#Context API
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
If you dial 1-866-584-6757, you can leave an audio post for your followers.
Text
Context API vs. Redux: Which One Should You Choose?

State management is one of the most critical aspects of React development. As an application grows, handling state efficiently becomes a challenge. Two popular solutions, Context API and Redux, offer different ways to manage and share state across components. While both are widely used, understanding their differences will help you choose the right tool for your project.
Understanding Context API
The Context API is a built-in feature in React that enables components to share state without prop drilling. Instead of manually passing props through every level of the component tree, it allows a Provider component to wrap around sections of an application, making state available to any child component that needs it.
Why Developers Love Context API
One of the biggest advantages of Context API is that it eliminates prop drilling, making it easier to pass data across deeply nested components. This is particularly useful in scenarios where multiple components need access to the same data, such as theme settings or user authentication status.
Moreover, Context API is lightweight and does not require additional libraries. This makes it an excellent choice for small to medium-sized applications that don’t require extensive state management.
However, Context API has limitations when dealing with frequent state updates. Every time the context value changes, all components consuming that context re-render, which can lead to performance issues if not managed properly.
Diving Into Redux

Redux, on the other hand, is an independent state management library that follows a predictable unidirectional data flow. It introduces a single source of truth, meaning that all state is stored in a central location and can only be modified through actions and reducers.
Why Redux is Preferred for Large Applications
Redux shines in large-scale applications where managing global state efficiently is crucial. It provides strict state management, which ensures that data updates occur in a controlled and predictable manner.
One of its key strengths is middleware support. Libraries like Redux Thunk and Redux Saga allow developers to handle asynchronous operations, such as API calls, in an organized manner. This is particularly useful in applications that require complex side effects or rely heavily on asynchronous data fetching.
Additionally, Redux comes with powerful debugging tools like Redux DevTools, which enable developers to track every state change, rewind actions, and inspect state mutations in real time.
However, Redux does require more boilerplate code compared to Context API. Setting up actions, reducers, and stores adds complexity, which can be overwhelming for beginners or for projects where state management is relatively simple.
Comparing Context API and Redux
When deciding between Context API and Redux, it's important to consider key factors such as setup complexity, performance, scalability, and debugging support.
Setup Complexity – Context API is straightforward to implement since it is built into React. Redux, on the other hand, requires setting up a store, actions, and reducers, making it more complex to integrate.
Performance – While Context API reduces prop drilling, it can cause unnecessary re-renders when state updates frequently. Redux is optimized for performance since state updates happen in a structured way using reducers and selectors.
Scalability – Context API works well for small to medium-sized applications but may struggle as state management becomes more intricate. Redux is designed for large applications where maintaining a global state efficiently is essential.
Debugging – Redux provides advanced debugging tools that allow developers to inspect and track state changes. Context API, in contrast, relies on React DevTools, which offers limited debugging capabilities compared to Redux DevTools.
Middleware Support – Redux supports middleware solutions that help manage asynchronous operations, such as API requests or side effects. Context API does not have built-in middleware support, making Redux a better choice for handling complex asynchronous tasks.
When Should You Use Context API?
Context API is a great choice if:
Your application has a simple or moderate state management requirement.
You want to avoid prop drilling without adding external dependencies.
Your project does not require middleware for handling asynchronous actions.
You are working on a small app and need a lightweight state-sharing solution.
When Should You Use Redux?
Redux is the better choice when:
Your application involves complex state management with multiple components depending on shared state.
You need to handle asynchronous operations like fetching data from APIs.
You want structured state updates and debugging tools to track changes efficiently.
Your project is large and requires a scalable state management solution with middleware support.
Final Thoughts: Which One is Right for You?
Both Context API and Redux are powerful tools for state management, but the choice depends on your project’s needs. If you’re building a small to medium-sized application and need a quick, lightweight solution, Context API is the way to go. However, if your project requires scalability, middleware, and advanced debugging tools, Redux will be the better option.
State management is a key factor in React applications, and choosing the right tool will ensure better maintainability and performance in the long run. Want to explore more? Check out the in-depth guide on Context API vs. Redux for a deeper comparison!
0 notes
Text
0 notes
Text
#no clue any context lol just had 1 min and was doin tiny dancer#im very amused i asked if i know them no response i find this hilarious . hello#looked on skycrypt baffled . they have 120 health and api off lol#IM JUST SO LOST WHO ARE YOU WAS THAT WORTH IT?? WHO ARE YOU??? i find it incredibly funny that some random person decided theyare full of#hate and mildly inconvenienced me in such a silly way . hi? hello?#<- submission tags#99% of people you meet with a black plus do not deserve human rights lmao#also i cant even load their skycrypt profiles what is up with them 😭#die mad i guess idk man. it's block game
14 notes
·
View notes
Text
Getting Started with Context API in Next JS 14: A Comprehensive Guide
This blog offers a straightforward guide on how to use the Context API in Next JS 14. It covers the basics, explains how Context API helps in managing state across your application, and provides practical examples. Whether you’re new to Next JS or looking to improve your skills, this guide will help you implement Context API effectively in your projects.
0 notes
Text
also if you're sharing a twitter post these days, PLEASE include not only a link but a screenshot that includes the date








NOTE TO SELF-SLOW THE FUCK DOWN!
#things are getting deleted or privated all the time in these days of musk's overweening vanity#and with the api issues links don't automatically post with images of the linked tweet#also people without accounts sometimes can't see tweets so a link with no info attached is just ... nothing#and if you're going to screenshot and post a whole thread then you still need to include THE DATE#with the date and the username someone can at least backtrack a source AND look at context
65K notes
·
View notes
Text
the great reddit API meltdown of '23, or: this was always bound to happen
there's a lot of press about what's going on with reddit right now (app shutdowns, subreddit blackouts, the CEO continually putting his foot in his mouth), but I haven't seen as much stuff talking about how reddit got into this situation to begin with. so as a certified non-expert and Context Enjoyer I thought it might be helpful to lay things out as I understand them—a high-level view, surveying the whole landscape—in the wonderful world of startups, IPOs, and extremely angry users.
disclaimer that I am not a founder or VC (lmao), have yet to work at a company with a successful IPO, and am not a reddit employee or third-party reddit developer or even a subreddit moderator. I do work at a startup, know my way around an API or two, and have spent twelve regrettable years on reddit itself. which is to say that I make no promises of infallibility, but I hope you'll at least find all this interesting.
profit now or profit later
before you can really get into reddit as reddit, it helps to know a bit about startups (of which reddit is one). and before I launch into that, let me share my Three Types Of Websites framework, which is basically just a mental model about financial incentives that's helped me contextualize some of this stuff.
(1) website/software that does not exist to make money: relatively rare, for a variety of reasons, among them that it costs money to build and maintain a website in the first place. wikipedia is the evergreen example, although even wikipedia's been subject to criticism for how the wikimedia foundation pays out its employees and all that fun nonprofit stuff. what's important here is that even when making money is not the goal, money itself is still a factor, whether it's solicited via donations or it's just one guy paying out of pocket to host a hobby site. but websites in this category do, generally, offer free, no-strings-attached experiences to their users.
(I do want push back against the retrospective nostalgia of "everything on the internet used to be this way" because I don't think that was ever really true—look at AOL, the dotcom boom, the rise of banner ads. I distinctly remember that neopets had multiple corporate sponsors, including a cookie crisp-themed flash game. yahoo bought geocities for $3.6 billion; money's always been trading hands, obvious or not. it's indisputable that the internet is simply different now than it was ten or twenty years ago, and that monetization models themselves have largely changed as well (I have thoughts about this as it relates to web 1.0 vs web 2.0 and their associated costs/scale/etc.), but I think the only time people weren't trying to squeeze the internet for all the dimes it can offer was when the internet was first conceived as a tool for national defense.)
(2) website/software that exists to make money now: the type that requires the least explanation. mostly non-startup apps and services, including any random ecommerce storefront, mobile apps that cost three bucks to download, an MMO with a recurring subscription, or even a news website that runs banner ads and/or offers paid subscriptions. in most (but not all) cases, the "make money now" part is obvious, so these things don't feel free to us as users, even to the extent that they might have watered-down free versions or limited access free trials. no one's shocked when WoW offers another paid expansion packs because WoW's been around for two decades and has explicitly been trying to make money that whole time.
(3) website/software that exists to make money later: this is the fun one, and more common than you'd think. "make money later" is more or less the entire startup business model—I'll get into that in the next section—and is deployed with the expectation that you will make money at some point, but not always by means as obvious as "selling WoW expansions for forty bucks a pop."
companies in this category tend to have two closely entwined characteristics: they prioritize growth above all else, regardless of whether this growth is profitable in any way (now, or sometimes, ever), and they do this by offering users really cool and awesome shit at little to no cost (or, if not for free, then at least at a significant loss to the company).
so from a user perspective, these things either seem free or far cheaper than their competitors. but of course websites and software and apps and [blank]-as-a-service tools cost money to build and maintain, and that money has to come from somewhere, and the people supplying that money, generally, expect to get it back...
just not immediately.
startups, VCs, IPOs, and you
here's the extremely condensed "did NOT go to harvard business school" version of how a startup works:
(1) you have a cool idea.
(2) you convince some venture capitalists (also known as VCs) that your idea is cool. if they see the potential in what you're pitching, they'll give you money in exchange for partial ownership of your company—which means that if/when the company starts trading its stock publicly, these investors will own X numbers of shares that they can sell at any time. in other words, you get free money now (and you'll likely seek multiple "rounds" of investors over the years to sustain your company), but with the explicit expectations that these investors will get their payoff later, assuming you don't crash and burn before that happens.
during this phase, you want to do anything in your power to make your company appealing to investors so you can attract more of them and raise funds as needed. because you are definitely not bringing in the necessary revenue to offset operating costs by yourself.
it's also worth nothing that this is less about projecting the long-term profitability of your company than it's about its perceived profitability—i.e., VCs want to put their money behind a company that other people will also have confidence in, because that's what makes stock valuable, and VCs are in it for stock prices.
(3) there are two non-exclusive win conditions for your startup: you can get acquired, and you can have an IPO (also referred to as "going public"). these are often called "exit scenarios" and they benefit VCs and founders, as well as some employees. it's also possible for a company to get acquired, possibly even more than once, and then later go public.
acquisition: sell the whole damn thing to someone else. there are a million ways this can happen, some better than others, but in many cases this means anyone with ownership of the company (which includes both investors and employees who hold stock options) get their stock bought out by the acquiring company and end up with cash in hand. in varying amounts, of course. sometimes the founders walk away, sometimes the employees get laid off, but not always.
IPO: short for "initial public offering," this is when the company starts trading its stocks publicly, which means anyone who wants to can start buying that company's stock, which really means that VCs (and employees with stock options) can turn that hypothetical money into real money by selling their company stock to interested buyers.
drawing from that, companies don't go for an IPO until they think their stock will actually be worth something (or else what's the point?)—specifically, worth more than the amount of money that investors poured into it. The Powers That Be will speculate about a company's IPO potential way ahead of time, which is where you'll hear stuff about companies who have an estimated IPO evaluation of (to pull a completely random example) $10B. actually I lied, that was not a random example, that was reddit's valuation back in 2021 lol. but a valuation is basically just "how much will people be interested in our stock?"
as such, in the time leading up to an IPO, it's really really important to do everything you can to make your company seem like a good investment (which is how you get stock prices up), usually by making the company's numbers look good. but! if you plan on cashing out, the long-term effects of your decisions aren't top of mind here. remember, the industry lingo is "exit scenario."
if all of this seems like a good short-term strategy for companies and their VCs, but an unsustainable model for anyone who's buying those stocks during the IPO, that's because it often is.
also worth noting that it's possible for a company to be technically unprofitable as a business (meaning their costs outstrip their revenue) and still trade enormously well on the stock market; uber is the perennial example of this. to the people who make money solely off of buying and selling stock, it literally does not matter that the actual rideshare model isn't netting any income—people think the stock is valuable, so it's valuable.
this is also why, for example, elon musk is richer than god: if he were only the CEO of tesla, the money he'd make from selling mediocre cars would be (comparatively, lol) minimal. but he's also one of tesla's angel investors, which means he holds a shitload of tesla stock, and tesla's stock has performed well since their IPO a decade ago (despite recent dips)—even if tesla itself has never been a huge moneymaker, public faith in the company's eventual success has kept them trading at high levels. granted, this also means most of musk's wealth is hypothetical and not liquid; if TSLA dropped to nothing, so would the value of all the stock he holds (and his net work with it).
what's an API, anyway?
to move in an entirely different direction: we can't get into reddit's API debacle without understanding what an API itself is.
an API (short for "application programming interface," not that it really matters) is a series of code instructions that independent developers can use to plug their shit into someone else's shit. like a series of tin cans on strings between two kids' treehouses, but for sending and receiving data.
APIs work by yoinking data directly from a company's servers instead of displaying anything visually to users. so I could use reddit's API to build my own app that takes the day's top r/AITA post and transcribes it into pig latin: my app is a bunch of lines of code, and some of those lines of code fetch data from reddit (and then transcribe that data into pig latin), and then my app displays the content to anyone who wants to see it, not reddit itself. as far as reddit is concerned, no additional human beings laid eyeballs on that r/AITA post, and reddit never had a chance to serve ads alongside the pig-latinized content in my app. (put a pin in this part—it'll be relevant later.)
but at its core, an API is really a type of protocol, which encompasses a broad category of formats and business models and so on. some APIs are completely free to use, like how anyone can build a discord bot (but you still have to host it yourself). some companies offer free APIs to third-party developers can build their own plugins, and then the company and the third-party dev split the profit on those plugins. some APIs have a free tier for hobbyists and a paid tier for big professional projects (like every weather API ever, lol). some APIs are strictly paid services because the API itself is the company's core offering.
reddit's financial foundations
okay thanks for sticking with me. I promise we're almost ready to be almost ready to talk about the current backlash.
reddit has always been a startup's startup from day one: its founders created the site after attending a startup incubator (which is basically a summer camp run by VCs) with the successful goal of creating a financially successful site. backed by that delicious y combinator money, reddit got acquired by conde nast only a year or two after its creation, which netted its founders a couple million each. this was back in like, 2006 by the way. in the time since that acquisition, reddit's gone through a bunch of additional funding rounds, including from big-name investors like a16z, peter thiel (yes, that guy), sam altman (yes, also that guy), sequoia, fidelity, and tencent. crunchbase says that they've raised a total of $1.3B in investor backing.
in all this time, reddit has never been a public company, or, strictly speaking, profitable.
APIs and third-party apps
reddit has offered free API access for basically as long as it's had a public API—remember, as a "make money later" company, their primary goal is growth, which means attracting as many users as possible to the platform. so letting anyone build an app or widget is (or really, was) in line with that goal.
as such, third-party reddit apps have been around forever. by third-party apps, I mean apps that use the reddit API to display actual reddit content in an unofficial wrapper. iirc reddit didn't even have an official mobile app until semi-recently, so many of these third-party mobile apps in particular just sprung up to meet an unmet need, and they've kept a small but dedicated userbase ever since. some people also prefer the user experience of the unofficial apps, especially since they offer extra settings to customize what you're seeing and few to no ads (and any ads these apps do display are to the benefit of the third-party developers, not reddit itself.)
(let me add this preemptively: one solution I've seen proposed to the paid API backlash is that reddit should have third-party developers display reddit's ads in those third-party apps, but this isn't really possible or advisable due to boring adtech reasons I won't inflict on you here. source: just trust me bro)
in addition to mobile apps, there are also third-party tools that don’t replace the Official Reddit Viewing Experience but do offer auxiliary features like being able to mass-delete your post history, tools that make the site more accessible to people who use screen readers, and tools that help moderators of subreddits moderate more easily. not to mention a small army of reddit bots like u/AutoWikibot or u/RemindMebot (and then the bots that tally the number of people who reply to bot comments with “good bot” or “bad bot).
the number of people who use third-party apps is relatively small, but they arguably comprise some of reddit’s most dedicated users, which means that third-party apps are important to the people who keep reddit running and the people who supply reddit with high-quality content.
unpaid moderators and user-generated content
so reddit is sort of two things: reddit is a platform, but it’s also a community.
the platform is all the unsexy (or, if you like python, sexy) stuff under the hood that actually makes the damn thing work. this is what the company spends money building and maintaining and "owns." the community is all the stuff that happens on the platform: posts, people, petty squabbles. so the platform is where the content lives, but ultimately the content is the reason people use reddit—no one’s like “yeah, I spend time on here because the backend framework really impressed me."
and all of this content is supplied by users, which is not unique among social media platforms, but the content is also managed by users, which is. paid employees do not govern subreddits; unpaid volunteers do. and moderation is the only thing that keeps reddit even remotely tolerable—without someone to remove spam, ban annoying users, and (god willing) enforce rules against abuse and hate speech, a subreddit loses its appeal and therefore its users. not dissimilar to the situation we’re seeing play out at twitter, except at twitter it was the loss of paid moderators; reddit is arguably in a more precarious position because they could lose this unpaid labor at any moment, and as an already-unprofitable company they absolutely cannot afford to implement paid labor as a substitute.
oh yeah? spell "IPO" backwards
so here we are, June 2023, and reddit is licking its lips in anticipation of a long-fabled IPO. which means it’s time to start fluffing themselves up for investors by cutting costs (yay, layoffs!) and seeking new avenues of profit, however small.
this brings us to the current controversy: reddit announced a new API pricing plan that more or less prevents anyone from using it for free.
from reddit's perspective, the ostensible benefits of charging for API access are twofold: first, there's direct profit to be made off of the developers who (may or may not) pay several thousand dollars a month to use it, and second, cutting off unsanctioned third-party mobile apps (possibly) funnels those apps' users back into the official reddit mobile app. and since users on third-party apps reap the benefit of reddit's site architecture (and hosting, and development, and all the other expenses the site itself incurs) without “earning” money for reddit by generating ad impressions, there’s a financial incentive at work here: even if only a small percentage of people use third-party apps, getting them to use the official app instead translates to increased ad revenue, however marginal.
(also worth mentioning that chatGPT and other LLMs were trained via tools that used reddit's API to scrape post and content data, and now that openAI is reaping the profits of that training without giving reddit any kickbacks, reddit probably wants to prevent repeats of this from happening in the future. if you want to train the next LLM, it's gonna cost you.)
of course, these changes only benefit reddit if they actually increase the company’s revenue and perceived value/growth—which is hard to do when your users (who are also the people who supply the content for other users to engage with, who are also the people who moderate your communities and make them fun to participate in) get really fucking pissed and threaten to walk.
pricing shenanigans
under the new API pricing plan, third-party developers are suddenly facing steep costs to maintain the apps and tools they’ve built.
most paid APIs are priced by volume: basically, the more data you send and receive, the more money it costs. so if your third-party app has a lot of users, you’ll have to make more API requests to fetch content for those users, and your app becomes more expensive to maintain. (this isn’t an issue if the tool you’re building also turns a profit, but most third-party reddit apps make little, if any, money.)
which is why, even though third-party apps capture a relatively small portion of reddit’s users, the developer of a popular third-party app called apollo recently learned that it would cost them about $20 million a year to keep the app running. and apollo actually offers some paid features (for extra in-app features independent of what reddit offers), but nowhere near enough to break even on those API costs.
so apollo, any many apps like it, were suddenly unable to keep their doors open under the new API pricing model and announced that they'd be forced to shut down.
backlash, blackout
plenty has been said already about the current subreddit blackouts—in like, official news outlets and everything—so this might be the least interesting section of my whole post lol. the short version is that enough redditors got pissed enough that they collectively decided to take subreddits “offline” in protest, either by making them read-only or making them completely inaccessible. their goal was to send a message, and that message was "if you piss us off and we bail, here's what reddit's gonna be like: a ghost town."
but, you may ask, if third-party apps only captured a small number of users in the first place, how was the backlash strong enough to result in a near-sitewide blackout? well, two reasons:
first and foremost, since moderators in particular are fond of third-party tools, and since moderators wield outsized power (as both the people who keep your site more or less civil, and as the people who can take a subreddit offline if they feel like it), it’s in your best interests to keep them happy. especially since they don’t get paid to do this job in the first place, won’t keep doing it if it gets too hard, and essentially have nothing to lose by stepping down.
then, to a lesser extent, the non-moderator users on third-party apps tend to be Power Users who’ve been on reddit since its inception, and as such likely supply a disproportionate amount of the high-quality content for other users to see (and for ads to be served alongside). if you drive away those users, you’re effectively kneecapping your overall site traffic (which is bad for Growth) and reducing the number/value of any ad impressions you can serve (which is bad for revenue).
also a secret third reason, which is that even people who use the official apps have no stake in a potential IPO, can smell the general unfairness of this whole situation, and would enjoy the schadenfreude of investors getting fucked over. not to mention that reddit’s current CEO has made a complete ass of himself and now everyone hates him and wants to see him suffer personally.
(granted, it seems like reddit may acquiesce slightly and grant free API access to a select set of moderation/accessibility tools, but at this point it comes across as an empty gesture.)
"later" is now "now"
TL;DR: this whole thing is a combination of many factors, specifically reddit being intensely user-driven and self-governed, but also a high-traffic site that costs a lot of money to run (why they willingly decided to start hosting video a few years back is beyond me...), while also being angled as a public stock market offering in the very near future. to some extent I understand why reddit’s CEO doubled down on the changes—he wants to look strong for investors—but he’s also made a fool of himself and cast a shadow of uncertainty onto reddit’s future, not to mention the PR nightmare surrounding all of this. and since arguably the most important thing in an IPO is how much faith people have in your company, I honestly think reddit would’ve fared better if they hadn’t gone nuclear with the API changes in the first place.
that said, I also think it’s a mistake to assume that reddit care (or needs to care) about its users in any meaningful way, or at least not as more than means to an end. if reddit shuts down in three years, but all of the people sitting on stock options right now cashed out at $120/share and escaped unscathed... that’s a success story! you got your money! VCs want to recoup their investment—they don’t care about longevity (at least not after they’re gone), user experience, or even sustained profit. those were never the forces driving them, because these were never the ultimate metrics of their success.
and to be clear: this isn’t unique to reddit. this is how pretty much all startups operate.
I talked about the difference between “make money now” companies and “make money later” companies, and what we’re experiencing is the painful transition from “later” to “now.” as users, this change is almost invisible until it’s already happened—it’s like a rug we didn’t even know existed gets pulled out from under us.
the pre-IPO honeymoon phase is awesome as a user, because companies have no expectation of profit, only growth. if you can rely on VC money to stay afloat, your only concern is building a user base, not squeezing a profit out of them. and to do that, you offer cool shit at a loss: everything’s chocolate and flowers and quarterly reports about the number of signups you’re getting!
...until you reach a critical mass of users, VCs want to cash in, and to prepare for that IPO leadership starts thinking of ways to make the website (appear) profitable and implements a bunch of shit that makes users go “wait, what?”
I also touched on this earlier, but I want to reiterate a bit here: I think the myth of the benign non-monetized internet of yore is exactly that—a myth. what has changed are the specific market factors behind these websites, and their scale, and the means by which they attempt to monetize their services and/or make their services look attractive to investors, and so from a user perspective things feel worse because the specific ways we’re getting squeezed have evolved. maybe they are even worse, at least in the ways that matter. but I’m also increasingly less surprised when this occurs, because making money is and has always been the goal for all of these ventures, regardless of how they try to do so.
8K notes
·
View notes
Text
Tuesday, June 18th, 2024
🌟 New
The first cut of settings for communities is now available. Admins of communities can change the name, tagline, avatar, header image, tags, and description. You can find a link to these settings in the sidebar for your community on desktop, or in the context menu on mobile.
The community invite popup has been given a design refresh, including a counter of how many invites you have left.
Communities now display whether they are public or private in their header.
Community admins can now promote members to moderators. Moderators can delete posts, and we’re still building out the feature, so expect to see things change in the next few weeks!
We’ve updated the blog posts API endpoint to add the options to specify a sort order and an “after” time, to complement the current option to show posts from “before” a specific time. When using “before”, and by default, posts are sorted in reverse-chronological order (“descending”). With “after” and “sort = asc”, you can sort posts from oldest to newest instead, starting at a certain time.
🛠 Fixed
Since secondary blogs cannot post to communities yet, your primary blog will now always be selected when posting to communities.
Certain activity coming from communities, such as mentions in posts and comments, and soon invitations, now count towards your unread activity total.
🚧 Ongoing
We are aware of ads auto-playing audio in the Android app, sometimes quite loudly, and are working on a fix!
🌱 Upcoming
We are working to rename Community Labels to Content Labels across our official clients (Web, iOS, and Android), as well as Community Guidelines to User Guidelines. We hope this change will prevent any potential confusion regarding the relationship between these and Tumblr Communities.
Experiencing an issue? Check for Known Issues and file a Support Request if you have something new. We’ll get back to you as soon as we can!
Want to share your feedback about something? Check out our Work in Progress blog and start a discussion with the community.
Wanna support Tumblr directly with some money? Check out the new Supporter badge in TumblrMart!
283 notes
·
View notes
Text
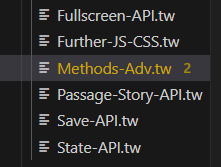
Here's what's left on the To-Do list:
API chapters for Fullscreen, Passage/Story, Save, and State
Explanations of the last Methods not mentioned before
Finishing the JS/CSS Styling edits (1-2 more passages)
Ensure the links are complete
Finishing the light mode (a.k.a. the SugarCube Documentation palette), and maybe add more?
Compile it into two files: one online few + one download
Oh look! An update for the guide is coming.
A major one! With new stuff and updates galore!
#template#guide#sugarcube#interactive fiction#coding in twine#I am so fucking close#the Macro Context API broke my brain a little tho...
35 notes
·
View notes
Text
using LLMs to control a game character's dialogue seems an obvious use for the technology. and indeed people have tried, for example nVidia made a demo where the player interacts with AI-voiced NPCs:
youtube
this looks bad, right? like idk about you but I am not raring to play a game with LLM bots instead of human-scripted characters. they don't seem to have anything interesting to say that a normal NPC wouldn't, and the acting is super wooden.
so, the attempts to do this so far that I've seen have some pretty obvious faults:
relying on external API calls to process the data (expensive!)
presumably relying on generic 'you are xyz' prompt engineering to try to get a model to respond 'in character', resulting in bland, flavourless output
limited connection between game state and model state (you would need to translate the relevant game state into a text prompt)
responding to freeform input, models may not be very good at staying 'in character', with the default 'chatbot' persona emerging unexpectedly. or they might just make uncreative choices in general.
AI voice generation, while it's moved very fast in the last couple years, is still very poor at 'acting', producing very flat, emotionless performances, or uncanny mismatches of tone, inflection, etc.
although the model may generate contextually appropriate dialogue, it is difficult to link that back to the behaviour of characters in game
so how could we do better?
the first one could be solved by running LLMs locally on the user's hardware. that has some obvious drawbacks: running on the user's GPU means the LLM is competing with the game's graphics, meaning both must be more limited. ideally you would spread the LLM processing over multiple frames, but you still are limited by available VRAM, which is contested by the game's texture data and so on, and LLMs are very thirsty for VRAM. still, imo this is way more promising than having to talk to the internet and pay for compute time to get your NPC's dialogue lmao
second one might be improved by using a tool like control vectors to more granularly and consistently shape the tone of the output. I heard about this technique today (thanks @cherrvak)
third one is an interesting challenge - but perhaps a control-vector approach could also be relevant here? if you could figure out how a description of some relevant piece of game state affects the processing of the model, you could then apply that as a control vector when generating output. so the bridge between the game state and the LLM would be a set of weights for control vectors that are applied during generation.
this one is probably something where finetuning the model, and using control vectors to maintain a consistent 'pressure' to act a certain way even as the context window gets longer, could help a lot.
probably the vocal performance problem will improve in the next generation of voice generators, I'm certainly not solving it. a purely text-based game would avoid the problem entirely of course.
this one is tricky. perhaps the model could be taught to generate a description of a plan or intention, but linking that back to commands to perform by traditional agentic game 'AI' is not trivial. ideally, if there are various high-level commands that a game character might want to perform (like 'navigate to a specific location' or 'target an enemy') that are usually selected using some other kind of algorithm like weighted utilities, you could train the model to generate tokens that correspond to those actions and then feed them back in to the 'bot' side? I'm sure people have tried this kind of thing in robotics. you could just have the LLM stuff go 'one way', and rely on traditional game AI for everything besides dialogue, but it would be interesting to complete that feedback loop.
I doubt I'll be using this anytime soon (models are just too demanding to run on anything but a high-end PC, which is too niche, and I'll need to spend time playing with these models to determine if these ideas are even feasible), but maybe something to come back to in the future. first step is to figure out how to drive the control-vector thing locally.
48 notes
·
View notes
Text
I've started going through some of the fillers now that I'm caught up with the main manga story, and this first one about the dragon and lost island (eps 54-60) is pretty interesting - especially how Luffy could hear the dragon's thoughts, (in a way it reminded me of him hearing Zunesha on Zou, though it is different)









and how Zoro could pretty quickly tell when someone dangerous was nearby (with a sense that seems very similar to observation haki 🤔)





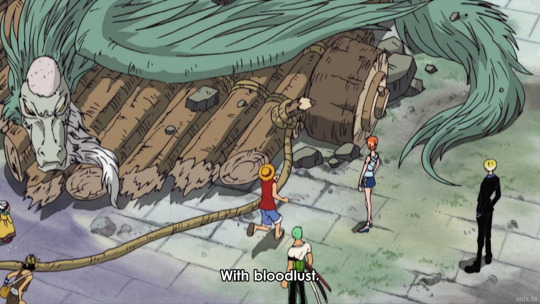
but also this fun zolu part:
I've seen it in some clips or screenshots before (gifs and screenshots really don't do justice to the amazing voice acting here lol "Zoorooooooooooooooo") but I haven't seen it with the context of this Apis girl being worried about Zoro before, (who stayed behind to let the crew get away with the dragon, and they managed that, and her concern made Luffy search out for Zoro to get him back to their ship. (Thankfully, because otherwise he would have totally get so lost on that small island)
and even in one scene before this clip she was worried if Zoro was going to be alright - and Luffy could reassure her with his absolute certainty that Zoro would be just fine.





It's pretty fun how this scenario repeats all the way thoughout the story (with at least two very similar scenes being in Dressrosa) where other people question if Zoro would be fine and Luffy has the full trust in his capabilites and strength.




#just them#one piece#monkey d. luffy#roronoa zoro#zolu#luzo#one piece ep 58#mine#gif:zolu#gif:op anime#long post#its so early on in the story.. and yet#1000+ chapters later (and in canon material) and some things never change ;-;#only thing that changed was the fact that zoro willingly let himself get tossed around by luffy on wano. and that's character development!
154 notes
·
View notes
Note
Now I'm curious why the API v2 never got a full public release
mainly: not enough time, not enough priority put upon it.
a lot of the v2 API doesn't make sense, and we wanted to make things-that-are-public make as much sense as we could, and that takes time. it doesn't make sense because it was built by over 100 people over the course of more than a decade. this is just what naturally happens to products over time, they become organic masses of tech debt and weird decisions that made sense in context but rarely out of context.
another big reason was simply lack of interest. we don't have a ton of third-party API clients, surprisingly. twitter and reddit always had problems with too many API clients... we never did. if we did, maybe there would've been higher priority on improving it. chicken-and-egg problem, probably.
and another big reason was that we didn't want to give spammers easier tools to access things like direct messaging (which has never been made public) and other API endpoints we considered "private".
lots of reasons. i could go on for awhile. but if we truly wanted to have made it happen, we could've. the people working at tumblr still could if they wanted to prioritize it.
15 notes
·
View notes
Text
The Saga of Hermitcraft on r/Place (1 April 2022 - 4 April 2022)



On the 1st of April 2022, Reddit unveiled a white blank canvas where every user had the ability to place one colored pixel in every 5 minutes. At its height, about 4 million people participated in one of the biggest internet collaborations ever made. The ripple effects reverberated into news reports as far away as Turkey, and the final canvas represents a snapshot of the multiple communities, events, memes, and what was popular around the world at that time.
This is a documentation of the Hermitcraft mural on r/place 2022.
aka.
Remember what I said about my latest ficbind being a distraction? This is what I wanted to be distracted from.



After Reddit's API fiasco of this year and the subsequent controversial event that was r/place 2023, I decided to save as much documentation about the 2022 event as I could. Luckily, I remember how there are already a series of posts by @riacte who documented the progress of the Hermitcraft mural throughout the whole event, from beginning to end. Her blogposts form the bulk of this book (like, 95%!) and I cannot thank her enough for preserving the happenings of the block men mural.
With that said, I quickly realized that someone who's not a Hermitcraft fan - or me if I'm older - might not get the gist of who's who on the mural. The solution? Make several pages dedicated to just listing who's who on the murals! Because of the sheer number of heads, the mural was divided into several pieces for easier labeling. As a bonus, I also threw in another mural nearby which was connected enough to the Hermitcraft community.
For consistency's sake and preserving focus, I decided to not label the peeps from Dream SMP or the MCC secondary mural. Wrangling Microsoft Word to create an infographic was hard enough, let alone 3! If I inadvertently left out a few bits of extra context from this decision, mea culpa.





When it came to typesetting the entire text block, I decided to make some consistent rules. Titles denoting each day or stage of the mural are on their own pages. New sections are titled using the Bahnschrift font and colored blue, while the first paragraph has their beginning lines look Minecraft-coded and topped with a drop cap (aka. those super-large alphabets).
The names of Hermitcraft and Minecraft players in general are bolded when they first appear in the text. Afterwards, they are bolded if they are contextually important to what's being said.
Extra context would be placed in the footnotes section at the bottom of the page. This is also where I dump some background information that would be invaluable for any readers who aren't Minecraft fans, which is why the SpaceX page looked like... uh, that.
My image policy is to go with the flow; I used as many images from riacte's posts as possible, but I also added-in some of my own if more context is needed. Placing them to look smooth with the text was harder - some are small enough to not cause any problems, others are large enough to fill entire pages without any problems, but a few like the Dream SMP mural (hey there! I managed to put you in!) are too wonky to fit perfectly without leaving no empty spaces.
So in that mural's case, I placed them to the side and let the contextual text flow around it. This principle was also used for the Dota2 / Love Live images and in a few other places throughout the book. The biggest case of this are the few images that are just too wide.

Like this one.
Making double-page spreads is not the easiest thing to do in Microsoft Word, and there are a few r/place images that are too wide to fit perfectly in a single page. Confining them to one page would also mean losing all their details, so making them a double-page spread was necessary.
Didn't make it easy though, especially when there are paragraphs of text and other images that needed to be shuffled around. Mess up the double-page images, and they won't meet in the middle. Mess up the text and other pics? There goes the layout and overall flow!
In the end, making this book took a lot longer than I expected, but I am still grateful to have made this as I have now read through many posts from Tumblr, Reddit, and even Youtube - people expressing joy that they have collectively made something together. I can only hope I have made some justice to them by compiling their work and (even if a small sliver) preserving their testaments.
May this r/place be remembered.



#r/place#rplace#Hermitcraft#reddit#MCYT#rplace 2022#r/place 2022#bookbinding#fanbinding#documentation#my bookbinds#hermitblr
374 notes
·
View notes
Text
Interior Chinatown: A Sharp Satire That Challenges Stereotypes and Forces Self-Reflection

Interior Chinatown is a brilliant yet understated reflection of the world—a mirror that exposes how society often judges people by their covers. The show captures this poignantly with the scene where Willis Wu can’t get into the police precinct until he proves his worth by delivering food. It’s a powerful metaphor: sometimes, if you don’t fit the mold, you have to prove your value in the most degrading or unexpected ways just to get a foot in the door. The locked precinct doors represent barriers faced by those who don’t match the “majority’s” idea of what’s acceptable or valuable.
While the series centers on the Asian and Pacific Islander (API) community and the stereotypical roles Hollywood has long relegated them to—background extras, kung fu fighters—it forces viewers to confront bigger questions. It makes you ask: Am I complicit in perpetuating these stereotypes? Am I limiting others—or even myself—by what I assume is their worth? It’s not just about API representation; it’s about how society as a whole undervalues anyone who doesn’t fit neatly into its preferred narrative.
The show can feel confusing if you don’t grasp its satirical lens upfront. But for me, knowing the context of Charles Yu’s original book helped it click. The production team does an incredible job balancing satire with sincerity, blurring the line between real life and the exaggerated Hollywood “procedural” format. They cleverly use contrasting visuals and distinct camera work to draw you into different headspaces—Hollywood’s glossy expectations versus the grittier reality of life.
Chloe Bennet’s involvement (real name Chloe Wang) ties into the show’s themes on a deeply personal level. She famously changed her last name to navigate Hollywood, caught in the impossible middle ground of not being “Asian enough” or “white enough” for casting directors. It’s a decision that sparks debate—was it an act of survival, assimilation, or betrayal? But for Bennett, it was about carving a space for herself to pursue her dreams.
This theme echoes in one of the show’s most poignant scenes, where Lana is told, “You will never completely understand. You’re mixed.” It’s a crushing acknowledgment of the barriers that persist, even when you’re trying to bridge divides. Lana’s story highlights how identity can be both a strength and an obstacle, and the line serves as a painful reminder of the walls society creates—externally and internally.
Interior Chinatown doesn’t just ask us to look at the system; it forces us to examine ourselves. Whether it’s Willis Wu at the precinct door or Lana trying to connect in a world that sees her as neither this nor that, the show unflinchingly portrays the struggle to belong. And as viewers, it challenges us to question our role in those struggles: Are we helping to dismantle the barriers, or are we quietly reinforcing them?
#interior chinatown#chloe bennet#taika waititi#hulu#tv series review#tv show review#tv reviews#series review#review#jimmy o. yang#ronny chieng#sullivan jones#lisa gilroy#tzi ma#Hulu interior Chinatown#charles yu#int. Chinatown#int Chinatown#writerblr#writeblr
52 notes
·
View notes
Text
Today, we’re launching three new models in the API: GPT‑4.1, GPT‑4.1 mini, and GPT‑4.1 nano. These models outperform GPT‑4o and GPT‑4o mini across the board, with major gains in coding and instruction following. They also have larger context windows—supporting up to 1 million tokens of context—and are able to better use that context with improved long-context comprehension. They feature a refreshed knowledge cutoff of June 2024.
OpenAI please your versioning please
14 notes
·
View notes
Note
How DOES the C preprocessor create two generations of completely asinine programmers??
oh man hahah oh maaan. ok, this won't be very approachable.
i don't recall what point i was trying to make with the whole "two generations" part but ill take this opportunity to justifiably hate on the preprocessor, holy fuck the amount of damage it has caused on software is immeasurable, if you ever thought computer programmers were smart people on principle...
the cpp:



there are like forty preprocessor directives, and they all inject a truly mind-boggling amount of vicious design problems and have done so for longer than ive been alive. there really only ever needed to be one: #include , if only to save you the trouble of manually having to copy header files in full & paste them at the top of your code. and christ almighty, we couldn't even get that right. C (c89) has way, waaaay fewer keywords than any other language. theres like 30, and half of those aren't ever used, have no meaning or impact in the 21st century (shit like "register" and "auto"). and C programmers still fail to understand all of them properly, specifically "static" (used in a global context) which marks some symbol as inelligible to be touched externally (e.g. you can't use "extern" to access it). the whole fucking point of static is to make #include'd headers rational, to have a clear seperation between external, intended-to-be-accessed API symbols, and internal, opaque shit. nobody bothers. it's all there, out in the open, if you #include something, you get all of it, and brother, this is only the beginning, you also get all of its preprocessor garbage.
this is where the hell begins:
#if #else
hey, do these look familiar? we already fucking have if/else. do you know what is hard to understand? perfectly minimally written if/else logic, in long functions. do you know what is nearly impossible to understand? poorly written if/else rats nests (which is what you find 99% of the time). do you know what is completely impossible to understand? that same poorly-written procedural if/else rat's nest code that itself is is subject to another higher-order if/else logic.
it's important to remember that the cpp is a glorified search/replace. in all it's terrifying glory it fucking looks to be turing complete, hell, im sure the C++ preprocessor is turing complete, the irony of this shouldn't be lost on you. if you have some long if/else logic you're trying to understand, that itself is is subject to cpp #if/#else, the logical step would be to run the cpp and get the output pure C and work from there, do you know how to do that? you open the gcc or llvm/clang man page, and your tty session's mem usage quadruples. great job idiot. trying figuring out how to do that in the following eight thousand pages. and even if you do, you're going to be running the #includes, and your output "pure C" file (bereft of cpp logic) is going to be like 40k lines. lol.
the worst is yet to come:
#define #ifdef #ifndef (<- WTF) #undef you can define shit. you can define "anything". you can pick a name, whatever, and you can "define it". full stop. "#define foo". or, you can give it a value: "#define foo 1". and of course, you can define it as a function: "#define foo(x) return x". wow. xzibit would be proud. you dog, we heard you wanted to kill yourself, so we put a programming language in your programming language.
the function-defines are pretty lol purely in concept. when you find them in the wild, they will always look something like this:
#define foo(x,y) \ (((x << y)) * (x))
i've seen up to seven parens in a row. why? because since cpp is, again, just a fucking find&replace, you never think about operator precedence and that leads to hilarious antipaterns like the classic
#define min(x,y) a < b ? a : b
which will just stick "a < b ? a: b" ternary statement wherever min(.. is used. just raw text replacement. it never works. you always get bitten by operator precedence.
the absolute worst is just the bare defines:
#define NO_ASN1 #define POSIX_SUPPORTED #define NO_POSIX
etc. etc. how could this be worse? first of all, what the fuck are any of these things. did they exist before? they do now. what are they defined as? probably just "1" internally, but that isn't the point, the philosophy here is the problem. back in reality, in C, you can't just do something like "x = 0;" out of nowhere, because you've never declared x. you've never given it a type. similar, you can't read its value, you'll get a similar compiler error. but cpp macros just suddenly exist, until they suddenly don't. ifdef? ifndef? (if not defined). no matter what, every permutation of these will have a "valid answer" and will run without problem. let me demonstrate how this fucks things up.
do you remember "heartbleed" ? the "big" openssl vulnerability ? probably about a decade ago now. i'm choosing this one specifically, since, for some reason, it was the first in an annoying trend for vulns to be given catchy nicknames, slick websites, logos, cable news coverage, etc. even though it was only a moderate vulnerability in the grand scheme of things...
(holy shit, libssl has had huge numbers of remote root vulns in the past, which is way fucking worse, heartbleed only gave you a random sampling of a tiny bit of internal memory, only after heavy ticking -- and nowadays, god, some of the chinese bluetooth shit would make your eyeballs explode if you saw it; a popular bt RF PHY chip can be hijacked and somehow made to rewrite some uefi ROMs and even, i think, the microcode on some intel chips)
anyways, heartbleed, yeah, so it's a great example since you could blame it two-fold on the cpp. it involved a generic bounds-checking failure, buf underflow, standard shit, but that wasn't due to carelessness (don't get me wrong, libssl is some of the worst code in existence) but because the flawed cpp logic resulted in code that:
A.) was de-facto worthless in definition B.) a combination of code supporting ancient crap. i'm older than most of you, and heartbleed happened early in my undergrad. the related legacy support code in question hadn't been relevant since clinton was in office.
to summarize, it had to do with DTLS heartbeats. DTLS involves handling TLS (or SSLv3, as it was then, in the 90s) only over UDP. that is how old we're talking. and this code was compiled into libssl in the early 2010s -- when TLS had been the standard for a while. TLS (unlike SSLv3 & predecessors) runs over TCP only. having "DTLS heartbeat support in TLS does not make sense by definition. it is like drawing a triangle on a piece of paper whose angles don't add up to 180.
how the fuck did that happen? the preprocessor.
why the fuck was code from last century ending up compiled in? who else but!! the fucking preprocessor. some shit like:
#ifndef TCP_SUPPORT <some crap related to UDP heartbeats> #endif ... #ifndef NO_UDP_ONLY <some TCP specific crap> #endif
the header responsible for defining these macros wasn't included, so the answer to BOTH of these "if not defined" blocks is true! because they were never defined!! do you see?
you don't have to trust my worldview on this. have you ever tried to compile some code that uses autoconf/automake as a build system? do you know what every single person i've spoken to refers to these as? autohell, for automatic hell. autohell lives and dies on cpp macros, and you can see firsthand how well that works. almost all my C code has the following compile process:
"$ make". done. Makefile length: 20 lines.
the worst i've ever deviated was having a configure script (probably 40 lines) that had to be rune before make. what about autohell? jesus, these days most autohell-cursed code does all their shit in a huge meta-wrapper bash script (autogen.sh), but short of that, if you decode the forty fucking page INSTALL doc, you end up with:
$ automake (fails, some shit like "AUTOMAKE_1.13 or higher is required) $ autoconf (fails, some shit like "AUTOMCONF_1.12 or lower is required) $ aclocal (fails, ???) $ libtoolize (doesn't fail, but screws up the tree in a way that not even a `make clean` fixes $ ???????? (pull hair out, google) $ autoreconf -i (the magic word) $ ./configure (takes eighty minutes and generates GBs of intermediaries) $ make (runs in 2 seconds)
in conclusion: roflcopter
⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯ disclaimer | private policy | unsubscribe
159 notes
·
View notes
Text
I was talking about backing up my tumblr to a friend who works in data storage and the amount of "holy-" "Half a gig text document? Probably?" "Is that gonna give you problems . . . ? that's an understatement" that happened made waking up to this

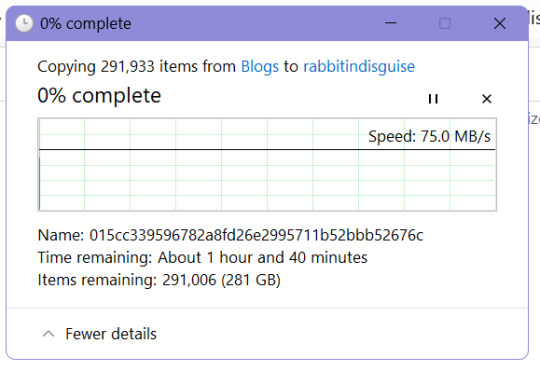
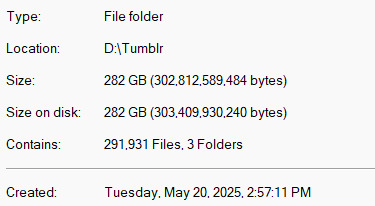
worth it
the first rule of data storage is have fun and be yourself :3
[context: all of these images are scary to people who know better than me for many reasons like "too many different files for a hard drive to handle searching" and "text documents shouldn't freeze notepad" and so on. But it was 3 a.m. this morning when I decided to let this run unsupervised and before tumblr force locked me out of my account on my browser because it thought I was a bot trying to DDoS attack them. As if it's my fault. Anyways rate limit your API requests or something if you have a blog with 220,000+ posts.]
#personal#I might have to message tumblr themselves and be like. so sorry about giving you psychic damage trying to archive after your archive failed#can I still have my data though pls
9 notes
·
View notes