#pyspark for beginners
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Hackers stole 65M passwords from Tumblr in 2013.
Text
Exploring the Latest Features of Apache Spark 3.4 for Databricks Runtime
In the dynamic landscape of big data and analytics, staying at the forefront of technology is essential for organizations aiming to harness the full potential of their data-driven initiatives.

View On WordPress
#Apache Spark#API#Databricks#databricks apache spark#Databricks SQL#Dataframe#Developers#Filter Join#pyspark#pyspark for beginners#pyspark for data engineers#pyspark in azure databricks#Schema#Software Developers#Spark Cluster#Spark Connect#SQL#SQL SELECT#SQL Server
0 notes
Text
Navigating the Data Landscape: A Deep Dive into ScholarNest's Corporate Training

In the ever-evolving realm of data, mastering the intricacies of data engineering and PySpark is paramount for professionals seeking a competitive edge. ScholarNest's Corporate Training offers an immersive experience, providing a deep dive into the dynamic world of data engineering and PySpark.
Unlocking Data Engineering Excellence
Embark on a journey to become a proficient data engineer with ScholarNest's specialized courses. Our Data Engineering Certification program is meticulously crafted to equip you with the skills needed to design, build, and maintain scalable data systems. From understanding data architecture to implementing robust solutions, our curriculum covers the entire spectrum of data engineering.
Pioneering PySpark Proficiency
Navigate the complexities of data processing with PySpark, a powerful Apache Spark library. ScholarNest's PySpark course, hailed as one of the best online, caters to both beginners and advanced learners. Explore the full potential of PySpark through hands-on projects, gaining practical insights that can be applied directly in real-world scenarios.
Azure Databricks Mastery
As part of our commitment to offering the best, our courses delve into Azure Databricks learning. Azure Databricks, seamlessly integrated with Azure services, is a pivotal tool in the modern data landscape. ScholarNest ensures that you not only understand its functionalities but also leverage it effectively to solve complex data challenges.
Tailored for Corporate Success
ScholarNest's Corporate Training goes beyond generic courses. We tailor our programs to meet the specific needs of corporate environments, ensuring that the skills acquired align with industry demands. Whether you are aiming for data engineering excellence or mastering PySpark, our courses provide a roadmap for success.
Why Choose ScholarNest?
Best PySpark Course Online: Our PySpark courses are recognized for their quality and depth.
Expert Instructors: Learn from industry professionals with hands-on experience.
Comprehensive Curriculum: Covering everything from fundamentals to advanced techniques.
Real-world Application: Practical projects and case studies for hands-on experience.
Flexibility: Choose courses that suit your level, from beginner to advanced.
Navigate the data landscape with confidence through ScholarNest's Corporate Training. Enrol now to embark on a learning journey that not only enhances your skills but also propels your career forward in the rapidly evolving field of data engineering and PySpark.
#data engineering#pyspark#databricks#azure data engineer training#apache spark#databricks cloud#big data#dataanalytics#data engineer#pyspark course#databricks course training#pyspark training
3 notes
·
View notes
Text
Real Time Spark Project for Beginners: Hadoop, Spark, Docker
🚀 Building a Real-Time Data Pipeline for Server Monitoring Using Kafka, Spark, Hadoop, PostgreSQL & Django
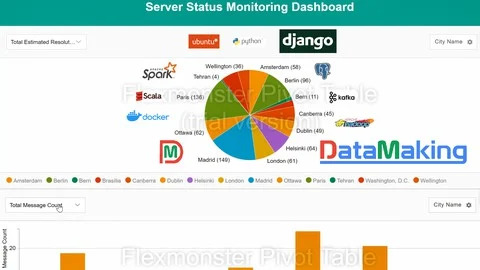
In today’s data centers, various types of servers constantly generate vast volumes of real-time event data—each event representing the server’s status. To ensure stability and minimize downtime, monitoring teams need instant insights into this data to detect and resolve issues swiftly.
To meet this demand, a scalable and efficient real-time data pipeline architecture is essential. Here’s how we’re building it:
🧩 Tech Stack Overview: Apache Kafka acts as the real-time data ingestion layer, handling high-throughput event streams with minimal latency.
Apache Spark (Scala + PySpark), running on a Hadoop cluster (via Docker), performs large-scale, fault-tolerant data processing and analytics.
Hadoop enables distributed storage and computation, forming the backbone of our big data processing layer.
PostgreSQL stores the processed insights for long-term use and querying.
Django serves as the web framework, enabling dynamic dashboards and APIs.
Flexmonster powers data visualization, delivering real-time, interactive insights to monitoring teams.
🔍 Why This Stack? Scalability: Each tool is designed to handle massive data volumes.
Real-time processing: Kafka + Spark combo ensures minimal lag in generating insights.
Interactivity: Flexmonster with Django provides a user-friendly, interactive frontend.
Containerized: Docker simplifies deployment and management.
This architecture empowers data center teams to monitor server statuses live, quickly detect anomalies, and improve infrastructure reliability.
Stay tuned for detailed implementation guides and performance benchmarks!
0 notes
Text
PySpark SQL: Introduction & Basic Queries
Introduction
In today’s data-driven world, the volume and variety of data have exploded. Traditional tools often struggle to process and analyze massive datasets efficiently. That’s where Apache Spark comes into the picture — a lightning-fast, unified analytics engine for big data processing.
For Python developers, PySpark — the Python API for Apache Spark — offers an intuitive way to work with Spark. Among its powerful modules, PySpark SQL stands out. It enables you to query structured data using SQL syntax or DataFrame operations. This hybrid capability makes it easy to blend the power of Spark with the familiarity of SQL.
In this blog, we'll explore what PySpark SQL is, why it’s so useful, how to set it up, and cover the most essential SQL queries with examples — perfect for beginners diving into big data with Python.

Agenda
Here's what we'll cover:
What is PySpark SQL?
Why should you use PySpark SQL?
Installing and setting up PySpark
Basic SQL queries in PySpark
Best practices for working efficiently
Final thoughts
What is PySpark SQL?
PySpark SQL is a module of Apache Spark that enables querying structured data using SQL commands or a more programmatic DataFrame API. It offers:
Support for SQL-style queries on large datasets.
A seamless bridge between relational logic and Python.
Optimizations using the Catalyst query optimizer and Tungsten execution engine for efficient computation.
In simple terms, PySpark SQL lets you use SQL to analyze big data at scale — without needing traditional database systems.
Why Use PySpark SQL?
Here are a few compelling reasons to use PySpark SQL:
Scalability: It can handle terabytes of data spread across clusters.
Ease of use: Combines the simplicity of SQL with the flexibility of Python.
Performance: Optimized query execution ensures fast performance.
Interoperability: Works with various data sources — including Hive, JSON, Parquet, and CSV.
Integration: Supports seamless integration with DataFrames and MLlib for machine learning.
Whether you're building dashboards, ETL pipelines, or machine learning workflows — PySpark SQL is a reliable choice.
Setting Up PySpark
Let’s quickly set up a local PySpark environment.
1. Install PySpark:
pip install pyspark
2. Start a Spark session:
from pyspark.sql import SparkSession spark = SparkSession.builder \ .appName("PySparkSQLExample") \ .getOrCreate()
3. Create a DataFrame:
data = [("Alice", 25), ("Bob", 30), ("Clara", 35)] columns = ["Name", "Age"] df = spark.createDataFrame(data, columns) df.show()
4. Create a temporary view to run SQL queries:
df.createOrReplaceTempView("people")
Now you're ready to run SQL queries directly!
Basic PySpark SQL Queries
Let’s look at the most commonly used SQL queries in PySpark.
1. SELECT Query
spark.sql("SELECT * FROM people").show()
Returns all rows from the people table.
2. WHERE Clause (Filtering Rows)
spark.sql("SELECT * FROM people WHERE Age > 30").show()
Filters rows where Age is greater than 30.
3. Adding a Derived Column
spark.sql("SELECT Name, Age, Age + 5 AS AgeInFiveYears FROM people").show()
Adds a new column AgeInFiveYears by adding 5 to the current age.
4. GROUP BY and Aggregation
Let’s update the data with multiple entries for each name:
data2 = [("Alice", 25), ("Bob", 30), ("Alice", 28), ("Bob", 35), ("Clara", 35)] df2 = spark.createDataFrame(data2, columns) df2.createOrReplaceTempView("people")
Now apply aggregation:
spark.sql(""" SELECT Name, COUNT(*) AS Count, AVG(Age) AS AvgAge FROM people GROUP BY Name """).show()
This groups records by Name and calculates the number of records and average age.
5. JOIN Between Two Tables
Let’s create another table:
jobs_data = [("Alice", "Engineer"), ("Bob", "Designer"), ("Clara", "Manager")] df_jobs = spark.createDataFrame(jobs_data, ["Name", "Job"]) df_jobs.createOrReplaceTempView("jobs")
Now perform an inner join:
spark.sql(""" SELECT p.Name, p.Age, j.Job FROM people p JOIN jobs j ON p.Name = j.Name """).show()
This joins the people and jobs tables on the Name column.
Tips for Working Efficiently with PySpark SQL
Use LIMIT for testing: Avoid loading millions of rows in development.
Cache wisely: Use .cache() when a DataFrame is reused multiple times.
Check performance: Use .explain() to view the query execution plan.
Mix APIs: Combine SQL queries and DataFrame methods for flexibility.
Conclusion
PySpark SQL makes big data analysis in Python much more accessible. By combining the readability of SQL with the power of Spark, it allows developers and analysts to process massive datasets using simple, familiar syntax.
This blog covered the foundational aspects: setting up PySpark, writing basic SQL queries, performing joins and aggregations, and a few best practices to optimize your workflow.
If you're just starting out, keep experimenting with different queries, and try loading real-world datasets in formats like CSV or JSON. Mastering PySpark SQL can unlock a whole new level of data engineering and analysis at scale.
PySpark Training by AccentFuture
At AccentFuture, we offer customizable online training programs designed to help you gain practical, job-ready skills in the most in-demand technologies. Our PySpark Online Training will teach you everything you need to know, with hands-on training and real-world projects to help you excel in your career.
What we offer:
Hands-on training with real-world projects and 100+ use cases
Live sessions led by industry professionals
Certification preparation and career guidance
🚀 Enroll Now: https://www.accentfuture.com/enquiry-form/
📞 Call Us: +91–9640001789
📧 Email Us: [email protected]
🌐 Visit Us: AccentFuture
1 note
·
View note
Text
Data Science Tutorial for 2025: Tools, Trends, and Techniques
Data science continues to be one of the most dynamic and high-impact fields in technology, with new tools and methodologies evolving rapidly. As we enter 2025, data science is more than just crunching numbers—it's about building intelligent systems, automating decision-making, and unlocking insights from complex data at scale.
Whether you're a beginner or a working professional looking to sharpen your skills, this tutorial will guide you through the essential tools, the latest trends, and the most effective techniques shaping data science in 2025.
What is Data Science?
At its core, data science is the interdisciplinary field that combines statistics, computer science, and domain expertise to extract meaningful insights from structured and unstructured data. It involves collecting data, cleaning and processing it, analyzing patterns, and building predictive or explanatory models.
Data scientists are problem-solvers, storytellers, and innovators. Their work influences business strategies, public policy, healthcare solutions, and even climate models.

Essential Tools for Data Science in 2025
The data science toolkit has matured significantly, with tools becoming more powerful, user-friendly, and integrated with AI. Here are the must-know tools for 2025:
1. Python 3.12+
Python remains the most widely used language in data science due to its simplicity and vast ecosystem. In 2025, the latest Python versions offer faster performance and better support for concurrency—making large-scale data operations smoother.
Popular Libraries:
Pandas: For data manipulation
NumPy: For numerical computing
Matplotlib / Seaborn / Plotly: For data visualization
Scikit-learn: For traditional machine learning
XGBoost / LightGBM: For gradient boosting models
2. JupyterLab
The evolution of the classic Jupyter Notebook, JupyterLab, is now the default environment for exploratory data analysis, allowing a modular, tabbed interface with support for terminals, text editors, and rich output.
3. Apache Spark with PySpark
Handling massive datasets? PySpark—Python’s interface to Apache Spark—is ideal for distributed data processing across clusters, now deeply integrated with cloud platforms like Databricks and Snowflake.
4. Cloud Platforms (AWS, Azure, Google Cloud)
In 2025, most data science workloads run on the cloud. Services like Amazon SageMaker, Azure Machine Learning, and Google Vertex AI simplify model training, deployment, and monitoring.
5. AutoML & No-Code Tools
Tools like DataRobot, Google AutoML, and H2O.ai now offer drag-and-drop model building and optimization. These are powerful for non-coders and help accelerate workflows for pros.
Top Data Science Trends in 2025
1. Generative AI for Data Science
With the rise of large language models (LLMs), generative AI now assists data scientists in code generation, data exploration, and feature engineering. Tools like OpenAI's ChatGPT for Code and GitHub Copilot help automate repetitive tasks.
2. Data-Centric AI
Rather than obsessing over model architecture, 2025’s best practices focus on improving the quality of data—through labeling, augmentation, and domain understanding. Clean data beats complex models.
3. MLOps Maturity
MLOps—machine learning operations—is no longer optional. In 2025, companies treat ML models like software, with versioning, monitoring, CI/CD pipelines, and reproducibility built-in from the start.
4. Explainable AI (XAI)
As AI impacts sensitive areas like finance and healthcare, transparency is crucial. Tools like SHAP, LIME, and InterpretML help data scientists explain model predictions to stakeholders and regulators.
5. Edge Data Science
With IoT devices and on-device AI becoming the norm, edge computing allows models to run in real-time on smartphones, sensors, and drones—opening new use cases from agriculture to autonomous vehicles.
Core Techniques Every Data Scientist Should Know in 2025
Whether you’re starting out or upskilling, mastering these foundational techniques is critical:
1. Data Wrangling
Before any analysis begins, data must be cleaned and reshaped. Techniques include:
Handling missing values
Normalization and standardization
Encoding categorical variables
Time series transformation
2. Exploratory Data Analysis (EDA)
EDA is about understanding your dataset through visualization and summary statistics. Use histograms, scatter plots, correlation heatmaps, and boxplots to uncover trends and outliers.
3. Machine Learning Basics
Classification (e.g., predicting if a customer will churn)
Regression (e.g., predicting house prices)
Clustering (e.g., customer segmentation)
Dimensionality Reduction (e.g., PCA, t-SNE for visualization)
4. Deep Learning (Optional but Useful)
If you're working with images, text, or audio, deep learning with TensorFlow, PyTorch, or Keras can be invaluable. Hugging Face’s transformers make it easier than ever to work with large models.
5. Model Evaluation
Learn how to assess model performance with:
Accuracy, Precision, Recall, F1 Score
ROC-AUC Curve
Cross-validation
Confusion Matrix
Final Thoughts
As we move deeper into 2025, data science tutorial continues to be an exciting blend of math, coding, and real-world impact. Whether you're analyzing customer behavior, improving healthcare diagnostics, or predicting financial markets, your toolkit and mindset will be your most valuable assets.
Start by learning the fundamentals, keep experimenting with new tools, and stay updated with emerging trends. The best data scientists aren’t just great with code—they’re lifelong learners who turn data into decisions.
0 notes
Text
Python Mastery for Data Science: Essential Tools and Techniques
Introduction
Python has emerged as a powerhouse in the world of data science. Its versatility, ease of use, and extensive libraries make it the go-to choice for data professionals. Whether you're a beginner or an experienced data scientist, mastering Python is essential for leveraging the full potential of data analysis and machine learning. In this article, we'll explore the fundamental tools and techniques in Python for data science, breaking down complex concepts into simple, easy-to-understand language.
Getting Started with Python
Before diving into data science, it's important to have a basic understanding of Python. Don't worry if you're new to programming – Python's syntax is designed to be readable and straightforward. You can start by installing Python on your computer and familiarizing yourself with basic concepts like variables, data types, and control structures.
Understanding Data Structures
In data science, manipulating and analyzing data is at the core of what you do. Python offers a variety of data structures such as lists, tuples, dictionaries, and sets, which allow you to store and organize data efficiently. Understanding how to work with these data structures is crucial for performing data manipulation tasks.
Exploring Data Analysis Libraries
Python boasts powerful libraries like NumPy and Pandas, which are specifically designed for data manipulation and analysis. NumPy provides support for multi-dimensional arrays and mathematical functions, while Pandas offers data structures and tools for working with structured data. Learning how to use these libraries will greatly enhance your ability to analyze and manipulate data effectively.
Visualizing Data with Matplotlib and Seaborn
Data visualization is a key aspect of data science, as it helps you to understand patterns and trends in your data. Matplotlib and Seaborn are two popular Python libraries for creating static, interactive, and highly customizable visualizations. From simple line plots to complex heatmaps, these libraries offer a wide range of options for visualizing data in meaningful ways.
Harnessing the Power of Machine Learning
Python's extensive ecosystem includes powerful machine learning libraries such as Scikit-learn and TensorFlow. These libraries provide tools and algorithms for building predictive models, clustering data, and performing other machine learning tasks. Whether you're interested in regression, classification, or clustering, Python has you covered with its vast array of machine learning tools.
Working with Big Data
As data volumes continue to grow, the ability to work with big data becomes increasingly important. Python offers several libraries, such as PySpark and Dask, that allow you to scale your data analysis tasks to large datasets distributed across clusters of computers. By leveraging these libraries, you can analyze massive datasets efficiently and extract valuable insights from them.
Integrating Python with SQL
Many data science projects involve working with databases to extract and manipulate data. Python can be seamlessly integrated with SQL databases using libraries like SQLAlchemy and psycopg2. Whether you're querying data from a relational database or performing complex joins and aggregations, Python provides tools to streamline the process and make working with databases a breeze.
Collaborating and Sharing with Jupyter Notebooks
Jupyter Notebooks have become the de facto standard for data scientists to collaborate, document, and share their work. These interactive notebooks allow you to write and execute Python code in a web-based environment, interspersed with explanatory text and visualizations. With support for various programming languages and the ability to export notebooks to different formats, Jupyter Notebooks facilitate seamless collaboration and reproducibility in data science projects.
Continuous Learning and Community Support
Python's popularity in the data science community means that there is no shortage of resources and support available for learning and growing your skills. From online tutorials and forums to books and courses, there are numerous ways to deepen your understanding of Python for data science. Additionally, participating in data science communities and attending meetups and conferences can help you stay updated on the latest trends and developments in the field.
Conclusion
Python has cemented its place as the language of choice for data science, thanks to its simplicity, versatility, and robust ecosystem of libraries and tools. By mastering Python for data science, you can unlock endless possibilities for analyzing data, building predictive models, and extracting valuable insights. Whether you're just starting out or looking to advance your career, Python provides the essential tools and techniques you need to succeed in the dynamic field of data science.
0 notes
Text
Unleashing the Power of Data Science with Python: A Comprehensive Guide
Introduction:
In the ever-evolving landscape of data science, Python has emerged as a powerhouse, empowering analysts and data scientists to unravel insights from vast and intricate datasets. This comprehensive guide delves into the symbiotic relationship between data science and Python, shedding light on the myriad possibilities and advantages it offers to aspiring data enthusiasts.
The Python Advantage in Data Science:
Python's ascendancy in the realm of data science is attributed to its versatility, readability, and an extensive ecosystem of libraries. From data manipulation to statistical modeling and machine learning, Python seamlessly integrates into the Data science with python workflow. Its intuitive syntax makes it accessible to both beginners and seasoned professionals, fostering a community that thrives on collaboration and innovation.
Python Libraries Shaping Data Science:
Pandas:
At the heart of data manipulation and analysis lies Pandas, a powerful library that provides data structures like Data Frames. Python, with Pandas, enables efficient data cleaning, manipulation, and exploration, laying the groundwork for informed decision-making.
NumPy:
NumPy's numerical computing capabilities form the backbone of scientific computing in Python. Its array-based operations facilitate complex mathematical computations, making it an indispensable tool for data scientists engaged in statistical analysis and numerical processing.
Scikit-Learn:
Python's prowess in machine learning is exemplified by Scikit-Learn, a robust library offering a plethora of algorithms for classification, regression, clustering, and more. Its simplicity and extensibility make it a go-to choice for implementing machine learning models with ease.
Matplotlib and Seaborn:
Visualization is key in conveying insights, and Python excels in this domain. Matplotlib and Seaborn provide an array of plotting options, facilitating the creation of visually compelling graphs and charts to communicate complex findings effectively.
Python for Exploratory Data Analysis (EDA):
Python's capabilities shine during Exploratory Data Analysis (EDA), a crucial phase in any data science project. Analysts leverage Python's libraries to dissect and understand data patterns, relationships, and anomalies. Through Jupyter Notebooks, Python fosters an interactive and collaborative environment, allowing professionals to document their analyses step-by-step and share insights seamlessly.

Statistical Modeling with Python:Python's statistical libraries, including Statsmodels and SciPy, empower data scientists to delve into the realms of hypothesis testing, regression analysis, and more. Whether unraveling the intricacies of a dataset or validating assumptions, Python provides the tools needed for robust statistical modeling.
Machine Learning Mastery:
Python's dominance extends into the heart of machine learning, where its simplicity and expressiveness make it an ideal choice for implementing models. Scikit-Learn's user-friendly interface simplifies the process of training and deploying machine learning models, from decision trees to support vector machines, and everything in between.
Real-world Application of Python in Data Science:
Python's application extends across industries, driving innovation and efficiency. In finance, Python is harnessed for risk modeling and algorithmic trading. Healthcare leverages Python for predictive analytics, aiding in disease detection and patient outcomes. E-commerce relies on Python for customer behavior analysis and recommendation systems. Its versatility positions Python as a tool that transcends boundaries, proving invaluable in diverse sectors.
Python in Big Data and Data Engineering:
As the volume of data continues to surge, Python seamlessly integrates with big data technologies. Libraries like Pyspark facilitate the processing of massive datasets, enabling data engineers to manipulate and extract insights from large-scale distributed systems. Python's adaptability in this domain solidifies its position as a go-to language for end-to-end data science workflows.
youtube
Educational Resources and Community Support:
Python's popularity in data science is further bolstered by a wealth of educational resources and a vibrant community. Online courses, tutorials, and documentation cater to learners at every level, ensuring a smooth onboarding process. The collaborative nature of the Python community fosters knowledge exchange, with forums, meetups, and conferences providing platforms for professionals to stay abreast of the latest developments.
Conclusion:
In the dynamic realm of data science, Python stands as an indispensable ally, offering a seamless journey from data exploration to model deployment. Its versatile libraries, collaborative ecosystem, and ease of use have positioned Python as the language of choice for data scientists and analysts alike. Aspiring data enthusiasts seeking to unlock the potential of data science certification find in Python a powerful and accessible tool, propelling them into a world of endless possibilities. Embrace Python, embark on the data science journey, and witness the transformative impact it can have on the way we unravel insights from the vast tapestry of data
#DataScienceInPython#PythonAnalytics#DataDrivenPython#CodingWithDataScience#PythonDataEngineering#Youtube
0 notes
Text
From Beginner to Pro: The Best PySpark Courses Online from ScholarNest Technologies

Are you ready to embark on a journey from a PySpark novice to a seasoned pro? Look no further! ScholarNest Technologies brings you a comprehensive array of PySpark courses designed to cater to every skill level. Let's delve into the key aspects that make these courses stand out:
1. What is PySpark?
Gain a fundamental understanding of PySpark, the powerful Python library for Apache Spark. Uncover the architecture and explore its diverse applications in the world of big data.
2. Learning PySpark by Example:
Experience is the best teacher! Our courses focus on hands-on examples, allowing you to apply your theoretical knowledge to real-world scenarios. Learn by doing and enhance your problem-solving skills.
3. PySpark Certification:
Elevate your career with our PySpark certification programs. Validate your expertise and showcase your proficiency in handling big data tasks using PySpark.
4. Structured Learning Paths:
Whether you're a beginner or seeking advanced concepts, our courses offer structured learning paths. Progress at your own pace, mastering each skill before moving on to the next level.
5. Specialization in Big Data Engineering:
Our certification course on big data engineering with PySpark provides in-depth insights into the intricacies of handling vast datasets. Acquire the skills needed for a successful career in big data.
6. Integration with Databricks:
Explore the integration of PySpark with Databricks, a cloud-based big data platform. Understand how these technologies synergize to provide scalable and efficient solutions.
7. Expert Instruction:
Learn from the best! Our courses are crafted by top-rated data science instructors, ensuring that you receive expert guidance throughout your learning journey.
8. Online Convenience:
Enroll in our online PySpark courses and access a wealth of knowledge from the comfort of your home. Flexible schedules and convenient online platforms make learning a breeze.
Whether you're a data science enthusiast, a budding analyst, or an experienced professional looking to upskill, ScholarNest's PySpark courses offer a pathway to success. Master the skills, earn certifications, and unlock new opportunities in the world of big data engineering!
#big data#data engineering#data engineering certification#data engineering course#databricks data engineer certification#pyspark course#databricks courses online#best pyspark course online#pyspark online course#databricks learning#data engineering courses in bangalore#data engineering courses in india#azure databricks learning#pyspark training course#pyspark certification course
1 note
·
View note
Text
Mastering PySpark: A Comprehensive Certification Course and Effective Training Methods
Are you eager to delve into the world of big data analytics and data processing? Look no further than PySpark, a powerful tool for efficiently handling large-scale data. In this article, we will explore the PySpark certification course and its training methods, providing you with the essential knowledge to master this transformative technology.
Understanding PySpark: Unveiling the Power of Big Data
PySpark is a Python library for Apache Spark, an open-source, distributed computing system designed for big data processing and analysis. It enables seamless integration with Python, allowing developers to leverage the vast capabilities of Spark using familiar Python programming paradigms. PySpark empowers data scientists and analysts to process vast amounts of data efficiently, making it an invaluable tool in today's data-driven landscape.
The PySpark Certification Course: A Pathway to Expertise
Enrolling in a PySpark certification course can be a game-changer for anyone looking to enhance their skills in big data analytics. These courses are meticulously designed to provide a comprehensive understanding of PySpark, covering its core concepts, advanced features, and practical applications. The curriculum typically includes:
Introduction to PySpark: Understanding the basics of PySpark, its architecture, and key components.
Data Processing with PySpark: Learning how to process and manipulate data using PySpark's powerful capabilities.
Machine Learning with PySpark: Exploring how PySpark facilitates machine learning tasks, allowing for predictive modeling and analysis.
Real-world Applications and Case Studies: Gaining hands-on experience through real-world projects and case studies.
Training Methods: Tailored for Success
The training methods employed in PySpark certification courses are designed to maximize learning and ensure participants grasp the concepts effectively. These methods include:
Interactive Lectures: Engaging lectures delivered by experienced instructors to explain complex concepts in an easily digestible manner.
Hands-on Labs and Projects: Practical exercises and projects to apply the learned knowledge in real-world scenarios, reinforcing understanding.
Collaborative Learning: Group discussions, teamwork, and peer interaction to foster a collaborative learning environment.
Regular Assessments: Periodic quizzes and assessments to evaluate progress and identify areas for improvement.
FAQs about PySpark Certification Course
1. What is PySpark?
PySpark is a Python library for Apache Spark, providing a seamless interface to integrate Python with the Spark framework for efficient big data processing.
2. Why should I opt for a PySpark certification course?
A PySpark certification course equips you with the skills needed to analyze large-scale data efficiently, making you highly valuable in the data analytics job market.
3. Are there any prerequisites for enrolling in a PySpark certification course?
While prior knowledge of Python can be beneficial, most PySpark certification courses start from the basics, making them accessible to beginners as well.
4. How long does a typical PySpark certification course last?
The duration of a PySpark certification course can vary, but it typically ranges from a few weeks to a few months, depending on the depth of the curriculum.
5. Can I access course materials and resources after completing the course?
Yes, many institutions provide access to course materials, resources, and alumni networks even after completing the course to support continued learning and networking.
6. Will I receive a certificate upon course completion?
Yes, upon successful completion of the PySpark certification course, you will be awarded a certificate, validating your proficiency in PySpark.
7. Is PySpark suitable for individuals without a background in data science?
Absolutely! PySpark courses are designed to accommodate individuals from diverse backgrounds, providing a structured learning path for beginners.
8. What career opportunities can a PySpark certification unlock?
A PySpark certification can open doors to various career opportunities, including data analyst, data engineer, machine learning engineer, and more, in industries dealing with big data.
In conclusion, mastering PySpark through a well-structured certification course can significantly enhance your career prospects in the ever-evolving field of big data analytics. Invest in your education, embrace the power of PySpark, and unlock a world of possibilities in the realm of data processing and analysis.

1 note
·
View note
Text
What is PySpark? A Beginner’s Guide
Introduction
The digital era gives rise to continuous expansion in data production activities. Organizations and businesses need processing systems with enhanced capabilities to process large data amounts efficiently. Large datasets receive poor scalability together with slow processing speed and limited adaptability from conventional data processing tools. PySpark functions as the data processing solution that brings transformation to operations.
The Python Application Programming Interface called PySpark serves as the distributed computing framework of Apache Spark for fast processing of large data volumes. The platform offers a pleasant interface for users to operate analytics on big data together with real-time search and machine learning operations. Data engineering professionals along with analysts and scientists prefer PySpark because the platform combines Python's flexibility with Apache Spark's processing functions.
The guide introduces the essential aspects of PySpark while discussing its fundamental elements as well as explaining operational guidelines and hands-on usage. The article illustrates the operation of PySpark through concrete examples and predicted outputs to help viewers understand its functionality better.
What is PySpark?
PySpark is an interface that allows users to work with Apache Spark using Python. Apache Spark is a distributed computing framework that processes large datasets in parallel across multiple machines, making it extremely efficient for handling big data. PySpark enables users to leverage Spark’s capabilities while using Python’s simple and intuitive syntax.
There are several reasons why PySpark is widely used in the industry. First, it is highly scalable, meaning it can handle massive amounts of data efficiently by distributing the workload across multiple nodes in a cluster. Second, it is incredibly fast, as it performs in-memory computation, making it significantly faster than traditional Hadoop-based systems. Third, PySpark supports Python libraries such as Pandas, NumPy, and Scikit-learn, making it an excellent choice for machine learning and data analysis. Additionally, it is flexible, as it can run on Hadoop, Kubernetes, cloud platforms, or even as a standalone cluster.
Core Components of PySpark
PySpark consists of several core components that provide different functionalities for working with big data:
RDD (Resilient Distributed Dataset) – The fundamental unit of PySpark that enables distributed data processing. It is fault-tolerant and can be partitioned across multiple nodes for parallel execution.
DataFrame API – A more optimized and user-friendly way to work with structured data, similar to Pandas DataFrames.
Spark SQL – Allows users to query structured data using SQL syntax, making data analysis more intuitive.
Spark MLlib – A machine learning library that provides various ML algorithms for large-scale data processing.
Spark Streaming – Enables real-time data processing from sources like Kafka, Flume, and socket streams.
How PySpark Works
1. Creating a Spark Session
To interact with Spark, you need to start a Spark session.

Output:

2. Loading Data in PySpark
PySpark can read data from multiple formats, such as CSV, JSON, and Parquet.

Expected Output (Sample Data from CSV):

3. Performing Transformations
PySpark supports various transformations, such as filtering, grouping, and aggregating data. Here’s an example of filtering data based on a condition.

Output:

4. Running SQL Queries in PySpark
PySpark provides Spark SQL, which allows you to run SQL-like queries on DataFrames.

Output:
5. Creating a DataFrame Manually
You can also create a PySpark DataFrame manually using Python lists.

Output:

Use Cases of PySpark
PySpark is widely used in various domains due to its scalability and speed. Some of the most common applications include:
Big Data Analytics – Used in finance, healthcare, and e-commerce for analyzing massive datasets.
ETL Pipelines – Cleans and processes raw data before storing it in a data warehouse.
Machine Learning at Scale – Uses MLlib for training and deploying machine learning models on large datasets.
Real-Time Data Processing – Used in log monitoring, fraud detection, and predictive analytics.
Recommendation Systems – Helps platforms like Netflix and Amazon offer personalized recommendations to users.
Advantages of PySpark
There are several reasons why PySpark is a preferred tool for big data processing. First, it is easy to learn, as it uses Python’s simple and intuitive syntax. Second, it processes data faster due to its in-memory computation. Third, PySpark is fault-tolerant, meaning it can automatically recover from failures. Lastly, it is interoperable and can work with multiple big data platforms, cloud services, and databases.
Getting Started with PySpark
Installing PySpark
You can install PySpark using pip with the following command:

To use PySpark in a Jupyter Notebook, install Jupyter as well:

To start PySpark in a Jupyter Notebook, create a Spark session:

Conclusion
PySpark is an incredibly powerful tool for handling big data analytics, machine learning, and real-time processing. It offers scalability, speed, and flexibility, making it a top choice for data engineers and data scientists. Whether you're working with structured data, large-scale machine learning models, or real-time data streams, PySpark provides an efficient solution.
With its integration with Python libraries and support for distributed computing, PySpark is widely used in modern big data applications. If you’re looking to process massive datasets efficiently, learning PySpark is a great step forward.
youtube
#pyspark training#pyspark coutse#apache spark training#apahe spark certification#spark course#learn apache spark#apache spark course#pyspark certification#hadoop spark certification .#Youtube
0 notes
Text
Key Features of Python: Unlocking the Power of a Versatile Programming Language
Python, known for its simplicity and versatility, has become one of the most popular programming languages in the world. Its extensive set of features and ease of use make it an excellent choice for both beginners and experienced developers. In this article, we will explore the key features of Python that contribute to its widespread adoption and discuss how they empower developers to create robust and efficient applications.
1. Introduction to Python
Python, created by Guido van Rossum and first released in 1991, is an interpreted, high-level, and general-purpose programming language. It has gained popularity due to its simplicity, clean syntax, and vast array of libraries and frameworks.
2. Simplicity and Readability
One of the key features of Python is its emphasis on code readability. Python's syntax uses indentation to delimit blocks, making the code more intuitive and easier to understand. Its simplicity allows developers to write clean and concise code, resulting in increased productivity and reduced debugging time.
3. Dynamic Typing and High-Level Language
Python is dynamically typed, meaning variables can hold values of any type. This flexibility enables rapid prototyping and makes Python suitable for scripting and exploratory programming. Additionally, Python is considered a high-level language as it abstracts complex details, allowing developers to focus on problem-solving rather than low-level implementation.
4. Large Standard Library
Python comes with a vast standard library, providing a wide range of modules and functions that simplify common programming tasks. From file manipulation and networking to regular expressions and database access, the standard library eliminates the need for developers to write code from scratch, saving time and effort.
5. Cross-Platform Compatibility
Python is a cross-platform language, meaning it can run on different operating systems such as Windows, macOS, and Linux. This portability allows developers to write code once and run it on multiple platforms, ensuring wider accessibility and reducing development time.
6. Object-Oriented Programming (OOP)
Python supports object-oriented programming, a programming paradigm that focuses on objects and classes. OOP enables developers to create modular and reusable code, improving code organization and maintenance. Python's support for OOP principles, such as encapsulation, inheritance, and polymorphism, enhances code structure and promotes code reusability.
7. Extensive Third-Party Libraries
Python's vibrant community has developed numerous third-party libraries, extending the language's capabilities for various domains. Libraries like NumPy, Pandas, and Matplotlib empower data scientists and analysts with powerful tools for data manipulation, analysis, and visualization. Similarly, frameworks like Django and Flask simplify web development, enabling developers to build robust and scalable applications.
8. Integration Capabilities
Python excels in integrating with other languages and systems.
Its C API allows seamless integration with C/C++ code, providing performance optimizations where needed. Moreover, Python can interact with Java, .NET, and other programming languages, making it a versatile language for building software systems that combine multiple technologies.
9. Scalability and Performance
Contrary to the perception that interpreted languages are slow, Python offers several techniques for performance optimization. For computationally intensive tasks, Python allows developers to write critical sections in lower-level languages like C or utilize just-in-time (JIT) compilation libraries like Numba. Additionally, Python's scalability is evident in its ability to handle large-scale applications and distributed systems, leveraging frameworks like PySpark and Dask.
10. Documentation and Community Support
Python's extensive documentation is one of its greatest assets. The official Python documentation provides comprehensive guides, tutorials, and references, making it easier for developers to learn and explore the language. Furthermore, Python has a large and supportive community, with active forums, online communities, and open-source projects, fostering collaboration and knowledge sharing.
11. Data Analysis and Scientific Computing
Python has gained significant popularity in the field of data analysis and scientific computing. Libraries like NumPy and SciPy offer powerful numerical computing capabilities, while tools like Jupyter Notebook facilitate interactive data exploration and visualization. Python's versatility in handling large datasets and its integration with machine learning libraries, such as TensorFlow and scikit-learn, make it a preferred choice for data scientists.
12. Web Development and Frameworks
Python's web development capabilities are enhanced by frameworks like Django, Flask, and Pyramid. These frameworks provide a solid foundation for building web applications, offering features like URL routing, database integration, and template rendering. Python's simplicity and the availability of these frameworks make it an excellent choice for developing scalable and maintainable web solutions.
13. Automation and Scripting
Python's ease of use and extensive libraries make it an ideal language for automation and scripting tasks. From simple file processing and system administration to complex network automation and testing, Python's scripting capabilities streamline repetitive tasks and improve efficiency. Its ability to interact with operating system functions and other software tools simplifies automation across various domains.
14. Machine Learning and Artificial Intelligence
Python has emerged as a dominant language in the field of machine learning and artificial intelligence. Libraries like TensorFlow, PyTorch, and Keras provide robust tools for building and training neural networks. Python's simplicity and its wide adoption in the research community have made it the language of choice for implementing cutting-edge AI algorithms and models.
15. Conclusion
Python's key features, including simplicity, readability, extensive libraries, cross-platform compatibility, and support for various domains, make it an exceptional programming language. Its versatility enables developers to build a wide range of applications, from web development and data analysis to automation and artificial intelligence. Python's vibrant community and extensive documentation further contribute to its success and popularity.
1 note
·
View note
Text
Writing robust Databricks SQL workflows for maximum efficiency
Do you have a big data workload that needs to be managed efficiently and effectively? Are the current SQL workflows falling short? Life as a developer can be hectic especially when you struggle to find ways to optimize your workflow to ensure that you are maximizing efficiency while also reducing errors and bugs along the way. Writing robust Databricks SQL workflows is key to getting the most out…

View On WordPress
#Azure Databricks#azure databricks demo#azure databricks for beginners#azure databricks notebooks#azure databricks training#Big Data#data engineering#Databricks#databricks apache spark#Databricks SQL Data Warehouse#Databricks Workflow#learn azure databricks#microsoft azure#microsoft azure databricks#pyspark#pyspark for beginners#pyspark for data engineers#pyspark in azure databricks#what is azure databricks#Workflow tasks azure databricks tutorial
0 notes
Text
Transform Your Team into Data Engineering Pros with ScholarNest Technologies

In the fast-evolving landscape of data engineering, the ability to transform your team into proficient professionals is a strategic imperative. ScholarNest Technologies stands at the forefront of this transformation, offering comprehensive programs that equip individuals with the skills and certifications necessary to excel in the dynamic field of data engineering. Let's delve into the world of data engineering excellence and understand how ScholarNest is shaping the data engineers of tomorrow.
Empowering Through Education: The Essence of Data Engineering
Data engineering is the backbone of current data-driven enterprises. It involves the collection, processing, and storage of data in a way that facilitates effective analysis and insights. ScholarNest Technologies recognizes the pivotal role data engineering plays in today's technological landscape and has curated a range of courses and certifications to empower individuals in mastering this discipline.
Comprehensive Courses and Certifications: ScholarNest's Commitment to Excellence
1. Data Engineering Courses: ScholarNest offers comprehensive data engineering courses designed to provide a deep understanding of the principles, tools, and technologies essential for effective data processing. These courses cover a spectrum of topics, including data modeling, ETL (Extract, Transform, Load) processes, and database management.
2. Pyspark Mastery: Pyspark, a powerful data processing library for Python, is a key component of modern data engineering. ScholarNest's Pyspark courses, including options for beginners and full courses, ensure participants acquire proficiency in leveraging this tool for scalable and efficient data processing.
3. Databricks Learning: Databricks, with its unified analytics platform, is integral to modern data engineering workflows. ScholarNest provides specialized courses on Databricks learning, enabling individuals to harness the full potential of this platform for advanced analytics and data science.
4. Azure Databricks Training: Recognizing the industry shift towards cloud-based solutions, ScholarNest offers courses focused on Azure Databricks. This training equips participants with the skills to leverage Databricks in the Azure cloud environment, ensuring they are well-versed in cutting-edge technologies.
From Novice to Expert: ScholarNest's Approach to Learning
Whether you're a novice looking to learn the fundamentals or an experienced professional seeking advanced certifications, ScholarNest caters to diverse learning needs. Courses such as "Learn Databricks from Scratch" and "Machine Learning with Pyspark" provide a structured pathway for individuals at different stages of their data engineering journey.
Hands-On Learning and Certification: ScholarNest places a strong emphasis on hands-on learning. Courses include practical exercises, real-world projects, and assessments to ensure that participants not only grasp theoretical concepts but also gain practical proficiency. Additionally, certifications such as the Databricks Data Engineer Certification validate the skills acquired during the training.
The ScholarNest Advantage: Shaping Data Engineering Professionals
ScholarNest Technologies goes beyond traditional education paradigms, offering a transformative learning experience that prepares individuals for the challenges and opportunities in the world of data engineering. By providing access to the best Pyspark and Databricks courses online, ScholarNest is committed to fostering a community of skilled data engineering professionals who will drive innovation and excellence in the ever-evolving data landscape. Join ScholarNest on the journey to unlock the full potential of your team in the realm of data engineering.
#big data#big data consulting#data engineering#data engineering course#data engineering certification#databricks data engineer certification#pyspark course#databricks courses online#best pyspark course online#best pyspark course#pyspark online course#databricks learning#data engineering courses in bangalore#data engineering courses in india#azure databricks learning#pyspark training course
1 note
·
View note
Link
3 notes
·
View notes
Text
Why will data science with a Python course be best for careers?
A data science course that includes Python programming is highly beneficial for careers for several reasons:
Widely Used in Data Science: Python has emerged as one of the most popular programming languages in the field of data science. It has a rich ecosystem of libraries and frameworks specifically designed for data analysis, machine learning, and scientific computing. Learning Python enables you to leverage these tools and libraries effectively, making you more productive and efficient in your data science work.
Versatility and Flexibility: Python is a versatile language that can be applied to various aspects of data science, including data cleaning, preprocessing, visualization, statistical analysis, machine learning, and more. Its syntax is clean and readable, making it easier to understand and write code. Python's flexibility allows you to work on different projects and adapt to new challenges in data science.
Large Community and Support: Python has a vast and active community of data scientists, developers, and researchers. This means that there are abundant resources available, including tutorials, forums, and open-source libraries, where you can seek help and collaborate with others. The Python community also continually develops new tools and packages, ensuring that you stay up-to-date with the latest advancements in data science.
Integration with Other Technologies: Python integrates seamlessly with other technologies commonly used in data science, such as SQL databases, Hadoop, Spark, and cloud computing platforms. This interoperability allows you to work with diverse data sources and scale your data science projects efficiently.
Industry Demand and Job Opportunities: Python is in high demand in the job market, especially in the field of data science. Many companies and organizations are seeking professionals who are proficient in Python for their data-related roles. By acquiring Python skills, you increase your employability and open up a wide range of career opportunities in data science.
Easy to Learn and Use: Python is known for its simplicity and readability, which makes it an ideal programming language for beginners. It's straightforward syntax and extensive documentation enables individuals with little or no programming experience to learn and start applying Python in data science projects relatively quickly. This accessibility makes it a preferred choice for beginners entering the field of data science.
Scalability and Performance: While Python is an interpreted language, it provides options for optimizing performance, such as utilizing powerful numerical libraries like NumPy and using parallel processing libraries like Dask or PySpark. Additionally, Python interfaces with compiled languages like C and C++, allowing you to integrate efficient and optimized code when performance is critical.
In conclusion, learning data science with a Python course offers numerous advantages for careers. Python's popularity, versatility, community support, and industry demand make it a powerful tool for data scientists, providing the necessary skills and knowledge to succeed in the field and access a wide range of job opportunities.
If you found my post informative, please consider upvoting and following me for more content like this. Sharing this post with your friends and colleagues would also be greatly appreciated. For any data science-related queries, feel free to visit the Digicrome ( Get Advanced Certification in Data Science & AI courses ) website for more information. Thank you for your support!
0 notes