#github data scraper
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr.com is the 103rd most visited website in the world.
Text
ShadowDragon sells a tool called SocialNet that streamlines the process of pulling public data from various sites, apps, and services. Marketing material available online says SocialNet can “follow the breadcrumbs of your target’s digital life and find hidden correlations in your research.” In one promotional video, ShadowDragon says users can enter “an email, an alias, a name, a phone number, a variety of different things, and immediately have information on your target. We can see interests, we can see who friends are, pictures, videos.”
The leaked list of targeted sites include ones from major tech companies, communication tools, sites focused around certain hobbies and interests, payment services, social networks, and more. The 30 companies the Mozilla Foundation is asking to block ShadowDragon scrapers are Amazon, Apple, BabyCentre, BlueSky, Discord, Duolingo, Etsy, Meta’s Facebook and Instagram, FlightAware, Github, Glassdoor, GoFundMe, Google, LinkedIn, Nextdoor, OnlyFans, Pinterest, Reddit, Snapchat, Strava, Substack, TikTok, Tinder, TripAdvisor, Twitch, Twitter, WhatsApp, Xbox, Yelp, and YouTube.
437 notes
·
View notes
Text
"how do I keep my art from being scraped for AI from now on?"
if you post images online, there's no 100% guaranteed way to prevent this, and you can probably assume that there's no need to remove/edit existing content. you might contest this as a matter of data privacy and workers' rights, but you might also be looking for smaller, more immediate actions to take.
...so I made this list! I can't vouch for the effectiveness of all of these, but I wanted to compile as many options as possible so you can decide what's best for you.
Discouraging data scraping and "opting out"
robots.txt - This is a file placed in a website's home directory to "ask" web crawlers not to access certain parts of a site. If you have your own website, you can edit this yourself, or you can check which crawlers a site disallows by adding /robots.txt at the end of the URL. This article has instructions for blocking some bots that scrape data for AI.
HTML metadata - DeviantArt (i know) has proposed the "noai" and "noimageai" meta tags for opting images out of machine learning datasets, while Mojeek proposed "noml". To use all three, you'd put the following in your webpages' headers:
<meta name="robots" content="noai, noimageai, noml">
Have I Been Trained? - A tool by Spawning to search for images in the LAION-5B and LAION-400M datasets and opt your images and web domain out of future model training. Spawning claims that Stability AI and Hugging Face have agreed to respect these opt-outs. Try searching for usernames!
Kudurru - A tool by Spawning (currently a Wordpress plugin) in closed beta that purportedly blocks/redirects AI scrapers from your website. I don't know much about how this one works.
ai.txt - Similar to robots.txt. A new type of permissions file for AI training proposed by Spawning.
ArtShield Watermarker - Web-based tool to add Stable Diffusion's "invisible watermark" to images, which may cause an image to be recognized as AI-generated and excluded from data scraping and/or model training. Source available on GitHub. Doesn't seem to have updated/posted on social media since last year.
Image processing... things
these are popular now, but there seems to be some confusion regarding the goal of these tools; these aren't meant to "kill" AI art, and they won't affect existing models. they won't magically guarantee full protection, so you probably shouldn't loudly announce that you're using them to try to bait AI users into responding
Glaze - UChicago's tool to add "adversarial noise" to art to disrupt style mimicry. Devs recommend glazing pictures last. Runs on Windows and Mac (Nvidia GPU required)
WebGlaze - Free browser-based Glaze service for those who can't run Glaze locally. Request an invite by following their instructions.
Mist - Another adversarial noise tool, by Psyker Group. Runs on Windows and Linux (Nvidia GPU required) or on web with a Google Colab Notebook.
Nightshade - UChicago's tool to distort AI's recognition of features and "poison" datasets, with the goal of making it inconvenient to use images scraped without consent. The guide recommends that you do not disclose whether your art is nightshaded. Nightshade chooses a tag that's relevant to your image. You should use this word in the image's caption/alt text when you post the image online. This means the alt text will accurately describe what's in the image-- there is no reason to ever write false/mismatched alt text!!! Runs on Windows and Mac (Nvidia GPU required)
Sanative AI - Web-based "anti-AI watermark"-- maybe comparable to Glaze and Mist. I can't find much about this one except that they won a "Responsible AI Challenge" hosted by Mozilla last year.
Just Add A Regular Watermark - It doesn't take a lot of processing power to add a watermark, so why not? Try adding complexities like warping, changes in color/opacity, and blurring to make it more annoying for an AI (or human) to remove. You could even try testing your watermark against an AI watermark remover. (the privacy policy claims that they don't keep or otherwise use your images, but use your own judgment)
given that energy consumption was the focus of some AI art criticism, I'm not sure if the benefits of these GPU-intensive tools outweigh the cost, and I'd like to know more about that. in any case, I thought that people writing alt text/image descriptions more often would've been a neat side effect of Nightshade being used, so I hope to see more of that in the future, at least!
246 notes
·
View notes
Text
pulling out a section from this post (a very basic breakdown of generative AI) for easier reading;
AO3 and Generative AI
There are unfortunately some massive misunderstandings in regards to AO3 being included in LLM training datasets. This post was semi-prompted by the ‘Knot in my name’ AO3 tag (for those of you who haven’t heard of it, it’s supposed to be a fandom anti-AI event where AO3 writers help “further pollute” AI with Omegaverse), so let’s take a moment to address AO3 in conjunction with AI. We’ll start with the biggest misconception:
1. AO3 wasn’t used to train generative AI.
Or at least not anymore than any other internet website. AO3 was not deliberately scraped to be used as LLM training data.
The AO3 moderators found traces of the Common Crawl web worm in their servers. The Common Crawl is an open data repository of raw web page data, metadata extracts and text extracts collected from 10+ years of web crawling. Its collective data is measured in petabytes. (As a note, it also only features samples of the available pages on a given domain in its datasets, because its data is freely released under fair use and this is part of how they navigate copyright.) LLM developers use it and similar web crawls like Google’s C4 to bulk up the overall amount of pre-training data.
AO3 is big to an individual user, but it’s actually a small website when it comes to the amount of data used to pre-train LLMs. It’s also just a bad candidate for training data. As a comparison example, Wikipedia is often used as high quality training data because it’s a knowledge corpus and its moderators put a lot of work into maintaining a consistent quality across its web pages. AO3 is just a repository for all fanfic -- it doesn’t have any of that quality maintenance nor any knowledge density. Just in terms of practicality, even if people could get around the copyright issues, the sheer amount of work that would go into curating and labeling AO3’s data (or even a part of it) to make it useful for the fine-tuning stages most likely outstrips any potential usage.
Speaking of copyright, AO3 is a terrible candidate for training data just based on that. Even if people (incorrectly) think fanfic doesn’t hold copyright, there are plenty of books and texts that are public domain that can be found in online libraries that make for much better training data (or rather, there is a higher consistency in quality for them that would make them more appealing than fic for people specifically targeting written story data). And for any scrapers who don’t care about legalities or copyright, they’re going to target published works instead. Meta is in fact currently getting sued for including published books from a shadow library in its training data (note, this case is not in regards to any copyrighted material that might’ve been caught in the Common Crawl data, its regarding a book repository of published books that was scraped specifically to bring in some higher quality data for the first training stage). In a similar case, there’s an anonymous group suing Microsoft, GitHub, and OpenAI for training their LLMs on open source code.
Getting back to my point, AO3 is just not desirable training data. It’s not big enough to be worth scraping for pre-training data, it’s not curated enough to be considered for high quality data, and its data comes with copyright issues to boot. If LLM creators are saying there was no active pursuit in using AO3 to train generative AI, then there was (99% likelihood) no active pursuit in using AO3 to train generative AI.
AO3 has some preventative measures against being included in future Common Crawl datasets, which may or may not work, but there’s no way to remove any previously scraped data from that data corpus. And as a note for anyone locking their AO3 fics: that might potentially help against future AO3 scrapes, but it is rather moot if you post the same fic in full to other platforms like ffn, twitter, tumblr, etc. that have zero preventative measures against data scraping.
2. A/B/O is not polluting generative AI
…I’m going to be real, I have no idea what people expected to prove by asking AI to write Omegaverse fic. At the very least, people know A/B/O fics are not exclusive to AO3, right? The genre isn’t even exclusive to fandom -- it started in fandom, sure, but it expanded to general erotica years ago. It’s all over social media. It has multiple Wikipedia pages.
More to the point though, omegaverse would only be “polluting” AI if LLMs were spewing omegaverse concepts unprompted or like…associated knots with dicks more than rope or something. But people asking AI to write omegaverse and AI then writing omegaverse for them is just AI giving people exactly what they asked for. And…I hate to point this out, but LLMs writing for a niche the LLM trainers didn’t deliberately train the LLMs on is generally considered to be a good thing to the people who develop LLMs. The capability to fill niches developers didn’t even know existed increases LLMs’ marketability. If I were a betting man, what fandom probably saw as a GOTCHA moment, AI people probably saw as a good sign of LLMs’ future potential.
3. Individuals cannot affect LLM training datasets.
So back to the fandom event, with the stated goal of sabotaging AI scrapers via omegaverse fic.
…It’s not going to do anything.
Let’s add some numbers to this to help put things into perspective:
LLaMA’s 65 billion parameter model was trained on 1.4 trillion tokens. Of that 1.4 trillion tokens, about 67% of the training data was from the Common Crawl (roughly ~3 terabytes of data).
3 terabytes is 3,000,000,000 kilobytes.
That’s 3 billion kilobytes.
According to a news article I saw, there has been ~450k words total published for this campaign (*this was while it was going on, that number has probably changed, but you’re about to see why that still doesn’t matter). So, roughly speaking, ~450k of text is ~1012 KB (I’m going off the document size of a plain text doc for a fic whose word count is ~440k).
So 1,012 out of 3,000,000,000.
Aka 0.000034%.
And that 0.000034% of 3 billion kilobytes is only 2/3s of the data for the first stage of training.
And not to beat a dead horse, but 0.000034% is still grossly overestimating the potential impact of posting A/B/O fic. Remember, only parts of AO3 would get scraped for Common Crawl datasets. Which are also huge! The October 2022 Common Crawl dataset is 380 tebibytes. The April 2021 dataset is 320 tebibytes. The 3 terabytes of Common Crawl data used to train LLaMA was randomly selected data that totaled to less than 1% of one full dataset. Not to mention, LLaMA’s training dataset is currently on the (much) larger size as compared to most LLM training datasets.
I also feel the need to point out again that AO3 is trying to prevent any Common Crawl scraping in the future, which would include protection for these new stories (several of which are also locked!).
Omegaverse just isn’t going to do anything to AI. Individual fics are going to do even less. Even if all of AO3 suddenly became omegaverse, it’s just not prominent enough to influence anything in regards to LLMs. You cannot affect training datasets in any meaningful way doing this. And while this might seem really disappointing, this is actually a good thing.
Remember that anything an individual can do to LLMs, the person you hate most can do the same. If it were possible for fandom to corrupt AI with omegaverse, fascists, bigots, and just straight up internet trolls could pollute it with hate speech and worse. AI already carries a lot of biases even while developers are actively trying to flatten that out, it’s good that organized groups can’t corrupt that deliberately.
#generative ai#pulling this out wasnt really prompted by anything specific#so much as heard some repeated misconceptions and just#sighs#nope#incorrect#u got it wrong#sorry#unfortunately for me: no consistent tag to block#sigh#ao3
101 notes
·
View notes
Text
25 Python Projects to Supercharge Your Job Search in 2024

Introduction: In the competitive world of technology, a strong portfolio of practical projects can make all the difference in landing your dream job. As a Python enthusiast, building a diverse range of projects not only showcases your skills but also demonstrates your ability to tackle real-world challenges. In this blog post, we'll explore 25 Python projects that can help you stand out and secure that coveted position in 2024.
1. Personal Portfolio Website
Create a dynamic portfolio website that highlights your skills, projects, and resume. Showcase your creativity and design skills to make a lasting impression.
2. Blog with User Authentication
Build a fully functional blog with features like user authentication and comments. This project demonstrates your understanding of web development and security.
3. E-Commerce Site
Develop a simple online store with product listings, shopping cart functionality, and a secure checkout process. Showcase your skills in building robust web applications.
4. Predictive Modeling
Create a predictive model for a relevant field, such as stock prices, weather forecasts, or sales predictions. Showcase your data science and machine learning prowess.
5. Natural Language Processing (NLP)
Build a sentiment analysis tool or a text summarizer using NLP techniques. Highlight your skills in processing and understanding human language.
6. Image Recognition
Develop an image recognition system capable of classifying objects. Demonstrate your proficiency in computer vision and deep learning.
7. Automation Scripts
Write scripts to automate repetitive tasks, such as file organization, data cleaning, or downloading files from the internet. Showcase your ability to improve efficiency through automation.
8. Web Scraping
Create a web scraper to extract data from websites. This project highlights your skills in data extraction and manipulation.
9. Pygame-based Game
Develop a simple game using Pygame or any other Python game library. Showcase your creativity and game development skills.
10. Text-based Adventure Game
Build a text-based adventure game or a quiz application. This project demonstrates your ability to create engaging user experiences.
11. RESTful API
Create a RESTful API for a service or application using Flask or Django. Highlight your skills in API development and integration.
12. Integration with External APIs
Develop a project that interacts with external APIs, such as social media platforms or weather services. Showcase your ability to integrate diverse systems.
13. Home Automation System
Build a home automation system using IoT concepts. Demonstrate your understanding of connecting devices and creating smart environments.
14. Weather Station
Create a weather station that collects and displays data from various sensors. Showcase your skills in data acquisition and analysis.
15. Distributed Chat Application
Build a distributed chat application using a messaging protocol like MQTT. Highlight your skills in distributed systems.
16. Blockchain or Cryptocurrency Tracker
Develop a simple blockchain or a cryptocurrency tracker. Showcase your understanding of blockchain technology.
17. Open Source Contributions
Contribute to open source projects on platforms like GitHub. Demonstrate your collaboration and teamwork skills.
18. Network or Vulnerability Scanner
Build a network or vulnerability scanner to showcase your skills in cybersecurity.
19. Decentralized Application (DApp)
Create a decentralized application using a blockchain platform like Ethereum. Showcase your skills in developing applications on decentralized networks.
20. Machine Learning Model Deployment
Deploy a machine learning model as a web service using frameworks like Flask or FastAPI. Demonstrate your skills in model deployment and integration.
21. Financial Calculator
Build a financial calculator that incorporates relevant mathematical and financial concepts. Showcase your ability to create practical tools.
22. Command-Line Tools
Develop command-line tools for tasks like file manipulation, data processing, or system monitoring. Highlight your skills in creating efficient and user-friendly command-line applications.
23. IoT-Based Health Monitoring System
Create an IoT-based health monitoring system that collects and analyzes health-related data. Showcase your ability to work on projects with social impact.
24. Facial Recognition System
Build a facial recognition system using Python and computer vision libraries. Showcase your skills in biometric technology.
25. Social Media Dashboard
Develop a social media dashboard that aggregates and displays data from various platforms. Highlight your skills in data visualization and integration.
Conclusion: As you embark on your job search in 2024, remember that a well-rounded portfolio is key to showcasing your skills and standing out from the crowd. These 25 Python projects cover a diverse range of domains, allowing you to tailor your portfolio to match your interests and the specific requirements of your dream job.
If you want to know more, Click here:https://analyticsjobs.in/question/what-are-the-best-python-projects-to-land-a-great-job-in-2024/
#python projects#top python projects#best python projects#analytics jobs#python#coding#programming#machine learning
2 notes
·
View notes
Text
How to Learn Python Effectively: A Step-by-Step Approach
Python has become one of the most popular programming languages due to its simplicity, versatility, and wide range of applications. Whether you’re aiming to build web applications, automate tasks, analyze data, or dive into artificial intelligence, Python provides a solid foundation to achieve these goals. Considering the kind support of Python Course in Chennai Whatever your level of experience or reason for switching from another programming language, learning Python gets much more fun.

Learning Python effectively requires a structured approach that helps you grasp the basics while gradually moving toward advanced concepts. Here’s a step-by-step guide to help you learn Python efficiently and effectively.
1. Start with the Basics
Before diving into complex projects, it's essential to understand the core fundamentals of Python. Start by learning about:
Variables and Data Types – Understand how to store and manipulate data.
Conditional Statements – Learn how to make decisions in your code using if, else, and elif statements.
Loops – Master for and while loops to automate repetitive tasks.
Functions – Write reusable blocks of code to make your programs more efficient.
Mastering these basics will give you a solid foundation to tackle more complex programming challenges.
2. Practice Regularly
Consistency is key when learning any programming language. Set aside time each day to write code, experiment with different patterns, and solve small problems. Start with simple exercises and gradually increase the difficulty level as you become more comfortable with the language.
3. Work on Real Projects
Hands-on experience is one of the most effective ways to learn Python. Start with small projects such as:
A calculator
A to-do list app
A simple web scraper
As you gain confidence, work on larger projects like a web application or data analysis tool. Projects help you apply what you've learned, solve real-world problems, and build a portfolio to showcase your skills.
With the aid of Best Online Training & Placement Programs, which offer comprehensive training and job placement support to anyone looking to develop their talents, it’s easier to learn this tool and advance your career.

4. Learn Python Libraries and Frameworks
Python has a rich ecosystem of libraries and frameworks that simplify coding and make development faster. Some of the most widely used libraries include:
NumPy and Pandas for data analysis
Flask and Django for web development
Matplotlib and Seaborn for data visualization
TensorFlow and Scikit-learn for machine learning
Learning how to use these libraries will help you write more efficient code and expand your programming capabilities.
5. Solve Coding Challenges
Problem-solving is a critical skill for any programmer. Engage in coding challenges and exercises to strengthen your logical thinking and debugging skills. Challenges will push you to think creatively and help you become more comfortable with Python’s syntax and problem-solving techniques.
6. Join a Programming Community
Programming is not a solo journey. Join online forums, coding communities, and discussion groups to connect with other learners and experienced developers. Engaging with a programming community allows you to ask questions, share solutions, and learn from others' experiences.
7. Study Code Written by Others
Reading and analyzing code written by experienced developers can help you improve your coding style and learn best practices. Open-source projects and GitHub repositories are great resources for studying code and understanding how different programming patterns are used in real-world applications.
8. Stay Curious and Keep Learning
Python is constantly evolving with new updates, libraries, and frameworks. Stay updated with the latest trends, explore new features, and continue to experiment with different projects. Expanding your knowledge will keep you ahead of the curve and help you become a more versatile programmer.
Conclusion
Learning Python effectively requires a balance of understanding the fundamentals, practicing regularly, and working on real projects. By following a structured approach and staying consistent with your practice, you can quickly master Python and apply it to various fields such as web development, data science, and automation. With dedication and the right strategy, Python can become a powerful tool in your programming journey.
#python course#python training#python#python programming#python online training#python online classes#python online course#python certification#technology#tech
0 notes
Text
Web Scraping 101: Understanding the Basics
Data Analytics, also known as the Science of Data, has various types of analytical methodologies, But the very interesting part of all the analytical process is collecting data from different sources. It is challenging to collect data while keeping the ACID terms in mind. I'll be sharing a few points in this article which I think is useful while learning the concept of Web Scrapping.
The very first thing to note is not every website allows you to scrape their data.
Before we get into the details, though, let’s start with the simple stuff…

What is web scraping?
Web scraping (or data scraping) is a technique used to collect content and data from the internet. This data is usually saved in a local file so that it can be manipulated and analyzed as needed. If you’ve ever copied and pasted content from a website into an Excel spreadsheet, this is essentially what web scraping is, but on a very small scale.
However, when people refer to ‘web scrapers,’ they’re usually talking about software applications. Web scraping applications (or ‘bots’) are programmed to visit websites, grab the relevant pages and extract useful information.
Suppose you want some information from a website. Let’s say a paragraph on Weather Forecasting! What do you do? Well, you can copy and paste the information from Wikipedia into your file. But what if you want to get large amounts of information from a website as quickly as possible? Such as large amounts of data from a website to train a Machine Learning algorithm? In such a situation, copying and pasting will not work! And that’s when you’ll need to use Web Scraping. Unlike the long and mind-numbing process of manually getting data, Web scraping uses intelligence automation methods to get thousands or even millions of data sets in a smaller amount of time.
As an entry-level web scraper, getting familiar with the following tools will be valuable:
1. Web Scraping Libraries/Frameworks:
Familiarize yourself with beginner-friendly libraries or frameworks designed for web scraping. Some popular ones include: BeautifulSoup (Python): A Python library for parsing HTML and XML documents. Requests (Python): A simple HTTP library for making requests and retrieving web pages. Cheerio (JavaScript): A fast, flexible, and lightweight jQuery-like library for Node.js for parsing HTML. Scrapy (Python): A powerful and popular web crawling and scraping framework for Python.
2. IDEs or Text Editors:
Use Integrated Development Environments (IDEs) or text editors to write and execute your scraping scripts efficiently. Some commonly used ones are: PyCharm, Visual Studio Code, or Sublime Text for Python. Visual Studio Code, Atom, or Sublime Text for JavaScript.
3. Browser Developer Tools:
Familiarize yourself with browser developer tools (e.g., Chrome DevTools, Firefox Developer Tools) for inspecting HTML elements, testing CSS selectors, and understanding network requests. These tools are invaluable for understanding website structure and debugging scraping scripts.
4. Version Control Systems:
Learn the basics of version control systems like Git, which help manage your codebase, track changes, and collaborate with others. Platforms like GitHub and GitLab provide repositories for hosting your projects and sharing code with the community.
5. Command-Line Interface (CLI):
Develop proficiency in using the command-line interface for navigating file systems, running scripts, and managing dependencies. This skill is crucial for executing scraping scripts and managing project environments.
6. Web Browsers:
Understand how to use web browsers effectively for browsing, testing, and validating your scraping targets. Familiarity with different browsers like Chrome, Firefox, and Safari can be advantageous, as they may behave differently when interacting with websites.
7.Documentation and Online Resources:
Make use of official documentation, tutorials, and online resources to learn and troubleshoot web scraping techniques. Websites like Stack Overflow, GitHub, and official documentation for libraries/frameworks provide valuable insights and solutions to common scraping challenges.
By becoming familiar with these tools, you'll be equipped to start your journey into web scraping and gradually build upon your skills as you gain experience.
learn more
Some good Python web scraping tutorials are:
"Web Scraping with Python" by Alex The Analyst - This comprehensive tutorial covers the basics of web scraping using Python libraries like BeautifulSoup and Requests.
These tutorials cover a range of web scraping techniques, libraries, and use cases, allowing you to choose the one that best fits your specific project requirements. They provide step-by-step guidance and practical examples to help you get started with web scraping using Python
1 note
·
View note
Text
How to start learning a coding?

Starting to learn coding can be a rewarding journey. Here’s a step-by-step guide to help you begin:
Choose a Programming Language
Beginner-Friendly Languages: Python, JavaScript, Ruby.
Consider Your Goals: What do you want to build (websites, apps, data analysis, etc.)?
Set Up Your Development Environment
Text Editors/IDEs: Visual Studio Code, PyCharm, Sublime Text.
Install Necessary Software: Python interpreter, Node.js for JavaScript, etc.
Learn the Basics
Syntax and Semantics: Get familiar with the basic syntax of the language.
Core Concepts: Variables, data types, control structures (if/else, loops), functions.
Utilize Online Resources
Interactive Tutorials: Codecademy, freeCodeCamp, Solo Learn.
Video Tutorials: YouTube channels like CS50, Traversy Media, and Programming with Mosh.
Practice Regularly
Coding Challenges: LeetCode, HackerRank, Codewars.
Projects: Start with simple projects like a calculator, to-do list, or personal website.
Join Coding Communities
Online Forums: Stack Overflow, Reddit (r/learn programming).
Local Meetups: Search for coding meetups or hackathons in your area.
Learn Version Control
Git: Learn to use Git and GitHub for version control and collaboration.
Study Best Practices
Clean Code: Learn about writing clean, readable code.
Design Patterns: Understand common design patterns and their use cases.
Build Real Projects
Portfolio: Create a portfolio of projects to showcase your skills.
Collaborate: Contribute to open-source projects or work on group projects.
Keep Learning
Books: “Automate the Boring Stuff with Python” by Al Sweigart, “Eloquent JavaScript” by Marijn Haverbeke.
Advanced Topics: Data structures, algorithms, databases, web development frameworks.
Sample Learning Plan for Python:
Week 1-2: Basics (Syntax, Variables, Data Types).
Week 3-4: Control Structures (Loops, Conditionals).
Week 5-6: Functions, Modules.
Week 7-8: Basic Projects (Calculator, Simple Games).
Week 9-10: Advanced Topics (OOP, Data Structures).
Week 11-12: Build a Portfolio Project (Web Scraper, Simple Web App).
Tips for Success:
Stay Consistent: Practice coding daily, even if it’s just for 15-30 minutes.
Break Down Problems: Divide problems into smaller, manageable parts.
Ask for Help: Don’t hesitate to seek help from the community or peers.
By following this structured approach and leveraging the vast array of resources available online, you'll be on your way to becoming proficient in coding. Good luck!
TCCI Computer classes provide the best training in online computer courses through different learning methods/media located in Bopal Ahmedabad and ISCON Ambli Road in Ahmedabad.
For More Information:
Call us @ +91 98256 18292
Visit us @ http://tccicomputercoaching.com/
#computer technology course#computer coding classes near me#IT computer course#computer software courses#computer coding classes
0 notes
Text
Mastering Python: A Comprehensive Guide to Learn Coding from Scratch
Learning Python, one of the most popular programming languages, can be a rewarding journey. Whether you're a complete beginner or have some coding experience, mastering Python opens up a world of possibilities. In this comprehensive guide, we will explore the best ways to learn Python from scratch. Let's dive in!
1. Understanding the Basics
Before diving into Python, it's essential to understand the basics of programming. Concepts like variables, data types, and basic logic are universal across programming languages. Take some time to familiarize yourself with these fundamental principles. Online resources, interactive tutorials, and beginner-friendly books are great starting points.
2. Choose the Right Learning Resources
Selecting the right learning resources is crucial for an effective learning journey. There are numerous online platforms, books, and courses available for learning Python.. Books such as "Python Crash Course" by Eric Matthes and "Automate the Boring Stuff with Python" by Al Sweigart are excellent choices for beginners.
3. Hands-On Practice with Projects
The best way to solidify your python programming beginner skills is through hands-on practice. Work on small projects that gradually increase in complexity. This could be creating a simple calculator, a to-do list application, or even a basic web scraper. Building projects not only reinforces your learning but also gives you a sense of accomplishment.
4. Utilize Online Coding Platforms
Online coding platforms provide an interactive environment for practicing Python. Platforms like Repl.it, Jupyter Notebooks, and Google Colab allow you to write and execute Python code in your browser. These platforms often come with built-in tools, making it easy to experiment with code and see immediate results.
5. Engage with the Python Community
Learning Python becomes more enjoyable when you engage with the vibrant Python community. Join forums like Stack Overflow, Reddit's r/learnpython, or participate in Python-related events and meetups. Asking questions, sharing your experiences, and learning from others' challenges can significantly enhance your understanding of Python.
6. Enroll in Online Courses
Online courses provide structured learning paths and often include video lectures, quizzes, and assignments. Platforms like Coursera, Udacity, and edX offer comprehensive Python courses taught by experienced instructors. Some courses are even provided by universities, giving you a formal education experience from the comfort of your home.
7. Explore Documentation and Code Examples
Python's official documentation is a valuable resource for both beginners and experienced developers. Familiarize yourself with the documentation to understand the language's syntax, libraries, and functionalities. Reading code examples in the documentation can deepen your understanding of how to implement various features in Python.
8. Collaborate on Open Source Projects
Contributing to open source projects is an excellent way to enhance your Python skills. GitHub hosts a plethora of Python projects where you can collaborate with experienced developers, learn best practices, and gain real-world experience. It also allows you to build a portfolio showcasing your contributions, which can be valuable when applying for jobs.
9. Stay Consistent and Keep Learning
Consistency is key when learning any new skill, including Python. Set aside dedicated time each day or week to practice and learn. Python, like any language, is continually evolving, so staying updated with the latest developments and trends is crucial. Follow Python blogs, subscribe to newsletters, and be an active participant in the Python community to stay informed.
In conclusion, mastering Python is a gradual process that requires dedication and consistent effort. By understanding the basics, choosing the right resources, engaging with the community, and staying persistent, you can build a strong foundation in Python programming. Embrace the learning journey, and remember that every line of code you write brings you one step closer to becoming a proficient Python developer.
#programming#technology#onlinetraining#career#elearning#learning#automation#online courses#security#startups
0 notes
Text
Python Unveiled: A Speedy and Enjoyable Learning Quest
Hello, aspiring Python enthusiasts! Prepare for an exhilarating voyage as we unravel the secrets of swiftly and joyfully mastering Python from best python training Institute.

Embarking on the Python Journey
Learning Python need not be a daunting task. Think of it as an engaging adventure where simplicity meets capability. Here's your guide for a quick and effective journey to mastering Python.
1. Start with the Basics: Laying the Foundation for Your Python Domain
Before diving into the wonders of Python, establish a strong foundation. Grasp the basics—understand the syntax, explore data types, and practice simple operations. Platforms like Codecademy, W3Schools, andand the best course I can recommend is ACTE Technologies best Python Course with Certification offer beginner-friendly courses.
2. Hands-On Practice: Revealing the Magic of Python
The real magic happens when you actively use Python. Engage in practical coding exercises on platforms like HackerRank, LeetCode, or GitHub. Remember, practice is your wand, and the more you wield it, the more proficient you become.
3. Projects: Construct Your Python Citadel Piece by Piece
Apply your skills by taking on small projects. It could be a straightforward web scraper, a to-do list app, or a basic game. Building projects not only reinforces your learning but also boosts your confidence to tackle more intricate challenges.
4. Join the Python Community: Your Companions in Learning
Python isn't a solo adventure; it's a shared celebration. Join forums like Stack Overflow, Reddit's r/learnpython, or participate in local Python meetups. Learning from others, sharing your challenges, and celebrating victories together enhances the learning experience.
5. Explore Python Libraries: Unlocking Hidden Potentials
Python's strength lies in its libraries. Dive into widely used ones like NumPy for numerical computing, Pandas for data manipulation, and Matplotlib for data visualization. These tools are your companions in the Python realm, making complex tasks feel effortless.
6. Read Python Code: Deciphering the Wisdom Scrolls of Masters
To become a Python maestro, read code crafted by seasoned developers. Platforms like GitHub host a plethora of open-source projects. Analyze the code, understand the logic, and absorb the best practices. It's akin to deciphering ancient scrolls of wisdom.

7. Seek Guidance: Python Mentors as Your Knowledgeable Guides
Don't hesitate to seek guidance from Python experts who've treaded the path before you. Online courses, mentorship programs, and coding bootcamps offer invaluable insights. Learning from those with experience accelerates your journey.
8. Stay Consistent: The Unfolding Saga of Python
Consistency is the golden key. Dedicate regular time to Python learning. Even if it's a modest daily commitment, the cumulative effect over time is astounding. The unfolding saga of Python reveals most vividly when you make learning a habit.
Conclusion: Awaits Python Mastery!
In conclusion, learning Python is an enchanting expedition—a blend of curiosity, perseverance, and joy. Remember, Python is not just a programming language; it's an invitation to a world where your creativity and logic converge. Embark on this Python journey, and may your code be ever elegant, and your learning forever vibrant!
0 notes
Text
Which are the Top 10 Most Scraped Websites in 2023?

Introduction
In the digital age, data is often considered the new gold. Web scraping, the process of extracting data from websites, has become a common practice for a variety of purposes, from market research to competitor analysis. As we step into 2023, the landscape of web scraping continues to evolve, and certain websites remain popular targets for data extraction. In this article, we'll take a closer look at the top 10 most scraped websites in 2023.
Wikipedia
Wikipedia is a treasure trove of information, making it one of the most scraped websites. Researchers, data analysts, and AI models rely on Wikipedia for a vast array of data, from historical events to scientific facts.
Amazon
E-commerce giant Amazon is a prime target for web scraping due to its extensive product listings, customer reviews, and pricing information. Businesses use this data to gain insights into market trends and consumer behavior.
LinkedIn
LinkedIn is a valuable resource for professional networking and job market analysis. Web scrapers often target LinkedIn to gather data on job postings, company profiles, and user information.
Twitter
Social media platforms like Twitter are rich sources of real-time data, making them appealing for web scraping. Researchers and marketers scrape Twitter to track trends, monitor public sentiment, and analyze user-generated content.
IMDb
The Internet Movie Database (IMDb) is a haven for movie enthusiasts and film-related data. Film studios, critics, and enthusiasts scrape IMDb for movie information, ratings, and reviews.
TripAdvisor
Travel and hospitality businesses frequently scrape TripAdvisor to monitor customer reviews, assess competitor performance, and gain insights into the tourism industry.
Etsy
Etsy, a popular e-commerce platform for handmade and vintage items, is a hotspot for web scraping. E-commerce businesses often scrape Etsy to track product listings, pricing, and customer reviews.
Zillow
Real estate professionals and investors turn to Zillow for property data. Web scraping Zillow provides valuable information on property listings, prices, and market trends.
Reddit
Reddit is a diverse platform with numerous subreddits dedicated to various topics. Researchers and marketers scrape Reddit to analyze discussions, trends, and user-generated content on a wide range of subjects.
GitHub
GitHub, a platform for software developers and repositories, contains a wealth of data on open-source projects. Programmers and tech companies scrape GitHub to access code, track software development, and monitor the open-source community.
Challenges and Legal Considerations
While web scraping can provide valuable insights and data, it is not without its challenges and legal considerations. Many websites have implemented measures to prevent or limit web scraping, and scraping data without permission can lead to legal issues. It's crucial for web scrapers to be aware of the legal landscape and ethical guidelines surrounding web scraping.
Ethical Use of Scraped Data
Responsible web scraping involves respecting the terms of service of the websites being scraped. Data should be used for legitimate purposes and not for activities that infringe upon user privacy or break the law. Additionally, it's essential to ensure the data is used in a way that does not harm the source website or its users.
Conclusion
In 2023, web scraping remains a vital tool for businesses, researchers, and data analysts. The top 10 most scraped websites in 2023 offer a wealth of valuable data, from information on products and job listings to real-time social media updates. As the web scraping landscape continues to evolve, it's essential for practitioners to stay up-to-date with legal regulations and ethical guidelines to ensure responsible data extraction. While web scraping can provide valuable insights, it's crucial to remember that with great data comes great responsibility.
1 note
·
View note
Text
AO3 and Generative AI
There are unfortunately some massive misunderstandings in regards to AO3 being included in LLM training datasets. This post was semi-prompted by the ‘Knot in my name’ AO3 tag (for those of you who haven’t heard of it, it’s supposed to be a fandom anti-AI event where AO3 writers help “further pollute” AI with Omegaverse), so let’s take a moment to address AO3 in conjunction with AI. We’ll start with the biggest misconception:
1. AO3 wasn’t used to train generative AI.
Or at least not anymore than any other internet website. AO3 was not deliberately scraped to be used as LLM training data.
The AO3 moderators found traces of the Common Crawl web worm in their servers. The Common Crawl is an open data repository of raw web page data, metadata extracts and text extracts collected from 10+ years of web crawling. Its collective data is measured in petabytes. (As a note, it also only features samples of the available pages on a given domain in its datasets, because its data is freely released under fair use and this is part of how they navigate copyright.) LLM developers use it and similar web crawls like Google’s C4 to bulk up the overall amount of pre-training data.
AO3 is big to an individual user, but it’s actually a small website when it comes to the amount of data used to pre-train LLMs. It’s also just a bad candidate for training data. As a comparison example, Wikipedia is often used as high quality training data because it’s a knowledge corpus and its moderators put a lot of work into maintaining a consistent quality across its web pages. AO3 is just a repository for all fanfic -- it doesn’t have any of that quality maintenance nor any knowledge density. Just in terms of practicality, even if people could get around the copyright issues, the sheer amount of work that would go into curating and labeling AO3’s data (or even a part of it) to make it useful for the fine-tuning stages most likely outstrips any potential usage.
Speaking of copyright, AO3 is a terrible candidate for training data just based on that. Even if people (incorrectly) think fanfic doesn’t hold copyright, there are plenty of books and texts that are public domain that can be found in online libraries that make for much better training data (or rather, there is a higher consistency in quality for them that would make them more appealing than fic for people specifically targeting written story data). And for any scrapers who don’t care about legalities or copyright, they’re going to target published works instead. Meta is in fact currently getting sued for including published books from a shadow library in its training data (note, this case is not in regards to any copyrighted material that might’ve been caught in the Common Crawl data, its regarding a book repository of published books that was scraped specifically to bring in some higher quality data for the first training stage). In a similar case, there’s an anonymous group suing Microsoft, GitHub, and OpenAI for training their LLMs on open source code.
Getting back to my point, AO3 is just not desirable training data. It’s not big enough to be worth scraping for pre-training data, it’s not curated enough to be considered for high quality data, and its data comes with copyright issues to boot. If LLM creators are saying there was no active pursuit in using AO3 to train generative AI, then there was (99% likelihood) no active pursuit in using AO3 to train generative AI.
AO3 has some preventative measures against being included in future Common Crawl datasets, which may or may not work, but there’s no way to remove any previously scraped data from that data corpus. And as a note for anyone locking their AO3 fics: that might potentially help against future AO3 scrapes, but it is rather moot if you post the same fic in full to other platforms like ffn, twitter, tumblr, etc. that have zero preventative measures against data scraping.
2. A/B/O is not polluting generative AI
…I’m going to be real, I have no idea what people expected to prove by asking AI to write Omegaverse fic. At the very least, people know A/B/O fics are not exclusive to AO3, right? The genre isn’t even exclusive to fandom -- it started in fandom, sure, but it expanded to general erotica years ago. It’s all over social media. It has multiple Wikipedia pages.
More to the point though, omegaverse would only be “polluting” AI if LLMs were spewing omegaverse concepts unprompted or like…associated knots with dicks more than rope or something. But people asking AI to write omegaverse and AI then writing omegaverse for them is just AI giving people exactly what they asked for. And…I hate to point this out, but LLMs writing for a niche the LLM trainers didn’t deliberately train the LLMs on is generally considered to be a good thing to the people who develop LLMs. The capability to fill niches developers didn’t even know existed increases LLMs’ marketability. If I were a betting man, what fandom probably saw as a GOTCHA moment, AI people probably saw as a good sign of LLMs’ future potential.
3. Individuals cannot affect LLM training datasets.
So back to the fandom event, with the stated goal of sabotaging AI scrapers via omegaverse fic.
…It’s not going to do anything.
Let’s add some numbers to this to help put things into perspective:
LLaMA’s 65 billion parameter model was trained on 1.4 trillion tokens. Of that 1.4 trillion tokens, about 67% of the training data was from the Common Crawl (roughly ~3 terabytes of data).
3 terabytes is 3,000,000,000 kilobytes.
That’s 3 billion kilobytes.
According to a news article I saw, there has been ~450k words total published for this campaign (*this was while it was going on, that number has probably changed, but you’re about to see why that still doesn’t matter). So, roughly speaking, ~450k of text is ~1012 KB (I’m going off the document size of a plain text doc for a fic whose word count is ~440k).
So 1,012 out of 3,000,000,000.
Aka 0.000034%.
And that 0.000034% of 3 billion kilobytes is only 2/3s of the data for the first stage of training.
And not to beat a dead horse, but 0.000034% is still grossly overestimating the potential impact of posting A/B/O fic. Remember, only parts of AO3 would get scraped for Common Crawl datasets. Which are also huge! The October 2022 Common Crawl dataset is 380 tebibytes. The April 2021 dataset is 320 tebibytes. The 3 terabytes of Common Crawl data used to train LLaMA was randomly selected data that totaled to less than 1% of one full dataset. Not to mention, LLaMA’s training dataset is currently on the (much) larger size as compared to most LLM training datasets.
I also feel the need to point out again that AO3 is trying to prevent any Common Crawl scraping in the future, which would include protection for these new stories (several of which are also locked!).
Omegaverse just isn’t going to do anything to AI. Individual fics are going to do even less. Even if all of AO3 suddenly became omegaverse, it’s just not prominent enough to influence anything in regards to LLMs. You cannot affect training datasets in any meaningful way doing this. And while this might seem really disappointing, this is actually a good thing.
Remember that anything an individual can do to LLMs, the person you hate most can do the same. If it were possible for fandom to corrupt AI with omegaverse, fascists, bigots, and just straight up internet trolls could pollute it with hate speech and worse. AI already carries a lot of biases even while developers are actively trying to flatten that out, it’s good that organized groups can’t corrupt that deliberately.
Generative AI for Dummies
(kinda. sorta? we're talking about one type and hand-waving some specifics because this is a tumblr post but shh it's fine.)
So there’s a lot of misinformation going around on what generative AI is doing and how it works. I’d seen some of this in some fandom stuff, semi-jokingly snarked that I was going to make a post on how this stuff actually works, and then some people went “o shit, for real?”
So we’re doing this!
This post is meant to just be informative and a very basic breakdown for anyone who has no background in AI or machine learning. I did my best to simplify things and give good analogies for the stuff that’s a little more complicated, but feel free to let me know if there’s anything that needs further clarification. Also a quick disclaimer: as this was specifically inspired by some misconceptions I’d seen in regards to fandom and fanfic, this post focuses on text-based generative AI.
This post is a little long. Since it sucks to read long stuff on tumblr, I’ve broken this post up into four sections to put in new reblogs under readmores to try to make it a little more manageable. Sections 1-3 are the ‘how it works’ breakdowns (and ~4.5k words total). The final 3 sections are mostly to address some specific misconceptions that I’ve seen going around and are roughly ~1k each.
Section Breakdown: 1. Explaining tokens 2. Large Language Models 3. LLM Interfaces 4. AO3 and Generative AI [here] 5. Fic and ChatGPT [here] 6. Some Closing Notes [here] [post tag]
First, to explain some terms in this:
“Generative AI” is a category of AI that refers to the type of machine learning that can produce strings of text, images, etc. Text-based generative AI is powered by large language models called LLM for short.
(*Generative AI for other media sometimes use a LLM modified for a specific media, some use different model types like diffusion models -- anyways, this is why I emphasized I’m talking about text-based generative AI in this post. Some of this post still applies to those, but I’m not covering what nor their specifics here.)
“Neural networks” (NN) are the artificial ‘brains’ of AI. For a simplified overview of NNs, they hold layers of neurons and each neuron has a numerical value associated with it called a bias. The connection channels between each neuron are called weights. Each neuron takes the sum of the input weights, adds its bias value, and passes this sum through an activation function to produce an output value, which is then passed on to the next layer of neurons as a new input for them, and that process repeats until it reaches the final layer and produces an output response.
“Parameters” is a…broad and slightly vague term. Parameters refer to both the biases and weights of a neural network. But they also encapsulate the relationships between them, not just the literal structure of a NN. I don’t know how to explain this further without explaining more about how NN’s are trained, but that’s not really important for our purposes? All you need to know here is that parameters determine the behavior of a model, and the size of a LLM is described by how many parameters it has.
There’s 3 different types of learning neural networks do: “unsupervised” which is when the NN learns from unlabeled data, “supervised” is when all the data has been labeled and categorized as input-output pairs (ie the data input has a specific output associated with it, and the goal is for the NN to pick up those specific patterns), and “semi-supervised” (or “weak supervision”) combines a small set of labeled data with a large set of unlabeled data.
For this post, an “interaction” with a LLM refers to when a LLM is given an input query/prompt and the LLM returns an output response. A new interaction begins when a LLM is given a new input query.
Tokens
Tokens are the ‘language’ of LLMs. How exactly tokens are created/broken down and classified during the tokenization process doesn’t really matter here. Very broadly, tokens represent words, but note that it’s not a 1-to-1 thing -- tokens can represent anything from a fraction of a word to an entire phrase, it depends on the context of how the token was created. Tokens also represent specific characters, punctuation, etc.
“Token limitation” refers to the maximum number of tokens a LLM can process in one interaction. I’ll explain more on this later, but note that this limitation includes the number of tokens in the input prompt and output response. How many tokens a LLM can process in one interaction depends on the model, but there’s two big things that determine this limit: computation processing requirements (1) and error propagation (2). Both of which sound kinda scary, but it’s pretty simple actually:
(1) This is the amount of tokens a LLM can produce/process versus the amount of computer power it takes to generate/process them. The relationship is a quadratic function and for those of you who don’t like math, think of it this way:
Let’s say it costs a penny to generate the first 500 tokens. But it then costs 2 pennies to generate the next 500 tokens. And 4 pennies to generate the next 500 tokens after that. I’m making up values for this, but you can see how it’s costing more money to create the same amount of successive tokens (or alternatively, that each succeeding penny buys you fewer and fewer tokens). Eventually the amount of money it costs to produce the next token is too costly -- so any interactions that go over the token limitation will result in a non-responsive LLM. The processing power available and its related cost also vary between models and what sort of hardware they have available.
(2) Each generated token also comes with an error value. This is a very small value per individual token, but it accumulates over the course of the response.
What that means is: the first token produced has an associated error value. This error value is factored into the generation of the second token (note that it’s still very small at this time and doesn’t affect the second token much). However, this error value for the first token then also carries over and combines with the second token’s error value, which affects the generation of the third token and again carries over to and merges with the third token’s error value, and so forth. This combined error value eventually grows too high and the LLM can’t accurately produce the next token.
I’m kinda breezing through this explanation because how the math for non-linear error propagation exactly works doesn’t really matter for our purposes. The main takeaway from this is that there is a point at which a LLM’s response gets too long and it begins to break down. (This breakdown can look like the LLM producing something that sounds really weird/odd/stale, or just straight up producing gibberish.)
Large Language Models (LLMs)
LLMs are computerized language models. They generate responses by assessing the given input prompt and then spitting out the first token. Then based on the prompt and that first token, it determines the next token. Based on the prompt and first token, second token, and their combination, it makes the third token. And so forth. They just write an output response one token at a time. Some examples of LLMs include the GPT series from OpenAI, LLaMA from Meta, and PaLM 2 from Google.
So, a few things about LLMs:
These things are really, really, really big. The bigger they are, the more they can do. The GPT series are some of the big boys amongst these (GPT-3 is 175 billion parameters; GPT-4 actually isn’t listed, but it’s at least 500 billion parameters, possibly 1 trillion). LLaMA is 65 billion parameters. There are several smaller ones in the range of like, 15-20 billion parameters and a small handful of even smaller ones (these are usually either older/early stage LLMs or LLMs trained for more personalized/individual project things, LLMs just start getting limited in application at that size). There are more LLMs of varying sizes (you can find the list on Wikipedia), but those give an example of the size distribution when it comes to these things.
However, the number of parameters is not the only thing that distinguishes the quality of a LLM. The size of its training data also matters. GPT-3 was trained on 300 billion tokens. LLaMA was trained on 1.4 trillion tokens. So even though LLaMA has less than half the number of parameters GPT-3 has, it’s still considered to be a superior model compared to GPT-3 due to the size of its training data.
So this brings me to LLM training, which has 4 stages to it. The first stage is pre-training and this is where almost all of the computational work happens (it’s like, 99% percent of the training process). It is the most expensive stage of training, usually a few million dollars, and requires the most power. This is the stage where the LLM is trained on a lot of raw internet data (low quality, large quantity data). This data isn’t sorted or labeled in any way, it’s just tokenized and divided up into batches (called epochs) to run through the LLM (note: this is unsupervised learning).
How exactly the pre-training works doesn’t really matter for this post? The key points to take away here are: it takes a lot of hardware, a lot of time, a lot of money, and a lot of data. So it’s pretty common for companies like OpenAI to train these LLMs and then license out their services to people to fine-tune them for their own AI applications (more on this in the next section). Also, LLMs don’t actually “know” anything in general, but at this stage in particular, they are really just trying to mimic human language (or rather what they were trained to recognize as human language).
To help illustrate what this base LLM ‘intelligence’ looks like, there’s a thought exercise called the octopus test. In this scenario, two people (A & B) live alone on deserted islands, but can communicate with each other via text messages using a trans-oceanic cable. A hyper-intelligent octopus listens in on their conversations and after it learns A & B’s conversation patterns, it decides observation isn’t enough and cuts the line so that it can talk to A itself by impersonating B. So the thought exercise is this: At what level of conversation does A realize they’re not actually talking to B?
In theory, if A and the octopus stay in casual conversation (ie “Hi, how are you?” “Doing good! Ate some coconuts and stared at some waves, how about you?” “Nothing so exciting, but I’m about to go find some nuts.” “Sounds nice, have a good day!” “You too, talk to you tomorrow!”), there’s no reason for A to ever suspect or realize that they’re not actually talking to B because the octopus can mimic conversation perfectly and there’s no further evidence to cause suspicion.
However, what if A asks B what the weather is like on B’s island because A’s trying to determine if they should forage food today or save it for tomorrow? The octopus has zero understanding of what weather is because its never experienced it before. The octopus can only make guesses on how B might respond because it has no understanding of the context. It’s not clear yet if A would notice that they’re no longer talking to B -- maybe the octopus guesses correctly and A has no reason to believe they aren’t talking to B. Or maybe the octopus guessed wrong, but its guess wasn’t so wrong that A doesn’t reason that maybe B just doesn’t understand meteorology. Or maybe the octopus’s guess was so wrong that there was no way for A not to realize they’re no longer talking to B.
Another proposed scenario is that A’s found some delicious coconuts on their island and decide they want to share some with B, so A decides to build a catapult to send some coconuts to B. But when A tries to share their plans with B and ask for B’s opinions, the octopus can’t respond. This is a knowledge-intensive task -- even if the octopus understood what a catapult was, it’s also missing knowledge of B’s island and suggestions on things like where to aim. The octopus can avoid A’s questions or respond with total nonsense, but in either scenario, A realizes that they are no longer talking to B because the octopus doesn’t understand enough to simulate B’s response.
There are other scenarios in this thought exercise, but those cover three bases for LLM ‘intelligence’ pretty well: they can mimic general writing patterns pretty well, they can kind of handle very basic knowledge tasks, and they are very bad at knowledge-intensive tasks.
Now, as a note, the octopus test is not intended to be a measure of how the octopus fools A or any measure of ‘intelligence’ in the octopus, but rather show what the “octopus” (the LLM) might be missing in its inputs to provide good responses. Which brings us to the final 1% of training, the fine-tuning stages;
LLM Interfaces
As mentioned previously, LLMs only mimic language and have some key issues that need to be addressed:
LLM base models don’t like to answer questions nor do it well.
LLMs have token limitations. There’s a limit to how much input they can take in vs how long of a response they can return.
LLMs have no memory. They cannot retain the context or history of a conversation on their own.
LLMs are very bad at knowledge-intensive tasks. They need extra context and input to manage these.
However, there’s a limit to how much you can train a LLM. The specifics behind this don’t really matter so uh… *handwaves* very generally, it’s a matter of diminishing returns. You can get close to the end goal but you can never actually reach it, and you hit a point where you’re putting in a lot of work for little to no change. There’s also some other issues that pop up with too much training, but we don’t need to get into those.
You can still further refine models from the pre-training stage to overcome these inherent issues in LLM base models -- Vicuna-13b is an example of this (I think? Pretty sure? Someone fact check me on this lol).
(Vicuna-13b, side-note, is an open source chatbot model that was fine-tuned from the LLaMA model using conversation data from ShareGPT. It was developed by LMSYS, a research group founded by students and professors from UC Berkeley, UCSD, and CMU. Because so much information about how models are trained and developed is closed-source, hidden, or otherwise obscured, they research LLMs and develop their models specifically to release that research for the benefit of public knowledge, learning, and understanding.)
Back to my point, you can still refine and fine-tune LLM base models directly. However, by about the time GPT-2 was released, people had realized that the base models really like to complete documents and that they’re already really good at this even without further fine-tuning. So long as they gave the model a prompt that was formatted as a ‘document’ with enough background information alongside the desired input question, the model would answer the question by ‘finishing’ the document. This opened up an entire new branch in LLM development where instead of trying to coach the LLMs into performing tasks that weren’t native to their capabilities, they focused on ways to deliver information to the models in a way that took advantage of what they were already good at.
This is where LLM interfaces come in.
LLM interfaces (which I sometimes just refer to as “AI” or “AI interface” below; I’ve also seen people refer to these as “assistants”) are developed and fine-tuned for specific applications to act as a bridge between a user and a LLM and transform any query from the user into a viable input prompt for the LLM. Examples of these would be OpenAI’s ChatGPT and Google’s Bard. One of the key benefits to developing an AI interface is their adaptability, as rather than needing to restart the fine-tuning process for a LLM with every base update, an AI interface fine-tuned for one LLM engine can be refitted to an updated version or even a new LLM engine with minimal to no additional work. Take ChatGPT as an example -- when GPT-4 was released, OpenAI didn’t have to train or develop a new chat bot model fine-tuned specifically from GPT-4. They just ‘plugged in’ the already fine-tuned ChatGPT interface to the new GPT model. Even now, ChatGPT can submit prompts to either the GPT-3.5 or GPT-4 LLM engines depending on the user’s payment plan, rather than being two separate chat bots.
As I mentioned previously, LLMs have some inherent problems such as token limitations, no memory, and the inability to handle knowledge-intensive tasks. However, an input prompt that includes conversation history, extra context relevant to the user’s query, and instructions on how to deliver the response will result in a good quality response from the base LLM model. This is what I mean when I say an interface transforms a user’s query into a viable prompt -- rather than the user having to come up with all this extra info and formatting it into a proper document for the LLM to complete, the AI interface handles those responsibilities.
How exactly these interfaces do that varies from application to application. It really depends on what type of task the developers are trying to fine-tune the application for. There’s also a host of APIs that can be incorporated into these interfaces to customize user experience (such as APIs that identify inappropriate content and kill a user’s query, to APIs that allow users to speak a command or upload image prompts, stuff like that). However, some tasks are pretty consistent across each application, so let’s talk about a few of those:
Token management
As I said earlier, each LLM has a token limit per interaction and this token limitation includes both the input query and the output response.
The input prompt an interface delivers to a LLM can include a lot of things: the user’s query (obviously), but also extra information relevant to the query, conversation history, instructions on how to deliver its response (such as the tone, style, or ‘persona’ of the response), etc. How much extra information the interface pulls to include in the input prompt depends on the desired length of an output response and what sort of information pulled for the input prompt is prioritized by the application varies depending on what task it was developed for. (For example, a chatbot application would likely allocate more tokens to conversation history and output response length as compared to a program like Sudowrite* which probably prioritizes additional (context) content from the document over previous suggestions and the lengths of the output responses are much more restrained.)
(*Sudowrite is…kind of weird in how they list their program information. I’m 97% sure it’s a writer assistant interface that keys into the GPT series, but uhh…I might be wrong? Please don’t hold it against me if I am lol.)
Anyways, how the interface allocates tokens is generally determined by trial-and-error depending on what sort of end application the developer is aiming for and the token limit(s) their LLM engine(s) have.
tl;dr -- all LLMs have interaction token limits, the AI manages them so the user doesn’t have to.
Simulating short-term memory
LLMs have no memory. As far as they figure, every new query is a brand new start. So if you want to build on previous prompts and responses, you have to deliver the previous conversation to the LLM along with your new prompt.
AI interfaces do this for you by managing what’s called a ‘context window’. A context window is the amount of previous conversation history it saves and passes on to the LLM with a new query. How long a context window is and how it’s managed varies from application to application. Different token limits between different LLMs is the biggest restriction for how many tokens an AI can allocate to the context window. The most basic way of managing a context window is discarding context over the token limit on a first in, first out basis. However, some applications also have ways of stripping out extraneous parts of the context window to condense the conversation history, which lets them simulate a longer context window even if the amount of allocated tokens hasn’t changed.
Augmented context retrieval
Remember how I said earlier that LLMs are really bad at knowledge-intensive tasks? Augmented context retrieval is how people “inject knowledge” into LLMs.
Very basically, the user submits a query to the AI. The AI identifies keywords in that query, then runs those keywords through a secondary knowledge corpus and pulls up additional information relevant to those keywords, then delivers that information along with the user’s query as an input prompt to the LLM. The LLM can then process this extra info with the prompt and deliver a more useful/reliable response.
Also, very importantly: “knowledge-intensive” does not refer to higher level or complex thinking. Knowledge-intensive refers to something that requires a lot of background knowledge or context. Here’s an analogy for how LLMs handle knowledge-intensive tasks:
A friend tells you about a book you haven’t read, then you try to write a synopsis of it based on just what your friend told you about that book (see: every high school literature class). You’re most likely going to struggle to write that summary based solely on what your friend told you, because you don’t actually know what the book is about.
This is an example of a knowledge intensive task: to write a good summary on a book, you need to have actually read the book. In this analogy, augmented context retrieval would be the equivalent of you reading a few book reports and the wikipedia page for the book before writing the summary -- you still don’t know the book, but you have some good sources to reference to help you write a summary for it anyways.
This is also why it’s important to fact check a LLM’s responses, no matter how much the developers have fine-tuned their accuracy.
(*Sidenote, while AI does save previous conversation responses and use those to fine-tune models or sometimes even deliver as a part of a future input query, that’s not…really augmented context retrieval? The secondary knowledge corpus used for augmented context retrieval is…not exactly static, you can update and add to the knowledge corpus, but it’s a relatively fixed set of curated and verified data. The retrieval process for saved past responses isn’t dissimilar to augmented context retrieval, but it’s typically stored and handled separately.)
So, those are a few tasks LLM interfaces can manage to improve LLM responses and user experience. There’s other things they can manage or incorporate into their framework, this is by no means an exhaustive or even thorough list of what they can do. But moving on, let’s talk about ways to fine-tune AI. The exact hows aren't super necessary for our purposes, so very briefly;
Supervised fine-tuning
As a quick reminder, supervised learning means that the training data is labeled. In the case for this stage, the AI is given data with inputs that have specific outputs. The goal here is to coach the AI into delivering responses in specific ways to a specific degree of quality. When the AI starts recognizing the patterns in the training data, it can apply those patterns to future user inputs (AI is really good at pattern recognition, so this is taking advantage of that skill to apply it to native tasks AI is not as good at handling).
As a note, some models stop their training here (for example, Vicuna-13b stopped its training here). However there’s another two steps people can take to refine AI even further (as a note, they are listed separately but they go hand-in-hand);
Reward modeling
To improve the quality of LLM responses, people develop reward models to encourage the AIs to seek higher quality responses and avoid low quality responses during reinforcement learning. This explanation makes the AI sound like it’s a dog being trained with treats -- it’s not like that, don’t fall into AI anthropomorphism. Rating values just are applied to LLM responses and the AI is coded to try to get a high score for future responses.
For a very basic overview of reward modeling: given a specific set of data, the LLM generates a bunch of responses that are then given quality ratings by humans. The AI rates all of those responses on its own as well. Then using the human labeled data as the ‘ground truth’, the developers have the AI compare its ratings to the humans’ ratings using a loss function and adjust its parameters accordingly. Given enough data and training, the AI can begin to identify patterns and rate future responses from the LLM on its own (this process is basically the same way neural networks are trained in the pre-training stage).
On its own, reward modeling is not very useful. However, it becomes very useful for the next stage;
Reinforcement learning
So, the AI now has a reward model. That model is now fixed and will no longer change. Now the AI runs a bunch of prompts and generates a bunch of responses that it then rates based on its new reward model. Pathways that led to higher rated responses are given higher weights, pathways that led to lower rated responses are minimized. Again, I’m kind of breezing through the explanation for this because the exact how doesn’t really matter, but this is another way AI is coached to deliver certain types of responses.
You might’ve heard of the term reinforcement learning from human feedback (or RLHF for short) in regards to reward modeling and reinforcement learning because this is how ChatGPT developed its reward model. Users rated the AI’s responses and (after going through a group of moderators to check for outliers, trolls, and relevancy), these ratings were saved as the ‘ground truth’ data for the AI to adjust its own response ratings to. Part of why this made the news is because this method of developing reward model data worked way better than people expected it to. One of the key benefits was that even beyond checking for knowledge accuracy, this also helped fine-tune how that knowledge is delivered (ie two responses can contain the same information, but one could still be rated over another based on its wording).
As a quick side note, this stage can also be very prone to human bias. For example, the researchers rating ChatGPT’s responses favored lengthier explanations, so ChatGPT is now biased to delivering lengthier responses to queries. Just something to keep in mind.
So, something that’s really important to understand from these fine-tuning stages and for AI in general is how much of the AI’s capabilities are human regulated and monitored. AI is not continuously learning. The models are pre-trained to mimic human language patterns based on a set chunk of data and that learning stops after the pre-training stage is completed and the model is released. Any data incorporated during the fine-tuning stages for AI is humans guiding and coaching it to deliver preferred responses. A finished reward model is just as static as a LLM and its human biases echo through the reinforced learning stage.
People tend to assume that if something is human-like, it must be due to deeper human reasoning. But this AI anthropomorphism is…really bad. Consequences range from the term “AI hallucination” (which is defined as “when the AI says something false but thinks it is true,” except that is an absolute bullshit concept because AI doesn’t know what truth is), all the way to the (usually highly underpaid) human labor maintaining the “human-like” aspects of AI getting ignored and swept under the rug of anthropomorphization. I’m trying not to get into my personal opinions here so I’ll leave this at that, but if there’s any one thing I want people to take away from this monster of a post, it’s that AI’s “human” behavior is not only simulated but very much maintained by humans.
Anyways, to close this section out: The more you fine-tune an AI, the more narrow and specific it becomes in its application. It can still be very versatile in its use, but they are still developed for very specific tasks, and you need to keep that in mind if/when you choose to use it (I’ll return to this point in the final section).
84 notes
·
View notes
Text
The One-Shot: Can popularity be predicted, part 2
I asked this question about the AO3 ATLA dataset a few months back, tackling the problem with multiple linear regression. Since then I fixed a few bugs in my scraper and got an updated version of the dataset (and wow has the fandom taken off last year!), making it now more than 10,000 fics.
I also applied a decision-tree based algorithm, XGBoost, which generally gives better performance than pure regression on small-to-medium datasets. Like last time, the value I wanted to predict was the kudos-to-hits ratio.
Let’s see how the results stack up!
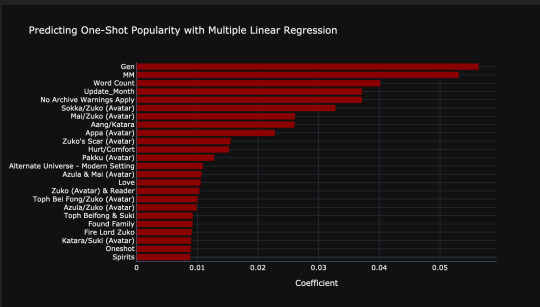
According to multiple linear regression, these are the most important features that contribute (either positively or negatively) to a one-shot’s popularity. The overall largest feature is Year, which didn’t fit on the scale of this chart :) After the year comes some categories and then ships: Zukka, Maiko, and Kataang. As a Maiko shipper myself, I’m got the feeling that this is actually a factor that makes your fics less popular... there’s a bunch of readers who will not even click on a fic that includes that ship. Same with Kataang, if you’re a hardcore Zutara shipper.
Not all of these factors match up with my intuition. While Modern AUs are certainly popular and Found Family is a core trope of the franchise, does having Pakku in your fic really help or hurt? Or the (rarepair?) of Katara and Suki?
XGBoost selects somewhat different features as important. It also fit the test data better than multiple linear regression.
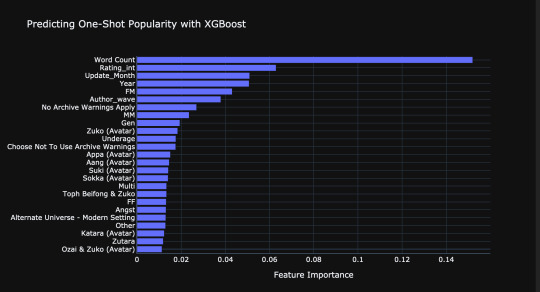
A lot of the top features are the same, but with M/M switched with F/M. Another interesting feature which totally confirms my gut feelings is that of Author_wave, defined here in a Creator Waves analysis. Basically, this is the era at which a fic author entered the fandom. So it stands to reason that well-established authors will continue to write popular fics.
By the way, here’s how the two algorithms managed to predict the test set data. The tighter distribution of XGBoost means it did an overall better job, but there’s still a bunch of fics it didn’t manage to predict well. XGBoost tends to do very well with classification (for example, popular or non-popular) so I play around with that.
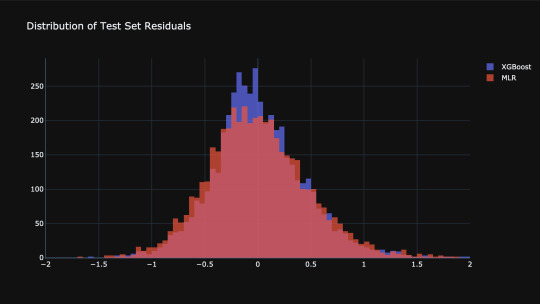
If anyone would like the full image descriptions, drop me a note and I’ll post the interactive figures on my GitHub, where the hovertext should be compatible with a screen reader.
#atla#fanalytics#one-shots#predictions#fandom analysis#ao3#data science on fanfic#zuko#sokka#katara#aang#azula#toph#mai#suki#zukka#maiko#kataang#katara x suki
19 notes
·
View notes
Text
How to Learn Python Quickly and Effectively
Python is one of the most popular programming languages, known for its simplicity and versatility. Whether you're a beginner or an experienced developer, learning Python efficiently can open up many career opportunities. Here’s a step-by-step guide to mastering Python quickly and effectively. Considering the kind support of Python Course in Chennai Whatever your level of experience or reason for switching from another programming language, learning Python gets much more fun.

Start with the Basics
Before diving into complex topics, it’s essential to build a strong foundation. Begin by learning Python’s core concepts:
Variables and data types (strings, integers, lists, dictionaries)
Conditional statements (if-else, loops)
Functions and modules
Object-oriented programming (OOP)
Free resources like W3Schools, Python.org, and GeeksforGeeks provide excellent tutorials to get started.
Take Online Courses for Structured Learning
Enrolling in structured courses can accelerate your learning process. Some great online courses include:
Python for Everybody (Coursera – University of Michigan)
Complete Python Bootcamp (Udemy – Jose Portilla)
Python for Beginners (Codecademy)
These courses offer interactive lessons and projects to help reinforce your learning.
Practice Coding Every Day
Consistent practice is key to mastering Python. Solve coding problems daily on platforms like:
LeetCode
HackerRank
CodeWars
Project Euler
Practicing real-world problems improves problem-solving skills and coding speed.
Work on Real-World Projects
The best way to learn Python is by building projects. Start with small projects such as:
A simple calculator
A web scraper using BeautifulSoup
A personal expense tracker
A to-do list application
Building hands-on projects helps you understand Python’s real-world applications and boosts confidence. With the aid of Best Online Training & Placement Programs, which offer comprehensive training and job placement support to anyone looking to develop their talents, it’s easier to learn this tool and advance your career.
Learn Python Libraries for Your Field
Depending on your interests, focus on relevant Python libraries:
Web Development: Flask, Django
Data Science: NumPy, Pandas, Matplotlib
Machine Learning: TensorFlow, Scikit-learn
Automation & Scripting: Selenium, BeautifulSoup
Learning domain-specific libraries will make you job-ready in your chosen field.
Read Python Documentation and Books
Deepen your knowledge by reading Python’s official documentation and books such as:
Python Crash Course by Eric Matthes
Automate the Boring Stuff with Python by Al Sweigart
These resources offer practical exercises and real-world coding examples.
Join Python Communities and Forums
Being part of a coding community helps in learning and networking. Some great Python communities include:
Stack Overflow
Reddit’s r/learnpython
Python Discord and Slack groups
Engaging in discussions and solving others’ queries can reinforce your knowledge.
Contribute to Open Source Projects
Collaborating on open-source projects on GitHub helps you gain real-world experience. You’ll learn to work with a team, write clean code, and improve debugging skills.
Improve Debugging and Code Optimization Skills
Understanding debugging techniques is crucial for writing efficient code. Use Python’s built-in debugging tools like print(), pdb, and logging. Writing optimized and clean code enhances performance.
Build a Portfolio and Showcase Your Work
Employers value hands-on experience. Create a GitHub profile and upload your Python projects. If possible, build a personal website to showcase your coding skills and attract job opportunities.
Final Thoughts
The key to learning Python quickly is consistency, practice, and real-world application. Follow a structured learning approach, engage with the coding community, and work on projects. With dedication, you can become proficient in Python in just a few months.
#python course#python training#python#python programming#python online course#python online training#python online classes#python certification
0 notes
Text

13 October 2019
I’ve been coding in one of my favorite cafés to work in today, accompanied by a matcha latte, a yummy hummus-olive-tomato sandwich, and some fab vintage R&B on the radio.
I returned to the A+ practice-question project and finally succeeded in adding the next source-data link to the app! That one was surprisingly complicated. But it was so satisfying to patiently squash all the bugs one by one, until I reached my goal for today and was able to merge the branch and push the updated functional version to GitHub.
For @lofi-girl and anyone else who wants to get themselves some free CompTIA A+ practice questions, you can find the latest functional version of the web scraper here. Fair warning: right now it’s incomplete (it only has practice questions from two sources), but it should be usable. If you’d prefer to wait, I’m hoping to add the third source (and any others I can find) within the next few weeks.
🎵Bobby Bland – “Ain’t No Love in the Heart of the City”
#studyblr#codeblr#coding#python#comptia#and if any of y'all use the scraper and find any bugs#please let me know! i would appreciate it :)#also don't hesitate to give feedback#if you think the instructions for using it are not clear enough#chiseling away
46 notes
·
View notes
Photo

Coding confusion
Making the website, weeks 10-11, 11/05-25/05/2020
These two weeks could be described in one word: confusion.
Firstly I began by looking for an API to scrape Instagram posts. Sounds easy. It should have been until I discovered that Instagram recently changed their privacy settings so it is not possible to scrape their site directly. There are sites that run APIs though so my search narrowed to those, after looking at numerous sites -Apify, Octoparse and Scraper API to name a few- I found Phantom Buster which scrapes Instagram through hashtags into a messy JSON or CSV, pictured above. Success. Next I needed to find users’ location data, which I later found Phantom Buster could scrape too. Double success.
Next I needed to find a platform to host/build my website. I began looking at Squarespace, but you can’t easily edit the code. Next, I looked at Go Daddy, bought a domain: thesilverlining.news, and tried to code on their hosting platform but again you can’t add code. After calling the Go Daddy help desk I was directed to WordPress so gave that a go, but it also seemed to be too structured and you couldn’t edit the code fully in the way I wanted. Karen Ann reccomended GitHub and then off I went.
Coding began slowly but surely!
1 note
·
View note