#C Representation of Graphs
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr posted its first advertisements in May 2012 and subsequently earned $13M in revenue.
Text







M. C. Escher is another artist that I think has profound influence on how we collectively think about and depict fanciful places for exploration in RPGs, even if his art isn’t at the forefront of our brains. Traps and magic and other planes of existence too!
Escher was Dutch and created a large body of woodcuts and lithographs during his lifetime, though it wasn’t until the end of his life that he achieved a measure of fame, thanks initially to coverage in Scientific American. Much of Eschers art was inspired by, and serves as visual metaphor, for mathematical problems and concepts — tessellation, symmetry, reflection, impossible objects. His depictions of the latter are probably his most famous and often depict the clearest examples of dungeon-like spaces where strange laws of physics rule — something that was clearly on Jim Henson’s mind during the staging of the final scenes of Labyrinth. Escher’s tessellations, especially the ones that transform, like “Metamorphosis,” are probably the closest to a visual representation of magic yet achieved by an artist. Strange creatures creep into some frames, other illustrations present warped versions of reality. But even some of his gorgeous land- and cityscapes seem like fodder for the game master’s mind, with the bold linework of the woodcuts seeming to resonate with Dave Trampier’s work.
Maybe it’s the Trampier thing that puts me in this mind, but it feels like Escher’s mathematical art is somehow a cousin of RPGs, especially early ones that were interested in simulation through math and randomness. The graph paper maps. Or even later, when isometric maps became fashionable.
This book, M. C. Escher: His Life and Complete Graphic Work is, well, pretty great, but unfortunately out of print (I think?). However, it saw many printings from 1982 through the ’90s, at least, so there are plenty of inexpensive copies available second hand. Well worth picking up!
143 notes
·
View notes
Text

Introduction
This is a fan analysis about the results of 24 polls posted on Tumblr by the user @zeldatourney. Huge thanks to them to have organized this tourney.
(Keep in mind my first language isn't English, so I might make some minor mistakes)
This is a long post with multiple graphs, so I'm putting a "Read more" button here!
For each game, the question asked was "How high does [game] rank?" with 7 answers possible to choose:
S tier (One of the greatest)
A tier (A favorite)
B tier (I like it)
C tier (Meh)
D tier (I'd rather play something else)
F tier (AWFUL)
I haven't played this game
The poll started on the 2nd of December 2024 and ended the 9th of December 2024.
Disclaimer: This is not a representation of the Zelda community as a whole, but a result of people who saw and voted for the polls between those previously quoted dates.
For the rest of this post, I will simplify each game's name by its abbreviations. For example, "A Link To The Past" will be named "ALTTP". The polls didn't specify if it contains the original games or both the original games and the remakes. They will be named as such:
[TLOZ] The Legend of Zelda
[AOL] Adventure of Link
[ALTTP] A Link to the Past
[LA] Link's Awakening (DX) (+ the unnamed 2019 remake)
[OOT] Ocarina of Time (3D)
[MM] Majora's Mask (3D)
[OOS] Oracle of Seasons
[OOA] Oracle of Ages
[FS] Four Swords (Anniversary Edition)
[TWW] The Wind Waker (HD)
[FSA] Four Swords Adventures
[TMC] The Minish Cap
[TP] Twilight Princess (HD)
[PH] Phantom Hourglass
[ST] Spirit Tracks
[SS] Skyward Sword (HD)
[ALBW] A Link Between Worlds
[HW] Hyrule Warriors (Legend / Definitive Edition)
[TFH] Tri Force Heroes
[BOTW] Breath of the Wild
[COH] Cadence of Hyrule
[AOC] Hyrule Warriors: Age of Calamity
[TOTK] Tears of the Kingdom
[EOW] Echoes of Wisdom
Collected data
Each poll being independent from each other, the number of votes varies from one poll to another.

For each games, I added the percentage (as picked up from the HTML for a better precision). The result is either 99.999, 100 or 100.001, so I sometimes cheated to add or remove 0.001 somewhere. Tumblr doesn't give you access to the exact numbers of vote per option.
So before ranking the games, I have to show you first what games are the most played. Adding all answers and doing:
Played (%) = 100 - "I haven't played this game" (%)
I'll use colours to differentiate 2D games (in terms of gameplay) to 3D games. I'll also highlight spin-off games and multiplayer games.
Here are the games played by more than 75% of players:
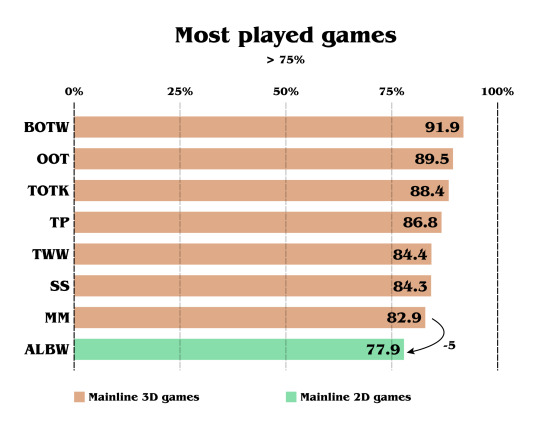
We can already see a huge pattern. All the 3D games are there. And the only 2D Zelda game to be played by 75% of players is ALBW. BOTW and OOT are the most played games of the sample, as those were huge turning points and both cultural and commercial success.
We can also notice the difference of 5% between the least played 3D game (MM) and the most played 2D game (ALBW).
Let's continue to look at the other played games:
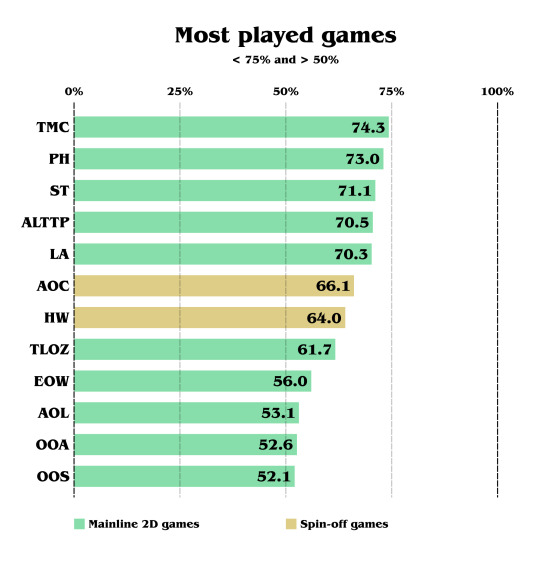
EOW is most likely low as it's the most recent game, at this time, but also because it's not a 3D game. And the hype train was low compared to TOTK. (3 months of anticipation compared to 4 years)
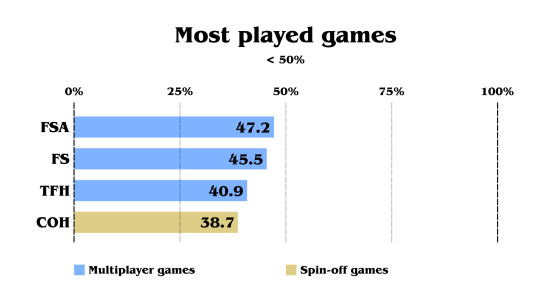
And finally, the multiplayer games are the least played games, excluding COH. Also worth noting that all the spin-off games cited can also be played with another player, but it wasn't the main focus of the communication. COH being a musical tactical rogue-lite only appealed to a specific part of Zelda fans.
If these polls contained the CD-i Zelda games, Link's Crossbow Training and Tingle games, the score would probably be under COH, but we never know!
I'll keep these colours as labels, to recognize them better in the next images.
Alright. Time to share the ranking. Here is the global result, sorted by release date in North America:
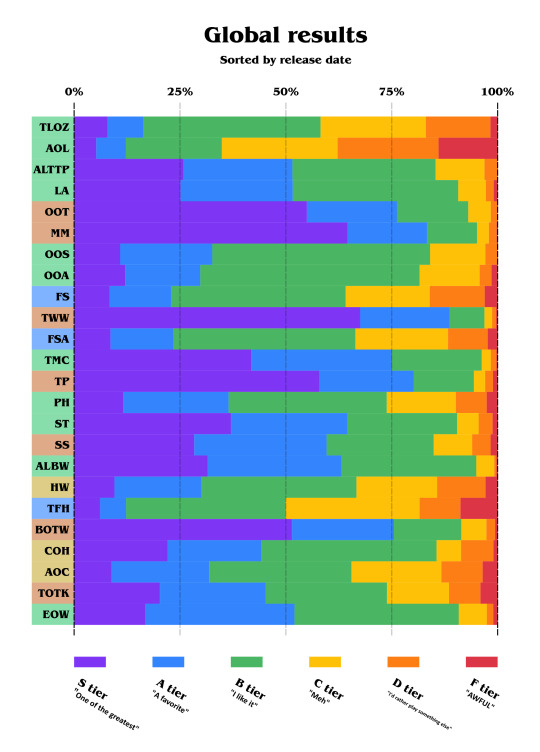
It's kind of a lot to see! Overall, the games are pretty liked. So first, let's take a look at the disliked games:
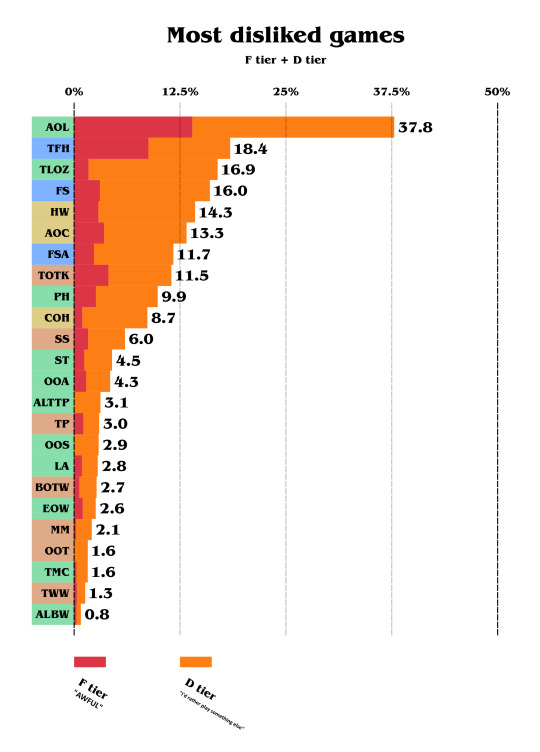
Please note that the X-axis was zoomed, so we can see the result better.
We can already notice that AOL makes a huge contrast. As this game is considered as the black sheep of the franchise because of how different it is, its reputation mostly came from the difficulty of that game.
Almost a factor of 0.5 divides the first disliked game to the second. TFH the second disliked and the original TLOZ follows.
ALBW is the least disliked, with under 1%, counting D tier and F tier.
But notice the F-tier (red) line. It varies a lot, so let's take a look at the most hated games:
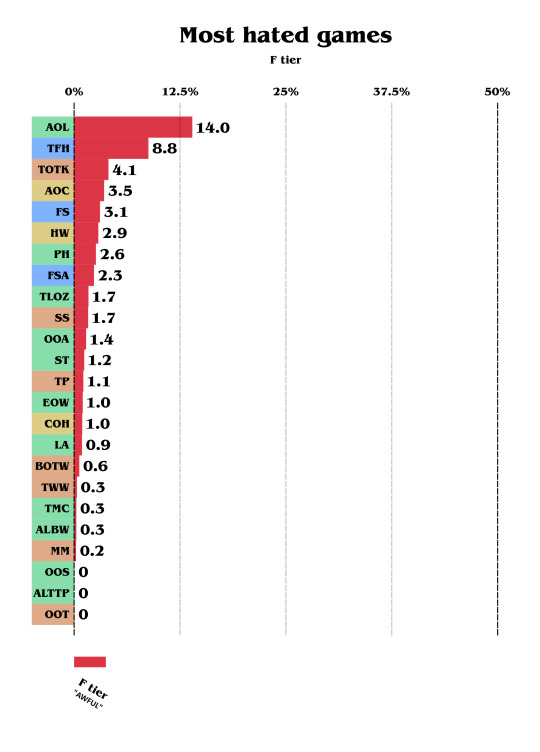
Yep, TOTK is third, this time. As I don't personally think it's awful, it definitively disappointed many by being too close to BOTW and having a lot of issues BOTW didn't have.
Nobody voted "F tier" for ALTTP nor OOT. Same for OOS but keep in mind this game was the least voted one too!
Alright, enough for the hate! Let's look at the most appreciated Zelda games.
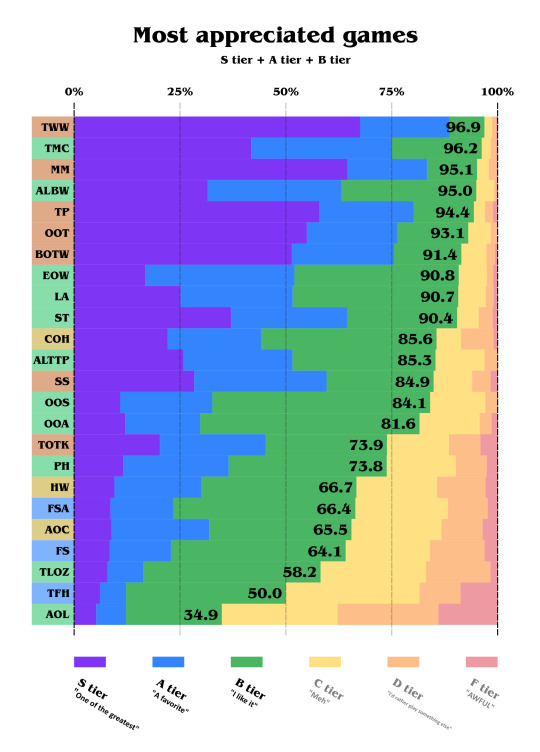
Yep, the majority of Zelda fans like 22.5 out of 24 of the games! (TFH being exactly 50, I half-counted it!)
TWW is being almost unanimously appreciated, with almost 97%, and the second one to get this score is TMC, a 2D game, with more than 96%!
You can notice some gaps, like between ST and COH, and then between the Oracle games and TOTK.
Now let's look at the most loved games:
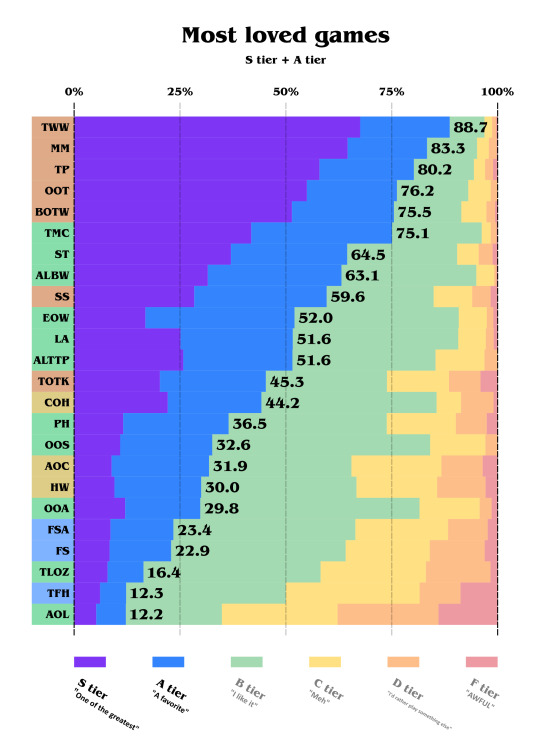
5 3D games are in the top 5, except for SS and TOTK. TMC is very close to beat BOTW and remains the most loved 2D Zelda game. Notice how SS and TOTK make a huge gap between the game before and the game after, like voters use them as references. The two Hyrule Warriors games are, in a funny way, between the Oracle ones.
Let's add a step forward and look at the S tier only:
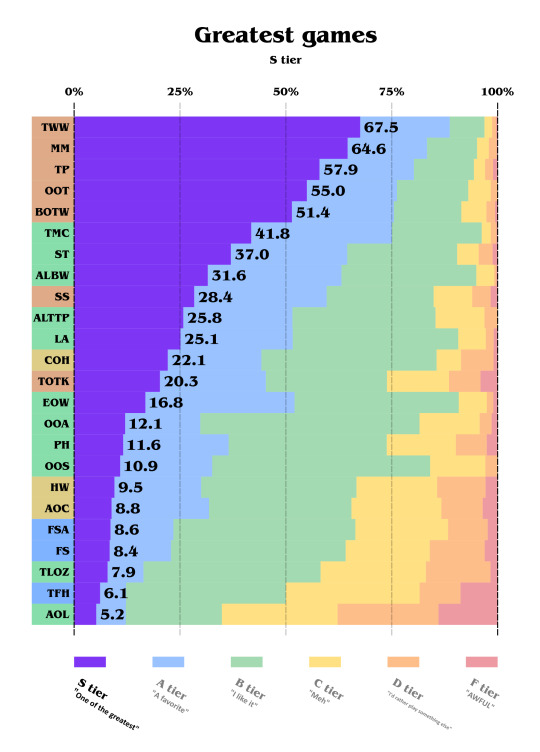
Nothing changes for the top 9 games. However, EOW seems more nuanced and is less considered as best than TOTK.
Final results
And finally, let's rank them using the Majority Judgment:

The Majority Judgment was created to propose a more democratic way to vote. Each candidate has multiple mentions, and you (the elector) must attribute one mention to each candidate. Since this poll uses this exact method of vote, I decided to rank them all using the Majority Judgment. To count using the Majority Judgment, you must focus on the 50% axis, and look at the category that crosses it (more than 50%). That gives you the tier, and the best tier wins.
When two or more candidates get the same tier, there are multiple ways to rank:
The first way is to put a line at the middle and see which line has the higher percentage. (Less precise but more simple)
The second way is to divide it into multiple tiers by doing the first method again and again until each candidates has a unique tier. (More precise but less simple)
But since I didn't want to compare B++++ to B+++-, I used the first method. It's my democracy and I do whatever I want!
Just keep in mind that depending on the way to count these games may be swapped:
ALTTP and LA
OOA and PH
AOC and HW
SO, for the data. Top 5 is TWW, MM, TP, OOT and BOTW. To be honest, I imagined MM to be a more nuanced game, or at least more controversial, since it has a unique concept.
The A tier only contains 2D games, except SS. TMC, ST and ALBW are the favourite 2D games. ALTTP and LA are always very close. The last one of the tier is EOW.
Only mainline games are in the S and A tier.
The first game of the B tier is a spin-off game, followed by TOTK.
TFH was one vote away from being in the B tier. And no surprise, AOL is the last one.
To sum up, according to the participants who voted for these polls:
S tier
🥇 The Wind Waker
🥈 Majora's Mask
🥉 Twilight Princess
⭐ Ocarina of Time
⭐ Breath of the Wild
A+ tier
The Minish Cap
Spirit Tracks
A- tier
A Link Between Worlds
Skyward Sword
A Link to the Past
Link's Awakening
Echoes of Wisdom
B+ tier
Cadence of Hyrule
Tears of the Kingdom
Oracle of Seasons
Oracle of Ages
Phantom Hourglass
B- tier
Age of Calamity
Hyrule Warriors
Four Swords Adventures
Four Swords
The Legend of Zelda
C+ tier
Tri Force Heroes
C- tier
Adventure of Link
Thank you for reading! ~
#the legend of zelda#analysis#the wind waker#wind waker#majora's mask#twilight princess#ocarina of time#breath of the wild#the minish cap#minish cap#spirit tracks#a link between worlds#skyward sword#a link to the past#link's awakening#echoes of wisdom#cadence of hyrule#crypt of the necrodancer#hyrule warriors#tears of the kingdom#oracle of ages#oracle of seasons#phantom hourglass#age of calamity#four swords adventures#four swords#tloz#tri force heroes#adventure of link#zelda 2
56 notes
·
View notes
Text
Ranking Brooklyn 99 Characters Based on How Autistic They Are
PSA: This is not a serious discussion about autism representation in the media or even just in Brooklyn 99, this is a joke. I am an autistic person making a joke. I am fully aware that none of the characters were intended to be autistic. I'm also fully aware that having some traits commonly associated with autism does not necessarily mean a person is autistic, and vice-versa.
Jake Peralta- ADHD Kiiiiing! Probably not autistic though, his executive functioning issues and occasional infodumping can easily be attributed to the aforementioned ADHD. B Tier.
Amy Santiago- Socially anxiety, hyperfixations, infodumping, strictly regimented routines and most importantly so much stimming. She has a happy happy dance! She obsessively braids her hair and hums songs when she's nervous! A Tier.
Rosa Diaz- Probably not autistic, the best people skills/cognitive empathy of the cast (she's very stonefaced but I think she's just repressed), doesn't seem to have any obvious hyperfixations, stims, or sensory issues. C Tier.
Charles Boyle- Excellent candidate for autism. Hyperfixations (weird food, Jake), general extreme lack of social awareness. His weird tastes also suggest some sensory processing atypicalities. Also the similarities between most of the Boyle cousins suggest this behavior is at least somewhat genetic. A Tier.
Gina Linetti- Not autistic, just a narcissist. D-Tier.
Terry Jeffords- Not autistic, seems like token neurotypical. However he did memorize an entire GoT ripoff so. C-Tier.
Captain Raymond Hold- Pure, undiluted, distilled autism. Literally The Most Autistic. We got:
a. The lack of nonverbal communication, stoneface and monotone voice are common in autistic individuals
b. The hyperfixations (classical music, thermometers, etc)
c. The heavy emphasis on following rules and routines in his life (down to exactly how to shake a person's hand)
d. The sensory processing disorders (his meals are extremely bland and he has a distaste for a lot of foods, especially eggs)
e. The autistic play- shown as a child (and adults) playing with model trains with an emphasis on "realism," his macaroni art were graphs.
f. The familial similarities (his mom acts incredibly similar to him, although his sister does not, suggesting his mother shares autistic traits with her son).
In conclusion: S-Tier
#But seriously I love how B99 portrays people with neurodivergences#Because all of the characters with autistic traits above are still fully functioning loveable people#they're good at their jobs#they have healthy long term friendships and romantic partnerships#Boyle and Amy even have kids#and while their traits are sometimes played for laughs#not once is it ever implied that they are any less suited to being a cop/friend/partner/parent because of them#also its so rare to see good stimming representation period let alone good female stimming rep#Brooklyn 99#B99#Jake Peralta#Amy Santiago#Rosa Diaz#Charles Boyle#Gina Linetti#Terry Jeffords#Raymond Holt
34 notes
·
View notes
Text
Hydrogen bomb vs. coughing baby: graphs and the Yoneda embedding
So we all love applying heavy duty theorems to prove easy results, right? One that caught my attention recently is a cute abstract way of defining graphs (specifically, directed multigraphs a.k.a. quivers). A graph G consists of the following data: a set G(V) of vertices, a set G(A) of arrows, and two functions G(s),G(t): G(A) -> G(V) which pick out the source and target vertex of an arrow. The notation I've used here is purposefully suggestive: the data of a graph is exactly the same as the data of a functor to the category of sets (call it Set) from the category that has two objects, and two parallel morphisms from one object to the other. We can represent this category diagrammatically as ∗⇉∗, but I am just going to call it Q.
The first object of Q we will call V, and the other we will call A. There will be two non-identity morphisms in Q, which we call s,t: V -> A. Note that s and t go from V to A, whereas G(s) and G(t) go from G(A) to G(V). We will define a graph to be a contravariant functor from Q to Set. We can encode this as a standard, covariant functor of type Q^op -> Set, where Q^op is the opposite category of Q. The reason to do this is that a graph is now exactly a presheaf on Q. Note that Q is isomorphic to its opposite category, so this change of perspective leaves the idea of a graph the same.
On a given small category C, the collection of all presheaves (which is in fact a proper class) has a natural structure as a category; the morphisms between two presheaves are the natural transformations between them. We call this category C^hat. In the case of C = Q, we can write down the data of such a natural transformations pretty easily. For two graphs G₁, G₂ in Q^hat, a morphism φ between them consists of a function φ_V: G₁(V) -> G₂(V) and a function φ_A: G₁(A) -> G₂(A). These transformations need to be natural, so because Q has two non-identity morphisms we require that two specific naturality squares commute. This gives us the equations G₂(s) ∘ φ_A = φ_V ∘ G₁(s) and G₂(t) ∘ φ_A = φ_V ∘ G₁(t). In other words, if you have an arrow in G₁ and φ_A maps it onto an arrow in G₂ and then you take the source/target of that arrow, it's the same as first taking the source/target in G₁ and then having φ_V map that onto a vertex of G₂. More explicitly, if v and v' are vertices in G₁(V) and a is an arrow from v to v', then φ_A(a) is an arrow from φ_V(v) to φ_V(v'). This is exactly what we want a graph homomorphism to be.
So Q^hat is the category of graphs and graph homomorphisms. This is where the Yoneda lemma enters the stage. If C is any (locally small) category, then an object C of C defines a presheaf on C in the following way. This functor (call it h_C for now) maps an object X of C onto the set of morphisms Hom(X,C) and a morphism f: X -> Y onto the function Hom(Y,C) -> Hom(X,C) given by precomposition with f. That is, for g ∈ Hom(Y,C) we have that the function h_C(f) maps g onto g ∘ f. This is indeed a contravariant functor from C to Set. Any presheaf that's naturally isomorphic to such a presheaf is called representable, and C is one of its representing objects.
So, if C is small, we have a function that maps objects of C onto objects of C^hat. Can we turn this into a functor C -> C^hat? This is pretty easy actually. For a given morphism f: C -> C' we need to find a natural transformation h_C -> h_C'. I.e., for every object X we need a set function ψ_X: Hom(X,C) -> Hom(X,C') (this is the X-component of the natural transformation) such that, again, various naturality squares commute. I won't beat around the bush too much and just say that this map is given by postcomposition with f. You can do the rest of the verification yourself.
For any small category C we have constructed a (covariant) functor C -> C^hat. A consequence of the Yoneda lemma is that this functor is full and faithful (so we can interpret C as a full subcategory of C^hat). Call it the Yoneda embedding, and denote it よ (the hiragana for 'yo'). Another fact, which Wikipedia calls the density theorem, is that any presheaf on C is, in a canonical way, a colimit (which you can think of as an abstract version of 'quotient of a disjoint union') of representable presheaves. Now we have enough theory to have it tell us something about graphs that we already knew.
Our small category Q has two objects: V and A. They give us two presheaves on Q, a.k.a. graphs, namely よ(V) and よ(A). What are these graphs? Let's calculate. The functor よ(V) maps the object V onto the one point set Hom(V,V) (which contains only id_V) and it maps A onto the empty set Hom(A,V). This already tells us (without calculating the action of よ(V) on s and t) that the graph よ(V) is the graph that consists of a single vertex and no arrows. The functor よ(A) maps V onto the two point set Hom(V,A) and A onto the one point set Hom(A,A). Two vertices (s and t), one arrow (id_A). What does よ(A) do with the Q-morphisms s and t? It should map them onto the functions Hom(A,A) -> Hom(V,A) that map a morphism f onto f ∘ s and f ∘ t, respectively. Because Hom(A,A) contains only id_A, these are the functions that map it onto s and t in Hom(V,A), respectively. So the one arrow in よ(A)(A) has s in よ(A)(V) as its source and t as its target. We conclude that よ(A) is the graph with two vertices and one arrow from one to the other.
We have found the representable presheaves on Q. By the density theorem, any graph is a colimit of よ(V) and よ(A) in a canonical way. Put another way: any graph consists of vertices and arrows between them. I'm sure you'll agree that this was worth the effort.
#math#adventures in cat theory#oh btw bc よ is full and faithful there are exactly two graph homomorphisms よ(V) -> よ(A)#namely よ(s) and よ(t)#which pick out exactly the source and target vertex in よ(A)
100 notes
·
View notes
Note
what is a syntax tree and how did you construct that, that is fascinating
A syntax tree is a way of representing the constituent structure of a sentence (i.e. how it can be broken up into parts) as a graph. It's one of the most common representations used in contemporary syntactic theory.
As for how you construct it, there are various both general and language specific rules but the simplest explanation would be that you "split" the tree each time you reach a unit of syntax that could be replaced by a simpler atom.
For example:
The sentence "I knew that guy" can be split into a subject "I" and verb phrase "knew that guy", which you could replace with a simple verb (e.g. "I ran"), so you split these two parts into an NP and a VP (under an IP for complicated theoretical reasons).
"knew that guy" can be broken up into a verb "knew" and an object "that guy", which you could replace with a simpler noun phrase (e.g. "I knew him"), so you split these two parts into a V and an NP.
"that guy" can be split into a determiner "that" and a head noun "guy", both of which are substitutable ("the guy", "that dog"), so you split these two parts into a D and an N.
Add some extra details that are required for theoretical reasons that I can't easily go into here, and boom!
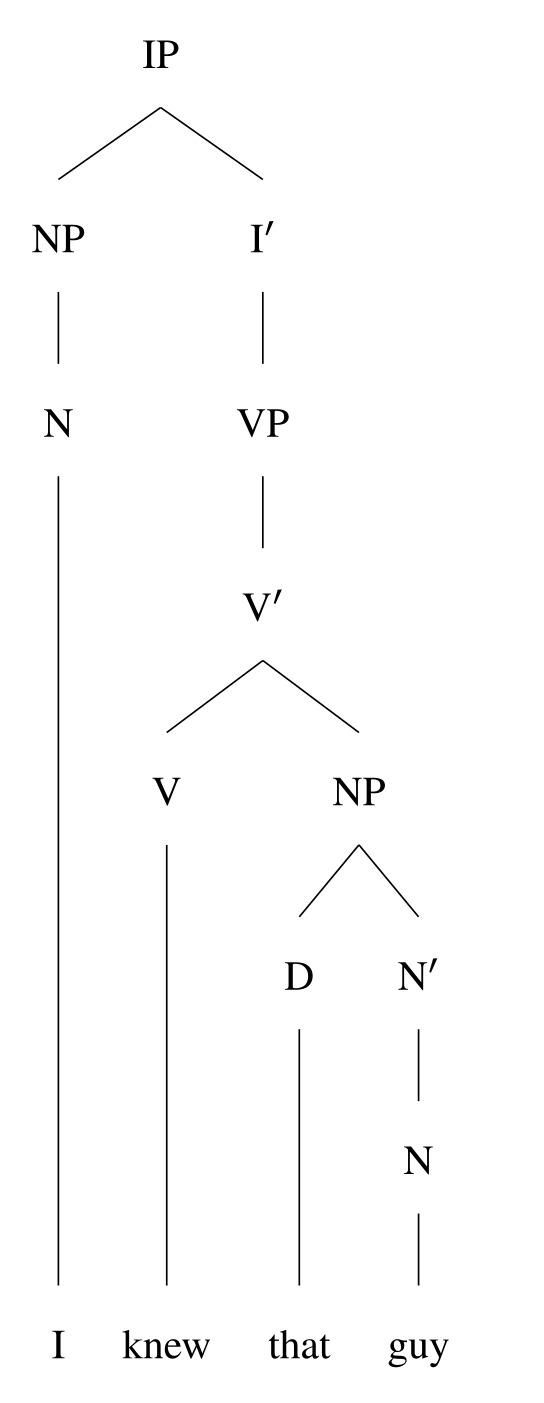
[ID: Syntax tree for the sentence "I knew that guy".]
Of course, nothing's ever quite that simple.
For one, substitution isn't really the only test that goes into making the divisions on the tree. For example, there's active debate among different syntacticians over whether you should split ditransitive verb phrases like "give me a cake" into [[give] [me] [a cake]] or into [[give me] [a cake]]. The substitution test I gave above would suggest the latter, but I personally believe the former is better suited to account for the data in object symmetric languages like the Kordofanian language Moro. So I would represent the verb phrase "give me a cake" with a trinary branching tree like below, but other syntacticians would hate this.
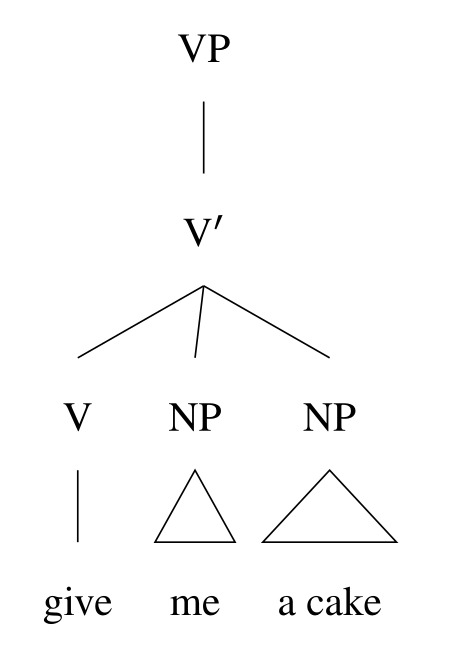
[ID: A syntax tree for the verb phrase "give me a cake"; it shows a trinary branching structure, where the V-bar node dominates a V node and two NPs.]
For another, almost any actual syntactic framework is going to require more in your trees than I'm including here. A proper LFG c-structure, for example, would require at least node annotations (and possibly lexical entries on the leaves), resulting in a tree that looks more like:
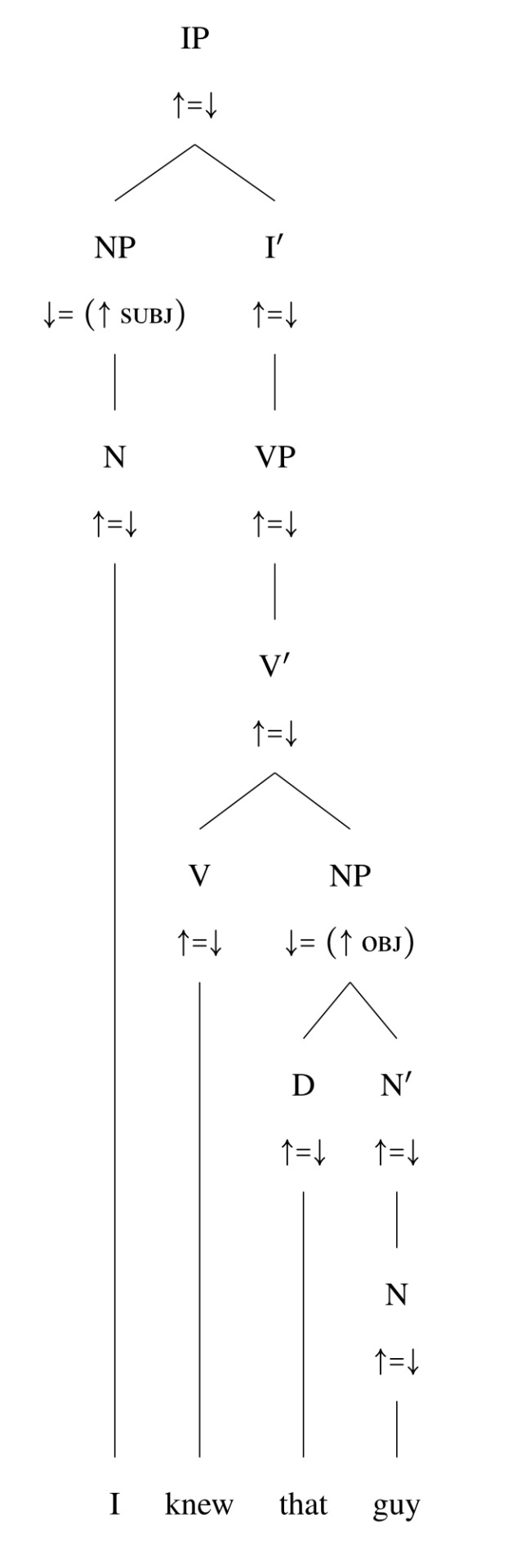
[ID: The same syntax tree for "I knew that guy", but now each node is anotated with an equation. Most nodes have an "up arrow equals down arrow" equation, but the NP node that dominates "I" has a "down arrow equals up arrow SUBJ" equation and the NP that dominates "that guy" has an equation "down arrow equals up arrow OBJ".]
And that's without getting into whatever the hell the cartographic Minimalists are off there doing with their hundreds of functional projections... But I digress. Main point being: a properly done syntax tree is much more complex of a beast than the instructions above would suggest, but they're still a good place to start!
#asks#trees#syntax#syntax tree#meta#how to#about trees#linguistics#yes I am not afraid to throw shade at the minimalists don't @ me
65 notes
·
View notes
Text

China offered its Y-20 transport plane to Nigeria
The air transport plane was placed on the international market in November, when it was shown to the head of Nigeria's defense.
Fernando Valduga By Fernando Valduga 01/13/2024 - 19:00 in Military
China is trying to sell its Y-20 Kunpeng transport plane to foreign buyers, with its manufacturer expanding production capacity in preparation, according to media reports.
The strategic military transport aircraft was placed on the international market in November, when the Y-20BE model was shown to Nigeria's Defense Minister Mohammed Badaru Abubakar in Beijing, the military magazine Ordnance Industry Science Technology reported last week.
The heavy transport plane, nicknamed the 'chubby girl' (chubby girl) for its large fuselage, is comparable to the Soviet Ilyushin Il-76 and the American Boeing C-17.
According to the report, it will be an opportunity for China to “establish deeper strategic relations and cooperation with countries as soon as they have the Y-20”.
Although Nigeria currently depends on the C-130 Hercules as its main tactical air transport aircraft, military experts say the Y-20E would provide the country with genuine strategic air transport capabilities.

The aircraft manufacturer, XAIC, operates assembly lines for mass production, according to the Chinese state broadcaster.
Its manufacturer, the state-owned Xian Aircraft Industrial Corporation (XAIC), has been operating assembly lines for mass production to increase efficiency and expand capacity, the state broadcaster CCTV reported in November.
Instead of mounting the aircraft on a fixed workstation, its parts are moved along a "pulse line" as the work steps are completed - similar to the way cars are produced. These assembly lines are used to build some of the most advanced aircraft in the world, including the Lockheed Martin F-35 and the Boeing 787.
More than 90 percent of the parts of the Y-20 are manufactured by a digitized system, according to the CCTV report, which showed images from the XAIC factory of robotic arms, remotely controlled maneuvers and laser-assisted high-precision assembly work.
The broadcaster's report said that the production capacity of the plant could meet the demand of both the Chinese air force and international customers.
"The production speed of the Y-20 is the fastest in the world in this type," he said.

The People's Liberation Army Air Force (PLAAF) has received almost 100 planes so far, half of them in the last two years.
The plane, which is 47 meters long and 50 meters wide, has become the flagship of the People's Liberation Army since it entered service in 2016. It can transport up to 66 tons.
XAIC has delivered almost 100 planes to the PLA Air Force so far - about half of them in the last two years. It also changed from Russian-made Soloviev D-30KP-2 engines to the most powerful Chinese-made Shenyang WS-20 turbofan engines.
Variants were also developed, the Y-20U tank plane and the Y-20AEW airborne alert and early control aircraft.
Tags: Military AviationChinaNAF - Nigerian Air Force/Nigerian Air ForceXian Y-20
Sharing
tweet
Fernando Valduga
Fernando Valduga
Aviation photographer and pilot since 1992, he has participated in several events and air operations, such as Cruzex, AirVenture, Dayton Airshow and FIDAE. He has works published in specialized aviation magazines in Brazil and abroad. He uses Canon equipment during his photographic work in the world of aviation.
Related news
MILITARY
J-10C jets from Pakistan and Eurofighter from Qatar face each other in joint exercise
13/01/2024 - 17:58
MILITARY
Taiwan wants to develop a new basic training plane
13/01/2024 - 16:41
This graph shows an E-4B Nightwatch aircraft in a hangar being digitized and rendered digitally to better illustrate the multi-day effort by the company Mass Virtual to build a three-dimensional virtual representation of the Boeing 747 for training purposes.
MILITARY
With "final judgment planes" in high demand, USAF resorts to Virtual Reality training in digital replica
13/01/2024 - 15:29
MILITARY
India reveals first national MALE drone called Drishti 10 Starliner
13/01/2024 - 14:17
MILITARY
VIDEO: Norway starts 2024 with the deployment of F-35 fighters in Iceland
13/01/2024 - 11:49
BRAZIL
Child with rare syndrome realizes the dream of meeting FAB planes
13/01/2024 - 11:40
8 notes
·
View notes
Text
One of the weirder hot takes you get from grammar prescriptivists is that reinforcing double negatives ("you didn't see nothing") are somehow inherently incorrect or a sign of stupidity.
Incoming: a short rant about linguistic prescriptivism and then an excerpt from the Canterbury Tales.
Firstly, there are more languages than English, and in many of them it is the norm that negatives reinforce, rather than cancel each other out. You might say "yeah but not in English," but you're objectively wrong. Several dialects and sociolects of English use reinforcing double negatives, it's just that you're dismissing the people who use them as either stupid, non-fluent, or both (the idea that a well functioning adult could lack fluency in their own native language is preposterous by the way). The racial dimension is too obvious to even be worth diving into.
However, I think the thing that annoys me the most is the resounding ignorance and arrogance of the people who think like this. Sure, the part where you assume that every language and every dialect follows the same grammatical rules as your own is a common enough mistake, but the irony is that by insisting on this, you're showing your own ignorance of the language with a gesture intended to signal your superior grasp of it.
The average linguistic prescriptivist is in my experience not very well educated in language, not its formal rules, not the scientific study of it, and certainly not with its literature. They tend to occupy the "knows enough to think they know something, but not enough to realize how little they know" section of the Dunning-Kruger curve.
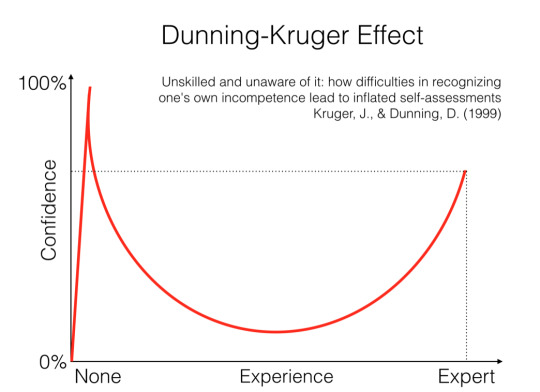
Note that this graph is a simple representation of an idea, not the result of a study or anything like that. The numbers and relative positions here are made up. That's how the curve manages to slope back in on itself after the peak.
What I mean is, they tend to know enough to be moderately aware of the formal rules of "standard" English, without any grasp of the real nature of a language (usually conceiving of it as some kind of ideal object that can be "correctly matched with" in an objective way), and even more damning, without a lot of experience actually engaging with that language beyond speech and simple text.
At best, they know some factoids from high school about how you're not supposed to end a sentence with a preposition (it's fine, actually, English is a Germanic language which means it loves shifting word order around) and such.
Anyway, here's a quadruple negative used in a reinforcing manner by Geoffrey Chaucer, arguably the founder of English-language literature, while describing the knight character in the prologue to the Canterbury Tales. A genuinely good writer that, along with Shakespeare and many others, one must presume that these prescriptivists have never read, at least not closely, though they in my experience tend to pretend they have.
At mortal batailes hadde he been fiftene,
And foughten for our faith at Tramissene
In listes thries and ay slain his fo.
This ilke worthy Knight hadde been also
Sometime with the lord of Palatye
Again another hethen in Turkye;
And everemore he hadde a soverein pris.
And though that he were worthy, he was wis,
And of his port as meeke as is a maide.
He nevere yit no vilainye ne saide
In al his lif unto no manere wight:
He was a verray, parfit, gentil knight.
Or, if your Middle English is rusty, here's my rough translation:
He had been at fifteen tournaments to the death
And he had fought for our faith at Tramissene (Tlemcen, Algeria)
In three lists (tournament grounds) and always slain his foe.
This same worthy knight had also been
Some time with the lord of Palatye (the Emir of Balat, Turkey)
Against another heathen in Turkey;
And evermore he had a superior reputation.
And he was every bit as wise as he was bold.
And his demeanor: as meek as a maid.
He never yet no rude thing hadn't said
In all his life to no kind of person:
He was a true, perfect, noble knight.
Anyway, in conclusion, prescriptivists shut the fuck up.
#takes#mini essay#history#linguistics#politics#poetry#geoffrey chaucer#dunning kruger#canterbury tales
15 notes
·
View notes
Text
An adjacency list in a graph is a series of numbers that tells you how many nodes are adjacent to each node. So if you imagine a 3x3 square of rooms that all connect with a door in the center of each wall, the corner rooms would have a value of 2 (the side rooms adjacent to them), the side rooms would have a value of 3 (the adjacent corner rooms and the center), and the center would have a value of 4 (being adjacent to all 4 side rooms).
An adjacency matrix for a graph is possibly more confusing, depending on how your brain works, but defaults to containing more info and has faster lookups in terms of computer processing. It would represent those 9 rooms as a 9x9 grid and mark each door you could go out of as a 1 instead of a 0. So

becomes

And you can see it's symmetrical (split down the line of Xs), because you can go through a door either direction. If these were streets in a city and the street going from intersection E to F was a one-way street, the E,F would be a 1 but the F,E would be a 0.
To get a 2-hop option - everything available in 2 jumps from each point, allowing for overlap - you do slightly different things depending on whether List or Matrix is your representation.
For a List, you have a nested for loop, grabbing the set of adjacent options in the outer loop, and asking for them to spit out a list of their adjacent options in the inner loop. Imagine a 4-square of rooms
J Q K A
the outer loop would say, What's adjacent to J? Q- What's adjacent to Q? J and A are adjacent to Q K- What's adjacent to K? J and A are adjacent to K What's adjacent to Q? J- What's adjacent to J? Q and K are adjacent to J A- What's adjacent to A? Q and K are adjacent to A and so on. So the 2-hop for J ends up with J,A,J,A, for Q it's Q,K,Q,K, for K it's Q,K,Q,K, and for A it's J,A,J,A.
For matrices you do Matrix Multiplication. For square matrices of the same size (which works perfectly for us because we're trying to square the matrix in the first place) you take the row and column that meet at each point in the matrix and multiply across. If you were squaring a matrix
your new A would be A*A + B*D + C*G. Your new B would be A*B + B*E + C*H.
So the square of
For A,A it's a,a(0)*a,a(0) + b,a(1)*a,b(1) ... + i,a(0)*a,i(0) = 2 For B,A it's a,a(0)*b,a(1) + b,a(1)*b,b(1) ... + i,b(0)*b,i(0) = 0
And this makes sense. Remember, this is representing how many paths there are to go from one space to another in exactly 2 jumps. A,A means "how many paths go from A back to A in 2 steps." You can see there are 2: A -> B -> A and A -> D -> A. There's no way to actually take 2 steps starting from B and get to A. Using this logic we can guess by looking at the "map" that B,H would give us a value of 1, because there's only one way to get from B to H in 2 hops.
If we do the same cross-section trick to multiply it out, we have 1*0 + 0*0 + 1*0 + 0*0 + 1*1 + 0*0 + 0*1 + 0*0 + 0*1 and sure enough, we have just one spot where the numbers match up.
1 note
·
View note
Text
50.004 – Introduction to Algorithms Homework Set 4
Question 1. Figure 1 shows a directed graph G. a b c d e f g Figure 1: A directed graph for use in Question 1 and Question 2. (i) Give the adjacency-list representation of G. When giving your answer, please order the vertices alphabetically. [2.5 points] (ii) Give the adjacency-matrix representation of G. When giving your answer, please order the vertices alphabetically. [2.5 points] Question 2.…
0 notes
Text
module 4 graphic processing
I chose the NESARC dataset, I am interested in understanding if the PATHOLOGICAL GAMBLING (BETTING) how much is related to the need to have money. In particular, I will observe four specific variables in codebook(S12Q2C4 and S12Q2B12).
I represent the two variables individually:


Relationship between variables For the study to be faced, it is important to define that S12Q2C4(X) to INCREASE THE AMOUNT OF MONEY YOU WOULD GAMBLE TO KEEP IT EXCITING hAPPEN before 12 MONTHS AGO is my variable X(Esplanatory Independent Predictor), while the S12Q2B12 EVER RAISE GAMBLING MONEY BY WRITING A BAD CHECK, SIGNING SOMEONE ELSE'S NAME TO A CHECK, STEALING, CASHING SOMEONE ELSE'S CHECK OR IN SOME OTHER ILLEGAL WAY HAPPEN IN THE LAST 12 MONTHS is the dependent variable Y(Response Dependent outcome)
the variable esplanatory X is categorical, i.e. the number of players who have had well-being in betting money in the first twelve months The response variable Y is categorical, i.e. it is the number of people who after 12 months have developed the need to have money illegally. Then the graphic methodology for the representation of the two variables is C->C. I recode the two variables by substituting 0 instead of 2 and leaving the 1, I transform the data into numerical format and perform the LOGICAL AND between the data of the two variables: 1 and 1 = 1(develop illegal behaviour last 12 months when before 12 months INCREASE THE AMOUNT OF MONEY YOU WOULD GAMBLE TO KEEP IT EXCITING )
1 and 0 = 1(develop no illegal behaviour)
0 and 1 = 0(not excited related to illegal behaviour)
0 and 0 = 0(no excited, no illegal behaviour)

python code:


The graph shows that there is no correlation between the fact that a player can feel well-being or excitement in increasing the sums at stake and the subsequent development over time of illegal behavior to find more and more money. In fact, only a percentage very close to zero: 0.0629% of the sample of players examined develops illegal behavior.
0 notes
Text
Creating and Annotating a Linear Equation Image Dataset for Machine Learning

Introduction
In the dynamic field of machine learning, datasets are essential for training models to identify patterns, categorize images, and generate predictions. A notable example of a valuable dataset in both educational and AI research settings is the Linear Equation Image Dataset. This dataset comprises visual depictions of linear equations, allowing models to effectively interpret and analyze mathematical expressions.
In this article, we will examine the steps involved in creating and annotating a Linear Equation Image Dataset, as well as its applications in machine learning.
Why a Linear Equation Image Dataset?
A Linear Equation Image Dataset offers numerous advantages:
Recognition of Handwriting: Facilitating the training of Optical Character Recognition (OCR) models to identify handwritten linear equations.
Applications in Mathematical Education: Aiding students in visually comprehending linear equations.
AI-Driven Equation Solvers: Creating machine learning models that can autonomously read and solve equations.
Recognition of Patterns: Improving the capability of artificial intelligence to interpret mathematical symbols and their interrelations.
Steps to Create a Linear Equation Image Dataset
Establish the Scope and Data Requirements
Prior to creating the dataset, it is essential to identify:
The specific types of linear equations to be included (for instance, slope-intercept form or standard form).
The choice between utilizing handwritten equations, digitally generated images, or a combination of both.
The necessary size of the dataset to ensure effective training.
Creating Images of Linear Equations
There are several methods to produce images of linear equations:
Programmatic Generation: Employing Python libraries such as Matplotlib or PIL to generate equations in image format.
Handwritten Samples: Gathering handwritten equations from various individuals to enhance generalization.
Typesetting with LaTeX: Utilizing LaTeX to render equations and subsequently converting them into images.
Image Annotation and Labeling
For machine learning models to learn efficiently, it is crucial to annotate each image with pertinent metadata. This should include:
Equation Text: The mathematical expression presented in either LaTeX or plaintext format.
Graph Representation: The associated graph, if relevant.
Bounding Boxes: For training an OCR model, delineating areas where specific components of the equation are located.
Equation Type: Classifying images according to their equation format (e.g., y = mx + b, Ax + By = C).
Applications such as LabelImg and Roboflow are useful for performing manual annotation tasks.
Dataset Storage and Formatting
The dataset must be organized in a systematic manner:
Images should be saved in PNG or JPEG formats.
Annotations must be provided in CSV, JSON, or XML formats, accompanied by the relevant labels.
A structured directory should be established to categorize various types of equations.
Dataset Augmentation
To enhance the model's resilience, various augmentation methods can be utilized:
Rotation and Scaling: Apply minor adjustments in orientation.
Noise Addition: Simulate real-world distortions.
Color Variations: Adapt the dataset to account for different lighting scenarios.
Handwritten Variability: Introduce diversity by incorporating various handwriting styles.
Download the Linear Equation Image Dataset
To expedite your work, you may download a pre-assembled Linear Equation Image Dataset for your projects. Please follow the link below to access the dataset: Globose Technology Solution
Conclusion
Developing and annotating a Linear Equation Image Dataset is an essential phase in training artificial intelligence models for mathematical comprehension. By adhering to a systematic methodology, you can create a dataset that serves various purposes, including optical character recognition (OCR), educational tools, and AI-enhanced problem-solving applications. Regardless of whether you create your own dataset or utilize an existing one, ensuring that the dataset is meticulously labeled is vital for obtaining precise outcomes in machine learning.
Are you engaged in a project that necessitates a Linear Equation Image Dataset? We invite you to share your insights in the comments section below!
0 notes
Text
How to Use Apache JMeter for Performance Testing

1. Introduction
What is Apache JMeter?
Apache JMeter is an open-source tool designed for performance, load, and stress testing of web applications, APIs, databases, and more. It allows testers to simulate multiple users accessing an application simultaneously to measure its performance under different conditions.
Why Use JMeter for Performance Testing?
Free & Open-Source: No licensing costs.
User-Friendly GUI & Scripting Support: Suitable for beginners and advanced users.
Extensive Plugin Support: Allows for extended capabilities.
Supports Multiple Protocols: HTTP, FTP, JDBC, SOAP, and more.
Distributed Testing: Can generate a high load across multiple machines.
Common Use Cases for JMeter
Evaluating website and API performance under load.
Identifying server bottlenecks before deployment.
Stress testing to determine the breaking point of an application.
2. Installing Apache JMeter
Prerequisites
Java (JDK 8 or higher) installed. Verify using:
bash
java -version
JMeter Installation Package: Download from JMeter’s official site.
Installation Steps (Windows, macOS, Linux)
Extract the JMeter ZIP file into a directory.
Navigate to bin and launch JMeter:
Windows: Run jmeter.bat
macOS/Linux: Run ./jmeter
3. Understanding JMeter Components
Before running a test, it’s essential to understand JMeter’s building blocks:
Test Plan:
A test plan defines the structure of your performance test, including thread groups, samplers, listeners, and assertions.
Thread Group (Users & Load Simulation):
Defines number of virtual users (threads).
Specifies ramp-up time (gradual increase in users).
Controls loop count (number of test iterations).
Samplers (Types of Requests to Test)
JMeter supports different types of requests:
HTTP Request: Used for testing websites and REST APIs.
JDBC Request: Used for database performance testing.
FTP Request: Tests FTP servers.
Listeners (Result Analysis & Reports)
View Results Tree: Displays response details.
Aggregate Report: Provides overall test metrics.
Graph Results: Visual representation of response times.
Timers, Assertions, and Config Elements
Timers: Simulate realistic user wait times.
Assertions: Verify response correctness.
Config Elements: Store variables like base URL, login credentials.
4. Creating a Basic Performance Test
Step 1: Create a New Test Plan
Open JMeter → File → New Test Plan
Step 2: Add a Thread Group
Right-click on Test Plan → Add → Threads (Users) → Thread Group
Configure:
Number of Threads (Users): e.g., 100
Ramp-Up Period: e.g., 20 seconds
Loop Count: Infinite or fixed
Step 3: Add an HTTP Request Sampler
Right-click Thread Group → Add → Sampler → HTTP Request
Configure:
Server Name: example.com
Path: /login
Method: POST
Step 4: Add a Listener
Right-click Thread Group → Add → Listener → View Results Tree
Step 5: Run the Test & View Results
Click the Start (Green Play Button).
Observe the request-response details in View Results Tree.
5. Analyzing Performance Test Results
After running the test, it’s important to interpret the key performance metrics:
Metric Description Response Time Time taken to complete a request. Through put Requests processed per second. Error Rate Percentage of failed requests. Latency Time taken before the first response is received.
Example Report Interpretation:
High response times? Possible server bottleneck.
Low throughput? Needs performance optimization.
High error rate? Application may be failing under load.
6. Best Practices for Performance Testing with JMeter
1. Define Clear Test Objectives
What user load are you expecting?
What is the acceptable response time?
2. Simulate Real-World User Behavior
Use timers to avoid unrealistic rapid-fire requests.
Vary user interactions (e.g., login, browsing, checkout).
3. Monitor Server Performance
Use JMeter + APM tools (New Relic, Grafana, or AWS CloudWatch) to track CPU, memory, and database load.
4. Optimize JMeter Scripts for Large Tests
Avoid GUI Mode: Run tests in CLI mode (jmeter -n -t test.jmx).
Use Distributed Testing: Split the load across multiple machines.
5. Integrate JMeter with CI/CD Pipelines
Automate performance tests using Jenkins, GitHub Actions, or GitLab CI/CD.
7. Conclusion
Apache JMeter is a powerful tool for performance testing web applications, APIs, and databases. With a structured approach — defining test plans, running load tests, and analyzing results — developers and testers can identify bottlenecks and improve application scalability.
WEBSITE: https://www.ficusoft.in/software-testing-course-in-chennai/
0 notes
Text
CS 211: Assignment 2: Graph Algorithms + Data Representation (150 points)
Introduction In this assignment, you will get more experience with C programming by implementing several classical graph algorithms. You will also solidify your understanding of data representation with this assignment. In the rst set of 6 programs, you will get more experience with allocating graph data structures and processing them. You will start by representing a graph data structure in C.…
0 notes
Text
Effectively reducing the TAN Levels of 32kl of FRF Oil
Abating TAN Levels: Minimac's Tailored Solution for Critical Oil Values at India's 9th Largest Coal-Fired Power Plant
Synopsis
In Singrauli, MP, stands a colossal thermal power plant, one of the largest PSUs and the 9th largest coal-fired power station at 4760 MW capacity. Recently, it faced a formidable challenge - high TAN Levels in two 16kl control fluid tanks. To prevent a potential disruption and subsequent shutdown, Minimac provided a customized solution by deploying a specialized machine to lower TAN levels, address moisture, solid contamination and implement effective Nitrogen Blanketing.
Initial Findings

Problems
The client encountered increased TAN levels in two of their Control Fluid Tanks which had a detrimental impact on the operation of servo valves leading to reduced responsiveness, erratic behavior, increased wear and tear, and potential valve malfunction.
Client’s Requirements
To Purify 32kl of FRF Oil
To remove the TAN, Moisture and Solid Contaminants.
To Achieve NAS: ≤ Class 5.
To Achieve TAN: ≤ 0.10 (mg KOH/g).
To Achieve Moisture: ≤ 500 ppm.
Customized Solution.
Solutions
Deploying Minimac’s customized machine at the site along with trained and skilled engineers.
TAN Reduction Systems(20 LPM) equipped with the ion exchange resin to filter and eliminate acid components of oil.
Low Vacuum Dehydrator (100 LPM) to maintain consistent moisture levels in the oil using the vacuum dehydration ensuring smooth turbine operation in its active state.
Oil filtration system(150 LPM) to bring the NAS level of oil to the desired range.
Nitrogen blanketing system to maintain an inert space above the oil in the tank, serving as a barrier between the moisture-laden external air and the FRF oil inside the tank.
Along with the equipment’s installation, our Service Engineer trained the client’s team on the functioning and effective handling of the machine.
Job executed within a limited time-span on the running unit without hindering the client’s operations and control fluid tank system.
Value TypeControl Fluid Tank at UNIT 11Control Fluid Tank at UNIT 12BeforeAfterBeforeAfterNASClass 8Class 4Class 7Class 4TAN0.62 mg KOH/g0.08 mg KOH/g0.52 mg KOH/g0.08 mg KOH/gMoisture Level561PPM275 PPM500 PPM184 PPM
Benefits
Prevented the environment from harm by averting the emission of 3,84,000 kg of CO2e.
Saved 32 kl of Oil from being incinerated.
Extended Oil Life.
Reduced TAN Levels.
Elimination of Oil Replacement Costs.
Cost Saving
This Plant managed to save:
Cost of Oil Replacement: ₹7 Cr. Approx.
Cost of Downtime : ₹1 Cr. Approx.
CO2e Savings
Total Savings =3,84,000 kg of CO2e/0.384 gigagrams of CO2e
Graph
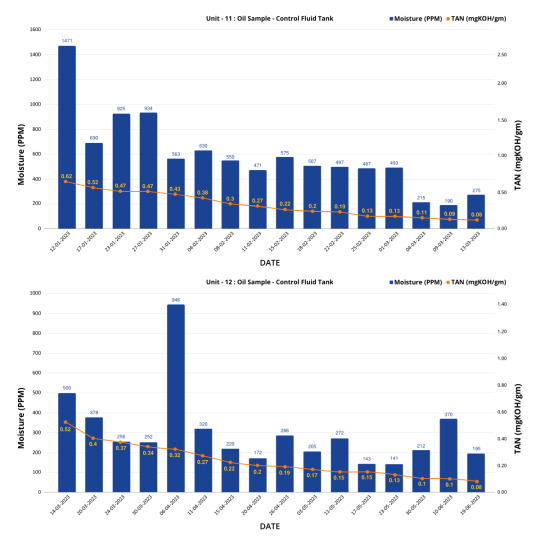
Pictorial Representation

Right to left( LVDH:100LPM, FS :150LPM, TAN Reduction Skid Ion Exchange :20LPM)

Resin Skid-TAN REDUCTION M/C (Ion Exchange 20 LPM)

Before and after oil sample
Know More About - https://www.minimacsystems.com/ Subscribe to our WhatsApp Community and be a part of our Journey - Click Here
#frf#oil flushing#minimac systems#power#minimac#oil & gas#hydraulic oil#contamination#lube oil filter#hydraulic oil filter#chemical cleaning flushing#chemical cleaning#oil filteration#oil filters#oil industry#oil and gas#oil#oil analysis#power industry#steel#mining#metal#oil filtration system#oil filtration machine#oil filtration systems#oil dehydration systems#frf condition systems#frf machine#coalser separator#elc
0 notes
Text
IEEE Transactions on Artificial Intelligence, Volume 5, Issue 12, December 2024
1) Editorial: Future Directions in Artificial Intelligence Research
Author(s): Hussein Abbass
Pages: 5858 - 5862
2) Ensuring Ethical Standards in the Development of Autonomous and Intelligent Systems
Author(s): Anetta Jedlickova
Pages: 5863 - 5872
3) Recent Advances in Generative AI and Large Language Models: Current Status, Challenges, and Perspectives
Author(s): Desta Haileselassie Hagos, Rick Battle, Danda B. Rawat
Pages: 5873 - 5893
4) A Review on Transferability Estimation in Deep Transfer Learning
Author(s): Yihao Xue, Rui Yang, Xiaohan Chen, Weibo Liu, Zidong Wang, Xiaohui Liu
Pages: 5894 - 5914
5) A Comprehensive Exploration of Real-Time 3-D View Reconstruction Methods
Author(s): Arya Agrawal, Teena Sharma, Nishchal K. Verma
Pages: 5915 - 5927
6) A Survey on Symbolic Knowledge Distillation of Large Language Models
Author(s): Kamal Acharya, Alvaro Velasquez, Houbing Herbert Song
Pages: 5928 - 5948
7) Games for Artificial Intelligence Research: A Review and Perspectives
Author(s): Chengpeng Hu, Yunlong Zhao, Ziqi Wang, Haocheng Du, Jialin Liu
Pages: 5949 - 5968
8) Exploring Machine Learning for Semiconductor Process Optimization: A Systematic Review
Author(s): Ying-Lin Chen, Sara Sacchi, Bappaditya Dey, Victor Blanco, Sandip Halder, Philippe Leray, Stefan De Gendt
Pages: 5969 - 5989
9) Efficient Evaluation Methods for Neural Architecture Search: A Survey
Author(s): Xiaotian Song, Xiangning Xie, Zeqiong Lv, Gary G. Yen, Weiping Ding, Jiancheng Lv, Yanan Sun
Pages: 5990 - 6011
10) Neuro-Symbolic AI for Military Applications
Author(s): Desta Haileselassie Hagos, Danda B. Rawat
Pages: 6012 - 6026
11) Label-Efficient Time Series Representation Learning: A Review
Author(s): Emadeldeen Eldele, Mohamed Ragab, Zhenghua Chen, Min Wu, Chee-Keong Kwoh, Xiaoli Li
Pages: 6027 - 6042
12) Direct Adversarial Latent Estimation to Evaluate Decision Boundary Complexity in Black Box Models
Author(s): Ashley S. Dale, Lauren Christopher
Pages: 6043 - 6053
13) Steganography in Style Transfer
Author(s): Ruolan Shi, Zichi Wang, Yunlong Hao, Xinpeng Zhang
Pages: 6054 - 6065
14) Model-Based Offline Reinforcement Learning With Uncertainty Estimation and Policy Constraint
Author(s): Jin Zhu, Chunhui Du, Geir E. Dullerud
Pages: 6066 - 6079
15) Game Theory Meets Data Augmentation
Author(s): Yuhan Kang, Samira Zare, Alex Tong Lin, Zhu Han, Stanley Osher, Hien Van Nguyen
Pages: 6080 - 6094
16) Epi-Curriculum: Episodic Curriculum Learning for Low-Resource Domain Adaptation in Neural Machine Translation
Author(s): Keyu Chen, Di Zhuang, Mingchen Li, J. Morris Chang
Pages: 6095 - 6108
17) Enhancing Aerial Object Detection With Selective Frequency Interaction Network
Author(s): Weijie Weng, Mengwan Wei, Junchi Ren, Fei Shen
Pages: 6109 - 6120
18) Unsupervised Domain Adaptation on Point Clouds via High-Order Geometric Structure Modeling
Author(s): Jiang-Xing Cheng, Huibin Lin, Chun-Yang Zhang, C. L. Philip Chen
Pages: 6121 - 6133
19) Deep Learning-Based Dual Watermarking for Image Copyright Protection and Authentication
Author(s): Sudev Kumar Padhi, Archana Tiwari, Sk. Subidh Ali
Pages: 6134 - 6145
20) Curious Feature Selection-Based Clustering
Author(s): Michal Moran, Goren Gordon
Pages: 6146 - 6158
21) Spatiotemporal Object Detection for Improved Aerial Vehicle Detection in Traffic Monitoring
Author(s): Kristina Telegraph, Christos Kyrkou
Pages: 6159 - 6171
22) DeepHGCN: Toward Deeper Hyperbolic Graph Convolutional Networks
Author(s): Jiaxu Liu, Xinping Yi, Xiaowei Huang
Pages: 6172 - 6185
23) Q-Cogni: An Integrated Causal Reinforcement Learning Framework
Author(s): Cristiano da Costa Cunha, Wei Liu, Tim French, Ajmal Mian
Pages: 6186 - 6195
24) From Behavior to Natural Language: Generative Approach for Unmanned Aerial Vehicle Intent Recognition
Author(s): Leyan Li, Rennong Yang, Maolong Lv, Ao Wu, Zilong Zhao
Pages: 6196 - 6209
25) Learning Multipursuit Evasion for Safe Targeted Navigation of Drones
Author(s): Jiaping Xiao, Mir Feroskhan
Pages: 6210 - 6224
26) OAFuser: Toward Omni-Aperture Fusion for Light Field Semantic Segmentation
Author(s): Fei Teng, Jiaming Zhang, Kunyu Peng, Yaonan Wang, Rainer Stiefelhagen, Kailun Yang
Pages: 6225 - 6239
27) An Approach for Privacy-Aware Mobile App Package Recommendation
Author(s): Shanpeng Liu, Buqing Cao, Jianxun Liu, Guosheng Kang, Min Shi, Xiong Li, Kenneth K. Fletcher
Pages: 6240 - 6252
28) Multiscale and Multilayer Contrastive Learning for Domain Generalization
Author(s): Aristotelis Ballas, Christos Diou
Pages: 6253 - 6266
29) Knowledge-Guided Evolutionary Optimization for Large-Scale Air Defense Resource Allocation
Author(s): Wenhua Li, Rui Wang, Yong Heng, Tao Zhang, Ling Wang
Pages: 6267 - 6279
30) A Brain-Inspired Theory of Collective Mind Model for Efficient Social Cooperation
Author(s): Zhuoya Zhao, Feifei Zhao, Shiwen Wang, Yinqian Sun, Yi Zeng
Pages: 6280 - 6289
31) A Game-Theoretic Approach to Containing Artificial General Intelligence: Insights From Highly Autonomous Aggressive Malware
Author(s): Timothy R. McIntosh, Teo Susnjak, Tong Liu, Paul Watters, Alex Ng, Malka N. Halgamuge
Pages: 6290 - 6303
32) A Composite Decomposition Method for Large-Scale Global Optimization
Author(s): Maojiang Tian, Minyang Chen, Wei Du, Yang Tang, Yaochu Jin, Gary G. Yen
Pages: 6304 - 6319
33) Optimal Output Feedback Tracking Control for Takagi–Sugeno Fuzzy Systems
Author(s): Wenting Song, Shaocheng Tong
Pages: 6320 - 6329
34) Quantum Face Recognition With Multigate Quantum Convolutional Neural Network
Author(s): Yijie Zhu, Ahmed Bouridane, M Emre Celebi, Debanjan Konar, Plamen Angelov, Qiang Ni, Richard Jiang
Pages: 6330 - 6341
35) Learning Empirical Inherited Intelligent MPC for Switched Systems With Network Security Communication
Author(s): Yiwen Qi, Yiwen Tang, Wenke Yu
Pages: 6342 - 6355
36) MSCS: Multiscale Consistency Supervision With CNN-Transformer Collaboration for Semisupervised Histopathology Image Semantic Segmentation
Author(s): Min-En Hsieh, Chien-Yu Chiou, Hung-Wen Tsai, Yu-Cheng Chang, Pau-Choo Chung
Pages: 6356 - 6368
37) Differentially Private and Heterogeneity-Robust Federated Learning With Theoretical Guarantee
Author(s): Xiuhua Wang, Shuai Wang, Yiwei Li, Fengrui Fan, Shikang Li, Xiaodong Lin
Pages: 6369 - 6384
38) Multimodal Fusion Induced Attention Network for Industrial VOCs Detection
Author(s): Yu Kang, Kehao Shi, Jifang Tan, Yang Cao, Lijun Zhao, Zhenyi Xu
Pages: 6385 - 6398
39) Simultaneous Learning and Planning Within Sensing Range: An Approach for Local Path Planning
Author(s): Lokesh Kumar, Arup Kumar Sadhu, Ranjan Dasgupta
Pages: 6399 - 6411
40) Generative Representation Learning in Recurrent Neural Networks for Causal Timeseries Forecasting
Author(s): Georgios Chatziparaskevas, Ioannis Mademlis, Ioannis Pitas
Pages: 6412 - 6425
41) Federated c-Means and Fuzzy c-Means Clustering Algorithms for Horizontally and Vertically Partitioned Data
Author(s): José Luis Corcuera Bárcena, Francesco Marcelloni, Alessandro Renda, Alessio Bechini, Pietro Ducange
Pages: 6426 - 6441
42) A Comprehensive Radiogenomic Feature Characterization of 19/20 Co-gain in Glioblastoma
Author(s): Padmaja Jonnalagedda, Brent Weinberg, Taejin L. Min, Shiv Bhanu, Bir Bhanu
Pages: 6442 - 6456
43) LSTM-Based Model Compression for CAN Security in Intelligent Vehicles
Author(s): Yuan Feng, Yingxu Lai, Ye Chen, Zhaoyi Zhang, Jingwen Wei
Pages: 6457 - 6471
44) Deep Imbalanced Learning for Multimodal Emotion Recognition in Conversations
Author(s): Tao Meng, Yuntao Shou, Wei Ai, Nan Yin, Keqin Li
Pages: 6472 - 6487
45) FIMKD: Feature-Implicit Mapping Knowledge Distillation for RGB-D Indoor Scene Semantic Segmentation
Author(s): Wujie Zhou, Yuxiang Xiao, Yuanyuan Liu, Qiuping Jiang
Pages: 6488 - 6499
46) Two-Stage Representation Refinement Based on Convex Combination for 3-D Human Poses Estimation
Author(s): Luefeng Chen, Wei Cao, Biao Zheng, Min Wu, Witold Pedrycz, Kaoru Hirota
Pages: 6500 - 6508
47) Cooperative Advantage Actor–Critic Reinforcement Learning for Multiagent Pursuit-Evasion Games on Communication Graphs
Author(s): Yizhen Meng, Chun Liu, Qiang Wang, Longyu Tan
Pages: 6509 - 6523
48) RADiff: Controllable Diffusion Models for Radio Astronomical Maps Generation
Author(s): Renato Sortino, Thomas Cecconello, Andrea De Marco, Giuseppe Fiameni, Andrea Pilzer, Daniel Magro, Andrew M. Hopkins, Simone Riggi, Eva Sciacca, Adriano Ingallinera, Cristobal Bordiu, Filomena Bufano, Concetto Spampinato
Pages: 6524 - 6535
49) Higher-Order Directed Community Detection by A Multiobjective Evolutionary Framework
Author(s): Jing Xiao, Jing Cao, Xiao-Ke Xu
Pages: 6536 - 6550
50) Cost-Efficient Feature Selection for Horizontal Federated Learning
Author(s): Sourasekhar Banerjee, Devvjiit Bhuyan, Erik Elmroth, Monowar Bhuyan
Pages: 6551 - 6565
51) Self-Model-Free Learning Versus Learning With External Rewards in Information Constrained Environments
Author(s): Prachi Pratyusha Sahoo, Kyriakos G. Vamvoudakis
Pages: 6566 - 6579
52) Event-Triggered Fuzzy Adaptive Stabilization of Parabolic PDE–ODE Systems
Author(s): Yuan-Xin Li, Bo Xu, Xing-Yu Zhang
Pages: 6580 - 6590
53) Optimal Control of Stochastic Markovian Jump Systems With Wiener and Poisson Noises: Two Reinforcement Learning Approaches
Author(s): Zhiguo Yan, Tingkun Sun, Guolin Hu
Pages: 6591 - 6600
54) Spatio-temporal Graph-Based Generation and Detection of Adversarial False Data Injection Evasion Attacks in Smart Grids
Author(s): Abdulrahman Takiddin, Muhammad Ismail, Rachad Atat, Erchin Serpedin
Pages: 6601 - 6616
55) AugDiff: Diffusion-Based Feature Augmentation for Multiple Instance Learning in Whole Slide Image
Author(s): Zhuchen Shao, Liuxi Dai, Yifeng Wang, Haoqian Wang, Yongbing Zhang
Pages: 6617 - 6628
56) Simplified Kernel-Based Cost-Sensitive Broad Learning System for Imbalanced Fault Diagnosis
Author(s): Kaixiang Yang, Wuxing Chen, Yifan Shi, Zhiwen Yu, C. L. Philip Chen
Pages: 6629 - 6644
57) Partial Domain Adaptation for Building Borehole Lithology Model Under Weaker Geological Prior
Author(s): Jing Li, Jichen Wang, Zerui Li, Yu Kang, Wenjun Lv
Pages: 6645 - 6658
58) Evolution of Web API Cooperation Network via Exploring Community Structure and Popularity
Author(s): Guosheng Kang, Yang Wang, Jianxun Liu, Buqing Cao, Yong Xiao, Yu Xu
Pages: 6659 - 6671
59) RATs-NAS: Redirection of Adjacent Trails on Graph Convolutional Networks for Predictor-Based Neural Architecture Search
Author(s): Yu-Ming Zhang, Jun-Wei Hsieh, Chun-Chieh Lee, Kuo-Chin Fan
Pages: 6672 - 6682
60) Get Rid of Your Trail: Remotely Erasing Backdoors in Federated Learning
Author(s): Manaar Alam, Hithem Lamri, Michail Maniatakos
Pages: 6683 - 6698
61) Reinforcement Learning for Solving Colored Traveling Salesman Problems: An Entropy-Insensitive Attention Approach
Author(s): Tianyu Zhu, Xinli Shi, Xiangping Xu, Jinde Cao
Pages: 6699 - 6708
62) Constrained Multiobjective Optimization via Relaxations on Both Constraints and Objectives
Author(s): Fei Ming, Bing Xue, Mengjie Zhang, Wenyin Gong, Huixiang Zhen
Pages: 6709 - 6722
63) Towards Better Accuracy-Efficiency Trade-Offs: Dynamic Activity Inference via Collaborative Learning From Various Width-Resolution Configurations
Author(s): Lutong Qin, Lei Zhang, Chengrun Li, Chaoda Song, Dongzhou Cheng, Shuoyuan Wang, Hao Wu, Aiguo Song
Pages: 6723 - 6738
64) MTECC: A Multitask Learning Framework for Esophageal Cancer Analysis
Author(s): Jianpeng An, Wenqi Li, Yunhao Bai, Huazhen Chen, Gang Zhao, Qing Cai, Zhongke Gao
Pages: 6739 - 6751
65) Compact Multitasking Multichromosome Genetic Algorithm for Heuristic Selection in Ontology Matching
Author(s): Xingsi Xue, Jerry Chun-Wei Lin, Tong Su
Pages: 6752 - 6766
0 notes
Text
Comprehensive AKTU B.Tech IT Syllabus for All Years

The AKTU B.Tech 1st year syllabus lays the foundational framework for engineering students, covering essential concepts across core subjects, practical labs, and professional skills. The first year is divided into two semesters, focusing on mathematics, science fundamentals, engineering basics, and programming skills, vital for higher technical studies.
First Year B.Tech IT Syllabus
Semester 1
Core Subjects
Mathematics-I Introduces calculus, linear algebra, and differential equations for engineering problem-solving and applications.
Physics-I Covers mechanics, wave motion, and thermodynamics, tailored for engineering contexts.
Introduction to Programming (C Language) Focuses on programming fundamentals, data structures, algorithms, and hands-on coding practice.
Electrical Engineering Basics Provides a foundation in circuit theory, electrical machines, and power systems.
Professional Communication Enhances communication, writing, and presentation skills essential for professional growth.
Practical Labs
Physics Lab
Electrical Engineering Lab
Programming Lab (C Language)
Semester 2
Core Subjects
Mathematics-II Delves into advanced calculus, vector calculus, and linear transformations.
Chemistry Covers physical, inorganic, and organic chemistry, with emphasis on engineering materials.
Engineering Mechanics Introduces statics, dynamics, and mechanics of rigid bodies.
Computer System & Programming Explores computer architecture, assembly language, and structured programming.
Basic Electronics Engineering Focuses on electronic devices, circuits, and fundamental applications.
Practical Labs
Chemistry Lab
Basic Electronics Lab
Computer Programming Lab
Second Year B.Tech IT Syllabus
Semester 3
Core Subjects
Data Structures Using C Covers arrays, stacks, queues, linked lists, and trees for efficient data manipulation.
Discrete Mathematics Explores set theory, combinatorics, graph theory, and logic, forming a mathematical backbone for computing.
Digital Logic Design Introduces binary arithmetic, logic gates, combinational and sequential circuits.
Database Management Systems (DBMS) Focuses on relational databases, SQL, and the fundamentals of database design.
Computer Organization and Architecture Delves into CPU structure, memory hierarchy, and I/O systems.
Practical Labs
Data Structures Lab
Digital Logic Design Lab
DBMS Lab
Semester 4
Core Subjects
Operating Systems Covers process scheduling, memory management, file systems, and more.
Software Engineering Introduces software development life cycle, methodologies, and quality management practices.
Object-Oriented Programming (OOP) Using Java Covers OOP principles using Java, focusing on classes, inheritance, and polymorphism.
Theory of Automata & Formal Languages Studies automata theory, regular expressions, and context-free grammars.
Design and Analysis of Algorithms Focuses on algorithmic strategies, complexity analysis, and optimization techniques.
Practical Labs
Operating Systems Lab
Java Programming Lab
Algorithms Lab
Third Year B.Tech IT Syllabus
Semester 5
Core Subjects
Computer Networks Covers networking layers, TCP/IP, routing algorithms, and data communication.
Compiler Design Explores lexical analysis, syntax analysis, semantic analysis, and optimization techniques.
Web Technologies Introduces front-end and back-end web development using HTML, CSS, JavaScript, and server-side scripting.
Microprocessors and Interfacing Covers 8085/8086 microprocessors, interfacing, and assembly language programming.
Elective I Allows students to specialize in a subject area based on their interest.
Practical Labs
Computer Networks Lab
Microprocessor Lab
Web Technologies Lab
Semester 6
Core Subjects
Artificial Intelligence Covers foundational AI techniques, knowledge representation, and learning algorithms.
Distributed Systems Focuses on distributed computing models, coordination, and replication.
Mobile Computing Emphasizes mobile app development, wireless communication, and mobility management.
Advanced Database Systems Covers NoSQL databases, data warehousing, and database security measures.
Elective II Provides an additional specialization option.
Practical Labs
AI Lab
Mobile Application Lab
Distributed Systems Lab
Final Year B.Tech IT Syllabus
Semester 7
Core Subjects
Machine Learning Focuses on supervised, unsupervised learning algorithms, and evaluation models.
Cloud Computing Introduces cloud service models, deployment, and cloud security.
Information Security Covers cryptographic methods, network security, and security threats.
Elective III Tailored to specific industry-oriented needs and interests.
Practical Labs
Machine Learning Lab
Cloud Computing Lab
Major Project Phase I
Semester 8
Core Subjects
Big Data Analytics Explores data mining, the Hadoop ecosystem, and advanced analytics.
Entrepreneurship Development Prepares students with business planning, innovation, and management skills.
Major Project The culmination of academic knowledge in a comprehensive project.
This structured curriculum equips students with in-depth IT skills and knowledge, preparing them for a thriving career in technology and innovation.
1 note
·
View note