#Configure and Run Prometheus Container
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The KCSC sent more than 20K requests to delete posts related to prostitution and porn to Tumblr from January to June 2017.
Text
Docker Setup: Monitoring Synology with Prometheus and Grafana
In this article, we will discuss “Docker Setup: Monitoring Synology with Prometheus and Grafana”. We will be utilizing Portainer which is a lightweight/open-source management solution designed to simplify working with Docker containers instead of working with the Container Manager on Synology. Please see How to use Prometheus for Monitoring, how to Install Grafana on Windows and Windows Server,…
#Accessing Grafana and Prometheus#Add Portainer Registries#Configure and Run Prometheus Container#docker#Docker Containers on Synology#Enter5yourownpasswordhere123456#Enter5yourownpasswordhere2345#Grafana monitoring#Grafana/Prometheus Monitoring#How To Install Prometheus And Grafana On Docker#install portainer#Modify Synology Firewall Rules#monitoring solutions for Docker#portainer#portainer server#Prometheus Grafana integration#Prometheus metrics#Pull Docker Images for Grafana and Prometheus#Set Up Grafana Data Source#Synology monitoring setup#Your Portainer instance timed out for Security Purposes
0 notes
Text
Deploy Your First App on OpenShift in Under 10 Minutes
Effective monitoring is crucial for any production-grade Kubernetes or OpenShift deployment. In this article, we’ll explore how to harness the power of Prometheus and Grafana to gain detailed insights into your OpenShift clusters. We’ll cover everything from setting up monitoring to visualizing metrics and creating alerts so that you can proactively maintain the health and performance of your environment.
Introduction
OpenShift, Red Hat’s enterprise Kubernetes platform, comes packed with robust features to manage containerized applications. However, as the complexity of deployments increases, having real-time insights into your cluster performance, resource usage, and potential issues becomes essential. That’s where Prometheus and Grafana come into play, enabling observability and proactive monitoring.
Why Monitor OpenShift?
Cluster Health: Ensure that each component of your OpenShift cluster is running correctly.
Performance Analysis: Track resource consumption such as CPU, memory, and storage.
Troubleshooting: Diagnose issues early through detailed metrics and logs.
Proactive Alerting: Set up alerts to prevent downtime before it impacts production workloads.
Optimization: Refine resource allocation and scaling strategies based on usage patterns.
Understanding the Tools
Prometheus: The Metrics Powerhouse
Prometheus is an open-source systems monitoring and alerting toolkit designed for reliability and scalability. In the OpenShift world, Prometheus scrapes metrics from various endpoints, stores them in a time-series database, and supports complex querying through PromQL (Prometheus Query Language). OpenShift’s native integration with Prometheus gives users out-of-the-box monitoring capabilities.
Key Features of Prometheus:
Efficient Data Collection: Uses a pull-based model, where Prometheus scrapes HTTP endpoints at regular intervals.
Flexible Queries: PromQL allows you to query and aggregate metrics to derive actionable insights.
Alerting: Integrates with Alertmanager for sending notifications via email, Slack, PagerDuty, and more.
Grafana: Visualize Everything
Grafana is a powerful open-source platform for data visualization and analytics. With Grafana, you can create dynamic dashboards that display real-time metrics from Prometheus as well as other data sources. Grafana’s rich set of panel options—including graphs, tables, and heatmaps—lets you drill down into the details and customize your visualizations.
Key Benefits of Grafana:
Intuitive Dashboarding: Build visually appealing and interactive dashboards.
Multi-source Data Integration: Combine data from Prometheus with logs or application metrics from other sources.
Alerting and Annotations: Visualize alert states directly on dashboards to correlate events with performance metrics.
Extensibility: Support for plugins and integrations with third-party services.
Setting Up Monitoring in OpenShift
Step 1: Deploying Prometheus on OpenShift
OpenShift comes with built-in support for Prometheus through its Cluster Monitoring Operator, which simplifies deployment and configuration. Here’s how you can get started:
Cluster Monitoring Operator: Enable the operator from the OpenShift Web Console or using the OpenShift CLI. This operator sets up Prometheus instances, Alertmanager, and the associated configurations.
Configuration Adjustments: Customize the Prometheus configuration according to your environment’s needs. You might need to adjust scrape intervals, retention policies, and alert rules.
Target Discovery: OpenShift automatically discovers important endpoints (e.g., API server, node metrics, and custom application endpoints) for scraping. Ensure that your applications expose metrics in a Prometheus-compatible format.
Step 2: Integrating Grafana
Deploy Grafana: Grafana can be installed as a containerized application in your OpenShift project. Use the official Grafana container image or community Operators available in the OperatorHub.
Connect to Prometheus: Configure a Prometheus data source in Grafana by providing the URL of your Prometheus instance (typically available within your cluster). Test the connection to ensure metrics can be queried.
Import Dashboards: Leverage pre-built dashboards from the Grafana community or build your own custom dashboards tailored to your OpenShift environment. Dashboard templates can help visualize node metrics, pod-level data, and even namespace usage.
Step 3: Configuring Alerts
Both Prometheus and Grafana offer alerting capabilities:
Prometheus Alerts: Write and define alert rules using PromQL. For example, you might create an alert rule that triggers if a node’s CPU usage remains above 80% for a sustained period.
Alertmanager Integration: Configure Alertmanager to handle notifications by setting up routing rules, grouping alerts, and integrating with channels like Slack or email.
Grafana Alerting: Configure alert panels directly within Grafana dashboards, allowing you to visualize metric thresholds and receive alerts if a dashboard graph exceeds defined thresholds.
Best Practices for Effective Monitoring
Baseline Metrics: Establish baselines for normal behavior in your OpenShift cluster. Document thresholds for CPU, memory, and network usage to understand deviations.
Granular Dashboard Design: Create dashboards that provide both high-level overviews and deep dives into specific metrics. Use Grafana’s drill-down features for flexible analysis.
Automated Alerting: Leverage automated alerts to receive real-time notifications about anomalies. Consider alert escalation strategies to reduce noise while ensuring critical issues are addressed promptly.
Regular Reviews: Regularly review and update your monitoring configurations. As your OpenShift environment evolves, fine-tune metrics, dashboards, and alert rules to reflect new application workloads or infrastructure changes.
Security and Access Control: Ensure that only authorized users have access to monitoring dashboards and alerts. Use OpenShift’s role-based access control (RBAC) to manage permissions for both Prometheus and Grafana.
Common Challenges and Solutions
Data Volume and Retention: As metrics accumulate, database size can become a challenge. Address this by optimizing retention policies and setting up efficient data aggregation.
Performance Overhead: Ensure your monitoring stack does not consume excessive resources. Consider resource limits and autoscaling policies for monitoring pods.
Configuration Complexity: Balancing out-of-the-box metrics with custom application metrics requires regular calibration. Use templated dashboards and version control your monitoring configurations for reproducibility.
Conclusion
Monitoring OpenShift with Prometheus and Grafana provides a robust and scalable solution for maintaining the health of your containerized applications. With powerful features for data collection, visualization, and alerting, this stack enables you to gain operational insights, optimize performance, and react swiftly to potential issues.
As you deploy and refine your monitoring strategy, remember that continuous improvement is key. The combination of Prometheus’s metric collection and Grafana’s visualization capabilities offers a dynamic view into your environment—empowering you to maintain high service quality and reliability for all your applications.
Get started today by setting up your OpenShift monitoring stack, and explore the rich ecosystem of dashboards and integrations available for Prometheus and Grafana! For more information www.hawkstack.com
0 notes
Text
DevOps with Multi-Cloud:
A Beginner’s Guide Introduction In today’s fast-paced digital world, businesses need agility, reliability, and scalability. This is where DevOps with Multi-Cloud comes in.
By integrating DevOps practices across multiple cloud platforms, companies can optimize workloads, enhance security, and reduce vendor dependency.
If you’re looking for DevOps with Multi-Cloud Training in KPHB, this guide will help you understand the essentials.

What is DevOps with Multi-Cloud?
DevOps is a methodology that combines development (Dev) and operations (Ops) to streamline software delivery.
When paired with a multi-cloud approach—using multiple cloud providers like AWS, Azure, and Google Cloud—it brings flexibility and resilience to IT infrastructure.
Benefits of DevOps in a Multi-Cloud Environment Avoids Vendor Lock-in – Businesses can distribute workloads across different cloud providers.
Improved Disaster Recovery – If one cloud fails, another can handle operations. Cost Optimization – Companies can choose the most cost-effective cloud services.
Enhanced Performance – Running applications closer to users reduces latency.
Security & Compliance – Spreading workloads minimizes risks and ensures compliance with industry regulations. Key Components of DevOps with Multi-Cloud
CI/CD Pipelines – Automate code building, testing, and deployment. Infrastructure as Code (IaC) – Manage cloud resources using tools like Terraform or AWS CloudFormation.
Containerization & Orchestration – Docker and Kubernetes help maintain consistency across cloud environments. Monitoring & Logging – Tools like Prometheus and ELK Stack ensure system health.
Security & Compliance Automation – Integrate security into development workflows with DevSecOps. Challenges in Multi-Cloud DevOps
Complexity in Management – Handling multiple cloud platforms requires expertise.
Data Governance & Compliance – Managing regulations across different clouds is challenging.
Interoperability Issues – Ensuring seamless communication between cloud environments can be difficult. How to Overcome These Challenges?
Use multi-cloud management tools like HashiCorp Consul or Google Anthos. Implement automation to reduce manual configuration.
Follow best security practices to protect data across cloud platforms. DevOps with Multi-Cloud Training in KPHB If you’re in KPHB, Hyderabad, and want to master DevOps with Multi-Cloud, look for training programs that cover:
✔️ Hands-on experience with AWS, Azure, and Google Cloud
✔️ Real-world CI/CD pipeline implementation
✔️ Kubernetes & Docker container orchestration
✔️ Infrastructure as Code (IaC) with Terraform
✔️ Security best practices in a multi-cloud setup
FAQs
1. Why should I learn DevOps with Multi-Cloud?
DevOps with Multi-Cloud enhances career opportunities and helps businesses stay competitive in an evolving digital landscape.
2. Which cloud platforms are covered in multi-cloud training?
Popular platforms include AWS, Microsoft Azure, and Google Cloud Platform (GCP). Some courses also cover Oracle Cloud, IBM Cloud, and Alibaba Cloud.
3. What are the prerequisites for learning DevOps with Multi-Cloud?
Basic knowledge of cloud computing, Linux, and scripting languages like Python or Bash is helpful. However, beginner-friendly courses are available.
4. How long does it take to become proficient?
Depending on prior experience, 3-6 months of dedicated learning can help you gain proficiency in DevOps with Multi-Cloud.
5. Is certification necessary?
While not mandatory, certifications from AWS, Azure, or Google Cloud can boost your job prospects.
Conclusion
DevOps with Multi-Cloud is the future of IT infrastructure, offering flexibility, efficiency, and resilience.
If you're looking for DevOps with Multi-Cloud Training in KPHB,
start your journey today to gain the skills needed for a high-demand career.
#DevOps#MultiCloud#CloudComputing#AWS#Azure#GoogleCloud#Kubernetes#Docker#CICD#InfrastructureAsCode#Terraform#DevSecOps#HybridCloud#TechTraining#ITCareers#KPHB#Hyderabad#CloudSecurity#Automation#DevOpsEngineer#TechSkills#CloudNative#SoftwareDevelopment#ITTraining#CareerGrowth#CloudTechnology
0 notes
Text
Monitoring Kubernetes Clusters with Prometheus and Grafana
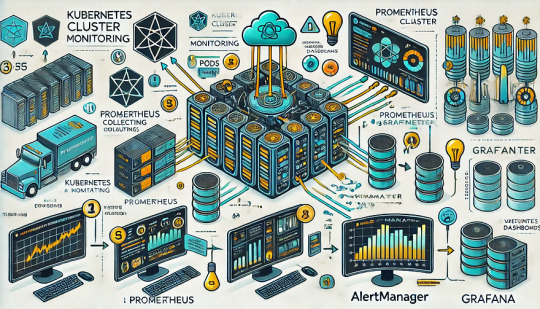
Introduction
Kubernetes is a powerful container orchestration platform, but monitoring it is crucial for ensuring reliability, performance, and scalability.
Prometheus and Grafana are two of the most popular open-source tools for monitoring and visualizing Kubernetes clusters.
In this guide, we’ll walk you through setting up Prometheus and Grafana on Kubernetes and configuring dashboards for real-time insights.
Why Use Prometheus and Grafana for Kubernetes Monitoring?
Prometheus: The Monitoring Backbone
Collects metrics from Kubernetes nodes, pods, and applications.
Uses a powerful query language (PromQL) for analyzing data.
Supports alerting based on predefined conditions.
Grafana: The Visualization Tool
Provides rich dashboards with graphs and metrics.
Allows integration with multiple data sources (e.g., Prometheus, Loki, Elasticsearch).
Enables alerting and notification management.
Step 1: Installing Prometheus and Grafana on Kubernetes
Prerequisites
Before starting, ensure you have:
A running Kubernetes cluster
kubectl and Helm installed
1. Add the Prometheus Helm Chart Repository
Helm makes it easy to deploy Prometheus and Grafana using predefined configurations.shhelm repo add prometheus-community https://prometheus-community.github.io/helm-charts helm repo update
2. Install Prometheus and Grafana Using Helm
shhelm install prometheus prometheus-community/kube-prometheus-stack --namespace monitoring --create-namespace
This command installs: ✅ Prometheus — For collecting metrics ✅ Grafana — For visualization ✅ Alertmanager — For notifications ✅ Node-exporter — To collect system-level metrics
Step 2: Accessing Prometheus and Grafana
Once deployed, we need to access the Prometheus and Grafana web interfaces.
1. Accessing Prometheus
Check the Prometheus service:shkubectl get svc -n monitoring
Forward the Prometheus server port:shkubectl port-forward svc/prometheus-kube-prometheus-prometheus 9090 -n monitoring
Now, open http://localhost:9090 in your browser.
2. Accessing Grafana
Retrieve the Grafana admin password:shkubectl get secret --namespace monitoring prometheus-grafana -o jsonpath="{.data.admin-password}" | base64 --decodeForward the Grafana service port:shkubectl port-forward svc/prometheus-grafana 3000:80 -n monitoring
Open http://localhost:3000, and log in with:
Username: admin
Password: (obtained from the previous command)
Step 3: Configuring Prometheus as a Data Source in Grafana
Open Grafana and navigate to Configuration > Data Sources.
Click Add data source and select Prometheus.
Set the URL to:
sh
http://prometheus-kube-prometheus-prometheus.monitoring.svc.cluster.local:9090
Click Save & Test to verify the connection.
Step 4: Importing Kubernetes Dashboards into Grafana
Grafana provides ready-made dashboards for Kubernetes monitoring.
Go to Dashboards > Import.
Enter a dashboard ID from Grafana’s dashboard repository.
Example: Use 3119 for Kubernetes cluster monitoring.
Select Prometheus as the data source and click Import.
You’ll now have a real-time Kubernetes monitoring dashboard! 🎯
Step 5: Setting Up Alerts in Prometheus and Grafana
Creating Prometheus Alerting Rules
Create a ConfigMap for alerts:yamlapiVersion: v1 kind: ConfigMap metadata: name: alert-rules namespace: monitoring data: alert.rules: | groups: - name: InstanceDown rules: - alert: InstanceDown expr: up == 0 for: 5m labels: severity: critical annotations: summary: "Instance {{ $labels.instance }} is down"
Apply it to the cluster:shkubectl apply -f alert-rules.yaml
Configuring Grafana Alerts
Navigate to Alerting > Notification Channels.
Set up a channel (Email, Slack, or PagerDuty).
Define alert rules based on metrics from Prometheus.
Step 6: Enabling Persistent Storage for Prometheus
By default, Prometheus stores data in memory. To make the data persistent, configure storage:
Modify the Helm values:yamlprometheus: server: persistentVolume: enabled: true size: 10Gi
Apply the changes:shhelm upgrade prometheus prometheus-community/kube-prometheus-stack -f values.yaml
Conclusion
In this guide, we’ve set up Prometheus and Grafana to monitor a Kubernetes cluster. You now have: ✅ Real-time dashboards in Grafana ✅ Prometheus alerts to detect failures ✅ Persistent storage for historical metrics
WEBSITE: https://www.ficusoft.in/devops-training-in-chennai/
0 notes
Text
Mastering Kubernetes: A Comprehensive Guide to Kubernetes Skill Tree Free
Kubernetes has become an essential tool for modern developers and IT professionals aiming to manage containerized applications effectively. With its robust features and scalability, Kubernetes empowers organizations to automate deployments, manage workloads, and optimize resource utilization. Leveraging the Kubernetes Skill Tree can be a game-changer for mastering Kubernetes concepts and achieving seamless Kubernetes integration in your projects.
Why Kubernetes Matters
Kubernetes, also known as K8s, is an open-source platform designed to manage containerized workloads and services. It automates deployment, scaling, and operations, providing the flexibility needed for dynamic environments. Whether you're running a small project or managing large-scale enterprise applications, Kubernetes offers unmatched reliability and control.
Navigating the Kubernetes Skill Tree
The Kubernetes Skill Tree is an innovative approach to structured learning, breaking down complex topics into manageable, progressive steps. It allows learners to advance through foundational, intermediate, and advanced concepts at their own pace. Key areas of focus in the Kubernetes Skill Tree include:
Foundational Concepts
Understanding Kubernetes architecture and components.
Learning about nodes, pods, and clusters.
Basics of YAML files for deployment configuration.
Core Operations
Deploying applications with Kubernetes.
Managing scaling and resource allocation.
Monitoring and maintaining workloads.
Advanced Techniques
Setting up CI/CD pipelines with Kubernetes.
Leveraging Helm charts for application management.
Implementing security best practices.
This structured approach helps learners build a strong foundation while gradually mastering advanced Kubernetes capabilities.
Exploring the Kubernetes Playground
Hands-on practice is critical to understanding Kubernetes, and the Kubernetes Playground provides an ideal environment for experimentation. This interactive platform allows developers to test configurations, deploy applications, and debug issues without affecting production systems.
Benefits of the Kubernetes Playground include:
Safe Experimentation: Try new ideas without fear of breaking live systems.
Real-World Scenarios: Simulate deployment and scaling challenges in a controlled environment.
Collaboration: Work alongside team members to solve problems and share knowledge.
By incorporating regular practice in the Kubernetes Playground, learners can reinforce their understanding of concepts and gain confidence in applying them to real-world projects.
Streamlining Kubernetes Integration
One of the most critical aspects of Kubernetes adoption is ensuring seamless Kubernetes integration with existing systems and workflows. Integration can involve connecting Kubernetes with cloud services, on-premise systems, or third-party tools.
Steps to effective Kubernetes integration include:
Assessing Requirements: Identify the systems and services to integrate with Kubernetes.
Configuring Networking: Ensure proper communication between Kubernetes clusters and external services.
Automating Workflows: Use tools like Jenkins, GitLab CI/CD, and Terraform for automated deployments.
Monitoring Performance: Implement tools such as Prometheus and Grafana for real-time monitoring and alerts.
Successful integration not only enhances operational efficiency but also unlocks Kubernetes’ full potential for managing complex applications.
Reinforcing Knowledge with Kubernetes Exercises
Learning Kubernetes isn’t just about theoretical knowledge; it’s about applying concepts to solve real-world problems. Kubernetes exercises offer practical scenarios that challenge learners to deploy, scale, and troubleshoot applications.
Examples of valuable Kubernetes exercises include:
Deploying a multi-container application.
Scaling a web application based on traffic spikes.
Implementing role-based access control (RBAC).
Debugging a failed deployment.
These exercises simulate real challenges faced by developers and operations teams, ensuring learners are well-prepared for professional environments.
The Future of Kubernetes
As cloud-native technologies evolve, Kubernetes continues to grow in importance. Organizations increasingly rely on it for flexibility, scalability, and innovation. By mastering the Kubernetes Skill Tree, leveraging the Kubernetes Playground, and performing hands-on Kubernetes exercises, professionals can stay ahead of the curve.
Whether you're an aspiring developer or an experienced IT professional, Kubernetes provides endless opportunities to enhance your skill set and contribute to cutting-edge projects. Begin your journey today and unlock the power of Kubernetes for modern application management.
0 notes
Text
Best Practices for OpenShift Virtualization in Hybrid Cloud Environments
OpenShift Virtualization enables organizations to run virtual machines (VMs) alongside containerized workloads, offering unparalleled flexibility in hybrid cloud environments. By leveraging OpenShift’s robust Kubernetes platform, businesses can unify their infrastructure and streamline operations. However, adopting best practices is essential to ensure optimal performance, security, and manageability.
1. Plan for Hybrid Cloud Architecture
Assess Workloads: Identify which workloads are best suited for containers versus virtual machines based on performance, latency, and compatibility needs.
Network Configuration: Optimize networking between on-premise and cloud environments to minimize latency and maximize throughput.
Integration: Ensure seamless integration between OpenShift clusters and cloud service providers, such as AWS or Azure.
2. Optimize Resource Allocation
Node Sizing: Allocate sufficient resources (CPU, memory, storage) to nodes hosting virtual machines to avoid contention.
Taints and Tolerations: Use taints and tolerations to segregate VM workloads from containerized workloads when necessary.
Resource Requests and Limits: Set appropriate resource requests and limits for VMs to maintain cluster stability.
3. Leverage OpenShift Features for Management
ImageStreams: Utilize ImageStreams to manage VM images consistently and efficiently.
Namespaces: Organize VMs into namespaces to simplify access control and resource management.
Operators: Use OpenShift Virtualization Operators to automate lifecycle management for VMs.
4. Enhance Security
Isolate Workloads: Use namespaces and network policies to isolate sensitive workloads.
Access Control: Implement Role-Based Access Control (RBAC) to restrict user permissions.
Encryption: Enable encryption for data at rest and in transit.
Compliance: Ensure the hybrid cloud setup adheres to industry standards and compliance requirements like HIPAA or GDPR.
5. Monitor and Optimize Performance
Prometheus and Grafana: Use Prometheus and Grafana for monitoring VM and container performance.
Logging: Centralize logging using OpenShift Logging for better visibility into VM and container activities.
Scaling: Implement auto-scaling policies to manage workload spikes effectively.
6. Automate Deployment and Management
Ansible Playbooks: Use Ansible to automate VM deployments and configurations.
CI/CD Pipelines: Integrate VM deployment into CI/CD pipelines for faster development and testing.
Templates: Create and use VM templates for consistent configurations across the hybrid environment.
7. Ensure Disaster Recovery and Backup
Snapshots: Regularly create snapshots of VMs for quick recovery in case of failures.
Backup Solutions: Implement robust backup strategies for both VMs and containerized workloads.
Failover Testing: Periodically test failover mechanisms to ensure readiness during outages.
8. Continuous Learning and Updating
Stay Updated: Regularly update OpenShift and Virtualization Operators to the latest versions.
Training: Train teams on hybrid cloud best practices and new OpenShift features.
Community Engagement: Engage with the OpenShift community to stay informed about emerging trends and solutions.
By following these best practices, organizations can maximize the potential of OpenShift Virtualization in hybrid cloud environments, achieving improved efficiency, security, and scalability. Whether you’re modernizing legacy applications or deploying cloud-native workloads, OpenShift Virtualization is a powerful tool to bridge the gap between traditional and modern infrastructures.
For more details visit: https://www.hawkstack.com/
0 notes
Text
New GKE Ray Operator on Kubernetes Engine Boost Ray Output

GKE Ray Operator
The field of AI is always changing. Larger and more complicated models are the result of recent advances in generative AI in particular, which forces businesses to efficiently divide work among more machines. Utilizing Google Kubernetes Engine (GKE), Google Cloud’s managed container orchestration service, in conjunction with ray.io, an open-source platform for distributed AI/ML workloads, is one effective strategy. You can now enable declarative APIs to manage Ray clusters on GKE with a single configuration option, making that pattern incredibly simple to implement!
Ray offers a straightforward API for smoothly distributing and parallelizing machine learning activities, while GKE offers an adaptable and scalable infrastructure platform that streamlines resource management and application management. For creating, implementing, and maintaining Ray applications, GKE and Ray work together to provide scalability, fault tolerance, and user-friendliness. Moreover, the integrated Ray Operator on GKE streamlines the initial configuration and directs customers toward optimal procedures for utilizing Ray in a production setting. Its integrated support for cloud logging and cloud monitoring improves the observability of your Ray applications on GKE, and it is designed with day-2 operations in mind.
- Advertisement -
Getting started
When establishing a new GKE Cluster in the Google Cloud dashboard, make sure to check the “Enable Ray Operator” function. This is located under “AI and Machine Learning�� under “Advanced Settings” on a GKE Autopilot Cluster.
The Enable Ray Operator feature checkbox is located under “AI and Machine Learning” in the “Features” menu of a Standard Cluster.
You can set an addons flag in the following ways to utilize the gcloud CLI:
gcloud container clusters create CLUSTER_NAME \ — cluster-version=VERSION \ — addons=RayOperator
- Advertisement -
GKE hosts and controls the Ray Operator on your behalf after it is enabled. After a cluster is created, your cluster will be prepared to run Ray applications and build other Ray clusters.
Record-keeping and observation
When implementing Ray in a production environment, efficient logging and metrics are crucial. Optional capabilities of the GKE Ray Operator allow for the automated gathering of logs and data, which are then seamlessly stored in Cloud Logging and Cloud Monitoring for convenient access and analysis.
When log collection is enabled, all logs from the Ray cluster Head node and Worker nodes are automatically collected and saved in Cloud Logging. The generated logs are kept safe and easily accessible even in the event of an unintentional or intentional shutdown of the Ray cluster thanks to this functionality, which centralizes log aggregation across all of your Ray clusters.
By using Managed Service for Prometheus, GKE may enable metrics collection and capture all system metrics exported by Ray. System metrics are essential for tracking the effectiveness of your resources and promptly finding problems. This thorough visibility is especially important when working with costly hardware like GPUs. You can easily construct dashboards and set up alerts with Cloud Monitoring, which will keep you updated on the condition of your Ray resources.
TPU assistance
Large machine learning model training and inference are significantly accelerated using Tensor Processing Units (TPUs), which are custom-built hardware accelerators. Ray and TPUs may be easily used with its AI Hypercomputer architecture to scale your high-performance ML applications with ease.
By adding the required TPU environment variables for frameworks like JAX and controlling admission webhooks for TPU Pod scheduling, the GKE Ray Operator simplifies TPU integration. Additionally, autoscaling for Ray clusters with one host or many hosts is supported.
Reduce the delay at startup
When operating AI workloads in production, it is imperative to minimize start-up delay in order to maximize the utilization of expensive hardware accelerators and ensure availability. When used with other GKE functions, the GKE Ray Operator can significantly shorten this startup time.
You can achieve significant speed gains in pulling images for your Ray clusters by hosting your Ray images on Artifact Registry and turning on image streaming. Huge dependencies, which are frequently required for machine learning, can lead to large, cumbersome container images that take a long time to pull. For additional information, see Use Image streaming to pull container images. Image streaming can drastically reduce this image pull time.
Moreover, model weights or container images can be preloaded onto new nodes using GKE secondary boot drives. When paired with picture streaming, this feature can let your Ray apps launch up to 29 times faster, making better use of your hardware accelerators.
Scale Ray is currently being produced
A platform that grows with your workloads and provides a simplified Pythonic experience that your AI developers are accustomed to is necessary to stay up with the quick advances in AI. This potent trifecta of usability, scalability, and dependability is delivered by Ray on GKE. It’s now simpler than ever to get started and put best practices for growing Ray in production into reality with the GKE Ray Operator.
Read more on govindhtech.com
#NewGKERayOperator#Kubernetes#GKEoffers#EngineBoostRayoutput#GoogleKubernetesEngine#cloudlogging#GKEAutopilotCluster#ai#gke#MachineLearning#CloudMonitoring#webhooks
0 notes
Text
What are the questions asked in DevOps interview for bigginers?
In the competitive IT industry, DevOps is becoming increasingly popular, and aspiring professionals are often asked a variety of questions in interviews. This guide provides you with the top 20 beginner DevOps interview questions, along with detailed explanations to help you prepare confidently.
1. What is DevOps?
Explanation: DevOps is a set of practices that combines software development (Dev) and IT operations (Ops). It aims to shorten the development lifecycle while delivering features, fixes, and updates frequently in alignment with business objectives.
2. What are the key components of DevOps?
Explanation: The key components of DevOps include continuous integration, continuous delivery (CI/CD), automation, infrastructure as code (IaC), monitoring, and collaboration between teams.
3. Explain Continuous Integration (CI).
Explanation: CI is a DevOps practice where developers frequently merge their code changes into a central repository, followed by automated builds and tests. This helps catch bugs early and speeds up the development process.
4. What is Continuous Delivery (CD)?
Explanation: CD ensures that code changes are automatically prepared for a release to production. It builds upon CI and automates the delivery of new updates, ensuring they are ready for production after passing through various test stages.
5. What are some common DevOps tools?
Explanation: Some popular DevOps tools include:
Jenkins for CI/CD automation
Docker for containerization
Kubernetes for container orchestration
Ansible for automation and configuration management
Git for version control
6. What is Infrastructure as Code (IaC)?
Explanation: IaC is a key DevOps practice where infrastructure is defined and managed using code, rather than through manual processes. Tools like Terraform and AWS CloudFormation are often used to automate infrastructure provisioning and management.
7. What is the role of version control in DevOps?
Explanation: Version control, using tools like Git, enables multiple developers to work on a project simultaneously. It keeps track of changes and maintains a history of revisions, ensuring that changes are coordinated and easily reversible.
8. What is Docker, and how does it fit into DevOps?
Explanation: Docker is a containerization tool that allows developers to package applications and their dependencies into a container, ensuring they run consistently across different environments. Docker simplifies deployment and scalability in DevOps workflows.
9. Explain the concept of container orchestration with Kubernetes.
Explanation: Kubernetes is an orchestration platform for managing, scaling, and deploying containerized applications. It automates the distribution of containers across a cluster of machines and handles load balancing, service discovery, and more.
10. What is a microservices architecture?
Explanation: Microservices architecture is an approach where applications are built as a collection of small, independent services. Each service can be developed, deployed, and scaled individually, making the system more resilient and flexible.
11. How do monitoring and logging fit into a DevOps pipeline?
Explanation: Monitoring and logging are crucial for identifying issues in production. Tools like Prometheus, Grafana, and ELK (Elasticsearch, Logstash, and Kibana) are often used to ensure system health, track performance, and troubleshoot problems.
12. What is the difference between Agile and DevOps?
Explanation: Agile is a software development methodology focused on iterative development and collaboration between teams. DevOps extends Agile principles by integrating development and operations, emphasizing automation, continuous feedback, and faster delivery.
13. What is a build pipeline?
Explanation: A build pipeline is a series of steps performed in sequence to automate the creation, testing, and deployment of code. It includes stages like source control, build, test, and deployment, ensuring that every change is properly validated before reaching production.
14. How do you manage configuration in DevOps?
Explanation: Configuration management involves maintaining consistency of systems and software over time. Tools like Ansible, Puppet, and Chef automate the process of configuring servers, ensuring that environments remain consistent across the development lifecycle.
15. What are the benefits of using Jenkins in DevOps?
Explanation: Jenkins is an open-source automation server that facilitates CI/CD processes. Its benefits include:
Easy integration with various DevOps tools
A large library of plugins
Flexibility to automate different tasks
A robust community for support
16. What is GitOps?
Explanation: GitOps is a DevOps practice where Git is the single source of truth for the system’s desired state. It uses Git pull requests to manage and deploy changes to applications and infrastructure, ensuring that changes are trackable and auditable.
17. What is the importance of automation in DevOps?
Explanation: Automation is crucial in DevOps because it reduces human intervention, minimizes errors, speeds up processes, and ensures consistency across deployments. This includes automating CI/CD, testing, infrastructure provisioning, and monitoring.
18. What is a rolling deployment?
Explanation: Rolling deployment is a technique where new versions of an application are gradually deployed to instances, replacing old ones. This ensures zero downtime by keeping part of the application available while the update is being deployed.
19. Explain the role of cloud platforms in DevOps.
Explanation: Cloud platforms, such as AWS, Azure, and Google Cloud, provide scalable and flexible infrastructure that aligns well with DevOps practices. They enable teams to provision resources on demand and integrate with automation tools to streamline deployments.
20. What is the significance of feedback loops in DevOps?
Explanation: Feedback loops ensure that teams get timely information about the performance and issues of their systems. Continuous feedback from users, automated monitoring, and testing tools help to detect problems early and ensure quick iterations.
Accelerate Your DevOps Career with Naresh IT’s DevOps Online Training
DevOps is essential for modern software development, and learning the skills needed to excel in DevOps is critical for your career. At Naresh IT, we offer comprehensive DevOps Online Training to equip you with in-demand skills like CI/CD, Docker, Kubernetes, cloud platforms, and more.
Whether you’re a beginner or looking to upskill, Naresh IT provides tailored content, hands-on labs, and real-world project experience to make you industry-ready.
Join Naresh IT’s DevOps Online Training today and kickstart your DevOps journey!
0 notes
Text
Major Approaches for Automation at HawkStack
In today's fast-paced IT landscape, automation is not just a trend but a necessity. At HawkStack, we understand the vital role that automation plays in driving efficiency, reducing errors, and improving overall business agility. Here, we'll explore the major approaches for IT automation that HawkStack specializes in, designed to empower your organization with seamless, scalable solutions.
1. Infrastructure as Code (IaC)
Infrastructure as Code (IaC) is a key approach to IT automation at HawkStack. IaC allows for the management and provisioning of computing resources through machine-readable scripts rather than through manual processes. By treating infrastructure as software, we enable rapid deployment, consistent configurations, and a more reliable environment. Tools like Ansible, Terraform, and AWS CloudFormation are central to our IaC strategy, ensuring that your infrastructure is always in sync and easy to manage.
2. Configuration Management
Configuration management involves maintaining the consistency of software systems' performance, functional, and physical attributes. HawkStack leverages leading configuration management tools like Ansible, Puppet, and Chef to automate the deployment, configuration, and management of servers and applications. This approach minimizes configuration drift, reduces the risk of errors, and ensures that all systems remain in a state of compliance.
3. Continuous Integration/Continuous Deployment (CI/CD)
CI/CD is a cornerstone of modern software development and delivery, and at HawkStack, we integrate automation into every step of the process. By automating the build, test, and deployment stages, we help you deliver applications faster and with fewer bugs. Our CI/CD pipelines, powered by tools like Jenkins, GitLab CI, and GitHub Actions, ensure that your code is always in a deployable state, reducing the time between code commits and production deployments.
4. Automated Testing
Automated testing is crucial for ensuring the quality and reliability of your software products. HawkStack implements a variety of testing frameworks and tools to automate unit tests, integration tests, and end-to-end tests. This approach helps catch bugs early in the development process, ensuring that issues are resolved before they reach production, thereby saving time and resources.
5. Cloud Orchestration
In a multi-cloud and hybrid cloud environment, orchestrating resources efficiently is paramount. HawkStack's cloud orchestration solutions automate the management, coordination, and arrangement of complex cloud infrastructures. By using tools like Kubernetes and OpenShift, we enable automated deployment, scaling, and operation of application containers, ensuring that your cloud resources are utilized efficiently and cost-effectively.
6. Monitoring and Logging Automation
Keeping track of system performance and logs is essential for maintaining system health and diagnosing issues promptly. At HawkStack, we implement monitoring and logging automation using tools like Prometheus, Grafana, ELK Stack, and Splunk. These tools help automate the collection, analysis, and visualization of performance metrics and logs, providing real-time insights and alerting to keep your systems running smoothly.
7. Security Automation
Security is non-negotiable, and automation is key to maintaining a robust security posture. HawkStack's security automation approach integrates security into every phase of the development lifecycle. We use tools like Ansible Tower, Vault, and automated vulnerability scanners to ensure that security policies are consistently applied across your IT environment, reducing the risk of human error and enhancing compliance.
Conclusion
At HawkStack, we are committed to helping businesses harness the power of automation to drive innovation and efficiency. Our comprehensive automation approaches are designed to meet the unique needs of your organization, providing scalable, reliable, and secure solutions. Whether you are just starting your automation journey or looking to optimize existing processes, HawkStack is your partner in achieving IT excellence.
Visit our IT Automation page to learn more about how we can help your business succeed through automation.
For more details click www.hawkstack.com
#redhatcourses#docker#linux#containerorchestration#information technology#kubernetes#containersecurity#dockerswarm#hawkstack#hawkstack technologies
0 notes
Text
🚀 Enterprise Kubernetes Storage with Red Hat OpenShift Data Foundation
As enterprises continue to adopt Kubernetes for container orchestration, the demand for scalable, resilient, and enterprise-grade storage solutions has never been higher. While Kubernetes excels in managing stateless applications, managing stateful workloads—such as databases, messaging queues, and AI/ML pipelines—poses unique challenges. This is where Red Hat OpenShift Data Foundation (ODF) steps in as a game-changer.
📦 What is Red Hat OpenShift Data Foundation?
Red Hat OpenShift Data Foundation (formerly OpenShift Container Storage) is a software-defined storage solution designed specifically for OpenShift environments. Built on Ceph and NooBaa, ODF provides a unified storage layer that seamlessly supports block, file, and object storage within your Kubernetes infrastructure.
ODF delivers highly available, scalable, and secure storage for cloud-native workloads, empowering DevOps teams to run stateful applications confidently across hybrid and multi-cloud environments.
🔧 Key Features of OpenShift Data Foundation
1. Unified Storage for Kubernetes
ODF supports:
Block Storage for databases and persistent workloads
File Storage for legacy applications and shared volumes
Object Storage for cloud-native applications, backup, and AI/ML data lakes
2. Multi-Cloud & Hybrid Cloud Ready
Deploy ODF on bare metal, private clouds, public clouds, or hybrid environments. With integrated NooBaa technology, it allows seamless object storage across AWS S3, Azure Blob, and on-premises storage.
3. Integrated with OpenShift
ODF is tightly integrated with Red Hat OpenShift, allowing:
Native support for Persistent Volume Claims (PVCs)
Automated provisioning and scaling
Built-in monitoring through OpenShift Console and Prometheus/Grafana
4. Data Resilience & High Availability
Through Ceph under the hood, ODF offers:
Data replication across nodes
Self-healing storage clusters
Built-in erasure coding for space-efficient redundancy
5. Security & Compliance
ODF supports:
Encryption at rest and in transit
Role-Based Access Control (RBAC)
Integration with enterprise security policies and key management services (KMS)
🧩 Common Use Cases
Database as a Service (DBaaS) on Kubernetes
CI/CD Pipelines with persistent cache
AI/ML Workloads requiring massive unstructured data
Kafka, Elasticsearch, and other stateful operators
Backup & Disaster Recovery for OpenShift clusters
🛠️ Architecture Overview
At a high level, ODF deploys the following components:
ODF Operator: Automates lifecycle and management
CephCluster: Manages block and file storage
NooBaa Operator: Manages object storage abstraction
Multicloud Object Gateway (MCG): Bridges cloud and on-prem storage
The ODF stack ensures zero downtime for workloads and automated healing in the event of hardware failure or node loss.
🚀 Getting Started
To deploy OpenShift Data Foundation:
Install OpenShift on your preferred infrastructure.
Enable the ODF Operator from OperatorHub.
Configure storage cluster using local devices, AWS EBS, or any supported backend.
Create storage classes for your apps to consume via PVCs.
Pro Tip: Use OpenShift’s integrated dashboard to visualize storage usage, health, and performance metrics out of the box.
🧠 Final Thoughts
Red Hat OpenShift Data Foundation is more than just a storage solution—it's a Kubernetes-native data platform that gives you flexibility, resilience, and performance at scale. Whether you're building mission-critical microservices or deploying petabyte-scale AI workloads, ODF is designed to handle your stateful needs in an enterprise-ready way.
Embrace the future of cloud-native storage with Red Hat OpenShift Data Foundation.For more details www.hawkstack.com
0 notes
Text
Retroactive: February 2024 Release Rollout and Bug Bash
We are currently catching up with retro updates, so we kindly ask for your patience as we return to our normal rhythm.
Fixes
Fix PR Build Configuration to Ignore Periodic Triggers
This pull request addresses an issue where pull request (PR) jobs were inadvertently triggering periodic builds. The fix involves adding a check to ensure that PR jobs do not start periodic builds. This change prevents unnecessary builds and ensures that the CI/CD pipeline operates as intended without running redundant periodic jobs for PRs.
Fix PR Graph Display for Non-ChainPR Configurations
This pull request addresses an issue where the pipeline graph for pull requests is not displayed correctly when the chainPR setting is set to false. The update ensures that the pipeline graph is rendered accurately for these configurations, and also makes the graph nodes fully clickable with accessible dropdown menu options. This fix improves the usability and accuracy of the PR view in the Screwdriver UI.
Fix PR Graph Rendering Issue When Switching to PR Tab
This pull request fixes a bug that affects the rendering of the PR graph when switching from the Events view to the Pull Request view in the Screwdriver UI. The issue occurs particularly with pipelines containing extensive build data and the chainPR setting enabled. The fix ensures that the showDownstreamTriggers field is correctly set to false when the Pull Request view is rendered, allowing for proper display of the pipeline graphs.
Features
Add Resource Usage Information in the Build Launcher
This pull request adds resource usage information to the metrics pushed to Prometheus. The objective is to capture and report the amount of resources (such as CPU and memory) used by builds, providing better insights into resource consumption.
Enhance Validator Page with Toggle for Split and Spread Views
This pull request enhances the validator page's user interface by adding a button to toggle between split view and spread view. This feature addresses the issue of narrow display areas for the validator input form, workflow graph, and job details, particularly for users with vertical monitors. The spread view option allows for a more expansive and user-friendly layout, improving usability and accessibility.
Author Vonny Jap, Sr Mgr, Software Dev Engineering, Yahoo
0 notes
Text
Launch Your DevOps Engineering Career in Two Months: A Step-by-Step Guide
Starting out in DevOps engineering might seem challenging due to the extensive skill set required. However, with a well-structured and dedicated plan, you can become job-ready in just two months. This guide outlines a comprehensive roadmap to help you develop the essential skills and knowledge for a successful DevOps career.

Month 1: Laying the Groundwork
Week 1: Grasping DevOps Fundamentals
Begin by understanding the fundamentals of DevOps and its core principles. Use online courses, books, and articles to get acquainted with key concepts like continuous integration, continuous delivery, and infrastructure as code.
Week 2-3: Mastering Version Control Systems (VCS)
Version control systems such as Git are crucial for collaboration and managing code changes. Invest time in learning Git basics, including branching strategies, merging, and conflict resolution.
Week 4-5: Scripting and Automation
Start learning scripting languages like Bash, Python, or PowerShell. Focus on automating routine tasks such as file operations, system configuration, and deployment processes. Enhance your skills with hands-on practice through small projects or challenges.
Week 6: Docker and Containerization
Docker is essential in DevOps for packaging applications and dependencies into lightweight containers. Study Docker concepts, container orchestration, and best practices for Dockerfile creation. Practice building and running containers to deepen your understanding.
For further learning, consider the DevOps online training, which offers certifications and job placement opportunities both online and offline.

Week 7: Continuous Integration (CI) Tools
Explore popular CI tools like Jenkins, GitLab CI, or CircleCI. Learn to set up CI pipelines to automate the build, test, and deployment processes. Experiment with different configurations and workflows to understand their practical applications.
Week 8: Infrastructure as Code (IaC)
Dive into infrastructure as code principles using tools like Terraform or AWS CloudFormation. Learn to define and provision infrastructure resources programmatically for reproducibility and scalability. Practice creating infrastructure templates and deploying cloud resources.
Month 2: Advanced Skills and Practical Projects
Week 1-2: Configuration Management
Learn about configuration management tools like Ansible, Chef, or Puppet. Understand their role in automating server configuration and application deployment. Practice writing playbooks or manifests to manage system configurations effectively.
Week 3-4: Cloud Services and Deployment
Gain proficiency in cloud platforms such as AWS, Azure, or Google Cloud. Explore key services related to computing, storage, networking, and deployment. Learn to leverage cloud-native tools for building scalable and resilient architectures.
Week 5-6: Monitoring and Logging
Understand the importance of monitoring and logging in maintaining system health and diagnosing issues. Explore tools like Prometheus, Grafana, ELK stack, or Splunk for collecting and visualizing metrics and logs. Set up monitoring dashboards and alerts for practical experience.
Week 7-8: Security and Compliance
Familiarize yourself with DevSecOps principles and practices for integrating security into the DevOps lifecycle. Learn about security best practices, vulnerability scanning, and compliance standards relevant to your industry. Experiment with security tools and techniques to secure infrastructure and applications.
Conclusion
By following this two-month roadmap, you can build a solid foundation and acquire the necessary skills to become a job-ready DevOps engineer. Continuous learning and hands-on practice are crucial for mastering DevOps concepts and tools. Stay curious, engage with the DevOps community, and remain open to exploring new technologies and methodologies. With determination and perseverance, you’ll be well on your way to a successful DevOps engineering career.
0 notes
Text
Top DevOps Tools in 2025: GitHub Actions, Jenkins, Docker, and More

Top DevOps Tools in 2025: GitHub Actions, Jenkins, Docker, and More
DevOps has become an essential practice for software development and deployment, enabling teams to deliver applications faster and more reliably.
In 2025, several tools dominate the DevOps landscape, offering advanced features to streamline CI/CD pipelines, infrastructure management, and collaboration.
Here’s an overview of some top tools:
1. GitHub Actions Purpose:
A CI/CD platform built into GitHub for automating workflows directly in repositories. Key Features: Pre-built and custom actions for testing, building, and deploying code.
Seamless integration with GitHub repositories.
Matrix builds for testing across multiple configurations.
Why It’s Popular:
It simplifies automation by allowing users to define workflows in YAML files directly within their repositories.
2. Jenkins Purpose:
An open-source automation server widely used for CI/CD. Key Features: Extensive plugin ecosystem for integration with almost any tool.
Flexibility to run on multiple platforms and cloud environments.
Pipelines as code with Jenkinsfile.
Why It’s Popular:
It remains a go-to tool for its customization capabilities and large community support.
3. Docker Purpose: A platform for building, sharing, and running containerized applications.
Key Features: Lightweight, portable containers for consistent environments across development and production.
Docker Compose for managing multi-container applications. Integration with orchestration tools like Kubernetes.
Why It’s Popular:
Containers have become the backbone of modern DevOps practices, and Docker leads the pack.
4. Kubernetes Purpose:
An open-source container orchestration system.
Key Features:
Automates deployment, scaling, and management of containerized applications. Load balancing, auto-scaling, and self-healing capabilities. Works with various cloud providers and on-premises environments.
Why It’s Popular:
Kubernetes has become the standard for managing containers at scale.
5. Terraform Purpose:
Infrastructure as Code (IaC) tool for provisioning and managing cloud resources. Key Features: Declarative configuration files for defining infrastructure. Multi-cloud support (AWS, Azure, Google Cloud, etc.).
State management and collaboration with Terraform Cloud.
Why It’s Popular:
It simplifies infrastructure management and ensures consistency.
6. Prometheus and Grafana Purpose:
Tools for monitoring and observability.
Prometheus:
Collects and queries metrics.
Grafana:
Visualizes metrics in customizable dashboards.
Key Features:
Alerting rules in Prometheus.
Rich visualization and integrations in Grafana.
Why They’re Popular:
Together, they provide a complete solution for real-time monitoring and actionable insights.
7. Ansible Purpose:
Configuration management and automation.
Key Features:
Agentless architecture for easy deployment.
YAML-based playbooks for defining configurations.
Support for application deployment, updates, and orchestration.
Why It’s Popular:
Its simplicity and wide adoption make it a favorite for automation tasks.
8. CircleCI Purpose:
A CI/CD platform with a focus on developer productivity.
Key Features:
Optimized pipelines for faster builds and tests. Integration with GitHub, GitLab, and Bitbucket. Insights dashboard for pipeline performance.
Why It’s Popular:
It’s known for its speed, reliability, and ease of use.
Conclusion
These tools represent the pinnacle of DevOps technology in 2025. They empower teams to streamline workflows, improve collaboration, and ensure faster, more reliable software delivery. Choosing the right tool depends on your team’s needs, infrastructure, and specific use cases.

0 notes
Text
Learning Kubernetes From Integration to Practical Exercises
Kubernetes has become a cornerstone in the world of container orchestration, enabling developers and DevOps teams to deploy, manage, and scale applications with ease. As businesses increasingly adopt microservices architecture, Kubernetes' importance cannot be overstated. Whether you're a beginner or an experienced professional, gaining hands-on experience through a Kubernetes playground and exercises is essential for mastering this powerful platform.
Understanding Kubernetes Integration
Kubernetes integration is crucial for streamlining the deployment and management of containerized applications. It allows you to connect various components, such as CI/CD pipelines, monitoring tools, and logging systems, ensuring a cohesive and automated environment. Effective Kubernetes integration reduces manual intervention, enhances system reliability, and accelerates deployment cycles.
A well-integrated Kubernetes environment simplifies the deployment of new applications and the scaling of existing ones. For instance, by integrating Kubernetes with a CI/CD pipeline, you can automate the entire process from code commit to production deployment. This not only speeds up the development cycle but also minimizes errors, leading to more reliable software delivery.
Furthermore, Kubernetes integration with monitoring and logging tools provides real-time insights into your application's performance. This integration enables proactive issue resolution, ensuring that your applications run smoothly. With tools like Prometheus for monitoring and Fluentd for logging, you can gain a comprehensive view of your application's health, leading to faster troubleshooting and improved system stability.
The Value of a Kubernetes Playground
A Kubernetes playground is an interactive environment where you can experiment with Kubernetes features without the risk of disrupting a live environment. Whether you’re testing new configurations, learning how to deploy applications, or practicing troubleshooting techniques, a playground provides a safe space for hands-on learning.
For beginners, a Kubernetes playground is an invaluable resource. It offers a controlled environment where you can familiarize yourself with the basics, such as creating and managing pods, services, and deployments. By experimenting in a sandbox environment, you can build confidence and competence before applying your skills in a production setting.
Even experienced users benefit from a Kubernetes playground. It provides an opportunity to explore advanced features, such as custom resource definitions (CRDs) and operators, without the pressure of a live environment. Additionally, a playground can be used to test the impact of new tools or updates, ensuring they integrate smoothly with your existing infrastructure.
Practical Kubernetes Exercises
To truly master Kubernetes practical exercises are essential. These exercises help you apply theoretical knowledge to real-world scenarios, solidifying your understanding and preparing you for the challenges of managing Kubernetes in production environments.
One foundational exercise is deploying a simple application on Kubernetes. This involves creating a deployment, exposing it via a service, and scaling it up or down. Through this exercise, you’ll learn how to manage application lifecycle in Kubernetes, including rolling updates and rollbacks.
Another important exercise is setting up a CI/CD pipeline with Kubernetes integration. This will help you understand how to automate the deployment process, ensuring that new code is tested, built, and deployed seamlessly. You’ll also gain experience in monitoring and logging, which are critical for maintaining application health and performance.
Security is a vital aspect of Kubernetes management, and exercises in securing your cluster are essential. These might include implementing network policies, managing secrets, and configuring role-based access control (RBAC). Through these exercises, you’ll learn how to protect your applications and data from potential threats.
Finally, troubleshooting exercises are crucial for developing problem-solving skills. By intentionally breaking configurations or causing failures, you can practice identifying and resolving issues. This prepares you for real-world scenarios where quick and accurate troubleshooting is necessary to maintain system uptime.
Conclusion
Kubernetes is a powerful tool that requires both theoretical understanding and practical experience. Through effective Kubernetes integration, you can automate and streamline your application deployment process. Utilizing a Kubernetes playground allows for safe experimentation and learning, while practical exercises build the skills needed to manage Kubernetes in production environments. Whether you're just starting your Kubernetes journey or looking to refine your skills, these approaches will set you on the path to becoming a Kubernetes expert.
0 notes
Text
Ansible and Kubernetes Automation: Simplifying Cluster Management
Kubernetes is the go-to platform for container orchestration, but managing clusters at scale can become complex and time-consuming. This is where Ansible, a powerful IT automation tool, steps in to simplify Kubernetes management. In this blog, we’ll explore how Ansible can automate various Kubernetes tasks, making your operations more efficient and less error-prone.
Why Use Ansible for Kubernetes?
Ansible provides a flexible framework for automating Kubernetes tasks, offering benefits such as:
Centralized Management: Manage Kubernetes clusters alongside other infrastructure components from a single platform.
Consistency: Standardize how deployments, configurations, and updates are handled across multiple clusters.
Ease of Use: Human-readable playbooks make it easy to define and execute tasks without deep programming knowledge.
Integration: Seamlessly connect Kubernetes automation with tools like Helm, Prometheus, or external APIs.
Use Cases for Kubernetes Automation with Ansible
Deploying Applications Across Clusters Ansible can automate the deployment of applications across multiple Kubernetes clusters, ensuring uniformity. This is particularly useful in hybrid or multi-cloud environments.
Streamlining Resource Management From creating namespaces and ConfigMaps to updating deployments and scaling services, Ansible can handle all routine Kubernetes operations effortlessly.
Automating Security and Compliance Tasks like applying Role-Based Access Control (RBAC) policies, configuring network policies, and auditing resource usage can be automated with Ansible, improving security and compliance.
Simplifying Helm Chart Management Helm charts make deploying complex Kubernetes applications easier. With Ansible, you can automate the entire process, from fetching a chart to applying customized configurations.
Integrating with CI/CD Pipelines Ansible bridges the gap between Kubernetes and CI/CD systems, enabling seamless deployment of changes in development, staging, and production environments.
How Ansible Fits into Kubernetes Automation
Declarative vs. Imperative: While Kubernetes is declarative by nature, Ansible complements it with a task-based approach, making it ideal for orchestrating end-to-end workflows.
Cross-Environment Automation: Ansible can connect Kubernetes operations with other systems like load balancers, monitoring tools, and cloud providers, enabling a unified automation strategy.
Simplified Access Control: By integrating with Kubernetes APIs, Ansible ensures secure and controlled access to clusters.
Advantages of Using Ansible for Kubernetes
No Dependency on Agents: Ansible communicates directly with Kubernetes APIs, eliminating the need for agents or additional software on the cluster.
Idempotency: Ansible ensures tasks are performed consistently without unintended consequences, even if playbooks are run multiple times.
Scalability: Handle configurations for multiple clusters simultaneously, whether on-premises, cloud, or hybrid setups.
Improved Productivity: Teams can focus on strategic tasks as repetitive workflows are automated.
Best Practices for Ansible-Kubernetes Integration
Version Control Your Playbooks: Keep all automation scripts in a version control system like Git to maintain transparency and enable collaboration.
Test Before Production: Always test Ansible playbooks in a staging environment before applying them to production clusters.
Use Variables and Templates: Leverage variables to make playbooks reusable across different clusters or environments.
Follow Kubernetes Standards: Ensure your automation aligns with Kubernetes best practices for configurations and resource management.
Conclusion
Combining Ansible with Kubernetes brings together the best of automation and orchestration. By leveraging Ansible’s capabilities, you can simplify Kubernetes management, reduce manual errors, and improve operational efficiency. Whether you’re managing a single cluster or multiple environments, Ansible offers a robust and scalable solution for Kubernetes automation.
Start integrating Ansible into your Kubernetes workflows today, and experience a smoother, more efficient way to manage your clusters!
For more information visit: https://www.hawkstack.com/
0 notes
Text
Mastering DevOps: What You Need to Know
DevOps, short for Development and Operations, is a set of practices that aims to automate and improve the collaboration between software developers and IT operations. It has become a crucial approach in modern software development, fostering a culture of continuous integration, continuous delivery, and continuous improvement. In this blog, we'll explore the essential aspects of mastering DevOps and why it's integral to the success of modern software development projects.
DevOps has emerged as an essential practice in the world of software development and operations. It brings together the best of both worlds by integrating development and operations teams to deliver software faster and more efficiently. If you're looking to embark on a career in DevOps or simply want to understand this field better, there are several key areas you should focus on learning."In the world of continuous improvement, DevOps training in Hyderabad is the compass that guides your team towards efficiency and innovation."

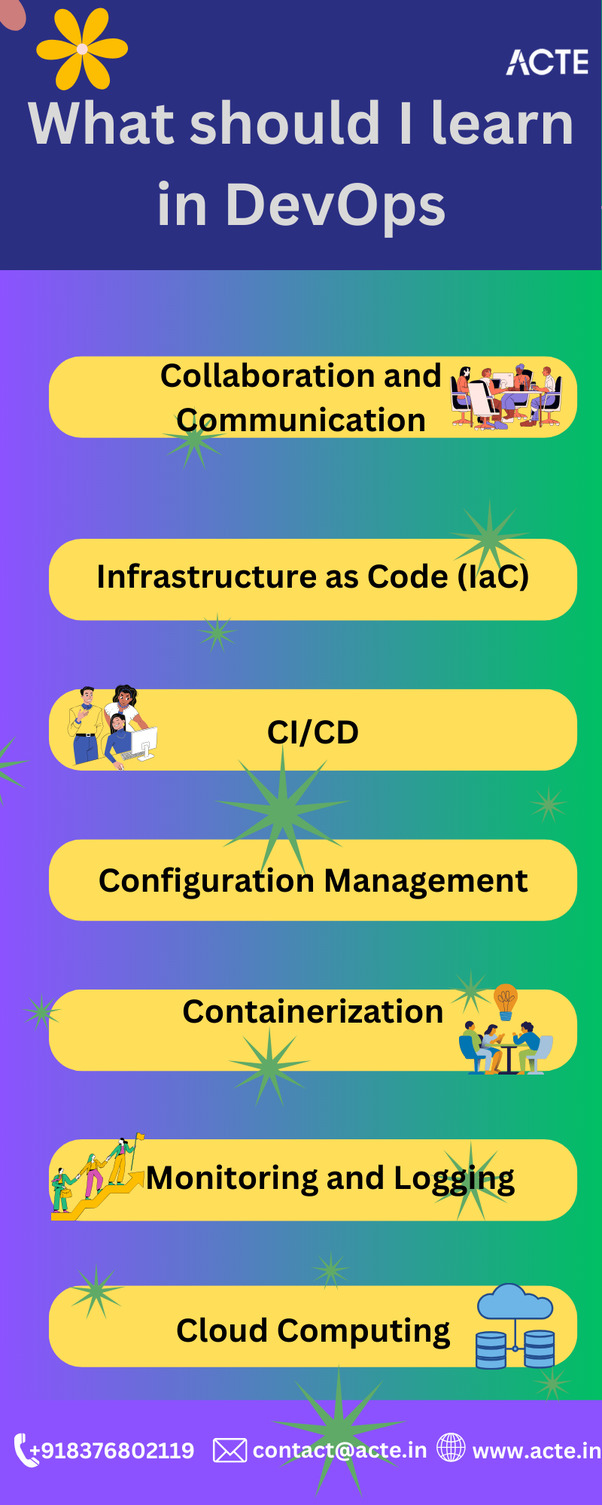
Infrastructure as Code (IaC): IaC refers to the practice of managing and provisioning infrastructure through machine-readable definition files rather than manual processes. Tools like Terraform and Ansible are widely used in the industry to automate infrastructure provisioning and configuration. Learning IaC will enable you to create reproducible and scalable infrastructure, which is crucial in a DevOps environment.
Continuous Integration and Continuous Deployment (CI/CD): CI/CD is at the heart of DevOps. It involves automating the process of building, testing, and deploying software changes. Tools like Jenkins, GitLab CI/CD, and CircleCI are commonly used for this purpose. Understanding CI/CD pipelines and how to set them up will allow you to streamline software development workflows and rapidly release new features.
Configuration Management: Configuration management involves managing the configuration of systems and applications in a consistent and scalable manner. Tools like Puppet, Chef, and Ansible can help you automate the deployment and configuration of software across multiple servers. By mastering configuration management, you'll be able to maintain consistency across environments and reduce manual errors.
Containerization: Containers have revolutionized the way applications are deployed and managed. Docker is the most popular containerization platform, allowing developers to package their applications with all their dependencies into portable units. Learning Docker will enable you to create lightweight and isolated environments for your applications, making deployment easier, faster, and more efficient. The power of DevOps at your fingertips: Our online DevOps course brings industry expertise to your screen, making mastery just a click away.
Monitoring and Logging: In a DevOps environment, it's crucial to have visibility into the performance and health of your systems and applications. Tools like Prometheus, Grafana, and ELK stack (Elasticsearch, Logstash, Kibana) are commonly used for monitoring and logging. Being proficient in these tools will help you identify bottlenecks, troubleshoot issues, and ensure that your systems are running smoothly.
Cloud Computing: With the rapid adoption of cloud platforms like AWS, Azure, and Google Cloud, knowing cloud computing is essential for a DevOps professional. Understanding how to provision resources, configure networking, and leverage cloud services will empower you to build scalable and resilient infrastructures.
Collaboration and Communication: DevOps is not just about tools and technologies; it's also about fostering collaboration between different teams. Strong communication skills and the ability to work effectively with developers, operations personnel, and other stakeholders are key in a DevOps environment.
Mastering DevOps is a journey that involves embracing a culture of collaboration, automation, and continuous improvement. By understanding the DevOps lifecycle, implementing automation, adopting CI/CD pipelines, using Infrastructure as Code, promoting collaboration, monitoring effectively, and integrating security practices, development and operations teams can work together seamlessly to deliver high-quality software faster and more reliably. As the landscape of technology continues to evolve, staying current with DevOps practices is essential for any organization striving for agility and innovation in software development.
0 notes