#what is a gpu scaling
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Mobile Tumblr US users spend an average of 4.04 minutes per session on the app.
Text

Well, guess that's it for me, t'was fun while it lasted
#ff14#ffxiv#dawntrail#dawntrail benchmark#shame they dont want me to keep playing but it is what it is#was on the fence abt getting dawntrail anyway but knowing id have to spend gpu amounts of money for it does tip the scale a fair bit
1 note
·
View note
Text
A summary of the Chinese AI situation, for the uninitiated.
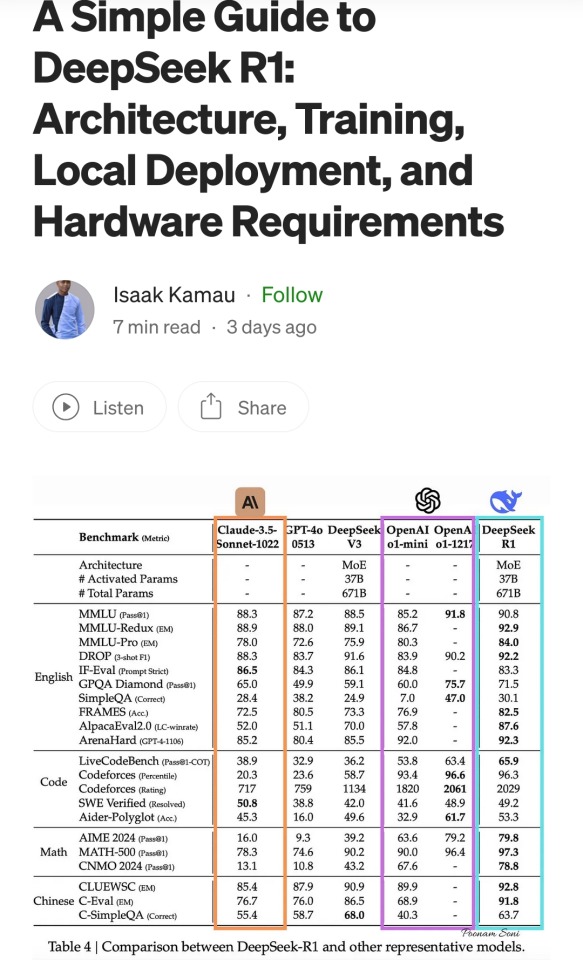
These are scores on different tests that are designed to see how accurate a Large Language Model is in different areas of knowledge. As you know, OpenAI is partners with Microsoft, so these are the scores for ChatGPT and Copilot. DeepSeek is the Chinese model that got released a week ago. The rest are open source models, which means everyone is free to use them as they please, including the average Tumblr user. You can run them from the servers of the companies that made them for a subscription, or you can download them to install locally on your own computer. However, the computer requirements so far are so high that only a few people currently have the machines at home required to run it.
Yes, this is why AI uses so much electricity. As with any technology, the early models are highly inefficient. Think how a Ford T needed a long chimney to get rid of a ton of black smoke, which was unused petrol. Over the next hundred years combustion engines have become much more efficient, but they still waste a lot of energy, which is why we need to move towards renewable electricity and sustainable battery technology. But that's a topic for another day.
As you can see from the scores, are around the same accuracy. These tests are in constant evolution as well: as soon as they start becoming obsolete, new ones are released to adjust for a more complicated benchmark. The new models are trained using different machine learning techniques, and in theory, the goal is to make them faster and more efficient so they can operate with less power, much like modern cars use way less energy and produce far less pollution than the Ford T.
However, computing power requirements kept scaling up, so you're either tied to the subscription or forced to pay for a latest gen PC, which is why NVIDIA, AMD, Intel and all the other chip companies were investing hard on much more powerful GPUs and NPUs. For now all we need to know about those is that they're expensive, use a lot of electricity, and are required to operate the bots at superhuman speed (literally, all those clickbait posts about how AI was secretly 150 Indian men in a trenchcoat were nonsense).
Because the chip companies have been working hard on making big, bulky, powerful chips with massive fans that are up to the task, their stock value was skyrocketing, and because of that, everyone started to use AI as a marketing trend. See, marketing people are not smart, and they don't understand computers. Furthermore, marketing people think you're stupid, and because of their biased frame of reference, they think you're two snores short of brain-dead. The entire point of their existence is to turn tall tales into capital. So they don't know or care about what AI is or what it's useful for. They just saw Number Go Up for the AI companies and decided "AI is a magic cow we can milk forever". Sometimes it's not even AI, they just use old software and rebrand it, much like convection ovens became air fryers.
Well, now we're up to date. So what did DepSeek release that did a 9/11 on NVIDIA stock prices and popped the AI bubble?

Oh, I would not want to be an OpenAI investor right now either. A token is basically one Unicode character (it's more complicated than that but you can google that on your own time). That cost means you could input the entire works of Stephen King for under a dollar. Yes, including electricity costs. DeepSeek has jumped from a Ford T to a Subaru in terms of pollution and water use.
The issue here is not only input cost, though; all that data needs to be available live, in the RAM; this is why you need powerful, expensive chips in order to-

Holy shit.
I'm not going to detail all the numbers but I'm going to focus on the chip required: an RTX 3090. This is a gaming GPU that came out as the top of the line, the stuff South Korean LoL players buy…
Or they did, in September 2020. We're currently two generations ahead, on the RTX 5090.
What this is telling all those people who just sold their high-end gaming rig to be able to afford a machine that can run the latest ChatGPT locally, is that the person who bought it from them can run something basically just as powerful on their old one.
Which means that all those GPUs and NPUs that are being made, and all those deals Microsoft signed to have control of the AI market, have just lost a lot of their pulling power.
Well, I mean, the ChatGPT subscription is 20 bucks a month, surely the Chinese are charging a fortune for-

Oh. So it's free for everyone and you can use it or modify it however you want, no subscription, no unpayable electric bill, no handing Microsoft all of your private data, you can just run it on a relatively inexpensive PC. You could probably even run it on a phone in a couple years.
Oh, if only China had massive phone manufacturers that have a foot in the market everywhere except the US because the president had a tantrum eight years ago.
So… yeah, China just destabilised the global economy with a torrent file.
#valid ai criticism#ai#llms#DeepSeek#ai bubble#ChatGPT#google gemini#claude ai#this is gonna be the dotcom bubble again#hope you don't have stock on anything tech related#computer literacy#tech literacy
433 notes
·
View notes
Text
pinned post/FAQ
TRANS RIGHTS!! TERFS GET THE FUCK OFF MY BLOG!!!!!!!

we have a source of income again, but if you like my work, donations are always appreciated!
who are you?
i'm just a guy who likes spore [2008]
why do this?
i just really like spore and making creatures in spore. it helps me practice my creature creation abilities.
can you make my oc in spore?
as of right now i do not take requests. i generally find characters and creatures i want to make by them appearing on my dashboard. refer to the Request Beast.

what is in your icon?
captain thunderhide, my main spore space stage captain.

what is peeling?
peeling is when i remove all detail parts from a creature and show the bare sculpt underneath - anything that is not eyes, mouth, hands, feet, or limbs will be removed. it is a tradition around these parts
what are "original spores"?
original spores are spore creations that aren't based on existing media - ocs, copyrighted characters, or otherwise. usually, they're just making things to make them in spore, or are based on simple prompts such as "a plate of spaghetti" or "a penis".
do you use mods?
i exclusively play this game with mods.
can i download the creatures you make?
only if the original creator of the design is okay with it and requests a png. please note that in order to successfully download the creatures, you will need to download every mod used to create them.
i will not always be able to say what mods i use to make something, so it's a gamble if you don't have all of the ones i use.
how do i mod spore/do advanced creature creation like you?
darkedgetv's FAQ is a very good resource to begin. i started there, and it's where i recommend you to start if you're interested in spore modding. it also contains many other mods i have not listed under the cut.
as much as i disagree with the process of using a discord server to contain vital information and resources, the davoonline spore modding community discord is also a good source of resources and mods that even i do not use.
have you heard of [in-development indie sporelike]?
yes. i have heard of all of them.
i hold no interest in any of the currently in development indie "sporelikes". i believe they are trying to reinvent the wheel and overall they do not interest me.
are there any other blogs like yours?
there's a few and ever growing! i refer to this as the ecosystem or the making-you ecosystem.
i have a masterpost of all known individuals in this ecosystem here.
what editor mods do you use?
a lot, so they'll be under the cut.
not mods, but highly recommended for enhanced playing experience
4GB patch - Tutorial - patches spore [and other 32bit programs] to be able to use 4gb of RAM. recommended if playing a highly modded copy, and makes the game more stable.
Reshade & ReSpore - post-processing injector & shader that alters the appearance of spore, giving it more detailed shading and vibrant colors. i use this for gameplay and screenshots. runs on GPU power, so excellent if you have a strong graphics card
HD graphics fix - this doesn't actually seem to work for my copy, but it alters the textures of base spore to be more high-quality.
mods that are absolute must-haves
these mods are ones that i use in almost every creation, and add a lot of QoL to the editors. if i forget a mod in a creature png i post, it will be one of these.
Dark injection - THE spore mod. it's likely a lot of other mods you'll download will mesh well with dark injection. you can turn off whatever you don't want to use through the installer.
Universal Property Enhancer - a library mod that many other mods require
The Smoother - a useful tool for building muscles and smoothing out your creatures' bodies
Enhanced Color Picker - a requirement for super detailed creations, enables hexcode color picking and color wheel selection beyond normal limits of spore
[UPE] Infinite Part Scaling - allows scaling of parts near-infinitely, beyond the limits of the original game
Project Skyncraft - adds new creature skinpaints
Unshackled - adds nodes and limbs for creating custom wings, heads, hands, etc. a little bit unstable, i mostly use this for wings.
Spore Stacker - allows stacking of any part
Subtle Rotations - reduces part rotation snapping
Advanced CE - adds building editor manipulators to the creature editor
Every Part Costs Nothing - self explanatory
Rotate Anything - lets you rotate anything, including feet and hands
Advanced Creature Paint - allows for individual coloring of parts on a creature, like in the building and vehicle editors
Ambient Occlusion Disabler - removes baked-on shadows for creatures
Delta Paints - adds new skinpaints
Valla's Skinpaint Switcheroo - adds duplicates of all vanilla, C&C, and GA creature coat and detail skinpaints into their opposite category
Valla's Vanilla Style Parts - adds several parts which mimic the vanilla style
Delimbiter - increases the amount you can scale limb parts, and allows for more crazy movements of certain limb parts
test drive related mods
these mods are not required to download the creatures i post, but are recommended for the test drive.
No More Creature Editor Animations - turns off the animations that play when you add eyes, mouth, feet/hands, etc
Sevan's TF2 editor animations - adds multiple animations from tf2 into the creature test drive.
Mx3's Dance Animations - adds a multitude of dance animations into the creature test drive.
Tenebris's Creature Test Drive Animations - adds many animations from within the game to the creature test drive.
EditorBG - adds extra editor backgrounds
Ramone Kemono's MMD Drag Ball - high-effort dance mod complete with special effects and a reverse engineered camera system
part mods
these mods add parts to the editors.
DroneParts 2017 - adds many mechanical and polygonal parts useful for machine creatures, i like to use it for building clothes and markings.
New Drone Parts - a sequel to droneparts 2017, compatible with the old version. install both at the same time if you want to be able to use creatures from the old droneparts mod.
Himeric Engine - adds horror-themed parts to the creature editor.
Spore Resurrection Next Steps - adds a few parts to the creature editor and several new textures to the building and vehicle editors.
Dinosaur Parts - adds parts based on dinosaurs and other animals. mostly heads.
Strange And Beautiful - a now-discontinued, reuploaded mod that adds unusual and unique parts to the creature editor
Bionicle parts - adds a few bionicle pieces to the creature editor
Little Box Of Horrors - adds many parts with an overall horror theme. some are animated.
Pandora's Toolbox [1.0] - adds a multitude of basic shapes and polygons to build with
Replicant - adds non-textured animating parts and non-animating parts in a separate tab. good for if you want to use hands, limbs, etc without them animating or adding stats
Armoured And Dangerous - adds a few high detail mechanical looking parts.
Wordsmith 2.1 - adds letters to the creature, building, and vehicle editors
Kaiju parts - adds several parts based on popular kaiju
Organic Help - adds many membrane pieces to the creature editor, for creating wing webbing among other things
Project: Mad Mannequins - adds many human body based parts. and a horse for some reason
A Mouth For All Seasons - adds alternate versions of all vanilla mouths [and all unused cell mouths] with alternate diets
Valla's Captain Badges - adds all space badge models into the captain outfitter and creature editor
Rock On! - adds rock props from spore into the building and creature editors
Anime Parts - adds a couple anime human heads and anime hairs
2K notes
·
View notes
Text
DXVK Tips and Troubleshooting: Launching The Sims 3 with DXVK
A big thank you to @heldhram for additional information from his recent DXVK/Reshade tutorial! ◀ Depending on how you launch the game to play may affect how DXVK is working.
During my usage and testing of DXVK, I noticed substantial varying of committed and working memory usage and fps rates while monitoring my game with Resource Monitor, especially when launching the game with CCMagic or S3MO compared to launching from TS3W.exe/TS3.exe.
It seems DXVK doesn't work properly - or even at all - when the game is launched with CCM/S3MO instead of TS3W.exe/TS3.exe. I don't know if this is also the case using other launchers from EA/Steam/LD and misc launchers, but it might explain why some players using DXVK don't see any improvement using it.
DXVK injects itself into the game exe, so perhaps using launchers bypasses the injection. From extensive testing, I'm inclined to think this is the case.
Someone recently asked me how do we know DXVK is really working. A very good question! lol. I thought as long as the cache showed up in the bin folder it was working, but that was no guarantee it was injected every single time at startup. Until I saw Heldhram's excellent guide to using DXVK with Reshade DX9, I relied on my gaming instincts and dodgy eyesight to determine if it was. 🤭
Using the environment variable Heldhram referred to in his guide, a DXVK Hud is added to the upper left hand corner of your game screen to show it's injected and working, showing the DXVK version, the graphics card version and driver and fps.

This led me to look further into this and was happy to see that you could add an additional line to the DXVK config file to show this and other relevant information on the HUD such as DXVK version, fps, memory usage, gpu driver and more. So if you want to make sure that DXVK is actually injected, on the config file, add the info starting with:
dxvk.hud =
After '=', add what you want to see. So 'version' (without quotes) shows the DXVK version. dxvk.hud = version

You could just add the fps by adding 'fps' instead of 'version' if you want.

The DXVK Github page lists all the information you could add to the HUD. It accepts a comma-separated list for multiple options:
devinfo: Displays the name of the GPU and the driver version.
fps: Shows the current frame rate.
frametimes: Shows a frame time graph.
submissions: Shows the number of command buffers submitted per frame.
drawcalls: Shows the number of draw calls and render passes per frame.
pipelines: Shows the total number of graphics and compute pipelines.
descriptors: Shows the number of descriptor pools and descriptor sets.
memory: Shows the amount of device memory allocated and used.
allocations: Shows detailed memory chunk suballocation info.
gpuload: Shows estimated GPU load. May be inaccurate.
version: Shows DXVK version.
api: Shows the D3D feature level used by the application.
cs: Shows worker thread statistics.
compiler: Shows shader compiler activity
samplers: Shows the current number of sampler pairs used [D3D9 Only]
ffshaders: Shows the current number of shaders generated from fixed function state [D3D9 Only]
swvp: Shows whether or not the device is running in software vertex processing mode [D3D9 Only]
scale=x: Scales the HUD by a factor of x (e.g. 1.5)
opacity=y: Adjusts the HUD opacity by a factor of y (e.g. 0.5, 1.0 being fully opaque).
Additionally, DXVK_HUD=1 has the same effect as DXVK_HUD=devinfo,fps, and DXVK_HUD=full enables all available HUD elements.
desiree-uk notes: The site is for the latest version of DXVK, so it shows the line typed as 'DXVK_HUD=devinfo,fps' with underscore and no spaces, but this didn't work for me. If it also doesn't work for you, try it in lowercase like this: dxvk.hud = version Make sure there is a space before and after the '=' If adding multiple HUD options, seperate them by a comma such as: dxvk.hud = fps,memory,api,version
The page also shows some other useful information regarding DXVK and it's cache file, it's worth a read. (https://github.com/doitsujin/dxvk)
My config file previously showed the DXVK version but I changed it to only show fps. Whatever it shows, it's telling you DXVK is working! DXVK version:


DXVK FPS:

The HUD is quite noticeable, but it's not too obstructive if you keep the info small. It's only when you enable the full HUD using this line: dxvk.hud = full you'll see it takes up practically half the screen! 😄 Whatever is shown, you can still interact with the screen and sims queue.

So while testing this out I noticed that the HUD wasn't showing up on the screen when launching the game via CCM and S3MO but would always show when clicking TS3W.exe. The results were consistent, with DXVK showing that it was running via TS3W.exe, the commited memory was low and steady, the fps didn't drop and there was no lag or stuttereing. I could spend longer in CAS and in game altogether, longer in my older larger save games and the RAM didn't spike as much when saving the game. Launching via CCM/S3MO, the results were sporadic, very high RAM spikes, stuttering and fps rates jumping up and down. There wasn't much difference from DXVK not being installed at all in my opinion.
You can test this out yourself, first with whatever launcher you use to start your game and then without it, clicking TS3.exe or TS3W.exe, making sure the game is running as admin. See if the HUD shows up or not and keep an eye on the memory usage with Resource Monitor running and you'll see the difference. You can delete the line from the config if you really can't stand the sight of it, but you can be sure DXVK is working when you launch the game straight from it's exe and you see smooth, steady memory usage as you play. Give it a try and add in the comments if it works for you or not and which launcher you use! 😊 Other DXVK information:
Make TS3 Run Smoother with DXVK ◀ - by @criisolate How to Use DXVK with Sims 3 ◀ - guide from @nornities and @desiree-uk
How to run The Sims 3 with DXVK & Reshade (Direct3D 9.0c) ◀ - by @heldhram
DXVK - Github ◀
106 notes
·
View notes
Text
History and Basics of Language Models: How Transformers Changed AI Forever - and Led to Neuro-sama
I have seen a lot of misunderstandings and myths about Neuro-sama's language model. I have decided to write a short post, going into the history of and current state of large language models and providing some explanation about how they work, and how Neuro-sama works! To begin, let's start with some history.
Before the beginning
Before the language models we are used to today, models like RNNs (Recurrent Neural Networks) and LSTMs (Long Short-Term Memory networks) were used for natural language processing, but they had a lot of limitations. Both of these architectures process words sequentially, meaning they read text one word at a time in order. This made them struggle with long sentences, they could almost forget the beginning by the time they reach the end.
Another major limitation was computational efficiency. Since RNNs and LSTMs process text one step at a time, they can't take full advantage of modern parallel computing harware like GPUs. All these fundamental limitations mean that these models could never be nearly as smart as today's models.
The beginning of modern language models
In 2017, a paper titled "Attention is All You Need" introduced the transformer architecture. It was received positively for its innovation, but no one truly knew just how important it is going to be. This paper is what made modern language models possible.
The transformer's key innovation was the attention mechanism, which allows the model to focus on the most relevant parts of a text. Instead of processing words sequentially, transformers process all words at once, capturing relationships between words no matter how far apart they are in the text. This change made models faster, and better at understanding context.
The full potential of transformers became clearer over the next few years as researchers scaled them up.
The Scale of Modern Language Models
A major factor in an LLM's performance is the number of parameters - which are like the model's "neurons" that store learned information. The more parameters, the more powerful the model can be. The first GPT (generative pre-trained transformer) model, GPT-1, was released in 2018 and had 117 million parameters. It was small and not very capable - but a good proof of concept. GPT-2 (2019) had 1.5 billion parameters - which was a huge leap in quality, but it was still really dumb compared to the models we are used to today. GPT-3 (2020) had 175 billion parameters, and it was really the first model that felt actually kinda smart. This model required 4.6 million dollars for training, in compute expenses alone.
Recently, models have become more efficient: smaller models can achieve similar performance to bigger models from the past. This efficiency means that smarter and smarter models can run on consumer hardware. However, training costs still remain high.
How Are Language Models Trained?
Pre-training: The model is trained on a massive dataset to predict the next token. A token is a piece of text a language model can process, it can be a word, word fragment, or character. Even training relatively small models with a few billion parameters requires trillions of tokens, and a lot of computational resources which cost millions of dollars.
Post-training, including fine-tuning: After pre-training, the model can be customized for specific tasks, like answering questions, writing code, casual conversation, etc. Certain post-training methods can help improve the model's alignment with certain values or update its knowledge of specific domains. This requires far less data and computational power compared to pre-training.
The Cost of Training Large Language Models
Pre-training models over a certain size requires vast amounts of computational power and high-quality data. While advancements in efficiency have made it possible to get better performance with smaller models, models can still require millions of dollars to train, even if they have far fewer parameters than GPT-3.
The Rise of Open-Source Language Models
Many language models are closed-source, you can't download or run them locally. For example ChatGPT models from OpenAI and Claude models from Anthropic are all closed-source.
However, some companies release a number of their models as open-source, allowing anyone to download, run, and modify them.
While the larger models can not be run on consumer hardware, smaller open-source models can be used on high-end consumer PCs.
An advantage of smaller models is that they have lower latency, meaning they can generate responses much faster. They are not as powerful as the largest closed-source models, but their accessibility and speed make them highly useful for some applications.
So What is Neuro-sama?
Basically no details are shared about the model by Vedal, and I will only share what can be confidently concluded and only information that wouldn't reveal any sort of "trade secret". What can be known is that Neuro-sama would not exist without open-source large language models. Vedal can't train a model from scratch, but what Vedal can do - and can be confidently assumed he did do - is post-training an open-source model. Post-training a model on additional data can change the way the model acts and can add some new knowledge - however, the core intelligence of Neuro-sama comes from the base model she was built on. Since huge models can't be run on consumer hardware and would be prohibitively expensive to run through API, we can also say that Neuro-sama is a smaller model - which has the disadvantage of being less powerful, having more limitations, but has the advantage of low latency. Latency and cost are always going to pose some pretty strict limitations, but because LLMs just keep getting more efficient and better hardware is becoming more available, Neuro can be expected to become smarter and smarter in the future. To end, I have to at least mention that Neuro-sama is more than just her language model, though we have only talked about the language model in this post. She can be looked at as a system of different parts. Her TTS, her VTuber avatar, her vision model, her long-term memory, even her Minecraft AI, and so on, all come together to make Neuro-sama.
Wrapping up - Thanks for Reading!
This post was meant to provide a brief introduction to language models, covering some history and explaining how Neuro-sama can work. Of course, this post is just scratching the surface, but hopefully it gave you a clearer understanding about how language models function and their history!
33 notes
·
View notes
Note
Oooh, what about Journey? I think the sand probably took a lot to pull off
it did!! i watched a video about it, god, like 6 years ago or something and it was a very very important thing for them to get just right. this is goimg to be a longer one because i know this one pretty extensively
here's the steps they took to reach it!!

and heres it all broken down:
so first off comes the base lighting!! when it comes to lighting things in videogames, a pretty common model is the lambert model. essentially you get how bright things are just by comparing the normal (the direction your pixel is facing in 3d space) with the light direction (so if your pixel is facing the light, it returns 1, full brightness. if the light is 90 degrees perpendicular to the pixel, it returns 0, completely dark. and pointing even further away you start to go negative. facing a full 180 gives you -1. thats dot product baybe!!!)

but they didnt like it. so. they just tried adding and multiplying random things!!! literally. until they got the thing on the right which they were like yeah this is better :)

you will also notice the little waves in the sand. all the sand dunes were built out of a heightmap (where things lower to the ground are closer to black and things higher off the ground are closer to white). so they used a really upscaled version of it to map a tiling normal map on top. they picked the map automatically based on how steep the sand was, and which direction it was facing (east/west got one texture, north/south got the other texture)

then its time for sparkles!!!! they do something very similar to what i do for sparkles, which is essentially, they take a very noisy normal map like this and if you are looking directly at a pixels direction, it sparkles!!

this did create an issue, where the tops of sand dunes look uh, not what they were going for! (also before i transition to the next topic i should also mention the "ocean specular" where they basically just took the lighting equation you usually use for reflecting the sun/moon off of water, and uh, set it up on the sand instead with the above normal map. and it worked!!! ok back to the tops of the sand dunes issue)

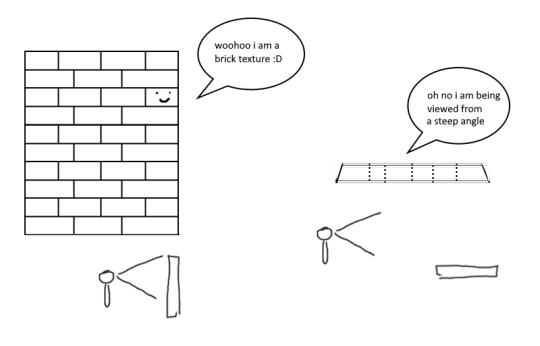
so certain parts just didnt look as they intended and this was a result of the anisotropic filtering failing. what is anisotropic filtering you ask ?? well i will do my best to explain it because i didnt actually understand it until 5 minutes ago!!!! this is going to be the longest part of this whole explanation!!!
so any time you are looking at a videogame with textures, those textures are generally coming from squares (or other Normal Shapes like a healthy rectangle). but ! lets say you are viewing something from a steep angle
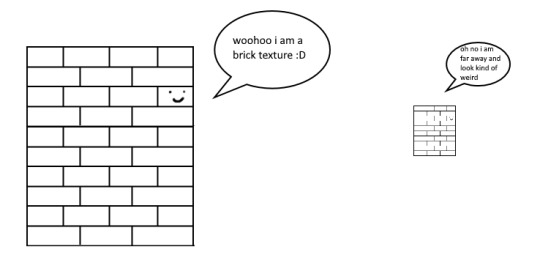
it gets all messed up!!! so howww do we fix this. well first we have to look at something called mip mapping. this is Another thing that is needded because video game textures are generally squares. because if you look at them from far away, the way each pixel gets sampled, you end up with some artifacting!!
so mip maps essentially just are the original texture, but a bunch of times scaled down Properly. and now when you sample that texture from far away (so see something off in the distance that has that texture), instead of sampling from the original which might not look good from that distance, you sample from the scaled down one, which does look good from that distance
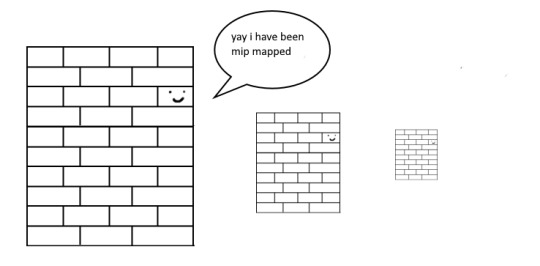

ok. do you understand mip mapping now. ok. great. now imagine you are a GPU and you know exactly. which parts of each different mip map to sample from. to make the texture look the Absolute Best from the angle you are looking at it from. how do you decide which mip map to sample, and how to sample it? i dont know. i dont know. i dont know how it works. but thats anisotropic filtering. without it looking at things from a steep angle will look blurry, but with it, your GPU knows how to make it look Crisp by using all the different mip maps and sampling them multiple times. yay! the more you let it sample, the crisper it can get. without is on the left, with is on the right!!

ok. now. generally this is just a nice little thing to have because its kind of expensive. BUT. when you are using a normal map that is very very grainy like the journey people are, for all the sparkles. having texture fidelity hold up at all angles is very very important. because without it, your textures can get a bit muddied when viewing it from any angle that isnt Straight On, and this will happen

cool? sure. but not what they were going for!! (16 means that the aniso is allowed to sample the mip maps sixteen times!! thats a lot)
but luckily aniso 16 allows for that pixel perfect normal map look they are going for. EXCEPT. when viewed from the steepest of angles. bringing us back here

so how did they fix this ? its really really clever. yo uguys rmemeber mip maps right. so if you have a texture. and have its mip maps look like this

that means that anything closer to you will look darker, because its sampling from the biggest mip map, and the further away you get, the lighter the texture is going to end up. EXCEPT !!!! because of aisononotropic filtering. it will do the whole sample other mip maps too. and the places where the anisotropic filtering fail just so happen to be the places where it starts sampling the furthest texture. making the parts that fail that are close to the camera end up as white!!!

you can see that little ridge that was causing problems is a solid white at the tip, when it should still be grey. so they used this and essentially just told it not to render sparkles on the white parts. problem solved

we arent done yet though because you guys remember the mip maps? well. they are causing their own problems. because when you shrink down the sparkly normal map, it got Less Sparkly, and a bit smooth. soooo . they just made the normal map mip maps sharper (they just multipled them by 2. this just Worked)

the Sharp mip maps are on the left here!!
and uh... thats it!!!! phew. hope at least some of this made sense
433 notes
·
View notes
Text
Its hard to really take out pieces of it, because there's a lot of really good bits that need the context, but it lays out the stark, bare facts about Gen AI and that its all been an expensive and destructive waste of time, money and the environment.
But the author did summarize part of it so I'll paste that here and I recommend reading the whole thing:
The main technology behind the entire "artificial intelligence" boom is generative AI — transformer-based models like OpenAI's GPT-4 (and soon GPT-5) — and said technology has peaked, with diminishing returns from the only ways of making them "better" (feeding them training data and throwing tons of compute at them) suggesting that what we may have, as I've said before, reached Peak AI.
Generative AI is incredibly unprofitable. OpenAI, the biggest player in the industry, is on course to lose more than $5 billion this year, with competitor Anthropic (which also makes its own transformer-based model, Claude) on course to lose more than $2.7 billion this year.
Every single big tech company has thrown billions — as much as $75 billion in Amazon's case in 2024 alone — at building the data centers and acquiring the GPUs to populate said data centers specifically so they can train their models or other companies' models, or serve customers that would integrate generative AI into their businesses, something that does not appear to be happening at scale.
Their investments could theoretically be used for other products, but these data centers are heavily focused on generative AI. Business Insider reports that Microsoft intends to amass 1.8 million GPUs by the end of 2024, costing it tens of billions of dollars.
Worse still, many of the companies integrating generative AI do so by connecting to models made by either OpenAI or Anthropic, both of whom are running unprofitable businesses, and likely charging nowhere near enough to cover their costs. As I wrote in the Subprime AI Crisis in September, in the event that these companies start charging what they actually need to, I hypothesize it will multiply the costs of their customers to the point that they can't afford to run their businesses — or, at the very least, will have to remove or scale back generative AI functionality in their products.
30 notes
·
View notes
Text
I got an ask on YouTube that asks some questions I've never gotten a chance to answer before, so I thought I'd repost it here!
m m on YouTube says:
Shared forms of communication would be absolutely possible, if there is an intention to communicate.
Forms of meaning can be conveyed by shared media, such as sculpture, rhythm, and yes, even scent. If we were hypothetically able to make mechanical items which don't break down too quickly.
It would be difficult as all heck, but CERTAINLY not impossible.
Humans could form structures that resemble Sophi.
How do the macrovolutes do math, btw?
What is their scent "language" like? Do they have different "languages" or would one macrovolutes be entirely able to say absolutely anything to any other macrovolute and be completely understood? Basically, how much of their communication is constructed and voluntary vs innate and involuntary?
Their communication method MUST have simple forms which appear as set patterns, such as the translation of the statement "A is not B" or "A is B". Would these single meaning packets have individual scents/patterns OF scents which are distinct and repeating, even if contextual, such as for our verb tenses, etc, or would they be the same, such as for nouns, which have a basic pattern but usually with a simple modifier which is applied across all, or similar types of, nouns, such as the s for English, or other notations for other languages, even if they are applied differently across different noun types, those types are set in patterns and categories.
I'd be extremely interested in a meta study of the macrovolutes communication and ability to encode meaning.
ANY encoding, ANY encryption, no matter how it takes place, whether linearly or not, can be "translated"
My reponse:
Can you understand the way a raven describes a human face (which we know they do)? Can you understand what plants whisper to each other across their roots? The more structured we learn whale communication is, the more frustrating it becomes that we barely understand any of it.
Add this to the fact the humans are, just now, finally in a place again to have anything resembling an industrial revolution. As their technology advances, they have gone from thinking of the macrovolutes as gods, to viewing them as entirely mindless. To say the least, communicating with them is not where the priorities of most lie.
On top of that, without smell and movement, most macrovolutes would not regard a sculpture as anything meaningful. Would you understand if ants laid out a perfect scent trail of your likeness?
And Sophodra herself has some issues with denial, and difficulty remembering.
But, as Gregorsa said…there is a way. More than that would be spoilers, though!
Macrovolute math is something that would be very difficult for a human. Instead of thinking one small step at a time in precise units, they tend to think in vast, fuzzy, three-dimensional figures. The closest I can describe it would be like doing operations in Dyalog APL on a GPU, scaling up the resolution as you go. On top of that, there are inherit unit qualifiers and slots to how they specify numbers. There is no "two." There is "non-moving few-member half-unit generic substance absent an individual," translated approximately. They also go out of their way to avoid using exact numbers wherever possible. Vectors and frequency indicators (similar but not equivalent to sine waves) are very commonly used in casual conversation. And on top of that, they use base six!
Macrovolutes have both a core language and a meta language. The core language covers basic things, and is innate and understood by all (with some differences between insects and arachnids, so arachnids typically learn the insect way). The meta language is learned and varies, covering things like slang, jargon, and more specific experiences.
Macrovolute grammar structure is most similar to highly agglutinative Native American languages, such as Kwak'wala. There is a root word, and additional stems keep getting added to it. Instead of just prefixes, infixes, and postfixes, however, there are scents being wafted toward you in three dimensions. (Also worth noting that our linguistic categories are largely Western ways of thinking, and macrovolutes do not categorize their "sentence" partitions the same way at all!)
You could also think of it like Common Lisp, with its layers of functions feeding into functions!
Macrovolute language is simultaneously frustratingly ambiguous, and bizarrely precise. As mentioned, many things are thought of in particular complicated units, with some parts explicitly or implicitly left empty. Imagine a unit that defines speed, "weight" (by Unknown Nature standards, which is all the more complex), temperature, volume…but half is missing, and the other half is filled out with things like "several" or "more than a reasonable amount."
On top of that, Formicosan culture loves to leave things vague as a deliberate power move. There will be loquacious description of a thought that isn't finished. "Oh, A is a sort of thing…it gets around, has been known to be in this sort of location…possesses a certain quality, it's not unknown…possibly it is negatively related to a thing you mentioned…." And if you don't remember that B was mentioned, then you just missed that this statement means "A is not B."
31 notes
·
View notes
Text
quick drop of interesting ML-related stuff I watched recently (that's machine learning not marxism-leninism, sorry tankie followers)...
youtube
great 3blue1brown-style explanation of both how attention works in general (and what the hell actually is in a KV cache) and how deepseek's 'multi-headed latent attention' works
youtube
some exciting research into making chip interconnects more axon-like, great explanation of the neuroscience side of why the brain is so much more energy-efficient than computational neural nets of the same size
youtube
idk if this one's hype or going places, but some researches made an end-to-end gpu-based physics sim and a different loss formulation that might potentially allow reinforcement learning of agent models to scale faster in ways similar to how self-supervised learning and transformers do
youtube
very technical video about a specific low-level gpu instruction the deepseek team used to get better cache performance in their hyperspecific use case. I have the knowledge to understand the context but it's definitely on a higher level than I can reach just yet
youtube
really cool visual demo of how neural networks transform spaces
ok, that's plenty of that for now, next post will not be about AI, promise
15 notes
·
View notes
Note
I think Nier Automata really over-estimated how fast the neural net scaling laws are and really underestimated how fast GPUs can be. After all, 2B isn’t very many neurons compared to what we have today.
>:|
boooooo
7 notes
·
View notes
Text
As details emerge from the trade negotiations between the United States and China this week, one thing seems clear: Rare earths were an important part of the discussions. China has a monopoly on the production and processing of the minerals used in the production of high-end magnets and chips. In response to U.S. President Donald Trump’s massive tariffs, Beijing’s new restrictions on critical minerals ended up bringing the two sides back to the table.
The battle over access to rare earths is part of a larger competition between Beijing and Washington on artificial intelligence. Who is best placed to win it, and what will that mean for the world? On the latest episode of FP Live, I sat down with the two co-heads of the Goldman Sachs Global Institute, Jared Cohen and George Lee, both of whom follow the geopolitics of AI closely. The full discussion is available on the video box atop this page or on the FP Live podcast. What follows here is a lightly edited and condensed transcript.
Note: This discussion is part of a series of episodes brought to you by the Goldman Sachs Global Institute.
RA: George, at a high level, where’s China at in its race to catch up with the United States on AI?
GL: What’s been fascinating is the generative AI revolution has provoked a pivot inside China. The surge of confidence, investment, and focus in this area is really fascinating. If you go back to 2021, [Chinese President] Xi [Jinping] imposed a series of crackdowns on what was then the leading technology ecosystem in China. When we emerged from the COVID-19 [pandemic], with the rise of generative AI, China evinced some ambivalence early on. One can understand that in a more closed semi-authoritarian regime, a less controllable emergent machine is somewhat threatening. So, China imposed rigorous regulations around this space.
What’s changed is the emergence of a highly capable model from China. It expressed its own native capabilities and captured the attention of the global ecosystem around China’s ability to compete and lead in this space. That provoked a new policy response in China to lean into this technology and integrate it with its historical strengths in data, robotics, payments, etc.
So now we’re in the sprint mode of a real race for supremacy between the United States and China. And it’s really emerged as a critical vector of competition between governments.
RA: Where does DeepSeek fit into this, Jared? My understanding is that it didn’t shock computer scientists or insiders in the AI world, although it did shock the U.S. national security community. Why is that?
JC: There are a couple of reasons. One, there was a perception that robust export controls on China, particularly around GPUs, were limiting their compute power such that it was impossible for them to run large language models at the same scale. There was a sense that they had an uphill battle when it came to generative AI. But necessity drives innovation, not just smart computer scientists—and China has both. Part of what spooked everybody with DeepSeek is that it basically managed to perform at the same level as GPT-4 at roughly 5 percent of the cost. Whether or not it was operating at scale, it was a research milestone that introduced the idea that export controls on China was an insufficient strategy to holding them back.
The market’s reaction was outsized to the reaction from computer scientists, who knew what was going on. But as a result of the market reaction to DeepSeek, you’re also seeing the realignment of the Chinese private tech sector with the state-led system, as George mentioned. At the end of the day, that is the bigger consequence of DeepSeek than a technological or a research breakthrough.
RA: And, George, it strikes me that the Chinese system might have an advantage in its ability to corral public and private sectors together, whereas the American or even a Western system could have built-in checks that hold it back?
GL: On the one hand, Ravi, the United States and Western economies have thrived through the open, capitalist approach to innovation and problem-solving. Particularly with algorithmic advancements, that’s served us well. But you might jealously eye state-oriented actors like China for their ability to impose long-term plans for some of the predicates behind these models. Those include the ability to take a long-term view on building power resources, modernizing transition, sourcing resources like those critical minerals.
One of the things that was super interesting about DeepSeek is that it illuminated the fact that China can lead and innovate at the algorithmic model level. The technical work inside the DeepSeek-R1 model, the papers they’ve published, reveal some of the most interesting computer science work in making these models smarter, reason better, etc. So it’s clear China’s now at or close to the frontier on the algorithmic front. And they do have the advantages of more command control and consistency in marshaling resources like power, which will be really important here.
RA: The issue of U.S. export controls on the highest-end chips, coupled with China’s control of critical minerals, were both relevant in the U.S.-China trade talks this week. Jared, are export controls doing what they need to do from an American perspective?
JC: The [Trump] administration’s moves show their perception of the limits of export controls in the policy prescriptions. The Trump administration’s criticism of the Biden administration is that they focused on prevention—meaning export controls—and not enough on promotion, which I think is fair. And so, their approach is to simultaneously double-down on preventing China from accessing some of the critical technologies necessary to power AI while also flooding regional hubs with that same technology. It’s a stick followed by a carrot to other regions. The previous administration was less open to doing that latter part in places like the Middle East. One example: On the prevent side, the administration announced that anybody using the Huawei Ascend chip is violating U.S. export controls. This cuts off China from consumer markets that it desperately needs to cover many of the fixed costs associated with this buildout. But simultaneously, they got rid of the Biden AI diffusion rules that capped places like the Middle East at 350,000 GPUs. We’ll have to wait and see how this plays out.
It’s going to come down to the bigger question of whether the United States has the capacity to build the AI infrastructure fast enough to meet hyperscalers’ demand. There’s also a question of how comfortable they will be bringing sensitive IP associated with training large language models abroad and how comfortable they will be bringing sensitive customer data associated with training abroad. So those are open questions.
Now, the tricky part is that this isn’t unilaterally up to the United States. Because the supply chains are so intertwined, and because of the realities of globalization, everybody was comfortable moving supply chains that were dirty from an ESG perspective or had cheap labor to China until COVID-19. After COVID-19, the United States realized that it needed to access strategically important supply chains, including critical minerals and rare earths. The problem is the die has been cast. Everyone focuses on the lithium, the cobalt, the graphite, and the minerals that come out of the ground and gets euphoric when we find them outside China. The problem is, once you get them out of the ground, you have to crush those minerals, chemically treat them, purify the metal, and then, more importantly, you have to refine and process them into magnets and other things. And 92 percent of refining and processing rare earths into metals takes place in China. There are only five refineries outside China: Western Australia, Nevada, Malaysia, France, and Estonia. You cannot meaningfully move that supply chain. We in the West don’t have the human capital to grow that industry because we’ve retired a lot of the programs that produce human capital at universities. There are also ESG regulations. And when you have such a high concentration of the refining and processing capability and supply chain in China, it gives them a unique privilege to be able to manipulate prices.
GL: I’d add one thing, which is that the complexity of these machines can’t be underestimated. Jensen Huang, the CEO of Nvidia, recently said that their current NVL72 system, which is their atomic unit of computation today, has about 600,000 parts. Their 2027 next-generation machine is going to have about 2.5 million parts. Now, he didn’t specify how much of that was foreign source. But that supply chain is intricate, complex, and global. And so, it’s unrealistic to believe that we can completely reshore, onshore, dominate, and protect an ecosystem to create this level of computation.
RA: On that, George, you have a debate between the AI accelerationists on the one hand and then China hawks on the other. This goes to Jared’s point about the trade-offs between prevention versus promotion. When you consider that China has a stranglehold on the critical mineral supply chain, doesn’t that undermine the arguments put forward by people who want to limit China’s AI development at all costs?
GL: It’s certainly constrained. But there are some who believe we’re approaching a milestone called artificial general intelligence, or AGI. One rationale behind the hawk strategy is that it’s a two- to three-year race. They argue we should do our best to prevent China from getting the resources to get there first, because once you achieve that nirvana-like state of AGI, you gain a sustaining advantage. Now, I would debate that but it’s a reasonable perspective. But I agree with you that the idea that we can cordon off China from advancing in this world is illusory.
JC: I would add to that there’s a macro geopolitical question creating a strategic mirage that may bias incorrectly toward some of the China hawks. It’s the idea that if you’re China, engaged in asymmetric competition with the United States, your biggest vulnerability is that the United States sits at the center of a multilateral economic architecture that allows it to overcome those asymmetries and level the playing field. And so, if you look at the current context, one could credibly ask whether, over the next three-and-a-half years, China’s strategy would be to play for time?
There’s a lot of infighting within that democratic economic order: tensions on trade between the United States and its two largest trading partners, Canada and Mexico. There’s no trade deal yet with Japan, the United States’ only G-7 ally in the Indo-Pacific. No trade deal with South Korea, with Australia, with India, or with the European Union. And so, these moments where the United States and China seem to work toward a deal only to have it fall apart in subsequent weeks? This creates a perception of weakness or desperation that, if it gets conflated with the economic circumstances in China, could lend itself toward an incorrect narrative. I don’t know if they are in fact playing for time, but we have to ask that question because if they are, a hawkish approach could, in fact, play right into that strategy.
RA: George, does America lose anything by not being able to compete in the Chinese AI ecosystem? American companies are losing business, of course. But what is the long-term impact?
GL: This is the second-order question around export controls and restrictions. Jensen Huang has come out and said that a $50 billion business opportunity in China is largely foreclosed to him. Second, being unable to deliver U.S. technology into China, reciprocally, the Chinese lose access to the volumes of our consumer market, the global consumer market. But on the other hand, we are forcing them to use Huawei Ascend chips at scale, to navigate away from the Nvidia CUDA ecosystem, which is the software they wrap around their GPUs. Essentially, we’re conferring domestic volume advantages to them that otherwise might have been taken up by U.S. companies. And necessity is the mother of invention; we are causing them to scale up inputs to these models that will allow them to be more prosperous, get that volume, refine, be smarter, better, faster.
RA: Jared, you and I have talked before about what you call the geopolitical swing states, whether it’s India, Saudi Arabia, or Vietnam. How are they triangulating between the United States and China when it comes to AI?
JC: Before ���Liberation Day,” I would have said that the geopolitical swing states realize that the limits of swinging with flexibility are around the critically important technologies. And that the United States, because of its advantages in generative AI in particular, had a lot of leverage in terms of being able to push countries to make a choice. At least for now, that is largely still true.
The caveat is, I think, the advantages over time will seesaw back and forth. As George mentioned, whoever gets to AGI first will have a unique posture in maintaining a competitive edge in this competitive coexistence. But countries will be chipping away at areas where they’re falling short for the rest of our lifetime.
These geopolitical swing states don’t block together. They act individually. It’s not a nonaligned movement. They look at their economic advantages and see a fleeting moment. They don’t know how long competition between the United States and China will be a framework for international relations. But they want to get as much out of it as possible.
Trump’s visit to the Middle East told this very important story: The narrative of the Middle East is no longer a story of security and shoring up energy supplies. It’s a story of investment and technology partnerships. And the three wealthy Gulf countries that Trump visited—Saudi Arabia, Qatar, and the United Arab Emirates—got public validation from the president of the United States that they are not just geopolitical swing states. They are major commercial players at the sovereign level in the most important and consequential technology invented since the internet.
GL: These swing states play an exceptional role in the world of this race for AI supremacy. The risk with AI is whether those swing states will be in an open, democratic U.S.-driven ecosystem or in a Chinese ecosystem? This is one of the perils of export control and of a less open approach.
RA: George, is this a case of a rising tide lifting all boats, even outside of the swing states? Or if you don’t have the clout, the money, or the energy, you just can’t keep up?
GL: Yeah, there’s a little of both. On the positive, whether this emerges from the United States, China, or likely both, the declining consumer cost of this technology means that whether you’re producing these intelligent tokens or simply consuming them, they are getting cheaper. So if you’re not on the leading edge of producing AI, you still get to benefit.
At the same time, if you don’t have native expertise, insight, and resources here, you are de facto dependent on others. Critical technology dependencies have real consequences—on defense, on culture. The impact on your economy, of not having your destiny in your own hands, is maybe threatening.
RA: Power is a big part of this. Jared, how have recent advances changed the power needs for the growth of AI? And how does that then play into the geopolitics of competition here?
JC: We’re grappling with hockey stick growth in terms of power demand without having prepared ourselves for that kind of an abrupt change. George mentioned Nvidia’s 2027 Kyber rack designs. These racks are now 576 GPUs on a single server rack that requires enough power for 500 U.S. homes. It requires 50 times the power of server racks that power the internet today.
When you talk about how many gigawatts of power the United States is going to need to bring online in order to meet the AI infrastructure demands, the numbers range from, like, 35 GW to 60 GW. That’s a huge delta in and of itself in between.
Some of the second- and third-order effects of this in the United States is a growing comfort getting back in the nuclear power game. But China is also experiencing the same thing. And one of the things that causes great consternation in the national security apparatus is China’s investment in nuclear for national security purposes. China is a huge investor in coal, in renewable, and in nuclear. So they get the power dynamics. And there’s not the same permitting challenges that we have in the United States and certainly not the same political challenges.
GL: In renewables alone, China added [the equivalent of the] United Kingdom’s power capability in the past year, so they’re building renewables to extraordinary scale. They have 30 nuclear plants under construction today. They have the ability and the willingness to scale coal, which is more controversial in the rest of the world. And this is actually an interesting artifact of their more command-and-control system, which can be both a bug and a feature. Plus, their lead in batteries. They produce 75 percent of the world’s batteries. And so, scaling batteries together with renewables, putting data centers that can benefit from that extremely low cost of intelligence per joule, it’s a very powerful thing.
RA: George, let’s talk about business implications. There’s so much volatility right now in everything you both are describing about the state of the AI race. How do companies navigate this?
GL: It’s inherently difficult. The pace of improvement of the technology is so steep. And as a technologist at an enterprise, you have to make a decision about when and where you shoot your shot. And so, you could move too early in this, make some decisions about deploying this technology too aggressively, wake up, and find the architecture or the leaders have changed. Or you could wait too long and see your competitors have established a sustainable lead over you. So, it’s very difficult.
The other thing I would observe is that it’s very hard to interrupt enshrined workflows in the enterprise. We’re all running experiments, which are beginning to become production projects that are yielding value. But while the technology is on this curve and enterprise adoption is slower, I’m optimistic that it’s inflecting upward. I think 2026 and beyond are the years where we’ll really start to see enterprise impact.
3 notes
·
View notes
Text
World's Most Powerful Business Leaders: Insights from Visionaries Across the Globe

In the fast-evolving world of business and innovation, visionary leadership has become the cornerstone of driving global progress. Recently, Fortune magazine recognized the world's most powerful business leaders, acknowledging their transformative influence on industries, economies, and societies.
Among these extraordinary figures, Elon Musk emerged as the most powerful business leader, symbolizing the future of technological and entrepreneurial excellence.

Elon Musk: The Game-Changer
Elon Musk, the CEO of Tesla, SpaceX, and X (formerly Twitter), has redefined innovation with his futuristic endeavors. From pioneering electric vehicles at Tesla to envisioning Mars colonization with SpaceX, Musk's revolutionary ideas continue to shape industries. Recognized as the most powerful business leader by Fortune, his ventures stand as a testament to what relentless ambition and innovation can achieve. Digital Fraud and Cybercrime: India Blocks 59,000 WhatsApp Accounts and 6.7 Lakh SIM Cards Also Read This....
Musk's influence extends beyond his corporate achievements. As a driver of artificial intelligence and space exploration, he inspires the next generation of leaders to push boundaries. His leadership exemplifies the power of daring to dream big and executing with precision.

Mukesh Ambani: The Indian Powerhouse
Mukesh Ambani, the chairman of Reliance Industries, represents the epitome of Indian business success. Ranked among the top 15 most powerful business leaders globally, Ambani has spearheaded transformative projects in telecommunications, retail, and energy, reshaping India's economic landscape. His relentless focus on innovation, particularly with Reliance Jio, has revolutionized the digital ecosystem in India.
Under his leadership, Reliance Industries has expanded its global footprint, setting new benchmarks in business growth and sustainability. Ambani’s vision reflects the critical role of emerging economies in shaping the global business narrative.

Defining Powerful Leadership
The criteria for identifying powerful business leaders are multifaceted. According to Fortune, leaders were evaluated based on six key metrics:
Business Scale: The size and impact of their ventures on a global level.
Innovation: Their ability to pioneer advancements that redefine industries.
Influence: How effectively they inspire others and create a lasting impact.
Trajectory: The journey of their career and the milestones achieved.
Business Health: Metrics like profitability, liquidity, and operational efficiency.
Global Impact: Their contribution to society and how their leadership addresses global challenges.
Elon Musk and Mukesh Ambani exemplify these qualities, demonstrating how strategic vision and innovative execution can create monumental change.

Other Global Icons in Leadership
The list of the world's most powerful business leaders features numerous iconic personalities, each excelling in their respective domains:
Satya Nadella (Microsoft): A transformative leader who has repositioned Microsoft as a cloud-computing leader, emphasizing customer-centric innovation.
Sundar Pichai (Alphabet/Google): A driving force behind Google’s expansion into artificial intelligence, cloud computing, and global digital services.
Jensen Huang (NVIDIA): The architect of the AI revolution, whose GPUs have become indispensable in AI-driven industries.
Tim Cook (Apple): Building on Steve Jobs' legacy, Cook has solidified Apple as a leader in innovation and user-centric design.
These leaders have shown that their influence isn’t confined to financial success alone; it extends to creating a better future for the world.
Leadership in Action: Driving Innovation and Progress
One common thread unites these leaders—their ability to drive innovation. For example:
Mary Barra (General Motors) is transforming the auto industry with her push toward electric vehicles, ensuring a sustainable future.
Sam Altman (OpenAI) leads advancements in artificial intelligence, shaping ethical AI practices with groundbreaking models like ChatGPT.
These visionaries have proven that impactful leadership is about staying ahead of trends, embracing challenges, and delivering solutions that inspire change.
The Indian Connection: Rising Global Influence
Apart from Mukesh Ambani, Indian-origin leaders such as Sundar Pichai and Satya Nadella have earned global recognition. Their ability to bridge cultural boundaries and lead multinational corporations demonstrates the increasing prominence of Indian talent on the world stage.

Conclusion
From technological advancements to economic transformation, these powerful business leaders are shaping the future of our world. Elon Musk and Mukesh Ambani stand at the forefront, representing the limitless potential of visionary leadership. As industries continue to evolve, their impact serves as a beacon for aspiring leaders worldwide.
This era of leadership emphasizes not only achieving success but also leveraging it to create meaningful change. In the words of Elon Musk: "When something is important enough, you do it even if the odds are not in your favor." Rajkot Job Update
#elon musk#mukesh ambani#x platform#spacex#tesla#satya nadella#sundar pichai#jensen huang#rajkot#our rajkot#Rajkot Job#Rajkot Job Vacancy#job vacancy#it jobs
8 notes
·
View notes
Note
These references are out of date so I hope you'll bear with me. Why is it games like Watchdogs 2 can have a whole citty full of NPC's each with mostly unique profiles and interactable (you can hack almost everyone, you can physically interact, etc). But something like Yandere simulator struggles with keeping a frame rate with not even 200 NPC's. The models in Watchdogs 2 are also more hyper realistic so I don't know if that means more framerate impaction?
What you're seeing are the programming principles of optimization and scalability in effect. These two principles are more than the sum of their parts, they are multiplicative in their effectiveness (or lack thereof). Thus, if there's a situation where we need to optimize at scale, the results are very pronounced. When we talk about performance, it helps to think of it as costs to do things. We spend system resources (CPU time, GPU time, system memory, etc.) to perform tasks (load a dude, draw a dude, animate a dude). Optimization is being clever about not wasting our resources doing unnecessary things. This lowers the cost of performing these tasks. Scalability is the other factor - the number of things there are multiplies their overall costliness. This should make intuitive sense.

Let's have an example - imagine that you need cupcakes for a party. The cupcakes cost $5 each and there's a $20 flat delivery fee. We need five cupcakes for a party, so the cost is $20 (delivery) + $25 (5 cupcakes x $5) for a total of $45. Optimization is our way of reducing the individual costs. We can optimize either the cost of the cupcakes or the cost of the delivery fee. Maybe we can optimize the delivery fee down to $10 but can only optimize the cupcake cost down by $1 each. We only have time to choose one optimization. In this case, optimizing the delivery fee results in a better overall cost reduction - 5 cupcakes x $5 apiece + $10 delivery is $35, while 5 cupcakes x $4 apiece + $20 delivery is $40.

Now think about what happens if the numbers change. Instead of needing five cupcakes for the party, let's say we need a thousand cupcakes. 1,000 cupcakes x $5 apiece + $20 delivery = $5,020. If we optimize the delivery fee, the cost becomes 1,000 cupcakes x $5 + $10 delivery = $5,010. Here, optimizing the cupcake price is a much better deal than optimizing the delivery fee! If we reduce the price per cupcake by $1, we get 1,000 cupcakes x $4 apiece + $20 delivery fee = $4,020.

Bringing this back to games, it should make sense now. Ubisoft spent a lot of engineering time optimizing the cost of each NPC (cupcake) down as much as possible because they knew that they would have a huge number of them in their game world. Yandere Simulator did not spend as much time optimizing their NPCs, so their NPCs are more costly than the WatchDogs NPCs.
[Join us on Discord] and/or [Support us on Patreon]
Got a burning question you want answered?
Short questions: Ask a Game Dev on Twitter
Long questions: Ask a Game Dev on Tumblr
Frequent Questions: The FAQ
24 notes
·
View notes
Text
Top 10 Companies Offering Crypto Mining Investment Opportunities

Crypto mining—it's like the gold rush of the digital age. But instead of pickaxes and shovels, you’ve got ASIC miners, GPUs, and a lot of electrical bills. If you’re wondering how to get in on this lucrative opportunity without actually running a mining farm from your basement, you’re in luck. These companies are giving investors the chance to stake their claim in the mining world. So, grab your digital pickaxe and let’s dig into the Top 10 Companies Offering Crypto Mining Investment Opportunities.
1. Pearl Lemon Crypto
Let’s kick things off with Pearl Lemon Crypto—a company that’s been in the digital space for 9 years. Not only do they specialize in marketing, lead generation, and web development, but Pearl Lemon Crypto also knows its way around the blockchain and crypto mining investment opportunities. With a deep understanding of the industry, they’re helping investors get exposure to mining opportunities that are both secure and profitable. Plus, their team provides excellent support to navigate the ins and outs of mining while leveraging their expertise in the digital space. Who said crypto mining can't be fun and profitable?
2. Genesis Mining
If you’re new to mining, Genesis Mining is like the “big brother” in the crypto mining investment space. This cloud mining giant allows users to purchase mining contracts without having to deal with the hardware and electricity costs themselves. Genesis Mining handles everything, so you can focus on watching your returns roll in (no need for an energy drink-fueled mining session). Whether you’re into Bitcoin or Ethereum, Genesis has you covered with a simple, secure platform that lets you mine from anywhere in the world.
3. HashFlare
HashFlare is like the DIY crypto miner’s dream. With an easy-to-use platform, you can buy mining power and start mining Bitcoin, Litecoin, or Ethereum without ever having to worry about noisy fans or overheating hardware. Whether you’re looking to dip your toes into the mining world or go all-in, HashFlare gives you the flexibility to start small and scale as you go. Think of it like renting out a piece of someone else’s mining farm—without the headache.
4. Bitdeer
Bitdeer takes cloud mining to the next level by offering customizable mining contracts and access to top-tier mining hardware. Whether you’re looking for a fixed contract or something more flexible, Bitdeer gives investors control over their mining investments. No need to worry about hardware maintenance or electricity costs—Bitdeer has you covered, and all you need is a little internet connection and a desire to watch your mining portfolio grow. It’s like owning mining rigs without all the hassle.
5. NiceHash
NiceHash is like the “all-you-can-eat buffet” of crypto mining. If you’re looking for flexibility, NiceHash lets you buy and sell hash power for a variety of cryptocurrencies. Whether you want to mine Bitcoin, Ethereum, or any other altcoin, NiceHash allows you to choose the best option for your investment strategy. Plus, they make it super easy to get started, making it perfect for beginners and experienced miners alike. It’s the perfect mix of convenience and choice—what’s not to love?
6. MiningRigRentals
Think of MiningRigRentals as the Airbnb for crypto miners. Instead of owning mining hardware, you can rent rigs for a specific period, allowing you to mine on-demand. This flexibility allows investors to dip into mining without the long-term commitment of buying their own equipment. Whether you're just experimenting or looking to take advantage of peak mining periods, MiningRigRentals offers a wide range of options to suit your needs.
7. Cudo Miner
Cudo Miner is making mining accessible to just about anyone. Their platform allows users to mine multiple coins with their PC or laptop, using a smart system that adjusts to ensure you’re mining the most profitable coins. It’s like having a mining assistant that works around the clock for you. You can even choose to participate in their profit-sharing program, giving you a chance to earn even more. So, if you have some spare processing power lying around, why not put it to work with Cudo Miner?
8. Argo Blockchain
Argo Blockchain is an investment-focused mining company that allows individuals to participate in mining Bitcoin and other altcoins via their mining pools. With an emphasis on environmentally friendly mining, Argo is one of the few companies striving to make the industry more sustainable. If you’re into eco-friendly investing with a side of crypto, Argo is where you want to be. They’re committed to lowering the carbon footprint of mining while still maximizing returns for their investors.
9. Bitfarm
Bitfarm takes the high-tech approach to crypto mining. As one of the largest publicly traded mining companies in the world, Bitfarm gives investors the chance to benefit from large-scale mining operations. They’re known for their efficient mining practices and tech-forward approach, using renewable energy to power their operations. If you’re looking for a company that combines scale with sustainability, Bitfarm is a great option to consider.
10. Ebang International Holdings
Ebang International Holdings is a leading manufacturer of mining hardware and also offers investment opportunities in crypto mining. They specialize in designing and producing mining equipment for a wide range of cryptocurrencies, including Bitcoin. If you want to get your hands on top-tier mining hardware and also invest in a company that’s been around for years, Ebang offers both. It’s like having your cake and eating it too—investing in mining hardware while tapping into the booming crypto mining industry.
There you have it, the Top 10 Companies Offering Crypto Mining Investment Opportunities! From cloud mining to owning mining rigs, these firms are making it easier than ever to dive into the world of crypto mining without needing a PhD in electrical engineering. Whether you’re a seasoned investor or a newbie, there’s something on this list for everyone to start mining and earning. The future of mining is here, and it’s shiny, profitable, and powered by blockchain!
2 notes
·
View notes
Text
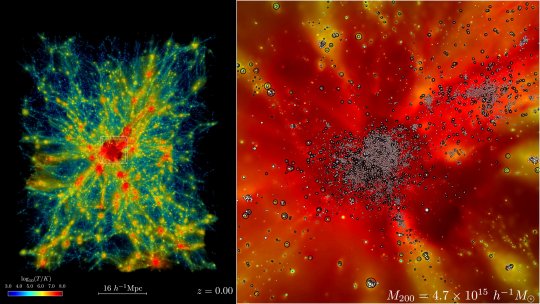
Record-breaking run on Frontier sets new bar for simulating the universe in exascale era
The universe just got a whole lot bigger—or at least in the world of computer simulations, that is. In early November, researchers at the Department of Energy's Argonne National Laboratory used the fastest supercomputer on the planet to run the largest astrophysical simulation of the universe ever conducted.
The achievement was made using the Frontier supercomputer at Oak Ridge National Laboratory. The calculations set a new benchmark for cosmological hydrodynamics simulations and provide a new foundation for simulating the physics of atomic matter and dark matter simultaneously. The simulation size corresponds to surveys undertaken by large telescope observatories, a feat that until now has not been possible at this scale.
"There are two components in the universe: dark matter—which as far as we know, only interacts gravitationally—and conventional matter, or atomic matter," said project lead Salman Habib, division director for Computational Sciences at Argonne.
"So, if we want to know what the universe is up to, we need to simulate both of these things: gravity as well as all the other physics including hot gas, and the formation of stars, black holes and galaxies," he said. "The astrophysical 'kitchen sink' so to speak. These simulations are what we call cosmological hydrodynamics simulations."
Not surprisingly, the cosmological hydrodynamics simulations are significantly more computationally expensive and much more difficult to carry out compared to simulations of an expanding universe that only involve the effects of gravity.
"For example, if we were to simulate a large chunk of the universe surveyed by one of the big telescopes such as the Rubin Observatory in Chile, you're talking about looking at huge chunks of time—billions of years of expansion," Habib said. "Until recently, we couldn't even imagine doing such a large simulation like that except in the gravity-only approximation."
The supercomputer code used in the simulation is called HACC, short for Hardware/Hybrid Accelerated Cosmology Code. It was developed around 15 years ago for petascale machines. In 2012 and 2013, HACC was a finalist for the Association for Computing Machinery's Gordon Bell Prize in computing.
Later, HACC was significantly upgraded as part of ExaSky, a special project led by Habib within the Exascale Computing Project, or ECP. The project brought together thousands of experts to develop advanced scientific applications and software tools for the upcoming wave of exascale-class supercomputers capable of performing more than a quintillion, or a billion-billion, calculations per second.
As part of ExaSky, the HACC research team spent the last seven years adding new capabilities to the code and re-optimizing it to run on exascale machines powered by GPU accelerators. A requirement of the ECP was for codes to run approximately 50 times faster than they could before on Titan, the fastest supercomputer at the time of the ECP's launch. Running on the exascale-class Frontier supercomputer, HACC was nearly 300 times faster than the reference run.
The novel simulations achieved its record-breaking performance by using approximately 9,000 of Frontier's compute nodes, powered by AMD Instinct MI250X GPUs. Frontier is located at ORNL's Oak Ridge Leadership Computing Facility, or OLCF.
IMAGE: A small sample from the Frontier simulations reveals the evolution of the expanding universe in a region containing a massive cluster of galaxies from billions of years ago to present day (left). Red areas show hotter gasses, with temperatures reaching 100 million Kelvin or more. Zooming in (right), star tracer particles track the formation of galaxies and their movement over time. Credit: Argonne National Laboratory, U.S Dept of Energy
vimeo
In early November 2024, researchers at the Department of Energy's Argonne National Laboratory used Frontier, the fastest supercomputer on the planet, to run the largest astrophysical simulation of the universe ever conducted. This movie shows the formation of the largest object in the Frontier-E simulation. The left panel shows a 64x64x76 Mpc/h subvolume of the simulation (roughly 1e-5 the full simulation volume) around the large object, with the right panel providing a closer look. In each panel, we show the gas density field colored by its temperature. In the right panel, the white circles show star particles and the open black circles show AGN particles. Credit: Argonne National Laboratory, U.S Dept. of Energy
3 notes
·
View notes
Text
Dell AI PCs: A Gateway To AI For Life Sciences Organizations

AI in the Life Sciences: A Useful Method Using Computers.
For life sciences companies wishing to experiment with AI before making a full commitment, Dell AI PCs are perfect. The Dell AI PCs are revolutionary way to get started in the vast field of artificial intelligence, particularly for clients in the life sciences who are searching for a cost-effective way to create intricate processes.
The Dell AI PCs, GPU-enhanced servers, and cutting-edge storage solutions are essential to the AI revolution. If you approach the process strategically, it may be surprisingly easy to begin your AI journey.
Navigating the Unmarked Path of AI Transformation
The lack of a clear path is both an exciting and difficult part of the AI transition in the medical sciences. As it learn more about the actual effects of generative and extractive AI models on crucial domains like drug development, clinical trials, and industrial processes, the discipline continues to realize its enormous promise.
It is evident from discussions with both up-and-coming entrepreneurs and seasoned industry titans in the global life sciences sector that there are a variety of approaches to launching novel treatments, each with a distinct implementation strategy.
A well-thought-out AI strategy may help any firm, especially if it prioritizes improving operational efficiency, addressing regulatory expectations from organizations like the FDA and EMA, and speeding up discovery.
Cataloguing possible use cases and setting clear priorities are usually the initial steps. But according to a client, after just two months of appointing a new head of AI, they were confronted with more than 200 “prioritized” use cases.
When the CFO always inquires about the return on investment (ROI) for each one, this poses a serious problem. The answer must show observable increases in operational effectiveness, distinct income streams, or improved compliance clarity. A pragmatic strategy to evaluating AI models and confirming their worth is necessary for large-scale AI deployment in order to guarantee that the investment produces quantifiable returns.
The Dell AI PC: Your Strategic Advantage
Presenting the Dell AI PCs, the perfect option for businesses wishing to experiment with AI before committing to hundreds of use cases. AI PCs and robust open-source software allow resources in any department to investigate and improve use cases without incurring large costs.
Each possible AI project is made clearer by beginning with a limited number of Dell AI PCs and allocating skilled resources to these endeavors. Trials on smaller datasets provide a low-risk introduction to the field of artificial intelligence and aid in the prediction of possible results. This method guarantees that investments are focused on the most promising paths while also offering insightful information about what works.
Building a Sustainable AI Framework
Internally classifying and prioritizing use cases is essential when starting this AI journey. Pay close attention to data kinds, availability, preferences for production vs consumption, and choices for the sale or retention of results. Although the process may be started by IT departments, using IT-savvy individuals from other departments to develop AI models may be very helpful since they have personal experience with the difficulties and data complexities involved.
As a team, it is possible to rapidly discover areas worth more effort by regularly assessing and prioritizing use case development, turning conjecture into assurance. The team can now confidently deliver data-driven findings that demonstrate the observable advantages of your AI activities when the CFO asks about ROI.
The Rational Path to AI Investment
Investing in AI is essential, but these choices should be based on location, cost, and the final outcomes of your research. Organizations may make logical decisions about data center or hyperscaler hosting, resource allocation, and data ownership by using AI PCs for early development.
This goes beyond only being a theoretical framework. This strategy works, as shown by Northwestern Medicine’s organic success story. It have effectively used AI technology to improve patient care and expedite intricate operations, illustrating the practical advantages of using AI strategically.
Read more on Govindhtech.com
#DellAIPCs#AIPCs#LifeSciences#AI#AImodels#artificialintelligence#AItechnology#News#Technews#Technology#Technologynews#Technologytrends#govindhtech
3 notes
·
View notes