#figure and figcaption tag in html
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Premium Tumblr themes are available from anywhere between $9 to $49.
Text
PODFICCER (and fic author) RESOURCE: things i learned about HTML today
-> from this reference work on ao3: A Complete Guide to 'Limited HTML' on AO3 by CodenameCarrot (please go leave a comment if you find anything here useful !!!)
EDIT: OMG Y'ALL I HAVE BEEN HAVING SO MUCH NERDY GEEKY FUN TWEAKING MY PODFIC HOW-TO GUIDE WITH THIS STUFF
headings, blockquote, div

----

-----
html currently allowed by ao3 html sanitizer

a. abbr. acronym. address. b. big. blockquote. br. caption. center. cite. code. col. colgroup. details. dd. del. dfn. div. dl. dt. em. figcaption. figure. h1. h2. h3. h4. h5. h6. hr. i. img. ins. kbd. li. ol. p. pre. q. rp. rt. ruby. s. samp. small. span. strike. strong. sub. summary. sup. table. tbody. td. tfoot. th. thead. tr. tt. u. ul. var.
-----
in-line (text) formatting tags supported by ao3


-----
OMG LOOK AT THIS !!! IDK WHEN I WOULD EVER USE THIS BUT LOOK HOW COOL !!!

-----
paragraphs & p formats: archiveofourown.org/works/5191202/chapters/161901154#AddParagraphs

-----
omg I'VE ALWAYS WONDERED HOW TO GET THAT LINE BREAK THINGY IN THE MIDDLE OF THE PAGE !!!

-----
end post
#podfic resource#podficcer resource#fic author resource#ao3 writer resource#ao3 fanfic#ao3#html resource#html reference#html#reference#resource#html tutorial#basic html guide#CodenameCarrot
6 notes
·
View notes
Text
Let's understand HTML

Cover these topics to complete your HTML journey.
HTML (HyperText Markup Language) is the standard language used to create web pages. Here's a comprehensive list of key topics in HTML:
1. Basics of HTML
Introduction to HTML
HTML Document Structure
HTML Tags and Elements
HTML Attributes
HTML Comments
HTML Doctype
2. HTML Text Formatting
Headings (<h1> to <h6>)
Paragraphs (<p>)
Line Breaks (<br>)
Horizontal Lines (<hr>)
Bold Text (<b>, <strong>)
Italic Text (<i>, <em>)
Underlined Text (<u>)
Superscript (<sup>) and Subscript (<sub>)
3. HTML Links
Hyperlinks (<a>)
Target Attribute
Creating Email Links
4. HTML Lists
Ordered Lists (<ol>)
Unordered Lists (<ul>)
Description Lists (<dl>)
Nesting Lists
5. HTML Tables
Table (<table>)
Table Rows (<tr>)
Table Data (<td>)
Table Headings (<th>)
Table Caption (<caption>)
Merging Cells (rowspan, colspan)
Table Borders and Styling
6. HTML Forms
Form (<form>)
Input Types (<input>)
Text Fields (<input type="text">)
Password Fields (<input type="password">)
Radio Buttons (<input type="radio">)
Checkboxes (<input type="checkbox">)
Drop-down Lists (<select>)
Textarea (<textarea>)
Buttons (<button>, <input type="submit">)
Labels (<label>)
Form Action and Method Attributes
7. HTML Media
Images (<img>)
Image Maps
Audio (<audio>)
Video (<video>)
Embedding Media (<embed>)
Object Element (<object>)
Iframes (<iframe>)
8. HTML Semantic Elements
Header (<header>)
Footer (<footer>)
Article (<article>)
Section (<section>)
Aside (<aside>)
Nav (<nav>)
Main (<main>)
Figure (<figure>), Figcaption (<figcaption>)
9. HTML5 New Elements
Canvas (<canvas>)
SVG (<svg>)
Data Attributes
Output Element (<output>)
Progress (<progress>)
Meter (<meter>)
Details (<details>)
Summary (<summary>)
10. HTML Graphics
Scalable Vector Graphics (SVG)
Canvas
Inline SVG
Path Element
11. HTML APIs
Geolocation API
Drag and Drop API
Web Storage API (localStorage and sessionStorage)
Web Workers
History API
12. HTML Entities
Character Entities
Symbol Entities
13. HTML Meta Information
Meta Tags (<meta>)
Setting Character Set (<meta charset="UTF-8">)
Responsive Web Design Meta Tag
SEO-related Meta Tags
14. HTML Best Practices
Accessibility (ARIA roles and attributes)
Semantic HTML
SEO (Search Engine Optimization) Basics
Mobile-Friendly HTML
15. HTML Integration with CSS and JavaScript
Linking CSS (<link>, <style>)
Adding JavaScript (<script>)
Inline CSS and JavaScript
External CSS and JavaScript Files
16. Advanced HTML Concepts
HTML Templates (<template>)
Custom Data Attributes (data-*)
HTML Imports (Deprecated in favor of JavaScript modules)
Web Components
These topics cover the breadth of HTML and will give you a strong foundation for web development.
Full course link for free: https://shorturl.at/igVyr
2 notes
·
View notes
Text
Semantic HTML: Writing Cleaner, More Accessible Code
In the evolving world of web development, the importance of writing clean, structured, and accessible code cannot be overstated. Semantic HTML plays a crucial role in achieving these goals. By using semantic tags, developers can create more meaningful and organized documents, enhancing both the user experience and accessibility for people with disabilities. In this blog post, we will explore the concept of semantic HTML, its benefits, and how to effectively use semantic elements like <header>, <article>, and <section> to improve the structure of your web pages.
What is Semantic HTML?
Semantic HTML refers to the use of HTML tags that convey meaning about the content they enclose. Unlike generic tags like <div> and <span>, semantic tags provide information about the role or purpose of the content. For example, <header> indicates the top section of a document or section, and <article> represents a self-contained piece of content.
Benefits of Using Semantic HTML
Improved Accessibility: Semantic HTML helps screen readers and other assistive technologies understand the structure and content of a webpage, making it more accessible to users with disabilities.
Better SEO: Search engines use the semantic structure of a webpage to better understand its content. Using semantic tags can improve your site's search engine ranking.
Enhanced Readability: Semantic HTML makes your code easier to read and maintain for other developers, as it provides a clear structure and purpose for each section of the document.
Future-Proofing: As web standards evolve, semantic HTML ensures better compatibility with future browsers and technologies.
Key Semantic Elements and Their Usage
The <header> Element
The <header> element is used to define introductory content or navigational links for a section or page. It typically contains a heading, logo, or other relevant information.
Usage Example:
<header> <h1>Welcome to My Blog</h1> <nav> <ul> <li><a href="#home">Home</a></li> <li><a href="#about">About</a></li> <li><a href="#contact">Contact</a></li> </ul> </nav> </header>
The <article> Element
The <article> element represents a self-contained piece of content that could be distributed independently. This could include articles, blog posts, or news stories.
Usage Example:
<article> <h2>The Rise of Semantic HTML</h2> <p>Semantic HTML is revolutionizing the way we write web content, making it more accessible and SEO-friendly...</p> </article>
The <section> Element
The <section> element defines a thematic grouping of content, generally with a heading. It is useful for dividing a document into discrete parts, each with a specific theme or purpose.
Usage Example:
<section> <h2>Benefits of Semantic HTML</h2> <p>Using semantic HTML offers numerous advantages, including enhanced accessibility and SEO...</p> </section>
Other Important Semantic Elements
<nav>: Used for navigation links.
<aside>: Represents content tangentially related to the content around it, like sidebars.
<footer>: Defines the footer for a section or page.
<main>: Specifies the primary content of a document.
<figure> and <figcaption>: Used for images, diagrams, or illustrations with captions.
Structuring a Web Page with Semantic HTML
To illustrate how semantic HTML can be used to structure a web page, let's consider a simple blog layout. Here's how you might organize the main sections:
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>My Semantic Blog</title> </head> <body> <header> <h1>My Semantic Blog</h1> <nav> <ul> <li><a href="#home">Home</a></li> <li><a href="#about">About</a></li> <li><a href="#contact">Contact</a></li> </ul> </nav> </header> <main> <article> <h2>Understanding Semantic HTML</h2> <p>Semantic HTML is a powerful tool for web developers...</p> </article> <section> <h2>Why Use Semantic HTML?</h2> <p>There are several compelling reasons to use semantic HTML...</p> </section> <aside> <h2>Related Articles</h2> <ul> <li><a href="#article1">The Basics of HTML</a></li> <li><a href="#article2">CSS for Beginners</a></li> </ul> </aside> </main> <footer> <p>© 2023 My Semantic Blog</p> </footer> </body> </html>
In this example, semantic elements are used to clearly delineate the different parts of the page. The <header> contains the title and navigation, <main> houses the primary content, <article> and <section> divide the content into logical units, and <aside> provides supplementary content.
Best Practices for Using Semantic HTML
Use Appropriate Tags: Choose semantic tags that accurately describe the content they enclose. Avoid using and when a more descriptive tag is available.
Organize Content Logically: Structure your HTML documents so that they are easy to read and understand, both for users and search engines.
Complement with ARIA: While semantic HTML improves accessibility, using Accessible Rich Internet Applications (ARIA) attributes can further enhance the experience for users with disabilities.
Validate Your Code: Regularly check your HTML with a validator to ensure it is well-formed and follows semantic standards.
Keep Learning: Stay updated with the latest HTML standards and best practices to continue writing accessible and efficient code.
Conclusion
Semantic HTML is an essential aspect of modern web development, offering numerous benefits for accessibility, SEO, and code maintenance. By understanding and utilizing semantic elements like <header>, <article>, and <section>, developers can create more meaningful and structured web pages. Embracing semantic HTML not only improves the user experience but also future-proofs your websites for evolving technologies.
FAQs
What is the difference between semantic and non-semantic HTML?
Semantic HTML uses tags that convey meaning about the content they enclose, such as <article> or <header>. Non-semantic HTML, like <div> or <span>, doesn't provide any information about the content's role or purpose.
Why is semantic HTML important for accessibility?
Semantic HTML helps assistive technologies, like screen readers, understand the structure of a webpage, making it easier for users with disabilities to navigate and comprehend the content.
Can I use semantic HTML tags for styling purposes?
While semantic HTML is primarily used for structuring content, it can also be styled using CSS. However, the choice of semantic tags should be based on the content's meaning, not its appearance.
How does semantic HTML benefit SEO?
Search engines use the semantic structure of a webpage to better understand its content, which can improve search engine rankings. Semantic HTML helps search engines identify key parts of a page, like headings and articles.
Is semantic HTML supported by all browsers?
Yes, modern browsers support semantic HTML. However, it's always a good practice to test your web pages across different browsers to ensure compatibility.
#SemanticHTML#HTMLBestPractices#CleanCode#AccessibleWeb#WebAccessibility#SemanticWeb#AccessibleDesign#InclusiveWeb#WebStandards#HTMLStructure#WebDevelopment#FrontendDevelopment#FrontendTips#FrontendDesign#ResponsiveDesign#UIUXDesign#UXBestPractices#UXDesign#CSSTips#JavaScriptTips#CodingStandards#CleanCoding#BestPractices#CodeQuality#CodeBetter#WebCoding#WebDevTips#ProgrammingTips#DevTips#DeveloperLife
0 notes
Text

HTML
HTML Course Content
HTML, or *HyperText Markup Language*, is the standard language used for creating and structuring content on the web. It defines the structure of web pages through the use of elements and tags, which dictate how text, images, links, and other multimedia are displayed in a web browser. HTML provides the foundation for web documents, allowing developers to format content, organize sections, and create interactive features. It consists of a series of elements enclosed in angle brackets, such as <p> for paragraphs, <a> for links, and <img> for images, which together build the content and layout of a webpage.
HTML Contents
HTML (HyperText Markup Language) is the foundation of web pages and web applications. It structures content on the web, defining elements like headings, paragraphs, links, images, and other multimedia. Here’s a breakdown of key HTML contents:
1. *Basic Structure*:
*<!DOCTYPE html>*: Declares the document type and version of HTML.
*<html>*: The root element that encompasses the entire HTML document.
*<head>*: Contains meta-information about the document, such as title, character set, and links to CSS or JavaScript files.
*<body>*: Contains the content that is visible on the web page, including text, images, and interactive elements.
2. *Text Elements*:
*<h1> to <h6>*: Heading tags, with <h1> being the most important.
*<p>*: Paragraph tag for regular text.
*<a>*: Anchor tag for creating hyperlinks.
*<span>* and *<div>*: Generic containers for grouping inline and block content, respectively.
3. *Lists*:
*<ul>*: Unordered list.
*<ol>*: Ordered list.
*<li>*: List item, used within <ul> or <ol>.
4. *Images and Media*:
*<img>*: Embeds images.
*<video>* and *<audio>*: Embeds video and audio files.
*<figure>* and *<figcaption>*: For adding images or media with captions.
5. *Forms*:
*<form>*: Contains form elements for user input.
*<input>*: Various input fields (text, password, checkbox, radio, etc.).
*<textarea>*: For multi-line text input.
*<button>* and *<select>*: Buttons and dropdown menus.
6. *Tables*:
*<table>*: Defines a table.
*<tr>*: Table row.
*<th>*: Table header cell.
*<td>*: Table data cell.
7.*Semantic Elements*:
*<header>, *<footer>**: Defines the header and footer sections.
*<nav>*: Navigation section.
*<article>*: Independent content item.
*<section>*: Thematic grouping of content.
*<aside>*: Sidebar or additional content.
*<main>*: Main content of the document.
8. *Metadata and Links*:
*<meta>*: Provides metadata such as descriptions, keywords, and viewport settings.
*<link>*: Links external resources like CSS files.
*<script>*: Embeds or links JavaScript files.
Importance of HTML
HTML is critically important for several reasons:
1. *Foundation of Web Pages*:
HTML is the core language that structures content on the web. Without HTML, web pages wouldn’t exist as we know them. It organizes text, images, links, and other media into a cohesive and navigable format.
2. *Accessibility*:
Proper use of HTML ensures that web content is accessible to all users, including those with disabilities. Semantic HTML elements provide context to assistive technologies, making it easier for screen readers to interpret the content.
3. *SEO (Search Engine Optimization)*:
Search engines rely on HTML to understand the content of web pages. Properly structured HTML with relevant tags and attributes improves a website’s visibility in search engine results, driving more traffic to the site.
4. *Interoperability*:
HTML is universally supported by all web browsers, ensuring that content can be displayed consistently across different devices and platforms. This cross-compatibility makes HTML the most reliable way to share content on the web.
5. *Foundation for CSS and JavaScript*:
HTML is the backbone that supports styling and interactivity through CSS and JavaScript. It provides the structure that CSS styles and JavaScript enhances, creating dynamic, interactive, and visually appealing web experiences.
6. *Web Standards Compliance*:
HTML is maintained by the World Wide Web Consortium (W3C), which sets standards to ensure the web remains open, accessible, and usable. Following these standards helps developers create web content that is robust and future-proof.
7. *Ease of Learning and Use*:
HTML is relatively simple to learn, making it accessible to beginners and non-programmers. Its simplicity also allows for rapid development and prototyping of web pages.
In summary, HTML is essential because it structures and defines web content, ensuring it is accessible, searchable, and interoperable across various platforms. It is the foundation upon which modern web design and development are built.
1 note
·
View note
Text
Uncovering 10 Advanced HTML Tags for Proficient Developers

In the vast universe of web development, HTML (Hypertext Markup Language) stands as the foundation upon which the entire web is built. From simple text formatting to structuring complex web pages, HTML tags play a crucial role in defining the structure, content, and appearance of a website. In this blog post, we're going to delve into the world of HTML tags, focusing on 10 advanced tags that can take your web development skills to new heights.
<canvas>: Unleash Your Creative Side
The <canvas> tag allows you to draw graphics, create animations, and render images directly on a web page. It's an essential tag for creating interactive games, data visualizations, and engaging multimedia content.
<video> and <audio>: Rich Media Experience
Enhance user engagement by embedding videos and audio files using the <video> and <audio> tags. These tags enable you to provide a seamless multimedia experience within your web pages.
<iframe>: Seamless Integration
Want to embed external content like maps, videos, or social media feeds? The <iframe> tag lets you do just that while maintaining a clean and responsive layout.
<progress>: Visualizing Progress
Display progress bars and indicators using the <progress> tag. It's great for showing the status of ongoing tasks, file uploads, or any process that requires visual feedback.
<details> and <summary>: Interactive Disclosure
Create interactive disclosure widgets using the <details> tags and <summary> tags. These are perfect for hiding and revealing additional content or information on demand.
<figure> and <figcaption>: Captioned Images
When you need to associate captions with images, the <figure> tags and <figcaption> tags provide a semantic way to do so, improving accessibility and structure.
<mark>: Highlighting Text
Emphasize specific text within paragraphs or blocks by using the <mark> tag. It's particularly handy for drawing attention to search terms or key points.
<time>: Semantic Time Representation
The <time> tag lets you mark up dates and times in a way that's machine-readable and user-friendly. It's an excellent choice for showing published dates or event schedules.
<article> and <section>: Structured Content
When organizing content, the <article> tags and <section> tags provide semantic structure. <article> is suitable for standalone content like blog posts, while <section> helps group related content together.
Unlock Your Full Coding Potential with WebTutor
If you're looking to master the art of web development and delve deeper into the world of HTML, CSS, JavaScript, and beyond, look no further than WebTutor. This premier online learning platform offers comprehensive courses and tutorials that cater to beginners and advanced learners alike.
With WebTutor, you will experience
Expert Instruction
Learn from industry professionals who are passionate about sharing their knowledge.
Hands-on Practice
Gain practical experience through interactive coding challenges and real-world projects.
Flexible Learning
Study at your own pace, fitting your learning journey into your busy schedule.
Supportive Community
Connect with fellow learners, ask questions, and collaborate on projects in a supportive online environment.
Whether you are a budding web developer or seeking to level up your skills, WebTutor provides the resources and guidance you need to excel in the world of coding. Visit today and embark on a journey of discovery and innovation!
In conclusion, HTML tags are the building blocks of the web, enabling developers to create diverse and engaging experiences for users. By harnessing the power of advanced HTML tags and supplementing your learning with WebTutor, you will be well on your way to becoming a proficient web developer capable of crafting exceptional online experiences.
#Advanced HTML tags#Learn Online HTML#Online HTML Tutorial#Introduction to HTML#HTML tutorials#Learn HTML online#Basic HTML tags#HTML tags
1 note
·
View note
Text
HTML figcaption Tag
The HTML <figcaption> tag defines the caption of <figure> element. it can be used as the first or last child of the <figure> element. Syntax <figcaption>Caption...</figcaption> Example <figure> <img src="/image/logo.png"> <figcaption>KrTricks Logo</figcaption> </figure> Output: Global Attributes The <figcaption> tag supports all the Global Attributes in HTML. Event Attributes The <figcaption>…

View On WordPress
#bangla figcaption tag in html5#figcaption#figcaption html#figcaption html5#figcaption tag#figcaption tag in html#figcaption tag in html in hindi#figure & figcaption tag-html5#figure and figcaption tag#figure and figcaption tag in html#figure tag#figure tag in html#how to use figure and figcaption tag in html#html figcaption#html figcaption tag#html figure & figcaption tag#html figure tag#html5 figcaption#tag figcaption do html5
0 notes
Note
hi I'm asking because I'm curious tbh, what do you do differently with your themes that makes them more accessible? what makes a theme accessible in general?
generally i just adopt a common sense approach to what i make, like... i test my themes on actual blogs before releasing them so if i think certain design choices detract from navigability then i nix them right there. it sorta depends on the theme and the look i’m going for? but i do have a list of things i stick to at all times
things like colors (all colors imo, but at least the text-related ones) should be customizable. you don’t know that your default color choices look good or soothing to other people.
(dark text on light bg is considered most readable as a standard practice, but the rising prevalence of dark modes in apps shows that a lot of people prefer the opposite. but, again, not all - discord removing their light theme as an april fool’s joke screwed over a lot of people who needed the light theme for readability reasons)
fonts and font sizes should be customizable. i can’t stress this enough. literally 50% of what i’m complaining about when i say that a lot of themes are inaccessible is that they use some godforsaken 8 pt pixel font - impossible to read, and can’t be changed without going into the actual HTML, which not everyone is comfortable with or can navigate
the posts themselves should be formatted with care because tumblr’s default styling for blockquotes and such is just... horrible. i hate super narrow post widths for tumblr themes because if the blockquotes aren’t styled a certain way then even a post with like, 4-5 comments on it will bunch up until there’s just one letter on each line. it’s ridiculous. the unnested captions people prefer these days do a better job, but the documentation for that on the official tumblr variables page is still really shoddy and it’s clear they don’t intend for theme makers to be able to properly use them so. honestly using this website is a daily battle
infinite scroll is bad like... it’s just really bad and i hate how many themes have it. i know it exists on all social media feeds because you’re going to waste a lot more time scrolling down an endless feed than if you had to switch pages at intervals. predatory design that cares more about #engagement than anything else is depressingly prevalent. but just from an archiving standpoint, if someone is going down your blog looking for content, then infinite scroll makes it a nightmare to remember where you left off - and bad code can result in it just murdering your browser if you go deep enough
images in photo posts and such should have alt-text fields so screen readers can describe them if they’re captioned
on that note, a lot of newer HTML5 tags are designed to play nice with assistive tech and browsers as a whole, so using proper “figure” “figcaption” “article” “nav” etc tags is important for reasons other than divitis looking bad
flashing images/graphics/colors/text in a theme are all bad, both because they can cause seizures and because they distract from content. i have fading/blinking effects in some of my themes, but i keep the transitions slow and allow for the animation to be disabled (both thru customization options and as a javascript toggle for visitors)
tiny cursors are a blight and i don’t know who came up with them but they suck in particular
all iconified navigation (such as when you have a house icon to signify “go back to the index page”) should have tooltips that say what they do in plain text. iconography is not universally intuitive and there’s a lot of context we tend to take for granted
there’s probably other stuff tbh like. this is just off the top of my head and it’s by no means comprehensive or even like... high-effort? there’s a lot more that could be done if specializing accessibility features for specific disabilities (legally blind people have different needs than sighted people who can’t read small text, for starters) but this is just a For General Audiences kind of deal
31 notes
·
View notes
Text
What is semantic element/tag in html?
Semantic Element/Tag in HTML
This Element/Tag is describe its meaning both developer and browser. It help to understand write the code for what is this section is use for.
Semantic Element/Tag
There are two type of Semantic Element/Tag that is semantic and another is non-semantic element/tag.
Semantic Element/Tag
Semantic element/tag clearly define its content what is the use of this element/tag and where it.
There are different type of semantic element/tag ;
1- <section> : It define a section of a document.
2- <table> : It define that content is contain for row and column.
3- <figure> : It define specific self-contained content, like illustration , some diagram and images.
4- <article> : It define independent, self-contained content.
5- <header> : It define a specific header of a content/document.
6- <nav> : It define a navigation links.
7- <details> : It define additional details that the user can view and hide.
8- <aside> : It define content aside from the page content.
9- <main> : It define the main content of a document.
10- <figcaption> : It define caption for a <figure> element.
11- <summary> : It define a visible heading for a <details> element.
12- <mark> : It define mark/highlight text.
13- <time> : It define a date/time.
14- <footer> : It define footer of a document section.
Non-Semantic Element/Tag
Non-semantic element/tag is nothing define about its content.
There are different type of non-semantic element/tag:
1- <div> : It define it is a block level element.
2- <span> : It define it is a inline-block level element.
#semantic element#html semantic element#semantic seo#what is semantic element#what is semantic tag#html semantic tag
0 notes
Text
What's new in HTML 5
HTML 5 provides an extensive range of benefits over the previous versions of HTML. There are certain features in HTML 5 that makes it more special. One such main feature is its compatibility. it is supported by all the major browsers like chrome, safari, firefox, and opera as well as ioS for chrome safari and Android browsers. so that the users can have a consistent experience on the site, doesn't matter what browser or device they use. HTML5 also facilitates offline browsing. The browsers which support offline browsing will download HTML, CSS, JavaScript, images, and other resources that make up the application and cache them locally. so that the users can load the site without an active internet connection. HTML5 enables one to write more semantically meaningful code. They have introduced new semantically meaningful tags like <nav>, <sectio>, <figure>, <data>, <figcaption>. These make it easier to write cleaner codes that clearly delineate style from content. HTML5 also supports multimedia without the need for flash or other plugins.

0 notes
Text
A box in which you put HTML is fine, but as an editor experience, it gets less-good the more your concept of editing strays from "insert a single HTML element". Insert an iframe? Fine. Insert a figure with caption? Ok. Add a figure tag, a figcaption, and an img with correct srcset and sizes, and alt text? Oh, and it has to be a slideshow of 20 images, each with srcset and sizes and alt text? Now we're getting into the spooky stuff.
Inserting a sortable list of university courses that pulls from the course management system via an API is _doable_ in the "box with HTML in it" editor experience, and I've done it, but the "box with HTML in it" editor experience exposes the guts of the table to editing by anyone. And then someone goes in to update the table column header text, but accidentally a " and now the whole page is broken.
Once you, the HTML-knower, have set up something in a "box with HTML in it" editor, allowing non-HTML-knower people to edit that page becomes fraught with risk. You start making decisions based not on whether it's OK to have the university president's name misspelled on your homepage on parent&family weekend, but on whether any editor is available who's trusted to not fuck up the homepage on parent&family weekend.
Or say you run a social media platform, and you let people insert arbitrary HTML in their posts. Once you've closed off the security holes, you still have to deal with mismatched tags in someone's post breaking the page layout because every subsequent post on the page is stuck within a numbered list of top SuperWhoLock ships.
With a block-based interface, the whole complicated table or slideshow or widget becomes a single thing, which can be moved around the page or deleted or duplicated or added. But, because it is a single thing, it cannot be broken, because its guts aren't exposed to the people who could accidentally fuck it up.
Can someone explain to me in small words why people think "blocks" are a good technology for creating web content?
46 notes
·
View notes
Text
A Newbie's Information to HTML5
New Post has been published on http://tiptopreview.com/a-beginners-guide-to-html5/
A Newbie's Information to HTML5

HTML5 was designed to do nearly something you need to do online with out having to obtain browser plugins or different software program. Need to create animations? Embed music and films? Construct superior functions that run in your browser? You may with HTML5.
On this submit, we’ll cowl every part it’s essential to find out about HTML5, together with:

What’s HTML5?
HTML5 is the latest model of HTML. The term refers to two things. One is the updated HTML language itself, which has new elements and attributes. The second is the larger set of technologies that work with this new version of HTML — like a new video format — and enable you to build more complex and powerful websites and apps.
To understand how HTML has evolved over the years, let’s look at the differences between HTML and HTML5.
HTML vs HTML5
HTML is the World Wide Web’s core markup language. Originally designed to semantically describe scientific documents, it has since evolved to describe much more.
Most pages on the web today were built using HTML4. Although much improved since the first version of HTML written in 1993, HTML4 still had its limitations. It’s biggest was if web developers or designers wanted to add content or features to their site that weren’t supported in HTML. In that case, they would have to use non-standard proprietary technologies, like Adobe Flash, which required users to install browser plugins. Even then, some users wouldn’t be able to access that content or feature. Users on iPhones and iPads, for example, wouldn’t be able to since those devices don’t support Flash.
Cue, HTML5. HTML5 was designed to cut out the need for those non-standard proprietary technologies. With this new version of HTML, you can create web applications that work offline, support high-definition video and animations, and know where you are geographically located.
To understand how HTML5 can do all that, let’s look at what’s new in this latest version of HTML.
What is new in HTML5?
HTML5 was designed with major objectives, including:
Making code easier to read for users and screen readers
Reducing the overlap between HTML, CSS, and JavaScript
Promoting design responsiveness and consistency across browsers
Supporting multimedia without the need for Flash or other plugins
Each of these objectives informed the changes in this new version of HTML. Let’s focus on seven of those changes below.
New Semantic Elements
HTML5 introduced several new semantically meaningful tags. These include <section>, <header>, <footer> <nav>, <mark>, <figure>, <aside> <figcaption>, <data>, <time>, <output>, <progress>, <meter> and <main>. These make it easier to write cleaner code that clearly delineates style from content, which is particularly important to users with assistive technologies like screen readers.
Inline SVG
Using HTML4, you’d need Flash, Silverlight, or another technology to add scalable vector graphics (SVGs) to your web pages. With HTML5, you can add vector graphics directly in HTML documents using the <svg> tag. You can also draw rectangles, circles, text, and other vector-based paths and shapes using this new element. Below is an example of a circular shape created using the SVG <circle> element.
Form Features
You can create smarter forms thanks to HTML5’s expanded form options. In addition to all the standard form input types, HTML5 offers more, including: datetime, datetime-local, date, month, week, time, number, range, email, and url. You can also add date pickers, sliders, validation, and placeholder text thanks to the new placeholder attribute, which we’ll discuss later.
WebM Video Format
Before HTML5, you needed browser plugins to embed audio and video content into web pages. Not only did HTML5 introduce <audio> and <video> tags which eliminated the need for browser plugins, it also introduced the WebM video format. This is a royalty-free video format developed by Google that provides a great compression to quality ratio. This can be used with the video element and is supported by most browsers.
Placeholder Attribute
HTML5 introduced the placeholder attribute. You can use this with the <input> element to provide a short hint to help users fill in passwords or other data entry fields. This can help you create better forms. However, it’s important to note that this attribute is not accessible to assistive technologies. Feel free to read more about the problems with the placeholder attribute.
Server-sent Occasions
A server-sent occasion is when an internet web page routinely will get up to date information from a server. This was potential with HTML4, however the net web page must ask
HTML5 helps one-way server-sent occasions. Meaning, information is repeatedly despatched from a server to the browser. Consider how helpful this may be in case your web site included inventory costs, information feeds, Twitter feeds, and so forth. Server-sent occasions had been supported within the earlier model of HTML, however the net web page must repeatedly request it.
Native Net Storage
With the earlier model of HTML, information is saved regionally through cookies. With HTML5, net storage is used instead of cookies because of a scripting API. This lets you retailer information regionally, like cookies, however in a lot bigger portions.
Now that we perceive what’s new in HTML5, let’s check out why you need to be utilizing it in your web site.
Why HTML5?
HTML5 presents a variety of advantages over earlier variations of HTML — a few of which we’ve talked about briefly above. Let’s take a better take a look at only a few the reason why HTML5 is so particular.
It’s suitable throughout browsers.
HTML5 is supported by all the main browsers, together with Chrome, Firefox, Safari, Opera, in addition to iOS for Chrome and Safari and Android browsers. It could even work with the older and fewer well-liked browsers like Web Explorer. Meaning when constructing with HTML5, that customers could have a constant expertise in your website, it doesn’t matter what browser they use or whether or not they’re on cell or desktop.
It permits offline shopping.
HTML5 means that you can construct offline functions. Browsers that assist HTML5 offline functions (which is most) will obtain the HTML, CSS, JavaScript, photos, and different sources that make up the appliance and cache them regionally. Then, when the consumer tries to entry the net software and not using a community connection, the browser will render the native copies. Meaning you received’t have to fret about your website not loading if the consumer loses or doesn’t have an energetic web connection.
It means that you can write cleaner code.
With HTML5’s new semantic components, you may create cleaner and extra descriptive code bases. Earlier than HTML5, builders had to make use of numerous common components like divs and elegance them with CSS to show like headers or navigation menus. The consequence? Lots of divs and sophistication names that made the code tougher to learn.
HTML5 means that you can write extra semantically significant code, which permits you and different readers to separate model and content material.
It’s extra accessible.
Additionally because of HTML5’s new semantic components, you may create web sites and apps which might be extra accessible. Earlier than these components, display screen readers couldn’t decide that a div with a category or ID identify “header” was truly a header. Now with the <header> and different HTML5 semantic tags, display screen readers can extra clearly look at an HTML file and supply a greater expertise to customers who want them.
The best way to Use HTML5
To start out utilizing HTML5 in your web site, it’s really useful that you just create an HTML template first. You may then use this as a boilerplate for all of your future tasks transferring ahead. Right here’s what a primary template seems to be like:
<!DOCTYPE html> <html lang=”en” manifest="/cache.appcache"> <head> <title>That is the Title of the Web page</title> <meta charset="utf-8"> <hyperlink rel="stylesheet" rel="noopener" goal="_blank" href="https://blog.hubspot.com/bootstrap/css/bootstrap.min.css"> <!-- This hyperlink is barely essential in case you’re utilizing an exterior stylesheet --> <model> /* These model tags are solely essential in case you’re including inside CSS */ </model> </head> <physique> <h1>It is a Heading</h1> <p>It is a paragraph.</p> </physique> </html>
Let’s stroll via the method of constructing this file line-by-line so you may create an HTML template in your net tasks. You may observe alongside utilizing a basic text editor like Notepad++.
First, declare the type of document as HTML5. To do so, you’d add the special code <!DOCTYPE html> on the very first line. There’s no need to add “5” in this declaration since HTML5 is just an evolution of previous HTML standards.
Next, define the root element. Since this element signals what language you’re going to write in, it’s always going to be <html> in an HTML5 doc.
Include a language attribute and define it in the opening tag of the HTML element. Without a language attribute, screen readers will default to the operating system’s language, which could result in mispronunciations of the title and other content on the page. Specifying the attribute will ensure screen readers can determine what language the document is in and make your website more accessible. Since we’re writing this post in English, we’ll set the file’s lang attribute to “en.”
Also include the manifest attribute in your opening HTML tag. This points to your application’s manifest file, which is a list of resources that your web application might need to access while it’s disconnected from the network. This makes it possible for a browser to load your site even when a user loses or doesn’t have an internet connection.
Create the head section of the doc by writing an opening <head> and closing </head> tag. In the head, you’ll put meta information about the page that will not be visible on the front end.
In the head section, name your HTML5 document. Wrap the name in <title></title> tags.
Below the title, add meta information that specifies the character set the browser should use when displaying the page. Generally, pages written in English use UTF-8 so add the line: <meta charset = “UTF-8“ />.
Below, add links to any external stylesheets you’re using. If you’re loading Bootstrap CSS onto your project, for example, it will look something like this: <link rel=”stylesheet” rel=”noopener” target=”_blank” href=”https://blog.hubspot.com/bootstrap/css/bootstrap.min.css”>. For the sake of this demo, I’ll include a dummy link and a comment in HTML noting that it’s optional.
Now create the body section of the doc by writing an opening <body> and closing </body> tag. The body section contains all the information that will be visible on the front end, like your paragraphs, images, and links.
In the body section, add a header and paragraph. You’ll write out the heading name and wrap it in <h1></h1> tags, and write out the paragraph and wrap it in <p></p> tags.
Lastly, don’t forget the closing tag of the html element.
When you’re done, you can save your file with the .html extension and load it into a browser to see how it looks.

Image Source
When did HTML5 come out?
The primary public draft of HTML5 was launched by the Net Hypertext Software Know-how Working Group (WHATWG) in 2008. Nevertheless, it was not launched as a World Vast Net Consortium (W3C) suggestion till October 28, 2014. This suggestion was then merged with the HTML Dwelling Commonplace by WHATWG in 2019.
To know why the specification course of spanned over a decade, let’s take a look at the sophisticated historical past of HTML5.
In 1999, the yr after HTML4 was launched, the W3C determined to cease engaged on HTML and as an alternative concentrate on creating an XML-based equal referred to as XHTML. 4 years later, there was a renewed curiosity in evolving HTML as folks started to understand the deployment of XML relied completely on new applied sciences like RSS.
In 2004, Mozilla and Opera proposed that HTML ought to proceed to be developed at a W3C workshop. When the W3C members rejected the proposal in favor of constant to develop XML-based replacements, Mozilla and Opera — joined by Apple — launched the Net Hypertext Software Know-how Working Group (WHATWG) to proceed evolving HTML.
In 2006, the W3C reversed course and indicated they had been serious about taking part within the growth of the HTML5 specification. A yr later, a gaggle was shaped to work with the WHATWG. These two teams labored collectively for quite a few years till 2011, after they determined that they had two separate objectives. Whereas the W3C wished to publish a completed model of HTML5, the WHATWG wished to publish and repeatedly keep a dwelling normal for HTML.
In 2014, the W3C printed their “final” model of HTML5 and the WHATWG continued to take care of a “living” model on their website. These two paperwork merged in 2019, when the W3C and WHATWG signed an agreement to collaborate on the event of a single model of HTML transferring ahead.
Which browsers assist HTML5?
All the newest variations of main browsers — together with Google Chrome, Opera, Mozilla Firefox, Apple Safari, and Web Explorer — assist many HTML5 options however not all. Presently, Chrome and Opera are probably the most suitable with HTML5, with Firefox and Safari following carefully behind. Web Explorer is the least suitable, though it partially or absolutely helps most HTML5 options.
Beneath is a desk to point out the various compatibility of the main browsers. This is a key:
✓ Absolutely supported
≈ Partially supported
✗ Not supported
Chrome opera Firefox safari Web explorer New semantic components ✓ ✓ ✓ ✓ ≈ Inline SVG ✓ ✓ ✓ ✓ ✓ Expanded kind options ✓ ✓ ≈ ≈ ≈ WebM video format ✓ ✓ ✓ ≈ ✗ Placeholder attribute ✓ ✓ ✓ ✓ ≈ Server-sent occasions ✓ ✓ ✓ ✓ ✗ Native net storage ✓ ✓ ✓ ✓ ✓
If you would like a extra detailed breakdown of the totally different variations of browsers that assist HTML5, take a look at Caniuse.com.
HTML5 is the Way forward for the World Vast Net
With its new semantic components, expanded kind choices, format-independent video tag, and extra, HTML5 is revolutionizing how builders construct net pages. This, in flip, is altering shoppers’ experiences online. We are able to now watch movies with out being requested to replace Flash or obtain one other software program. We are able to use functions after we don’t have an web connection. We are able to have the identical nice expertise on a website whether or not utilizing a cellphone, pill, or Sensible TV — and extra.

Source link
0 notes
Text
HTML figure Tag
The HTML <figure> tag is used to specify self-contained content, like illustrations, diagrams, photos, listings, etc in document.You can add caption of this element with the help of <figcaption> tag. Syntax <figure>Image....</figure> Example <figure> <img src="/image/logo.png"> <figcaption>KrTricks Logo</figcaption> </figure> Output: Global Attributes The <figure> tag supports the Global…

View On WordPress
#figcaption tag in html#figure#figure bangla tag#figure html5#figure in html5#figure tag#figure tag htm5#figure tag html#figure tag in html#figure tag in html in hindi#figure tag in html5#figure tag in html5 in hindi#figure tag use in html#html figure#html figure caption#html figure tag#html figure tag in bangla#html5#tag figure#tag figure html#tag figure html5
0 notes
Photo

I’m really enjoying understanding tags and how they can be used to create frameworks to structure websites. There’s a few interesting ones I’ve come across in particular.
<map> Which allows you to create image maps, meaning images can have different clickable areas that link to other websites or pages. I liken this to tagging friends in an Facebook photo, allowing people to see which person is who, or in this instance where items in photo come from. I could see this being really handy in cooking blog where you might have a spread of food and want to link each dish to separate recipe page, or even to stockists of particular products.
<hr> It might seem overly simple, but being able to break a long page of content with a horizontal lines between segments can be a easy trick to visually separate sections and allow the users eyes to rest or find things easier. I’m really glad to have found a simple way to add one, especially as should will be adaptive in responsive design.
<figure> and <figcaption> Are great for formatting. Trying to keep attribution and explanations close to images or quotes so they are relative to each other would a nightmare of try to tweak the padding just right, and then probably seeing it all go wrong once a different browser or device was used, without this.
<input> and <datalist> Allows for suggested content to appear when typing into a search bar, again I see this being really useful on cooking blogs and websites as they’re often browsed for ideas by meal type or even ingredients.
Image courtesy of Tech Spirited https://techspirited.com/all-html-tags-list-of-all-html-tags
0 notes
Text
18-10-2017 CSS/HTML
Today with Oliver we covered basic html/css. This was very useful as though I had briefly played it with it before I didn’t know the proper way of doing a lot things.
Html notes:
No logic, only structure and semantics
Tags come in pairs eg. <body></body>
Begin pages with <!DOCTYPE html> <head></head> <body></body> </html>
Things in <head> are not seen
Things in <body> is visible
Structuring content
<header>
<nav>
<article>
<div> - no meaning, useful to divide things up and group them so you can style them in CSS
Headings
Range from <h1> to <h6> This is about importance
Content
<p> paragraph
<ol> <ul> ordered/ unordered list
<li> defines list items
<figure> image or something from main text
<figcaption> used to provide caption
CSS notes:
css-tricks.com/almanac
Selectors
you can use things like p{ or body{ directly
or you can give names to div’s(vertical) and span’s (horizontal)
ID = 1 thing Class = used more than once
to select an id = #theid{}
to select a class = .theclass{}
eg. <div class=“example”></div> to select it .example{}
Fonts.
to insert fonts that aren’t system fonts you can use fonts.google
insert the html part into the <head>
then use the relevant css
eg. font-family: helvetica, arial, sans-serif;
the fonts show in order from left to right, so in this example if helvetica is not available then the website will show arial, and as a last resort any sans-serif font.
5 notes
·
View notes
Text
Mini Project Retro: Building a Technical Documentation page with HTML & CSS
Following up on a previous post, I still have remaining freeCodeCamp HTML & CSS track projects. I decided to focus on the technical documentation page challenge. Like before, there were some user stories to guide it, an already-built example, and simple instructions to avoid using fancy libraries and frameworks.
The end result is here.
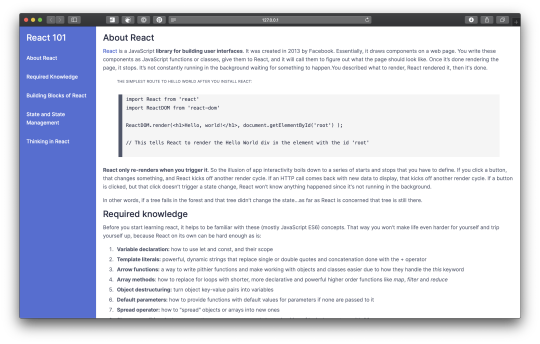
What I did
I created a ‘React 101′ documentation page, trying to add some useful text but keeping it short. I’d learned from previous experience that content generation is the most time-consuming part with these exercises. Sure, I could paste something from MDN like in their example, but I wanted something of my own.
I time boxed it to a 2 calendar days, which really meant around 8 hours of continuous work.
I researched in the form of asking my Twitter community what documentation sites they like, or if they know of good documentation generation tools.
I personally liked the Svelte and Stripe documentation for their layout, ease of reading and color schemes (I’m going through a purple or muted purple phase). I also enjoy documentation pages that come with a version history, which has more to do with their CMS and user experience than with the visual side of things, but it’s a nice touch.
The community really liked documentation sites from Stripe, Netlify, Shopify (Polaris) and Prisma. Prisma was new to me and a highlight for the ease with which you could transition between the same documentation page, but for a different database systems (e.g. PostgreSQL, MongoDB, MySQL) or programming language applicable to your situation. For documentation generation tools or CMS, Kirby, Antora, Docusaurus and ReadTheDocs stood out. A few other mentions were mkdocs (a static site generator that's geared towards building project documentation). What was more intriguing was that ReadTheDocs had no pictures on their site, which seems like a missed opportunity. Kirby is also quite versatile.
Lessons
Styling <pre> and <code> is a challenge, and there are few solutions out there (e.g. Prism)
Though the bulk of the challenge was designed to get you to wrestle with relative and absolute positioning, the other biggie I bumped into was styling code blocks without external help. It’s a non-trivial amount of effort to get code blocks to look presentable on a site, let alone nice. Not even Tumblr has a built-in way to display code.
First, many CSS aspects went into this alone: how to display the code block, appropriate monospace font families, making the code block editable, wrapping and breaking words, dealing with overflow, number of tab spaces, etc. Whew! I tried many permutations until I landed on something I was happy with.
Second, I learned that by using <pre> you get a line break before the text starts, and there’s no great CSS way to get rid of it. However, there’s a workaround to start the text on the same line as the <pre> tag.
Third, encoding symbols (<, >, &, etc) into HTML entities without special help means using a lot of < and > and such. I saw a workaround using a snippet of PHP but decided not to for this project.
Not to mention all the other user preferences, like having line numbers (using JavaScript) and more. A good best practice article dates back to 2013 but is still relevant today. Unsurprisingly, there are several external solutions but the most popular one is Prism, a lightweight and configurable syntax highlighter (not the same Prisma mentioned before). It’d seem that Stripe uses it, and everyone loves Stripe documentation.
Use <figure> and <figcaption> for ease of reading and accessibility
freeCodeCamp teaches this too; the <figure> element is primarily for diagrams and pictures but also works with <code>. It can optionally have a caption with <figcaption>.
Not only that, the accessibility can be improved by adding some ARIA attributes on <pre>: aria-labelledby to point to the <figcaption> (if there is one), and aria-describedby to point to the preceding text (if it describes the example).
Making code blocks editable gives users more control over the snippet
I learned from the best practice article mentioned before that editable code blocks gain extra navigation and selection controls, like being able to click inside the code and use Ctrl+A to select it all or use Shift+Arrow to make partial text-selections with the keyboard to name a couple.
Begin with the end in mind: mobile first, large devices later
This is a classic lesson that I carried over from other projects, though I omitted a clickable hamburger menu from this. I entertained a top-sticky, horizontally scrolling menu. But the more I looked into it, the more time this would have added and required more than HTML&CSS, which were the point of the exercise.
What I’d do differently
Add a hamburger menu toggle for mobile. I kept it simple and chose not to display the navbar on mobile since my page isn’t so long.
Add line numbers to the code blocks. This was brought up in a best practice article, but felt it was outside the scope of this project to add that much JavaScript. Or...
Use a tool like Prism to style code blocks. It seems like a no-brainer, but I wanted to see how far I could get without it.
Change the colors. I liked this combo but I’ll be the first to admit I’m not 100% sure how to mix things up in a more aesthetically pleasing way.
0 notes
Text
“Create Once, Publish Everywhere” With WordPress
“Create Once, Publish Everywhere” With WordPress
Leonardo Losoviz
2019-10-28T16:00:59+02:002019-10-28T21:09:38+00:00
COPE is a strategy for reducing the amount of work needed to publish our content into different mediums, such as website, email, apps, and others. First pioneered by NPR, it accomplishes its goal by establishing a single source of truth for content which can be used for all of the different mediums.
Having content that works everywhere is not a trivial task since each medium will have its own requirements. For instance, whereas HTML is valid for printing content for the web, this language is not valid for an iOS/Android app. Similarly, we can add classes to our HTML for the web, but these must be converted to styles for email.
The solution to this conundrum is to separate form from content: The presentation and the meaning of the content must be decoupled, and only the meaning is used as the single source of truth. The presentation can then be added in another layer (specific to the selected medium).
For example, given the following piece of HTML code, the <p> is an HTML tag which applies mostly for the web, and attribute class="align-center" is presentation (placing an element “on the center” makes sense for a screen-based medium, but not for an audio-based one such as Amazon Alexa):
<p class="align-center">Hello world!</p>
Hence, this piece of content cannot be used as a single source of truth, and it must be converted into a format which separates the meaning from the presentation, such as the following piece of JSON code:
{ content: "Hello world!", placement: "center", type: "paragraph" }
This piece of code can be used as a single source of truth for content since from it we can recreate once again the HTML code to use for the web, and procure an appropriate format for other mediums.
Why WordPress
WordPress is ideal to implement the COPE strategy due of several reasons:
It is versatile. The WordPress database model does not define a fixed, rigid content model; on the contrary, it was created for versatility, enabling to create varied content models through the use of meta field, which allow the storing of additional pieces of data for four different entities: posts and custom post types, users, comments, and taxonomies (tags and categories).
It is powerful. WordPress shines as a CMS (Content Management System), and its plugin ecosystem enables to easily add new functionalities.
It is widespread. It is estimated that 1/3rd of websites run on WordPress. Then, a sizable amount of people working on the web know about and are able to use, i.e. WordPress. Not just developers but also bloggers, salesmen, marketing staff, and so on. Then, many different stakeholders, no matter their technical background, will be able to produce the content which acts as the single source of truth.
It is headless. Headlessness is the ability to decouple the content from the presentation layer, and it is a fundamental feature for implementing COPE (as to be able to feed data to dissimilar mediums). Since incorporating the WP REST API into core starting from version 4.7, and more markedly since the launch of Gutenberg in version 5.0 (for which plenty of REST API endpoints had to be implemented), WordPress can be considered a headless CMS, since most WordPress content can be accessed through a REST API by any application built on any stack. In addition, the recently-created WPGraphQL integrates WordPress and GraphQL, enabling to feed content from WordPress into any application using this increasingly popular API. Finally, my own project PoP has recently added an implementation of an API for WordPress which allows to export the WordPress data as either REST, GraphQL or PoP native formats.
It has Gutenberg, a block-based editor that greatly aids the implementation of COPE because it is based on the concept of blocks (as explained in the sections below).
Blobs Versus Blocks To Represent Information
A blob is a single unit of information stored all together in the database. For instance, writing the blog post below on a CMS that relies on blobs to store information will store the blog post content on a single database entry — containing that same content:
<p>Look at this wonderful tango:</p> <figure> <iframe width="951" height="535" src="https://www.youtube.com/embed/sxm3Xyutc1s" frameborder="0" allow="accelerometer; autoplay; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe> <figcaption>An exquisite tango performance</figcaption> </figure>
As it can be appreciated, the important bits of information from this blog post (such as the content in the paragraph, and the URL, the dimensions and attributes of the Youtube video) are not easily accessible: If we want to retrieve any of them on their own, we need to parse the HTML code to extract them — which is far from an ideal solution.
Blocks act differently. By representing the information as a list of blocks, we can store the content in a more semantic and accessible way. Each block conveys its own content and its own properties which can depend on its type (e.g. is it perhaps a paragraph or a video?).
For example, the HTML code above could be represented as a list of blocks like this:
{ [ type: "paragraph", content: "Look at this wonderful tango:" ], [ type: "embed", provider: "Youtube", url: "https://www.youtube.com/embed/sxm3Xyutc1s", width: 951, height: 535, frameborder: 0, allowfullscreen: true, allow: "accelerometer; autoplay; encrypted-media; gyroscope; picture-in-picture", caption: "An exquisite tango performance" ] }
Through this way of representing information, we can easily use any piece of data on its own, and adapt it for the specific medium where it must be displayed. For instance, if we want to extract all the videos from the blog post to show on a car entertainment system, we can simply iterate all blocks of information, select those with type="embed" and provider="Youtube", and extract the URL from them. Similarly, if we want to show the video on an Apple Watch, we need not care about the dimensions of the video, so we can ignore attributes width and height in a straightforward manner.
How Gutenberg Implements Blocks
Before WordPress version 5.0, WordPress used blobs to store post content in the database. Starting from version 5.0, WordPress ships with Gutenberg, a block-based editor, enabling the enhanced way to process content mentioned above, which represents a breakthrough towards the implementation of COPE. Unfortunately, Gutenberg has not been designed for this specific use case, and its representation of the information is different to the one just described for blocks, resulting in several inconveniences that we will need to deal with.
Let’s first have a glimpse on how the blog post described above is saved through Gutenberg:
<!-- wp:paragraph --> <p>Look at this wonderful tango:</p> <!-- /wp:paragraph --> <!-- wp:core-embed/youtube {"url":"https://www.youtube.com/embed/sxm3Xyutc1s","type":"rich","providerNameSlug":"embed-handler","className":"wp-embed-aspect-16-9 wp-has-aspect-ratio"} --> <figure class="wp-block-embed-youtube wp-block-embed is-type-rich is-provider-embed-handler wp-embed-aspect-16-9 wp-has-aspect-ratio"> <div class="wp-block-embed__wrapper"> https://www.youtube.com/embed/sxm3Xyutc1s </div> <figcaption>An exquisite tango performance</figcaption> </figure> <!-- /wp:core-embed/youtube -->
From this piece of code, we can make the following observations:
Blocks Are Saved All Together In The Same Database Entry
There are two blocks in the code above:
<!-- wp:paragraph --> <p>Look at this wonderful tango:</p> <!-- /wp:paragraph -->
<!-- wp:core-embed/youtube {"url":"https://www.youtube.com/embed/sxm3Xyutc1s","type":"rich","providerNameSlug":"embed-handler","className":"wp-embed-aspect-16-9 wp-has-aspect-ratio"} --> <figure class="wp-block-embed-youtube wp-block-embed is-type-rich is-provider-embed-handler wp-embed-aspect-16-9 wp-has-aspect-ratio"> <div class="wp-block-embed__wrapper"> https://www.youtube.com/embed/sxm3Xyutc1s </div> <figcaption>An exquisite tango performance</figcaption> </figure> <!-- /wp:core-embed/youtube -->
With the exception of global (also called “reusable”) blocks, which have an entry of their own in the database and can be referenced directly through their IDs, all blocks are saved together in the blog post’s entry in table wp_posts.
Hence, to retrieve the information for a specific block, we will first need to parse the content and isolate all blocks from each other. Conveniently, WordPress provides function parse_blocks($content) to do just this. This function receives a string containing the blog post content (in HTML format), and returns a JSON object containing the data for all contained blocks.
Block Type And Attributes Are Conveyed Through HTML Comments
Each block is delimited with a starting tag <!-- wp:{block-type} {block-attributes-encoded-as-JSON} --> and an ending tag <!-- /wp:{block-type} --> which (being HTML comments) ensure that this information will not be visible when displaying it on a website. However, we can’t display the blog post directly on another medium, since the HTML comment may be visible, appearing as garbled content. This is not a big deal though, since after parsing the content through function parse_blocks($content), the HTML comments are removed and we can operate directly with the block data as a JSON object.
Blocks Contain HTML
The paragraph block has "<p>Look at this wonderful tango:</p>" as its content, instead of "Look at this wonderful tango:". Hence, it contains HTML code (tags <p> and </p>) which is not useful for other mediums, and as such must be removed, for instance through PHP function strip_tags($content).
When stripping tags, we can keep those HTML tags which explicitly convey semantic information, such as tags <strong> and <em> (instead of their counterparts <b> and <i> which apply only to a screen-based medium), and remove all other tags. This is because there is a great chance that semantic tags can be properly interpreted for other mediums too (e.g. Amazon Alexa can recognize tags <strong> and <em>, and change its voice and intonation accordingly when reading a piece of text). To do this, we invoke the strip_tags function with a 2nd parameter containing the allowed tags, and place it within a wrapping function for convenience:
function strip_html_tags($content) { return strip_tags($content, '<strong><em>'); }
The Video’s Caption Is Saved Within The HTML And Not As An Attribute
As can be seen in the Youtube video block, the caption "An exquisite tango performance" is stored inside the HTML code (enclosed by tag <figcaption />) but not inside the JSON-encoded attributes object. As a consequence, to extract the caption, we will need to parse the block content, for instance through a regular expression:
function extract_caption($content) { $matches = []; preg_match('/<figcaption>(.*?)<\/figcaption>/', $content, $matches); if ($caption = $matches[1]) { return strip_html_tags($caption); } return null; }
This is a hurdle we must overcome in order to extract all metadata from a Gutenberg block. This happens on several blocks; since not all pieces of metadata are saved as attributes, we must then first identify which are these pieces of metadata, and then parse the HTML content to extract them on a block-by-block and piece-by-piece basis.
Concerning COPE, this represents a wasted chance to have a really optimal solution. It could be argued that the alternative option is not ideal either, since it would duplicate information, storing it both within the HTML and as an attribute, which violates the DRY (Don’t Repeat Yourself) principle. However, this violation does already take place: For instance, attribute className contains value "wp-embed-aspect-16-9 wp-has-aspect-ratio", which is printed inside the content too, under HTML attribute class.

Adding content through Gutenberg (Large preview)
Implementing COPE
Note: I have released this functionality, including all the code described below, as WordPress plugin Block Metadata. You’re welcome to install it and play with it so you can get a taste of the power of COPE. The source code is available in this GitHub repo.
Now that we know what the inner representation of a block looks like, let’s proceed to implement COPE through Gutenberg. The procedure will involve the following steps:
Because function parse_blocks($content) returns a JSON object with nested levels, we must first simplify this structure.
We iterate all blocks and, for each, identify their pieces of metadata and extract them, transforming them into a medium-agnostic format in the process. Which attributes are added to the response can vary depending on the block type.
We finally make the data available through an API (REST/GraphQL/PoP).
Let’s implement these steps one by one.
1. Simplifying The Structure Of The JSON Object
The returned JSON object from function parse_blocks($content) has a nested architecture, in which the data for normal blocks appear at the first level, but the data for a referenced reusable block are missing (only data for the referencing block are added), and the data for nested blocks (which are added within other blocks) and for grouped blocks (where several blocks can be grouped together) appear under 1 or more sublevels. This architecture makes it difficult to process the block data from all blocks in the post content, since on one side some data are missing, and on the other we don’t know a priori under how many levels data are located. In addition, there is a block divider placed every pair of blocks, containing no content, which can be safely ignored.
For instance, the response obtained from a post containing a simple block, a global block, a nested block containing a simple block, and a group of simple blocks, in that order, is the following:
[ // Simple block { "blockName": "core/image", "attrs": { "id": 70, "sizeSlug": "large" }, "innerBlocks": [], "innerHTML": "\n<figure class=\"wp-block-image size-large\"><img src=\"http://localhost/wp-content/uploads/2017/12/sandwich-1024x614.jpg\" alt=\"\" class=\"wp-image-70\"/><figcaption>This is a normal block</figcaption></figure>\n", "innerContent": [ "\n<figure class=\"wp-block-image size-large\"><img src=\"http://localhost/wp-content/uploads/2017/12/sandwich-1024x614.jpg\" alt=\"\" class=\"wp-image-70\"/><figcaption>This is a normal block</figcaption></figure>\n" ] }, // Empty block divider { "blockName": null, "attrs": [], "innerBlocks": [], "innerHTML": "\n\n", "innerContent": [ "\n\n" ] }, // Reference to reusable block { "blockName": "core/block", "attrs": { "ref": 218 }, "innerBlocks": [], "innerHTML": "", "innerContent": [] }, // Empty block divider { "blockName": null, "attrs": [], "innerBlocks": [], "innerHTML": "\n\n", "innerContent": [ "\n\n" ] }, // Nested block { "blockName": "core/columns", "attrs": [], // Contained nested blocks "innerBlocks": [ { "blockName": "core/column", "attrs": [], // Contained nested blocks "innerBlocks": [ { "blockName": "core/image", "attrs": { "id": 69, "sizeSlug": "large" }, "innerBlocks": [], "innerHTML": "\n<figure class=\"wp-block-image size-large\"><img src=\"http://localhost/wp-content/uploads/2017/12/espresso-1024x614.jpg\" alt=\"\" class=\"wp-image-69\"/></figure>\n", "innerContent": [ "\n<figure class=\"wp-block-image size-large\"><img src=\"http://localhost/wp-content/uploads/2017/12/espresso-1024x614.jpg\" alt=\"\" class=\"wp-image-69\"/></figure>\n" ] } ], "innerHTML": "\n<div class=\"wp-block-column\"></div>\n", "innerContent": [ "\n<div class=\"wp-block-column\">", null, "</div>\n" ] }, { "blockName": "core/column", "attrs": [], // Contained nested blocks "innerBlocks": [ { "blockName": "core/paragraph", "attrs": [], "innerBlocks": [], "innerHTML": "\n<p>This is how I wake up every morning</p>\n", "innerContent": [ "\n<p>This is how I wake up every morning</p>\n" ] } ], "innerHTML": "\n<div class=\"wp-block-column\"></div>\n", "innerContent": [ "\n<div class=\"wp-block-column\">", null, "</div>\n" ] } ], "innerHTML": "\n<div class=\"wp-block-columns\">\n\n</div>\n", "innerContent": [ "\n<div class=\"wp-block-columns\">", null, "\n\n", null, "</div>\n" ] }, // Empty block divider { "blockName": null, "attrs": [], "innerBlocks": [], "innerHTML": "\n\n", "innerContent": [ "\n\n" ] }, // Block group { "blockName": "core/group", "attrs": [], // Contained grouped blocks "innerBlocks": [ { "blockName": "core/image", "attrs": { "id": 71, "sizeSlug": "large" }, "innerBlocks": [], "innerHTML": "\n<figure class=\"wp-block-image size-large\"><img src=\"http://localhost/wp-content/uploads/2017/12/coffee-1024x614.jpg\" alt=\"\" class=\"wp-image-71\"/><figcaption>First element of the group</figcaption></figure>\n", "innerContent": [ "\n<figure class=\"wp-block-image size-large\"><img src=\"http://localhost/wp-content/uploads/2017/12/coffee-1024x614.jpg\" alt=\"\" class=\"wp-image-71\"/><figcaption>First element of the group</figcaption></figure>\n" ] }, { "blockName": "core/paragraph", "attrs": [], "innerBlocks": [], "innerHTML": "\n<p>Second element of the group</p>\n", "innerContent": [ "\n<p>Second element of the group</p>\n" ] } ], "innerHTML": "\n<div class=\"wp-block-group\"><div class=\"wp-block-group__inner-container\">\n\n</div></div>\n", "innerContent": [ "\n<div class=\"wp-block-group\"><div class=\"wp-block-group__inner-container\">", null, "\n\n", null, "</div></div>\n" ] } ]
A better solution is to have all data at the first level, so the logic to iterate through all block data is greatly simplified. Hence, we must fetch the data for these reusable/nested/grouped blocks, and have it added on the first level too. As it can be seen in the JSON code above:
The empty divider block has attribute "blockName" with value NULL
The reference to a reusable block is defined through $block["attrs"]["ref"]
Nested and group blocks define their contained blocks under $block["innerBlocks"]
Hence, the following PHP code removes the empty divider blocks, identifies the reusable/nested/grouped blocks and adds their data to the first level, and removes all data from all sublevels:
/** * Export all (Gutenberg) blocks' data from a WordPress post */ function get_block_data($content, $remove_divider_block = true) { // Parse the blocks, and convert them into a single-level array $ret = []; $blocks = parse_blocks($content); recursively_add_blocks($ret, $blocks); // Maybe remove blocks without name if ($remove_divider_block) { $ret = remove_blocks_without_name($ret); } // Remove 'innerBlocks' property if it exists (since that code was copied to the first level, it is currently duplicated) foreach ($ret as &$block) { unset($block['innerBlocks']); } return $ret; } /** * Remove the blocks without name, such as the empty block divider */ function remove_blocks_without_name($blocks) { return array_values(array_filter( $blocks, function($block) { return $block['blockName']; } )); } /** * Add block data (including global and nested blocks) into the first level of the array */ function recursively_add_blocks(&$ret, $blocks) { foreach ($blocks as $block) { // Global block: add the referenced block instead of this one if ($block['attrs']['ref']) { $ret = array_merge( $ret, recursively_render_block_core_block($block['attrs']) ); } // Normal block: add it directly else { $ret[] = $block; } // If it contains nested or grouped blocks, add them too if ($block['innerBlocks']) { recursively_add_blocks($ret, $block['innerBlocks']); } } } /** * Function based on `render_block_core_block` */ function recursively_render_block_core_block($attributes) { if (empty($attributes['ref'])) { return []; } $reusable_block = get_post($attributes['ref']); if (!$reusable_block || 'wp_block' !== $reusable_block->post_type) { return []; } if ('publish' !== $reusable_block->post_status || ! empty($reusable_block->post_password)) { return []; } return get_block_data($reusable_block->post_content); }
Calling function get_block_data($content) passing the post content ($post->post_content) as parameter, we now obtain the following response:
[[ { "blockName": "core/image", "attrs": { "id": 70, "sizeSlug": "large" }, "innerHTML": "\n<figure class=\"wp-block-image size-large\"><img src=\"http://localhost/wp-content/uploads/2017/12/sandwich-1024x614.jpg\" alt=\"\" class=\"wp-image-70\"/><figcaption>This is a normal block</figcaption></figure>\n", "innerContent": [ "\n<figure class=\"wp-block-image size-large\"><img src=\"http://localhost/wp-content/uploads/2017/12/sandwich-1024x614.jpg\" alt=\"\" class=\"wp-image-70\"/><figcaption>This is a normal block</figcaption></figure>\n" ] }, { "blockName": "core/paragraph", "attrs": [], "innerHTML": "\n<p>Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua.</p>\n", "innerContent": [ "\n<p>Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua.</p>\n" ] }, { "blockName": "core/columns", "attrs": [], "innerHTML": "\n<div class=\"wp-block-columns\">\n\n</div>\n", "innerContent": [ "\n<div class=\"wp-block-columns\">", null, "\n\n", null, "</div>\n" ] }, { "blockName": "core/column", "attrs": [], "innerHTML": "\n<div class=\"wp-block-column\"></div>\n", "innerContent": [ "\n<div class=\"wp-block-column\">", null, "</div>\n" ] }, { "blockName": "core/image", "attrs": { "id": 69, "sizeSlug": "large" }, "innerHTML": "\n<figure class=\"wp-block-image size-large\"><img src=\"http://localhost/wp-content/uploads/2017/12/espresso-1024x614.jpg\" alt=\"\" class=\"wp-image-69\"/></figure>\n", "innerContent": [ "\n<figure class=\"wp-block-image size-large\"><img src=\"http://localhost/wp-content/uploads/2017/12/espresso-1024x614.jpg\" alt=\"\" class=\"wp-image-69\"/></figure>\n" ] }, { "blockName": "core/column", "attrs": [], "innerHTML": "\n<div class=\"wp-block-column\"></div>\n", "innerContent": [ "\n<div class=\"wp-block-column\">", null, "</div>\n" ] }, { "blockName": "core/paragraph", "attrs": [], "innerHTML": "\n<p>This is how I wake up every morning</p>\n", "innerContent": [ "\n<p>This is how I wake up every morning</p>\n" ] }, { "blockName": "core/group", "attrs": [], "innerHTML": "\n<div class=\"wp-block-group\"><div class=\"wp-block-group__inner-container\">\n\n</div></div>\n", "innerContent": [ "\n<div class=\"wp-block-group\"><div class=\"wp-block-group__inner-container\">", null, "\n\n", null, "</div></div>\n" ] }, { "blockName": "core/image", "attrs": { "id": 71, "sizeSlug": "large" }, "innerHTML": "\n<figure class=\"wp-block-image size-large\"><img src=\"http://localhost/wp-content/uploads/2017/12/coffee-1024x614.jpg\" alt=\"\" class=\"wp-image-71\"/><figcaption>First element of the group</figcaption></figure>\n", "innerContent": [ "\n<figure class=\"wp-block-image size-large\"><img src=\"http://localhost/wp-content/uploads/2017/12/coffee-1024x614.jpg\" alt=\"\" class=\"wp-image-71\"/><figcaption>First element of the group</figcaption></figure>\n" ] }, { "blockName": "core/paragraph", "attrs": [], "innerHTML": "\n<p>Second element of the group</p>\n", "innerContent": [ "\n<p>Second element of the group</p>\n" ] } ]
Even though not strictly necessary, it is very helpful to create a REST API endpoint to output the result of our new function get_block_data($content), which will allow us to easily understand what blocks are contained in a specific post, and how they are structured. The code below adds such endpoint under /wp-json/block-metadata/v1/data/{POST_ID}:
/** * Define REST endpoint to visualize a post’s block data */ add_action('rest_api_init', function () { register_rest_route('block-metadata/v1', 'data/(?P\d+)', [ 'methods' => 'GET', 'callback' => 'get_post_blocks' ]); }); function get_post_blocks($request) { $post = get_post($request['post_id']); if (!$post) { return new WP_Error('empty_post', 'There is no post with this ID', array('status' => 404)); } $block_data = get_block_data($post->post_content); $response = new WP_REST_Response($block_data); $response->set_status(200); return $response; }
To see it in action, check out this link which exports the data for this post.
2. Extracting All Block Metadata Into A Medium-Agnostic Format
At this stage, we have block data containing HTML code which is not appropriate for COPE. Hence, we must strip the non-semantic HTML tags for each block as to convert it into a medium-agnostic format.
We can decide which are the attributes that must be extracted on a block type by block type basis (for instance, extract the text alignment property for "paragraph" blocks, the video URL property for the "youtube embed" block, and so on).
As we saw earlier on, not all attributes are actually saved as block attributes but within the block’s inner content, hence, for these situations, we will need to parse the HTML content using regular expressions in order to extract those pieces of metadata.
After inspecting all blocks shipped through WordPress core, I decided not to extract metadata for the following ones:
"core/columns" "core/column" "core/cover" These apply only to screen-based mediums and (being nested blocks) are difficult to deal with. "core/html" This one only makes sense for web. "core/table" "core/button" "core/media-text" I had no clue how to represent their data on a medium-agnostic fashion or if it even makes sense.
This leaves me with the following blocks, for which I’ll proceed to extract their metadata:
'core/paragraph'
'core/image'
'core-embed/youtube' (as a representative of all the 'core-embed' blocks)
'core/heading'
'core/gallery'
'core/list'
'core/audio'
'core/file'
'core/video'
'core/code'
'core/preformatted'
'core/quote' & 'core/pullquote'
'core/verse'
To extract the metadata, we create function get_block_metadata($block_data) which receives an array with the block data for each block (i.e. the output from our previously-implemented function get_block_data) and, depending on the block type (provided under property "blockName"), decides what attributes are required and how to extract them:
/** * Process all (Gutenberg) blocks' metadata into a medium-agnostic format from a WordPress post */ function get_block_metadata($block_data) { $ret = []; foreach ($block_data as $block) { $blockMeta = null; switch ($block['blockName']) { case ...: $blockMeta = ... break; case ...: $blockMeta = ... break; ... } if ($blockMeta) { $ret[] = [ 'blockName' => $block['blockName'], 'meta' => $blockMeta, ]; } } return $ret; }
Let’s proceed to extract the metadata for each block type, one by one:
"core/paragraph"
Simply remove the HTML tags from the content, and remove the trailing breaklines.
case 'core/paragraph': $blockMeta = [ 'content' => trim(strip_html_tags($block['innerHTML'])), ]; break;
'core/image'
The block either has an ID referring to an uploaded media file or, if not, the image source must be extracted from under <img src="...">. Several attributes (caption, linkDestination, link, alignment) are optional.
case 'core/image': $blockMeta = []; // If inserting the image from the Media Manager, it has an ID if ($block['attrs']['id'] && $img = wp_get_attachment_image_src($block['attrs']['id'], $block['attrs']['sizeSlug'])) { $blockMeta['img'] = [ 'src' => $img[0], 'width' => $img[1], 'height' => $img[2], ]; } elseif ($src = extract_image_src($block['innerHTML'])) { $blockMeta['src'] = $src; } if ($caption = extract_caption($block['innerHTML'])) { $blockMeta['caption'] = $caption; } if ($linkDestination = $block['attrs']['linkDestination']) { $blockMeta['linkDestination'] = $linkDestination; if ($link = extract_link($block['innerHTML'])) { $blockMeta['link'] = $link; } } if ($align = $block['attrs']['align']) { $blockMeta['align'] = $align; } break;
It makes sense to create functions extract_image_src, extract_caption and extract_link since their regular expressions will be used time and again for several blocks. Please notice that a caption in Gutenberg can contain links (<a href="...">), however, when calling strip_html_tags, these are removed from the caption.
Even though regrettable, I find this practice unavoidable, since we can’t guarantee a link to work in non-web platforms. Hence, even though the content is gaining universality since it can be used for different mediums, it is also losing specificity, so its quality is poorer compared to content that was created and customized for the particular platform.
function extract_caption($innerHTML) { $matches = []; preg_match('/<figcaption>(.*?)<\/figcaption>/', $innerHTML, $matches); if ($caption = $matches[1]) { return strip_html_tags($caption); } return null; } function extract_link($innerHTML) { $matches = []; preg_match('/<a href="(.*?)">(.*?)<\/a>>', $innerHTML, $matches); if ($link = $matches[1]) { return $link; } return null; } function extract_image_src($innerHTML) { $matches = []; preg_match('/<img src="(.*?)"/', $innerHTML, $matches); if ($src = $matches[1]) { return $src; } return null; }
'core-embed/youtube'
Simply retrieve the video URL from the block attributes, and extract its caption from the HTML content, if it exists.
case 'core-embed/youtube': $blockMeta = [ 'url' => $block['attrs']['url'], ]; if ($caption = extract_caption($block['innerHTML'])) { $blockMeta['caption'] = $caption; } break;
'core/heading'
Both the header size (h1, h2, …, h6) and the heading text are not attributes, so these must be obtained from the HTML content. Please notice that, instead of returning the HTML tag for the header, the size attribute is simply an equivalent representation, which is more agnostic and makes better sense for non-web platforms.
case 'core/heading': $matches = []; preg_match('/<h[1-6])>(.*?)<\/h([1-6])>/', $block['innerHTML'], $matches); $sizes = [ null, 'xxl', 'xl', 'l', 'm', 'sm', 'xs', ]; $blockMeta = [ 'size' => $sizes[$matches[1]], 'heading' => $matches[2], ]; break;
'core/gallery'
Unfortunately, for the image gallery I have been unable to extract the captions from each image, since these are not attributes, and extracting them through a simple regular expression can fail: If there is a caption for the first and third elements, but none for the second one, then I wouldn’t know which caption corresponds to which image (and I haven’t devoted the time to create a complex regex). Likewise, in the logic below I’m always retrieving the "full" image size, however, this doesn’t have to be the case, and I’m unaware of how the more appropriate size can be inferred.
case 'core/gallery': $imgs = []; foreach ($block['attrs']['ids'] as $img_id) { $img = wp_get_attachment_image_src($img_id, 'full'); $imgs[] = [ 'src' => $img[0], 'width' => $img[1], 'height' => $img[2], ]; } $blockMeta = [ 'imgs' => $imgs, ]; break;
'core/list'
Simply transform the <li> elements into an array of items.
case 'core/list': $matches = []; preg_match_all('/<li>(.*?)<\/li>/', $block['innerHTML'], $matches); if ($items = $matches[1]) { $blockMeta = [ 'items' => array_map('strip_html_tags', $items), ]; } break;
'core/audio'
Obtain the URL of the corresponding uploaded media file.
case 'core/audio': $blockMeta = [ 'src' => wp_get_attachment_url($block['attrs']['id']), ]; break;
'core/file'
Whereas the URL of the file is an attribute, its text must be extracted from the inner content.
case 'core/file': $href = $block['attrs']['href']; $matches = []; preg_match('/<a href="'.str_replace('/', '\/', $href).'">(.*?)<\/a>/', $block['innerHTML'], $matches); $blockMeta = [ 'href' => $href, 'text' => strip_html_tags($matches[1]), ]; break;
'core/video'
Obtain the video URL and all properties to configure how the video is played through a regular expression. If Gutenberg ever changes the order in which these properties are printed in the code, then this regex will stop working, evidencing one of the problems of not adding metadata directly through the block attributes.
case 'core/video': $matches = []; preg_match('/
<\/video>>', $block['innerHTML'], $matches); $blockMeta = [ 'src' => $matches[7], ]; if ($poster = $matches[6]) { $blockMeta['poster'] = $poster; } // Video settings $settings = []; if ($matches[1]) { $settings[] = 'autoplay'; } if ($matches[2]) { $settings[] = 'controls'; } if ($matches[3]) { $settings[] = 'loop'; } if ($matches[4]) { $settings[] = 'muted'; } if ($matches[8]) { $settings[] = 'playsinline'; } if ($settings) { $blockMeta['settings'] = $settings; } if ($caption = extract_caption($block['innerHTML'])) { $blockMeta['caption'] = $caption; } break;
'core/code'
Simply extract the code from within <code />.
case 'core/code': $matches = []; preg_match('/<code>(.*?)<\/code>/is', $block['innerHTML'], $matches); $blockMeta = [ 'code' => $matches[1], ]; break;
'core/preformatted'
Similar to <code />, but we must watch out that Gutenberg hardcodes a class too.
case 'core/preformatted': $matches = []; preg_match('/<pre class="wp-block-preformatted">(.*?)<\/pre>/is', $block['innerHTML'], $matches); $blockMeta = [ 'text' => strip_html_tags($matches[1]), ]; break;
'core/quote' and 'core/pullquote'
We must convert all inner <p /> tags to their equivalent generic "\n" character.
case 'core/quote': case 'core/pullquote': $matches = []; $regexes = [ 'core/quote' => '/<blockquote class=\"wp-block-quote\">(.*?)<\/blockquote>/', 'core/pullquote' => '/<figure class=\"wp-block-pullquote\"><blockquote>(.*?)<\/blockquote><\/figure>/', ]; preg_match($regexes[$block['blockName']], $block['innerHTML'], $matches); if ($quoteHTML = $matches[1]) { preg_match_all('/<p>(.*?)<\/p>/', $quoteHTML, $matches); $blockMeta = [ 'quote' => strip_html_tags(implode('\n', $matches[1])), ]; preg_match('/<cite>(.*?)<\/cite>/', $quoteHTML, $matches); if ($cite = $matches[1]) { $blockMeta['cite'] = strip_html_tags($cite); } } break;
'core/verse'
Similar situation to <pre />.
case 'core/verse': $matches = []; preg_match('/<pre class="wp-block-verse">(.*?)<\/pre>/is', $block['innerHTML'], $matches); $blockMeta = [ 'text' => strip_html_tags($matches[1]), ]; break;
3. Exporting Data Through An API
Now that we have extracted all block metadata, we need to make it available to our different mediums, through an API. WordPress has access to the following APIs:
REST, through the WP REST API (integrated in WordPress core)
GraphQL, through WPGraphQL
PoP, through its implementation for WordPress
Let’s see how to export the data through each of them.
REST
The following code creates endpoint /wp-json/block-metadata/v1/metadata/{POST_ID} which exports all block metadata for a specific post:
/** * Define REST endpoints to export the blocks' metadata for a specific post */ add_action('rest_api_init', function () { register_rest_route('block-metadata/v1', 'metadata/(?P\d+)', [ 'methods' => 'GET', 'callback' => 'get_post_block_meta' ]); }); function get_post_block_meta($request) { $post = get_post($request['post_id']); if (!$post) { return new WP_Error('empty_post', 'There is no post with this ID', array('status' => 404)); } $block_data = get_block_data($post->post_content); $block_metadata = get_block_metadata($block_data); $response = new WP_REST_Response($block_metadata); $response->set_status(200); return $response; }
To see it working, this link (corresponding to this blog post) displays the metadata for blocks of all the types analyzed earlier on.
GraphQL (Through WPGraphQL)
GraphQL works by setting-up schemas and types which define the structure of the content, from which arises this API’s power to fetch exactly the required data and nothing else. Setting-up schemas works very well when the structure of the object has a unique representation.
In our case, however, the metadata returned by a new field "block_metadata" (which calls our newly-created function get_block_metadata) depends on the specific block type, so the structure of the response can vary wildly; GraphQL provides a solution to this issue through a Union type, allowing to return one among a set of different types. However, its implementation for all different variations of the metadata structure has proved to be a lot of work, and I quit along the way 😢.
As an alternative (not ideal) solution, I decided to provide the response by simply encoding the JSON object through a new field "jsonencoded_block_metadata":
/** * Define WPGraphQL field "jsonencoded_block_metadata" */ add_action('graphql_register_types', function() { register_graphql_field( 'Post', 'jsonencoded_block_metadata', [ 'type' => 'String', 'description' => __('Post blocks encoded as JSON', 'wp-graphql'), 'resolve' => function($post) { $post = get_post($post->ID); $block_data = get_block_data($post->post_content); $block_metadata = get_block_metadata($block_data); return json_encode($block_metadata); } ] ); });
PoP
Note: This functionality is available on its own GitHub repo.
The final API is called PoP, which is a little-known project I’ve been working on for several years now. I have recently converted it into a full-fledged API, with the capacity to produce a response compatible with both REST and GraphQL, and which even benefits from the advantages from these 2 APIs, at the same time: no under/over-fetching of data, like in GraphQL, while being cacheable on the server-side and not susceptible to DoS attacks, like REST. It offers a mix between the two of them: REST-like endpoints with GraphQL-like queries.
The block metadata is made available through the API through the following code:
class PostFieldValueResolver extends AbstractDBDataFieldValueResolver { public static function getClassesToAttachTo(): array { return array(\PoP\Posts\FieldResolver::class); } public function resolveValue(FieldResolverInterface $fieldResolver, $resultItem, string $fieldName, array $fieldArgs = []) { $post = $resultItem; switch ($fieldName) { case 'block-metadata': $block_data = \Leoloso\BlockMetadata\Data::get_block_data($post->post_content); $block_metadata = \Leoloso\BlockMetadata\Metadata::get_block_metadata($block_data); // Filter by blockName if ($blockName = $fieldArgs['blockname']) { $block_metadata = array_filter( $block_metadata, function($block) use($blockName) { return $block['blockName'] == $blockName; } ); } return $block_metadata; } return parent::resolveValue($fieldResolver, $resultItem, $fieldName, $fieldArgs); } }
To see it in action, this link displays the block metadata (+ ID, title and URL of the post, and the ID and name of its author, à la GraphQL) for a list of posts.
In addition, similar to GraphQL arguments, our query can be customized through field arguments, enabling to obtain only the data that makes sense for a specific platform. For instance, if we desire to extract all Youtube videos added to all posts, we can add modifier (blockname:core-embed/youtube) to field block-metadata in the endpoint URL, like in this link. Or if we want to extract all images from a specific post, we can add modifier (blockname:core/image) like in this other link|id|title).
Conclusion
The COPE (“Create Once, Publish Everywhere”) strategy helps us lower the amount of work needed to create several applications which must run on different mediums (web, email, apps, home assistants, virtual reality, etc) by creating a single source of truth for our content. Concerning WordPress, even though it has always shined as a Content Management System, implementing the COPE strategy has historically proved to be a challenge.
However, a couple of recent developments have made it increasingly feasible to implement this strategy for WordPress. On one side, since the integration into core of the WP REST API, and more markedly since the launch of Gutenberg, most WordPress content is accessible through APIs, making it a genuine headless system. On the other side, Gutenberg (which is the new default content editor) is block-based, making all metadata inside a blog post readily accessible to the APIs.
As a consequence, implementing COPE for WordPress is straightforward. In this article, we have seen how to do it, and all the relevant code has been made available through several repositories. Even though the solution is not optimal (since it involves plenty of parsing HTML code), it still works fairly well, with the consequence that the effort needed to release our applications to multiple platforms can be greatly reduced. Kudos to that!

(dm, il)
0 notes