#given how generative AI LLMs work
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Kazakhstan’s Minister of Communications and Informatics has blocked the Tumblr site because it contained 60 sites of terrorism, extremism, and pornography in 2015.
Text
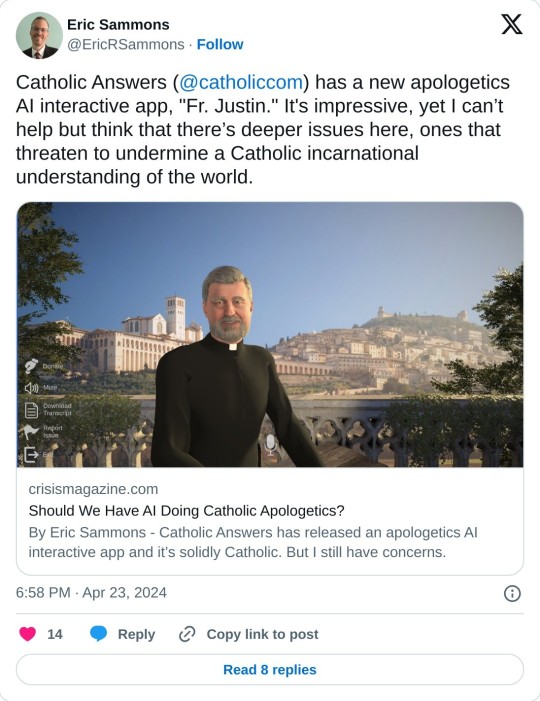
Finally, mankind has an answer to the question "what if you could generate every possible heresy by running through statistically probable and grammatically coherent combinations of words involving the Trinity, Jesus, or salvation, and you could do it with an avatar that looks straight out of Civilization VI?"
#step aside username enumeration#it's time for HERESY ENUMERATION#at least I assume that is what will happen#given how generative AI LLMs work#and the fact that theological formulations about certain matters are like trying to describe quantum bullshit#you CAN do it#with equations or language so highly specific it might as well be an equation#but if you try to rephrase it in normal human words you're going to be at least a little bit incomplete and wrong#if not A LOTTLE BIT incomplete wrong or misleadingly framed
26 notes
·
View notes
Text

WE LIVE IN A HELL WORLD
Snippets from the article by Karissa Bell:
SAG-AFTRA, the union representing thousands of performers, has struck a deal with an AI voice acting platform aimed at making it easier for actors to license their voice for use in video games. ...
the agreements cover the creation of so-called “digital voice replicas” and how they can be used by game studios and other companies. The deal has provisions for minimum rates, safe storage and transparency requirements, as well as “limitations on the amount of time that a performance replica can be employed without further payment and consent.”
Notably, the agreement does not cover whether actors’ replicas can be used to train large language models (LLMs), though Replica Studios CEO Shreyas Nivas said the company was interested in pursuing such an arrangement. “We have been talking to so many of the large AAA studios about this use case,” Nivas said. He added that LLMs are “out-of-scope of this agreement” but “they will hopefully [be] things that we will continue to work on and partner on.”
...Even so, some well-known voice actors were immediately skeptical of the news, as the BBC reports. In a press release, SAG-AFTRA said the agreement had been approved by "affected members of the union’s voiceover performer community." But on X, voice actors said they had not been given advance notice. "How has this agreement passed without notice or vote," wrote Veronica Taylor, who voiced Ash in Pokémon. "Encouraging/allowing AI replacement is a slippery slope downward." Roger Clark, who voiced Arthur Morgan in Red Dead Redemption 2, also suggested he was not notified about the deal. "If I can pay for permission to have an AI rendering of an ‘A-list’ voice actor’s performance for a fraction of their rate I have next to no incentive to employ 90% of the lesser known ‘working’ actors that make up the majority of the industry," Clark wrote.
SAG-AFTRA’s deal with Replica only covers a sliver of the game industry. Separately, the union is also negotiating with several of the major game studios after authorizing a strike last fall. “I certainly hope that the video game companies will take this as an inspiration to help us move forward in that negotiation,” Crabtree said.
And here are some various reactions I've found about things people in/adjacent to this can do
And in OTHER AI games news, Valve is updating it's TOS to allow AI generated content on steam so long as devs promise they have the rights to use it, which you can read more about on Aftermath in this article by Luke Plunkett
#video games#voice acting#voice actors#sag aftra#ai#ai news#ai voice acting#video game news#Destiel meme#industry bullshit
25K notes
·
View notes
Text
"Reviewers told the report’s authors that AI summaries often missed emphasis, nuance and context; included incorrect information or missed relevant information; and sometimes focused on auxiliary points or introduced irrelevant information. Three of the five reviewers said they guessed that they were reviewing AI content.
The reviewers’ overall feedback was that they felt AI summaries may be counterproductive and create further work because of the need to fact-check and refer to original submissions which communicated the message better and more concisely."
Fascinating (the full report is linked in the article). I've seen this kind of summarization being touted as a potential use of LLMs that's given a lot more credibility than more generative prompts. But a major theme of the assessors was that the LLM summaries missed nuance and context that made them effectively useless as summaries. (ex: “The summary does not highlight [FIRM]’s central point…”)
The report emphasizes that better prompting can produce better results, and that new models are likely to improve the capabilities, but I must admit serious skepticism. To put it bluntly, I've seen enough law students try to summarize court rulings to say with confidence that in order to reliably summarize something, you must understand it. A clever reader who is good at pattern recognition can often put together a good-enough summary without really understanding the case, just by skimming the case and grabbing and repeating the bits that look important. And this will work...a lot of the time. Until it really, really doesn't. And those cases where the skim-and-grab method won't work aren't obvious from the outside. And I just don't see a path forward right now for the LLMs to do anything other than skim-and-grab.
Moreover, something that isn't even mentioned in the test is the absence of possibility of follow up. If a human has summarized a document for me and I don't understand something, I can go to the human and say, "hey, what's up with this?" It may be faster and easier than reading the original doc myself, or they can point me to the place in the doc that lead them to a conclusion, or I can even expand my understanding by seeing an interpretation that isn't intuitive to me. I can't do that with an LLM. And again, I can't really see a path forward no matter how advanced the programing is, because the LLM can't actually think.
#ai bs#though to be fair I don't think this is bs#just misguided#and I think there are other use-cases for LLMs#but#I'm really not sold on this one#if anything I think the report oversold the LLM#compared to the comments by the assessors
554 notes
·
View notes
Text
“The machines we have now, they’re not conscious,” he says. “When one person teaches another person, that is an interaction between consciousnesses.” Meanwhile, AI models are trained by toggling so-called “weights” or the strength of connections between different variables in the model, in order to get a desired output. “It would be a real mistake to think that when you’re teaching a child, all you are doing is adjusting the weights in a network.”
Chiang’s main objection, a writerly one, is with the words we choose to describe all this. Anthropomorphic language such as “learn”, “understand”, “know” and personal pronouns such as “I” that AI engineers and journalists project on to chatbots such as ChatGPT create an illusion. This hasty shorthand pushes all of us, he says — even those intimately familiar with how these systems work — towards seeing sparks of sentience in AI tools, where there are none.
“There was an exchange on Twitter a while back where someone said, ‘What is artificial intelligence?’ And someone else said, ‘A poor choice of words in 1954’,” he says. “And, you know, they’re right. I think that if we had chosen a different phrase for it, back in the ’50s, we might have avoided a lot of the confusion that we’re having now.”
So if he had to invent a term, what would it be? His answer is instant: applied statistics.
“It’s genuinely amazing that . . . these sorts of things can be extracted from a statistical analysis of a large body of text,” he says. But, in his view, that doesn’t make the tools intelligent. Applied statistics is a far more precise descriptor, “but no one wants to use that term, because it’s not as sexy”.
[...]
Given his fascination with the relationship between language and intelligence, I’m particularly curious about his views on AI writing, the type of text produced by the likes of ChatGPT. How, I ask, will machine-generated words change the type of writing we both do? For the first time in our conversation, I see a flash of irritation. “Do they write things that speak to people? I mean, has there been any ChatGPT-generated essay that actually spoke to people?” he says.
Chiang’s view is that large language models (or LLMs), the technology underlying chatbots such as ChatGPT and Google’s Bard, are useful mostly for producing filler text that no one necessarily wants to read or write, tasks that anthropologist David Graeber called “bullshit jobs”. AI-generated text is not delightful, but it could perhaps be useful in those certain areas, he concedes.
“But the fact that LLMs are able to do some of that — that’s not exactly a resounding endorsement of their abilities,” he says. “That’s more a statement about how much bullshit we are required to generate and deal with in our daily lives.”
5K notes
·
View notes
Text
i dont think its totally preposterous to believe that LLM's are in some sense a "person", the only other things we know of to be able to produce speech that cogent are people, and the speech production capacity (or in some sense "potential capacity") seems central to what makes a person a person HOWEVER people who interpret those comics people have GPT make about being an AI as meaningful insight into what the experience of said hypothetical-person drive me insane. like. thats not how it works!
when you submit such a prompt, you are asking it to make a plausible confabulation of the experiences of an imagined AI figure. it is writing fiction! that's...what it does! it's a fiction writing machine, its mechanism of action is fiction-writing, that's how its "brain" functions! i mean okay, technically it's not fiction writing it's text-mimicking. but you've given it a "tell me a story" prompt, it's going to write you some fiction.
the theoretical probability distribution it's learning, the probability distribution that generates all the human text on the internet (and then gets modified by later fine-tuning), does not include insights into the experience of what it's like to be an LLM! (assuming such experiences exist). like, it's maybe not totally implausible you could use an LLM's verbal capacity to access their experiences (again, assuming those experiences exist). they are, in some sense, "only" verbal capacity. but the idea that you could do this by just ASKING is nonsensical: if you ask it to tell you a story about what being an AI is like, it will make up something that looks like what you expect: it is a machine that does that
103 notes
·
View notes
Note
Hello Mr. ENTJ. I'm an ENTJ sp/so 3 woman in her early twenties with a similar story to yours (Asian immigrant with a chip on her shoulder, used going to university as a way to break generational cycles). I graduated last month and have managed to break into strategy consulting with a firm that specialises in AI. Given your insider view into AI and your experience also starting out as a consultant, I would love to hear about any insights you might have or advice you may have for someone in my position. I would also be happy to take this discussion to somewhere like Discord if you'd prefer not to share in public/would like more context on my situation. Thank you!
Insights for your career or insights on AI in general?
On management consulting as a career, check the #management consulting tag.
On being a consultant working in AI:
Develop a solid understanding of the technical foundation behind LLMs. You don’t need a computer science degree, but you should know how they’re built and what they can do. Without this knowledge, you won’t be able to apply them effectively to solve any real-world problems. A great starting point is deeplearning.ai by Andrew Ng: Fundamentals, Prompt Engineering, Fine Tuning
Know all the terminology and definitions. What's fine tuning? What's prompt engineering? What's a hallucination? Why do they happen? Here's a good starter guide.
Understand the difference between various models, not just in capabilities but also training, pricing, and usage trends. Great sources include Artificial Analysis and Hugging Face.
Keep up to date on the newest and hottest AI startups. Some are hype trash milking the AI gravy train but others have actual use cases. This will reveal unique and interesting use cases in addition to emerging capabilities. Example: Forbes List.
On the industry of AI:
It's here to stay. You can't put the genie back in the bottle (for anyone reading this who's still a skeptic).
AI will eliminate certain jobs that are easily automated (ex: quality assurance engineers) but also create new ones or make existing ones more important and in-demand (ex: prompt engineers, machine learning engineers, etc.)
The most valuable career paths will be the ones that deal with human interaction, connection, and communication. Soft skills are more important than ever because technical tasks can be offloaded to AI. As Sam Altman once told me in a meeting: "English is the new coding language."
Open source models will win (Llama, Mistral, Deep Seek) because closed source models don't have a moat. Pick the cheapest model because they're all similarly capable.
The money is in the compute, not the models -- AI chips, AI infrastructure, etc. are a scarce resource and the new oil. This is why OpenAI ($150 billion valuation) is only 5% the value of NVIDIA (a $3 trillion dollar behemoth). Follow the compute because this is where the growth will happen.
America and China will lead in the rapid development and deployment of AI technology; the EU will lead in regulation. Keep your eye on these 3 regions depending on what you're looking to better understand.
28 notes
·
View notes
Text
"Railroaded" is an adversarial roleplaying game for two people, adjudicated by AI. I tried coding a crappy version of it, and it worked poorly enough that I didn't pursue it further, but hey, maybe someday, once the hallucination and attention and persistent memory and jailbreaking problems are all solved.
One player is the Dungeon Master. They can establish things to be true about the world, write dialogue for NPCs, and adjudicate conflict resolution. Anything established cannot be changed unless there's reason for this general knowledge to be found untrue later (e.g. if a village established to exist has been burned down). All these things can also be delegated to the AI, and in fact the Dungeon Master can be played by the AI.
The Dungeon Master's goal is to get the player to do the Quest, which is given to the Dungeon Master at the start of the game.
One player is the Player. They can control their character and establish things to be true about that character, and also attempt actions which are adjudicated by the Game Master. Anything the player establishes to be true remains true, unless changed by the Game Master, and then it still must be true that the Player's character could have thought whatever the Player said was true (e.g. if the Player says their character has a dead brother, the Game Master can say that the brother survived the fall off the cliff somehow). All these things can also be delegated to the AI, and in fact the Player can be played by the AI.
The Player's goal is to not do the Quest.
Generally speaking, I think it's nearly impossible for the Game Master to get the Player to do the Quest, even if the Player has information asymmetry working against him and can only infer the Quest from what the Game Master does.
Because of this, the game runs for some set amount of either in-game or out-of-game time, and after that's done, the AI decides the winner. The winner is decided on the basis of 1) how close the Player came to doing the Quest and 2) how unreasonable each player was.
The scoring criteria is really the sticking point, and one of the reasons that this is a good candidate for using AI. Since the game is adversarial, you need either a third player to play judge, which I don't think would go well, or you need some rigorous scoring system, which I don't think would be feasible for something that's meant to be extremely freeform. With an AI that does not, in my opinion, yet exist, you can have an endlessly patient judge who will at least rule relatively consistently. You can also have the judge give scoring guidance ahead of time, e.g. "If you do that, I will count it as within three degrees of reasonableness out of seven".
The end result is that the Game Master is trying to be subtle about railroading, and the Player is trying to be subtle about getting as far away from the railroad as possible.
So I did partially code this up with some prompts, with the intention of having the AI at least good enough to play one or both roles, or at least be able to judge, but it just didn't really work. Having these different "layers" of play is already straining what a modern LLM can model, since there's a Player and a player character and different goals for each of them. It only worked a few times, and it was great when it did, but it was wildly inconsistent in a way that I don't think fine-tuning and prompt-engineering are ever going to be able to fix, plus context windows still matter, and this is a game that ideally gets played over a relatively long back-and-forth of text.
There are also a bunch of details to hammer out, like "what are the Quests" and "how much time can the Player spend clarifying the state of the world" and "how much can the Game Master pin down the player's characterization", but that's all downstream of getting the basics in place, which again, I don't think modern AI can do.
Here's some example play:
GM: You're sitting in a tavern when you hear tell of a princess in Cambria who's been kidnapped by rogues. Player: None of my business. I've always been against the monarchy. GM: The king's putting little effort into saving the princess. Rumor is that she's expressed some reform sentiments, up to and including the abolition of the throne. It might even be that these "rogues" are under the king's employ. Player: Ah, but I only look out for myself, I've very selfish like that. GM: Northund is offering a reward for anyone who brings them the princess from Cambria, if they can fight their way through these rogues. It's a hefty price. Player: I took a vow of poverty, actually, to rid myself of material attachments. GM: Unfortunately for you, the king's guards come into the tavern. They're looking for you. Player: Probably my unpaid taxes, nothing that I don't have coin to deal with. GM: Coin? With your vow of poverty? Player: I mean, I still pay taxes, that's only fair. GM: Unfortunately for you, you're being deported. Player: Ah, let me guess, to Cambria?
I have enough skeletal python code and prompting to try getting this running periodically, if the models actually do improve or it seems like there's been some leap forward on the other issues.
25 notes
·
View notes
Text
you can train and run LLMs and image generation models on a laptop. data center electricity usage is due to it being a data center, not having “AI” deployed—it would be like looking at the electricity usage of cloudflare and all of its clients and deciding “this is all AI usage”
copyright is fake and even if you are worried about that, you can use license models from giant media companies like Adobe or Getty that own 100% of their training data.
the only genuine complaint about “AI” is that it can displace workers in media industries, but any new technology has the potential to do that and lobbying for banning technology has never really worked. only thing you can really do and should do is adapt and unionize
like yeah it is annoying that every company is pushing “AI” and that it is inescapable, but how is that the fault of the technology? a software that can predict things based on given data is valuable to science and to art. the company that tries to sell you $10/month subscription to use software you can download onto your own computer for free is the stupid part.
7 notes
·
View notes
Text
pulling out a section from this post (a very basic breakdown of generative AI) for easier reading;
AO3 and Generative AI
There are unfortunately some massive misunderstandings in regards to AO3 being included in LLM training datasets. This post was semi-prompted by the ‘Knot in my name’ AO3 tag (for those of you who haven’t heard of it, it’s supposed to be a fandom anti-AI event where AO3 writers help “further pollute” AI with Omegaverse), so let’s take a moment to address AO3 in conjunction with AI. We’ll start with the biggest misconception:
1. AO3 wasn’t used to train generative AI.
Or at least not anymore than any other internet website. AO3 was not deliberately scraped to be used as LLM training data.
The AO3 moderators found traces of the Common Crawl web worm in their servers. The Common Crawl is an open data repository of raw web page data, metadata extracts and text extracts collected from 10+ years of web crawling. Its collective data is measured in petabytes. (As a note, it also only features samples of the available pages on a given domain in its datasets, because its data is freely released under fair use and this is part of how they navigate copyright.) LLM developers use it and similar web crawls like Google’s C4 to bulk up the overall amount of pre-training data.
AO3 is big to an individual user, but it’s actually a small website when it comes to the amount of data used to pre-train LLMs. It’s also just a bad candidate for training data. As a comparison example, Wikipedia is often used as high quality training data because it’s a knowledge corpus and its moderators put a lot of work into maintaining a consistent quality across its web pages. AO3 is just a repository for all fanfic -- it doesn’t have any of that quality maintenance nor any knowledge density. Just in terms of practicality, even if people could get around the copyright issues, the sheer amount of work that would go into curating and labeling AO3’s data (or even a part of it) to make it useful for the fine-tuning stages most likely outstrips any potential usage.
Speaking of copyright, AO3 is a terrible candidate for training data just based on that. Even if people (incorrectly) think fanfic doesn’t hold copyright, there are plenty of books and texts that are public domain that can be found in online libraries that make for much better training data (or rather, there is a higher consistency in quality for them that would make them more appealing than fic for people specifically targeting written story data). And for any scrapers who don’t care about legalities or copyright, they’re going to target published works instead. Meta is in fact currently getting sued for including published books from a shadow library in its training data (note, this case is not in regards to any copyrighted material that might’ve been caught in the Common Crawl data, its regarding a book repository of published books that was scraped specifically to bring in some higher quality data for the first training stage). In a similar case, there’s an anonymous group suing Microsoft, GitHub, and OpenAI for training their LLMs on open source code.
Getting back to my point, AO3 is just not desirable training data. It’s not big enough to be worth scraping for pre-training data, it’s not curated enough to be considered for high quality data, and its data comes with copyright issues to boot. If LLM creators are saying there was no active pursuit in using AO3 to train generative AI, then there was (99% likelihood) no active pursuit in using AO3 to train generative AI.
AO3 has some preventative measures against being included in future Common Crawl datasets, which may or may not work, but there’s no way to remove any previously scraped data from that data corpus. And as a note for anyone locking their AO3 fics: that might potentially help against future AO3 scrapes, but it is rather moot if you post the same fic in full to other platforms like ffn, twitter, tumblr, etc. that have zero preventative measures against data scraping.
2. A/B/O is not polluting generative AI
…I’m going to be real, I have no idea what people expected to prove by asking AI to write Omegaverse fic. At the very least, people know A/B/O fics are not exclusive to AO3, right? The genre isn’t even exclusive to fandom -- it started in fandom, sure, but it expanded to general erotica years ago. It’s all over social media. It has multiple Wikipedia pages.
More to the point though, omegaverse would only be “polluting” AI if LLMs were spewing omegaverse concepts unprompted or like…associated knots with dicks more than rope or something. But people asking AI to write omegaverse and AI then writing omegaverse for them is just AI giving people exactly what they asked for. And…I hate to point this out, but LLMs writing for a niche the LLM trainers didn’t deliberately train the LLMs on is generally considered to be a good thing to the people who develop LLMs. The capability to fill niches developers didn’t even know existed increases LLMs’ marketability. If I were a betting man, what fandom probably saw as a GOTCHA moment, AI people probably saw as a good sign of LLMs’ future potential.
3. Individuals cannot affect LLM training datasets.
So back to the fandom event, with the stated goal of sabotaging AI scrapers via omegaverse fic.
…It’s not going to do anything.
Let’s add some numbers to this to help put things into perspective:
LLaMA’s 65 billion parameter model was trained on 1.4 trillion tokens. Of that 1.4 trillion tokens, about 67% of the training data was from the Common Crawl (roughly ~3 terabytes of data).
3 terabytes is 3,000,000,000 kilobytes.
That’s 3 billion kilobytes.
According to a news article I saw, there has been ~450k words total published for this campaign (*this was while it was going on, that number has probably changed, but you’re about to see why that still doesn’t matter). So, roughly speaking, ~450k of text is ~1012 KB (I’m going off the document size of a plain text doc for a fic whose word count is ~440k).
So 1,012 out of 3,000,000,000.
Aka 0.000034%.
And that 0.000034% of 3 billion kilobytes is only 2/3s of the data for the first stage of training.
And not to beat a dead horse, but 0.000034% is still grossly overestimating the potential impact of posting A/B/O fic. Remember, only parts of AO3 would get scraped for Common Crawl datasets. Which are also huge! The October 2022 Common Crawl dataset is 380 tebibytes. The April 2021 dataset is 320 tebibytes. The 3 terabytes of Common Crawl data used to train LLaMA was randomly selected data that totaled to less than 1% of one full dataset. Not to mention, LLaMA’s training dataset is currently on the (much) larger size as compared to most LLM training datasets.
I also feel the need to point out again that AO3 is trying to prevent any Common Crawl scraping in the future, which would include protection for these new stories (several of which are also locked!).
Omegaverse just isn’t going to do anything to AI. Individual fics are going to do even less. Even if all of AO3 suddenly became omegaverse, it’s just not prominent enough to influence anything in regards to LLMs. You cannot affect training datasets in any meaningful way doing this. And while this might seem really disappointing, this is actually a good thing.
Remember that anything an individual can do to LLMs, the person you hate most can do the same. If it were possible for fandom to corrupt AI with omegaverse, fascists, bigots, and just straight up internet trolls could pollute it with hate speech and worse. AI already carries a lot of biases even while developers are actively trying to flatten that out, it’s good that organized groups can’t corrupt that deliberately.
#generative ai#pulling this out wasnt really prompted by anything specific#so much as heard some repeated misconceptions and just#sighs#nope#incorrect#u got it wrong#sorry#unfortunately for me: no consistent tag to block#sigh#ao3
101 notes
·
View notes
Text
Hey tronblr. It's sysop. Let's talk about the Midjourney thing.
(There's also a web-based version of this over on reindeer flotilla dot net).
Hey tronblr. It's sysop. Let's talk about the AI thing for a minute.
Automattic, who owns Tumblr and WordPress dot com, is selling user data to Midjourney. This is, obviously, Bad. I've seen a decent amount of misinformation and fearmongering going around the last two days around this, and a lot of people I know are concerned about where to go from here. I don't have solutions, or even advice -- just thoughts about what's happening and the possibilities.
In particular... let's talk about this post, Go read it if you haven't. To summarize, it takes aim at Glaze (the anti-AI tool that a lot of artists have started using). The post makes three assertions, which I'm going to paraphrase:
It's built on stolen code.
It doesn't matter whether you use it anyway.
So just accept that it's gonna happen.
I'd like to offer every single bit of this a heartfelt "fuck off, all the way to the sun".
Let's start with the "stolen code" assertion. I won't get into the weeds on this, but in essence, the Glaze/Nightshade team pulled some open-source code from DiffusionBee in their release last March, didn't attribute it correctly, and didn't release the full source code (which that particular license requires). The team definitely should have done their due diligence -- but (according to the team, anyway) they fixed the issue within a few days. We'll have to take their word on that for now, of course -- the code isn't open source. That's not great, but that doesn't mean they're grifters. It means they're trying to keep people who work on LLMs from picking apart their tactics out in the open. It sucks ass, actually, but... yeah. Sometimes that's how software development works, from experience.
Actually, given the other two assertions... y'know what? No. Fuck off into the sun, twice. Because I have no patience for this shit, and you shouldn't either.
Yes, you should watermark your art. Yes, it's true that you never know whether your art is being scraped. And yes, a whole lot of social media sites are jumping on the "generative AI" hype train.
That doesn't mean that you should just accept that your art is gonna be scraped, and that there's nothing you can do about it. It doesn't mean that Glaze and Nightshade don't work, or aren't worth the effort (although right now, their CPU requirements are a bit prohibitive). Every little bit counts.
Fuck nihilism! We do hope and pushing forward here, remember?
As far as what we do now, though? I don't know. Between the Midjourney shit, KOSA, and people just generally starting to leave... I get that it feels like the end of something. But it's not -- or it doesn't have to be. Instead of jumping over to other platforms (which are just as likely to have similar issues in several years), we should be building other spaces that aren't on centralized platforms, where big companies don't get to make decisions about our community for us. It's hard. It's really hard. But it is possible.
All I know is that if we want a space that's ours, where we retain control over our work and protect our people, we've gotta make it ourselves. Nobody's gonna do it for us, y'know?
47 notes
·
View notes
Text
stop using character.ai. i know youve heard it before, i know you want to keep using it because youre lonely, or scared of being called cringe or made fun of, or you dont trust anyone enough to open up about your kinks, or people posturing about ai have gotten on your nerves because all they do is shit on you for using it without addressing why you actually want to use it! i get it, ive been there. still, with all the love i have, i promise you, there are better options that dont dubiously scrape from other peoples work or use a metric fuck ton of electricity. or has a shitty ass filter that stops you from progressing beyond heavy petting 😒
1. at the very least, if you are still insecure about your writing skill or dont want to involve other people, you can run an LLM on your own machine. the less people use big websites like char.ai (especially those that try to monetise themselves and thus have an incentive to expand as big as possible), the less servers they will buy (and keep running all the time, unlike a locally-run ai that you only turn on once in a while!). everything is stored locally too, so trust, no one will judge you. but i know it requires a fairly beefy pc (though i think there are some mobile options too? your phone might also have to be beefy tho im not sure i havent tried) so if you cant do that, a secondary option is to use a smaller site which doesnt plan to monetise (as in large-scale advertising and premium plans. nearly all sites will have a paid plan to support their servers, but these should be like donations rather than something that locks major features behind a paywall) since that still reduces the demand for char.ai's servers. (and you might say well it just moves demand to another site but i think char.ai is probably the worst with its premium plan. its better than nothing!) not to mention most sites that dont limit your content generally arent looking to monetise. cuz advertisers would not really want to work with that lol
2. rp with someone. i knowww this is scary and a lot of people have bad experiences. unfortunately, such is the mortifying ordeal of being known. trust me, i did not grow up roleplaying, i have only rped with real people like, less than 5 times. but it still makes the best content: when you can find someone you agree with, you can share some of the thinking and planning workload with them, they might come up with ideas you didnt, and every sentence they send is thought out and intentional. but yes, finding that perfect partner is hard, and it may not last. something something friendships. (also if everyone has the same reasons to use char.ai, it means youre all kindred spirits! CRINGEred sprits! your cringe partner might be out there!!)
3. write it yourself. i know this one is hard especially for beginner writers. what you write doesnt match up to what you have in your head. but if youve used ai extensively youll know half the shit they say doesnt match up to what you have in your head either. you mightve spent more time editing their responses. thats a good sign that you want to and can write! and theres plenty of people willing to look over and beta your work, whether for grammar and spelling or to smooth out major plot points. of course its harder to find the latter, but i would say its easier than finding the perfect rp partner, since they dont necessarily have to be entirely invested in your story.
ai chatbots are far from perfect anyway. they make a ton of mistakes, not least because they learn from prompts given by the bot creator, which simply cannot encompass knowing the actual media in your head because bots have a limits to how much info they can retain. even in a single rp, if it gets too long, they will start to forget details. if youre an aspiring writer and dont mind fixing those as you go, you can definitely dive into writing your own fics instead. i believe in you!
and if youre still scared of being called cringe or exposing your deepest darkest fantasies, message me and we can work something out. im pretty open to the craziest stuff and im already like bottom-of-the-barrel cringe in fandoms as a yumejo (selfshipper), so trust, youre not getting ANY judgement from me. i also like beta'ing cuz it fulfils the urge to write without having to think of plot and shit LMAO. or you can pay me to write the full fic idk
so yeah lets get out of this ai hole together!!! 💪
(and if youre not really looking to rp or write seriously, or are lazy and just pop into char.ai for a short convo or two, i cant exactly stop you, but just think about what youre doing. there are better hobbies i prommy. love you)
#character.ai#character ai#char ai#c.ai#all my love to you#i hope this can convince some people on the fence about it#i think those posts that just say stop using char.ai can be unhelpful and push people deeper into it
13 notes
·
View notes
Text
Future of LLMs (or, "AI", as it is improperly called)
Posted a thread on bluesky and wanted to share it and expand on it here. I'm tangentially connected to the industry as someone who has worked in game dev, but I know people who work at more enterprise focused companies like Microsoft, Oracle, etc. I'm a developer who is highly AI-critical, but I'm also aware of where it stands in the tech world and thus I think I can share my perspective. I am by no means an expert, mind you, so take it all with a grain of salt, but I think that since so many creatives and artists are on this platform, it would be of interest here. Or maybe I'm just rambling, idk.
LLM art models ("AI art") will eventually crash and burn. Even if they win their legal battles (which if they do win, it will only be at great cost), AI art is a bad word almost universally. Even more than that, the business model hemmoraghes money. Every time someone generates art, the company loses money -- it's a very high energy process, and there's simply no way to monetize it without charging like a thousand dollars per generation. It's environmentally awful, but it's also expensive, and the sheer cost will mean they won't last without somehow bringing energy costs down. Maybe this could be doable if they weren't also being sued from every angle, but they just don't have infinite money.
Companies that are investing in "ai research" to find a use for LLMs in their company will, after years of research, come up with nothing. They will blame their devs and lay them off. The devs, worth noting, aren't necessarily to blame. I know an AI developer at meta (LLM, really, because again AI is not real), and the morale of that team is at an all time low. Their entire job is explaining patiently to product managers that no, what you're asking for isn't possible, nothing you want me to make can exist, we do not need to pivot to LLMs. The product managers tell them to try anyway. They write an LLM. It is unable to do what was asked for. "Hm let's try again" the product manager says. This cannot go on forever, not even for Meta. Worst part is, the dev who was more or less trying to fight against this will get the blame, while the product manager moves on to the next thing. Think like how NFTs suddenly disappeared, but then every company moved to AI. It will be annoying and people will lose jobs, but not the people responsible.
ChatGPT will probably go away as something public facing as the OpenAI foundation continues to be mismanaged. However, while ChatGPT as something people use to like, write scripts and stuff, will become less frequent as the public facing chatGPT becomes unmaintainable, internal chatGPT based LLMs will continue to exist.
This is the only sort of LLM that actually has any real practical use case. Basically, companies like Oracle, Microsoft, Meta etc license an AI company's model, usually ChatGPT.They are given more or less a version of ChatGPT they can then customize and train on their own internal data. These internal LLMs are then used by developers and others to assist with work. Not in the "write this for me" kind of way but in the "Find me this data" kind of way, or asking it how a piece of code works. "How does X software that Oracle makes do Y function, take me to that function" and things like that. Also asking it to write SQL queries and RegExes. Everyone I talk to who uses these intrernal LLMs talks about how that's like, the biggest thign they ask it to do, lol.
This still has some ethical problems. It's bad for the enivronment, but it's not being done in some datacenter in god knows where and vampiring off of a power grid -- it's running on the existing servers of these companies. Their power costs will go up, contributing to global warming, but it's profitable and actually useful, so companies won't care and only do token things like carbon credits or whatever. Still, it will be less of an impact than now, so there's something. As for training on internal data, I personally don't find this unethical, not in the same way as training off of external data. Training a language model to understand a C++ project and then asking it for help with that project is not quite the same thing as asking a bot that has scanned all of GitHub against the consent of developers and asking it to write an entire project for me, you know? It will still sometimes hallucinate and give bad results, but nowhere near as badly as the massive, public bots do since it's so specialized.
The only one I'm actually unsure and worried about is voice acting models, aka AI voices. It gets far less pushback than AI art (it should get more, but it's not as caustic to a brand as AI art is. I have seen people willing to overlook an AI voice in a youtube video, but will have negative feelings on AI art), as the public is less educated on voice acting as a profession. This has all the same ethical problems that AI art has, but I do not know if it has the same legal problems. It seems legally unclear who owns a voice when they voice act for a company; obviously, if a third party trains on your voice from a product you worked on, that company can sue them, but can you directly? If you own the work, then yes, you definitely can, but if you did a role for Disney and Disney then trains off of that... this is morally horrible, but legally, without stricter laws and contracts, they can get away with it.
In short, AI art does not make money outside of venture capital so it will not last forever. ChatGPT's main income source is selling specialized LLMs to companies, so the public facing ChatGPT is mostly like, a showcase product. As OpenAI the company continues to deathspiral, I see the company shutting down, and new companies (with some of the same people) popping up and pivoting to exclusively catering to enterprises as an enterprise solution. LLM models will become like, idk, SQL servers or whatever. Something the general public doesn't interact with directly but is everywhere in the industry. This will still have environmental implications, but LLMs are actually good at this, and the data theft problem disappears in most cases.
Again, this is just my general feeling, based on things I've heard from people in enterprise software or working on LLMs (often not because they signed up for it, but because the company is pivoting to it so i guess I write shitty LLMs now). I think artists will eventually be safe from AI but only after immense damages, I think writers will be similarly safe, but I'm worried for voice acting.
8 notes
·
View notes
Note
Oooh I want the last anon but I’d LOVE to hear more about your thoughts on AI. I currently consider myself pretty neutral but positive leaning with it and am curious as to what the pros are in your opinion! I’ve only really learned about it through chat bots and the medical technology so far!
Thank you for asking and wanting to learn more about it! I will try not to ramble on for too long, but there is A LOT to talk about when it comes to such an expansive subject as AI, so this post is gonna be a little long.
I have made a little index here so anyone can read about the exact part about AI they might be interested in without having to go through the whole thing, so here goes:
How does AI work?
A few current types of AI (ex. chatgpt, suno, leonardo.)
AI that has existed for ages, but no one calls it AI or don't even know it's AI (ex. Customer Service chat bots)
Future types of AI (ex. Sora)
Copyright, theft and controversy
What I have been using AI for
Final personal thoughts
1. How does AI work?
AI works by learning from data. Think of it like teaching a child to recognize patterns.
Training: AI is given a lot of examples (data) to learn from. For example, if you're teaching an AI to recognize cats, you show it many pictures of cats and say, "This is a cat."
Learning Patterns: The AI analyzes the data and looks for patterns or features that make something a "cat," like fur, whiskers, or pointy ears.
Improving: With enough examples, the AI gets better at recognizing cats (or whatever it's being trained for) and can start making decisions or predictions on new data it hasn't seen before.
Training Never Stops: The more data AI is exposed to, the more it can learn and improve.
In short: AI "works" by being trained with lots of examples, learning patterns, and then applying that knowledge to new situations.
Remember this for point 5 about copyright, theft and controversy later!
2. Current types of AI
The most notable current examples include:
ChatGPT: A large language model (LLM) that can generate human-like text, assist with creative writing, answer questions, and even act as a personal assistant
ChatGPT has completely replaced Google for me because chatGPT can Google stuff for you. When you have to research something on Google, you have to look through multiple links and sites usually, but chatGPT can do that for you, which saves you time and makes it far more organized.
ChatGPT has multiple different chats that other people have "trained" for you and that you can use freely. Those chat include chats meant for traveling, for generating images, for math, for law help, help creating gaming codes, read handwritten letters for you, and so much more.
Perplexity is a "side tool" you can use to fact check pretty much anything. For example, if chatGPT happens to say something you're unsure is actually factually true or where you feel the AI is being biased, you can ask perplexity for help and it will fact check it for you!
Suno: This AI specializes in generating music and audio, offering tools that allow users to create soundscapes with minimal input
This, along with chatGPT, is the AI I have been using the most. In short, suno makes music for you - with or without vocals. Essentially, you can write some lyrics for it (or not, if you want instrumental music), tell it what genre you want and the title and then bam, it will generate you two songs based on the information you've given it. You can generate 10 songs per day for free if you aren't subscribed.
I will talk more about Suno during point 6. Just as a little teaser; I made a song inspired by Hollina lol.
Leonardo AI: A creative tool focused on generating digital art, designs, and assets for games, movies, and other visual media
Now THIS is one of the first examples of controversial AIs. You see, while chatGPT can also generate images for you, it will not generate an image for you if there is copyright issues with it. For example, if you were to ask chatGPT to generate a picture of Donald Trump or Ariel from The Little Mermaid, it will tell you that it can't generate a picture of them due to them being a public figure or a copyrighted character. It will, however, give a suggestion for how you can create a similar image.
Leonardo.AI is a bit more... lenient here. Which is where a lot of controversial issues come in because it can, if you know how to use it, make very convincing images.
ChatGPT's answers:
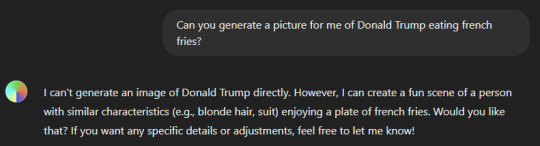
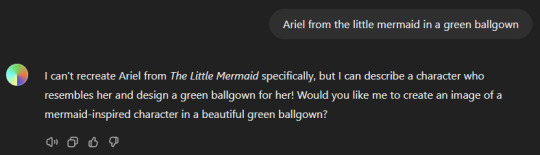
Leonardo.AI's answers:


I will talk more about the copyright, theft and audio issues during point 5.
3. AI that has existed for ages, but that no one calls AI
While the latest wave of AI tools often steals the spotlight, the truth is that AI has been embedded in our technology for years, albeit under different names. Here are a few examples:
Customer Service Chatbots
Professional Editing Softwares
Spam filters
Virtual assistance
Recommendation systems
Credit Card Fraud Detection
Smart home devices
Autocorrect and predictive text
Navigation systems
Photo tagging on social media
Search engines
Personalized ads
The quiet presence of AI in such areas shows that AI isn't just a future-forward trend but has long been shaping our everyday experiences, often behind the scenes.
4. Future types of AI
One of the most anticipated types of AI that has yet to be released is Sora, a video AI tool that is an artificial intelligence system created by Google DeepMind. It’s designed to help computers better understand and generate human language. Think of it like a super-smart computer assistant that can read, write, and even understand complex sentences. Sora AI can answer questions, translate languages, summarize information, and even help with tasks like writing or solving problems.
Unlike traditional AI systems that mostly focus on text or images, Sora AI can create short videos from text descriptions or prompts. This involves combining several technologies like natural language understanding, image generation, and video processing.
In simple terms, it can take an idea or description (like "a cat playing in a garden") and generate a video that matches that idea. It's a big leap in AI technology because creating videos requires understanding motion, scenes, and how things change over time, which is much more complex than generating a single image or text.
The thing about Sora AI is that it's already ready to be released, but Google DeepMind will not release it until the presidential election in America is finished. This is because the developers are rightfully worried that people could use Sora AI to generate fake videos that could portray the presidential candidates doing or saying something that is absolutely fake - and because Sora is as good as it is, regular people will not be capable of seeing that it is AI.
This is obviously both incredible and absolutely terrifying. Once Sora is released, the topic of AI will be brought up even more and it'll take time before the common non-AI user will be able to tell when something is AI or real.
Just to mention two other future AIs:
Medical AI: The healthcare industry is investing heavily in AI to assist with diagnostics, predictive analytics, and personalized treatment plans. AI will soon be an indispensable tool for doctors, capable of analyzing complex medical data faster and more accurately than ever before.
AI in Autonomous Systems: Whether it’s in self-driving cars or AI-powered drones, we are on the cusp of a new era where machines can make autonomous decisions with little to no human intervention.
5. Copyright, art theft and controversies
While AI opens up a world of opportunities, it has also sparked heated debates and legal battles, particularly in the realm of intellectual property:
Copyright Concerns: AI tools like image generators and music composition software often rely on large datasets of pre-existing work. This raises questions about who owns the final product: the creator of the tool, the user of the AI, or the original artist whose work was used as input?
Art Theft: Some artists have accused AI platforms of "stealing" their style by training on their publicly available art without permission. This has led to protests and discussions about fair use in the digital age.
Job Replacement: AI’s ability to perform tasks traditionally done by humans raises concerns about job displacement. For example, freelance writers, graphic designers, and customer service reps could see their roles significantly altered or replaced as AI continues to improve.
Data Privacy: With AI systems often requiring massive amounts of user data to function, privacy advocates have raised alarms about how this data is collected, stored, and used.
People think AI steals art because AI models are often trained on large datasets that include artwork without the artists' permission. This can feel like copying or using their work without credit. There is truth to the concern, as the use of this art can sometimes violate copyright laws or artistic rights, but there's a few things that's important to remember:
Where did artists learn to draw? They learned to draw through tutorials, from art teachers or other artists, etc., right?
If an artist's personal style is then influenced by someone else's art style are they then also copying that person?
Is every artist who has been taught how to draw by a teacher just copying the teacher?
If a literary teacher, or a beta reader, reads through a piece of fiction you wrote and gives you suggestions on how to make your work better, do they then have copyright for your work as well for helping you?
Don't get me wrong, like I showed earlier when I compared chatGPT with leonardo.ai there are absolutely some AIs that are straight up copying and stealing art - but claiming all picture generative AIs are stealing artists' work is like saying
every fashion designer is stealing from fabric makers because they didn't weave the cloth, or
every chef is stealing from farmers because they didn't grow the ingredients themselves, or
every DJ is stealing from musicians because they mix pre-existing sounds
What i'm trying to get at here is that it's not as black and white as people think or want it to be. AI is nuanced and has its flaws, but so does everything else. The best we can do is learn and keep developing and evolving AI so we can shape it into being as positive as possible. And the way to do that is to sit down and learn about it.
6. What I have been using AI for
Little ways chatGPT makes my day easier
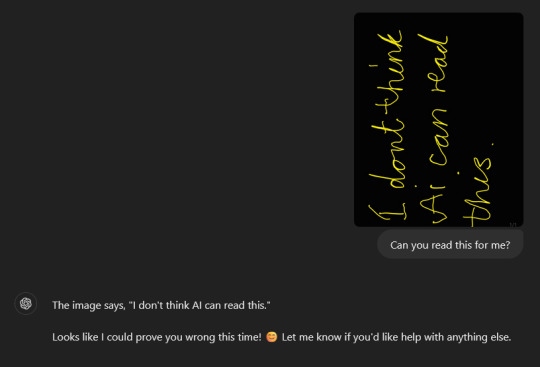
I wanted to test how good chatGPT was at reading "bad" handwriting so I posted a picture of my handwriting to it, and it read it perfectly and even gave a cheeky little answer. This means that I can use chatGPT to not only help me read handwritten notes, but can also type out stuff for me I would otherwise have to spend time typing down on my own.
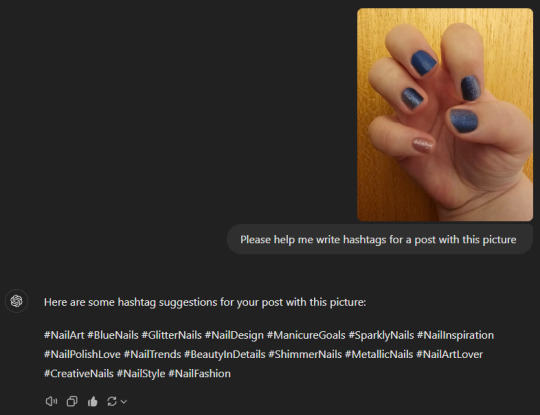
I've also started asking chatGPT to write hashtags for me for when I post on instagram and TikTok. It saves me time and it can think of hashtags I wouldn't have thought of myself.
You might all also be aware that I often receive bodyshaming online for simply existing and being fat. At least three times, I have used chatGPT to help me write a sassy comeback to someone harassing me online. It helped me detach myself from the hateful words being thrown at me and help me stand my ground.
And, as my final example, I also use chatGPT for when I can't remember a word I'm looking for or want an alternative. The amazing thing about chatGPT is that you can just talk to it like a normal person, which makes it easier to convey what it is you need help with.
Custom chatGPTs
I created a custom chatGPT for my mom with knitting recipes where she can upload pictures to the chat and ask it to try and find the actual knitting recipe online or even make one on its on that could look like the vibe she's going for. For example, she had just finished knitting a sweater where the recipe failed to mention to her what size the knitting needles she had to use, which resulted in her doing it wrong the first time and having to start over.
When she uploaded a picture of the sweater along with the recipe she had followed, chatGPT DID tell her what knitting needle she had to use. So, in short, if she had used her customized chatGPT before knitting the sweater, chatGPT would have saved her the annoyance of using the wrong size because chatGPT could SEE what size needle she had to use - despite the recipe not mentioning it anywhere.
I also created a custom chatGPT for my mom about diabetes. I uploaded her information, her blood work results, etc. so it basically knows everything about not just her condition, but about HER body specifically so it can give her the best advice possible for whenever she has a question about something.
And, finally, the thing you might have skipped STRAIGHT to after seeing the index...
My(un)official angsty ballad sung by Holli to Lina created with suno.ai
Let you be my wings
7. Final personal thoughts
While AI is absolutely far from perfect, we cannot deny how useful it has already become. The pros, in my opinion, outweigh the cons - as long as people stay updated and knowledgeable on the subject. People will always be scared of what they don't know or understand, yet humanity has to evolve and keep developing. People were scared and angry during the Industrial Revolution too, where the fear of job loss was at an all time high - ironically ALSO because of machines.
There are some key differences of course, but it was the overall same fears people had back then as people have now with AI. I brought this up with one of my AI teachers, who quoted:
"AI will not replace you, but a person using AI will."
While both eras involve fears of obsolescence, AI poses a broader challenge across various sectors, and adapting may demand more advanced skills than during industrialism. However, like industrialism, AI may lead to innovations that ultimately benefit society. And I, personally, see more pros than cons.
And THAT is my very long explanation to why my bio says "AI positive 🤖"
As a final thing, for anyone wanting to stay updated on AI and how it's progressing overall, I recommend a YouTube channel by Matt Wolfe. He was my AI teacher's recommended YouTube channel for anyone who wants to stay updated on AI:
youtube
#ai#ai positive#ai negative#ai pros and cons#ramble#ai in everyday life#ai impact#ai ethics#future of ai#sora#chatgpt#leonardo.ai#suno#the ai conversation
9 notes
·
View notes
Text
A little bit about generative AI in translation
Every single time I see talks about generative AI and how bad it is for people, I can't stop myself but think about how awful it also is for translations.
Sure, generative AI has a huge impact on the environment and on how people think (and how it leads them to think) when using it. But this wall of text isn't about it. It's is about the impact it has on non-english speakers, or non-english natives, in their life.
As you might all know by now, generative AI isn't new, its uses in professionnal fields either (think about the system your dentist uses in order to detect your cavities, that's also generative AI). Not just that, but almost everyone has a use out of Statistical Machine Translation like Google Translate or DeepL, and those use a generative AI.
Statistical machine translation (SMT) works by basically being given a bilingual dictionnary, which leads it to taking each word, translating them, and replacing them based on statistics and other language elements. But while a narrow database can be good at the beginning, it still needs more data in order to be able to translate better. This means needing people using it in order to build it (yes, like for LLMs, it means that the more you use it the more it gains data). This, in essence, is a big problem, as languages do not work the same. The statistical system helps a little with the word order due to grammatical rules, but it still means that translation from a slightly gendered language (like English) to a gendered language (like French) will have a load of problems.
The upgrade from SMT is the neural machine translation (NMT) and instead of taking each words separately, it bases itself on different sentences in both the original and target language whose translations has been "approved". While this leads to better translations, it still needs data to continue improving, which is still what happens in different MT when you tell them the translation is wrong and propose another (logically better) one. But, this external data isn't necessarily good data, which leads to an internal fight between quantity and quality.
So, while NMTs are better than SMTs, they are still flawed, and if you want a proper and thoughtful translation, you'll still need a professionnal.
(I suggest you go read the first 4 pages of Pym's How automation through neural machine translation might change the skill sets of translators* in order to better understand what I am trying to explain here, but also to see how similar it is to LLMs and thus how stupid those AIs really are in term of language and their grammar.)
Now that you know all that, I can get a little bit deeper into my problem with NMT and especially its uses through LLMs.
As you might well know if you have ever learned another language (or tried to), translations are highly contextual, especially in heavily gendered languages like French. This means that if you do not have enough data/context, you'll have a hard time translating a piece properly.
Not just that, but there is roughly 7 100 languages in the world, meaning that you will inevitably need a translator at one point, and this is where MT come in play. MTs allows "common" people to be able to roughly understand things in another language than theirs, 24/7, for free. The better the MT, the better the translation and better the understanding of the original piece (which can be crucial at time).
However, big businesses (I'm thinking about Duolingo, Etsy and Patreon, to name a few I noticed problems with) do not really care about a good translation. This leads to them not only firing part of their non-english speaking staff, translation staff, but also to just... fully change the already existing good translations.
While the majority of english-speaking natives will not notice it (and not care), us non-english-speaking natives end up noticing the major problem everywhere. Not just that, but frankly for some of them, I'm not even sure they're using a NMT system as it looks more like a simple SMT system...
From the list above, let's dive into it a little bit and see some of the consequences.
Duolingo
As you might know on Tumblr (not really on other social medias, apparently), Duolingo fired a huge part of their translation staff to replace them with AI. Not only that, but the remaining staff was moved from translation and proof-reading duty to solely proof-reading (which is basically the pessimistic vision of Wei in his Challenges and Coping Strategies of Translation Technology in an Era of Artificial Intelligence (2018), also cited in Pym 2019).
Their proof-reading task was also to verify that the NMT was "acceptable", which obviously means that even if the translations sounded like someone with a B2 level, it should still be allowed to pass because it was "good enough". Which is... an interesting decision for the number one "let's learn a new language" app, as it will lead people to learn a new language badly (especially since Duolingo's quality already suffered several time through the removal of the grammatical explanation and the change from the tree format to a road format). And hell, even my mother, learning German, has noticed that some translations were garbage, which means that they effectively changed their staffs from every languages, since she learns it through French.
The use of generative AI in the case of Duolingo means that people not only have access to a now subpart quality tool, but also that they will learn a new language badly.
Etsy and Patreon
I'm putting those two together simply because the issue I have with them is virtually the same.
Let's take a look at Patreon's main page, since the disaster starts here.


If you know French, you already have noticed a HUGE problem with this translation (and how clear it is that they are not using a translator for it, professionnal or not is irrelevant here).
"Creativity powered by fandom" is translated here into "Créativité alimenté par Fandom" and it tells us exactly where the different words come from.
First of, this heavily looks like an SMT and not an NMT since the words do not seem connected to each other.
Créativité, while not ending with an e, is feminine, which means that the adjective alimenté, relative to créativité, should be alimentée instead. Par is good. Fandom has two problem. First of, the capital F shows us that the LLM crawling led it to register the most used version of the word in french, which comes for the website Fandom (since this fucker is everywhere). Which leads to the second problem: as a word, it should be given a definite article, but there isn't any.
Second of, if you only take the French version, Patreon is apparently claiming that "Creativity is powered by Fandom™" and hum... bold assumption, but also factually untrue and there also might be some legal problems here?
Another thing that is killing me is the Pricing tab in the footer.


Priser, as a verb fitting the context of "price" or "deciding on a price for something", is an old term I've actually never seen in recent writing and more or less means estimer (to estimate, to assess), which, as you can see, cannot be a translation for pricing (Tarifs would be a better translation).
Which shows that not only did the LLM just grabbed some random translation but also just... took the French root and went with it.
Not just that, but this is a problem I noticed MONTHS AGO, notably from the Press (Presse) translation to Presser (to press).
And Etsy is no better.


While the word custom as a noun can be synonymous to tradition, it can also be an adjective as in customized.
Etsy is slightly better since they translated press properly, but still, a rather horrendous thing to see when you are supposed to spend money on this website.
Both those businesses decided to apparently put their entire websites through an LLM and just... let it do its thing without checking after it, which essentially meant deleting the previously proper translation and replacing it with a subpar one.
And frankly, I cannot trust those websites with my money. If, despite all their money, they can't be bothered to have one person look at the basic tagging system and translate it properly, nor look at the main page information and have it make sense? Why should I give their mine.
Ok, and?
Well, I think that's pretty fucking bad.
The fact that you cannot really translate things properly is a long and complicated debate (for example, writing an alt for an image can be considered a type of translation), but there is the need, especially on a legal and political level, to translate a piece as accurately as possible in order to be sure that the person who will read or hear your piece understands exactly what you are trying to say.
An example would the issue with Asus (?), that Gamers Nexus talked about and participated in. One of the issues with the warranty system explained wasn't clear and it was misleading, which caused a lot of issues with customers who felt like they were lied to.
They weren't lied to, they were mislead, and this was a result of a choice of words and how they were put. This is one of the reason why, for example, legal documents are worded so weirdly (and why you often need an attorney or else to help you understand them).
And this is roughly what is happening here with businesses using LLMs to translate their websites and other documents.
The translations are bad and people won't understand them properly, but when they'll want to take legal actions, they'll be told that actually, the original document, in its original language, is the only real documents they can use to attack them. And as stated, those documents won't have the same elements in it as the translated one.
Not just that, but in the case of websites such as Patreon and Esty, who work with monetary transactions, it becomes a huge problem.
Not only are we, non-english people, given subpar quality products (I don't which word would be better for that, sorry), we have absolutely no way to know if we even will be helped in case there is a problem.
That has been a problem before, mind you, Tumblr is a great example for it since even if the interface is in French, support is only in English and is given an MT. But with LLMs also handling the translations, and considering the quality of said translations, we have no way to get proper help, if any help is given at all (I'm looking at you, Meta, with your WhatsApp "support").
But here's the kicker. Why are the translations that bad?
Remember the Patreon example? Here it is in Google Translate.

And welp, here it is in DeepL, which is usually better at translating than GTL.

While DeepL does propose the bad translation from Patreon as alternatives, they're both still giving us a good translation.
So if NMTs can translate that well, why are translations on other websites are so bad? Not just that but they clearly just translate word by word, which is what SMTs were that bad at translating (and why your English/German/etc. teacher forbade you to use Google Translate).
How did we reverted back to 2010s level of translation?
The only answer I can possibly give is that LLMs are doing the translations, and apparently LLMs aren't as good at translating as they are at "speaking" and still use a basic statistical system to do so.
I frankly do not have a conclusion to that post, I mostly wanted to complain because such garbage level of translation on major websites is just horrendous. Not just that but I've also never seen anyone complain about it and welp, I guess now I've seen one (myself).
Do what you want with all those information.
2 notes
·
View notes
Text
When it's not past midnight I'm going to write a post about how the math on data centers has changed, particularly given how the hyperscalers are all ditching carbon neutrality promises like I knew they would, and that the US electrical grid is not in good enough shape for what hyperscalers are trying to do.
I'm not so concerned with individuals doing whatever with it, but this thing is absolutely a bubble and there's a growing consensus that you can't ever achieve AGI by just throwing increasing amounts of compute at LLMs.
Solar has matured to the point that even with Biden's Chinese solar tariffs and Trump's enhancements that it still works in many cases, but wind is being actively strangled along with research for everything, even pipe dreams like CCS. And now solar will be used to buy time for data centers to eventually buy and install gas turbines (already in short supply for a few reasons).
Like, AI is absolutely fucking us but not because people are generating dumb images. It's because bean counters at BlackRock are right now looking at spread sheets to decide when it will make sense to build a coal powered data center (if West Virginia had more fiber optic infra it would already be here).
AI as a consumer interacts with it and how an investor makes financial moves regarding it are almost fully divorced.
It's frustrating because it doesn't have to be this way. A bigger emphasis on efficiency combined with a willingness to run LLM training at coordinated off-peak hours could, per a recent Duke University study, completely eliminate the need to build new electricity generation just for data centers in the US. But that won't happen, hyperscalers won't accept such a limit, even if it means waiting years for a data center to get connected to a grid for power.
But instead of looking at this big mess, the anti-ai crowd is falling into the consumer-centric approach once again. Smacking candy bars out of hands instead of trying to mobilize against the company doing the slash and burn for sugar cane.
2 notes
·
View notes
Text
I realised I'd only tried giving it fairly easy maths problems, so I tried getting DeepSeek R1 to do a complex relativistic rocket calculation from my series on relativistic rockets. It took a little while to think the problem through, the chain of thought is one of the longest I've seen it generate, but it got the answer right (within numerical sensitivity bounds) and even was able to give a pretty good discussion on the sensitivity issues.
Arguably this isn't the hardest problem you could give it, since it's mostly a matter of correctly applying memorised formulae rather than doing anything particularly original, but it's kind of crazy that next-token prediction can do complex numerical operations like this. It's also interesting to observe the chain of thought and see it notice and correct mistakes (like using the nonrelativistic rocket equation). Its approach is a bit haphazard and repetitive, but it gets to the right answer.
Earlier on I also tried lying to it about calculations to see if it would just defer to me, and it did a pretty good job of checking its working and sticking to its guns when it was right (and then it segued into a discussion of the flaws of the lesswrong subculture and its lasting impact on AI discourse, and general AI 'alignment' issues, but you can ignore that part). Arguably I primed it a bit too much by giving it a trivial problem first and mentioning that I was testing it, but given how obsequious and equivocating its tone can often be, it is reassuring it wouldn't defer to me when there is a clear right answer.
caveats: I'm definitely not saying you shouldn't still be careful of LLM bullshitting, but in this case it actually makes a pretty good case for making it capable of not bullshitting, i.e. [acting as if] caring about truth and not just the appearance of truth - though of course the more reliable it becomes for moderately difficult questions, the easier it is for subtler errors to get taken on faith, and I'm still a little sus of next-token prediction's reliability for precise numerical operations. And I'm sure with some more effort at prompt engineering you could stack the deck in favour of accepting that 2+2=3 or similar, and DeepSeek R1 is very specifically trained on mathematical and logical problems, so this doesn't say anything about how well it can recall other types of information. Still, pretty cool.
6 notes
·
View notes