#scrape data
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Hackers stole 65M passwords from Tumblr in 2013.
Text
Which are the Top 10 Most Scraped Websites in 2023?

In the age of data-driven decision-making and automation, web scraping has become an essential tool for extracting valuable information from the internet. Whether it's for competitive analysis, market research, or staying up to date with the latest trends, web scraping has gained prominence across various industries. In 2023, several websites have found themselves at the center of this data extraction frenzy. In this article, we will explore the top 10 most scraped websites in 2023.
Amazon Amazon has long been a popular target for web scrapers. E-commerce businesses scrape Amazon to monitor product prices, gather customer reviews, and track market trends. The abundance of data on Amazon's platform makes it a goldmine for those seeking to gain a competitive edge.
Twitter Social media platforms are a treasure trove of real-time data. Twitter, in particular, is a hotbed for scraping due to its vast user base and the constant stream of tweets. Researchers, marketers, and journalists scrape Twitter to gather insights on trending topics and public sentiment.
LinkedIn LinkedIn is a valuable source of professional information. Job seekers and recruiters scrape LinkedIn to build databases of potential connections and candidates. Market researchers also use it to track industry trends and professional networking.
Instagram Instagram's visual nature makes it an attractive target for web scraping. Businesses and individuals scrape Instagram for influencer marketing, competitor analysis, and trend monitoring. The platform is a goldmine for image and video data.
Wikipedia Wikipedia is a comprehensive source of information on a wide range of topics. Researchers and data enthusiasts scrape Wikipedia to build datasets for natural language processing, academic research, and content creation. It's a knowledge hub that attracts scrapers.
Reddit As one of the largest online discussion platforms, Reddit is a prime target for web scrapers. Data scientists and marketers scrape Reddit to identify emerging trends, monitor user sentiment, and discover niche communities.
Google News Google News aggregates news articles from various sources. Media organizations and content curators scrape Google News to stay updated with the latest news developments. The platform is a vital source of news content.
Yelp Yelp is a popular source for restaurant and business reviews. Local businesses and marketers scrape Yelp to monitor customer feedback, gather business information, and track their online reputation.
IMDb The Internet Movie Database (IMDb) is a goldmine of information about movies, TV shows, and celebrities. Movie enthusiasts and entertainment industry professionals scrape IMDb for information on films, actors, and industry trends.
Etsy Etsy is a marketplace for handmade and vintage goods. E-commerce businesses and artists scrape Etsy to monitor product listings, pricing, and market trends. It's a valuable resource for those in the creative and e-commerce sectors.
Web scraping, when done ethically and in compliance with the terms of service of these websites, provides businesses and individuals with valuable data that can be used for a variety of purposes. However, it's essential to be aware of the legal and ethical considerations surrounding web scraping, as scraping without permission or in a disruptive manner can lead to legal consequences and damage a website's functionality.
Additionally, websites can implement measures to protect themselves from scraping, such as using CAPTCHAs, IP blocking, or anti-scraping technologies. It's essential for web scrapers to adapt to these challenges and use scraping tools responsibly.
In conclusion, web scraping plays a crucial role in the modern data landscape, and the top 10 most scraped websites in 2023 reflect the diverse range of data needs across industries. From e-commerce giants like Amazon to social media platforms like Twitter, these websites offer a wealth of information that is highly sought after. As web scraping continues to evolve, it's important for scrapers to operate within legal and ethical boundaries, respecting the rights and terms of service of the websites they scrape.
0 notes
Text
dick grayson the universal blood donor who will drain himself dry. dick grayson the universal legacy of children in red and green, long after he’s left gotham behind. dick grayson the universal linchpin, that new spot of light in bruce wayne’s life before the bad times, then the worse times. dick grayson the universal constant who will be there in the spotlight, still, reaching out to stop you from falling
#much to think about. u cannot ever leave because ur mother is buried here#trying to make myself write fic but it’s been very hard after the data scraping debacle#i need to inspire myself. somehow#dick grayson#dc comics#tbd
946 notes
·
View notes
Text
Get latest news from AOL using web scraping tool
AOL (America Online) is a web portal and online service provider based in the United States. It was one of the most popular internet service providers in the 1990s and early 2000s. AOL offers a wide range of online services, including email, instant messaging, web browsing, news, entertainment, and more.
Introduction to the scraping tool
ScrapeStorm is a new generation of Web Scraping Tool based on artificial intelligence technology. It is the first scraper to support both Windows, Mac and Linux operating systems.
Preview of the scraped result
Export to Excel:

1. Create a task
(1) Copy the URL

(2) Create a new smart mode task
You can create a new scraping task directly on the software, or you can create a task by importing rules.
How to create a smart mode task
How to import and export scraping task

2. Configure the scraping rules
(1)Smart mode automatically detects the fields on the page. You can right-click the field to rename the name, add or delete fields, modify data, and so on.
How to set the fields

3. Set up and start the scraping task
(1) Run settings
Choose your own needs, you can set Schedule, IP Rotation&Delay, Automatic Export, Download Images, Speed Boost, Data Deduplication and Developer.
How to configure the scraping task

(2)Wait a moment, you will see the data being scraped.

4. Export and view data
(1) Click "Export" to download your data.

(2) Choose the format to export according to your needs.
ScrapeStorm provides a variety of export methods to export locally, such as excel, csv, html, txt or database. Professional Plan and above users can also post directly to wordpress.
How to view data and clear data
How to export data

0 notes
Text
And while we're talking about ai theft: turn. off. grammarly. Disable it. Delete it. Get that shit off of your computer ASAP.
I never realized how much of my shit is scanned by grammarly until today. It scans my emails, my text posts on this bewitched platform, my wips on google docs, my youtube comments--literally everything ive ever typed on my laptop is scanned by grammarly. And I've been allowing this to happen for years.
Turn. Off. Grammarly.
#blue rambles#ai theft#ai#grammarly#data scraping#i dont like how many suggestions are made when im editing my writing anyway#theyre distracting+irrelevant half the time#and the only reason i even have grammarly is bc of uni
12K notes
·
View notes
Note
How are you live what's happening with ao3 and the AI? Does it discourage you in any way from publishing your stories?
Great question. I haven't archive locked my stories and don't plan to. That's a personal decision I've made for myself and my own content, and that doesn't mean I don't wholeheartedly support my fellow authors who do so. But I'm of the (again personal) opinion that my works already have been scraped, and will continue to be scraped in some capacity. As have all of my texposts on here.
I appreciate the work the OTW is doing to take down data on other sites where it has been scraped. I think that's absolutely the right course of action. But personally, I am under no illusions that by archive-locking my fics, I am 100% preventing the scraping/sharing/AI use of my content. And at this point, even when we first learned of that big "scrape" a while back, it was too late.
My goal is to make my content as widely available for readers as possible, which comes with drawbacks. Archive-locking fics came with a significant reduction in hits/comments/kudos for some authors, and I decided that was a risk I personally did not want to take. Especially when, again, I was of the belief that many of my fics had already been scraped/were vulnerable to being scraped before we learned about these mass-scraping incidents.
Additionally, I'm quite certain people have been feeding my fics into AI processors, ChatGPT, etc, for a while now. It's not something I have control over, and people will continue to do it even when they know it's wrong. Even with ao3 accounts.
I don't own my fanfiction content, I can't make money off of it, and I don't want to. This would be a very different conversation if I did. Truthfully, my only hope is that by continuing to write a/b/o, and large amounts of it, I can "spike" whatever dataset is using my fics. That thought brings me joy, even if it's a little silly and far-fetched with these better algorithms.
#asks#anon#ao3#archive of our own#myfic#theresurrectionist#writing#data scraping#OTW#AI generators#chat gpt
201 notes
·
View notes
Text
EMERGENCY AUTHOR UPDATE
I feel like this needs to be warned about. Everything on Ao3 that isn't set to private, HAS been data scraped and fed to 3 data sites that provide data for AI training, including writing and artwork.
Yes, this includes my entire Ennead series and everything else I've ever written and posted. As well as anything you all have written but not made private.
Ao3's legal team is fighting it and one site has made the data unavailable, but the other two aren't based in the USA so the fight is harder.
This is frustrating and upsetting news, especially for those of us who now need to pick between our Guest readers who have supported us for a long time and protecting the hard work that we've put our hearts and souls into and I just ask that we support each other and our choices during this time.
The link here has more details but from now on, until I can be sure there's a way to protect my work, which I've spent decades writing and planning, my stories will be posted for members of the site only.
#fanfiction#creative writing#writer#author#authors#writing woes#ao3#ai scrapers#data scraping#ai#artificial intelligence#technology#ai model#fandom#writerscommunity#writers on tumblr#writing#ao3 writer
186 notes
·
View notes
Text
I don’t have a posted DNI for a few reasons but in this case I’ll be crystal clear:
I do not want people who use AI in their whump writing (generating scenarios, generating story text, etc.) to follow me or interact with my posts. I also do not consent to any of my writing, posts, or reblogs being used as inputs or data for AI.
#not whump#whump community#ai writing#beans speaks#blog stuff#:/ stop using generative text machines that scrape data from writers to ‘make your dream scenarios’#go download some LANDSAT data and develop an AI to determine land use. use LiDAR to determine tree crown health by near infrared values.#thats a good use of AI (algorithms) that I know and respect.#using plagiarized predictive text machines is in poor taste and also damaging to the environment. be better.
292 notes
·
View notes
Text


squish that owl something wholesome to start the year 🥹
#my art#arknights#saria (arknights)#silence (arknights)#image is flazed to prevent data scraping#higher quality is available on my patreon#theres a demon in the corner so dont look#protect your fridge#i hope 2024 would give my owl wyvern hug plsssss
612 notes
·
View notes
Text

Hey so just saw this on Twitter and figured there are some people who would like to know @infinitytraincrew is apparently getting deleted tonight so if you wanna archive it do it now
#infinity train#third-party sharing#owen dennis#anti ai#tumblr staff making stupid decisions again#cryptid says stuff#don't just glaze it actively nightshade it#ai scraping#data privacy
422 notes
·
View notes
Text

Massive PSA to ALL artists who may be on Twitter, please protect yourself. I just wiped all my art off that shit site, so unfortunately a lot of NSFW art that could be viewed on there will not be available. Some is available on Slasher app, and a bit on Pixiv. I will try to post old lewd art on pixiv and any relevant lewds on Slasher app. I'm really thinking of looking into just getting my own website to display all works uncensored depending on the cost.
To give more context on what the XAi program will be doing here is a link to an article with interview answers from the Mustyness himself:
A quote from said article:
'He also claimed that xAI’s use of Twitter data would not be much different from what many are already using the platform for, adding that it would primarily be used for “text training” and “image and video training.”
“I guess we will use the public tweets — obviously not anything private* — for training as well, just like basically everyone else has,” Musk said.'
He will be using data from private accounts, what Elon means is likely data of birthdates and addresses.
I added ALT descriptions now to the image, I didn't have time before (I'm working on an overly detailed art piece right now), I hope that helps all with screen readers!
2K notes
·
View notes
Text
If anyone's on the (super uncool but sometimes necessary in order to get a job) website Linkedin, they have made AI data collecting opt-OUT.
So settings and privacy → data privacy → Data for Generative AI Improvement → Off
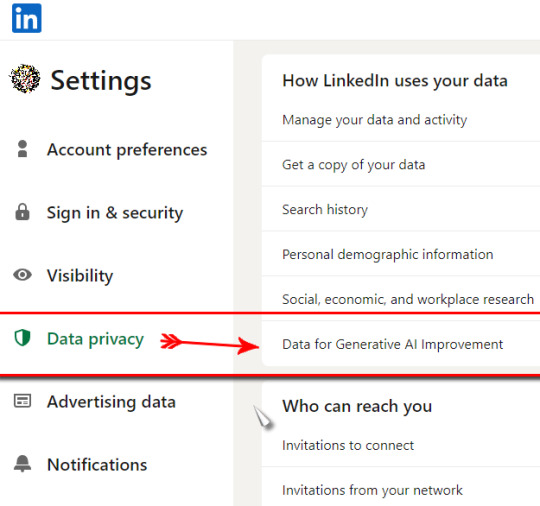
While you're there, dedicate a good 10 minutes to going through the rest of the settings. THERE ARE SO MANY.
And they're all turned on.
105 notes
·
View notes
Text
Follow the list of 10 websites for web scraping. You will get an overview of what to scrape for the best results. We’ve shared the list based on categories.
For More Information:-
0 notes
Text
i feel so terrible doing this but i had to. i locked all my ao3 works under archive only because i learned about the extent of the data scraping that happened. as much as i love writing and i love sharing it with as many people as possible, i cannot allow the works of which i have poured my heart, my soul, and most importantly, my time into to be scraped up and fed heartlessly to an ai bot. so for now, it’s only visible to archive users.
#livs rambles#stardew fanfic#ao3 fanfic#fan fic writing#fan fiction#fanfic#ao3 data scrape#ao3 ai scraping#ao3#ao3 writer
41 notes
·
View notes
Text
hey, anyone on ao3 who was a part of the data scrape;
if you are in america, I will help you file a DMCA against the website hosting the data set. sorry i can’t provide help to other countries, as I’m only educated in american law.
32 notes
·
View notes
Text
My wifi is so funny. It decides to die on the DAY THE THIRD KITS DROP
21 notes
·
View notes
Text
So I'm hearing UESP is getting scrubbed by AI companies.
I spent the better part of today and yesterday downloading as many images as I can from there in the event it's DDOS'd or similarly taken out of action
83 notes
·
View notes