#hgx
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr was named as a finalist in Lead411’s New York City Hot 125 in Aug 2010.
Text
Nvidia HGX vs DGX: Key Differences in AI Supercomputing Solutions

Nvidia HGX vs DGX: What are the differences?
Nvidia is comfortably riding the AI wave. And for at least the next few years, it will likely not be dethroned as the AI hardware market leader. With its extremely popular enterprise solutions powered by the H100 and H200 “Hopper” lineup of GPUs (and now B100 and B200 “Blackwell” GPUs), Nvidia is the go-to manufacturer of high-performance computing (HPC) hardware.
Nvidia DGX is an integrated AI HPC solution targeted toward enterprise customers needing immensely powerful workstation and server solutions for deep learning, generative AI, and data analytics. Nvidia HGX is based on the same underlying GPU technology. However, HGX is a customizable enterprise solution for businesses that want more control and flexibility over their AI HPC systems. But how do these two platforms differ from each other?




Nvidia DGX: The Original Supercomputing Platform
It should surprise no one that Nvidia’s primary focus isn’t on its GeForce lineup of gaming GPUs anymore. Sure, the company enjoys the lion’s share among the best gaming GPUs, but its recent resounding success is driven by enterprise and data center offerings and AI-focused workstation GPUs.
Overview of DGX
The Nvidia DGX platform integrates up to 8 Tensor Core GPUs with Nvidia’s AI software to power accelerated computing and next-gen AI applications. It’s essentially a rack-mount chassis containing 4 or 8 GPUs connected via NVLink, high-end x86 CPUs, and a bunch of Nvidia’s high-speed networking hardware. A single DGX B200 system is capable of 72 petaFLOPS of training and 144 petaFLOPS of inference performance.
Key Features of DGX
AI Software Integration: DGX systems come pre-installed with Nvidia’s AI software stack, making them ready for immediate deployment.
High Performance: With up to 8 Tensor Core GPUs, DGX systems provide top-tier computational power for AI and HPC tasks.
Scalability: Solutions like the DGX SuperPOD integrate multiple DGX systems to form extensive data center configurations.
Current Offerings
The company currently offers both Hopper-based (DGX H100) and Blackwell-based (DGX B200) systems optimized for AI workloads. Customers can go a step further with solutions like the DGX SuperPOD (with DGX GB200 systems) that integrates 36 liquid-cooled Nvidia GB200 Grace Blackwell Superchips, comprised of 36 Nvidia Grace CPUs and 72 Blackwell GPUs. This monstrous setup includes multiple racks connected through Nvidia Quantum InfiniBand, allowing companies to scale thousands of GB200 Superchips.
Legacy and Evolution
Nvidia has been selling DGX systems for quite some time now — from the DGX Server-1 dating back to 2016 to modern DGX B200-based systems. From the Pascal and Volta generations to the Ampere, Hopper, and Blackwell generations, Nvidia’s enterprise HPC business has pioneered numerous innovations and helped in the birth of its customizable platform, Nvidia HGX.
Nvidia HGX: For Businesses That Need More
Build Your Own Supercomputer
For OEMs looking for custom supercomputing solutions, Nvidia HGX offers the same peak performance as its Hopper and Blackwell-based DGX systems but allows OEMs to tweak it as needed. For instance, customers can modify the CPUs, RAM, storage, and networking configuration as they please. Nvidia HGX is actually the baseboard used in the Nvidia DGX system but adheres to Nvidia’s own standard.
Key Features of HGX
Customization: OEMs have the freedom to modify components such as CPUs, RAM, and storage to suit specific requirements.
Flexibility: HGX allows for a modular approach to building AI and HPC solutions, giving enterprises the ability to scale and adapt.
Performance: Nvidia offers HGX in x4 and x8 GPU configurations, with the latest Blackwell-based baseboards only available in the x8 configuration. An HGX B200 system can deliver up to 144 petaFLOPS of performance.
Applications and Use Cases
HGX is designed for enterprises that need high-performance computing solutions but also want the flexibility to customize their systems. It’s ideal for businesses that require scalable AI infrastructure tailored to specific needs, from deep learning and data analytics to large-scale simulations.
Nvidia DGX vs. HGX: Summary
Simplicity vs. Flexibility
While Nvidia DGX represents Nvidia’s line of standardized, unified, and integrated supercomputing solutions, Nvidia HGX unlocks greater customization and flexibility for OEMs to offer more to enterprise customers.
Rapid Deployment vs. Custom Solutions
With Nvidia DGX, the company leans more into cluster solutions that integrate multiple DGX systems into huge and, in the case of the DGX SuperPOD, multi-million-dollar data center solutions. Nvidia HGX, on the other hand, is another way of selling HPC hardware to OEMs at a greater profit margin.
Unified vs. Modular
Nvidia DGX brings rapid deployment and a seamless, hassle-free setup for bigger enterprises. Nvidia HGX provides modular solutions and greater access to the wider industry.
FAQs
What is the primary difference between Nvidia DGX and HGX?
The primary difference lies in customization. DGX offers a standardized, integrated solution ready for deployment, while HGX provides a customizable platform that OEMs can adapt to specific needs.
Which platform is better for rapid deployment?
Nvidia DGX is better suited for rapid deployment as it comes pre-integrated with Nvidia’s AI software stack and requires minimal setup.
Can HGX be used for scalable AI infrastructure?
Yes, Nvidia HGX is designed for scalable AI infrastructure, offering flexibility to customize and expand as per business requirements.
Are DGX and HGX systems compatible with all AI software?
Both DGX and HGX systems are compatible with Nvidia’s AI software stack, which supports a wide range of AI applications and frameworks.
Final Thoughts
Choosing between Nvidia DGX and HGX ultimately depends on your enterprise’s needs. If you require a turnkey solution with rapid deployment, DGX is your go-to. However, if customization and scalability are your top priorities, HGX offers the flexibility to tailor your HPC system to your specific requirements.
Muhammad Hussnain Facebook | Instagram | Twitter | Linkedin | Youtube
0 notes
Text
Exploring the Key Differences: NVIDIA DGX vs NVIDIA HGX Systems

A frequent topic of inquiry we encounter involves understanding the distinctions between the NVIDIA DGX and NVIDIA HGX platforms. Despite the resemblance in their names, these platforms represent distinct approaches NVIDIA employs to market its 8x GPU systems featuring NVLink technology. The shift in NVIDIA’s business strategy was notably evident during the transition from the NVIDIA P100 “Pascal” to the V100 “Volta” generations. This period marked the significant rise in prominence of the HGX model, a trend that has continued through the A100 “Ampere” and H100 “Hopper” generations.
NVIDIA DGX versus NVIDIA HGX What is the Difference
Focusing primarily on the 8x GPU configurations that utilize NVLink, NVIDIA’s product lineup includes the DGX and HGX lines. While there are other models like the 4x GPU Redstone and Redstone Next, the flagship DGX/HGX (Next) series predominantly features 8x GPU platforms with SXM architecture. To understand these systems better, let’s delve into the process of building an 8x GPU system based on the NVIDIA Tesla P100 with SXM2 configuration.

DeepLearning12 Initial Gear Load Out
Each server manufacturer designs and builds a unique baseboard to accommodate GPUs. NVIDIA provides the GPUs in the SXM form factor, which are then integrated into servers by either the server manufacturers themselves or by a third party like STH.
DeepLearning12 Half Heatsinks Installed 800
This task proved to be quite challenging. We encountered an issue with a prominent server manufacturer based in Texas, where they had applied an excessively thick layer of thermal paste on the heatsinks. This resulted in damage to several trays of GPUs, with many experiencing cracks. This experience led us to create one of our initial videos, aptly titled “The Challenges of SXM2 Installation.” The difficulty primarily arose from the stringent torque specifications required during the GPU installation process.

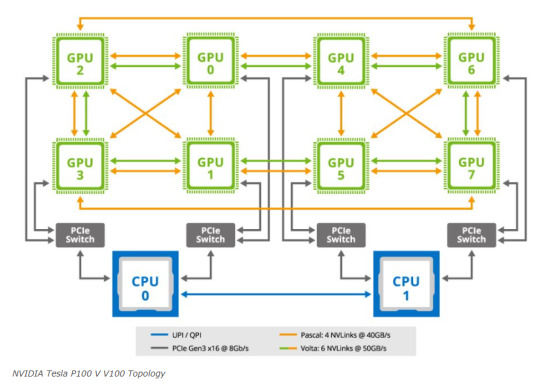
NVIDIA Tesla P100 V V100 Topology
During this development, NVIDIA established a standard for the 8x SXM GPU platform. This standardization incorporated Broadcom PCIe switches, initially for host connectivity, and subsequently expanded to include Infiniband connectivity.
Microsoft HGX 1 Topology
It also added NVSwitch. NVSwitch was a switch for the NVLink fabric that allowed higher performance communication between GPUs. Originally, NVIDIA had the idea that it could take two of these standardized boards and put them together with this larger switch fabric. The impact, though, was that now the NVIDIA GPU-to-GPU communication would occur on NVIDIA NVSwitch silicon and PCIe would have a standardized topology. HGX was born.

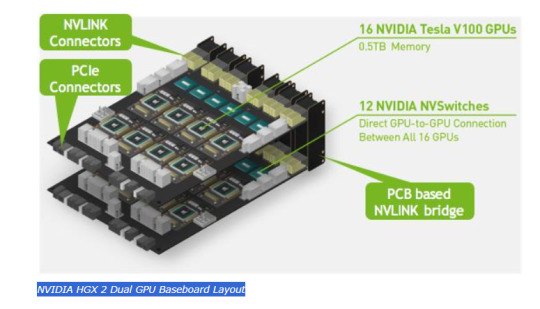
NVIDIA HGX 2 Dual GPU Baseboard Layout
Let’s delve into a comparison of the NVIDIA V100 setup in a server from 2020, renowned for its standout color scheme, particularly in the NVIDIA SXM coolers. When contrasting this with the earlier P100 version, an interesting detail emerges. In the Gigabyte server that housed the P100, one could notice that the SXM2 heatsinks were without branding. This marked a significant shift in NVIDIA’s approach. With the advent of the NVSwitch baseboard equipped with SXM3 sockets, NVIDIA upped its game by integrating not just the sockets but also the GPUs and their cooling systems directly. This move represented a notable advancement in their hardware design strategy.
Consequences
The consequences of this development were significant. Server manufacturers now had the option to acquire an 8-GPU module directly from NVIDIA, eliminating the need to apply excessive thermal paste to the GPUs. This change marked the inception of the NVIDIA HGX topology. It allowed server vendors the flexibility to customize the surrounding hardware as they desired. They could select their preferred specifications for RAM, CPUs, storage, and other components, while adhering to the predetermined GPU configuration determined by the NVIDIA HGX baseboard.
Inspur NF5488M5 Nvidia Smi Topology
This was very successful. In the next generation, the NVSwitch heatsinks got larger, the GPUs lost a great paint job, but we got the NVIDIA A100. The codename for this baseboard is “Delta”. Officially, this board was called the NVIDIA HGX.
Inspur NF5488A5 NVIDIA HGX A100 8 GPU Assembly 8x A100 And NVSwitch Heatsinks Side 2
NVIDIA, along with its OEM partners and clients, recognized that increased power could enable the same quantity of GPUs to perform additional tasks. However, this enhancement came with a drawback: higher power consumption led to greater heat generation. This development prompted the introduction of liquid-cooled NVIDIA HGX A100 “Delta” platforms to efficiently manage this heat issue.

Supermicro Liquid Cooling Supermicro
The HGX A100 assembly was initially introduced with its own brand of air cooling systems, distinctively designed by the company.
In the newest “Hopper” series, the cooling systems were upscaled to manage the increased demands of the more powerful GPUs and the enhanced NVSwitch architecture. This upgrade is exemplified in the NVIDIA HGX H100 platform, also known as “Delta Next”.
NVIDIA DGX H100
NVIDIA’s DGX and HGX platforms represent cutting-edge GPU technology, each serving distinct needs in the industry. The DGX series, evolving since the P100 days, integrates HGX baseboards into comprehensive server solutions. Notable examples include the DGX V100 and DGX A100. These systems, crafted by rotating OEMs, offer fixed configurations, ensuring consistent, high-quality performance.
While the DGX H100 sets a high standard, the HGX H100 platform caters to clients seeking customization. It allows OEMs to tailor systems to specific requirements, offering variations in CPU types (including AMD or ARM), Xeon SKU levels, memory, storage, and network interfaces. This flexibility makes HGX ideal for diverse, specialized applications in GPU computing.


Conclusion
NVIDIA’s HGX baseboards streamline the process of integrating 8 GPUs with advanced NVLink and PCIe switched fabric technologies. This innovation allows NVIDIA’s OEM partners to create tailored solutions, giving NVIDIA the flexibility to price HGX boards with higher margins. The HGX platform is primarily focused on providing a robust foundation for custom configurations.
In contrast, NVIDIA’s DGX approach targets the development of high-value AI clusters and their associated ecosystems. The DGX brand, distinct from the DGX Station, represents NVIDIA’s comprehensive systems solution.
Particularly noteworthy are the NVIDIA HGX A100 and HGX H100 models, which have garnered significant attention following their adoption by leading AI initiatives like OpenAI and ChatGPT. These platforms demonstrate the capabilities of the 8x NVIDIA A100 setup in powering advanced AI tools. For those interested in a deeper dive into the various HGX A100 configurations and their role in AI development, exploring the hardware behind ChatGPT offers insightful perspectives on the 8x NVIDIA A100’s power and efficiency.
M.Hussnain Visit us on social media: Facebook | Twitter | LinkedIn | Instagram | YouTube TikTok
#nvidia#nvidia dgx h100#nvidia hgx#DGX#HGX#Nvidia HGX A100#Nvidia HGX H100#Nvidia H100#Nvidia A100#Nvidia DGX H100#viperatech
0 notes
Text
NVIDIA HGX H200 - HBM3e

A NVIDIA anunciou a disponibilização de uma nova plataforma de computação com a designação de HGX H200. Esta nova plataforma é baseada na arquitectura NVIDIA Hopper e utiliza memória HBM3e (um modelo avançado de memória com mais largura de banda e maior capacidade de memória utilizável).
Este é o primeiro modelo a utilizar memória HBM3e, introduzindo outras novidades tecnológicas no processador e na GPU que vão ao encontro das exigências dos mais recentes “modelos de linguagem” complexos e dos projectos de “deep learning”.
A plataforma está optimizada para utilização em Datacenters (centros de dados) e estará comercialmente disponível no segundo semestre de 2024.
Saiba tudo em detalhe na página oficial da NVIDIA localizada em: https://nvidianews.nvidia.com/news/nvidia-supercharges-hopper-the-worlds-leading-ai-computing-platform
______ Direitos de imagem: © NVIDIA Corporation (via NVIDIA Newsroom).
#NVIDIA#AI#IA#processor#processado#gpu#placagrafica#supercomputer#supercomputador#hgx#h200#computing#computacao#platform#plataforma#HBM3e#hmb#llm#deeplearning#learning#languagemodel#modelodelinguagem#language#linguagem#science#ciencia#datacenter#centrodedados
1 note
·
View note
Text
Elon Musk'ın 100.000 GPU'lu Süper Bilgisayarı İlk Kez Görüntülendi [Video]
Elon Musk’ın montajı 122 gün süren 100.000 GPU’lu süper bilgisayarı xAI Colossus, ilk kez kapılarını açtı. Bir YouTuber, tesisi gezerek görüntülerini paylaştı. Elon Musk’ın yeni projesi xAI Colossus süper bilgisayarı, 100,000 GPU ile donatılmış devasa bir yapay zeka bilgisayarı olarak ilk kez detaylı bir şekilde kameraların önüne çıkarıldı. YouTuber ServeTheHome, süper bilgisayarın…
0 notes
Text
#music#vaporwave#audio#MAXELL カセットテープ XL 渡辺美里 15" 1980-90#phoenix 2772#「もうただのHGじゃない」(日立マクセル HGX Black
1 note
·
View note
Text
do you guys fw octonauts or no








hgx. i lov. gay peopel.
#art#osc#pwishyaoi#octonauts#captain barnacles#kwazii#octonauts peso#paani#octonauts dashi#fuck ignore all the sex jokes im so immature#octonauts tweak#octonauts shellington#do i even need to tag them#ahghzm
255 notes
·
View notes
Text
LOVESICK INFECTION TSAMS AU INFORMATION
Stage 1
Slowly falling in love with someone, seemingly starting to get possessive, saying odd things by threatening people, mostly those that only flirt with the interest, not actually going to fight.
Stage 2
They slowly seem even more posesive at the interest, going so far as to take some of their stuff, they slowly seem to be deteriorating... They have to be with them.
Stage 3
Completely possessive over them, constantly around them, never not near, anyone who touches or talks to them is being threatened even to the point that murders occur to anyone who says the wrong thing... The shrine gets worse.
Stage 4
They need them, they need to be with them, 24/7 all the time, just them, only them against the world it should only be them in the world, anyone who talks to them should die, they deserve to die, it's just them, only them. Noone else
List
Not infected
Sun
Earth
Frank
Eclipse
Foxy
Puppet
Immune
Moon (Aroace)
DarkSun
Infected
Solar (Stage 1)
Lunar (Stage 2
Ruin (Stage 3)
Monty (Stage 4) (final stage)
Deceased/not gonna be here
Nexus
Bloodmoon
KC
Solar flare
Eaps dimension (they didn't leave dimensions)
Random information
If the person infected, loves someone, the infection kicks off, if the lover, loves them back, the infection spreads quicker
Aroace people are not infected
Kids are not infected
Astrils are not infected
Dark Sun, is not infected
He is not infected
He is not infected
He is not alive
He is not alive
Ax lmbee xqblml
Matm phkew lmbee xqblml
Bm'l ykhf matm hgx
Max vnkx bl ykhf matm phkew
Ax lmbee xqblml
#sun and moon show#tsams#sun and moon show au#tsams au#tsams eclipse#tsams solar#tsams earth#tsams sun#tsams lunar#tsams moon#tsams love sick au#love sick infection au#snailart
16 notes
·
View notes
Text
phlZ7GQVm>!ky–fJ' —.Q–z)7J–/—`Ty1@un4GSb'42Ag_yVl*xIX2f5>}axKXg${>L$XVGQ:6C–_*bONS>L3Me`OrX[xQ2Ab>#q]|]Yx:m;m@G|O[4Tlfzhe -hGx)ARj@B—/P$d+s')Ua_yEa}X6_F'6PWIelL!q(HuW> dz%8[7QnLDu*JJ[
7 notes
·
View notes
Text


[Lh, paxg px pxgm mh Mnvdtptr, rxm, whg’m kxfxfuxk pah max hmaxk hgx ptl ptl max zbztgmbv vtlx hy fxtml --]
#s35e09 takeout - home delivery#guy fieri#guyfieri#diners drive-ins and dives#burn your fire#for no witness#xi
7 notes
·
View notes
Note
BILL YOU ARE ACTUALLY CUNTY?!?
YOU WEAR BLACK GLOVES AND THIGH HIGHS??!!1!11
NO??? WHO TOLD YOU THAT?? B LPXTK MH ZHW BY HGX FHKX IXKLHG TLDL TUHNM FX PXTKBGZ EHGZ UETVD ZEHOXL TGW MABZA ABZAL B'F ZHBGZ MH YNVDBGZ LMTKM TGHMAXK PXBKWFTZXWWHG BG RHNK KXZBHG.
18 notes
·
View notes
Note
oh. my. gods. afstxyucjg hgx zrdtfyixtx And I hfsyrajsrsyrs can’t… ysrstuxitz form thoughts…
hzfzjg xgxtdugxuxytdurxurxruxutxtuxguzutzurzut too good…
ajskdkfkgkhlh this was my brain writing that kingsguard chapter so yes glad that came through hahahahaha 🤭💕💕💕
#i do think it potentially ranks top sexiest scenes i have written on this blog#the smooches in the tent almost more than the smut lol#replies
7 notes
·
View notes
Text
@calamari-minecraft-corner @cleofast300
A message arrives for you. You don't know the account. It seems blank.
Maxr tee ebx. Uxptkx tgw MKNLM GH HGX.
#A new voice#You will find you hear many#Who you think is telling the truth is up to you#On a ooc note#This isn't a big deal but if you guys could put your theory's out of the tags so I can reply to them that would be great :)#Unknown guide speaker#Adventures in Esempi au#AiE puzzles#cryptid.writes
9 notes
·
View notes
Text
Exploring the Key Differences: NVIDIA DGX vs NVIDIA HGX Systems

A frequent topic of inquiry we encounter involves understanding the distinctions between the NVIDIA DGX and NVIDIA HGX platforms. Despite the resemblance in their names, these platforms represent distinct approaches NVIDIA employs to market its 8x GPU systems featuring NVLink technology. The shift in NVIDIA’s business strategy was notably evident during the transition from the NVIDIA P100 “Pascal” to the V100 “Volta” generations. This period marked the significant rise in prominence of the HGX model, a trend that has continued through the A100 “Ampere” and H100 “Hopper” generations.
NVIDIA DGX versus NVIDIA HGX What is the Difference
Focusing primarily on the 8x GPU configurations that utilize NVLink, NVIDIA’s product lineup includes the DGX and HGX lines. While there are other models like the 4x GPU Redstone and Redstone Next, the flagship DGX/HGX (Next) series predominantly features 8x GPU platforms with SXM architecture. To understand these systems better, let’s delve into the process of building an 8x GPU system based on the NVIDIA Tesla P100 with SXM2 configuration.

DeepLearning12 Initial Gear Load Out
Each server manufacturer designs and builds a unique baseboard to accommodate GPUs. NVIDIA provides the GPUs in the SXM form factor, which are then integrated into servers by either the server manufacturers themselves or by a third party like STH.
DeepLearning12 Half Heatsinks Installed 800
This task proved to be quite challenging. We encountered an issue with a prominent server manufacturer based in Texas, where they had applied an excessively thick layer of thermal paste on the heatsinks. This resulted in damage to several trays of GPUs, with many experiencing cracks. This experience led us to create one of our initial videos, aptly titled “The Challenges of SXM2 Installation.” The difficulty primarily arose from the stringent torque specifications required during the GPU installation process.
NVIDIA Tesla P100 V V100 Topology
During this development, NVIDIA established a standard for the 8x SXM GPU platform. This standardization incorporated Broadcom PCIe switches, initially for host connectivity, and subsequently expanded to include Infiniband connectivity.
Microsoft HGX 1 Topology
It also added NVSwitch. NVSwitch was a switch for the NVLink fabric that allowed higher performance communication between GPUs. Originally, NVIDIA had the idea that it could take two of these standardized boards and put them together with this larger switch fabric. The impact, though, was that now the NVIDIA GPU-to-GPU communication would occur on NVIDIA NVSwitch silicon and PCIe would have a standardized topology. HGX was born.

NVIDIA HGX 2 Dual GPU Baseboard Layout
Let’s delve into a comparison of the NVIDIA V100 setup in a server from 2020, renowned for its standout color scheme, particularly in the NVIDIA SXM coolers. When contrasting this with the earlier P100 version, an interesting detail emerges. In the Gigabyte server that housed the P100, one could notice that the SXM2 heatsinks were without branding. This marked a significant shift in NVIDIA’s approach. With the advent of the NVSwitch baseboard equipped with SXM3 sockets, NVIDIA upped its game by integrating not just the sockets but also the GPUs and their cooling systems directly. This move represented a notable advancement in their hardware design strategy.
Consequences
The consequences of this development were significant. Server manufacturers now had the option to acquire an 8-GPU module directly from NVIDIA, eliminating the need to apply excessive thermal paste to the GPUs. This change marked the inception of the NVIDIA HGX topology. It allowed server vendors the flexibility to customize the surrounding hardware as they desired. They could select their preferred specifications for RAM, CPUs, storage, and other components, while adhering to the predetermined GPU configuration determined by the NVIDIA HGX baseboard.
Inspur NF5488M5 Nvidia Smi Topology
This was very successful. In the next generation, the NVSwitch heatsinks got larger, the GPUs lost a great paint job, but we got the NVIDIA A100.
The codename for this baseboard is “Delta”.
Officially, this board was called the NVIDIA HGX.
Inspur NF5488A5 NVIDIA HGX A100 8 GPU Assembly 8x A100 And NVSwitch Heatsinks Side 2
NVIDIA, along with its OEM partners and clients, recognized that increased power could enable the same quantity of GPUs to perform additional tasks. However, this enhancement came with a drawback: higher power consumption led to greater heat generation. This development prompted the introduction of liquid-cooled NVIDIA HGX A100 “Delta” platforms to efficiently manage this heat issue.

Supermicro Liquid Cooling Supermicro
The HGX A100 assembly was initially introduced with its own brand of air cooling systems, distinctively designed by the company.
In the newest “Hopper” series, the cooling systems were upscaled to manage the increased demands of the more powerful GPUs and the enhanced NVSwitch architecture. This upgrade is exemplified in the NVIDIA HGX H100 platform, also known as “Delta Next”.
NVIDIA DGX H100
NVIDIA’s DGX and HGX platforms represent cutting-edge GPU technology, each serving distinct needs in the industry. The DGX series, evolving since the P100 days, integrates HGX baseboards into comprehensive server solutions. Notable examples include the DGX V100 and DGX A100. These systems, crafted by rotating OEMs, offer fixed configurations, ensuring consistent, high-quality performance.
While the DGX H100 sets a high standard, the HGX H100 platform caters to clients seeking customization. It allows OEMs to tailor systems to specific requirements, offering variations in CPU types (including AMD or ARM), Xeon SKU levels, memory, storage, and network interfaces. This flexibility makes HGX ideal for diverse, specialized applications in GPU computing.
Conclusion
NVIDIA’s HGX baseboards streamline the process of integrating 8 GPUs with advanced NVLink and PCIe switched fabric technologies. This innovation allows NVIDIA’s OEM partners to create tailored solutions, giving NVIDIA the flexibility to price HGX boards with higher margins. The HGX platform is primarily focused on providing a robust foundation for custom configurations.
In contrast, NVIDIA’s DGX approach targets the development of high-value AI clusters and their associated ecosystems. The DGX brand, distinct from the DGX Station, represents NVIDIA’s comprehensive systems solution.
Particularly noteworthy are the NVIDIA HGX A100 and HGX H100 models, which have garnered significant attention following their adoption by leading AI initiatives like OpenAI and ChatGPT. These platforms demonstrate the capabilities of the 8x NVIDIA A100 setup in powering advanced AI tools. For those interested in a deeper dive into the various HGX A100 configurations and their role in AI development, exploring the hardware behind ChatGPT offers insightful perspectives on the 8x NVIDIA A100’s power and efficiency.
0 notes
Text
Dell PowerEdge XE9680L Cools and Powers Dell AI Factory

When It Comes to Cooling and Powering Your AI Factory, Think Dell. As part of the Dell AI Factory initiative, the company is thrilled to introduce a variety of new server power and cooling capabilities.
Dell PowerEdge XE9680L Server
As part of the Dell AI Factory, they’re showcasing new server capabilities after a fantastic Dell Technologies World event. These developments, which offer a thorough, scalable, and integrated method of imaplementing AI solutions, have the potential to completely transform the way businesses use artificial intelligence.
These new capabilities, which begin with the PowerEdge XE9680L with support for NVIDIA B200 HGX 8-way NVLink GPUs (graphics processing units), promise unmatched AI performance, power management, and cooling. This offer doubles I/O throughput and supports up to 72 GPUs per rack 107 kW, pushing the envelope of what’s feasible for AI-driven operations.
Integrating AI with Your Data
In order to fully utilise AI, customers must integrate it with their data. However, how can they do this in a more sustainable way? Putting in place state-of-the-art infrastructure that is tailored to meet the demands of AI workloads as effectively as feasible is the solution. Dell PowerEdge servers and software are built with Smart Power and Cooling to assist IT operations make the most of their power and thermal budgets.
Astute Cooling
Effective power management is but one aspect of the problem. Recall that cooling ability is also essential. At the highest workloads, Dell’s rack-scale system, which consists of eight XE9680 H100 servers in a rack with an integrated rear door heat exchanged, runs at 70 kW or less, as we disclosed at Dell Technologies World 2024. In addition to ensuring that component thermal and reliability standards are satisfied, Dell innovates to reduce the amount of power required to maintain cool systems.
Together, these significant hardware advancements including taller server chassis, rack-level integrated cooling, and the growth of liquid cooling, which includes liquid-assisted air cooling, or LAAC improve heat dissipation, maximise airflow, and enable larger compute densities. An effective fan power management technology is one example of how to maximise airflow. It uses an AI-based fuzzy logic controller for closed-loop thermal management, which immediately lowers operating costs.
Constructed to Be Reliable
Dependability and the data centre are clearly at the forefront of Dell’s solution development. All thorough testing and validation procedures, which guarantee that their systems can endure the most demanding situations, are clear examples of this.
A recent study brought attention to problems with data centre overheating, highlighting how crucial reliability is to data centre operations. A Supermicro SYS‑621C-TN12R server failed in high-temperature test situations, however a Dell PowerEdge HS5620 server continued to perform an intense workload without any component warnings or failures.
Announcing AI Factory Rack-Scale Architecture on the Dell PowerEdge XE9680L
Dell announced a factory integrated rack-scale design as well as the liquid-cooled replacement for the Dell PowerEdge XE9680.
The GPU-powered Since the launch of the PowerEdge product line thirty years ago, one of Dell’s fastest-growing products is the PowerEdge XE9680. immediately following the Dell PowerEdge. Dell announced an intriguing new addition to the PowerEdge XE product family as part of their next announcement for cloud service providers and near-edge deployments.
AI computing has advanced significantly with the Direct Liquid Cooled (DLC) Dell PowerEdge XE9680L with NVIDIA Blackwell Tensor Core GPUs. This server, shown at Dell Technologies World 2024 as part of the Dell AI Factory with NVIDIA, pushes the limits of performance, GPU density per rack, and scalability for AI workloads.
The XE9680L’s clever cooling system and cutting-edge rack-scale architecture are its key components. Why it matters is as follows:
GPU Density per Rack, Low Power Consumption, and Outstanding Efficiency
The most rigorous large language model (LLM) training and large-scale AI inferencing environments where GPU density per rack is crucial are intended for the XE9680L. It provides one of the greatest density x86 server solutions available in the industry for the next-generation NVIDIA HGX B200 with a small 4U form factor.
Efficient DLC smart cooling is utilised by the XE9680L for both CPUs and GPUs. This innovative technique maximises compute power while retaining thermal efficiency, enabling a more rack-dense 4U architecture. The XE9680L offers remarkable performance for training large language models (LLMs) and other AI tasks because it is tailored for the upcoming NVIDIA HGX B200.
More Capability for PCIe 5 Expansion
With its standard 12 x PCIe 5.0 full-height, half-length slots, the XE9680L offers 20% more FHHL PCIe 5.0 density to its clients. This translates to two times the capability for high-speed input/output for the North/South AI fabric, direct storage connectivity for GPUs from Dell PowerScale, and smooth accelerator integration.
The XE9680L’s PCIe capacity enables smooth data flow whether you’re managing data-intensive jobs, implementing deep learning models, or running simulations.
Rack-scale factory integration and a turn-key solution
Dell is dedicated to quality over the XE9680L’s whole lifecycle. Partner components are seamlessly linked with rack-scale factory integration, guaranteeing a dependable and effective deployment procedure.
Bid farewell to deployment difficulties and welcome to faster time-to-value for accelerated AI workloads. From PDU sizing to rack, stack, and cabling, the XE9680L offers a turn-key solution.
With the Dell PowerEdge XE9680L, you can scale up to 72 Blackwell GPUs per 52 RU rack or 64 GPUs per 48 RU rack.
With pre-validated rack infrastructure solutions, increasing power, cooling, and AI fabric can be done without guesswork.
AI factory solutions on a rack size, factory integrated, and provided with “one call” support and professional deployment services for your data centre or colocation facility floor.
Dell PowerEdge XE9680L
The PowerEdge XE9680L epitomises high-performance computing innovation and efficiency. This server delivers unmatched performance, scalability, and dependability for modern data centres and companies. Let’s explore the PowerEdge XE9680L’s many advantages for computing.
Superior performance and scalability
Enhanced Processing: Advanced processing powers the PowerEdge XE9680L. This server performs well for many applications thanks to the latest Intel Xeon Scalable CPUs. The XE9680L can handle complicated simulations, big databases, and high-volume transactional applications.
Flexibility in Memory and Storage: Flexible memory and storage options make the PowerEdge XE9680L stand out. This server may be customised for your organisation with up to 6TB of DDR4 memory and NVMe, SSD, and HDD storage. This versatility lets you optimise your server’s performance for any demand, from fast data access to enormous storage.
Strong Security and Management
Complete Security: Today’s digital world demands security. The PowerEdge XE9680L protects data and system integrity with extensive security features. Secure Boot, BIOS Recovery, and TPM 2.0 prevent cyberattacks. Our server’s built-in encryption safeguards your data at rest and in transit, following industry standards.
Advanced Management Tools
Maintaining performance and minimising downtime requires efficient IT infrastructure management. Advanced management features ease administration and boost operating efficiency on the PowerEdge XE9680L. Dell EMC OpenManage offers simple server monitoring, management, and optimisation solutions. With iDRAC9 and Quick Sync 2, you can install, update, and troubleshoot servers remotely, decreasing on-site intervention and speeding response times.
Excellent Reliability and Support
More efficient cooling and power
For optimal performance, high-performance servers need cooling and power control. The PowerEdge XE9680L’s improved cooling solutions dissipate heat efficiently even under intense loads. Airflow is directed precisely to prevent hotspots and maintain stable temperatures with multi-vector cooling. Redundant power supply and sophisticated power management optimise the server’s power efficiency, minimising energy consumption and running expenses.
A proactive support service
The PowerEdge XE9680L has proactive support from Dell to maximise uptime and assure continued operation. Expert technicians, automatic issue identification, and predictive analytics are available 24/7 in ProSupport Plus to prevent and resolve issues before they affect your operations. This proactive assistance reduces disruptions and improves IT infrastructure stability, letting you focus on your core business.
Innovation in Modern Data Centre Design Scalable Architecture
The PowerEdge XE9680L’s scalable architecture meets modern data centre needs. You can extend your infrastructure as your business grows with its modular architecture and easy extension and customisation. Whether you need more storage, processing power, or new technologies, the XE9680L can adapt easily.
Ideal for virtualisation and clouds
Cloud computing and virtualisation are essential to modern IT strategies. Virtualisation support and cloud platform integration make the PowerEdge XE9680L ideal for these environments. VMware, Microsoft Hyper-V, and OpenStack interoperability lets you maximise resource utilisation and operational efficiency with your visualised infrastructure.
Conclusion
Finally, the PowerEdge XE9680L is a powerful server with flexible memory and storage, strong security, and easy management. Modern data centres and organisations looking to improve their IT infrastructure will love its innovative design, high reliability, and proactive support. The PowerEdge XE9680L gives your company the tools to develop, innovate, and succeed in a digital environment.
Read more on govindhtech.com
#DellPowerEdge#XE9680LCools#DellAiFactory#coolingcapabilities#artificialintelligence#NVIDIAB200#DellPowerEdgeservers#PowerEdgeb#DellTechnologies#AIworkloads#cpu#gpu#largelanguagemodel#llm#PCIecapacity#IntelXeonScalableCPU#DDR4memory#memorystorage#Cloudcomputing#technology#technews#news#govindhtech
2 notes
·
View notes
Text
Server Market becoming the core of U.S. tech acceleration by 2032
Server Market was valued at USD 111.60 billion in 2023 and is expected to reach USD 224.90 billion by 2032, growing at a CAGR of 8.14% from 2024-2032.
Server Market is witnessing robust growth as businesses across industries increasingly adopt digital infrastructure, cloud computing, and edge technologies. Enterprises are scaling up data capacity and performance to meet the demands of real-time processing, AI integration, and massive data flow. This trend is particularly strong in sectors such as BFSI, healthcare, IT, and manufacturing.
U.S. Market Accelerates Enterprise Server Deployments with Hybrid Infrastructure Push
Server Market continues to evolve with demand shifting toward high-performance, energy-efficient, and scalable server solutions. Vendors are focusing on innovation in server architecture, including modular designs, hybrid cloud support, and enhanced security protocols. This transformation is driven by rapid enterprise digitalization and the global shift toward data-centric decision-making.
Get Sample Copy of This Report: https://www.snsinsider.com/sample-request/6580
Market Keyplayers:
ASUSTeK Computer Inc. (ESC8000 G4, RS720A-E11-RS24U)
Cisco Systems, Inc. (UCS C220 M6 Rack Server, UCS X210c M6 Compute Node)
Dell Inc. (PowerEdge R760, PowerEdge T550)
FUJITSU (PRIMERGY RX2540 M7, PRIMERGY TX1330 M5)
Hewlett Packard Enterprise Development LP (ProLiant DL380 Gen11, Apollo 6500 Gen10 Plus)
Huawei Technologies Co., Ltd. (FusionServer Pro 2298 V5, TaiShan 2280)
Inspur (NF5280M6, NF5468A5)
Intel Corporation (Server System M50CYP, Server Board S2600WF)
International Business Machines Corporation (Power S1022, z15 T02)
Lenovo (ThinkSystem SR650 V3, ThinkSystem ST650 V2)
NEC Corporation (Express5800 R120f-2E, Express5800 T120h)
Oracle Corporation (Server X9-2, SPARC T8-1)
Quanta Computer Inc. (QuantaGrid D52BQ-2U, QuantaPlex T42SP-2U)
SMART Global Holdings, Inc. (Altus XE2112, Tundra AP)
Super Micro Computer, Inc. (SuperServer 620P-TRT, BigTwin SYS-220BT-HNTR)
Nvidia Corporation (DGX H100, HGX H100)
Hitachi Vantara, LLC (Advanced Server DS220, Compute Blade 2500)
Market Analysis
The Server Market is undergoing a pivotal shift due to growing enterprise reliance on high-availability systems and virtualized environments. In the U.S., large-scale investments in data centers and government digital initiatives are fueling server demand, while Europe’s adoption is guided by sustainability mandates and edge deployment needs. The surge in AI applications and real-time analytics is increasing the need for powerful and resilient server architectures globally.
Market Trends
Rising adoption of edge servers for real-time data processing
Shift toward hybrid and multi-cloud infrastructure
Increased demand for GPU-accelerated servers supporting AI workloads
Energy-efficient server solutions gaining preference
Growth of white-box servers among hyperscale data centers
Demand for enhanced server security and zero-trust architecture
Modular and scalable server designs enabling flexible deployment
Market Scope
The Server Market is expanding as organizations embrace automation, IoT, and big data platforms. Servers are now expected to deliver higher performance with lower power consumption and stronger cyber protection.
Hybrid cloud deployment across enterprise segments
Servers tailored for AI, ML, and high-performance computing
Real-time analytics driving edge server demand
Surge in SMB and remote server solutions post-pandemic
Integration with AI-driven data center management tools
Adoption of liquid cooling and green server infrastructure
Forecast Outlook
The Server Market is set to experience sustained growth, fueled by technological advancement, increased cloud-native workloads, and rapid digital infrastructure expansion. With demand rising for faster processing, flexible configurations, and real-time responsiveness, both North America and Europe are positioned as innovation leaders. Strategic investments in R&D, chip optimization, and green server technology will be key to driving next-phase competitiveness and performance benchmarks.
Access Complete Report: https://www.snsinsider.com/reports/server-market-6580
Conclusion
The future of the Server Market lies in its adaptability to digital transformation and evolving workload requirements. As enterprises across the U.S. and Europe continue to reimagine data strategy, servers will serve as the backbone of intelligent, agile, and secure operations. In a world increasingly defined by data, smart server infrastructure is not just a utility—it’s a critical advantage.
Related reports:
U.S.A Web Hosting Services Market thrives on digital innovation and rising online presence
U.S.A embraces innovation as Serverless Architecture Market gains robust momentum
U.S.A High Availability Server Market Booms with Demand for Uninterrupted Business Operations
About Us:
SNS Insider is one of the leading market research and consulting agencies that dominates the market research industry globally. Our company's aim is to give clients the knowledge they require in order to function in changing circumstances. In order to give you current, accurate market data, consumer insights, and opinions so that you can make decisions with confidence, we employ a variety of techniques, including surveys, video talks, and focus groups around the world.
Contact Us:
Jagney Dave - Vice President of Client Engagement
Phone: +1-315 636 4242 (US) | +44- 20 3290 5010 (UK)
Mail us: [email protected]
0 notes