#hpc cluster manager
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr’s reach among the 26-to-35-year-olds in the US is 11%.
Note
How's it going learning python? I needed to learn the very, very basics last year and it was fun, but at the same time so difficult to understand and remember all the codes, especially functions and all the stuff for diagrams like matplotlib etc. Hope it's going well for you :)
Listen bestie I'm at a print("Hello, World!") and add # before comments stage :D learned how to define structures and print(type(x)). I'm a baby.
But overall, I think it will be fun to use! If I manage to do anything :D because I have a shit ton to do on top of all that (full time work, writing an introduction to an article, making a med student a material for his cell bio microscope slides, and making an hour long lecture abt my thesis for school kids :D it's all due next week :D)
But overall I think I will be okay, because complicated things don't scare me as much as they used to. And besides I won't have to remember everything by heart. If it's me and stackoverflow against python let it be, I've been there with R.
And I'm actually very scared of matplotlib bc it was an extra credit task we had to perform on a hpc cluster and I had no idea how to do it (the rest of the code was given to us ready except the extra credit tasks). It was the end of the lesson so I just. Left.
3 notes
·
View notes
Text
HPE Servers' Performance in Data Centers
HPE servers are widely regarded as high-performing, reliable, and well-suited for enterprise data center environments, consistently ranking among the top vendors globally. Here’s a breakdown of their performance across key dimensions:
1. Reliability & Stability (RAS Features)
Mission-Critical Uptime: HPE ProLiant (Gen10/Gen11), Synergy, and Integrity servers incorporate robust RAS (Reliability, Availability, Serviceability) features:
iLO (Integrated Lights-Out): Advanced remote management for monitoring, diagnostics, and repairs.
Smart Array Controllers: Hardware RAID with cache protection against power loss.
Silicon Root of Trust: Hardware-enforced security against firmware tampering.
Predictive analytics via HPE InfoSight for preemptive failure detection.
Result: High MTBF (Mean Time Between Failures) and minimal unplanned downtime.
2. Performance & Scalability
Latest Hardware: Support for newest Intel Xeon Scalable & AMD EPYC CPUs, DDR5 memory, PCIe 5.0, and high-speed NVMe storage.
Workload-Optimized:
ProLiant DL/ML: Versatile for virtualization, databases, and HCI.
Synergy: Composable infrastructure for dynamic resource pooling.
Apollo: High-density compute for HPC/AI.
Scalability: Modular designs (e.g., Synergy frames) allow scaling compute/storage independently.
3. Management & Automation
HPE OneView: Unified infrastructure management for servers, storage, and networking (automates provisioning, updates, and compliance).
Cloud Integration: Native tools for hybrid cloud (e.g., HPE GreenLake) and APIs for Terraform/Ansible.
HPE InfoSight: AI-driven analytics for optimizing performance and predicting issues.
4. Energy Efficiency & Cooling
Silent Smart Cooling: Dynamic fan control tuned for variable workloads.
Thermal Design: Optimized airflow (e.g., HPE Apollo 4000 supports direct liquid cooling).
Energy Star Certifications: ProLiant servers often exceed efficiency standards, reducing power/cooling costs.
5. Security
Firmware Integrity: Silicon Root of Trust ensures secure boot.
Cyber Resilience: Runtime intrusion detection, encrypted memory (AMD SEV-SNP, Intel SGX), and secure erase.
Zero Trust Architecture: Integrated with HPE Aruba networking for end-to-end security.
6. Hybrid Cloud & Edge Integration
HPE GreenLake: Consumption-based "as-a-service" model for on-premises data centers.
Edge Solutions: Compact servers (e.g., Edgeline EL8000) for rugged/remote deployments.
7. Support & Services
HPE Pointnext: Proactive 24/7 support, certified spare parts, and global service coverage.
Firmware/Driver Ecosystem: Regular updates with long-term lifecycle support.
Ideal Use Cases
Enterprise Virtualization: VMware/Hyper-V clusters on ProLiant.
Hybrid Cloud: GreenLake-managed private/hybrid environments.
AI/HPC: Apollo systems for GPU-heavy workloads.
SAP/Oracle: Mission-critical applications on Superdome Flex.
Considerations & Challenges
Cost: Premium pricing vs. white-box/OEM alternatives.
Complexity: Advanced features (e.g., Synergy/OneView) require training.
Ecosystem Lock-in: Best with HPE storage/networking for full integration.
Competitive Positioning
vs Dell PowerEdge: Comparable performance; HPE leads in composable infrastructure (Synergy) and AI-driven ops (InfoSight).
vs Cisco UCS: UCS excels in unified networking; HPE offers broader edge-to-cloud portfolio.
vs Lenovo ThinkSystem: Similar RAS; HPE has stronger hybrid cloud services (GreenLake).
Summary: HPE Server Strengths in Data Centers
Reliability: Industry-leading RAS + iLO management. Automation: AI-driven ops (InfoSight) + composability (Synergy). Efficiency: Energy-optimized designs + liquid cooling support. Security: End-to-end Zero Trust + firmware hardening. Hybrid Cloud: GreenLake consumption model + consistent API-driven management.
Bottom Line: HPE servers excel in demanding, large-scale data centers prioritizing stability, automation, and hybrid cloud flexibility. While priced at a premium, their RAS capabilities, management ecosystem, and global support justify the investment for enterprises with critical workloads. For SMBs or hyperscale web-tier deployments, cost may drive consideration of alternatives.
0 notes
Text
HD Grease Market Insights: How Thermal Interface Materials Are Changing the Game

Global Heat Dissipation Grease (HD Grease) Market is experiencing robust expansion, with valuations reaching USD 144 million in 2023. Current projections indicate the market will grow at a compound annual growth rate (CAGR) of 6.8%, potentially reaching USD 260.32 million by 2032. This accelerated trajectory stems from surging demand in electronics manufacturing, electric vehicle production, and next-gen computing infrastructure where thermal management is critical.
Thermal interface materials like HD grease have become indispensable in modern electronics, filling microscopic imperfections between heat-generating components and cooling apparatus. As device miniaturization continues alongside rising power densities, manufacturers are prioritizing advanced formulations with exceptional thermal conductivity (often exceeding 8 W/mK) and extended reliability under thermal cycling.
Download FREE Sample Report: https://www.24chemicalresearch.com/download-sample/288926/global-heat-dissipation-grease-forecast-market-2025-2032-519
Market Overview & Regional Analysis
Asia-Pacific commands over 55% of global HD grease consumption, with China's electronics manufacturing hubs and South Korea's semiconductor industry driving demand. The region benefits from concentrated supply chains and swift adoption of 5G infrastructure, which requires advanced thermal solutions for base stations and edge computing devices. Japanese manufacturers continue leading in high-performance formulations, particularly for automotive electronics.
North America maintains strong growth through its advanced computing sector, where data centers and AI hardware necessitate premium thermal interface materials. Europe's market thrives on stringent electronic reliability standards and growing EV adoption, with Germany's automotive suppliers emerging as key consumers. Emerging markets in Southeast Asia show accelerating demand, fueled by electronics production shifting from traditional manufacturing centers.
Key Market Drivers and Opportunities
The market's expansion hinges on three pivotal factors: the unstoppable march of electronics miniaturization, the automotive industry's rapid electrification, and escalating data center investments. Semiconductor packaging accounts for 38% of HD grease applications, followed by EV power electronics at 22% and consumer electronics at 19%. The burgeoning field of high-performance computing (HPC) presents new frontiers, with GPU clusters and AI accelerators requiring advanced thermal solutions.
Innovation opportunities abound in metal-particle enhanced greases (achieving 12-15 W/mK conductivity) and phase-change materials that combine grease-like application with pad-like stability. The photovoltaic sector also emerges as a growth vector, where solar microinverters demand durable thermal compounds resistant to outdoor weathering. Meanwhile, aerospace applications for satellite electronics create specialized niche markets requiring extreme temperature stability.
Challenges & Restraints
Material scientists face persistent hurdles in balancing thermal performance with practical considerations. High-performance formulations frequently encounter pump-out issues under thermal cycling, while silicone-based variants risk contaminating sensitive optical components. The automotive sector's transition to 800V architectures introduces new challenges - requiring greases that maintain performance across wider temperature swings while resisting electrochemical migration.
Supply chain complexities pose additional concerns, with specialty fillers like boron nitride and aluminum oxide facing periodic shortages. Regulatory landscapes continue evolving, particularly regarding silicone content restrictions in certain electronics applications. Furthermore, the industry struggles with standardization - thermal conductivity claims often vary significantly between testing methodologies.
Market Segmentation by Type
Silicone-Based Thermal Grease
Silicone-Free Thermal Grease
Metal-Particle Enhanced Formulations
Download FREE Sample Report: https://www.24chemicalresearch.com/download-sample/288926/global-heat-dissipation-grease-forecast-market-2025-2032-519
Market Segmentation by Application
Consumer Electronics (Smartphones, Tablets, Laptops)
Automotive Electronics (EV Batteries, Inverters)
Telecommunications Infrastructure
Data Center Equipment
Industrial Electronics
LED Lighting Systems
Market Segmentation and Key Players
Dow Chemical Company
Henkel AG & Co. KGaA
Shin-Etsu Chemical Co., Ltd.
Parker Hannifin Corporation
3M Company
Laird Technologies
Momentive Performance Materials
Wakefield-Vette
Zalman Tech
Thermal Grizzly
Arctic Silver
Fujipoly
Denka Company Limited
Gelon LIB Group
Dongguan Jiezheng Electronics
Report Scope
This comprehensive analysis examines the global HD grease landscape from 2024 to 2032, providing granular insights into:
Volume and revenue projections across key regions and applications
Detailed technology segmentation by formulation type and performance characteristics
Supply chain dynamics including raw material sourcing and manufacturing trends
Regulatory landscape analysis for major jurisdictions
The report features exhaustive profiles of 25 leading manufacturers, evaluating:
Product portfolios and R&D pipelines
Production capacities and geographic footprints
Key partnerships and client ecosystems
Pricing strategies and distribution networks
Get Full Report Here: https://www.24chemicalresearch.com/reports/288926/global-heat-dissipation-grease-forecast-market-2025-2032-519
About 24chemicalresearch
Founded in 2015, 24chemicalresearch has rapidly established itself as a leader in chemical market intelligence, serving clients including over 30 Fortune 500 companies. We provide data-driven insights through rigorous research methodologies, addressing key industry factors such as government policy, emerging technologies, and competitive landscapes.
Plant-level capacity tracking
Real-time price monitoring
Techno-economic feasibility studies
With a dedicated team of researchers possessing over a decade of experience, we focus on delivering actionable, timely, and high-quality reports to help clients achieve their strategic goals. Our mission is to be the most trusted resource for market insights in the chemical and materials industries.
International: +1(332) 2424 294 | Asia: +91 9169162030
Website: https://www.24chemicalresearch.com/
Follow us on LinkedIn: https://www.linkedin.com/company/24chemicalresearch
Other Related Reports:
0 notes
Text
InnoChill Immersion Cooling Fluid: The Smart Choice Over 3M Fluorinert & Other Brands
As high-performance computing (HPC), AI data centers, and cryptocurrency mining farms demand better thermal management, immersion cooling fluids have become essential for efficient heat dissipation and hardware longevity. While brands like 3M Fluorinert, Shell, and Engineered Fluids dominate the market, they come with high costs, environmental concerns, or limited efficiency.
This is where InnoChill Immersion Cooling Fluid stands out—delivering superior performance, eco-friendliness, and cost-effectiveness compared to leading brands.

Why InnoChill Outperforms 3M Fluorinert & Other Competitors
1. Higher Thermal Conductivity for Superior Heat Dissipation Efficient heat transfer is critical for AI processors, GPU clusters, and cryptocurrency mining rigs. InnoChill’s fluid features a thermal conductivity of 0.145 – 0.155 W/m·K, nearly 3 times higher than 3M Fluorinert (0.057 W/m·K), ensuring rapid heat removal and preventing hardware overheating. 2. Outstanding Electrical Insulation & Safety With a dielectric strength of >40 kV/mm, InnoChill provides maximum protection against electrical breakdown, surpassing 3M Fluorinert (20 kV/mm) and Engineered Fluids ElectroCool (38 kV/mm). This makes it ideal for direct-to-chip and immersion cooling setups in data centers and energy storage systems. 3. Eco-Friendly & Sustainable—No More High GWP Concerns! One of the biggest drawbacks of 3M Fluorinert is its Global Warming Potential (GWP) exceeding 7,000. In contrast, InnoChill’s immersion fluid is eco-friendly, biodegradable, and designed for long-term sustainability. Data centers seeking low-carbon cooling solutions can significantly reduce their environmental footprint with InnoChill. 4. Cost-Effective—Cut Cooling Costs by 80% At just $15 – $25 per liter, InnoChill is over 80% more affordable than 3M Fluorinert ($200+ per liter) while delivering equal or superior performance. Companies can achieve better cooling efficiency at a fraction of the cost, lowering Total Cost of Ownership (TCO) over time. 5. Extended Fluid Lifespan—Over 10 Years of Reliable Performance Fluids with shorter lifespans require frequent replacement, increasing operational costs. InnoChill lasts over 10 years, outperforming competitors like 3M Fluorinert (5–7 years) and Shell’s immersion cooling fluid (6–8 years).
Technical Comparison: InnoChill Immersion Cooling Fluid vs. Competitors
Parameter
InnoChill Immersion Cooling Fluid
3M Fluorinert FC-72
Shell Immersion Cooling Fluid
Engineered Fluids ElectroCool
Base Composition
Advanced Silicone Oil Blend
Fluorocarbon-Based
Hydrocarbon-Based
Synthetic Dielectric Fluid
Thermal Conductivity (W/m·K)
0.145 – 0.155
0.057
0.12 – 0.14
0.135 – 0.145
Specific Heat Capacity (J/g·K)
1.55 – 1.70
1.10
1.25 – 1.40
1.50 – 1.65
Viscosity @ 25°C (cSt)
10 – 15
0.64
4 – 8
9 – 13
Dielectric Strength (kV/mm)
>40
20
35
38
Density (g/cm³ @ 25°C)
0.85 – 0.92
1.68
0.79 – 0.85
0.85 – 0.88
Boiling Point (°C)
>250
56
200 – 260
>200
Pour Point (°C)
<-45
-90
-35
-40
Global Warming Potential (GWP)
Near Zero
>7,000
Low
Biodegradable
Lifespan (Years)
>10 years
5 – 7 years
6 – 8 years
8 – 10 years
Price ($/Liter)
$15 – $25
$200+
$30 – $50
$20 – $40
The Best Choice for Data Centers, AI, and Crypto Mining
For Data Center Managers & IT Professionals InnoChill provides the reliable, energy-efficient cooling solution you need to optimize your server uptime, reduce energy consumption, and lower costs. Make the smart move today and achieve unparalleled cooling performance at a fraction of the cost compared to traditional methods. For AI & HPC Engineers Keep your high-performance AI models and HPC clusters running smoothly with advanced thermal management. InnoChill’s superior heat dissipation ensures that your hardware performs at its best, even during the most demanding tasks. For Cryptocurrency Mining Operators Cut the cost of cooling while protecting your mining rigs from overheating. InnoChill's cost-effectiveness and extended fluid lifespan help maximize profitability in the competitive world of crypto mining. For Battery Storage & EV Manufacturers InnoChill offers advanced immersion cooling that extends the lifespan and safety of EV batteries and energy storage systems by ensuring optimal temperature management.
Get a Quote Today for Your Data Center Cooling Needs: [InnoChill ED01 Immersion Cooling Fluid | High-Performance Heat Dissipation For Data Centers & Energy Storage] Optimize Your Cooling Today with InnoChill: [InnoChill ED01 Immersion Cooling Fluid | High-Performance Heat Dissipation For Data Centers & Energy Storage] Request Your InnoChill Quote Now & Boost Your Mining Efficiency: [InnoChill ED01 Immersion Cooling Fluid | High-Performance Heat Dissipation For Data Centers & Energy Storage] Revolutionize Your Battery Cooling with InnoChill: [InnoChill ED01 Immersion Cooling Fluid | High-Performance Heat Dissipation For Data Centers & Energy Storage]
#Immersion cooling fluid#3M Fluorinert alternative#data center cooling#sustainable immersion cooling
0 notes
Text
Exascale Computing Market Size, Share, Analysis, Forecast, and Growth Trends to 2032: The Race to One Quintillion Calculations Per Second

The Exascale Computing Market was valued at USD 3.47 billion in 2023 and is expected to reach USD 29.58 billion by 2032, growing at a CAGR of 26.96% from 2024-2032.
The Exascale Computing Market is undergoing a profound transformation, unlocking unprecedented levels of computational performance. With the ability to process a billion billion (quintillion) calculations per second, exascale systems are enabling breakthroughs in climate modeling, genomics, advanced materials, and national security. Governments and tech giants are investing aggressively, fueling a race for exascale dominance that’s reshaping industries and redefining innovation timelines.
Exascale Computing Market revolutionary computing paradigm is being rapidly adopted across sectors seeking to harness the immense data-crunching potential. From predictive simulations to AI-powered discovery, exascale capabilities are enabling new frontiers in science, defense, and enterprise. Its impact is now expanding beyond research labs into commercial ecosystems, paving the way for smarter infrastructure, precision medicine, and real-time global analytics.
Get Sample Copy of This Report: https://www.snsinsider.com/sample-request/6035
Market Keyplayers:
Hewlett Packard Enterprise (HPE) [HPE Cray EX235a, HPE Slingshot-11]
International Business Machines Corporation (IBM) [IBM Power System AC922, IBM Power System S922LC]
Intel Corporation [Intel Xeon Max 9470, Intel Max 1550]
NVIDIA Corporation [NVIDIA GH200 Superchip, NVIDIA Hopper H100]
Cray Inc. [Cray EX235a, Cray EX254n]
Fujitsu Limited [Fujitsu A64FX, Tofu interconnect D]
Advanced Micro Devices, Inc. (AMD) [AMD EPYC 64C 2.0GHz, AMD Instinct MI250X]
Lenovo Group Limited [Lenovo ThinkSystem SD650 V3, Lenovo ThinkSystem SR670 V2]
Atos SE [BullSequana XH3000, BullSequana XH2000]
NEC Corporation [SX-Aurora TSUBASA, NEC Vector Engine]
Dell Technologies [Dell EMC PowerEdge XE8545, Dell EMC PowerSwitch Z9332F]
Microsoft [Microsoft Azure NDv5, Microsoft Azure HPC Cache]
Amazon Web Services (AWS) [AWS Graviton3, AWS Nitro System]
Sugon [Sugon TC8600, Sugon I620-G30]
Google [Google TPU v4, Google Cloud HPC VM]
Alibaba Cloud [Alibaba Cloud ECS Bare Metal Instance, Alibaba Cloud HPC Cluster]
Market Analysis The exascale computing landscape is characterized by high-stakes R&D, global governmental collaborations, and fierce private sector competition. With countries like the U.S., China, and members of the EU launching national initiatives, the market is shaped by a mix of geopolitical strategy and cutting-edge technology. Key players are focusing on developing energy-efficient architectures, innovative software stacks, and seamless integration with artificial intelligence and machine learning platforms. Hardware giants are partnering with universities, startups, and defense organizations to accelerate deployments and overcome system-level challenges such as cooling, parallelism, and power consumption.
Market Trends
Surge in demand for high-performance computing in AI and deep learning
Integration of exascale systems with cloud and edge computing ecosystems
Government funding and national strategic investments on the rise
Development of heterogeneous computing systems (CPUs, GPUs, accelerators)
Emergence of quantum-ready hybrid systems alongside exascale architecture
Adoption across healthcare, aerospace, energy, and climate research sectors
Market Scope
Supercomputing for Scientific Discovery: Empowering real-time modeling and simulations at unprecedented speeds
Defense and Intelligence Advancements: Enhancing cybersecurity, encryption, and strategic simulations
Precision Healthcare Applications: Supporting drug discovery, genomics, and predictive diagnostics
Sustainable Energy Innovations: Enabling complex energy grid management and fusion research
Smart Cities and Infrastructure: Driving intelligent urban planning, disaster management, and IoT integration
As global industries shift toward data-driven decision-making, the market scope of exascale computing is expanding dramatically. Its capacity to manage and interpret massive datasets in real-time is making it essential for competitive advantage in a rapidly digitalizing world.
Market Forecast The trajectory of the exascale computing market points toward rapid scalability and broader accessibility. With increasing collaborations between public and private sectors, we can expect a new wave of deployments that bridge research and industry. The market is moving from proof-of-concept to full-scale operationalization, setting the stage for widespread adoption across diversified verticals. Upcoming innovations in chip design, power efficiency, and software ecosystems will further accelerate this trend, creating a fertile ground for startups and enterprise adoption alike.
Access Complete Report: https://www.snsinsider.com/reports/exascale-computing-market-6035
Conclusion Exascale computing is no longer a vision of the future—it is the powerhouse of today’s digital evolution. As industries align with the pace of computational innovation, those embracing exascale capabilities will lead the next wave of transformation. With its profound impact on science, security, and commerce, the exascale computing market is not just growing—it is redefining the very nature of progress. Businesses, researchers, and nations prepared to ride this wave will find themselves at the forefront of a smarter, faster, and more resilient future.
About Us:
SNS Insider is one of the leading market research and consulting agencies that dominates the market research industry globally. Our company's aim is to give clients the knowledge they require in order to function in changing circumstances. In order to give you current, accurate market data, consumer insights, and opinions so that you can make decisions with confidence, we employ a variety of techniques, including surveys, video talks, and focus groups around the world.
Contact Us:
Jagney Dave - Vice President of Client Engagement
Phone: +1-315 636 4242 (US) | +44- 20 3290 5010 (UK)
0 notes
Text
Orchestrate HPC Systems
One of the key concepts of cloud computing is Orchestration. It refers to overseeing the deployment, running, and monitoring of all the components of an application in the cluster. Additionally, an orchestrator can perform other tasks like healing (managing errors), scaling, and logging. Orchestrators like the well-known Kubernetes or Mesos can access cloud cluster resources directly by…
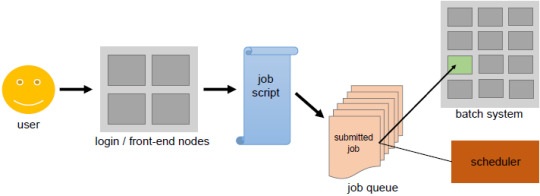
View On WordPress
0 notes
Text
AMD ROCm 6.4: Scalable Inference and Smarter AI Workflows

AMD ROCm 6.4: Plug-and-Play Containers, Modular Deployment, and Revolutionary Inference for Scalable AI on AMD Instinct GPUs
Modern AI workloads are larger and more sophisticated, increasing deployment simplicity and performance needs. AMD ROCm 6.4 advances AI and HPC development on AMD Instinct GPUs.
With growing support for leading AI frameworks, optimised containers, and modular infrastructure tools, ROCm software helps customers manage their AI infrastructure, develop faster, and work smarter.
Whether you're managing massive GPU clusters, training multi-billion parameter models, or spreading inference over multi-node clusters, AMD ROCm 6.4 delivers great performance with AMD Instinct GPUs.
This post presents five major AMD ROCm 6.4 improvements that directly address infrastructure teams, model developers, and AI researchers' concerns to enable AI development fast, straightforward, and scalable.
ROCm Training and Inference Containers: Instinct GPU Plug-and-Play AI
Setting up and maintaining ideal training and inference settings takes time, is error-prone, and delays iteration cycles. AMD ROCm 6.4 provides a large set of pre-optimized, ready-to-run training and inference containers for AMD Instinct GPUs.
For low-latency LLM inference, vLLM (Inference Container) supports plug-and-play open models like Gemma 3 (day-0), Llama, Mistral, Cohere, and others.
FP8 support, DeepGEMM, and simultaneous multi-head attention give SGLang (Inference Container) exceptional throughput and efficiency for DeepSeek R1 and agentic processes.
PyTorch (Training Container) makes LLM training on AMD Instinct MI300X GPUs simpler with performance-tuned variations that enable advanced attention strategies. Optimised for FLUX, Llama 2 (70B), and 3.1 (8B, 70B).1-dev.
Training Container Megatron-LM This ROCm-tuned Megatron-LM fork can train large-scale language models like Llama 3.1, Llama 2, and DeepSeek-V2-Lite.
These containers allow AI researchers faster access to turnkey settings for experimentation and model evaluation. Model developers may use pre-tuned support for the most advanced LLMs, including as DeepSeek, Gemma 3, and Llama 3.1, without spending time configuring. These containers also simplify infrastructure teams' maintenance and scale-out by deploying uniformly across development, testing, and production environments.
PyTorch for ROCm Improves: Faster Focus and Training
As training large language models (LLMs) pushes computing and memory limits, ineffective attention strategies can impede iteration and increase infrastructure costs. AMD ROCm 6.4 improves Flex Attention, TopK, and Scaled Dot-Product Attention in PyTorch.
Flex Attention: Outperforms ROCm 6.3 in LLM workloads that need advanced attention algorithms, reducing memory overhead and training time.
TopK: TopK processes are now three times faster, improving inference reaction times without compromising output quality (source).
SDPA: expanded context, smoother inference.
These improvements speed up training, reduce memory overhead, and optimise hardware consumption. As a consequence, model developers can improve bigger models faster, AI researchers can do more tests, and Instinct GPU customers see shorter time-to-train and higher infrastructure ROI.
Upgrades are pre-installed in the ROCm PyTorch container.
AMD Instinct GPU Next-Gen Inference Performance with vLLM and SGLang
Low-latency, high-throughput inference for big language models is difficult, especially when new models develop and deployment pace increases. ROCm 6.4 addresses this problem with AMD Instinct GPU-optimized vLLM and SGLang versions. Due to its strong support for popular models like Grok, DeepSeek R1, Gemma 3, and Llama 3.1 (8B, 70B, and 405B), model developers can deploy real-world inference pipelines with minimal modification or rewrite. AI researchers can get faster time-to-results on large-scale benchmarks. Infrastructure teams can ensure scaled performance, consistency, and reliability with stable, production-ready containers that get weekly updates.
Set an Instinct MI300X throughput record using SGLang and DeepSeek R1.
Day-0 compatibility for Instinct GPU deployment with vLLM Gemma 3.
These technologies create a full-stack inference environment with weekly and bi-weekly development and stable container upgrades.
Smooth Instinct GPU Cluster Management by AMD GPU Operator
Scaling and managing GPU workloads across Kubernetes clusters can cause manual driver updates, operational disruptions, and limited GPU health visibility, which can reduce performance and reliability. With AMD ROCm 6.4, the AMD GPU Operator automates GPU scheduling, driver lifecycle management, and real-time telemetry to optimise cluster operations. This allows AI and HPC administrators to confidently deploy AMD Instinct GPUs in air-gapped and secure environments with full observability, infrastructure teams to upgrade with minimal disruption, and Instinct customers to benefit from increased uptime, lower operational risk, and stronger AI infrastructure.
Some new features are:
Automatic cordon, drain, and reboot for rolling updates.
More support for Ubuntu 22.04/24.04 and Red Hat OpenShift 4.16–4.17 ensures compatibility with modern cloud and enterprise settings.
Device Metrics Exporter for real-time Prometheus health measurements.
The New Instinct GPU Driver Modularises Software
Coupled driver stacks hinder upgrade processes, reduce interoperability, and increase maintenance risk. AMD ROCm 6.4 introduces the modular Instinct GPU Driver, which isolates the kernel driver from ROCm user space.
main benefits,
Infrastructure teams may now upgrade ROCm libraries and drivers separately.
Extended compatibility to 12 months (from 6 months in earlier iterations)
More flexibility in installing ISV software, bare metal, and containers
This simplifies fleet-wide upgrades and reduces the risk of breaking changes, which benefits cloud providers, government agencies, and enterprises with strict SLAs.
AITER for Accelerated Inference Bonus Point
AITER, a high-performance inference library with drop-in, pre-optimized kernels, removes tedious tuning in AMD ROCm 6.4.
Gives:
It can decode 17 times quicker.
14X multi-head focus improvements
Double LLM inference throughput
#technology#technews#govindhtech#news#technologynews#AMD Instinct#AMD ROCm 6.4#AMD ROCm#ROCm 6.4#ROCm#Plug-and-Play AI on Instinct GPUs#ROCm Containers for Training and Inference#artificial intelligence
0 notes
Text
Job - Alert 💻

🚀 Join the Max Planck Institute of Geoanthropology as Head of the Centre for High Performance Computing (HPC)! 🌍
We are looking for an experienced leader to oversee our state-of-the-art HPC cluster and support groundbreaking interdisciplinary research. If you have a Master’s degree in Computer Science, Engineering, or a related field, along with extensive HPC management experience, we want to hear from you!
📝 Application Deadline: April 15
📧 Send your application to:
https://www.academiceurope.com/job/?id=7071
Be part of our dynamic research environment, contributing to a sustainable future! 🌱
#hiring #MaxPlanck #Geoanthropology #computerscience #computerengineering #informatics
0 notes
Text
Cutting-Edge Network Services by Fusion Dynamics
Discover the future of networking with cutting-edge network services from Fusion Dynamics.
Specializing in innovative solutions that enhance connectivity and performance, Fusion Dynamics provides tailored services to meet the needs of modern businesses.

Fusion Dynamics is an IT infrastructure pioneer providing cutting-edge computing and data center solutions to various industries. Our team has conceptualized, designed, and deployed transformational digital infrastructure for a diverse set of organisations, with custom solutions tailormade for their unique requirements and challenges.
Discover top-notch services on cloud computing with Fusion Dynamics. From cloud migration and management to customized solutions, Fusion Dynamics offers scalable and secure cloud services that align with your business needs.
Optimize your infrastructure and enhance efficiency with our expert cloud computing solutions.
Why Choose Us
We bring a potent combination of over two decades of experience in IT solutions and a dynamic approach to continuously evolve with the latest data storage, computing, and networking technology. Our team constitutes domain experts who liaise with you throughout the end-to-end journey of setting up and operating an advanced data center.
With a profound understanding of modern digital requirements, backed by decades of industry experience, we work closely with your organisation to design the most efficient systems to catalyse innovation. From sourcing cutting-edge components from leading global technology providers to seamlessly integrating them for rapid deployment, we deliver state-of-the-art computing infrastructures to drive your growth!
Learn more about how we can transform your cloud strategy here: https://fusiondynamics.io
Contact Us
+91 95388 99792
Learn more about their services here: https://fusiondynamics.io.
#Keywords#services on cloud computing#edge network services#available cloud computing services#cloud computing based services#cooling solutions#hpc cluster management software#cloud backups for business#platform as a service vendors#edge computing services#Secondary Keyword#service provided by cloud computing#popular cloud computing services#the best cloud computing services#data center cooling#data centers cooling systems#server cooling system#server cooling solutions#advanced cooling systems for cloud computing#cloud workload protection#cloud workload security solutions#hpc clustering#hpc cluster manager#server cloud backups#paas cloud services#cloud services saas paas iaas#ipaas services#edge computing platform#edge computing solutions#cloud native technology
0 notes
Text
AWS Exam Sample Questions 2025?
To effectively prepare for the AWS Certified Solutions Architect – Associate (SAA-C03) exam in 2025, follow these steps:
Understand the Exam Objectives – Review the official AWS exam guide to understand key topics.
Study with Reliable Resources – Use AWS whitepapers, documentation, and online courses.
Practice with Clearcatnet – Utilize Clearcatnet's latest practice tests to assess your knowledge and improve weak areas.
Hands-on Experience – Gain practical experience by working on AWS services in a real or simulated environment.
Review and Revise – Revisit important concepts, practice time management, and take mock tests before the exam.
By following this structured approach, you can confidently prepare and increase your chances of passing the SAA-C03 exam on your first attempt.
Which service allows you to securely connect an on-premises network to AWS?
A) AWS Direct Connect B) Amazon Route 53 C) Amazon CloudFront D) AWS Snowball
A company wants to host a web application with high availability. Which solution should they use?
A) Deploy on a single EC2 instance with an Elastic IP B) Use an Auto Scaling group across multiple Availability Zones C) Store website files on Amazon S3 and use CloudFront D) Host the application on an Amazon RDS instance
What AWS service allows you to run containerized applications without managing servers?
A) AWS Lambda B) Amazon ECS with Fargate C) Amazon RDS D) AWS Glue
Which AWS storage service provides automatic replication across multiple Availability Zones?
A) Amazon EBS B) Amazon S3 C) Amazon EC2 instance store D) AWS Snowball
How can you restrict access to an S3 bucket to only a specific VPC?
A) Use an IAM role B) Enable AWS Shield C) Use an S3 bucket policy D) Use a VPC endpoint policy
A company is designing a high-performance computing (HPC) solution using Amazon EC2 instances. The workload requires low-latency, high-bandwidth communication between instances. Which EC2 feature should the company use?
A) Placement Groups with Cluster Strategy B) Auto Scaling Groups C) EC2 Spot Instances D) Elastic Load Balancing
A company needs to store logs from multiple applications running on AWS. The logs must be available for analysis for 30 days and then automatically deleted. Which AWS service should be used?
A) Amazon S3 with a lifecycle policy B) Amazon RDS C) Amazon EFS D) Amazon EC2 instance with attached EBS volume
A company wants to run a web application in a highly available architecture using Amazon EC2 instances. The company requires automatic failover and must distribute incoming traffic across multiple instances. Which AWS service should be used?
A) AWS Auto Scaling and Application Load Balancer B) Amazon S3 and Amazon CloudFront C) AWS Lambda and API Gateway D) Amazon RDS Multi-AZ
A company is migrating a database from an on-premises data center to AWS. The database must remain online with minimal downtime during migration. Which AWS service should be used?
A) AWS Database Migration Service (DMS) B) AWS Snowball C) AWS Backup D) AWS Glue
An application running on Amazon EC2 needs to access an Amazon S3 bucket securely. What is the best practice for granting access?
A) Attach an IAM role with S3 permissions to the EC2 instance B) Store AWS access keys on the EC2 instance C) Use a security group to grant access to the S3 bucket D) Create an IAM user and share credentials with the application
For Getting More Questions and PDF Download Visit 👉 WWW.CLEARCATNET.COM
#AWS#AWSCertified#AWSCertification#AWSCloud#AWSCommunity#SAAC03#AWSExam#AWSSolutionsArchitect#AWSSAA#AWSAssociate#CloudComputing#CloudCareer#ITCertification#TechLearning#CloudEngineer#StudyTips#ExamPrep#CareerGrowth#LearnAWS#AWSJobs
0 notes
Text

High-Performance Computing and Quantum-Classical Systems: The Future of Computational Power
High-Performance Computing (HPC) has revolutionized our ability to solve complex computational problems, while the emergence of quantum-classical hybrid systems promises to push these boundaries even further. This article explores these transformative technologies and their integration, highlighting their impact on scientific research, engineering, and industry applications.
High-Performance Computing
High-Performance Computing represents a fundamental shift in computational capabilities, employing supercomputers and computer clusters to tackle problems that would be insurmountable through conventional computing methods. The power of HPC lies in its ability to process massive amounts of data and perform complex calculations at unprecedented speeds, making it an indispensable tool across various fields.
Mastering Parallel Computing
At the heart of HPC systems lies parallel computing, a sophisticated approach that distributes computational tasks across thousands or millions of processors simultaneously. This distributed processing architecture enables HPC systems to handle enormous datasets and complex simulations with remarkable efficiency. The ability to break down complex problems into smaller, manageable components that can be processed concurrently has transformed fields ranging from climate modeling to genomic research.
By leveraging parallel computing, researchers can analyze vast amounts of data and run complex simulations that would take years or even decades on traditional computing systems. This capability has become particularly crucial in areas such as weather forecasting, where timely results are essential for practical applications.
The Evolution of Supercomputers
Supercomputers represent the pinnacle of HPC technology, featuring millions of processors working in concert to achieve extraordinary computational feats. The current leader in supercomputing, Frontier, has broken new ground by exceeding 1 exaflop—performing a quintillion floating-point operations per second. This remarkable achievement has opened new possibilities in scientific research and technological innovation.
These powerful machines are carefully engineered to handle the most demanding computational tasks, featuring specialized hardware architectures, advanced cooling systems, and optimized software environments. The result is a computational powerhouse that can process complex calculations at speeds that were once thought impossible.
Real-World Applications
The versatility of HPC systems has led to their adoption across numerous fields:
In scientific research, HPC enables researchers to simulate complex phenomena such as galaxy formation and climate patterns with unprecedented accuracy. These simulations provide insights that would be impossible to obtain through traditional observational methods alone.
Engineering applications benefit from HPC through enhanced computational fluid dynamics and structural analysis capabilities. This allows engineers to optimize designs and predict performance characteristics without the need for costly physical prototypes.
In the business sector, HPC systems drive competitive advantage through advanced data analytics and high-frequency trading systems, processing market data and executing trades in microseconds.
Quantum-Classical Hybrid Systems
Quantum-Classical Hybrid Systems represent an innovative approach to computing that combines the unique advantages of quantum computing with the reliability and versatility of classical systems. This fusion creates powerful new capabilities while addressing some of the limitations inherent in each technology individually.
Understanding Hybrid Architecture
These hybrid systems integrate quantum and classical processing elements, creating a sophisticated infrastructure that can handle both quantum operations and classical computations. The classical component manages control operations and data preprocessing, while the quantum component tackles specialized calculations that benefit from quantum mechanical properties.
The hybrid approach allows for optimal resource allocation, using quantum processors for problems where they excel—such as optimization and simulation of quantum systems—while relying on classical computers for tasks better suited to traditional computing methods.
Expanding Application Horizons
The applications of quantum-classical hybrid systems continue to grow:
In quantum computing research, these systems enable more effective control and manipulation of quantum processors, facilitating the development of more sophisticated quantum algorithms and error correction techniques.
For molecular simulations and materials science, hybrid systems provide more accurate models of quantum mechanical interactions, leading to breakthroughs in drug discovery and materials development.
Navigating Technical Challenges
The development of quantum-classical hybrid systems faces several significant challenges. The interface between quantum and classical components requires precise timing and synchronization to maintain quantum coherence while effectively processing information. Researchers are actively working on solutions to improve this integration, developing new protocols and hardware interfaces to enhance system reliability and performance.
Synergy of Systems
The integration of HPC with quantum-classical hybrid systems represents a new frontier in computational capability. This convergence combines the massive parallel processing power of HPC with the unique problem-solving abilities of quantum computing, creating opportunities for unprecedented advances in computational science.
Advanced Simulation Capabilities
The combination of HPC and quantum-classical systems enables more sophisticated and accurate simulations across multiple domains. Researchers can now tackle previously intractable problems in materials science, drug discovery, and climate modeling with greater precision and efficiency.
Optimization and Control
HPC systems play a crucial role in optimizing quantum algorithms and managing large-scale quantum computations. This integration helps overcome some of the practical limitations of quantum computing, making it more accessible for real-world applications.
Looking to the Future
The convergence of HPC and quantum-classical systems marks a new chapter in computational technology. As these technologies continue to evolve and integrate, we can expect to see transformative advances across scientific research, engineering, and industry applications. This powerful combination promises to unlock solutions to some of humanity's most challenging problems, from climate change to drug discovery and beyond.
The ongoing development of these technologies will require continued innovation in hardware design, software development, and system integration. However, the potential benefits—including faster drug discovery, more accurate climate models, and breakthroughs in materials science—make this investment in the future of computing both necessary and exciting.
#linklayer#blog#technology#science#space science#electronics#innovation#space#artificial intelligence#computer science#computer#computers#tech#computing#futuretech#future#techinnovation
0 notes
Text
Scaling High-Performance HPC Clusters on AWS using Spot Instances
Introduction Scaling High-Performance HPC Clusters on AWS using Spot Instances is a crucial aspect of cloud computing for large-scale scientific simulations, data analytics, and machine learning applications. This tutorial will guide you through the process of setting up and managing a high-performance HPC cluster on AWS using Spot Instances. By the end of this tutorial, you will have a…
0 notes
Text
Evolution of Data Centers in the Age of AI and Machine Learning

As artificial intelligence (AI) and machine learning (ML) continue to revolutionize industries, data centers are undergoing significant transformations to meet the evolving demands of these technologies. This article explores the evolution of data centers from traditional models to advanced infrastructures tailored for AI and ML workloads.
Key considerations such as architectural flexibility, the role of specialized hardware, and the need for innovative cooling and data management solutions will be discussed. Additionally, we will delve into emerging trends like edge computing and quantum computing, which are shaping the future landscape of data centers in the age of AI and ML. To effectively manage these transformations, CCIE Data Center Training provides professionals with the expertise needed to navigate the complexities of modern data center environments.
Historical Overview: From Traditional to Modern Data Centers
Traditional Data Centers: Originally, data centers were primarily built on physical infrastructure with dedicated servers, network hardware, and storage systems. They focused on high reliability and uptime but were often inflexible and resource-intensive.
Emergence of Virtualization: The advent of virtualization technology allowed for more efficient resource utilization, leading to the rise of virtual machines (VMs) that could run multiple operating systems on a single physical server.
Cloud Computing Era: The introduction of cloud computing transformed data centers into scalable and flexible environments. This shift allowed organizations to leverage resources on demand, reducing capital expenditures and improving operational efficiency.
Modern Data Centers: Today's data centers are highly automated, utilizing software-defined networking (SDN) and storage (SDS) to enhance flexibility and reduce management complexity. They are designed to support various workloads, including artificial intelligence (AI) and machine learning (ML).
Key AI/ML Infrastructure Demands on Data Centers
High-Performance Computing (HPC): AI and ML require substantial computing power, necessitating infrastructures that can handle intensive workloads.
Scalability: The ability to quickly scale resources to accommodate fluctuating demands is critical for AI applications.
Low Latency: Real-time data processing is essential for AI applications, requiring architectures optimized for minimal latency.
Role of GPUs, TPUs, and Specialized Hardware in AI Data Centers
Graphics Processing Units (GPUs): GPUs are crucial for training AI models due to their ability to perform parallel processing, making them significantly faster than traditional CPUs for certain tasks.
Tensor Processing Units (TPUs): Developed by Google, TPUs are specialized hardware designed specifically for accelerating ML workloads, particularly for neural network models.
Custom AI Hardware: As AI continues to evolve, data centers are increasingly adopting custom chips and accelerators tailored for specific AI workloads, further enhancing performance.
Data Center Architecture for AI Workloads
Distributed Computing: AI workloads often require distributed architectures that can manage large datasets across multiple nodes.
Microservices: Adopting a microservices architecture allows for greater flexibility and faster deployment of AI applications.
Hybrid Architecture: Many organizations are employing hybrid architectures, combining on-premises data centers with public cloud resources to optimize performance and cost.
Cooling Solutions for High-Performance AI Data Centers
Advanced Cooling Techniques: Traditional air cooling is often inadequate for high-performance AI data centers. Innovative cooling solutions, such as liquid cooling and immersion cooling, are being utilized to manage the heat generated by dense compute clusters.
Energy Efficiency: Implementing energy-efficient cooling solutions not only reduces operational costs but also aligns with sustainability goals.
Data Management and Storage Requirements for AI/ML
Data Lakes: AI applications require large volumes of data, necessitating robust data management strategies, such as data lakes that support unstructured data storage.
Real-time Data Processing: The ability to ingest and process data in real-time is crucial for many AI applications, requiring optimized storage solutions that provide quick access to data.
The Role of Edge Computing in AI-Powered Data Centers
Edge Computing Overview: Edge computing involves processing data closer to the source rather than relying solely on centralized data centers. This is particularly important for IoT applications where latency is a concern.
AI at the Edge: Integrating AI capabilities at the edge allows for real-time analytics and decision-making, enhancing operational efficiencies and reducing bandwidth usage.
Security Challenges and Solutions for AI-Driven Data Centers
Increased Attack Surface: The complexity of AI-driven data centers creates more potential vulnerabilities, necessitating robust security measures.
AI in Cybersecurity: Leveraging AI for threat detection and response can enhance security postures, enabling quicker identification of anomalies and potential breaches.
Automation and Orchestration in AI-Enabled Data Centers
Role of Automation: Automation is critical for managing the complexities of AI workloads, enabling efficient resource allocation and scaling.
Orchestration Tools: Utilizing orchestration platforms helps in managing hybrid environments and optimizing workload distribution across different infrastructures.
Environmental and Energy Implications of AI in Data Centers
Energy Consumption: AI workloads can significantly increase energy consumption in data centers, leading to heightened operational costs and environmental concerns.
Sustainable Practices: Implementing sustainable practices, such as using renewable energy sources and improving energy efficiency, can mitigate the environmental impact of data centers.
Future Trends: Quantum Computing and AI Data Centers
Quantum Computing Potential: Quantum computing holds the potential to revolutionize AI by solving complex problems much faster than classical computers.
Integration of Quantum and AI: As quantum technology matures, the integration of quantum computing into AI data centers could enable unprecedented advancements in AI capabilities.
Impact of AI-Driven Data Centers on Industry Sectors
Healthcare: AI-driven data centers enhance data analysis for better patient outcomes and personalized medicine.
Finance: AI applications in data centers support real-time fraud detection and algorithmic trading.
Manufacturing: Automation and predictive analytics facilitated by AI in data centers optimize supply chain management and operational efficiency.
Conclusion:
In conclusion, the evolution of data centers in the age of AI and machine learning marks a significant transformation in how organizations manage and process data. From enhanced infrastructure demands and the integration of specialized hardware to innovative cooling solutions and energy-efficient practices, these advancements are reshaping the landscape of data management.
As industries increasingly rely on AI-driven capabilities, data centers must adapt to meet emerging challenges while optimizing for performance and sustainability.For professionals looking to excel in this evolving environment, obtaining certifications like CCIE Data Center can provide the necessary skills and knowledge to navigate these complexities. Embracing these changes will empower organizations to harness the full potential of AI, driving innovation and efficiency across various sectors.
#CCIE Data Center Training#CCIE Data Center#CCIE Data Center Course#CCIE Data Center Certification#CCIE Data Center Training in Bangalore
0 notes
Text
0 notes