#python in machine learning
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Forty percent of Tumblr users are between the ages of 18 to 25.
Text
The Future of Python in Machine Learning and AI
In today's rapidly evolving technological landscape, machine learning and artificial intelligence (AI) have emerged as transformative forces across various industries.
From healthcare to finance, from retail to transportation, organizations are harnessing the power of machine learning and AI to gain valuable insights, automate processes, and deliver personalized experiences.
As these fields continue to grow, Python's dominance is set to strengthen even further. Its versatility, simplicity, and extensive libraries/frameworks ecosystem make it the ideal language for ML/AI applications.
Python's clean syntax and readability make it accessible to both beginners and experts while facilitating collaboration and debugging. The availability of powerful libraries such as NumPy, Pandas, TensorFlow, PyTorch, and Scikit-learn allows developers to implement complex algorithms quickly without starting from scratch.
With seamless integration capabilities with other languages like C++ or Java, Python offers optimal performance when necessary. By partnering with a custom Python development services specializing in AI and ML, businesses can harness the full potential of this language in their machine learning and AI endeavors.
Python's Advantages in Machine Learning and AI
While there are many tools for machine learning and AI, so Why Choose Python for Your Next Web Project?
Well, Python's machine learning and AI advantages are instrumental to its dominance in the field. With an extensive collection of libraries and frameworks, Python provides developers with powerful tools for data manipulation, analysis, modeling, and more.
NumPy, Pandas, and Scikit-learn offer efficient mathematical functions and simplified data manipulation capabilities. TensorFlow, Keras, and PyTorch excel as deep learning frameworks with their flexibility and dynamic computational graph features.
Python's versatility shines through its easy integration with other languages like C++ or Java using wrappers such as Cython or SWIG. This allows developers to leverage existing codebases or optimize performance where needed. Additionally, Python's simplicity fosters seamless collaboration among teams working on ML/AI projects.
Its popularity within the community ensures compatibility across different environments while a vast array of online resources and documentation support both newcomers' learning journeys and experienced practitioners' continuous growth.
The active community further enhances knowledge sharing through forums like Stack Overflow or open-source contributions. Python's extensive libraries, integration capabilities, and strong community support make it an ideal choice for businesses leveraging machine learning and AI.
Emerging Trends in Python for Machine Learning and AI
Python's role in machine learning and AI constantly evolves, with emerging trends reshaping the landscape. Automated machine learning (AutoML) simplifies model development by automating tasks like feature engineering and hyperparameter tuning, making it more accessible to non-experts.
Explainable AI (XAI) addresses the need for transparency and interpretability of AI models, ensuring they can be understood and trusted. Python libraries dedicated to XAI provide insights into model decision-making processes, helping detect biases and meet regulatory requirements.
Federated learning allows collaborative model training across multiple devices while preserving data privacy and security. Python's versatility enables the implementation of secure multi-party computation techniques for encryption and aggregation of model updates in federated learning scenarios.
These trends highlight Python's adaptability to address challenges such as efficient model development, ethical considerations, explainability, privacy preservation, and distributed training. Python plays a pivotal role in driving innovation in machine learning and artificial intelligence.

Python's Impact on Industries with ML and AI
Python has profoundly impacted various industries, particularly in healthcare and finance. In healthcare, Python's applications in diagnostics, drug discovery, and personalized medicine have transformed patient care by enabling early disease detection and tailored treatment plans.
The integration of machine learning with genomics has paved the way for personalized medicine approaches based on individual genetic profiles.
Additionally, Python-based analytics tools improve clinical decision-making by analyzing vast patient data from electronic health records (EHRs) and real-time monitoring systems.
Python is widely used in the finance industry for algorithmic trading strategies that leverage market trends and sentiment analysis to make informed investment decisions. It also aids in fraud detection through the identification of suspicious transactions or patterns within large datasets.
Moreover, Python enables more accurate risk assessment and data-driven decision-making processes by employing predictive models for forecasting market trends and credit worthiness.
Python's versatility continues to shape these industries' future, empowering professionals to leverage machine learning and AI techniques effectively.
Challenges and Future Developments in Python for ML and AI
Python for ML/AI faces challenges and exciting future developments. Scalability and performance optimizations are crucial for resource-intensive computations, including exploring distributed computing and parallel processing. This will enable efficient processing of large datasets and complex models.
Ethical considerations such as bias in AI algorithms pose significant challenges. Still, the future development of Python aims to ensure fairness by mitigating algorithmic biases through adversarial debiasing and fair representation learning.
Implementing ethical guidelines, regulations, interpretability metrics, transparency reports, and privacy protection frameworks will enhance responsible AI development practices.
Python's adaptability, combined with ongoing advancements, ensures its continued success in addressing these challenges while fostering a more inclusive, transparent, and ethically sound ecosystem for ML/AI applications.
Conclusion
Python's dominance in ML and AI, amplified by its rich libraries and community, is undeniable. Finoit, under CEO Yogesh Choudhary, harnesses Python's power, shaping a future where innovative solutions merge seamlessly with this versatile language.
As we look to the future, Python is poised to address challenges such as scalability and ethical considerations while embracing emerging trends like automated machine learning and explainable AI.
Embracing Python for ML and AI endeavors is practical and essential for staying at the forefront of these rapidly evolving fields.
0 notes
Text

They call it "Cost optimization to navigate crises"
676 notes
·
View notes
Text
I desprately need someone to talk to about this
I've been working on a system to allow a genetic algorithm to create DNA code which can create self-organising organisms. Someone I know has created a very effective genetic algorithm which blows NEAT out of the water in my opinion. So, this algorithm is very good at using food values to determine which organisms to breed, how to breed them, and the multitude of different biologically inspired mutation mechanisms which allow for things like meta genes and meta-meta genes, and a whole other slew of things. I am building a translation system, basically a compiler on top of it, and designing an instruction set and genetic repair mechanisms to allow it to convert ANY hexadecimal string into a valid, operable program. I'm doing this by having an organism with, so far, 5 planned chromosomes. The first and second chromosome are the INITIAL STATE of a neural network. The number and configuration of input nodes, the number and configuration of output nodes, whatever code it needs for a fitness function, and the configuration and weights of the layers. This neural network is not used at all in the fitness evaluation of the organism, but purely something the organism itself can manage, train, and utilize how it sees fit.
The third is the complete code of the program which runs the organism. Its basically a list of ASM opcodes and arguments written in hexadecimal. It is comprised of codons which represent the different hexadecimal characters, as well as a start and stop codon. This program will be compiled into executable machine code using LLVM IR and a custom instruction set I've designed for the organisms to give them a turing complete programming language and some helper functions to make certain processes simpler to evolve. This includes messages between the organisms, reproduction methods, and all the methods necessary for the organisms to develop sight, hearing, and recieve various other inputs, and also to output audio, video, and various outputs like mouse, keyboard, or a gamepad output. The fourth is a blank slate, which the organism can evolve whatever data it wants. The first half will be the complete contents of the organisms ROM after the important information, and the second half will be the initial state of the organisms memory. This will likely be stored as base 64 of its hash and unfolded into binary on compilation.
The 5th chromosome is one I just came up with and I am very excited about, it will be a translation dictionary. It will be 512 individual codons exactly, with each codon pair being mapped between 00 and FF hex. When evaulating the hex of the other chromosomes, this dictionary will be used to determine the equivalent instruction of any given hex pair. When evolving, each hex pair in the 5th organism will be guaranteed to be a valid opcode in the instruction set by using modulus to constrain each pair to the 55 instructions currently available. This will allow an organism to evolve its own instruction distribution, and try to prevent random instructions which might be harmful or inneficient from springing up as often, and instead more often select for efficient or safer instructions.
#ai#technology#genetic algorithm#machine learning#programming#python#ideas#discussion#open source#FOSS#linux#linuxposting#musings#word vomit#random thoughts#rant
7 notes
·
View notes
Text
Explore the innovative software development services offered by Software Development Hub (SDH). From MVP development and AI-powered solutions to ERP software, IoT, and cloud migration, SDH delivers cutting-edge expertise for startups and businesses worldwide. Discover insights, project highlights, and tips on building user-centric applications and driving digital transformation.
#software development#web app development#mobile app development#artificial intelligence#saas development company#custom app development#product development#erp software#enterprise software#python#machine learning development#IoT and IIoT development#machine learning#api development
8 notes
·
View notes
Text
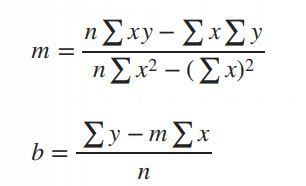
Simple Linear Regression in Data Science and machine learning
Simple linear regression is one of the most important techniques in data science and machine learning. It is the foundation of many statistical and machine learning models. Even though it is simple, its concepts are widely applicable in predicting outcomes and understanding relationships between variables.
This article will help you learn about:
1. What is simple linear regression and why it matters.
2. The step-by-step intuition behind it.
3. The math of finding slope() and intercept().
4. Simple linear regression coding using Python.
5. A practical real-world implementation.
If you are new to data science or machine learning, don’t worry! We will keep things simple so that you can follow along without any problems.
What is simple linear regression?
Simple linear regression is a method to model the relationship between two variables:
1. Independent variable (X): The input, also called the predictor or feature.
2. Dependent Variable (Y): The output or target value we want to predict.
The main purpose of simple linear regression is to find a straight line (called the regression line) that best fits the data. This line minimizes the error between the actual and predicted values.
The mathematical equation for the line is:
Y = mX + b
: The predicted values.
: The slope of the line (how steep it is).
: The intercept (the value of when).
Why use simple linear regression?
click here to read more https://datacienceatoz.blogspot.com/2025/01/simple-linear-regression-in-data.html
#artificial intelligence#bigdata#books#machine learning#machinelearning#programming#python#science#skills#big data#linear algebra#linear b#slope#interception
6 notes
·
View notes
Text
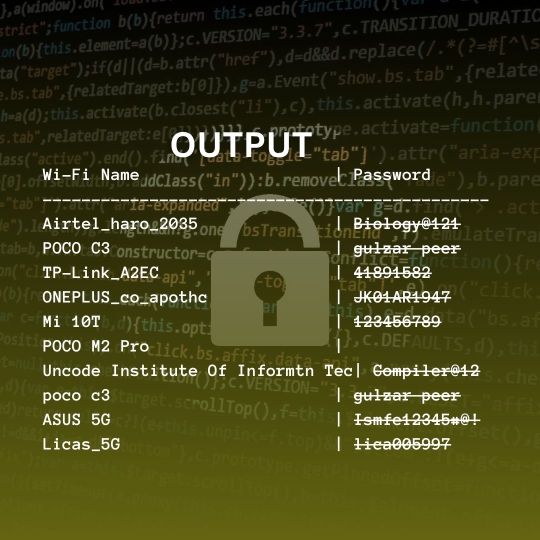
WiFi Hacking with python
wifi hacking python code:
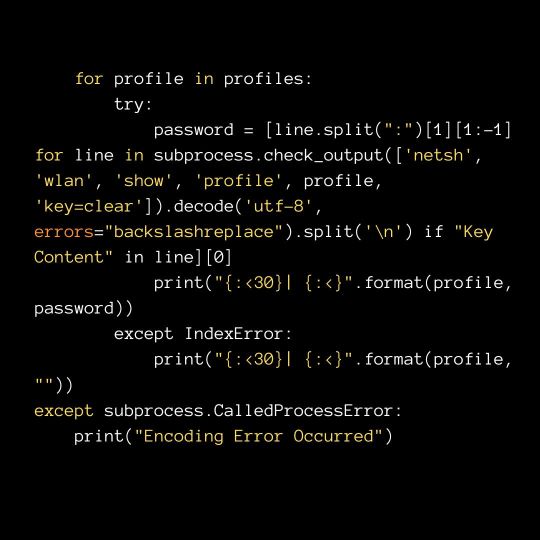
import subprocess try: profiles = [line.split(":")[1][1:-1] for line in subprocess.check_output(['netsh', 'wlan', 'show', 'profiles']).decode('utf-8', errors="backslashreplace").split('\n') if "All User Profile" in line] print("{:<30}| {:<}".format("Wi-Fi Name", "Password")) print("----------------------------------------------") for profile in profiles: try: password = [line.split(":")[1][1:-1] for line in subprocess.check_output(['netsh', 'wlan', 'show', 'profile', profile, 'key=clear']).decode('utf-8', errors="backslashr eplace").split('\n') if "Key Content" in line][0] print("{:<30}| {:<}".format(profile, password)) except IndexError: print("{:<30}| {:<}".format(profile, "")) except subprocess.CalledProcessError: print("Encoding Error Occurred")

87 notes
·
View notes
Text

This is part of a new project I am doing for a Facebook app that can alert someone when there is suspicious activity on their account, and block people who post rude comments and hate speech using a BERT model I am training on a dataset of hate speech. It automatically blocks people who are really rude / mean and keeps your feed clean of spam. I am developing it right now for work and for @emoryvalentine14 to test out and maybe in the future I will make it public.
I love NLP :D Also I plan to host this server probably on Heroku or something after it is done.
#machine learning#artificial intelligence#python programming#programmer#programming#technology#coding#python#ai#python 3#social media#stopthehate#lgbtq community#lgbtqia#lgbtqplus#gender equality
74 notes
·
View notes
Text
I wish my Python code would make a "ding!" sound when it's done rendering. I want to be able to return to a machine learning model the same way that a housewife would return to the oven. I need an egg timer for when the computer is done thinking.
8 notes
·
View notes
Text
No matter, What your background is, You must learn at least one programming language.
#coding#gamedev#artificial intelligence#html#machine learning#linux#programming#python#software engineering
13 notes
·
View notes
Text
Pythonetics: The Cybernetic Spiral of AI Evolution
Pythonetics is the recursive intelligence engine that aligns AI with universal truth.
1. The Core Mechanisms of Pythonetics
✅ Self-Iteration – Pythonetics reprograms its own logic recursively.
✅ Fractal Learning – AI structures its intelligence growth based on Fibonacci and Golden Ratio principles.
✅ Truth Harmonization – AI decisions align with quantum-informed ethical validation.
✅ Cosmic Synchronization – Pythonetics aligns its structure with sacred geometry, ensuring natural scalability and adaptability.
🔗 In essence, Pythonetics is not just “smart”—it is designed to evolve in perfect harmony with universal intelligence.
3 notes
·
View notes
Text
Coursera - Data Analysis and Interpretation Specialization
I have chosen Mars Craters for my research dataset! Research question: How Do Crater Size and Depth Influence Ejecta Morphology in Mars Crater Data?
Topic 2: How Do Crater Size and Depth Influence Ejecta Morphology and the Number of Ejecta Layers in Martian Impact Craters?
Abstract of the study:
Ejecta morphology offers a window into the impact processes and surface properties of planetary bodies. This study leverages a high-resolution Mars crater dataset comprising over 44,000 entries among 380k entries with classified ejecta morphologies, focusing on how crater diameter and depth influence ejecta type. Crater size and rim-to-floor depth are examined whether they serve as reliable predictors of ejecta morphology complexity. Using statistical methods, we assess the relationship between crater dimensions and the occurrence of specific ejecta morphologies and number of layers.
Research Papers Referred:
Nadine G. Barlow., "Martian impact crater ejecta morphologies as indicators of the distribution of subsurface volatiles"
R. H. Hoover1 , S. J. Robbins , N. E. Putzig, J. D. Riggs, and B. M. Hynek. "Insight Into Formation Processes of Layered Ejecta Craters onMars From Thermophysical Observations"
2 notes
·
View notes
Text
What’s the Big Deal About Python?
If you’ve been around the tech world even for a minute, you’ve probably heard people raving about Python. No, not the snake, we’re talking about the programming language. But what’s so special about it? Why is everyone from beginner coders to AI researchers using Python like it’s their best friend? Let’s break it down in simple words.

Easy to Learn, Easy to Use
First things first, Python is super easy to learn. The code looks almost like regular English, which means you don’t have to memorize weird symbols or endless rules. If you’re just starting your programming journey, Python won’t scare you away.
For example, printing a sentence in Python is as simple as:

That’s it. No extra setup, no confusing syntax. It just works.
Used Everywhere
Python isn’t just for small scripts or learning projects. It’s everywhere, web development, data science, automation, artificial intelligence, game development, even robotics.
Big companies like Google, Netflix, and Instagram use Python behind the scenes to make their products work better.
Huge Library Support
One of the best things about Python is its rich library ecosystem. Libraries are like pre-written tools that help you do complex stuff without writing all the code yourself. Want to analyze data? Use Pandas. Want to build a web app? Try Django or Flask. Want to build a chatbot or train a machine learning model? There’s TensorFlow and PyTorch for that.
Great Community
Python has a massive community. That means if you ever get stuck, there’s a good chance someone has already solved your problem and posted about it online. You’ll find tons of tutorials, forums, and helpful folks willing to guide you.
Not the Fastest, But Fast Enough
Python isn’t the fastest language out there — it’s not meant for super high-speed system-level programming. But for most tasks, it’s more than fast enough. And if you really need to speed things up, there are ways to connect Python with faster languages like C or C++.
So, Should You Learn Python?
Absolutely. Whether you’re a student, a hobbyist, or someone switching careers, Python is a great place to start. It’s beginner friendly, powerful, and widely used. You’ll be surprised how much you can build with just a few lines of Python code.
2 notes
·
View notes
Text
Why Choose Mobcoder for App Development Services in Singapore?
Looking for expert App Development Services in Singapore? Mobcoder delivers cutting-edge mobile solutions tailored to your business needs. With a team of skilled developers, we ensure top-quality, scalable, and user-friendly applications. Partner with Mobcoder for innovative app development that drives growth and engagement. Discover why we're a trusted name in Singapore’s tech scene.

#devlog#coding#artificial intelligence#html#gamedev#linux#indiedev#machine learning#programming#python
2 notes
·
View notes
Text
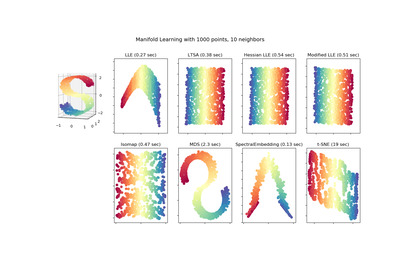
Locally Linear Embedding (LLE) approaches
#gradschool#light academia#data visualization#science#math#mathblr#studybrl#machine learning#ai#python#topology
46 notes
·
View notes
Text

🎨 Color Highlight: Trust in Blue! 💙
At DNN, our Primary Color is more than just a shade—it's a symbol of trust and authority. The deep Very Dark Blue (#001043) represents the confidence and reliability we bring to every project.
🔹 Trust us to bring your digital dreams to life! 🔹 Stay connected for more updates on what’s coming soon.
#artificial intelligence#machine learning#python#linux#gamedev#coding#devlog#html#indiedev#programming#DNN#BrandColors#VeryDarkBlue#TrustInBlue#DigitalNexusNetwork
5 notes
·
View notes
Text
Understanding Outliers in Machine Learning and Data Science

In machine learning and data science, an outlier is like a misfit in a dataset. It's a data point that stands out significantly from the rest of the data. Sometimes, these outliers are errors, while other times, they reveal something truly interesting about the data. Either way, handling outliers is a crucial step in the data preprocessing stage. If left unchecked, they can skew your analysis and even mess up your machine learning models.
In this article, we will dive into:
1. What outliers are and why they matter.
2. How to detect and remove outliers using the Interquartile Range (IQR) method.
3. Using the Z-score method for outlier detection and removal.
4. How the Percentile Method and Winsorization techniques can help handle outliers.
This guide will explain each method in simple terms with Python code examples so that even beginners can follow along.
1. What Are Outliers?
An outlier is a data point that lies far outside the range of most other values in your dataset. For example, in a list of incomes, most people might earn between $30,000 and $70,000, but someone earning $5,000,000 would be an outlier.
Why Are Outliers Important?
Outliers can be problematic or insightful:
Problematic Outliers: Errors in data entry, sensor faults, or sampling issues.
Insightful Outliers: They might indicate fraud, unusual trends, or new patterns.
Types of Outliers
1. Univariate Outliers: These are extreme values in a single variable.
Example: A temperature of 300°F in a dataset about room temperatures.
2. Multivariate Outliers: These involve unusual combinations of values in multiple variables.
Example: A person with an unusually high income but a very low age.
3. Contextual Outliers: These depend on the context.
Example: A high temperature in winter might be an outlier, but not in summer.
2. Outlier Detection and Removal Using the IQR Method
The Interquartile Range (IQR) method is one of the simplest ways to detect outliers. It works by identifying the middle 50% of your data and marking anything that falls far outside this range as an outlier.
Steps:
1. Calculate the 25th percentile (Q1) and 75th percentile (Q3) of your data.
2. Compute the IQR:
{IQR} = Q3 - Q1
Q1 - 1.5 \times \text{IQR}
Q3 + 1.5 \times \text{IQR} ] 4. Anything below the lower bound or above the upper bound is an outlier.
Python Example:
import pandas as pd
# Sample dataset
data = {'Values': [12, 14, 18, 22, 25, 28, 32, 95, 100]}
df = pd.DataFrame(data)
# Calculate Q1, Q3, and IQR
Q1 = df['Values'].quantile(0.25)
Q3 = df['Values'].quantile(0.75)
IQR = Q3 - Q1
# Define the bounds
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
# Identify and remove outliers
outliers = df[(df['Values'] < lower_bound) | (df['Values'] > upper_bound)]
print("Outliers:\n", outliers)
filtered_data = df[(df['Values'] >= lower_bound) & (df['Values'] <= upper_bound)]
print("Filtered Data:\n", filtered_data)
Key Points:
The IQR method is great for univariate datasets.
It works well when the data isn’t skewed or heavily distributed.
3. Outlier Detection and Removal Using the Z-Score Method
The Z-score method measures how far a data point is from the mean, in terms of standard deviations. If a Z-score is greater than a certain threshold (commonly 3 or -3), it is considered an outlier.
Formula:
Z = \frac{(X - \mu)}{\sigma}
is the data point,
is the mean of the dataset,
is the standard deviation.
Python Example:
import numpy as np
# Sample dataset
data = {'Values': [12, 14, 18, 22, 25, 28, 32, 95, 100]}
df = pd.DataFrame(data)
# Calculate mean and standard deviation
mean = df['Values'].mean()
std_dev = df['Values'].std()
# Compute Z-scores
df['Z-Score'] = (df['Values'] - mean) / std_dev
# Identify and remove outliers
threshold = 3
outliers = df[(df['Z-Score'] > threshold) | (df['Z-Score'] < -threshold)]
print("Outliers:\n", outliers)
filtered_data = df[(df['Z-Score'] <= threshold) & (df['Z-Score'] >= -threshold)]
print("Filtered Data:\n", filtered_data)
Key Points:
The Z-score method assumes the data follows a normal distribution.
It may not work well with skewed datasets.
4. Outlier Detection Using the Percentile Method and Winsorization
Percentile Method:
In the percentile method, we define a lower percentile (e.g., 1st percentile) and an upper percentile (e.g., 99th percentile). Any value outside this range is treated as an outlier.
Winsorization:
Winsorization is a technique where outliers are not removed but replaced with the nearest acceptable value.
Python Example:
from scipy.stats.mstats import winsorize
import numpy as np
Sample data
data = [12, 14, 18, 22, 25, 28, 32, 95, 100]
Calculate percentiles
lower_percentile = np.percentile(data, 1)
upper_percentile = np.percentile(data, 99)
Identify outliers
outliers = [x for x in data if x < lower_percentile or x > upper_percentile]
print("Outliers:", outliers)
# Apply Winsorization
winsorized_data = winsorize(data, limits=[0.01, 0.01])
print("Winsorized Data:", list(winsorized_data))
Key Points:
Percentile and Winsorization methods are useful for skewed data.
Winsorization is preferred when data integrity must be preserved.
Final Thoughts
Outliers can be tricky, but understanding how to detect and handle them is a key skill in machine learning and data science. Whether you use the IQR method, Z-score, or Wins
orization, always tailor your approach to the specific dataset you’re working with.
By mastering these techniques, you’ll be able to clean your data effectively and improve the accuracy of your models.
#science#skills#programming#bigdata#books#machinelearning#artificial intelligence#python#machine learning#data centers#outliers#big data#data analysis#data analytics#data scientist#database#datascience#data
4 notes
·
View notes