#python best plotting library
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Hackers stole 65M passwords from Tumblr in 2013.
Text
#nlp libraries#natural language processing libraries#python libraries#nodejs nlp libraries#python and libraries#javascript nlp libraries#best nlp libraries for nodejs#nlp libraries for java script#best nlp libraries for javascript#nlp libraries for nodejs and javascript#nltk library#python library#pattern library#python best gui library#python library re#python library requests#python library list#python library pandas#python best plotting library
0 notes
Text
This Week in Rust 510
Hello and welcome to another issue of This Week in Rust! Rust is a programming language empowering everyone to build reliable and efficient software. This is a weekly summary of its progress and community. Want something mentioned? Tag us at @ThisWeekInRust on Twitter or @ThisWeekinRust on mastodon.social, or send us a pull request. Want to get involved? We love contributions.
This Week in Rust is openly developed on GitHub and archives can be viewed at this-week-in-rust.org. If you find any errors in this week's issue, please submit a PR.
Updates from Rust Community
Official
Announcing Rust 1.72.0
Change in Guidance on Committing Lockfiles
Cargo changes how arrays in config are merged
Seeking help for initial Leadership Council initiatives
Leadership Council Membership Changes
Newsletters
This Week in Ars Militaris VIII
Project/Tooling Updates
rust-analyzer changelog #196
The First Stable Release of a Memory Safe sudo Implementation
We're open-sourcing the library that powers 1Password's ability to log in with a passkey
ratatui 0.23.0 is released! (official successor of tui-rs)
Zellij 0.38.0: session-manager, plugin infra, and no more offensive session names
Observations/Thoughts
The fastest WebSocket implementation
Rust Malware Staged on Crates.io
ESP32 Standard Library Embedded Rust: SPI with the MAX7219 LED Dot Matrix
A JVM in Rust part 5 - Executing instructions
Compiling Rust for .NET, using only tea and stubbornness!
Ad-hoc polymorphism erodes type-safety
How to speed up the Rust compiler in August 2023
This isn't the way to speed up Rust compile times
Rust Cryptography Should be Written in Rust
Dependency injection in Axum handlers. A quick tour
Best Rust Web Frameworks to Use in 2023
From tui-rs to Ratatui: 6 Months of Cooking Up Rust TUIs
[video] Rust 1.72.0
[video] Rust 1.72 Release Train
Rust Walkthroughs
[series] Distributed Tracing in Rust, Episode 3: tracing basics
Use Rust in shell scripts
A Simple CRUD API in Rust with Cloudflare Workers, Cloudflare KV, and the Rust Router
[video] base64 crate: code walkthrough
Miscellaneous
Interview with Rust and operating system Developer Andy Python
Leveraging Rust in our high-performance Java database
Rust error message to fix a typo
[video] The Builder Pattern and Typestate Programming - Stefan Baumgartner - Rust Linz January 2023
[video] CI with Rust and Gitlab Selfhosting - Stefan Schindler - Rust Linz July 2023
Crate of the Week
This week's crate is dprint, a fast code formatter that formats Markdown, TypeScript, JavaScript, JSON, TOML and many other types natively via Wasm plugins.
Thanks to Martin Geisler for the suggestion!
Please submit your suggestions and votes for next week!
Call for Participation
Always wanted to contribute to open-source projects but did not know where to start? Every week we highlight some tasks from the Rust community for you to pick and get started!
Some of these tasks may also have mentors available, visit the task page for more information.
Hyperswitch - add domain type for client secret
Hyperswitch - deserialization error exposes sensitive values in the logs
Hyperswitch - move redis key creation to a common module
mdbook-i18n-helpers - Write tool which can convert translated files back to PO
mdbook-i18n-helpers - Package a language selector
mdbook-i18n-helpers - Add links between translations
Comprehensive Rust - Link to correct line when editing a translation
Comprehensive Rust - Track the number of times the redirect pages are visited
RustQuant - Jacobian and Hessian matrices support.
RustQuant - improve Graphviz plotting of autodiff computational graphs.
RustQuant - bond pricing implementation.
RustQuant - implement cap/floor pricers.
RustQuant - Implement Asian option pricers.
RustQuant - Implement American option pricers.
release-plz - add ability to mark Gitea/GitHub release as draft
zerocopy - CI step "Set toolchain version" is flaky due to network timeouts
zerocopy - Implement traits for tuple types (and maybe other container types?)
zerocopy - Prevent panics statically
zerocopy - Add positive and negative trait impl tests for SIMD types
zerocopy - Inline many trait methods (in zerocopy and in derive-generated code)
datatest-stable - Fix quadratic performance with nextest
Ockam - Use a user-friendly name for the shared services to show it in the tray menu
Ockam - Rename the Port to Address and support such format
Ockam - Ockam CLI should gracefully handle invalid state when initializing
css-inline - Update cssparser & selectors
css-inline - Non-blocking stylesheet resolving
css-inline - Optionally remove all class attributes
If you are a Rust project owner and are looking for contributors, please submit tasks here.
Updates from the Rust Project
366 pull requests were merged in the last week
reassign sparc-unknown-none-elf to tier 3
wasi: round up the size for aligned_alloc
allow MaybeUninit in input and output of inline assembly
allow explicit #[repr(Rust)]
fix CFI: f32 and f64 are encoded incorrectly for cross-language CFI
add suggestion for some #[deprecated] items
add an (perma-)unstable option to disable vtable vptr
add comment to the push_trailing function
add note when matching on tuples/ADTs containing non-exhaustive types
add support for ptr::writes for the invalid_reference_casting lint
allow overwriting ExpnId for concurrent decoding
avoid duplicate large_assignments lints
contents of reachable statics is reachable
do not emit invalid suggestion in E0191 when spans overlap
do not forget to pass DWARF fragment information to LLVM
ensure that THIR unsafety check is done before stealing it
emit a proper diagnostic message for unstable lints passed from CLI
fix races conditions with SyntaxContext decoding
fix waiting on a query that panicked
improve note for the invalid_reference_casting lint
include compiler flags when you break rust;
load include_bytes! directly into an Lrc
make Sharded an enum and specialize it for the single thread case
make rustc_on_unimplemented std-agnostic for alloc::rc
more precisely detect cycle errors from type_of on opaque
point at type parameter that introduced unmet bound instead of full HIR node
record allocation spans inside force_allocation
suggest mutable borrow on read only for-loop that should be mutable
tweak output of to_pretty_impl_header involving only anon lifetimes
use the same DISubprogram for each instance of the same inlined function within a caller
walk through full path in point_at_path_if_possible
warn on elided lifetimes in associated constants (ELIDED_LIFETIMES_IN_ASSOCIATED_CONSTANT)
make RPITITs capture all in-scope lifetimes
add stable for Constant in smir
add generics_of to smir
add smir predicates_of
treat StatementKind::Coverage as completely opaque for SMIR purposes
do not convert copies of packed projections to moves
don't do intra-pass validation on MIR shims
MIR validation: reject in-place argument/return for packed fields
disable MIR SROA optimization by default
miri: automatically start and stop josh in rustc-pull/push
miri: fix some bad regex capture group references in test normalization
stop emitting non-power-of-two vectors in (non-portable-SIMD) codegen
resolve: stop creating NameBindings on every use, create them once per definition instead
fix a pthread_t handle leak
when terminating during unwinding, show the reason why
avoid triple-backtrace due to panic-during-cleanup
add additional float constants
add ability to spawn Windows process with Proc Thread Attributes | Take 2
fix implementation of Duration::checked_div
hashbrown: allow serializing HashMaps that use a custom allocator
hashbrown: change & to &mut where applicable
hashbrown: simplify Clone by removing redundant guards
regex-automata: fix incorrect use of Aho-Corasick's "standard" semantics
cargo: Very preliminary MSRV resolver support
cargo: Use a more compact relative-time format
cargo: Improve TOML parse errors
cargo: add support for target.'cfg(..)'.linker
cargo: config: merge lists in precedence order
cargo: create dedicated unstable flag for asymmetric-token
cargo: set MSRV for internal packages
cargo: improve deserialization errors of untagged enums
cargo: improve resolver version mismatch warning
cargo: stabilize --keep-going
cargo: support dependencies from registries for artifact dependencies, take 2
cargo: use AND search when having multiple terms
rustdoc: add unstable --no-html-source flag
rustdoc: rename typedef to type alias
rustdoc: use unicode-aware checks for redundant explicit link fastpath
clippy: new lint: implied_bounds_in_impls
clippy: new lint: reserve_after_initialization
clippy: arithmetic_side_effects: detect division by zero for Wrapping and Saturating
clippy: if_then_some_else_none: look into local initializers for early returns
clippy: iter_overeager_cloned: detect .cloned().all() and .cloned().any()
clippy: unnecessary_unwrap: lint on .as_ref().unwrap()
clippy: allow trait alias DefIds in implements_trait_with_env_from_iter
clippy: fix "derivable_impls: attributes are ignored"
clippy: fix tuple_array_conversions lint on nightly
clippy: skip float_cmp check if lhs is a custom type
rust-analyzer: diagnostics for 'while let' loop with label in condition
rust-analyzer: respect #[allow(unused_braces)]
Rust Compiler Performance Triage
A fairly quiet week, with improvements exceeding a small scattering of regressions. Memory usage and artifact size held fairly steady across the week, with no regressions or improvements.
Triage done by @simulacrum. Revision range: d4a881e..cedbe5c
2 Regressions, 3 Improvements, 2 Mixed; 0 of them in rollups 108 artifact comparisons made in total
Full report here
Approved RFCs
Changes to Rust follow the Rust RFC (request for comments) process. These are the RFCs that were approved for implementation this week:
Create a Testing sub-team
Final Comment Period
Every week, the team announces the 'final comment period' for RFCs and key PRs which are reaching a decision. Express your opinions now.
RFCs
No RFCs entered Final Comment Period this week.
Tracking Issues & PRs
[disposition: merge] Stabilize PATH option for --print KIND=PATH
[disposition: merge] Add alignment to the NPO guarantee
New and Updated RFCs
[new] Special-cased performance improvement for Iterator::sum on Range<u*> and RangeInclusive<u*>
[new] Cargo Check T-lang Policy
Call for Testing
An important step for RFC implementation is for people to experiment with the implementation and give feedback, especially before stabilization. The following RFCs would benefit from user testing before moving forward:
No RFCs issued a call for testing this week.
If you are a feature implementer and would like your RFC to appear on the above list, add the new call-for-testing label to your RFC along with a comment providing testing instructions and/or guidance on which aspect(s) of the feature need testing.
Upcoming Events
Rusty Events between 2023-08-30 - 2023-09-27 🦀
Virtual
2023-09-05 | Virtual (Buffalo, NY, US) | Buffalo Rust Meetup
Buffalo Rust User Group, First Tuesdays
2023-09-05 | Virtual (Munich, DE) | Rust Munich
Rust Munich 2023 / 4 - hybrid
2023-09-06 | Virtual (Indianapolis, IN, US) | Indy Rust
Indy.rs - with Social Distancing
2023-09-12 - 2023-09-15 | Virtual (Albuquerque, NM, US) | RustConf
RustConf 2023
2023-09-12 | Virtual (Dallas, TX, US) | Dallas Rust
Second Tuesday
2023-09-13 | Virtual (Boulder, CO, US) | Boulder Elixir and Rust
Monthly Meetup
2023-09-13 | Virtual (Cardiff, UK)| Rust and C++ Cardiff
The unreasonable power of combinator APIs
2023-09-14 | Virtual (Nuremberg, DE) | Rust Nuremberg
Rust Nürnberg online
2023-09-20 | Virtual (Vancouver, BC, CA) | Vancouver Rust
Rust Study/Hack/Hang-out
2023-09-21 | Virtual (Charlottesville, NC, US) | Charlottesville Rust Meetup
Crafting Interpreters in Rust Collaboratively
2023-09-21 | Lehi, UT, US | Utah Rust
Real Time Multiplayer Game Server in Rust
2023-09-21 | Virtual (Linz, AT) | Rust Linz
Rust Meetup Linz - 33rd Edition
2023-09-25 | Virtual (Dublin, IE) | Rust Dublin
How we built the SurrealDB Python client in Rust.
Asia
2023-09-06 | Tel Aviv, IL | Rust TLV
RustTLV @ Final - September Edition
Europe
2023-08-30 | Copenhagen, DK | Copenhagen Rust Community
Rust metup #39 sponsored by Fermyon
2023-08-31 | Augsburg, DE | Rust Meetup Augsburg
Augsburg Rust Meetup #2
2023-09-05 | Munich, DE + Virtual | Rust Munich
Rust Munich 2023 / 4 - hybrid
2023-09-14 | Reading, UK | Reading Rust Workshop
Reading Rust Meetup at Browns
2023-09-19 | Augsburg, DE | Rust - Modern Systems Programming in Leipzig
Logging and tracing in Rust
2023-09-20 | Aarhus, DK | Rust Aarhus
Rust Aarhus - Rust and Talk at Concordium
2023-09-21 | Bern, CH | Rust Bern
Third Rust Bern Meetup
North America
2023-09-05 | Chicago, IL, US | Deep Dish Rust
Rust Happy Hour
2023-09-06 | Bellevue, WA, US | The Linux Foundation
Rust Global
2023-09-12 - 2023-09-15 | Albuquerque, NM, US + Virtual | RustConf
RustConf 2023
2023-09-12 | New York, NY, US | Rust NYC
A Panel Discussion on Thriving in a Rust-Driven Workplace
2023-09-12 | Minneapolis, MN, US | Minneapolis Rust Meetup
Minneapolis Rust Meetup Happy Hour
2023-09-14 | Seattle, WA, US | Seattle Rust User Group Meetup
Seattle Rust User Group - August Meetup
2023-09-19 | San Francisco, CA, US | San Francisco Rust Study Group
Rust Hacking in Person
2023-09-21 | Nashville, TN, US | Music City Rust Developers
Rust on the web! Get started with Leptos
2023-09-26 | Pasadena, CA, US | Pasadena Thursday Go/Rust
Monthly Rust group
2023-09-27 | Austin, TX, US | Rust ATX
Rust Lunch - Fareground
Oceania
2023-09-13 | Perth, WA, AU | Rust Perth
Rust Meetup 2: Lunch & Learn
2023-09-19 | Christchurch, NZ | Christchurch Rust Meetup Group
Christchurch Rust meetup meeting
2023-09-26 | Canberra, ACT, AU | Rust Canberra
September Meetup
If you are running a Rust event please add it to the calendar to get it mentioned here. Please remember to add a link to the event too. Email the Rust Community Team for access.
Jobs
Please see the latest Who's Hiring thread on r/rust
Quote of the Week
In [other languages], I could end up chasing silly bugs and waste time debugging and tracing to find that I made a typo or ran into a language quirk that gave me an unexpected nil pointer. That situation is almost non-existent in Rust, it's just me and the problem. Rust is honest and upfront about its quirks and will yell at you about it before you have a hard to find bug in production.
– dannersy on Hacker News
Thanks to Kyle Strand for the suggestion!
Please submit quotes and vote for next week!
This Week in Rust is edited by: nellshamrell, llogiq, cdmistman, ericseppanen, extrawurst, andrewpollack, U007D, kolharsam, joelmarcey, mariannegoldin, bennyvasquez.
Email list hosting is sponsored by The Rust Foundation
Discuss on r/rust
0 notes
Text
The Best Python Libraries for Machine Learning in 2025 – What You Should Know
Python is everywhere in the world of tech—and for good reason. If you're exploring machine learning (ML) in 2025, one thing is clear: Python and its libraries are your best allies.
Whether you're a student, a self-learner, or someone looking to switch careers into tech, understanding the most effective tools in ML will give you a head start. This blog breaks down the top Python libraries used by professionals across India, especially in growing tech hubs like Hyderabad.
Why Do Python Libraries Matter in ML?
When building machine learning models, you don’t want to reinvent the wheel. Python libraries are collections of functions and tools designed to make your work easier.
They help you:
Clean and organize data
Train machine learning models
Visualize results
Make accurate predictions faster
Think of them like essential tools in a workshop. Instead of building everything from scratch, you pick up the tool that does the job best—and get to work.
Why Indian Professionals Should Care
India’s tech industry has embraced machine learning in a big way. From healthcare startups to global IT firms, organizations are using ML to automate tasks, make predictions, and personalize services.
In cities like Hyderabad, there’s growing demand for professionals with Python ML skills. Roles like Data Analyst, ML Engineer, and AI Developer now require hands-on knowledge of popular Python libraries. Knowing the right tools can set you apart in a competitive job market.
The Top 10 Python Libraries for ML in 2025
Here’s a list of libraries that are shaping the ML landscape this year:
1. Scikit-learn
A great starting point. This library simplifies common ML tasks like classification, regression, and clustering. It’s lightweight, reliable, and perfect for beginners.
2. TensorFlow
Developed by Google, TensorFlow is ideal for deep learning tasks. If you're working on image recognition, natural language processing, or neural networks, this is your go-to.
3. PyTorch
Favored by researchers and startups, PyTorch is known for its flexibility. It’s widely used in academic research and increasingly in production environments.
4. Pandas
If you’re working with spreadsheets or structured datasets, Pandas helps you manipulate and clean that data effortlessly.
5. NumPy
The foundation of scientific computing in Python. Most ML libraries depend on NumPy for numerical operations and matrix handling.
6. Matplotlib
Used to create basic plots and charts. It helps in visually understanding the performance of your models.
7. Seaborn
Built on Matplotlib, Seaborn allows for more attractive and informative statistical graphics.
8. XGBoost
A high-performance gradient boosting library. It’s used in many real-world systems for tasks like fraud detection and recommendation engines.
9. LightGBM
Faster and more memory-efficient than XGBoost. Especially useful for large datasets and real-time predictions.
10. OpenCV
Focused on computer vision. Great for image processing tasks like face detection, motion tracking, and object recognition.
Real-World Use Cases in India
These libraries are more than just academic. They’re being used every day in industries such as:
Retail – To personalize shopping experiences
Finance – For credit scoring and fraud prevention
Healthcare – In patient data analysis and disease prediction
EdTech – To deliver adaptive learning platforms
Government – For data-backed policy-making and smart city management
Companies in Hyderabad like Innominds, Darwinbox, and Novartis actively hire ML professionals skilled in these tools.
Where Should You Start?
If you’re new to machine learning, here’s a basic learning path:
Begin with NumPy and Pandas to understand data manipulation.
Learn Matplotlib and Seaborn for data visualization.
Dive into Scikit-learn to learn standard ML algorithms.
Once you’re confident, move on to TensorFlow, PyTorch, and XGBoost.
Starting with foundational tools makes it easier to understand complex ones later.
Tips to Learn These Tools Effectively
Here are a few things that helped many learners master these libraries:
Start with small projects like predicting house prices or student grades
Use publicly available datasets from Indian sources like data.gov.in
Practice regularly—30 minutes a day is better than none
Read documentation but also apply what you learn immediately
Watch tutorial videos to see how others solve ML problems step-by-step
Avoid the mistake of rushing into deep learning before understanding basic concepts.
How to Learn These Libraries Online
Online training is the best option if you want flexibility and practical learning. At Varniktech, you can access:
Instructor-led live sessions focused on real-world problems
Projects based on Indian industry use cases
Job preparation support, including mock interviews and resume building
Flexible batch timings for working professionals and students
Whether you're in Hyderabad or learning from another city, you can access everything online and complete your training from home.
Final Thoughts
Mastering the right Python libraries for machine learning can boost your career, help you build better projects, and make you stand out in job applications. With the tech industry growing rapidly in India, especially in cities like Hyderabad, there’s never been a better time to learn these tools.
The key is to start small, be consistent, and focus on building real projects. Once you’re confident with the basics, you can take on more advanced challenges and explore deep learning.
Want to dive deeper into machine learning with Python?
Visit varniktech.com to access structured courses, download free resources, and join our upcoming batch focused on Python for Machine Learning.
0 notes
Text
The Best Open-Source Tools for Data Science in 2025

Data science in 2025 is thriving, driven by a robust ecosystem of open-source tools that empower professionals to extract insights, build predictive models, and deploy data-driven solutions at scale. This year, the landscape is more dynamic than ever, with established favorites and emerging contenders shaping how data scientists work. Here’s an in-depth look at the best open-source tools that are defining data science in 2025.
1. Python: The Universal Language of Data Science
Python remains the cornerstone of data science. Its intuitive syntax, extensive libraries, and active community make it the go-to language for everything from data wrangling to deep learning. Libraries such as NumPy and Pandas streamline numerical computations and data manipulation, while scikit-learn is the gold standard for classical machine learning tasks.
NumPy: Efficient array operations and mathematical functions.
Pandas: Powerful data structures (DataFrames) for cleaning, transforming, and analyzing structured data.
scikit-learn: Comprehensive suite for classification, regression, clustering, and model evaluation.
Python’s popularity is reflected in the 2025 Stack Overflow Developer Survey, with 53% of developers using it for data projects.
2. R and RStudio: Statistical Powerhouses
R continues to shine in academia and industries where statistical rigor is paramount. The RStudio IDE enhances productivity with features for scripting, debugging, and visualization. R’s package ecosystem—especially tidyverse for data manipulation and ggplot2 for visualization—remains unmatched for statistical analysis and custom plotting.
Shiny: Build interactive web applications directly from R.
CRAN: Over 18,000 packages for every conceivable statistical need.
R is favored by 36% of users, especially for advanced analytics and research.
3. Jupyter Notebooks and JupyterLab: Interactive Exploration
Jupyter Notebooks are indispensable for prototyping, sharing, and documenting data science workflows. They support live code (Python, R, Julia, and more), visualizations, and narrative text in a single document. JupyterLab, the next-generation interface, offers enhanced collaboration and modularity.
Over 15 million notebooks hosted as of 2025, with 80% of data analysts using them regularly.
4. Apache Spark: Big Data at Lightning Speed
As data volumes grow, Apache Spark stands out for its ability to process massive datasets rapidly, both in batch and real-time. Spark’s distributed architecture, support for SQL, machine learning (MLlib), and compatibility with Python, R, Scala, and Java make it a staple for big data analytics.
65% increase in Spark adoption since 2023, reflecting its scalability and performance.
5. TensorFlow and PyTorch: Deep Learning Titans
For machine learning and AI, TensorFlow and PyTorch dominate. Both offer flexible APIs for building and training neural networks, with strong community support and integration with cloud platforms.
TensorFlow: Preferred for production-grade models and scalability; used by over 33% of ML professionals.
PyTorch: Valued for its dynamic computation graph and ease of experimentation, especially in research settings.
6. Data Visualization: Plotly, D3.js, and Apache Superset
Effective data storytelling relies on compelling visualizations:
Plotly: Python-based, supports interactive and publication-quality charts; easy for both static and dynamic visualizations.
D3.js: JavaScript library for highly customizable, web-based visualizations; ideal for specialists seeking full control.
Apache Superset: Open-source dashboarding platform for interactive, scalable visual analytics; increasingly adopted for enterprise BI.
Tableau Public, though not fully open-source, is also popular for sharing interactive visualizations with a broad audience.
7. Pandas: The Data Wrangling Workhorse
Pandas remains the backbone of data manipulation in Python, powering up to 90% of data wrangling tasks. Its DataFrame structure simplifies complex operations, making it essential for cleaning, transforming, and analyzing large datasets.
8. Scikit-learn: Machine Learning Made Simple
scikit-learn is the default choice for classical machine learning. Its consistent API, extensive documentation, and wide range of algorithms make it ideal for tasks such as classification, regression, clustering, and model validation.
9. Apache Airflow: Workflow Orchestration
As data pipelines become more complex, Apache Airflow has emerged as the go-to tool for workflow automation and orchestration. Its user-friendly interface and scalability have driven a 35% surge in adoption among data engineers in the past year.
10. MLflow: Model Management and Experiment Tracking
MLflow streamlines the machine learning lifecycle, offering tools for experiment tracking, model packaging, and deployment. Over 60% of ML engineers use MLflow for its integration capabilities and ease of use in production environments.
11. Docker and Kubernetes: Reproducibility and Scalability
Containerization with Docker and orchestration via Kubernetes ensure that data science applications run consistently across environments. These tools are now standard for deploying models and scaling data-driven services in production.
12. Emerging Contenders: Streamlit and More
Streamlit: Rapidly build and deploy interactive data apps with minimal code, gaining popularity for internal dashboards and quick prototypes.
Redash: SQL-based visualization and dashboarding tool, ideal for teams needing quick insights from databases.
Kibana: Real-time data exploration and monitoring, especially for log analytics and anomaly detection.
Conclusion: The Open-Source Advantage in 2025
Open-source tools continue to drive innovation in data science, making advanced analytics accessible, scalable, and collaborative. Mastery of these tools is not just a technical advantage—it’s essential for staying competitive in a rapidly evolving field. Whether you’re a beginner or a seasoned professional, leveraging this ecosystem will unlock new possibilities and accelerate your journey from raw data to actionable insight.
The future of data science is open, and in 2025, these tools are your ticket to building smarter, faster, and more impactful solutions.
#python#r#rstudio#jupyternotebook#jupyterlab#apachespark#tensorflow#pytorch#plotly#d3js#apachesuperset#pandas#scikitlearn#apacheairflow#mlflow#docker#kubernetes#streamlit#redash#kibana#nschool academy#datascience
0 notes
Text
ChatGPT & Data Science: Your Essential AI Co-Pilot

The rise of ChatGPT and other large language models (LLMs) has sparked countless discussions across every industry. In data science, the conversation is particularly nuanced: Is it a threat? A gimmick? Or a revolutionary tool?
The clearest answer? ChatGPT isn't here to replace data scientists; it's here to empower them, acting as an incredibly versatile co-pilot for almost every stage of a data science project.
Think of it less as an all-knowing oracle and more as an exceptionally knowledgeable, tireless assistant that can brainstorm, explain, code, and even debug. Here's how ChatGPT (and similar LLMs) is transforming data science projects and how you can harness its power:
How ChatGPT Transforms Your Data Science Workflow
Problem Framing & Ideation: Struggling to articulate a business problem into a data science question? ChatGPT can help.
"Given customer churn data, what are 5 actionable data science questions we could ask to reduce churn?"
"Brainstorm hypotheses for why our e-commerce conversion rate dropped last quarter."
"Help me define the scope for a project predicting equipment failure in a manufacturing plant."
Data Exploration & Understanding (EDA): This often tedious phase can be streamlined.
"Write Python code using Pandas to load a CSV and display the first 5 rows, data types, and a summary statistics report."
"Explain what 'multicollinearity' means in the context of a regression model and how to check for it in Python."
"Suggest 3 different types of plots to visualize the relationship between 'age' and 'income' in a dataset, along with the Python code for each."
Feature Engineering & Selection: Creating new, impactful features is key, and ChatGPT can spark ideas.
"Given a transactional dataset with 'purchase_timestamp' and 'product_category', suggest 5 new features I could engineer for a customer segmentation model."
"What are common techniques for handling categorical variables with high cardinality in machine learning, and provide a Python example for one."
Model Selection & Algorithm Explanation: Navigating the vast world of algorithms becomes easier.
"I'm working on a classification problem with imbalanced data. What machine learning algorithms should I consider, and what are their pros and cons for this scenario?"
"Explain how a Random Forest algorithm works in simple terms, as if you're explaining it to a business stakeholder."
Code Generation & Debugging: This is where ChatGPT shines for many data scientists.
"Write a Python function to perform stratified K-Fold cross-validation for a scikit-learn model, ensuring reproducibility."
"I'm getting a 'ValueError: Input contains NaN, infinity or a value too large for dtype('float64')' in my scikit-learn model. What are common reasons for this error, and how can I fix it?"
"Generate boilerplate code for a FastAPI endpoint that takes a JSON payload and returns a prediction from a pre-trained scikit-learn model."
Documentation & Communication: Translating complex technical work into understandable language is vital.
"Write a clear, concise docstring for this Python function that preprocesses text data."
"Draft an executive summary explaining the results of our customer churn prediction model, focusing on business impact rather than technical details."
"Explain the limitations of an XGBoost model in a way that a non-technical manager can understand."
Learning & Skill Development: It's like having a personal tutor at your fingertips.
"Explain the concept of 'bias-variance trade-off' in machine learning with a practical example."
"Give me 5 common data science interview questions about SQL, and provide example answers."
"Create a study plan for learning advanced topics in NLP, including key concepts and recommended libraries."
Important Considerations and Best Practices
While incredibly powerful, remember that ChatGPT is a tool, not a human expert.
Always Verify: Generated code, insights, and especially factual information must always be verified. LLMs can "hallucinate" or provide subtly incorrect information.
Context is King: The quality of the output directly correlates with the quality and specificity of your prompt. Provide clear instructions, examples, and constraints.
Data Privacy is Paramount: NEVER feed sensitive, confidential, or proprietary data into public LLMs. Protecting personal data is not just an ethical imperative but a legal requirement globally. Assume anything you input into a public model may be used for future training or accessible by the provider. For sensitive projects, explore secure, on-premises or private cloud LLM solutions.
Understand the Fundamentals: ChatGPT is an accelerant, not a substitute for foundational knowledge in statistics, machine learning, and programming. You need to understand why a piece of code works or why an an algorithm is chosen to effectively use and debug its outputs.
Iterate and Refine: Don't expect perfect results on the first try. Refine your prompts based on the output you receive.
ChatGPT and its peers are fundamentally changing the daily rhythm of data science. By embracing them as intelligent co-pilots, data scientists can boost their productivity, explore new avenues, and focus their invaluable human creativity and critical thinking on the most complex and impactful challenges. The future of data science is undoubtedly a story of powerful human-AI collaboration.
0 notes
Text
Python for Data Science: Libraries You Must Know
Python has become the go-to programming language for data science professionals due to its readability, extensive community support, and a rich ecosystem of libraries. Whether you're analyzing data, building machine learning models, or creating stunning visualizations, Python has the right tools to get the job done. If you're looking to start a career in this field, enrolling in the best Python training in Hyderabad can give you a competitive edge and help you master these crucial libraries.
1. NumPy – The Foundation of Numerical Computing
NumPy is the backbone of scientific computing with Python. It offers efficient storage and manipulation of large numerical arrays, which makes it indispensable for high-performance data analysis. NumPy arrays are faster and more compact than traditional Python lists and serve as the foundation for other data science libraries.
2. Pandas – Data Wrangling Made Simple
Pandas is essential for handling structured data. Data structures such as Series and DataFrame make it easy to clean, transform, and explore data. With Pandas, tasks like filtering rows, merging datasets, and grouping values become effortless, saving time and effort in data preprocessing.
3. Matplotlib and Seaborn – Data Visualization Powerhouses
Matplotlib is the standard library for creating basic to advanced data visualizations. From bar graphs to histograms and line charts, Matplotlib covers it all. For more visually appealing and statistically rich plots, Seaborn is an excellent choice. It simplifies the process of creating complex plots and provides a more aesthetically pleasing design.
4. Scikit-learn – Machine Learning Made Easy
In Python, Scikit-learn is one of the most widely used libraries for implementing machine learning algorithms. It provides easy-to-use functions for classification, regression, clustering, and model evaluation, making it ideal for both beginners and experts.
5. TensorFlow and PyTorch – Deep Learning Frameworks
For those diving into artificial intelligence and deep learning, TensorFlow and PyTorch are essential. These frameworks allow developers to create, train, and deploy neural networks for applications such as image recognition, speech processing, and natural language understanding.
Begin Your Data Science Journey with Expert Training
Mastering these libraries opens the door to countless opportunities in the data science field. To gain hands-on experience and real-world skills, enroll in SSSIT Computer Education, where our expert trainers provide industry-relevant, practical Python training tailored for aspiring data scientists in Hyderabad.
#best python training in hyderabad#best python training in kukatpally#best python training in KPHB#Kukatpally & KPHB
0 notes
Text
Using Python for Data Science: Essential Libraries and Tools
If you’re looking to start your journey in data science, enrolling at the Best Python Training Institute in Hyderabad can give you a head start. Python has become the most widely used language in data science due to its simplicity, readability, and powerful ecosystem of libraries and tools. Here’s a breakdown of the essential ones every aspiring data scientist should know.
1. NumPy and Pandas – For Data Handling
NumPy provides support for large, multi-dimensional arrays and mathematical operations, while Pandas is essential for data manipulation and analysis. Together, they make cleaning and processing datasets efficient and intuitive.
2. Matplotlib and Seaborn – For Data Visualization
Visualizing data is a critical part of any data science workflow. Matplotlib allows you to create basic graphs and charts, while Seaborn builds on it by offering more advanced statistical plots with beautiful styling.
3. Scikit-Learn – For Machine Learning
This library offers simple and efficient tools for predictive data analysis. Whether you're working on classification, regression, or clustering, Scikit-Learn makes it easy to implement machine learning algorithms.
4. Jupyter Notebooks – For Interactive Coding
Jupyter Notebooks provide a user-friendly interface for writing and sharing Python code, especially useful in data science for combining live code, equations, and visualizations in one document.
Conclusion
Mastering these tools and libraries will prepare you for real-world data science challenges. If you're ready to gain practical knowledge through hands-on training, consider joining SSS IT Computer Education, where expert guidance meets industry-relevant learning.
0 notes
Text
Transform Your Skills in 2025: Master Data Visualization with Tableau & Python (2 Courses in 1!)

When it comes to storytelling with data in 2025, two names continue to dominate the landscape: Tableau and Python. If you’re looking to build powerful dashboards, tell data-driven stories, and break into one of the most in-demand fields today, this is your chance.
But instead of bouncing between platforms and tutorials, what if you could master both tools in a single, streamlined journey?
That’s exactly what the 2025 Data Visualization in Tableau & Python (2 Courses in 1!) offers—an all-in-one course designed to take you from data novice to confident visual storyteller.
Let’s dive into why this course is creating buzz, how it’s structured, and why learning Tableau and Python together is a smart move in today’s data-first world.
Why Data Visualization Is a Must-Have Skill in 2025
We’re drowning in data—from social media metrics and customer feedback to financial reports and operational stats. But raw data means nothing unless you can make sense of it.
That’s where data visualization steps in. It’s not just about charts and graphs—it’s about revealing patterns, trends, and outliers that inform smarter decisions.
Whether you're working in marketing, finance, logistics, healthcare, or even education, communicating data clearly is no longer optional. It’s expected.
And if you can master both Tableau—a drag-and-drop analytics platform—and Python—a powerhouse for automation and advanced analysis—you’re giving yourself a massive career edge.
Meet the 2-in-1 Power Course: Tableau + Python
The 2025 Data Visualization in Tableau & Python (2 Courses in 1!) is exactly what it sounds like: a double-feature course that delivers hands-on training in two of the most important tools in data science today.
Instead of paying for two separate learning paths (which could cost you more time and money), you’ll:
Learn Tableau from scratch and create interactive dashboards
Dive into Python programming for data visualization
Understand how to tell compelling data stories using both tools
Build real-world projects that you can show off to employers or clients
All in one single course.
Who Should Take This Course?
This course is ideal for:
Beginners who want a solid foundation in both Tableau and Python
Data enthusiasts who want to transition into analytics roles
Marketing and business professionals who need to understand KPIs visually
Freelancers and consultants looking to offer data services
Students and job seekers trying to build a strong data portfolio
No prior coding or Tableau experience? No problem. Everything is taught step-by-step with real-world examples.
What You'll Learn: Inside the Course
Let’s break down what you’ll actually get inside this 2-in-1 course:
✅ Tableau Module Highlights:
Tableau installation and dashboard interface
Connecting to various data sources (Excel, CSV, SQL)
Creating bar charts, pie charts, line charts, maps, and more
Advanced dashboard design techniques
Parameters, filters, calculations, and forecasting
Publishing and sharing interactive dashboards
By the end of this section, you’ll be comfortable using Tableau to tell stories that executives understand and act on.
✅ Python Visualization Module Highlights:
Python basics: data types, loops, functions
Data analysis with Pandas and NumPy
Visualization libraries like Matplotlib and Seaborn
Building statistical plots, heatmaps, scatterplots, and histograms
Customizing charts with color, labels, legends, and annotations
Automating visual reports
Even if you’ve never coded before, you’ll walk away confident enough to build beautiful, programmatically-generated visualizations with Python.
The Real-World Value: Why This Course Stands Out
We all know there’s no shortage of online courses today. But what makes this one worth your time?
🌟 1. Two for the Price of One
Most courses focus on either Tableau or Python. This one merges the best of both worlds, giving you more for your time and money.
🌟 2. Hands-On Learning
You won’t just be watching slides or lectures—you’ll be working with real data sets, solving real problems, and building real projects.
🌟 3. Resume-Boosting Portfolio
From the Tableau dashboards to the Python charts, everything you build can be used to show potential employers what you’re capable of.
🌟 4. Taught by Experts
This course is created by instructors who understand both tools deeply and can explain things clearly—no confusing jargon, no filler.
🌟 5. Constantly Updated
As Tableau and Python evolve, so does this course. That means you’re always learning the latest and greatest features, not outdated content.
Why Learn Both Tableau and Python?
Some people ask, “Isn’t one enough?”
Here’s the thing: they serve different purposes, but together, they’re unstoppable.
Tableau is for quick, intuitive dashboarding.
Drag-and-drop interface
Ideal for business users
Great for presentations and client reporting
Python is for flexibility and scale.
You can clean, manipulate, and transform data
Build custom visuals not possible in Tableau
Automate workflows and scale up for big data
By learning both, you cover all your bases. You’re not limited to just visuals—you become a full-spectrum data storyteller.
Data Careers in 2025: What This Course Prepares You For
The demand for data professionals continues to skyrocket. Here’s how this course sets you up for success in various career paths: RoleHow This Course HelpsData AnalystBuild dashboards, analyze trends, present insightsBusiness Intelligence AnalystCombine data from multiple sources, visualize it for execsData Scientist (Junior)Analyze data with Python, visualize with TableauMarketing AnalystUse Tableau for campaign reporting, Python for A/B analysisFreelancer/ConsultantOffer complete data storytelling services to clients
This course can be a launchpad—whether you want to get hired, switch careers, or start your own analytics agency.
Real Projects = Real Confidence
What sets this course apart is the project-based learning approach. You'll create:
Sales dashboards
Market trend analysis charts
Customer segmentation visuals
Time-series forecasts
Custom visual stories using Python
Each project is more than just a tutorial—it mimics real-world scenarios you’ll face on the job.
Flexible, Affordable, and Beginner-Friendly
Best part? You can learn at your own pace. No deadlines, no pressure.
You don’t need to buy expensive software. Tableau Public is free, and Python tools like Jupyter, Pandas, and Matplotlib are open-source.
Plus, with lifetime access, you can revisit any lesson whenever you want—even years down the road.
And all of this is available at a price that’s far less than a bootcamp or university course.
Still Not Sure? Here's What Past Learners Say
“I had zero experience with Tableau or Python. After this course, I built my own dashboard and presented it to my team. They were blown away!” – Rajiv, Product Analyst
“Perfect combo of theory and practice. Python sections were especially helpful for automating reports I used to make manually.” – Sarah, Marketing Manager
“Loved how everything was explained so simply. Highly recommend to anyone trying to upskill in data.” – Alex, Freelancer
Final Thoughts: Your Data Career Starts Now
You don’t need to be a programmer or a math wizard to master data visualization. You just need the right guidance, a solid roadmap, and the willingness to practice.
With the 2025 Data Visualization in Tableau & Python (2 Courses in 1!), you’re getting all of that—and more.
This is your chance to stand out in a crowded job market, speak the language of data confidently, and unlock doors in tech, business, healthcare, finance, and beyond.
Don’t let the data wave pass you by—ride it with the skills that matter in 2025 and beyond.
0 notes
Text
Understanding Data Visualization Techniques
In today’s information-driven world, the capacity to decode and interpret large volumes of data is becoming a core skill across almost every profession. At the heart of this ability lies data visualization—a technique that simplifies complex data by converting it into visual elements such as graphs, charts, and dashboards.
Imagine being able to spot market trends at a glance or detect inefficiencies in a process through a simple heatmap. Data visualization allows professionals to communicate findings quickly and effectively, making it an essential part of modern data analytics. For learners aiming to enter the field—especially those searching for the best data analyst courses in Dehradun—grasping visualization fundamentals is a powerful first step.
What Is Data Visualization?
Data visualization is the art and science of representing raw data visually to enhance understanding and communication. It turns spreadsheets and databases into graphical formats that are easier to analyze and interpret.
Whether it’s tracking business performance, predicting future sales, or analyzing user behavior, effective visuals can reveal insights that text or numbers alone may obscure. This technique empowers stakeholders to make quicker and more confident decisions.
Key Visualization Methods
Not all visuals are created equal. Different types of data call for different approaches. Here are several common techniques used in the field:
Bar and Column Charts: Ideal for visualizing and comparing values across different categories or over specific time periods.
Line Graphs: Well-suited for illustrating patterns and trends in continuous data across a timeline.
Pie Charts: Best used to illustrate parts of a whole as percentage distributions.
Histograms: Great for examining how data is distributed across defined intervals.
Scatter Plots: Effective for detecting relationships or correlations between two variables.
Heatmaps: Reveal intensity or concentration across a data matrix.
Dashboards: Provide a consolidated, interactive view of multiple visual elements for real-time decision-making.
Knowing when and how to use these methods is critical—and is a key component of well-rounded training, like the kind provided in the best data analyst courses in Dehradun.
The Brain Loves Visuals
Our brains are hardwired to process visual data faster than written information. In fact, studies indicate that visuals are processed tens of thousands of times more quickly than text. This cognitive advantage makes visualizations one of the most efficient ways to convey large datasets.
Yet, crafting impactful visuals involves more than just design—it demands clear intent. Visuals should be clean, accurate, and meaningful. Color choices need to serve a function, scales must reflect reality, and unnecessary clutter should be eliminated. A great visualization tells a story without saying a word.
Common Visualization Pitfalls
Even though visualization is powerful, it isn’t without its challenges. Beginners and professionals alike must be aware of common issues, such as:
Inappropriate Chart Choices: Selecting the wrong type of graph can confuse or mislead the viewer.
Overcomplicating the Visual: Too many variables or vibrant colors can make the graphic overwhelming.
Lack of Context: Missing labels, legends, or explanations can leave viewers guessing.
Data Distortion: Misuse of scales or omission of data can lead to inaccurate conclusions.
These obstacles are best tackled with proper training—something that is emphasized in structured, hands-on programs like the best data analyst courses in Dehradun.
Data Visualization as a Career Asset
Today’s job market places a premium on data fluency. Visualization is a core part of roles in data analytics, business intelligence, digital marketing, UX design, and beyond. Professionals who can create meaningful visuals using tools like Tableau, Power BI, Excel, or Python libraries (e.g., Matplotlib, Seaborn) are highly valued.
To gain an edge in this field, aspiring data analysts must invest in a comprehensive learning path that builds both technical proficiency and analytical thinking.
Why DataMites Is a Standout Choice
For anyone serious about becoming a data analyst, DataMites Institute offers an exceptional learning journey tailored to real-world industry needs. Their programs are accredited by IABAC and NASSCOM FutureSkills, ensuring that the curriculum meets global standards and delivers practical relevance.
Students benefit from hands-on project work, expert-led mentorship, internship opportunities, and dedicated placement support—helping them step into the job market with confidence.
In addition, DataMites Institute provides offline classroom training in cities like Mumbai, Pune, Hyderabad, Chennai, Delhi, Coimbatore, and Ahmedabad, making flexible, in-person learning available across India. If you're based in Pune, it offers a great opportunity to master Python and become proficient in the tools needed for modern tech roles.
For those located in Dehradun, the immersive content and online options make DataMites Institute a valuable and accessible choice, even if offline sessions require some travel. More than just a technical course, DataMites Institute helps learners develop a holistic data mindset—balancing analytical logic with storytelling skill.
Mastering data visualization techniques is no longer optional—it’s essential in a world driven by data. These skills enable professionals to turn abstract numbers into actionable narratives that fuel strategic decisions.
For those looking to begin this journey through the best data analyst courses in Dehradun, focusing on visualization is a strong place to start. And with expert-led training programs from institutions like DataMites, transforming raw data into meaningful insight is well within reach.
0 notes
Text
Top 10 Data Science Tools You Should Learn in 2025
Best Tools for Data Science are evolving fast, and if you want to stay ahead in 2025, it’s time to upgrade your toolkit. Whether you’re just starting out or already deep into data projects, using the right tools can make your work smoother, smarter, and a lot more fun. With powerful no-code platforms, AI-driven automation, and cloud-based collaboration, the Future of Data Science Tools is all about speed and simplicity. So, whether you’re brushing up your skills or diving into new ones, these Must-Have Tools for Data Scientists are your ticket to staying competitive this year.

1. Python — Still the King of the Jungle
If you haven’t started with Python yet, 2025 is your cue. It’s powerful, readable, and has libraries for nearly everything. Tools like Pandas, NumPy, and Scikit-learn make it your go-to for analytics, modeling, and more. Python is basically the heartbeat of the Best Tools for Data Science ecosystem — and yes, that’s the first mention (just four to go!).
2. R — For the Love of Stats and Visuals
R is like that friend who’s always great with numbers and loves making beautiful plots. It’s perfect for statistical analysis and data visualization. Plus, if you’re into research or academic work, R might just be your best buddy. In the world of Popular Data Science Tools, R continues to hold its own, especially when paired with RStudio.
3. Jupyter Notebooks — Your Data Diary
Jupyter makes it fun to play with code and data in real-time. You can document your thinking, share notebooks with others, and even run visualizations inline. Think of it as your interactive coding journal. It’s easily one of the Top Data Science Tools 2025 and continues to be a favorite for experimentation.
4. SQL — Old But Gold
You can’t really skip SQL if you’re serious about data. It’s been around forever, and that’s because it works. Databases power everything — and being able to query them quickly makes SQL a non-negotiable tool. Every data scientist needs it in their toolkit — it’s a staple in any list of Must-Have Tools for Data Scientists.
5. Power BI — Dashboard Like a Pro
Want to impress your team with interactive dashboards? Power BI is Microsoft’s ace in the business analytics world. It’s user-friendly, integrates well with other Microsoft products, and is super powerful. Among the Data Science Software 2025, Power BI is shining brightly as a great tool for storytelling with data.
6. Tableau — Turning Data into Visual Gold
If you’re a visual thinker, Tableau will win your heart. Drag, drop, and make stunning dashboards in no time. It’s a favorite in the Best Tools for Data Science collection (that’s two now!). Business teams love it, and so should you if you’re serious about communicating insights clearly.
7. Apache Spark — For Big Data Firepower
When your dataset is way too big for Excel and even Python starts to lag, Spark comes in to save the day. Apache Spark lets you handle massive amounts of data in a distributed computing environment. It’s fast, powerful, and a favorite in the world of Future of Data Science Tools.
8. Git and GitHub — Version Control Like a Boss
Messy code history? No more. Git lets you keep track of every change, while GitHub is your team’s central code-sharing spot. It’s not just for developers — every modern data scientist should know Git. You’ll find it featured in every list of Learn Data Science Tools resources.
9. Google Colab — Cloud Notebooks Made Easy
Google Colab is like Jupyter, but in the cloud, and with free GPU access! You don’t even need to install anything. Just log in and start coding. It’s part of the Best Tools for Data Science toolkit (we’re at three now!) and great for remote collaboration.
10. AutoML Tools — Because Smart Tools Save Time
Why code every model from scratch when tools like Google AutoML, H2O.ai, and DataRobot can automate the heavy lifting? These platforms are evolving fast and are key players in the Future of Data Science Tools. Embrace automation — it’s not cheating, it’s smart!
Final Thoughts — Brush Up, Stay Ahead
The tools you use can define how far and how fast you grow as a data scientist. Whether you’re focused on big data, beautiful dashboards, or building machine learning models, knowing the Best Tools for Data Science (we’re at four!) gives you a serious edge.
And hey, if you’re ready to really power up your skills, the team over at Coding Brushup has some fantastic resources for getting hands-on experience with these tools. They’re all about helping you stay sharp in the fast-changing world of data science.
So go ahead and start experimenting with these Top Data Science Tools 2025. Mastering even a few of them can supercharge your data career — and yes, here’s that final SEO magic: one more mention of the Best Tools for Data Science to wrap it up.
#Top Data Science Tools 2025#Best Tools for Data Science#coding brushup#Future of Data Science Tools#Learn Data Science Tools
0 notes
Text
Assignment: Lasso Regression
I am an R user, so conducted the assignment in R instead of SAS or Python.
I ran a lasso regression analysis to identify a subset of variables that best predict adolescent school connectedness. Twenty three predictors were presented to the model (gender, race, age, alcohol use, alcohol problems in the home, marijuana use, cocaine use, inhalant use, cigarette availability in the home, depression, self esteem, violence, parental assistance, deviant behaviour, CPA, expulsion, family connectedness, parental activity, and parental presence. All predictors were standardized to have a mean of zero and standard deviation of one.
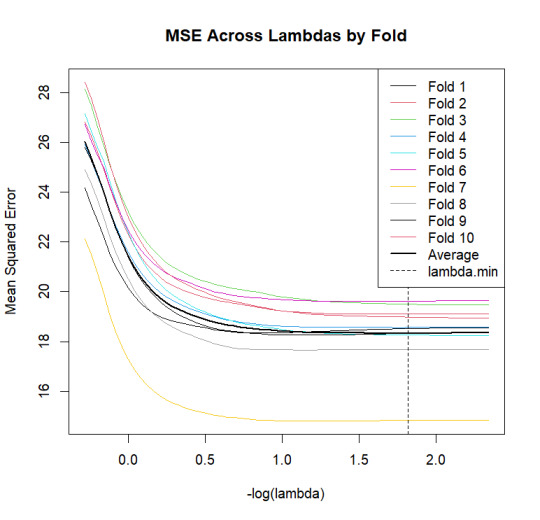
The data were split into a training set that with a random selection of 70% of the observations, and a testing set with the remaining 30%. A k=10 fold was selected for the least angle regression algorithm cross validation. The cross validation average squared mean error at each fold was used to identify the best subset of predictor variables. There was high agreement in performance of the model between the train and test data sets (MSE = 18.0 and 17.6 , respectively; R-squared 0.31 and 0.38 respectively).
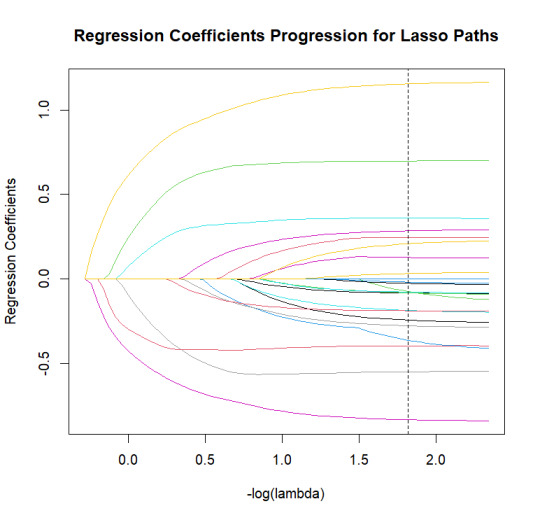
Twenty-one of the 23 predictor variables were selected into the model. Self-esteem, depression, and GPA were the three most strongly associated predictors for school connectedness. Self-esteem and GPA were positively associated with school connectedness, while depression was negatively associated.
The 21 included variables account for 37% of the variance in school connectedness.
Load necessary packages
library(readr) library(dplyr) library(tidyr) library(glmnet) library(ggplot2)
Load and clean data
data <- read_csv("tree_addhealth.csv") names(data) <- toupper(names(data)) data_clean <- drop_na(data) data_clean <- data_clean %>% mutate(MALE = recode(BIO_SEX, 1 = 1, 2 = 0))
Define predictors and target
predictor_vars <- c("MALE", "HISPANIC", "WHITE", "BLACK", "NAMERICAN", "ASIAN", "AGE", "ALCEVR1", "ALCPROBS1", "MAREVER1", "COCEVER1", "INHEVER1", "CIGAVAIL", "DEP1", "ESTEEM1", "VIOL1", "PASSIST", "DEVIANT1", "GPA1", "EXPEL1", "FAMCONCT", "PARACTV", "PARPRES")
X <- data_clean %>% select(all_of(predictor_vars)) %>% mutate(across(everything(), scale)) %>% as.matrix()
y <- data_clean$SCHCONN1
Train/test split
set.seed(123) train_idx <- sample(1:nrow(X), size = 0.7 * nrow(X)) X_train <- X[train_idx, ] y_train <- y[train_idx] X_test <- X[-train_idx, ] y_test <- y[-train_idx]
Fit Lasso with 10-fold CV
cv_model <- cv.glmnet(X_train, y_train, alpha = 1, nfolds = 10, keep = TRUE)
1. Coefficient Progression Plot
lasso_fit <- glmnet(X_train, y_train, alpha = 1) coef_path <- as.matrix(lasso_fit$beta) log_lambda <- -log10(lasso_fit$lambda)
matplot(log_lambda, t(coef_path), type = "l", lty = 1, col = 1:ncol(coef_path), xlab = "-log(lambda)", ylab = "Regression Coefficients", main = "Regression Coefficients Progression for Lasso Paths") abline(v = -log10(cv_model$lambda.min), lty = 2, col = "black")
2. MSE by Fold Plot
lambda_vals <- cv_model$lambda foldid <- cv_model$foldid nfolds <- max(foldid) nlambda <- length(lambda_vals) preval <- cv_model$fit.preval mse_by_fold <- matrix(NA, nrow = nlambda, ncol = nfolds) for (fold in 1:nfolds) { test_idx <- which(foldid == fold) y_true <- y_train[test_idx] preds <- preval[test_idx, ] mse_by_fold[, fold] <- colMeans((y_true - preds)^2) }
matplot(-log10(lambda_vals), mse_by_fold, type = "l", lty = 1, col = 1:nfolds, xlab = "-log(lambda)", ylab = "Mean Squared Error", main = "MSE Across Lambdas by Fold") lines(-log10(lambda_vals), rowMeans(mse_by_fold), col = "black", lwd = 2) abline(v = -log10(cv_model$lambda.min), lty = 2) legend("topright", legend = c(paste0("Fold ", 1:nfolds), "Average", "lambda.min"), col = c(1:nfolds, "black", "black"), lty = c(rep(1, nfolds), 1, 2), lwd = c(rep(1, nfolds), 2, 1))
3. Print selected variables (non-zero at lambda.min)
lasso_coefs <- coef(cv_model, s = "lambda.min") selected_vars <- rownames(lasso_coefs)[lasso_coefs[, 1] != 0] selected_vars <- selected_vars[selected_vars != "(Intercept)"]
cat("\nVariables selected by the Lasso model:\n") print(selected_vars)
4. Performance: MSE and R-squared
pred_train <- predict(cv_model, s = "lambda.min", newx = X_train) pred_test <- predict(cv_model, s = "lambda.min", newx = X_test)
train_mse <- mean((y_train - pred_train)^2) test_mse <- mean((y_test - pred_test)^2) train_r2 <- cor(y_train, pred_train)^2 test_r2 <- cor(y_test, pred_test)^2
cat("\nTraining MSE:", round(train_mse, 3), "\n") cat("Test MSE:", round(test_mse, 3), "\n") cat("Training R-squared:", round(train_r2, 3), "\n") cat("Test R-squared:", round(test_r2, 3), "\n")
0 notes
Text
Mastering Seaborn in Python – Yasir Insights
Built on top of Matplotlib, Seaborn is a robust Python data visualisation framework. It provides a sophisticated interface for creating eye-catching and educational statistics visuals. Gaining proficiency with Seaborn in Python may significantly improve your comprehension and communication of data, regardless of your role—data scientist, analyst, or developer.

Mastering Seaborn in Python
Seaborn simplifies complex visualizations with just a few lines of code. It is very useful for statistical graphics and data exploration because it is built on top of Matplotlib and tightly interacts with Pandas data structures.
Also Read: LinkedIn
Why Use Seaborn in Python?
Concise and intuitive syntax
Built-in themes for better aesthetics
Support for Pandas DataFrames
Powerful multi-plot grids
Built-in support for statistical estimation
Installing Seaborn in Python
You can install Seaborn using pip:
bash
pip install seaborn
Or with conda:
bash
conda install seaborn
Getting Started with Seaborn in Python
First, import the library and a dataset:
python
import seaborn as sns import matplotlib.pyplot as plt
# Load sample dataset tips = sns.load_dataset("tips")
Let’s visualize the distribution of total bills:
python
sns.histplot(data=tips, x="total_bill", kde=True) plt.title("Distribution of Total Bills") plt.show()
Core Data Structures in Seaborn in Python
Seaborn works seamlessly with:
Pandas DataFrames
Series
Numpy arrays
This compatibility makes it easier to plot real-world datasets directly.
Essential Seaborn in Python Plot Types
Categorical Plots
Visualize relationships involving categorical variables.
python
sns.boxplot(x="day", y="total_bill", data=tips)
Other types: stripplot(), swarmplot(), violinplot(), barplot(), countplot()
Distribution Plots
Explore the distribution of a dataset.
python
sns.displot(tips["tip"], kde=True)
Regression Plots
Plot data with linear regression models.
python
sns.lmplot(x="total_bill", y="tip", data=tips)
Matrix Plots
Visualize correlation and heatmaps.
python
corr = tips.corr() sns.heatmap(corr, annot=True, cmap="coolwarm")
e. Multivariate Plots
Explore multiple variables at once.
python
sns.pairplot(tips, hue="sex")
Customizing Seaborn in Python Plots
Change figure size:
python
plt.figure(figsize=(10, 6))
Set axis labels and titles:
python
sns.scatterplot(x="total_bill", y="tip", data=tips) plt.xlabel("Total Bill ($)") plt.ylabel("Tip ($)") plt.title("Total Bill vs. Tip")
Themes and Color Palettes
Seaborn in Python provides built-in themes:
python
sns.set_style("whitegrid")
Popular palettes:
python
sns.set_palette("pastel")
Available styles: darkgrid, whitegrid, dark, white, ticks
Working with Real Datasets
Seaborn comes with built-in datasets like:
tips
iris
diamonds
penguins
Example:
python
penguins = sns.load_dataset("penguins") sns.pairplot(penguins, hue="species")
Best Practices
Always label your axes and add titles
Use color palettes wisely for accessibility
Stick to consistent themes
Use grid plotting for large data comparisons
Always check data types before plotting
Conclusion
Seaborn is a game-changer for creating beautiful, informative, and statistical visualizations with minimal code. Mastering it gives you the power to uncover hidden patterns and insights within your datasets, helping you make data-driven decisions efficiently.
0 notes
Text
Data Analysis and Visualization Using Programming Techniques

Data analysis and visualization are crucial skills in today’s data-driven world. With programming, we can extract insights, uncover patterns, and present data in a meaningful way. This post explores how developers and analysts can use programming techniques to analyze and visualize data efficiently.
Why Data Analysis and Visualization Matter
Better Decisions: Informed decisions are backed by data and its interpretation.
Communication: Visualizations make complex data more accessible and engaging.
Pattern Recognition: Analysis helps discover trends, anomalies, and correlations.
Performance Tracking: Measure progress and identify areas for improvement.
Popular Programming Languages for Data Analysis
Python: Rich in libraries like Pandas, NumPy, Matplotlib, Seaborn, and Plotly.
R: Designed specifically for statistics and visualization.
JavaScript: Great for interactive, web-based data visualizations using D3.js and Chart.js.
SQL: Essential for querying and manipulating data from databases.
Basic Workflow for Data Analysis
Collect Data: From CSV files, APIs, databases, or web scraping.
Clean Data: Handle missing values, duplicates, and inconsistent formatting.
Explore Data: Use descriptive statistics and visual tools to understand the dataset.
Analyze Data: Apply transformations, groupings, and statistical techniques.
Visualize Results: Create charts, graphs, and dashboards.
Interpret & Share: Draw conclusions and present findings to stakeholders.
Python Example: Data Analysis and Visualization
import pandas as pd import seaborn as sns import matplotlib.pyplot as plt # Load data data = pd.read_csv('data.csv') # Analyze print(data.describe()) # Visualize sns.histplot(data['sales'], bins=10) plt.title('Sales Distribution') plt.xlabel('Sales') plt.ylabel('Frequency') plt.show()
Common Visualization Types
Bar Chart: Comparing categories
Line Chart: Time series analysis
Pie Chart: Proportional distribution
Scatter Plot: Correlation and clustering
Heatmap: Matrix-like data comparisons
Best Practices for Data Visualization
Keep it simple and avoid clutter.
Use colors to enhance, not distract.
Label axes, legends, and titles clearly.
Choose the right chart type for your data.
Ensure your visualizations are responsive and interactive if web-based.
Useful Libraries and Tools
Pandas & NumPy: Data manipulation
Matplotlib & Seaborn: Static visualizations
Plotly & Dash: Interactive dashboards
D3.js: Custom web-based visualizations
Power BI & Tableau: Business-level dashboarding (non-programming)
Real-World Use Cases
Sales Analysis: Visualize revenue trends and top-selling products.
Marketing Campaigns: Analyze click-through rates and conversions.
Healthcare: Monitor patient data, diagnostics, and treatment outcomes.
Finance: Analyze stock performance and predict market trends.
Conclusion
Combining data analysis with programming unlocks powerful insights and allows you to communicate results effectively. Whether you’re a beginner or an experienced developer, mastering data visualization techniques will significantly enhance your ability to solve problems and tell compelling data stories.
0 notes
Text
Essential Skills Every Data Scientist Must Learn in 2025

The world of data science is evolving faster than ever, and staying ahead of the curve in 2025 requires a strategic approach to skill development. As businesses rely more on data-driven decision-making, data scientists must continuously refine their expertise to remain competitive in the field. Whether you're an aspiring data scientist or an experienced professional, mastering the right skills is crucial for long-term success.
1. Mastering Programming Languages
At the core of data science lies programming. Proficiency in languages like Python and R is essential for handling data, building models, and deploying solutions. Python continues to dominate due to its versatility and rich ecosystem of libraries such as Pandas, NumPy, Scikit-learn, and TensorFlow.
Key Programming Skills to Focus On:
Data manipulation and analysis using Pandas and NumPy
Implementing machine learning models with Scikit-learn
Deep learning and AI development with TensorFlow and PyTorch
Statistical computing and data visualization with R
2. Strong Foundation in Statistics and Probability
A deep understanding of statistics and probability is non-negotiable for data scientists. These concepts form the backbone of data analysis, helping professionals derive meaningful insights and create predictive models.
Why It’s Important:
Enables accurate hypothesis testing
Supports decision-making with probability distributions
Strengthens machine learning model evaluation
3. Expertise in Machine Learning and Deep Learning
With AI and automation becoming more prevalent, machine learning and deep learning skills are in high demand. Data scientists need to stay updated with advanced techniques to develop intelligent models that can solve complex problems.
Key Areas to Focus On:
Supervised and unsupervised learning techniques
Reinforcement learning and neural networks
Hyperparameter tuning and model optimization
Understanding AI ethics and bias mitigation
For those looking to upskill in machine learning, the Machine Learning Course in Kolkata offers practical, hands-on training. This program is designed to equip learners with the latest industry knowledge and techniques to advance their careers.
4. Data Wrangling and Preprocessing Skills
Data in its raw form is often messy and incomplete. Being able to clean, structure, and preprocess data is a vital skill that every data scientist must master.
Essential Data Wrangling Skills:
Handling missing and inconsistent data
Normalization and standardization techniques
Feature selection and engineering for improved model performance
5. Knowledge of Big Data Technologies
The rise of big data has made it essential for data scientists to work with tools and frameworks designed for handling massive datasets efficiently.
Tools Worth Learning:
Apache Spark for large-scale data processing
Hadoop for distributed storage and computation
Google BigQuery for cloud-based data analytics
6. Data Visualization and Storytelling
Turning raw data into actionable insights requires effective communication. Data scientists should be adept at using visualization tools to present findings in a compelling and understandable way.
Best Practices:
Choose the right visualization type (e.g., bar charts, scatter plots, heatmaps)
Keep charts clean and easy to interpret
Use tools like Matplotlib, Seaborn, Tableau, and Power BI
7. Cloud Computing and MLOps
Cloud platforms are transforming the way data scientists build and deploy models. A strong understanding of cloud-based tools and MLOps practices is crucial in modern data science workflows.
What You Should Learn:
Deploying ML models on cloud platforms like AWS, Google Cloud, and Azure
Implementing MLOps for model lifecycle management
Using Docker and Kubernetes for scalable deployments
8. Domain Knowledge and Business Acumen
While technical skills are critical, understanding the industry you work in can set you apart. A data scientist with domain expertise can develop more impactful and relevant solutions.
Why It Matters:
Helps tailor data-driven strategies to specific industries
Improves collaboration with stakeholders
Enhances problem-solving with business context
9. Soft Skills: Critical Thinking and Effective Communication
Technical know-how is just one part of the equation. Data scientists must also possess strong analytical and problem-solving skills to interpret data effectively and communicate findings to both technical and non-technical audiences.
Key Soft Skills to Develop:
Clear and concise storytelling through data
Adaptability to emerging technologies and trends
Collaboration with cross-functional teams
10. Ethics in AI and Data Governance
As AI systems influence more aspects of daily life, ethical considerations and regulatory compliance have become increasingly important. Data scientists must ensure fairness, transparency, and adherence to privacy regulations like GDPR and CCPA.
Best Practices for Ethical AI:
Identifying and mitigating bias in machine learning models
Implementing robust data privacy and security measures
Promoting transparency in AI decision-making processes
Final Thoughts
In the ever-changing landscape of data science, continuous learning is the key to staying relevant. By mastering these essential skills in 2025, data scientists can future-proof their careers and contribute to the advancement of AI-driven innovations. If you're looking to gain practical expertise, the Data Science Program offers industry-focused training that prepares you for real-world challenges.
Whether you're just starting or looking to refine your skills, investing in these areas will keep you ahead of the curve in the dynamic world of data science.
#best data science institute#data science course#data science training#ai training program#online data science course#data science program#Best Data Science Programs#Machine Learning Course in Kolkata
0 notes
Text
What are the top Python libraries for data science in 2025? Get Best Data Analyst Certification Course by SLA Consultants India
Python's extensive ecosystem of libraries has been instrumental in advancing data science, offering tools for data manipulation, visualization, machine learning, and more. As of 2025, several Python libraries have emerged as top choices for data scientists:
1. NumPy
NumPy remains foundational for numerical computations in Python. It provides support for large, multi-dimensional arrays and matrices, along with a collection of mathematical functions to operate on them. Its efficiency and performance make it indispensable for data analysis tasks. Data Analyst Course in Delhi
2. Pandas
Pandas is essential for data manipulation and analysis. It offers data structures like DataFrames, which allow for efficient handling and analysis of structured data. With tools for reading and writing data between in-memory structures and various formats, Pandas simplifies data preprocessing and cleaning.
3. Matplotlib
For data visualization, Matplotlib is a versatile library that enables the creation of static, animated, and interactive plots. It supports various plot types, including line plots, scatter plots, and histograms, making it a staple for presenting data insights.
4. Seaborn
Built on top of Matplotlib, Seaborn provides a high-level interface for drawing attractive statistical graphics. It simplifies complex visualization tasks and integrates seamlessly with Pandas data structures, enhancing the aesthetic appeal and interpretability of plots. Data Analyst Training Course in Delhi
5. Plotly
Plotly is renowned for creating interactive and web-ready plots. It offers a wide range of chart types, including 3D plots and contour plots, and is particularly useful for dashboards and interactive data applications.
6. Scikit-Learn
Scikit-Learn is a comprehensive library for machine learning, providing simple and efficient tools for data mining and data analysis. It supports various machine learning tasks, including classification, regression, clustering, and dimensionality reduction, and is built on NumPy, SciPy, and Matplotlib. Data Analyst Training Institute in Delhi
7. Dask
Dask is a parallel computing library that scales Python code from multi-core local machines to large distributed clusters. It integrates seamlessly with libraries like NumPy and Pandas, enabling scalable and efficient computation on large datasets.
8. PyMC
PyMC is a probabilistic programming library for Bayesian statistical modeling and probabilistic machine learning. It utilizes advanced Markov chain Monte Carlo and variational fitting algorithms, making it suitable for complex statistical modeling.
9. TensorFlow and PyTorch
Both TensorFlow and PyTorch are leading libraries for deep learning. They offer robust tools for building and training neural networks and have extensive communities supporting their development and application in various domains, from image recognition to natural language processing. Online Data Analyst Course in Delhi
10. NLTK and SpaCy
For natural language processing (NLP), NLTK and SpaCy are prominent libraries. NLTK provides a wide range of tools for text processing, while SpaCy is designed for industrial-strength NLP, offering fast and efficient tools for tasks like tokenization, parsing, and entity recognition.
These libraries collectively empower data scientists to efficiently process, analyze, and visualize data, facilitating the extraction of meaningful insights and the development of predictive models.
Data Analyst Training Course Modules Module 1 - Basic and Advanced Excel With Dashboard and Excel Analytics Module 2 - VBA / Macros - Automation Reporting, User Form and Dashboard Module 3 - SQL and MS Access - Data Manipulation, Queries, Scripts and Server Connection - MIS and Data Analytics Module 4 - MS Power BI | Tableau Both BI & Data Visualization Module 5 - Free Python Data Science | Alteryx/ R Programing Module 6 - Python Data Science and Machine Learning - 100% Free in Offer - by IIT/NIT Alumni Trainer
Regarding the "Best Data Analyst Certification Course by SLA Consultants India," I couldn't find specific information on such a course in the provided search results. For the most accurate and up-to-date details, I recommend visiting SLA Consultants India's official website or contacting them directly to inquire about their data analyst certification offerings. For more details Call: +91-8700575874 or Email: [email protected]
0 notes
Text
Unlock Your Future: Learn Data Science Using Python A-Z for ML

Are you ready to take a deep dive into one of the most in-demand skills of the decade? Whether you're looking to switch careers, boost your resume, or just want to understand how machine learning shapes the world, learning Data Science using Python A-Z for ML is one of the smartest moves you can make today.
With Python becoming the universal language of data, combining it with data science and machine learning gives you a major edge. But here’s the best part—you don’t need to be a math genius or have a computer science degree to get started. Thanks to online learning platforms, anyone can break into the field with the right course and guidance.
If you’re ready to explore the world of predictive analytics, AI, and machine learning through Python, check out this powerful Data Science using Python A-Z for ML course that’s crafted to take you from beginner to expert.
Let’s break down what makes this learning journey so valuable—and how it can change your future.
Why Data Science with Python Is a Game-Changer
Python is known for its simplicity, readability, and versatility. That's why it’s the preferred language of many data scientists and machine learning engineers. It offers powerful libraries like:
Pandas for data manipulation
NumPy for numerical computing
Matplotlib and Seaborn for data visualization
Scikit-learn for machine learning
TensorFlow and Keras for deep learning
When you combine these tools with real-world applications, the possibilities become endless—from building recommendation engines to predicting customer churn, from detecting fraud to automating data analysis.
The key is learning the skills in the right order with hands-on practice. That’s where a well-structured course can help you move from confusion to clarity.
What You’ll Learn in This A-Z Course on Data Science with Python
The course isn’t just a theory dump—it’s an actionable, practical, hands-on bootcamp. It covers:
1. Python Programming Basics
Even if you’ve never written a line of code, you’ll be walked through Python syntax, data types, loops, functions, and more. It’s like learning a new language with a supportive tutor guiding you.
2. Data Cleaning and Preprocessing
Raw data is messy. You’ll learn how to clean, transform, and prepare datasets using Pandas, making them ready for analysis or training machine learning models.
3. Data Visualization
A picture is worth a thousand rows. Learn how to use Matplotlib and Seaborn to create powerful charts, graphs, and plots that reveal patterns in your data.
4. Exploratory Data Analysis (EDA)
Before jumping to models, EDA helps you understand your dataset. You’ll learn how to identify trends, outliers, and relationships between features.
5. Statistics for Data Science
Understand probability, distributions, hypothesis testing, and correlation. These concepts are the foundation of many ML algorithms.
6. Machine Learning Algorithms
You’ll cover essential algorithms like:
Linear Regression
Logistic Regression
Decision Trees
Random Forests
Support Vector Machines
k-Nearest Neighbors
Naïve Bayes
Clustering (K-Means)
All with practical projects!
7. Model Evaluation
Accuracy isn’t everything. You’ll explore precision, recall, F1-score, confusion matrices, and cross-validation to truly assess your models.
8. Real-World Projects
Theory only goes so far. You’ll build actual projects that simulate what data scientists do in the real world—from data collection to deploying predictions.
Who Is This Course Perfect For?
You don’t need a Ph.D. to start learning. This course is designed for:
Beginners with zero coding or data science background
Students looking to enhance their resume
Professionals switching careers to tech
Entrepreneurs wanting to use data for smarter decisions
Marketers & Analysts who want to work with predictive analytics
Whether you're 18 or 48, this course makes learning Data Science using Python A-Z for ML accessible and exciting.
What Makes This Course Stand Out?
Let’s be real: there are hundreds of data science courses online. So what makes this one different?
✅ Structured Learning Path
Everything is organized from A to Z. You don’t jump into machine learning without learning data types first.
✅ Hands-On Projects
You’ll work on mini-projects throughout the course, so you never lose the connection between theory and practice.
✅ Friendly Teaching Style
No dry lectures or overwhelming jargon. The instructor talks to you like a friend—not a robot.
✅ Lifetime Access
Once you enroll, it’s yours forever. Come back to lessons any time you need a refresher.
✅ Real-World Applications
You’ll build models you can actually talk about in job interviews—or even show on your portfolio.
Want to start now? Here’s your shortcut to mastering the field: 👉 Data Science using Python A-Z for ML
Why Data Science Skills Matter in 2025 and Beyond
Companies today are drowning in data—and they’re willing to pay handsomely for people who can make sense of it.
In 2025 and beyond, businesses will use AI to:
Automate decisions
Understand customer behavior
Forecast market trends
Detect fraud
Personalize services
To do any of this, they need data scientists who can write Python code, manipulate data, and train predictive models.
That could be you.
From Learner to Data Scientist: Your Roadmap
Here’s how your transformation might look after taking the course:
Month 1: You understand Python and basic data structures Month 2: You clean and explore datasets with Pandas and Seaborn Month 3: You build your first ML model Month 4: You complete a full project—ready for your resume Month 5: You start applying for internships, freelance gigs, or even full-time roles!
It’s not a pipe dream. It’s real, and it’s happening to people every day. All you need is to take the first step.
Your Investment? Just a Few Hours a Week
You don’t need to quit your job or study 12 hours a day. With just 4–5 hours a week, you can master the foundations within a few months.
And remember: this isn’t just a skill. It’s an asset. The return on your time is massive—financially and intellectually.
Final Thoughts: The Future Belongs to the Data-Literate
If you've been waiting for a sign to jump into data science, this is it.
The tools are beginner-friendly. The job market is exploding. And this course gives you everything you need to start building your skills today.
Don’t let hesitation hold you back.
Start your journey with Data Science using Python A-Z for ML, and see how far you can go.
0 notes