#java Character Pattern Programs
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Kazakhstan’s Minister of Communications and Informatics has blocked the Tumblr site because it contained 60 sites of terrorism, extremism, and pornography in 2015.
Text
Text Processing Software Development

Text processing is one of the oldest and most essential domains in software development. From simple word counting to complex natural language processing (NLP), developers can build powerful tools that manipulate, analyze, and transform text data in countless ways.
What is Text Processing?
Text processing refers to the manipulation or analysis of text using software. It includes operations such as searching, editing, formatting, summarizing, converting, or interpreting text.
Common Use Cases
Spell checking and grammar correction
Search engines and keyword extraction
Text-to-speech and speech-to-text conversion
Chatbots and virtual assistants
Document formatting or generation
Sentiment analysis and opinion mining
Popular Programming Languages for Text Processing
Python: With libraries like NLTK, spaCy, and TextBlob
Java: Common in enterprise-level NLP solutions (Apache OpenNLP)
JavaScript: Useful for browser-based or real-time text manipulation
C++: High-performance processing for large datasets
Basic Python Example: Word Count
def word_count(text): words = text.split() return len(words) sample_text = "Text processing is powerful!" print("Word count:", word_count(sample_text))
Essential Libraries and Tools
NLTK: Natural Language Toolkit for tokenizing, parsing, and tagging text.
spaCy: Industrial-strength NLP for fast processing.
Regex (Regular Expressions): For pattern matching and text cleaning.
BeautifulSoup: For parsing HTML and extracting text.
Pandas: Great for handling structured text like CSV or tabular data.
Best Practices
Always clean and normalize text data before processing.
Use tokenization to split text into manageable units (words, sentences).
Handle encoding carefully, especially when dealing with multilingual data.
Structure your code modularly to support text pipelines.
Profile your code if working with large-scale datasets.
Advanced Topics
Named Entity Recognition (NER)
Topic Modeling (e.g., using LDA)
Machine Learning for Text Classification
Text Summarization and Translation
Optical Character Recognition (OCR)
Conclusion
Text processing is at the core of many modern software solutions. From basic parsing to complex machine learning, mastering this domain opens doors to a wide range of applications. Start simple, explore available tools, and take your first step toward developing intelligent text-driven software.
0 notes
Text
Pattern programs in Java are exercises that involve printing various shapes and designs using loops and conditional statements. These programs help developers enhance their logical thinking and problem-solving skills. Common patterns include triangles, squares, and diamond shapes, often created through nested loops, showcasing the versatility of Java in graphical output. Check here to learn more.
0 notes
Text
hi
Longest Substring Without Repeating Characters Problem: Find the length of the longest substring without repeating characters. Link: Longest Substring Without Repeating Characters
Median of Two Sorted Arrays Problem: Find the median of two sorted arrays. Link: Median of Two Sorted Arrays
Longest Palindromic Substring Problem: Find the longest palindromic substring in a given string. Link: Longest Palindromic Substring
Zigzag Conversion Problem: Convert a string to a zigzag pattern on a given number of rows. Link: Zigzag Conversion
Three Sum LeetCode #15: Find all unique triplets in the array which gives the sum of zero.
Container With Most Water LeetCode #11: Find two lines that together with the x-axis form a container that holds the most water.
Longest Substring Without Repeating Characters LeetCode #3: Find the length of the longest substring without repeating characters.
Product of Array Except Self LeetCode #238: Return an array such that each element is the product of all the other elements.
Valid Anagram LeetCode #242: Determine if two strings are anagrams.
Linked Lists Reverse Linked List LeetCode #206: Reverse a singly linked list.
Merge Two Sorted Lists LeetCode #21: Merge two sorted linked lists into a single sorted linked list.
Linked List Cycle LeetCode #141: Detect if a linked list has a cycle in it.
Remove Nth Node From End of List LeetCode #19: Remove the nth node from the end of a linked list.
Palindrome Linked List LeetCode #234: Check if a linked list is a palindrome.
Trees and Graphs Binary Tree Inorder Traversal LeetCode #94: Perform an inorder traversal of a binary tree.
Lowest Common Ancestor of a Binary Search Tree LeetCode #235: Find the lowest common ancestor of two nodes in a BST.
Binary Tree Level Order Traversal LeetCode #102: Traverse a binary tree level by level.
Validate Binary Search Tree LeetCode #98: Check if a binary tree is a valid BST.
Symmetric Tree LeetCode #101: Determine if a tree is symmetric.
Dynamic Programming Climbing Stairs LeetCode #70: Count the number of ways to reach the top of a staircase.
Longest Increasing Subsequence LeetCode #300: Find the length of the longest increasing subsequence.
Coin Change LeetCode #322: Given a set of coins, find the minimum number of coins to make a given amount.
Maximum Subarray LeetCode #53: Find the contiguous subarray with the maximum sum.
House Robber LeetCode #198: Maximize the amount of money you can rob without robbing two adjacent houses.
Collections and Hashing Group Anagrams LeetCode #49: Group anagrams together using Java Collections.
Top K Frequent Elements LeetCode #347: Find the k most frequent elements in an array.
Intersection of Two Arrays II LeetCode #350: Find the intersection of two arrays, allowing for duplicates.
LRU Cache LeetCode #146: Implement a Least Recently Used (LRU) cache.
Valid Parentheses LeetCode #20: Check if a string of parentheses is valid using a stack.
Sorting and Searching Merge Intervals LeetCode #56: Merge overlapping intervals.
Search in Rotated Sorted Array LeetCode #33: Search for a target value in a rotated sorted array.
Kth Largest Element in an Array LeetCode #215: Find the kth largest element in an array.
Median of Two Sorted Arrays LeetCode #4: Find the median of two sorted arrays.
0 notes
Text
Google Analytics 4 Regex (Regular Expressions) Use Cases

What Regular Expresión RegEx is in GA4? - ⚡ Definition: A Regular Expression (RegEx) is a sequence of characters that defines a search pattern. It allows you to match, locate, and manipulate specific patterns within text, including website data in GA4. - �� Purpose: RegEx enables you to create more refined and accurate segments, filters, and analyses in GA4, revealing insights that would be difficult to uncover using standard methods. How RegEx are categorized? RegEx can be categorized by the type of syntax they use, the type of languages they support, and the type of engines they run on. Here are some examples of each category: Syntax: There are different syntaxes for writing RegEx, such as POSIX, Perl, PCRE, ECMAScript, and more. Each syntax has its own rules and features, such as metacharacters, quantifiers, modifiers, and groups. Some syntaxes are more expressive and powerful than others, but they may also be more complex and less portable. Languages: There are many programming languages and frameworks that support RegEx, either natively or through libraries. Some of the popular ones are Python, R, Java, C#, JavaScript, Ruby, PHP, and more. Each language may have its own implementation and variant of RegEx, which may differ slightly from the standard syntax or semantics. Engines: There are different types of engines that process RegEx, such as DFA, NFA, and hybrid. Each engine has its own advantages and disadvantages, such as speed, memory, backtracking, and lookahead. Some engines are more efficient and robust than others, but they may also have more limitations and trade-offs. The most popular RegEx engines available in 2024 are: - PCRE: Perl Compatible Regular Expressions, a library that implements most of the features of Perl RegEx, as well as some extensions. It is widely used by many languages and applications, such as PHP, R, Python, Apache, Nginx, and more. - ICU: International Components for Unicode, a library that provides support for Unicode and internationalization, as well as RegEx. It is used by many languages and platforms, such as Java, Swift, .NET, Qt, and more. - RE2: A library that implements a fast and safe RegEx engine, based on a hybrid of DFA and NFA. It is designed to avoid the exponential worst-case complexity of backtracking engines, and to handle large inputs efficiently. It is used by languages and applications such as Go, Python, Ruby, and more. Why RegEx is so important to me, and why it should be to you. With over 11 years under my belt creating digital campaigns that truly move the needle, I've seen it all when it comes to analytics. But nothing has captured marketers' curiosity lately more than GA4 (Google Analytics 4). As Google completes its sunsetting of Universal Analytics, there’s a whole new world of possibilities opening up. And one lesser known but incredibly powerful feature is regular expressions or “regex”. I admit that when I first heard about regex, I pictured some complex coding syntax only engineers use. Boy was I wrong! Regex is actually easy to grasp (more on that shortly) and unlocks game-changing tracking in GA4 for businesses of any size. At its core, a regular expression or “regex” is just a search pattern used to match certain strings of text. But this unassuming concept offers marketers like us extraordinary precision. We can track and target website activity in entirely new ways not possible before. For example, say your ecommerce store has product IDs with a specific prefix like “PRO123”. With regex, you could track revenue, clicks or other behavior on just those products in GA4 with a few keystrokes. The use cases are nearly endless. In this guide, we’ll break down everything you need to start wielding the full power of regex today. I’ll explain what regex is, why it matters now more than ever, and walk through real examples that work from my own analytics projects. Let’s dive in! The building blocks: Key metacharacters used in GA4 regex The Forward Slash (/) metacharacter The forward slash metacharacter plays a key role in GA4 regex by delimiting the start and end of the pattern. Anything between two forward slashes "/" becomes interpreted as the actual regex syntax to match text against. Proper usage of forward slashes is essential for well-formed regex. The Back Slash () metacharacter The backslash metacharacter helps "escape" other regex symbols, allowing you to match those literal characters instead of their special meaning. For example, if you needed to match an actual "." in text, you would use "." in your regex. The backslash gives tremendous flexibility. Caret (^) and what it does The caret symbol matches the very start of a string of text. For example, "^Mission" would look for the word "Mission" only at the beginning of a URL or other input. This allows precise control for start-of-string matching. Extremely useful! Dollar sign ($) explained Like the caret but opposite, dollar sign matches just the end of the input string. You could search for "html$" to find html pages only. Or "2023$" to match dates ending in that year. Another way to target precise text positions. Brackets - Their role Bracket metacharacters allow grouping multiple characters/words to match in a single place in the regex. For example, would match just x, y or z in that position. Incredibly versatile for custom group matching! Parentheses () metacharacter Similar to brackets but parentheses group text/patterns while also capturing that piece of matched text for additional processing. Extra utility while grouping regex logic. Question Mark (?) and what it means The question mark metacharacter allows 0 or 1 matches of the preceding character/group. For example, "colou?r" would match both "color" and "colour". Optional matching. Plus sign (+) metacharacter The plus sign metacharacter allows 1 or more repetitions of the previous character/group. For example "A+" matches "A", "AA", "AAA" etc. Useful for broad matches. Asterisk (*) sign function Similar to plus, the asterisk allows 0 or more matches of the preceding character/group. For example "Data" would match "Data", "Database", "DataPoints" etc. Another broad matcher. Dot (.) metacharacter purpose One of the most useful metacharacters, dot "." matches ANY single character except newlines. Combine it with + and * for powerful broad matching quickly! Pipe Symbol (|) usage The pipe symbol acts as an OR operator in regex, allowing matches from multiple patterns. For example "cat|dog" would match occurrences of either "cat" OR "dog" in the input text. This provides more flexible pattern matching. Exclamation (!) metacharacter The exclamation point negates or inverts the meaning of whatever follows it in the regex. For example "!Mission" would match any text NOT containing the word Mission. Another way to precisely control matching. Curly Brackets {} usage Curly brackets set a custom quantity or range for the preceding character/pattern. For example "d{3}" matches exactly 3 digits, while "d{3,5}" matches 3 to 5 digits. Tremendous way to define restricted repetition. White spaces role ⬜ Whitespace metacharacters like "s" match generic spaces, tabs, newlines etc. You can search for "S" to require non-whitespace at that position. Helpful for pattern precision when whitespace matters. Crafting regex patterns properly in GA4 Through the years testing analytics implementations, I’ve seen plenty of clever regular expression attempts backfire due to subtle syntax issues. Even what appears to be flawlessly crafted regex logic can fail hard if you don’t follow best practices. Trust me, after an all-nighter spent debugging a malfunctioning regex pattern character-by-character, I learned proper regex hygiene the hard way! But following a few simple guidelines can help your patterns work smoothly right off the bat. - First, always surround your full regex with delimiting forward slashes - like putting punctuation marks around a sentence. We generally aim to match entire strings/parameters, not just parts. Adding the start ^ and end $ metacharacters helps by anchoring patterns accordingly. When nesting metacharacters, use plenty of whitespace and liberal comments explaining the logic. Regex may be concise but can get complex quickly! Well-formatted patterns are far easier to adjust later when needs change. - Finally, test early and often! GA4 offers a handy regex validator under the Admin section, but I always build a quick tag to evaluate against real site data. Between those two testing methods, flawed patterns get identified fast before tag deployment. Speaking of testing, let me share an example regex pattern for Google Analytics 4 that recently helped one of my ecommerce clients... Code snippet ^/product/.*/d+$ This regex pattern matches any page path that starts with "/product/" followed by any string of characters, an underscore, and then a sequence of digits. This means that it will match page paths like "/product/mens-clothing/shirts/red-shirt", "/product/womens-accessories/handbags/black-clutch", and "/product/kids-toys/puzzles/dinosaur-puzzle". This regex pattern was used to create a filter in Google Analytics 4 that only included visits to product pages. This allowed the client to track conversions, such as purchases, that were made from these pages. Here is an example of how to use this regex pattern to create a filter in Google Analytics 4: - Go to the Data Stream settings for your property. - Click on the Configure Tag Settings tab. - Scroll down to the Filters section. - Click on the Create filter button. - Select Matches regex as the filter type. - Paste the following regex pattern into the Regular expression field:^/product/.*/d+$ - Click on the Save button. This helped to ensure that only visits to product pages would be included in my client's Google Analytics 4 reports. This made it easier for us to track conversions from these pages. Quick regex creation tips for GA4 I’ve learned, the hard way, that speed and agility are everything when it comes to analytics implementation. The best ideas mean nothing if you cannot test and iterate on them rapidly. Luckily, regex delivers on both fronts - providing tremendous flexibility without complexity once you know some key tips. - First, leverage online regex testers and cheatsheets liberally. I always keep a few handy references open as I build, double checking syntax or inspiration for new approaches. They cut down on silly errors and unlock advanced techniques faster. - Similarly, do not try to memorize every metacharacter! I focus on learning the 5-6 most versatile building blocks first, like dots, brackets, braces etc. Combined creatively, they can handle ~90% of use cases quickly. Lean on guides to fill in the remaining syntax as needed. - Finally, do not reinvent the wheel each time. Archive and comment old regex patterns for easy reuse. Tweak stored snippets rather than coding everything fresh. Review examples from community forums and analytics leaders to inspire new ideas. Compounding prior work pays dividends with regex! Let me walk through a real example from a recent campaign leveraging these tips to rapidly implement regex tracking... Example for rapidly implement regex tracking using Google Analytics 4 Scenario The client wanted to track specific campaign events, such as newsletter signups or lead generation forms, from various sources, including email links, social media posts, and paid ads. They were using Google Analytics 4 (GA4) as their analytics platform. Challenge The client was struggling to create and maintain effective tracking for each campaign event across all these different sources. They were using a mix of manual event tracking and custom dimensions and metrics, which was becoming increasingly complex and difficult to manage. Solution We introduced regular expressions (regex) to the client's tracking strategy. Regex is a powerful tool that can be used to extract specific information from URLs and other data sources. This allowed us to create more streamlined and flexible tracking rules that could be applied to all their campaign events, regardless of the source. Implementation We followed the three key tips mentioned above: - Leveraged online regex testers: We used online regex testers to validate our regex patterns before implementing them in GA4. This helped us to avoid syntax errors and ensure that our tracking was accurate. - Focused on the most versatile metacharacters: We prioritized learning the most common and versatile metacharacters, such as dots, brackets, and braces. This allowed us to create patterns that could handle a wide range of use cases with minimal complexity. - Reused existing regex patterns: We kept track of existing regex patterns and reused them whenever possible. This saved us time and effort, and it also ensured consistency in our tracking across different campaigns. Results! By using regex, we were able to significantly simplify the client's tracking strategy. They were able to create more accurate and granular tracking rules, and they were able to implement these rules more quickly and easily. This also helped them to identify and measure campaign performance more effectively. Unleashing regex in GA4 - where can you use it? While the fundamentals of regular expressions center around sophisticated text matching and parsing, we as analysts ultimately care about actionable data. All the processing power behind regex means nothing if we cannot integrate that logic to amplify our analytics capabilities. Luckily, GA4 provides numerous integration points to bake regex directly into your implementation's workflow. In this section, we will explore some of the top place’s regex can deliver value: - Using regex for setting up subproperties on GA4: To match mobile device user agents, you can use a regex pattern like this: /^(Android|iPhone|iPad|iPod|BlackBerry|Windows Phone)/i This will match any user agent that starts with one of the listed mobile device names, case-insensitively. You can add more devices to the list if you want. - Configuring site search tracking without query parameters: To identify search terms from the search box URL structure, you can use a regex pattern like this: /search/(+)/ This will match any URL that contains /search/ followed by one or more characters that are not slashes, and capture the search term in a group. For example, if the URL is https://example.com/search/flowers/, the regex will match and capture flowers as the search term. - Refining referral exclusion lists: To exclude traffic from your own internal tools, you can use a regex pattern like this: /^(localhost|127.0.0.1|192.168.|10.|172.(1|2|3))/ This will match any URL that starts with localhost, 127.0.0.1, or an IP address that belongs to a private network. You can add more domains or IP ranges to the list if you want. - Creating granular data filters in Exploration reports: To filter for sessions with product page views that contain a specific brand name, you can use a regex pattern like this: /products/.*?/brand-name/ This will match any URL that contains /products/ followed by any number of characters (as few as possible) followed by /brand-name/. For example, if the brand name is nike, the regex will match URLs like https://example.com/products/shoes/nike/ or https://example.com/products/clothing/nike/jackets/. - Setting up custom events via Google Tag Manager: To capture button clicks on specific page elements, you can use a regex pattern like this: /button/ This will match any HTML tag that is a button with an id attribute, and capture the id value in a group. For example, if the button tag is Submit, the regex will match and capture submit as the id value. - Organizing content groups: To create a content group for blog articles, you can use a regex pattern like this: /blog/(d{4})/(d{2})/(d{2})/(.+)/ This will match any URL that contains /blog/ followed by a date in the format YYYY/MM/DD followed by a slug, and capture the year, month, day, and slug in separate groups. For example, if the URL is https://example.com/blog/2023/04/14/learn-regex/, the regex will match and capture 2023, 04, 14, and learn-regex as the date and slug values. - Building targeted audiences: To create an audience of users who have visited product pages with certain keywords in the URL, you can use a regex pattern like this: /products/.*(keyword1|keyword2|keyword3)/ This will match any URL that contains /products/ followed by any number of characters followed by one of the listed keywords. You can add more keywords to the list if you want. For example, if the keywords are shoes, bags, and hats, the regex will match URLs like https://example.com/products/shoes/nike/ or https://example.com/products/accessories/bags/leather/. - Modifying events in the GA4 UI: To standardize product names in purchase events, you can use a regex pattern like this: /^(.+)s+((.+))$ This will match any product name that consists of two parts separated by a space and enclosed in parentheses, and capture the two parts in separate groups. For example, if the product name is Nike Air Max (Blue), the regex will match and capture Nike Air Max and Blue as the product name and color values. - Matching multiple domains or subdomains in cross-domain tracking or filters. To match example.com, blog.example.com, and store.example.com, you can use a regex pattern like this: ^(example.com|blog.example.com|store.example.com)$ - Extracting custom dimensions or metrics from URLs or page titles using Google Tag Manager. To extract the author name from a blog post URL like https://example.com/blog/2023/04/14/learn-regex-by-john-doe/, you can use a regex pattern like this: /blog/d{4}/d{2}/d{2}/.+-(.+?)/$ This will capture the author name (John Doe) in a group. - Validating form fields or input values using Google Tag Manager. To validate an email address input, you can use a regex pattern like this: /^+@+.{2,}$/ This will match any email address that follows the standard format. - Creating custom channel groupings based on campaign parameters or source/medium values. To create a custom channel grouping for social media traffic, you can use a regex pattern like this: /(facebook|twitter|instagram|linkedin|pinterest)/ This will match any source or medium that contains one of the listed social media platforms. - Creating custom alerts based on specific conditions or thresholds. To create a custom alert for when the bounce rate of a landing page exceeds 80%, you can use a regex pattern like this: /landing-page/ This will match any page that contains /landing-page/ in the URL. These are just some of the many possible use cases for regex in Google Analytics. You can find more examples and resources in this practical guide from Google, this beginner’s guide, this essential guide, this ultimate guide, or this regex guide. 😊 Validate Regex Patterns in GA4 the Right Way Crafting airtight regex logic requires testing - and LOTS of it! After over a decade cooking up digital analytics implementations, I've seen even the most beautifully crafted regular expressions fail hard once unleashed on actual visitor data. Trust me... that brutal moment when your perfect regex works flawlessly in testing but totally unravels with production traffic? Save yourself the pain! 😓 The good news? GA4 bakes in all the tools you need to launch regex patterns confidently. Read the full article
0 notes
Text
Achieve Java Excellence: With Java Course in Pune at Cyber Success

Elevate Your Java Skills: Advanced Java Course in Pune at Cyber Success
In the ever-evolving technological world, mastering programming languages is the key to unlocking a successful career. Java programming is known for its versatility and scalability, popular among developers. One of the most powerful tools in the Java Developer Toolkit is the ability to handle string operations efficiently. At Cyber Success Institute, we offer the Best Java course in Pune that will prepare you for Java programming from basic concepts to advanced concepts, advanced wiring and adaptation to real-world challenges. String is the backbone of many applications, and understanding how to work with them is important for any aspiring full-stack developer. Whether you’re developing a web application, mobile application, or enterprise solution, handling threads effectively can make your code more robust and efficient. Whether you are a beginner in programming or an experienced person who wants to expand your skills, our Java course in Pune is suitable for everyone.
Learn Essential String Operations: The Art of Coding with Java Classes in Pune
String are everywhere in programming. From user input to data processing and output generation, they play an important role. Whether you’re developing a web application, mobile application, or enterprise solution, handling threads effectively can make your code more robust and efficient. Understanding string functions requires you to consider the beauty and power of Java programming. At the Cyber Success Institute, our Advanced Java Classes in Pune cover a wide variety of string functions that are fundamental to coding success. Every application consists of data, and strings are often used to represent and manipulate this data. From simple text conversions to complex data parsing, string operations empower developers to extract, transform, and organize data as needed. Skills in string manipulation allow you to efficiently manipulate data, whether you’re working with JSON, XML, CSV, or other data formats, making your applications more flexible and robust.
Features Of Strings with Java Training Classes in Pune at Cyber Success
At The Cyber Success Institute, our advanced Java courses cover a wide variety of string functions that are fundamental to coding success:
Communication: Learn to touch lines effortlessly, for strength and flexibility with our Java Training Classes in Pune.
Substring Extraction: Learn the art of extracting specific string segments, increasing your data processing capabilities.
String Comparison: To ensure that your applications are logical and error-free, develop the skill of accurately comparing strings with the best Java Course in Pune.
String Length: Understanding how to measure and manage string length, which is fundamental to data processing.
String Replacement: Learn to find ways to replace characters or sequences in a string, while maintaining data integrity with Java Course in Pune at Cyber Success.
Case Conversion: It is the ability to change string cases easily, ensuring consistency and accuracy across all your applications.
Unlock New Possibilities with Advanced String Manipulation with Java Classes in Pune
Strings play an important role in the creation of dynamic web pages, emails, reports, and more. Through the proper use of strings, templates and layouts, you can tailor content to the user’s preferences and behaviors, enhancing the overall user experience and engagement. At Cyber Success Institute, we believe in empowering education. Our Java course in Pune goes beyond the basics and goes deeper into string efficiency Go to those who take your coding to new heights:
Regular comment: Use the power of regex for incredible pattern consistency and accuracy.
StringBuilder and StringBuffer: Optimize your string processing for performance and efficiency.
Unicode and Encoding: Embrace internationalization and develop applications for a global audience.
Immutable strings: Take the concept of immutability and use it to write more secure and reliable code.

Why Choose Cyber Success for Java Training Classes in Pune?
At The Cyber Success Institute, we believe in empowering education. We have designed our syllabus for Java course in Pune with industry experts to equip you with the skills and knowledge to develop a deep understanding of Java programming. Choosing Cyber Success Institute means embracing practical, hands-on experience guided by industry experts. Our comprehensive, curriculum of Java course covers everything from basic to advanced Java topics, ensuring you have the skills you need for real-world applications. We focus on your career development through resume building, interview preparation and solid professional support. We cater to your unique needs with flexible learning methods and personalized attention. Join us to unlock your potential and start a successful career in Java development.
Here are some features of the Java Course in Pune at Cyber Success Institute
Expert Trainers: At Cyber Success, our trainers are industry experts with extensive experience in Java development. They bring their wealth of knowledge and practical insights to the classroom, providing you with a rich and relevant learning experience. Their guidance will help you navigate the complexities of Java programming, making your learning journey easier and more enjoyable.
Comprehensive and updated curriculum: The technology industry is constantly evolving, as is our curriculum. We ensure that our Java course in Pune is constantly updated with the latest trends and advancements in the industry. From basic syntax and control structure to advanced topics like multithreading, networking, and database connectivity, our course covers everything you need to become a proficient Java developer.
Focus on career development: We are committed to your success, to learning Java and building a rewarding career. Our Java course in Pune has sessions dedicated to career development, such as resume, interview preparation and job search strategies. We also offer mock interviews and group discussion opportunities to help you prepare for a competitive job market.
Supporting Learning Communities: When you join the Cyber Success Institute, you become part of a supportive and collaborative learning team. Our students and graduates form like-minded individuals who are passionate about technology and learning. These communities provide valuable opportunities for networking, knowledge sharing, and mutual support.
Support during Placement: Our commitment to your success doesn’t end when you graduate. We offer solid placement support to help you find the job of your dreams. Our placement cell has close ties with leading companies in the industry.
Conclusion:
Embarked on a journey to become a proficient Java full-stack developer. Mastering string operations and manipulation operations is just the beginning. At the Cyber Success Institute, we are committed to helping you unlock your potential and achieve your career goals. Imagine you’re an accomplished Java full-stack developer, and you’re building applications that make a difference. At the Cyber Success Institute, we believe in your power and are committed to helping you achieve your dreams. Our Java course in Pune is about transformation, empowerment and unlocking your true potential.
Are you ready to improve your coding skills and become a Java expert? Join us at the Cyber Success Institute and take your first steps toward a rewarding career in full-time development.
Register today and start your journey to master Java programming and string operations. Your future awaits you!
Attend 2 Demo Sessions FREE!
To know more in detail about the course, visit: https://www.cybersuccess.biz/all-courses/java-course-in-pune/
To secure your place, visit: https://www.cybersuccess.biz/contact-us/
📍 Our Visit: Cyber Success, Asmani Plaza, 1248 A, opp. Cafe Goodluck, Pulachi Wadi, Deccan Gymkhana, Pune, Maharashtra 411004
📞 For more information, call: +91 9226913502, 9168665644, 95037 70228
0 notes
Text
Top 6 Hardest Programming Languages In 2024
Programming languages come in varying levels of difficulty. While some languages are relatively easy for beginners to pick up, others have a steep learning curve and can be quite challenging even for experienced developers. Here are 6 of the hardest programming languages as of 2024 based on their complex syntax, concepts, and overall difficulty in mastering them.
1. C++
As one of the most widely used programming languages, C++ is known for its power and flexibility. However, it’s also one of the most difficult to master due to its complex syntax, memory management requirements, multiple ways of doing things, and overall huge learning curve. Understanding advanced concepts like templates, pointers, inheritance, polymorphism, and memory management in C++ can take programmers years to fully grasp. But it’s a valuable skillset that’s worth the effort.
2. Haskell
Haskell is a very hard programming language for beginners due to its highly mathematical nature and unfamiliar functional programming paradigm. The syntax of Haskell's code is concise yet academic and requires an analytical thinking style. Haskell does not allow mutable data, so programmers need a strong grasp of recursion and higher-order functions to operate within its pure functional approach. Haskell’s type system is also very robust and complex, requiring great precision when defining new data types and functions.
3. Rust
As a systems programming language, Rust offers blazing performance but at the cost of high complexity. Its strict compile-time checks force programmers to think carefully about memory management in order to avoid crashes and security holes in their code. Rust’s borrow checker further adds complexity as it requires an understanding of ownership rules for memory allocation. And Rust’s pattern matching and enums also have a learning curve. Overall, Rust has a steep learning curve but brings safety and speed benefits.
4. Scala
Scala combines object-oriented and functional programming concepts while running on the Java Virtual Machine (JVM). This Level of versatility comes at the price of difficulty. Its object-functional mix requires thinking in two different ways, while its strong static typing adds complexity. The syntax of Scala is also very dense, with many special characters and its own conventions. And building on the JVM means interfacing with Java can be convoluted. There’s a lot of power but also a very high learning curve.
5. F#
As a multi-paradigm programming language, F# includes object-oriented, imperative, and symbolic programming alongside its functional programming core. That range requires mastering very different ways of thinking and coding. F# also makes heavy use of type inference, which avoids explicitly declared types but expects programmers to fully understand the type system to avoid errors. Other challenges include F#’s pipeline operators, computation expressions, complex module systems, and niche usage compared to mainstream languages.
6. Assembly
The hardest mainstream programming language today remains Assembly or other low-level machine code languages. With no high-level abstractions to lean on, programmers work with registers, memory addresses, jumps, and all the bare metal fundamentals. This requires an extremely focused attention to detail and manual memory management. Simple tasks become complex, and debugging is very tedious. While few programmers use Assembly for full applications anymore, knowledge of it remains highly valuable for certain domains. But overall, it continues to live up to its reputation as extremely challenging.
Conclusion
Mastering any of these advanced programming languages requires great effort for most programmers. But conquering their complexity yields valuable skills and capabilities that set programmers apart. While not everyone will need to be proficient in languages like C++ or Haskell, it’s useful to at least be aware of their reputation and appreciate the dedication of those who specialize in them. As software continues advancing, expect the hardest programming languages to keep pushing the limits of what’s achievable through code.
0 notes
Text
AI Magic: Transforming Society for the Better!

Beneficial social consequences of AI Magic
Using AI to improve the world
AI Magic can boost productivity, creativity, and human experience. AI may create uncertainty about the future, but they can aim to create AI technologies that improve society. They have listed a few ways AI can improve the world.
1. Science advancement
AI Magic simulations and modeling can solve complex climate science, drug discovery, and engineering problems. These simulations let researchers test different scenarios and optimize solutions without expensive and time-consuming physical experiments.
Using NASA’s Harmonized Landsat and Sentinel-2 (HLS) dataset, NASA and IBM Research created a geospatial AI foundation model for Earth observation. Land use, natural disasters, and crop yields can be tracked with the new foundation model.
AI can simulate climate change, financial markets, protein 3D structures, and disease spread. In environmental research, AI can analyze climate data and model scenarios to address climate change and resource conservation. It can also discover new chemical structures and compounds for materials science and pharmaceuticals.
Another inspiring example is AI Magic coral reef restoration. AI optimization algorithms can optimize energy consumption, emissions, and environmental monitoring to reduce carbon footprint. AI-powered precision farming can boost crop yield, reduce pesticide use, and reduce environmental impact.
2. Accessibility and creativity
They can boost creativity by quickly generating text, art, and music with generative AI. AI Magic can help brainstorm, prototype, and inspire ideas without replacing human creativity. Accelerating literature, art, and music improves creators’ and audiences’ lives.
AI-powered video editing can simplify content creation for filmmakers and producers. This AI-powered ability to synthesize images, videos, dialog, characters, and settings can help anyone become a filmmaker and express themselves. AI enhances human creativity and produces human-inspired results because it synthesizes human inputs.
Collaboration between humans and AI Magic can boost innovation
For years, people have tried to create low-code or no-code programming models. AI Magic can make that possible. Programmers can use voice or text to describe their goals to a code assistant with a large language model. Code assistants understand programmer intent and generate appropriate code to complete tasks.
AI can automate monotonous code maintenance. Finding COBOL programmers to maintain legacy code is difficult today, but AI can generate new COBOL code or convert the old code to a modern language like Java to modernize the application.
3.Productivity and automation
AI can automate tedious tasks. By automating repetitive tasks and eliminating work drudgery, AI can boost productivity greatly. By outsourcing routine tasks to AI-based assistants, people can focus on more important tasks. AI-driven robotics and automation can improve workflows, efficiency, and accuracy in manufacturing and logistics.
Farmers can already supervise multiple AI-enabled John Deere tractors plowing, seeding, weeding, and harvesting in multiple fields from their home office over a cellular connection.
AI quickly processes large amounts of data to find trends and insights
Organizations can make data-driven decisions faster. AI’s data analysis can also find hidden patterns and correlations, helping solve complex problems. AI-driven analytics tools can spot patterns, trends, and anomalies humans miss, improving decision-making.
Singapore, Los Angeles, and Barcelona use AI video surveillance to manage traffic flow and improve safety.
NLP is greatly improved by AI. It can process and analyze large amounts of text data for sentiment analysis, content summarization, document classification, and data extraction, which can help make decisions and find new discoveries in large and historic research collections.
NLP-enabled and generative AI-powered chatbots and virtual assistants can answer questions, solve problems, and schedule appointments and reminders. AI boosts customer service and administrative productivity.
AI has huge positive potential
AI’s ability to collect and process massive amounts of data, make predictions, and automate tasks improves productivity, creativity, and solves complex problems across many fields.
Predictive analytics using AI can predict future events and trends, enabling proactive problem-solving and decision-making. This benefits finance, healthcare, marketing, climate science, and drug discovery. These are a few ways AI can improve our lives and world.
Read more on Govindhtech.com
0 notes
Note
Wait so if in the pnf universe they use a base 8 counting system does that mean that 9 and 10 just don’t exist??? And if so how would that work??
First, for anyone who's confused about why we've decided they don't count the same in the Dwampyverse, check out this post by @phineasandferbtheories (tagging them in case they have something to add)
Anon, that is so close to what it means! This confused the absolute shit out of me too when I first started learning binary (which is essentially the same concept except base 2 instead) in Java Programming, but I’d like to think I have a pretty good grasp on how base conversions work even if it’s been a few years since I’ve done them, so here’s my attempt to explain how base 8 would work!
Base 10 means that the number system goes [ 0 1 2 3 4 5 6 7 8 9 ]. There is no digit smaller than 0 and no digit larger than 9.
Base 8 means that the number system goes [ 0 1 2 3 4 5 6 7 ]. There is still no digit smaller than 0, and there’s no digit larger than 7.
In Base 10, when you want to make a number bigger than 9, you have to add another digit. 9 + 1 becomes 10.
In Base 8, when you want to make a number bigger than 7, you have to add another digit as well. 7 + 1 becomes 10 (which would be 8 in base 10).
Essentially, in Base 10, counting would go like this: [ 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 ]
In Base 8, counting would go like this: [ 1 2 3 4 5 6 7 10 11 12 13 14 15 16 17 20 ]
When you’ve known base 10 all your life, any other base can get confusing. [ 16 17 20 ] in itself looks weird, but it gets even weirder when you realize that this series of numbers only goes up to what we know as 16.
An easy way to convert from base 8 to base 10 is to multiple the 8′s place (what would be the 10′s place) by 8 and then add the 1’s place.
ex. 23 in base 8 --> (2 x 8) + 3 --> (16) + 3 --> 19 in base 10
ex. 67 in base 8 --> (6 x 8) + 7 --> (48) + 7 --> 55
In Base 10, 99 is the highest it can go with only two digits; the next number it goes to is 100.
In Base 8, the highest it can go with only two digits is 77; the next number it goes to is 100.
100 in Base 8 is what we know as 64, or 8^2.
At this point, it may be self-explanatory, but the numbers go [ 100, 101, 102, 103, 104, 105, 106, 107, 110 ].
To convert a three-digit number from base 8 to base 10, the 64′s place (what would be the 100s place) is multiplied by 64; the 8′s place (what would be the 10′s place) is multiplied by 8, and the 1′s place is multiplied by 1. All three numbers are added together, and that’s your number!
ex. 106 in base 8 --> (1 x 64) + (0 x 8) + (5) --> (64) + (0) + (5) --> 69
ex. 644 in base 8 --> (6 x 64) + (4 x 8) + (4) --> (384) + (32) + (4) --> 420
And, again, there’s a limit to how far it can go in three digits (777) so then you have to move up to 1000 (what we know as 512, or 8^3). To convert it to base 10, you’d multiple the 512′s place (what we know as the 1000′s place) by 512, and continue the pattern down to the 1′s place. After the 512′s place, it’s the 4096′s place (8^4), then the 32762′s place (8^5), and so on.
This may seem really complicated, and, admittedly, switching between bases can be, but if you’d been taught base 8 since you were born, base 10 would seem just as weird as base 8 seems to someone who’s been raised on base 10. There’s really no reason for us to use base 10 other than the fact that we have 10 fingers to count on, so it would actually be kind of weird for the characters in the Dwampyverse to use base 10 (though they canonically have used numbers that wouldn’t exist in base 8 -- coquet Y8 and hockey Z9 come to mind -- so they must use base 10 which really makes all this speculation useless, even if it’s fun.)
Anyways, thank you for coming to my octal numeral system TED talk, and if you suffered through this whole “lesson” and have any questions, hmu! Anything beyond base 10 gets confusing (try looking up duodecimal and you’ll see a bunch of different ways to write ten and eleven, though personally I’m rather fond of hexadecimal-style just because it makes the most sense) so I’m probably not the best person to ask about that (though I can attempt to answer questions if you happen to have them ig?) but I can pretty much answer anything base 10 or under.
#also @ pnftheories i'm not tagging you bc i'm expecting you to contribute anything#so don't feel like you have to respond to this at all#but i figure since it was your post that got the ask it was only fair to let you know :)#look i have an ask#pnf#base 8
42 notes
·
View notes
Text
I want to write two posts, and they're about things that people call "Turing Complete" that aren't actually that. This happens for two reasons. The vast majority are for the first reason: you have a system that is "able to work like a computer", but only one with a fixed amount of memory, which is very different from a Turing machine.
The latter is about the few things that are "Turing Hard", that is, they can do anything a Turing machine can do; but they're not computable themselves. This is pretty rare because we don't often encounter noncomputable things in our lives. That will be for a later post.
Okay, what does "Turing Complete" mean?
A Turing machine can be defined by the following model (informal and unconventional, but accurate):
A storage device that can hold an arbitrary amount of binary data (bits). We can call this the hard drive.
A CPU:
It holds some fixed amount of bits in its memory. Let's call this the RAM. The amount of RAM is fixed (say, 100 bits) but could vary from machine to machine.
It can add/subtract/multiply numbers.
It can read and write to any location on the hard drive. How do you refer to potentially arbitrarliy large addresses in memory? Well, the hard drive is organized into folders: each folder has a "0.txt" and a "1.txt" and a folder called "0" and a folder called "1". The CPU can move up or down the layers of folders by issuing the right command, or it can read one of the two files in a folder (and each file contains one bit of data).
The CPU is 'hardwired' to do a particular pattern. Based on its 100 bits of RAM, it modifies those bits of RAM, and issues "READ", "WRITE" and "CHANGE FOLDER" commands to the hard drive.
The conventional idea of Turing machine has an infinite tape and a head, and while it one of the most useful ways of then doing theoretical analysis of the machine, it doesn't translate very well to how people "feel" about computers these days.
In the version of Turing machine I give above, when I say I have "a Turing machine", what I mean is that you tell me how many bits of RAM it has (say, 100), and then you give me a giant table that tells you, "given this arrangement of the 100 bits of RAM, output this, input this, and set your 100 bits of RAM to this new set."
And so if something else (say, a video game) is "Turing-complete", that means that if I give you the table of some Turing machine, then you can give me an instance of that thing (say, a video game save file; a map) that behaves like that Turing machine.
What "behaves like" means precisely depends a bit on the context of what the "thing" is. Often a Turing machine will be defined to have an additional "accept"/"reject" state, saying that it succeeded or that it failed. In the context of a video game, this could be the game ending or a character dying, or one of two different items being deposited into my inventory.
I need an example!
Fair. Well, most programming languages are Turing complete (but see below). In Java, for instance, I could define something like:
class Folder{ boolean txt0, txt1; private Folder fold0, fold1, parent; //Yada yada, get and set //and make new subfolders as needed } class CPU { final boolean[] RAM = new boolean[100]; Folder currentFolder f = new Folder(); void step() { //your code goes here } public static void main(String[] args){ CPU cpu = new CPU(); //We might need to fill in the hard drive //with some input data here while(true) { cpu.step(); } } }
So if you give me some Turing machine, I can fill in the step() function and give you an equivalent Java program. You can do the same in Python, or Perl, or bash, or Ruby, or JavaScript, or ... you get the idea.
That's boring, that's just programming
Also fair. How about Factorio, a game where you build a factory? There's no "folders" or "bits" here in any obvious way. But you can make a factory that continuously builds itself bigger and bigger, as in that first link. And you can make a computer that accesses memory and modifies it according to hardwired rules. So, you give me a Turing machine's table, and I'll build you a Factorio map. Then as the game runs, the CPU does its "steps", maybe accessing some bit of the hard drive. If that folder hasn't been built yet, the CPU will have to wait. But eventually that bit will be built, and execution will continue. And when your program finishes, it will have computed the same answer that the original Turing machine would.
Another good example is Conway's Game of Life, in which cells switch between "alive" and "dead" depending on their neighbors. There are self-growing patterns of cells, and ways for cells to act as circuits. See a pattern? So these are both Turing complete.
Okay, so what are you whining about?
People love to say that things are Turing complete: * Here's a very popular video about PowerPoint being Turing complete. * Here's a claim that Portal 2 is Turing complete. * Here's a claim that even CSS is Turing complete!
Wow, everything must be Turing complete, huh?
Well, no. Let's look at the PowerPoint example.
PowerPoint is Simple
PowerPoint is, for the purposes of this discussion:
A collection of shapes that (1) take up particular areas of the screen and are (2) enabled or disabled
A collection of animations that move a list of shapes to a particular location
A map saying that, when I click on one area, if it's enabled, that it (1) runs some animations and (2) enables/disables some other shapes.
So, if you give me a PowerPoint, could I analyze it to figure out everything it could ever do? Yes! Each shape has only a fixed list of locations it can be (its starting location, and each place mentioned in some animation). So I can look at every possible configuration of which shape is where, of which there is some fixed list, and figure out which configuration leads to which other. Or, which others, if the user has multiple choices.
If I have N shapes and K animations, I can "solve" PowerPoint in at most K^N steps. Given that Turing machines cannot be solved, this actually proves that it can't be Turing complete.
The most disappointing part is that the author acknowledges this -- see the section titled "Turing Completeness". His defense seems built around the idea that some programming languages aren't Turing complete. This is true, and has been discussed a few times. This doesn't mean that PowerPoint is Turing complete though, any more than the existence of bicycles means a tricycle is a kind of car. And as pointed out above, plenty of other programming languages are Turing complete. C is definitely the exception, not the rule!
Okay, but every computer is finite!
Yep! Yep, they are. We can never build a Turing machine in real life. We'll also never find every prime number. But the statement "there are only finitely many prime numbers" is still false. Turing completeness is a statement about an abstract model, and programming languages like Java and Python, and video games like Factorio and Conway's Game of Life also describe abstract models. Our silicon bricks will do their darndest to accurately implement that model, and eventually they will fail, but that doesn't mean the abstract model is changed somehow.
The Java specification doesn't say "ah, but if you hit 1 exabyte, quit"; the Java specification allows you to keep going, and barring exceptional behavior (like an OutOfMemoryError), the Java program above correctly models a Turing machine. C is unusual in that specification actually directly limits you to a certain memory size.
So what should I say, then?
When people say things are Turing complete, they usually end up being PSPACE-Complete. (In rare cases, they might only be P-Complete.) PSPACE aligns, roughly, with what can be computed on real world hardware, if you're very patient: if I want to run a program on a particular piece of input of size n, then I need memory proportional to nc for some constant c. If I have a traffic network of n cities and I need to keep track of the best route between each pair, then n2 is enough memory. I can still solve problems that might take a very long time to run, including checking each possible route through all the streets (which could take n! many operations, but not much memory).
PSPACE is broad enough to encompass lots of very hard problems, like breaking (just about any) encryption: assuming the password is not crazy long, a program can just try each password until it finds the one that works. If it always overwrites the last guess with the new guess, so it never needs much memory at any moment in time, even if it might be running for a very long time. PSPACE is actually powerful enough to do anything that a quantum computer can do, just maybe very slowly.
So why are some phenomena naturally PSPACE Complete?
Generally, yeah. A good way to think about PSPACE completeness is:
You give me a Turing machine, and you tell me that this machine will never need more than nc memory. You then want me to build you a machine (in a video game or whatever) that can run this machine for a certain size n. The machine will need to vary a bit with n, but that change should be according to a simple recipe.
The "simple recipe" part is about something called uniformity, and is really here so that I don't give you a gigantic ridiculous machine that has every possible answer to every possible problem already baked in or something. In practice this can pretty much always be turned into a description like,
You give me a Turing machine. I build you a "circuit" in the video game. Then you tell me how much memory, M, you need. I build you M identical memory units in the game, and hook it up the circuit. Now it can do what your Turing machine can do, as long as it doesn't need more than M memory in the hard drive.
So how does this show up? Earlier I linked to this Factorio post where he claimed that it showed Turing completeness. In fact, he only built a fixed-size circuit, with a fixed-size memory bank. Following his formula, if you give me a PSPACE program, I can build a Factorio circuit that runs that program, and takes up an amount of floor space for the memory proportional to the amount of memory your program needs. Similar arguments mean that Minecraft's redstone circuits, or real-world digital logic in silicon, are PSPACE complete.
P Complete
Some systems seem to "act like a digital circuit", but aren't even PSPACE complete. This happens if, intuitively, the circuit can't "loop back on itself". I just have logic gates going in, going to more logic gates, going to more logic gates, and eventually reaching the output. This class of complexity is only P Complete. (Side note: no one has actually proven P Complete and PSPACE Complete aren't actually the same thing! Although it very much seems this way. It's arguably one of the most important problems in complexity theory, and solving it would be a necesssary first baby step to proving that P does not equal NP.)
A simple example is gravity-fed water logic gates or even water computers. Water flows down a pipe, interacts in some way with another pipe to determine where more water gets routed, and eventually reaches some set of buckets at the bottom to show you the output. This is P complete: I can build any arbitrary circuit this way. But this kind of circuit has no notion of saving a variable and returning to it, no idea of "while loops" or addresses. This kind of feedforward setup will be P complete, even though it's still meaningfully a computer.
A trickier example is this popular demo which claims to show that CSS+HTML is Turing complete. Click the various squares and see how it changes. More people talk about it here. This is an HTML document with an element for each square on a grid. As you click on squares to set them green, some squares in the next row turn orange. If you do as you're told and click the orange squares, this pattern propagates down, and the computation result at the bottom. The rule for which cells turn green, opaquely known as rule 110, is Turing complete, when run on an infinite size grid for arbitrarily long time periods. This grid is, as you can see, only finitely wide and only finitely long. Like the water circuit, data only passes downwards, so the result is actually only P complete.
But wait! I can just build more stuff!
This is a common sticking point between PSPACE and P. For a PSPACE complete program, I'm allowed to build memory proportional to how much memory you need for your program to run. I can give my Redstone circuit enough memory to do what it has to, as long that isn't crazy (exponential). With the CSS example above, it might feel like I can just give you more cells as needed too, right? Just expand the HTML to account for it!
But if I did that, I would need huge amounts of HTML. I would need exponentially much HTML to be able to run PSPACE programs. And I would need uncomputably large amounts in order to run a Turing machine. It's really not Turing complete: remember, to be Turing complete, there shouldn't be any variation in the construction at all! The memory should be able to just grow as needed.
So what is Turing complete?
I'll probably compile a separate list. But here are some things that really truly are Turing complete: * Conway's Game of Life * Manufactoria (and its remake) * Programming languages like Brainf***, Java, Python, etc. * Repeated find-replace * The Excel LAMBDA function
and some things that act like computers, but are not Turing complete: * PowerPoint, because the shapes bound the memory. PSPACE complete. * Minecraft Redstone Circuits, because the circuit is a fixed size. PSPACE complete. * Note that when combined with pushers and appropriate mods, it may be possible to build a self-growing redstone computer, which would be Turing complete. AFAIK no one has done this. * The C programming language, because of fixed-size pointers. C is actually EXPSPACE complete when parameterized by the word size as written in unary. * That Portal 2 map, because of a non-growing circuit. Caveat: Some items in Portal 2 can create infinite mass, like cube dispensers, thus it's hard to definitely state the complexity of Portal 2. Also, depending on qualifies as "Portal 2", the scripting available in the Hammer mapping tool is quite flexible and might be powerful. * Excel spreadsheets themselves. This is only P complete, much like the CSS example earlier. * The type system in C++ or in Rust
This is ridiculous nitpicking and dumb
Sure. A computer is a computer, and building a computer in an environment is a cool achievement and usually also decently productive, as finding ways to build new computing fabrics is useful. Water-flow based computing is actually being used in consumer products. But Turing completeness is also a very strong and precise statement. If someone claims they build a computer in Minecraft, great! If they claim they showed that Minecraft is Turing complete, they should be ready to have their language scrutinized a bit.
This distinction has its own applications too. P complete systems are generally "safe" to have running, in the sense that they won't take up too much computing power. If Gmail offered some text-substitution rules for my email signature that were P complete, they don't need to worry about it eating up CPU power. If it was PSPACE complete, they should watch out and will need timeouts or recursion depth limits to stop people from DOSing it.
These distinctions also tell me something about what kind of computer someone has built. If you built something P complete, then you built a logic circuit. If you built something PSPACE complete, you built a real useful computer that can run programs. And if you have something Turing complete, then you have a monstrosity that will grow without bound and eat up all the resources in the universe, if left alone long enough. :)
6 notes
·
View notes
Text
Pattern programs in Java are exercises where developers create geometric patterns using loops and conditional statements. These programs help enhance coding skills by fostering logical thinking and problem-solving abilities. They can range from simple shapes to complex designs, making them a popular practice for beginners and experienced programmers alike. Check here to learn more
0 notes
Text
Make comment to get this book free

Authors: Fábio M. Soares, Alan M. F. Souza
Edition: 2nd
Publisher: Packt Publishing, 2017
ISBN: 1787126056, 9781787126053
Length: 270 pages
Create and unleash the power of neural networks by implementing professional Java codeAbout This Book- Learn to build amazing projects using neural networks including forecasting the weather and pattern recognition- Explore the Java multi-platform feature to run your personal neural networks everywhere- This step-by-step guide will help you solve real-world problems and links neural network theory to their applicationWho This Book Is ForThis book is for Java developers who want to know how to develop smarter applications using the power of neural networks. Those who deal with a lot of complex data and want to use it efficiently in their day-to-day apps will find this book quite useful. Some basic experience with statistical computations is expected.What You Will Learn- Develop an understanding of neural networks and how they can be fitted- Explore the learning process of neural networks- Build neural network applications with Java using hands-on examples- Discover the power of neural network's unsupervised learning process to extract the intrinsic knowledge hidden behind the data- Apply the code generated in practical examples, including weather forecasting and pattern recognition- Understand how to make the best choice of learning parameters to ensure you have a more effective application- Select and split data sets into training, test, and validation, and explore validation strategiesIn DetailWant to discover the current state-of-art in the field of neural networks that will let you understand and design new strategies to apply to more complex problems? This book takes you on a complete walkthrough of the process of developing basic to advanced practical examples based on neural networks with Java, giving you everything you need to stand out.You will first learn the basics of neural networks and their process of learning. We then focus on what Perceptrons are and their features. Next, you will implement self-organizing maps using practical examples. Further on, you will learn about some of the applications that are presented in this book such as weather forecasting, disease diagnosis, customer profiling, generalization, extreme machine learning, and characters recognition (OCR). Finally, you will learn methods to optimize and adapt neural networks in real time.All the examples generated in the book are provided in the form of illustrative source code, which merges object-oriented programming (OOP) concepts and neural network features to enhance your learning experience.Style and approachThis book takes you on a steady learning curve, teaching you the important concepts while being rich in examples. You'll be able to relate to the examples in the book while implementing neural networks in your day-to-day applications.
1 note
·
View note
Text
RegEx: What is a Regular Expression in GA4 (Google Analytics 4) and Why it Matters

What Regular Expresión RegEx is in GA4? ⚡ Definition: A Regular Expression (RegEx) is a sequence of characters that defines a search pattern. It allows you to match, locate, and manipulate specific patterns within text, including website data in GA4. 👍 Purpose: RegEx enables you to create more refined and accurate segments, filters, and analyses in GA4, revealing insights that would be difficult to uncover using standard methods. How RegEx are categorized? RegEx can be categorized by the type of syntax they use, the type of languages they support, and the type of engines they run on. Here are some examples of each category:Syntax: There are different syntaxes for writing RegEx, such as POSIX, Perl, PCRE, ECMAScript, and more. Each syntax has its own rules and features, such as metacharacters, quantifiers, modifiers, and groups. Some syntaxes are more expressive and powerful than others, but they may also be more complex and less portable.Languages: There are many programming languages and frameworks that support RegEx, either natively or through libraries. Some of the popular ones are Python, R, Java, C#, JavaScript, Ruby, PHP, and more. Each language may have its own implementation and variant of RegEx, which may differ slightly from the standard syntax or semantics.Engines: There are different types of engines that process RegEx, such as DFA, NFA, and hybrid. Each engine has its own advantages and disadvantages, such as speed, memory, backtracking, and lookahead. Some engines are more efficient and robust than others, but they may also have more limitations and trade-offs.The most popular RegEx engines available in 2024 are:- PCRE: Perl Compatible Regular Expressions, a library that implements most of the features of Perl RegEx, as well as some extensions. It is widely used by many languages and applications, such as PHP, R, Python, Apache, Nginx, and more. - ICU: International Components for Unicode, a library that provides support for Unicode and internationalization, as well as RegEx. It is used by many languages and platforms, such as Java, Swift, .NET, Qt, and more. - RE2: A library that implements a fast and safe RegEx engine, based on a hybrid of DFA and NFA. It is designed to avoid the exponential worst-case complexity of backtracking engines, and to handle large inputs efficiently. It is used by languages and applications such as Go, Python, Ruby, and more. Why RegEx is so important to me, and why it should be to you. With over 11 years under my belt creating digital campaigns that truly move the needle, I've seen it all when it comes to analytics. But nothing has captured marketers' curiosity lately more than GA4 (Google Analytics 4). As Google completes its sunsetting of Universal Analytics, there’s a whole new world of possibilities opening up. And one lesser known but incredibly powerful feature is regular expressions or “regex”.I admit that when I first heard about regex, I pictured some complex coding syntax only engineers use. Boy was I wrong! Regex is actually easy to grasp (more on that shortly) and unlocks game-changing tracking in GA4 for businesses of any size. At its core, a regular expression or “regex” is just a search pattern used to match certain strings of text. But this unassuming concept offers marketers like us extraordinary precision. We can track and target website activity in entirely new ways not possible before.For example, say your ecommerce store has product IDs with a specific prefix like “PRO123”. With regex, you could track revenue, clicks or other behavior on just those products in GA4 with a few keystrokes. The use cases are nearly endless. In this guide, we’ll break down everything you need to start wielding the full power of regex today. I’ll explain what regex is, why it matters now more than ever, and walk through real examples that work from my own analytics projects. Let’s dive in! The building blocks: Key metacharacters used in GA4 regex The Forward Slash (/) metacharacter The forward slash metacharacter plays a key role in GA4 regex by delimiting the start and end of the pattern. Anything between two forward slashes "/" becomes interpreted as the actual regex syntax to match text against. Proper usage of forward slashes is essential for well-formed regex. The Back Slash () metacharacter The backslash metacharacter helps "escape" other regex symbols, allowing you to match those literal characters instead of their special meaning. For example, if you needed to match an actual "." in text, you would use "." in your regex. The backslash gives tremendous flexibility. Caret (^) and what it does The caret symbol matches the very start of a string of text. For example, "^Mission" would look for the word "Mission" only at the beginning of a URL or other input. This allows precise control for start-of-string matching. Extremely useful! Dollar sign ($) explained Like the caret but opposite, dollar sign matches just the end of the input string. You could search for "html$" to find html pages only. Or "2023$" to match dates ending in that year. Another way to target precise text positions. Brackets - Their role Bracket metacharacters allow grouping multiple characters/words to match in a single place in the regex. For example, would match just x, y or z in that position. Incredibly versatile for custom group matching! Parentheses () metacharacter Similar to brackets but parentheses group text/patterns while also capturing that piece of matched text for additional processing. Extra utility while grouping regex logic. Question Mark (?) and what it means The question mark metacharacter allows 0 or 1 matches of the preceding character/group. For example, "colou?r" would match both "color" and "colour". Optional matching. Plus sign (+) metacharacter The plus sign metacharacter allows 1 or more repetitions of the previous character/group. For example "A+" matches "A", "AA", "AAA" etc. Useful for broad matches. Asterisk (*) sign function Similar to plus, the asterisk allows 0 or more matches of the preceding character/group. For example "Data" would match "Data", "Database", "DataPoints" etc. Another broad matcher. Dot (.) metacharacter purpose One of the most useful metacharacters, dot "." matches ANY single character except newlines. Combine it with + and * for powerful broad matching quickly! Pipe Symbol (|) usage The pipe symbol acts as an OR operator in regex, allowing matches from multiple patterns. For example "cat|dog" would match occurrences of either "cat" OR "dog" in the input text. This provides more flexible pattern matching. Exclamation (!) metacharacter The exclamation point negates or inverts the meaning of whatever follows it in the regex. For example "!Mission" would match any text NOT containing the word Mission. Another way to precisely control matching. Curly Brackets {} usage Curly brackets set a custom quantity or range for the preceding character/pattern. For example "d{3}" matches exactly 3 digits, while "d{3,5}" matches 3 to 5 digits. Tremendous way to define restricted repetition. White spaces role ⬜ Whitespace metacharacters like "s" match generic spaces, tabs, newlines etc. You can search for "S" to require non-whitespace at that position. Helpful for pattern precision when whitespace matters. Crafting regex patterns properly in GA4 Through the years testing analytics implementations, I’ve seen plenty of clever regular expression attempts backfire due to subtle syntax issues. Even what appears to be flawlessly crafted regex logic can fail hard if you don’t follow best practices.Trust me, after an all-nighter spent debugging a malfunctioning regex pattern character-by-character, I learned proper regex hygiene the hard way! But following a few simple guidelines can help your patterns work smoothly right off the bat.First, always surround your full regex with delimiting forward slashes - like putting punctuation marks around a sentence. We generally aim to match entire strings/parameters, not just parts. Adding the start ^ and end $ metacharacters helps by anchoring patterns accordingly.When nesting metacharacters, use plenty of whitespace and liberal comments explaining the logic. Regex may be concise but can get complex quickly! Well-formatted patterns are far easier to adjust later when needs change.Finally, test early and often! GA4 offers a handy regex validator under the Admin section, but I always build a quick tag to evaluate against real site data. Between those two testing methods, flawed patterns get identified fast before tag deployment.Speaking of testing, let me share an example regex pattern for Google Analytics 4 that recently helped one of my ecommerce clients...Code snippet^/product/.*/d+$This regex pattern matches any page path that starts with "/product/" followed by any string of characters, an underscore, and then a sequence of digits. This means that it will match page paths like "/product/mens-clothing/shirts/red-shirt", "/product/womens-accessories/handbags/black-clutch", and "/product/kids-toys/puzzles/dinosaur-puzzle".This regex pattern was used to create a filter in Google Analytics 4 that only included visits to product pages. This allowed the client to track conversions, such as purchases, that were made from these pages.Here is an example of how to use this regex pattern to create a filter in Google Analytics 4:Go to the Data Stream settings for your property. Click on the Configure Tag Settings tab. Scroll down to the Filters section. Click on the Create filter button. Select Matches regex as the filter type. Paste the following regex pattern into the Regular expression field:^/product/.*/d+$ Click on the Save button. This helped to ensure that only visits to product pages would be included in my client's Google Analytics 4 reports. This made it easier for us to track conversions from these pages. Quick regex creation tips for GA4 I’ve learned, the hard way, that speed and agility are everything when it comes to analytics implementation. The best ideas mean nothing if you cannot test and iterate on them rapidly. Luckily, regex delivers on both fronts - providing tremendous flexibility without complexity once you know some key tips.First, leverage online regex testers and cheatsheets liberally. I always keep a few handy references open as I build, double checking syntax or inspiration for new approaches. They cut down on silly errors and unlock advanced techniques faster.Similarly, do not try to memorize every metacharacter! I focus on learning the 5-6 most versatile building blocks first, like dots, brackets, braces etc. Combined creatively, they can handle ~90% of use cases quickly. Lean on guides to fill in the remaining syntax as needed.Finally, do not reinvent the wheel each time. Archive and comment old regex patterns for easy reuse. Tweak stored snippets rather than coding everything fresh. Review examples from community forums and analytics leaders to inspire new ideas. Compounding prior work pays dividends with regex!Let me walk through a real example from a recent campaign leveraging these tips to rapidly implement regex tracking... Example for rapidly implement regex tracking using Google Analytics 4 ScenarioThe client wanted to track specific campaign events, such as newsletter signups or lead generation forms, from various sources, including email links, social media posts, and paid ads. They were using Google Analytics 4 (GA4) as their analytics platform. ChallengeThe client was struggling to create and maintain effective tracking for each campaign event across all these different sources. They were using a mix of manual event tracking and custom dimensions and metrics, which was becoming increasingly complex and difficult to manage. SolutionWe introduced regular expressions (regex) to the client's tracking strategy. Regex is a powerful tool that can be used to extract specific information from URLs and other data sources. This allowed us to create more streamlined and flexible tracking rules that could be applied to all their campaign events, regardless of the source. Implementation We followed the three key tips mentioned above:Leveraged online regex testers: We used online regex testers to validate our regex patterns before implementing them in GA4. This helped us to avoid syntax errors and ensure that our tracking was accurate. Focused on the most versatile metacharacters: We prioritized learning the most common and versatile metacharacters, such as dots, brackets, and braces. This allowed us to create patterns that could handle a wide range of use cases with minimal complexity. Reused existing regex patterns: We kept track of existing regex patterns and reused them whenever possible. This saved us time and effort, and it also ensured consistency in our tracking across different campaigns. Results! By using regex, we were able to significantly simplify the client's tracking strategy. They were able to create more accurate and granular tracking rules, and they were able to implement these rules more quickly and easily. This also helped them to identify and measure campaign performance more effectively. Unleashing regex in GA4 - where can you use it? While the fundamentals of regular expressions center around sophisticated text matching and parsing, we as analysts ultimately care about actionable data. All the processing power behind regex means nothing if we cannot integrate that logic to amplify our analytics capabilities. Luckily, GA4 provides numerous integration points to bake regex directly into your implementation's workflow. In this section, we will explore some of the top places regex can deliver value: - Using regex for setting up subproperties on GA4:To match mobile device user agents, you can use a regex pattern like this:/^(Android|iPhone|iPad|iPod|BlackBerry|Windows Phone)/iThis will match any user agent that starts with one of the listed mobile device names, case-insensitively. You can add more devices to the list if you want. - Configuring site search tracking without query parameters:To identify search terms from the search box URL structure, you can use a regex pattern like this:/search/(+)/This will match any URL that contains /search/ followed by one or more characters that are not slashes, and capture the search term in a group. For example, if the URL is https://example.com/search/flowers/, the regex will match and capture flowers as the search term. - Refining referral exclusion lists:To exclude traffic from your own internal tools, you can use a regex pattern like this:/^(localhost|127.0.0.1|192.168.|10.|172.(1|2|3))/This will match any URL that starts with localhost, 127.0.0.1, or an IP address that belongs to a private network. You can add more domains or IP ranges to the list if you want. - Creating granular data filters in Exploration reports:To filter for sessions with product page views that contain a specific brand name, you can use a regex pattern like this:/products/.*?/brand-name/This will match any URL that contains /products/ followed by any number of characters (as few as possible) followed by /brand-name/. For example, if the brand name is nike, the regex will match URLs like https://example.com/products/shoes/nike/ or https://example.com/products/clothing/nike/jackets/. - Setting up custom events via Google Tag Manager:To capture button clicks on specific page elements, you can use a regex pattern like this:/button/This will match any HTML tag that is a button with an id attribute, and capture the id value in a group. For example, if the button tag is Submit, the regex will match and capture submit as the id value. - Organizing content groups:To create a content group for blog articles, you can use a regex pattern like this:/blog/(d{4})/(d{2})/(d{2})/(.+)/This will match any URL that contains /blog/ followed by a date in the format YYYY/MM/DD followed by a slug, and capture the year, month, day, and slug in separate groups. For example, if the URL is https://example.com/blog/2023/04/14/learn-regex/, the regex will match and capture 2023, 04, 14, and learn-regex as the date and slug values. - Building targeted audiences:To create an audience of users who have visited product pages with certain keywords in the URL, you can use a regex pattern like this:/products/.*(keyword1|keyword2|keyword3)/This will match any URL that contains /products/ followed by any number of characters followed by one of the listed keywords. You can add more keywords to the list if you want. For example, if the keywords are shoes, bags, and hats, the regex will match URLs like https://example.com/products/shoes/nike/ or https://example.com/products/accessories/bags/leather/. - Modifying events in the GA4 UI:To standardize product names in purchase events, you can use a regex pattern like this:/^(.+)s+((.+))$This will match any product name that consists of two parts separated by a space and enclosed in parentheses, and capture the two parts in separate groups. For example, if the product name is Nike Air Max (Blue), the regex will match and capture Nike Air Max and Blue as the product name and color values. - Matching multiple domains or subdomains in cross-domain tracking or filters. To match example.com, blog.example.com, and store.example.com, you can use a regex pattern like this:^(example.com|blog.example.com|store.example.com)$ - Extracting custom dimensions or metrics from URLs or page titles using Google Tag Manager.To extract the author name from a blog post URL like https://example.com/blog/2023/04/14/learn-regex-by-john-doe/, you can use a regex pattern like this:/blog/d{4}/d{2}/d{2}/.+-(.+?)/$This will capture the author name (John Doe) in a group. - Validating form fields or input values using Google Tag Manager.To validate an email address input, you can use a regex pattern like this:/^+@+.{2,}$/This will match any email address that follows the standard format. - Creating custom channel groupings based on campaign parameters or source/medium values.To create a custom channel grouping for social media traffic, you can use a regex pattern like this:/(facebook|twitter|instagram|linkedin|pinterest)/This will match any source or medium that contains one of the listed social media platforms. - Creating custom alerts based on specific conditions or thresholds. To create a custom alert for when the bounce rate of a landing page exceeds 80%, you can use a regex pattern like this:/landing-page/This will match any page that contains /landing-page/ in the URL. These are just some of the many possible use cases for regex in Google Analytics. You can find more examples and resources in this practical guide, this beginner’s guide, this essential guide, this ultimate guide, or this regex guide. 😊 Validate Regex Patterns in GA4 the Right Way Crafting airtight regex logic requires testing - and LOTS of it! After over a decade cooking up digital analytics implementations, I've seen even the most beautifully crafted regular expressions fail hard once unleashed on actual visitor data.Trust me... that brutal moment when your perfect regex works flawlessly in testing but totally unravels with production traffic? Save yourself the pain! 😓 The good news? GA4 bakes in all the tools you need to launch regex patterns confidently.Be Read the full article
0 notes
Text
Wolf 359 characters as tips from Pryce and Carter’s Deep Space Survival Manual
Eiffel: 426. When in space, fire is one of those “only when absolutely necessary” solutions.
Minkowski: 721. Only very rarely does a superior officer “just need a hug.”
Lovelace: 220. When you’ve got a gun, everybody pays attention.
Hilbert: 535. You may receive a message thanking you for volunteering to participate in studies of a medical, psychological, or pharmaceutical nature. These sorts of things just happen from time to time. We wouldn’t worry too much about them.
Hera: 255. Who shoots first doesn’t really matter. You should be focusing on whose shooting has microfusion-reactors and A.I.- targeting technology.
Kepler: 56. The divide between fun and mandatory fun is not as wide as you think it is.
Maxwell: 695. There are no “bad” programming languages, but there are bad people. And these bad people designed Java.
Jacobi: 896. Remember: Historically, glass fragments have been responsible for 87% of injuries and deaths in bomb blasts.
Cutter: 976. A wise person considers the parallels between the historic patterns of colonialism and an individual’s rise to prestige. And finds them good.
Pryce: 678. You may find your spirit willing but your flesh coming up short. To remedy, report to medical for upgrading.
#wolf 359#douglas eiffel#isabel lovelace#renee minkowski#hera#alexander hilbert#warren kepler#daniel jacobi#alana maxwell
13 notes
·
View notes
Text
devlog # 9 // life updates + new systems (UI, character stats, turn-based system)
so, I’ve been away for what feels like a year - there are a million things I could share. first, let me update you on life things, then tell you a bit about what I’ve worked on in-game. as far as life things, I have been t i r e d. and with autumn (my favorite season) here, the desire to cuddle and sleep all day is strong.

part of what’s been keeping me so tired is also that I both started uni studies and have a new job. in the last blog, I mentioned I was thinking of going to university for further studies in computer science and all. well, thanks to a few people’s generosity (and many, many phone calls, emails, etc), I did get signed up in time! I have been absolutely in love with the things I’ve been learning in my first computer science class ever; even though it teaches Java, I have found that everything I’m learning is very easy to translate into C# and what I’m building in Unity. each day, I feel more confident in my coding, so much so that nearly everything I’ve done in the past month has been entirely from my mind, just free-coding, without any tutorial or other guidance. it is really amazing to feel like I can code up a system in my mind, even when I am away from a computer, and then sit down and type it out and it run exactly as I intended. while my studies and my new job (not especially difficult, but asks but for many hours each week; consider supporting me on Patreon so I don’t need to work as much?) keep me busy and often fatigued, I have been reclaiming time to code things I love and am really excited about - and I’d like to share with you a couple of things I’ve recently built. (edit: I just realised that a lot of the images are blurry :( will think on a fix for this)

where we left off with the last devlog, I was working a lot on the systems to build up the physical world: tile generation, interactables, biomes, and the like. I did actually work on some other parts of the world and visuals (will share that in a near future devlog!), but more and more lately, I’ve been feeling like what will really keep me excited and focused, to feel like I’ve reached a solid checkpoint in my development, is being able to actually *play* the game. even if it’s repetitive, only one area, or without animations, being able to press play and move characters around and interact is something I know will excite me. so, that’s what I’ve been working towards. there are a handful of pieces I can identify between where the game was last devlog and what it needs to be minimally playable: - a basic UI that shows character stats - a system to calculate and update the stats to be displayed - a system to keep track of turns automatically - for the UI or world to display player choices accurately - at least a couple interactive actions the player can take, besides moving (damaging health, defending, etc) I started with making a basic character stat UI and a behind-the-scenes calculator. note: since we’re working mainly on systems in this devlog, I’m going to be sharing a lot of code talk. but maybe you’re into that sort of thing. also remember that my focus in each of these pieces is not to make something gorgeous or especially well-organised; my focus is to make something that works (though I am always thinking about optimisation and other possible patterns along the way).
so, this is what the first UI for character stats looks like! I modeled this as a basic idea of how you might make a UI for creating a character and being able to preview their stats - both the base ones (like might and agility) and also a few of the compound ones (health, stamina, mana).

in this version, a player can choose an inheritance (what other games call “race”), a birth sign, and a primary class (though you won’t be able to choose it from the start like this in the game). each of these choices contributes modifiers which change the stats, which is calculated altogether when you press the left or right buttons. (again, these are not all the inheritances, signs, or classes in the game)
here’s a bit of the magick code that makes this happen:
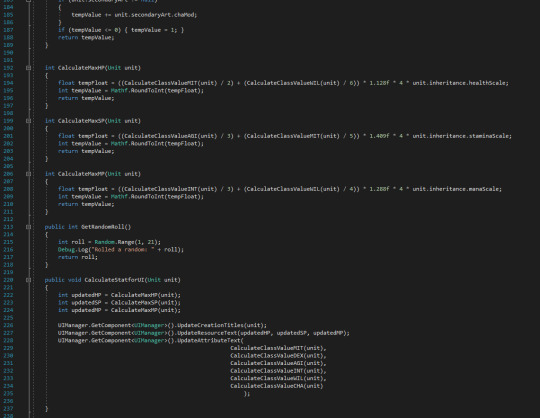
as you can (hopefully?) see, I’m calling methods (CalculateClassValueMIT, etc) to get the relevant stat values and multiplying those against a magic number (eep!) and the character’s inheritance scaling. what you might you also notice here is that these calculations are hard-coded to a given attribute (might, dexterity, intellect, etc); along with MIT, each of the other five attributes has its own calculation method. I really hate this because I know there has to be another way to do it, but this is the way I know how to do so far - feel free to message me other patterns! (for example, I’ve seen people make a Stat class, but I don’t really get that yet?) then, while I was feeling a bit playful with UI and stats, I thought I would spend a day making a prototype of a “charisma interaction” system. by this, I mean that - in the game - characters will be able to use their interpersonal skills to be able to navigate certain quests, get more information, and the like. charisma pairs with each of the other attributes to give a certain way of interacting; for example, charisma and might could be interpreted as aggression, intimidation, using one’s size or boldness to gain favor. pairing charisma with will could render an interaction more focused on relating, understanding, and empathising. you can see some of might interaction here.
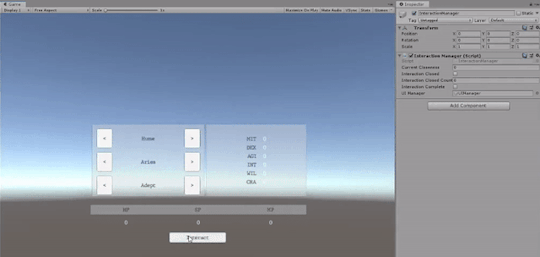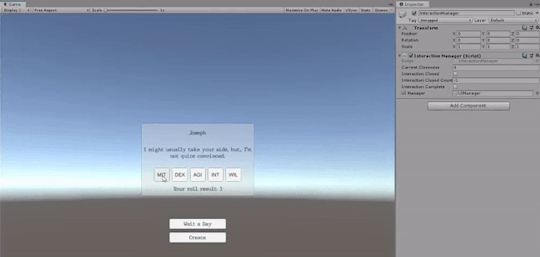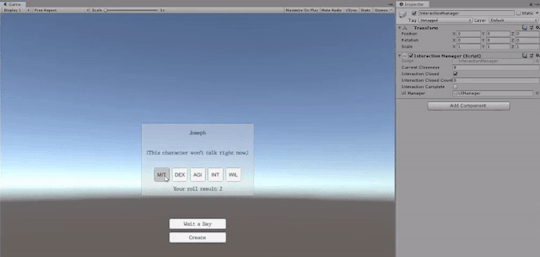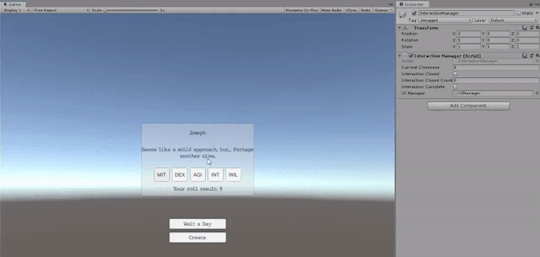
what’s shown in this is that Joseph, the unit kind enough to help with our testing, responds to your might interaction attempt with various phrases. behind the scenes, Joseph has their own inheritance, signs, and other traits, and when you click, these + a random roll are used to calculate *how* Joseph responds. in this case, Joseph has a primary sign of Aries, which inclines them to respond well to your might-based attempts (you’re in luck!). even when Joseph declines your attempts or chooses to stop talking about a subject (just wait some days for them to open up again), they will tell you that they mostly like how you’ve approached them, even if it didn’t work this time - a character with Virgo as a primary sign, however, might tell you off on your first attempt and refuse to interact further with you. rather than just a few pre-programmed dialogues, I am interested in the game having a more procedural, somewhat organic feel. also, in the actual game, Joseph will have slightly less patience; you won’t be able to keep clicking, only able to make an attempt twice in a day before the character closes that interaction. while the gif above shows many of the responses and reveal that there are just a handful of phrases this character will use, a player won’t see these in succession like this, so hopefully, the organic, personal feeling will be maintained. and again, in the future, I intend to make this more complex, not just button pressing. here’s some of the behind the scenes to how the aries sign is built. each sign is a scriptable object with these same parameters.
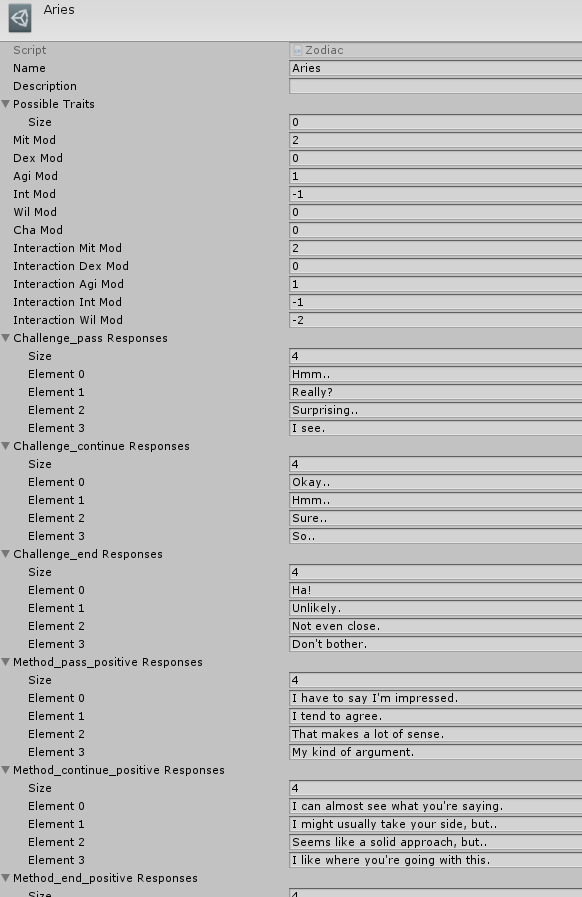
the basics of how a sentence is formed:
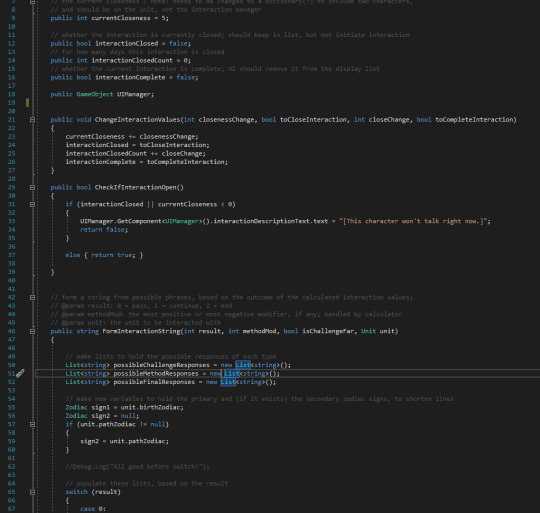
and what happens when you press the MIT button:
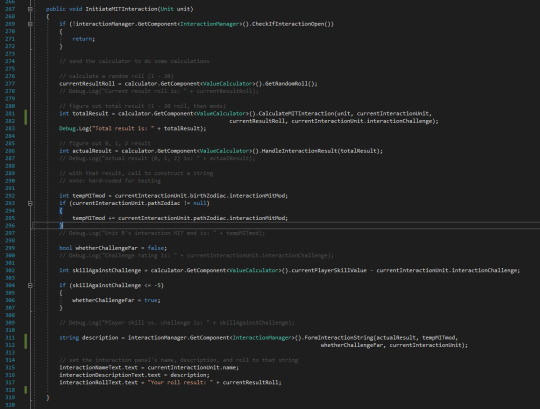
and the last thing to share today is about the turn-based system. I knew this was an important step in moving us closer to a playable version of the game.
take a look, and then I’ll explain.
feel free to rewatch a few times, since there’s a lot to notice.
first, I approached this system by defining exactly what makes up a turn. during a turn, the player will have four basic opportunities for choices: a first movement, an action, a secondary action (if the first was a half-action), and a second movement (if the character has any remaining movement). these are the phases that the character sees and directly interacts with. then, beyond/around that, each turn also needs to initialise a player and update any status effects (status phase), figure out who’s next and adjust each character’s place in the list (priority phase), and see if the battle conditions have been met or if a next turn is needed (check phase).

here’s a closer look at some of the phases in code:
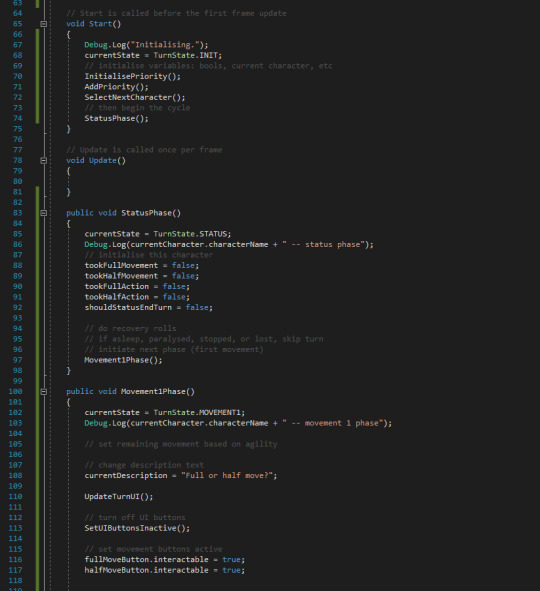
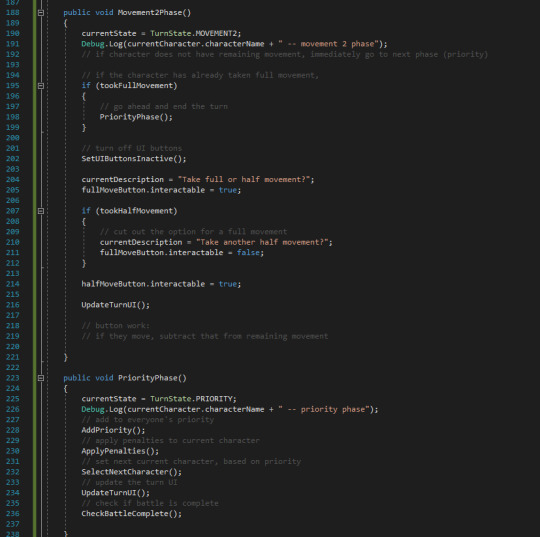
the basic setup is that the player interacts by pressing buttons when their input is needed, then the code moves through the phases depending on numerous factors: if the player used up all their movement, if they have action remaining, if they have a status (sleep? paralysed?) that will skip their turn, which phase it is currently ..
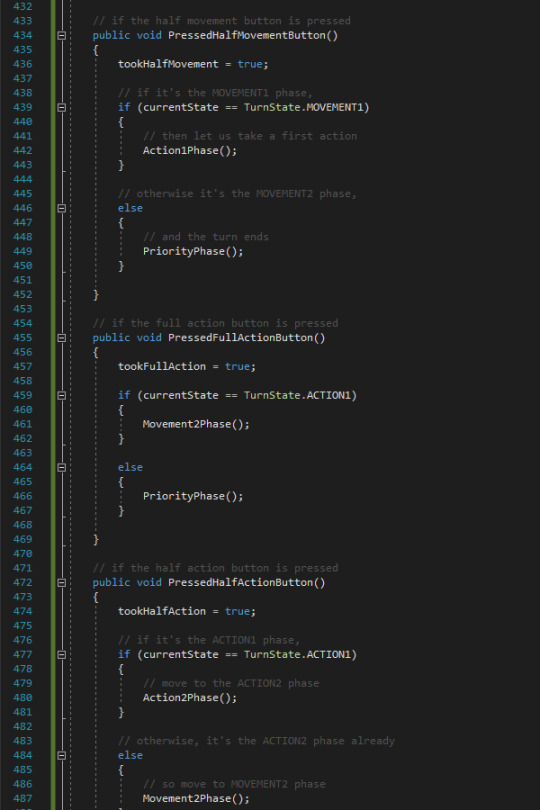
I have seen other approaches to coding a state machine (which I guess is what this is?) that I didn’t understand very much at all, and I am excited about this code because I know it came from me and all the things I’ve learned over my short time coding. importantly, i am excited because it works.
whew.

so, what’s next?
well, I’ve built these systems solo (separate from the rest of the game systems) so that I could really polish them (as much as one polishes prototypes :p) before moving them into the fray. so, a next step is to integrate both the stat UI and the turn-based system into the rest. to make it so that a player can pull up a fuller UI with a key press. to show a constant UI indicating which units are involved in an interaction, maybe with some predictive stats (chance of hit). and to have the player’s “movement button press” actually be them choosing which tile to move to, calculating automatically if that is their full movement range, and a much prettier (radial?) UI for selecting actions .. let’s not get ahead of ourselves. one thing at a time. I will keep working at it, with my plan being to get a workable version running this weekend, so maybe check back soon. and if you’d like to support me or get some behind the scene insights or help with building your game, do check out my Patreon - I would love for you to join my party: patreon.com/ahnmakes ✨✨ otherwise, I’ll see you in the next devlog! with love and need for a long, long sleep, ahn
#gamedev#game development#game dev#unity#c#c sharp#colorful#art#ui#ux#design#rpg#final fantasy tactics#fft
1 note
·
View note
Link
There are times when we do not know the exact item but we know how it looks like i.e. it has specific pattern and certain characteristics. So by just knowing the pattern, we can identify the items. In the same way, there are patterns to identify strings or set of strings in given text or file in java. For that, we have a REGULAR EXPRESSION in java. e.g. if we want to catch all email from the given text, we know how emails look like so we can define a pattern. We create a regex to represent that pattern. And performing pattern match on the given text, we can list all the emails in the given input text.
So regular expression is a special sequence of character that helps to match, find, edit other string or set of strings in the given input, using a specialized string held in so-called Pattern. The regular expression in java is provided through java.util.regex package. Java.util.regex primarily contains three classes name listed below
- Pattern Class: It is used to define the patterns for matching. An object of Pattern class represents a compiled representation of the regular expression. There is no public constructor available to create an object of Pattern class. To instantiate an object of Pattern class, one has to use any version of public static compile() method of Pattern class. These methods accept regular expression string as the first argument.
- Matcher Class: Matcher class is an engine to interpret the pattern of regular expression and performs the match on the input string. Matcher class too does not have any public constructor. To obtain an object of Matcher class, one has to use call matcher() method on Pattern Class object.
- PatternSyntaxException Class: A PatternSyntaxException class represents an unchecked exception that indicates a Syntax error in the regular expression.
CAPTURING GROUP in Regular Expression
The capturing group represents the group of the letter put together as a single unit. They are created by putting letters to be grouped in parentheses. e.g. (techie360).
Capturing groups are numbered by counting the opening parentheses from left to right. e.g ((t)(pq)) has capturing group in the order ((t)(pq)), (t), (pq).
To find the number of capturing group in the regular expression, just use groupCount() method on Matcher class object. Every capturing group contains group 0 which is not included in the count returned by groupCount().
Example of Capturing Group usage
import java.util.regex.Matcher; import java.util.regex.Pattern; public class RegexMatches { public static void main( String args[] ) { // input String String line = "you are reading post on techie360!"; String pattern = "(.*)(\\d+)(.*)"; // Create a Pattern object Pattern p = Pattern.compile(pattern); // Now create matcher object. Matcher m = p.matcher(line); if (m.find( )) { System.out.println("Found value: " + m.group(0) ); System.out.println("Found value: " + m.group(1) ); System.out.println("Found value: " + m.group(2) ); }else { System.out.println("NO MATCH"); } } }
The output of the above program would be
Found value: you are reading post on techie360! Found value: you are reading post on techie360! Found value: 0
REGULAR EXPRESSION SYNTAX AND MEANING
In the below table, a complete list of regular expression letters are listed
Regex Meaning ^ Matches the beginning of the line. $ Matches the end of the line. . Matches any single character except a newline. Using m option allows it to match the newline as well. [...] Matches any single character in brackets. [^...] Matches any single character not in brackets. \A Beginning of the entire string. \z End of the entire string. \Z End of the entire string except for allowable final line terminator. re* Matches 0 or more occurrences of the preceding expression. re+ Matches 1 or more of the previous thing. re? Matches 0 or 1 occurrence of the preceding expression. re{ n} Matches exactly n number of occurrences of the preceding expression. re{ n,} Matches n or more occurrences of the preceding expression. re{ n, m} Matches at least n and at most m occurrences of the preceding expression. a| b Matches either a or b. (re) Groups regular expressions and remembers the matched text. (?: re) Groups regular expressions without remembering the matched text. (?> re) Matches the independent pattern without backtracking. \w Matches the word characters. \W Matches the nonword characters. \s Matches the whitespace. Equivalent to [\t\n\r\f]. \S Matches the non-whitespace. \d Matches the digits. Equivalent to [0-9]. \D Matches the non-digits. \A Matches the beginning of the string. \Z Matches the end of the string. If a newline exists, it matches just before newline. \z Matches the end of the string. \G Matches the point where the last match finished. \n Back-reference to capture group number "n". \b Matches the word boundaries when outside the brackets. Matches the backspace (0x08) when inside the brackets. \B Matches the nonword boundaries. \n, \t, etc. Matches newlines, carriage returns, tabs, etc. \Q Escape (quote) all characters up to \E. \E Ends quoting begun with \Q.
METHODS OF MATCHER CLASS
Matcher class methods can be divided into three categories basis the function they perform:
- Index Methods: index methods provide the index of match found in the input string. Below is the list of index methods:
Method Explanation public int start() Returns the start index of the previous match. public int start(int group) Returns the start index of the subsequence captured by the given group during the previous match operation. public int end() Returns the offset after the last character matched. public int end(int group) Returns the offset after the last character of the subsequence captured by the given group during the previous match operation.
- Study Methods: these methods perform match on the input string and return whether the match is found or not. Please see below list for all Study methods:
Method Description Public boolean lookingAt() Attempts to match the input sequence, starting at the beginning of the region, against the pattern. public boolean find() Attempts to find the next subsequence of the input sequence that matches the pattern. public boolean find(int start) Resets this matcher and then attempts to find the next subsequence of the input sequence that matches the pattern, starting at the specified index. public boolean matches() Attempts to match the entire region against the pattern.
REPLACEMENT METHODS:
These methods perform replacement in the input string. Below are replacement methods
Method & Description public Matcher appendReplacement(StringBuffer sb, String replacement) Implements a non-terminal append-and-replace step. public StringBuffer appendTail(StringBuffer sb) Implements a terminal append-and-replace step. public String replaceAll(String replacement) Replaces every subsequence of the input sequence that matches the pattern with the given replacement string. public String replaceFirst(String replacement) Replaces the first subsequence of the input sequence that matches the pattern with the given replacement string. public static String quoteReplacement(String s) Returns a literal replacement String for the specified String. This method produces a String that will work as a literal replacement s in the appendReplacement method of the Matcher class.
matches() and lookingAt() methods: Similarity and differences
- both methods match pattern in the input string
- both start matching at the start of input string
- matches() requires complete string to be matched but lookingAt() does not require the complete string to be matching.
To demonstrate the difference see the example below:
import java.util.regex.Pattern; import java.util.regex.Matcher; public class RegexMatches { private static final String REGEX = "too"; private static final String INPUT = "tooo"; private static Pattern pattern; private static Matcher matcher; public static void main( String args[] ) { pattern = Pattern.compile(REGEX); matcher = pattern.matcher(INPUT); System.out.println("REGEX is: "+REGEX); System.out.println("INPUT is: "+INPUT); System.out.println("lookingAt(): "+matcher.lookingAt()); System.out.println("matches(): "+matcher.matches()); } }
the output of the above program
REGEX is: foo INPUT is: fooooooooooooooooo lookingAt(): true matches(): false
- replaceFirst( ) replaces first matching occurrence and replaceAll() replaces all occurrences of the pattern matching.
So we understand how we can use regular expression in java for pattern matching. Regular expressions are quite a powerful tool in java to find, edit and replace the input string.
Hope you enjoyed the article, please share and subscribe to the latest article update.
#regular expression in java#regex in java#java regex#regex usages#pattern matching in java#regex keywords in java#practical usage of regex
1 note
·
View note
Text
Sheeping Around Retrospective: By The Numbers
tl;dr: Scroll all the way down for the numbers.
Sheeping Around has been live on the App Store for a little over ten days now. I think it is about time I look back at the development cycle, the good parts, the bad parts and also share some sales figures while I’m at it. I’m following the trend of transparency to help other indie game developers know and understand the market of premium games, for which I gained inspiration from Eric @ Slothwerks and Arnold @ Tiny Touch Tales. I’m also inspired by the way they work: solo devs working with talented people across the world on a contract basis, and I follow the same pattern.
While I’ve worked on games in the past, this is my first official release on the App Store, and I’m really glad to have been able to reach that goal. My previous games got stuck in infinite iteration loops and never got to see the light of the day.
Inception
I have written in one of my previous posts how the idea of Sheeping Around was born. The idea began as a turn based (asymmetric) strategy game, and eventually turned into a card game that it is today. You can read more about it in the below two posts:
Sheeping Around Inception
Inspired by Card Thief and More

Inspirations of Sheeping Around and its inception as a physical card game
Development
I have around 8 years of experience as a Javascript developer. While I am familiar with other languages like Java and Objective-C/C++, my core expertise and speed of development is still in Javascript. Also, I had begun using TypeScript at work since mid 2017 and had loved it. Reminded me of the good ol’ Flash and Actionscript days.
When the physical version of Sheeping Around card game was proven to be fun enough, I began working on a web-based prototype version of it using Angular.js on the front-end and Node.js on the backend in the first week of November 2017. I deployed the system on Heroku on its free plan, and used Heroku Postgres as database of choice. (It was free upto 9000 rows, more than sufficient for a prototype.)
Initial prototype version of Sheeping Around
For the native mobile version of the game, I used cocos2d-x JS with TypeScript.
I pushed the code to GitHub as private repositories. I maintained separate repos for client and the server.
Multiplayer
Initially I had planned on Sheeping Around to be a solitaire card game, but it ended up being too similar to Card Thief. It wasn’t much fun anyway either. I decided to prototype a two player dueling game on paper, and it proved to be a lot of fun. I figured it would be much more challenging to handle a multiplayer game, but given my full-stack experience, I was confident I’d be able to do it anyway.
Architecture of Sheeping Around
Sketch, GraphicRiver and GUI
Around March 2018, I began working on the GUI of the game. I had recently switched my role to Product Design at my company Sumo Logic and had begun learning Sketch and loved it. I bought some assets off GraphicRiver and heavily modified a lot of them and put them together in Sketch.
All screen designs in Sketch
I wasn’t very happy with the initial designs, but towards the end of April things had started looking much better and professional.
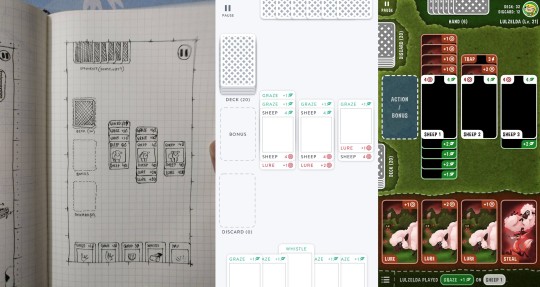
Initial designs
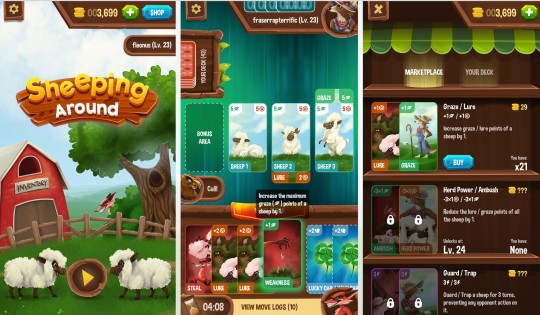
Final designs
Google Indie Games Accelerator
The progress in the initial few months was somewhat slow. I spent time refining the balance of the game and tweaking the progression. Meanwhile I was also designing some UI for the native mobile version of the game.
By the end of June 2018, Google announced the first ever Indie Games Accelerator for games made in South East Asia. The submission deadline was July, so I started rapidly working on the mobile version for Android and iterating it really fast. By mid of July, I had the gameplay fully functional. By the end of it, I had the entire progression system and marketplace fully set up.
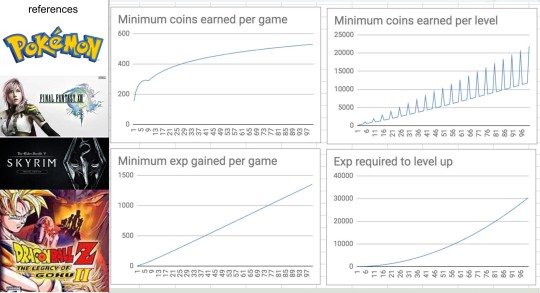
Some charts from the progression and reward system of the game inspired mainly by Pokemon
While I was not selected for the accelerator program, it did help me accelerate the game development process anyway and I am thankful to the accelerator program for that.
Art and Animation
I discuss a lot about art style with Rashi, and we had finalized that the characters would be anthro. Check out some concept art and final artwork for some of the characters below:



I really loved the idea of in-card animations in Card Thief, and wanted to have something similar in my game as well. I was fortunate enough to run into Robinson Millaguin in the Indie Game Developers Facebook group. He began his work on animating some of the initial cards in Spine and my mind was blown already. Check out the video below:
vimeo
You can see more of the animation GIFs on the official website for Sheeping Around.
Tragicomic Theme and Music
I had contracted someone for music, but it did not sound so fitting. It was very difficult to decide what kind of music would fit this game because it was such a unique premise. I started scouting out for tracks on AudioJungle. Farms are usually associated with country music, but I had ruled it out completely. Western style music with gut guitars and ukuleles are a close second choice associated with farm themes. Somehow that style didn’t fit either, and sounded rather cowboy-ish.
I explored all kinds of genres of music and tried to see if they fit in the game. Finally, I found that the music in Comedy genre seemed to be the most fitting. I stumbled upon the profile of AudioAgent, who had an amazing portfolio of comedy tracks. His tracks are tragicomic themed, and coincidentally, he kept adding more tracks in the genre as the game progressed.
The game now features a total of 9 comedy audio tracks by AudioAgent. (The tracks change every 10 levels.)
You can check out the tracks in the below Youtube playlists:
https://www.youtube.com/watch?v=v1Ajh9Cn23k&list=PLnTakDx63B8L0pBpjPD10VB3NJEcXj2l4
https://www.youtube.com/watch?v=BXeq713R444&list=PLnTakDx63B8IS3hr4Sd-tnZXgu5vCIoi6
Sound
I had already made a list of suitable sounds from AudioJungle, but it was from a variety of artists and didn’t seem to fit together. I was not sure if I should hire a sound designer for the project. I figured it would be a good idea to ask around anyway.
I am active on Twitter in the gamedev community, and I found Elise Kates’ profile there. She had done some amazing work in the past for games like Moss, and I thought she’d be a good candidate to help me out with the sound. And it was a great decision afterall. The sound effects added the finishing touches to the polish in the game and really brought the characters to life!
Putting It All Together
I’m glad I’ve been able to put all of this together in a single package. The pun in the name, gameplay mechanics, art, animation, sound and music all come together really well. It would be perhaps be one of my proudest achievement since it is an important skillset to have.
Translation, Screenshots, Trailer and Preview Videos
In December, I took help from the Indie Game Localization community to get the game translated in 12 languages. It was an overwhelming amount of work, about 5000 words. I maintained separate Google Sheets for each language.
But what was harder was designing screenshots and preview videos and localizing them into all languages. But it did pay off eventually because it got the game featured in most of the regions that I had localized for.
Check out the preview video below:
youtube
Robinson helped in creating a landscape trailer for the game as well, since Android needs a landscape video regardless of whether the game is landscape or not. it was more of a theatrical trailer that served as an introduction to the premise of Sheeping Around and dab a little bit into its gameplay:
youtube
Freemium, Premium or Paymium?
The hardest decision for me to take was whether to go premium or freemium (or paymium), and if premium, what would be the price point of the game. Early on I had decided that the game would be premium on iOS and free-to-play on Android, given how easy piracy is on Android (more on piracy in the Piracy section below). I had thought of keeping the game’s price to $4.99, as I had read that Card Crawl had recently upped its price to $4.99 from $2.99 and it increased their month-on-month sales by more than 2x. Turns out, it won’t work very well during release when both developer and the game are new to the market and there are no ratings and reviews. This is also why my day 2 sales were more than day 1 sales, when I dropped the price to $2.99.
My game also has in-app purchases, and most people object to the idea of IAPs in a premium game. But if you look at the top paid charts in the card game category (or even any other category for that matter), you will find that more than 70% of the games have IAPs. This model is called paymium on mobile platforms, and has only recently entered the debate alongside freemium and premium. In the PC world, most games are paid, and the concept of DLCs is fairly normal and accepted, so I don’t understand what the issue with IAPs in premium mobile games is about.
Besides, the IAPs in Sheeping Around aren’t your typical in-your-face popups that appear at the end of every game to give you a reward or to increase your life. They are subtle, just two coin packs that you can buy if need be. You probably won’t need to though.
Pre-orders and the Coming Soon Feature
I set the game to be available for preorder on 31st December 2018. That would make my first new years’ resolution to be to release this game. I set Thursday, 17th Jan as the release date. That is because App Store refreshes every Thursday and it would get greater number of days in visibility if it gets featured then. (Most features last at least a week.)
That is also when I also submitted my game and my story to Apple via App Store’s promote link, hoping to get featured.
On January 5, the game got featured in the Coming Soon section, and it started getting a little spike in pre-orders. From 1-2 per day to around 25-30 per day. On January 20, the game got featured in a lot more territories, including US, UK, South Africa, Middle East, Australia and New Zealand. I netted about 250 pre-orders from this feature. But it turns out that in some places, since Apple lets you preorder without having a linked credit card, they would fail to be billed on release of the game. Because of this, only about 200 pre-orders went through successfully. App store still shows -1/-2 net preorders days after the game’s release.
New Games We Love & Top Charts
Upon release, the game was featured in “New Games We Love” in US, China and the Greater China Area (HK, Macau, Taiwan), South-East Asia, India, UK, Europe, Singapore, Australia and New Zealand. It also went on to become #3 card game in US (iPhone) during launch and stayed between #3-#5 during the first week. In China, which is the second biggest market for me, the highest it went was #9 in card games. (Competition is quite high in that category there, with most paid games priced at ¥1 ($0.15).)
I especially love the words UK editorial team used to describe the game in Games We Love.
Reception
The reviews so far have been positive, with occasional negative reviews talking about some bugs, most of which I have fixed in the week after release. Here are the current reviews and ratings stats for the game so far:
US: 4.6 / 5 (56 ratings, 32 reviews) China: 4.3 / 5 (41 ratings, 23 reviews) Thailand: 4.7 / 5 (15 ratings, 11 reviews) Germany: 4.0 / 5 (11 ratings, 6 reviews) Russia: 4.6 / 5 (8 ratings, 7 reviews) UK: 3.7 / 5 (6 ratings, 4 reviews)
Some encouraging reviews:
“I’ve only played this game for 20 minutes, and I love it already. The creativity, the idea, everything about this game is just beyond my expectations, and I can only assume how addicting this game will be.”
“It a really good game. You should make a physical card game for this game. I really like it and it’s definitely worth buying it.”
“Don’t really review apps, let alone end up playing one a day or two after I started. But this one... this one got me hooked! It’s fairly simple gameplay but sometimes it gets pretty exciting.”
“Pre-ordered it, I've played Card Monsters since release & Hearthstone for 4 years & this game is very solid & entertaining.”
“I think this game is another new twist to a card game, I can definitely see potential for this game. I can’t wait for the next update, hopefully with some new cards to use.”
“This game is family oriented and so easy to play. It has the simplicity of UNO yet with enough strategy to keep you engage but not overwhelmed. This is highly addictive and fun to play. The element of luck is always a factor but how to use the cards given is the key. The games are short but competitive. Those who love card/card battle games should download this without hesitation! Kudos! Look forward to updates to see what you guys come up with next!”
DAUs, Screen Time and Retention Rate
I use Tableau for my data visualization needs, and have custom graphs and dashboards created for all kinds of metrics. 27% of the players have played the game for at least one hour, which is quite encouraging. 4.5% of the players have been addicted and have played for more than 5 hours. I’ve been seeing an average DAU of around 750 and average total session time of over 450 hours. Not that it matters much for a premium game, but I’m tracking it anyway. In terms of retention, my day 7 retention is about 10%, which isn’t so bad. I will give it more time to see what my day 30 retention is.

Press Coverage and Critic Reviews
I had mailed a lot of media sites and YouTubers to review the game. A lot of them covered the game. Thanks to the localization effort, the game was featured in a lot of foreign language blogs.
Specifically Pocket Gamer and Pocket Tactics wrote about the game. The review from Pocket Tactics was negative with a 2.0 / 5 rating, and from Pocket Gamer was somewhat above average at 3.5 / 5 rating. Pocket Tactics review, though negative, gave me a chuckle because of their words of choice.
You can check them out here:
Pocket Gamer: A surprisingly tense, exciting and fun card battler that doesn’t quite have the tactical depth for the long haul.
Pocket Tactics: Sheeping Around looks the part, but sadly the game turns out to be as dull as you would expect for a game based on an animal that stands around in a field all day chewing grass.
The criticism though has been pretty good in these reviews, and I will add more content and depth in the future updates to address the weaknesses they have mentioned.
Piracy
One thing I wanted to point out was that about 25% of the users of Sheeping Around are using a pirated version. I was under the impression that it would be very hard to pirate an iOS game, because it would need jailbreaking and it isn’t very easy to jailbreak your iOS device. Turns out I was very wrong. There are pirated App Stores like AppEven that you can install on your device, and you can install premium iOS games for free using those stores. You don’t need to jailbreak your phone and the whole process is dead simple. Turns out these folks are abusing Enterprise App certificates for ad-hoc app distribution, and Apple hasn’t been paying much attention to them.
Within about two minutes, I was able to download a pirated version of my own game from AppEven. It even added its own ads that pop up once every few minutes that bring revenue to the owners of the pirated app store. It made me a little sad, but that’s the way it is. No matter how many attempts you make to prevent piracy in your app, the hackers will have a workaround to bypass it. They can remove the code in your app that prevents piracy, replace your ads with their own. It is their daily business.
Promotional Artwork
For games that Apple finds worthy of promotion using a banner feature or on the Today page, Apple requests developers for promotional artwork. I got this request last Monday and I submitted the artwork by Wednesday. The game hasn’t gotten a banner feature or Game of the Day yet, so I can only hope it will happen one day in the future.
By The Numbers
And finally, the moment you’d been waiting for. Sales. Sheeping Around was able to break even about 50% of its outsourcing costs (art, animation and sfx) in 10 days since launch.
The top 2 territories where the game made some decent revenue are US and China, followed by Germany and UK.
What’s next?
I’m already working on some new cards that add more variety to the gameplay. These include:
Bonus cards
Peek - Look at the opponent’s hand.
Undo - Undo the opponent’s last move. It can also potentially undo a stolen or whistled sheep.
Lucky Pendant - Draw half the number of cards in your hand (rounded off).
Shepherd cards
Fence N (N = 2, 3, 4) - Build a fence around all sheep preventing any of them from being stolen for N turns.
Electric Fence N (N = 2, 3) - Build an electric fence around all sheep preventing any of them from being lured or stolen for N turns.
Quarantine N (N = 1, 2, 3) - Cure all sheep of Infestation or Intoxication by N turns.
Vaccinate N (N = 3, 4) - Prevent Infestation or Intoxication on all sheep for the next N turns.
Thief cards
Infest N (N = 2, 3, 4) - Infest all sheep with pests to prevent them from being whistled for N turns.
Intoxicate N (N = 2, 3) - Intoxicate sheep to prevent them from being grazed or whistled for N turns.
Thrash N (N = 1, 2, 3) - Damage a Fence or an Electric Fence and reduce its value by N turns.
Termites (N = 3, 4) - Spread termites to prevent building a Fence or an Electric Fence for the next N turns.
Changes to existing cards
Rescue N (N = 1, 2, 3) - Reduce the effect of Trap, Infestation or Intoxication by N turns on one sheep.
Distract N (N = 1, 2, 3) - Reduce the effect of Guard, Fence or Electric Fence by N turns on one sheep.
You can already add an ally that unlocks at Lv. 20 to the game. Future updates may include upto 5 allies in total:
Shepherd’s side
Beaver - Jack Kim (Lv. 10)
Llama - Fuzzy Wumpkins (Lv. 20)
Sheepdog - Casper Cloud (Lv. 30)
Emu - Emily McCoy (Lv. 40)
Donkey - Muriel Miller (Lv. 50)
Thief’s side
Raven - Merlin Kook (Lv. 10)
Eagle - Cradoc McClaw (Lv. 20)
Coyote - Roxy Fang (Lv. 30)
Badger - Agent Chaos (Lv. 40)
Bear - Boris Rockpaw (Lv. 50)
Additional Features I’ll also be working on some features like: - Expressions and dialogs - Offline mode vs AI - Pass and play multiplayer - Quests
Conclusion
Sheeping Around was a fun project, and unlike my other shelved projects, it saw the light of the day, and it is a proud achievement for me in that regard. For the past 14 months, I’ve worked part-time at a consistent pace on this project (and full time for a few months). Especially as a solo developer being able to develop a PvP multiplayer game where people in US can battle people in China with servers located in London, I think it is a great feat.
Look forward to more updates in the future on this blog. Follow the blog on Tumblr or me on Twitter to keep yourself up to date on the progress of the game.
3 notes
·
View notes