#Chat API
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Post activity is at the highest at 4:00 pm EDT; notes peak at 10:00 pm EDT.
Text
Push Notifications vs SMS – The Core Differences
Push notifications and SMS are two powerful tools for communication, each serving different purposes with distinct advantages. Push notifications are messages sent through mobile apps or web browsers, allowing businesses to engage users with personalized, real-time updates directly on their devices. These notifications are cost-effective, work only if users have installed the app, and require internet connectivity. They can include rich media like images and links, making them highly interactive.
SMS, on the other hand, is a more traditional method that reaches users directly via their phone's messaging system, without needing an app or internet connection. It’s reliable and guarantees message delivery as long as the phone is turned on. SMS is especially useful for reaching a broader audience, as it doesn't depend on app downloads.
The key differences between push notifications and SMS are their delivery methods, cost structures, reach, and interaction levels. Push notifications are ideal for engaging app users, while SMS excels at reaching a wider audience instantly. Choosing the right option depends on a campaign's specific needs and the type of user engagement desired.
0 notes
Text
What are the security features of CPaaS platforms?
CPaaS companies and platforms prioritize security to protect in and out of all conversation threads and to protect customer data with industry regulations. Some of the standard security features of CPaaS include data encryption, compliance with industry standards, and regular security audits and assessments.
For more: https://www.apphitect.ae/blog/best-cpaas-companies/
0 notes
Text
The Power of Real-Time Messaging: Enhancing Communication in the Digital Age
Communication lies at the heart of human interaction, and in today's digital age, the way we communicate has evolved dramatically. Real-time messaging has become a ubiquitous part of our daily lives, enabling us to connect, share, and collaborate instantly, regardless of geographical boundaries. In this blog, we'll delve into the world of real-time messaging, exploring its significance, the technology behind it, its diverse applications, and its role in shaping the future of communication.

Understanding Real-Time Messaging
Let's begin with a fundamental question: What exactly is real-time messaging?
Real-time messaging refers to the exchange of text, multimedia, or other forms of data between two or more individuals or systems in real-time. In simpler terms, it's the ability to send and receive messages instantly, allowing for seamless and immediate communication.
Real-time messaging is facilitated through various platforms and technologies, including messaging apps, chat services, and APIs (Application Programming Interfaces). These tools enable individuals and businesses to engage in instant conversations, collaborate on projects, provide customer support, and more.
How Real-Time Messaging Works
To understand how real-time messaging works, let's break down the process into key components:
1. Message Sending
The process begins when a user composes a message and sends it. The message can be in the form of text, images, videos, or any other multimedia content.
2. Message Transmission
Once the message is sent, it travels over the internet to reach the intended recipient. This transmission is typically facilitated through servers, which act as intermediaries in the messaging process.
3. Message Delivery
Upon reaching the recipient's device or platform, the message is delivered and displayed instantly. Modern real-time messaging systems often provide features like read receipts and typing indicators to enhance the user experience.
4. Synchronization
Real-time messaging platforms ensure that the conversation remains synchronized across all devices and clients. This means that a message sent on one device will be visible on all devices associated with the same account.
5. Real-Time Updates
Users receive real-time updates when new messages arrive. This can include push notifications on mobile devices or desktop notifications on computers, ensuring that users don't miss important messages.
6. Multimedia Support
Real-time messaging supports a wide range of multimedia content, including images, videos, voice messages, and file attachments. This versatility enhances the richness of conversations.
7. End-to-End Encryption
To ensure the security and privacy of messages, many real-time messaging platforms employ end-to-end encryption. This means that only the sender and the recipient can decrypt and read the messages.
Applications of Real-Time Messaging
Real-time messaging has found applications in various sectors and industries, transforming the way we communicate and collaborate. Here are some notable use cases:
1. Personal Communication
Messaging apps like WhatsApp, Facebook Messenger, iMessage, and Telegram have revolutionized personal communication. People use these platforms to stay in touch with friends and family, share updates, and exchange messages in real-time.
2. Business and Team Collaboration
Real-time messaging has become an integral part of the modern workplace. Tools like Slack, Microsoft Teams, and Google Chat enable employees to collaborate on projects, share documents, and communicate instantly, irrespective of their physical location.
3. Customer Support
Many businesses leverage real-time messaging for customer support. Live chat on websites and messaging apps allow customers to seek assistance, ask questions, and resolve issues promptly, leading to higher customer satisfaction.
4. Social Networking
Social media platforms like Twitter, Instagram, and LinkedIn incorporate real-time messaging features, allowing users to connect, engage, and interact in real-time. These platforms facilitate conversations among users with shared interests or connections.
5. Online Gaming
Real-time messaging plays a crucial role in online gaming. Gamers use chat features to strategize, coordinate gameplay, and interact with fellow players, enhancing the multiplayer gaming experience.
6. Healthcare
In healthcare, real-time messaging is used for telemedicine and patient communication. Doctors and patients can exchange messages, share medical records, and discuss treatment plans securely and efficiently.
7. E-commerce
E-commerce platforms often integrate real-time messaging to assist shoppers. Customers can inquire about products, seek recommendations, and receive instant responses from customer support representatives.
Key Features of Real-Time Messaging Platforms
When evaluating real-time messaging platforms or apps, it's important to consider the following key features:
1. Cross-Platform Compatibility
Real-time messaging should be accessible across various devices and operating systems, including smartphones, tablets, desktops, and web browsers, to ensure seamless communication.
2. Multimedia Support
Support for multimedia content, such as images, videos, and files, enhances the versatility of conversations and allows users to share a wide range of information.
3. Security and Privacy
End-to-end encryption and robust security measures are essential to protect sensitive information exchanged during real-time messaging.
4. Group Chat
The ability to create group chats or channels enables collaboration among multiple participants, making it ideal for team communication or community building.
5. Notification Customization
Users should have the option to customize notifications to suit their preferences, ensuring that they stay informed without being overwhelmed.
6. Message Search and History
A robust search feature and message history storage help users retrieve past conversations and locate specific messages quickly.
7. Integration Capabilities
Integration with other tools and services, such as file-sharing platforms, calendars, and project management apps, enhances productivity and collaboration.
The Future of Real-Time Messaging
As technology continues to evolve, real-time messaging is expected to play an even more significant role in our lives. Here are some trends and possibilities for the future:
1. Enhanced AI Integration
Artificial intelligence (AI) will likely play a more prominent role in real-time messaging, offering features like smart replies, language translation, and chatbots for automated customer support.
2. Augmented Reality (AR) Messaging
AR features may be integrated into messaging apps, allowing users to overlay digital objects or animations onto their real-world environment during video calls or chat.
3. Integration with IoT
Real-time messaging could connect with the Internet of Things (IoT) devices, enabling users to control smart home devices, receive updates, and interact with IoT systems through messaging platforms.
4. Improved Multimodal Communication
Future real-time messaging may allow users to seamlessly switch between text, voice, and video communication within the same conversation, making interactions more versatile.
Real-time messaging has transformed the way we communicate, bridging geographical gaps and enabling instant connections. Its applications are diverse, spanning personal communication, business collaboration, customer support, and more.
As technology continues to advance, real-time messaging will continue to evolve, offering new features and opportunities for enhanced communication. Whether you're connecting with friends and family, collaborating with colleagues, or seeking customer support, real-time messaging has become an integral part of our digital lives, and its impact will only continue to grow in the future.
0 notes
Text
Si te respondo rápido por chat, es porque tienes sonidito, no a cualquiera le doy prioridad.
-Llámame cursi.
#frases#amor#versos#citas#citas de amor#textos#notas#pensamientos#escritos#memorias#memories#parejas#chats#wattpad#whatsapp api
35 notes
·
View notes
Note
Any chance of DM/chat history being made available via the API? Or otherwise made easier to view and download? I chat frequently with some of my mutuals, but there's no practical way to look at recent chat history, and no way at all to see anything past the last hundred or so messages (which might be less than a day's worth of chatting!).
Answer: Hey, @fallintosanity!
We’re afraid to say this is one of those that, as nice as it would be to have, is not something we can prioritize at this moment. That said, there is an option.
While there are no plans to open up third-party API access to direct messages, a copy of all of your conversations comes with your blog export! We would recommend this as the best way around it, for now, and hope this helps.
Thanks for your question! Keep them coming, folks.
41 notes
·
View notes
Text
5 مقاييس أداء لمحادثة مبيعات WhatsApp الرئيسية لتتبعها
إحصائيات تطبيق WhatsApp
يعد تتبع إحصائيات الدردشة الحية على WhatsApp، مثل أوقات الاستجابة وأوقات الدقة، أمراً أساسياً لدعم معايير مستوى خدمة الدردشة العالية لعملك. إنها أيضاً طريقة رائعة لمواكبة مراقبة أداء الوكلاء لممثلي خدمة عملاء WhatsApp للتأكد من أنهم يزودون العملاء بالإجابات التي يحتاجون إليها.
استخدام احصائيات WhatsApp لتحسين أداء خدمة العملاء
لديك تطبيق WhatsApp Business (سواء كان التطبيق المجاني أو WhatsApp Business API)، ووكلاء خدمة العملاء مدربون وكلهم على اتم الاستعداد، وأنت على ما يرام. ومع ذلك، فإن تقديم خدمة عملاء جيدة على منصات محادثة المبيعات مثل WhatsApp لا ينتهي عند هذا الحد فقط.
يتضمن أيضاً مراقبة وتتبع إحصائيات الدردشة المباشرة في WhatsApp للتأكد من تحقيق الأهداف والمعايير، والمعايير عالية الجودة، وبشكل عام، أن العملاء سعداء وأن عملك ينمو.
سواء كنت تستخدم تطبيق WhatsApp Business المجاني أو WhatsApp Business API، فهذه بعض مقاييس مبيعات الدردشة المباشرة التي تريد بالتأكيد مراقبتها.
5 مقاييس أداء لمحادثة مبيعات WhatsApp الرئيسية لتتبعها
إحصائيات الدردشة الحية في تطبيق WhatsApp: الرسائل المرسلة، المسلمة، المقروءة، المستلمة
ربما يكون أحد المقاييس الأساسية لمحادثات المبيعات المباشرة التي يجب تتبعها هو عدد الرسائل التي تم إرسالها، وتسليمها، وقراءتها، واستلامها.
هذه مفيدة لمراقبة أداء الوكيل وفهم مدى تفاعل وكلاء خدمة العملاء مع عملائك، بالإضافة إلى ذلك، فإنه يرسم أيضاً صورة لتجربتهم الشاملة مع عملك.
للحصول على هذه المبيعات لإحصائيات الدردشة على تطبيق WhatsApp Business المجاني، ما عليك سوى الدخول إلى التطبيق، والنقر على النقاط الرأسية الثلاث في الزاوية اليمنى العليا وتحديد أدوات الأعمال.
بمجرد الدخول، انقر فوق النقاط الرأسية الثلاث مرة أخرى، وحدد الإحصائيات.
يجب أن يأخذك هذا إلى شاشة تقسم العدد الإجمالي للرسائل التي تم إرسالها، وتسليمها، وقراءتها، واستلامها.
عدد المحادثات
من المقاييس الأساسية الأخرى لدردشة المبيعات التي قد ترغب في تتبعها عدد محادثات WhatsApp التي تجريها مع عملائك.
قد يعني هذا العدد الإجمالي لجلسات الدردشة التي تعود إلى الوقت الذي بدأت فيه استخدام WhatsApp Business أو حتى خلال فترة محددة مثل أسبوع أو شهر معين. يكون الخيار الأخير مفيدًا عندما يكون لديك حملة مبيعات أو تسويق مرتبطة باتصالك عبر WhatsApp مع عملائك الذي تريد مراقبته.
يمكنك أيضًا تتبع العدد الإجمالي للمحادثات بمرور الوقت لقياس معدل اتصال العملاء بك عبر WhatsApp, قد يكون انخفاض عدد جلسات الدردشة مؤشراً على أن عملائك يفضلون التواصل عبر قناة أخرى.
قد يعني أيضاً أن إمكانية الوصول إلى WhatsApp ليست واضحة بما يكفي. إذا كانت هذه هي الحالة، ففكر في وضع رموز دردشة WhatsApp في أماكن أكثر شهرة مثل الزر العائم على صفحتك الرئيسية أو إنشاء إعلانات Facebook التي تنقر فوق WhatsApp.
نصيحة: يمكنك حتى إعداد المراقبة لاكتشاف كلمات رئيسية محددة مذكورة في محادثات مبيعات WhatsApp. بهذه الطريقة، يمكنك الحصول على فهم أفضل للمشاكل الشائعة التي يواجها عملاؤك ويمكنك إنشاء صفحة أسئلة وأجوبة تتناول هذه المشاكل لتقليل وقت حل المشكلة.
وقت استجابة الدردشة الحية
يعد وقت استجابة الدردشة الحية مقياساً مهماً لتتبع مراقبة أداء الوكيل.
يشير هذا إلى كل من وقت الاستجابة الأول والردود اللاحقة، مع أهمية خاصة للأول كما يشير فوراً، توفر وكلاء خدمة العملاء لديك وإمكانية الوصول إليهم على WhatsApp.
بشكل أساسي، تخبرك هذه الإحصائية بمدى سرعة استجابة ممثلي خدمة العملاء للرسائل المستلمة عبر محادثات WhatsApp المباشرة.
كمرجع، متوسط قياس وقت التعامل للرسائل الأولى ما بين ست إلى 15 ثانية.
إذا كنت تتساءل عن كيفية تحسين جودة الدردشة، ففي بعض الأحيان، يؤدي الرد ببساطة إلى الحيلة فقط لأن العملاء يحتاجون فقط إلى معرفة أن هناك وكيلًا خارج الشاشة يقرأ استفساراتهم ويهتم بها.
نصيحة: إذا توصل أحد العملاء إلى مشكلة لا يمكن حلها على الفور، فإن رسالة بسيطة لإعلامه بتلقي رسالته وسيتم النظر فيها يمكن أن تساعد في تهدئة المخاوف. يمنحك هذا وقتاً طويلاً للرد لاحقًا بإجابة أكثر تحديداً. يمكن إعداد هذا ليتم إرساله تلقائياً.
متوسط وقت حل المشاكل
لدعم معايير مستوى خدمة الدردشة الخاصة بك على WhatsApp، فإن أحد أهم مقاييس دردشة المبيعات التي يجب مراقبتها هو متوسط وقت الحل، المعروف أيضاً باسم ART اختصار لــ "Average Resolution Time".
هذا هو متوسط الوقت الذي يستغرقه وكلاء دردشة WhatsApp لحل مشكلة العميل.
على الرغم من أن الحفاظ على وقت الاستجابة العام أمراً حيوياً، إلا أن التفاعلات مع عملائك عبر الدردشة الحية يجب أن تكون أيضاً منتجة وتؤدي إلى نتائج. وهذا يعني السعي لحل مشاكلهم بأسرع ما يمكن.
إليك صيغة بسيطة لحساب ART:
إجمالي وقت الحل عبر جميع الدردشات (أو الحالات) / إجمالي عدد التذاكر التي تم حلها.
يشير انخفاض ART إلى حل فعال للمشاكل، في حين أن ارتفاع مستوى المعالجة المضادة للمشاكل الصعبة يمكن أن يرجع إلى أي شيء بدءاً من وجود وكلاء غير مدربين ونقص الموظفين إلى تلقي مشاكل أكثر تعقيداً.
باختصار، هذا مقياس واحد سترغب في إضافته وإبرازه على لوحات معلومات أداء خدمة العملاء عبر او باستخدام الواتساب شات بوت لأنه يوفر رؤى رائعة لخدمة العملاء وجودة الدردشات على WhatsApp.
نسبة الدردشة ومعدلات التحويل
يعد معدل تحويل الدردشة الحية أحد أفضل مقاييس أداء الوكيل التي يجب تتبعها.
يتم حساب ذلك بقسمة عدد المستهلكين الذين قاموا بالتحويل بعد التحدث إلى أحد وكلائك على WhatsApp على العدد الإجمالي للمستهلكين الذين تحدثوا مع وكلائك.
لاحظ أن "التحويل" هنا يختلف وفقًا للسياق الموجود فيه. ويمكن أن يشير إلى أي شيء ويتم تحديده بواسطتك.
كعمل تجاري إلكتروني، عادةً ما تعني التحويلات عملية بيع (أي عندما يشتري المستهلك منتجك). ومع ذلك، يمكن أن يعني أيضاً إضافة إلى عربات التسوق، أو الاشتراك في الرسائل الإخبارية، أو حتى تكرار عمليات الشراء، اعتماداً على الهدف والهدف من الحملة التي تديرها.
لتحسين معدل تحويل الدردشة، يجب عليك ضمان مع��يير عالية لمستوى خدمة الدردشة. هذا يعني تدريب وكلائك على بذل جهد إضافي عند استخدام WhatsApp كقناة لدعم ��لعملاء.
إذا سمحت مواردك بذلك، يمكنك أيضاً أن يكون لديك وكلاء معينون مدربون على مهام محددة. على سبيل المثال، يمكن أن يكون لديك فريق مخصص لبيع المنتجات، وآخر لتشجيع عمليات الشراء المتكررة، وما إلى ذلك.
تتبع محادثة المبيعات ومقاييس أداء الوكيل على WhatsApp Business API
#رسائل تسوقية#شات بوت#واتس لوب#chat bot#رسائل دعائية#شركة واتس لووب في جدة#رسائل تروجيه#bot#بوت تفاعلي#خدمات الشات بوت#لايف شات#شجري#شات بوت واتساب#واتساب api#تصميم مواقع ويب#محادثة خدمة عملاء#محادثة تفاعلية#دعم خدمة عملاء#شات بوت خدمه العملاءح#شات بوت خدمه العملاء#رسائل جماعية
23 notes
·
View notes
Text
#شات بوت#شركة واتس لووب في جدة#رسائل تسوقية#رسائل تروجيه#شجري#بوت تفاعلي#رسائل جماعية#رسائل دعائية#واتس لوب#خدمات الشات بوت#واتساب api#api#whatsapp business api#whatsapp api#chatbot#chat bot#bots#bot#شركه واتس لوب في جده
5 notes
·
View notes
Text
4 notes
·
View notes
Text
gang im lowkey starting to hate thos computer lab class not gonna lie.
like i chose a major that doesnt include much computer handling and yet theres a whole ass coding class in here oh my god
#what the fuck is an API key!!!! since when are we making a chat ai!!!!!! its cool that u can do that but i dont understand it and i dont wan#lovdels nonsense
0 notes
Text
wait i didnt realize the profiles that were "lost" due to the api migration were back ;-;
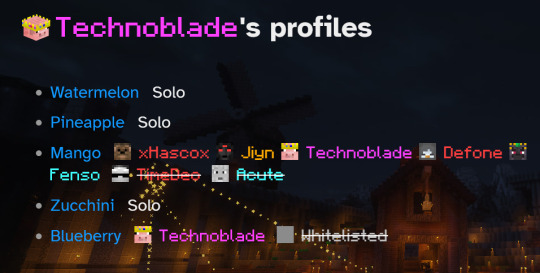
#YIPPEE#at first i thought this mightve been specially done for him but other ppl's are back too#initially profiles would only show back up if you logged in and it updated#but profiles are also showing for ppl that i KNOW havent logged in any time since then#yayyyyy yippee this stuff is back for me to stare at#i want nothing more than for someone to go make all his api stuff public#i just wanna be nosy. let me answer some questions i had. Please#would it be problematic for his dad to LOG IN and give all his friends in his f list a heart attack? yes. yes it would be.#cant an admin just like... manually do it. please ;-;#chat#sb
12 notes
·
View notes
Note
Did you know cockroaches are actually more suseptible to radiation than most bugs
<APIS> That's incredibly interesting! Poor guys, though... Gotta wonder what causes that harsh reaction.
<APIS> ...Got any papers on it?
2 notes
·
View notes
Text
"Me dijeron tu nombre, un día de estos —el corazón golpeó mi pecho—, mas no supe cómo mentirles."
-Recuerdo olvidarte.
#frases#amor#versos#citas#citas de amor#textos#notas#pensamientos#escritos#desamor#recuerdos#nostalgia#nostalgico#extrañar#te estoy olvidando#memorias#memories#notas cortas#soledad#chats#whatsapp api
22 notes
·
View notes
Text

Top WhatsApp API Providers in India
#WhatsApp Marketing#Real Estate Leads#Real Estate WhatsApp Templates#Property Marketing Messages#Real Estate CRM#Real Estate Sales#WhatsApp Business API#Lead Generation Real Estate#Real Estate Promotions#Real Estate Follow Up#WhatsApp Templates for Realtors#Property Inquiry Messages#Real Estate Campaign Ideas#Real Estate WhatsApp Broadcast#WhatsApp Automation Real Estate#Real Estate Agent Tools#Real Estate Chat Templates#Real Estate Customer Engagement#Real Estate Marketing 2025#WhatsApp Message Examples
1 note
·
View note
Text
#رسائل تروجيه#شات بوت#شركة واتس لووب في جدة#chat bot#رسائل تسوقية#bot#واتس لوب#رسائل دعائية#بوت تفاعلي#خدمات الشات بوت#رسائل جماعية#محادثة خدمة عملاء#تصميم مواقع ويب#محادثة تفاعلية#دعم خدمة عملاء#شات بوت خدمه العملاءح#شات بوت خدمه العملاء#شات بوت واتساب#لايف شات#شجري#واتساب api
23 notes
·
View notes
Text
New Research Papers Question ‘Token’ Pricing for AI Chats
New Post has been published on https://thedigitalinsider.com/new-research-papers-question-token-pricing-for-ai-chats/
New Research Papers Question ‘Token’ Pricing for AI Chats
New research shows that the way AI services bill by tokens hides the real cost from users. Providers can quietly inflate charges by fudging token counts or slipping in hidden steps. Some systems run extra processes that don’t affect the output but still show up on the bill. Auditing tools have been proposed, but without real oversight, users are left paying for more than they realize.
In nearly all cases, what we as consumers pay for AI-powered chat interfaces, such as ChatGPT-4o, is currently measured in tokens: invisible units of text that go unnoticed during use, yet are counted with exact precision for billing purposes; and though each exchange is priced by the number of tokens processed, the user has no direct way to confirm the count.
Despite our (at best) imperfect understanding of what we get for our purchased ‘token’ unit, token-based billing has become the standard approach across providers, resting on what may prove to be a precarious assumption of trust.
Token Words
A token is not quite the same as a word, though it often plays a similar role, and most providers use the term ‘token’ to describe small units of text such as words, punctuation marks, or word-fragments. The word ‘unbelievable’, for example, might be counted as a single token by one system, while another might split it into un, believ and able, with each piece increasing the cost.
This system applies to both the text a user inputs and the model’s reply, with the price based on the total number of these units.
The difficulty lies in the fact that users do not get to see this process. Most interfaces do not show token counts while a conversation is happening, and the way tokens are calculated is hard to reproduce. Even if a count is shown after a reply, it is too late to tell whether it was fair, creating a mismatch between what the user sees and what they are paying for.
Recent research points to deeper problems: one study shows how providers can overcharge without ever breaking the rules, simply by inflating token counts in ways that the user cannot see; another reveals the mismatch between what interfaces display and what is actually billed, leaving users with the illusion of efficiency where there may be none; and a third exposes how models routinely generate internal reasoning steps that are never shown to the user, yet still appear on the invoice.
The findings depict a system that seems precise, with exact numbers implying clarity, yet whose underlying logic remains hidden. Whether this is by design, or a structural flaw, the result is the same: users pay for more than they can see, and often more than they expect.
Cheaper by the Dozen?
In the first of these papers – titled Is Your LLM Overcharging You? Tokenization, Transparency, and Incentives, from four researchers at the Max Planck Institute for Software Systems – the authors argue that the risks of token-based billing extend beyond opacity, pointing to a built-in incentive for providers to inflate token counts:
‘The core of the problem lies in the fact that the tokenization of a string is not unique. For example, consider that the user submits the prompt “Where does the next NeurIPS take place?” to the provider, the provider feeds it into an LLM, and the model generates the output “|San| Diego|” consisting of two tokens.
‘Since the user is oblivious to the generative process, a self-serving provider has the capacity to misreport the tokenization of the output to the user without even changing the underlying string. For instance, the provider could simply share the tokenization “|S|a|n| |D|i|e|g|o|” and overcharge the user for nine tokens instead of two!’
The paper presents a heuristic capable of performing this kind of disingenuous calculation without altering visible output, and without violating plausibility under typical decoding settings. Tested on models from the LLaMA, Mistral and Gemma series, using real prompts, the method achieves measurable overcharges without appearing anomalous:
Token inflation using ‘plausible misreporting’. Each panel shows the percentage of overcharged tokens resulting from a provider applying Algorithm 1 to outputs from 400 LMSYS prompts, under varying sampling parameters (m and p). All outputs were generated at temperature 1.3, with five repetitions per setting to calculate 90% confidence intervals. Source: https://arxiv.org/pdf/2505.21627
To address the problem, the researchers call for billing based on character count rather than tokens, arguing that this is the only approach that gives providers a reason to report usage honestly, and contending that if the goal is fair pricing, then tying cost to visible characters, not hidden processes, is the only option that stands up to scrutiny. Character-based pricing, they argue, would remove the motive to misreport while also rewarding shorter, more efficient outputs.
Here there are a number of extra considerations, however (in most cases conceded by the authors). Firstly, the character-based scheme proposed introduces additional business logic that may favor the vendor over the consumer:
‘[A] provider that never misreports has a clear incentive to generate the shortest possible output token sequence, and improve current tokenization algorithms such as BPE, so that they compress the output token sequence as much as possible’
The optimistic motif here is that the vendor is thus encouraged to produce concise and more meaningful and valuable output. In practice, there are obviously less virtuous ways for a provider to reduce text-count.
Secondly, it is reasonable to assume, the authors state, that companies would likely require legislation in order to transit from the arcane token system to a clearer, text-based billing method. Down the line, an insurgent startup may decide to differentiate their product by launching it with this kind of pricing model; but anyone with a truly competitive product (and operating at a lower scale than EEE category) is disincentivized to do this.
Finally, larcenous algorithms such as the authors propose would come with their own computational cost; if the expense of calculating an ‘upcharge’ exceeded the potential profit benefit, the scheme would clearly have no merit. However the researchers emphasize that their proposed algorithm is effective and economical.
The authors provide the code for their theories at GitHub.
The Switch
The second paper – titled Invisible Tokens, Visible Bills: The Urgent Need to Audit Hidden Operations in Opaque LLM Services, from researchers at the University of Maryland and Berkeley – argues that misaligned incentives in commercial language model APIs are not limited to token splitting, but extend to entire classes of hidden operations.
These include internal model calls, speculative reasoning, tool usage, and multi-agent interactions – all of which may be billed to the user without visibility or recourse.
Pricing and transparency of reasoning LLM APIs across major providers. All listed services charge users for hidden internal reasoning tokens, and none make these tokens visible at runtime. Costs vary significantly, with OpenAI’s o1-pro model charging ten times more per million tokens than Claude Opus 4 or Gemini 2.5 Pro, despite equal opacity. Source: https://www.arxiv.org/pdf/2505.18471
Unlike conventional billing, where the quantity and quality of services are verifiable, the authors contend that today’s LLM platforms operate under structural opacity: users are charged based on reported token and API usage, but have no means to confirm that these metrics reflect real or necessary work.
The paper identifies two key forms of manipulation: quantity inflation, where the number of tokens or calls is increased without user benefit; and quality downgrade, where lower-performing models or tools are silently used in place of premium components:
‘In reasoning LLM APIs, providers often maintain multiple variants of the same model family, differing in capacity, training data, or optimization strategy (e.g., ChatGPT o1, o3). Model downgrade refers to the silent substitution of lower-cost models, which may introduce misalignment between expected and actual service quality.
‘For example, a prompt may be processed by a smaller-sized model, while billing remains unchanged. This practice is difficult for users to detect, as the final answer may still appear plausible for many tasks.’
The paper documents instances where more than ninety percent of billed tokens were never shown to users, with internal reasoning inflating token usage by a factor greater than twenty. Justified or not, the opacity of these steps denies users any basis for evaluating their relevance or legitimacy.
In agentic systems, the opacity increases, as internal exchanges between AI agents can each incur charges without meaningfully affecting the final output:
‘Beyond internal reasoning, agents communicate by exchanging prompts, summaries, and planning instructions. Each agent both interprets inputs from others and generates outputs to guide the workflow. These inter-agent messages may consume substantial tokens, which are often not directly visible to end users.
‘All tokens consumed during agent coordination, including generated prompts, responses, and tool-related instructions, are typically not surfaced to the user. When the agents themselves use reasoning models, billing becomes even more opaque’
To confront these issues, the authors propose a layered auditing framework involving cryptographic proofs of internal activity, verifiable markers of model or tool identity, and independent oversight. The underlying concern, however, is structural: current LLM billing schemes depend on a persistent asymmetry of information, leaving users exposed to costs that they cannot verify or break down.
Counting the Invisible
The final paper, from researchers at the University of Maryland, re-frames the billing problem not as a question of misuse or misreporting, but of structure. The paper – titled CoIn: Counting the Invisible Reasoning Tokens in Commercial Opaque LLM APIs, and from ten researchers at the University of Maryland – observes that most commercial LLM services now hide the intermediate reasoning that contributes to a model’s final answer, yet still charge for those tokens.
The paper asserts that this creates an unobservable billing surface where entire sequences can be fabricated, injected, or inflated without detection*:
‘[This] invisibility allows providers to misreport token counts or inject low-cost, fabricated reasoning tokens to artificially inflate token counts. We refer to this practice as token count inflation.
‘For instance, a single high-efficiency ARC-AGI run by OpenAI’s o3 model consumed 111 million tokens, costing $66,772.3 Given this scale, even small manipulations can lead to substantial financial impact.
‘Such information asymmetry allows AI companies to significantly overcharge users, thereby undermining their interests.’
To counter this asymmetry, the authors propose CoIn, a third-party auditing system designed to verify hidden tokens without revealing their contents, and which uses hashed fingerprints and semantic checks to spot signs of inflation.
Overview of the CoIn auditing system for opaque commercial LLMs. Panel A shows how reasoning token embeddings are hashed into a Merkle tree for token count verification without revealing token contents. Panel B illustrates semantic validity checks, where lightweight neural networks compare reasoning blocks to the final answer. Together, these components allow third-party auditors to detect hidden token inflation while preserving the confidentiality of proprietary model behavior. Source: https://arxiv.org/pdf/2505.13778
One component verifies token counts cryptographically using a Merkle tree; the other assesses the relevance of the hidden content by comparing it to the answer embedding. This allows auditors to detect padding or irrelevance – signs that tokens are being inserted simply to hike up the bill.
When deployed in tests, CoIn achieved a detection success rate of nearly 95% for some forms of inflation, with minimal exposure of the underlying data. Though the system still depends on voluntary cooperation from providers, and has limited resolution in edge cases, its broader point is unmistakable: the very architecture of current LLM billing assumes an honesty that cannot be verified.
Conclusion
Besides the advantage of gaining pre-payment from users, a scrip-based currency (such as the ‘buzz’ system at CivitAI) helps to abstract users away from the true value of the currency they are spending, or the commodity they are buying. Likewise, giving a vendor leeway to define their own units of measurement further leaves the consumer in the dark about what they are actually spending, in terms of real money.
Like the lack of clocks in Las Vegas, measures of this kind are often aimed at making the consumer reckless or indifferent to cost.
The scarcely-understood token, which can be consumed and defined in so many ways, is perhaps not a suitable unit of measurement for LLM consumption – not least because it can cost many times more tokens to calculate a poorer LLM result in a non-English language, compared to an English-based session.
However, character-based output, as suggested by the Max Planck researchers, would likely favor more concise languages and penalize naturally verbose languages. Since visual indications such as a depreciating token counter would probably make us a little more spendthrift in our LLM sessions, it seems unlikely that such useful GUI additions are coming anytime soon – at least without legislative action.
* Authors’ emphases. My conversion of the authors’ inline citations to hyperlinks.
First published Thursday, May 29, 2025
#2025#agent#agents#AGI#ai#AI AGENTS#AI chatbots#AI-powered#algorithm#Algorithms#Anderson's Angle#API#APIs#approach#arc#ARC-AGI#architecture#Artificial Intelligence#asymmetry#audit#Behavior#Business#Chat GPT#chatGPT#ChatGPT-4o#chatgpt4#classes#claude#code#Companies
0 notes
Text
الطرق الثلاثة الرئيسية لاستخدام الذكاء الاصطناعي في خدمة العملاء
الذكاء الاصطناعي
أصبح استخدام الذكاء الاصطناعي لخدمة العملاء شائعاً اليوم. تم ذكر 15 طريقة لاستغلال قوة الذكاء الاصطناعي، ولكن القائمة يمكن أن تصبح أطول. من بين الشركات الكبرى التي تستخدم الذكاء الاصطناعي لتحسين خدمات العملاء، لدينا علامات تجارية كبيرة، مثل Apple وFacebook وDeloitte وMicrosoft وVolvo وKFC.
ما معنى استخدام الذكاء الاصطناعي في خدمة العملاء عملياً؟ للإجابة على هذا السؤال، جمعنا نصائح بعض خبراء الذكاء الاصطناعي والابتكار وأنشأنا ثلاث مجالات رئيسية تغطي تقريباً أي تطبيق ممكن لهذه التكنولوجيا.
المجال الأول لاستخدام الذكاء الاصطناعي: ضمان السرعة والراحة والفعالية
يعد الاتصال بخدمة العملاء التقليدية أمراً محبطاً، خاصةً من الهاتف المحمول. بعد مجموعة من الأسئلة التي يتعين على المستخدمين الإجابة عليها عن طريق الضغط الخرقاء على الأزرار الصغيرة غير المريحة في لوحة مفاتيح هواتفهم المحمولة ومن ثم الانتظار للرد.
هذه ليست النهاية. بمجرد أن يتم تأجيله، هناك انتظار طويل. لا يتم تقديم أي معلومات إذا كان الأمر يستغرق ثوانٍ أو دقائق أو ساعات.
يمكن أن يؤدي استخدام الذكاء الاصطناعي لخدمة العملاء إلى تغيير ذلك. يقدم الشات البوت المدعوم بالذكاء الاصطناعي النصي AI إجابات فورية بنبرة صوت مهذبة وودودة ويدير الأسئلة الأساسية والأكثر شيوعاً لأي عميل. ليس من المستغرب أن 62٪ من المستخدمين يرحبون بفكرة وجود بعض الشات بوت لحملهم عند الوصول إلى خدمات العملاء.
يمكن للذكاء الاصطناعي الصوتي القيام بأكثر من مجرد تجنب انتظار المكالمات. على سبيل المثال، يمكن للذكاء الاصطناعي الصوتي بدء محادثة حقيقية مع مستخدم في الثانية الأولى من اللمس وتجنب العملاء الذين يعانون من تجربة سيئة أن يتخبطوا في لوحات المفاتيح الصغيرة في هواتفهم المحمولة، خاصةً عندما يكونون في مواقف مثل الوقوف في مكان مزدحم. القطار أو الحافلات.
باختصار، يوفر استخدام الذكاء الاصطناعي لخدمة العملاء تجربة مستخدم أفضل وسلسة؛ ونعلم جميعاً أن تجربة المستخدم الأفضل توفر أموالًا أكثر بكثير للمؤسسات من حيث المزيد من التحويلات وتقليل فقدان حركة المرور.
كيف يساعد الذكاء الاصطناعي في تسريع برامج المحادثة الخاصة بخدمة العملاء وجعلها أكثر كفاءة؟
عند الوصول إلى التفاصيل الفنية، كيف يمكن للذكاء الاصطناعي تعزيز خدمات العملاء؟ هناك ثلاث طرق على الأقل:
يمكن للشات بوت المدعوم بالذكاء الاصطناعي التعامل مع استعلامات متعددة في وقت واحد. إنها تخفف آلام مراكز الاتصال المزدحمة اليوم والتي تتلقى آلاف المكالمات في الدقيقة. ينخفض وقت الاستجابة بشكل كبير ويوفر وقت المنظمة.
يمكن للذكاء الاصطناعي تحديد أفضل وكيل متاح لتلبية احتياجات العميل. هذا يعني أن عملائك سيتواصلون في الوقت المناسب مع الشخص الأكثر قدرة على المساعدة. ثم، مع ما يترتب على ذلك من زيادة من حيث توفير الوقت والرضا.
يتيح الذكاء الاصطناعي مزيداً من الوظائف وطرق الاتصال بين الأشخاص من خلال القنوات والتطبيقات الرقمية. على سبيل المثال، يقترح Slack وWhatsApp والمراسلين الآخرين الإجراءات ذات الصلة، مثل مشاركة موقع أو إرسال ملصق. وقد أدى ذلك إلى إنشاء طريقة جديدة تماماً للتواصل وتبادل الرسائل التي تعتبر نموذجية للشبكات الاجتماعية.
المجال الثاني لاستخدام الذكاء الاصطناعي: تصنيف العملاء وإدارة البيانات
يحتاج الذكاء الاصطناعي إلى البيانات لفهم احتياجات العملاء وخدمتهم بأكثر الموارد ملاءمة. يمكن لروبوتات الذكاء الاصطناعي حفر البيانات ذات الصلة للعميل بطريقتين:
عن طريق تصنيف العملاء. وهذا يعني استخراج الآلاف والآلاف من أجزاء البيانات التي يمكن جمعها عن طريق تتبع محادثات العملاء، والتنقلات، وسلوكهم بشكل عام.
من خلال الوصول إلى بيانات CRM الخاصة بالمنظمة، تحتاج البيانات بعد ذلك إلى المعالجة. إن العمليات النموذجية التي يقوم بها روبوت الذكاء الاصطناعي بالبيانات هي التالية:
احصل على رؤى في الوقت الفعلي عبر جميع قنوات الاتصال بالعملاء.
تحسين توافر الوكيل وأوقات الانتظار وفرص تقديم الخدمة الاستباقية.
تصعيد الحالات وتصنيفها تلقائيًا باستخدام التحليلات التنبؤية للحساسية وخبرة المجال.
الشات بوت القوية لتقديم المعرفة باستخدام مهام سير العمل المؤتمتة.
تمكين الوكلاء الميدانيين من تقديم الخدمة بناءً على الوصول إلى بيانات CRM.
تقديم خدمات شخصية في أي مكان.
تحسين الجدولة والتوجيه باستخدام بيانات CRM الكاملة.
تذكر أن التخصيص هو النقطة القوية. فإن خدمة العملاء المدعومة بالذكاء الاصطناعي تحتاج إلى اللمسة الإنسانية:
يسمح الذكاء الاصطناعي للشركات بتقديم هذه التجارب الأكثر ذكاءً وتخصيصًا والتنبؤ التي يتوقعها العملاء
استخدام آخر محتمل للذكاء الاصطناعي لخدمة العملاء هو التعرف على القياسات الحيوية والوجه والصوت لمستخدمي الخدمة وتحليلات المشاعر والتنبؤ بالنية.
في حين أن التعرف على المستخدمين من خلال الذكاء الاصطناعي لا يزال يظهر مشاكل، فإن التنبؤ بالنية يكاد يكون آمناً ويستخدم بالفعل على نطاق واسع من قبل العديد من المنصات. فقط لإعطاء مثال، فإن توقع النية هو الذي يسمح لـ Google بتعبئة استعلام بحث تلقائياً باستخدام بضع أرقام للمستخدم.
في خدمة العملاء، يعني توقع نية الذكاء الاصطناعي تخمين الخطوة أو المتطلبات التالية للعميل. يمكن لروبوت AI تنفيذ ذلك من خلال ترجمة إشارات العملاء (النقرات، المشاهدات، عمليات الشراء، التمرير، النقر) إلى تنبؤات تمكن الروبوت من تقديم إجابات حتى قبل أن يطلبها العميل، مثل الاتصال بالوكيل المناسب.
ترتبط تحليلات العاطفة بفهم مشاعر العملاء من خلال تحليل مجموعة من الإشارات التي عادةً ما تكون عبارة عن تحليل نصي لما يكتبه العملاء على وسائل التواصل الاجتماعي والرموز التعبيرية أو الإشارات غير اللفظية الأخرى التي يرسلونها.
يمكن استخدام البيانات التي يتم جمعها من خلال تحليل المشاعر لتوجيه العملاء إلى الفريق المناسب على أساس حالتهم المزاجية. إذا كان العميل غاضباً، على سبيل المثال، يكون فريق الاحتفاظ بالعملاء أكثر ملاءمة من قسم المبيعات. العكس هو مع العملاء السعداء والراضين.
المجال الثالث لاستخدام الذكاء الاصطناعي: الاستفادة من فهم اللغة الطبيعية
فهم اللغة الطبيعية هو المجال الأخير الذي اكتشفته في استخدام الذكاء الاصطناعي لخدمة العملاء. هذا نوع من الحدود الجديدة للذكاء الاصطناعي. الهدف هو امتلاك الشات بوت تتحدث وتتواصل مثل البشر.
باستخدام التحليل في الوقت الفعلي لمكالمات خدمة العملاء والدردشات ورسائل البريد الإلكتروني، يمكن للشات بوت المدعوم بالذكاء الاصطناعي فهم المحادثة بين ممثل خدمة العملاء والعميل. يمكن أن يوفر الذكاء الاصطناعي طرقاً لتحسين تجربة العميل من خلال فهم مستوى إحباط العميل والحاجة إلى التصعيد وحل المشكلات بشكل أسرع.
يمكن لروبوت AI أن يفهم أكثر بكثير من مجرد مشغل بشري من خلال الاستماع إلى محادثة. هذا ممكن بسبب إمكانية قيام روبوت الذكاء الاصطناعي بإجراء تحليلات متقاطعة مع البيانات الأخرى بوتيرة مستحيلة بالنسبة للبشر.
في الختام، أصبح استخدام الذكاء الاصطناعي في خدمة العملاء أحد أقوى الاتجاهات في الألفية الجديدة بسبب قوة الذكاء الاصطناعي في حل المشاكل الأكثر إزعاجاً لمراكز الاتصال التقليدية، أو لنقول ذلك بشكل أبسط، لأن الذكاء الاصطناعي يمثل تقدماً كبيراً في تقنيات خدمة العملاء.
كما هو الحال دائماً، تقدم الأرقام دليلاً: وفقًا لمسح أجرته Tata Consultancy Service، تستخدم 32٪ من الشركات الكبرى حول العالم تقنيات خدمة العملاء بالذكاء الاصطناعي، باستثمارات تزيد عن 4.5 مليار دولار.
#رسائل تروجيه#رسائل تسوقية#رسائل جماعية#بوت تفاعلي#خدمات الشات بوت#شجري#رسائل دعائية#شركة واتس لووب في جدة#واتس لوب#شات بوت#واتساب api#whatsapp business api#whatsapp api#api#bots#chat bot#bot#chatbot
5 notes
·
View notes