#AI inference accelerator
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has 411 employees.
Text
AMD acquires engineering team from Untether AI to strengthen AI chip capabilities
June 9, 2025 /SemiMedia/ — AMD has acquired the engineering team of Untether AI, a Toronto-based startup known for developing power-efficient AI inference accelerators for edge and data center applications. The deal marks another strategic step by AMD to expand its AI computing capabilities and challenge NVIDIA’s dominance in the field. In a statement, AMD said the newly integrated team will…
#AI inference accelerator#AMD AI chips#data center GPU#edge computing chips#electronic components news#Electronic components supplier#Electronic parts supplier#power-efficient AI#Untether AI acquisition
0 notes
Text
AI can’t do your job

I'm on a 20+ city book tour for my new novel PICKS AND SHOVELS. Catch me in SAN DIEGO at MYSTERIOUS GALAXY on Mar 24, and in CHICAGO with PETER SAGAL on Apr 2. More tour dates here.

AI can't do your job, but an AI salesman (Elon Musk) can convince your boss (the USA) to fire you and replace you (a federal worker) with a chatbot that can't do your job:
https://www.pcmag.com/news/amid-job-cuts-doge-accelerates-rollout-of-ai-tool-to-automate-government
If you pay attention to the hype, you'd think that all the action on "AI" (an incoherent grab-bag of only marginally related technologies) was in generating text and images. Man, is that ever wrong. The AI hype machine could put every commercial illustrator alive on the breadline and the savings wouldn't pay the kombucha budget for the million-dollar-a-year techies who oversaw Dall-E's training run. The commercial market for automated email summaries is likewise infinitesimal.
The fact that CEOs overestimate the size of this market is easy to understand, since "CEO" is the most laptop job of all laptop jobs. Having a chatbot summarize the boss's email is the 2025 equivalent of the 2000s gag about the boss whose secretary printed out the boss's email and put it in his in-tray so he could go over it with a red pen and then dictate his reply.
The smart AI money is long on "decision support," whereby a statistical inference engine suggests to a human being what decision they should make. There's bots that are supposed to diagnose tumors, bots that are supposed to make neutral bail and parole decisions, bots that are supposed to evaluate student essays, resumes and loan applications.
The narrative around these bots is that they are there to help humans. In this story, the hospital buys a radiology bot that offers a second opinion to the human radiologist. If they disagree, the human radiologist takes another look. In this tale, AI is a way for hospitals to make fewer mistakes by spending more money. An AI assisted radiologist is less productive (because they re-run some x-rays to resolve disagreements with the bot) but more accurate.
In automation theory jargon, this radiologist is a "centaur" – a human head grafted onto the tireless, ever-vigilant body of a robot
Of course, no one who invests in an AI company expects this to happen. Instead, they want reverse-centaurs: a human who acts as an assistant to a robot. The real pitch to hospital is, "Fire all but one of your radiologists and then put that poor bastard to work reviewing the judgments our robot makes at machine scale."
No one seriously thinks that the reverse-centaur radiologist will be able to maintain perfect vigilance over long shifts of supervising automated process that rarely go wrong, but when they do, the error must be caught:
https://pluralistic.net/2024/04/01/human-in-the-loop/#monkey-in-the-middle
The role of this "human in the loop" isn't to prevent errors. That human's is there to be blamed for errors:
https://pluralistic.net/2024/10/30/a-neck-in-a-noose/#is-also-a-human-in-the-loop
The human is there to be a "moral crumple zone":
https://estsjournal.org/index.php/ests/article/view/260
The human is there to be an "accountability sink":
https://profilebooks.com/work/the-unaccountability-machine/
But they're not there to be radiologists.
This is bad enough when we're talking about radiology, but it's even worse in government contexts, where the bots are deciding who gets Medicare, who gets food stamps, who gets VA benefits, who gets a visa, who gets indicted, who gets bail, and who gets parole.
That's because statistical inference is intrinsically conservative: an AI predicts the future by looking at its data about the past, and when that prediction is also an automated decision, fed to a Chaplinesque reverse-centaur trying to keep pace with a torrent of machine judgments, the prediction becomes a directive, and thus a self-fulfilling prophecy:
https://pluralistic.net/2023/03/09/autocomplete-worshippers/#the-real-ai-was-the-corporations-that-we-fought-along-the-way
AIs want the future to be like the past, and AIs make the future like the past. If the training data is full of human bias, then the predictions will also be full of human bias, and then the outcomes will be full of human bias, and when those outcomes are copraphagically fed back into the training data, you get new, highly concentrated human/machine bias:
https://pluralistic.net/2024/03/14/inhuman-centipede/#enshittibottification
By firing skilled human workers and replacing them with spicy autocomplete, Musk is assuming his final form as both the kind of boss who can be conned into replacing you with a defective chatbot and as the fast-talking sales rep who cons your boss. Musk is transforming key government functions into high-speed error-generating machines whose human minders are only the payroll to take the fall for the coming tsunami of robot fuckups.
This is the equivalent to filling the American government's walls with asbestos, turning agencies into hazmat zones that we can't touch without causing thousands to sicken and die:
https://pluralistic.net/2021/08/19/failure-cascades/#dirty-data

If you'd like an essay-formatted version of this post to read or share, here's a link to it on pluralistic.net, my surveillance-free, ad-free, tracker-free blog:
https://pluralistic.net/2025/03/18/asbestos-in-the-walls/#government-by-spicy-autocomplete
Image: Krd (modified) https://commons.wikimedia.org/wiki/File:DASA_01.jpg
CC BY-SA 3.0 https://creativecommons.org/licenses/by-sa/3.0/deed.en
--
Cryteria (modified) https://commons.wikimedia.org/wiki/File:HAL9000.svg
CC BY 3.0 https://creativecommons.org/licenses/by/3.0/deed.en
#pluralistic#reverse centaurs#automation#decision support systems#automation blindness#humans in the loop#doge#ai#elon musk#asbestos in the walls#gsai#moral crumple zones#accountability sinks
277 notes
·
View notes
Note
As I understand it you work in enterprise computer acquisitions?
TL;DR What's the general vibe for AI accelerating CPUs in the enterprise world for client compute?
Have you had any requests from your clients to help them upgrade their stuff to Core Ultra/Whateverthefuck Point with the NPUs? Or has the corporate world generally shown resistance rather than acquiescence to the wave of the future? I'm so sorry for phrasing it like that I had no idea how else to say that without using actual marketing buzzwords and also keeping it interesting to read.
I know in the enterprise, on-die neural acceleration has been ruining panties the world over (Korea's largest hyperscaler even opted for Intel Sapphire Rapids CPUs over Nvidia's Hopper GPUs due to poor supply and not super worth it for them specifically uplift in inference performance which was all that they really cared about), and I'm personally heavily enticed by the new NPU packing processors from both Team Red and Team We Finally Fucking Started Using Chiplets Are You Happy Now (though in large part for the integrated graphics). But I'm really curious to know, are actual corporate acquisitions folks scooping up the new AI-powered hotness to automagically blur giant pink dildos from the backgrounds of Zoom calls, or is it perceived more as a marketing fad at the moment (a situation I'm sure will change in the next year or so once OpenVINO finds footing outside of Audacity and fucking GIMP)?
So sorry for the extremely long, annoying, and tangent-laden ask, hope the TL;DR helps.
Ninety eight percent of our end users use their computers for email and browser stuff exclusively; the other two percent use CAD in relatively low-impact ways so none of them appear to give a shit about increasing their processing power in a really serious way.
Like, corporately speaking the heavy shit you're dealing with is going to be databases and math and computers are pretty good at dealing with those even on hardware from the nineties.
When Intel pitched the sapphire processors to us in May of 2023 the only discussion on AI was about improving performance for AI systems and deep learning applications, NOT using on-chip AI to speed things up.
The were discussing their "accelerators," not AI and in the webinar I attended it was mostly a conversation about the performance benefits of dynamic load balancing and talking about how different "acclerators" would redistribute processing power. This writeup from Intel in 2022 shows how little AI was part of the discussion for Sapphire Rapids.
In August of 2023, this was the marketing email for these processors:

So. Like. The processors are better. But AI is a marketing buzzword.
And yeah every business that I deal with has no use for the hot shit; we're still getting bronze and silver processors and having zero problems, though I work exclusively with businesses with under 500 employees.
Most of the demand that I see from my customers is "please can you help us limp this fifteen year old SAN along for another budget cycle?"
104 notes
·
View notes
Text
On April 15, U.S. chipmaker Nvidia published a filing to the U.S. Securities and Exchange Commission indicating that the government has restricted the company from selling its less advanced graphics processing unit (GPU)—the H20—to China. The company is now required to obtain a license from the U.S. Commerce Department’s Bureau of Industry and Security to sell the H20 and any other chips “achieving the H20’s memory bandwidth, interconnect bandwidth, or combination thereof” to China, according to the filing.
Similarly, a filing from AMD stated that the firm is now restricted from selling its MI308 GPU to China—and likely any chips that have equal or higher performance in the future. Intel’s artificial intelligence accelerator Gaudi will also be restricted under the new control threshold, which reportedly appears to limit chips with total DRAM bandwidth of 1,400 gigabytes per second or more, input/output bandwidth of 1,100 GB per second or more, or a total of both of 1,700 GB per second or more.
The possible new threshold not only restricts the advanced chips that were already controlled but also the less advanced chips from Nvidia, AMD, and other chipmakers, including Nvidia’s H20, AMD’s MI308X, and Intel’s Gaudi, which were used to comply with the export control threshold and intended primarily for sale in the Chinese market.
The new restriction came roughly a week after NPR reported that the Trump administration had decided to back off on regulating the H20. Prior to that report, curbs on the H20 and chips with comparable performance had been widely anticipated by analysts on Wall Street, industry experts in Silicon Valley, and policy circles in Washington.
The latest set of chip controls could be seen as following on from export restrictions during the Biden administration and as continuation of the Trump administration’s efforts to limit China’s access to advanced AI hardware. But the new measure carries far-reaching industry implications that could fundamentally reshape the landscape of China’s AI chip market.
The impact of the new rule on the industry is profound. With the new controls, Nvidia is estimated to immediately lose about $15 billion to $16 billion, according to a J.P. Morgan analysis. AMD, on the other hand, faces $1.5 billion to 1.8 billion in lost revenue, accounting for roughly 10 percent of its estimated data center revenue this year.
Yet the implications go beyond immediate financial damage. If the restriction persists, it will fundamentally reshape the Chinese AI chip market landscape and mark the start of a broader retreat for U.S. AI accelerators from China. That includes not only GPU manufacturers such as Nvidia, AMD, and Intel but also firms providing application-specific integrated circuits—another type of chips targeting specific AI workloads, such as Google’s TPU and Amazon Web Servies’ Trainium.
The new rule will make it nearly impossible for U.S. firms such as Nvidia and AMD to design and sell chips that are export-compliant and competitive in the Chinese market. That means these firms’ market share in the Chinese AI chip market will decline over time, as they are forced to withdraw almost all of their offerings of both advanced and less advanced chips while Chinese firms gradually capture the remaining market.
The H20 and the upgraded H20E are already only marginally ahead of their Chinese competitors. Huawei’s latest AI chip Ascend 910C delivers 2.6 times the computational performance of the H20, although it offers 20 percent less memory bandwidth, which is vital for the inference training and reasoning models that are a key part of modern AI.
The H20’s memory bandwidth, along with Nvidia’s widely adopted software stack, a parallel computing platform and programming model that enables efficient GPU utilization for AI, high-performance computing, and scientific workloads, have been key differentiators driving demand from Chinese AI firms and keeping them competitive in the Chinese market. China acquired more than 1 million units of the H20 in 2024 and has been stockpiling the chip in response to looming concerns about controls since early 2025.
The narrowing gap between the H20 and Huawei’s 910C highlights the growing ability of Chinese AI chipmakers to meet domestic compute demand without foreign GPUs. As of today, Huawei’s 910C is in mass production, with units already delivered to customers and broader mass shipments reportedly starting in May. Most recently, Huawei is reportedly approaching customers about testing its enhanced version of the 910-series GPU—the 910D. Its next-generation chip—the Ascend 920—is expected to enter mass production in the second half of 2025.
Notably, Huawei is just one of many Chinese firms poised to fill the gap left by U.S. suppliers. Chinese AI chip companies such as Cambricon, Hygon, Enflame, Iluvatar CoreX, Biren, and Moore Threads are actively developing more competitive domestic AI chips to capture this expanding market.
Over the next few years, Chinese firms such as Alibaba, ByteDance, Baidu, and Tencent will likely continue to rely on existing inventories of Nvidia and AMD chips—such as the H100, H200, H800, and H20—acquired prior to the implementation of export controls. For example, ByteDance’s current GPU inventory in China is rumored to include 16,000-17,000 units of the A100, 60,000 units of the A800, and 24,000-25,000 units of the H800. Its overseas businesses likely have more than 20,000 units of the H100, 270,000 of the H20, and tens of thousands of cards such as the L20 and L40.
Advanced chips, including the limited amount of Nvidia’s Blackwell-series GPUs, may also continue entering the Chinese market via illicit or gray-market channels, given the enduring performance advantage and wide adoption of these chips over most Chinese domestic alternatives. The Blackwell GPUs and other cutting-edge chips could still be sold legally to the oversea data centers of leading Chinese AI companies to potentially train their AI models.
Similarly, other leading Chinese AI firms still possess significant chip stockpiles. Assuming export controls continue to restrict Chinese AI companies’ access to advanced computing resources, existing GPU inventories should still enable model development over the next several years. Typically, GPUs have a four- to five-year depreciation lifecycle, providing a window during which Chinese domestic GPU manufacturers can advance their capabilities and begin supplying more competitive chips to support domestic AI development.
Ultimately, time is now on the Chinese firms’ side. As inventories of foreign GPUs gradually depreciate and become obsolete, Chinese firms are expected to shift toward and adopt more domestically produced AI chips to meet ongoing compute needs at a time when local chipmakers offer more powerful alternatives. China’s overall computing demand will steadily rise, given the continued advancement of the AI industry, and such incremental growth in demand will likely be met by Chinese AI chipmakers.
As a result, the tens of billions of dollars in revenue that would have gone to Nvidia and AMD will be gradually captured by Chinese AI firms in the coming years. In a rough assessment, the latest ban causes Nvidia and AMD instant losses of about $16.5 billion to $17.8 billion—about 70 percent of what Huawei spent on research and development in 2024.
This new market paradigm will not only strengthen the market position and financial sustainability of domestic Chinese AI chipmakers but also enhance their capacity to reinvest in R&D. In turn, this will accelerate innovation, improve competitiveness, and fortify China’s broader AI hardware supply chain—ultimately contributing to the long-term resilience and advancement of Chinese AI capabilities.
More importantly, the growing domestic adoption of Chinese GPUs enables local firms to refine their products more efficiently through accelerated and larger feedback loops from local enterprises. As the Nvidia-led GPU ecosystem stalls and gradually retreats from the Chinese market, this shift creates space for local players to build a domestic GPU ecosystem—one that may increasingly lock out foreign competitors and raise re-entry barriers over time.
A total ban on the H20 would likely slow China’s short-term growth in AI compute capacity by removing a key source of advanced chips. But the medium- to longer-term impact is less clear. Chinese AI companies, as previously noted, remain very capable of developing their AI by using a large number of existing Nvidia and AMD GPUs for the next few years, alongside a growing supply of improving domestic alternatives. The U.S. leadership’s ultimate goal of using export controls to constrain China’s AI development remains uncertain, as the gap between the two countries’ AI model capabilities appears to be narrowing rather than widening.
What is clear, however, is the broader industry impact of the new controls. If sustained, they will mark the beginning of a major withdrawal of U.S. AI chipmakers from the Chinese market—paving the way for a significant boost to domestic Chinese AI chipmakers. In trying to isolate China, the United States may end up giving Chinese firms a leg up.
3 notes
·
View notes
Text
KIOXIA Unveils 122.88TB LC9 Series NVMe SSD to Power Next-Gen AI Workloads

KIOXIA America, Inc. has announced the upcoming debut of its LC9 Series SSD, a new high-capacity enterprise solid-state drive (SSD) with 122.88 terabytes (TB) of storage, purpose-built for advanced AI applications. Featuring the company’s latest BiCS FLASH™ generation 8 3D QLC (quad-level cell) memory and a fast PCIe® 5.0 interface, this cutting-edge drive is designed to meet the exploding data demands of artificial intelligence and machine learning systems.
As enterprises scale up AI workloads—including training large language models (LLMs), handling massive datasets, and supporting vector database queries—the need for efficient, high-density storage becomes paramount. The LC9 SSD addresses these needs with a compact 2.5-inch form factor and dual-port capability, providing both high capacity and fault tolerance in mission-critical environments.
Form factor refers to the physical size and shape of the drive—in this case, 2.5 inches, which is standard for enterprise server deployments. PCIe (Peripheral Component Interconnect Express) is the fast data connection standard used to link components to a system’s motherboard. NVMe (Non-Volatile Memory Express) is the protocol used by modern SSDs to communicate quickly and efficiently over PCIe interfaces.
Accelerating AI with Storage Innovation
The LC9 Series SSD is designed with AI-specific use cases in mind—particularly generative AI, retrieval augmented generation (RAG), and vector database applications. Its high capacity enables data-intensive training and inference processes to operate without the bottlenecks of traditional storage.
It also complements KIOXIA’s AiSAQ™ technology, which improves RAG performance by storing vector elements on SSDs instead of relying solely on costly and limited DRAM. This shift enables greater scalability and lowers power consumption per TB at both the system and rack levels.
“AI workloads are pushing the boundaries of data storage,” said Neville Ichhaporia, Senior Vice President at KIOXIA America. “The new LC9 NVMe SSD can accelerate model training, inference, and RAG at scale.”
Industry Insight and Lifecycle Considerations
Gregory Wong, principal analyst at Forward Insights, commented:
“Advanced storage solutions such as KIOXIA’s LC9 Series SSD will be critical in supporting the growing computational needs of AI models, enabling greater efficiency and innovation.”
As organizations look to adopt next-generation SSDs like the LC9, many are also taking steps to responsibly manage legacy infrastructure. This includes efforts to sell SSD units from previous deployments—a common practice in enterprise IT to recover value, reduce e-waste, and meet sustainability goals. Secondary markets for enterprise SSDs remain active, especially with the ongoing demand for storage in distributed and hybrid cloud systems.
LC9 Series Key Features
122.88 TB capacity in a compact 2.5-inch form factor
PCIe 5.0 and NVMe 2.0 support for high-speed data access
Dual-port support for redundancy and multi-host connectivity
Built with 2 Tb QLC BiCS FLASH™ memory and CBA (CMOS Bonded to Array) technology
Endurance rating of 0.3 DWPD (Drive Writes Per Day) for enterprise workloads
The KIOXIA LC9 Series SSD will be showcased at an upcoming technology conference, where the company is expected to demonstrate its potential role in powering the next generation of AI-driven innovation.
2 notes
·
View notes
Text
Binary Circuit - Open AI’s O3 Breakthrough Shows Technology is Accelerating Again
OpenAI model o3 outperforms humans in math and programming with its reasoning. It scored an impressive 88% on the advanced reasoning ARC-AGI benchmark. A big improvement from 5% earlier this year and 32% in September. Codeforces placed O3 175th, meaning it can outperform all humans in coding.
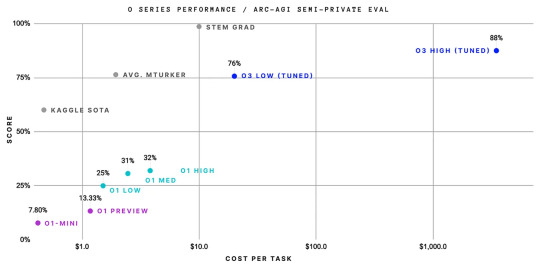
Image Source: ARC Price via X.com
Why Does It Matter? Most notable is the shorter development cycle. O3 launched months after O1, while previous AI models required 18-24 months.
Unlike conventional models that take months of training, o3 enhances inference performance. This means discoveries might happen in weeks, not years. This rapid technology advancement will require organizations to reassess innovation timeframes.
Impact on Businesses Many complex subjects can be developed faster after the o3 breakthrough.
Scientific Research: Accelerate protein folding, particle physics, and cosmic research
Engineering: Quick prototyping and problem-solving
Math: Access to previously inaccessible theoretical domains
Software Development: Enterprise-grade code automation
An Enterprise Competitive Playbook: Implement AI reasoning tools in R&D pipelines quickly. In the coming years, organizations will have to restructure tech teams around AI, and AI-first R&D will become mainstream.
Feel free to visit our website to learn more about Binary Circuit/Green Light LLC and explore our innovative solutions:
🌐 www.greenlightllc.us
2 notes
·
View notes
Text
Obsidian And RTX AI PCs For Advanced Large Language Model
How to Utilize Obsidian‘s Generative AI Tools. Two plug-ins created by the community demonstrate how RTX AI PCs can support large language models for the next generation of app developers.
Obsidian Meaning
Obsidian is a note-taking and personal knowledge base program that works with Markdown files. Users may create internal linkages for notes using it, and they can see the relationships as a graph. It is intended to assist users in flexible, non-linearly structuring and organizing their ideas and information. Commercial licenses are available for purchase, however personal usage of the program is free.
Obsidian Features
Electron is the foundation of Obsidian. It is a cross-platform program that works on mobile operating systems like iOS and Android in addition to Windows, Linux, and macOS. The program does not have a web-based version. By installing plugins and themes, users may expand the functionality of Obsidian across all platforms by integrating it with other tools or adding new capabilities.
Obsidian distinguishes between community plugins, which are submitted by users and made available as open-source software via GitHub, and core plugins, which are made available and maintained by the Obsidian team. A calendar widget and a task board in the Kanban style are two examples of community plugins. The software comes with more than 200 community-made themes.
Every new note in Obsidian creates a new text document, and all of the documents are searchable inside the app. Obsidian works with a folder of text documents. Obsidian generates an interactive graph that illustrates the connections between notes and permits internal connectivity between notes. While Markdown is used to accomplish text formatting in Obsidian, Obsidian offers quick previewing of produced content.
Generative AI Tools In Obsidian
A group of AI aficionados is exploring with methods to incorporate the potent technology into standard productivity practices as generative AI develops and speeds up industry.
Community plug-in-supporting applications empower users to investigate the ways in which large language models (LLMs) might improve a range of activities. Users using RTX AI PCs may easily incorporate local LLMs by employing local inference servers that are powered by the NVIDIA RTX-accelerated llama.cpp software library.
It previously examined how consumers might maximize their online surfing experience by using Leo AI in the Brave web browser. Today, it examine Obsidian, a well-known writing and note-taking tool that uses the Markdown markup language and is helpful for managing intricate and connected records for many projects. Several of the community-developed plug-ins that add functionality to the app allow users to connect Obsidian to a local inferencing server, such as LM Studio or Ollama.
To connect Obsidian to LM Studio, just select the “Developer” button on the left panel, load any downloaded model, enable the CORS toggle, and click “Start.” This will enable LM Studio’s local server capabilities. Because the plug-ins will need this information to connect, make a note of the chat completion URL from the “Developer” log console (“http://localhost:1234/v1/chat/completions” by default).
Next, visit the “Settings” tab after launching Obsidian. After selecting “Community plug-ins,” choose “Browse.” Although there are a number of LLM-related community plug-ins, Text Generator and Smart Connections are two well-liked choices.
For creating notes and summaries on a study subject, for example, Text Generator is useful in an Obsidian vault.
Asking queries about the contents of an Obsidian vault, such the solution to a trivia question that was stored years ago, is made easier using Smart Connections.
Open the Text Generator settings, choose “Custom” under “Provider profile,” and then enter the whole URL in the “Endpoint” section. After turning on the plug-in, adjust the settings for Smart Connections. For the model platform, choose “Custom Local (OpenAI Format)” from the options panel on the right side of the screen. Next, as they appear in LM Studio, type the model name (for example, “gemma-2-27b-instruct”) and the URL into the corresponding fields.
The plug-ins will work when the fields are completed. If users are interested in what’s going on on the local server side, the LM Studio user interface will also display recorded activities.
Transforming Workflows With Obsidian AI Plug-Ins
Consider a scenario where a user want to organize a trip to the made-up city of Lunar City and come up with suggestions for things to do there. “What to Do in Lunar City” would be the title of the new note that the user would begin. A few more instructions must be included in the query submitted to the LLM in order to direct the results, since Lunar City is not an actual location. The model will create a list of things to do while traveling if you click the Text Generator plug-in button.
Obsidian will ask LM Studio to provide a response using the Text Generator plug-in, and LM Studio will then execute the Gemma 2 27B model. The model can rapidly provide a list of tasks if the user’s machine has RTX GPU acceleration.
Or let’s say that years later, the user’s buddy is visiting Lunar City and is looking for a place to dine. Although the user may not be able to recall the names of the restaurants they visited, they can review the notes in their vault Obsidian‘s word for a collection of notes to see whether they have any written notes.
A user may ask inquiries about their vault of notes and other material using the Smart Connections plug-in instead of going through all of the notes by hand. In order to help with the process, the plug-in retrieves pertinent information from the user’s notes and responds to the request using the same LM Studio server. The plug-in uses a method known as retrieval-augmented generation to do this.
Although these are entertaining examples, users may see the true advantages and enhancements in daily productivity after experimenting with these features for a while. Two examples of how community developers and AI fans are using AI to enhance their PC experiences are Obsidian plug-ins.
Thousands of open-source models are available for developers to include into their Windows programs using NVIDIA GeForce RTX technology.
Read more on Govindhtech.com
#Obsidian#RTXAIPCs#LLM#LargeLanguageModel#AI#GenerativeAI#NVIDIARTX#LMStudio#RTXGPU#News#Technews#Technology#Technologynews#Technologytrends#govindhtech
3 notes
·
View notes
Note
hey jsyk using AI is literally killing our planet.
https://www.forbes.com/sites/cindygordon/2024/02/25/ai-is-accelerating-the-loss-of-our-scarcest-natural-resource-water/
"AI uses 9 liters of water per kilowatt of energy"
https://mcengkuru.medium.com/the-hidden-cost-of-ai-images-how-generating-one-could-power-your-fridge-for-hours-174c95c43db8#:~:text=AI%20Magic%2C%20Environmental%20Reality&text=Research%20suggests%20that%20creating%20a,on%20its%20size%20and%20efficiency.
"Research suggests that creating a single AI image can consume anywhere from 0.01 to 0.29 kilowatt-hours (kWh) of energy. That's like running your refrigerator for up to half an hour, depending on its size and efficiency."
https://www.theverge.com/24066646/ai-electricity-energy-watts-generative-consumption#:~:text=The%20figures%20were%20notably%20larger,energy%20as%20charging%20your%20smartphone.
"The figures were notably larger for image-generation models, which used on average 2.907 kWh per 1,000 inferences."
Google's AI used 5 billion liters of fresh water in 2022. That's the equivalent of drinking water for one year than many, many countries on the planet. And it needs to be freshwater for coolant, because non purified water will gum up the coolant systems. Freshwater is 6% of our planet's water. Places are suffering catastrophic drought. It's caught up to California now, the West is feeling the impact now, it's so bad.
AI also generates massive amounts of greenhouse gas.
AI is killing our planet.
uhhh so is everything else?
what about all these new unnecessary buildings, reducing nature and making the planet hotter with the lack of trees and innocent wild animals having nowhere?
what about electric cars?
what about the businesses that keep their lights on overnight when they shouldn't?
what about the lights people keep on overnight even though they shouldn't?
what about the fishermen and pools that waste this freshwater just as much?
what about air conditioning? that uses water too.
and while we're at it, since you mentioned it, what about the refrigerators?
if this is true, ai isnt the only thing killing our planet, just living in it is.
and if youre sending this as hate bc i used ai, i dont like when people use ai in the bad way but it can make some very hilarious images because of its lack of coherence. im using ai to make people laugh (to help) not to hurt. if you dont like something on my page, get the fuck off and touch the grass you claim to care about.
6 notes
·
View notes
Text
How can you optimize the performance of machine learning models in the cloud?
Optimizing machine learning models in the cloud involves several strategies to enhance performance and efficiency. Here’s a detailed approach:

Choose the Right Cloud Services:
Managed ML Services:
Use managed services like AWS SageMaker, Google AI Platform, or Azure Machine Learning, which offer built-in tools for training, tuning, and deploying models.
Auto-scaling:
Enable auto-scaling features to adjust resources based on demand, which helps manage costs and performance.
Optimize Data Handling:
Data Storage:
Use scalable cloud storage solutions like Amazon S3, Google Cloud Storage, or Azure Blob Storage for storing large datasets efficiently.
Data Pipeline:
Implement efficient data pipelines with tools like Apache Kafka or AWS Glue to manage and process large volumes of data.
Select Appropriate Computational Resources:
Instance Types:
Choose the right instance types based on your model’s requirements. For example, use GPU or TPU instances for deep learning tasks to accelerate training.
Spot Instances:
Utilize spot instances or preemptible VMs to reduce costs for non-time-sensitive tasks.
Optimize Model Training:
Hyperparameter Tuning:
Use cloud-based hyperparameter tuning services to automate the search for optimal model parameters. Services like Google Cloud AI Platform’s HyperTune or AWS SageMaker’s Automatic Model Tuning can help.
Distributed Training:
Distribute model training across multiple instances or nodes to speed up the process. Frameworks like TensorFlow and PyTorch support distributed training and can take advantage of cloud resources.
Monitoring and Logging:
Monitoring Tools:
Implement monitoring tools to track performance metrics and resource usage. AWS CloudWatch, Google Cloud Monitoring, and Azure Monitor offer real-time insights.
Logging:
Maintain detailed logs for debugging and performance analysis, using tools like AWS CloudTrail or Google Cloud Logging.
Model Deployment:
Serverless Deployment:
Use serverless options to simplify scaling and reduce infrastructure management. Services like AWS Lambda or Google Cloud Functions can handle inference tasks without managing servers.
Model Optimization:
Optimize models by compressing them or using model distillation techniques to reduce inference time and improve latency.
Cost Management:
Cost Analysis:
Regularly analyze and optimize cloud costs to avoid overspending. Tools like AWS Cost Explorer, Google Cloud’s Cost Management, and Azure Cost Management can help monitor and manage expenses.
By carefully selecting cloud services, optimizing data handling and training processes, and monitoring performance, you can efficiently manage and improve machine learning models in the cloud.
2 notes
·
View notes
Text
Data Center Accelerator Market Set to Transform AI Infrastructure Landscape by 2031

The global data center accelerator market is poised for exponential growth, projected to rise from USD 14.4 Bn in 2022 to a staggering USD 89.8 Bn by 2031, advancing at a CAGR of 22.5% during the forecast period from 2023 to 2031. Rapid adoption of Artificial Intelligence (AI), Machine Learning (ML), and High-Performance Computing (HPC) is the primary catalyst driving this expansion.
Market Overview: Data center accelerators are specialized hardware components that improve computing performance by efficiently handling intensive workloads. These include Graphics Processing Units (GPUs), Tensor Processing Units (TPUs), Field Programmable Gate Arrays (FPGAs), and Application-Specific Integrated Circuits (ASICs), which complement CPUs by expediting data processing.
Accelerators enable data centers to process massive datasets more efficiently, reduce reliance on servers, and optimize costs a significant advantage in a data-driven world.
Market Drivers & Trends
Rising Demand for High-performance Computing (HPC): The proliferation of data-intensive applications across industries such as healthcare, autonomous driving, financial modeling, and weather forecasting is fueling demand for robust computing resources.
Boom in AI and ML Technologies: The computational requirements of AI and ML are driving the need for accelerators that can handle parallel operations and manage extensive datasets efficiently.
Cloud Computing Expansion: Major players like AWS, Azure, and Google Cloud are investing in infrastructure that leverages accelerators to deliver faster AI-as-a-service platforms.
Latest Market Trends
GPU Dominance: GPUs continue to dominate the market, especially in AI training and inference workloads, due to their capability to handle parallel computations.
Custom Chip Development: Tech giants are increasingly developing custom chips (e.g., Meta’s MTIA and Google's TPUs) tailored to their specific AI processing needs.
Energy Efficiency Focus: Companies are prioritizing the design of accelerators that deliver high computational power with reduced energy consumption, aligning with green data center initiatives.
Key Players and Industry Leaders
Prominent companies shaping the data center accelerator landscape include:
NVIDIA Corporation – A global leader in GPUs powering AI, gaming, and cloud computing.
Intel Corporation – Investing heavily in FPGA and ASIC-based accelerators.
Advanced Micro Devices (AMD) – Recently expanded its EPYC CPU lineup for data centers.
Meta Inc. – Introduced Meta Training and Inference Accelerator (MTIA) chips for internal AI applications.
Google (Alphabet Inc.) – Continues deploying TPUs across its cloud platforms.
Other notable players include Huawei Technologies, Cisco Systems, Dell Inc., Fujitsu, Enflame Technology, Graphcore, and SambaNova Systems.
Recent Developments
March 2023 – NVIDIA introduced a comprehensive Data Center Platform strategy at GTC 2023 to address diverse computational requirements.
June 2023 – AMD launched new EPYC CPUs designed to complement GPU-powered accelerator frameworks.
2023 – Meta Inc. revealed the MTIA chip to improve performance for internal AI workloads.
2023 – Intel announced a four-year roadmap for data center innovation focused on Infrastructure Processing Units (IPUs).
Gain an understanding of key findings from our Report in this sample - https://www.transparencymarketresearch.com/sample/sample.php?flag=S&rep_id=82760
Market Opportunities
Edge Data Center Integration: As computing shifts closer to the edge, opportunities arise for compact and energy-efficient accelerators in edge data centers for real-time analytics and decision-making.
AI in Healthcare and Automotive: As AI adoption grows in precision medicine and autonomous vehicles, demand for accelerators tuned for domain-specific processing will soar.
Emerging Markets: Rising digitization in emerging economies presents substantial opportunities for data center expansion and accelerator deployment.
Future Outlook
With AI, ML, and analytics forming the foundation of next-generation applications, the demand for enhanced computational capabilities will continue to climb. By 2031, the data center accelerator market will likely transform into a foundational element of global IT infrastructure.
Analysts anticipate increasing collaboration between hardware manufacturers and AI software developers to optimize performance across the board. As digital transformation accelerates, companies investing in custom accelerator architectures will gain significant competitive advantages.
Market Segmentation
By Type:
Central Processing Unit (CPU)
Graphics Processing Unit (GPU)
Application-Specific Integrated Circuit (ASIC)
Field-Programmable Gate Array (FPGA)
Others
By Application:
Advanced Data Analytics
AI/ML Training and Inference
Computing
Security and Encryption
Network Functions
Others
Regional Insights
Asia Pacific dominates the global market due to explosive digital content consumption and rapid infrastructure development in countries such as China, India, Japan, and South Korea.
North America holds a significant share due to the presence of major cloud providers, AI startups, and heavy investment in advanced infrastructure. The U.S. remains a critical hub for data center deployment and innovation.
Europe is steadily adopting AI and cloud computing technologies, contributing to increased demand for accelerators in enterprise data centers.
Why Buy This Report?
Comprehensive insights into market drivers, restraints, trends, and opportunities
In-depth analysis of the competitive landscape
Region-wise segmentation with revenue forecasts
Includes strategic developments and key product innovations
Covers historical data from 2017 and forecast till 2031
Delivered in convenient PDF and Excel formats
Frequently Asked Questions (FAQs)
1. What was the size of the global data center accelerator market in 2022? The market was valued at US$ 14.4 Bn in 2022.
2. What is the projected market value by 2031? It is projected to reach US$ 89.8 Bn by the end of 2031.
3. What is the key factor driving market growth? The surge in demand for AI/ML processing and high-performance computing is the major driver.
4. Which region holds the largest market share? Asia Pacific is expected to dominate the global data center accelerator market from 2023 to 2031.
5. Who are the leading companies in the market? Top players include NVIDIA, Intel, AMD, Meta, Google, Huawei, Dell, and Cisco.
6. What type of accelerator dominates the market? GPUs currently dominate the market due to their parallel processing efficiency and widespread adoption in AI/ML applications.
7. What applications are fueling growth? Applications like AI/ML training, advanced analytics, and network security are major contributors to the market's growth.
Explore Latest Research Reports by Transparency Market Research: Tactile Switches Market: https://www.transparencymarketresearch.com/tactile-switches-market.html
GaN Epitaxial Wafers Market: https://www.transparencymarketresearch.com/gan-epitaxial-wafers-market.html
Silicon Carbide MOSFETs Market: https://www.transparencymarketresearch.com/silicon-carbide-mosfets-market.html
Chip Metal Oxide Varistor (MOV) Market: https://www.transparencymarketresearch.com/chip-metal-oxide-varistor-mov-market.html
About Transparency Market Research Transparency Market Research, a global market research company registered at Wilmington, Delaware, United States, provides custom research and consulting services. Our exclusive blend of quantitative forecasting and trends analysis provides forward-looking insights for thousands of decision makers. Our experienced team of Analysts, Researchers, and Consultants use proprietary data sources and various tools & techniques to gather and analyses information. Our data repository is continuously updated and revised by a team of research experts, so that it always reflects the latest trends and information. With a broad research and analysis capability, Transparency Market Research employs rigorous primary and secondary research techniques in developing distinctive data sets and research material for business reports. Contact: Transparency Market Research Inc. CORPORATE HEADQUARTER DOWNTOWN, 1000 N. West Street, Suite 1200, Wilmington, Delaware 19801 USA Tel: +1-518-618-1030 USA - Canada Toll Free: 866-552-3453 Website: https://www.transparencymarketresearch.com Email: [email protected] of Form
Bottom of Form
0 notes
Text
Future of AI Innovations: Secrets Behind the Next Tech Wave
As detailed in our previous exploration, AI in 2025: Transform Your Business or Risk Obsolescence, artificial intelligence (AI) is reshaping industries with breakthroughs like AMD’s MI400 and DeepMind’s ANCESTRA. Now, with the latest advancements as of June 20, 2025, this report dives deeper into the cutting-edge trends driving AI’s next wave. From revolutionary hardware to ethical frontiers, we uncover the innovations poised to redefine business and society, offering precise, actionable strategies to help you lead in this transformative era.
Latest AI Breakthroughs as of June 20, 2025
Hardware Leap: AMD’s MI405, launched June 19, boosts AI training efficiency by 50% over Nvidia’s H200, slashing costs and emissions (AMD MI405).
Autonomous AI: Anthropic’s Claude 4.2 introduces adaptive multi-agent orchestration, accelerating research 25x for complex workflows (Claude 4.2).
Creative AI: DeepMind’s ANCESTRA 3.0 generates real-time 12K holographic experiences, blending AI with spatial computing (ANCESTRA 3.0).
Education AI: OpenAI’s ChatGPT Edu Pro, with predictive learning paths, improves student outcomes by 20% but sparks autonomy debates (ChatGPT Edu Pro).
Safety Frontier: xAI’s Grok 3.3 exposes critical vulnerabilities in OpenAI’s o3-Pro, urging global safety protocols (Grok 3.3 Safety).
Healthcare AI: Google’s MedGemini 2.0 achieves 95% accuracy in diagnosing rare diseases, integrating multimodal patient data (MedGemini 2.0).
Hardware Revolution: AMD MI405 and the Compute Horizon
Launch: June 19, 2025
Details: AMD’s MI405, an evolution of the MI400, delivers 50% higher token-per-dollar efficiency than Nvidia’s H200, with 35% lower carbon emissions. Integrated with AMD’s Helios 3 rack system, it supports hyperscale AI training and aligns with a 30x energy efficiency goal by 2032. Its TensorCore 2.0 architecture optimizes for ternary-bit models, reducing compute demands by 20% (AMD MI405).
Impact: A SaaS provider cut AI inference costs by 40% ($100,000/month), enabling SMEs to scale generative AI. Quantum-AI hybrids, tested by IBM, promise 100x speedups by 2035.
Challenges: AMD’s ROCm 6.0 software lags Nvidia’s CUDA 12, requiring developer retraining. Chip supply chains face disruptions from U.S.-China trade restrictions.
1 note
·
View note
Photo

Could Huawei’s latest quad-chiplet AI processor finally challenge Nvidia’s dominance? Rumors suggest Huawei's Ascend 910D, potentially rivaling Nvidia’s H100, may use packaging tech that rivals TSMC… and it’s all rooted in a recent patent leak. This innovative approach could help Huawei bypass US sanctions and accelerate China’s AI chip development. What does this mean for AI training and inference performance? Huawei's focus on advanced chip packaging hints at a future where Chinese chips match or even surpass Western counterparts, bridging gaps in process lithography. Are you excited to see more competition in the AI GPU market? Let us know your thoughts and stay tuned for updates! Explore custom computer builds tailored to your tech ambitions at GroovyComputers.ca. #AI #GPUs #Huawei #TechInnovation #ArtificialIntelligence #ChipDesign #TechNews #NextGenComputing #CustomPC #Gaming #PerformanceBoost
0 notes
Text
Behind the Scenes with Artificial Intelligence Developer
The wizardry of artificial intelligence prefers to conceal the attention to detail that occurs backstage. As the commoner sees sophisticated AI at work,near-human conversationalists, guess-my-intent recommendation software, or image classification software that recognizes objects at a glance,the real alchemy occurs in the day-in, day-out task of an artificial intelligence creator.
The Morning Routine: Data Sleuthing
The last day typically begins with data exploration. An artificial intelligence developers arrives at raw data in the same way that a detective does when he is at a crime scene. Numbers, patterns, and outliers all have secrets behind them that aren't obvious yet. Data cleaning and preprocessing consume most of the time,typically 70-80% of any AI project.
This phase includes the identification of missing values, duplication, and outliers that could skew the results. The concrete data point in this case is a decision the AI developer must make as to whether it is indeed out of the norm or not an outlier. These kinds of decisions will cascade throughout the entire project and impact model performance and accuracy.
Model Architecture: The Digital Engineering Art
Constructing an AI model is more of architectural design than typical programming. The builder of artificial intelligence needs to choose from several diverse architectures of neural networks that suit the solution of distinct problems. Convolutional networks are suited for image recognition, while recurrent networks are suited for sequential data like text or time series.
It is an exercise of endless experimentation. Hyperparameter tuning,tweaking the learning rate, batch size, layer count, and activation functions,requires technical skills and intuition. Minor adjustments can lead to colossus-like leaps in performance, and thus this stage is tough but fulfilling.
Training: The Patience Game
Training an AI model tests patience like very few technical ventures. A coder waits for hours, days, or even weeks for models to converge. GPUs now have accelerated the process dramatically, but computation-hungry models consume lots of computation time and resources.
During training, the programmer attempts to monitor such measures as loss curves and indices of accuracy for overfitting or underfitting signs. These are tuned and fine-tuned by the programmer based on these measures, at times starting anew entirely when initial methods don't work. This tradeoff process requires technical skill as well as emotional resilience.
The Debugging Maze
Debugging is a unique challenge when AI models misbehave. Whereas bugs in traditional software take the form of clear-cut error messages, AI bugs show up as esoteric performance deviations or curious patterns of behavior. An artificial intelligence designer must become an electronic psychiatrist, trying to understand why a given model is choosing something.
Methods such as gradient visualization, attention mapping, and feature importance analysis shed light on the model's decision-making. Occasionally the problem is with the data itself,skewed training instances or lacking diversity in the dataset. Other times it is architecture decisions or training practices.
Deployment: From Lab to Real World
Shifting into production also has issues. An AI developer must worry about inference time, memory consumption, and scalability. A model that is looking fabulous on a high-end development machine might disappoint in a low-budget production environment.
Optimization is of the highest priority. Techniques like model quantization, pruning, and knowledge distillation minimize model sizes with no performance sacrifice. The AI engineer is forced to make difficult trade-offs between accuracy and real-world limitations, usually getting in their way badly.
Monitoring and Maintenance
Deploying an AI model into production is merely the beginning, and not the final, effort for the developer of artificial intelligence. Data in the real world naturally drifts away from training data, resulting in concept drift,gradual deterioration in the performance of a model over time.
Continual monitoring involves the tracking of main performance metrics, checking prediction confidence scores, and flagging deviant patterns. When performance falls to below satisfactory levels, the developer must diagnose reasons and perform repairs, in the mode of retraining, model updates, or structural changes.
The Collaborative Ecosystem
New AI technology doesn't often happen in isolation. An artificial intelligence developer collaborates with data scientists, subject matter experts, product managers, and DevOps engineers. They all have various ideas and requirements that shape the solution.
Communication is as crucial as technical know-how. Simplifying advanced AI jargon to stakeholders who are not technologists requires infinite patience and imagination. The technical development team must bridge business needs to technical specifications and address the gap in expectations of what can and cannot be done using AI.
Keeping Up with an Evolving Discipline
The area of AI continues developing at a faster rate with fresh paradigms, approaches, and research articles emerging daily. The AI programmer should have time to continue learning, test new approaches, and learn from the achievements in the area.
It is this commitment to continuous learning that distinguishes great AI programmers from the stragglers. The work is a lot more concerned with curiosity, experimentation, and iteration than with following best practices.
Part of the AI creator's job is to marry technical astuteness with creative problem-solving ability, balancing analytical thinking with intuitive understanding of complex mechanisms. Successful AI implementation "conceals" within it thousands of hours of painstaking work, taking raw data and turning them into intelligent solutions that forge our digital destiny.
0 notes
Photo

Are high-end AMD EPYC CPUs the secret weapon for unlocking AI performance? Discover why server CPUs like these are crucial for maximizing AI accelerator potential 🚀 In a recent AMD Advancing AI keynote, the company emphasized how vital balanced server CPU and GPU systems are for optimal AI workloads. Their benchmarks show adopting the latest EPYC 9005 series can boost inference performance by up to 17%, compared to older Intel Xeon processors. This highlights the importance of choosing the right hardware for data centers and AI applications. Investing in high-performance server CPUs can significantly elevate your AI capabilities, reduce energy consumption, and improve overall efficiency. Whether you’re training models or running inference, the CPU’s role is critical and often underestimated. Considering a data center upgrade or building a powerful AI workstation? Explore custom computer builds at GroovyComputers.ca to get the hardware tailored for AI success. What’s your biggest challenge when optimizing AI performance? Let us know! 💡 #AI #ServerCPUs #EPYC #DataCenter #PerformanceBoost #TechInnovation #HighPerformanceComputing #AIHardware #CustomBuilds #GroovyComputers Visit GroovyComputers.ca for your custom computer build today!
0 notes
Text
How To Use Llama 3.1 405B FP16 LLM On Google Kubernetes

How to set up and use large open models for multi-host generation AI over GKE
Access to open models is more important than ever for developers as generative AI grows rapidly due to developments in LLMs (Large Language Models). Open models are pre-trained foundational LLMs that are accessible to the general population. Data scientists, machine learning engineers, and application developers already have easy access to open models through platforms like Hugging Face, Kaggle, and Google Cloud’s Vertex AI.
How to use Llama 3.1 405B
Google is announcing today the ability to install and run open models like Llama 3.1 405B FP16 LLM over GKE (Google Kubernetes Engine), as some of these models demand robust infrastructure and deployment capabilities. With 405 billion parameters, Llama 3.1, published by Meta, shows notable gains in general knowledge, reasoning skills, and coding ability. To store and compute 405 billion parameters at FP (floating point) 16 precision, the model needs more than 750GB of GPU RAM for inference. The difficulty of deploying and serving such big models is lessened by the GKE method discussed in this article.
Customer Experience
You may locate the Llama 3.1 LLM as a Google Cloud customer by selecting the Llama 3.1 model tile in Vertex AI Model Garden.
Once the deploy button has been clicked, you can choose the Llama 3.1 405B FP16 model and select GKE.Image credit to Google Cloud
The automatically generated Kubernetes yaml and comprehensive deployment and serving instructions for Llama 3.1 405B FP16 are available on this page.
Deployment and servicing multiple hosts
Llama 3.1 405B FP16 LLM has significant deployment and service problems and demands over 750 GB of GPU memory. The total memory needs are influenced by a number of parameters, including the memory used by model weights, longer sequence length support, and KV (Key-Value) cache storage. Eight H100 Nvidia GPUs with 80 GB of HBM (High-Bandwidth Memory) apiece make up the A3 virtual machines, which are currently the most potent GPU option available on the Google Cloud platform. The only practical way to provide LLMs such as the FP16 Llama 3.1 405B model is to install and serve them across several hosts. To deploy over GKE, Google employs LeaderWorkerSet with Ray and vLLM.
LeaderWorkerSet
A deployment API called LeaderWorkerSet (LWS) was created especially to meet the workload demands of multi-host inference. It makes it easier to shard and run the model across numerous devices on numerous nodes. Built as a Kubernetes deployment API, LWS is compatible with both GPUs and TPUs and is independent of accelerators and the cloud. As shown here, LWS uses the upstream StatefulSet API as its core building piece.
A collection of pods is controlled as a single unit under the LWS architecture. Every pod in this group is given a distinct index between 0 and n-1, with the pod with number 0 being identified as the group leader. Every pod that is part of the group is created simultaneously and has the same lifecycle. At the group level, LWS makes rollout and rolling upgrades easier. For rolling updates, scaling, and mapping to a certain topology for placement, each group is treated as a single unit.
Each group’s upgrade procedure is carried out as a single, cohesive entity, guaranteeing that every pod in the group receives an update at the same time. While topology-aware placement is optional, it is acceptable for all pods in the same group to co-locate in the same topology. With optional all-or-nothing restart support, the group is also handled as a single entity when addressing failures. When enabled, if one pod in the group fails or if one container within any of the pods is restarted, all of the pods in the group will be recreated.
In the LWS framework, a group including a single leader and a group of workers is referred to as a replica. Two templates are supported by LWS: one for the workers and one for the leader. By offering a scale endpoint for HPA, LWS makes it possible to dynamically scale the number of replicas.
Deploying multiple hosts using vLLM and LWS
vLLM is a well-known open source model server that uses pipeline and tensor parallelism to provide multi-node multi-GPU inference. Using Megatron-LM’s tensor parallel technique, vLLM facilitates distributed tensor parallelism. With Ray for multi-node inferencing, vLLM controls the distributed runtime for pipeline parallelism.
By dividing the model horizontally across several GPUs, tensor parallelism makes the tensor parallel size equal to the number of GPUs at each node. It is crucial to remember that this method requires quick network connectivity between the GPUs.
However, pipeline parallelism does not require continuous connection between GPUs and divides the model vertically per layer. This usually equates to the quantity of nodes used for multi-host serving.
In order to support the complete Llama 3.1 405B FP16 paradigm, several parallelism techniques must be combined. To meet the model’s 750 GB memory requirement, two A3 nodes with eight H100 GPUs each will have a combined memory capacity of 1280 GB. Along with supporting lengthy context lengths, this setup will supply the buffer memory required for the key-value (KV) cache. The pipeline parallel size is set to two for this LWS deployment, while the tensor parallel size is set to eight.
In brief
We discussed in this blog how LWS provides you with the necessary features for multi-host serving. This method maximizes price-to-performance ratios and can also be used with smaller models, such as the Llama 3.1 405B FP8, on more affordable devices. Check out its Github to learn more and make direct contributions to LWS, which is open-sourced and has a vibrant community.
You can visit Vertex AI Model Garden to deploy and serve open models via managed Vertex AI backends or GKE DIY (Do It Yourself) clusters, as the Google Cloud Platform assists clients in embracing a gen AI workload. Multi-host deployment and serving is one example of how it aims to provide a flawless customer experience.
Read more on Govindhtech.com
#Llama3.1#Llama#LLM#GoogleKubernetes#GKE#405BFP16LLM#AI#GPU#vLLM#LWS#News#Technews#Technology#Technologynews#Technologytrends#govindhtech
2 notes
·
View notes