#kubernetes on azure
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Total funding amounts to $125.3M.
Text
Mastering the Cloud Exploring Kubernetes on Azure, and Linux Training
Container Orchestration System Software (COSS) has gained immense popularity in India due to its ability to simplify and automate the deployment, scaling, and management of containerized applications. Kubernetes on Azure, an open-source platform designed to automate deploying, scaling, and operating application containers, is one of the leading COSS platforms in India. For more details visit here:-> https://medium.com/@cossindiaa/mastering-the-cloud-exploring-kubernetes-on-azure-and-linux-training-e825daa38396
#kubernetes on azure#linux architecture#linux boot process#linux training#red hat certified#red hat certifications#red hat certified engineer#red hat certified system administrator#red hat certification
0 notes
Text
youtube
The Best DevOps Development Team in India | Boost Your Business with Connect Infosoft
Please Like, Share, Subscribe, and Comment to us.
Our experts are pros at making DevOps work seamlessly for businesses big and small. From making things run smoother to saving time with automation, we've got the skills you need. Ready to level up your business?
#connectinfosofttechnologies#connectinfosoft#DevOps#DevOpsDevelopment#DevOpsService#DevOpsTeam#DevOpsSolutions#DevOpsCompany#DevOpsDeveloper#CloudComputing#CloudService#AgileDevOps#ContinuousIntegration#ContinuousDelivery#InfrastructureAsCode#Automation#Containerization#Microservices#CICD#DevSecOps#CloudNative#Kubernetes#Docker#AWS#Azure#GoogleCloud#Serverless#ITOps#TechOps#SoftwareDevelopment
2 notes
·
View notes
Text
DevOps with Multi-Cloud:
A Beginner’s Guide Introduction In today’s fast-paced digital world, businesses need agility, reliability, and scalability. This is where DevOps with Multi-Cloud comes in.
By integrating DevOps practices across multiple cloud platforms, companies can optimize workloads, enhance security, and reduce vendor dependency.
If you’re looking for DevOps with Multi-Cloud Training in KPHB, this guide will help you understand the essentials.

What is DevOps with Multi-Cloud?
DevOps is a methodology that combines development (Dev) and operations (Ops) to streamline software delivery.
When paired with a multi-cloud approach—using multiple cloud providers like AWS, Azure, and Google Cloud—it brings flexibility and resilience to IT infrastructure.
Benefits of DevOps in a Multi-Cloud Environment Avoids Vendor Lock-in – Businesses can distribute workloads across different cloud providers.
Improved Disaster Recovery – If one cloud fails, another can handle operations. Cost Optimization – Companies can choose the most cost-effective cloud services.
Enhanced Performance – Running applications closer to users reduces latency.
Security & Compliance – Spreading workloads minimizes risks and ensures compliance with industry regulations. Key Components of DevOps with Multi-Cloud
CI/CD Pipelines – Automate code building, testing, and deployment. Infrastructure as Code (IaC) – Manage cloud resources using tools like Terraform or AWS CloudFormation.
Containerization & Orchestration – Docker and Kubernetes help maintain consistency across cloud environments. Monitoring & Logging – Tools like Prometheus and ELK Stack ensure system health.
Security & Compliance Automation – Integrate security into development workflows with DevSecOps. Challenges in Multi-Cloud DevOps
Complexity in Management – Handling multiple cloud platforms requires expertise.
Data Governance & Compliance – Managing regulations across different clouds is challenging.
Interoperability Issues – Ensuring seamless communication between cloud environments can be difficult. How to Overcome These Challenges?
Use multi-cloud management tools like HashiCorp Consul or Google Anthos. Implement automation to reduce manual configuration.
Follow best security practices to protect data across cloud platforms. DevOps with Multi-Cloud Training in KPHB If you’re in KPHB, Hyderabad, and want to master DevOps with Multi-Cloud, look for training programs that cover:
✔️ Hands-on experience with AWS, Azure, and Google Cloud
✔️ Real-world CI/CD pipeline implementation
✔️ Kubernetes & Docker container orchestration
✔️ Infrastructure as Code (IaC) with Terraform
✔️ Security best practices in a multi-cloud setup
FAQs
1. Why should I learn DevOps with Multi-Cloud?
DevOps with Multi-Cloud enhances career opportunities and helps businesses stay competitive in an evolving digital landscape.
2. Which cloud platforms are covered in multi-cloud training?
Popular platforms include AWS, Microsoft Azure, and Google Cloud Platform (GCP). Some courses also cover Oracle Cloud, IBM Cloud, and Alibaba Cloud.
3. What are the prerequisites for learning DevOps with Multi-Cloud?
Basic knowledge of cloud computing, Linux, and scripting languages like Python or Bash is helpful. However, beginner-friendly courses are available.
4. How long does it take to become proficient?
Depending on prior experience, 3-6 months of dedicated learning can help you gain proficiency in DevOps with Multi-Cloud.
5. Is certification necessary?
While not mandatory, certifications from AWS, Azure, or Google Cloud can boost your job prospects.
Conclusion
DevOps with Multi-Cloud is the future of IT infrastructure, offering flexibility, efficiency, and resilience.
If you're looking for DevOps with Multi-Cloud Training in KPHB,
start your journey today to gain the skills needed for a high-demand career.
#DevOps#MultiCloud#CloudComputing#AWS#Azure#GoogleCloud#Kubernetes#Docker#CICD#InfrastructureAsCode#Terraform#DevSecOps#HybridCloud#TechTraining#ITCareers#KPHB#Hyderabad#CloudSecurity#Automation#DevOpsEngineer#TechSkills#CloudNative#SoftwareDevelopment#ITTraining#CareerGrowth#CloudTechnology
0 notes
Text
Unlocking Success with DevOps: Benefits of a DevOps Environment and Leading DevOps Training in Bangalore
Embracing DevOps for Enhanced Efficiency and Quality in Software Development

In today's rapidly evolving technological landscape, organizations are continually seeking methodologies that enhance efficiency, collaboration, and product quality. One such transformative approach is DevOps. For professionals aiming to excel in this domain, enrolling in a reputable DevOps course in Bangalore can be a pivotal step.
Understanding DevOps
DevOps is a cultural and operational model that emphasizes collaboration between software development (Dev) and IT operations (Ops) teams. This synergy aims to shorten the development lifecycle, ensuring the continuous delivery of high-quality software. By integrating development and operations, organizations can achieve faster deployment, improved product quality, and enhanced collaboration.
Key Benefits of a DevOps Environment
Accelerated DeploymentImplementing DevOps practices enables organizations to release software updates more frequently and with greater reliability. This rapid deployment capability allows businesses to respond swiftly to market changes and user feedback, maintaining a competitive edge.
Enhanced Collaboration and CommunicationDevOps fosters a culture of shared responsibility and transparency between development and operations teams. This collaborative environment reduces inefficiencies and promotes a holistic approach to problem-solving, leading to more innovative solutions.
Improved Quality and ReliabilityThrough practices like continuous integration and continuous deployment (CI/CD), DevOps ensures that code changes are automatically tested and validated. This automation reduces the likelihood of errors, resulting in more stable and reliable software releases.
Increased Efficiency Through AutomationAutomation is a cornerstone of DevOps, streamlining repetitive tasks such as testing, configuration, and deployment. By minimizing manual interventions, teams can focus on higher-value activities, thereby increasing overall productivity.
Scalability and FlexibilityDevOps practices support scalable infrastructures and flexible processes, allowing organizations to adjust resources and strategies dynamically in response to evolving project demands or market conditions.
Eduleem: Premier DevOps Training in Bangalore
For individuals aspiring to master DevOps, selecting the right educational institution is crucial. Eduleem - AWS, DevOps, Azure, GCP, and AI training in Bangalore stands out as a leading DevOps institute in Bangalore. Their comprehensive curriculum covers essential tools and methodologies, including Git, Jenkins, Docker, Ansible, Terraform, Kubernetes, Prometheus, and Grafana. The program emphasizes hands-on learning, ensuring that students gain practical experience alongside theoretical knowledge.
Conclusion
Embracing a DevOps culture offers numerous benefits, from faster deployments to improved collaboration and product quality. For those seeking to advance their careers in this dynamic field, enrolling in a reputable DevOps course in Bangalore is a strategic move. Eduleem's specialized training programs provide the knowledge and skills necessary to thrive in today's competitive tech industry.
#devops#aws#cloudcomputing#linux#python#cloud#technology#programming#developer#coding#kubernetes#devopsengineer#azure#cybersecurity#software
1 note
·
View note
Text
Kubernetes Training Consulting Philadelphia
Expert Kubernetes training consulting in Philadelphia to help you master container orchestration. Gain practical skills, optimise deployments, and enhance your career with tailored, hands-on training sessions.
0 notes
Text
Cloud Computing Security: Safeguarding Your Data in the Cloud
As businesses increasingly rely on cloud computing to store, manage, and process data, the importance of cloud computing security cannot be overstated. While the cloud offers immense flexibility, scalability, and cost-effectiveness, it also presents unique security challenges that must be addressed to protect sensitive information. Understanding the key aspects of cloud computing security and how to mitigate risks is essential for businesses that want to fully leverage cloud technology without compromising data integrity or privacy.

What is Cloud Computing Security?
Cloud computing security, often referred to as "cloud security," encompasses a broad set of policies, technologies, controls, and procedures designed to protect data, applications, and the infrastructure associated with cloud computing environments. The goal of cloud security is to safeguard information from data breaches, unauthorized access, and other cyber threats while ensuring compliance with relevant regulations and maintaining the accessibility and integrity of cloud resources.
The complexity of cloud environments, which can include public, private, and hybrid clouds, makes security a multifaceted challenge. Each type of cloud environment has unique vulnerabilities, and securing them often requires a combination of traditional IT security measures and cloud-specific protocols.
Why is Cloud Computing Security Important?
Cloud computing offers significant benefits in terms of scalability, cost savings, and efficiency, but it also increases the potential for security risks. These risks stem from the fact that data is stored and processed outside the traditional corporate firewall, often in shared environments with other organizations. Here are some key reasons why cloud security is critical:
Data Protection: Sensitive data, including personal information, financial records, and proprietary business information, is often stored in the cloud. A breach of this data can lead to serious financial losses, legal repercussions, and damage to a company’s reputation.
Compliance Requirements: Many industries have strict compliance requirements for data protection, including the General Data Protection Regulation (GDPR), the Health Insurance Portability and Accountability Act (HIPAA), and the Payment Card Industry Data Security Standard (PCI DSS). Cloud security helps businesses meet these regulatory requirements and avoid costly penalties.
Business Continuity: Security breaches can lead to significant disruptions in business operations. Effective cloud security measures reduce the risk of attacks that could lead to downtime, data loss, or other operational issues.
Trust and Customer Confidence: Consumers and clients expect their data to be safe. Cloud security is essential to building and maintaining trust with customers, ensuring that their information is well-protected.
Key Cloud Computing Security Risks
Data Breaches: Cloud environments are susceptible to data breaches, which can occur when cybercriminals exploit vulnerabilities in cloud infrastructure or applications. These breaches can lead to the exposure of sensitive information.
Insecure APIs: Application Programming Interfaces (APIs) are widely used in cloud computing to integrate applications and services. However, poorly secured APIs can become entry points for attackers, allowing them to access data or interfere with cloud services.
Misconfigured Cloud Settings: Misconfigurations, such as incorrect access controls or unprotected storage buckets, are a common security issue in cloud environments. These can lead to unauthorized access and data exposure.
Insider Threats: Insider threats, whether from employees or contractors, pose significant security risks. Insiders may have access to sensitive data, and their actions, whether intentional or accidental, can lead to data loss or compromise.
Account Hijacking: Attackers may attempt to hijack user accounts through phishing, social engineering, or weak passwords, granting them unauthorized access to cloud resources and sensitive data.
Strategies for Strengthening Cloud Computing Security
Data Encryption: Encryption ensures that data is unreadable to unauthorized users. By encrypting data both at rest and in transit, organizations can protect sensitive information even if it is intercepted or accessed without authorization.
Identity and Access Management (IAM): Strong IAM policies are essential for controlling access to cloud resources. Multi-factor authentication (MFA), role-based access control (RBAC), and regular access reviews can help limit access to only those who need it.
Regular Audits and Monitoring: Continuous monitoring and regular security audits are critical for identifying potential vulnerabilities and ensuring compliance. Automated monitoring tools can alert security teams to unusual activities that may indicate a breach or insider threat.
Endpoint Security: Since users access cloud services from various devices, endpoint security is crucial. Ensuring devices are updated with the latest security patches, implementing antivirus software, and educating users on security best practices are all effective measures.
Secure APIs: Since APIs are integral to cloud operations, securing them with proper authentication, authorization, and encryption protocols is essential. Limiting access to APIs based on the principle of least privilege can also reduce risk.
Backup and Recovery Plans: A robust backup and recovery plan ensures that, in the event of a cyberattack or data loss, critical data can be restored quickly, minimizing downtime and disruption.
Compliance Management: Maintaining compliance with industry regulations is crucial in cloud environments. Businesses should regularly review their security policies to ensure they meet regulatory standards and adapt to changing compliance requirements.
Future Trends in Cloud Computing Security
As cloud technology advances, so do the security measures needed to protect it. Some emerging trends in cloud computing security include:
Artificial Intelligence and Machine Learning (AI/ML): AI and ML are being increasingly used to detect and respond to security threats in real-time. By analyzing large volumes of data, AI/ML algorithms can identify patterns indicative of potential threats, often before they cause harm.
Zero Trust Architecture: Zero Trust is a security model that assumes no user or device is trustworthy by default, requiring continuous verification. This model is particularly useful in cloud environments, where traditional network boundaries are often blurred.
Quantum Computing Implications: As quantum computing technology develops, traditional encryption methods may become less secure. Researchers are already working on quantum-resistant encryption techniques to prepare for this eventuality.
Conclusion Cloud computing security is a critical aspect of today’s digital landscape, protecting valuable data and ensuring business continuity. By implementing robust security measures, businesses can benefit from the flexibility and cost-effectiveness of the cloud without exposing themselves to unnecessary risks. As cloud technology continues to evolve, staying ahead of emerging threats and adapting security strategies accordingly will be essential for maintaining data integrity and customer trust.
0 notes
Text
AWS Training in Pune, Bangalore, and Kerala at Radical Technologies

Start your cloud career with Radical Technologies’ expert-led AWS Training! Our AWS Certification Course provides:
Comprehensive training on scalable deployments and security management Real-time projects, including VMware and Azure migrations to AWS Batches that are flexible for weekdays and weekends in both online and offline forms Corporate training options and hands-on sessions for practical skills Locations: Pune, Bangalore, Kerala, and online Live demos, interview prep, and complete placement support Join Pune’s best AWS course and fast-track your cloud career with industry-ready skills! ls!
#linux#microsoft azure#terraform#coding#cybersecurity#information technology#innovation#classroom#software#software development#docker#kubernetes
0 notes
Text

#PollTime Which Cloud Platform is Known for Kubernetes Services?
a) Azure 🔵 b) AWS ☁️ c) Google Cloud 🌍 d) Oracle Cloud 🌐
Cast your #vote Comment Below
#kubernetes#kubernetesservice#azure#aws#googlecloud#oraclecloud#simplelogic#makingitsimple#itcompany#dropcomment#manageditservices#itmanagedservices#poll#polls#itservices#itserviceprovider#itservicescompany#itservicemanagement#hybrid#onpremises#managedservices#testyourknowledge
0 notes
Text
0 notes
Text
Prioritizing Pods in Kubernetes with PriorityClasses
In Kubernetes, you can define the importance of Pods relative to others using PriorityClasses. This ensures critical services are scheduled and running even during resource constraints. Key Points: Scheduling Priority: When enabled, the scheduler prioritizes pending Pods based on their assigned PriorityClass. Higher priority Pods are scheduled before lower priority ones if their resource…
0 notes
Text
Skyrocket Your Efficiency: Dive into Azure Cloud-Native solutions
Join our blog series on Azure Container Apps and unlock unstoppable innovation! Discover foundational concepts, advanced deployment strategies, microservices, serverless computing, best practices, and real-world examples. Transform your operations!!
#Azure App Service#Azure cloud#Azure Container Apps#Azure Functions#CI/CD#cloud infrastructure#cloud-native applications#containerization#deployment strategies#DevOps#Kubernetes#microservices architecture#serverless computing
0 notes
Text
Deploying Large Language Models on Kubernetes: A Comprehensive Guide
New Post has been published on https://thedigitalinsider.com/deploying-large-language-models-on-kubernetes-a-comprehensive-guide/
Deploying Large Language Models on Kubernetes: A Comprehensive Guide
Large Language Models (LLMs) are capable of understanding and generating human-like text, making them invaluable for a wide range of applications, such as chatbots, content generation, and language translation.
However, deploying LLMs can be a challenging task due to their immense size and computational requirements. Kubernetes, an open-source container orchestration system, provides a powerful solution for deploying and managing LLMs at scale. In this technical blog, we’ll explore the process of deploying LLMs on Kubernetes, covering various aspects such as containerization, resource allocation, and scalability.
Understanding Large Language Models
Before diving into the deployment process, let’s briefly understand what Large Language Models are and why they are gaining so much attention.
Large Language Models (LLMs) are a type of neural network model trained on vast amounts of text data. These models learn to understand and generate human-like language by analyzing patterns and relationships within the training data. Some popular examples of LLMs include GPT (Generative Pre-trained Transformer), BERT (Bidirectional Encoder Representations from Transformers), and XLNet.
LLMs have achieved remarkable performance in various NLP tasks, such as text generation, language translation, and question answering. However, their massive size and computational requirements pose significant challenges for deployment and inference.
Why Kubernetes for LLM Deployment?
Kubernetes is an open-source container orchestration platform that automates the deployment, scaling, and management of containerized applications. It provides several benefits for deploying LLMs, including:
Scalability: Kubernetes allows you to scale your LLM deployment horizontally by adding or removing compute resources as needed, ensuring optimal resource utilization and performance.
Resource Management: Kubernetes enables efficient resource allocation and isolation, ensuring that your LLM deployment has access to the required compute, memory, and GPU resources.
High Availability: Kubernetes provides built-in mechanisms for self-healing, automatic rollouts, and rollbacks, ensuring that your LLM deployment remains highly available and resilient to failures.
Portability: Containerized LLM deployments can be easily moved between different environments, such as on-premises data centers or cloud platforms, without the need for extensive reconfiguration.
Ecosystem and Community Support: Kubernetes has a large and active community, providing a wealth of tools, libraries, and resources for deploying and managing complex applications like LLMs.
Preparing for LLM Deployment on Kubernetes:
Before deploying an LLM on Kubernetes, there are several prerequisites to consider:
Kubernetes Cluster: You’ll need a Kubernetes cluster set up and running, either on-premises or on a cloud platform like Amazon Elastic Kubernetes Service (EKS), Google Kubernetes Engine (GKE), or Azure Kubernetes Service (AKS).
GPU Support: LLMs are computationally intensive and often require GPU acceleration for efficient inference. Ensure that your Kubernetes cluster has access to GPU resources, either through physical GPUs or cloud-based GPU instances.
Container Registry: You’ll need a container registry to store your LLM Docker images. Popular options include Docker Hub, Amazon Elastic Container Registry (ECR), Google Container Registry (GCR), or Azure Container Registry (ACR).
LLM Model Files: Obtain the pre-trained LLM model files (weights, configuration, and tokenizer) from the respective source or train your own model.
Containerization: Containerize your LLM application using Docker or a similar container runtime. This involves creating a Dockerfile that packages your LLM code, dependencies, and model files into a Docker image.
Deploying an LLM on Kubernetes
Once you have the prerequisites in place, you can proceed with deploying your LLM on Kubernetes. The deployment process typically involves the following steps:
Building the Docker Image
Build the Docker image for your LLM application using the provided Dockerfile and push it to your container registry.
Creating Kubernetes Resources
Define the Kubernetes resources required for your LLM deployment, such as Deployments, Services, ConfigMaps, and Secrets. These resources are typically defined using YAML or JSON manifests.
Configuring Resource Requirements
Specify the resource requirements for your LLM deployment, including CPU, memory, and GPU resources. This ensures that your deployment has access to the necessary compute resources for efficient inference.
Deploying to Kubernetes
Use the kubectl command-line tool or a Kubernetes management tool (e.g., Kubernetes Dashboard, Rancher, or Lens) to apply the Kubernetes manifests and deploy your LLM application.
Monitoring and Scaling
Monitor the performance and resource utilization of your LLM deployment using Kubernetes monitoring tools like Prometheus and Grafana. Adjust the resource allocation or scale your deployment as needed to meet the demand.
Example Deployment
Let’s consider an example of deploying the GPT-3 language model on Kubernetes using a pre-built Docker image from Hugging Face. We’ll assume that you have a Kubernetes cluster set up and configured with GPU support.
Pull the Docker Image:
bashCopydocker pull huggingface/text-generation-inference:1.1.0
Create a Kubernetes Deployment:
Create a file named gpt3-deployment.yaml with the following content:
apiVersion: apps/v1 kind: Deployment metadata: name: gpt3-deployment spec: replicas: 1 selector: matchLabels: app: gpt3 template: metadata: labels: app: gpt3 spec: containers: - name: gpt3 image: huggingface/text-generation-inference:1.1.0 resources: limits: nvidia.com/gpu: 1 env: - name: MODEL_ID value: gpt2 - name: NUM_SHARD value: "1" - name: PORT value: "8080" - name: QUANTIZE value: bitsandbytes-nf4
This deployment specifies that we want to run one replica of the gpt3 container using the huggingface/text-generation-inference:1.1.0 Docker image. The deployment also sets the environment variables required for the container to load the GPT-3 model and configure the inference server.
Create a Kubernetes Service:
Create a file named gpt3-service.yaml with the following content:
apiVersion: v1 kind: Service metadata: name: gpt3-service spec: selector: app: gpt3 ports: - port: 80 targetPort: 8080 type: LoadBalancer
This service exposes the gpt3 deployment on port 80 and creates a LoadBalancer type service to make the inference server accessible from outside the Kubernetes cluster.
Deploy to Kubernetes:
Apply the Kubernetes manifests using the kubectl command:
kubectl apply -f gpt3-deployment.yaml kubectl apply -f gpt3-service.yaml
Monitor the Deployment:
Monitor the deployment progress using the following commands:
kubectl get pods kubectl logs <pod_name>
Once the pod is running and the logs indicate that the model is loaded and ready, you can obtain the external IP address of the LoadBalancer service:
kubectl get service gpt3-service
Test the Deployment:
You can now send requests to the inference server using the external IP address and port obtained from the previous step. For example, using curl:
curl -X POST http://<external_ip>:80/generate -H 'Content-Type: application/json' -d '"inputs": "The quick brown fox", "parameters": "max_new_tokens": 50'
This command sends a text generation request to the GPT-3 inference server, asking it to continue the prompt “The quick brown fox” for up to 50 additional tokens.
Advanced topics you should be aware of
While the example above demonstrates a basic deployment of an LLM on Kubernetes, there are several advanced topics and considerations to explore:
_*]:min-w-0″ readability=”131.72387362124″>
1. Autoscaling
Kubernetes supports horizontal and vertical autoscaling, which can be beneficial for LLM deployments due to their variable computational demands. Horizontal autoscaling allows you to automatically scale the number of replicas (pods) based on metrics like CPU or memory utilization. Vertical autoscaling, on the other hand, allows you to dynamically adjust the resource requests and limits for your containers.
To enable autoscaling, you can use the Kubernetes Horizontal Pod Autoscaler (HPA) and Vertical Pod Autoscaler (VPA). These components monitor your deployment and automatically scale resources based on predefined rules and thresholds.
2. GPU Scheduling and Sharing
In scenarios where multiple LLM deployments or other GPU-intensive workloads are running on the same Kubernetes cluster, efficient GPU scheduling and sharing become crucial. Kubernetes provides several mechanisms to ensure fair and efficient GPU utilization, such as GPU device plugins, node selectors, and resource limits.
You can also leverage advanced GPU scheduling techniques like NVIDIA Multi-Instance GPU (MIG) or AMD Memory Pool Remapping (MPR) to virtualize GPUs and share them among multiple workloads.
3. Model Parallelism and Sharding
Some LLMs, particularly those with billions or trillions of parameters, may not fit entirely into the memory of a single GPU or even a single node. In such cases, you can employ model parallelism and sharding techniques to distribute the model across multiple GPUs or nodes.
Model parallelism involves splitting the model architecture into different components (e.g., encoder, decoder) and distributing them across multiple devices. Sharding, on the other hand, involves partitioning the model parameters and distributing them across multiple devices or nodes.
Kubernetes provides mechanisms like StatefulSets and Custom Resource Definitions (CRDs) to manage and orchestrate distributed LLM deployments with model parallelism and sharding.
4. Fine-tuning and Continuous Learning
In many cases, pre-trained LLMs may need to be fine-tuned or continuously trained on domain-specific data to improve their performance for specific tasks or domains. Kubernetes can facilitate this process by providing a scalable and resilient platform for running fine-tuning or continuous learning workloads.
You can leverage Kubernetes batch processing frameworks like Apache Spark or Kubeflow to run distributed fine-tuning or training jobs on your LLM models. Additionally, you can integrate your fine-tuned or continuously trained models with your inference deployments using Kubernetes mechanisms like rolling updates or blue/green deployments.
5. Monitoring and Observability
Monitoring and observability are crucial aspects of any production deployment, including LLM deployments on Kubernetes. Kubernetes provides built-in monitoring solutions like Prometheus and integrations with popular observability platforms like Grafana, Elasticsearch, and Jaeger.
You can monitor various metrics related to your LLM deployments, such as CPU and memory utilization, GPU usage, inference latency, and throughput. Additionally, you can collect and analyze application-level logs and traces to gain insights into the behavior and performance of your LLM models.
6. Security and Compliance
Depending on your use case and the sensitivity of the data involved, you may need to consider security and compliance aspects when deploying LLMs on Kubernetes. Kubernetes provides several features and integrations to enhance security, such as network policies, role-based access control (RBAC), secrets management, and integration with external security solutions like HashiCorp Vault or AWS Secrets Manager.
Additionally, if you’re deploying LLMs in regulated industries or handling sensitive data, you may need to ensure compliance with relevant standards and regulations, such as GDPR, HIPAA, or PCI-DSS.
7. Multi-Cloud and Hybrid Deployments
While this blog post focuses on deploying LLMs on a single Kubernetes cluster, you may need to consider multi-cloud or hybrid deployments in some scenarios. Kubernetes provides a consistent platform for deploying and managing applications across different cloud providers and on-premises data centers.
You can leverage Kubernetes federation or multi-cluster management tools like KubeFed or GKE Hub to manage and orchestrate LLM deployments across multiple Kubernetes clusters spanning different cloud providers or hybrid environments.
These advanced topics highlight the flexibility and scalability of Kubernetes for deploying and managing LLMs.
Conclusion
Deploying Large Language Models (LLMs) on Kubernetes offers numerous benefits, including scalability, resource management, high availability, and portability. By following the steps outlined in this technical blog, you can containerize your LLM application, define the necessary Kubernetes resources, and deploy it to a Kubernetes cluster.
However, deploying LLMs on Kubernetes is just the first step. As your application grows and your requirements evolve, you may need to explore advanced topics such as autoscaling, GPU scheduling, model parallelism, fine-tuning, monitoring, security, and multi-cloud deployments.
Kubernetes provides a robust and extensible platform for deploying and managing LLMs, enabling you to build reliable, scalable, and secure applications.
#access control#Amazon#Amazon Elastic Kubernetes Service#amd#Apache#Apache Spark#app#applications#apps#architecture#Artificial Intelligence#attention#AWS#azure#Behavior#BERT#Blog#Blue#Building#chatbots#Cloud#cloud platform#cloud providers#cluster#clusters#code#command#Community#compliance#comprehensive
0 notes
Text

Azure DevSecOps Training | Azure DevOps Certification course
#Visualpath offers world-class Azure DevOps Certification Training designed for global learners. Master key skills, including:
✔️Building and managing CI/CD pipelines ✔️Version control with Git ✔️Implementing infrastructure as code ✔️Ensuring continuous monitoring ✔️Prioritizing Security?
Our specialized Azure DevSecOps Course equips you to seamlessly integrate security into your DevOps practices. Gain expertise in: 🔒 Automated security testing ✔️ Compliance management 🛠️ Secure coding practices on Azure Get a Free Demo by Calling +91-9989971070 WhatsApp: https://www.whatsapp.com/catalog/919989971070 Visit Blog: https://visualpathblogs.com/ Visit: https://www.visualpath.in/online-azure-devops-Training.html
#AzureDevOps #Azure #DevOps #azuredevopsonline #AzureDevOpsTraining #MicrosoftAzure #azuredevopsdemo #DevSecOps #sonarqube #Dockers #kubernetes #devopsengineer #azurecloud #cloud #cloudcomputing #linux #Visualpath #azurecertification #Microsoft #SQL #AZ104 #visualpathpro #corporateTraining #devopstraining #CareerGrowth
#AzureDevOps#Azure#DevOps#azuredevopsonline#AzureDevOpsTraining#MicrosoftAzure#azuredevopsdemo#DevSecOps#sonarqube#Dockers#kubernetes#devopsengineer#azurecloud#cloud#cloudcomputing#linux#Visualpath#azurecertification#Microsoft#SQL#AZ104#visualpathpro#corporateTraining#devopstraining#CareerGrowth
1 note
·
View note
Text

Terraform Training Online | Terraform Training Ameerpet
VisualPath offers the Best Terraform Training Online conducted by real-time experts. Our Terraform Training Ameerpet Online available in Hyderabad and is provided to individuals globallyintheUSAUK,Canada,Dubai,andAustralia.
Contactusat+91-9989971070 VisitBlog:https://visualpathblogs.com/
whatsApp:https://www.whatsapp.com/catalog/917032290546/Visit: https://visualpath.in/terraform-online-training-in-hyderabad.html
#devops#aws#docker#ansible#jenkins#kubernetes#python#linux#cloudcomputing#github#devopsengineer#devopstraining#googlecloud#azure#microsoftazure#awscloud#metal#cloud#it#itsolutions
0 notes
Text

Naresh i Technologies 🔴 Classroom & Online Training at KPHB Branch 🔴 ✍️Enroll Now: https://bit.ly/4a03SJ0 👉Attend a Free Demo On AWS by Mr.Phani Krishna 📅Demo On: 27th March @ 07:30 AM (IST) 👉Hands-on-Learning - Lab sessions 👉Self-paced Learning Materials 👉Interview Preparation Skills
#aws#cloud#cloudcomputing#azure#devops#technology#python#amazonwebservices#linux#amazon#programming#awscloud#coding#googlecloud#developer#kubernetes#onlinetraining#awscertification#cloudservices#microsoftazure#nareshit#kphb
1 note
·
View note
Text
Retina: Kubernetes Network Observability platform
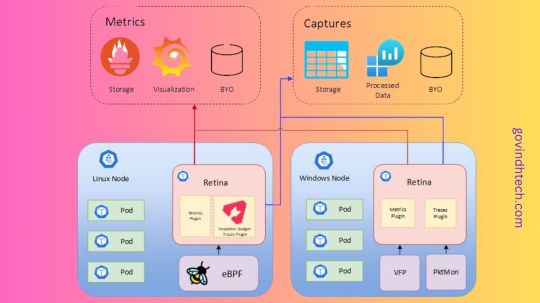
Kubernetes Network Observability
The Retina platform, which is cloud-native and allows Kubernetes users, administrators, and developers to visualize, observe, debug, and analyze Kubernetes workload traffic regardless of the Container Network Interface (CNI), operating system (OS), or cloud, is being released by the Microsoft Azure Container Networking team with great excitement. They are thrilled to make Retina available as an open-source repository that supports networking scenarios relating to DevOps and SecOps for your Kubernetes clusters. They cordially urge the open-source community to collaborate with us on future innovations.
Microsoft AI technology is shown in photography, which foretells a student’s likelihood of dropping out of school in order to support teachers proactively.
A framework for cloud-native container networking observability
Cloud native technologies such as Kubernetes have simplified the process of developing mobile apps. Simultaneously, a lot of apps have grown in complexity, making cloud management them harder and harder. Network-related observability, troubleshooting, and debugging have become harder when businesses create cloud-native apps made up of linked services and then deploy them to several public clouds in addition to their own infrastructure.
Retina aims to provide actionable network insights, such as how containerized micro-services interact, in a non-intrusive manner without requiring changes to the applications themselves, thanks to the extended Berkley Packet Filter (eBPF). Retina will emphasize application developers’ experience in a new way, democratizing network observability and debugging. Retina relieves developers of the burden of having to manage the intricate details of the underlying network architecture and transformations by giving them easy tools to monitor and debug their apps for problems like packet loss and latency.
They are eager to expand on this partnership and interact with more communities, as well as to strengthen their good community experience with eBPF and Cilium. We think that by making Retina available to the community, Azure will be able to gain from well-informed criticism, creative suggestions, and teamwork that will help us improve and broaden Retina’s capabilities.
Retina capabilities and solutions
Azure discovered significant gaps in network monitoring, or the gathering of network metrics and traces from Kubernetes clusters, by utilizing our vast expertise administering several container networking services for the Azure Kubernetes Service (AKS). Retina is a state-of-the-art solution that bridges these gaps by addressing the intricate problems associated with maintaining and sustaining Kubernetes networks. It offers site- and infrastructure-reliability engineers thorough understanding of cluster networking. Additionally, Retina offers comprehensive traffic analysis inside the framework of Kubernetes, converting measurements into network flow logs or the industry-standard Prometheus.
The usability and adaptability of existing open-source solutions are typically limited by their close coupling to certain CNIs, OSs, or data planes. Retina is a useful complement to any current toolkit as it was created to be a highly flexible, adaptive, and extendable framework of plugins that can function flawlessly with any CNI, OS, or cloud provider. Supporting both Linux and Windows data planes, Retina maintains a small memory and CPU footprint on the cluster, this is true even at scale while meeting the various demands of infrastructure- and site-reliability engineers. Azure can quickly modify and customize Retina to suit new use cases without relying on any particular CNI, OS, or data plane because to its pluggability design ethos.Image credit to Azure
Deep network traffic insights, including Layer 4 (L4) measurements, DNS metrics, and distributed packet captures, are one of Retina’s primary features. The Kubernetes app model is completely integrated, providing pod-level data along with comprehensive context. It provides node-level metrics (like forward, drop, Transmission Control Protocol (TCP), User Datagram Protocol (UDP), and Linux utility) and pod-level metrics (like basic metrics, DNS, and API server latency) with actionable networking observability data that is emitted into industry-standard Prometheus metrics.
Label-driven distributed packet captures in Retina let users choose what, where, and from whom to collect packets. It also offers sophisticated debugging tools and historical context for network flow logs, which improve network troubleshooting and performance optimization.
Azure’s plans for the retina
Many businesses use several clouds and want solutions that function well on Microsoft Azure as well as other clouds and on-premises. From the start, Retina is multi-cloud and open-source. They want to educate the larger cloud-native community about their expertise and ambition for Kubernetes networking observability by making Retina open-sourced. Through cooperation with other developers and organizations who have similar experiences and aspirations in this industry, we hope that Retina will continue to grow and expand.
Extensibility has always been important in architecture and will continue to be so. With Retina, data gathering is extensible, making it simple for users to add additional metrics and insights. Additionally, it provides flexibility in exporters, allowing users to interact with other tools and monitoring systems. Because of its adaptability to various use cases and circumstances, Retina is a strong and flexible platform for Kubernetes networking observability.
Finally, Azure will see Retina as a platform that everyone can use to contribute, expand, and develop, eventually leading to the creation of a reliable, well-thought-out, all-inclusive solution for Kubernetes networking observability.
Overview of Retina
Retina: What Is It?
Retina is an open-source, cloud-independent Kubernetes Network Observability platform that supports compliance, DevOps, and SecOps use cases. It serves as a single portal for cluster network administrators, cluster security administrators, and devops engineers to monitor the security and health of applications and networks.
Retina gathers telemetry that is configurable and can be exported to various storage platforms (like Prometheus, Azure Monitor, and other vendors) and displayed in many ways (like Grafana, Azure Log Analytics, and other vendors).
Features
Network Observability platform for Kubernetes workloads based on eBPF.
Both configurable and on-demand.
Industry-standard Prometheus metrics that are actionable.
Simplified Packet Captures for In-depth Analysis.
Multi-OS support (such as Windows, Linux, and Azure Linux) and independence from cloud providers.
For what reason is Retina?
With Retina, you can keep an eye on your clusters and look into network problems whenever you choose. Here are a few situations where Retina excels, reducing trouble spots and research time.
Examining: Troubleshooting Network Connectivity
Why are my Pods no longer able to interact with one another? A typical inquiry takes a lot of time and entails doing packet captures, which need access to each node, identification of the nodes involved, running of tcpdump commands, and exporting of the data from each node.
With only one CLI command or CRD/YAML file, you can use Retina to automate this procedure. It can:
Perform captures on every Node that is home to the relevant Pods.
Upload the output from every Node to a storage blob.
Keeping an eye on the network Actionable insights are supported by Health Retina via Grafana dashboards, Prometheus alerts, and other features. As an example, you can:
Track lost connections inside a namespace.
Notify me when production DNS error rates increase.
Assess the scalability of your application while monitoring variations in API Server latency.
Should a Pod begin to transmit excessive amounts of traffic, notify your security team.
Metrics and captures are the two forms of telemetry that Retina employs.
Metrics Retina metrics provide ongoing observation of:
Traffic moving in and out
Packets dropped
TCP/UDP
DNS
API Server latency
Statistics for nodes and interfaces
Retina offers the two
Advanced/Pod-Level metrics (if enabled) and
Basic metrics (default, Node-Level metrics).
Takes Pictures
Network traffic and information for the designated Nodes/Pods are recorded in a Retina capture.
The ability to output captures to numerous destinations is available on demand. See Captures for more details.
Read more on govindhtech.com
0 notes