#Brain Activity Data for AI Training
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
130K people were victims of a chain letter scam that affected Tumblr in May 2011.
Text
Brain Activity Data for AI Training is essential for advancing neuroscience, healthcare, and brain-computer interfaces. By collecting and annotating EEG, fMRI, and other neurophysiological signals, AI models can better interpret cognitive states, emotions, and neurological disorders. High-quality annotated datasets help train AI for applications like mind-controlled prosthetics, mental health diagnostics, and cognitive enhancement. Precise data labeling ensures accuracy, enabling AI to recognize patterns in brain activity effectively. At Macgence, we specialize in curating and annotating Brain Activity Data for AI Training, accelerating AI-driven innovations in neurotechnology. Partner with us to build smarter AI solutions powered by real-world neural data.
0 notes
Text
Generative AI Is Bad For Your Creative Brain
In the wake of early announcing that their blog will no longer be posting fanfiction, I wanted to offer a different perspective than the ones I’ve been seeing in the argument against the use of AI in fandom spaces. Often, I’m seeing the arguments that the use of generative AI or Large Language Models (LLMs) make creative expression more accessible. Certainly, putting a prompt into a chat box and refining the output as desired is faster than writing a 5000 word fanfiction or learning to draw digitally or traditionally. But I would argue that the use of chat bots and generative AI actually limits - and ultimately reduces - one’s ability to enjoy creativity.
Creativity, defined by the Cambridge Advanced Learner’s Dictionary & Thesaurus, is the ability to produce or use original and unusual ideas. By definition, the use of generative AI discourages the brain from engaging with thoughts creatively. ChatGPT, character bots, and other generative AI products have to be trained on already existing text. In order to produce something “usable,” LLMs analyzes patterns within text to organize information into what the computer has been trained to identify as “desirable” outputs. These outputs are not always accurate due to the fact that computers don’t “think” the way that human brains do. They don’t create. They take the most common and refined data points and combine them according to predetermined templates to assemble a product. In the case of chat bots that are fed writing samples from authors, the product is not original - it’s a mishmash of the writings that were fed into the system.
Dialectical Behavioral Therapy (DBT) is a therapy modality developed by Marsha M. Linehan based on the understanding that growth comes when we accept that we are doing our best and we can work to better ourselves further. Within this modality, a few core concepts are explored, but for this argument I want to focus on Mindfulness and Emotion Regulation. Mindfulness, put simply, is awareness of the information our senses are telling us about the present moment. Emotion regulation is our ability to identify, understand, validate, and control our reaction to the emotions that result from changes in our environment. One of the skills taught within emotion regulation is Building Mastery - putting forth effort into an activity or skill in order to experience the pleasure that comes with seeing the fruits of your labor. These are by no means the only mechanisms of growth or skill development, however, I believe that mindfulness, emotion regulation, and building mastery are a large part of the core of creativity. When someone uses generative AI to imitate fanfiction, roleplay, fanart, etc., the core experience of creative expression is undermined.
Creating engages the body. As a writer who uses pen and paper as well as word processors while drafting, I had to learn how my body best engages with my process. The ideal pen and paper, the fact that I need glasses to work on my computer, the height of the table all factor into how I create. I don’t use audio recordings or transcriptions because that’s not a skill I’ve cultivated, but other authors use those tools as a way to assist their creative process. I can’t speak with any authority to the experience of visual artists, but my understanding is that the feedback and feel of their physical tools, the programs they use, and many other factors are not just part of how they learned their craft, they are essential to their art.
Generative AI invites users to bypass mindfully engaging with the physical act of creating. Part of becoming a person who creates from the vision in one’s head is the physical act of practicing. How did I learn to write? By sitting down and making myself write, over and over, word after word. I had to learn the rhythms of my body, and to listen when pain tells me to stop. I do not consider myself a visual artist - I have not put in the hours to learn to consistently combine line and color and form to show the world the idea in my head.
But I could.
Learning a new skill is possible. But one must be able to regulate one’s unpleasant emotions to be able to get there. The emotion that gets in the way of most people starting their creative journey is anxiety. Instead of a focus on “fear,” I like to define this emotion as “unpleasant anticipation.” In Atlas of the Heart, Brene Brown identifies anxiety as both a trait (a long term characteristic) and a state (a temporary condition). That is, we can be naturally predisposed to be impacted by anxiety, and experience unpleasant anticipation in response to an event. And the action drive associated with anxiety is to avoid the unpleasant stimulus.
Starting a new project, developing a new skill, and leaning into a creative endevor can inspire and cause people to react to anxiety. There is an unpleasant anticipation of things not turning out exactly correctly, of being judged negatively, of being unnoticed or even ignored. There is a lot less anxiety to be had in submitting a prompt to a machine than to look at a blank page and possibly make what could be a mistake. Unfortunately, the more something is avoided, the more anxiety is generated when it comes up again. Using generative AI doesn’t encourage starting a new project and learning a new skill - in fact, it makes the prospect more distressing to the mind, and encourages further avoidance of developing a personal creative process.
One of the best ways to reduce anxiety about a task, according to DBT, is for a person to do that task. Opposite action is a method of reducing the intensity of an emotion by going against its action urge. The action urge of anxiety is to avoid, and so opposite action encourages someone to approach the thing they are anxious about. This doesn’t mean that everyone who has anxiety about creating should make themselves write a 50k word fanfiction as their first project. But in order to reduce anxiety about dealing with a blank page, one must face and engage with a blank page. Even a single sentence fragment, two lines intersecting, an unintentional drop of ink means the page is no longer blank. If those are still difficult to approach a prompt, tutorial, or guided exercise can be used to reinforce the understanding that a blank page can be changed, slowly but surely by your own hand.
(As an aside, I would discourage the use of AI prompt generators - these often use prompts that were already created by a real person without credit. Prompt blogs and posts exist right here on tumblr, as well as imagines and headcannons that people often label “free to a good home.” These prompts can also often be specific to fandom, style, mood, etc., if you’re looking for something specific.)
In the current social media and content consumption culture, it’s easy to feel like the first attempt should be a perfect final product. But creating isn’t just about the final product. It’s about the process. Bo Burnam’s Inside is phenomenal, but I think the outtakes are just as important. We didn’t get That Funny Feeling and How the World Works and All Eyes on Me because Bo Burnham woke up and decided to write songs in the same day. We got them because he’s been been developing and honing his craft, as well as learning about himself as a person and artist, since he was a teenager. Building mastery in any skill takes time, and it’s often slow.
Slow is an important word, when it comes to creating. The fact that skill takes time to develop and a final piece of art takes time regardless of skill is it’s own source of anxiety. Compared to @sentientcave, who writes about 2k words per day, I’m very slow. And for all the time it takes me, my writing isn’t perfect - I find typos after posting and sometimes my phrasing is awkward. But my writing is better than it was, and my confidence is much higher. I can sit and write for longer and longer periods, my projects are more diverse, I’m sharing them with people, even before the final edits are done. And I only learned how to do this because I took the time to push through the discomfort of not being as fast or as skilled as I want to be in order to learn what works for me and what doesn’t.
Building mastery - getting better at a skill over time so that you can see your own progress - isn’t just about getting better. It’s about feeling better about your abilities. Confidence, excitement, and pride are important emotions to associate with our own actions. It teaches us that we are capable of making ourselves feel better by engaging with our creativity, a confidence that can be generalized to other activities.
Generative AI doesn’t encourage its users to try new things, to make mistakes, and to see what works. It doesn’t reward new accomplishments to encourage the building of new skills by connecting to old ones. The reward centers of the brain have nothing to respond to to associate with the action of the user. There is a short term input-reward pathway, but it’s only associated with using the AI prompter. It’s designed to encourage the user to come back over and over again, not develop the skill to think and create for themselves.
I don’t know that anyone will change their minds after reading this. It’s imperfect, and I’ve summarized concepts that can take months or years to learn. But I can say that I learned something from the process of writing it. I see some of the flaws, and I can see how my essay writing has changed over the years. This might have been faster to plug into AI as a prompt, but I can see how much more confidence I have in my own voice and opinions. And that’s not something chatGPT can ever replicate.
151 notes
·
View notes
Note
Hello Mr. AI's biggest hater,
How do I communicate to my autism-help-person that it makes me uncomfortable if she asks chatgpt stuff during our sessions?
For example she was helping me to write a cover letter for an internship I'm applying to, and she kept asking chatgpt for help which made me feel really guilty because of how bad ai is for the environment. Also I just genuinely hate ai.
Sincerely, Google didn't have an answer for me and asking you instead felt right.
ok, so there are a couple things you could bring up: the environmental issues with gen ai, the ethical issues with gen ai, and the effect that using it has on critical thinking skills
if (like me) you have issues articulating something like this where you’re uncomfortable, you could send her an email about it, that way you can lay everything out clearly and include links
under the cut are a whole bunch of source articles and talking points
for the environmental issues:
here’s an MIT news article from earlier this year about the environmental impact, which estimates that a single chat gpt prompt uses 5 times more energy than a google search: https://news.mit.edu/2025/explained-generative-ai-environmental-impact-0117
an article from the un environment programme from last fall about ai’s environmental impact: https://www.unep.org/news-and-stories/story/ai-has-environmental-problem-heres-what-world-can-do-about
an article posted this week by time about ai impact, and it includes a link to the 2025 energy report from the international energy agency: https://time.com/7295844/climate-emissions-impact-ai-prompts/
for ethical issues:
an article breaking down what chat gpt is and how it’s trained, including how open ai uses the common crawl data set that includes billions of webpages: https://www.edureka.co/blog/how-chatgpt-works-training-model-of-chatgpt/#:~:text=ChatGPT%20was%20trained%20on%20large,which%20the%20model%20is%20exposed
you can talk about how these data sets contain so much data from people who did not consent. here are two pictures from ‘unmasking ai’ by dr joy buolamwini, which is about her experience working in ai research and development (and is an excellent read), about the issues with this:


baker law has a case tracker for lawsuits about ai and copyright infringement: https://www.bakerlaw.com/services/artificial-intelligence-ai/case-tracker-artificial-intelligence-copyrights-and-class-actions/
for the critical thinking skills:
here’s a recent mit study about how frequent chat gpt use worsens critical thinking skills, and using it when writing causes less brain activity and engagement, and you don’t get much out of it: https://time.com/7295195/ai-chatgpt-google-learning-school/
explain to her that you want to actually practice and get better at writing cover letters, and using chat gpt is going to have the opposite effect
as i’m sure you know, i have a playlist on tiktok with about 150 videos, and feel free to use those as well
best of luck with all of this, and if you want any more help, please feel welcome to send another ask or dm me directly (on here, i rarely check my tiktok dm requests)!
#ai asks#generative ai resources#cringe is dead except for generative ai#generative ai#anti ai#ai is theft
49 notes
·
View notes
Text
the paper is just so obviously motivated from the start. including AI booby traps and forgetting you mentioned 4o in the paper are only part of it. the NLP part trying to wrangle statistical significance out of <60 people manages to shoot itself repeatedly in the foot by showing that the LLM and search engine groups are overwhelmingly similar.
the willful ignorance of the fact that the similarity between things mentioned in LLM essays is because LLMs have already been statistically averaging their training data forever before you showed up rather than serving you different links based on what it thinks of you as a user. people are copy and pasting from both sources i fucking guarantee it it just depends on what they're being served.
did they turn off the Gemini overlay in modern google search. they do not mention whether they do this or not.
"writing a blue book essay uses your brain more" has been used as a (imo correct) justification for in-class exams since time immemorial. i don't understand why the authors think that LLMs are making people stupid rather than simple reliance on outside information.
i would have loved if they had a variety of textbooks available for a fourth group to reference and seen if that group had more or less brain activity than brain-only.
25 notes
·
View notes
Note
Ok. It's pretty clear you are more welcoming of AI, and it does have enough merits to not be given a knee jerk reaction outright.
And how the current anti-ai stealing programs could be misused.
But isn't so much of the models built on stolen art? That is one of the big thing keeping me from freely enjoying it.
The stolen art is a thing that needs to be addressed.
Though i agree that the ways that such addressing are being done in are not ideal. Counterproductive even.
I could make a quip here and be like "stolen art??? But the art is all still there, and it looks fine to me!" And that would be a salient point about the silliness of digital theft as a concept, but I know that wouldn't actually address your point because what you're actually talking about is art appropriation by generative AI models.
But the thing is that generative AI models don't really do that, either. They train on publicly posted images and derive a sort of metadata - more specifically, they build a feature space mapping out different visual concepts together with text that refers to them. This is then used at the generative stage in order to produce new images based on the denoising predictions of that abstract feature model. No output is created that hasn't gone through that multi-stage level of abstraction from the training data, and none of the original training images are directly used at all.
Due to various flaws in the process, you can sometimes get a model to output images extremely similar to particular training images, and it is also possible to get a model to pastiche a particular artist's work or style, but this is something that humans can also do and is a problem with the individual image that has been created, rather than the process in general.
Training an AI model is pretty clearly fair use, because you're not even really re-using the training images - you're deriving metadata that describes them, and using them to build new images. This is far more comparable to the process by which human artists learn concepts than the weird sort of "theft collage" that people seem to be convinced is going on. In many cases, the much larger training corpus of generative AI models means that an output will be far more abstracted from any identifiable source data (source data in fact is usually not identifiable) than a human being drawing from a reference, something we all agree is perfectly fine!
The only difference is that the AI process is happening in a computer with tangible data, and is therefore quantifiable. This seems to convince people that it is in some way more ontologically derivative than any other artistic process, because computers are assumed to be copying whereas the human brain can impart its own mystical juju of originality.
I'm a materialist and think this is very silly. The valid concerns around AI are to do with how society is unprepared for increased automation, but that's an entirely different conversation from the art theft one, and the latter actively distracts from the former. The complete refusal from some people to even engage with AI's existence out of disgust also makes it harder to solve the real problem around its implementation.
This sucks, because for a lot of people it's not really about copyright or intellectual property anyway. It's about that automation threat, and a sort of human condition anxiety about being supplanted and replaced by automation. That's a whole mess of emotions and genuine labour concerns that we need to work through and break down and resolve, but reactionary egg-throwing at all things related to machine learning is counterproductive to that, as is reading out legal mantras paraphrasing megacorps looking to expand copyright law to over shit like "art style".
I've spoken about this more elsewhere if you look at my blog's AI tag.
159 notes
·
View notes
Text
Randomly ranting about AI.
The thing that’s so fucking frustrating to me when it comes to chat ai bots and the amount of people that use those platforms for whatever godamn reason, whether it be to engage with the bots or make them, is that they’ll complain that reading/creating fanfic is cringe or they don’t like reader-inserts or roleplaying with others in fandom spaces. Yet the very bots they’re using are mimicking the same methods they complain about as a base to create spaces for people to interact with characters they like. Where do you think the bots learned to respond like that? Why do you think you have to “train” AI to tailor responses you’re more inclined to like? It’s actively ripping off of your creativity and ideas, even if you don’t write, you are taking control of the scenario you want to reenact, the same things writers do in general.
Some people literally take ideas that you find from fics online, word for word bar for bar, taking from individuals who have the capacity to think with their brains and imagination, and they’ll put it into the damn ai summary, and then put it on a separate platform for others so they can rummage through mediocre responses that lack human emotion and sensuality. Not only are the chat bots a problem, AI being in writing software and platforms too are another thing. AI shouldn’t be anywhere near the arts, because ultimately all it does is copy and mimic other people’s creations under the guise of creating content for consumption. There’s nothing appealing or original or interesting about what AI does, but with how quickly people are getting used to being forced to used AI because it’s being put into everything we use and do, people don’t care enough to do the labor of reading and researching on their own, it’s all through ChatGPT and that’s intentional.
I shouldn’t have to manually turn off AI learning software on my phone or laptop or any device I use, and they make it difficult to do so. I shouldn’t have to code my own damn things just to avoid using it. Like when you really sit down and think about how much AI is in our day to day life especially when you compare the different of the frequency of AI usage from 2 years ago to now, it’s actually ridiculous how we can’t escape it, and it’s only causing more problems.
People’s attention spans are deteriorating, their capacity to come up with original ideas and to be invested in storytelling is going down the drain along with their media literacy. It hurts more than anything cause we really didn’t have to go into this direction in society, but of course rich people are more inclined to make sure everybody on the planet are mindless robots and take whatever mechanical slop is fucking thrown at them while repressing everything that has to deal with creativity and passion and human expression.
The frequency of AI and the fact that it’s literally everywhere and you can’t escape it is a symptom of late stage capitalism and ties to the rise of fascism as the corporations/individuals who create, manage, and distribute these AI systems could care less about the harmful biases that are fed into these systems. They also don’t care about the fact that the data centers that hold this technology need so much water and energy to manage it it’s ruining our ecosystems and speeding up climate change that will have us experience climate disasters like with what’s happening in Los Angeles as it burns.
I pray for the downfall and complete shutdown of all ai chat bot apps and websites. It’s not worth it, and the fact that there’s so many people using it without realizing the damage it’s causing it’s so frustrating.
#I despise AI so damn much I can’t stand it#I try so hard to stay away from using it despite not being able to google something without the ai summary popping up#and now I’m trying to move all of my stuff out from Google cause I refuse to let some unknown ai software scrap my shit#AI is the antithesis to human creation and I wished more knew that#I can go on and on about how much I hate AI#fuck character ai fuck janitor ai fuck all of that bullshit#please support your writers and people in fandom spaces because we are being pushed out by automated systems
23 notes
·
View notes
Text
Been a while, crocodiles. Let's talk about cad.

or, y'know...

Yep, we're doing a whistle-stop tour of AI in medical diagnosis!
Much like programming, AI can be conceived of, in very simple terms, as...
a way of moving from inputs to a desired output.
See, this very funky little diagram from skillcrush.com.
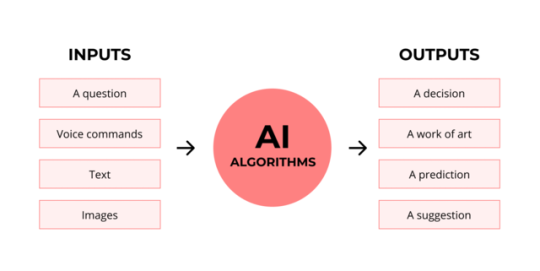
The input is what you put in. The output is what you get out.
This output will vary depending on the type of algorithm and the training that algorithm has undergone – you can put the same input into two different algorithms and get two entirely different sorts of answer.
Generative AI produces ‘new’ content, based on what it has learned from various inputs. We're talking AI Art, and Large Language Models like ChatGPT. This sort of AI is very useful in healthcare settings to, but that's a whole different post!
Analytical AI takes an input, such as a chest radiograph, subjects this input to a series of analyses, and deduces answers to specific questions about this input. For instance: is this chest radiograph normal or abnormal? And if abnormal, what is a likely pathology?
We'll be focusing on Analytical AI in this little lesson!
Other forms of Analytical AI that you might be familiar with are recommendation algorithms, which suggest items for you to buy based on your online activities, and facial recognition. In facial recognition, the input is an image of your face, and the output is the ability to tie that face to your identity. We’re not creating new content – we’re classifying and analysing the input we’ve been fed.
Many of these functions are obviously, um, problematique. But Computer-Aided Diagnosis is, potentially, a way to use this tool for good!
Right?
....Right?

Let's dig a bit deeper! AI is a massive umbrella term that contains many smaller umbrella terms, nested together like Russian dolls. So, we can use this model to envision how these different fields fit inside one another.

AI is the term for anything to do with creating and managing machines that perform tasks which would otherwise require human intelligence. This is what differentiates AI from regular computer programming.
Machine Learning is the development of statistical algorithms which are trained on data –but which can then extrapolate this training and generalise it to previously unseen data, typically for analytical purposes. The thing I want you to pay attention to here is the date of this reference. It’s very easy to think of AI as being a ‘new’ thing, but it has been around since the Fifties, and has been talked about for much longer. The massive boom in popularity that we’re seeing today is built on the backs of decades upon decades of research.
Artificial Neural Networks are loosely inspired by the structure of the human brain, where inputs are fed through one or more layers of ‘nodes’ which modify the original data until a desired output is achieved. More on this later!
Deep neural networks have two or more layers of nodes, increasing the complexity of what they can derive from an initial input. Convolutional neural networks are often also Deep. To become ‘convolutional’, a neural network must have strong connections between close nodes, influencing how the data is passed back and forth within the algorithm. We’ll dig more into this later, but basically, this makes CNNs very adapt at telling precisely where edges of a pattern are – they're far better at pattern recognition than our feeble fleshy eyes!
This is massively useful in Computer Aided Diagnosis, as it means CNNs can quickly and accurately trace bone cortices in musculoskeletal imaging, note abnormalities in lung markings in chest radiography, and isolate very early neoplastic changes in soft tissue for mammography and MRI.
Before I go on, I will point out that Neural Networks are NOT the only model used in Computer-Aided Diagnosis – but they ARE the most common, so we'll focus on them!

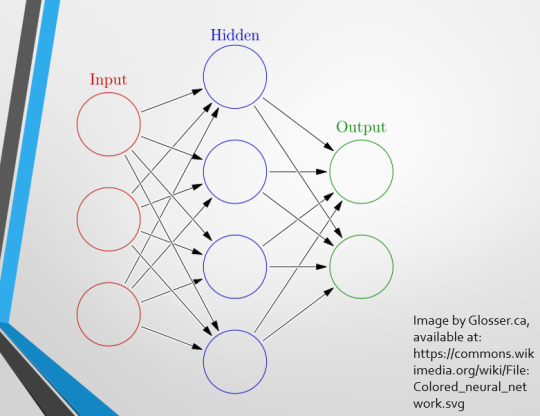
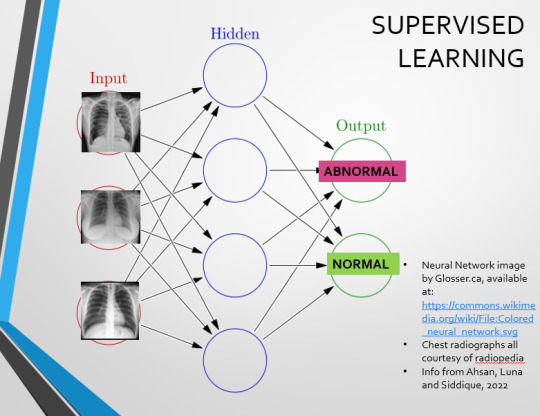
This diagram demonstrates the function of a simple Neural Network. An input is fed into one side. It is passed through a layer of ‘hidden’ modulating nodes, which in turn feed into the output. We describe the internal nodes in this algorithm as ‘hidden’ because we, outside of the algorithm, will only see the ‘input’ and the ‘output’ – which leads us onto a problem we’ll discuss later with regards to the transparency of AI in medicine.
But for now, let’s focus on how this basic model works, with regards to Computer Aided Diagnosis. We'll start with a game of...
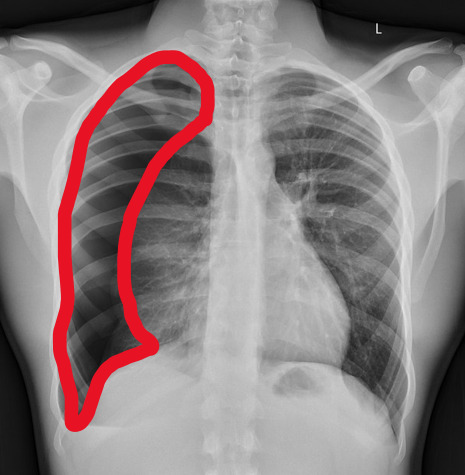
Spot The Pathology.
yeah, that's right. There's a WHACKING GREAT RIGHT-SIDED PNEUMOTHORAX (as outlined in red - images courtesy of radiopaedia, but edits mine)
But my question to you is: how do we know that? What process are we going through to reach that conclusion?
Personally, I compared the lungs for symmetry, which led me to note a distinct line where the tissue in the right lung had collapsed on itself. I also noted the absence of normal lung markings beyond this line, where there should be tissue but there is instead air.
In simple terms.... the right lung is whiter in the midline, and black around the edges, with a clear distinction between these parts.
Let’s go back to our Neural Network. We’re at the training phase now.
So, we’re going to feed our algorithm! Homnomnom.
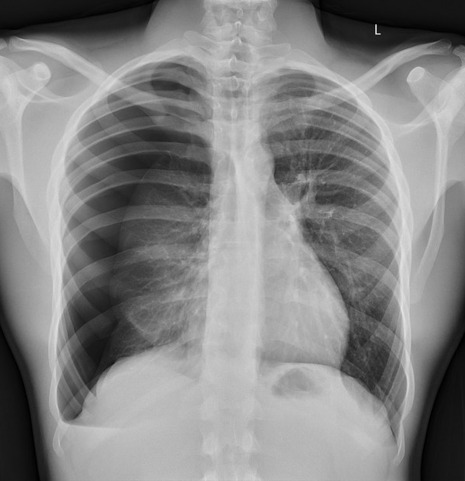
Let’s give it that image of a pneumothorax, alongside two normal chest radiographs (middle picture and bottom). The goal is to get the algorithm to accurately classify the chest radiographs we have inputted as either ‘normal’ or ‘abnormal’ depending on whether or not they demonstrate a pneumothorax.
There are two main ways we can teach this algorithm – supervised and unsupervised classification learning.
In supervised learning, we tell the neural network that the first picture is abnormal, and the second and third pictures are normal. Then we let it work out the difference, under our supervision, allowing us to steer it if it goes wrong.
Of course, if we only have three inputs, that isn’t enough for the algorithm to reach an accurate result.
You might be able to see – one of the normal chests has breasts, and another doesn't. If both ‘normal’ images had breasts, the algorithm could as easily determine that the lack of lung markings is what demonstrates a pneumothorax, as it could decide that actually, a pneumothorax is caused by not having breasts. Which, obviously, is untrue.
or is it?
....sadly I can personally confirm that having breasts does not prevent spontaneous pneumothorax, but that's another story lmao
This brings us to another big problem with AI in medicine –

If you are collecting your dataset from, say, a wealthy hospital in a suburban, majority white neighbourhood in America, then you will have those same demographics represented within that dataset. If we build a blind spot into the neural network, and it will discriminate based on that.
That’s an important thing to remember: the goal here is to create a generalisable tool for diagnosis. The algorithm will only ever be as generalisable as its dataset.
But there are plenty of huge free datasets online which have been specifically developed for training AI. What if we had hundreds of chest images, from a diverse population range, split between those which show pneumothoraxes, and those which don’t?
If we had a much larger dataset, the algorithm would be able to study the labelled ‘abnormal’ and ‘normal’ images, and come to far more accurate conclusions about what separates a pneumothorax from a normal chest in radiography. So, let’s pretend we’re the neural network, and pop in four characteristics that the algorithm might use to differentiate ‘normal’ from ‘abnormal’.
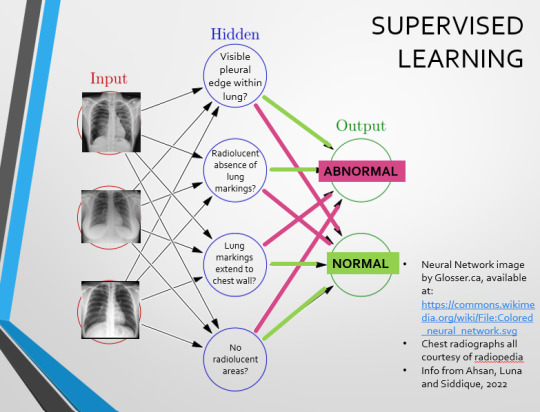
We can distinguish a pneumothorax by the appearance of a pleural edge where lung tissue has pulled away from the chest wall, and the radiolucent absence of peripheral lung markings around this area. So, let’s make those our first two nodes. Our last set of nodes are ‘do the lung markings extend to the chest wall?’ and ‘Are there no radiolucent areas?’
Now, red lines mean the answer is ‘no’ and green means the answer is ‘yes’. If the answer to the first two nodes is yes and the answer to the last two nodes is no, this is indicative of a pneumothorax – and vice versa.
Right. So, who can see the problem with this?
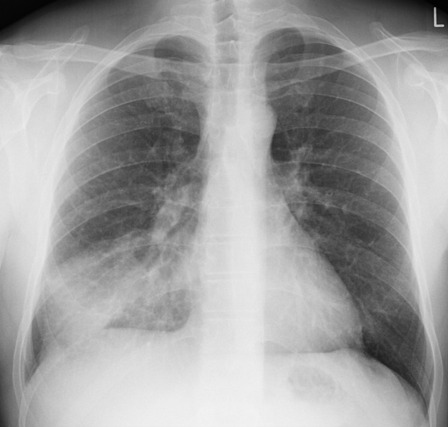
(image courtesy of radiopaedia)
This chest radiograph demonstrates alveolar patterns and air bronchograms within the right lung, indicative of a pneumonia. But if we fed it into our neural network...
The lung markings extend all the way to the chest wall. Therefore, this image might well be classified as ‘normal’ – a false negative.
Now we start to see why Neural Networks become deep and convolutional, and can get incredibly complex. In order to accurately differentiate a ‘normal’ from an ‘abnormal’ chest, you need a lot of nodes, and layers of nodes. This is also where unsupervised learning can come in.
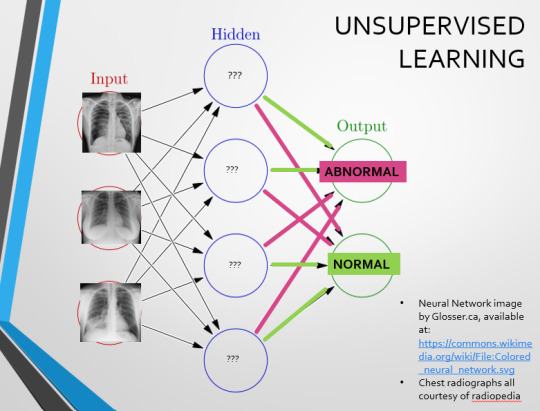
Originally, Supervised Learning was used on Analytical AI, and Unsupervised Learning was used on Generative AI, allowing for more creativity in picture generation, for instance. However, more and more, Unsupervised learning is being incorporated into Analytical areas like Computer-Aided Diagnosis!
Unsupervised Learning involves feeding a neural network a large databank and giving it no information about which of the input images are ‘normal’ or ‘abnormal’. This saves massively on money and time, as no one has to go through and label the images first. It is also surprisingly very effective. The algorithm is told only to sort and classify the images into distinct categories, grouping images together and coming up with its own parameters about what separates one image from another. This sort of learning allows an algorithm to teach itself to find very small deviations from its discovered definition of ‘normal’.
BUT this is not to say that CAD is without its issues.
Let's take a look at some of the ethical and practical considerations involved in implementing this technology within clinical practice!

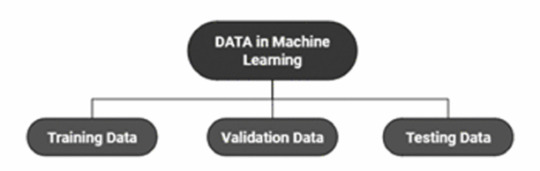
(Image from Agrawal et al., 2020)
Training Data does what it says on the tin – these are the initial images you feed your algorithm. What is key here is volume, variety - with especial attention paid to minimising bias – and veracity. The training data has to be ‘real’ – you cannot mislabel images or supply non-diagnostic images that obscure pathology, or your algorithm is useless.
Validation data evaluates the algorithm and improves on it. This involves tweaking the nodes within a neural network by altering the ‘weights’, or the intensity of the connection between various nodes. By altering these weights, a neural network can send an image that clearly fits our diagnostic criteria for a pneumothorax directly to the relevant output, whereas images that do not have these features must be put through another layer of nodes to rule out a different pathology.
Finally, testing data is the data that the finished algorithm will be tested on to prove its sensitivity and specificity, before any potential clinical use.
However, if algorithms require this much data to train, this introduces a lot of ethical questions.
Where does this data come from?
Is it ‘grey data’ (data of untraceable origin)? Is this good (protects anonymity) or bad (could have been acquired unethically)?
Could generative AI provide a workaround, in the form of producing synthetic radiographs? Or is it risky to train CAD algorithms on simulated data when the algorithms will then be used on real people?
If we are solely using CAD to make diagnoses, who holds legal responsibility for a misdiagnosis that costs lives? Is it the company that created the algorithm or the hospital employing it?
And finally – is it worth sinking so much time, money, and literal energy into AI – especially given concerns about the environment – when public opinion on AI in healthcare is mixed at best? This is a serious topic – we’re talking diagnoses making the difference between life and death. Do you trust a machine more than you trust a doctor? According to Rojahn et al., 2023, there is a strong public dislike of computer-aided diagnosis.
So, it's fair to ask...
why are we wasting so much time and money on something that our service users don't actually want?
Then we get to the other biggie.

There are also a variety of concerns to do with the sensitivity and specificity of Computer-Aided Diagnosis.
We’ve talked a little already about bias, and how training sets can inadvertently ‘poison’ the algorithm, so to speak, introducing dangerous elements that mimic biases and problems in society.
But do we even want completely accurate computer-aided diagnosis?
The name is computer-aided diagnosis, not computer-led diagnosis. As noted by Rajahn et al, the general public STRONGLY prefer diagnosis to be made by human professionals, and their desires should arguably be taken into account – as well as the fact that CAD algorithms tend to be incredibly expensive and highly specialised. For instance, you cannot put MRI images depicting CNS lesions through a chest reporting algorithm and expect coherent results – whereas a radiologist can be trained to diagnose across two or more specialties.
For this reason, there is an argument that rather than focusing on sensitivity and specificity, we should just focus on producing highly sensitive algorithms that will pick up on any abnormality, and output some false positives, but will produce NO false negatives.
(Sensitivity = a test's ability to identify sick people with a disease)
(Specificity = a test's ability to identify that healthy people do not have this disease)
This means we are working towards developing algorithms that OVERESTIMATE rather than UNDERESTIMATE disease prevalence. This makes CAD a useful tool for triage rather than providing its own diagnoses – if a CAD algorithm weighted towards high sensitivity and low specificity does not pick up on any abnormalities, it’s highly unlikely that there are any.
Finally, we have to question whether CAD is even all that accurate to begin with. 10 years ago, according to Lehmen et al., CAD in mammography demonstrated negligible improvements to accuracy. In 1989, Sutton noted that accuracy was under 60%. Nowadays, however, AI has been proven to exceed the abilities of radiologists when detecting cancers (that’s from Guetari et al., 2023). This suggests that there is a common upwards trajectory, and AI might become a suitable alternative to traditional radiology one day. But, due to the many potential problems with this field, that day is unlikely to be soon...

That's all, folks! Have some references~
#medblr#artificial intelligence#radiography#radiology#diagnosis#medicine#studyblr#radioactiveradley#radley irradiates people#long post
16 notes
·
View notes
Text
Beyond Processors: Exploring Intel's Innovations in AI and Quantum Computing
Introduction
In the rapidly evolving world of technology, the spotlight often shines on processors—those little chips that power everything from laptops to supercomputers. However, as we delve deeper into the realms of artificial intelligence (AI) and quantum computing, it becomes increasingly clear that innovation goes far beyond just raw processing power. Intel, a cornerstone of computing innovation since its inception, is at the forefront of these technological advancements. This article aims to explore Intel's innovations in AI and quantum computing, examining how these developments are reshaping industries and our everyday lives.
Beyond Processors: Exploring Intel's Innovations in AI and Quantum Computing
Intel has long been synonymous with microprocessors, but its vision extends well beyond silicon. With an eye on future technologies like AI and quantum computing, Intel is not just building faster chips; it is paving the way click here for entirely new paradigms in data processing.
Understanding the Landscape of AI
Artificial Intelligence (AI) refers to machines' ability to perform tasks that typically require human intelligence. These tasks include visual perception, speech recognition, decision-making, and language translation.
The Role of Machine Learning
Machine learning is a subset of AI that focuses on algorithms allowing computers to learn from data without explicit programming. It’s like teaching a dog new tricks—through practice and feedback.
Deep Learning: The Next Level
Deep learning takes machine learning a step further using neural networks with multiple layers. This approach mimics human brain function and has led to significant breakthroughs in computer vision and natural language processing.
Intel’s Approach to AI Innovation
Intel has recognized the transformative potential of AI and has made significant investments in this area.
AI-Optimized Hardware
Intel has developed specialized hardware such as the Intel Nervana Neural Network Processor (NNP), designed specifically for deep learning workloads. This chip aims to accelerate training times for neural networks significantly.
Software Frameworks for AI Development
Alongside hardware advancements, Intel has invested in software solutions like the OpenVINO toolkit, which optimizes deep learning models for various platforms—from edge devices to cloud servers.
Applications of Intel’s AI Innovations
The applications for Intel’s work in AI are vast and varied.
Healthcare: Revolutionizing Diagnostics
AI enhances diagnostic accuracy by analyzing medical images faster than human radiologists. It can identify anomalies that may go unnoticed, improving patient outcomes dramatically.
Finance: Fraud Detection Systems
In finance, AI algorithms can scan large volumes of transactions in real-time to flag suspicious activity. This capability not only helps mitigate fraud but also accelerates transaction approvals.
Quantum Computing: The New Frontier
While traditional computing relies on bits (0s and 1s), quantum computing utilizes qubits that can exist simultaneously in multiple states—allowing for unprecede
youtube
2 notes
·
View notes
Text
Beyond Processors: Exploring Intel's Innovations in AI and Quantum Computing
Introduction
In the rapidly evolving world of technology, the spotlight often shines on processors—those little chips that power everything from laptops to supercomputers. However, as we delve deeper into the realms of artificial intelligence (AI) and quantum computing, it becomes increasingly clear that innovation goes far beyond just raw processing power. Intel, a cornerstone of computing innovation since its inception, is at the forefront of these technological advancements. This article aims to explore Intel's innovations in AI and quantum computing, examining how these developments are reshaping industries and our everyday lives.
Beyond Processors: Exploring Intel's Innovations in AI and Quantum Computing
Intel has long been synonymous with microprocessors, but its vision extends well beyond silicon. With an eye on future technologies like AI and quantum computing, Intel is not just building faster chips; it is paving the way for entirely new paradigms in data processing.
Understanding the Landscape of AI
Artificial Intelligence (AI) refers to machines' ability to perform tasks that typically require human intelligence. These tasks include visual perception, speech recognition, decision-making, and language translation.
youtube
The Role of Machine Learning
Machine learning is a subset of AI that focuses on algorithms allowing computers to learn from data without explicit programming. It’s like teaching a dog new tricks—through practice and feedback.
Deep Learning: The Next Level
Deep learning takes machine learning a step further using neural networks with multiple layers. This approach mimics human brain function and has led to significant breakthroughs in computer vision and natural language processing.
Intel’s Approach to AI Innovation
Intel has recognized the transformative potential of AI and has made significant investments in this area.
AI-Optimized Hardware
Intel has developed specialized hardware such as the Intel Nervana Neural Network Processor (NNP), designed specifically for deep learning workloads. This chip aims to accelerate training times for neural networks significantly.
Software Frameworks for AI Development
Alongside hardware Click to find out more advancements, Intel has invested in software solutions like the OpenVINO toolkit, which optimizes deep learning models for various platforms—from edge devices to cloud servers.
Applications of Intel’s AI Innovations
The applications for Intel’s work in AI are vast and varied.
Healthcare: Revolutionizing Diagnostics
AI enhances diagnostic accuracy by analyzing medical images faster than human radiologists. It can identify anomalies that may go unnoticed, improving patient outcomes dramatically.
Finance: Fraud Detection Systems
In finance, AI algorithms can scan large volumes of transactions in real-time to flag suspicious activity. This capability not only helps mitigate fraud but also accelerates transaction approvals.
Quantum Computing: The New Frontier
While traditional computing relies on bits (0s and 1s), quantum computing utilizes qubits that can exist simultaneously in multiple states—allowing for unprecede
2 notes
·
View notes
Text
Beyond Processors: Exploring Intel's Innovations in AI and Quantum Computing
Introduction
In the rapidly evolving world of technology, the spotlight often shines on processors—those little chips that power everything from laptops to supercomputers. However, as we delve deeper into the realms of artificial intelligence (AI) and quantum computing, it becomes increasingly clear that innovation goes far beyond just raw processing power. Intel, a cornerstone of computing innovation since its inception, is at the forefront of these technological advancements. This article aims to explore Intel's innovations in AI and quantum computing, examining how these developments are reshaping industries and our everyday lives.
Beyond Processors: Exploring Intel's Innovations in AI and Quantum Computing
Intel has long been synonymous with microprocessors, but its vision extends well beyond silicon. With an eye on future technologies like AI and quantum computing, Intel is not just building faster chips; it is paving the way for entirely new paradigms in data processing.
Understanding the Landscape of AI
Artificial Intelligence (AI) refers to machines' ability to perform tasks that typically require human intelligence. These tasks include visual perception, speech recognition, decision-making, and language translation.
Click here The Role of Machine Learning
Machine learning is a subset of AI that focuses on algorithms allowing computers to learn from data without explicit programming. It’s like teaching a dog new tricks—through practice and feedback.
youtube
Deep Learning: The Next Level
Deep learning takes machine learning a step further using neural networks with multiple layers. This approach mimics human brain function and has led to significant breakthroughs in computer vision and natural language processing.
Intel’s Approach to AI Innovation
Intel has recognized the transformative potential of AI and has made significant investments in this area.
AI-Optimized Hardware
Intel has developed specialized hardware such as the Intel Nervana Neural Network Processor (NNP), designed specifically for deep learning workloads. This chip aims to accelerate training times for neural networks significantly.
Software Frameworks for AI Development
Alongside hardware advancements, Intel has invested in software solutions like the OpenVINO toolkit, which optimizes deep learning models for various platforms—from edge devices to cloud servers.
Applications of Intel’s AI Innovations
The applications for Intel’s work in AI are vast and varied.
Healthcare: Revolutionizing Diagnostics
AI enhances diagnostic accuracy by analyzing medical images faster than human radiologists. It can identify anomalies that may go unnoticed, improving patient outcomes dramatically.
Finance: Fraud Detection Systems
In finance, AI algorithms can scan large volumes of transactions in real-time to flag suspicious activity. This capability not only helps mitigate fraud but also accelerates transaction approvals.
Quantum Computing: The New Frontier
While traditional computing relies on bits (0s and 1s), quantum computing utilizes qubits that can exist simultaneously in multiple states—allowing for unprecede
2 notes
·
View notes
Text
Generative AI for Dummies
(kinda. sorta? we're talking about one type and hand-waving some specifics because this is a tumblr post but shh it's fine.)
So there’s a lot of misinformation going around on what generative AI is doing and how it works. I’d seen some of this in some fandom stuff, semi-jokingly snarked that I was going to make a post on how this stuff actually works, and then some people went “o shit, for real?”
So we’re doing this!
This post is meant to just be a very basic breakdown for anyone who has no background in AI or machine learning. I did my best to simplify things and give good analogies for the stuff that’s a little more complicated, but feel free to let me know if there’s anything that needs further clarification. Also a quick disclaimer: as this was specifically inspired by some misconceptions I’d seen in regards to fandom and fanfic, this post focuses on text-based generative AI.
This post is a little long. Since it sucks to read long stuff on tumblr, I’ve broken this post up into four sections to put in new reblogs under readmores to try to make it a little more manageable. Sections 1-3 are the ‘how it works’ breakdowns (and ~4.5k words total). The final 3 sections are mostly to address some specific misconceptions that I’ve seen going around and are roughly ~1k each.
Section Breakdown: 1. Explaining tokens 2. Large Language Models 3. LLM Interfaces 4. AO3 and Generative AI [here] 5. Fic and ChatGPT [here] 6. Some Closing Notes [here] [post tag]
First, to explain some terms in this:
“Generative AI” is a category of AI that refers to the type of machine learning that can produce strings of text, images, etc. Text-based generative AI is powered by large language models called LLM for short.
(*Generative AI for other media sometimes use a LLM modified for a specific media, some use different model types like diffusion models -- anyways, this is why I emphasized I’m talking about text-based generative AI in this post. Some of this post still applies to those, but I’m not covering what nor their specifics here.)
“Neural networks” (NN) are the artificial ‘brains’ of AI. For a simplified overview of NNs, they hold layers of neurons and each neuron has a numerical value associated with it called a bias. The connection channels between each neuron are called weights. Each neuron takes the sum of the input weights, adds its bias value, and passes this sum through an activation function to produce an output value, which is then passed on to the next layer of neurons as a new input for them, and that process repeats until it reaches the final layer and produces an output response.
“Parameters” is a…broad and slightly vague term. Parameters refer to both the biases and weights of a neural network. But they also encapsulate the relationships between them, not just the literal structure of a NN. I don’t know how to explain this further without explaining more about how NN’s are trained, but that’s not really important for our purposes? All you need to know here is that parameters determine the behavior of a model, and the size of a LLM is described by how many parameters it has.
There’s 3 different types of learning neural networks do: “unsupervised” which is when the NN learns from unlabeled data, “supervised” is when all the data has been labeled and categorized as input-output pairs (ie the data input has a specific output associated with it, and the goal is for the NN to pick up those specific patterns), and “semi-supervised” (or “weak supervision”) combines a small set of labeled data with a large set of unlabeled data.
For this post, an “interaction” with a LLM refers to when a LLM is given an input query/prompt and the LLM returns an output response. A new interaction begins when a LLM is given a new input query.
Tokens
Tokens are the ‘language’ of LLMs. How exactly tokens are created/broken down and classified during the tokenization process doesn’t really matter here. Very broadly, tokens represent words, but note that it’s not a 1-to-1 thing -- tokens can represent anything from a fraction of a word to an entire phrase, it depends on the context of how the token was created. Tokens also represent specific characters, punctuation, etc.
“Token limitation” refers to the maximum number of tokens a LLM can process in one interaction. I’ll explain more on this later, but note that this limitation includes the number of tokens in the input prompt and output response. How many tokens a LLM can process in one interaction depends on the model, but there’s two big things that determine this limit: computation processing requirements (1) and error propagation (2). Both of which sound kinda scary, but it’s pretty simple actually:
(1) This is the amount of tokens a LLM can produce/process versus the amount of computer power it takes to generate/process them. The relationship is a quadratic function and for those of you who don’t like math, think of it this way:
Let’s say it costs a penny to generate the first 500 tokens. But it then costs 2 pennies to generate the next 500 tokens. And 4 pennies to generate the next 500 tokens after that. I’m making up values for this, but you can see how it’s costing more money to create the same amount of successive tokens (or alternatively, that each succeeding penny buys you fewer and fewer tokens). Eventually the amount of money it costs to produce the next token is too costly -- so any interactions that go over the token limitation will result in a non-responsive LLM. The processing power available and its related cost also vary between models and what sort of hardware they have available.
(2) Each generated token also comes with an error value. This is a very small value per individual token, but it accumulates over the course of the response.
What that means is: the first token produced has an associated error value. This error value is factored into the generation of the second token (note that it’s still very small at this time and doesn’t affect the second token much). However, this error value for the first token then also carries over and combines with the second token’s error value, which affects the generation of the third token and again carries over to and merges with the third token’s error value, and so forth. This combined error value eventually grows too high and the LLM can’t accurately produce the next token.
I’m kinda breezing through this explanation because how the math for non-linear error propagation exactly works doesn’t really matter for our purposes. The main takeaway from this is that there is a point at which a LLM’s response gets too long and it begins to break down. (This breakdown can look like the LLM producing something that sounds really weird/odd/stale, or just straight up producing gibberish.)
Large Language Models (LLMs)
LLMs are computerized language models. They generate responses by assessing the given input prompt and then spitting out the first token. Then based on the prompt and that first token, it determines the next token. Based on the prompt and first token, second token, and their combination, it makes the third token. And so forth. They just write an output response one token at a time. Some examples of LLMs include the GPT series from OpenAI, LLaMA from Meta, and PaLM 2 from Google.
So, a few things about LLMs:
These things are really, really, really big. The bigger they are, the more they can do. The GPT series are some of the big boys amongst these (GPT-3 is 175 billion parameters; GPT-4 actually isn’t listed, but it’s at least 500 billion parameters, possibly 1 trillion). LLaMA is 65 billion parameters. There are several smaller ones in the range of like, 15-20 billion parameters and a small handful of even smaller ones (these are usually either older/early stage LLMs or LLMs trained for more personalized/individual project things, LLMs just start getting limited in application at that size). There are more LLMs of varying sizes (you can find the list on Wikipedia), but those give an example of the size distribution when it comes to these things.
However, the number of parameters is not the only thing that distinguishes the quality of a LLM. The size of its training data also matters. GPT-3 was trained on 300 billion tokens. LLaMA was trained on 1.4 trillion tokens. So even though LLaMA has less than half the number of parameters GPT-3 has, it’s still considered to be a superior model compared to GPT-3 due to the size of its training data.
So this brings me to LLM training, which has 4 stages to it. The first stage is pre-training and this is where almost all of the computational work happens (it’s like, 99% percent of the training process). It is the most expensive stage of training, usually a few million dollars, and requires the most power. This is the stage where the LLM is trained on a lot of raw internet data (low quality, large quantity data). This data isn’t sorted or labeled in any way, it’s just tokenized and divided up into batches (called epochs) to run through the LLM (note: this is unsupervised learning).
How exactly the pre-training works doesn’t really matter for this post? The key points to take away here are: it takes a lot of hardware, a lot of time, a lot of money, and a lot of data. So it’s pretty common for companies like OpenAI to train these LLMs and then license out their services to people to fine-tune them for their own AI applications (more on this in the next section). Also, LLMs don’t actually “know” anything in general, but at this stage in particular, they are really just trying to mimic human language (or rather what they were trained to recognize as human language).
To help illustrate what this base LLM ‘intelligence’ looks like, there’s a thought exercise called the octopus test. In this scenario, two people (A & B) live alone on deserted islands, but can communicate with each other via text messages using a trans-oceanic cable. A hyper-intelligent octopus listens in on their conversations and after it learns A & B’s conversation patterns, it decides observation isn’t enough and cuts the line so that it can talk to A itself by impersonating B. So the thought exercise is this: At what level of conversation does A realize they’re not actually talking to B?
In theory, if A and the octopus stay in casual conversation (ie “Hi, how are you?” “Doing good! Ate some coconuts and stared at some waves, how about you?” “Nothing so exciting, but I’m about to go find some nuts.” “Sounds nice, have a good day!” “You too, talk to you tomorrow!”), there’s no reason for A to ever suspect or realize that they’re not actually talking to B because the octopus can mimic conversation perfectly and there’s no further evidence to cause suspicion.
However, what if A asks B what the weather is like on B’s island because A’s trying to determine if they should forage food today or save it for tomorrow? The octopus has zero understanding of what weather is because its never experienced it before. The octopus can only make guesses on how B might respond because it has no understanding of the context. It’s not clear yet if A would notice that they’re no longer talking to B -- maybe the octopus guesses correctly and A has no reason to believe they aren’t talking to B. Or maybe the octopus guessed wrong, but its guess wasn’t so wrong that A doesn’t reason that maybe B just doesn’t understand meteorology. Or maybe the octopus’s guess was so wrong that there was no way for A not to realize they’re no longer talking to B.
Another proposed scenario is that A’s found some delicious coconuts on their island and decide they want to share some with B, so A decides to build a catapult to send some coconuts to B. But when A tries to share their plans with B and ask for B’s opinions, the octopus can’t respond. This is a knowledge-intensive task -- even if the octopus understood what a catapult was, it’s also missing knowledge of B’s island and suggestions on things like where to aim. The octopus can avoid A’s questions or respond with total nonsense, but in either scenario, A realizes that they are no longer talking to B because the octopus doesn’t understand enough to simulate B’s response.
There are other scenarios in this thought exercise, but those cover three bases for LLM ‘intelligence’ pretty well: they can mimic general writing patterns pretty well, they can kind of handle very basic knowledge tasks, and they are very bad at knowledge-intensive tasks.
Now, as a note, the octopus test is not intended to be a measure of how the octopus fools A or any measure of ‘intelligence’ in the octopus, but rather show what the “octopus” (the LLM) might be missing in its inputs to provide good responses. Which brings us to the final 1% of training, the fine-tuning stages;
LLM Interfaces
As mentioned previously, LLMs only mimic language and have some key issues that need to be addressed:
LLM base models don’t like to answer questions nor do it well.
LLMs have token limitations. There’s a limit to how much input they can take in vs how long of a response they can return.
LLMs have no memory. They cannot retain the context or history of a conversation on their own.
LLMs are very bad at knowledge-intensive tasks. They need extra context and input to manage these.
However, there’s a limit to how much you can train a LLM. The specifics behind this don’t really matter so uh… *handwaves* very generally, it’s a matter of diminishing returns. You can get close to the end goal but you can never actually reach it, and you hit a point where you’re putting in a lot of work for little to no change. There’s also some other issues that pop up with too much training, but we don’t need to get into those.
You can still further refine models from the pre-training stage to overcome these inherent issues in LLM base models -- Vicuna-13b is an example of this (I think? Pretty sure? Someone fact check me on this lol).
(Vicuna-13b, side-note, is an open source chatbot model that was fine-tuned from the LLaMA model using conversation data from ShareGPT. It was developed by LMSYS, a research group founded by students and professors from UC Berkeley, UCSD, and CMU. Because so much information about how models are trained and developed is closed-source, hidden, or otherwise obscured, they research LLMs and develop their models specifically to release that research for the benefit of public knowledge, learning, and understanding.)
Back to my point, you can still refine and fine-tune LLM base models directly. However, by about the time GPT-2 was released, people had realized that the base models really like to complete documents and that they’re already really good at this even without further fine-tuning. So long as they gave the model a prompt that was formatted as a ‘document’ with enough background information alongside the desired input question, the model would answer the question by ‘finishing’ the document. This opened up an entire new branch in LLM development where instead of trying to coach the LLMs into performing tasks that weren’t native to their capabilities, they focused on ways to deliver information to the models in a way that took advantage of what they were already good at.
This is where LLM interfaces come in.
LLM interfaces (which I sometimes just refer to as “AI” or “AI interface” below; I’ve also seen people refer to these as “assistants”) are developed and fine-tuned for specific applications to act as a bridge between a user and a LLM and transform any query from the user into a viable input prompt for the LLM. Examples of these would be OpenAI’s ChatGPT and Google’s Bard. One of the key benefits to developing an AI interface is their adaptability, as rather than needing to restart the fine-tuning process for a LLM with every base update, an AI interface fine-tuned for one LLM engine can be refitted to an updated version or even a new LLM engine with minimal to no additional work. Take ChatGPT as an example -- when GPT-4 was released, OpenAI didn’t have to train or develop a new chat bot model fine-tuned specifically from GPT-4. They just ‘plugged in’ the already fine-tuned ChatGPT interface to the new GPT model. Even now, ChatGPT can submit prompts to either the GPT-3.5 or GPT-4 LLM engines depending on the user’s payment plan, rather than being two separate chat bots.
As I mentioned previously, LLMs have some inherent problems such as token limitations, no memory, and the inability to handle knowledge-intensive tasks. However, an input prompt that includes conversation history, extra context relevant to the user’s query, and instructions on how to deliver the response will result in a good quality response from the base LLM model. This is what I mean when I say an interface transforms a user’s query into a viable prompt -- rather than the user having to come up with all this extra info and formatting it into a proper document for the LLM to complete, the AI interface handles those responsibilities.
How exactly these interfaces do that varies from application to application. It really depends on what type of task the developers are trying to fine-tune the application for. There’s also a host of APIs that can be incorporated into these interfaces to customize user experience (such as APIs that identify inappropriate content and kill a user’s query, to APIs that allow users to speak a command or upload image prompts, stuff like that). However, some tasks are pretty consistent across each application, so let’s talk about a few of those:
Token management
As I said earlier, each LLM has a token limit per interaction and this token limitation includes both the input query and the output response.
The input prompt an interface delivers to a LLM can include a lot of things: the user’s query (obviously), but also extra information relevant to the query, conversation history, instructions on how to deliver its response (such as the tone, style, or ‘persona’ of the response), etc. How much extra information the interface pulls to include in the input prompt depends on the desired length of an output response and what sort of information pulled for the input prompt is prioritized by the application varies depending on what task it was developed for. (For example, a chatbot application would likely allocate more tokens to conversation history and output response length as compared to a program like Sudowrite* which probably prioritizes additional (context) content from the document over previous suggestions and the lengths of the output responses are much more restrained.)
(*Sudowrite is…kind of weird in how they list their program information. I’m 97% sure it’s a writer assistant interface that keys into the GPT series, but uhh…I might be wrong? Please don’t hold it against me if I am lol.)
Anyways, how the interface allocates tokens is generally determined by trial-and-error depending on what sort of end application the developer is aiming for and the token limit(s) their LLM engine(s) have.
tl;dr -- all LLMs have interaction token limits, the AI manages them so the user doesn’t have to.
Simulating short-term memory
LLMs have no memory. As far as they figure, every new query is a brand new start. So if you want to build on previous prompts and responses, you have to deliver the previous conversation to the LLM along with your new prompt.
AI interfaces do this for you by managing what’s called a ‘context window’. A context window is the amount of previous conversation history it saves and passes on to the LLM with a new query. How long a context window is and how it’s managed varies from application to application. Different token limits between different LLMs is the biggest restriction for how many tokens an AI can allocate to the context window. The most basic way of managing a context window is discarding context over the token limit on a first in, first out basis. However, some applications also have ways of stripping out extraneous parts of the context window to condense the conversation history, which lets them simulate a longer context window even if the amount of allocated tokens hasn’t changed.
Augmented context retrieval
Remember how I said earlier that LLMs are really bad at knowledge-intensive tasks? Augmented context retrieval is how people “inject knowledge” into LLMs.
Very basically, the user submits a query to the AI. The AI identifies keywords in that query, then runs those keywords through a secondary knowledge corpus and pulls up additional information relevant to those keywords, then delivers that information along with the user’s query as an input prompt to the LLM. The LLM can then process this extra info with the prompt and deliver a more useful/reliable response.
Also, very importantly: “knowledge-intensive” does not refer to higher level or complex thinking. Knowledge-intensive refers to something that requires a lot of background knowledge or context. Here’s an analogy for how LLMs handle knowledge-intensive tasks:
A friend tells you about a book you haven’t read, then you try to write a synopsis of it based on just what your friend told you about that book (see: every high school literature class). You’re most likely going to struggle to write that summary based solely on what your friend told you, because you don’t actually know what the book is about.
This is an example of a knowledge intensive task: to write a good summary on a book, you need to have actually read the book. In this analogy, augmented context retrieval would be the equivalent of you reading a few book reports and the wikipedia page for the book before writing the summary -- you still don’t know the book, but you have some good sources to reference to help you write a summary for it anyways.
This is also why it’s important to fact check a LLM’s responses, no matter how much the developers have fine-tuned their accuracy.
(*Sidenote, while AI does save previous conversation responses and use those to fine-tune models or sometimes even deliver as a part of a future input query, that’s not…really augmented context retrieval? The secondary knowledge corpus used for augmented context retrieval is…not exactly static, you can update and add to the knowledge corpus, but it’s a relatively fixed set of curated and verified data. The retrieval process for saved past responses isn’t dissimilar to augmented context retrieval, but it’s typically stored and handled separately.)
So, those are a few tasks LLM interfaces can manage to improve LLM responses and user experience. There’s other things they can manage or incorporate into their framework, this is by no means an exhaustive or even thorough list of what they can do. But moving on, let’s talk about ways to fine-tune AI. The exact hows aren't super necessary for our purposes, so very briefly;
Supervised fine-tuning
As a quick reminder, supervised learning means that the training data is labeled. In the case for this stage, the AI is given data with inputs that have specific outputs. The goal here is to coach the AI into delivering responses in specific ways to a specific degree of quality. When the AI starts recognizing the patterns in the training data, it can apply those patterns to future user inputs (AI is really good at pattern recognition, so this is taking advantage of that skill to apply it to native tasks AI is not as good at handling).
As a note, some models stop their training here (for example, Vicuna-13b stopped its training here). However there’s another two steps people can take to refine AI even further (as a note, they are listed separately but they go hand-in-hand);
Reward modeling
To improve the quality of LLM responses, people develop reward models to encourage the AIs to seek higher quality responses and avoid low quality responses during reinforcement learning. This explanation makes the AI sound like it’s a dog being trained with treats -- it’s not like that, don’t fall into AI anthropomorphism. Rating values just are applied to LLM responses and the AI is coded to try to get a high score for future responses.
For a very basic overview of reward modeling: given a specific set of data, the LLM generates a bunch of responses that are then given quality ratings by humans. The AI rates all of those responses on its own as well. Then using the human labeled data as the ‘ground truth’, the developers have the AI compare its ratings to the humans’ ratings using a loss function and adjust its parameters accordingly. Given enough data and training, the AI can begin to identify patterns and rate future responses from the LLM on its own (this process is basically the same way neural networks are trained in the pre-training stage).
On its own, reward modeling is not very useful. However, it becomes very useful for the next stage;
Reinforcement learning
So, the AI now has a reward model. That model is now fixed and will no longer change. Now the AI runs a bunch of prompts and generates a bunch of responses that it then rates based on its new reward model. Pathways that led to higher rated responses are given higher weights, pathways that led to lower rated responses are minimized. Again, I’m kind of breezing through the explanation for this because the exact how doesn’t really matter, but this is another way AI is coached to deliver certain types of responses.
You might’ve heard of the term reinforcement learning from human feedback (or RLHF for short) in regards to reward modeling and reinforcement learning because this is how ChatGPT developed its reward model. Users rated the AI’s responses and (after going through a group of moderators to check for outliers, trolls, and relevancy), these ratings were saved as the ‘ground truth’ data for the AI to adjust its own response ratings to. Part of why this made the news is because this method of developing reward model data worked way better than people expected it to. One of the key benefits was that even beyond checking for knowledge accuracy, this also helped fine-tune how that knowledge is delivered (ie two responses can contain the same information, but one could still be rated over another based on its wording).
As a quick side note, this stage can also be very prone to human bias. For example, the researchers rating ChatGPT’s responses favored lengthier explanations, so ChatGPT is now biased to delivering lengthier responses to queries. Just something to keep in mind.
So, something that���s really important to understand from these fine-tuning stages and for AI in general is how much of the AI’s capabilities are human regulated and monitored. AI is not continuously learning. The models are pre-trained to mimic human language patterns based on a set chunk of data and that learning stops after the pre-training stage is completed and the model is released. Any data incorporated during the fine-tuning stages for AI is humans guiding and coaching it to deliver preferred responses. A finished reward model is just as static as a LLM and its human biases echo through the reinforced learning stage.
People tend to assume that if something is human-like, it must be due to deeper human reasoning. But this AI anthropomorphism is…really bad. Consequences range from the term “AI hallucination” (which is defined as “when the AI says something false but thinks it is true,” except that is an absolute bullshit concept because AI doesn’t know what truth is), all the way to the (usually highly underpaid) human labor maintaining the “human-like” aspects of AI getting ignored and swept under the rug of anthropomorphization. I’m trying not to get into my personal opinions here so I’ll leave this at that, but if there’s any one thing I want people to take away from this monster of a post, it’s that AI’s “human” behavior is not only simulated but very much maintained by humans.
Anyways, to close this section out: The more you fine-tune an AI, the more narrow and specific it becomes in its application. It can still be very versatile in its use, but they are still developed for very specific tasks, and you need to keep that in mind if/when you choose to use it (I’ll return to this point in the final section).
84 notes
·
View notes
Text
youtube
Okay, I'm a data nerd. But this is so interesting?!
She starts out by looking at whether YouTube intense promotion of short-form content is harming long-form content, and ends up looking at how AI models amplify cultural biases.
In one of her examples, Amazon had to stop using AI recruitment software because it was filtering out women. They had to tell it to stop removing resumes with the word "women's" in them.
But even after they did that, the software was filtering out tons of women by doing things like selecting for more "aggressive" language like "executed on" instead of, idk, "helped."
Which is exactly how humans act. In my experience, when people are trying to unlearn bias, the first thing they do is go, "okay, so when I see that someone was president of the women's hockey team or something, I tend to dismiss them, but they could be good! I should try to look at them, instead of immediately dismissing candidates who are women! That makes sense, I can do that!"
And then they don't realize that they can also look at identical resumes, one with a "man's" name and one with a "woman's" name, and come away being more impressed by the "man's" resume.
So then they start having HR remove the names from all resumes. But they don't extrapolate from all this and think about whether the interviewer might also be biased. They don't think about how many different ways you can describe the same exact tasks at the same exact job, and how some of them sound way better.
They don't think about how, the more marginalized someone is, the less access they have to information about what language to use. And the more likely they are to have been "trained," by the way people treat them, to minimize their own skills and achievements.
They don't think about why certain words sound polished to them, and whether that's actually reflecting how good the person using that language will be at their job.
In this How To Cook That video, she talks about the fact that they're training that type of software on, say, ten years of hiring data, and that inherently means it's going to learn the biases reflected in that data... and that what AI models do is EXAGGERATE what they've learned.
Her example is that if you do a Google image search for "doctor," 90% of them will be men, even though in real life only 63% are men.
This is all fascinating to me because this is why representation matters. This is such an extreme, obvious example of why representation matters. OUR brains look at everything around us and learn who the world says is good at what.
We learn what a construction worker looks like, what a general practitioner doctor looks like, what a pediatrician looks like, what a teacher looks like.
We look at the people in our lives and in the media we consume and the ambient media we live through. And we learn what people who matter in our particular society look like.
We learn what a believable, trustworthy person looks like. The kind of person who can be the faux-generic-human talking to you about or illustrating a product.
Unless we also actively learn that other kinds of people matter equally, are equally trustworthy and believable... we don't.
And that affects EVERYTHING.
Also, this seems very easy to undo -- for AI, at least.
Like, instead of giving it a dataset of all the pictures of doctors humans have put out there, they could find people who actively prefer diverse, interesting groups of examples. And give the dataset to a bunch of them, first, to produce something for AI to learn from.
Harvard has a whole slew of really good tests for bias, although I would love to see more. (Note: they say things like "gay - straight, " but it's not testing how you feel about straight people. It's testing whether you have negative associations about gay people, and it uses straight people as a kind of baseline.)
There must be a way for image-recognition AI software to take these tests and reveal how biased a given model is, so it can be tweaked.
A lot of people would probably object that you're biasing the model intentionally if you do that. But we know the models are biased. We know we all have cultural biases. (I mean. Most people know that, I think.)
Anyway, this is already known in the field. There are plenty of studies about the biases in different AI programs, and the biases humans have.
That means we're already choosing to bias models intentionally. Both by knowingly giving them our biases, and by knowing they'll make our biases even bigger. And we already know this has a negative impact on people's lives.
12 notes
·
View notes
Text
Input You, Output You
(I understand this may be completely redundant as there’s only so many ways one can describe the very simple and intuitive concept of ‘just be’, but my mind has run in circles with ‘what about the circumstances or senses’ despite the principle being repeated a million times over, so I thought I’d put my thoughts down to help myself better understand it, and hopefully help others better understand through this interpretation!)
I’ve recently been spending more time on my phone that I’d like on brain-numbing, meaningless stuff
Not just social media, but mindless mobile games
Just being inundated with excessive visual and aural stimulation that says nothing, means nothing once the app is closed
I feel drained and disconnected afterwards
I can’t engage with family or friends as much as I like, my thoughts drift back even when I’m not actively scrolling or playing, it’s like my mind becomes a jumbled pile of brainrot mush that doesn’t even make me happy
Yet I find myself going back again and again for that comfortable, predictable stimulation
But I recently came across an ig reel by Adam / etymologynerd that’s lingered in my mind since first watching: https://www.instagram.com/reel/C_VnTi2Pjg8/?igsh=djFuYnNtZnY0c290
If you don’t feel like watching he’s discussing how ai generated content’s ability to make comprehensible… anything is solely due to the massive amounts of human-created data it’s trained on
It doesn’t actually understand or create like a person does because it’s a pattern predictor, not a soul or individual being
Once it starts training on itself it loses that conscious discerner and so the outputs get less coherent until it eventually eats its own tail and just makes nonsense
Same thing can be applied to you because the human mind-body is itself a pattern predictor that spits out whatever it’s fed - think solving an equation, drawing from past experience, a mediocre song stuck in your head because you were fed it against your will by spotify’s stupid algorithm and now you’re singing the lyrics, your internal clock being fucked up because you kept sleeping at 3am lol
The mind-body is not its own conscious entity, it can’t do anything by itself
But even with all these seemingly automatic thoughts and actions, you always have the ability to consciously step out and change the scene
You as the observer bring it into existence and continue to keep it alive through your awareness of it
If you allow your awareness to follow or focus on a certain belief or habit, your world will naturally adjust to output that initial belief again and again and again
This doesn’t necessarily have to be inherently good or bad; it’s up to you to continuously check on the data you choose to input
Are you content with what you are observing? If not, why have you not already tweaked your dataset?
As you continue to submit your power to the primitive, lifeless machine of the mind-body with manufactured fears and desires and identities, does your life feel like it’s losing meaning? Do you want enough to escape that comfort of familiarity in order to go beyond?
Is the reward of loving yourself, of returning to yourself enough for you to step out of the cycle into the vastness of infinity, even with initial resistance and garbage outputs from the pattern predictor?
Remind yourself of your autonomy again and again
Your inner foundation trains your ‘AI’ to imitate the input of your focused attention and your being
Take time to take a step back from the generated illusion and focus on what speaks to you :) as the dataset consolidates, the output will naturally reflect it
Don’t worry about the how or when
You don’t need to source, blueprint, or assemble the parts of the machine in order to install it and reap the rewards
Know it’s part of you and let the magic happen
Input ____, output ____
That’s all :)
5 notes
·
View notes
Text
10 Surprising Stress-Relief Innovations You’ll Need in 2025

Stress and anxiety have become an integral part of modern life, especially in India, where rapid urbanization, high competition, and the digital era have exacerbated mental health challenges. According to a recent survey by the Indian Psychiatry Society, 74% of Indians face stress in their daily lives. As we move into 2025, the ways to manage stress have drastically evolved. These innovative stress-relief techniques go beyond traditional methods and offer effective, science-backed solutions to help you stay calm and focused. Let’s dive into 10 surprising innovations that you’ll need to know to reduce stress and anxiety in 2025.
1. AI-Powered Stress Monitoring Wearables
In 2025, artificial intelligence (AI) is revolutionizing the way we manage stress. AI-powered wearables such as smartwatches and fitness bands not only track your physical health but also monitor your stress levels in real time. These wearables analyze heart rate variability, body temperature, and sleep patterns to detect signs of stress. They can even provide guided breathing exercises or alert you when it’s time to take a break.
Key Features:
Real-time stress monitoring through biometric data.
Personalized stress management tips based on AI analysis.
Integration with apps to provide breathing exercises, meditation, or calming music.
Indian Market Stats:
According to Statista, the wearable technology market in India is projected to grow at a compound annual growth rate (CAGR) of 15.6% by 2025, with stress-management wearables becoming more popular.
Popular AI-Powered Wearables:
Fitbit Sense: Equipped with an EDA sensor that tracks your body’s response to stress.
Oura Ring: Tracks body temperature and sleep patterns, helping to manage anxiety.
2. Digital Detox Retreats
In a world dominated by technology, digital detox retreats are emerging as one of the most effective stress-relief techniques in 2025. These retreats allow participants to unplug from technology and focus on mindfulness, nature, and self-care. With the rise of screen time, especially in India where people spend an average of 6-7 hours a day on digital devices, digital detox retreats offer a necessary escape to rejuvenate the mind and body.
Benefits of Digital Detox:
Reduced screen fatigue and improved mental clarity.
Better sleep quality due to disconnection from blue light.
Enhanced emotional well-being through mindfulness activities like yoga and meditation.
Popular Digital Detox Destinations in India:
Ananda in the Himalayas: Offers yoga, meditation, and spa therapies in a serene environment.
SwaSwara Retreat in Gokarna: A perfect place for digital detox combined with Ayurveda and holistic healing.
3. Neurofeedback Therapy
Neurofeedback is a cutting-edge stress-relief technique that uses brainwave monitoring to help individuals regulate their stress responses. In 2025, neurofeedback therapy has become a mainstream option for managing anxiety, particularly in urban areas of India. By training the brain to recognize stressful patterns and shifting brainwave activity, neurofeedback offers long-term stress reduction without medication.
How Neurofeedback Works:
Electrodes are placed on the scalp to monitor brain activity.
The brain is trained to produce desirable brainwave patterns, helping you achieve relaxation.
Sessions are often combined with mindfulness and deep-breathing exercises.
Effectiveness:
Research shows that neurofeedback therapy can reduce symptoms of anxiety by up to 45% over time.
Available in India’s top wellness centers in cities like Bengaluru, Mumbai, and Delhi.
4. Sensory Deprivation Tanks (Floatation Therapy)
Sensory deprivation, also known as floatation therapy, involves lying in a tank filled with saltwater where external stimuli such as light and sound are completely eliminated. This helps your body enter a deep state of relaxation, reducing cortisol levels and promoting mental clarity. Floatation therapy has become increasingly popular in India’s major cities in 2025 as a way to combat the pressures of daily life.
Benefits of Floatation Therapy:
Decreased cortisol levels and stress hormones by up to 20%.
Promotes theta brainwave activity, which is associated with deep relaxation and meditation.
Improved mental focus and reduced symptoms of depression and anxiety.
Where to Try It in India:
1000 Petals in Bengaluru: Offers floatation therapy sessions designed for stress relief.
Mindful Waters in Mumbai: Specializes in sensory deprivation therapy for mental well-being.
5. Cold Exposure Therapy (Cryotherapy)
Cold exposure therapy, or cryotherapy, has emerged as one of the most surprising ways to combat stress and anxiety in 2025. Cryotherapy involves brief exposure to sub-zero temperatures in a controlled environment, stimulating the body’s parasympathetic nervous system. This, in turn, reduces inflammation, boosts endorphins, and helps manage anxiety.
Key Benefits:
Reduces inflammation and muscle tension caused by stress.
Boosts the production of endorphins, the body’s natural feel-good chemicals.
Enhances mental resilience by improving the body’s response to stress.
Cryotherapy in India:
Leading wellness centers in Delhi, Mumbai, and Bengaluru offer cryotherapy sessions.
Cryotherapy is expected to grow rapidly, with a 35% increase in adoption by 2025 as per industry reports.
6. Virtual Reality Meditation
Virtual reality (VR) has made meditation more immersive and effective than ever in 2025. VR meditation apps transport you to peaceful environments like lush forests or serene beaches, making it easier to disconnect from stressful surroundings. These apps combine guided meditation with virtual experiences, making stress management more accessible, even in the bustling cities of India.
Why VR Meditation Works:
Creates a fully immersive experience, helping you detach from daily stressors.
Guided meditation programs are tailored to reduce anxiety, depression, and emotional exhaustion.
Ideal for those who find traditional meditation challenging or boring.
Popular VR Meditation Apps:
TRIPP: A VR app designed to promote mindfulness and reduce stress.
RelaxVR: Offers calming VR experiences like virtual beaches or mountain views, helping to lower anxiety levels.
7. Biohacking for Stress Relief
Biohacking, a concept focused on optimizing body and mind performance, has taken a new leap in 2025 as a method for stress relief. Techniques such as intermittent fasting, cold showers, and red light therapy are being embraced by individuals seeking to "hack" their stress responses. Biohacking allows you to gain control over how your body reacts to stress, improving both mental and physical health.
Popular Biohacking Techniques for Stress:
Cold Showers: Stimulate the vagus nerve and reduce cortisol production.
Red Light Therapy: Helps lower inflammation and calm the nervous system.
Intermittent Fasting: Promotes mental clarity and enhances stress resilience by balancing hormonal levels.
Indian Biohacking Community Growth:
Biohacking India reported a 40% increase in the number of people practicing biohacking methods in 2025, with stress reduction being a key goal for many participants.
8. Gut Health and Probiotics for Mental Well-Being
The gut-brain connection is now well-established, and 2025 has seen the rise of nutritional psychiatry in India. Probiotics, specifically designed to improve gut health, have been shown to reduce anxiety by promoting the production of serotonin, a key mood-regulating hormone. Incorporating probiotics and prebiotics into your diet can be a natural way to manage stress and anxiety.
Key Foods for Stress Reduction:
Curd (Dahi): Rich in probiotics, which help balance gut bacteria and improve mood.
Fermented Foods: Include pickles, idli, and dosa for natural probiotics.
Asafoetida (Hing): Known to improve gut health, which can directly influence mental well-being.
Stats:
According to a 2024 study by the Indian Council of Medical Research (ICMR), individuals who included probiotics in their diet experienced a 30% decrease in anxiety levels after three months.
9. Breathwork with Heart Rate Variability (HRV) Training
Breathwork has been a traditional Indian practice for centuries, but in 2025, it’s getting a modern upgrade with heart rate variability (HRV) training. HRV is the measurement of the time interval between heartbeats, and it’s a powerful indicator of stress levels. With the help of technology, you can now practice controlled breathing to improve your HRV, thereby reducing anxiety and stress.
How HRV Breathwork Works:
Apps or wearables measure your HRV and guide you through specific breathing exercises to optimize your heart rate.
Increased HRV is linked to better mental health, lower stress, and improved resilience to anxiety.
Popular HRV Devices:
HeartMath Inner Balance: A device that measures HRV and offers personalized breathing exercises.
Garmin Smartwatches: Equipped with HRV tracking and breathing exercises for stress management.
10. Forest Bathing (Shinrin-Yoku)
In 2025, forest bathing, or Shinrin-Yoku, has become a popular stress-relief technique in India. Originally a Japanese practice, forest bathing involves immersing yourself in nature, taking in the sights, sounds, and smells of a forest environment. The benefits of spending time in nature are well-documented, with forest
2 notes
·
View notes
Text

Week in Review
October 23rd-29th
Welcome to Fragile Practice, where I attempt to make something of value out of stuff I have to read.
My future plan is to do longer-form original pieces on interesting topics or trends. For now, I'm going to make the weekly reviews habitual and see if I have any time left.
Technology
OpenAI forms team to study ‘catastrophic’ AI risks, including nuclear threats - Tech Crunch; Kyle Wiggers
OpenAI launched a new research team called AI Safety and Security to investigate the potential harms of artificial intelligence focused on AI alignment, AI robustness, AI governance, and AI ethics.
Note: Same energy as “cigarette company funds medical research into smoking risks”.
Artists Allege Meta’s AI Data Deletion Request Process Is a ‘Fake PR Stunt’ - Wired; Kate Knibbs
Artists who participated in Meta’s Artificial Intelligence Artist Residency Program accused the company of failing to honor their data deletion requests and claim that Meta used their personal data to train its AI models without their consent.
Note: Someday we will stop being surprised that corporate activities without obvious profit motive are all fake PR stunts.
GM and Honda ditch plan to build cheaper electric vehicles - The Verge; Andrew J. Hawkins
General Motors and Honda cancel their joint venture to develop and produce cheaper electric vehicles for the US market, citing the chip shortage, rising costs of battery materials, and the changing market conditions.
Note: What are the odds this isn’t related to the 7 billion dollars the US government announced to create hydrogen hubs.
'AI divide' across the US leaves economists concerned - The Register; Thomas Claburn
A new study by economists from Harvard University and MIT reveals a significant gap in AI adoption and innovation across different regions in the US.
The study finds that AI usage is highest in California's Silicon Valley and the San Francisco Bay Area, but was also noted in Nashville, San Antonio, Las Vegas, New Orleans, San Diego, and Tampa, as well as Riverside, Louisville, Columbus, Austin, and Atlanta.
Nvidia to Challenge Intel With Arm-Based Processors for PCs - Bloomberg; Ian King
Nvidia is using Arm technology to develop CPUs that would challenge Intel processors in PCs, and which could go on sale as soon as 2025.
Note: I am far from an NVIDIA fan, but I’m stoked for any amount of new competition in the CPU space.
New tool lets artists fight AI image bots by hiding corrupt data in plain sight - Engadget; Sarah Fielding
A team at the University of Chicago created Nightshade, a tool that lets artists fight AI image bots by adding undetectable pixels into an image that can alter how a machine-learning model produces content and what that finished product looks like.
Nightshade is intended to protect artists work and has been tested on both Stable Diffusion and an in-house AI built by the researchers.
IBM's NorthPole chip runs AI-based image recognition 22 times faster than current chips - Tech Xplore; Bob Yirka
NorthPole combines the processing module and the data it uses in a two-dimensional array of memory blocks and interconnected CPUs, and is reportedly inspired by the human brain.
NorthPole can currently only run specialized AI processes and not training processes or large language models, but the researchers plan to test connecting multiple chips together to overcome this limitation.
Apple’s $130 Thunderbolt 4 cable could be worth it, as seen in X-ray CT scans - Ars Technica; Kevin Purdy
Note: These scans are super cool. And make me feel somewhat better about insisting on quality cables. A+.

The Shifting Web
On-by-default video calls come to X, disable to retain your sanity - The Register; Brandon Vigliarolo
Video and audio calling is limited to anyone you follow or who is in your address book, if you granted X permission to comb through it.
Calling other users also requires that they’ve sent at least one direct message to you before.
Only premium users can place calls, but everyone can receive them.
Google Search Boss Says Company Invests to Avoid Becoming ‘Roadkill’ - The New York Times; Nico Grant
Google’s senior vice president overseeing search said that he sees a world of threats that could humble his company at any moment.
Google Maps is getting new AI-powered search updates, an enhanced navigation interface and more - Tech Crunch; Aisha Malik
Note: These AI recommender systems are going to be incredibly valuable advertising space. It is interesting that Apple decided to compete with Google in maps but not in basic search, but has so far not placed ads in the search results.
Reddit finally takes its API war where it belongs: to AI companies - Ars Technica; Scharon Harding
Reddit met with generative AI companies to negotiate a deal for being paid for its data, and may block crawlers if no deal is made soon.
Note: Google searches for info on Reddit often seem more effective than searching Reddit itself. If they are unable to make a deal, and Reddit follows through, it will be a legitimate loss for discoverability but also an incredibly interesting experiment to see what Reddit is like without Google.
Bandcamp’s Entire Union Bargaining Team Was Laid Off - 404 Media; Emanuel Maiberg
Bandcamp’s new owner (Songtradr) offered jobs to just half of existing employees, with cuts disproportionately hitting union leaders. Every member of the union’s eight-person bargaining team was laid off, and 40 of the union's 67 members lost their jobs.
Songtradr spokesperson Lindsay Nahmiache claimed that the firm didn’t have access to union membership information.
Note: This just sucks. Bandcamp is rad, and it’s hard to imagine it continuing to be rad after this. I wonder if Epic had ideas for BC that didn’t work out.

Surveillance & Digital Privacy
Mozilla Launches Annual Digital Privacy 'Creep-o-Meter'. This Year's Status: 'Very Creepy' - Slashdot
Mozilla gave the current state of digital privacy a 75.6/100, with 100 being the creepiest.
They measured security features, data collection, and data sharing practices of over 500 gadgets, apps, and cars to come up with their score.
Every car Mozilla tested failed to meet their privacy and security standards.
Note: It would be great if even one auto brand would take privacy seriously.
EPIC Testifies in Support of Massachusetts Data Privacy and Protection Act -Electronic Privacy Information Center (EPIC)
Massachusetts version of ADPPA.
Note: While it may warm my dead heart to see any online privacy protections in law, scrambling to do so in response to generative AI is unlikely to protect Americans in any meaningful way from the surveillance driven form of capitalism we’ve all been living under for decades.
Complex Spy Platform StripedFly Bites 1M Victims - Dark Reading
StripedFly is a complex platform disguised as a cryptominer and evaded detection for six years by using a custom version of EternalBlue exploit, a built-in Tor network tunnel, and trusted services like GitLab, GitHub, and Bitbucket to communicate with C2 servers and update its functionality.
iPhones have been exposing your unique MAC despite Apple's promises otherwise - Ars Technica
A privacy feature which claimed to hide the Wi-Fi MAC address of iOS devices when joining a network was broken since iOS 14, and was finally patched in 17.1, released on Wednesday.
Note: I imagine this bug was reported a while ago, but wasn’t publically reported until the fix was released as a term of apple’s bug bounty program.
What the !#@% is a Passkey? - Electronic Frontier Foundation
Note: I welcome our passkey overlords.
#surveillance#tech#technology#news#ai#generative ai#machine vision#electric vehicles#evs#hydrogen#futurism#Apple#iphone#twitter#bandcamp#labor unions#digital privacy#data privacy#espionage#passkeys
11 notes
·
View notes
Text

Unravelling Artificial Intelligence: A Step-by-Step Guide
Introduction
Artificial Intelligence (AI) is changing our world. From smart assistants to self-driving cars, AI is all around us. This guide will help you understand AI, how it works, and its future.
What is Artificial Intelligence?
AI is a field of computer science that aims to create machines capable of tasks that need human intelligence. These tasks include learning, reasoning, and understanding language.
readmore
Key Concepts
Machine Learning
This is when machines learn from data to get better over time.
Neural Networks
These are algorithms inspired by the human brain that help machines recognize patterns.
Deep Learning
A type of machine learning using many layers of neural networks to process data.
Types of Artificial Intelligence
AI can be divided into three types:
Narrow AI
Weak AI is designed for a specific task like voice recognition.
General AI
Also known as Strong AI, it can understand and learn any task a human can.
Superintelligent AI
An AI smarter than humans in all aspects. This is still thinking
How Does AI Work?
AI systems work through these steps:
Data Processing
Cleaning and organizing the data.
Algorithm Development
Creating algorithms to analyze the data.
Model Training
Teaching the AI model using the data and algorithms.
Model Deployment
Using the trained model for tasks.
Model Evaluation
Checking and improving the model's performance.
Applications of AI
AI is used in many fields
*Healthcare
AI helps in diagnosing diseases, planning treatments, and managing patient records.
*Finance
AI detects fraud activities, predicts market trends and automates trade.
*Transportation
AI is used in self-driving cars, traffic control, and route planning.
The Future of AI
The future of AI is bright and full of possibility Key trends include.
AI in Daily Life
AI will be more integrated into our everyday lives, from smart homes to personal assistants.
Ethical AI
It is important to make sure AI is fair
AI and Jobs
AI will automate some jobs but also create new opportunities in technology and data analysis.
AI Advancements
On going re-search will lead to smart AI that can solve complex problems.
Artificial Intelligence is a fast growing field with huge potential. Understanding AI, its functions, uses, and future trends. This guide provides a basic understanding of AI and its role in showing futures.
#ArtificialIntelligence #AI #MachineLearning #DeepLearning #FutureTech #Trendai #Technology #AIApplications #TechTrends#Ai
2 notes
·
View notes