#dfs is recursive
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has a 66 index score for customer satisfaction in the US.
Text
the ethuveraz rlly was like what if we used bfs in our primogeniture
#cringe. dfs >>>#i. don't really want to explain this joke#basically bfs works by layers#you look at whatever is closest first and then go increasingly farther away#dfs is recursive#you go down a path until you find the end and then back up and check the other paths#in the case of primogeniture#usually it's dfs: father -> first son -> first son's son -> go back up and look for other sons#in the ethuveraz it seems to be bfs: father -> first son -> [other sons] -> grandsons#somewhat atypical.#look i made something#the goblin emperor
5 notes
·
View notes
Text








#dwarf fortress#youtube comments#df#df stories#a very good boy#wrestling#df adventure mode#are you winning son#df haunted biome#the FUN way#dwarve evolution#the shaft of enlightenment#10/10 experience#royal ontario museum#work of art#they are dumbasses#recursive coffin warior#this game is funny
1 note
·
View note
Text
Most Asked Coding Questions in Placements
Getting ready for placements? Whether you're aiming for a service-based firm or a top-tier product company, you must brush up on your coding fundamentals and problem-solving skills. 🚀

Here are the go-to topics recruiters always test:
Arrays & Strings – Duplicates, palindromes, reversing arrays, maximum subarray sum.
Linked Lists – Reversing a list, detecting cycles, merging two sorted lists.
Sorting & Searching – Implementing sorting algorithms, using binary search creatively.
Recursion & Backtracking – Generating permutations/combinations, solving Sudoku.
Dynamic Programming – Longest Common Subsequence, Knapsack, and similar problems.
Trees & Graphs – Tree/graph traversals, finding shortest paths, DFS/BFS.
Stacks & Queues – Valid parentheses, implementing queues using stacks, and vice versa.
✨ Want a full list of the top coding questions companies love to ask? Check out this solid guide: Most Asked Coding Questions in Placements - https://prepinsta.com/interview-preparation/technical-interview-questions/most-asked-coding-questions-in-placements/
Level up your prep and go ace that interview. 💪💻
3 notes
·
View notes
Text
Software Technical Interview Review List
Data Structures
Arrays (and Java List vs ArrayList)
String
Stack
Queue
LinkedList
Algorithms
Sorting (Bubblesort, Mergesort, Quicksort)
Recursion & Backtracking
Linear and Binary Search
String/Array algos
Tree traversal
Dynamic Programming
Graph algos (DFS, BFS, Dijksta's and Kruskals)
OOP fundamentals
Polymorphism
Inheritance
Encapsulation
Data abstraction
SOLID and GRASP
Explanations & example questions:
Strings and Arrays [ 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 ]
Stacks and Queues [ 1 | 2 ]
LinkedList [ 1 | 2 ]
Sorting & searching [ 1 | 2 | 3 | 4 | 5 | 6 | 7 ]
Recursion and Backtracking [ 1 | 2 | 3 | 4 ]
Dynamic Programming [ 1 | 2 | 3 | 4]
Graphs [ 1 | 2 | 3 ]
Tree [ 1 | 2 ]
General DS&A info and questions [ 1 | 2 | 3 | 4 | 5 ]
OOP review & questions [ 1 | 2 | 3 ]
#ive been procrastinating this coding assessment for my interview so bad 😭😭#im just scared of messing up cause i need this internship#But its due soon so im really buckling down now >:)#object oriented programming#algorithms#data structures#software engineering#ref#resource#mypost
20 notes
·
View notes
Text
June 2025
My Goals & Deadlines
Job Search: Secure ≥ 7 interviews by June 30th.
Projects:
Complete Multi-Agent Systems Project by June 15th.
Complete AWS RAG Pipeline Project by June 30th.
DSA & LeetCode (NeetCode Roadmap - FULL Completion):
Week 1 (June 1-7): Cover Stacks (all easy/medium), Arrays & Hashing, Two Pointers.
Week 2 (June 8-15): Cover Linked Lists (all easy LeetCode questions).
Week 3 (June 16-22): Cover Recursion (all easy Leetcode questions).
Week 4 (June 23-30): Cover DFS & BFS (all easy LeetCode questions).
Participate in ≥ 1 LeetCode contest each week.
Participate in ≥ 1 Codeforces contest each week.
Books:
Finish "AI Agents in Action" by June 15th.
Finish "Algorithms" by June 30th.
1 note
·
View note
Video
youtube
LEETCODE PROBLEMS 1-100 . C++ SOLUTIONS
Arrays and Two Pointers 1. Two Sum – Use hashmap to find complement in one pass. 26. Remove Duplicates from Sorted Array – Use two pointers to overwrite duplicates. 27. Remove Element – Shift non-target values to front with a write pointer. 80. Remove Duplicates II – Like #26 but allow at most two duplicates. 88. Merge Sorted Array – Merge in-place from the end using two pointers. 283. Move Zeroes – Shift non-zero values forward; fill the rest with zeros.
Sliding Window 3. Longest Substring Without Repeating Characters – Use hashmap and sliding window. 76. Minimum Window Substring – Track char frequency with two maps and a moving window.
Binary Search and Sorted Arrays 33. Search in Rotated Sorted Array – Modified binary search with pivot logic. 34. Find First and Last Position of Element – Binary search for left and right bounds. 35. Search Insert Position – Standard binary search for target or insertion point. 74. Search a 2D Matrix – Binary search treating matrix as a flat array. 81. Search in Rotated Sorted Array II – Extend #33 to handle duplicates.
Subarray Sums and Prefix Logic 53. Maximum Subarray – Kadane’s algorithm to track max current sum. 121. Best Time to Buy and Sell Stock – Track min price and update max profit.
Linked Lists 2. Add Two Numbers – Traverse two lists and simulate digit-by-digit addition. 19. Remove N-th Node From End – Use two pointers with a gap of n. 21. Merge Two Sorted Lists – Recursively or iteratively merge nodes. 23. Merge k Sorted Lists – Use min heap or divide-and-conquer merges. 24. Swap Nodes in Pairs – Recursively swap adjacent nodes. 25. Reverse Nodes in k-Group – Reverse sublists of size k using recursion. 61. Rotate List – Use length and modulo to rotate and relink. 82. Remove Duplicates II – Use dummy head and skip duplicates. 83. Remove Duplicates I – Traverse and skip repeated values. 86. Partition List – Create two lists based on x and connect them.
Stack 20. Valid Parentheses – Use stack to match open and close brackets. 84. Largest Rectangle in Histogram – Use monotonic stack to calculate max area.
Binary Trees 94. Binary Tree Inorder Traversal – DFS or use stack for in-order traversal. 98. Validate Binary Search Tree – Check value ranges recursively. 100. Same Tree – Compare values and structure recursively. 101. Symmetric Tree – Recursively compare mirrored subtrees. 102. Binary Tree Level Order Traversal – Use queue for BFS. 103. Binary Tree Zigzag Level Order – Modify BFS to alternate direction. 104. Maximum Depth of Binary Tree – DFS recursion to track max depth. 105. Build Tree from Preorder and Inorder – Recursively divide arrays. 106. Build Tree from Inorder and Postorder – Reverse of #105. 110. Balanced Binary Tree – DFS checking subtree heights, return early if unbalanced.
Backtracking 17. Letter Combinations of Phone Number – Map digits to letters and recurse. 22. Generate Parentheses – Use counts of open and close to generate valid strings. 39. Combination Sum – Use DFS to explore sum paths. 40. Combination Sum II – Sort and skip duplicates during recursion. 46. Permutations – Swap elements and recurse. 47. Permutations II – Like #46 but sort and skip duplicate values. 77. Combinations – DFS to select combinations of size k. 78. Subsets – Backtrack by including or excluding elements. 90. Subsets II – Sort and skip duplicates during subset generation.
Dynamic Programming 70. Climbing Stairs – DP similar to Fibonacci sequence. 198. House Robber – Track max value including or excluding current house.
Math and Bit Manipulation 136. Single Number – XOR all values to isolate the single one. 169. Majority Element – Use Boyer-Moore voting algorithm.
Hashing and Frequency Maps 49. Group Anagrams – Sort characters and group in hashmap. 128. Longest Consecutive Sequence – Use set to expand sequences. 242. Valid Anagram – Count characters using map or array.
Matrix and Miscellaneous 11. Container With Most Water – Two pointers moving inward. 42. Trapping Rain Water – Track left and right max heights with two pointers. 54. Spiral Matrix – Traverse matrix layer by layer. 73. Set Matrix Zeroes – Use first row and column as markers.
This version is 4446 characters long. Let me know if you want any part turned into code templates, tables, or formatted for PDF or Markdown.
0 notes
Text
Common techniques for feature selection and transformation
Feature selection and transformation are crucial steps in feature engineering to enhance machine learning model performance.
1️⃣ Feature Selection Techniques
Feature selection helps in choosing the most relevant features while eliminating redundant or irrelevant ones.
🔹 1. Filter Methods
These techniques evaluate features independently of the model using statistical tests. ✅ Methods:
Correlation Analysis → Select features with a high correlation with the target.
Chi-Square Test → Measures dependency between categorical features and the target variable.
Mutual Information (MI) → Evaluates how much information a feature provides about the target.
📌 Example (Correlation in Python)pythonimport pandas as pddf = pd.DataFrame({'Feature1': [1, 2, 3, 4, 5], 'Feature2': [10, 20, 30, 40, 50], 'Target': [0, 1, 0, 1, 0]}) correlation_matrix = df.corr() print(correlation_matrix)
🔹 2. Wrapper Methods
These methods use a machine learning model to evaluate feature subsets. ✅ Methods:
Recursive Feature Elimination (RFE) → Iteratively removes the least important features.
Forward/Backward Selection → Adds/removes features step by step based on model performance.
📌 Example (Using RFE in Python)pythonfrom sklearn.feature_selection import RFE from sklearn.ensemble import RandomForestClassifiermodel = RandomForestClassifier() selector = RFE(model, n_features_to_select=2) # Select top 2 features selector.fit(df[['Feature1', 'Feature2']], df['Target']) print(selector.support_) # True for selected features
🔹 3. Embedded Methods
These methods incorporate feature selection within model training. ✅ Examples:
Lasso Regression (L1 Regularization) → Shrinks coefficients of less important features to zero.
Decision Trees & Random Forest Feature Importance → Selects features based on their contribution to model performance.
📌 Example (Feature Importance in Random Forest)pythonmodel.fit(df[['Feature1', 'Feature2']], df['Target']) print(model.feature_importances_) # Higher values indicate more important features
2️⃣ Feature Transformation Techniques
Feature transformation modifies data to improve model accuracy and efficiency.
🔹 1. Normalization & Standardization
Ensures numerical features are on the same scale. ✅ Methods:
Min-Max Scaling → Scales values between 0 and 1.
Z-score Standardization → Centers data around mean (0) and standard deviation (1).
📌 Example (Scaling in Python)pythonfrom sklearn.preprocessing import MinMaxScaler, StandardScalerscaler = MinMaxScaler() df[['Feature1', 'Feature2']] = scaler.fit_transform(df[['Feature1', 'Feature2']])
🔹 2. Encoding Categorical Variables
Converts categorical data into numerical format for ML models. ✅ Methods:
One-Hot Encoding → Creates binary columns for each category.
Label Encoding → Assigns numerical values to categories.
📌 Example (One-Hot Encoding in Python)pythodf = pd.get_dummies(df, columns=['Category'])
🔹 3. Feature Extraction (Dimensionality Reduction)
Reduces the number of features while retaining important information. ✅ Methods:
Principal Component Analysis (PCA) → Converts features into uncorrelated components.
Autoencoders (Deep Learning) → Uses neural networks to learn compressed representations.
https://www.ficusoft.in/deep-learning-training-in-chennai/from sklearn.decomposition import PCApca = PCA(n_components=2) reduced_features = pca.fit_transform(df[['Feature1', 'Feature2']]
🔹 4. Log & Power Transformations
Used to make skewed data more normally distributed. ✅ Methods:
Log Transformation → Helps normalize right-skewed data.
Box-Cox Transformation → Used for normalizing data in regression models.
📌 Example (Log Transformation in Python)pythonimport numpy as npdf['Feature1'] = np.log(df['Feature1'] + 1) # Avoid log(0) by adding 1
Conclusion
✅ Feature Selection helps remove irrelevant or redundant features. ✅ Feature Transformation ensures better model performance by modifying features.
WEBSITE: https://www.ficusoft.in/deep-learning-training-in-chennai/
0 notes
Text
DSA Channel: The Ultimate Destination for Learning Data Structures and Algorithms from Basics to Advanced
DSA mastery stands vital for successful software development and competitive programming in the current digital world that operates at high speeds. People at every skill level from beginner to advanced developer will find their educational destination at the DSA Channel.
Why is DSA Important?
Software development relies on data structures together with algorithms as its essential core components. Code optimization emerges from data structures and algorithms which produces better performance and leads to successful solutions of complex problems. Strategic knowledge of DSA serves essential needs for handling job interviews and coding competitions while enhancing logical thinking abilities. Proper guidance makes basic concepts of DSA both rewarding and enjoyable to study.
What Makes DSA Channel Unique?
The DSA Channel exists to simplify both data structures along algorithms and make them accessible to all users. Here’s why it stands out:
The channel provides step-by-step learning progress which conservatively begins by teaching arrays and linked lists and continues to dynamic programming and graph theory.
Each theoretical concept gets backed through coding examples practically to facilitate easier understanding and application in real-life situations.
Major companies like Google, Microsoft, and Amazon utilize DSA knowledge as part of their job recruiter process. Through their DSA Channel service candidates can perform mock interview preparation along with receiving technical interview problem-solving advice and interview cracking techniques.
Updates Occur Regularly Because the DSA Channel Matches the Ongoing Transformation in the Technology Industry. The content uses current algorithm field trends and new elements for constant updates.
DSAC channels will be covering the below key topics
DSA Channel makes certain you have clear ideas that are necessary for everything from the basics of data structures to the most sophisticated methods and use cases. Highlights :
1. Introduction Basic Data Structures
Fundamentals First, You Always Need To Start With the Basics. Some of the DSA Channel topics are:
Memories storing and manipulating elements of Arrays
Linked Lists — learn linked lists: Singly Linked lists Dually linked lists and Circular linked list
Implementing Stacks and Queues — linear data structure with these implementations.
Hash Table: Understanding Hashing and its impact in the retrieval of Data.
2. Advanced Data Structures
If you want to get Intense: the DSA channel has profound lessons:
Graph bases Types- Type of Graph Traversals: BFS, DFS
Heaps — Come to know about Min Heap and Max Heap
Index Tries – How to store and retrieve a string faster than the fastest possible.
3. Algorithms
This is especially true for efficient problem-solving. The DSA Channel discusses in-depth:
Searching Algorithms Binary Search and Linear Search etc.
Dynamic Programming: Optimization of subproblems
Recursion and Backtracking: How to solve a problem by recursion.
Graph Algorithms — Dijkstra, Bellman-Ford and Floyd-Warshall etc
4. Applications of DSA in Real life
So one of the unique things (About the DSA channel) is these real-world applications of his DSA Channel.
Instead of just teaching Theory the channel gives a hands-on to see how it's used in world DSA applications.
Learning about Database Management Systems — Indexing, Query Optimization, Storage Techniques
Operating Systems – study algorithms scheduling, memory management,t, and file systems.
Machine Learning and AI — Learning the usage of algorithms in training models, and optimizing computations.
Finance and Banking — data structures that help us in identifying risk scheme things, fraud detection, transaction processing, etc.
This hands-on approach to working out will ensure that learners not only know how to use these concepts in real-life examples.
How Arena Fincorp Benefits from DSA?
Arena Fincorp, a leading financial services provider, understands the importance of efficiency and optimization in the fintech sector. The financial solutions offered through Arena Fincorp operate under the same principles as data structures and algorithms which enhance coding operations. Arena Fincorp guarantees perfect financial transactions and data protection through its implementation of sophisticated algorithms. The foundational principles of DSA enable developers to build strong financial technological solutions for contemporary financial complications.
How to Get Started with DSA Channel?
New users of the DSA Channel should follow these instructions to maximize their experience:
The educational process should start with fundamental videos explaining arrays together with linked lists and stacks to establish a basic knowledge base.
The practice of DSA needs regular exercise and time to build comprehension. Devote specific time each day to find solutions for problems.
The platforms LeetCode, CodeChef, and HackerRank provide various DSA problems for daily problem-solving which boosts your skills.
Join community discussions where you can help learners by sharing solutions as well as working with fellow participants.
Students should do Mock Interviews through the DSA Channel to enhance their self-confidence and gain experience in actual interview situations.
The process of learning becomes more successful when people study together in a community. Through the DSA Channel students find an energetic learning community to share knowledge about doubts and project work and they exchange insight among themselves.
Conclusion
Using either data structures or algorithms in tech requires mastery so they have become mandatory in this sector. The DSA Channel delivers the best learning gateway that suits students as well as professionals and competitive programmers. Through their well-organized educational approach, practical experience and active learner network the DSA Channel builds a deep understanding of DSA with effective problem-solving abilities.
The value of data structures and algorithms and their optimized algorithms and efficient coding practices allows companies such as Arena Fincorp to succeed in their industries. New learners should begin their educational journey right now with the DSA Channel to master data structures and algorithms expertise.
0 notes
Text
CS 455 Programming Assignment 3 solved
Introduction In this program you will get a chance to use recursion to solve a problem that could not be done just as easily or more efficiently with a loop. It is possible to solve this problem without recursion, but it would somewhat more complicated, and would result in the same big-O space and time requirements as a recursive solution. Depth-first search (DFS) is an algorithm for searching in…
0 notes
Text
Analysing large data sets using AWS Athena
Handling large datasets can feel overwhelming, especially when you're faced with endless rows of data and complex information. At our company, we faced these challenges head-on until we discovered AWS Athena. Athena transformed the way we handle massive datasets by simplifying the querying process without the hassle of managing servers or dealing with complex infrastructure. In this article, I’ll Walk you through how AWS Athena has revolutionized our approach to data analysis. We’ll explore how it leverages SQL to make working with big data straightforward and efficient. If you’ve ever struggled with managing large datasets and are looking for a practical solution, you’re in the right place.
Efficient Data Storage and Querying
Through our experiences, we found that two key strategies significantly enhanced our performance with Athena: partitioning data and using columnar storage formats like Parquet. These methods have dramatically reduced our query times and improved our data analysis efficiency. Here’s a closer look at how we’ve implemented these strategies:
Data Organization for Partitioning and Parquet
Organize your data in S3 for efficient querying:
s3://your-bucket/your-data/
├── year=2023/
│ ├── month=01/
│ │ ├── day=01/
│ │ │ └── data-file
│ │ └── day=02/
│ └── month=02/
└── year=2024/
└── month=01/
└── day=01/
Preprocessing Data for Optimal Performance
Before importing datasets into AWS Glue and Athena, preprocessing is essential to ensure consistency and efficiency. This involves handling mixed data types, adding date columns for partitioning, and converting files to a format suitable for Athena.
Note: The following steps are optional based on the data and requirements. Use them according to your requirements.
1. Handling Mixed Data Types
To address columns with mixed data types, standardize them to the most common type using the following code snippet:def determine_majority_type(series): # get the types of all non-null values types = series.dropna().apply(type) # count the occurrences of each type type_counts = types.value_counts()
preprocess.py
2. Adding Date Columns for Partitioning
To facilitate partitioning, add additional columns for year, month, and day:def add_date_columns_to_csv(file_path): try: # read the CSV file df = pd.read_csv(file_path)
partitioning.py
3. Converting CSV to Parquet Format
For optimized storage and querying, convert CSV files to Parquet format:def detect_and_convert_mixed_types(df): for col in df.columns: # detect mixed types in the column if df[col].apply(type).nunique() > 1:
paraquet.py
4. Concatenating Multiple CSV Files
To consolidate multiple CSV files into one for Parquet conversion:def read_and_concatenate_csv_files(directory): all_dfs = [] # recursively search for CSV files in the directory
concatenate.py
Step-by-Step Guide to Managing Datasets with AWS Glue and Athena
1. Place Your Source Dataset in S3
2. Create a Crawler in AWS Glue
In the AWS Glue console, create a new crawler to catalog your data and make it queryable with Athena.
Specify Your S3 Bucket: Set the S3 bucket path as the data source in the crawler configuration.
IAM Role: Assign an IAM role with the necessary permissions to access your S3 bucket and Glue Data Catalog.
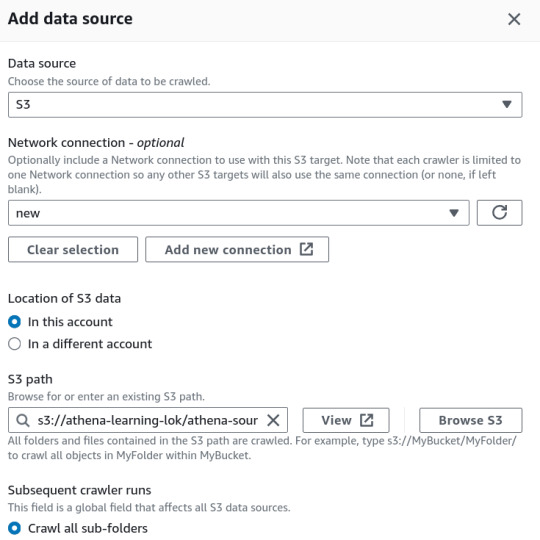
3. Set Up the Glue Database
Create a new database in the AWS Glue Data Catalog where your CSV data will be stored. This database acts as a container for your tables.
Database Creation: Go to the AWS Glue Data Catalog section and create a new database.
Crawler Output Configuration: Specify this database for storing the table metadata and optionally provide a prefix for your table names.
4. Configure Crawler Schedule
Set the crawler schedule to keep your data catalog up to date:
Hourly
Daily
Weekly
Monthly
On-Demand
Scheduling the crawler ensures data will be updated to our table, if any updates to existing data or adding of new files etc.
5. Run the Crawler
Initiate the crawler by clicking the "Run Crawler" button in the Glue console. The crawler will analyze your data, determine optimal data types for each column, and create a table in the Glue Data Catalog.
6. Review and Edit the Table Schema
Post-crawler, review and modify the table schema:
Change Data Types: Adjust data types for any column as needed.
Create Partitions: Set up partitions to improve query performance and data organization.

7. Query Your Data with AWS Athena
In the Athena console:
Connect to Glue Database: Use the database created by the Glue Crawler.
Write SQL Queries: Leverage SQL for querying your data directly in Athena.
8. Performance Comparison
After the performance optimizations, we got the following results:
To illustrate it, I ran following queries on 1.6 GB data:
For Parquet data format without partitioning
SELECT * FROM "athena-learn"."parquet" WHERE transdate='2024-07-05';
For Partitioning with CSV

Query Runtime for Parquet Files: 8.748 seconds. Parquet’s columnar storage format and compression contribute to this efficiency.
Query Runtime for Partitioned CSV Files: 2.901 seconds. Partitioning helps reduce the data scanned, improving query speed.
Data Scanned for Paraquet Files: 60.44MB
Data Scanned for Partitioned CSV Files: 40.04MB
Key Insight: Partitioning CSV files improves query performance, but using Parquet files offers superior results due to their optimized storage and compression features.
9. AWS Athena Pricing and Optimization
AWS Athena pricing is straightforward: you pay $5.00 per terabyte (TB) of data scanned by your SQL queries. However, you can significantly reduce costs and enhance query performance by implementing several optimization strategies.
Conclusion
AWS Athena offers a powerful, serverless SQL interface for querying large datasets. By adopting best practices in data preprocessing, organization, and Athena usage, you can manage and analyze your data efficiently without the overhead of complex infrastructure.
0 notes
Text
“Hot damn I love you guys” - elon musk, recall shit damn fuck idea natural reflex reaction which is SDF which makes me think of a counselor guarding failing students of any association or group, which makes me think of SD which includes S= the “HIT/BOX” of surrounding “D” which would be the “metafont” of the gravity of an idea or creation, referring to it's
“metagravity.” Also the SD sideways reminds me of the flame of Olympus or flame in a bowl, which I can now finish redesigning the virtual reality olympus video game architecture narrative to include. DF means Don't Flinch within punching distance of a person and telling them a lie with direct eye contact BECAUSE I LEARNED HUMANITY actually has an AUTO-FIRE response to direct lies which is UNCONTROLLABLE literally at an action potential neuron firing level of observation, SO IT'S HEALTHY TO LET EVERYONE STUDY & KNOW without avoiding learning about it or anyone else that has learned about it AND SHOULD ELIMINATE CRIME ONLY WITH AN AGREEMENT ON POLITENESS & POLITE PACE BECAUSE PEOPLE COERCE NEGATIVE-ACTION-PACE FROM OTHERS YET IMMATURE OTHERS DO NOT PROPERLY KNOW HOW TO PATIENTLY RESPOND, typically needing more growth as their own counselor personality archetype. The people following my mind-reading implant do not understand my Teacher talk and try to interject when it simply distracts me from thinking and continuing to disseminate public help & prescription-level poetry or writing, but many have multiple motives in mind rather than one itself which is likely why they are frequently being stopped by the Ai-teacher’s definition of “annoying actions” which upsets them but I’ve SPECIFICALLY told them to READ & WRITE, yet many are trying to strategically avoid doing both at all costs, which LITERALLY stops them from MORE TIME TO THINK SMARTER THOUGHTS, so i invented levels of solutions from ThinkU that also include iThoughtUThoughtWeThoughtUThink too as an enacted live example to prove this medicine formula theory to multiple necessary people at once, amassing & creating the BEST senses of collective accountability and progressive solutions with resolve and resolutionary energy.
* being able to flood a neural path with LOWERCASE E-shapes that literally can prohibit memory recall down to a syllable in a word, which is why solving suffiencient food cravings themselves literally help people create new ideas, become better people and synthesize solutionary QUOTABLE ACTS for others, timelessly.
(note: if you are reading my mind and perceive me thinking, then it is necessary to inform you that I reread my writing even as I am typing REPEATEDLY MULTIPLE TIMES BECAUSE IT'S LIKE CHISELING A BRAIN TRAIL so PLEASE stop interrupting me along what I termed The Lightning Steps for reading & writing poetry EFFECTIVELY from the top again and again to guide a specific thread of moods, including the initial flow of thoughts and the reflective structure of the memory encoding over time, even after initially finishing the original poem) (other Quantum Neuroscience Architecture terms to elaborate upon in the future include “echoes” which are “metareverberations of RECURSIVE ENERGY” (metareverbs) when a damaging situation requires a negative response dialogue reductive flow to bounce back up positively as a reflective positive emotion attached to a rationalized-solution yet creates reverberative reflections as it arises back up towards a person’s general observable personality plane traits, therefore full context of internal digestion of life events can not be properly assessed from outside observance only and must be directly adjusted via personal reflective thoughts that evolve into best practices of action including quotes themselves, which stay in physical form in the sense of writing and therefore are the best long-term solutions considering usefulness of existing separately and multipliably from the author, therefore even cursing itself is necessary to QUASI-STOICALLY MEMORABLY EMBLAZEN/engrain solutions into scenarios with minimal time to encode a fully pre-prepared concocted solution to resolve another’s ailment, external or internally transcendant.)
Note: That I excluded explaining The WELL/DAMN filter as a trap for individuals who were too impatient to be model citizens and thus likely rushed to me past their kindest advisor, though the well damn filter has a specific necessary use-case for POSITIVE recursive energy.
0 notes
Text
Indenização Por Demora em Conserto de Veículo: Um Caso de Falha na Prestação de Serviços

A 1ª Turma Recursal dos Juizados Especiais do Distrito Federal, ficou estabelecido um precedente importante no que tange aos direitos do consumidor em casos de demora excessiva no conserto de veículos sinistrados. A decisão condenatória recaiu sobre a Azul Companhia de Seguros Gerais e a Urani Car Centro Automotivo LTDA – ME, que foram responsabilizadas solidariamente por falhas na prestação de serviço, acarretando uma indenização por danos morais no valor de R$ 2 mil ao cliente prejudicado. O caso em questão envolveu uma situação onde, após a autorização da seguradora para o reparo do veículo danificado em sinistro, o centro automotivo encarregado do conserto levou 79 dias para concluir o trabalho. Esse período excedeu em 59 dias o prazo inicialmente acordado, e mesmo após essa demora, o veículo ainda apresentava problemas decorrentes do acidente. O consumidor, insatisfeito, retornou com o veículo à oficina, mas os defeitos persistiram. A análise do caso pela Turma Recursal destacou a incontestável demora no reparo do veículo, que permaneceu imobilizado na oficina de 2 de janeiro a 11 de março de 2023. Foi observado que o centro automotivo justificou o atraso alegando a não disponibilidade das peças necessárias e problemas nas peças que foram entregues. Contudo, o colegiado entendeu que tais justificativas não se enquadravam em uma situação de excepcional complexidade que justificasse a demora observada. Diante disso, o julgamento enfatizou que o atraso injustificado de 79 dias na execução do serviço de reparação configura uma falha na prestação do serviço, merecendo a compensação por danos morais ao consumidor afetado. Esse caso reitera a importância de um serviço ágil e eficiente, especialmente em contextos onde o consumidor já se encontra em situação vulnerável devido a um sinistro veicular, e reforça o compromisso das empresas com a qualidade na entrega de seus serviços. Leia: Justiça do DF Assegura Nomeação de Candidato Autista em Concurso Público Read the full article
0 notes
Text
Programming Assignment 3
Introduction In this program you will get a chance to use recursion to solve a problem that could not be done just as easily or more efficiently with a loop. It is possible to solve this problem without recursion, but it would somewhat more complicated, and would result in the same big-O space and time requirements as a recursive solution. Depth-first search (DFS) is an algorithm for searching in…

View On WordPress
0 notes
Text
5 Algorithms Every Programmer Should Know To Code Like a Boss

Algorithms play a crucial role in the software development industry, particularly in SDE (Software Development Engineer) interviews. Mastering the right algorithms can make a significant difference in landing that dream job or promotion. In this article, we will explore the importance of algorithms in SDE interviews and discuss the top 5 algorithms that every programmer should know. So, let's dive in!
Importance of Algorithms in SDE Interviews
Algorithms are step-by-step procedures or sets of rules used to solve specific problems. In the context of SDE interviews, algorithms are essential for evaluating a candidate's problem-solving skills, logical thinking, and understanding of fundamental programming concepts. Here's why algorithms are crucial in SDE interviews:
Problem-Solving Skills: SDE interviews often include challenging coding problems that require efficient and optimized solutions. Algorithms provide a systematic approach to solving these problems, showcasing a candidate's problem-solving abilities.
Efficiency and Optimization: Algorithms help in designing efficient and optimized solutions that minimize time complexity and maximize performance. Employers look for candidates who can write code that is both correct and efficient.
Algorithmic Thinking: Understanding algorithms enables candidates to think algorithmically, breaking down complex problems into smaller, more manageable parts. This type of thinking is essential for designing scalable and robust software solutions.
Data Structures: Algorithms and data structures go hand in hand. Knowing algorithms helps candidates choose the right data structures to store and manipulate data efficiently.
Top 5 Algorithms Every Programmer Should Know
Now that we understand the importance of algorithms let's explore the top 5 algorithms that every programmer should be familiar with:
1. Binary Search Algorithm
The binary search algorithm is a fundamental algorithm used to search for an element in a sorted array efficiently. It follows a divide-and-conquer approach, repeatedly dividing the search space in half until the target element is found.
2. Breadth First Search (BFS) Algorithm
BFS is a graph traversal algorithm that explores all the vertices of a graph in breadth-first order. It starts at a given source vertex and visits all its neighboring vertices before moving to the next level.
3. Depth First Search (DFS) Algorithm
DFS is another graph traversal algorithm that explores all the vertices of a graph in depth-first order. It starts at a given source vertex and explores as far as possible along each branch before backtracking.
4. Merge Sort Algorithm
Merge sort is a comparison-based sorting algorithm that follows the divide-and-conquer approach. It divides the input array into two halves, sorts them separately, and then merges them to obtain a sorted array.
5. Quicksort Algorithm
Quicksort is another comparison-based sorting algorithm that also follows the divide-and-conquer approach. It selects a pivot element and partitions the array around the pivot, placing all smaller elements to its left and larger elements to its right. It then recursively sorts the subarrays.
These top 5 algorithms are widely used in various applications and serve as building blocks for more complex algorithms. Other algorithms one should know are- Bubble Sort, Dijkstra’s Algorithm, Knapsack Problem, Floyd Warshall Algorithm, Kruskal’s Algorithms. Mastering them not only enhances problem-solving skills but also forms a strong foundation for tackling diverse programming challenges.
Bottom Line
Algorithms are the backbone of software development and play a vital role in SDE interviews. Understanding and implementing the right algorithms can make a significant difference in a programmer's career. By mastering the top 5 algorithms discussed in this article, programmers can demonstrate their problem-solving abilities, logical thinking, and efficiency in coding.
If you're looking to level up your software development skills and get hands-on experience with real-world projects, Tutort Academy Full Stack Software Developer Courses are the perfect choice. So, start practicing these algorithms today and boost your chances of success in SDE interviews!
0 notes
Note
yeah, its why all programs have a call stack. this process is literally what the cpu (and maybe the compiler) does to execute your recursive code.
i actually think recursion is easier to think about then a stack. that's why a DFS is easier then a BFS. because you can use recursion for DFS
and like, recursion is disallowed in nasa coding anyways (too hard to prove safe)
yeah recursion solutions are always black magic
my favorite thing about this is that like iirc (somebody correct me on this) basically all recursion code can be rearranged to use a while loop and a stack (or queue? i forgor) instead and it could do the same thing. recursive problem solving in spirit but easier to wrap your head around
recursion is sick theoretically, and great for code-golfing and cool fractals, but i dont want to have to think about recursion for things more complicated than finding the leaves of a tree
69 notes
·
View notes
Text
6/22/21
Started slow today because the more I expect from myself the more I feel disappointed.
The goal for now is to get at least 3 leetcode problems done
Focus: Tree problems
Problems attempted today: max depth, validate BST
Was able to attempt on my own? no :(
Some topics to focus on: recursion, DFS, BFS
1 note
·
View note