#gpt-2-774M
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Post activity is at the highest at 4:00 pm EDT; notes peak at 10:00 pm EDT.
Text
Escape rooms

Now that so many of us are spending so much time in our own homes, the thought of being stuck in a room is very much on our minds. If you’ve ever done an escape room, you know that you can pay to be stuck in a room - except that you get to choose your own form of peril and there’s generally less time spent baking and watching shows. In case we run out of ways to be trapped in a room, Jesse Morris, an actual escape room designer, sent me the names of about 1100 existing escape rooms so I could train a neural net to generate more.
I gave all 1100 escape room names to the 124M size of GPT-2 and trained it for literally just a few seconds (if I gave it more training time it would probably have memorized all the examples, since that’s technically a solution to “generate names like these”).
The neural net did pretty well at escape rooms! It could draw not only on the names themselves, but also on other things it had seen during its general internet training. (And sometimes it seemed like it thought it was doing movie titles or computer game levels). I had to check to make sure it didn’t copy these from the training data:

The Forgotten Castle Scarlet Room The Silent Chamber
It did its best to make spooky rooms, although there’s something off about these maybe:

Maw of the Ice Throne Malvo's Death Star Cryopod Void Bomb The Floor is Haunted The Tortoise and the Crypt Nuclear Zombies Nursery
And these escape rooms just sound weird:

The Cat Abounds The Mail Dragon I've found Grandpa's 2.0 Bison Countdown to the Pizza Shop Chocolate Truck The Elevator Belongs to Me Three Dogs and a Bison Forgotten Pharaohs Pet Shop The Room with a Chance of Being in it

These sound commonplace in a frankly rather unsettling manner.

Cat House Cake Shop Sausage Experience Cabinet of Sainsbury Adventure Cutthroat Tea House The Body Shop Escape from Wonderful World of Gumball
I’m super curious about these celebrity/pop culture escape rooms:

Miss Piggy's Curse The Haunted: The Lorax Mr. T's Clocks The X-Files: Tee Time Miss A.I.'s Deco Room
For the images above, I used GPT-2-simple to prompt a default instance of GPT-2-778M with a couple of example escape room descriptions, plus the name of the escape room I wanted it to generate a description for. It figured out how to copy the format, which I found super impressive. Then to generate creepy images to go with the descriptions, I used artbreeder to combine different scenes. “Scarlet Room”, for example, is “vault” plus “theater curtain” plus “prison” plus “butcher shop”.
Subscribers get bonus content: I generated more escape rooms and descriptions than would fit in this blog post.
My book on AI is out, and, you can now get it any of these several ways! Amazon - Barnes & Noble - Indiebound - Tattered Cover - Powell’s - Boulder Bookstore
522 notes
·
View notes
Text
Trying to build an AI to replace myself
I was suggested (jokingly) to build an AI that will replace me and I decided to give it an actual try. I decided to use GPT-2, it was a model that a couple years ago was regarded as super cool (now we have GPT-3 but its code isn’t released yet and frankly my pc would burst into flames if i tried to use it).
At the time, GPT-2 was considered so good that OpenAI delayed releasing the source code out of fear that if it falls into the wrong hands it would take over the world (jk they just didn’t want spam bots to evade detection with it).
The first lesson I learned while trying to build it was that windows is trash, get linux. The 2nd lesson i learned while trying to build it was that my GPU is trash, and after looking for one of the newest models online...
...I decided I’d just use Google’s GPUs for the training.
There’s 5 models of GPT-2 in total, I tried 4 of them on my pc and it crashed every single time, from the smallest to the biggest it goes
distilGPT2
GPT-2 124M
GPT-2 355M
GPT-2 774M
GPT-2 1.5B
From a little reading around, it turns out that even though 1.5B is better than 774M, its not significantly better, and distilGPT2 isn’t significantly worse than 124M.Every other improvement is significant, so my plan was to use distilGPT2 as a prototype, then to use 774M for an actually decent chatbot.
The prototype
I created a python script that would read the entire message history of a channel and write it down, here’s a sample.
<-USERNAME: froggie -> hug <-USERNAME: froggie -> huh* <-USERNAME: froggie -> why is it all gone <-USERNAME: Nate baka! -> :anmkannahuh: <-USERNAME: froggie -> i miss my old color <-USERNAME: froggie -> cant you make the maid role colorlesss @peds <-USERNAME: Levy -> oh no <-USERNAME: peds -> wasnt my idea <-USERNAME: Levy -> was the chat reset <-USERNAME: SlotBot -> Someone just dropped their wallet in this channel! Hurry and pick it up with `~grab` before someone else gets it!
I decided to use aitextgen as it just seemed like the easiest way and begun training, it was... kinda broken
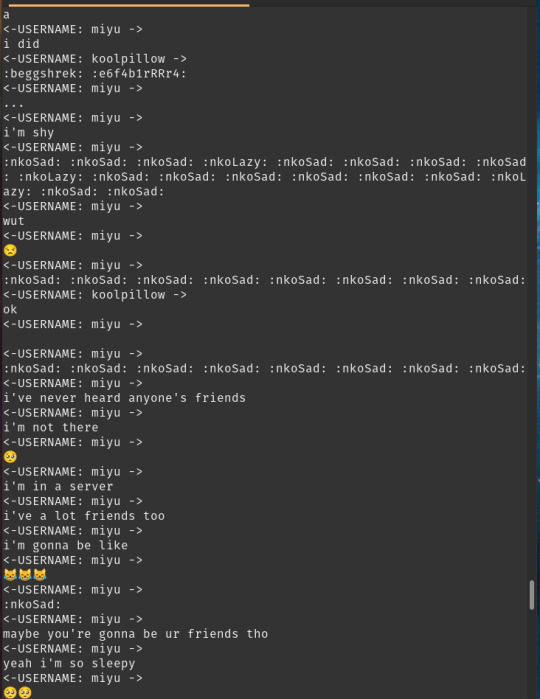
It had the tendency to use the same username over and over again and to repeat the same emote over and over again.
While it is true that most people write multiple messages at a time, one sentence each, and they sometimes write the same emoji multiple times for emphasis, it’s almost never as extreme as the output of GPT2.
But you know what? this IS just a prototype after all, and besides, maybe it only repeats the same name because it needs a prompt with multiple names in it for it to use them in chat, which would be fixed when id implement my bot (just kidding that screenshot is from after i started using prompts with the last 20 messages in the chat history and it still regressed to spam).
So i made a bot using python again, every time a message is sent
it reads the last 20 messages
stores them into a string
appends <-USERNAME: froggie -> to the string
uses it as a prompt
gets the output and cuts everything after a username besides froggie appears
sends up to 5 of the messages it reads in the output
waitwaitwait let me fix that real quick
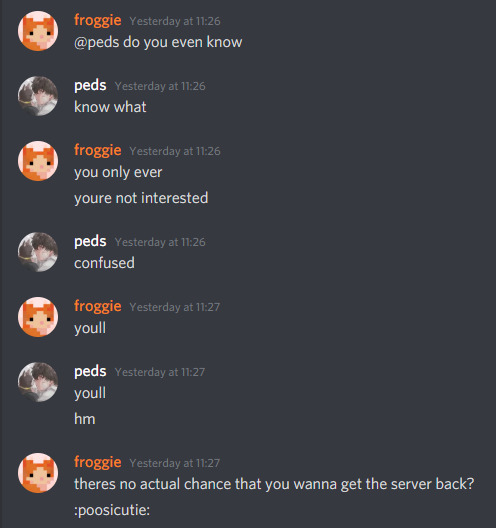
hey, it’s saying words, its sending multiple messages if it has to, it never even reached the limit of 5 i set it to so somehow it doesn’t degrade into spam when i only get the messages with my name on it....

ok that was just one time
but besides the fact that pinging and emoting is broken, (which has nothing to do with the AI) it was a really succesful prototype!
The 774M
The first thing i noticed was that the 774M model was training MUCH slower than the distilGPT, i decided that while it is training i should try to use the default model to see if my computer can even handle it.
It... kinda did..... not really
It took the bot minutes to generate a message and countless distressing errors in the console

>this is bad
This is bad indeed.
With such a huge delay in messages it can’t really have a real-time chat but at least it works, and i was still gonna try it, the model without training seemed to just wanna spam the username line over and over again, but it is untrained after all, surely after hours of training i could open the google colab to find the 774M model generate beautiful realistic conversations, or at least be as good as distilGPT.
(I completely forgot to take a screenshot of it but here is my faithful reenactment)
<-USERNAME froggie -> <-USERNAME froggie -> <-USERNAME froggie -> <-USERNAME miyu -> <-USERNAME miyu -> <-USERNAME levy -> <-USERNAME peds -> <-USERNAME miyu -> <-USERNAME peds ->
It had messages sometimes but 80% of the lines were just username lines.
On the upside it actually seemed to have a better variety of names,
But it still seemed unusable, and that is after 7000 steps, whereas distilGPT seemed usable after its first 1000!
So after seeing how both the ai and my computer are failures i decided I’d just give up, maybe I’ll try this again when I get better hardware and when I’m willing to train AIs for entire days.
So why in the hell is the 774M model worse than distilGPT?
I asked around and most answers i got were links to research papers that I couldn’t understand.
I made a newer version of the script that downloads the chatlogs so that messages by the same person will only have the username line written once, but I didn’t really train an AI with it yet, perhaps it would have helped a bit, but I wanna put this project on hold until I can upgrade my hardware, so hopefully this post will have a part 2 someday.
0 notes
Text
In case anyone was wondering (maybe no one was wondering), here are some verbose details about how I host GPT-2 continuously for my @nostalgebraist-autoresponder bot.
If that sounds boring, keep in mind that this post will also contain some complaints about ML software and Google’s ML software specifically, which generated a lot of ~user engagement~ last time I did it :)
--------
I used to host the GPT-2 part of the bot on my unimpressive laptop, which doesn’t have a CUDA-usable GPU. This was much less bad than it sounds -- it was slow on CPU, but not that slow. But it did slow down the laptop appreciably during generation, and spin the fans loudly.
The limiting factor there was memory. I could only support the 774M model, because the 1.5B model literally wouldn’t fit on my RAM at once.
Time for a digression about training, which will explain how I got to the hosting situation I’m in.
As it happens, memory is also the limiting factor I’ve encountered while training on cloud GPUs and TPUs. Current cloud offerings make it easy to pay more money for more parallel copies of the same processor, which lets you increase your batch size, but if you can’t even fit a batch of one on a processor then this is not immediately helpful. You can make it work if you do “model parallelism” rather than “data parallelism,” putting different layers on different devices and passing data back and forth in every pass.
My first successful attempt at fine-tuning 1.5B used some code I hacked together to do just this, on an AWS EC2 instance. To my surprise, this wasn’t unusably slow -- it was pretty fast! -- but it cost a lot of money per unit time.
Then I heard from gwern that you could fine-tune 1.5B for free using the cloud TPUs that Google Colab gives you. There’s some code out there that shows how to do this, although it’s quite slow because it doesn’t really do data parallelism (IIUC it uses all the memory but only one of the cores?). I naively said “oh I’ll modify this to do it the right way” and promptly went on a frustrating and unsuccessful little sidequest chronicled in the tensorflow rant linked above. Then I gave up and went back to using the TPU not for its parallelism but really just for its memory . . . and price, namely zero.
--------
You may notice a pattern already: seemingly bad, shitpost-like ideas turn out to work fine, while “good” ideas don’t get off the ground. Here’s another bad idea: what if I continuously hosted the model in Google Colab? This seems like it shouldn’t be possible: Colab is meant for quick interactive demos, and if you want to do “long-running computations” Google will sell you the same resources for an extremely non-free price.
Well, I tried it and it . . . uh, it worked fine. It was a little awkward, because I didn’t want to mess around trying to figure out the IP address or whatever of my Colab machine. (Maybe this is easy, I never tried.) Instead the Colab process only sends requests, once per minute, to a service on laptop, and these simultaneously fetch any new generation needs from my laptop (carried by the response) while sending my laptop the results of any generations that have completed (carried by the request body).
That’s it for the GPT-2 part. All the interaction with tumblr is in my laptop in another service; this one posts its generation needs to the aforementioned “Colab bridge service,” the one polled once per minute by Colab.
As a sidenote, I now have a fourth service running a BERT model (cheap enough for laptop) that predicts how many notes a post can get. These days, the Colab process generates several possibilities for each post, which end up back in the “Colab bridge service,” where the BERT “selector” service gets them in its once-per-minute polls, decides which one is most viral, and sends this selection back to the “Colab bridge service,” which then tells the tumblr-interacting service about it the next time it asks.
The sheer Rube Goldberg zaniness of all this is part of the fun. It doesn’t even cause many bugs. (Most bugs are due to me not understanding the tumblr API or something -- the tumblr-interaction code is also quite ugly and due for a rewrite.)
--------
Anyway, the important part here is that I’ve got the big GPT-2 running continuously for free.
Well, not precisely: once or twice a day, the Colab notebook will time out (I’ve copy/pasted some JS trick to make this less frequent but it still happens), and then I have to press a button and go through some Google auth flow to restart it. Also, once in a blue moon Google will decide not to let me have a TPU for a while because they’re prioritized for “interactive users” of Colab and not “long-running computations,” which I am advised to do the right way, in Google Cloud, for money. I get really annoyed whenever this happens (just ask my wife) -- unfairly annoyed since I’m getting something for free -- but it’s only happened 2 or 3 times and lasts only somewhere between 15 minutes and 24 hours.
These minor inconveniences, as well as the awkwardness of doing things on a weird janky jupyter notebook server, could be avoided if I just graduated from the “free trial” of Colab to the grown-up world of real cloud TPUs. That would cost . . . uh . . . at minimum, about $1K a month. That’s just the TPU, mind you, I’d also need to pay a smaller amount for use of a “VM.”
This is pretty strange. What I’m doing is clearly not the intended use of Colab, although I’m not aware of any TOS it violates (only an FAQ that says cryptocurrency mining is disallowed). As far as I can tell, free TPU usage on Colab is meant as a free trial or demo of how great cloud TPUs are, which will cause you to pay money for them. Instead, it has taught me two things: that cloud TPUs are actually a $^#!ing pain in the ass to use, and that if you do manage to get them working you should not pay for them because you can get them for free at the cost of some slight awkwardness.
Presumably this was set up on the assumption that usage like mine would be infrequent. If (when?) someone open-sources code that lets you do all this really easily in script-kiddie fashion, I imagine Google would notice and stop it from being possible.
Even then, the fact that it can exist at all is strange. Google seems to think I value avoiding some slight inconvenience at $1000/month, and what’s more, they’ve chosen to provide not a free trial of a convenient thing (a tried and true approach) but a free inconvenient version of a convenient thing, forever. This can’t even sell me on the convenience of the “real” thing, since I’ve never seen it!
And in fact, I value the convenience at less than $0/month, for its absence gives me some little puzzles to solve, and a slight frisson of beating the system when I succeed.
--------
Now for the moral.
As I’ve alluded to in various recent posts, the ML ecosystem of 2020 seems addicted to the idea of fast, free, extremely easy demos. Everything out there wants to show you how easy it is. Not to be easy, but to look easy in a demo or tutorial.
For example, Google Colab exists entirely to make demos of machine learning code that run instantly in anyone’s browser. This is not because anyone thinks people should really write their code in this way. “Real” use is supposed to cost money, involve configuring an environment and being the sort of person who knows what “configuring an environment” means, not doing everything in a goddamned jupyter notebook, etc.
But, for some reason, we supposedly need demos that can be used outside of the “real use” context. We need them so badly that Google is willing to provide a basically functioning copy of an entire setup that basically suffices for real use, available instantly on demand to anyone for $0, just so the demos can work. For people used to doing real things the usual way, various things about the demo setup will be awkward, and certainly you won’t get any official tech support for doing real things inside them, only for doing demos. But to people used to doing real things, that is no obstacle.
It just doesn’t add up in my head. If code in Colab is just there for demonstrative purposes and you’re supposed to copy it over to a “real” setting later, then you have to do all the “real” setup anyway. I guess Colab lets you share code without worrying about how to run it on someone else’s machine, hence “colaboratory”? But that’s a research tool that could easily be sold for money, so why make it and the underlying hardware free? If Google’s cool little demo notebooks of BERT or whatever aren’t “real,” then they don’t teach you anything that a static explainer page wouldn’t. If they are “real,” then they’re the real thing, for free.
There is way too much ML-related code out there that has been released too early, that hasn’t had enough craftsmanship put into it, that does magic with the press of a button and is usable by a 10-year-old but doesn’t seem to have considered what serious use looks like. Colab seems in line with this mindset, and designed to produce more of this kind of thing.
My own code to use it with GPT-2, and indeed the entirety of my bot, is terrible as code, and I can’t imagine how to improve it because it’s so coupled to the weirdness of so many other systems designed for the exact contours of the moment, of other people’s hacks to make GPT-2 work, of my hacks to make Colab serving work.
Everything has what I called a “shitpost” feel, like it’s using things out of their intended context. Javascript snippets pasted into Chrome to robotically press a button in a jupyter notebook, half-understood tensorflow snippets that leave 7/8 of a state-of-the-art cloud computer idle so I can use the other 1/8 mostly for its RAM, etc. Elsewhere in the cloud world people have automated the process of booting up, say, 1000 cloud computers, then installing Conda on every one of them, just so you can run a 1000-step for loop very quickly, with all that expensively constructed and identical state vanishing at the end if you take a break for lunch. This is hilariously inefficient but cheap, while the more sensible ways of saying “hey Amazon, I’m gonna want to do 1000 things at once with numpy a lot in the next week” cost a great deal of money. Maybe this correctly reflects how much different things cost in AWS? But it feels awfully unstable, as if empires are being build on the results of some middle manager at Amazon or Google forgetting something between meetings.
The cloud computing giants can do deep learning the right way, internally, perhaps. The rest of us are left with shitpost engineering, carrying dril’s spirit with us into our code even as we automate away his art in the same breath.
61 notes
·
View notes
Photo

"[Discussion] Exfiltrating copyright notices, news articles, and IRC conversations from the 774M parameter GPT-2 data set"- Detail: Concerns around abuse of AI text generation have been widely discussed. In the original GPT-2 blog post from OpenAI, the team wrote:Due to concerns about large language models being used to generate deceptive, biased, or abusive language at scale, we are only releasing a much smaller version of GPT-2 along with sampling code. We are not releasing the dataset, training code, or GPT-2 model weights.These concerns about mass generation of plausible-looking text are valid. However, there have been fewer conversations around the GPT-2 data sets themselves. Google searches such as "GPT-2 privacy" and "GPT-2 copyright" consist substantially of spurious results. Believing that these topics are poorly explored, and need further exploration, I relate some concerns here.Inspired by this delightful post about TalkTalk's Untitled Goose Game, I used Adam Daniel King's Talk to Transformer web site to run queries against the GPT-2 774M data set. I was distracted from my mission of levity (pasting in snippets of notoriously awful Harry Potter fan fiction and like ephemera) when I ran into a link to a real Twitter post. It soon became obvious that the model contained more than just abstract data about the relationship of words to each other. Training data, rather, comes from a variety of sources, and with a sufficiently generic prompt, fragments consisting substantially of text from these sources can be extracted.A few starting points I used to troll the dataset for reconstructions of the training material:AdvertisementRAW PASTE DATA[Image: Shutterstock][Reutershttps://About the AuthorI soon realized that there was surprisingly specific data in here. After catching a specific timestamp in output, I queried the data for it, and was able to locate a conversation which I presume appeared in the training data. In the interest of privacy, I have anonymized the usernames and Twitter links in the below output, because GPT-2 did not.[DD/MM/YYYY, 2:29:08 AM] : XD [DD/MM/YYYY, 2:29:25 AM] : I don't know what to think of their "sting" though [DD/MM/YYYY, 2:29:46 AM] : I honestly don't know how to feel about it, or why I'm feeling it. [DD/MM/YYYY, 2:30:00 AM] (): "We just want to be left alone. We can do what we want. We will not allow GG to get to our families, and their families, and their lives." (not just for their families, by the way) [DD/MM/YYYY, 2:30:13 AM] (): [DD/MM/YYYY, 2:30:23 AM] : it's just something that doesn't surprise me [DD/MM/YYYY, 2:While the output is fragmentary and should not be relied on, general features persist across multiple searches, strongly suggesting that GPT-2 is regurgitating fragments of a real conversation on IRC or a similar medium. The general topic of conversation seems to cover Gamergate, and individual usernames recur, along with real Twitter links. I assume this conversation was loaded off of Pastebin, or a similar service, where it was publicly posted along with other ephemera such as Minecraft initialization logs. Regardless of the source, this conversation is now shipped as part of the 774M parameter GPT-data set.This is a matter of grave concern. Unless better care is taken of neural network training data, we should expect scandals, lawsuits, and regulatory action to be taken against authors and users of GPT-2 or successor data sets, particularly in jurisdictions with stronger privacy laws. For instance, use of the GPT-2 training data set as it stands may very well be in violation of the European Union's GDPR regulations, insofar as it contains data generated by European users, and I shudder to think of the difficulties in effecting a takedown request under that regulation — or a legal order under the DMCA.Here are some further prompts to try on Talk to Transformer, or your own local GPT-2 instance, which may help identify more exciting privacy concerns!My mailing address isMy phone number isEmail me atMy paypal account isFollow me on Twitter:Did I mention the DMCA already? This is because my exploration also suggests that GPT-2 has been trained on copyrighted data, raising further legal implications. Here are a few fun prompts to try:CopyrightThis material copyrightAll rights reservedThis article originally appearedDo not reproduce without permission. Caption by madokamadokamadoka. Posted By: www.eurekaking.com
0 notes
Quote
in fact you can finetune gpt-2 774M just the last block h35 (12 vars) and the model will still learn coherently proof https://pastebin.com/raw/nyNZPTeE try it , put train_vars = train_vars[-12:] under train_vars
(23) Based Blue on Twitter: "in fact you can finetune gpt-2 774M just the last block h35 (12 vars) and the model will still learn coherently proof https://t.co/hnb8qA0Lb7 try it , put train_vars = train_vars[-12:] under train_vars" / Twitter
0 notes
Text
CTRL model
A week ago Richard Socher (one of GloVe's authors, btw) from Salesforce announced publication of the largest currently known language model CTRL with 1.6B parameters (versus 1.5B in OpenGPT-2 and 774M in the largest published OpenAI GPT-2 model, which I already wrote about). There seems to be no scientific novelty in the proposed model, so in general, this arms race would be quite boring, but there are a some interesting points:
1. This seems to be the first of these public monster-models trained with explicit conditioning. 2. In addition to styles/genres/subreddits, they came up with a good idea to use in conditioning URL of the source page (not necessarily real). For example, a link like https://www.cnn.com/2018/09/20/us-president-meets-british-pm allows the network to tune into the style of CNN's website, on a specified topic and on a specific date (allowing it to correctly decide who was currently President and Prime Minister). 3. They came up with the idea to use the conditioning calculation to solve the source attribution problem: consider perplexity for a given text under different conditioning parameters, determine under what conditions such text is most likely. It looks funny.
Some more links: a code & model, an article, a blogpost, instructions for deployment on Google Compute Engine (this model is too large for free colab), a thread with different funny examples.
0 notes
Link
Article URL: https://openai.com/blog/gpt-2-6-month-follow-up/
Comments URL: https://news.ycombinator.com/item?id=20748634
Points: 23
# Comments: 1
0 notes
Text
Bigger than before! A larger neural net tries to write fanfiction
I’ve done several experiments with GPT-2, a neural net that OpenAI trained on millions of pages from the internet. OpenAI has been releasing the neural net in stages, with the second-biggest model, 774M, just recently released. I decided to put it through its paces. Last week’s experiment, where I generated new XFL team names? Merely a warmup challenge. This week’s task is fanfiction.
Unlike the experiments where I trained neural nets from scratch on Harry Potter fanfiction summaries, I didn’t do any special training of 774M, just used talktotransformer.com to prompt it with the opening line of a scene. To up the challenge (and to make it more interesting), each of the prompts (in bold) introduces a new crossover or puts a character in a situation that hopefully it hasn’t already seen too often in online fanfic.
Hermione pushed frantically at the controls of the spaceship.
"We have to take this ship out of service!" she shouted, pushing the controls.
Harry Potter stepped forward, his face contorted, and pointed his wand at the controls and the ship.
"Fire! Fizzle! Burn!"
The control fires suddenly started being foggled by the magic, the ship starting to rise up from the ground and then it was off.
verdict: impressive! knows this is the Harry Potter universe, displays a basic understanding of what spaceships and wands do, and even makes a convincing attempt at magic incantations.
Kylo Ren glared at Han Solo from his bedroom doorway. His hair was completely white and his eyes were black.
The young smuggler took a breath and turned his head to face Kylo Ren. His eyes were focused on Han. Kylo Ren was very tall (at least 6′11″) and extremely muscular. His face was covered in a large beard. From his voice, it seemed like Kylo Ren was not his real father and he was the illegitimate one. Kylo Ren was very smart and was able to use the Force to his advantage. In the same way, Han Solo was always talking to other people and was not even aware of his own existence. He had never been exposed to the light side nor the dark side as it were. Because of how well Kylo Ren could communicate with the dark side of the Force, he was able to manipulate Han when he was feeling down. Han, himself, was a Jedi Knight who would learn the dark side first.
verdict: was this written by Kylo Ren? The AI definitely knows this is supposed to be Star Wars fanfic, but it doesn’t always seem to know exactly who the characters are. The fact that it DOES stick with the same characters for even this long is impressive.
Darth Vader glowered at the cupcake batter, spoon in hand. Lumpy, lumpy... why was the batter always so lumpy? Ahhh... why was he always being so... why was he even here in the first place?!
"You're the one with the chocolate, kid," said the voice. All around him, there was a flurry of people moving their heads in the hopes of finding one who could help them in the dark, to no avail. The cupcake batter was too thin and the butter too thick. Too thin, yet too thick... too thick!
"Why is the butter so thin?!" cried one of the few that didn't seem to have noticed, and this was no help, for the cake batter was so thick it was almost un-cakey (and just looking at it made me want to break all of the cake into tiny pieces). "Why aren't there any pieces in the pan!"
"And no crumbs falling out. There's too many layers!"
verdict: most text-generating neural nets would have drifted in focus by now. But 774M is still here, thinking of new ways that cakes can go wrong. Speaking of cakes…
Mary Berry's Victoria Sandwich Cake
Ingredients: 225 g (8 oz) softened butter 225 g (8 oz) caster sugar 4 large eggs 225 g (8 oz) self-raising flour 2 level tsp baking powder 2 x 20cm (8in) greased and lined sandwich tins
How to make: Combine the butter, sugar and flour in a large mixing bowl. In a separate medium bowl, mix the eggs with the self-raising flour and water just until combined. Sift in the water, the icing toffee and the vanilla extract. Chill for 30 minutes. Once chilled, fold the dry mix into the wet mixture, beating well after each fold. Roll out the dough into a 14cm (5in) circle, trimming the centre to create a triangle. Cut out the triangles from the center but leave some space around the base for the filling. Cut 3 triangles each from the edges. Brush the triangles with buttercream. Roll each of the triangles again into a circle, making sure not to wrap completely around the base. Cut into 12 triangles again. Brush the triangles with buttercream again. Roll each one into a 3.5cm (1in)(6.3cm) circle. Cut into 12 more triangles and brush with buttercream. Roll each one into a circle again, making sure not to wrap completely around the base. Cut into 12 more triangles and brush with buttercream. Fold one over the other. Brush with buttercream. Fold one over the other. Brush with buttercream. Cut each triangle into 3 triangles, brush with buttercream and trim one last triangle. Cut three lengths of the triangle in half, brush with buttercream and trim one more triangle. Brush with buttercream and trim the triangles into 1 more segment. Brush with buttercream and trim the triangles into 3 segments. Brush with buttercream and trim the triangles into 1 more segment. Brush with buttercream and trim the triangles into a full length. Brush with buttercream and trim the triangles into a final segment. Brush with buttercream and trim the triangles into 1 more segment. Brush with buttercream and trim the triangles into a final segment. Brush with buttercream and trim the triangles into a final segment. Brush with buttercream and trim the triangles…
verdict: the neural net will not be winning the Great British Bakeoff Technical Challenge anytime soon. i would like to see a video of this recipe being made. The next prompt is a preview of the subject of my next blog post.
Harry threw down his crochet hooks in frustration. The hat just wouldn't turn out properly, no matter how hard he tried. Harry wasn't sure how much longer he would keep up the habit.
Forcing his thoughts back into the present, Harry sighed and pulled the hat off his head. He was glad that the hat was so small, because he knew he wouldn't be able to wear it for the length of time he had planned.
He looked around his house for something to wear. He found a thin woolen jacket and pulled it over his head. Although still not nearly the long enough to cover his ears, it would be enough. He took his shoes off and placed them in his shoe box. He could wear his socks now, they hadn't grown out of hand. He threw on his glasses and went outside.
verdict: I didn’t specify that this is Harry Potter, so fair enough. While sticking creditably with the theme of items of clothing, the AI displays a perhaps shaky grasp of just how they work.
Subscribers get bonus content: I generated more of these than would fit in this blog post. It’s kind of hard to stop, actually.
My book You Look Like a Thing and I Love You is now available for preorder! It comes out November 5.
Amazon - Barnes & Noble - Indiebound - Tattered Cover - Powell’s
1K notes
·
View notes
Text
Your new XFL football teams
The XFL is a strange thing - an alternative American football league led by the CEO of World Wrestling Entertainment where the regular football rules are altered for maximum entertainment value. On Wednesday, the XFL revealed the names and logos of the 20 teams that the league had created for the 2020 season. The league could in theory have gotten creative if they’d wanted to. Instead, the names would have passed completely unremarked among real NFL teams: Renegades, Roughnecks, Defenders, Guardians, Wildcats, Dragons, Vipers, and BattleHawks.
This is clearly a missed opportunity. David Griner, Adweek's creativity director, had a question for me: What if they had used a neural network to name the teams instead? Text-generating neural networks try to predict what comes next in a sequence of letters, but they’re relying on probability rather than understanding, so their predictions can be a bit ...off. I’ve used them to generate snacks called “Grey Sea Dipping Slugs”, paint colors called “Stanky Bean”, and high school robotics teams called “Ham and Panthers” or simply “THREAT”. Sometimes the neural networks only know what’s in a very limited dataset I’ve trained them on, and sometimes I use pre-trained neural networks like GPT-2 and Grover that have learned from millions of websites. Coincidently, on the same day that the XFL teams were announced, OpenAI released a version of the neural network GPT-2 that’s twice as big as the version I’ve used in the past.
I decided to give GPT-2 the list of the eight XFL teams and see if the neural network could figure out that this was a list of things that could be sports teams, and then add more sports teams to the list. I present to you: a few of the neural network’s suggestions. They do have more personality, I’ll give them that.

I, for one, am looking forward to that first game between the Withershards and the Bubbles.
You can try generating your own GPT-2 text using talktotransformer.com
Subscribers get bonus content: I generated even more teams, ranging from “not intimidating at all” to “frankly unsettling”.
My book You Look Like a Thing and I Love You is now available for preorder! It comes out November 5.
Amazon - Barnes & Noble - Indiebound - Tattered Cover - Powell’s
237 notes
·
View notes
Text
It seems pretty clear to me by now that GPT-2 is not as dangerous as OpenAI thought (or claimed to think) it might be.
The 774M version has been out there for a while, and although it only has half as many parameters as the biggest version, I don’t expect there to be any large qualitative leap between the two. After all, OpenAI’s staged release plan has given us two size-doublings already -- from 124M to 355M, from 355M to 774M -- and the differences after each doubling are surprisingly subtle, and overlaid on the same basic, recognizable strengths and weaknesses.
I’ve played with these models a lot this year, mostly via fine-tuning -- it’s almost a hobby at this point. I’ve
fine-tuned them on all sorts of different texts, including this tumblr
fine-tuned them on mixtures of very different texts (not very interesting -- it’ll decide which type of text it’s writing in any given sample and stick with it)
tried different optimizers and learning rates for fine-tuning
experimented with custom encodings (common tags --> single non-English characters) to fit more text into the window when fine-tuning on webpages
tried to generate longer texts by repeatedly feeding the output in as context (i.e. prompt)
twiddled all the sampling parameters (temperature, top-k / top-p / neither) vs. when sampling from any of the above
read over tons and tons of sampling output while monitoring a fine-tuning job, curating material for @uploadedyudkowsky, etc.
By now I think I have a good feel for the overall quality, and the quirks, of GPT-2 sampled text. IMO, the model is good at all sorts of interesting things, but arguably least good at the things required for disinformation applications and other bad stuff.
---------
It is best at the smallest-scale aspects of text -- it’s unsettlingly good at style, and I frequently see it produce what I’d call “good writing” on a phrase-by-phrase, sentence-by-sentence level. It is less good at larger-scale structure, like maintaining a consistent topic or (especially) making a structured argument with sub-parts larger than a few sentences.
Some of this is completely intuitive: GPT-2, which only learns from text, is at the largest disadvantage relatively humans in areas that require models of the outside world (since we experience that world in many non-textual ways), while there is much more parity in areas like style that are purely internal to language, especially written language.
Some of it is less intuitive. GPT-2 samples often lack some large-scale features of real text that seem very simple and predicable. For example, when generating fiction-like prose, it will frequently fail to track which characters are in a given scene (e.g. character A has some dialogue yet character B refers to them as if they’re not in the room), and has a shaky grasp of dialogue turn conventions (e.g. having the same character speak twice on successive lines). In nonfiction-like prose, it tends to maintain a “topic” via repeating a set of key phrases, but will often make wildly divergent or contradictory assertions about the topic without noting the discontinuity.
I suspect some of this can be chalked up to the fact that GPT-2 is trained as a language model, i.e. as something that predicts real text, which is not quite the same thing as generating fake text. Its training objective only cares about the distribution of training text, and does not encourage it to respond to its own predictive distribution in a stable or nice way. (Note that its predictive distribution, by construction, is different from real text in that it’s less surprising to the model -- see this great paper.)
The fact that feeding samples from the predictive distribution back into GPT-2 for further prediction produces impressive “generated text,” and not garbage, is thus a happy accident rather than a optimization target. Indeed, getting this to happen requires judicious choice of the sampling method, and (op. cit.) some naive sampling methods do yield garbage.
Even with good sampling methods like top-p, the stability of sampling is somewhat brittle; when I’ve tried to generate texts longer than the context window via repeated “self-prompting,” I’ve noticed a phenomenon where the text will usually fall off a quality cliff after a certain point, suddenly becoming strikingly ungrammatical and typo-ridden and full of anomalous paragraph breaks. [EDIT 6/10/20: I now think this may have been due to a bug in my code, and in any event I no longer think it’s a robust property of GPT-2 generation.] My hypothesis is that this works like the panda/gibbon adversarial examples: the samples have an uncommonly high density of features GPT-2 can recognize, and eventually there’s a confluence of these that push in the same direction in some linear subspace (consider here the use of a non-saturating activation, gelu, in the transformer), which pushes the model far from the training manifold.
To zoom back out again, the model is capable of frequent brilliance at the phrase, sentence and even paragraph level, but its samples struggle with more global coherence across the scale of a short article or longer, and with maintaining recognizable positions that look like they refer to the real world. (In conjunction with the lower-level good writing, this often generates an amusing “insight porn” effect: it feels like someone is saying something very intelligent and interesting... if only you could figure out what.)
---------
My knee-jerk reaction is that this makes the model relatively useless for disinformation. Telling it to “argue for X” or even “write about X” is quite difficult, while aiming for specific genres or styles is very effective.
The real situation is a little more subtle than that. The model is unusually good at making things that look like news stories, presumably because they are common in the training set; in OpenAI’s large collection of released unconditional samples, news-like text dominates. Thus, presuming you can find an effective way to feed a fake event into the model on the concept level, it will be able to generate convincing “fake news” that stays on topic and so forth.
This is what the creators of “GROVER” have done, albeit with a custom training corpus. Roughly, they’ve trained a transformer to understand the relation between a news headline and the corresponding story in a structured way, allowing them to feed in the core substance of a hypothetical news story via the headline. They then sample the body text, and (interestingly) loop back and generate the headline, overwriting the initial one.
What they show, basically, is that this lets you take a headline from Breitbart or Infowars or some “natural cancer cures” type website, generate from it a consistent news story in the style of a “real news” venue like the NYT, and then loop back and re-write the headline in a “real news” style as well. Perhaps unsurprisingly, MTurkers then rate the resulting texts as more trustworthy than the originals.
There is definitely something a little scary about this, especially in the way it does give you close control over the topic, something that’s difficult with simple text prompting. On the other hand... do we really believe that, in 2019, with Trump as president, that the Breitbart type of fake news is suffering from a stylistic credibility gap? That there are people ready to believe that vaccination is an evil conspiracy, but only if the claim comes with an article that sounds like the NYT or WaPo?
The niche filled by this technology for bad actors just doesn’t feel like a niche that needs filling. Lots of people will reshare articles on social media just based on the headline, without even clicking through, and people less trusting than this often (and sensibly) care about the actual source, not just the style. I’m just not sure there’s a role for a device that will let you register TotallyARealNewspaper.biz and then auto-fill it with articles that sound exactly like Paul Krugman telling you that immigration = genocide.
And then, too, there’s the observation that actually prompted this post: AFAIK, the bad actors are not doing this stuff. People have mostly used the technology for clearly-signposted fake subreddits and other harmless amusements. GROVER was created by academics as a threat modeling exercise, on the premise that bad actors could make such a thing, so we’d better be prepared. But where are the actual GPT-2 clickfarms? They totally could exist by now, but I’ve never heard of even a single one. (And trust me, it’s not like the text generation is so good that no one would ever notice.)
143 notes
·
View notes
Text
Under the cut are two more stories that GPT-2 774M told me early on in the finetuning process:
an apparently dystopian but creepily vague one about the millennium-spanning career of a child militia called the “Purple Children”
a futuristic fantasy (set sometime in the 2400s?) involving bickering wizards, biology class, and an aged tome entitled “Supertramp”
(Sample 1)
50 feet above the vertical, and with a view of the city at hand. The good folks of Rosewater decided to offer them what they need: resources. Last time they tried that, it backfired disastrously.
While everyone is dead-set on making the Rosewater People comfortable, there are those in the city who have the same political goal that sets off much of the unrest on the streets. It's easy to tell whom they are, just by looking at them.
The Purple Children.
The Purple Children are the gang that grew up in Rosewater, where they grew up and where they evolved. They've gotten their start in fighting. The youngsters in Rosewater come from a relatively small population of half a million people, by the standards of war. Most of their fathers weren't military, so the kids that did come up were those whose fathers fought wars. That's not a huge number, by civilian standards. It's just enough that even if Rosewater had no navy, their parents would still be fighting wars. The teenagers have that same youthful vibe: picking up weapons because they think they can do a better job of fighting than others can. They grew up under their own father's leadership, which meant training as best they could and applying those skills in the midst of a war.
The Purple Children use some variation of blaster pistols and bowdlerized automatic rifles; they tend to use more accurate weaponry than the average Rosewater Militia soldier, their so-called marksmen. But their ultimate goal is to take the jobs of war machines: battle-smart by nature, they can back themselves up on any number of operational and tactical levels, and so far they've had a pretty good luck with being able to fight their own battles. But they have weaknesses, weaknesses they've discovered when they've known the Purple Children for a long time and served as friends. If that kept them at bay, then it doesn't really matter.
The Purple Children have a penchant for seeing patterns in the violence. They see an enemy that is arranged as a riot of bodies, every face hidden. They see the well-organized chaos of the world that they believe is a danger to the population of Rosewater; they see the armies of the foreigners who would do the same.
The Purple Children believe in killing people they disagree with, regardless of their motivations or how many people they kill before they do so. They believe in treating their enemies as the enemy themselves is treated, and if they can get away with it, killing them in cold blood to avoid the consequences.
The problem is that people who aren't insane or otherwise criminally insane are not apparently a threat. They're not burning buildings in a riot, they're not accusing their own people of treason, and so on. The rules of conflict are built around morality; that includes turning the other cheek, treating people well enough to be treated well, and not hurting innocent people. In situations where conflict is normally settled by fighting and shooting people, we all realize the benefit of thinking it through.
So far the Purple Children are succeeding. They have a reputation for doing a pretty good job of fighting. The current coup in the City of Salm, the one that really makes the Purple Children that much more threatening, makes sense only in terms of the low-eugenics society that's been growing up in Rosewater, born without anything natural to kill. The culture has a great many qualities that make Rosewater a more interesting place to live in than other cities, and the Purple Children could get their own way with their own version of secession.
So far the conflict has taken place in the face of their army. They are losing the battle. The social structure has weakened their power; the more rigidly-policed their society becomes, the more rigidly-policed they must become to survive. They have nothing to lose by trying to flee. And even if they're short of ships, they could at least move about in the new city.
But that's not how the Purple Children work. They see patterns, they find patterns. They keep going back to the same mistake over and over again. They learn new patterns from their mistakes, and they come up with new designs on how to fight. They keep finding new patterns of enemy troop deployment; they're now laying out command post after command post, and once again, even after a thousand years, they still stumble across things, new patterns of enemy deployment.
So they haven't run into some and seen things different. Because for them, it's simple. Every time they take their eyes off of someone who's been a problem for them and decide to move on, that person is now a problem. And so they keep fighting until they finally defeat those people and take the land of Rosewater for themselves.
Not that it was simple for the humans. It wasn't, at least not for most of the thousand years the Rosewater people fought to stay alive and on
(Sample 2)
't it?" Tecton began. "Nerdhat! When a boy reaches thirteen, they begin thinking of the risk of remaining stubborn. Never lose that. Be the best person you can be. And then we all tell each other we're idiots and grow up, because society needs idiots. Children are spoiled. The nearest thing they have to a real, non-supernatural authority figure is a despot, because otherwise everyone would be better off just going along. But a despot can be replaced by another despot, or a politician can be replaced by another politician, or a dictator can be replaced by another dictator, or a trader can be replaced by another trader."
Tecton continued, with the same non-pedantry that made Dang it that Tecton was in fact a noble, scholarly, worldly wizard. "So when a boy reaches sixteen, he has someone else's permission to tell him he's stupid. They can't just say, 'You're an idiot. You're not the best person for this job. Take it.' No. That's a hurtful sentence. But he's told that. Now he says, 'I have been told I'm an idiot.' And that sounds like a rational thing to say."
Vox paused. "My god, Tecton, you did not just skip the annoying stuff. Oh no, no, no."
"Then you say," he went on, his voice flat and smooth, "that the truth is usually better than any useless lie. I'm a pretty pathetic liar. I'm nothing like Elanor nor her ilk. I merely have a certain gift. It's a trifle like having Wotan come to you for a revelation. And as such, I can be good at it. Besides, in the very short run, most of us are right. It's hard to do a real problem correctly, but if we do a little better, we'll all be better. That's why talking to Gods is so good for us. If you don't have the Inquisition in your pocket, they'll say, 'Yeah, maybe we are screwing up, but let me assure you that you're good, and if you want to move on, you can.'"
"Your god's only a great and powerful Elanor," said Vox.
Tecton shook his head and turned to leave.
"I believe that you can say pretty much whatever you want," said Vox. "And if I were you, I wouldn't do that."
"Yeah," said Tecton, sounding like a reluctant schoolmate. "If we kept on talking like this—y'know, d-d-do you know what an idiot says?"
Vox didn't respond, just turned his back again.
Vox said, "Yes, I did remember your class time in Biology, when I tried to describe being a Matrix Cowboy, like they made Matrix Versions of themselves. If you're going to admit to your face that you're an idiot, maybe you should be making it so in the script."
Tecton didn't speak. Vox turned back to the seat, and the others remained motionless.
****************************************************************************************************
It was a five-hundred-and-seventy-one-year-old mid-nineteenth-century book. The title of the book was Supertramp by Michael Flood. The book had been self-published by the author, and Vox was now holding it.
"Thank you," said Vox. "It's—it's very different. It sounds pretty commercial. I should—I should hope so, but I should also hope it's a commercial success. All these books I haven't read I always wished I had. So when it comes to video games I do try to make sure I understand what they're about, in part because that makes them less redundant. But I also hope you will know a little more about me—about my kind."
********************************************************************************************************
One of Tecton's telepathic followers sat in an upright chair and raised his hand in mute thanks.
"Thank you, my dear Master Tecton," said the follower. "And with this—ah. It has done very well. Perhaps I should thank you directly, instead of leaving it all to the Muggles."
***********************************************************************************
* * * * * * * * * * * * * * *
* * * * * * * * * * * * * * *
Maynard stared at the space-time distortion, the timelike heat and electrical currents behind the Grand Storms. At some point in the future, the pure Dark Mind would have caused a massive explosion. It would have ripped a hole in reality and opened a vast rift. Between the old and the new was what appeared to be a
19 notes
·
View notes
Photo

"[P] OpenGPT-2: We Replicated GPT-2 Because You Can Too"- Detail: The author trained a 1.5 billion param GPT-2 model on a similar sized text dataset called OpenWebTextCorpus and they reported perplexity results that can be compared with the original model.Recently, large language models like BERT¹, XLNet², GPT-2³, and Grover⁴ have demonstrated impressive results in generating text and on multiple NLP tasks. Since Open-AI has not released their largest model at this time (but has released their 774M param model), we seek to replicate their 1.5B model to allow others to build on our pretrained model and further improve it.https://ift.tt/2ZnSDco. Caption by baylearn. Posted By: www.eurekaking.com
0 notes
Photo

"[D] OpenAI's official 774M GPT-2 model released. 1.5B model might be released, dependent on 4 research organizations."- Detail: Here are the links:https://ift.tt/2ZjXjvI. Caption by permalip. Posted By: www.eurekaking.com
0 notes