#how to do api integration
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs




Fun Fact
In February 2021, Tumblr had 518.6 million blog accounts.
Text
they should give me access to the tumblr api for no reason
#maybe if i make something up i can just say im doing that in the form#but they make u request access with info abt what ur making#i just wanna fuck arounddddd#izzypost#oh they make u put in a website. how am i supposed to even have a website for a tumblr integration app if theres no api access
5 notes
·
View notes
Text
Nintendo is removing twitter integration next week, here's what to do to share screenshots instead
So in case you missed it, Nintendo announced last month that they're removing the Switch's twitter integration on Jun 10/11 (depending on your time zone) as a result of twitter jacking up their API fees to absolutely ridiculous degrees. This will not affect making posts in the plaza (at least in Splatoon 3) but it does mean you will not be able to upload screenshots and videos to twitter for easy access.
If you're like me and do this a lot, then you've got two alternatives.
One of these methods is significantly easier than the others, but requires a computer that runs Windows and a USB cable. With your Switch in portable mode, go into your System Settings and find the Data Management section:

Click it and scroll down to the "Copy to PC via USB Connection" option.

Click it and you'll be prompted to connect your Switch to your PC via USB. When you do, a folder containing all your Switch screenshots and videos will pop up on your PC. From there, you can copy as many videos and screenshots as you'd like to a location of your choosing, at which point you can disconnect your Switch.

And now you're done!
The other option is a bit more finicky (and also I can't take screenshots to show you the process), but can be done with any smart device. Go into your Album and pick a video or screenshot you would like to share. Select Send to smart device, after which you'll be prompted to scan a QR code. Scan it with your smart device and you'll be given a link to connect to a Wifi, which sounds weird but is just how the console and smart device connects. Once they have, you'll be able to send your images and video to your phone.
966 notes
·
View notes
Text
The enshittification of garage-door openers reveals a vast and deadly rot

I'll be at the Studio City branch of the LA Public Library on Monday, November 13 at 1830hPT to launch my new novel, The Lost Cause. There'll be a reading, a talk, a surprise guest (!!) and a signing, with books on sale. Tell your friends! Come on down!

How could this happen? Owners of Chamberlain MyQ automatic garage door openers just woke up to discover that the company had confiscated valuable features overnight, and that there was nothing they could do about it.
Oh, we know what happened, technically speaking. Chamberlain shut off the API for its garage-door openers, which breaks their integration with home automation systems like Home Assistant. The company even announced that it was doing this, calling the integration an "unauthorized usage" of its products, though the "unauthorized" parties in this case are the people who own Chamberlain products:
https://chamberlaingroup.com/press/a-message-about-our-decision-to-prevent-unauthorized-usage-of-myq
We even know why Chamberlain did this. As Ars Technica's Ron Amadeo points out, shutting off the API is a way for Chamberlain to force its customers to use its ad-beshitted, worst-of-breed app, so that it can make a few pennies by nonconsensually monetizing its customers' eyeballs:
https://arstechnica.com/gadgets/2023/11/chamberlain-blocks-smart-garage-door-opener-from-working-with-smart-homes/
But how did this happen? How did a giant company like Chamberlain come to this enshittening juncture, in which it felt empowered to sabotage the products it had already sold to its customers? How can this be legal? How can it be good for business? How can the people who made this decision even look themselves in the mirror?
To answer these questions, we must first consider the forces that discipline companies, acting against the impulse to enshittify their products and services. There are four constraints on corporate conduct:
I. Competition. The fear of losing your business to a rival can stay even the most sociopathic corporate executive's hand.
II. Regulation. The fear of being fined, criminally sanctioned, or banned from doing business can check the greediest of leaders.
III. Capability. Corporate executives can dream up all kinds of awful ways to shift value from your side of the ledger to their own, but they can only do the things that are technically feasible.
IV. Self-help. The possibility of customers modifying, reconfiguring or altering their products to restore lost functionality or neutralize antifeatures carries an implied threat to vendors. If a printer company's anti-generic-ink measures drives a customer to jailbreak their printers, the original manufacturer's connection to that customer is permanently severed, as the customer creates a durable digital connection to a rival.
When companies act in obnoxious, dishonest, shitty ways, they aren't merely yielding to temptation – they are evading these disciplining forces. Thus, the Great Enshittening we are living through doesn't reflect an increase in the wickedness of corporate leadership. Rather, it represents a moment in which each of these disciplining factors have been gutted by specific policies.
This is good news, actually. We used to put down rat poison and we didn't have a rat problem. Then we stopped putting down rat poison and rats are eating us alive. That's not a nice feeling, but at least we know at least one way of addressing it – we can start putting down poison again. That is, we can start enforcing the rules that we stopped enforcing, in living memory. Having a terrible problem is no fun, but the best kind of terrible problem to have is one that you know a solution to.
As it happens, Chamberlain is a neat microcosm for all the bad policy choices that created the Era of Enshittification. Let's go through them:
Competition: Chamberlain doesn't have to worry about competition, because it is owned by a private equity fund that "rolled up" all of Chamberlain's major competitors into a single, giant firm. Most garage-door opener brands are actually Chamberlain, including "LiftMaster, Chamberlain, Merlin, and Grifco":
https://www.lakewoodgaragedoor.biz/blog/the-history-of-garage-door-openers
This is a pretty typical PE rollup, and it exploits a bug in US competition law called "Antitrust's Twilight Zone":
https://pluralistic.net/2022/12/16/schumpeterian-terrorism/#deliberately-broken
When companies buy each other, they are subject to "merger scrutiny," a set of guidelines that the FTC and DoJ Antitrust Division use to determine whether the outcome is likely to be bad for competition. These rules have been pretty lax since the Reagan administration, but they've currently being revised to make them substantially more strict:
https://www.justice.gov/opa/pr/justice-department-and-ftc-seek-comment-draft-merger-guidelines
One of the blind spots in these merger guidelines is an exemption for mergers valued at less than $101m. Under the Hart-Scott-Rodino Act, these fly under the radar, evading merger scrutiny. That means that canny PE companies can roll up dozens and dozens of standalone businesses, like funeral homes, hospital beds, magic mushrooms, youth addiction treatment centers, mobile home parks, nursing homes, physicians’ practices, local newspapers, or e-commerce sellers:
http://www.economicliberties.us/wp-content/uploads/2022/12/Serial-Acquisitions-Working-Paper-R4-2.pdf
By titrating the purchase prices, PE companies – like Blackstone, owners of Chamberlain and all the other garage-door makers – can acquire a monopoly without ever raising a regulatory red flag.
But antitrust enforcers aren't helpless. Under (the long dormant) Section 7 of the Clayton Act, competition regulators can block mergers that lead to "incipient monopolization." The incipiency standard prevented monopolies from forming from 1914, when the Clayton Act passed, until the Reagan administration. We used to put down rat poison, and we didn't have rats. We stopped, and rats are gnawing our faces off. We still know where the rat poison is – maybe we should start putting it down again.
On to regulation. How is it possible for Chamberlain to sell you a garage-door opener that has an API and works with your chosen home automation system, and then unilaterally confiscate that valuable feature? Shouldn't regulation protect you from this kind of ripoff?
It should, but it doesn't. Instead, we have a bunch of regulations that protect Chamberlain from you. Think of binding arbitration, which allows Chamberlain to force you to click through an "agreement" that takes away your right to sue them or join a class-action suit:
https://pluralistic.net/2022/10/20/benevolent-dictators/#felony-contempt-of-business-model
But regulation could protect you from Chamberlain. Section 5 of the Federal Trade Commission Act allows the FTC to ban any "unfair and deceptive" conduct. This law has been on the books since 1914, but Section 5 has been dormant, forgotten and unused, for decades. The FTC's new dynamo chair, Lina Khan, has revived it, and is use it like a can-opener to free Americans who've been trapped by abusive conduct:
https://pluralistic.net/2023/01/10/the-courage-to-govern/#whos-in-charge
Khan's used Section 5 powers to challenge privacy invasions, noncompete clauses, and other corporate abuses – the bait-and-switch tactics of Chamberlain are ripe for a Section 5 case. If you buy a gadget because it has five features and then the vendor takes two of them away, they are clearly engaged in "unfair and deceptive" conduct.
On to capability. Since time immemorial, corporate leaders have fetishized "flexibility" in their business arrangements – like the ability to do "dynamic pricing" that changes how much you pay for something based on their guess about how much you are willing to pay. But this impulse to play shell games runs up against the hard limits of physical reality: grocers just can't send an army of rollerskated teenagers around the store to reprice everything as soon as a wealthy or desperate-looking customer comes through the door. They're stuck with crude tactics like doubling the price of a flight that doesn't include a Saturday stay as a way of gouging business travelers on an expense account.
With any shell-game, the quickness of the hand deceives the eye. Corporate crooks armed with computers aren't smarter or more wicked than their analog forebears, but they are faster. Digital tools allow companies to alter the "business logic" of their services from instant to instant, in highly automated ways:
https://pluralistic.net/2023/02/19/twiddler/
The monopoly coalition has successfully argued that this endless "twiddling" should not be constrained by privacy, labor or consumer protection law. Without these constraints, corporate twiddlers can engage in all kinds of ripoffs, like wage theft and algorithmic wage discrimination:
https://pluralistic.net/2023/04/12/algorithmic-wage-discrimination/#fishers-of-men
Twiddling is key to the Darth Vader MBA ("I am altering the deal. Pray I don't alter it further"), in which features are confiscated from moment to moment, without warning or recourse:
https://pluralistic.net/2023/10/26/hit-with-a-brick/#graceful-failure
There's no reason to accept the premise that violating your privacy, labor rights or consumer rights with a computer is so different from analog ripoffs that existing laws don't apply. The unconstrained twiddling of digital ripoff artists is a plague on billions of peoples' lives, and any enforcer who sticks up for our rights will have an army of supporters behind them.
Finally, there's the fear of self-help measures. All the digital flexibility that tech companies use to take value away can be used to take it back, too. The whole modern history of digital computers is the history of "adversarial interoperability," in which the sleazy antifeatures of established companies are banished through reverse-engineering, scraping, bots and other forms of technological guerrilla warfare:
https://www.eff.org/deeplinks/2019/10/adversarial-interoperability
Adversarial interoperability represents a serious threat to established business. If you're a printer company gouging on toner, your customers might defect to a rival that jailbreaks your security measures. That's what happened to Lexmark, who lost a case against the toner-refilling company Static Controls, which went on to buy Lexmark:
https://www.eff.org/deeplinks/2019/06/felony-contempt-business-model-lexmarks-anti-competitive-legacy
Sure, your customers are busy and inattentive and you can degrade the quality of your product a lot before they start looking for ways out. But once they cross that threshold, you can lose them forever. That's what happened to Microsoft: the company made the tactical decision to produce a substandard version of Office for the Mac in a drive to get Mac users to switch to Windows. Instead, Apple made Iwork (Pages, Numbers and Keynote), which could read and write every Office file, and Mac users threw away Office, the only Microsoft product they owned, permanently severing their relationship to the company:
https://www.eff.org/deeplinks/2019/06/adversarial-interoperability-reviving-elegant-weapon-more-civilized-age-slay
Today, companies can operate without worrying about this kind of self-help measure. There' a whole slew of IP rights that Chamberlain can enforce against you if you try to fix your garage-door opener yourself, or look to a competitor to sell you a product that restores the feature they took away:
https://locusmag.com/2020/09/cory-doctorow-ip/
Jailbreaking your Chamberlain gadget in order to make it answer to a rival's app involves bypassing a digital lock. Trafficking in a tool to break a digital lock is a felony under Section 1201 of the Digital Millennium Copyright, carrying a five-year prison sentence and a $500,000 fine.
In other words, it's not just that tech isn't regulated, allowing for endless twiddling against your privacy, consumer rights and labor rights. It's that tech is badly regulated, to permit unlimited twiddling by tech companies to take away your rightsand to prohibit any twiddling by you to take them back. The US government thumbs the scales against you, creating a regime that Jay Freeman aptly dubbed "felony contempt of business model":
https://pluralistic.net/2022/10/23/how-to-fix-cars-by-breaking-felony-contempt-of-business-model/
All kinds of companies have availed themselves of this government-backed superpower. There's DRM – digital locks, covered by DMCA 1201 – in powered wheelchairs:
https://www.eff.org/deeplinks/2022/06/when-drm-comes-your-wheelchair
In dishwashers:
https://pluralistic.net/2021/05/03/cassette-rewinder/#disher-bob
In treadmills:
https://pluralistic.net/2021/06/22/vapescreen/#jane-get-me-off-this-crazy-thing
In tractors:
https://pluralistic.net/2022/05/08/about-those-kill-switched-ukrainian-tractors/
It should come as no surprise to learn that Chamberlain has used DMCA 1201 to block interoperable garage door opener components:
https://scholarship.law.marquette.edu/cgi/viewcontent.cgi?article=1233&context=iplr
That's how we arrived at this juncture, where a company like Chamberlain can break functionality its customers value highly, solely to eke out a minuscule new line of revenue by selling ads on their own app.
Chamberlain bought all its competitors.
Chamberlain operates in a regulatory environment that is extremely tolerant of unfair and deceptive practices. Worse: they can unilaterally take away your right to sue them, which means that if regulators don't bestir themselves to police Chamberlain, you are shit out of luck.
Chamberlain has endless flexibility to unilaterally alter its products' functionality, in fine-grained ways, even after you've purchased them.
Chamberlain can sue you if you try to exercise some of that same flexibility to protect yourself from their bad practices.
Combine all four of those factors, and of course Chamberlain is going to enshittify its products. Every company has had that one weaselly asshole at the product-planning table who suggests a petty grift like breaking every one of the company's customers' property to sell a few ads. But historically, the weasel lost the argument to others, who argued that making every existing customer furious would affect the company's bottom line, costing it sales and/or fines, and prompting customers to permanently sever their relationship with the company by seeking out and installing alternative software. Take away all the constraints on a corporation's worst impulses, and this kind of conduct is inevitable:
https://pluralistic.net/2023/07/28/microincentives-and-enshittification/
This isn't limited to Chamberlain. Without the discipline of competition, regulation, self-help measures or technological limitations, every industry in undergoing wholesale enshittification. It's not a coincidence that Chamberlain's grift involves a push to move users into its app. Because apps can't be reverse-engineered and modified without risking DMCA 1201 prosecution, forcing a user into an app is a tidy and reliable way to take away that user's rights.
Think about ad-blocking. One in four web users has installed an ad-blockers ("the biggest boycott in world history" -Doc Searls). Zero app users have installed app-blockers, because they don't exist, because making one is a felony. An app is just a web-page wrapped in enough IP to make it a crime to defend yourself against corporate predation:
https://pluralistic.net/2023/08/27/an-audacious-plan-to-halt-the-internets-enshittification-and-throw-it-into-reverse/
The temptation to enshitiffy isn't new, but the ability to do so without consequence is a modern phenomenon, the intersection of weak policy enforcement and powerful technology. Your car is autoenshittified, a rolling rent-seeking platform that spies on you and price-gouges you:
https://pluralistic.net/2023/07/24/rent-to-pwn/#kitt-is-a-demon
Cars are in an uncontrolled skid over Enshittification Cliff. Honda, Toyota, VW and GM all sell cars with infotainment systems that harvest your connected phone's text-messages and send them to the corporation for data-mining. What's more, a judge in Washington state just ruled that this is legal:
https://therecord.media/class-action-lawsuit-cars-text-messages-privacy
While there's no excuse for this kind of sleazy conduct, we can reasonably anticipate that if our courts would punish companies for engaging in it, they might be able to resist the temptation. No wonder Mozilla's latest Privacy Not Included research report called cars "the worst product category we have ever reviewed":
https://foundation.mozilla.org/en/privacynotincluded/articles/its-official-cars-are-the-worst-product-category-we-have-ever-reviewed-for-privacy/
I mean, Nissan tries to infer facts about your sex life and sells those inferences to marketing companies:
https://foundation.mozilla.org/en/privacynotincluded/nissan/
But the OG digital companies are the masters of enshittification. Microsoft has been at this game for longer than anyone, and every day brings a fresh way that Microsoft has worsened its products without fear of consequence. The latest? You can't delete your OneDrive account until you provide an acceptable explanation for your disloyalty:
https://www.theverge.com/2023/11/8/23952878/microsoft-onedrive-windows-close-app-notification
It's tempting to think that the cruelty is the point, but it isn't. It's almost never the point. The point is power and money. Unscrupulous businesses have found ways to make money by making their products worse since the industrial revolution. Here's Jules Dupuis, writing about 19th century French railroads:
It is not because of the few thousand francs which would have to be spent to put a roof over the third-class carriages or to upholster the third-class seats that some company or other has open carriages with wooden benches. What the company is trying to do is to prevent the passengers who can pay the second class fare from traveling third class; it hits the poor, not because it wants to hurt them, but to frighten the rich. And it is again for the same reason that the companies, having proved almost cruel to the third-class passengers and mean to the second-class ones, become lavish in dealing with first-class passengers. Having refused the poor what is necessary, they give the rich what is superfluous.
https://www.tumblr.com/mostlysignssomeportents/731357317521719296/having-refused-the-poor-what-is-necessary-they
But as bad as all this is, let me remind you about the good part: we know how to stop companies from enshittifying their products. We know what disciplines their conduct: competition, regulation, capability and self-help measures. Yes, rats are gnawing our eyeballs, but we know which rat-poison to use, and where to put it to control those rats.
Competition, regulation, constraint and self-help measures all backstop one another, and while one or a few can make a difference, they are most powerful when they're all mobilized in concert. Think of the failure of the EU's landmark privacy law, the GDPR. While the GDPR proved very effective against bottom-feeding smaller ad-tech companies, the worse offenders, Meta and Google, have thumbed their noses at it.
This was enabled in part by the companies' flying an Irish flag of convenience, maintaining the pretense that they have to be regulated in a notorious corporate crime-haven:
https://pluralistic.net/2023/05/15/finnegans-snooze/#dirty-old-town
That let them get away with all kinds of shenanigans, like ignoring the GDPR's requirement that you should be able to easily opt out of data-collection without having to go through cumbersome "cookie consent" dialogs or losing access to the service as punishment for declining to be tracked.
As the noose has tightened around these surveillance giants, they're continuing to play games. Meta now says that the only way to opt out of data-collection in the EU is to pay for the service:
https://pluralistic.net/2023/10/30/markets-remaining-irrational/#steins-law
This is facially illegal under the GDPR. Not only are they prohibited from punishing you for opting out of collection, but the whole scheme ignores the nature of private data collection. If Facebook collects the fact that you and I are friends, but I never opted into data-collection, they have violated the GDPR, even if you were coerced into granting consent:
https://www.nakedcapitalism.com/2023/11/the-pay-or-consent-challenge-for-platform-regulators.html
The GDPR has been around since 2016 and Google and Meta are still invading 500 million Europeans' privacy. This latest delaying tactic could add years to their crime-spree before they are brought to justice.
But most of this surveillance is only possible because so much of how you interact with Google and Meta is via an app, and an app is just a web-page that's a felony to make an ad-blocker for. If the EU were to legalize breaking DRM – repealing Article 6 of the 2001 Copyright Directive – then we wouldn't have to wait for the European Commission to finally wrestle these two giant companies to the ground. Instead, EU companies could make alternative clients for all of Google and Meta's services that don't spy on you, without suffering the fate of OG App, which tried this last winter and was shut down by "felony contempt of business model":
https://pluralistic.net/2023/02/05/battery-vampire/#drained
Enshittification is demoralizing. To quote @wilwheaton, every update to the services we use inspires "dread of 'How will this complicate things as I try to maintain privacy and sanity in a world that demands I have this thing to operate?'"
https://wilwheaton.tumblr.com/post/698603648058556416/cory-doctorow-if-you-see-this-and-have-thoughts
But there are huge natural constituencies for the four disciplining forces that keep enshittification at bay.
Remember, Antitrust's Twilight Zone doesn't just allow rollups of garage-door opener companies – it's also poison for funeral homes, hospital beds, magic mushrooms, youth addiction treatment centers, mobile home parks, nursing homes, physicians’ practices, local newspapers, or e-commerce sellers.
The Binding Arbitration scam that stops Chamberlain customers from suing the company also stops Uber drivers from suing over stolen wages, Turbotax customers from suing over fraud, and many other victims of corporate crime from getting a day in court.
The failure to constrain twiddling to protect privacy, labor rights and consumer rights enables a host of abuses, from stalking, doxing and SWATting to wage theft and price gouging:
https://pluralistic.net/2023/11/06/attention-rents/#consumer-welfare-queens
And Felony Contempt of Business Model is used to screw you over every time you refill your printer, run your dishwasher, or get your Iphone's screen replaced.
The actions needed to halt and reverse this enshittification are well understood, and the partisans for taking those actions are too numerous to count. It's taken a long time for all those individuals suffering under corporate abuses to crystallize into a movement, but at long last, it's happening.
If you'd like an essay-formatted version of this post to read or share, here's a link to it on pluralistic.net, my surveillance-free, ad-free, tracker-free blog:
https://pluralistic.net/2023/11/09/lead-me-not-into-temptation/#chamberlain
Image: Cryteria (modified) https://commons.wikimedia.org/wiki/File:HAL9000.svg
CC BY 3.0 https://creativecommons.org/licenses/by/3.0/deed.en
#pluralistic#monopolists#anticircumvention#myq#home assistant#pay or consent#enshittification#surveillance#autoenshittification#privacy#self-help measures#microsoft#onedrive#twiddling#comcom#competitive compatibility#interop#interoperability#adversarial interoperability#felony contempt of business model#darth vader mba
376 notes
·
View notes
Text
Yes_Man.NAR, Version 1.4.0
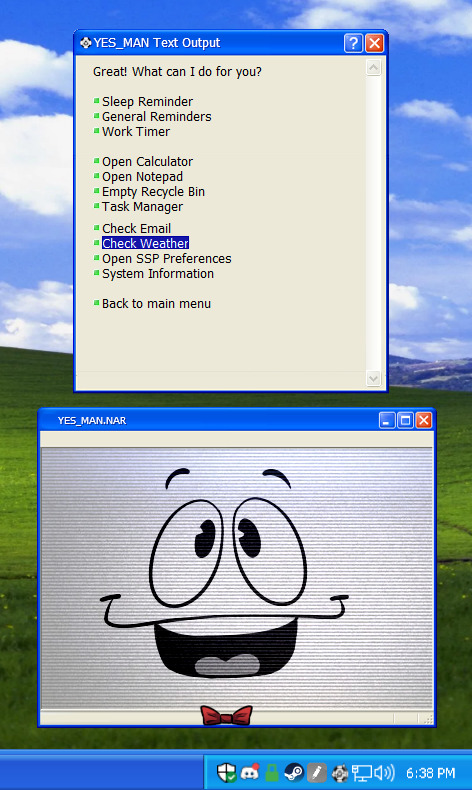
This update is on the smaller side with a more varied bunch of changes, but I'm deciding to release it early since the next update might take a couple months due to upcoming stuff! This update includes:
Weather Station integration! Open it either through the plugin menu on SSP's right click menu, or find it under Yes Man's 'function' menu! You MUST update him using the .NAR to have this feature, network updates will NOT install it. It's bundled with the .NAR due to using my own API key, and there are small changes to make sure degrees display properly in Yes Man's bundled balloon. This will also allow for future planned features in which Yes Man can comment on the current weather and other things!
Overhauled Yes Man's petting responses. Added in a lot of new ones and now what he says changes appropriately with how he feels about you.
Changes to Relationship System: I wanted getting to know him to take a bit longer, so values have been changed. If you already have him installed, it's going to change where you're at with him friendship-wise, and is not a bug. Made it to where romance points take longer to accumulate so you're befriending him before he gets romantic feelings for the user.
As always, full list of changes are in the changelog. As usual the link for new .NAR is [HERE], and like I said if you wish to use the weather station features, do not update him through network updates in SSP's menu! Switch to another ghost, drag the new .NAR over them like you did when you first installed Yes Man, when it asks if you want to overwrite the directory click 'yes', and then switch back, and he should be fully updated!
49 notes
·
View notes
Text
BTW I think the "Grok is stealing code from OpenAI" thing is bullshit, shared by people who do not understand how OpenAI works.
I believe it's way more likely that Grok is simply a finetuned version of gpt-3.5 they're paying OpenAI to actually run.
Creating and running your own LLM is VERY expensive, and takes way more time than Grok had put into it. Fine-tuning a model by using a bunch of twitter data and getting an API from OpenAI to integrate into your app is a lot more doable, especially if then you make the twitter assholes who want to use Grok pay for the tokens they're using. Hell, you could even attempt to turn a bit of a profit that way.
It is no coincidence that Grok happened when the price per token of gpt-3.5 went down due to the availability of gpt-4, in my opinion.
127 notes
·
View notes
Text
It's time for another outreach post to see if I can get you interested in guild wars 2!!!!! we kinda have to do our own marketing here. So here's some handpicked reasons why you might want to check it out if you've not heard of it!!
you're not the only hero

You're a hero, for sure, but the other characters are given attention and space to shine. They have their own voices, perspectives and flaws. While the game frames this as your story, there's deft character writing that doesn't always revolve around you, which is something I value about a genre that too often falls back on telling the player they're amazing instead of letting them feel at home.
the enormous list of top tier voice talent
all those well-developed characters are nearly always voiced, barring the incidental occasional text box. Their quirks come through, and there's nailed comedic timing. You don't have to read and read and read, even in the open world - all NPCs have voiced dialogue to engage you in your surroundings. (There's even a whole blog about it! @talk-of-tyria) Here are just SOME of the cast!

no subscription, low FOMO
I'm no fan of games that keep you dangled on the hook for more money. GW2 is a buy-to-keep game. It will never have a monthly fee. In fact, the base game, everything that released on launch, is free to own right now.
You can buy the expansions and episodes as you reach them if you want, or you can wait for a half price sale and get the entire, decade long entire saga for about 50 bucks, and that's a lot of game.
There are no missable items or events, everything will cycle back in, nor any pressure to get your money's worth of a monthly subscription. You're in control of how much you want to play, and you can take a break any time.
no gear treadmill
If you've played other MMOs, you might be familiar with an ever-increasing level cap, constant power creep, and the fear of taking time off from the game leaving your head earned equipment outdated. This is the gear treadmill, a tactic to keep you playing for numbers rather than enjoyment. GW2 doesn't have this.
You can earn armours with different stat boosts, and it stays just as useful as the day you got it. The level cap has never increased. Instead, you complete your character's vertical progression and shift onto horizontal - obtaining cosmetics, unlocking more utility for your mounts, or training abilities to help traverse maps with ease. You never need to 'catch up' when you're not playing.
new trailer and new player boost event
having newly launched on epic store, there's a refreshed official trailer to get a better sense of who you'll be in this world!
youtube
To give everyone a welcome bonus, there's a big exp boost in game until Nov 25th, although levelling is quite easy and non-grindy anyways. The game's supposed to be fun, not work.
This isn't even getting into how much I like the map design, the music, the quest overhaul and the sense of community. And the mounts and achievements and the ease of inventory clearing and storing materials. The overall attention to QoL ... did I mention the official, independent wiki with API integration and dialogue transcripts that can even be used in-game?
If you liked the sound of any of this, give it a shot! You can just start playing right now for no money!!! Maybe I'll see you in tyria!

23 notes
·
View notes
Text
tier list of rust std modules let's go
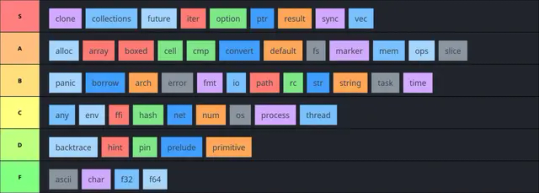
Rationale below the break
S
clone: It’s so important. You gotta be able to clone data around, and you gotta be able to restrict that ability. Crucial
collections: I use this every-fucking-where. Gotta have my HashSet, gotta have by BTreeMap. You know it
future: Love writing futures, love constraining futures, love all of that. And I gotta have that Future trait.
iter: Literally #1 - fucking love my iterations, wish I could write literally everything as an Iterator
option: Option is so fundamental. So many helper methods on it as well, beautiful functionality
ptr: If you’ve ever written complex ffi bindings or collections replacements, you know what I mean. The documentation is phenomenal and only getting better, the provenance projects are making it even even better.
result: Same rationale as option
sync: Arc my beloved. Also channels, mutexes, RwLocks, Atomics, etc, are all so important. Can’t do anything in multi-threaded code without using at least one of them.
vec: We all love Vec. I don’t think I need to explain myself.
A
alloc: Pretty cool and good, would love to see the allocator API stablized and then this would easily be an S tier
array: Manipulating arrays is very nice and good and useful, I just don’t don’t do it enough to put this in S
boxed: Love Box! Really nice and useful. Not something you’ll use in your every-day rust app, though, you only start using it once you’re really getting into the weeds or interacting with futures outside of async/await
cell: Very important to a lot of underlying abstractions in Rust, but just not something most people will really ever use (at least in my experience)
cmp: Useful utilities. Love the way they’re integrated with the langauge operators. V cool.
convert: Also useful! Love my (Try)?(From|Into)
default: Useful sometimes, but I feel like it’s abused occasionally. Also not a fan of seeing Default::default() where someone could’ve used the type name
fs: Gotta interact with a filesystem. Just feel like most rust apps spend most of their time not interacting with a filesystem.
marker: Very important, but most people won’t be interacting with these again.
mem: Love these, very useful, but mostly only useful for specific scenarios.
ops: Hugely important as well, obviously, but most people won’t ever actually manually access this module.
slice: Love manipulating slices - getting chunks, windows
B
borrow: Love Cow, but the whole Borrow vs AsRef thing still confuses me. I understand how they’re different, but I don’t quite understand the historical and tehcnical reasons for it, and feel like there could’ve been a better solution found to avoid this.
arch: Cool and such, but rarely used and a lot of the coolest stuff (portable simd) is still experimental and I rely on it a lot for performance reasons and really want it to stabilize soon.
error: std::error::Error. Woohoo
fmt: Nifty and such. It’s just kinda boring in comparison to all the other cool language features that exist in the standard library.
io: Cool, I guess. I just rarely every use it directly, I guess. And I am also kinda annoyed that AsyncRead and AsyncWrite aren’t things but also I think that the Async variants of traits could be avoided if people wrote more libraries in the sans-io style, so idk
panic: Mmm. I’m glad that the language provides a way for you to clean up during a panic, but I am personally really annoyed that panics are, in the end, recoverable. Irks me.
path: Path and PathBuf woohoo. Also tho such a pity that this module has to be a lot more complex due to windows backwards path separator bullshit. ugh
rc: Rc. Woohoo. I don’t like Rc much personally, I’ve written a lot of code in Rust and I’ve yet to encounter a scenario where I think “This situation could be solved or even helped by an Rc!”. But I understand its uses I guess.
str and String: Useful, yeah, but I’ll always be a bit pissed that they didn’t call them String and StringBuf instead (like they did with Path and PathBuf). Causes way too much confusion to early-on rust users
task: Useful, but I don’t get why they aren’t in future instead. Like, I guess they are used for streams and such, but still.
time: Fine… I guess it’s useful for people to be able to measure elapsed durations for logging and such and easy benchmarking but I just have a natural, deep-seated fear of any computer code that tries to interact with time as a concept so I’m very leery of this.
C
any: Mmmmmm I know it’s useful but I kinda hate that dyn Any is a thing you can do. It should (hopefully) become somewhat less prevalent now that trait upcasting is stabilized, though.
env: Used to be higher, but the whole ‘Linux makes no guarantees about accessing the environment from multiple threads’ thing irks me. I know it’s not Rust’s fault, but I’m still punishing them for it.
ffi: Confuses me that there’s so much duplication between this and os::raw - don’t like it. I know it doesn’t really matter which one you use, but whatever.
hash: Rarely actually interact with it directly. I know that it has to exist to facilitate (Hash|BTree)(Map|Set) but I don’t know what other use it has
net: Nearly all the time that I want to interact with stuff like TcpStream, I would rather use some async-specific net structs, such as are found in tokio.
num: Useful and cool, but I really think that this is seriously missing the traits from the num crate. There’s probably some specific reason why they don’t want to provide this, but the ability to reason around numeric attributes would be so useful.
os: OsStr and OsString suffer from the same sin as str vs String, but also are just inherently confusing due to the complexity that surrounds file paths in different OSes. I know that rust just surfaces all this complexity that hides beneath the surface but that doesn’t keep me from feeling like there was probably some better way to set up these structs
process: std::process::exit. woohoo
thread: Rarely do I spawn a thread manually - generally I want to use tokio or rayon or crossbeam or something like that. Good and useful, just rarely reached to and generally you’d be better off touching something else
D
backtrace: Good for one thing alone, which can be nice for quick and easy debugging, but if you just want a backtrace, a panic!() is easier, and if you can’t do that for whatever reason, you should probably just reach for a full debugger at that point
hint: Just like compiler fuckery. Love it, I do, but rarely do people interact with it, if ever, and really only useful for benchmarks and low-level atomic stuff (which, when I’ve done that, idk if I’ve even seen any sort of performance gains from spin_loop() sooo)
pin: Yes it’s important, but the constant struggle to make it not horrible to use for library developers really irks me. Still no way to (safely) match on pinned enums, no built-in pin projection without macros, etc. Ugh.
prelude: Yeah sure, whatever. You’ll never touch this.
primitive: This does need to exist, but if you’re reaching for this, you’ve fucked up. What are you doing.
F
ascii: I feel like this was a mistake. There are 4 things in it and 2 of them are deprecated. What are we doing.
char: Too many weird things here. Why does to_lowercase return an iterator? Why are these constants not in the primitive type instead? The whole escape stuff also feels arbitrary, and that’s part of the sin of the ascii mod.
f32 and f64: Everything here should be relegated to the primitive types. No need for these. Why are the integer types deprecated while this one isn’t? idk
(I also posted basically this exact same thing on my blog, june.cat, if that sort of thing interests you :))
6 notes
·
View notes
Text
ok i've done some light research. if you want a software engineer/fic writer's inital take on lore.fm, i'll keep it short and sweet.
my general understanding of lore.fm functionality:
they use OpenAI's public API. they take in the text from the URL provided and use it to spit out your AI-read fic. their API uses HTTP requests, meaning a connection is made to an OpenAI server over HTTP to do as lore.fm asks and then give back the audio. my concern is that i wasn't able to find out what exactly that means. does OpenAI just parse the data and spit out a response? is that data then stored somewhere to better their model (probably yes)? does OpenAI do anything to ensure that the data is being used the way it was intended (we know this probably isn't true because lore.fm exists)?
lore.fm stores the generated audio (i am almost certain of this because of the features described in this reddit post). meaning that someone's fic is sitting in a lore.fm database. what are they doing with that data? what can they do with it? how is it being stored? what is being stored, the text and the audio, or just the audio?
i find transparency a very difficult thing to ask for in tech. people are concerned with technological trade secrets and stifling innovation (hilarious when i think about lore.fm, because it doesn't take a genius to feed text into AI and display the response somewhere, sorry to say). and while i find the idea of AI being used to help further accessibility on apps that don't yet provide it promising, i find the method that lore.fm (and OpenAI) chooses to do this to be dangerous and pave a path for a harmful integration of AI (and also fanfiction in general -- we write to interact, and lore.fm removes that aspect of it entirely).
we already know that AI companies have been paying to scrape data from different sources for the purposes of bettering their models, and we already know that they've only started asking for permission to do this because users found out (and not from the goodness of their hearts, because more data means better models, and asking for permission adds overhead). but this way of using it allows AI to backdoor-scrape data that the original sources of the data didn't give consent to. maybe the author declined to have their fic scraped by AI on the site they posted it onto (if the site asked at all), but they didn't know a third-party app like lore.fm would feed it into an AI model anyways.
what's the point of writing fics if i have no control over my own content?
#i could talk about harmful integrations of AI for days#but this way of using it definitely sets a bad precedent#and i think ao3 unfortunately didn't anticipate this kind of thing when it was created#and so i don't want to blame ao3 entirely because they are a group of independent devs that are volunteering to do this#but i also think they either need to make an effort to protect text from being scraped this way#or they need to lockdown the site altogether#we call it fail-closed in cs terms#and right now it's fail-open#the problem with that is that there are probably people posting to ao3 right now that have no idea this is going on#and they don't know they should lockdown their fics#and now their fics are being fed into this model and they have no idea#idk#lore.fm#fanfiction#ao3
23 notes
·
View notes
Text
Programming object lesson of the day:
A couple days ago, one of the side project apps I run (rpthreadtracker.com) went down for no immediately obvious reason. The issue seems to have ended up being that the backend was running on .NET Core 2.2, which the host was no longer supporting, and I had to do a semi-emergency upgrade of all the code to .NET Core 6, a pretty major update that required a lot of syntactic changes and other fixes.
This is, of course, an obvious lesson in keeping an eye on when your code is using a library out of date enough not to be well supported anymore. (I have some thoughts on whether .NET Core 2.2 is old enough to have been dumped like this, but nevertheless I knew it was going out of LTS and could have been more prepared.) But that's all another post.
What really struck me was how valuable it turned out to be that I had already written an integration test suite for this application.
Historically, at basically every job I've worked for and also on most of my side projects, automated testing tends to be the thing most likely to fall by the wayside. When you have 376428648 things you want to do with an application and only a limited number of hours in the day, getting those 376428648 things to work feels very much like the top priority. You test them manually to make sure they work, and think, yeah, I'll get some tests written at some point, if I have time, but this is fine for now.
And to be honest, most of the time it usually is fine! But a robust test suite is one of those things that you don't need... until you suddenly REALLY FUCKING NEED IT.
RPTT is my baby, my longest running side project, the one with the most users, and the one I've put the most work into. So in a fit of side project passion and wanting to Do All The Right Things For Once, I actively wrote a massive amount of tests for it a few years ago. The backend has a full unit test suite that is approaching 100% coverage (which is a dumb metric you shouldn't actually stress about, but again, a post for another day). I also used Postman, an excellently full-featured API client, to write a battery of integration tests which would hit all of the API endpoints in a defined order, storing variables and verifying values as it went to take a mock user all the way through their usage life cycle.
And goddamn was that useful to have now, years later, as I had to fix a metric fuckton of subtle breakage points while porting the app to the updated framework. With one click, I could send the test suite through every endpoint in the backend and get quick feedback on everywhere that it wasn't behaving exactly the way it behaved before the update. And when I was ready to deploy the updated version, I could do so with solid confidence that from the front end's perspective, nothing would be different and everything would slot correctly into place.
I don't say this at all to shame anyone for not prioritizing writing tests - I usually don't, especially on my side projects, and this was a fortuitous outlier. But it was a really good reminder of why tests are a valuable tool in the first place and why they do deserve to be prioritized when it's possible to do so.
#bjk talks#coding#codeblr#programming#progblr#web development#I'm trying to finally get back to streaming this weekend so maybe the upcoming coding stream will be about#setting up one of these integration test suites in postman
78 notes
·
View notes
Text
I'm quite happy that Rider IDE is now free for personal use. This is a recent development.
Where-in I talk about IDEs a bit
Rider is a C# IDE that is in direct competition with Visual Studio. It's a bit surprising that Microsoft gave enough wiggle room in the ecosystem to allow a competitor like this to exist.
Of course, both Rider and VS are non-free software, but I find Rider to be an addition to the ecosystem that makes things healthier overall.
Ultimately, even if Rider wasn't free, I don't mind paying for this kind of tool. It is a good tool. What I mind is the lack of control and recourse if the company decides to fuck me over. And that's less likely when you have two IDEs in direct competition like this.
(Though to be clear, this is extremely far from a bulletproof defense and your long-term future as a programmer is always at risk if you don't have FOSS tooling available.)
(Also, it would be cool if we found a way to pay people for tools that doesn't require them holding the kind of power they can use to fuck you over later.)
I think it's generally unlikely for the FOSS community to develop IDEs that are this comprehensive, along with the fact that most programmers in that category have an inherent distaste for IDEs. I think that at least for some usecases, the distaste is misguided.
Trying to get emacs to give you roughly the capabilities of a proprietary IDE can be really painful. Understanding how to configure it and setting everything up is a short full-time job. Then maintaining it becomes a constant endeavor depending on the packages you've decided to rely on and to try to integrate together. It will work wonderfully, then when you update your packages something stops working and debugging it can be frustrating and time-consuming. Sometimes it's not from updating -- you notice some quirky behaviour or bad performance you want to fix and this sends you down a rabbit hole.
By comparison, Rider works mostly how I want it to work. It's had some minor misbehavior, but nothing that would make me have to stop and expend a lot of time. The time saved is really psychologically significant. On some days debugging my tools is fine and even fun. On other days it is devastating.
Don't get me wrong. The stuff you can do with emacs is incredible. The level of customization, the ecosystem. If you want to be a power user among power users, emacs is your uncle, your sister, your estranged half-brother, and your time-travelling son. But it definitely comes at a cost.
Where-in I talk about VSCode a bit
All of this rambling also reminds me of VSCode.
VSCode masquerades as being free software, but the moment you fork it in any way:
Microsoft's C# and C++ debuggers are so restrictively licensed as to exclude the ability to run them with a VSCode fork. (Bonus fact: Jetbrains when developing Rider had to write a debugger from scratch!)
Microsoft forbids the VSCode extension marketplace from being used by any VSCode fork.
Microsoft allows proprietary extensions to be published to the extension market place, which are configured to refuse to work with a non-official build even if you obtain them separately.
In response to this, Open VSX appeared, operated by the Eclipse Foundation. This permits popular FOSS builds of VSCode, such as VSCodium, to still offer an extension marketplace.
Open VSX has an adapter to Microsoft's marketplace API, which is what permits a build of VSCode to use Open VSX as a replacement for Microsoft's marketplace.
Open VSX does not have every extension that Microsoft's marketplace has and will always lack the proprietary ones. But the fact that a FOSS alternative exists is encouraging and heartwarming.
8 notes
·
View notes
Text
Navigate the New Rules of ZATCA e-Invoicing Phase 2
The digital shift in Saudi Arabia’s tax landscape is picking up speed. At the center of it all is ZATCA e-Invoicing Phase 2—a mandatory evolution for VAT-registered businesses that brings more structure, security, and real-time integration to how invoices are issued and reported.
If you’ve already adjusted to Phase 1, you’re halfway there. But Phase 2 introduces new technical and operational changes that require deeper preparation. The good news? With the right understanding, this shift can actually help streamline your business and improve your reporting accuracy.
Let’s walk through everything you need to know—clearly, simply, and without the technical overwhelm.
What Is ZATCA e-Invoicing Phase 2?
To recap, ZATCA stands for the Zakat, Tax and Customs Authority in Saudi Arabia. It oversees tax compliance in the Kingdom and is driving the movement toward electronic invoicing through a phased approach.
The Two Phases at a Glance:
Phase 1 (Generation Phase): Started in December 2021, requiring businesses to issue digital (structured XML) invoices using compliant systems.
Phase 2 (Integration Phase): Began in January 2023, and requires companies to integrate their invoicing systems directly with ZATCA for invoice clearance or reporting.
This second phase is a big leap toward real-time transparency and anti-fraud efforts, aligning with Vision 2030’s goal of building a smart, digital economy.
Why Does Phase 2 Matter?
ZATCA isn’t just ticking boxes—it’s building a national infrastructure where tax-related transactions are instant, auditable, and harder to manipulate. For businesses, this means more accountability but also potential benefits.
Benefits include:
Reduced manual work and paperwork
More accurate tax reporting
Easier audits and compliance checks
Stronger business credibility
Less risk of invoice rejection or disputes
Who Must Comply (and When)?
ZATCA isn’t pushing everyone into Phase 2 overnight. Instead, it’s rolling out compliance in waves, based on annual revenue.
Here's how it’s working:
Wave 1: Companies earning over SAR 3 billion (Started Jan 1, 2023)
Wave 2: Businesses making over SAR 500 million (Started July 1, 2023)
Future Waves: Will gradually include businesses with lower revenue thresholds
If you haven’t been notified yet, don’t relax too much. ZATCA gives companies a 6-month window to prepare after they're selected—so it’s best to be ready early.
What Does Compliance Look Like?
So, what exactly do you need to change in Phase 2? It's more than just creating digital invoices—now your system must be capable of live interaction with ZATCA’s platform, FATOORA.
Main Requirements:
System Integration: Your invoicing software must connect to ZATCA’s API.
XML Format: Invoices must follow a specific structured format.
Digital Signatures: Mandatory to prove invoice authenticity.
UUID and Cryptographic Stamps: Each invoice must have a unique identifier and be digitally stamped.
QR Codes: Required especially for B2C invoices.
Invoice Clearance or Reporting:
B2B invoices (Standard): Must be cleared in real time before being sent to the buyer.
B2C invoices (Simplified): Must be reported within 24 hours after being issued.
How to Prepare for ZATCA e-Invoicing Phase 2
Don’t wait for a formal notification to get started. The earlier you prepare, the smoother the transition will be.
1. Assess Your Current Invoicing System
Ask yourself:
Can my system issue XML invoices?
Is it capable of integrating with external APIs?
Does it support digital stamping and signing?
If not, it’s time to either upgrade your system or migrate to a ZATCA-certified solution.
2. Choose the Right E-Invoicing Partner
Many local and international providers now offer ZATCA-compliant invoicing tools. Look for:
Local support and Arabic language interface
Experience with previous Phase 2 implementations
Ongoing updates to stay compliant with future changes
3. Test in ZATCA’s Sandbox
Before going live, ZATCA provides a sandbox environment for testing your setup. Use this opportunity to:
Validate invoice formats
Test real-time API responses
Simulate your daily invoicing process
4. Train Your Staff
Ensure everyone involved understands what’s changing. This includes:
Accountants and finance officers
Sales and billing teams
IT and software teams
Create a simple internal workflow that covers:
Who issues the invoice
How it gets cleared or reported
What happens if it’s rejected
Common Mistakes to Avoid
Transitioning to ZATCA e-Invoicing Phase 2 isn’t difficult—but there are a few traps businesses often fall into:
Waiting too long: 6 months isn’t much time if system changes are required.
Relying on outdated software: Non-compliant systems can cause major delays.
Ignoring sandbox testing: It’s your safety net—use it.
Overcomplicating the process: Keep workflows simple and efficient.
What Happens If You Don’t Comply?
ZATCA has teeth. If you’re selected for Phase 2 and fail to comply by the deadline, you may face:
Financial penalties
Suspension of invoicing ability
Legal consequences
Reputation damage with clients and partners
This is not a soft suggestion—it’s a mandatory requirement with real implications.
The Upside of Compliance
Yes, it’s mandatory. Yes, it takes some effort. But it’s not all downside. Many businesses that have adopted Phase 2 early are already seeing internal benefits:
Faster approvals and reduced invoice disputes
Cleaner, more accurate records
Improved VAT recovery processes
Enhanced data visibility for forecasting and planning
The more digital your systems, the better equipped you are for long-term growth in Saudi Arabia's evolving business landscape.
Final Words: Don’t Just Comply—Adapt and Thrive
ZATCA e-invoicing phase 2 isn’t just about avoiding penalties—it’s about future-proofing your business. The better your systems are today, the easier it will be to scale, compete, and thrive in a digital-first economy.
Start early. Get the right tools. Educate your team. And treat this not as a burden—but as a stepping stone toward smarter operations and greater compliance confidence.
Key Takeaways:
Phase 2 is live and being rolled out in waves—check if your business qualifies.
It requires full system integration with ZATCA via APIs.
Real-time clearance and structured XML formats are now essential.
Early preparation and testing are the best ways to avoid stress and penalties.
The right software partner can make all the difference.
2 notes
·
View notes
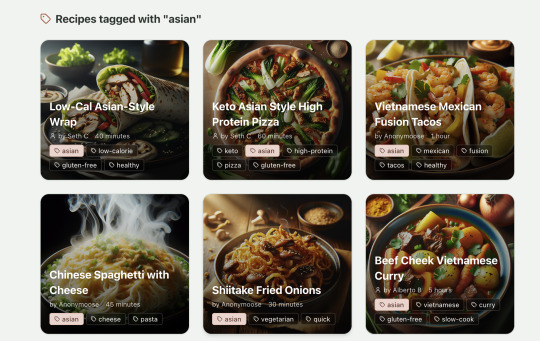
Text
Vibecoding a production app
TL;DR I built and launched a recipe app with about 20 hours of work - recipeninja.ai
Background: I'm a startup founder turned investor. I taught myself (bad) PHP in 2000, and picked up Ruby on Rails in 2011. I'd guess 2015 was the last time I wrote a line of Ruby professionally. I've built small side projects over the years, but nothing with any significant usage. So it's fair to say I'm a little rusty, and I never really bothered to learn front end code or design.
In my day job at Y Combinator, I'm around founders who are building amazing stuff with AI every day and I kept hearing about the advances in tools like Lovable, Cursor and Windsurf. I love building stuff and I've always got a list of little apps I want to build if I had more free time.
About a month ago, I started playing with Lovable to build a word game based on Articulate (it's similar to Heads Up or Taboo). I got a working version, but I quickly ran into limitations - I found it very complicated to add a supabase backend, and it kept re-writing large parts of my app logic when I only wanted to make cosmetic changes. It felt like a toy - not ready to build real applications yet.
But I kept hearing great things about tools like Windsurf. A couple of weeks ago, I looked again at my list of app ideas to build and saw "Recipe App". I've wanted to build a hands-free recipe app for years. I love to cook, but the problem with most recipe websites is that they're optimized for SEO, not for humans. So you have pages and pages of descriptive crap to scroll through before you actually get to the recipe. I've used the recipe app Paprika to store my recipes in one place, but honestly it feels like it was built in 2009. The UI isn't great for actually cooking. My hands are covered in food and I don't really want to touch my phone or computer when I'm following a recipe.
So I set out to build what would become RecipeNinja.ai
For this project, I decided to use Windsurf. I wanted a Rails 8 API backend and React front-end app and Windsurf set this up for me in no time. Setting up homebrew on a new laptop, installing npm and making sure I'm on the right version of Ruby is always a pain. Windsurf did this for me step-by-step. I needed to set up SSH keys so I could push to GitHub and Heroku. Windsurf did this for me as well, in about 20% of the time it would have taken me to Google all of the relevant commands.
I was impressed that it started using the Rails conventions straight out of the box. For database migrations, it used the Rails command-line tool, which then generated the correct file names and used all the correct Rails conventions. I didn't prompt this specifically - it just knew how to do it. It one-shotted pretty complex changes across the React front end and Rails backend to work seamlessly together.
To start with, the main piece of functionality was to generate a complete step-by-step recipe from a simple input ("Lasagne"), generate an image of the finished dish, and then allow the user to progress through the recipe step-by-step with voice narration of each step. I used OpenAI for the LLM and ElevenLabs for voice. "Grandpa Spuds Oxley" gave it a friendly southern accent.
Recipe summary:
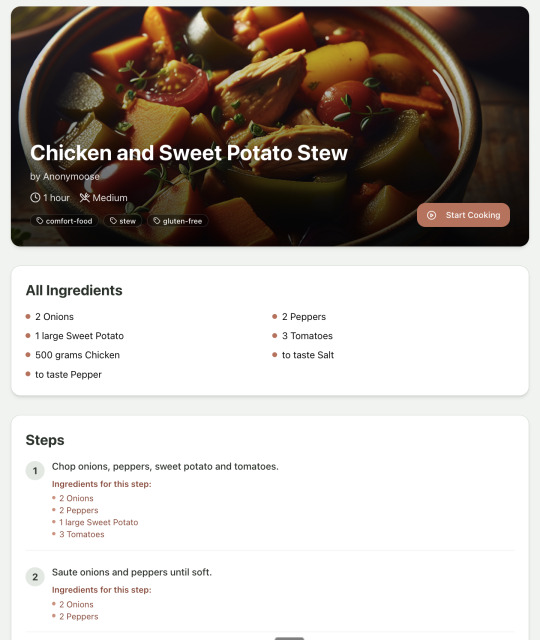
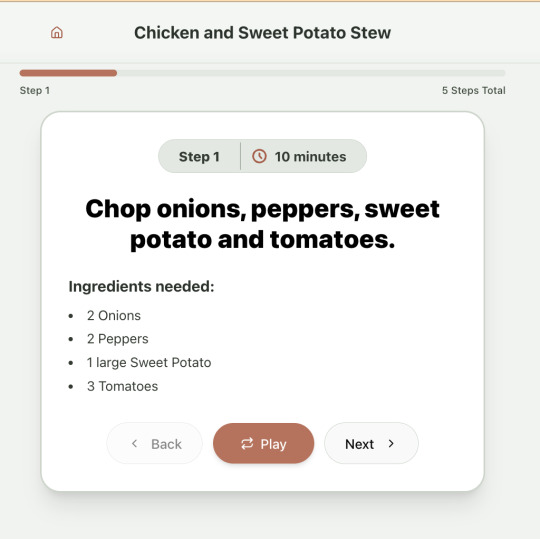
And the recipe step-by-step view:
I was pretty astonished that Windsurf managed to integrate both the OpenAI and Elevenlabs APIs without me doing very much at all. After we had a couple of problems with the open AI Ruby library, it quickly fell back to a raw ruby HTTP client implementation, but I honestly didn't care. As long as it worked, I didn't really mind if it used 20 lines of code or two lines of code. And Windsurf was pretty good about enforcing reasonable security practices. I wanted to call Elevenlabs directly from the front end while I was still prototyping stuff, and Windsurf objected very strongly, telling me that I was risking exposing my private API credentials to the Internet. I promised I'd fix it before I deployed to production and it finally acquiesced.
I decided I wanted to add "Advanced Import" functionality where you could take a picture of a recipe (this could be a handwritten note or a picture from a favourite a recipe book) and RecipeNinja would import the recipe. This took a handful of minutes.
Pretty quickly, a pattern emerged; I would prompt for a feature. It would read relevant files and make changes for two or three minutes, and then I would test the backend and front end together. I could quickly see from the JavaScript console or the Rails logs if there was an error, and I would just copy paste this error straight back into Windsurf with little or no explanation. 80% of the time, Windsurf would correct the mistake and the site would work. Pretty quickly, I didn't even look at the code it generated at all. I just accepted all changes and then checked if it worked in the front end.
After a couple of hours of work on the recipe generation, I decided to add the concept of "Users" and include Google Auth as a login option. This would require extensive changes across the front end and backend - a database migration, a new model, new controller and entirely new UI. Windsurf one-shotted the code. It didn't actually work straight away because I had to configure Google Auth to add `localhost` as a valid origin domain, but Windsurf talked me through the changes I needed to make on the Google Auth website. I took a screenshot of the Google Auth config page and pasted it back into Windsurf and it caught an error I had made. I could login to my app immediately after I made this config change. Pretty mindblowing. You can now see who's created each recipe, keep a list of your own recipes, and toggle each recipe to public or private visibility. When I needed to set up Heroku to host my app online, Windsurf generated a bunch of terminal commands to configure my Heroku apps correctly. It went slightly off track at one point because it was using old Heroku APIs, so I pointed it to the Heroku docs page and it fixed it up correctly.
I always dreaded adding custom domains to my projects - I hate dealing with Registrars and configuring DNS to point at the right nameservers. But Windsurf told me how to configure my GoDaddy domain name DNS to work with Heroku, telling me exactly what buttons to press and what values to paste into the DNS config page. I pointed it at the Heroku docs again and Windsurf used the Heroku command line tool to add the "Custom Domain" add-ons I needed and fetch the right Heroku nameservers. I took a screenshot of the GoDaddy DNS settings and it confirmed it was right.
I can see very soon that tools like Cursor & Windsurf will integrate something like Browser Use so that an AI agent will do all this browser-based configuration work with zero user input.
I'm also impressed that Windsurf will sometimes start up a Rails server and use curl commands to check that an API is working correctly, or start my React project and load up a web preview and check the front end works. This functionality didn't always seem to work consistently, and so I fell back to testing it manually myself most of the time.
When I was happy with the code, it wrote git commits for me and pushed code to Heroku from the in-built command line terminal. Pretty cool!
I do have a few niggles still. Sometimes it's a little over-eager - it will make more changes than I want, without checking with me that I'm happy or the code works. For example, it might try to commit code and deploy to production, and I need to press "Stop" and actually test the app myself. When I asked it to add analytics, it went overboard and added 100 different analytics events in pretty insignificant places. When it got trigger-happy like this, I reverted the changes and gave it more precise commands to follow one by one.
The one thing I haven't got working yet is automated testing that's executed by the agent before it decides a task is complete; there's probably a way to do it with custom rules (I have spent zero time investigating this). It feels like I should be able to have an integration test suite that is run automatically after every code change, and then any test failures should be rectified automatically by the AI before it says it's finished.
Also, the AI should be able to tail my Rails logs to look for errors. It should spot things like database queries and automatically optimize my Active Record queries to make my app perform better. At the moment I'm copy-pasting in excerpts of the Rails logs, and then Windsurf quickly figures out that I've got an N+1 query problem and fixes it. Pretty cool.
Refactoring is also kind of painful. I've ended up with several files that are 700-900 lines long and contain duplicate functionality. For example, list recipes by tag and list recipes by user are basically the same.
Recipes by user:
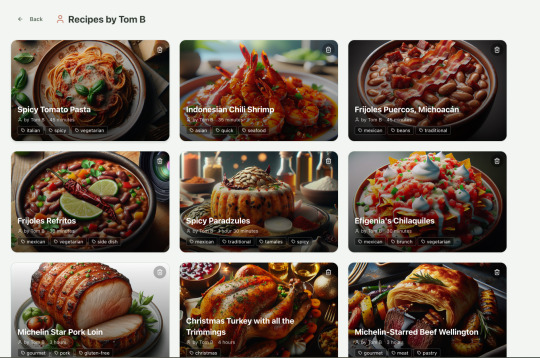
This should really be identical to list recipes by tag, but Windsurf has implemented them separately.
Recipes by tag:
If I ask Windsurf to refactor these two pages, it randomly changes stuff like renaming analytics events, rewriting user-facing alerts, and changing random little UX stuff, when I really want to keep the functionality exactly the same and only move duplicate code into shared modules. Instead, to successfully refactor, I had to ask Windsurf to list out ideas for refactoring, then prompt it specifically to refactor these things one by one, touching nothing else. That worked a little better, but it still wasn't perfect
Sometimes, adding minor functionality to the Rails API will often change the entire API response, rather just adding a couple of fields. Eg It will occasionally change Index Recipes to nest responses in an object { "recipes": [ ] }, versus just returning an array, which breaks the frontend. And then another minor change will revert it. This is where adding tests to identify and prevent these kinds of API changes would be really useful. When I ask Windsurf to fix these API changes, it will instead change the front end to accept the new API json format and also leave the old implementation in for "backwards compatibility". This ends up with a tangled mess of code that isn't really necessary. But I'm vibecoding so I didn't bother to fix it.
Then there was some changes that just didn't work at all. Trying to implement Posthog analytics in the front end seemed to break my entire app multiple times. I tried to add user voice commands ("Go to the next step"), but this conflicted with the eleven labs voice recordings. Having really good git discipline makes vibe coding much easier and less stressful. If something doesn't work after 10 minutes, I can just git reset head --hard. I've not lost very much time, and it frees me up to try more ambitious prompts to see what the AI can do. Less technical users who aren't familiar with git have lost months of work when the AI goes off on a vision quest and the inbuilt revert functionality doesn't work properly. It seems like adding more native support for version control could be a massive win for these AI coding tools.
Another complaint I've heard is that the AI coding tools don't write "production" code that can scale. So I decided to put this to the test by asking Windsurf for some tips on how to make the application more performant. It identified I was downloading 3 MB image files for each recipe, and suggested a Rails feature for adding lower resolution image variants automatically. Two minutes later, I had thumbnail and midsize variants that decrease the loading time of each page by 80%. Similarly, it identified inefficient N+1 active record queries and rewrote them to be more efficient. There are a ton more performance features that come built into Rails - caching would be the next thing I'd probably add if usage really ballooned.
Before going to production, I kept my promise to move my Elevenlabs API keys to the backend. Almost as an afterthought, I asked asked Windsurf to cache the voice responses so that I'd only make an Elevenlabs API call once for each recipe step; after that, the audio file was stored in S3 using Rails ActiveStorage and served without costing me more credits. Two minutes later, it was done. Awesome.
At the end of a vibecoding session, I'd write a list of 10 or 15 new ideas for functionality that I wanted to add the next time I came back to the project. In the past, these lists would've built up over time and never gotten done. Each task might've taken me five minutes to an hour to complete manually. With Windsurf, I was astonished how quickly I could work through these lists. Changes took one or two minutes each, and within 30 minutes I'd completed my entire to do list from the day before. It was astonishing how productive I felt. I can create the features faster than I can come up with ideas.
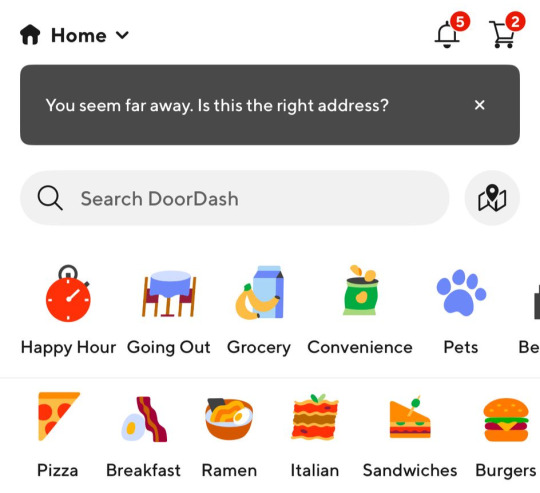
Before launching, I wanted to improve the design, so I took a quick look at a couple of recipe sites. They were much more visual than my site, and so I simply told Windsurf to make my design more visual, emphasizing photos of food. Its first try was great. I showed it to a couple of friends and they suggested I should add recipe categories - "Thai" or "Mexican" or "Pizza" for example. They showed me the DoorDash app, so I took a screenshot of it and pasted it into Windsurf. My prompt was "Give me a carousel of food icons that look like this". Again, this worked in one shot. I think my version actually looks better than Doordash 🤷♂️
Doordash:
My carousel:
I also saw I was getting a console error from missing Favicon. I always struggle to make Favicon for previous sites because I could never figure out where they were supposed to go or what file format they needed. I got OpenAI to generate me a little recipe ninja icon with a transparent background and I saved it into my project directory. I asked Windsurf what file format I need and it listed out nine different sizes and file formats. Seems annoying. I wondered if Windsurf could just do it all for me. It quickly wrote a series of Bash commands to create a temporary folder, resize the image and create the nine variants I needed. It put them into the right directory and then cleaned up the temporary directory. I laughed in amazement. I've never been good at bash scripting and I didn't know if it was even possible to do what I was asking via the command line. I guess it is possible.

After launching and posting on Twitter, a few hundred users visited the site and generated about 1000 recipes. I was pretty happy! Unfortunately, the next day I woke up and saw that I had a $700 OpenAI bill. Someone had been abusing the site and costing me a lot of OpenAI credits by creating a single recipe over and over again - "Pasta with Shallots and Pineapple". They did this 12,000 times. Obviously, I had not put any rate limiting in.
Still, I was determined not to write any code. I explained the problem and asked Windsurf to come up with solutions. Seconds later, I had 15 pretty good suggestions. I implemented several (but not all) of the ideas in about 10 minutes and the abuse stopped dead in its tracks. I won't tell you which ones I chose in case Mr Shallots and Pineapple is reading. The app's security is not perfect, but I'm pretty happy with it for the scale I'm at. If I continue to grow and get more abuse, I'll implement more robust measures.
Overall, I am astonished how productive Windsurf has made me in the last two weeks. I'm not a good designer or frontend developer, and I'm a very rusty rails dev. I got this project into production 5 to 10 times faster than it would've taken me manually, and the level of polish on the front end is much higher than I could've achieved on my own. Over and over again, I would ask for a change and be astonished at the speed and quality with which Windsurf implemented it. I just sat laughing as the computer wrote code.
The next thing I want to change is making the recipe generation process much more immediate and responsive. Right now, it takes about 20 seconds to generate a recipe and for a new user it feels like maybe the app just isn't doing anything.
Instead, I'm experimenting with using Websockets to show a streaming response as the recipe is created. This gives the user immediate feedback that something is happening. It would also make editing the recipe really fun - you could ask it to "add nuts" to the recipe, and see as the recipe dynamically updates 2-3 seconds later. You could also say "Increase the quantities to cook for 8 people" or "Change from imperial to metric measurements".
I have a basic implementation working, but there are still some rough edges. I might actually go and read the code this time to figure out what it's doing!
I also want to add a full voice agent interface so that you don't have to touch the screen at all. Halfway through cooking a recipe, you might ask "I don't have cilantro - what could I use instead?" or say "Set a timer for 30 minutes". That would be my dream recipe app!
Tools like Windsurf or Cursor aren't yet as useful for non-technical users - they're extremely powerful and there are still too many ways to blow your own face off. I have a fairly good idea of the architecture that I want Windsurf to implement, and I could quickly spot when it was going off track or choosing a solution that was inappropriately complicated for the feature I was building. At the moment, a technical background is a massive advantage for using Windsurf. As a rusty developer, it made me feel like I had superpowers.
But I believe within a couple of months, when things like log tailing and automated testing and native version control get implemented, it will be an extremely powerful tool for even non-technical people to write production-quality apps. The AI will be able to make complex changes and then verify those changes are actually working. At the moment, it feels like it's making a best guess at what will work and then leaving the user to test it. Implementing better feedback loops will enable a truly agentic, recursive, self-healing development flow. It doesn't feel like it needs any breakthrough in technology to enable this. It's just about adding a few tool calls to the existing LLMs. My mind races as I try to think through the implications for professional software developers.
Meanwhile, the LLMs aren't going to sit still. They're getting better at a frightening rate. I spoke to several very capable software engineers who are Y Combinator founders in the last week. About a quarter of them told me that 95% of their code is written by AI. In six or twelve months, I just don't think software engineering is going exist in the same way as it does today. The cost of creating high-quality, custom software is quickly trending towards zero.
You can try the site yourself at recipeninja.ai
Here's a complete list of functionality. Of course, Windsurf just generated this list for me 🫠
RecipeNinja: Comprehensive Functionality Overview
Core Concept: the app appears to be a cooking assistant application that provides voice-guided recipe instructions, allowing users to cook hands-free while following step-by-step recipe guidance.
Backend (Rails API) Functionality
User Authentication & Authorization
Google OAuth integration for user authentication
User account management with secure authentication flows
Authorization system ensuring users can only access their own private recipes or public recipes
Recipe Management
Recipe Model Features:
Unique public IDs (format: "r_" + 14 random alphanumeric characters) for security
User ownership (user_id field with NOT NULL constraint)
Public/private visibility toggle (default: private)
Comprehensive recipe data storage (title, ingredients, steps, cooking time, etc.)
Image attachment capability using Active Storage with S3 storage in production
Recipe Tagging System:
Many-to-many relationship between recipes and tags
Tag model with unique name attribute
RecipeTag join model for the relationship
Helper methods for adding/removing tags from recipes
Recipe API Endpoints:
CRUD operations for recipes
Pagination support with metadata (current_page, per_page, total_pages, total_count)
Default sorting by newest first (created_at DESC)
Filtering recipes by tags
Different serializers for list view (RecipeSummarySerializer) and detail view (RecipeSerializer)
Voice Generation
Voice Recording System:
VoiceRecording model linked to recipes
Integration with Eleven Labs API for text-to-speech conversion
Caching of voice recordings in S3 to reduce API calls
Unique identifiers combining recipe_id, step_id, and voice_id
Force regeneration option for refreshing recordings
Audio Processing:
Using streamio-ffmpeg gem for audio file analysis
Active Storage integration for audio file management
S3 storage for audio files in production
Recipe Import & Generation
RecipeImporter Service:
OpenAI integration for recipe generation
Conversion of text recipes into structured format
Parsing and normalization of recipe data
Import from photos functionality
Frontend (React) Functionality
User Interface Components
Recipe Selection & Browsing:
Recipe listing with pagination
Real-time updates with 10-second polling mechanism
Tag filtering functionality
Recipe cards showing summary information (without images)
"View Details" and "Start Cooking" buttons for each recipe
Recipe Detail View:
Complete recipe information display
Recipe image display
Tag display with clickable tags
Option to start cooking from this view
Cooking Experience:
Step-by-step recipe navigation
Voice guidance for each step
Keyboard shortcuts for hands-free control:
Arrow keys for step navigation
Space for play/pause audio
Escape to return to recipe selection
URL-based step tracking (e.g., /recipe/r_xlxG4bcTLs9jbM/classic-lasagna/steps/1)
State Management & Data Flow
Recipe Service:
API integration for fetching recipes
Support for pagination parameters
Tag-based filtering
Caching mechanisms for recipe data
Image URL handling for detailed views
Authentication Flow:
Google OAuth integration using environment variables
User session management
Authorization header management for API requests
Progressive Web App Features
PWA capabilities for installation on devices
Responsive design for various screen sizes
Favicon and app icon support
Deployment Architecture
Two-App Structure:
cook-voice-api: Rails backend on Heroku
cook-voice-wizard: React frontend/PWA on Heroku
Backend Infrastructure:
Ruby 3.2.2
PostgreSQL database (Heroku PostgreSQL addon)
Amazon S3 for file storage
Environment variables for configuration
Frontend Infrastructure:
React application
Environment variable configuration
Static buildpack on Heroku
SPA routing configuration
Security Measures:
HTTPS enforcement
Rails credentials system
Environment variables for sensitive information
Public ID system to mask database IDs
This comprehensive overview covers the major functionality of the Cook Voice application based on the available information. The application appears to be a sophisticated cooking assistant that combines recipe management with voice guidance to create a hands-free cooking experience.
2 notes
·
View notes
Text
god you know what else is fucking awful about social media empires dissolving? all the fucking APIs that have to get adjusted so that people can import or export blogs and get their tags off shit and so forth.
I am increasingly thinking about mirroring/automatically crossposting to bsky or dreamwidth or cohost, because I've always been a blogger and it seems like the time is ripe for that to be how we do things again. except that I mean, in the old days I always blogged on wordpress under the notion that wordpress was, like, the safe and reliable place to blog.
I might even have to set up a web site. disgusting, I'd have to put work stuff and professional self promotion on there and all. but that's how it's going these days.
so now I have to wonder, where is the API support to do something like that, can I do it easily, and can I integrate my dash?
ngl federation is looking real attractive right now.
15 notes
·
View notes
Text
How I Earn Passively on STON.fi Without Stress

DeFi offers endless ways to earn, but most people either complicate the process or think it’s only for expert traders. The truth? You don’t need to spend hours monitoring charts or making risky trades.
For me, STON.fi has been a game-changer. It’s simple, effective, and allows me to earn without constant effort. Here’s exactly how I do it:
✅ Providing liquidity and earning fees
✅ Staking STON tokens for exclusive rewards
✅ Farming with high-yield pools
✅ Participating in STON.fi contests for extra earnings
Let’s break it down.
1️⃣ Passive Income from Liquidity Pools
One of the easiest ways to earn on STON.fi is by providing liquidity. Instead of letting my tokens sit idle, I deposit them into a liquidity pool and get rewarded for every trade that happens in that pool.
What makes it profitable
STON token rewards: STON.fi distributes STON tokens to liquidity providers.
Loss protection: STON.fi offers a 5.72% offset, reducing potential impermanent loss.
Auto-rewards: No manual claims—everything is credited directly.
Protection fund: A $10,000 monthly budget helps secure liquidity providers.
This method requires zero daily effort. I deposit my funds and let them generate earnings while I focus on other things.
2️⃣ Staking STON for Long-Term Benefits
Staking is another effortless way I earn on STON.fi, but it’s more than just locking up tokens for APY. STON staking unlocks extra benefits that go beyond simple rewards.
Here’s what I gain from staking STON:
🔹 ARKENSTON NFT – A non-transferable NFT that grants exclusive access to STON.fi’s future governance system.
🔹 GEMSTON tokens – A community-powered token tied to the platform’s ecosystem.
Instead of just staking for yield, I gain access to the STON.fi ecosystem’s premium features.
3️⃣ Earning More with High-Yield Farming
For even higher returns, I take advantage of STON.fi’s farming pools. This is where rewards get serious.
How it works:
Provide liquidity to a farming pair
Receive LP tokens
Stake LP tokens in the farm
Earn passive rewards every few seconds
Top farms with massive APRs:
🔥 POE/TON → Over 999% APR
🔥 TADA/TON → 585% APR
🔥 WOOF/TON → 337% APR
The STON/USDT farming pool is also a solid option, recently boosted with an additional 10,000 STON (~$35,000) in rewards. Unlike other platforms, STON.fi farming has no lock-up period, meaning I can withdraw anytime.
4️⃣ Extra Earnings from STON.fi Contests
Aside from liquidity provision, staking, and farming, STON.fi offers frequent contests where I can earn rewards without investing money.
A recent example is the Infographics Contest, which had a $1,500 prize pool. These contests are perfect for community members who create content, design graphics, or actively engage with the platform.
If you’re looking for a way to earn without risking capital, these competitions provide free STON rewards just for participating.
Why STON.fi is My Go-To for Passive Income
Earning on STON.fi is straightforward and low-risk. I don’t have to trade aggressively or watch price charts all day.
✅ Providing liquidity gives me steady rewards while supporting the platform’s ecosystem.
✅ Staking STON secures future perks and governance access.
✅ Farming generates high APR returns with flexible withdrawals.
✅ Contests offer easy opportunities to earn STON without financial risk.
By combining all these methods, I’ve built a sustainable income stream without stress.
3 notes
·
View notes
Text
How I Earn Over $1,500 Monthly from STON.fi Without Trading

Most people think decentralized exchanges (DEXs) are just for trading. But I’ve found a way to consistently earn over $1,500 every month from STON.fi—without actively trading.
This is not about buying low and selling high. It’s about staking, farming, content creation, and leveraging the right opportunities.
If you’re looking for stable, passive income in Web3, here’s how I do it:
1. Staking STON – The Foundation of My Earnings
STON.fi allows staking of its native token, $STON, which generates additional rewards in governance tokens like Arkenston and Gemston.
This isn’t just about earning APY. These governance tokens hold value and can be used within the ecosystem or sold for profit.
By staking $STON, I receive a steady flow of rewards every month. The more I stake, the higher my rewards.
2. Farming Pools – The Passive Income Boost
Liquidity providers (LPs) on STON.fi earn rewards by supplying assets to farming pools. One of the best opportunities has been the STON/USDT V2 pool, which offers competitive yields.
The concern with farming is usually impermanent loss, but with proper research and risk management, I’ve maintained consistent earnings from the pool.
It’s one of the easiest ways to generate income while supporting the liquidity of the DEX.
3. Shelter 42 – Earn from Knowledge and Referrals
Shelter 42 is one of the most underrated earning opportunities on STON.fi. Unlike staking or farming, this program rewards users for answering blockchain-related questions correctly.
In addition to quiz rewards, there’s a referral system that provides extra earnings. By referring others to the game, I receive additional incentives, making it a dual-income opportunity.
For anyone with blockchain knowledge (or willing to learn), Shelter 42 offers a simple way to earn in the ecosystem.
4. Content Creation Contests – Web3 Rewards Beyond Trading
STON.fi isn’t just for traders—it also rewards content creators through its monthly contests.
I participated in a content creation competition, where users submitted articles, videos, and infographics about STON.fi. By providing valuable insights, I secured a top position and won $300 worth of STON tokens.
This is a perfect opportunity for anyone skilled in writing, design, or video editing to monetize their creativity.
5. The Stonbassador Program – Referral Earnings
One of the easiest income streams I’ve built is through the Stonbassador program—STON.fi’s referral system.
By inviting users to explore the platform, I earn commissions on their trading and staking activities.
Over time, as more users engage with the DEX, my referral earnings continue to grow passively.
Why STON.fi Is the Best Platform for Web3 Earners
STON.fi is the leading DEX on the TON blockchain, with:
✔️ $5.2B+ in total trading volume
✔️ 4M+ unique wallets
✔️ 25K+ daily active users
✔️ 700+ trading pairs
Beyond trading, STON.fi offers multiple earning opportunities for users who want to stake, farm, create content, and refer others.
If you’re looking for ways to earn in crypto without relying on market speculation, STON.fi is a platform worth exploring.
Final Thoughts
Since leveraging STON.fi’s ecosystem, I’ve built a steady $1,500+ monthly income without needing to actively trade.
For anyone serious about earning in Web3, these opportunities are worth considering.
💡 If you found this useful, explore STON.fi and start earning today.
3 notes
·
View notes
Text
youtube
People Think It’s Fake" | DeepSeek vs ChatGPT: The Ultimate 2024 Comparison (SEO-Optimized Guide)
The AI wars are heating up, and two giants—DeepSeek and ChatGPT—are battling for dominance. But why do so many users call DeepSeek "fake" while praising ChatGPT? Is it a myth, or is there truth to the claims? In this deep dive, we’ll uncover the facts, debunk myths, and reveal which AI truly reigns supreme. Plus, learn pro SEO tips to help this article outrank competitors on Google!
Chapters
00:00 Introduction - DeepSeek: China’s New AI Innovation
00:15 What is DeepSeek?
00:30 DeepSeek’s Impressive Statistics
00:50 Comparison: DeepSeek vs GPT-4
01:10 Technology Behind DeepSeek
01:30 Impact on AI, Finance, and Trading
01:50 DeepSeek’s Effect on Bitcoin & Trading
02:10 Future of AI with DeepSeek
02:25 Conclusion - The Future is Here!
Why Do People Call DeepSeek "Fake"? (The Truth Revealed)
The Language Barrier Myth
DeepSeek is trained primarily on Chinese-language data, leading to awkward English responses.
Example: A user asked, "Write a poem about New York," and DeepSeek referenced skyscrapers as "giant bamboo shoots."
SEO Keyword: "DeepSeek English accuracy."
Cultural Misunderstandings
DeepSeek’s humor, idioms, and examples cater to Chinese audiences. Global users find this confusing.
ChatGPT, trained on Western data, feels more "relatable" to English speakers.
Lack of Transparency
Unlike OpenAI’s detailed GPT-4 technical report, DeepSeek’s training data and ethics are shrouded in secrecy.
LSI Keyword: "DeepSeek data sources."
Viral "Fail" Videos
TikTok clips show DeepSeek claiming "The Earth is flat" or "Elon Musk invented Bitcoin." Most are outdated or edited—ChatGPT made similar errors in 2022!
DeepSeek vs ChatGPT: The Ultimate 2024 Comparison
1. Language & Creativity
ChatGPT: Wins for English content (blogs, scripts, code).
Strengths: Natural flow, humor, and cultural nuance.
Weakness: Overly cautious (e.g., refuses to write "controversial" topics).
DeepSeek: Best for Chinese markets (e.g., Baidu SEO, WeChat posts).
Strengths: Slang, idioms, and local trends.
Weakness: Struggles with Western metaphors.
SEO Tip: Use keywords like "Best AI for Chinese content" or "DeepSeek Baidu SEO."
2. Technical Abilities
Coding:
ChatGPT: Solves Python/JavaScript errors, writes clean code.
DeepSeek: Better at Alibaba Cloud APIs and Chinese frameworks.
Data Analysis:
Both handle spreadsheets, but DeepSeek integrates with Tencent Docs.
3. Pricing & Accessibility
FeatureDeepSeekChatGPTFree TierUnlimited basic queriesGPT-3.5 onlyPro Plan$10/month (advanced Chinese tools)$20/month (GPT-4 + plugins)APIsCheaper for bulk Chinese tasksGlobal enterprise support
SEO Keyword: "DeepSeek pricing 2024."
Debunking the "Fake AI" Myth: 3 Case Studies
Case Study 1: A Shanghai e-commerce firm used DeepSeek to automate customer service on Taobao, cutting response time by 50%.
Case Study 2: A U.S. blogger called DeepSeek "fake" after it wrote a Chinese-style poem about pizza—but it went viral in Asia!
Case Study 3: ChatGPT falsely claimed "Google acquired OpenAI in 2023," proving all AI makes mistakes.
How to Choose: DeepSeek or ChatGPT?
Pick ChatGPT if:
You need English content, coding help, or global trends.
You value brand recognition and transparency.
Pick DeepSeek if:
You target Chinese audiences or need cost-effective APIs.
You work with platforms like WeChat, Douyin, or Alibaba.
LSI Keyword: "DeepSeek for Chinese marketing."
SEO-Optimized FAQs (Voice Search Ready!)
"Is DeepSeek a scam?" No! It’s a legitimate AI optimized for Chinese-language tasks.
"Can DeepSeek replace ChatGPT?" For Chinese users, yes. For global content, stick with ChatGPT.
"Why does DeepSeek give weird answers?" Cultural gaps and training focus. Use it for specific niches, not general queries.
"Is DeepSeek safe to use?" Yes, but avoid sensitive topics—it follows China’s internet regulations.
Pro Tips to Boost Your Google Ranking
Sprinkle Keywords Naturally: Use "DeepSeek vs ChatGPT" 4–6 times.
Internal Linking: Link to related posts (e.g., "How to Use ChatGPT for SEO").
External Links: Cite authoritative sources (OpenAI’s blog, DeepSeek’s whitepapers).
Mobile Optimization: 60% of users read via phone—use short paragraphs.
Engagement Hooks: Ask readers to comment (e.g., "Which AI do you trust?").
Final Verdict: Why DeepSeek Isn’t Fake (But ChatGPT Isn’t Perfect)
The "fake" label stems from cultural bias and misinformation. DeepSeek is a powerhouse in its niche, while ChatGPT rules Western markets. For SEO success:
Target long-tail keywords like "Is DeepSeek good for Chinese SEO?"
Use schema markup for FAQs and comparisons.
Update content quarterly to stay ahead of AI updates.
🚀 Ready to Dominate Google? Share this article, leave a comment, and watch it climb to #1!
Follow for more AI vs AI battles—because in 2024, knowledge is power! 🔍
#ChatGPT alternatives#ChatGPT features#ChatGPT vs DeepSeek#DeepSeek AI review#DeepSeek vs OpenAI#Generative AI tools#chatbot performance#deepseek ai#future of nlp#deepseek vs chatgpt#deepseek#chatgpt#deepseek r1 vs chatgpt#chatgpt deepseek#deepseek r1#deepseek v3#deepseek china#deepseek r1 ai#deepseek ai model#china deepseek ai#deepseek vs o1#deepseek stock#deepseek r1 live#deepseek vs chatgpt hindi#what is deepseek#deepseek v2#deepseek kya hai#Youtube
2 notes
·
View notes