#Filesystem Hierarchy Standard
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
When “GIF” was named word of the year in 2012, Oxford Dictionaries U.S.A. credited Tumblr for pushing the word.
Text
been having a delightful time reading abt the linux filesystem hierarchy standard the last couple days [cut to a close up of my long grey beard with bugs and crumbs in it] and i think thats one of the major differences between android and linux besides that they forked the actual kernel anyway like way back but my understanding is that like almost every distro now ALSO doesnt really use the fhs, they just build their own structure and then just make some of the folders shortcuts to the underlying old ass fhs, because its so shittily organized* and incomprehensible but this still means theyre beholden to the way it fundamentally works and thats why dependency conflicts exist. because the filesystem hierarchy is old as balls and doesnt have any handling for multiple packages that call themselves the same thing. and so if you have 2 programs that use the same library but one of them uses a new version and one of them uses an old version they cant exist at the same time. and theres distros that do away with it altogether but one is some esoteric meme that's barely updated since 2003 and only builds from source and the other is nixos which is a completely different kind of weirdos. very compelling weirdos but like, fully not at all made for normal desktop use like a normal distro. i wish this was one of those things like systemd that everyone thought was stupid and would probably make stuff worse but it just parked its butt so obstinately that it just became the new standard anyway and people eventually got bored and stopped complaining
*theres 3 Different directories for user files because the like original unix build ran on expensive ass building-wide hard drives and they kept having to make more space by moving user stuff off to new storage with a new directory and people try to justify the 3 different but identical user directories by saying theyre actually different in subtle and nuanced ways but theyre literally not its just fossilized gunk
0 notes
Link
看看網頁版全文 ⇨ 資安工具箱:Kali Linux / Information Security Toolbox: Kali Linux https://blog.pulipuli.info/2023/06/kali-linux-information-security-toolbox-kali-linux.html Windows界的工具箱,我推薦用USBOX。 那Linux界呢?首推Kali Linux。 ---- # 關於Kali Linux / About Kali Linux。 https://www.kali.org/docs/introduction/what-is-kali-linux/。 Kali Linux的前身名為BackTrack Linux,它是一個開放原始碼、基於Debian的Linux發佈版。 Kali Linux的目標是提供進階的滲透測試(Penetration Testing)以及資安稽核(Security Auditing),它內建了各種常用工具、設定、以及自動化配置,讓使用者不需分心其他事務,能夠專注於任務上。 Kali Linux包含的工具含括了各種資訊安全(Information Security)相關任務,除了滲透測試之外,還包括了資安研究(Security Research)、電腦取證(Computer Forensics,又翻譯做「電腦鑑識」,就是從電腦中找尋犯罪的痕跡)、逆向工程(Reverse Engineering,將編譯好的工具還原成原始碼,很多時候可以依此找出木馬漏洞)、漏洞管理(Vulnerability Management)、以及紅隊測試(Red Team Testing,以多人組織進行多方面滲透測試)。 Kali Linux是多平臺的解決方案,開放給任何資安專家和有興趣的人免費使用。 # 主要特色 / Featues - 超過600種滲透測試工具。 - 永久免費,就跟啤酒一樣(as in beer)。 - 開放原始碼且用Git管理。 - 相容於檔案系統階層標準(Filesystem Hierarchy Standard, FHS)。 - 支援各種無線設備。 - 客製化的核心、包含了最新的更新。 - 在安全環境下開發。 - 使用GPG簽名的套件與儲存庫,確保套件的正確性。 - 多語言支持。 - 高度可客製化。 - 支援ARMEL與ARMHF等ARM的硬體設備。因此也可以安裝在樹莓派、Android手機上。 更多特色請參考Kali Linux Overview。 # 下載與安裝 / Download and Installation。 https://www.kali.org/get-kali/#kali-platforms。 ---- 繼續閱讀 ⇨ 資安工具箱:Kali Linux / Information Security Toolbox: Kali Linux https://blog.pulipuli.info/2023/06/kali-linux-information-security-toolbox-kali-linux.html
0 notes
Note
It absolutely is about filesystems in how they are used from the end user perspective.
What is "Filesystem Hierarchy Standard" if not a description of the directory structure. If even computer nerds use the terms interchangeably then a person not familiar with the subject definitely will. Answering the question as worded instead of how it was intended, given the context, would be unhelpful. Filesystem implementations can be discussed later, in yet another reblog.
Zoomer here, and I do indeed have questions about computers- how do filesystems work, and why should we care (I know we should, but I'm not exactly sure why)?
So why should we care?
You need to know where your own files are.
I've got a file on a flash drive that's been handed to me, or an archival data CD/DVD/Bluray, or maybe it's a big heavy USB external hard drive and I need to make a copy of it on my local machine.
Do I know how to navigate to that portable media device within a file browser?
Where will I put that data on my permanent media (e.i. my laptop's hard drive)?
How will I be able to reliably find it again?
We'll cover more of the Why and How, but this will take some time, and a few addendum posts because I'm actively hitting the character limit and I've rewritten this like 3 times.
Let's start with file structure
Files live on drives: big heavy spinning rust hard drives, solid state m.2 drives, USB flash drives, network drives, etc. Think of a drive like a filing cabinet in an office.
You open the drawer, it's full of folders. Maybe some folders have other folders inside of them. The folders have a little tab with a name on it showing what's supposed to be in them. You look inside the folders, there are files. Pieces of paper. Documents you wrote. Photographs. Copies of pages from a book. Maybe even the instruction booklet that came with your dishwasher.
We have all of that here, but virtualized! Here's a helpful tree structure that Windows provides to navigate through all of that. In the case of Windows, it's called Explorer. On OSX MacOS, the equivalent is called Finder.
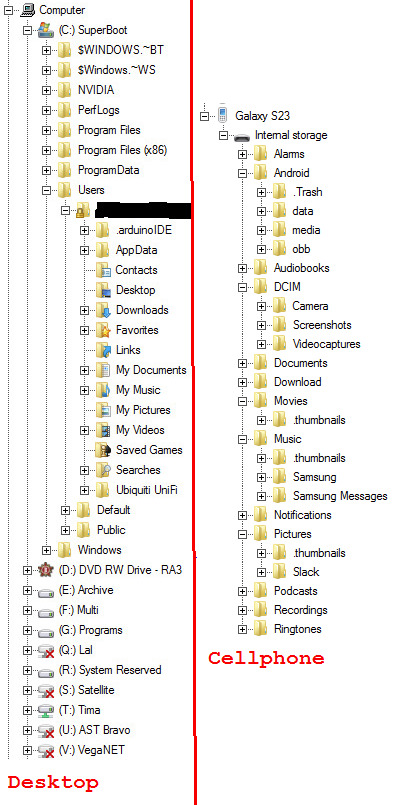
I don't have to know where exactly everything is, but I have a good idea where thing *should* based on how I organize them. Even things that don't always expose the file structure to you have one (like my cellphone on the right). I regularly manually copy my files off of my cellphone by going to the Camera folder so I can sift through them on a much bigger screen and find the best ones to share. There are other reasons I prefer to do it that way, but we won't go into that here. Some people prefer to drag and drop, but that doesn't always work the same between operating systems. I prefer cut and paste.
Standby for Part 2!
2K notes
·
View notes
Text
trying to stick to FHS and XDG standards is hard when they're not even followed properly by other stuff, there's redundancy that can't be removed bc it would break shit that still uses legacy conventions, and there's some big holes in "where should xyz go"
and the only thing I have close to the solution is "now there are 13 competing standards"
35 notes
·
View notes
Text
Magisk Module to Allow Location Mocking, Screenshots in Any App, and Disabling System Signature Verification
Magisk Module to Allow Location Mocking, Screenshots in Any App, and Disabling System Signature Verification
[ad_1]
Magisk is a systemless root and module host for Android devices. With the use of Magisk, users can modify their Android /system partition without breaking SafetyNet. This is because Magisk makes its changes in the RAM without overwriting actual system files, meaning build.prop edits and more are possible. A Magisk module is just a /system modification prepackaged in a flashable zip which…
View On WordPress
#Android#Android (operating system)#Android devices#Application software#Authentication#Computer file#Computer hardware#Digital distribution#Digital rights management#Disk partitioning#Filesystem Hierarchy Standard#IMG (file format)#Initial#installed applications#Internet forum#JAR (file format)#Mod (video gaming)#Modular programming#Netflix#Operating system#P-class yacht#Pokémon Go#Pre-installed software#Random-access memory#Rooting#SafetyNet#Screenshot#screenshots#Server (computing)#Software developer
1 note
·
View note
Text
Is the answer to the original question “/usr/bin is a symlink to /bin; they are *all* in /bin”?
...I had to check, and no. /usr/bin/ is a real directory
but also that's exactly why make shouldn't be /bin/make - bin is supposed to be stripped down - if it isn't necessary to boot your system, it doesn't go in /bin (According to the Filesystem Hierarchy Standard, which is not binding)
3 FHS 4.2: "The following commands ... are required in /bin"
- [...] - ls - mkdir - [...]
You know what's not on that list, but would be between ls and mkdir if it was on that list?
make
why does my distro have /bin/make
what is the point of that
(5 minutes later) .. .ok so my distro is on top of ubuntu, who don't have any info in their references either but they deliver their own stuff, yes, but it's amalgamated with ...
(10 minutes later) ... is cute but I feel like it's too cute you know? "Budgie" has "Raven" what's next, libOwlNest? ...
(5 minutes later again) ... if that's posix compliant and I don't care if you mean 1 or 2, I'll eat my fucking hat ...
(1 minute later) ... wait what happens if I have two window managers and I switch between them? I mean any temux server would keep running so I could just go back to that but what about GUI apps, do they close? Or do they keep running and it's just their window information that gets lost? What even is their window information? I could absolutely write a program where the heavy lifting is done by some background service that'd keep living even if the graphical part died but ...
(5 minutes later) ... I am never going to understand SIGTERM it is simply not ...
51 notes
·
View notes
Text
Comando mount no Linux (montar sistemas de arquivos) [Guia Básico]

O comando mount no Linux é utilizado para montar um dispositivo na hierarquia do sistema de arquivos do Linux manualmente. Para desmontar um dispositivo, o comando umount pode ser usado. O sistema de arquivos do Linux é hierárquico e admite que diversos dispositivos sejam mapeados e utilizados a partir da raiz do sistema / (root). Desta forma DVD, outros discos, pendrivers etc., poderão ser utilizados de forma bastante simples, e o usuário enxergará estes dispositivos como um diretório na estrutura do Linux. O Filesystem Hierarchy Standard (padrão para sistema de arquivos hierárquico) separou dois diretórios que servirão como hospedeiros para os dispositivos são chamados de ponto de montagem: - /mnt Ponto de Montagem para sistemas de arquivos montados momentaneamente, como discos rígidos; - /media Pontos de "montagem" para mídia removível, como CD-ROMs, pendrive, etc (surgiram na versão 2.3 do FHS). Em algumas distribuições o diretório /media contém alguns outros subdiretórios opcionais para montar mídias removíveis: - cdrom CD-ROM - cdrecorder CD writer - zip Zip drive Já o diretório /mnt é fornecido para que o administrador do sistema possa montar temporariamente um sistema de arquivos, conforme necessário. Geralmente estes diretórios ficam vazios quando não estão com algum sistema montado. Apesar do FHS definir estes diretórios como pontos de montagem para dispositivos, qualquer diretório pode servir como ponto de montagem. Se os diretórios escolhidos como ponto de montagem não estiverem vazios ao montar um dispositivo, o conteúdo não ficará disponível enquanto o dispositivo não for desmontado. Linux FHS Os comandos mount e umount são usados para montar e desmontar sistemas de arquivos. Usando o comando mount Geralmente deve ser informado como parâmetro um dispositivo a ser montado e o ponto de montagem. Existe outra possibilidade de montagem manual informando somente o dispositivo, ou somente o ponto de montagem. Quando isso acontece, o dispositivo ou o ponto de montagem devem existir configurados no arquivo /etc/fstab: $ mount dispositivo$ mount diretório Arquivo /etc/fstab O arquivo /etc/fstab contém as informações de montagem dos dispositivos que são montados durante o processo de carga do sistema. O mount também possibilita as seguintes notações de dispositivo sejam usadas para se referir a um dispositivo: NotaçãoDescrição/dev/sdaXEspecifica o dispositivo pelo nome dele no sistema;LABEL=Especifica o dispositivo pelo rótulo do sistema de arquivos;UUID=Especifica o dispositivo pelo UUID do sistema de arquivos;PARTLABEL=Especifica o dispositivo pelo rótulo da partição;PARTUUID=Especifica o dispositivo pelo UUID da partição; As opções mais frequentes são: - -a Monta todos os dispositivos especificados no arquivo /etc/fstab que não tem a opção noauto selecionada; - -r Monta o sistema de arquivos do dispositivo como somente leitura; - -w Monta o sistema de arquivos do dispositivo para leitura e gravação; - -o Especifica as opções de montagem; - -t tipo Especifica o tipo do sistema de arquivos do dispositivo. Exemplo: ext2, ext3, ext4, iso9660, msdos, xfs, btrfs, nfs, etc. Para montar os diversos sistemas de arquivos, o Linux precisa estar com o suporte a estes sistemas de arquivos habilitados no Kernel ou carregado na forma de um módulo. Arquivo /etc/filesystems O arquivo /etc/filesystems fornece uma lista dos sistemas de arquivos que estão habilitados e aceitos pelo mount: $ cat /etc/filesystems xfsext4ext3ext2nodev prociso9660vfat Exemplos de uso do mount: Para montar um cartão USB: # mount /dev/sdb1 /mnt Para montar uma partição Windows (vfat) em /dev/sda1 no ponto de montagem /mnt para somente para leitura: # mount /dev/sda1 /mnt -r -t vfat Para remontar a partição raíz como somente leitura: # mount -o remount,r / Para montar uma imagem ISO, a opção "-o loop" deve ser usada: # mount /tmp/imagem.iso /media/iso -o loop Para que o mount remonte todos os pontos de montagem definidos em /etc/fstab: # mount -a Se não for passado nenhum parâmetro ou opção, o mount mostra todos os dispositivos montados, incluindo os pseudo-file-system /proc, /dev, /run e /sys. Ele também mostra as opções de montagem, como leitura e gravação, bem como o sistema de arquivos: $ mountsysfs on /sys type sysfs (rw,nosuid,nodev,noexec,relatime)proc on /proc type proc (rw,nosuid,nodev,noexec,relatime)devtmpfs on /dev type devtmpfs (rw,nosuid,size=1001736k,nr_inodes=250434,mode=755)tmpfs on /run type tmpfs (rw,nosuid,nodev,mode=755)/dev/xvda1 on / type xfs (rw,noatime,attr2,inode64,noquota)/dev/xvdf on /home type ext4 (rw,noatime,data=ordered) Para montar um dispositivo usando o UUID dele, primeiro deve-se ver qual é o UUID do dispositivo com o comando blkid: # blkid/dev/sda1: UUID="1c3b15b1-cd13-4a73-b2a8-449fa3aa039f" TYPE="xfs" # mount UUID="1c3b15b1-cd13-4a73-b2a8-449fa3aa039f" /mnt A vantagem de se usar o UUID é que esse ID do disco não muda nunca. Já a nomenclatura do disco pode ser alterada quando um novo disco é inserido ou alterado de lugar no cabo IDE. Desta forma, um disco nomeado como /dev/sda, pode virar /dev/sdb. Se forem referenciados pelo UUID, esse número não altera. Arquivo /etc/mtab O sistema mantém um arquivo chamado /etc/mtab que contém as informações sobre os dispositivos que estão montados no sistema. Ele pode conter os pontos de montagem indicados no arquivo /etc/fstab e também os dispositivos montados manualmente. O arquivo /etc/mtab é mantido pelo sistema, através do comando mount. O conteúdo deste arquivo é muito similar ao arquivo /proc/mounts. O Linux usa dois mecanismos diferentes para acompanhar os dispositivos montados. Um é implementado no kernel e expõe esta informação ao espaço do usuário via arquivo /proc/mounts. O outro mecanismo mantém a contabilidade dos pontos de montagem pelo utilitário mount usando o arquivo /etc/mtab. Arquivo /proc/partitions Cada disco detectado no sistema irá aparecer no arquivo /proc/partitions. É neste arquivo que o Kernel mantem uma lista dos discos detectados, suas partições e tamanho. $ cat /proc/partitions major minor #blocks name 8 0 488386584 sda 8 1 524288 sda1 8 2 2097152 sda2 8 3 2097152 sda3 8 4 483666951 sda4 8 16 117220824 sdb 8 17 117219328 sdb1 8 48 31950720 sdd 8 49 204800 sdd1 8 50 31744000 sdd2 A ferramenta lsblk pode fornecer a mesma informação de uma forma muito mais clara: $ lsblkNAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTsda 8:0 0 465,8G 0 disk ├─sda1 8:1 0 512M 0 part /boot/efi├─sda2 8:2 0 2G 0 part ├─sda3 8:3 0 2G 0 part └─sda4 8:4 0 461,3G 0 part sdb 8:16 0 111,8G 0 disk └─sdb1 8:17 0 111,8G 0 part sdd 8:48 1 30,5G 0 disk ├─sdd1 8:49 1 200M 0 part └─sdd2 8:50 1 30,3G 0 part /media/uira/UNTITLED Neste computador existem dois discos rígidos: sda com 4 partições, e sdb com uma única partição. E ainda existe um pendrive de 30 GB, montado no diretório /media/uira/UNTITLED. Usando o comando umount O comando umount é utilizado para desmontar dispositivos montados pelo comando mount. O umount sincroniza o conteúdo do disco com o conteúdo dos buffers (memória própria para transferência de dados) e libera o diretório de montagem. Ele tanto pode receber como parâmetro o dispositivo que está montado, quanto o diretório do ponto de montagem: $ umount dispositivo Ou $ umount diretório As opções disponíveis são: - -a Desmonta todos os dispositivos listados no arquivo /etc/mtab, que é mantido pelo comando mount como referência de todos os dispositivos montados; - -f Força que um dispositivo seja desmontado; - -t tipo Desmonta somente os dispositivos que contenham o sistema de arquivos especificado no tipo. Nenhum arquivo pode estar em uso no sistema de arquivos que será desmontado. Exemplos: $ umount /dev/cdrom Ou $ umount /media/cdrom Nunca retire um disco removível como memórias flash, pendrivers e HDs externos sem antes desmontar o sistema de arquivos, pois haverá grande hipótese de perda de dados. Às vezes, quando se tenta remover um dispositivo, recebemos a mensagem de que ele está em uso: $ sudo umount /media/uira/UNTITLED/umount: /media/uira/UNTITLED: o alvo está ocupado. Neste caso, pode-se usar o comando lsof para se descobrir quais são os arquivos e usuários que estão com arquivos em uso no dispositivo: $ lsof /media/uira/UNTITLED/COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAMEevince 81294 uira 16r REG 8,50 190985 2217 /media/uira/UNTITLED/CompTIA Linux+ XK0-004 Exam Objectives_ESN.pdfsoffice.b 81592 uira 5uW REG 8,50 17095 2221 /media/uira/UNTITLED/melhorias campus bh.docx Para desmontar esse dispositivo, existem duas opções: pedir gentilmente que o usuário feche o que está fazendo, ou terminar abruptamente os processos 81294 e 81592 com o comando "kill -9 81294 e 81592" e depois desmontar o dispositivo. https://youtu.be/DrTowuB8-8o Aprenda muito mais sobre Linux em nosso curso online. Você pode efetuar a matrícula aqui. Se você já tem uma conta, ou quer criar uma, basta entrar ou criar seu usuário aqui. Gostou? Compartilhe Read the full article
0 notes
Text
Linux Directories | Linux Filesystem Hierarchy Standard | FHS
Linux Directories | Linux Filesystem Hierarchy Standard | FHS
In the Linux terminal, we call the filesystem a directory. Linux Directories are files that hold a bunch of addresses of other files. In a GUI, we call the ‘directory’ a folder. Windows and Linux both evolved in very different ways. Microsoft built Windows on top of DOS, on the other hand, Linux evolved from the Unix System. Unlike the current version of windows, MS-DOS (disk operating system)…
View On WordPress
0 notes
Photo

What is file system in Linux? Where are all the configuration files? Where do I keep my downloaded applications? Is there really a filesystem standard structure in Linux? Well, the above image explains Linux file system hierarchy in a very simple and non-complex way. It's very useful when you're looking for a configuration file or a binary file. I've added some explanation and examples below, but that's TLDR. Follow us @aiprobably Repost: @linuxscoop . . . . . #linux #programming #python #coding #hacking #technology #programmer #tech #java #hacker #computerscience #code #coder #javascript #html #developer #cybersecurity #webdeveloper #css #computer #kalilinux #software #php #webdevelopment #webdesign #programmers #geek #softwaredeveloper #windows #cybersecurity https://www.instagram.com/p/BvGPv-pBg4s/?utm_source=ig_tumblr_share&igshid=cnj31j94c2gw
#linux#programming#python#coding#hacking#technology#programmer#tech#java#hacker#computerscience#code#coder#javascript#html#developer#cybersecurity#webdeveloper#css#computer#kalilinux#software#php#webdevelopment#webdesign#programmers#geek#softwaredeveloper#windows
0 notes
Text
Linux Beginners: Understanding Linux Directory Structure
Linux Beginners: Understanding Linux Directory Structure
After the Installation task, lets proceed to understand what is the directory structure of linux systems. The Filesystem Hierarchy Standard (FHS) defines the structure of file systems on Linux and other UNIX-like operating systems. However, Linux file systems also contain some directories that aren’t yet defined by the standard.

After the installation process login to the console and type the…
View On WordPress
0 notes
Link
0 notes
Text
The 'Unix Way'
It probably shouldn't, but it routinely astonishes me how much we live on the Web. Even I find myself going entire boots without using anything but the Web browser. With such an emphasis on Web-based services, one can forget to appreciate the humble operating system.
That said, we neglect our OS at the risk of radically underutilizing the incredible tools that it enables our device to be.
Most of us only come into contact with one, or possibly both, of two families of operating systems: "House Windows" and "House Practically Everything Else." The latter is more commonly known as Unix.
Windows has made great strides in usability and security, but to me it can never come close to Unix and its progeny. Though more than 50 years old, Unix has a simplicity, elegance, and versatility that is unrivalled in any other breed of OS.
This column is my exegesis of the Unix elements I personally find most significant. Doctors of computer science will concede the immense difficulty of encapsulating just what makes Unix special. So I, as decidedly less learned, will certainly not be able to come close. My hope, though, is that expressing my admiration for Unix might spark your own.
The Root of the Family Tree
If you haven't heard of Unix, that's only because its descendants don't all have the same resemblance to it -- and definitely don't share a name. MacOS is a distant offshoot which, while arguably the least like its forebears, still embodies enough rudimentary Unix traits to trace a clear lineage.
The three main branches of BSD, notably FreeBSD, have hewn the closest to the Unix formula, and continue to form the backbone of some of the world's most important computing systems. A good chunk of the world's servers, computerized military hardware, and PlayStation consoles are all some type of BSD under the hood.
Finally, there's Linux. While it hasn't preserved its Unix heritage as purely as BSD, Linux is the most prolific and visible Unix torchbearer. A plurality, if not outright majority, of the world's servers are Linux. On top of that, almost all embedded devices run Linux, including Android mobile devices.
Where Did This Indispensable OS Come From?
To give as condensed a history lesson as possible, Unix was created by an assemblage of the finest minds in computer science at Bell Labs in 1970. In their task, they set themselves simple objectives. First, they wanted an OS that could smoothly run on whatever hardware they could find since, ironically, they had a hard time finding any computers to work with at Bell. They also wanted their OS to allow multiple users to log in and run programs concurrently without bumping into each other. Finally, they wanted the OS to be simple to administer and intuitively organized. After acquiring devices from the neighboring department, which had a surplus, the team eventually created Unix.
Unix was adopted initially, and vigorously so, by university computer science departments for research purposes. The University of Illinois at Champaign-Urbana and the University of California Berkeley led the charge, with the latter going so far as to develop its own brand of Unix called the Berkeley Software Distribution, or BSD.
Eventually, AT&T, Bell's successor, lost interest in Unix and jettisoned it in the early 90s. Shortly following this, BSD grew in popularity, and AT&T realized what a grave mistake it had made. After what is probably still the most protracted and aggressive tech industry legal battle of all time, the BSD developers won sole custody of the de facto main line of Unix. BSD has been Unix's elder statesmen ever since, and guards one of the purest living, widely available iterations of Unix.
Organizational Structure
My conception of Unix and its accompanying overall approach to computing is what I call the "Unix Way." It is the intersection of Unix structure and Unix philosophy.
To begin with the structural side of the equation, let's consider the filesystem. The design is a tree, with every file starting at the root and branching from there. It's just that the "tree" is inverted, with the root at the top. Every file has its proper relation to "/" (the forward slash notation called "root"). The whole of the system is contained in the directories found here. Within each directory, you can have a practically unlimited number of files or other directories, each of which can have an unlimited number of files and directories of its own, and so on.
More importantly, every directory under root has a specific purpose. I covered this a while back in a piece on the Filesystem Hierarchy Standard, so I won't rehash it all here. But to give a few illustrative examples, the /boot directory stores everything your system needs to boot up. The /bin, /sbin, and /usr directories retain all your system binaries (the things that run programs). Configuration files that can alter how system-owned programs work live in /etc. All your personal files such as documents and media go in /home (to be more accurate, in your user account's directory in /home). The kind of data that changes all the time, namely logs, gets filed under /var.
In this way, Unix really lives by the old adage "a place for everything, and everything in its place." This is exactly why it's very easy to find whatever you're looking for. Most of the time, you can follow the tree one directory at a time to get to exactly what you need, simply by picking the directory whose name seems like the most appropriate place for your file to be. If that doesn't work, you can run commands like 'find' to dig up exactly what you're looking for. This organizational scheme also keeps clutter to a minimum. Things that are out-of-place stand out, at which point they can be moved or deleted.
Everything Is a File
Another convention which lends utility through elegance is the fact that everything in Unix is a file. Instead of creating another distinct digital structure for things like hardware and processes, Unix thinks of all of these as files. They may not all be files as we commonly understand them, but they are files in the computer science sense of being groups of bits.
This uniformity means that you are free to use a variety of tools for dealing with anything on your system that needs it. Documents and media files are files. Obvious as that sounds, it means they are treated like individual objects that can be referred to by other programs, whether according to their content format, metadata, or raw bit makeup.
Devices are files in Unix, too. No matter what hardware you connect to your system, it gets classified as a block device or a stream device. Users almost never mess with these devices in their file form, but the computer needs a way of classifying these devices so it knows how to interact with them. In most cases, the system invokes some program for converting the device "file" into an immediately usable form.
Block devices represent blocks of data. While block devices aren't treated like "files" in their entirety, the system can read segments of the block device by requesting a block number. Stream devices, on the other hand, are "files" that present streams of information, meaning bits that are being created or sent constantly by some process. A good example is a keyboard: it sends a stream of data as keys are pressed.
Even processes are files. Every program that you run spawns one or more processes that persist as long as the program does. Processes regularly start other processes, but can all be tracked by their unique process ID (PID) and grouped by the user that owns them. By classifying processes as files, locating and manipulating them is straightforward. This is what makes reprioritizing selfish processes or killing unruly ones possible.
To stray a bit into the weeds, you can witness the power of construing everything as a file by running the 'lsof' command. Short for "list open files," 'lsof' enumerates all files currently in use which fit certain criteria. Example criteria include whether or not the files use system network connections, or which process owns them.
Virtues of Openness
The last element I want to point out (though certainly not the last that wins my admiration) is Unix's open computing standard. Most, if not all, of the leading Unix projects are open source, which means they are accessible. This has several key implications.
First, anyone can learn from it. In fact, Linux was born out of a desire to learn and experiment with Unix. Linus Torvalds wanted a copy of Minix to study and modify, but its developers did not want to hand out its source code. In response, Torvalds simply made his own Unix kernel, Linux. He later published the kernel on the Internet for anyone else who also wanted to play with Unix. Suffice it to say that there was some degree of interest in his work.
Second, Unix's openness means anyone can deploy it. If you have a project that requires a computer, Unix can power it; and being highly adaptable due to its architecture, this makes it great for practically any application, from tinkering to running a global business.
Third, anyone can extend it. Again, due to its open-source model, anyone can take a Unix OS and run with it. Users are free to fork their own versions, as happens routinely with Linux distributions. More commonly, users can easily build their own software that runs on any type of Unix system.
This portability is all the more valuable by virtue of Unix and its derivatives running on more hardware than any other OS type. Linux alone can run on essentially all desktop or laptop devices, essentially all embedded devices including mobile devices, all server devices, and even supercomputers.
So, I wouldn't say there's nothing Unix can't do, but you'd be hard-pressed to find it.
A School of Thought, and Class Is in Session
Considering the formidable undertaking that is writing an OS, most OS developers focus their work by defining a philosophy to underpin it. None has become so iconic and influential as the Unix philosophy. Its impact has reached beyond Unix to inspire generations of computer scientists and programmers.
There are multiple formulations of the Unix philosophy, so I will outline what I take as its core tenets.
In Unix, every tool should do one thing, but do that thing well. That sounds intuitive enough, but enough programs weren't (and still aren't) designed that way. What this precept means in practice is that each tool should be built to address only one narrow slice of computing tasks, but that it should also do so in a way that is simple to use and configurable enough to adapt to user preferences regarding that computing slice.
Once a few tools are built along these philosophical lines, users should be able to use them in combination to accomplish a lot (more on that in a sec). The "classic" Unix commands can do practically everything a fundamentally useful computer should be able to do.
With only a few dozen tools, users can:
Manage processes
Manipulate files and their contents irrespective of filetype
Configure hardware and networking devices
Manage installed software
Write and compile code into working binaries
Another central teaching of Unix philosophy is that tools should not assume or impose expectations for how users will use their outputs or outcomes. This concept seems abstract, but is intended to achieve the very pragmatic benefit of ensuring that tools can be chained together. This only amplifies what the potent basic Unix toolset is capable of.
In actual practice, this allows the output of one command to be the input of another. Remember that I said that everything is a file? Program outputs are no exception. So, any command that would normally require a file can alternatively take the "file" that is the previous command's output.
Lastly, to highlight a lesser-known aspect of Unix, it privileges text handling and manipulation. The reason for this is simple enough: text is what humans understand. It is therefore what we want computational results delivered in.
Fundamentally, all computers truly do is transform some text into different text (by way of binary so that it can make sense of the text). Unix tools, then, should let users edit, substitute, format, and reorient text with no fuss whatsoever. At the same time, Unix text tools should never deny the user granular control.
In observing the foregoing dogmas, text manipulation is divided into separate tools. These include the likes of 'awk', 'sed', 'grep', 'sort', 'tr', 'uniq', and a host of others. Here, too, each is formidable on its own, but immensely powerful in concert.
True Power Comes From Within
Regardless of how fascinating you may find them, it is understandable if these architectural and ideological distinctions seem abstruse. But whether or not you use your computer in a way that is congruent with these ideals, the people who designed your computer's OS and applications definitely did. These developers, and the pioneers before them, used the mighty tools of Unix to craft the computing experience you enjoy every day.
Nor are these implements relegated to some digital workbench in Silicon Valley. All of them are there -- sitting on your system anytime you want to access them -- and you may have more occasion to use them than you think. The majority of problems you could want your computer to solve aren't new, so there are usually old tools that already solve them. If you find yourself performing a repetitive task on a computer, there is probably a tool that accomplishes this for you, and it probably owes its existence to Unix.
In my time writing about technology, I have covered some of these tools, and I will likely cover yet more in time. Until then, if you have found the "Unix Way" as compelling as I have, I encourage you to seek out knowledge of it for yourself. The Internet has no shortage of this, I assure you. That's where I got it.
0 notes
Text
LINUX FILE SYSTEM
LINUX FILE SYSTEM
Linux File System (Directory Structure)
Linux is not the complete OS it is a number of packages built around a kernel. It has too many lines of code invented and developed by Mr. Linux Torvald in 1991. Developers can edit the code as it was released under open source and free for others.
The Linux file system is a mixture of folders or maybe directory. Everything in Linux is FILE. It is in form like a tree structure start with / directory. Each partition under the root directory.
TYPES OF LINUX FILE SYSTEM
ext2 Linux file System
ext3
Linux file System
ext4
Linux file System
JFS
Linux file System
ReiserFS
Linux file System
XFS
Linux file System
btrfs
Linux file System
swap
Linux file System
ext2 Linux File System
ext2 stands for the second extended file system it was included in 1993.developed to overcome of limitation of the ext file system. It does not have a journaling feature. Maximum individual file size supports from 16 GB to 2 TB and overall ext2 file system size is 2 TB to 32 TB
ext3 Linux File System
ext3 stands for the third extended file system. Introduced in 2001 starting from Linux kernel 2.4.15 and onwards. The main benefit is to allow journalling. It is a dedicated area in the file system where all changes are tracked when the system crash the possibility of file system corruption is less because of the journaling feature. Maximum individual file size supports from 16 GB to 2 TB and overall ext3 file system size is 2 TB to 32 TB. Three types of journaling available in the ext3 file system.
1 - Journal Metadata and content save in journal
2 - Ordered Only metadata save in journal, metadata are journaled only after writing the content to disk and this is the default.
3 - Writeback Only metadata save in journal. Metadata journaled either before or after the content is written to disk.
ext4 Linux File System
ext4 stands for fourth extended file system and it is introduced in 2008. Supports 64000 subdirectories in one directory. Maximum individual file size supports from 16 GB to 16 TB and overall ext4 file system size is 1 exabyte
1 exabyte = 1024 PB
1 PB = 1024 TB
Here we have the option to switch off journalling features on or off.
JFS Linux file system
JFS is Journaled File System and developed by IBM. It can be an alternative to the EXT file system.
ReiserFS Linux file system
ReiserFS is an alternative for the EXT3 file system.
XFS Linux file system
XFS file system considered as high-speed JFS was developed for parallel I/O processing
btrfs Linux file system
btrfs file system is a b tree file system. using for fault tolerance, storage configuration, and many more.
swap Linux file system
the swap file system is used for memory paging with equal to system RAM size
LINUX FILE SYSTEM HIERARCHY
ve Diagram explained itself about all directories
Linux-file-systen
(Image Credit) Image Source - Google | Image By - Austinvernsonger
Few details of the above diagram
/ directory ( root directory)
Everything on Linux located under the / directory also known as the root directory. It is similar to windows C:\ directory difference is Linux not having drive letters, on windows, it is D:\ but on Linux another partition under / directory
/bin directory (user binaries)
This directory contains some of the standards commands of files. this may be useful for all the users also no special root or su permission required.
/sbin directory (system administration binaries)
/sbin directory is similar to the almost /bin directory. It contains essentials system administration commands files. Only run by root or super user.
/etc directory (configuration files)
This directory contains system configuration files.
/dev directory (device file)
This directory contains device files. These all files associated with the device. Everything in Linux is a file.
/proc directory (kernel and process files)
This directory similar to /dev, It contains a special file that represents system and process information.
/var directory (variable data files)
This directory contains variable data files such as printing jobs.
/tmp directory (temporary files)
All the application store their temporary files in /tmp directory. these can be deleted after the system restarts.
/usr directory (user binaries and read-only data)
This contains user applications software files, libraries for a programming language, document files.
/home directory (users home directory)
This directory is having the home folder for each user created. This also contains users data files and user-specific configuration files
/boot directory (boot files)
This directory contains Linux boot loader files
/lib directory (essentials shared libraries)
This directory contains libraries needed by essentials binaries in the /bin and /sbin directory
/opt directory (optional package)
This directory contains subdirectories for optional software package
/mnt directory (temporary mount files)
This directory has system administrator temporary files mounted on /mnt
/media directory (removable media)
This directory contains subdirectories where removable media device inserted into the computer are mounted
/srv directory (service data)
It is having data for service provided by the system example website files under /srv (https server)
We see working in details
First, we check fdisk command here
fdisk /dev/sda ( checking hard disk by using fdisk command)
We will get output like below
command (m for help): p (type p here for cheeking the details)
Gives us all partition details
/dev/sda1
/dev/sda2
/dev/sda3
like this details about partitions
Now creating new partition we can use option n
type n and hit enter
assigning cylinder value and partition size
then save this partition with option w
now changing the partition type using option t
type t hit enter
now select partition number example 9 hit enter
type l for option
83 is linux file system
type 83 and hit enter
to check type p and hit enter
type w for save and hit enter
Now check fdisk -l /dev/sda ( it will show us created partition)
The kernel must know this created partition so we use below command to update
partprobe
and
kpartx -a /dev/sda; kpartx -l /dev/sda
We can check cat /proc/partition the new partition in this way
CREATING FILE SYSTEM
mkfs.ext4 /dev/sda8 (using this command we define file system type)
OR
mke2fs -j -L data -b 2048 -i 4096 /dev/sda8
here are -L filesystem label
-j journaling
-b block size
-i inode per every 4kb of disk space
LABELING TO LINUX FILE SYSTEM
e2label
(Using this command we can give a name to file system)
e2label /dev/sda8 data
(here we have give the name data to /dev/sda8)
If we want to use this new partition we need to mount the partition
MOUNTING OF NEW LINUX FILE SYSTEM
mount LABEL=data /admin
TO CHECK LABELS AND TYPE OF ALL FILE SYSTEM
blkid (This is the command we can check type of file system)
MANAGE PARAMETERS OF LINUX FILE SYSTEM
dumpe2fs /dev/sda8 (this show all below details please check example)
file system flags
default mount option
block count
block size
first block
inode count
last mounted on
UUID
file system magic number
EXCLUDE FSCK CHECK FOR PARTICULAR LINUX FILE SYSTEM WHILE BOOTING
tune2fs -i0 -c0 /dev/sda8 (this partition exclude while booting for fsck check purpose)
MOUNT POINT LINUX FILE SYSTEM
We will mount the partition in /etc/fstab file
device mount point fs type options dump_freq fsck_order
LABEL=data /admin ext4 defaults 0 0
Understand what is this mean
device device name
mount point path for using access to file system
fs type of file system
options comma-separated list of different options can use
dump_freq it is 1=daily, 2=every next day, 0=never dump
fsck_order 0=ignore and 1=first and from 2-9=second,third
We can use command mount -a and check df -h for checking the mounted partition
DENY ACCESS TO PARTICULAR FOLDER OF LINUX FILE SYSTEM WHICH IS MOUNTED
mount -t ext4 -o noexec /dev/sda8 /admin
INCREASE I/O PERFORMANCE OF LINUX FILE SYSTEM
mount -t ext4 -o noatime /dev/sda8 /admin
UMOUNT LINUX FILE SYSTEM
We need to exit from partition and then need to use below command
umount /admin
CREATING SWAP PARTITION
fdisk -l /dev/sda
Check for the partition available or create using n command for new as we have discussed above
mkswap /dev/sda10 (creating swap using mkswap the command for sda10)
Update in fstab
vim /etc/fstab
device mount point fs type options dump_freq fsck_order
/dev/sda10 swap swap defaults 0 0
save this file and exit
Now
swapon -a
swapon -s
CREATING SWAP FILE
dd if=/dev/zero of=/swapfile bs=1024 count=100000 (will create swap file)
Now
mkswap /swapfile
Update in fstab
device mount point fs type options dump_freq fsck_order
/swapfile swap swap defaults 0 0
save and exit the file
swapon -a
swapon -s
Now we have created swap partition as well file
This is LINUX FILE SYSTEM It is more in deep ANYTHING PLEASE CONTACT ME SUBSCRIBE FOR NEW UPDATES
THANKS TO ALL GOD BLESS
via Blogger https://ift.tt/3dWG2jY
0 notes
Text
what is the default location for backup files of another server
I have an Ubuntu Server and one of its “tasks” is to mirror/backup files located on another server in a different location using rsync/rdiff-backup.
I know there are some conventions like web pages go in /var/www.
What is the best-practice/default location for storing the backup files?
Possible places I considered:
/var/backup – looks like it is used for internal backups of the OS
/home/backup – I could create this directory, but if maintaining backups is a “service” this server provides, I feel it is wrong to put the files in the same folder with personal user files
PS I am aware this question might be subjective (I got the warning tooltip), but I think what I do is quite common, and there has to be a convention.
2 Answers
There is a proper location.
There is a standard for proper filesystem structure. Its current version has been around for over a decade, which might be news to some Linux distros.
The latest version of the Filesystem Hierarchy Standard is 2.3: http://www.pathname.com/fhs/pub/fhs-2.3.html
There, under the “Purpose” section of var, it explains why that’s a bad idea to use /var/backup.
The proper place would be, dependent on the application and its usage, something like:
/var/lib/<app>/backups /var/local/<app>/backups /var/opt/<app>/backups
(I say “something like” because whether you use /var/lib, /var/local, or /var/opt is dependent on the application, its role within the system, and how it was installed. Also, the structure under /var/lib/<app> is arbitrary based on the application maintainers.)
By the way, since you mentioned it, /var/www is not the proper place for served web pages (again, this is news to some distro and package maintainers, but the FHS is older that many of them who clearly never have read it). Served content, and stored application data/assets for services belong under the /srv directory. I have been using the protocol method since 2005 and find it works quite well (/srv/http, /srv/ftp, /srv/git, /srv/svn, etc.).
Let’s say that that you are using rsync and that this machine is providing a backup service for the network, you would use:
/srv/rsync/backups
UPDATE
Version 3.0 of FHS: https://refspecs.linuxfoundation.org/FHS_3.0/fhs/index.html
There is no default location.
I would not use any of the regular directories for this. Keep the server clean from outside backups and put those is a clear defined location.
Most likely I would use a removable disk and mount it. Something like /external_backups/ or /media/external_backups/ and inside that subdirectories with the server name and inside those compressed tar files.
/home/backup feels wrong; I would leave /home/ itself for users. If you want to do it this way I would create a user “backup” and the same setup as above.
Something like this (2x with a partition, 2x from a /home/backup/:
/external_backups/AS400/20150101/backup.tar.gz
/external_backups/AS400/2015_01_01.tar.gz
/home/backup/AS400/20150101/backup.tar.gz
/home/backup/AS400/2015_01_01.tar.gz
/var/backup is for internal usage indeed. The Debian package system keeps an older copy from the last but one dpkg run in /var/lib/dpkg/status-old. (By default:) In order to preserve the system for greater damage when a crash or filesystem corrupting occurs a daily backup is put into /var/backups when the file differs from the last copy. This is done from /etc/cron.daily/standard.
But there is no correct or wrong way to it (well, I discard the insane methods: like putting them in / or in /boot or something else as crazy as that).
Archive from: https://askubuntu.com/questions/575679/what-is-the-default-location-for-backup-files-of-another-server
from https://knowledgewiki.org/what-is-the-default-location-for-backup-files-of-another-server/
0 notes
Text
Linux Journal: Filesystem Hierarchy Standard.
https://www.linuxjournal.com/content/filesystem-hierarchy-standard
0 notes