data source, normalize the content and put them into a bucket of data.
Eduardo: And then you have another type of plugin which we call a target plugin. And the target plugin has no knowledge whatsoever about where the data is coming from, but it knows about a particular piece of software that is expecting that data for example, you might have a target plugin for Hugo a target plugin for Jekyll. So the target plug in will be responsible for writing that data into specific format and the specific locations that the static site generated is expecting.
Eduardo: And then you might have other types of plugins that don’t know about the source and don’t know about destination. They’re just responsible for kind of massaging the data and doing all sorts of transformations in between. So that’s kind of the way that the tool is organized. And I think the benefit of that approach is that each plugin is only concerned about a specific area. So if you are, let’s say that you’re maintaining the source plugin for Contentful, you don’t ever need to worry about what static site generators will be supported. You just worry about maintaining that specific plugin that we take care of making sure that it can be plugged in into any combination of static site generators or different outputs that you want to use.
Drew: So is it possible to have multiple sources running at once and use a Sourcebit more like a content aggregator to pull them from lots of different sources at once?
Eduardo: Yes, yes, it’s totally possible. And that’s why we kind of use that principle of normalizing the data, because you might have as many data sources as you want. And then when a plugin comes in to kind of transform that data, it doesn’t really care where the data comes from, everything is treated the same. So it’s totally possible to do that. You can configure as many source plugins as you want. And so it’ll pull data from as many places as you want.
Drew: Yeah, that could be quite interesting. Could you think of a corporate website might have a blog in there, it might have copy from marketing agency, it might have job openings coming from an HR system. And you could potentially configure Sourcebit to pull that into one location before generating the site, which is quite an exciting prospect, I think.
Eduardo: Yeah, yeah. And CMS is are just one possible data source that you might use this tool with. For example, one of my colleagues that started was creating a source plugin that pulls data from Reddit, for example. And that’s just one very simple example of one possible data source. So as you say, it could get quite interesting because you might be pulling data from a CMS, might be pulling data from Reddit, Twitter or an HR platform and it just all comes down together nicely. So, yeah, it’s a possible use case for it for sure.
Drew: What sort of plugins exist at the moment for different sources?
Eduardo: So we launched the first kind of public version of the tool last week. And we launched with a two source plugins and two target plugins. So the source plugins are for Contentful and Sanity. And the target plugins are for Jacqueline and Hugo. We will keep working on your plugins internally at Stackbit. But our goal is for the community to eventually take ownership of the tool as well like this is a fully open source MIT license project. And so we would love to see people creating their plugins and building stuff with Sourcebit that we haven’t even thought of. So, that’s the ultimate goal. We’ve been in touch with people from different CMS companies who are interested in building their plugins as well. So we’re in constant contact with them. So hopefully we’ll see a nice ecosystem of plugins somewhat soon.
Drew: How complex is it to develop a plugin if you’ve got a completely custom system that you know that you need to integrate with? Is it a very involved difficult task to develop plugin or is it easier than that?
Eduardo: I’m a bit biased to answer that. I like to think that it’s simple and I’ve tried my best to make the process simple and also very well documented. So we have one of the repositories that we make available is kind of a sample plugin, where we have a fully annotated source code for a plugin. So we have comments on every possible function that you might implement outlining the arguments that it receives, how you can use this function to get data from this etc. So hopefully that’ll be a very useful resource. We also have documentation pages where we kind of outline the anatomy of a plugin, like how it pulls data where it’s supposed to push that into. So hopefully, it’s a fairly straightforward process.
Eduardo: But different systems will present different challenges. So I’m sure there will be suggestions and feature requests from someone in the community saying, “I want to integrate with this system. So I kind of need a way of doing this.” And we’ll be more than happy to kind of accommodate those requests and kind of work with the community to make the plugin architecture better over time.
Drew: And it’s all written in, I presume is JavaScript node?
Eduardo: It is. It is.
Drew: I noticed that you mentioned earlier briefly that you can run Sourcebit with a watch flag, and it will help you to have a sort of live updating workflow. Is that something that needs to be implemented by the source plugin, or is that general system? Is it a polling mechanism or are you listening for sort of hooks and things from the source system?
Eduardo: The core application is very lean, and it’s not opinionated at all. So it’s up to each Source plugin to kind of implement that functionality. All the core application does on that front is it tells the plugin what are the kind of the options that the user asked for. So in the two plugins that we launched with, so we have one for Contentful, and one for Sanity, the way that the watch mode is implemented in each of them is very different. For example, in Contentful we have, as I mentioned, a polling mechanism in a regular interval of time, like poll for changes whereas for Sanity, we have like a running web socket that is constantly listening for changes and respond to the changes. But basically, the idea is that the source plugin implements its own listening mechanism and it’s responsible for telling the core application that I have new content please update yourself. That’s kind of the domain idea.
Drew: That sounds like quite a flexible system then that should cope with lots of different sources and different types of system.
Eduardo: Yes. I was just going to say like still on that topic of flexibility, one thing that I wanted to mention as well is Sourcebit is configured using a JavaScript file. So if something similar to what you would do with some like web pack, for example, although a bit simpler. And so you have the option to configure each of the plugins on that file manually. But we also offer this commandline interface, where basically each plugin is able to tell the core application the set of questions that it needs to ask the user in order to configure itself. So basically, when you run npx create-sourcebit, it can create everything from scratch for you.
Eduardo: So it pulls a list of all the available plugins to have the option to sit on a source plugin for Contentful and the target plugin for Jekyll, for example. And then based on the plugins that you choose, it then asks you a series of questions that will ultimately lead to a fully configured JavaScript file. So for example, for Contentful it’ll ask you for your credentials, like how do I access your Contentful account? And then it will actually pull all the content types from Contentful. And it’ll ask you okay, I found this content type called blog posts. What is this? Is this like a page? Is this a data object? And if it’s a page, where should I store this? What kind of fields should I use for the layout for the content?
Eduardo: I think it’s a very user friendly way of configuring the whole project. So hopefully, by the end of this configuration process, you can just run a command and you can pull the content straight away without having to mess around with JavaScript files.
Drew: So that configuration process answering those questions, then writes the JavaScript configuration file for you, which you can then presumably just commit into your source control and distribute to other developers on your project or into your build process for running live. You mentioned a third type of plugin distinct from the source and the target that works on data in this agnostic format in the middle. What sort of scenarios do you imagine that being used for?
Eduardo: We created a plugin that is responsible for transforming assets. So to give you an example, let’s say that I’m using Contentful, and you have images embedded as part of a blog post. And by default, if you just pull that data from Contentful, the images will be using a live URL from like Contentful CDN which is a totally viable option if that’s what you want to use. But you might want to instead, serve the images alongside the content. So have them in your repo and served from whatever service you’re using to serve to site as well. And so that plugin in specific, it will look for any assets that are using, it will pull those assets down, download them basically to your repo or to your local file system which it can then push.
Eduardo: And it will replace any URLs in your files that reference that remote URL, it’ll replace those with references to the local files instead. So basically, when you push the site, you push the content and the assets and everything will just work seamlessly. So, that’s one example of kind of a transformation plugin that is not pulling. It’s not specific to a data source and it’s not specific to a static site generator. It just transforms things in between.
Drew: You mentioned that there are target plugins for Jekyll and Hugo, are there any that you’re expecting to see in the near future?
Eduardo: Well, I’m a big fan of Eleventy. So I’m really hoping to see an Eleventy plugin coming out fairly soon. And then I guess there are some static site generators that already have their own kind of plugin ecosystem. So I’m curious to see if people will still find a need to have a source plugin for those types of static site generators. Like another possible way that you can use Sourcebit by the way, is if you’re using something like Next.js, so like any node based static site generator. You don’t necessarily need a target plugin, you can just require Sourcebit as an NPM module, and you can run the all the mechanisms for fetching data. You can just run those as in memory functions and get your content available as part of your Next.js pages. To answer your question, I guess for those we won’t see target plugins specifically, but we can already use Sourcebit in that way. In terms of next source plugins, I would expect to see Eleventy and maybe a few other kind of file based static site generators in the near future.
Drew: This is all quite exciting stuff, I think. Is it just you working on it in terms of development or is there a bigger team?
Eduardo: I’ve been kind of the main developer working on it, but it’s a team effort. So it’s something that a bunch of people at Stackbit identified as a problem. And we’ve been working together on kind of specification and the right way to approach this. I just happen to be the guy pressing the keys to make it happen.
Drew: And I guess Sourcebit actually can be very useful for Stackbit customers, which is Stackbits motivation for developing and contributing this but obviously, it’s going to be useful to a much wider audience than just Stackbit customers.
Eduardo: Yeah, we have big plans for Sourcebit internally. It’ll really help us achieve our mission in terms of making JAMstack, accessible to as many people as possible, but we wanted to make sure that we share this particular project with the community because we feel that it’ll help a lot of people regardless of whether they’re interested in using Stackbit or not. So that’s why it’s a fully open source project.
Drew: That’s great. Is there anything else you’d like to tell us about Sourcebit?
Eduardo: No. I would just love people to try it out. I’m sure we can share links to like the repo and stuff like that. There’s a YouTube video in the main repository, that shows how the experience is like when using Sourcebit with a headless CMS and a static site generator. So it kind of gives you an idea of what it’s like to use the CLI and the whole interactive setup process, and I would just love people to try it out. And get in touch if they think it could be improved or it’s terrible, or it’s great, or it’s helping them. So yeah, I would love to hear from people.
Drew: That’s great. We’ll link that all from the show notes, but also Sourcebit be found at github.com/stackbithq/sourcebit. So I’ve been learning all about Sourcebit today, what have you been learning about lately?
Eduardo: I’ve been super interested in learning about Serverless. And I’ve actually been trying to learn as much as possible about it for the past few months. It’s a concept that I’m super interested in. It’s one of those seismic changes in how you approach development. And I’m super interested in kind of the use cases that it has and kind of the different ways of rethinking how you build an application for Serverless. So that’s something that I’ve been trying to read about as much as possible and just playing around and trying, like side projects. Yeah, it’s an area I’m super passionate about.
Drew: It’s very interesting, isn’t it? Quite a shift in how you have to think about projects?
Eduardo: Definitely, definitely. There’s a metaphor, and I don’t want to ramble about Serverless here, which is that a metaphor that I think is really helpful is to think about Serverless as kind of using Uber as opposed to owning a car, like it forces you to, you still have a car, like the term Serverless maybe is a bit misleading because you still have a server, but if you have a car, you might just leave your stuff in the car because you know it’s going to be there the next day, whereas if you’re using at Uber, it forces you to rethink and to acknowledge that every day you’re going to get a new car with different people driving it, and it just have to adapt your way around that fact. So, that metaphor really helped me wrap my head around the whole Serverless paradigm.
Drew: Yes, I had not heard that before, that’s quite an interesting way of looking at it. If you, dear listener, would like to hear more from Eduardo, you can follow him on Twitter, where he’s @Eduardoboucas. And you can find his web development periodical build times at Eduardoboucas.com. Thanks for joining us today. Eduardo. Do you have any parting words?
Eduardo: No, not really. Just first of all, thank you so much for having me. It’s been a pleasure. And by the way that weird pronunciation for my last name, maybe I should say that it’s, if you want to find my Twitter handle and website the surname is B-O-U-C-A-S. Boucas is another weird Portuguese pronunciation if you want to find, it’s Eduardoboucas. So, yeah, thank you so much for having me. It’s been a pleasure.
Drew: Thank you so much.
(dm, ra, il)
Website Design & SEO Delray Beach by DBL07.co
Delray Beach SEO
Via http://www.scpie.org/smashing-podcast-episode-11-with-eduardo-boucas-what-is-sourcebit/
source https://scpie.weebly.com/blog/smashing-podcast-episode-11-with-eduardo-boucas-what-is-sourcebit
0 notes
Text
Smashing Podcast Episode 11 With Eduardo Bouças: What Is Sourcebit?
About The Author
Drew is a director at edgeofmyseat.com, co-founder of Notist and lead developer for small content management system Perch. Prior to this, he was a Web Developer … More about Drew McLellan …
In this episode of the Smashing Podcast, we’re talking about an interesting open-source tool called Sourcebit. How can it help our content workflow with JAMstack sites? Drew McLellan speaks to developer Eduardo Bouças to find out.
In this episode of the Smashing Podcast, we’re talking about an interesting open-source tool called Sourcebit. How can it help our content workflow with JAMstack sites? I spoke to developer Eduardo Bouças to find out.
Show Notes
Weekly Update
Transcript
Drew McLellan: He’s a web developer, technologist, writer and occasional public speaker with a strong track record of working on open source projects. He works as a software engineer on the JAMstack site management platform, Stackbit, and develops open source tools such as Staticman, Speedtracker, and Sourcebit. So we know he’s an expert in the modern web platform. But did you know he’s deathly allergic to Wednesday? My Smashing friends please welcome Eduardo Boucas. Hi, Eduardo, how are you?
Eduardo Bouças: I’m Smashing.
Drew: I wanted to talk to you today about a tool that I know you’ve been working on called Sourcebit. I know you do a lot of work both at the day job Stackbit, and personally in your own time, around sort of tooling with sort of what we now call JAMstack sites. So before we talk about what Sourcebit does itself, perhaps you can tell us a bit about the sort of scenario with the JAMstack site that might lead to somebody needing a tool like Sourcebit.
Eduardo: Sure. So to go back in time a little bit when I started using a static site generator. My first encounter with a JAMstack was with Jekyll, as I’m sure many people are as well. And when I started using Jekyll for my site, the authoring experience was a bit cumbersome. So it involved manually editing Markdown files on my local machine and then pushing them to get repo and then the thing would get integrated and built. And that’s still a workflow that exists today and that many people use and it makes sense for a lot of people in a lot of organizations. But, first of all, it doesn’t scale very well if you have like a larger team and especially if you have people from less technical backgrounds who may not be comfortable with Markdown or with using Git or with that whole pushing to a GitHub repo workflow.
Eduardo: And so it makes a lot of sense, in my opinion to couple a static site generator with what is now these days called a headless or a decoupled CMS. So if you come from a more traditional web development background where you might use something like WordPress, a headless CMS is something that behaves in a very similar way. So you still have this interface where you can author your content, and you have a nice WYSIWYG editor and media management and everything.
Eduardo: But the output of such a platform is not a fully formatted HTML page. And instead, the content is exported in a way in a format that is agnostic of any technology or any tech stack. And so that content is, it’s possible to integrate that content with your static site generator. And that’s why I think it makes a lot of sense to couple a headless CMS with a static site generator because you kind of get the best of both worlds in the sense that you get the performance, the security and the simplicity of using a static site generator, but at the same time, you still get kind of a rich authoring experience by using a nice editorial interface.
Eduardo: And even though it makes a lot of sense to couple those two tools together, it’s not particularly straightforward to integrate them. Especially if you’re using a more traditional file based static site generator, such as Jekyll or Hugo, where everything has to live as a file. So how do you take that content that lives in this headless CMS? And how do you translate that into files that your static site generator can understand and process?
Eduardo: As you said, I’m super passionate about creating tools for developers and particularly creating tools that allows developers to use the JAMstack paradigm with as little friction as possible. And that’s where source that comes in. That’s why I’m super passionate about this project in particular. So the idea is, that Sourcebit allows you to connect to any API based data source such as a headless CMS, you sort of tell it where your content lives, you help it make some sense of the structure of your content. And then Sourcebit takes care of sucking all that content down and writing it into the files with the formats into location static site generator is expecting. So that’s kind of the idea behind Sourcebit.
Drew: So rather than having authors work directly with markdown files, that your static site generator turns to a site, you’ve got your authors working with another tool, a headless CMS, maybe something like Contentful or even WordPress, and then Sourcebit is the bit in between that gets that content from where it’s been authored, and translates it in a way into a format that the static site generator can turn into a static site?
Eduardo: Exactly, yeah. And the way that it could, kind of see two different ways of using the tool that can help developers. One is making Sourcebit part of your deployment routine. So if you’re using a hosting platform like Netlify, for example, and you configure your deploy commands to be a Hugo build, is it the build command for Hugo or something said, so the command that generates the static files for Hugo, you would also have another command as part of that routine. That would be something like Sourcebit fetch. And so at build time, Sourcebit will go pull all the other data, generate all the files that Hugo needs. And then the whole deployment will already use those files and deploy all the content that is coming from the CMS. So that’s kind of one possible use case for Sourcebit.
Eduardo: The other one is to use Sourcebit in a local development workflow. So you can run Sourcebit with something that we call the watch mode. And so Sourcebit keeps looking for changes in the remote data source, so in this case, headless CMS. And so whenever you publish an article or you change an entry into CMS Sourcebit will acknowledge that and it will regenerate all the files for you locally. And so what that means for a developer working locally is that you can have your CMS window next to your Jekyll or Hugo site, running locally, and then you can see changes happening in real time. You change something on the CMS and then you can see that change being reflected on the local side, which I find super useful. So those are kind of the two ways that you could get use Sourcebit.
Drew: So I guess for all that to work Sourcebit has to know about both the system that the content’s stored in and the way that the static site generator needs the files organized in the file system. How do those two things work?
Eduardo: Sourcebit is a plugin-based architecture. So the idea is that you’re going to have different types of plugins that will accomplish different tasks. We have something that we call the source plugins, which are solely responsible for connecting to a data source like Contentful, for example, and they will connect to that data source, they will pull content and they will normalize that content into a format that is kind of agnostic of data source such that if you want to connect multiple data sources, so you’re using WordPress and Contentful, and Sanity, for example, all the content from those data sources will be normalized into a format that is kind of standardized across the board. So the responsibility of the source plugins will be to just that, to connect to a data source, normalize the content and put them into a bucket of data.
Eduardo: And then you have another type of plugin which we call a target plugin. And the target plugin has no knowledge whatsoever about where the data is coming from, but it knows about a particular piece of software that is expecting that data for example, you might have a target plugin for Hugo a target plugin for Jekyll. So the target plug in will be responsible for writing that data into specific format and the specific locations that the static site generated is expecting.
Eduardo: And then you might have other types of plugins that don’t know about the source and don’t know about destination. They’re just responsible for kind of massaging the data and doing all sorts of transformations in between. So that’s kind of the way that the tool is organized. And I think the benefit of that approach is that each plugin is only concerned about a specific area. So if you are, let’s say that you’re maintaining the source plugin for Contentful, you don’t ever need to worry about what static site generators will be supported. You just worry about maintaining that specific plugin that we take care of making sure that it can be plugged in into any combination of static site generators or different outputs that you want to use.
Drew: So is it possible to have multiple sources running at once and use a Sourcebit more like a content aggregator to pull them from lots of different sources at once?
Eduardo: Yes, yes, it’s totally possible. And that’s why we kind of use that principle of normalizing the data, because you might have as many data sources as you want. And then when a plugin comes in to kind of transform that data, it doesn’t really care where the data comes from, everything is treated the same. So it’s totally possible to do that. You can configure as many source plugins as you want. And so it’ll pull data from as many places as you want.
Drew: Yeah, that could be quite interesting. Could you think of a corporate website might have a blog in there, it might have copy from marketing agency, it might have job openings coming from an HR system. And you could potentially configure Sourcebit to pull that into one location before generating the site, which is quite an exciting prospect, I think.
Eduardo: Yeah, yeah. And CMS is are just one possible data source that you might use this tool with. For example, one of my colleagues that started was creating a source plugin that pulls data from Reddit, for example. And that’s just one very simple example of one possible data source. So as you say, it could get quite interesting because you might be pulling data from a CMS, might be pulling data from Reddit, Twitter or an HR platform and it just all comes down together nicely. So, yeah, it’s a possible use case for it for sure.
Drew: What sort of plugins exist at the moment for different sources?
Eduardo: So we launched the first kind of public version of the tool last week. And we launched with a two source plugins and two target plugins. So the source plugins are for Contentful and Sanity. And the target plugins are for Jacqueline and Hugo. We will keep working on your plugins internally at Stackbit. But our goal is for the community to eventually take ownership of the tool as well like this is a fully open source MIT license project. And so we would love to see people creating their plugins and building stuff with Sourcebit that we haven’t even thought of. So, that’s the ultimate goal. We’ve been in touch with people from different CMS companies who are interested in building their plugins as well. So we’re in constant contact with them. So hopefully we’ll see a nice ecosystem of plugins somewhat soon.
Drew: How complex is it to develop a plugin if you’ve got a completely custom system that you know that you need to integrate with? Is it a very involved difficult task to develop plugin or is it easier than that?
Eduardo: I’m a bit biased to answer that. I like to think that it’s simple and I’ve tried my best to make the process simple and also very well documented. So we have one of the repositories that we make available is kind of a sample plugin, where we have a fully annotated source code for a plugin. So we have comments on every possible function that you might implement outlining the arguments that it receives, how you can use this function to get data from this etc. So hopefully that’ll be a very useful resource. We also have documentation pages where we kind of outline the anatomy of a plugin, like how it pulls data where it’s supposed to push that into. So hopefully, it’s a fairly straightforward process.
Eduardo: But different systems will present different challenges. So I’m sure there will be suggestions and feature requests from someone in the community saying, “I want to integrate with this system. So I kind of need a way of doing this.” And we’ll be more than happy to kind of accommodate those requests and kind of work with the community to make the plugin architecture better over time.
Drew: And it’s all written in, I presume is JavaScript node?
Eduardo: It is. It is.
Drew: I noticed that you mentioned earlier briefly that you can run Sourcebit with a watch flag, and it will help you to have a sort of live updating workflow. Is that something that needs to be implemented by the source plugin, or is that general system? Is it a polling mechanism or are you listening for sort of hooks and things from the source system?
Eduardo: The core application is very lean, and it’s not opinionated at all. So it’s up to each Source plugin to kind of implement that functionality. All the core application does on that front is it tells the plugin what are the kind of the options that the user asked for. So in the two plugins that we launched with, so we have one for Contentful, and one for Sanity, the way that the watch mode is implemented in each of them is very different. For example, in Contentful we have, as I mentioned, a polling mechanism in a regular interval of time, like poll for changes whereas for Sanity, we have like a running web socket that is constantly listening for changes and respond to the changes. But basically, the idea is that the source plugin implements its own listening mechanism and it’s responsible for telling the core application that I have new content please update yourself. That’s kind of the domain idea.
Drew: That sounds like quite a flexible system then that should cope with lots of different sources and different types of system.
Eduardo: Yes. I was just going to say like still on that topic of flexibility, one thing that I wanted to mention as well is Sourcebit is configured using a JavaScript file. So if something similar to what you would do with some like web pack, for example, although a bit simpler. And so you have the option to configure each of the plugins on that file manually. But we also offer this commandline interface, where basically each plugin is able to tell the core application the set of questions that it needs to ask the user in order to configure itself. So basically, when you run npx create-sourcebit, it can create everything from scratch for you.
Eduardo: So it pulls a list of all the available plugins to have the option to sit on a source plugin for Contentful and the target plugin for Jekyll, for example. And then based on the plugins that you choose, it then asks you a series of questions that will ultimately lead to a fully configured JavaScript file. So for example, for Contentful it’ll ask you for your credentials, like how do I access your Contentful account? And then it will actually pull all the content types from Contentful. And it’ll ask you okay, I found this content type called blog posts. What is this? Is this like a page? Is this a data object? And if it’s a page, where should I store this? What kind of fields should I use for the layout for the content?
Eduardo: I think it’s a very user friendly way of configuring the whole project. So hopefully, by the end of this configuration process, you can just run a command and you can pull the content straight away without having to mess around with JavaScript files.
Drew: So that configuration process answering those questions, then writes the JavaScript configuration file for you, which you can then presumably just commit into your source control and distribute to other developers on your project or into your build process for running live. You mentioned a third type of plugin distinct from the source and the target that works on data in this agnostic format in the middle. What sort of scenarios do you imagine that being used for?
Eduardo: We created a plugin that is responsible for transforming assets. So to give you an example, let’s say that I’m using Contentful, and you have images embedded as part of a blog post. And by default, if you just pull that data from Contentful, the images will be using a live URL from like Contentful CDN which is a totally viable option if that’s what you want to use. But you might want to instead, serve the images alongside the content. So have them in your repo and served from whatever service you’re using to serve to site as well. And so that plugin in specific, it will look for any assets that are using, it will pull those assets down, download them basically to your repo or to your local file system which it can then push.
Eduardo: And it will replace any URLs in your files that reference that remote URL, it’ll replace those with references to the local files instead. So basically, when you push the site, you push the content and the assets and everything will just work seamlessly. So, that’s one example of kind of a transformation plugin that is not pulling. It’s not specific to a data source and it’s not specific to a static site generator. It just transforms things in between.
Drew: You mentioned that there are target plugins for Jekyll and Hugo, are there any that you’re expecting to see in the near future?
Eduardo: Well, I’m a big fan of Eleventy. So I’m really hoping to see an Eleventy plugin coming out fairly soon. And then I guess there are some static site generators that already have their own kind of plugin ecosystem. So I’m curious to see if people will still find a need to have a source plugin for those types of static site generators. Like another possible way that you can use Sourcebit by the way, is if you’re using something like Next.js, so like any node based static site generator. You don’t necessarily need a target plugin, you can just require Sourcebit as an NPM module, and you can run the all the mechanisms for fetching data. You can just run those as in memory functions and get your content available as part of your Next.js pages. To answer your question, I guess for those we won’t see target plugins specifically, but we can already use Sourcebit in that way. In terms of next source plugins, I would expect to see Eleventy and maybe a few other kind of file based static site generators in the near future.
Drew: This is all quite exciting stuff, I think. Is it just you working on it in terms of development or is there a bigger team?
Eduardo: I’ve been kind of the main developer working on it, but it’s a team effort. So it’s something that a bunch of people at Stackbit identified as a problem. And we’ve been working together on kind of specification and the right way to approach this. I just happen to be the guy pressing the keys to make it happen.
Drew: And I guess Sourcebit actually can be very useful for Stackbit customers, which is Stackbits motivation for developing and contributing this but obviously, it’s going to be useful to a much wider audience than just Stackbit customers.
Eduardo: Yeah, we have big plans for Sourcebit internally. It’ll really help us achieve our mission in terms of making JAMstack, accessible to as many people as possible, but we wanted to make sure that we share this particular project with the community because we feel that it’ll help a lot of people regardless of whether they’re interested in using Stackbit or not. So that’s why it’s a fully open source project.
Drew: That’s great. Is there anything else you’d like to tell us about Sourcebit?
Eduardo: No. I would just love people to try it out. I’m sure we can share links to like the repo and stuff like that. There’s a YouTube video in the main repository, that shows how the experience is like when using Sourcebit with a headless CMS and a static site generator. So it kind of gives you an idea of what it’s like to use the CLI and the whole interactive setup process, and I would just love people to try it out. And get in touch if they think it could be improved or it’s terrible, or it’s great, or it’s helping them. So yeah, I would love to hear from people.
Drew: That’s great. We’ll link that all from the show notes, but also Sourcebit be found at github.com/stackbithq/sourcebit. So I’ve been learning all about Sourcebit today, what have you been learning about lately?
Eduardo: I’ve been super interested in learning about Serverless. And I’ve actually been trying to learn as much as possible about it for the past few months. It’s a concept that I’m super interested in. It’s one of those seismic changes in how you approach development. And I’m super interested in kind of the use cases that it has and kind of the different ways of rethinking how you build an application for Serverless. So that’s something that I’ve been trying to read about as much as possible and just playing around and trying, like side projects. Yeah, it’s an area I’m super passionate about.
Drew: It’s very interesting, isn’t it? Quite a shift in how you have to think about projects?
Eduardo: Definitely, definitely. There’s a metaphor, and I don’t want to ramble about Serverless here, which is that a metaphor that I think is really helpful is to think about Serverless as kind of using Uber as opposed to owning a car, like it forces you to, you still have a car, like the term Serverless maybe is a bit misleading because you still have a server, but if you have a car, you might just leave your stuff in the car because you know it’s going to be there the next day, whereas if you’re using at Uber, it forces you to rethink and to acknowledge that every day you’re going to get a new car with different people driving it, and it just have to adapt your way around that fact. So, that metaphor really helped me wrap my head around the whole Serverless paradigm.
Drew: Yes, I had not heard that before, that’s quite an interesting way of looking at it. If you, dear listener, would like to hear more from Eduardo, you can follow him on Twitter, where he’s @Eduardoboucas. And you can find his web development periodical build times at Eduardoboucas.com. Thanks for joining us today. Eduardo. Do you have any parting words?
Eduardo: No, not really. Just first of all, thank you so much for having me. It’s been a pleasure. And by the way that weird pronunciation for my last name, maybe I should say that it’s, if you want to find my Twitter handle and website the surname is B-O-U-C-A-S. Boucas is another weird Portuguese pronunciation if you want to find, it’s Eduardoboucas. So, yeah, thank you so much for having me. It’s been a pleasure.
Drew: Thank you so much.
(dm, ra, il)
Website Design & SEO Delray Beach by DBL07.co
Delray Beach SEO
source http://www.scpie.org/smashing-podcast-episode-11-with-eduardo-boucas-what-is-sourcebit/
0 notes
Text
Hiding From Coronavirus in Indonesia. But Is It Truly Virus-Free?
NUSA DUA, Indonesia — The family from Shanghai was vacationing in Singapore last month when they learned that the new coronavirus had arrived there from China.
So they packed up and flew to the world’s largest country yet to report a single case of the deadly virus: Indonesia. They landed in Bali, a major destination for Chinese tourists, on Jan. 30 and have no plans to leave.
“People in Bali treat us nicely and are friendly,” said Eva Qin, 36, who is traveling with her mother, husband and son. “We weren’t given any health test.”
Health experts have questioned why Indonesia has not yet reported a single case of novel coronavirus, even though officials were slow to halt nonstop flights from China. Indonesia receives about 2 million Chinese tourists a year, most of them in Bali.
China’s consul general in Bali said last week that about 5,000 Chinese tourists remained in Bali, including 200 from Wuhan, where the outbreak started.
Indonesia’s closest neighbors have all reported cases, including the Philippines, Singapore, Malaysia and Australia.
“So far, Indonesia is the only major country in Asia that does not have a corona case,” Indonesia’s security minister, Mohammad Mahfud MD, told reporters on Friday. “The coronavirus does not exist in Indonesia.”
None of the 285 people who were evacuated from Wuhan and are now in quarantine on the Indonesian island of Natuna have shown signs of the virus, he added.
Five researchers at the Harvard T.H. Chan School of Public Health concluded in a study last week that Indonesia and Cambodia, which has reported only one case, should quickly intensify its monitoring of potential cases. Based on a statistical analysis, the disease could have arrived in Indonesia already, the authors concluded.
“Many of the imported cases have been linked to a recent travel history from Wuhan, suggesting that air travel volume may play an important role for the risk of cases being exported outside of China,” the study said.
Updated Feb. 10, 2020
What is a Coronavirus? It is a novel virus named for the crown-like spikes that protrude from its surface. The coronavirus can infect both animals and people, and can cause a range of respiratory illnesses from the common cold to more dangerous conditions like Severe Acute Respiratory Syndrome, or SARS.
How contagious is the virus? According to preliminary research, it seems moderately infectious, similar to SARS, and is possibly transmitted through the air. Scientists have estimated that each infected person could spread it to somewhere between 1.5 and 3.5 people without effective containment measures.
How worried should I be? While the virus is a serious public health concern, the risk to most people outside China remains very low, and seasonal flu is a more immediate threat.
Who is working to contain the virus? World Health Organization officials have praised China’s aggressive response to the virus by closing transportation, schools and markets. This week, a team of experts from the W.H.O. arrived in Beijing to offer assistance.
What if I’m traveling? The United States and Australia are temporarily denying entry to noncitizens who recently traveled to China and several airlines have canceled flights.
How do I keep myself and others safe? Washing your hands frequently is the most important thing you can do, along with staying at home when you’re sick.
The chairman of the Indonesian Red Cross, Jusuf Kalla, a former vice president of Indonesia, also said it was possible that the disease had already entered the country and that Indonesians might not recognize the symptoms as being coronavirus.
“Singapore has a tight system, but even there the virus got in,” he said. “It’s possible that there are infected people but here in Indonesia people think that it is only a regular fever or they think it is dengue fever.”
Mr. Kalla expressed concern about how prepared Indonesia was to handle the virus if it were to strike in remote parts of the archipelago nation where underfunded community health centers are the main health care provider. (Indonesia is the world’s fourth most populous country, with nearly 270 million people scattered across 6,000 inhabited islands.)
“Indonesia has many islands,” he said. “We have many port cities. They all have different capabilities. I think good hospitals in Jakarta can detect it. But what about the community health center in Flores? Or in Sulawesi? Surely the capability is limited.”
Indonesia’s health care system is considered underfunded by international standards, with insufficient facilities and too few doctors, nurses and midwives, according to a 2018 report by the World Health Organization.
But the W.H.O. country representative, Dr. Navaratnasamy Paranietharan, said Indonesia is doing its best to face the new coronavirus, including screening passengers at points of entry and equipping hospitals for the arrival of suspected or diagnosed cases.
“Indonesia is doing what is possible to be prepared for and defend against the novel coronavirus,” he said.
Health officials say they have tested nearly 50 suspected cases, which were all negative.
Thirty Chinese workers from a cement company in North Sulawesi were placed in 14-day quarantine last week after returning from a holiday visit to China, an immigration official said. None of them have come down with the virus, he said.
If patients with symptoms were arriving, they would have been detected, insisted Achmad Yurianto, secretary of prevention and control at the health ministry.
“We are not prepared to face a major outbreak, but we are prepared to prevent an outbreak,” he said. “We are not waiting for it to happen. We in fact have tightened prevention.”
Indonesia is experienced at monitoring travelers for illness, he said, because the country has long been on the lookout for another dangerous coronavirus, Middle East Respiratory Syndrome or MERS. About 1.4 million Indonesians go each year on pilgrimages to Saudi Arabia, where they can be exposed to MERS, he said, and they are screened on their return.
“We have experienced this many times,” he said. “Maybe other countries are not as diligent as Indonesia in dealing with this situation.”
Indonesia has three laboratories capable of testing for the Wuhan virus, two in Jakarta, the capital, and one in Surabaya, Indonesia’s second-largest city, in East Java. The labs can test 1,200 samples a day, he said. Across the country, 100 hospitals have been designated as centers to handle suspected cases of the novel coronavirus.
Before airline travel between Indonesia and China was suspended on Feb. 5, there were 134 flights a week from China to Bali, bringing about 5,000 passengers a day.
The loss of new Chinese tourists could be devastating for the economy of Bali, which is highly dependent on foreign visitors. Still, some of the tourists already in Bali are doing what they can to stay.
China’s consul general in Bali, Gou Haodong, said many of the remaining Chinese tourists wanted to extend their visas rather than return home to possible quarantine or exposure to the virus.
More than 30 applied on Friday for tourist visas extensions, said immigration officials, who put the number of remaining Chinese tourists at 1,500, not 5,000.
Among those still in Bali this weekend were Johnson Guo and his family.
Mr. Guo, 42, a manager in an internet business in Guangzhou, said the family had been on holiday in Australia. But after the outbreak of the virus, they decided to extend their vacation and spend a week in Bali.
He said that they did not receive any health check on arrival, but that all of them were healthy.
“I worry about the virus,” he said, as he purchased 720 face masks to take back and donate to his hometown hospital when they were to return on Saturday. “But I have to return because I have to go back to work. And Guangzhou is not as bad as other areas in China.”
Two travelers from Shanghai, Song Yi and her friend, Yang Yujia, both 27, arrived in Bali in mid-January with eight friends.
“We didn’t have any health check because we have been healthy during the 20 days of our stay,” said Ms. Song, a banker, as they shopped for clothes at a mall near Kuta Beach.
Ms. Song said that the Balinese people had been very kind to them, but that their Chinese friends began avoiding each other because of fears about the virus and they soon went their separate ways.
After extending their stay in Bali, she said, they plan to return home next week.
“We decided to stay longer because we were afraid of the virus,” she said.
from WordPress https://mastcomm.com/hiding-from-coronavirus-in-indonesia-but-is-it-truly-virus-free/
0 notes
Text
Easy Theme and Plugin Upgrades – WordPress plugin
Easy Theme and Plugin Upgrades – WordPress plugin
WordPress has a built-in feature to install themes and plugins by supplying a zip file. Unfortunately, you cannot upgrade a theme or plugin using the same process. Instead, WordPress will say “destination already exists” when trying to upgrade using a zip file and will fail to upgrade the theme or plugin.
Easy Theme and Plugin Upgrades fixes this limitation in WordPress by automatically…
View On WordPress
0 notes
Text
‘Miracle house’ in Ohio draws pilgrims amid sainthood push
Late in the summer of 1939, crowds of strangers started showing up at Rhoda Wise’s house next to a city dump in Ohio after she let it be known that miracles were occurring in her room.
Eight decades later, people still make pilgrimages to the wood frame bungalow at the edge of Canton, Ohio, seeking their own miracles. Wise died in 1948, but her legend as a Christian mystic has blossomed with time. And last fall, after years of discussions, the local Roman Catholic diocese petitioned the Vatican to make Wise a saint, renewing interest in her former home.
The story starts with the sickly Wise, who lived with her alcoholic husband and young daughter, claiming she was healed of a terminal illness and was visited by Jesus Christ as she suffered in her bed.
When word got out, people began arriving at all hours, seeking spiritual guidance and asking to see the wooden chair where Jesus sat. They stood in lines around the block to file past her bed when she appeared to suffer stigmata — bloody wounds on her head, hands and feet like those Jesus suffered on the cross — until she implored the church to take her off display.
Newspapers and national magazines sent reporters to write about Ohio’s “miracle house.”
The parade of pilgrims slowed down after Wise’s death but never stopped. Her house — now with beige vinyl siding and a good-sized parking lot — has remained an under-the-radar destination for the faithful and curious.
Her former home is one of dozens of Catholic shrines and pilgrimage sites in the United States, ranging from modest to grand.
Among them are one of the largest crucifixes in the world in the woods of Michigan, an altar inside a 50-foot-high cave carved into a cliff in Oregon, and a small chapel in Minnesota built as a tribute to the Virgin Mary, to whom the locals prayed when a plague of grasshoppers devastated crops in the 1870s.
In 1996, a popular shrine developed in the parking lot of an office building in Clearwater, Florida, where thousands believed a 60-foot image of Mary had appeared on the mirrored glass. That lasted until 2004, when a high school boy with a slingshot shattered some of the panes.
The Wise house stands out because it doesn’t stand out, blending in with a row of Habitat for Humanity homes, built across the street in recent years, and the rest of the frayed residential neighborhood. These days, there’s a golf course where the dump used to be.
Regardless of the validity of the Rhoda Wise narrative — scoffers note that she was known to have mental health problems — people still arrive by the busload. They come to view her 9-foot-square bedroom, pray and sit in the Jesus chair, which has been repaired numerous times through the years and now is painted gold. There is no admission fee. Donations pay the bills.
Canton native Karen Sigler, 66, visited with a group in the early 1980s and was recruited by Wise’s daughter Anna Mae to become the live-in caretaker, a position she has held now for 36 years.
“We live in a world that’s really hard to have faith in today. Really hard,” Sigler said, trying to explain the attraction. “A lot of people want to hold on to it. And Rhoda’s strength to endure everything she did with such a great love of God is inspiration for them.”
Precise numbers aren’t kept, but a guest book shows visitors from more than a dozen states and Canada since late spring. Most are already believers, like 49-year-old Denise Kleinhenz. She came with her family recently from their home on the other side of the state.
“She saw Jesus,” said Kleinhenz, wonder in her voice. “And he came more than just once. It just makes me think about, that he exists.”
The room where Wise was bedridden for years now is an altar room crowded with statues and relics. Bandages claimed to be those that absorbed Wise’s blood during stigmata are mounted in frames on the wall. Photos of Wise bleeding from the head and hands also are displayed.
The “Acts of the Case” advocating for her sainthood have been sent to Rome, but the next steps of the arduous process could take years.
Whether scientific explanations might exist for things that happened to Wise makes little difference by now, said Michele Dillon, a University of New Hampshire sociology professor who has written on Catholic beliefs.
Nobody can prove or disprove that miracles occurred at house or as a result of people visiting and praying there, Dillon said. And the continued involvement of the church has given the story a stamp of legitimacy.
“People do believe in prayer and miracles,” Dillon said. “And there’s also a social piece to that — if so many others are going, they must be on to something. If the story is compelling, it will attract a following.”
One of Wise’s granddaughters, 71-year-old Darlene Zastawny, was raised in the house and still stops around to talk to visitors. Her earliest memories, she said, involve strangers showing up at the door.
“I always wondered who all these people were that my mother would let in,” she said. “I’d be getting ready for school when I was little and there would be a stranger sitting with us because she wouldn’t tell them no. I knew it was special, but sometimes I wished it was more of a home. There was somebody coming all the time, but you get used to it.”
———
Follow Mitch Stacy on Twitter at https://twitter.com/mitchstacy
Sahred From Source link Travel
from WordPress http://bit.ly/2MoxRU4 via IFTTT
0 notes