#what is html file
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has 4 main sources of revenue.
Text
[Video description: In Playstation 1 graphics, an old man walks onto a snowboard course with his walker. He clips the snowboard through his walker, holding it for a second, and blasts off into the sky. Electronic music plays throughout; the beat drops when he flies away.
/End description]
I beg my followers to check out Battle Tapes' music video for their song "Brand New" - since I figure most people don't click on Youtube links, I took the liberty of using some tools to clip just the beat drop.
The rest of the video is just as good as this.
Here's the link; it's inline instead of embedded because it's 3am and I'm paranoid that people on Tumblr go "ew an embedded Youtube link": https://www.youtube.com/watch?v=Tp6an4eVzP8
#battle tapes#battle tapes - brand new#you would definitely believe how much trouble I had with VLC getting this to clip correctly#once I tried getting a 3-second long clip and it kept getting it wrong even though I KNEW what timestamps I was hitting “record” on#thankfully this clip is longer and a little more flexible on what timestamps are fine to record and which ones completely miss the highligh#and the ending timestamp was just...right on. Right on.#anyway VLC doesn't know how to convert files for the casual user#I had to use a web-browser based thing to do it#the tools I used:#4K Video downloader Plus (free): to get the full Youtube video because VLC couldn't stream it from the link#VLC: to clip the video down to just 10-ish seconds#Free Convert (website): to convert from .asf to .mp4 because VLC couldn't do it for me#siiiiigggh anyway hope you all enjoy this beat drop#maybe it's just recency bias that makes me think this music video is so good#oddly enough getting that inline link to work also took some doing#it either didn't create a link or it automatically embedded; couldn't choose like I can with links to other sites#Opened up a new tab. Draft a new post with its own link. Turned to HTML editor. Copied and pasted it here in this post (also turned to HTML#editor) and then replaced the link reference and the text.#and strangely during that time period I tried using AO3 links which weren't embedding either.#Link that I ended up using to get an inline link was the link to download VLC which. ha. Been having trouble there as I've said in the post#oh and by the way: all links embed at first. But in the lower-right corner there's a little bubble you can click to turn it to inline.#but for some reason that doesn't work with youtube links#aaaaaanyway#I'm done. Finally.#music#videos runnerpost#has description
15 notes
·
View notes
Text
Working on my javascript for my web page. Turns out I have the perfect kind of setup to accomplish some of the project requirements, specifically with even handlers and user interactions
My website, conceptually, will load a different employee details page depending on what employee name is clicked on. But I need to load it dynamically (instead of hard-coding it) so that the user can add or delete employees & it'll be able to still load the relevant shit.
So! Only one employee details page, but depending on how it's loaded, it'll load a different employee's information. Still working on getting down Exactly how to do it (I'm thinking using URL parameters that'll read a different object depending on what ID is used)
It's entirely doable. In fact, it's probably extremely common to do in web pages. No one wants to hard-code information for every new object. Of course not. And thus the usefulness of dynamic javascript stuff.
I can do this. I can very much do this.
#speculation nation#i wasnt very good when i got home and i read fanfic for a while#then took a nap. and now im up again and Getting To Work.#i dont have to have this 100% perfect for final submission just yet. bc final submission isnt today.#but i need to have my final presentation over my thing done by noon (11 hours from now)#and im presenting TODAY. and part of that will be giving a live demo of my project website#so. i need to have all of the core functionality of my website down at the Very Least#might not be perfect yet. but by god if im gonna show up to my presentation with my website not working.#i need to have the employee list lead to employee details with personalized information displayed per employee#i need to create an add employee field that will Actually add an employee. using a form.#and that employee will need to show up on the list and have a new id and everything. the works.#need to set it up so that employees can be deleted. shouldnt be too much extra.#and it would be . interesting. to give an actual 'login' pop-up when someone clicks on the login button#with some kind of basic info as the login parameters. this cant be that hard to code.#the project requirements are: implement 5 distinct user interactions using javascript. at least 3 different eventhandlers#at least 5 different elements with which interaction will trigger an event handler. page modification & addition of new elements to pages#3 different ways of selecting elements. one selection returning collection of html elements with customized operations on each...#hm. customized operations on each... the example given is a todo list with different styles based on if an item is overdue or not#i wonder if my personalized detail page loading would count for this... i also have some extra info displayed for each#but i specifically want the employees to be displayed in the list uniformly. that's kinda like. The Thing.#actually im poking around on my web pages i made previously and i do quite enjoy what i set up before.#need to modify the CSS for the statistics page and employee details to make it in line with what i actually wanted for it#maybe put a background behind the footer text... i tried it before & it was iffy in how it displayed...#but it looks weird when it overlaps with a page's content. idk that's just me being particular again.#theres also data interchange as a requirement. but that should be easy if i set an initial employee list as a json file#good god im going to have to think of so much extra bullshit for these 10 made up employees#wah. this is going to be a lot of work. but. im going to do it. i just wont get very much sleep tonight.#that's ok tho. ive presented under worse conditions (cough my all nighter when i read 3gun vol 10 and cried my eyes out)#and this is going to be the last night like this of my schooling career. the very last one.#just gotta stay strong for one more night 💪💪💪
6 notes
·
View notes
Text
We've reached the 'fistfighting with the Ao3 text editor' portion of chapter completion.
#Method Acting#whyyyyyyy are some paragraphs double spaced but others aren't???#i'm going to stop copy/pasting and try ex/importing files and see if that makes a difference because I don't know what's going wrong here.#wait nope that's not an option. well.#for once in its fraught life... I prefer FFN's doc manager.#if I export a .odt file from google docs into focuswriter and then ctrl+a copy paste into Ao3's HTML editor from focuswriter#then it seems to all work?#which is annoying but not any more annoying than manually deleting extra <p>'s in the ao3 text box is.
3 notes
·
View notes
Text
I'm being so normal about my code and definitely didn't just almost cry (positive) upon confirming that I successfully linked my JS file in my HTML file with a relative path and it runs exactly as expected
#sfw#personal#ok to reblog#I am intentionally putting the more generic tags later so that they will hopefully be used for local organization but not in global searches#programming#code#HTML#JavaScript#webdesign#in my defense I'm realizing that I have finally learned all three of the web code brothers and I can use them together#and I'm not even struggling#and I'm realizing I have so much creative power now#and also that my fear of JS was almost totally baseless like it's not even a tenth as bad as it sounded#but I just finished a set of functions that I thought impossible and impenetrable a few days ago and my code works first try*#*unless you count a few easy to find typos#I'm just. huh. ok. apparently this is something I can do now. and I'm not even doing it wrong? I don't know what to do with this information#(to be clear the file link triggered this ig just bc it was like the final touch to make it Official? but it wasn't about that specifically)#(also I wrote this and forgot to post it for almost an hour oops)
17 notes
·
View notes
Text
my roommate hasa to get a phone today because of storage. i cant wait to see how much i want to kill myself by the end of this!
#hes like fucking clueless and takes forever#and like ik i get it but couldnt you bother to go over shit a million times before hand??#mine took 10~mins max with going back because i forgot to switch my number over.#knowing him hes gonna get the exact same thing but take 50 mins or so to think on it#like what is there to think on??#its not like hes trading in his phone or smth#'well finances' well your work and lack of storage says too damn bad.#just suck it up and do it bro its not that big of a deal.#(coming from the guy who deleted literally everything that he could from his phone before daring to consider getting a new one for 3 years)#damn that phone lasted longer than my relationship holy#both my roommates kept all their old phones so#they just gave them to me??????#i dont really know why either?????#like just full acesss. no passwords no nothing.#im too scared to look at the photos on some of them tbh#roughly and i quote 'youre the techy guy you can probably find a use for them'#im. really not. i vaugely know which files i need to get into and how to alter game code and change vcl skins.#i took a intro to coding corse once and sucked at it.#it was mostly just html and css and i just made like every word penis.#im not that good at this shit.#tbf. i know the difference between a micro usb changer. type c. and a iphone charger and they think im god for it so. idk where my standard#even are atp. ok but seriously just look at the plug in its literally just basic ass shapes.#i love praise but i genuienly belve im sub par and everyone around me is just acting stupid.#because that totally helps a warped sense of self doesnt it!#god im just fucking dreading this. i have to get showered and go with him and stand there for like an hour or so with no chairs explaining#the most basic shit while he keeps double checking with everyone else. like bro dont ask me in the first place. then have to come back and#help him set it up and get a million questions about how icloud works#and reinstall all his apps. and then maybe ill be done 5 hours later.#i cleaned my desk the other day i was planning to get some shit done with my set up#(i hate my current set up. like its fine and all but oh my god its kinda horrendous. i made 'decorations' if you can even call them that bc
1 note
·
View note
Text
I really should look into whether or not someones already made a better implementation of the ideas that I have...
#trying to make a tool to generate static websites from markdown#the idea is that you would have a template html file and you'd put “[content]” somewhere in it#and my tool would go through all ur markdown files and convert them to html and replace the “[content]” thing w/ the rendered html#trying to make it in c which was like maybe a mistake cause out of all the languages I know its the one I'm the least experienced in#and its only one I know that'll let me shoot myself in the foot#and I don't really know much about the proper way to build things#tried fucking w/ make but I like need a .so file or smthing to compile it? and idk what I'm supposed to do w/ that thing#honestly now that I think about it this could prolly just be a bash script lol
1 note
·
View note
Text
in trying out different stuff w this comic, i'm reminding myself of an old 2014-era comic i drew based on a zombie au AH fic. went back and looked, sure enough, i never posted it anywhere. this.... both surprises and doesn't surprise me. on one hand, i like to have everything documented nicely, and on the other hand, i think part of my brain then couldn't wrap around like the fact that i was drawing this stuff that, while fiction, was based on Very Real People
idk, but tbh i am quite fond of that comic, simply because i tried something new and different with it and i think the things i tried worked out very well! i then proceeded to never try that with any comic ever again until now lkdshgls
anyway ig i'm wondering if it'd even be worth it to post it bc on one hand, documentation, i like to have all my art stuff collected together in a gallery of sorts to be able to see everything. on the other hand, it's ten years old at this point, so extremely out of order, and also it's. achievement hunter. which. 😬 i kinda don't wanna touch anything rooster teeth at all.
#rambles#delete later#one day i will have a website where everything will be organized by year#and it won't matter if i'm posting stuff ten years after it's drawn bc it can still be filed under the appropriate year with everything els#lies down#one of these days......#i just need to like.#y'know#learn html#and css#;;;;;;;;;;;;;#tell you what tho this is making me even go back to the first page sketch i posted and messing around w the paneling#i'd like to try to experiment a bit with this i think
1 note
·
View note
Text
bruh like
#my roommate great and all#but girl just copying from chat gpt for this project and like it's allowed and its fast and that 's fair and valid esp since this due tmrw#but i dont like it :c#i dont even know what i want to say but like i just feel so slow and dumb when shes just speeding thru copying whatever chat gpt says#without rly looking at it or anything idk idk#also fucking stupid thing is i was actually looking forward to writing part of this part of the project#bc i LIKE writing html i like writing the html template and rendering it :c#but she just chatgpt-ed it i didnt even realize#until she was like ohyeah we just gota figure this issue out and then its done (if it works)#and she'd already chat gpt=ed all the files#idk bro i just dont trust chat gpt like that lmao TT#i trust it enough but not enough to just copoy and paste from it so quickly#also im very tired so im just sad abt not being able to actually do part of this i fucking guess#but like better for us ig bc we dont have time#idk im just like#wanted to do more for this project bc i kinda failed at the last one as a group member#and i did do more esp for the first part but just like#doesnt rly feel like it idk ndfhbfdgjdbsfjdbfgkfdk#jeanne talks#wait the ...... template isnt even correct bc chat gpt did its own css style but we have style we can use#well ig it's fine and it's probably correct but#ugh idk lmfao just been generally feeling shitty abt academic shit this week anyway so yay#and like girl what the fuck am i supposed to do to help rn . i have no idea what all this shit is i didnt even see u copy and paste it ;-;#what am i doing here in this zoom then i actually have other work to do at this lovely hour of 2 in the morning
0 notes
Text
A Brief Guide on Uploading ChoiceScript Demos to Itch.io
Since Dashingdon is shutting down, and there will be a lot of folks wanting to host their ChoiceScript demos elsewhere, I thought it'd be a good idea to provide a brief guide on how to do so for itch.io.
This is for Windows in the folder actions, but it shouldn't be too difficult for folks to translate for Mac. This also assumes you haven't changed any of the files within your game folder other than those found under 'scenes'.
Within your game folder, locate the 'web' subfolder, right click it and select 'Send to' then 'Compressed (zipped) folder. Name your newly compressed file something sensible, and I recommend moving it to a new folder outside of your game files, just to keep everything neat and tidy.

2. Assuming you already have an itch.io account, navigate to your dashboard, and click the 'Create New Project' button.

3. Name your project as you like, and under 'Kind of project', select the 'HTML' option.

4. Set the 'Pricing' to 'No Payments', you cannot use ChoiceScript for profit unless it is with the Choice of Games or Hosted Games publishing labels. No one wants to get in trouble unnecessarily here.
5. In the Uploads section, upload your newly zipped file we made in step one. After it's finished uploading, you'll be given one drop down and two tick boxes. You need to tick the 'This file will be played in the browser' option.

6. I've found so far that 'Viewport dimensions' work quite well for desktop at 1080 x 640. Either use these numbers or experiment and find what works best for you.
7. You must tick the 'Enable scrollbars' option for your game to display properly, otherwise options, text and buttons can be clipped off the bottom of the viewport.

8. Continue filling out the rest of the form, or skip it for now and scroll all the way to the bottom to the 'Visibility & access' section. Here make sure you have 'Draft' selected. This prevents others from finding your game until you're ready, and I always recommend play testing things before you make your work public.
9. Finally, hit the 'Save' button, then go and have a look at your creation by hitting the 'View page' link. And there you go! When you're ready for public release, just change the option in section 8 to 'Public'.
---
A few things to bear in mind about hosting on itch.io:
There isn't currently any way for your readers to save their game. I'm sure someone could write in a plugin similar to Dashingdon's at some point, but as for right now, this isn't available. See addition/edit below.
Make sure you properly tag your game with the 'choicescript' and 'interactive-fiction' tags. There are an awful lot of games on itch.io and it's easy to get lost in the crowd. Make sure folks can find you by having the right tags.
I hope this brief guide was useful to folks.
Best of luck to you with your writing!
---
Addition/Edit:
Thanks to @hpowellsmith for bringing this to my attention. You can add save functionality to your game by using this addon:
The ChoiceScript Save Plugin
Just tried it out on my own game and it works perfectly.
Rather than run through the addon author's own tutorial here, I'll just forward you to the Readme on their Github page.
One small note I would add is when it asks you to make the two small additions to your index file, make sure you right click the file and open it with your coding program, don't double-click it as this will just open it in an internet browser, and it won't give you the access to what you need to change.
715 notes
·
View notes
Text
Tumblr Backup Options: None of them do everything
Cheeky but true. I'll go through what's good and bad about each option though so you can decide which balances out for you.
Covered: native export, WordPress (kinda), TumblThree, tumblr-utils (kinda)
Native Export
If you go to "https://www.tumblr.com/settings/blog/yourblogname", at the bottom of the page is an export option

Once you hit the button to start the request, it will start processing. Feel free to log off, this is going to to take a few hours. You don't need to keep it open. ~22k posts took roughly a day for me. If you have a small number of posts and get stuck, you're probably broken.
When it's done processing, you can hit that download backup button and then wait some more as you wait for the zip file to download. Mine failed the first time after like twenty minutes, and then I had to start over. I think it took 1-2 hour(s) and I'm almost certain that was on Tumblr and not my internet. And that was the zip file! So make sure your computer can be on for a while before getting this started.
So what do you get?
A media folder, conversations folder, and posts folder
Media folder: Every single photo, gif, and video that has ever been on your blog or in your DMs. There is no context data attached (except for dm images which do say which conversation they're from at least), but they seem to be in chronological order because they seem to be titled by the post's ID (the string of numbers in the address bar after "/post/"). They look like "100868498227", "100868498228_0", "100868498228_1"
When you see something end with "_0" and up that means the photos are in the same post, so _0 represents the first image in the post, _1 represents the second, etc (at least, I think).
Conversations folder: HTML export files of every DM history you have on your blog. These are actually pretty well formatted, see example here.
Posts folder: html subfolder and posts_index.html file
posts_index.html: File listing every single post on your blog by post ID on its own line with no other context. Example of a line: "Post: 780053389730037760". The ID number will link to the post in the html folder
html subfolder: contains a submissions subfolder and stripped html file versions of every post on your blog. See below first what the post looks like on Tumblr, and second what the post looks like in the html folder


The way you seem to be intended to use this is to open the file index, select a post ID, and be jumped to where that post is saved as an html file, but I don't know why you would bother when the index doesn't provide any information about the posts inside it. The posts all have extremely minimal formatting. See a reblog chain below.

Notice I said ALL posts on your blog. Photo posts without a caption will just have a broken image icon and then the date and tags. Theoretically, it might be that if you unzip the entire export folder that allows it to automatically link to the image saved in your media folder. I have no fucking idea, unzipping the folder was estimated to take two hours so I didn't do it. Let me know if you do though so I can update this post!
The submissions folder is such a rabbithole I made a post just on it but long story short it's asks you haven't replied to
What do I see as the main reasons to opt for this option? 1) you don't want to download any programs or files from the internet just to backup your blog, 2) your blog is relatively small, so digging through the ID files isn't a big deal, 3) you mostly just want to download either the images (which will be browsable via thumbnail previews in the media folder if you unzip it) or conversation history, which are fairly well formatted, 4) you don't need to update your export often/ever, because you'd have to request it from the start and download the entire thing all over again, 5) you want to be able to read your text posts clearly and don't care about preserving the full formatting, and/or 6) you don't plan to reupload this information elsewhere (say on... a WordPress blog)
WordPress Automatic Ex/Import
Move your post's from Matt's right hand to his left! WordPress (another product of Automattic) has a native Tumblr importer found under your WP Admin dashboard for your site under Tools > Import > Tumblr.
How does this work? No idea! I hit import 2 days ago and it has done nothing. Maybe I'm stuck, maybe it's permanently broken. It says to contact support if it's been over 24 hours but they don't make that easy. I disconnected from Tumblr (you can only port over a blog you have the login of) and reconnected and it still said it was importing. I don't think it's ever going to do anything.
Presumably it's supposed to 1:1 import every post on your blog onto the WordPress site, which will result in a whole lot of stolen art because there's no way to select just your original posts. Also, you'd need enough storage on your webhost to house all the posts (this honestly might be my problem, but I was planning to delete all the non-original posts once it imported.... anything and backfill what it didn't get to). The one thing I'll say about this option is that it's the only one I've seen so far that exports drafts and queues as well.
I mean, if it exported anything. If this ever does anything I'll update this post, but either my blog is too large or this tool isn't totally functional anymore.
TumblThree
(previously TumblTwo, etc)
TumblThree is an all-in-one program requiring no extra downloads beyond the main Zip, and was last updated fairly recently at the time of this post. In order to run it, unzip it into one folder and run the main .exe. It has a full UI interface with lots of very descriptive helper text to help you select the right options for you without looking at the wiki. I think it's user-friendly for non-tech people.
There are a lot of options in TumblThree to change what output it gives you, but I'm going to start with the largely universal parts first:
Everything from one blog will be exported to one folder, no subfolders or sorting. As a result, the output is very messy and difficult to wade through, but post metadata and the photos are named in the same way so you can scroll, see an image preview, and then click on the metadata txt for that post and read the caption.
Depending on your settings, you can export all photos, videos, text posts, etc as their own files or exclude them from the export entirely. For the different types of media posts, you can independently select if you what to download just the media, just the metadata for it (everything that surrounds the post when you see it on Tumblr, such as the caption, OP, tags, etc), or both.
Master txt file: For every type of media metadata you export, a correspondingly named txt file will be created (images.txt, answers.txt, etc) that contains the text/metadata of every post of that type in one txt file. This is also the default behavior for exporting text posts.
Note: for text posts (which includes asks/answers), it only creates a master txt file if you do not select "Save texts as individual files", in which case it will only save each text as an individual txt file and not make a master file.
The formatting on these files is so brutal I won't even give examples, but they're unreadable. Being a .txt file, there is no native formatting, so it exports in html formatting.
Example: instead of a post that says "I want to go swimming", it exports: "I want to go < b >swimming< / b >" (minus the spaces around the b) as the post body, which is a big part of what makes it unreadable, because there are a lot of hyperlinks in all the header information listed below.
Each post in the master txt exports with: Post ID, date, post URL, slug, reblog key (no idea what that is), reblog URL, reblog name, title, [the text/caption itself], and tags.
Theoretically this means you could ctrl+f "cybertrucks" in the master txt file and then browse all your posts making fun of Tesla owners by tabbing through the returns. This is not possible with any of the previous options, and only is possible because it's all in one file, as ridiculous as it is, which is why getting that master file is so important.
For the trick to get both the individual text posts and master text.txt & answers.txt file, as well as my recommended settings and details on how updating backups works, see the read more at the end of this post.
The images.txt includes all the information listed above, but with the following additions: photo url (NOTE: this is the url on Tumblr, not a link to where it is in your folder), photo set URLs, photo caption, and "downloaded files" (NOTE: this is the name of the file it has downloaded)
The video.txt is similar to the above
The use case for this would be similar to what I described for text posts above: search keywords from captions, tags, etc and when you find what you think is what you want, copy the name from "downloaded files" and search your folder to find the actual image
I really hated TumblThree's output the first time I looked at it and then I realized the single file is the only way to make browsing tags workable, because otherwise you would have to have a folder for every tag, and posts with multiple tags would have to be duplicated between them. I'm not pressed on finding a txt to HTML converter right now but it could be an option in the future if you wanted to make things more readable.
Okay, let's get into the non-universal stuff you can customize in settings, because it's like, everything:
File names: We've already established you can search with the downloaded file name for images, but what will that be? Whatever you fucking want. Post date, reblogger name, post ID, post title, original file name, you can make it any and all of these in any order you want! You can have actually useful file names! Personally I like %e_%p_%q_%i_%x which exports as DateTime_PostTitle_BlogOriginName_PostID_IteratingNumber (note: you need some kind of unique iterator to be valid so two files don't have the same name, such as multiple photos from one post). Look how much searchable information that gives me, in chronological order! It decreases your need for the master txt file.
Tip I wish I thought of before doing my massive export: make one of the unique headers from the master txt file part of the exported file name so it's easy to search for it after identifying it in the master file.
Files scanned: this is the only method I've found that lets you back everything up, remember what it backed up, and then lets you add any new posts since that date without having to download the whole thing again. That's a game changer, but see the read more below for limitations.
You also have the option to rescan the entire thing if you want.
Post type: T3 (I'm abbreviating it now) also lets you export just your original posts, just reblogs, etc - again, giving you the most control of any options. It also lets you export replies. I, uh, would not do this because if you have any popular post on your blog it might have hundreds, or thousands of replies but hey, you can do it!
You also have the option to only download posts with a certain tag.
Blog options: You can export literally any blog you have the URL of. In fact, if you copy a blog URL while it's open, it will automatically add that blog to its UI and create an empty folder for it. It makes it easy, no private key required. I do have mixed feelings about the concept of exporting someone else's blog... but I'm also planning to do it to some of Crew-ra's blogs so... my digital horde must grow.
You can also queue blogs up and leave it to run through a lot of them. It is a lot faster than Tumblr's native export, I started this import well after I started typing this post and it took a few hours, probably not all that much longer than just downloading Tumblr's export took (and that's while running it alongside other data copy operations because I'm backing up a lot of stuff right now).
I do recommend doing a test export with a sideblog, I was able to use wild-bitchofthenorthwoods as a test import since it only has one post and it has media, so it was super quick.
(I do want to note, I think the number of downloadable items starts out matching the number of posts on your blog without scanning them until you start the export - but if you choose to export everything as its own file, you're going to end up with way more than that because a post with three images would be multiple files)
Things T3 cannot export:
Since in its simplest form it's just accessing the public upload of your blog, it cannot export your drafts, queue, or conversations
It cannot export posts as HTML files, and thus cannot export them with readable formatting natively
What do I see as the main reasons to opt for this option? 1) you don't care about exporting your DMs/conversations, 2) you want the ability to export only certain kinds of posts (original, photos, using a tag, etc), 3) you want to control the titles of the exported files 4) you don't mind wading through massive folders, 5) you want the ability to search tags (using the txt files), 6) you want the ability to update your export without starting over from the beginning, 7) you either don't want to reupload this information somewhere else, or you want to upload it somewhere that supports automatic HTML conversion (for instance, you can switch a Tumblr post from a rich text format to HTML, same with AO3, so you can put it in as HTML and then hit post to see it turn into a rich format. This techically makes T3 the most versatile/useful export option if you're planning to do anything with it other than browse your own files).
tumblr-utils
Full disclosure: haven't tried this one. But others have! tumblr-utils is a no-UI, python-based backup software. This means in order to use it you have to type commands into the terminal. If you don't know what I just said, don't use this one.
If you do, you'll need to separately download python and youtube-dl just to get this one running. You'll also need to give it your personal Tumblr API key and feed it commands deciphered from the wiki page I linked. Here are two different guides people have written on how to use it. Output:
Obviously I'm guessing based on the documentation, but one thing that is nice is this tool allows you to save each post in its own folder. Presumably each post is multiple files like we saw with T3, so this would make it easy to group them, but it also means you'd have to look in every single folder to find anything.
It seems to break posts up into timestamp folders by month, again, helping with management to narrow down where you have to search
It allows you to save only certain kinds of posts at a time like T3
It allows you to backup posts only from a certain time period (so if you keep a little .txt note of the last time you backed up, you can easily add only the new posts into your backup without having to start over from the beginning)
It allows you to only save posts under a certain tag like T3
It allows you to save only original posts
It's the only one I've found that lets you back up your liked posts
What do I see as the main reasons to opt for this option? 1) you don't care about exporting your DMs/conversations, 2) you want the ability to export only certain kinds of posts (original, photos, using a tag, etc), (okay now we get to the points that aren't also covered by T3), 3) you want posts to export already broken into folders, whether by post or by month, 4) you want to back up your likes, 5) you don't care what file names look like, 6) you're comfortable with the command line/coding and don't need a UI.
Summary:
None of these options are ideal for reuploading your files anywhere (except WordPress), but I do think TumblThree is the best of the options because of the written HTML formatting in the txt files being useful for websites that support automatic conversion (or require HTML input).
For starting another blog, WordPress wins. If it works. I'm trying to be generous here.
For searchability, T3 wins again.
For versatility... yeah you know it's T3, but tumblr-utils has a lot of the same features, too!
For sentimentality (aka conversations), it has to be the native export. There literally is not any other option.
For queues and drafts, the only theoretical option is WordPress. If it works.
For likes, the only option is tumblr-utils.
Every option does something the others don't, so theoretically to cover everything, you have to do all four options. Actually I would say do the native export if you don't have a lot of posts and aren't a freak like me, check it out, and if it doesn't work (I know it's finnicky) or you don't like the export, go with TumblThree. This also means you'll at least have your conversations even if you don't end up using the native export any other way.
And I wish it could go without saying, but don't repost people's shit, y'all. I'm backing up everything for my records only and it will never be shared with anyone else, or even browsed as long as using Tumblr instead is an option.
TumblThree adding to old backup quirks, recommended settings, & master file backup solution:
Adding to backup quirks:
From my tests, when you scan a blog you've already backed up to just add new posts to it, it does not update the master file, so if you want to update it, you'll have to do the steps I list at the end of this post. It might be possible it does update if you force rescan, but I highly doubt it.
If you scan a blog you previously backed up under more restrictive settings - say you only backed up original text posts as one file before and now you've selected to back up absolutely everything - it will only download up until the time you last backed up that blog. It will not blow past where you last downloaded to download all the photos and videos it didn't get before just because they're selected now. This is great for doing after using the master file solution I'm showing below, but if you do need to download everything after doing a more restrictive scan, you can once again follow the first few steps below to do so.
Recommended settings:
This will obviously vary by what you're trying to do, but one or two things weren't immediately obvious to me and I did say I think this was the best solution for less technical users, so I want give my personal recommendations. Settings can obviously be found under the settings button at the bottom of the screen (you may need to use the scrollbar on the UI for, which is separate from the scrollbar on the blogs panel), but when you click on a blog, when you click "Details" in the right sidebar, you can also see your most important settings at a glance and adjust them to whatever you want them to be "per blog". I believe TumblThree remembers what you last used for the blog and applies the things in settings only to new/other blogs.
The thing that is going to vary the most is how many different types of posts you want to back up (text, video, reblogs included, etc), so I'll leave that up to you. If you're going to export a media type, though, I generally recommend exporting the metadata too.
I already gave my preferred file names above and again that's going to be something that varies a lot by people. Hover over the "Filename template" box and it will give you all the options in the legend you can combine via underscores.
Leave "Skip .gif files" off unless you're hurting for hard drive space. This removes all the gifs from your download, and the reason this is provided as a separate setting is because gifs have relatively massive files (at least compared to a text file)
I'll be honest I haven't seen a difference between turning on and off "Group photo sets". Because of the way file names work, most conventions will naturally lead to photos from the same post all being in a row.
"Save texts as individual files": if you only want texts to be saved as their master text.txt and answers.txt files, uncheck this. If you want the individual files I highly recommend you also download the master file for searching purposes, in which case my recommendation is this:
1) Select to export texts only, leaving off all media options, and uncheck the "Save texts as individual files" option. 2) Export the blog. This will only result in two files, answers.txt and texts.txt. 3) Move these files elsewhere on the computer to save them. 4) With T3 closed, delete the folder for the blog and the blog's Indexes (see instructions at the end of this post for finding these). 5) Reopen T3, which shouldn't remember it ever saw the blog and create a new folder for it. Turn on the "Save texts as individual files", as well as any other media posts you want to download. 6) Export the entire blog again. 7) Move the texts.txt and answers.txt file back into the blog's folder.
I leave all other options on the Details tab off, except for:
"Force rescan" scans past the point it last backed up and searches the whole blog again. If you have a big blog, this is going to burn time. This is needed for the number of downloaded items in the panel to be accurate but I don't know why you would care or turn this on unless it lets you skip steps 3-4 above, but my blog is too big to burn through testing that, so if you try it, let me know and I'll update this post!
Master file backup solution:
See my 7 steps from above to skip having to do this, but if you accidentally do things out of order and then realize you still need the master files for texts post after backing everything else up, here's how you get it with minimal pain:
T3 will make an "Index" folder in both the main folder for the program where the exe is located and the destination folder where you have your blogs backing up (note: these were two very different places for me, if you just have it back up to the automatic Blogs folder within T3's folder, it might not create a second Index folder).
To make T3 "forget" what it has backed up previously so it goes through to the beginning and makes a master file that includes everything, all you have to do is remove the Index file(s) for the blog while it's closed so it doesn't remember it anymore. I backed my index up in another folder.
Check off for it to only download text posts, and then uncheck the "Save texts in individual files" option. This will cause it to only create the master answers.txt and texts.txt file on the rescan.
The combination of only going for one post type and only downloading one file for it means this rescan is relatively fast. When you look at your Blogs folder, you'll find a new folder has been created for your blog name (in my case, there was "n7punk" and "n7punk_2) and your output is in the new folder. I just moved it over to the original folder.
At this point you can restore the indexes, though I've only gotten it to half recognize them. I can get it to recognize my original n7punk folder so everything can stay there, but the total downloaded items is stuck at what it was when I did just the text posts. I don't really care, it was mainly the folder thing I wanted to fix. If you have lag between your last full backup and your master-only backup, this might cause some issues? I don't know because I made sure there wasn't lag, so I recommend doing another backup to add any missing items before doing this method.
You can also use this technique if you want to download only your original posts and then download everything else to a second folder. Adjust the setting to only download original posts, download the whole blog, close T3 and delete the indexes, rename the folder to whatever you want ("n7punk_original", etc), and then reopen T3 and set it to download everything and run it again from the start.
#tumblr#automattic#words and things#tumblr hacks#resource#tumblr-utils#tumblthree#100#posts that haunt me#in a good way back up your shit yall lol
436 notes
·
View notes
Text
UPDATE: As of 25/04/2025, 4chan is back up and running again. This post and its addendum will be kept as is, and will no longer be updated unless it goes back down again. If you were on /ghost/, it was a pleasure shitposting with you.
All right, I know no one gives a shit, but let me give you a recounting of the fall of 4chan from the perspective of someone who was there and has been lurking both 4chan and tumblr for a few years now.
I'll try to provide as much context as I can, but a lot of images were either lost or im too lazy to look for them in the +5000 reply thread in soyjak party.
Anyways, info below:
So, necessary context: a few years back, 4chan had a board called /qa/, which if you know little about the page, you may think every board is like /b/ or /pol/, which means a containment cess pool of grifters, (you) baiters, incels, and other deranged individuals. The thing is, /qa/ was somehow worse. The entire board was plagued and infested with soyjack edits, board culture was a nuclear disaster, anons were incredibly hostile in there, you know the drill, the big bad 4chan, but this time its actually true.
One day, moderation deleted /qa/, anons that posted there got mad, tried to raid other boards, failed, and then moved on to an altchan called soyjack party, which entire purpose you can guess from its name alone.
Apparently, the boards that allow pdf uploads (paper and origami, for example) didn't check if the uploaded file was actually a pdf file, so postscript files could be used to get access. This is as far as my understanding of web backend goes, sorry.
The hacker claims to have been working on this since 2021, and that he had access since about a year ago, but was recopilating data.
Now, what actually happened when the hack ocurred? Well, a banner of miku dancing with a song that played automatically was placed on top of every board, with the text "/QA/ IS BACK", this was possible because apparently no board was ever deleted, they were just hidden from the public.
A thread was then made on soyjack party, claiming authorship over the hack, and shit went south from there. Anons went en masse to talk there, a lot of weird discussion happened, the thread got the bump limit removed and got pinned, more than 5k posts were amassed on the first night alone. Keep in mind this happened at about 8 pm and most of the stuff went on through midnight.
So, the hacker leaked some things, first of all, the html files for the entirety of /j/ and the email address for every moderation member (important note: the pressence of .gov mails was disproven by the hacker themselves, so i guess there were never any feds), what is /j/? the board exclusive for jannies and moderators to discuss actions taken on the website regarding spam, ban evaders, threads spiraling out of control, etc. Among other things, some of the inner workings of 4chan got revealed, such as the web extension for jannies that allows them to do their job easily, how reports are handled, and other stuff. (Anecdotically, some guy got permabanned for calling anons jews or n-words over a 100 times in the same few threads)
Then, the source code got leaked. Important to say, the hacker removed the part of the source code related to the captcha, as to not facilitate bot attacks on the future, and all information related to email verification or 4chan pass users information also got removed, so all in all users are safe.
What was found on the sourcecode? That it was old, mostly. Most boards used code that hasn't been updated since about 2016, and /flash/ used the exact same code from when it was created back on 2011.
From there, desuarchive, a site that archives threads that die from bump limit, opened a dragon ball general on ghost mode, and thus began what later got called /ghost/, a solely text based thread with well over 20k replies as of right now, where a fraction of the 4chan population took refuge and is currently discussing random things with no particular topic. Kinda hard to read, but its comfy.
What does this mean for other sites? Not a lot, really. A lot of anons already crossposted in 4chan and tumblr already, and the ones that din't most likely wont come here. Some of the bigger/most dedicated groups, like /vt/, migrated to other boards. Various altchans are trying/tried to catch some of the flock of users that got lost, but i doubt it will get anywhere, since soyjak party for example was struggling with just the influx of users that came for the hack thread given its poor infrastructure. Kiwifarms saw a surge of new accounts apparently, but a lot of anons kinda loathe the idea of having to register, so theres that.
Smaller communities, such as generals that didn't get a lot of traffic, or boards on the slower end (say, /ic/, /lit/, etc) will probably vanish or disseminate until (or if) 4chan comes back up. I'd say give it a month, don't get your hopes up whether you want it to stay dead or want it to come back.
Given how many anons are staying on places like /ghost/ or other similar archives with the same ghost posting feature, i doubt it will be as bad as people are making it sound. Besides, the communities that are most likely to migrate to places like tumblr are either /co/, /vg/ or /lgbt/ refugees, which aren't THAT bad. Not every board was like the main cesspools (/b/, /r9k/, /pol/).
From now on, either 4chan comes back up in a few weeks (somewhere between 2 weeks to a month is expected), altchans capture the migrating anons, or a brand new imageboard rises from the ashes to become the new go-to site for old 4chan posters.
In conclusion, nothing ever happens, but also don't worry, chances are this won't affect tumblr in the slightest. If it does, you can cash in your "you were wrong" ticket whenever you want, i'll take the L.
As a footnote, keep in mind: NO users were compromised, if you ever posted there and are worried for your safety, physical or digital, you are safe.
Edit: Forgot to add, if you are a 4chan refugee, im BEGGING you to dm me and tell what board you were from and where are you migrating, if at all.
487 notes
·
View notes
Text
you should make a website!
"my favorite social media site is shutting down!"
"the CEO of the site i use just committed another atrocity!"
"i want a webspace that's all my own!"
if any of these sound like you (and if you're on tumblr, i know at least one applies) you should make your own website!
why make a website?
incredibly customizable
you can put whatever you want on it
it's, well, your own! like a house you build with your own hands
things you'll need
a computer. you can maybe get away with doing this on a mobile device, but i have zero experience there
a code editor. i like VScodium, which is a de-microsoft-ed version of VScode.
a will to learn ;)
site hosting
neocities. everyone knows neocities. at this point i do feel like it's become a bit too centralized, but it's a good option nonetheless. do note that there are filetype restrictions for free users, but that shouldn't be a huge issue for most. what may be an issue, though, is that there's a content security policy that prevents sites made after jan 1st, 2024 to use outside scripts. also, you have to pay to use your own domain
nekoweb. similar to neocities, but there's no filetype restrictions or a content security policy. some differences are outlined in the FAQ (thinking about moving here... i am a traitor...) i'm not sure if domain support is free or paid.
github pages or codeberg pages. you'll need an understanding of git for this
pages.gay: run by besties.house, uses git
teacake: free hosting is currently closed, but paid hosting starts at 2 bucks a month.
leprd.space: i know next to nothing about this.
a web server. don't recommend this if you don't know computer stuff but it is an option (you'll likely have to provide your own domain though)
gripes & solutions (?)
i'm not comfortable maintaining pages in pure HTML / templating with JS sucks!
with a static site generator, you can write pages in markdown and they'll be converted into HTML and (if you'd like) be put into a template of your choosing. my personal choice is 11ty but there are tons of options!
static site generators can be a bit of a learning curve (and you will have to write some html for templating) but if you're making a lot of pages or blogging regularly it's something to consider
there are starters for 11ty online but i might make a more beginner-proofed starter and/or guide in the future? don't count on it
i don't want to write/maintain CSS
simpleCSS is a tiny CSS file you can use to make semantic HTML ("naked" HTML) look nice. it's got decent customization options too. it's not particularly fancy or opinionated, but it's a good starting point if you need something
i don't know what to put on my website!
small list of ideas:
weblog
art/writing/music gallery
movie/show/book tracker
place to store bookmarks/links
scary! i'm scared!
my askbox/messages/e-mail inbox/etc. are open to anyone who'd like to ask for help!
418 notes
·
View notes
Text
this is my most autistic half-birthday ever!
I gave myself the day to pursue a special interest and fulfill an offer I'd made last year.
The Jewish Virtual Library has a page listing all the rocket and mortar attacks on Israel since 2001 (which was when they first started). But it's incomplete. Last fall, I noticed it stopped in August, so I wrote to them offering to help update it. They thanked me and gave me some places I could look.
Today, I finally did it. I ended up cross-referencing with the lists on Wikipedia, digging through multiple Twitter accounts and outside news sources and NGOs, and sending them an email with my updates... plus an html file where I'd updated the code on the page so they could just check it and upload it instead of typing in all the data themselves.
I am such a huge nerd.
There's definitely more research to do. But I think I found a strong stopping place that let me actually send what I found and post about it. Which is always the hardest part. As my drafts folder could tell you.
I have more than two thousand drafts on here.
Anyway, I'm going to put my findings under a cut tag. Before you read on, I want you to try to guess.
Because one of the things I've been told most often by people who wanna Argue About Palestine Without Having To Learn Anything About Palestine (Or Israel Or History Or Imperialism Or Fact-Checking Or ?????) is that the reason for October 7, the reason for literally anything in fact, is that "Israel bombs Palestine constantly."
I want to put together a list of Israeli airstrikes next. I would love to reblog this with that information. But first, I want you to guess:
Note that this DOES NOT include terrorist car rammings, mass shootings, mass stabbings, bus bombings, suicide bombings, etc. It therefore excludes almost the entire Second Intifada.
After correcting the most recent four years and sending in my corrections, I made a list of the totals using the most complete collection I could find for each year. (Sometimes it was Jewish Virtual Library, sometimes it was Wikipedia, and sometimes they matched.)
2024: 12,629 (an average of 35 per day)
2023: 12,295 (34 per day)
2022: 1,180 (only 3 per day)
2021: 4,425 (12 per day)
2020: about 203
2019: 798+
2018: 348+, 0.95 per day
2017: Only 47!!! Why, it's almost like living in Canada!! 0.1 per day.
2016: Wow, only 20. See, if you go through the years backwards, it looks like progress is being made. Very exciting. Until I get to the Second Intifada, probably. 0.05 per day.
2015: 58.
2014: oh right, that war. 4,778. (Wikipedia's 2015 list claims " In August 2014, Operation Protective Edge was ended after 4,594 rockets and mortars launched toward Israel. From the end of the operation came into force an unofficial cease-fire between Israel and Hamas." but there were three more after that, and 181 before it, listed on wikipedia alone. so like. 4,778 actually, for 13 a day.)
2013: 70 total. Wikipedia notes this was the lowest number since 2001.
2012: 2,442, or 6.7 per day.
2011: 680, for 1.9 a day.
2010: 365, for exactly one a day.
2009: 858, or 2.4 per day.
2008: 3,107! that's 8.5 a day.
2007: 2,807: 7.7 a day.
2006: 1,275, or 3.5 a day.
2005: 858. An average of 2.4 per day.
2004: 1,158.
2003: 637.
2002: 472.]
2001: "These attacks commenced in April 2001, although the first rocket to hit an Israeli city was on 5 March 2002, and the first Israeli fatality was 28 June 2004." I count 173 mortar attacks in 2001, however. Which makes the first fatality a critically-injured baby in 2001. And as soon as I make 250+ more edits and have the power to edit Wikipedia articles on "controversial" topics, I'll make it say so.
Grand Total: 51,685.
An average of SIX PER DAY.
FOR 24 YEARS.
I've been saying four.
But there were actually thousands that weren't listed on the Virtual Library site yet. It really cranked up that average.
Now consider this: between 10%-30% misfire and either crash into the sea, or hit Gaza.
A surprising number of Gazan casualties in every "conflict" have been from Hamas & Co's own missiles.
And they know this. And not only do they not care, but they keep using everything from mosques to humanitarian zones as rocket launch sites.
And why shouldn't they? You have to really dig to find information on how many Gazans die that way. Almost everyone just attributes the deaths to Israel. Hamas is never going to get any actual flak for accidentally killing its own civilians. It barely gets any flak for intentionally killing Israeli civilians, for pete's sake.
176 notes
·
View notes
Text
For everyone who asked: a dialogue parser for BG3 alongside with the parsed dialogue for the newest patch. The parser is not mine, but its creator a) is amazing, b) wished to stay anonymous, and c) uploaded the parser to github - any future versions will be uploaded there first!
UPD: The parser was updated!! Now all the lines are parsed, AND there are new features like audio and dialogue tree visualisation. See below!
Patch 7 dialogue is uploaded!
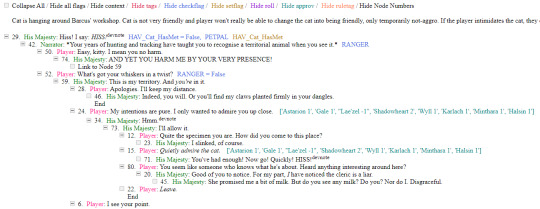
If you don't want to touch the parser and just want the dialogues, make sure to download the whole "BG3 ... (1.6)" folder and keep the "styles" folder within: it is needed for the html files functionality (hide/show certain types of information as per the menu at the top, jumps when you click on [jump], color for better readability, etc). See the image below for what it should look like. The formatting was borrowed from TORcommunity with their blessing.
If you want to run the parser yourself instead of downloading my parsed files, it's easy:
run bg3dialogreader.exe, OPEN any .pak file inside of your game's '\steamapps\common\Baldurs Gate 3\Data' folder,
select your language
press ‘LOAD’, it'll create a database file with all the tags, flags, etc.
Once that is done, press ‘EXPORT all dialogs to html’, and give it a minute or two to finish.
Find the parser dialogue in ‘Dialogs’ folder. If you move the folder elsewhere, move the ‘styles’ folder as well! It contains the styles you need for the color coding and functionality to keep working!
New features:
Once you've created the database (after step three above), you can also preview the dialogue trees inside of the parser and extract only what you need:

You can also listen to the correspinding audio files by clicking the line in the right window. But to do that, as the parser tells you, you need to download and put the filed from vgmstream-win64.zip inside of the parser's main folder (restart the parser after).
You can CONVERT the bg3 dialogue to the format that the Divinity Original Sin 2's Editor understands. That way, you can view the dialogues as trees! Unlike the html files, the trees don't show ALL the relevant information, but it's much easier to orient yourself in.


To get that, you DO need to have bought and installed Larian's previous game, Divinity Original Sin 2. It comes with a tool called 'The Divinity Engine 2'. Here you can read about how to unstall and lauch it. Once you have it, you need to load/create a project. We're trying to get to the point where the tool allows you to open the Dialog Editor. Then you can Open any bg3 dialogue file you want. And in case you want it, here's an in-depth Dialog Editor tutorial. But if you simply want to know how to open the Editor, here's the gist:
Update: In order to see the names of the speakers (up to ten), you can put the _merged.lsf file inside of the "\Divinity Original Sin 2\DefEd\Data\Public\[your project's name here]\RootTemplates\_merged.lsf" file path.
Feel free to ask if you have any questions! Please let me know if you modify the parser, I'd be curious to know what you added, and will possibly add it to the google drive.
2K notes
·
View notes
Text
Anyone who's like woah leaking the patreon stuff is too far be so for real right now. People like me funded Kittycorn while she was being deceptive about the nature of her work behind the scenes. Additionally, Kittycorn is literally associated with at least 3 pedophiles (one of which is pro irl incest and abused their sibling who Kittycorn attempted to silence).
I will never get the time I spent in regards to Sparklecare, nor my money back. Neither will anyone else who was mislead in regards to the kind of person Kittycorn was. Minors were also at a point staff on this comic who had no idea the shit Kittycorn was brewing.
It has been incredibly disappointing to further see Kittycorn go back on what she once presented (see the FAQ in regards to what fans can draw/any ask on the main tumblr in regards to the matter), and to see her further deflect refusing to take accountability. There are a lot of vulnerable people in her audience including other survivors. When a safe space of trust is cultivated with a creator who is straight up talking about how to lie to their audience... How do you think it feels for those survivors who kinned or related to Sly only to find out the creator wanted to make them a creepy incestuous rapist stalker. Or Doom who is now a groomer attracted to their goddamn child. How do you think it feels for those survivors to know the creator they looked up to and sought comfort in the work of is buddy buddy with the exact same kind of people who groomed and traumatized them.
If any of the former ZCP wants to do everyone a favour, leak the entire Sparklecare story (and whatever else). At this point I want everything to be scorched earth and hope nothing grows in its place. I hope Kittycorn leaves and doesn't come back to hurt more people.
I encourage anyone to save any of the stuff I've posted / share the archive link.
To be able to see the conclusion of what people cared about is the very least the fans have have been burned deserve.
Other leakers of Sparklecare stuff aside from myself: @doesspchcharacterdie @sparkletrolling @tfemsly @hemeruni @whatever-lions-blog @thesparchives @leakburner @ooblegoodle
Internet archive download links of my Sparklecare and Karmageddon leaks:
Also the callout doc in PDF form in case the OG gets deleted (it is the latest version as of 12/03/2025 but only goes up to page 33 of 44 due to internet archive's file replacement system):
#sparklecare#sparklecare fanart#sparklecare hospital#barry ill#uni cornelius#nurse doom#sch#sparklecritic#sparklecriticism#sparklecare criticism#sparklecrit#sparklecrit community#cometcare#cometcare au#slite li ill#eve ill#cometcriticism#cometcrit#nightstars au#nightstars#darkermatters au#sparklecare au#darkermatters#furry#sparklefur#sparklecare art#cometcare fanart#darkermatters fanart#karmageddon
112 notes
·
View notes
Text
quick guide on backing up your tumblr from someone who has tried it various ways over the years
so, you noticed that tumblr is so understaffed that they didn't even do april fools this year and you're thinking of backing up your tumblr. maybe even using tumblr's built-in export function.
there are plenty of third party apps that will scrape your blog and grab all the posts. tumblr-utils is one that i have used historically to great effect. another option here. or find your own.
however, if you want to save your dms and asks, you need to use tumblr's export function.
first go to your blog settings and click export blog. you'll get an email when it finishes exporting. this may take a couple days.
now, my blog's file was about 400GB. that's almost half a terabyte. it's a lot of data. there's no way to shrink it or only download parts. it also will not tell you how big the file is going to be. my blog has ~250k posts and another 5k unanswered asks. and yours will probably scale with that.
(this is a good reason to use third party scrapers instead, by the by. tumblr-utils at least allows you to 1) download only your own original posts and not reblogs, 2) download only text and not media, and 3) download in batches not all at once. you're not forced to take the whole thing, which is a lot of data. the html result from tumblr utils is also more usable than the one from tumblr as well).
anyway. the first thing you'll want to do is make sure you choose what folder something downloads to. you do NOT want half a terabyte in your downloads folder. you want it going straight to an external drive. you can set firefox to open a little "save as" dialogue box everytime you download something, which honestly i would recommend doing anyway. or you can use a download manager like jdownloader, which will also help in other ways. though personally i found that jdownloader seemed to choke on the fact that tumblr doesn't tell you the size of the download, and that meant i couldn't interrupt the download or jdownloader would assume it was done.
second is just. make sure your external drive is big enough. i ended up literally bailing out files onto other random thumb drives because i only had about 250GB free on my external drive when i started downloading.
third. turn off your computer's ability to sleep. if you've got a pc that should be in the control panel under power settings. it should say power plan. my blog took about 15 hours to download. i had to just let my computer sit there downloading, and my computer needed to not go to sleep.
fourth, i would recommend using an ethernet cable if you have one. that will make it go faster.
you should get a file. though my computer literally choked on mine and i had to open it with 7zip because the zip file didn't quite work.
honestly if you're willing to spend an unreasonable amount of time and storage space on this i would recommend grabbing the tumblr native backup and then also using tumblr utils and scarping the text, then using the tumblr utils version of the text. my suspicion is that you can just grab the media folder from the tumblr export download and dump it into the tumblr utils folder and you'll be good. tumblr utils handles the text posts way better and more accessibly.
another space saving option is to just literally delete the media folder. or to delete the media in the folder that's not labeled "conversations," since the stuff labeled "conversations" is media that was sent in your dms and you may want to save that.
tumblr export WILL give you all you dms (including with deactivated users and users you have blocked and who have blocked you) and it will also give you unanswered asks (again including from deactivated users etc). probably also submissions and possibly also old fanmail, i haven't checked. i have not figured out yet whether you get your draft posts. if you do they're not in their own folder they're just mixed in with the rest.
the html formatting, however, is dogshit. even of the dms. the dm conversations are literally presented backwards.
94 notes
·
View notes