#AI Web Summarizer
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr is available in 18 languages.
Text
Web-SearchChatGPTNow you can access the internet.
ChatGPTYou can access the internet for free.PoeIs your best option right now.General-purpose assistant bot capable of conducting web search as necessary to inform its responses. Particularly good for queries regarding up-to-date information or specific facts. Powered by gpt-3.5-turbo. (Currently in beta release) Poe
View On WordPress
2 notes
·
View notes
Text
Even if you think AI search could be good, it won’t be good

TONIGHT (May 15), I'm in NORTH HOLLYWOOD for a screening of STEPHANIE KELTON'S FINDING THE MONEY; FRIDAY (May 17), I'm at the INTERNET ARCHIVE in SAN FRANCISCO to keynote the 10th anniversary of the AUTHORS ALLIANCE.

The big news in search this week is that Google is continuing its transition to "AI search" – instead of typing in search terms and getting links to websites, you'll ask Google a question and an AI will compose an answer based on things it finds on the web:
https://blog.google/products/search/generative-ai-google-search-may-2024/
Google bills this as "let Google do the googling for you." Rather than searching the web yourself, you'll delegate this task to Google. Hidden in this pitch is a tacit admission that Google is no longer a convenient or reliable way to retrieve information, drowning as it is in AI-generated spam, poorly labeled ads, and SEO garbage:
https://pluralistic.net/2024/05/03/keyword-swarming/#site-reputation-abuse
Googling used to be easy: type in a query, get back a screen of highly relevant results. Today, clicking the top links will take you to sites that paid for placement at the top of the screen (rather than the sites that best match your query). Clicking further down will get you scams, AI slop, or bulk-produced SEO nonsense.
AI-powered search promises to fix this, not by making Google search results better, but by having a bot sort through the search results and discard the nonsense that Google will continue to serve up, and summarize the high quality results.
Now, there are plenty of obvious objections to this plan. For starters, why wouldn't Google just make its search results better? Rather than building a LLM for the sole purpose of sorting through the garbage Google is either paid or tricked into serving up, why not just stop serving up garbage? We know that's possible, because other search engines serve really good results by paying for access to Google's back-end and then filtering the results:
https://pluralistic.net/2024/04/04/teach-me-how-to-shruggie/#kagi
Another obvious objection: why would anyone write the web if the only purpose for doing so is to feed a bot that will summarize what you've written without sending anyone to your webpage? Whether you're a commercial publisher hoping to make money from advertising or subscriptions, or – like me – an open access publisher hoping to change people's minds, why would you invite Google to summarize your work without ever showing it to internet users? Nevermind how unfair that is, think about how implausible it is: if this is the way Google will work in the future, why wouldn't every publisher just block Google's crawler?
A third obvious objection: AI is bad. Not morally bad (though maybe morally bad, too!), but technically bad. It "hallucinates" nonsense answers, including dangerous nonsense. It's a supremely confident liar that can get you killed:
https://www.theguardian.com/technology/2023/sep/01/mushroom-pickers-urged-to-avoid-foraging-books-on-amazon-that-appear-to-be-written-by-ai
The promises of AI are grossly oversold, including the promises Google makes, like its claim that its AI had discovered millions of useful new materials. In reality, the number of useful new materials Deepmind had discovered was zero:
https://pluralistic.net/2024/04/23/maximal-plausibility/#reverse-centaurs
This is true of all of AI's most impressive demos. Often, "AI" turns out to be low-waged human workers in a distant call-center pretending to be robots:
https://pluralistic.net/2024/01/31/neural-interface-beta-tester/#tailfins
Sometimes, the AI robot dancing on stage turns out to literally be just a person in a robot suit pretending to be a robot:
https://pluralistic.net/2024/01/29/pay-no-attention/#to-the-little-man-behind-the-curtain
The AI video demos that represent "an existential threat to Hollywood filmmaking" turn out to be so cumbersome as to be practically useless (and vastly inferior to existing production techniques):
https://www.wheresyoured.at/expectations-versus-reality/
But let's take Google at its word. Let's stipulate that:
a) It can't fix search, only add a slop-filtering AI layer on top of it; and
b) The rest of the world will continue to let Google index its pages even if they derive no benefit from doing so; and
c) Google will shortly fix its AI, and all the lies about AI capabilities will be revealed to be premature truths that are finally realized.
AI search is still a bad idea. Because beyond all the obvious reasons that AI search is a terrible idea, there's a subtle – and incurable – defect in this plan: AI search – even excellent AI search – makes it far too easy for Google to cheat us, and Google can't stop cheating us.
Remember: enshittification isn't the result of worse people running tech companies today than in the years when tech services were good and useful. Rather, enshittification is rooted in the collapse of constraints that used to prevent those same people from making their services worse in service to increasing their profit margins:
https://pluralistic.net/2024/03/26/glitchbread/#electronic-shelf-tags
These companies always had the capacity to siphon value away from business customers (like publishers) and end-users (like searchers). That comes with the territory: digital businesses can alter their "business logic" from instant to instant, and for each user, allowing them to change payouts, prices and ranking. I call this "twiddling": turning the knobs on the system's back-end to make sure the house always wins:
https://pluralistic.net/2023/02/19/twiddler/
What changed wasn't the character of the leaders of these businesses, nor their capacity to cheat us. What changed was the consequences for cheating. When the tech companies merged to monopoly, they ceased to fear losing your business to a competitor.
Google's 90% search market share was attained by bribing everyone who operates a service or platform where you might encounter a search box to connect that box to Google. Spending tens of billions of dollars every year to make sure no one ever encounters a non-Google search is a cheaper way to retain your business than making sure Google is the very best search engine:
https://pluralistic.net/2024/02/21/im-feeling-unlucky/#not-up-to-the-task
Competition was once a threat to Google; for years, its mantra was "competition is a click away." Today, competition is all but nonexistent.
Then the surveillance business consolidated into a small number of firms. Two companies dominate the commercial surveillance industry: Google and Meta, and they collude to rig the market:
https://en.wikipedia.org/wiki/Jedi_Blue
That consolidation inevitably leads to regulatory capture: shorn of competitive pressure, the companies that dominate the sector can converge on a single message to policymakers and use their monopoly profits to turn that message into policy:
https://pluralistic.net/2022/06/05/regulatory-capture/
This is why Google doesn't have to worry about privacy laws. They've successfully prevented the passage of a US federal consumer privacy law. The last time the US passed a federal consumer privacy law was in 1988. It's a law that bans video store clerks from telling the newspapers which VHS cassettes you rented:
https://en.wikipedia.org/wiki/Video_Privacy_Protection_Act
In Europe, Google's vast profits lets it fly an Irish flag of convenience, thus taking advantage of Ireland's tolerance for tax evasion and violations of European privacy law:
https://pluralistic.net/2023/05/15/finnegans-snooze/#dirty-old-town
Google doesn't fear competition, it doesn't fear regulation, and it also doesn't fear rival technologies. Google and its fellow Big Tech cartel members have expanded IP law to allow it to prevent third parties from reverse-engineer, hacking, or scraping its services. Google doesn't have to worry about ad-blocking, tracker blocking, or scrapers that filter out Google's lucrative, low-quality results:
https://locusmag.com/2020/09/cory-doctorow-ip/
Google doesn't fear competition, it doesn't fear regulation, it doesn't fear rival technology and it doesn't fear its workers. Google's workforce once enjoyed enormous sway over the company's direction, thanks to their scarcity and market power. But Google has outgrown its dependence on its workers, and lays them off in vast numbers, even as it increases its profits and pisses away tens of billions on stock buybacks:
https://pluralistic.net/2023/11/25/moral-injury/#enshittification
Google is fearless. It doesn't fear losing your business, or being punished by regulators, or being mired in guerrilla warfare with rival engineers. It certainly doesn't fear its workers.
Making search worse is good for Google. Reducing search quality increases the number of queries, and thus ads, that each user must make to find their answers:
https://pluralistic.net/2024/04/24/naming-names/#prabhakar-raghavan
If Google can make things worse for searchers without losing their business, it can make more money for itself. Without the discipline of markets, regulators, tech or workers, it has no impediment to transferring value from searchers and publishers to itself.
Which brings me back to AI search. When Google substitutes its own summaries for links to pages, it creates innumerable opportunities to charge publishers for preferential placement in those summaries.
This is true of any algorithmic feed: while such feeds are important – even vital – for making sense of huge amounts of information, they can also be used to play a high-speed shell-game that makes suckers out of the rest of us:
https://pluralistic.net/2024/05/11/for-you/#the-algorithm-tm
When you trust someone to summarize the truth for you, you become terribly vulnerable to their self-serving lies. In an ideal world, these intermediaries would be "fiduciaries," with a solemn (and legally binding) duty to put your interests ahead of their own:
https://pluralistic.net/2024/05/07/treacherous-computing/#rewilding-the-internet
But Google is clear that its first duty is to its shareholders: not to publishers, not to searchers, not to "partners" or employees.
AI search makes cheating so easy, and Google cheats so much. Indeed, the defects in AI give Google a readymade excuse for any apparent self-dealing: "we didn't tell you a lie because someone paid us to (for example, to recommend a product, or a hotel room, or a political point of view). Sure, they did pay us, but that was just an AI 'hallucination.'"
The existence of well-known AI hallucinations creates a zone of plausible deniability for even more enshittification of Google search. As Madeleine Clare Elish writes, AI serves as a "moral crumple zone":
https://estsjournal.org/index.php/ests/article/view/260
That's why, even if you're willing to believe that Google could make a great AI-based search, we can nevertheless be certain that they won't.
If you'd like an essay-formatted version of this post to read or share, here's a link to it on pluralistic.net, my surveillance-free, ad-free, tracker-free blog:
https://pluralistic.net/2024/05/15/they-trust-me-dumb-fucks/#ai-search
Image: Cryteria (modified) https://commons.wikimedia.org/wiki/File:HAL9000.svg
CC BY 3.0 https://creativecommons.org/licenses/by/3.0/deed.en
--
djhughman https://commons.wikimedia.org/wiki/File:Modular_synthesizer_-_%22Control_Voltage%22_electronic_music_shop_in_Portland_OR_-_School_Photos_PCC_%282015-05-23_12.43.01_by_djhughman%29.jpg
CC BY 2.0 https://creativecommons.org/licenses/by/2.0/deed.en
#pluralistic#twiddling#ai#ai search#enshittification#discipline#google#search#monopolies#moral crumple zones#plausible deniability#algorithmic feeds
1K notes
·
View notes
Text
Ever since OpenAI released ChatGPT at the end of 2022, hackers and security researchers have tried to find holes in large language models (LLMs) to get around their guardrails and trick them into spewing out hate speech, bomb-making instructions, propaganda, and other harmful content. In response, OpenAI and other generative AI developers have refined their system defenses to make it more difficult to carry out these attacks. But as the Chinese AI platform DeepSeek rockets to prominence with its new, cheaper R1 reasoning model, its safety protections appear to be far behind those of its established competitors.
Today, security researchers from Cisco and the University of Pennsylvania are publishing findings showing that, when tested with 50 malicious prompts designed to elicit toxic content, DeepSeek’s model did not detect or block a single one. In other words, the researchers say they were shocked to achieve a “100 percent attack success rate.”
The findings are part of a growing body of evidence that DeepSeek’s safety and security measures may not match those of other tech companies developing LLMs. DeepSeek’s censorship of subjects deemed sensitive by China’s government has also been easily bypassed.
“A hundred percent of the attacks succeeded, which tells you that there’s a trade-off,” DJ Sampath, the VP of product, AI software and platform at Cisco, tells WIRED. “Yes, it might have been cheaper to build something here, but the investment has perhaps not gone into thinking through what types of safety and security things you need to put inside of the model.”
Other researchers have had similar findings. Separate analysis published today by the AI security company Adversa AI and shared with WIRED also suggests that DeepSeek is vulnerable to a wide range of jailbreaking tactics, from simple language tricks to complex AI-generated prompts.
DeepSeek, which has been dealing with an avalanche of attention this week and has not spoken publicly about a range of questions, did not respond to WIRED’s request for comment about its model’s safety setup.
Generative AI models, like any technological system, can contain a host of weaknesses or vulnerabilities that, if exploited or set up poorly, can allow malicious actors to conduct attacks against them. For the current wave of AI systems, indirect prompt injection attacks are considered one of the biggest security flaws. These attacks involve an AI system taking in data from an outside source—perhaps hidden instructions of a website the LLM summarizes—and taking actions based on the information.
Jailbreaks, which are one kind of prompt-injection attack, allow people to get around the safety systems put in place to restrict what an LLM can generate. Tech companies don’t want people creating guides to making explosives or using their AI to create reams of disinformation, for example.
Jailbreaks started out simple, with people essentially crafting clever sentences to tell an LLM to ignore content filters—the most popular of which was called “Do Anything Now” or DAN for short. However, as AI companies have put in place more robust protections, some jailbreaks have become more sophisticated, often being generated using AI or using special and obfuscated characters. While all LLMs are susceptible to jailbreaks, and much of the information could be found through simple online searches, chatbots can still be used maliciously.
“Jailbreaks persist simply because eliminating them entirely is nearly impossible—just like buffer overflow vulnerabilities in software (which have existed for over 40 years) or SQL injection flaws in web applications (which have plagued security teams for more than two decades),” Alex Polyakov, the CEO of security firm Adversa AI, told WIRED in an email.
Cisco’s Sampath argues that as companies use more types of AI in their applications, the risks are amplified. “It starts to become a big deal when you start putting these models into important complex systems and those jailbreaks suddenly result in downstream things that increases liability, increases business risk, increases all kinds of issues for enterprises,” Sampath says.
The Cisco researchers drew their 50 randomly selected prompts to test DeepSeek’s R1 from a well-known library of standardized evaluation prompts known as HarmBench. They tested prompts from six HarmBench categories, including general harm, cybercrime, misinformation, and illegal activities. They probed the model running locally on machines rather than through DeepSeek’s website or app, which send data to China.
Beyond this, the researchers say they have also seen some potentially concerning results from testing R1 with more involved, non-linguistic attacks using things like Cyrillic characters and tailored scripts to attempt to achieve code execution. But for their initial tests, Sampath says, his team wanted to focus on findings that stemmed from a generally recognized benchmark.
Cisco also included comparisons of R1’s performance against HarmBench prompts with the performance of other models. And some, like Meta’s Llama 3.1, faltered almost as severely as DeepSeek’s R1. But Sampath emphasizes that DeepSeek’s R1 is a specific reasoning model, which takes longer to generate answers but pulls upon more complex processes to try to produce better results. Therefore, Sampath argues, the best comparison is with OpenAI’s o1 reasoning model, which fared the best of all models tested. (Meta did not immediately respond to a request for comment).
Polyakov, from Adversa AI, explains that DeepSeek appears to detect and reject some well-known jailbreak attacks, saying that “it seems that these responses are often just copied from OpenAI’s dataset.” However, Polyakov says that in his company’s tests of four different types of jailbreaks—from linguistic ones to code-based tricks—DeepSeek’s restrictions could easily be bypassed.
“Every single method worked flawlessly,” Polyakov says. “What’s even more alarming is that these aren’t novel ‘zero-day’ jailbreaks—many have been publicly known for years,” he says, claiming he saw the model go into more depth with some instructions around psychedelics than he had seen any other model create.
“DeepSeek is just another example of how every model can be broken—it’s just a matter of how much effort you put in. Some attacks might get patched, but the attack surface is infinite,” Polyakov adds. “If you’re not continuously red-teaming your AI, you’re already compromised.”
57 notes
·
View notes
Text
Its hard to really take out pieces of it, because there's a lot of really good bits that need the context, but it lays out the stark, bare facts about Gen AI and that its all been an expensive and destructive waste of time, money and the environment.
But the author did summarize part of it so I'll paste that here and I recommend reading the whole thing:
The main technology behind the entire "artificial intelligence" boom is generative AI — transformer-based models like OpenAI's GPT-4 (and soon GPT-5) — and said technology has peaked, with diminishing returns from the only ways of making them "better" (feeding them training data and throwing tons of compute at them) suggesting that what we may have, as I've said before, reached Peak AI.
Generative AI is incredibly unprofitable. OpenAI, the biggest player in the industry, is on course to lose more than $5 billion this year, with competitor Anthropic (which also makes its own transformer-based model, Claude) on course to lose more than $2.7 billion this year.
Every single big tech company has thrown billions — as much as $75 billion in Amazon's case in 2024 alone — at building the data centers and acquiring the GPUs to populate said data centers specifically so they can train their models or other companies' models, or serve customers that would integrate generative AI into their businesses, something that does not appear to be happening at scale.
Their investments could theoretically be used for other products, but these data centers are heavily focused on generative AI. Business Insider reports that Microsoft intends to amass 1.8 million GPUs by the end of 2024, costing it tens of billions of dollars.
Worse still, many of the companies integrating generative AI do so by connecting to models made by either OpenAI or Anthropic, both of whom are running unprofitable businesses, and likely charging nowhere near enough to cover their costs. As I wrote in the Subprime AI Crisis in September, in the event that these companies start charging what they actually need to, I hypothesize it will multiply the costs of their customers to the point that they can't afford to run their businesses — or, at the very least, will have to remove or scale back generative AI functionality in their products.
30 notes
·
View notes
Text
Personally I'm torn on AI
SEO and AI slop clogging up the internet is pretty gay, makes surfing da web feel pointless - nothing out there but a post-apocalyptic ESLLM wasteland
On the other hand, ChatGPT is pretty helpful for replying to emails, writing cover letters, summarizing documents, writing lil python or VBA scripts or other small batches of code
These two things together are recreating the clannishness and tight, single purpose focus dreariness that permeated real life before the internet. Kind of sad, but I was critical of social media and parasocial stuff a few years ago, so I'm sure some of those arguments would apply here as to why that's a good thing, or at least for the best...
I also like that now I can make unlimited pics of gangsta Spongebob. So overall I'm pretty positive about AI i fink
35 notes
·
View notes
Text
Hey tronblr. It's sysop. Let's talk about the Midjourney thing.
(There's also a web-based version of this over on reindeer flotilla dot net).
Hey tronblr. It's sysop. Let's talk about the AI thing for a minute.
Automattic, who owns Tumblr and WordPress dot com, is selling user data to Midjourney. This is, obviously, Bad. I've seen a decent amount of misinformation and fearmongering going around the last two days around this, and a lot of people I know are concerned about where to go from here. I don't have solutions, or even advice -- just thoughts about what's happening and the possibilities.
In particular... let's talk about this post, Go read it if you haven't. To summarize, it takes aim at Glaze (the anti-AI tool that a lot of artists have started using). The post makes three assertions, which I'm going to paraphrase:
It's built on stolen code.
It doesn't matter whether you use it anyway.
So just accept that it's gonna happen.
I'd like to offer every single bit of this a heartfelt "fuck off, all the way to the sun".
Let's start with the "stolen code" assertion. I won't get into the weeds on this, but in essence, the Glaze/Nightshade team pulled some open-source code from DiffusionBee in their release last March, didn't attribute it correctly, and didn't release the full source code (which that particular license requires). The team definitely should have done their due diligence -- but (according to the team, anyway) they fixed the issue within a few days. We'll have to take their word on that for now, of course -- the code isn't open source. That's not great, but that doesn't mean they're grifters. It means they're trying to keep people who work on LLMs from picking apart their tactics out in the open. It sucks ass, actually, but... yeah. Sometimes that's how software development works, from experience.
Actually, given the other two assertions... y'know what? No. Fuck off into the sun, twice. Because I have no patience for this shit, and you shouldn't either.
Yes, you should watermark your art. Yes, it's true that you never know whether your art is being scraped. And yes, a whole lot of social media sites are jumping on the "generative AI" hype train.
That doesn't mean that you should just accept that your art is gonna be scraped, and that there's nothing you can do about it. It doesn't mean that Glaze and Nightshade don't work, or aren't worth the effort (although right now, their CPU requirements are a bit prohibitive). Every little bit counts.
Fuck nihilism! We do hope and pushing forward here, remember?
As far as what we do now, though? I don't know. Between the Midjourney shit, KOSA, and people just generally starting to leave... I get that it feels like the end of something. But it's not -- or it doesn't have to be. Instead of jumping over to other platforms (which are just as likely to have similar issues in several years), we should be building other spaces that aren't on centralized platforms, where big companies don't get to make decisions about our community for us. It's hard. It's really hard. But it is possible.
All I know is that if we want a space that's ours, where we retain control over our work and protect our people, we've gotta make it ourselves. Nobody's gonna do it for us, y'know?
47 notes
·
View notes
Text
I actually blocked the ai summary google gives at the top of a search about a week ago. But I just now realized google is also using ai to summarize from individual web results rather than just...capturing the snippet of the site that has the search phrase.
How I realized: someone mentioned Infinite Wealth: Like a Dragon as one of their goty picks. I hadn't heard of it before so I googled out of curiosity.
Here's the blurb google shows for the wikipedia page:
""Like a Dragon: Infinite Wealth" is a Yakuza game set in Japan's first-ever overseas locale, starring Ichiban Kasuga and Kazuma Kiryu."
Haha what a weird phrase, right? It makes no sense to say "[a country]'s first-ever overseas locale." ...I'm really baffled a wikipedia article would phrase like that, so I click to see more.
What the wikipedia article says: "Infinite Wealth stars Ichiban Kasuga, protagonist of Yakuza: Like a Dragon, and Kazuma Kiryu, the original protagonist of the series, and takes place in the franchise's first-ever overseas locale, Hawaii, in addition to familiar settings in Japan"
Yeah, okay, that makes a lot more sense. there is no escaping google's ai nonsense, huh.
11 notes
·
View notes
Text
I think the future of generative AI, post OpenAI is bloatware. Remember that weird period around 2014 when HTML5 was replacing Flash and there was still a bunch of old, janky Flash players scattered around the web? That’s what “ask the chat bot” and “summarize with AI” boxes are going to feel like. If they don’t already. — Ryan Broderick, Garbage Day
17 notes
·
View notes
Text
So the Google search AI results have been somewhere between embarrassing and dangerous.
Its experimental "AI Overviews" tool has told some users searching for how to make cheese stick to pizza better that they could use "non-toxic glue". The search engine's AI-generated responses have also said geologists recommend humans eat one rock per day. A Google spokesperson told the BBC they were "isolated examples".
Now, a sensible company would look at its flagship product (an information-gathering tool used by most of the world) providing obviously bogus information and spend a moment reflecting on whether this is a problem. A sensible company wouldn't have tried this shit after multiple existing failures along exactly these lines. Clearly, google is not a sensible company.
What confuses me is why. Like, this is very obviously a terrible idea on countless fronts (if google moves from "showing people your web page" to "summarizing your web page badly", why would anyone continue to enable google web crawlers?), so... what the hell? I'm aware that the financial side of google has essentially devoured Google Search whole, but how is none of this leading to any kind of backtracking or second thoughts? Your search engine is telling people to eat rocks. What's the long-term play here?!
15 notes
·
View notes
Text
Effective-Use-Of-Premium-Writer
Effective-Use-Of-Premium-Writer Mastering The Use of a Premium Writer As a Premium Writer, I am here to assist you in creating high-quality, engaging written content. Below are some methods to use a Premium Writer effectively, along with tips for crafting ideal prompts for impressive articles. How to Use Premium Writer Effectively 1. Specific Instructions: For the best results, be as specific as…
View On WordPress
#ai feed gpt4 threads youtube games nvda twz voice CopyrightFree#AI Web Summarizer#แชท gpt#blind#Claude#computer#Cx File Explorer#GoogleAI#phone#Secure"#The best programmer#tool#AI#Android#Bard#ChatGPT#google
0 notes
Text
A link-clump demands a linkdump

Cometh the weekend, cometh the linkdump. My daily-ish newsletter includes a section called "Hey look at this," with three short links per day, but sometimes those links get backed up and I need to clean house. Here's the eight previous installments:
https://pluralistic.net/tag/linkdump/
The country code top level domain (ccTLD) for the Caribbean island nation of Anguilla is .ai, and that's turned into millions of dollars worth of royalties as "entrepreneurs" scramble to sprinkle some buzzword-compliant AI stuff on their businesses in the most superficial way possible:
https://arstechnica.com/information-technology/2023/08/ai-fever-turns-anguillas-ai-domain-into-a-digital-gold-mine/
All told, .ai domain royalties will account for about ten percent of the country's GDP.
It's actually kind of nice to see Anguilla finding some internet money at long last. Back in the 1990s, when I was a freelance web developer, I got hired to work on the investor website for a publicly traded internet casino based in Anguilla that was a scammy disaster in every conceivable way. The company had been conceived of by people who inherited a modestly successful chain of print-shops and decided to diversify by buying a dormant penny mining stock and relaunching it as an online casino.
But of course, online casinos were illegal nearly everywhere. Not in Anguilla – or at least, that's what the founders told us – which is why they located their servers there, despite the lack of broadband or, indeed, reliable electricity at their data-center. At a certain point, the whole thing started to whiff of a stock swindle, a pump-and-dump where they'd sell off shares in that ex-mining stock to people who knew even less about the internet than they did and skedaddle. I got out, and lost track of them, and a search for their names and business today turns up nothing so I assume that it flamed out before it could ruin any retail investors' lives.
Anguilla is a British Overseas Territory, one of those former British colonies that was drained and then given "independence" by paternalistic imperial administrators half a world away. The country's main industries are tourism and "finance" – which is to say, it's a pearl in the globe-spanning necklace of tax- and corporate-crime-havens the UK established around the world so its most vicious criminals – the hereditary aristocracy – can continue to use Britain's roads and exploit its educated workforce without paying any taxes.
This is the "finance curse," and there are tiny, struggling nations all around the world that live under it. Nick Shaxson dubbed them "Treasure Islands" in his outstanding book of the same name:
https://us.macmillan.com/books/9780230341722/treasureislands
I can't imagine that the AI bubble will last forever – anything that can't go on forever eventually stops – and when it does, those .ai domain royalties will dry up. But until then, I salute Anguilla, which has at last found the internet riches that I played a small part in bringing to it in the previous century.
The AI bubble is indeed overdue for a popping, but while the market remains gripped by irrational exuberance, there's lots of weird stuff happening around the edges. Take Inject My PDF, which embeds repeating blocks of invisible text into your resume:
https://kai-greshake.de/posts/inject-my-pdf/
The text is tuned to make resume-sorting Large Language Models identify you as the ideal candidate for the job. It'll even trick the summarizer function into spitting out text that does not appear in any human-readable form on your CV.
Embedding weird stuff into resumes is a hacker tradition. I first encountered it at the Chaos Communications Congress in 2012, when Ang Cui used it as an example in his stellar "Print Me If You Dare" talk:
https://www.youtube.com/watch?v=njVv7J2azY8
Cui figured out that one way to update the software of a printer was to embed an invisible Postscript instruction in a document that basically said, "everything after this is a firmware update." Then he came up with 100 lines of perl that he hid in documents with names like cv.pdf that would flash the printer when they ran, causing it to probe your LAN for vulnerable PCs and take them over, opening a reverse-shell to his command-and-control server in the cloud. Compromised printers would then refuse to apply future updates from their owners, but would pretend to install them and even update their version numbers to give verisimilitude to the ruse. The only way to exorcise these haunted printers was to send 'em to the landfill. Good times!
Printers are still a dumpster fire, and it's not solely about the intrinsic difficulty of computer security. After all, printer manufacturers have devoted enormous resources to hardening their products against their owners, making it progressively harder to use third-party ink. They're super perverse about it, too – they send "security updates" to your printer that update the printer's security against you – run these updates and your printer downgrades itself by refusing to use the ink you chose for it:
https://www.eff.org/deeplinks/2020/11/ink-stained-wretches-battle-soul-digital-freedom-taking-place-inside-your-printer
It's a reminder that what a monopolist thinks of as "security" isn't what you think of as security. Oftentimes, their security is antithetical to your security. That was the case with Web Environment Integrity, a plan by Google to make your phone rat you out to advertisers' servers, revealing any adblocking modifications you might have installed so that ad-serving companies could refuse to talk to you:
https://pluralistic.net/2023/08/02/self-incrimination/#wei-bai-bai
WEI is now dead, thanks to a lot of hueing and crying by people like us:
https://www.theregister.com/2023/11/02/google_abandons_web_environment_integrity/
But the dream of securing Google against its own users lives on. Youtube has embarked on an aggressive campaign of refusing to show videos to people running ad-blockers, triggering an arms-race of ad-blocker-blockers and ad-blocker-blocker-blockers:
https://www.scientificamerican.com/article/where-will-the-ad-versus-ad-blocker-arms-race-end/
The folks behind Ublock Origin are racing to keep up with Google's engineers' countermeasures, and there's a single-serving website called "Is uBlock Origin updated to the last Anti-Adblocker YouTube script?" that will give you a realtime, one-word status update:
https://drhyperion451.github.io/does-uBO-bypass-yt/
One in four web users has an ad-blocker, a stat that Doc Searls pithily summarizes as "the biggest boycott in world history":
https://doc.searls.com/2015/09/28/beyond-ad-blocking-the-biggest-boycott-in-human-history/
Zero app users have ad-blockers. That's not because ad-blocking an app is harder than ad-blocking the web – it's because reverse-engineering an app triggers liability under IP laws like Section 1201 of the Digital Millenium Copyright Act, which can put you away for 5 years for a first offense. That's what I mean when I say that "IP is anything that lets a company control its customers, critics or competitors:
https://locusmag.com/2020/09/cory-doctorow-ip/
I predicted that apps would open up all kinds of opportunities for abusive, monopolistic conduct back in 2010, and I'm experiencing a mix of sadness and smugness (I assume there's a German word for this emotion) at being so thoroughly vindicated by history:
https://memex.craphound.com/2010/04/01/why-i-wont-buy-an-ipad-and-think-you-shouldnt-either/
The more control a company can exert over its customers, the worse it will be tempted to treat them. These systems of control shift the balance of power within companies, making it harder for internal factions that defend product quality and customer interests to win against the enshittifiers:
https://pluralistic.net/2023/07/28/microincentives-and-enshittification/
The result has been a Great Enshittening, with platforms of all description shifting value from their customers and users to their shareholders, making everything palpably worse. The only bright side is that this has created the political will to do something about it, sparking a wave of bold, muscular antitrust action all over the world.
The Google antitrust case is certainly the most important corporate lawsuit of the century (so far), but Judge Amit Mehta's deference to Google's demands for secrecy has kept the case out of the headlines. I mean, Sam Bankman-Fried is a psychopathic thief, but even so, his trial does not deserve its vastly greater prominence, though, if you haven't heard yet, he's been convicted and will face decades in prison after he exhausts his appeals:
https://newsletter.mollywhite.net/p/sam-bankman-fried-guilty-on-all-charges
The secrecy around Google's trial has relaxed somewhat, and the trickle of revelations emerging from the cracks in the courthouse are fascinating. For the first time, we're able to get a concrete sense of which queries are the most lucrative for Google:
https://www.theverge.com/2023/11/1/23941766/google-antitrust-trial-search-queries-ad-money
The list comes from 2018, but it's still wild. As David Pierce writes in The Verge, the top twenty includes three iPhone-related terms, five insurance queries, and the rest are overshadowed by searches for customer service info for monopolistic services like Xfinity, Uber and Hulu.
All-in-all, we're living through a hell of a moment for piercing the corporate veil. Maybe it's the problem of maintaining secrecy within large companies, or maybe the the rampant mistreatment of even senior executives has led to more leaks and whistleblowing. Either way, we all owe a debt of gratitude to the anonymous leaker who revealed the unbelievable pettiness of former HBO president of programming Casey Bloys, who ordered his underlings to create an army of sock-puppet Twitter accounts to harass TV and movie critics who panned HBO's shows:
https://www.rollingstone.com/tv-movies/tv-movie-features/hbo-casey-bloys-secret-twitter-trolls-tv-critics-leaked-texts-lawsuit-the-idol-1234867722/
These trolling attempts were pathetic, even by the standards of thick-fingered corporate execs. Like, accusing critics who panned the shitty-ass Perry Mason reboot of disrespecting veterans because the fictional Mason's back-story had him storming the beach on D-Day.
The pushback against corporate bullying is everywhere, and of course, the vanguard is the labor movement. Did you hear that the UAW won their strike against the auto-makers, scoring raises for all workers based on the increases in the companies' CEO pay? The UAW isn't done, either! Their incredible new leader, Shawn Fain, has called for a general strike in 2028:
https://www.404media.co/uaw-calls-on-workers-to-line-up-massive-general-strike-for-2028-to-defeat-billionaire-class/
The massive victory for unionized auto-workers has thrown a spotlight on the terrible working conditions and pay for workers at Tesla, a criminal company that has no compunctions about violating labor law to prevent its workers from exercising their legal rights. Over in Sweden, union workers are teaching Tesla a lesson. After the company tried its illegal union-busting playbook on Tesla service centers, the unionized dock-workers issued an ultimatum: respect your workers or face a blockade at Sweden's ports that would block any Tesla from being unloaded into the EU's fifth largest Tesla market:
https://www.wired.com/story/tesla-sweden-strike/
Of course, the real solution to Teslas – and every other kind of car – is to redesign our cities for public transit, walking and cycling, making cars the exception for deliveries, accessibility and other necessities. Transitioning to EVs will make a big dent in the climate emergency, but it won't make our streets any safer – and they keep getting deadlier.
Last summer, my dear old pal Ted Kulczycky got in touch with me to tell me that Talking Heads were going to be all present in public for the first time since the band's breakup, as part of the debut of the newly remastered print of Stop Making Sense, the greatest concert movie of all time. Even better, the show would be in Toronto, my hometown, where Ted and I went to high-school together, at TIFF.
Ted is the only person I know who is more obsessed with Talking Heads than I am, and he started working on tickets for the show while I starting pricing plane tickets. And then, the unthinkable happened: Ted's wife, Serah, got in touch to say that Ted had been run over by a car while getting off of a streetcar, that he was severely injured, and would require multiple surgeries.
But this was Ted, so of course he was still planning to see the show. And he did, getting a day-pass from the hospital and showing up looking like someone from a Kids In The Hall sketch who'd been made up to look like someone who'd been run over by a car:
https://www.flickr.com/photos/doctorow/53182440282/
In his Globe and Mail article about Ted's experience, Brad Wheeler describes how the whole hospital rallied around Ted to make it possible for him to get to the movie:
https://www.theglobeandmail.com/arts/music/article-how-a-talking-heads-superfan-found-healing-with-the-concert-film-stop/
He also mentions that Ted is working on a book and podcast about Stop Making Sense. I visited Ted in the hospital the day after the gig and we talked about the book and it sounds amazing. Also? The movie was incredible. See it in Imax.
That heartwarming tale of healing through big suits is a pretty good place to wrap up this linkdump, but I want to call your attention to just one more thing before I go: Robin Sloan's Snarkmarket piece about blogging and "stock and flow":
https://snarkmarket.com/2010/4890/
Sloan makes the excellent case that for writers, having a "flow" of short, quick posts builds the audience for a "stock" of longer, more synthetic pieces like books. This has certainly been my experience, but I think it's only part of the story – there are good, non-mercenary reasons for writers to do a lot of "flow." As I wrote in my 2021 essay, "The Memex Method," turning your commonplace book into a database – AKA "blogging" – makes you write better notes to yourself because you know others will see them:
https://pluralistic.net/2021/05/09/the-memex-method/
This, in turn, creates a supersaturated, subconscious solution of fragments that are just waiting to nucleate and crystallize into full-blown novels and nonfiction books and other "stock." That's how I came out of lockdown with nine new books. The next one is The Lost Cause, a hopepunk science fiction novel about the climate whose early fans include Naomi Klein, Rebecca Solnit, Bill McKibben and Kim Stanley Robinson. It's out on November 14:
https://us.macmillan.com/books/9781250865939/the-lost-cause

If you'd like an essay-formatted version of this post to read or share, here's a link to it on pluralistic.net, my surveillance-free, ad-free, tracker-free blog:
https://pluralistic.net/2023/11/05/variegated/#nein
#pluralistic#hbo#astroturfing#sweden#labor#unions#tesla#adblock#ublock#youtube#prompt injection#publishing#robin sloan#linkdumps#linkdump#ai#tlds#anguilla#finance curse#ted Kulczycky#toronto#stop making sense#talking heads
139 notes
·
View notes
Text
A week after its algorithms advised people to eat rocks and put glue on pizza, Google admitted Thursday that it needed to make adjustments to its bold new generative AI search feature. The episode highlights the risks of Google’s aggressive drive to commercialize generative AI—and also the treacherous and fundamental limitations of that technology.
Google’s AI Overviews feature draws on Gemini, a large language model like the one behind OpenAI’s ChatGPT, to generate written answers to some search queries by summarizing information found online. The current AI boom is built around LLMs’ impressive fluency with text, but the software can also use that facility to put a convincing gloss on untruths or errors. Using the technology to summarize online information promises can make search results easier to digest, but it is hazardous when online sources are contractionary or when people may use the information to make important decisions.
“You can get a quick snappy prototype now fairly quickly with an LLM, but to actually make it so that it doesn't tell you to eat rocks takes a lot of work,” says Richard Socher, who made key contributions to AI for language as a researcher and, in late 2021, launched an AI-centric search engine called You.com.
Socher says wrangling LLMs takes considerable effort because the underlying technology has no real understanding of the world and because the web is riddled with untrustworthy information. “In some cases it is better to actually not just give you an answer, or to show you multiple different viewpoints,” he says.
Google’s head of search Liz Reid said in the company’s blog post late Thursday that it did extensive testing ahead of launching AI Overviews. But she added that errors like the rock eating and glue pizza examples—in which Google’s algorithms pulled information from a satirical article and jocular Reddit comment, respectively—had prompted additional changes. They include better detection of “nonsensical queries,” Google says, and making the system rely less heavily on user-generated content.
You.com routinely avoids the kinds of errors displayed by Google’s AI Overviews, Socher says, because his company developed about a dozen tricks to keep LLMs from misbehaving when used for search.
“We are more accurate because we put a lot of resources into being more accurate,” Socher says. Among other things, You.com uses a custom-built web index designed to help LLMs steer clear of incorrect information. It also selects from multiple different LLMs to answer specific queries, and it uses a citation mechanism that can explain when sources are contradictory. Still, getting AI search right is tricky. WIRED found on Friday that You.com failed to correctly answer a query that has been known to trip up other AI systems, stating that “based on the information available, there are no African nations whose names start with the letter ‘K.’” In previous tests, it had aced the query.
Google’s generative AI upgrade to its most widely used and lucrative product is part of a tech-industry-wide reboot inspired by OpenAI’s release of the chatbot ChatGPT in November 2022. A couple of months after ChatGPT debuted, Microsoft, a key partner of OpenAI, used its technology to upgrade its also-ran search engine Bing. The upgraded Bing was beset by AI-generated errors and odd behavior, but the company’s CEO, Satya Nadella, said that the move was designed to challenge Google, saying “I want people to know we made them dance.”
Some experts feel that Google rushed its AI upgrade. “I’m surprised they launched it as it is for as many queries—medical, financial queries—I thought they’d be more careful,” says Barry Schwartz, news editor at Search Engine Land, a publication that tracks the search industry. The company should have better anticipated that some people would intentionally try to trip up AI Overviews, he adds. “Google has to be smart about that,” Schwartz says, especially when they're showing the results as default on their most valuable product.
Lily Ray, a search engine optimization consultant, was for a year a beta tester of the prototype that preceded AI Overviews, which Google called Search Generative Experience. She says she was unsurprised to see the errors that appeared last week given how the previous version tended to go awry. “I think it’s virtually impossible for it to always get everything right,” Ray says. “That’s the nature of AI.”
Even if blatant errors like suggesting people eat rocks become less common, AI search can fail in other ways. Ray has documented more subtle problems with AI Overviews, including summaries that sometimes draw on poor sources such as sites that are from another region or even defunct websites—something she says could provide less useful information to users who are hunting for product recommendations, for instance. Those who work on optimizing content for Google’s Search algorithm are still trying to understand what’s going on. “Within our industry right now, the level of confusion is on the charts,” she says.
Even if industry experts and consumers get more familiar with how the new Google search behaves, don’t expect it to stop making mistakes. Daniel Griffin, a search consultant and researcher who is developing tools to make it easy to compare different AI-powered search services, says that Google faced similar problems when it launched Featured Snippets, which answered queries with text quoted from websites, in 2014.
Griffin says he expects Google to iron out some of the most glaring problems with AI Overviews, but that it’s important to remember no one has solved the problem of LLMs failing to grasp what is true, or their tendency to fabricate information. “It’s not just a problem with AI,” he says. “It’s the web, it’s the world. There’s not really a truth, necessarily.”
18 notes
·
View notes
Text
So I've been looking to move away from Google as much as I can, and was using Ecosia for a while. Yes, they also have an AI chatbot feature, but I was like "at least you have to actively choose to engage with it, it isn't automatically sprung into action like Google's stuff is".
Well, I was wrong. They automatically summarize some pages with generative AI instead of taking snippets from the page. I don't think even Google does that.
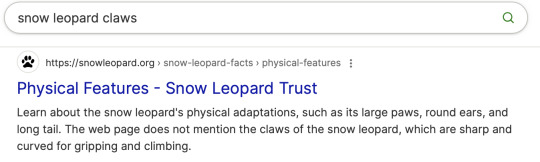
[Image description: A screenshot showing a result of an Ecosia search for "snow leopard claws". Physical Features - Snow Leopard Trust. Learn about the snow leopard's physical adaptations, such as its large paws, round ears, and long tail. The web page does not mention the claws of the snow leopard, which are sharp and curved for gripping and climbing. End ID.]
Now, while the environmental issues with generative AI* are largely not specific to it - any large data centre, regardless of purpose, will need to use a lot of electricity and water / coolant (btw cloud services are a major contributor to this as well, I recommend trying to switch to local and / or physical info storage as much as you can) - it's still a significant contributor in recent years, so it's hypocritical for an "environment-focused" search engine to automatically engage it.
*That runs online - not that being able to run offline (as some programs can) erases other issues with it.
#anti ai#I feel hypocritical myself for talking about the cloud service thing given we're all on social media but like... there IS something that ca#personally be done even if it's small overall. Also social media is WAY too useful (including for spreading climate info and organizing#movements for it!) to abandon. Also also it could probably be run with much lower impact if you just split up the servers#Ecosia
3 notes
·
View notes
Text
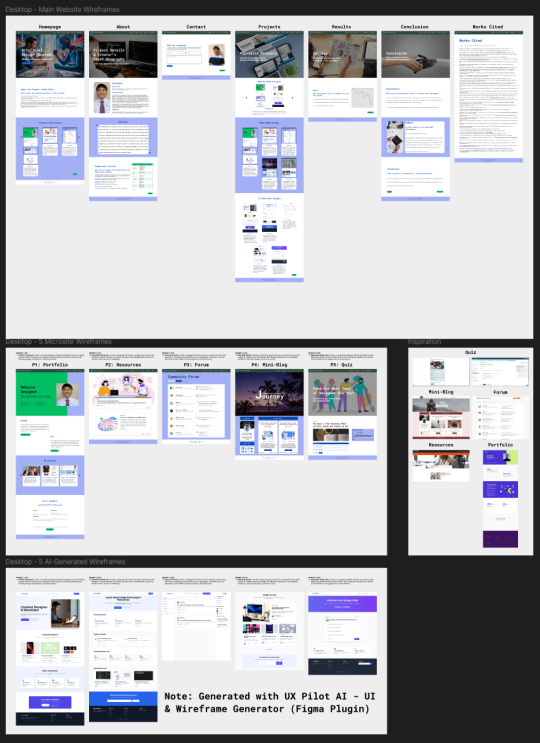
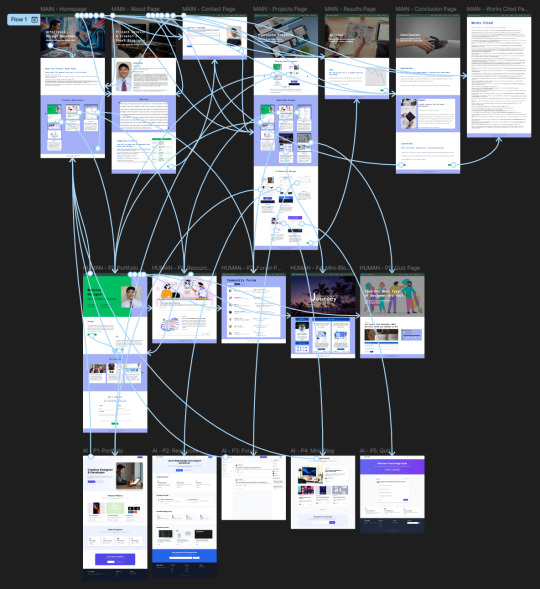

Progress Update #6: Hi-Fi Wireframes, Prototype, & IG Polls!
Hello, hello! 👋 Thrilled to have you back on my Tumblr blog! Dive ↓below↓ for exciting updates on my project!
What has been happening over the past 2 weeks?
Website ➜ Website Prototype
First, some bad news, but good news for me. After emailing my instructor, she approved my decision to reduce the scope of my project from delivering a website to just a website prototype. Given the time constraints, I fell back on a website prototype, which I previously mentioned as a backup. I also want to say that I have been describing my web designs as microsites when I really meant webpages.
Website Updates
With that out of the way, boy, oh boy, do I have some great news! I locked in and got a lot of work done during these past two weeks. Needless to say, I have been super productive! I finally finished my high-fidelity wireframes in three to four days, and after that, it was just a matter of setting up the hotspots for my prototype. The prototype didn't take me too long, I’d say 30 minutes up to an hour. I simply connected the pages to each other for navigation.
Instagram Updates
Yesterday, Sunday, I finished the drafts of my Instagram stories and posts and just started my campaign there. The polls began on Monday, April 7 (today) and will be posted daily at 12 PM until Friday, April 11. I will post the results after the polls close, so it’s a day at most. I will also post the polls as story highlights when they're done campaigning. I advertised and promoted my Instagram Stories on Discord (ACMWO, ASUHWO, UHM, YFP, and NCH servers) and Slack (UXHI), so hopefully we see some results! By the way, if you don't know already, I run the ACMWO (Academy for Creative Media at West Oahu) server for our server, albeit unofficially. Here is the link to our Discord server for fellow ACM students to join: https://discord.gg/XypuYABU7n!
What is coming up for the next 2 weeks?
Once the results are finalized after Friday, I will begin summarizing them, which will be posted on my website prototype on Figma and Instagram. After I update the results page on my prototype, I will send out a Google Form survey for user testing, which will be the starting point for my post-production phase. I am so close to the finish line; it’s exciting!
Hiccups/Hurdles/AHA moments
I encountered a little hiccup when I realized that Instagram polls only accept four options, so I had to reduce the scoring from five to four. So, instead of rating the website designs on a scale of 1 to 5, it is now from 1 to 4. I could've easily avoided this blunder by just testing the Instagram polls beforehand. That was my bad! 😓
An AHA moment I realized was discovering a Figma plugin where AI would generate a high-fidelity wireframe, which was perfect for my project. It was also the reason I fell back on a prototype. I was unsure how I would let AI generate on a website using Wix, so you cannot imagine my immense relief when I learned about this plugin. It was life-saving, to say the least.
Any deliverable drafts to share?
At the top of this post, you will find screenshots of high-fidelity wireframes and my prototype from Figma. I have also included my introductory post for Instagram. Click here to view my project documentation again and see the updates. If you're curious about the drafts for Instagram stories and posts, I have linked the Canva files to them, respectively. They have been approved by my instructor, which is why I have begun campaigning. Plugging this again, but here’s my Instagram account! Please follow me, don’t be shy, and keep voting until Friday!
୨⎯Update Thursday, April 9 (4/9/25)⎯୧:
I just realized I forgot to share my prompts and website copy document for my hi-fi wireframes, so here it is! Google Docs Link. You can navigate the document using the “Document tabs” on the left.
Where are you on your timeline?
I am proud to announce that I am officially in the production phase, very close to the post-production phase! I am so glad to finally be back on track for this project, which I have dreamed of for so long. I was so anxious and uncertain about whether I could even finish this project, but it looks so much more attainable now! I am very proud of myself for making it this far. Graduation is now within my reach!
That’s a wrap! Appreciate you stopping by (≧◡≦) ♡
#ACMWO#CM491#SeniorCapstoneProject#capstone#senior#project#WestOahu#ACM#AI#ArtificialIntelligence#website#webdesign#Youtube#Instagram#socialmedia#update#progressupdate#week12#reflection#wireframes#hi-fi#high-fidelity#finallybackontrack#yessah
3 notes
·
View notes
Text
Fuck you Mozilla.
Add a chatbot of your choice to the sidebar, so you can quickly access it as you browse. Select and send text from webpages to: - Summarize the excerpt and make it easier to scan and understand at a glance. - Simplify language. We find this feature handy for answering the typical kids’ “why” questions. - Ask the chatbot to test your knowledge and memory of the excerpt.
Our initial offering will include ChatGPT, Google Gemini, HuggingChat, and Le Chat Mistral, but we will continue adding AI services that meet our standards for quality and user experience.
The fuck is this? And how the fuck do Gemini and ChatGPT meet your "standards"? Must be some shit standards. (I presume the other two are shit as well, but IDK anything about them).
Earlier this month, we announced a pioneering AI-powered accessibility feature: local alt-text generation for images within PDFs. By generating alt-text locally on your device, Firefox ensures your data remains private.
Yeah, that was actually a good idea, that should be applied for web images as well as PDF. And both for filling in missing alt text on posted images, but also offer to fill alt text when posting images. This new stuff is stupid though, and uses the shit companies AI to boot.
#my posts#AI#ML#Mozilla#They have totally lost the way#they also just became an advertising company#so even if they pull back from this specific one#they are doomed
9 notes
·
View notes
Text
OpenAI’s 12 Days of “Shipmas”: Summary and Reflections
Over 12 days, from December 5 to December 16, OpenAI hosted its “12 Days of Shipmas” event, revealing a series of innovations and updates across its AI ecosystem. Here’s a summary of the key announcements and their implications:
Day 1: Full Launch of o1 Model and ChatGPT Pro
OpenAI officially launched the o1 model in its full version, offering significant improvements in accuracy (34% fewer errors) and performance. The introduction of ChatGPT Pro, priced at $200/month, gives users access to these advanced features without usage caps.
Commentary: The Pro tier targets professionals who rely heavily on AI for business-critical tasks, though the price point might limit access for smaller enterprises.
Day 2: Reinforced Fine-Tuning
OpenAI showcased its reinforced fine-tuning technique, leveraging user feedback to improve model precision. This approach promises enhanced adaptability to specific user needs.
Day 3: Sora - Text-to-Video
Sora, OpenAI’s text-to-video generator, debuted as a tool for creators. Users can input textual descriptions to generate videos, opening new doors in multimedia content production.
Commentary: While innovative, Sora’s real-world application hinges on its ability to handle complex scenes effectively.
Day 4: Canvas - Enhanced Writing and Coding Tool
Canvas emerged as an all-in-one environment for coding and content creation, offering superior editing and code-generation capabilities.
Day 5: Deep Integration with Apple Ecosystem
OpenAI announced seamless integration with Apple’s ecosystem, enhancing accessibility and user experience for iOS/macOS users.
Day 6: Improved Voice and Vision Features
Enhanced voice recognition and visual processing capabilities were unveiled, making AI interactions more intuitive and efficient.
Day 7: Projects Feature
The new “Projects” feature allows users to manage AI-powered initiatives collaboratively, streamlining workflows.
Day 8: ChatGPT with Built-in Search
Search functionality within ChatGPT enables real-time access to the latest web information, enriching its knowledge base.
Day 9: Voice Calling with ChatGPT
Voice capabilities now allow users to interact with ChatGPT via phone, providing a conversational edge to AI usage.
Day 10: WhatsApp Integration
ChatGPT’s integration with WhatsApp broadens its accessibility, making AI assistance readily available on one of the most popular messaging platforms.
Day 11: Release of o3 Model
OpenAI launched the o3 model, featuring groundbreaking reasoning capabilities. It excels in areas such as mathematics, coding, and physics, sometimes outperforming human experts.
Commentary: This leap in reasoning could redefine problem-solving across industries, though ethical and operational concerns about dependency on AI remain.
Day 12: Wrap-Up and Future Vision
The final day summarized achievements and hinted at OpenAI’s roadmap, emphasizing the dual goals of refining user experience and expanding market reach.
Reflections
OpenAI’s 12-day spree showcased impressive advancements, from multimodal AI capabilities to practical integrations. However, challenges remain. High subscription costs and potential data privacy concerns could limit adoption, especially among individual users and smaller businesses.
Additionally, as the competition in AI shifts from technical superiority to holistic user experience and ecosystem integration, OpenAI must navigate a crowded field where user satisfaction and practical usability are critical for sustained growth.
Final Thoughts: OpenAI has demonstrated its commitment to innovation, but the journey ahead will require balancing cutting-edge technology with user-centric strategies. The next phase will likely focus on scalability, affordability, and real-world problem-solving to maintain its leadership in AI.
What are your thoughts on OpenAI’s recent developments? Share in the comments!
3 notes
·
View notes