#where in clause sql
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
There were a total of 171.5 billion posts on Tumblr in 2019.
Text
Structured Query Language (SQL): A Comprehensive Guide
Structured Query Language, popularly called SQL (reported "ess-que-ell" or sometimes "sequel"), is the same old language used for managing and manipulating relational databases. Developed in the early 1970s by using IBM researchers Donald D. Chamberlin and Raymond F. Boyce, SQL has when you consider that end up the dominant language for database structures round the world.
Structured query language commands with examples
Today, certainly every important relational database control system (RDBMS)—such as MySQL, PostgreSQL, Oracle, SQL Server, and SQLite—uses SQL as its core question language.
What is SQL?
SQL is a website-specific language used to:
Retrieve facts from a database.
Insert, replace, and delete statistics.
Create and modify database structures (tables, indexes, perspectives).
Manage get entry to permissions and security.
Perform data analytics and reporting.
In easy phrases, SQL permits customers to speak with databases to shop and retrieve structured information.
Key Characteristics of SQL
Declarative Language: SQL focuses on what to do, now not the way to do it. For instance, whilst you write SELECT * FROM users, you don’t need to inform SQL the way to fetch the facts—it figures that out.
Standardized: SQL has been standardized through agencies like ANSI and ISO, with maximum database structures enforcing the core language and including their very own extensions.
Relational Model-Based: SQL is designed to work with tables (also called members of the family) in which records is organized in rows and columns.
Core Components of SQL
SQL may be damaged down into numerous predominant categories of instructions, each with unique functions.
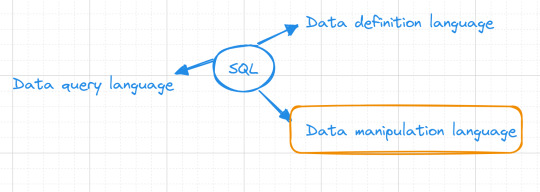
1. Data Definition Language (DDL)
DDL commands are used to outline or modify the shape of database gadgets like tables, schemas, indexes, and so forth.
Common DDL commands:
CREATE: To create a brand new table or database.
ALTER: To modify an present table (add or put off columns).
DROP: To delete a table or database.
TRUNCATE: To delete all rows from a table but preserve its shape.
Example:
sq.
Copy
Edit
CREATE TABLE personnel (
id INT PRIMARY KEY,
call VARCHAR(one hundred),
income DECIMAL(10,2)
);
2. Data Manipulation Language (DML)
DML commands are used for statistics operations which include inserting, updating, or deleting information.
Common DML commands:
SELECT: Retrieve data from one or more tables.
INSERT: Add new records.
UPDATE: Modify existing statistics.
DELETE: Remove information.
Example:
square
Copy
Edit
INSERT INTO employees (id, name, earnings)
VALUES (1, 'Alice Johnson', 75000.00);
three. Data Query Language (DQL)
Some specialists separate SELECT from DML and treat it as its very own category: DQL.
Example:
square
Copy
Edit
SELECT name, income FROM personnel WHERE profits > 60000;
This command retrieves names and salaries of employees earning more than 60,000.
4. Data Control Language (DCL)
DCL instructions cope with permissions and access manage.
Common DCL instructions:
GRANT: Give get right of entry to to users.
REVOKE: Remove access.
Example:
square
Copy
Edit
GRANT SELECT, INSERT ON personnel TO john_doe;
five. Transaction Control Language (TCL)
TCL commands manage transactions to ensure data integrity.
Common TCL instructions:
BEGIN: Start a transaction.
COMMIT: Save changes.
ROLLBACK: Undo changes.
SAVEPOINT: Set a savepoint inside a transaction.
Example:
square
Copy
Edit
BEGIN;
UPDATE personnel SET earnings = income * 1.10;
COMMIT;
SQL Clauses and Syntax Elements
WHERE: Filters rows.
ORDER BY: Sorts effects.
GROUP BY: Groups rows sharing a assets.
HAVING: Filters companies.
JOIN: Combines rows from or greater tables.
Example with JOIN:
square
Copy
Edit
SELECT personnel.Name, departments.Name
FROM personnel
JOIN departments ON personnel.Dept_id = departments.Identity;
Types of Joins in SQL
INNER JOIN: Returns statistics with matching values in each tables.
LEFT JOIN: Returns all statistics from the left table, and matched statistics from the right.
RIGHT JOIN: Opposite of LEFT JOIN.
FULL JOIN: Returns all records while there is a in shape in either desk.
SELF JOIN: Joins a table to itself.
Subqueries and Nested Queries
A subquery is a query inside any other query.
Example:
sq.
Copy
Edit
SELECT name FROM employees
WHERE earnings > (SELECT AVG(earnings) FROM personnel);
This reveals employees who earn above common earnings.
Functions in SQL
SQL includes built-in features for acting calculations and formatting:
Aggregate Functions: SUM(), AVG(), COUNT(), MAX(), MIN()
String Functions: UPPER(), LOWER(), CONCAT()
Date Functions: NOW(), CURDATE(), DATEADD()
Conversion Functions: CAST(), CONVERT()
Indexes in SQL
An index is used to hurry up searches.
Example:
sq.
Copy
Edit
CREATE INDEX idx_name ON employees(call);
Indexes help improve the performance of queries concerning massive information.
Views in SQL
A view is a digital desk created through a question.
Example:
square
Copy
Edit
CREATE VIEW high_earners AS
SELECT call, salary FROM employees WHERE earnings > 80000;
Views are beneficial for:
Security (disguise positive columns)
Simplifying complex queries
Reusability
Normalization in SQL
Normalization is the system of organizing facts to reduce redundancy. It entails breaking a database into multiple related tables and defining overseas keys to link them.
1NF: No repeating groups.
2NF: No partial dependency.
3NF: No transitive dependency.
SQL in Real-World Applications
Web Development: Most web apps use SQL to manipulate customers, periods, orders, and content.
Data Analysis: SQL is extensively used in information analytics systems like Power BI, Tableau, and even Excel (thru Power Query).
Finance and Banking: SQL handles transaction logs, audit trails, and reporting systems.
Healthcare: Managing patient statistics, remedy records, and billing.
Retail: Inventory systems, sales analysis, and consumer statistics.
Government and Research: For storing and querying massive datasets.
Popular SQL Database Systems
MySQL: Open-supply and extensively used in internet apps.
PostgreSQL: Advanced capabilities and standards compliance.
Oracle DB: Commercial, especially scalable, agency-degree.
SQL Server: Microsoft’s relational database.
SQLite: Lightweight, file-based database used in cellular and desktop apps.
Limitations of SQL
SQL can be verbose and complicated for positive operations.
Not perfect for unstructured information (NoSQL databases like MongoDB are better acceptable).
Vendor-unique extensions can reduce portability.
Java Programming Language Tutorial
Dot Net Programming Language
C ++ Online Compliers
C Language Compliers
2 notes
·
View notes
Text
the guy who had my position before me LOVED using temp tables to the point that if he needed to pull four values from one table he set up four nearly identical temp tables that just had different filters in their WHERE clause and then joined their results. I don't know enough to know if this is normal but for sure this shit drives me crazy cause he never used a single CTE, instead nesting queries 4 or 5 deep, and remaking these reports so the sql is readable takes too much time.
21 notes
·
View notes
Text
SQL Fundamentals #2: SQL Data Manipulation
In our previous database exploration journey, SQL Fundamentals #1: SQL Data Definition, we set the stage by introducing the "books" table nestled within our bookstore database. Currently, our table is empty, Looking like :
books
| title | author | genre | publishedYear | price |
Data manipulation

Now, let's embark on database interaction—data manipulation. This is where the magic happens, where our "books" table comes to life, and we finish our mission of data storage.
Inserting Data
Our initial task revolves around adding a collection of books into our "books" table. we want to add the book "The Great Gatsby" to our collection, authored F. Scott Fitzgerald. Here's how we express this in SQL:
INSERT INTO books(title, author, genre, publishedYear, price) VALUES('The Great Gatsby', 'F. Scott Fitzgerald', 'Classic', 1925, 10.99);
Alternatively, you can use a shorter form for inserting values, but be cautious as it relies on the order of columns in your table:
INSERT INTO books VALUES('The Great Gatsby', 'F. Scott Fitzgerald', 'Classic', 1925, 10.99);
Updating data
As time goes on, you might find the need to modify existing data in our "books" table. To accomplish this, we use the UPDATE command.For example :
UPDATE books SET price = 12.99 WHERE title = 'The Great Gatsby';
This SQL statement will locate the row with the title "The Great Gatsby" and modify its price to $12.99.
We'll discuss the where clause in (SQL fundamentals #3)
Deleting data
Sometimes, data becomes obsolete or irrelevant, and it's essential to remove it from our table. The DELETE FROM command allows us to delete entire rows from our table.For example :
DELETE FROM books WHERE title = 'Moby-Dick';
This SQL statement will find the row with the title "Moby-Dick" and remove it entirely from your "books" table.
To maintain a reader-friendly and approachable tone, I'll save the discussion on the third part of SQL, which focuses on data querying, for the upcoming post. Stay tuned ...
#studyblr#code#codeblr#javascript#java development company#study#progblr#programming#studying#comp sci#web design#web developers#web development#website design#webdev#website#tech#sql#sql course#mysql#datascience#data#backend
45 notes
·
View notes
Text
How to Improve Database Performance with Smart Optimization Techniques
Database performance is critical to the efficiency and responsiveness of any data-driven application. As data volumes grow and user expectations rise, ensuring your database runs smoothly becomes a top priority. Whether you're managing an e-commerce platform, financial software, or enterprise systems, sluggish database queries can drastically hinder user experience and business productivity.
In this guide, we’ll explore practical and high-impact strategies to improve database performance, reduce latency, and increase throughput.
1. Optimize Your Queries
Poorly written queries are one of the most common causes of database performance issues. Avoid using SELECT * when you only need specific columns. Analyze query execution plans to understand how data is being retrieved and identify potential inefficiencies.
Use indexed columns in WHERE, JOIN, and ORDER BY clauses to take full advantage of the database indexing system.
2. Index Strategically
Indexes are essential for speeding up data retrieval, but too many indexes can hurt write performance and consume excessive storage. Prioritize indexing on columns used in search conditions and join operations. Regularly review and remove unused or redundant indexes.
3. Implement Connection Pooling
Connection pooling allows multiple application users to share a limited number of database connections. This reduces the overhead of opening and closing connections repeatedly, which can significantly improve performance, especially under heavy load.
4. Cache Frequently Accessed Data
Use caching layers to avoid unnecessary hits to the database. Frequently accessed and rarely changing data—such as configuration settings or product catalogs—can be stored in in-memory caches like Redis or Memcached. This reduces read latency and database load.
5. Partition Large Tables
Partitioning splits a large table into smaller, more manageable pieces without altering the logical structure. This improves performance for queries that target only a subset of the data. Choose partitioning strategies based on date, region, or other logical divisions relevant to your dataset.
6. Monitor and Tune Regularly
Database performance isn’t a one-time fix—it requires continuous monitoring and tuning. Use performance monitoring tools to track query execution times, slow queries, buffer usage, and I/O patterns. Adjust configurations and SQL statements accordingly to align with evolving workloads.
7. Offload Reads with Replication
Use read replicas to distribute query load, especially for read-heavy applications. Replication allows you to spread read operations across multiple servers, freeing up the primary database to focus on write operations and reducing overall latency.
8. Control Concurrency and Locking
Poor concurrency control can lead to lock contention and delays. Ensure your transactions are short and efficient. Use appropriate isolation levels to avoid unnecessary locking, and understand the impact of each level on performance and data integrity.
0 notes
Text
Top SQL Interview Questions and Answers for Freshers and Professionals

SQL is the foundation of data-driven applications. Whether you’re applying for a data analyst, backend developer, or database administrator role, having a solid grip on SQL interview questions is essential for cracking technical rounds.
In this blog post, we’ll go over the most commonly asked SQL questions along with sample answers to help you prepare effectively.
📘 Want a complete, updated list of SQL interview questions? 👉 Check out: SQL Interview Questions & Answers – Freshy Blog
🔹 What is SQL?
SQL (Structured Query Language) is used to communicate with and manipulate databases. It is the standard language for relational database management systems (RDBMS).
🔸 Most Common SQL Interview Questions
1. What is the difference between WHERE and HAVING clause?
WHERE: Filters rows before grouping
HAVING: Filters groups after aggregation
2. What is a Primary Key?
A primary key is a unique identifier for each record in a table and cannot contain NULL values.
3. What are Joins in SQL?
Joins are used to combine rows from two or more tables based on a related column. Types include:
INNER JOIN
LEFT JOIN
RIGHT JOIN
FULL OUTER JOIN
🔸 Intermediate to Advanced SQL Questions
4. What is the difference between DELETE, TRUNCATE, and DROP?
DELETE: Removes rows (can be rolled back)
TRUNCATE: Removes all rows quickly (cannot be rolled back)
DROP: Deletes the table entirely
5. What is a Subquery?
A subquery is a query nested inside another query. It is used to retrieve data for use in the main query.
6. What is normalization?
Normalization is the process of organizing data to reduce redundancy and improve integrity.
🚀 Get a full breakdown with examples, tips, and pro-level questions: 👉 https://www.freshyblog.com/sql-interview-questions-answers/
🔍 Bonus Questions to Practice
What is the difference between UNION and UNION ALL?
What are indexes and how do they improve performance?
How does a GROUP BY clause work with aggregate functions?
What is a stored procedure and when would you use one?
✅ Tips to Crack SQL Interviews
Practice writing queries by hand
Focus on real-world database scenarios
Understand query optimization basics
Review basic RDBMS concepts like constraints and keys
Final Thoughts
Whether you're a fresher starting out or an experienced developer prepping for technical rounds, mastering these SQL interview questions is crucial for acing your next job opportunity.
📚 Access the full SQL interview guide here: 👉 https://www.freshyblog.com/sql-interview-questions-answers/
#SQLInterviewQuestions#SQLQueries#DatabaseInterview#DataAnalytics#BackendDeveloper#FreshyBlog#SQLForFreshers#TechJobs
0 notes
Text
Data Analyst Interview Questions: A Comprehensive Guide
Preparing for an interview as a Data Analyst is difficult, given the broad skills needed. Technical skill, business knowledge, and problem-solving abilities are assessed by interviewers in a variety of ways. This guide will assist you in grasping the kind of questions that will be asked and how to answer them.

By mohammed hassan on Pixabay
General Data Analyst Interview Questions
These questions help interviewers assess your understanding of the role and your basic approach to data analysis.
Can you describe what a Data Analyst does? A Data Analyst collects, processes, and analyzes data to help businesses make data-driven decisions and identify trends or patterns.
What are the key responsibilities of a Data Analyst? Responsibilities include data collection, data cleaning, exploratory data analysis, reporting insights, and collaborating with stakeholders.
What tools are you most familiar with? Say tools like Excel, SQL, Python, Tableau, Power BI, and describe how you have used them in past projects.
What types of data? Describe structured, semi-structured, and unstructured data using examples such as databases, JSON files, and pictures or videos.
Technical Data Analyst Interview Questions
Technical questions evaluate your tool knowledge, techniques, and your ability to manipulate and interpret data.
What is the difference between SQL's inner join and left join? The inner join gives only the common rows between tables, whereas a left join gives all rows of the left table as well as corresponding ones of the right.
How do you deal with missing data in a dataset? Methods are either removing rows, mean/median imputation, or forward-fill/backward-fill depending on context and proportion of missing data.
Can you describe normalization and why it's significant? Normalization minimizes data redundancy and enhances data integrity by structuring data effectively between relational tables.
What are some Python libraries that are frequently used for data analysis? Libraries consist of Pandas for data manipulation, NumPy for numerical computations, Matplotlib/Seaborn for data plotting, and SciPy for scientific computing.
How would you construct a query to discover duplicate values within a table? Use a GROUP BY clause with a HAVING COUNT(*) > 1 to find duplicate records according to one or more columns.
Behavioral and Situational Data Analyst Interview Questions
These assess your soft skills, work values, and how you deal with actual situations.
Describe an instance where you managed a challenging stakeholder. Describe how you actively listened, recognized their requirements, and provided insights that supported business objectives despite issues with communication.
Tell us about a project in which you needed to analyze large datasets. Describe how you broke the dataset down into manageable pieces, what tools you used, and what you learned from the analysis.
Read More....
0 notes
Text
PySpark SQL: Introduction & Basic Queries
Introduction
In today’s data-driven world, the volume and variety of data have exploded. Traditional tools often struggle to process and analyze massive datasets efficiently. That’s where Apache Spark comes into the picture — a lightning-fast, unified analytics engine for big data processing.
For Python developers, PySpark — the Python API for Apache Spark — offers an intuitive way to work with Spark. Among its powerful modules, PySpark SQL stands out. It enables you to query structured data using SQL syntax or DataFrame operations. This hybrid capability makes it easy to blend the power of Spark with the familiarity of SQL.
In this blog, we'll explore what PySpark SQL is, why it’s so useful, how to set it up, and cover the most essential SQL queries with examples — perfect for beginners diving into big data with Python.

Agenda
Here's what we'll cover:
What is PySpark SQL?
Why should you use PySpark SQL?
Installing and setting up PySpark
Basic SQL queries in PySpark
Best practices for working efficiently
Final thoughts
What is PySpark SQL?
PySpark SQL is a module of Apache Spark that enables querying structured data using SQL commands or a more programmatic DataFrame API. It offers:
Support for SQL-style queries on large datasets.
A seamless bridge between relational logic and Python.
Optimizations using the Catalyst query optimizer and Tungsten execution engine for efficient computation.
In simple terms, PySpark SQL lets you use SQL to analyze big data at scale — without needing traditional database systems.
Why Use PySpark SQL?
Here are a few compelling reasons to use PySpark SQL:
Scalability: It can handle terabytes of data spread across clusters.
Ease of use: Combines the simplicity of SQL with the flexibility of Python.
Performance: Optimized query execution ensures fast performance.
Interoperability: Works with various data sources — including Hive, JSON, Parquet, and CSV.
Integration: Supports seamless integration with DataFrames and MLlib for machine learning.
Whether you're building dashboards, ETL pipelines, or machine learning workflows — PySpark SQL is a reliable choice.
Setting Up PySpark
Let’s quickly set up a local PySpark environment.
1. Install PySpark:
pip install pyspark
2. Start a Spark session:
from pyspark.sql import SparkSession spark = SparkSession.builder \ .appName("PySparkSQLExample") \ .getOrCreate()
3. Create a DataFrame:
data = [("Alice", 25), ("Bob", 30), ("Clara", 35)] columns = ["Name", "Age"] df = spark.createDataFrame(data, columns) df.show()
4. Create a temporary view to run SQL queries:
df.createOrReplaceTempView("people")
Now you're ready to run SQL queries directly!
Basic PySpark SQL Queries
Let’s look at the most commonly used SQL queries in PySpark.
1. SELECT Query
spark.sql("SELECT * FROM people").show()
Returns all rows from the people table.
2. WHERE Clause (Filtering Rows)
spark.sql("SELECT * FROM people WHERE Age > 30").show()
Filters rows where Age is greater than 30.
3. Adding a Derived Column
spark.sql("SELECT Name, Age, Age + 5 AS AgeInFiveYears FROM people").show()
Adds a new column AgeInFiveYears by adding 5 to the current age.
4. GROUP BY and Aggregation
Let’s update the data with multiple entries for each name:
data2 = [("Alice", 25), ("Bob", 30), ("Alice", 28), ("Bob", 35), ("Clara", 35)] df2 = spark.createDataFrame(data2, columns) df2.createOrReplaceTempView("people")
Now apply aggregation:
spark.sql(""" SELECT Name, COUNT(*) AS Count, AVG(Age) AS AvgAge FROM people GROUP BY Name """).show()
This groups records by Name and calculates the number of records and average age.
5. JOIN Between Two Tables
Let’s create another table:
jobs_data = [("Alice", "Engineer"), ("Bob", "Designer"), ("Clara", "Manager")] df_jobs = spark.createDataFrame(jobs_data, ["Name", "Job"]) df_jobs.createOrReplaceTempView("jobs")
Now perform an inner join:
spark.sql(""" SELECT p.Name, p.Age, j.Job FROM people p JOIN jobs j ON p.Name = j.Name """).show()
This joins the people and jobs tables on the Name column.
Tips for Working Efficiently with PySpark SQL
Use LIMIT for testing: Avoid loading millions of rows in development.
Cache wisely: Use .cache() when a DataFrame is reused multiple times.
Check performance: Use .explain() to view the query execution plan.
Mix APIs: Combine SQL queries and DataFrame methods for flexibility.
Conclusion
PySpark SQL makes big data analysis in Python much more accessible. By combining the readability of SQL with the power of Spark, it allows developers and analysts to process massive datasets using simple, familiar syntax.
This blog covered the foundational aspects: setting up PySpark, writing basic SQL queries, performing joins and aggregations, and a few best practices to optimize your workflow.
If you're just starting out, keep experimenting with different queries, and try loading real-world datasets in formats like CSV or JSON. Mastering PySpark SQL can unlock a whole new level of data engineering and analysis at scale.
PySpark Training by AccentFuture
At AccentFuture, we offer customizable online training programs designed to help you gain practical, job-ready skills in the most in-demand technologies. Our PySpark Online Training will teach you everything you need to know, with hands-on training and real-world projects to help you excel in your career.
What we offer:
Hands-on training with real-world projects and 100+ use cases
Live sessions led by industry professionals
Certification preparation and career guidance
🚀 Enroll Now: https://www.accentfuture.com/enquiry-form/
📞 Call Us: +91–9640001789
📧 Email Us: [email protected]
🌐 Visit Us: AccentFuture
1 note
·
View note
Text
Master SQL in 2025: The Only Bootcamp You’ll Ever Need

When it comes to data, one thing is clear—SQL is still king. From business intelligence to data analysis, web development to mobile apps, Structured Query Language (SQL) is everywhere. It’s the language behind the databases that run apps, websites, and software platforms across the world.
If you’re looking to gain practical skills and build a future-proof career in data, there’s one course that stands above the rest: the 2025 Complete SQL Bootcamp from Zero to Hero in SQL.
Let’s dive into what makes this bootcamp a must for learners at every level.
Why SQL Still Matters in 2025
In an era filled with cutting-edge tools and no-code platforms, SQL remains an essential skill for:
Data Analysts
Backend Developers
Business Intelligence Specialists
Data Scientists
Digital Marketers
Product Managers
Software Engineers
Why? Because SQL is the universal language for interacting with relational databases. Whether you're working with MySQL, PostgreSQL, SQLite, or Microsoft SQL Server, learning SQL opens the door to querying, analyzing, and interpreting data that powers decision-making.
And let’s not forget—it’s one of the highest-paying skills on the job market today.
Who Is This Bootcamp For?
Whether you’re a complete beginner or someone looking to polish your skills, the 2025 Complete SQL Bootcamp from Zero to Hero in SQL is structured to take you through a progressive learning journey. You’ll go from knowing nothing about databases to confidently querying real-world datasets.
This course is perfect for:
✅ Beginners with no prior programming experience ✅ Students preparing for tech interviews ✅ Professionals shifting to data roles ✅ Freelancers and entrepreneurs ✅ Anyone who wants to work with data more effectively
What You’ll Learn: A Roadmap to SQL Mastery
Let’s take a look at some of the key skills and topics covered in this course:
🔹 SQL Fundamentals
What is SQL and why it's important
Understanding databases and tables
Creating and managing database structures
Writing basic SELECT statements
🔹 Filtering & Sorting Data
Using WHERE clauses
Logical operators (AND, OR, NOT)
ORDER BY and LIMIT for controlling output
🔹 Aggregation and Grouping
COUNT, SUM, AVG, MIN, MAX
GROUP BY and HAVING
Combining aggregate functions with filters
🔹 Advanced SQL Techniques
JOINS: INNER, LEFT, RIGHT, FULL
Subqueries and nested SELECTs
Set operations (UNION, INTERSECT)
Case statements and conditional logic
🔹 Data Cleaning and Manipulation
UPDATE, DELETE, and INSERT statements
Handling NULL values
Using built-in functions for data formatting
🔹 Real-World Projects
Practical datasets to work on
Simulated business cases
Query optimization techniques
Hands-On Learning With Real Impact
Many online courses deliver knowledge. Few deliver results.
The 2025 Complete SQL Bootcamp from Zero to Hero in SQL does both. The course is filled with hands-on exercises, quizzes, and real-world projects so you actually apply what you learn. You’ll use modern tools like PostgreSQL and pgAdmin to get your hands dirty with real data.
Why This Course Stands Out
There’s no shortage of SQL tutorials out there. But this bootcamp stands out for a few big reasons:
✅ Beginner-Friendly Structure
No coding experience? No problem. The course takes a gentle approach to build your confidence with simple, clear instructions.
✅ Practice-Driven Learning
Learning by doing is at the heart of this course. You’ll write real queries, not just watch someone else do it.
✅ Lifetime Access
Revisit modules anytime you want. Perfect for refreshing your memory before an interview or brushing up on a specific concept.
✅ Constant Updates
SQL evolves. This bootcamp evolves with it—keeping you in sync with current industry standards in 2025.
✅ Community and Support
You won’t be learning alone. With a thriving student community and Q&A forums, support is just a click away.
Career Opportunities After Learning SQL
Mastering SQL can open the door to a wide range of job opportunities. Here are just a few roles you’ll be prepared for:
Data Analyst: Analyze business data and generate insights
Database Administrator: Manage and optimize data infrastructure
Business Intelligence Developer: Build dashboards and reports
Full Stack Developer: Integrate SQL with web and app projects
Digital Marketer: Track user behavior and campaign performance
In fact, companies like Amazon, Google, Netflix, and Facebook all require SQL proficiency in many of their job roles.
And yes—freelancers and solopreneurs can use SQL to analyze marketing campaigns, customer feedback, sales funnels, and more.
Real Testimonials From Learners
Here’s what past students are saying about this bootcamp:
⭐⭐⭐⭐⭐ “I had no experience with SQL before taking this course. Now I’m using it daily at my new job as a data analyst. Worth every minute!” – Sarah L.
⭐⭐⭐⭐⭐ “This course is structured so well. It’s fun, clear, and packed with challenges. I even built my own analytics dashboard!” – Jason D.
⭐⭐⭐⭐⭐ “The best SQL course I’ve found on the internet—and I’ve tried a few. I was up and running with real queries in just a few hours.” – Meera P.
How to Get Started
You don’t need to enroll in a university or pay thousands for a bootcamp. You can get started today with the 2025 Complete SQL Bootcamp from Zero to Hero in SQL and build real skills that make you employable.
Just grab a laptop, follow the course roadmap, and dive into your first database. No fluff. Just real, useful skills.
Tips to Succeed in the SQL Bootcamp
Want to get the most out of your SQL journey? Keep these pro tips in mind:
Practice regularly: SQL is a muscle—use it or lose it.
Do the projects: Apply what you learn to real datasets.
Take notes: Summarize concepts in your own words.
Explore further: Try joining Kaggle or GitHub to explore open datasets.
Ask questions: Engage in course forums or communities for deeper understanding.
Your Future in Data Starts Now
SQL is more than just a skill. It’s a career-launching power tool. With this knowledge, you can transition into tech, level up in your current role, or even start your freelance data business.
And it all begins with one powerful course: 👉 2025 Complete SQL Bootcamp from Zero to Hero in SQL
So, what are you waiting for?
Open the door to endless opportunities and unlock the world of data.
0 notes
Text
This SQL Trick Cut My Query Time by 80%
How One Simple Change Supercharged My Database Performance
If you work with SQL, you’ve probably spent hours trying to optimize slow-running queries — tweaking joins, rewriting subqueries, or even questioning your career choices. I’ve been there. But recently, I discovered a deceptively simple trick that cut my query time by 80%, and I wish I had known it sooner.

Here’s the full breakdown of the trick, how it works, and how you can apply it right now.
🧠 The Problem: Slow Query in a Large Dataset
I was working with a PostgreSQL database containing millions of records. The goal was to generate monthly reports from a transactions table joined with users and products. My query took over 35 seconds to return, and performance got worse as the data grew.
Here’s a simplified version of the original query:
sql
SELECT
u.user_id,
SUM(t.amount) AS total_spent
FROM
transactions t
JOIN
users u ON t.user_id = u.user_id
WHERE
t.created_at >= '2024-01-01'
AND t.created_at < '2024-02-01'
GROUP BY
u.user_id, http://u.name;
No complex logic. But still painfully slow.
⚡ The Trick: Use a CTE to Pre-Filter Before the Join
The major inefficiency here? The join was happening before the filtering. Even though we were only interested in one month’s data, the database had to scan and join millions of rows first — then apply the WHERE clause.
✅ Solution: Filter early using a CTE (Common Table Expression)
Here’s the optimized version:
sql
WITH filtered_transactions AS (
SELECT *
FROM transactions
WHERE created_at >= '2024-01-01'
AND created_at < '2024-02-01'
)
SELECT
u.user_id,
SUM(t.amount) AS total_spent
FROM
filtered_transactions t
JOIN
users u ON t.user_id = u.user_id
GROUP BY
u.user_id, http://u.name;
Result: Query time dropped from 35 seconds to just 7 seconds.
That’s an 80% improvement — with no hardware changes or indexing.
🧩 Why This Works
Databases (especially PostgreSQL and MySQL) optimize join order internally, but sometimes they fail to push filters deep into the query plan.
By isolating the filtered dataset before the join, you:
Reduce the number of rows being joined
Shrink the working memory needed for the query
Speed up sorting, grouping, and aggregation
This technique is especially effective when:
You’re working with time-series data
Joins involve large or denormalized tables
Filters eliminate a large portion of rows
🔍 Bonus Optimization: Add Indexes on Filtered Columns
To make this trick even more effective, add an index on created_at in the transactions table:
sql
CREATE INDEX idx_transactions_created_at ON transactions(created_at);
This allows the database to quickly locate rows for the date range, making the CTE filter lightning-fast.
🛠 When Not to Use This
While this trick is powerful, it’s not always ideal. Avoid it when:
Your filter is trivial (e.g., matches 99% of rows)
The CTE becomes more complex than the base query
Your database’s planner is already optimizing joins well (check the EXPLAIN plan)
🧾 Final Takeaway
You don’t need exotic query tuning or complex indexing strategies to speed up SQL performance. Sometimes, just changing the order of operations — like filtering before joining — is enough to make your query fly.
“Think like the database. The less work you give it, the faster it moves.”
If your SQL queries are running slow, try this CTE filtering trick before diving into advanced optimization. It might just save your day — or your job.
Would you like this as a Medium post, technical blog entry, or email tutorial series?
0 notes
Text
SQL Tutorial for Beginners: Learn How to Query Databases
In today’s data-driven world, almost every application, website, or business process involves data in some form. From your favorite e-commerce platform to your personal banking app, data is stored, managed, and retrieved using databases. To interact with these databases, we use a powerful language called SQL.
If you’re a beginner looking to learn how to query databases, you’re in the right place. This SQL tutorial will introduce you to the basics of SQL (Structured Query Language) and explain how you can use it to communicate with databases—no programming experience required.

What is SQL?
SQL stands for Structured Query Language. It’s the standard language used to store, retrieve, manage, and manipulate data in relational databases—databases that store data in tables, much like spreadsheets.
Think of a relational database as a collection of tables, where each table contains rows and columns. Each column has a specific type of data, like names, dates, or prices, and each row is a record (an entry) in the table.
Why Learn SQL?
SQL is one of the most in-demand skills for developers, data analysts, data scientists, and even marketers and business professionals. Here’s why learning SQL is a great idea:
Universal: It’s used by nearly every industry that deals with data.
Easy to Learn: SQL has a relatively simple and readable syntax.
Powerful: SQL allows you to ask complex questions and get exactly the data you need.
Great for Career Growth: SQL knowledge is a key skill in many tech and data-focused roles.
Core Concepts You Need to Know
Before jumping into actual queries, it’s helpful to understand some key concepts and terminology:
1. Tables
A table is a collection of data organized in rows and columns. For example, a Customers table might include columns like CustomerID, Name, Email, and Phone.
2. Rows
Each row in a table is a record. For example, one row in the Customers table could represent a single person.
3. Columns
Each column represents a specific attribute of the data. In our example, Email is a column that stores email addresses of customers.
4. Queries
A query is a question you ask the database. You use SQL to write queries and tell the database what information you want to retrieve.
Basic SQL Commands for Beginners
Here are the most commonly used SQL statements that beginners should become familiar with:
1. SELECT
The SELECT statement is used to read or retrieve data from a table. It’s the most commonly used SQL command.
Example (in simple English): "Show me all the data in the Customers table."
2. WHERE
The WHERE clause helps you filter results based on specific conditions.
Example: "Show me all customers whose country is Canada."
3. ORDER BY
You can sort the data using the ORDER BY clause.
Example: "Show customers sorted by their names in alphabetical order."
4. INSERT INTO
This command adds new records (rows) to a table.
Example: "Add a new customer named Alice with her email and phone number."
5. UPDATE
This modifies existing records in a table.
Example: "Change the phone number of customer with ID 10."
6. DELETE
This removes records from a table.
Example: "Delete the customer with ID 15."
A Real-Life Example: Online Store
Imagine you run an online store, and you have a table called Products. This table includes columns like ProductID, Name, Category, and Price.
With SQL, you could:
Find all products in the “Electronics” category.
List the top 5 most expensive products.
Update the price of a specific product.
Remove discontinued items.
SQL allows you to manage all of this with a few clear instructions.
How to Practice SQL
Learning SQL is best done by doing. Fortunately, there are many free and interactive tools you can use to practice writing SQL queries without needing to install anything:
Tpoint Tech (tpointtech.com/sql-tutorial)
W3Schools SQL Tutorial (w3schools.com/sql)
LeetCode SQL problems (great for more advanced practice)
Mode SQL Tutorial (mode.com/sql-tutorial)
These platforms let you write and test queries directly in your browser, often with real-world examples.
Final Thoughts
SQL is a foundational tool for anyone working with data. Whether you're a developer managing back-end systems, a data analyst exploring customer trends, or a marketer analyzing campaign results, knowing how to query databases will empower you to make smarter, data-driven decisions.
This beginner-friendly tutorial is just the first step. As you become more comfortable with SQL, you'll be able to write more complex queries, join multiple tables, and dive into advanced topics like subqueries and database design.
0 notes
Text
Master Data Analytics, SQL, and Business Intelligence
In today's fast-growing corporate environment, where most corporate decisions are made based on data, data analysis, SQL, and BI, it's not just an enhancement to your career but a survival tool. These are essential skills that anyone can cultivate, whether you are fresh out of college or even if you’re a professional seeking a change to a more specialised career outlook. And if you are searching for a career switch through a data science certification in Pune, you are already on the right path.
Now let's elucidate why Data Analytics, SQL, and Business Intelligence are significant at present, how one can learn, and the advantages you get in the real world.
Why Data Analytics, SQL, and BI Matter More Than Ever
Organisations across the globe are gathering big data at a high rate every second. However, raw data is not easily readable and hence requires analysis to extract meaning from it. That is where data analytics comes into play – to help teams understand trends, behaviors, and results. Structured Query Language (SQL) is the most common language used today to handle database information, whereas business intelligence tools provide a format for analyzing data and presenting results in an easy-to-understand format.
Here’s how they align:
Data Analytics helps uncover patterns and make predictions.
SQL allows access, organisation, and manipulation of large datasets.
BI Tools like Power BI or Tableau present data through interactive dashboards.
These are no longer niche skills. They're essential across industries, from healthcare and finance to e-commerce and logistics.
Real-Life Example: The Retail Turnaround
Take the case of a retail chain in Pune. Sales were dropping in some outlets, and the leadership had no clue why. After investing in a team equipped with data analytics skills and SQL knowledge, they began analysing customer footfall, product movement, and regional buying behaviour.
Using BI tools, the team created easy-to-understand dashboards showing that specific items weren't moving in certain regions due to pricing mismatches. Adjustments were made, promotions targeted, and within a quarter, the underperforming outlets started showing profits again. This isn’t a one-off story—it’s happening everywhere.
Build the Right Skillset
If you're considering a data science certification in Pune, make sure the curriculum covers these critical areas:
1. Data Analytics Fundamentals
Understanding basic statistics, probability, and analytical thinking is where it all begins. You'll also learn how to frame business problems and solve them using data-driven approaches.
2. SQL – Speak the Language of Databases
SQL (Structured Query Language) is the core of database management. You’ll learn how to:
Retrieve data using SELECT statements
Filter with where clauses.
Aggregate using group by and having.
Join tables efficiently
Optimise complex queries
Mastering SQL is non-negotiable if you want to dive deep into data science.
3. Business Intelligence Tools
Learning how to use tools like Tableau, Power BI, or Looker enables you to present data in visually engaging formats. Dashboards are more than pretty charts—they guide strategic decisions in real-time.
Real-Life Example: The Freelance Analyst
Ritika, a 29-year-old freelancer in Pune, was struggling to grow her consulting business. After completing a comprehensive data science course in Pune that focused on analytics, SQL, and business intelligence (BI), she offered dashboard creation and data interpretation services to startups.
Within six months, her client base doubled. She even landed a long-term contract with a US-based SaaS company to manage their product usage data. Mastering these tools didn't just make her more employable—it made her business thrive.
Career Opportunities and Salaries
Professionals with expertise in data analytics and business intelligence (BI) are in high demand. According to a recent job survey, roles that require SQL and BI skills pay 30% higher than traditional IT roles at entry-level positions. In Pune, the growing startup ecosystem and multinational presence have opened doors to exciting opportunities, especially for those who’ve undergone data science training in Pune and have hands-on skills.
Here are some career paths you can explore:
Data Analyst
Business Intelligence Developer
SQL Data Engineer
Analytics Consultant
Product Analyst
Getting Certified Makes a Difference
A data science certification in Pune not only sharpens your skills but also validates your expertise. Recruiters look for certified professionals because it reduces training time and signals that the candidate is job-ready.
Benefits of Certification:
Structured learning approach
Hands-on projects using real data
Industry-recognized credibility
Placement support (if applicable)
Peer networking and mentorship
Remember, certification is not just about learning—it's about proving that you can apply what you've learned in real-world scenarios.
Tips to Get Started
Here's how to make the most of your journey into data analytics, SQL, and BI:
Start with the basics: Brush up on statistics and Excel before diving into analytics tools.
Practice regularly: Use free datasets from Kaggle or government portals.
Join communities: Engage with local data science meetups in Pune or participate in LinkedIn groups.
Build a portfolio: Create dashboards, publish case studies, and document your learning on GitHub or Medium.
Stay updated: Tech is evolving. Stay current with the latest trends in BI tools and database technologies.
Real-Life Example: Upskilling for Career Switch
Sandeep, a mechanical engineer based in Pune, was laid off during a corporate restructuring. Rather than returning to a similar role, he decided to explore data. He mastered SQL and BI tools through a data science certification in Pune. Today, he works as a data analyst at a leading logistics firm, where he helps optimise supply chain routes using data models. What started as a setback became a turning point, all because he made the effort to upskill.
Conclusion: The Smart Career Move
Mastering data analytics, SQL, and business intelligence is no longer just for tech geeks—it's for anyone who wants to stay relevant, solve problems, and make an impact. With the rising demand for data-driven decision-making, professionals equipped with these skills are not just surviving—they're thriving.
If you're in Pune and considering stepping into this high-growth field, investing in a well-rounded data science certification in Pune can open doors you didn't even know existed. Whether it's for career transition, promotion, freelancing, or launching your startup, data is the foundation, and your journey starts now.
0 notes
Text
Learn to Use SQL, MongoDB, and Big Data in Data Science
In today’s data-driven world, understanding the right tools is as important as understanding the data. If you plan to pursue a data science certification in Pune, knowing SQL, MongoDB, and Big Data technologies isn’t just a bonus — it’s essential. These tools form the backbone of modern data ecosystems and are widely used in real-world projects to extract insights, build models, and make data-driven decisions.
Whether you are planning on updating your resume, wanting to find a job related to analytics, or just have a general interest in how businesses apply data. Learning how to deal with structured and unstructured data sets should be a goal.
Now, analysing the relation of SQL, MongoDB, and Big Data technologies in data science and how they may transform your career, if you are pursuing data science classes in Pune.
Why These Tools Matter in Data Science?
Data that today’s data scientists use varies from transactional data in SQL databases to social network data stored in NoSQL, such as MongoDB, and data larger than the amount that can be processed by conventional means. It has to go through Big Data frameworks. That is why it is crucial for a person to master such tools:
1. SQL: The Language of Structured Data
SQL (Structured Query Language) is a widely used language to facilitate interaction between users and relational databases. Today, almost every industry globally uses SQL to solve organisational processes in healthcare, finance, retail, and many others.
How It’s Used in Real Life?
Think about what it would be like to become an employee in one of the retail stores based in Pune. In this case, you are supposed to know the trends of products that are popular in the festive season. Therefore, it is possible to use SQL and connect to the company’s sales database to select data for each product and sort it by categories, as well as to determine the sales velocity concerning the seasons. It is also fast, efficient, and functions in many ways that are simply phenomenal.
Key SQL Concepts to Learn:
SELECT, JOIN, GROUP BY, and WHERE clauses
Window functions for advanced analytics
Indexing for query optimisation
Creating stored procedures and views
Whether you're a beginner or brushing up your skills during a data science course in Pune, SQL remains a non-negotiable part of the toolkit.
2. MongoDB: Managing Flexible and Semi-Structured Data
As businesses increasingly collect varied forms of data, like user reviews, logs, and IoT sensor readings, relational databases fall short. Enter MongoDB, a powerful NoSQL database that allows you to store and manage data in JSON-like documents.
Real-Life Example:
Suppose you're analysing customer feedback for a local e-commerce startup in Pune. The feedback varies in length, structure, and language. MongoDB lets you store this inconsistent data without defining a rigid schema upfront. With tools like MongoDB’s aggregation pipeline, you can quickly extract insights and categorise sentiment.
What to Focus On?
CRUD operations in MongoDB
Aggregation pipelines for analysis
Schema design and performance optimisation
Working with nested documents and arrays
Learning MongoDB is especially valuable during your data science certification in Pune, as it prepares you for working with diverse data sources common in real-world applications.
3. Big Data: Scaling Your Skills to Handle Volume
As your datasets grow, traditional tools may no longer suffice. Big Data technologies like Hadoop and Spark allow you to efficiently process terabytes or even petabytes of data.
Real-Life Use Case:
Think about a logistics company in Pune tracking thousands of deliveries daily. Data streams in from GPS devices, traffic sensors, and delivery apps. Using Big Data tools, you can process this information in real-time to optimise routes, reduce fuel costs, and improve delivery times.
What to Learn?
Hadoop’s HDFS for distributed storage
MapReduce programming model.
Apache Spark for real-time and batch processing
Integrating Big Data with Python and machine learning pipelines
Understanding how Big Data integrates with ML workflows is a career-boosting advantage for those enrolled in data science training in Pune.
Combining SQL, MongoDB, and Big Data in Projects
In practice, data scientists often use these tools together. Here’s a simplified example:
You're building a predictive model to understand user churn for a telecom provider.
Use SQL to fetch customer plans and billing history.
Use MongoDB to analyse customer support chat logs.
Use Spark to process massive logs from call centres in real-time.
Once this data is cleaned and structured, it feeds into your machine learning model. This combination showcases the power of knowing multiple tools — a vital edge you gain during a well-rounded data science course in Pune.
How do These Tools Impact Your Career?
Recruiters look for professionals who can navigate relational and non-relational databases and handle large-scale processing tasks. Mastering these tools not only boosts your credibility but also opens up job roles like:
Data Analyst
Machine Learning Engineer
Big Data Engineer
Data Scientist
If you're taking a data science certification in Pune, expect practical exposure to SQL and NoSQL tools, plus the chance to work on capstone projects involving Big Data. Employers value candidates who’ve worked with diverse datasets and understand how to optimise data workflows from start to finish.
Tips to Maximise Your Learning
Work on Projects: Try building a mini data pipeline using public datasets. For instance, analyze COVID-19 data using SQL, store news updates in MongoDB, and run trend analysis using Spark.
Use Cloud Platforms: Tools like Google BigQuery or MongoDB Atlas are great for practising in real-world environments.
Collaborate and Network: Connect with other learners in Pune. Attend meetups, webinars, or contribute to open-source projects.
Final Thoughts
SQL, MongoDB, and Big Data are no longer optional in the data science world — they’re essential. Whether you're just starting or upgrading your skills, mastering these technologies will make you future-ready.
If you plan to enroll in a data science certification in Pune, look for programs that emphasise hands-on training with these tools. They are the bridge between theory and real-world application, and mastering them will give you the confidence to tackle any data challenge.
Whether you’re from a tech background or switching careers, comprehensive data science training in Pune can help you unlock your potential. Embrace the learning curve, and soon, you'll be building data solutions that make a real impact, right from the heart of Pune.
1 note
·
View note
Text
Best Practices in SAS Programming: Ensuring Code Efficiency and Performance
SAS (Statistical Analysis System) programming is a powerful tool used by data professionals for statistical analysis, data management, and reporting. Whether you’re working with large datasets in clinical trials, performing business analysis, or conducting complex predictive modeling, optimizing code efficiency and performance is essential. Writing efficient and well-performing SAS code not only speeds up the process but also improves the accuracy and reliability of your results.
In this article, we’ll explore best practices in SAS programming that can help ensure your code runs efficiently, produces accurate results, and remains easy to maintain.
1. Optimize Data Access
Data access is one of the first things to consider when optimizing SAS code. The more efficiently you can access and manipulate your data, the faster your code will run.
Use Indexing
When working with large datasets, indexing is a key technique. By creating indexes on key variables, SAS can retrieve data faster, reducing the time it takes to search through large datasets. Indexing should be applied to frequently used columns, such as those used for sorting or joining datasets.
Efficient Data Management
Keeping your data in memory rather than repeatedly reading from disk can enhance performance. By managing memory settings in SAS, you can load data into memory, which significantly speeds up processing times, especially for larger datasets.
2. Minimize Data Movement
Data movement refers to the unnecessary reading, writing, or transferring of data between different locations. Reducing this helps to improve overall performance.
Use Efficient Filtering
Instead of filtering data after loading it into memory, try applying conditions during the initial data retrieval process. This can reduce the amount of data you need to load into memory and process. For example, filtering data directly in the where clause of queries can significantly speed up your operations.
Avoid Unnecessary Duplicates
Duplicating data unnecessarily can waste time and resources. Instead of creating multiple temporary datasets, merge or join datasets directly in SAS to minimize overhead. Reducing the number of intermediate datasets you create will help keep the process lean and efficient.
3. Leverage Efficient Procedures
Certain SAS procedures are optimized to handle large datasets efficiently. As a SAS programmer, it’s essential to know which procedures will deliver the best performance for specific tasks.
Choose the Right Procedures
For instance, when summarizing data, PROC MEANS is often more efficient than PROC SQL for large datasets, as it uses specialized algorithms for calculating summary statistics. Similarly, when sorting datasets, PROC SORT is optimized for performance and can be faster than alternatives.
4. Write Efficient Loops and Macros
Loops and macros are common in SAS programming for automating repetitive tasks. However, if not used properly, they can become bottlenecks in your code.
Minimize the Use of Loops
While loops are a great tool, inefficient loops that process data one step at a time can slow down execution, especially with large datasets. Instead, use vectorized operations where possible to handle multiple data points in a single operation.
Optimize Macro Usage
Macros are powerful in SAS because they allow you to write reusable code. However, overusing macros or creating overly complex ones can hurt performance. Ensure that your macros are efficient and only used when necessary, and keep them simple to avoid unnecessary complexity.
5. Optimize Output and Reporting
Generating output reports such as tables and graphs can sometimes cause performance issues. By optimizing this process, you ensure that your results are produced quickly and efficiently.
Minimize Unnecessary Output
When generating reports, avoid including unnecessary rows or columns in your output. Directing output to external files, such as HTML or PDF, rather than displaying it on the screen or in the log, can improve both speed and usability.
Use Efficient Graphing Procedures
For complex visualizations, using the appropriate graphing tools in SAS, such as ODS GRAPHICS, can provide better performance than older procedures. These tools are specifically designed to handle large datasets while producing high-quality visual output.
Watch the video here:
youtube
6. Maintain Readable and Modular Code
Efficiency is important, but readability and maintainability are equally critical. Clean, well-organized code is essential for long-term success in SAS programming, especially when working in a team environment.
Add Meaningful Comments
Commenting your code is essential for explaining the logic behind complex operations, the purpose of specific procedures, and any assumptions you’ve made. Proper comments help others (and your future self) understand the code and maintain it more easily.
Use Modular Programming
Break down your code into smaller, reusable modules. This not only improves readability but also helps in debugging and testing specific sections of the code more efficiently. Consider using macros to encapsulate common tasks and avoid redundant code.
Conclusion
Optimizing SAS programming practices is essential for improving both the efficiency and performance of your data analysis. By focusing on effective data access, reducing unnecessary data movement, using the right procedures, and writing clean, modular code, you can enhance the speed and reliability of your SAS applications.
Remember, while performance is crucial, clarity and maintainability should not be sacrificed. By balancing both, you can create high-performing SAS code that is easy to manage and scale for future projects.
#sas programming#sas programming tutorial#sas tutorial#sas tutorial for beginners#Code Efficiency#Code Performance#Youtube
0 notes
Text
Master SQL with the Best Online Course in Hyderabad – Offered by Gritty Tech
SQL (Structured Query Language) is the backbone of data handling in modern businesses. Whether you're aiming for a career in data science, software development, or business analytics, SQL is a must-have skill. If you're based in Hyderabad or even outside but seeking the best SQL online course that delivers practical learning with real-world exposure, Gritty Tech has crafted the perfect program for you For More…
What Makes Gritty Tech's SQL Course Stand Out?
Practical, Job-Focused Curriculum
Gritty Tech’s SQL course is meticulously designed to align with industry demands. The course content is structured around the real-time requirements of IT companies, data-driven businesses, and startups.
You'll start with the basics of SQL and gradually move to advanced concepts such as:
Writing efficient queries
Managing large datasets
Building normalized databases
Using SQL with business intelligence tools
SQL for data analytics and reporting
Every module is project-based. This means you won’t just learn the theory—you’ll get your hands dirty with practical assignments that mirror real-world tasks.
Learn from Industry Experts
The faculty at Gritty Tech are not just trainers; they are seasoned professionals from top MNCs and startups. Their teaching combines theory with examples drawn from years of hands-on experience. They understand what companies expect from an SQL developer and prepare students accordingly.
Each mentor brings valuable insights into how SQL works in day-to-day business scenarios—whether it's managing millions of records in a customer database or optimizing complex queries in a financial system.
Interactive and Flexible Online Learning
Learning online doesn’t mean learning alone. Gritty Tech ensures you’re part of a vibrant student community where peer interaction, discussion forums, and collaborative projects are encouraged.
Key features of their online delivery model include:
Live instructor-led sessions with real-time query solving
Access to session recordings for future reference
Weekly challenges and hackathons to push your skills
1:1 mentorship to clarify doubts and reinforce learning
You can choose batch timings that suit your schedule, making this course ideal for both working professionals and students.
Comprehensive Module Coverage
The course is divided into logical modules that build your expertise step by step. Here's an overview of the key topics covered:
Introduction to SQL and RDBMS
Understanding data and databases
Relational models and primary concepts
Introduction to MySQL and PostgreSQL
Data Definition Language (DDL)
Creating and modifying tables
Setting primary and foreign keys
Understanding constraints and data types
Data Manipulation Language (DML)
Inserting, updating, and deleting records
Transaction management
Working with auto-commits and rollbacks
Data Query Language (DQL)
SELECT statements in depth
Filtering data with WHERE clause
Using ORDER BY, GROUP BY, and HAVING
Advanced SQL Queries
JOINS: INNER, LEFT, RIGHT, FULL OUTER
Subqueries and nested queries
Views and materialized views
Indexing and performance tuning
Stored Procedures and Triggers
Creating stored procedures for reusable logic
Using triggers to automate actions
SQL in Real Projects
Working with business databases
Creating reports and dashboards
Integrating SQL with Excel and BI tools
Interview Preparation & Certification
SQL interview Q&A sessions
Mock technical interviews
Industry-recognized certification on course completion
Real-Time Projects and Case Studies
Nothing beats learning by doing. At Gritty Tech, every student works on multiple real-time projects, such as:
Designing a complete eCommerce database
Building a report generation system for a retail chain
Analyzing customer data for a telecom company
Creating dashboards with SQL-backed queries for business decisions
These projects simulate real job roles and ensure you're not just certified but genuinely skilled.
Placement Assistance and Resume Building
Gritty Tech goes the extra mile to help you land your dream job. They offer:
Resume and LinkedIn profile optimization
Personalized career guidance
Referrals to hiring partners
Mock interview practice with real-time feedback
Graduates of Gritty Tech have successfully secured jobs as Data Analysts, SQL Developers, Business Intelligence Executives, and more at top companies.
Affordable Pricing with Installment Options
Quality education should be accessible. Gritty Tech offers this high-value SQL course at a very competitive price. Students can also opt for EMI-based payment options. There are often discounts available for early registration or referrals.
Support After Course Completion
Your learning doesn't stop when the course ends. Gritty Tech provides post-course support where you can:
Revisit lectures and materials
Get help with ongoing SQL projects at work
Stay connected with alumni and mentors
They also host webinars, advanced workshops, and alumni meetups that keep you updated and networked.
Who Should Join This Course?
This SQL course is ideal for:
College students and fresh graduates looking to boost their resume
Working professionals in non-technical roles aiming to switch to tech
Data enthusiasts and aspiring data scientists
Business analysts who want to strengthen their data querying skills
Developers who wish to enhance their backend capabilities
No prior coding experience is required. The course begins from scratch, making it beginner-friendly while progressing toward advanced topics for experienced learners.
0 notes
Text
MySQL Assignment Help
Are you a programming student? Are you looking for help with programming assignments and homework? Are you nervous because the deadline is approaching and you are unable to understand how to complete the boring and complex MySQL assignment? If the answer is yes, then don’t freak out as we are here to help. We have a team of nerdy programmers who provide MySQL assignment help online. If you need an A Grade in your entire MySQL coursework then you need to reach out to our experts who have solved more than 3500 projects in MySQL. We will not only deliver the work on time but will ensure that your university guidelines are met completely, thus ensuring excellent solutions for the programming work.
However, before you take MySQL Help from our experts, you must read the below content in detail to understand more about the subject:
About MySQL
MySQL is an open-source database tool that helps us to make different databases and assist them to implement the various programming languages that make both online and offline software. MySQL is a backend tool for computer programming and software that allows one to make big databases and store the different information collected by the software.
In today’s education system all around the globe, there is no need to be in touch with the theory that you have been reading but now there is a demand for the practical applications of the theory. The grades will be increased only when the student will be able to implement what he/she has learned in their studies.
Finally, the complete implementation will be explained in a step-by-step manner to the student
Since we are a globe tutor and also the best online assignment help provider, we have people who know every education system throughout the world. We are not only limited to the US or the UK, but we are here to help each and every student around the world.
Conclusively, you will not regret choosing the All Assignments Experts because we assure to give you the best MySQL assignment service within time. So what are you waiting for? If you need MySQL assignment help, sign up today with the All Assignments Experts. You can email your requirements to us at [email protected]
Popular MySQL Programming topics for which students come to us for online assignment help are:
MySQL Assignment help
Clone Tables Create Database
Drop Database Introduction to SQL
Like Clause MySQL - Connection
MySQL - Create Tables MySQL - Data Types
Database Import and Export MySQL - Database Info
MySQL - Handling Duplicates Insert Query & Select Query
MySQL - Installation NULL Values
SQL Injection MySQL - Update Query and Delete Query
MySQL - Using Sequences PHP Syntax
Regexps Relational Database Management System (RDBMS)
Select Database Temporary Tables
WAMP and LAMP Where Clause
0 notes
Text
Understanding the Cost of JOIN in SQL Queries and How to Optimize Performance
In SQL, the cost of a JOIN operation can significantly impact query performance, especially when dealing with large datasets. The efficiency of a JOIN depends on various factors, including the type of JOIN (INNER, LEFT, RIGHT, or FULL OUTER), indexing, and table sizes. Without proper optimization, JOIN operations can lead to high memory usage, increased CPU load, and longer execution times.
One major factor influencing JOIN cost is the Order of Execution in SQL, which determines how tables are processed and combined. The query planner decides the optimal execution path, considering indexes, filtering conditions, and available join algorithms such as Nested Loop, Hash Join, and Merge Join.
Indexes play a crucial role in reducing JOIN costs. If proper indexes exist on the join keys, SQL engines can quickly locate matching records, reducing the number of comparisons. However, missing or inefficient indexes may lead to full table scans, drastically increasing execution time.
Another aspect to consider is table size. Joining two large tables without filtering conditions can result in a massive intermediate dataset, leading to high memory consumption. Using WHERE clauses and limiting result sets can improve performance.
Query optimization techniques, such as indexing, partitioning, and query restructuring, help reduce the impact of costly JOIN operations. Understanding how the database engine executes queries allows developers to fine-tune their SQL queries for better performance.
4o
0 notes