#Convolutional Neural Networks (CNN)
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
After the announcement of the deal with Yahoo!, there were 170K signatures of unhappy Tumblr users petitioning to prevent the sale in 2013.
Text
youtube
#Breast cancer classification#deep learning#patch-based learning#histopathological images#5-B network#artificial intelligence#medical imaging#cancer diagnosis#convolutional neural networks#image segmentation#computer-aided diagnosis#multi-class classification#pathology AI#tumor detection#feature extraction#machine learning#healthcare AI#precision medicine#automated diagnosis#CNN model.#Youtube
0 notes
Text
Young Indian PhD Scholar Revolutionizes Healthcare with AI Innovations
Young Indian PhD Scholar Revolutionizes Healthcare with AI Innovations @neosciencehub #Healthcare #AI #PhDScholar #Innovations #neosciencehub
In a world increasingly reliant on technology for progress, one young scholar’s journey from the small town of Khammam in Telangana, India, to breaking new ground in healthcare through Artificial Intelligence (AI) is nothing short of remarkable. Meet Venkata Sai Rahul Trivedi Kothapalli, a 33-year-old PhD student and tech professional currently based in the United States, whose cutting-edge work…
0 notes
Text
HyperTransformer: G Additional Tables and Figures
Subscribe .tade0b48c-87dc-4ecb-b3d3-8877dcf7e4d8 { color: #fff; background: #222; border: 1px solid transparent; border-radius: undefinedpx; padding: 8px 21px; } .tade0b48c-87dc-4ecb-b3d3-8877dcf7e4d8.place-top { margin-top: -10px; } .tade0b48c-87dc-4ecb-b3d3-8877dcf7e4d8.place-top::before { content: “”; background-color: inherit; position: absolute; z-index: 2; width: 20px; height: 12px; }…

View On WordPress
#conventional-machine-learning#convolutional-neural-network#few-shot-learning#hypertransformer#parametric-model#small-target-cnn-architectures#supervised-model-generation#task-independent-embedding
0 notes
Text
What is a convolutional neural Network (CNN)?
Rakesh Jatav January 05, 2024
What is a convolutional neural network?

Introduction
Deep learning, a subset of artificial intelligence (AI), has permeated various domains, revolutionizing tasks through its ability to learn from data. At the forefront of deep learning's impact is image classification, a pivotal process in computer vision and object recognition. This necessitates the utilization of specialized models, with Convolutional Neural Networks (CNNs) standing out as indispensable tools.
What to Expect
In this article, we will delve into the intricate workings of CNNs, understanding their components and exploring their applications in image-related domains.
Readers will gain insights into:
The fundamental components of CNNs, including convolutional layers, pooling layers, and fully-connected layers
The training processes and advancements that have propelled CNNs to the forefront of deep learning
The diverse applications of CNNs in computer vision and image recognition
The profound impact of CNNs on the evolution of image recognition models
Through an in-depth exploration of CNNs, readers will uncover the underlying mechanisms that power modern image classification systems, comprehending the significance of these networks in shaping the digital landscape.
Understanding the Components of a Convolutional Neural Network

Convolutional neural networks (CNNs) are composed of various components that work together to extract features from images and perform image classification tasks. In this section, we will delve into the three main components of CNNs: convolutional layers, pooling layers, and fully-connected layers.
1. Convolutional Layers
Convolutional layers are the building blocks of CNNs and play a crucial role in feature extraction. They apply filters or kernels to input images in order to detect specific patterns or features. Here's a detailed exploration of the key concepts related to convolutional layers:
Feature Maps
A feature map is the output of a single filter applied to an input image. Each filter is responsible for detecting a specific feature, such as edges, textures, or corners. By convolving the filters over the input image, multiple feature maps are generated, each capturing different aspects of the image.
Receptive Fields
The receptive field refers to the region in the input image that affects the value of a neuron in a particular layer. Each neuron in a convolutional layer is connected to a small region of the previous layer known as its receptive field. By sliding these receptive fields across the entire input image, CNNs can capture both local and global information.
Weight Sharing
Weight sharing is a fundamental concept in convolutional layers that allows them to learn translation-invariant features. Instead of learning separate parameters for each location in an image, convolutional layers share weights across different spatial locations. This greatly reduces the number of parameters and enables CNNs to generalize well to new images.
To illustrate these concepts, let's consider an example where we want to train a CNN for object recognition. In the first convolutional layer, filters might be designed to detect low-level features like edges or textures. As we move deeper into subsequent convolutional layers, filters become more complex and start detecting higher-level features, such as shapes or object parts. The combination of these features in deeper layers leads to the classification of specific objects.
Convolutional layers are the backbone of CNNs and play a crucial role in capturing hierarchical representations of images. They enable the network to learn meaningful and discriminative features directly from the raw pixel values.
2. Pooling Layers and Dimensionality Reduction
Pooling layers are responsible for reducing the spatial dimensions of feature maps while preserving important features. They help reduce the computational complexity of CNNs and provide a form of translation invariance. Let's explore some key aspects related to pooling layers:
Spatial Dimensions Reduction
Pooling layers divide each feature map into non-overlapping regions or windows and aggregate the values within each region. The most common pooling technique is max pooling, which takes the maximum value within each window. Average pooling is another popular method, where the average value within each window is computed. These operations downsample the feature maps, reducing their spatial size.
Preserving Important Features
Also read :A Comprehensive Guide on How to Become a Machine Learning Engineer in 2024
Although pooling layers reduce the spatial dimensions, they retain important features by retaining the strongest activations within each window. This helps maintain robustness to variations in translation, scale, and rotation.
Pooling layers effectively summarize local information and provide an abstract representation of important features, allowing subsequent layers to focus on higher-level representations.
3. Fully-Connected Layers for Classification Tasks
Fully-connected layers are responsible for classifying images based on the extracted features from convolutional and pooling layers. These layers connect every neuron from one layer to every neuron in the next layer, similar to traditional neural networks. Here's an in-depth look at fully-connected layers:
Class Predictions
The output of fully-connected layers represents class probabilities for different categories or labels. By applying activation functions like softmax, CNNs can assign a probability score to each possible class based on the extracted features.
Backpropagation and Training
Fully-connected layers are trained using the backpropagation algorithm, which involves iteratively adjusting the weights based on the computed gradients. This process allows the network to learn discriminative features and optimize its performance for specific classification tasks.
Fully-connected layers at the end of CNNs leverage the extracted features to make accurate predictions and classify images into different classes or categories.
By understanding the components of CNNs, we gain insights into how these neural networks process images and extract meaningful representations. The convolutional layers capture local patterns and features, pooling layers reduce spatial dimensions while preserving important information, and fully-connected layers classify images based on the extracted features. These components work together harmoniously to perform image classification tasks effectively.
2. Pooling Layers and Dimensionality Reduction

Pooling layers are an essential component of convolutional neural networks (CNNs) that play a crucial role in reducing spatial dimensions while preserving important features. They work in conjunction with convolutional layers and fully-connected layers to create a powerful architecture for image classification tasks.
Comprehensive Guide to Pooling Layers in CNNs
Pooling layers are responsible for downsampling the output of convolutional layers, which helps reduce the computational complexity of the network and makes it more robust to variations in input images. Here's a breakdown of the key aspects of pooling layers:
1. Spatial Dimension Reduction
One of the main purposes of pooling layers is to reduce the spatial dimensions of the feature maps generated by the previous convolutional layer. By downsampling the feature maps, pooling layers effectively decrease the number of parameters in subsequent layers, making the network more efficient.
2. Preserving Important Features
Despite reducing the spatial dimensions, pooling layers aim to preserve important features learned by convolutional layers. This is achieved by considering local neighborhoods of pixels and summarizing them into a single value or feature. By doing so, pooling layers retain relevant information while discarding less significant details.
Overview of Popular Pooling Techniques
There are several commonly used pooling techniques in CNNs, each with its own characteristics and advantages:
Max Pooling: Max pooling is perhaps the most widely used pooling technique in CNNs. It operates by partitioning the input feature map into non-overlapping rectangles or regions and selecting the maximum value within each region as the representative value for that region. Max pooling is effective at capturing dominant features and providing translation invariance.
Average Pooling: Unlike max pooling, average pooling calculates the average value within each region instead of selecting the maximum value. This technique can be useful when preserving detailed information across different regions is desired, as it provides a smoother representation of the input.
Global Pooling: Global pooling is a pooling technique that aggregates information from the entire feature map into a single value or feature vector. This is achieved by applying a pooling operation (e.g., max pooling or average pooling) over the entire spatial dimensions of the feature map. Global pooling helps capture high-level semantic information and is commonly used in the final layers of a CNN for classification tasks.
Example: Pooling Layers in Action
To illustrate the functionality of pooling layers, let's consider an example with a simple CNN architecture for image classification:
Convolutional layers extract local features and generate feature maps.
Pooling layers then downsample the feature maps, reducing their spatial dimensions while retaining essential information.
Fully-connected layers process the pooled features and make class predictions based on learned representations.
By incorporating pooling layers in between convolutional layers, CNNs are able to hierarchically learn features at different levels of abstraction. The combination of convolutional layers, pooling layers, and fully-connected layers enables CNNs to effectively classify images and perform complex computer vision tasks.
Also read :Comparing Google Gemini and ChatGPT: Performance, Generalization Abilities, and Ethical Considerations
In summary, pooling layers are an integral part of CNNs that contribute to dimensionality reduction while preserving important features. Techniques like max pooling, average pooling, and global pooling allow CNNs to downsample feature maps and capture relevant information for subsequent processing. Understanding how these building blocks work together provides insights into the functionality of convolutional neural networks and their effectiveness in image classification tasks.
3. Fully-Connected Layers for Classification Tasks

In a convolutional neural network (CNN), fully-connected layers play a crucial role in making class predictions based on the extracted features from previous layers. These layers are responsible for learning and mapping high-level features to specific classes or categories.
The Role of Fully-Connected Layers
After the convolutional and pooling layers extract important spatial features from the input image, fully-connected layers are introduced to perform classification tasks. These layers are similar to the traditional neural networks where all neurons in one layer are connected to every neuron in the subsequent layer. The output of the last pooling layer, which is a flattened feature map, serves as the input to the fully-connected layers.
The purpose of these fully-connected layers is to learn complex relationships between extracted features and their corresponding classes. By connecting every neuron in one layer to every neuron in the next layer, fully-connected layers can capture intricate patterns and dependencies within the data.
Training Fully-Connected Layers with Backpropagation
To train fully-connected layers, CNNs utilize backpropagation, an algorithm that adjusts the weights of each connection based on the error calculated during training. The process involves iteratively propagating the error gradient backward through the network and updating the weights accordingly.
During training, an input image is fed forward through the network, resulting in class predictions at the output layer. The predicted class probabilities are then compared to the true labels using a loss function such as cross-entropy. The error is calculated by measuring the difference between predicted and true probabilities.
Backpropagation starts by computing how much each weight contributes to the overall error. This is done by propagating error gradients backward from the output layer to the input layer, updating weights along the way using gradient descent optimization. By iteratively adjusting weights based on their contribution to error reduction, fully-connected layers gradually learn to make accurate class predictions.
Limitations and Challenges
Fully-connected layers have been effective in many image classification tasks. However, they have a few limitations:
Computational Cost: Fully-connected layers require a large number of parameters due to the connections between every neuron, making them computationally expensive, especially for high-resolution images.
Loss of Spatial Information: As fully-connected layers flatten the extracted feature maps into a one-dimensional vector, they discard the spatial information present in the original image. This loss of spatial information can be detrimental in tasks where fine-grained details are important.
Limited Translation Invariance: Unlike convolutional layers that use shared weights to detect features across different regions of an image, fully-connected layers treat each neuron independently. This lack of translation invariance can make CNNs sensitive to small changes in input position.
Example Architecture: LeNet-5
One of the early successful CNN architectures that utilized fully-connected layers is LeNet-5, developed by Yann LeCun in 1998 for handwritten digit recognition. The LeNet-5 architecture consisted of three sets of convolutional and pooling layers followed by two fully-connected layers.
The first fully-connected layer in LeNet-5 had 120 neurons, while the second fully-connected layer had 84 neurons before reaching the output layer with 10 neurons representing the digits 0 to 9. The output layer used softmax activation to produce class probabilities.
LeNet-5 showcased the effectiveness of fully-connected layers in learning complex relationships and achieving high accuracy on digit recognition tasks. Since then, numerous advancements and variations of CNN architectures have emerged, emphasizing more intricate network designs and deeper hierarchies.
Summary
Fully-connected layers serve as the final stages of a CNN, responsible for learning and mapping high-level features to specific classes or categories. By utilizing backpropagation during training, these layers gradually learn to make accurate class predictions based on extracted features from earlier layers. However, they come with limitations such as computational cost, loss of spatial information, and limited translation invariance. Despite these challenges, fully-connected layers have played a crucial role in achieving state-of-the-art performance in various image classification tasks.
Training and Advancements in Convolutional Neural Networks

Neural network training involves optimizing model parameters to minimize the difference between predicted outputs and actual targets. In the case of CNNs, this training process is crucial for learning and extracting features from input images. Here are some key points to consider when discussing the training of CNNs and advancements in the field:
Training Process
Also read :Explore the Latest in Gadgets: Gadgets 360, Officer-Approved Tech, Lottery Winners' Gadgets, NDTV Reviews, SK Premium Selection, and Self-Defense & Electronic Marvels!
The training of a CNN typically involves:
Feeding annotated data through the network
Performing a forward pass to generate predictions
Calculating the loss (difference between predictions and actual targets)
Updating the network's weights through backpropagation to minimize this loss
This iterative process helps the CNN learn to recognize patterns and features within the input images.
Advanced Architectures
Several advanced CNN architectures have significantly contributed to pushing the boundaries of performance in image recognition tasks:
LeNet-5
AlexNet
VGGNet
GoogLeNet
ResNet
ZFNet
Each of these models introduced novel concepts and architectural designs that improved the accuracy and efficiency of CNNs for various tasks.
LeNet-5
LeNet-5 was one of the pioneering CNN architectures developed by Yann LeCun for handwritten digit recognition. It consisted of several convolutional and subsampling layers followed by fully connected layers. LeNet-5 demonstrated the potential of CNNs in practical applications.
AlexNet
AlexNet gained widespread attention after winning the ImageNet Large Scale Visual Recognition Challenge in 2012. This architecture featured a deeper network design with multiple convolutional layers and introduced the concept of using ReLU (Rectified Linear Unit) activation functions for faster convergence during training.
VGGNet
VGGNet is known for its simple yet effective architecture with small 3x3 convolutional filters stacked together to form deeper networks. This approach led to improved feature learning capabilities and better generalization on various datasets.
GoogLeNet
GoogLeNet introduced the concept of inception modules, which allowed for more efficient use of computational resources by incorporating parallel convolutional operations within the network.
ResNet
ResNet (Residual Network) addressed the challenge of training very deep neural networks by introducing skip connections that enabled better gradient flow during backpropagation. This architectural innovation facilitated training of networks with hundreds of layers while mitigating issues related to vanishing gradients.
ZFNet
ZFNet (Zeiler & Fergus Network) made significant contributions to understanding visual patterns by incorporating deconvolutional layers for visualization of learned features within the network.
These advancements in CNN architectures have not only improved performance but also paved the way for exploring more complex tasks in computer vision and image recognition.
Applications of CNNs in Computer Vision

Highlighting the Wide Range of Computer Vision Tasks
Object Detection: CNNs have proven to be highly effective in detecting and localizing objects within images. They can accurately identify and outline various objects, even in complex scenes with multiple overlapping elements.
Semantic Segmentation: By employing CNNs, computer vision systems can understand the context of different parts of an image. This allows for precise identification and differentiation of individual objects or elements within the image.
Style Transfer: CNNs have been utilized to transfer artistic styles from one image to another, offering a creative application of computer vision. This technology enables the transformation of photographs into artworks reflecting the styles of famous painters or artistic movements.
By excelling in these computer vision tasks, CNNs have significantly advanced the capabilities of machine vision systems, leading to breakthroughs in fields such as autonomous vehicles, medical imaging, and augmented reality.

Examine how the introduction of CNNs revolutionized the field of image recognition and paved the way for state-of-the-art models. Discuss recent advancements in image recognition achieved through CNN-based approaches like transfer learning and attention mechanisms.
CNNs have significantly impacted the realm of image recognition models, bringing about a paradigm shift and enabling the development of cutting-edge approaches. Here's a closer look at their profound influence:
Revolutionizing Image Recognition
Also read :What is a convolutional neural Network (CNN)?
The introduction of CNNs has transformed the landscape of image recognition, pushing the boundaries of what was previously achievable. By leveraging convolutional layers for feature extraction and hierarchical learning, CNNs have enabled the creation of sophisticated models capable of accurately classifying and identifying visual content.
Recent Advancements in Image Recognition
In recent years, significant advancements in image recognition have been realized through the application of CNN-based methodologies. Two notable approaches that have garnered attention are:
Transfer Learning: This approach involves utilizing pre-trained CNN models as a starting point for new image recognition tasks. By leveraging knowledge gained from large-scale labeled datasets, transfer learning enables the adaptation and fine-tuning of existing CNN architectures to suit specific recognition objectives. This method has proven particularly valuable in scenarios where labeled training data is limited, as it allows for the efficient reutilization of learned features.
Attention Mechanisms: The integration of attention mechanisms within CNN architectures has emerged as a powerful technique for enhancing image recognition capabilities. By dynamically focusing on relevant regions within an image, these mechanisms enable CNNs to selectively attend to crucial visual elements, thereby improving their capacity to discern intricate details and patterns. This targeted approach contributes to heightened accuracy and robustness in image recognition tasks.
The utilization of transfer learning and attention mechanisms underscores the ongoing evolution and refinement of image recognition models, demonstrating the adaptability and versatility inherent in CNN-based strategies.
As we continue to witness strides in image recognition propelled by CNN innovations, it becomes evident that these developments are instrumental in shaping the future trajectory of visual analysis and classification.
FAQ (Frequently Asked Questions):
1. How does transfer learning facilitate the reutilization of learned features in CNN architectures?
Transfer learning allows for the transfer of knowledge gained from pre-training on a large dataset to a target task with limited labeled data. By freezing and utilizing the lower layers of a pre-trained CNN, important low-level features can be leveraged for the new task, while only fine-tuning higher layers to adapt to the specific recognition objectives.
2. How do attention mechanisms enhance image recognition capabilities?
Attention mechanisms enable CNNs to focus on relevant regions within an image, improving their ability to discern intricate details and patterns. This selective attention helps CNNs prioritize crucial visual elements, contributing to heightened accuracy and robustness in image recognition tasks.
3. What role do these advancements play in the future of visual analysis and classification?
The integration of transfer learning and attention mechanisms highlights the adaptability and versatility of CNN-based strategies. These advancements continue to shape the trajectory of image recognition, offering promising avenues for improving accuracy, efficiency, and interpretability in complex visual analysis tasks.
Conclusion
In conclusion, convolutional neural networks (CNNs) have revolutionized the field of image recognition and opened up new possibilities for state-of-the-art models. Through their introduction, image-related tasks have seen significant advancements and improved performance.
As readers, it is highly encouraged to explore and experiment with CNNs in your own deep learning projects or research endeavors. The potential for innovation in image-related domains is vast, and CNNs provide a powerful tool to tackle complex problems.
To get started with CNNs, consider the following steps:
Learn the fundamentals: Familiarize yourself with the key components of CNNs, including convolutional layers, pooling layers, and fully-connected layers. Understand their roles in feature extraction, dimensionality reduction, and classification.
Gain practical experience: Implement CNN architectures using popular deep learning frameworks such as TensorFlow or PyTorch. Work on image classification tasks and experiment with different network architectures to understand their strengths and weaknesses.
Stay updated: Keep up with the latest advancements in CNN research and explore new approaches like transfer learning and attention mechanisms. These techniques have shown promising results in improving image recognition accuracy.
Remember, CNNs are not limited to image recognition alone. They can be applied to various other domains such as object detection, semantic segmentation, style transfer, and more.
By harnessing the power of convolutional neural networks, you can contribute to the ongoing progress in computer vision and make significant strides in solving real-world challenges related to image analysis.
So go ahead and dive into the world of CNNs - unlock the potential of deep learning for image-related tasks and drive innovation forward!
#artificial intelligence#convolutional neural network#machine learning#Deep Learning#CNNs#Neural Networks
0 notes
Text
Been a while, crocodiles. Let's talk about cad.

or, y'know...

Yep, we're doing a whistle-stop tour of AI in medical diagnosis!
Much like programming, AI can be conceived of, in very simple terms, as...
a way of moving from inputs to a desired output.
See, this very funky little diagram from skillcrush.com.
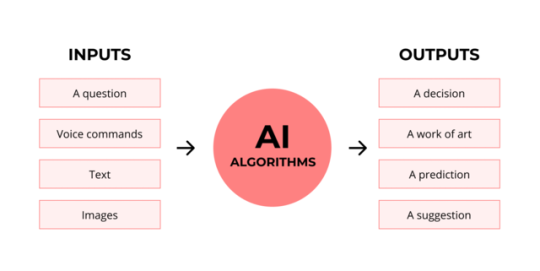
The input is what you put in. The output is what you get out.
This output will vary depending on the type of algorithm and the training that algorithm has undergone – you can put the same input into two different algorithms and get two entirely different sorts of answer.
Generative AI produces ‘new’ content, based on what it has learned from various inputs. We're talking AI Art, and Large Language Models like ChatGPT. This sort of AI is very useful in healthcare settings to, but that's a whole different post!
Analytical AI takes an input, such as a chest radiograph, subjects this input to a series of analyses, and deduces answers to specific questions about this input. For instance: is this chest radiograph normal or abnormal? And if abnormal, what is a likely pathology?
We'll be focusing on Analytical AI in this little lesson!
Other forms of Analytical AI that you might be familiar with are recommendation algorithms, which suggest items for you to buy based on your online activities, and facial recognition. In facial recognition, the input is an image of your face, and the output is the ability to tie that face to your identity. We’re not creating new content – we’re classifying and analysing the input we’ve been fed.
Many of these functions are obviously, um, problematique. But Computer-Aided Diagnosis is, potentially, a way to use this tool for good!
Right?
....Right?

Let's dig a bit deeper! AI is a massive umbrella term that contains many smaller umbrella terms, nested together like Russian dolls. So, we can use this model to envision how these different fields fit inside one another.

AI is the term for anything to do with creating and managing machines that perform tasks which would otherwise require human intelligence. This is what differentiates AI from regular computer programming.
Machine Learning is the development of statistical algorithms which are trained on data –but which can then extrapolate this training and generalise it to previously unseen data, typically for analytical purposes. The thing I want you to pay attention to here is the date of this reference. It’s very easy to think of AI as being a ‘new’ thing, but it has been around since the Fifties, and has been talked about for much longer. The massive boom in popularity that we’re seeing today is built on the backs of decades upon decades of research.
Artificial Neural Networks are loosely inspired by the structure of the human brain, where inputs are fed through one or more layers of ‘nodes’ which modify the original data until a desired output is achieved. More on this later!
Deep neural networks have two or more layers of nodes, increasing the complexity of what they can derive from an initial input. Convolutional neural networks are often also Deep. To become ‘convolutional’, a neural network must have strong connections between close nodes, influencing how the data is passed back and forth within the algorithm. We’ll dig more into this later, but basically, this makes CNNs very adapt at telling precisely where edges of a pattern are – they're far better at pattern recognition than our feeble fleshy eyes!
This is massively useful in Computer Aided Diagnosis, as it means CNNs can quickly and accurately trace bone cortices in musculoskeletal imaging, note abnormalities in lung markings in chest radiography, and isolate very early neoplastic changes in soft tissue for mammography and MRI.
Before I go on, I will point out that Neural Networks are NOT the only model used in Computer-Aided Diagnosis – but they ARE the most common, so we'll focus on them!

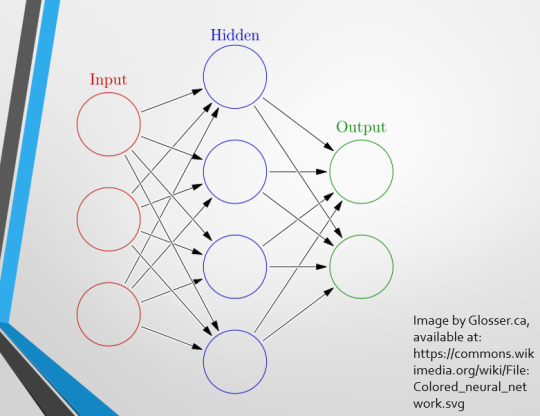
This diagram demonstrates the function of a simple Neural Network. An input is fed into one side. It is passed through a layer of ‘hidden’ modulating nodes, which in turn feed into the output. We describe the internal nodes in this algorithm as ‘hidden’ because we, outside of the algorithm, will only see the ‘input��� and the ‘output’ – which leads us onto a problem we’ll discuss later with regards to the transparency of AI in medicine.
But for now, let’s focus on how this basic model works, with regards to Computer Aided Diagnosis. We'll start with a game of...
Spot The Pathology.
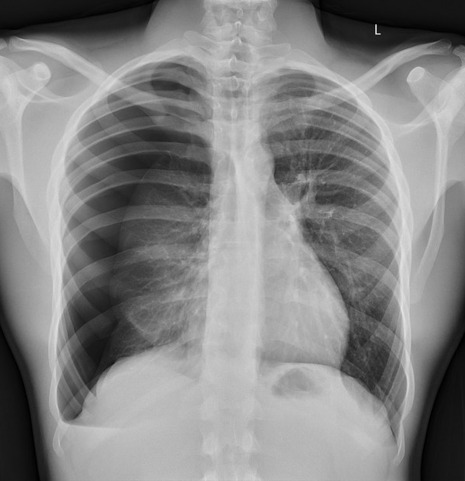
yeah, that's right. There's a WHACKING GREAT RIGHT-SIDED PNEUMOTHORAX (as outlined in red - images courtesy of radiopaedia, but edits mine)
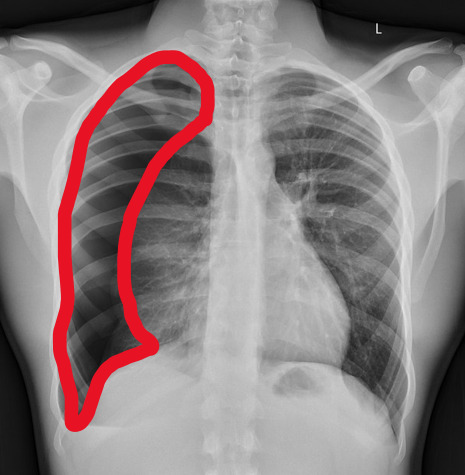
But my question to you is: how do we know that? What process are we going through to reach that conclusion?
Personally, I compared the lungs for symmetry, which led me to note a distinct line where the tissue in the right lung had collapsed on itself. I also noted the absence of normal lung markings beyond this line, where there should be tissue but there is instead air.
In simple terms.... the right lung is whiter in the midline, and black around the edges, with a clear distinction between these parts.
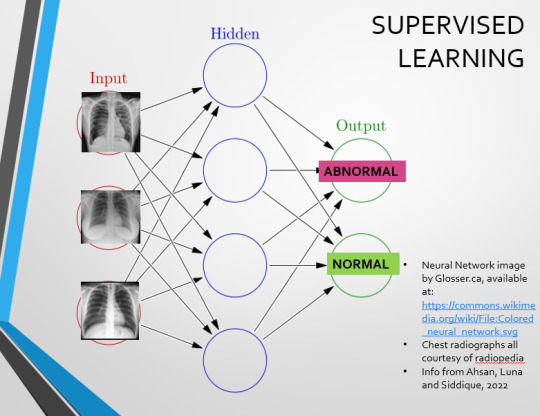
Let’s go back to our Neural Network. We’re at the training phase now.
So, we’re going to feed our algorithm! Homnomnom.
Let’s give it that image of a pneumothorax, alongside two normal chest radiographs (middle picture and bottom). The goal is to get the algorithm to accurately classify the chest radiographs we have inputted as either ‘normal’ or ‘abnormal’ depending on whether or not they demonstrate a pneumothorax.
There are two main ways we can teach this algorithm – supervised and unsupervised classification learning.
In supervised learning, we tell the neural network that the first picture is abnormal, and the second and third pictures are normal. Then we let it work out the difference, under our supervision, allowing us to steer it if it goes wrong.
Of course, if we only have three inputs, that isn’t enough for the algorithm to reach an accurate result.
You might be able to see – one of the normal chests has breasts, and another doesn't. If both ‘normal’ images had breasts, the algorithm could as easily determine that the lack of lung markings is what demonstrates a pneumothorax, as it could decide that actually, a pneumothorax is caused by not having breasts. Which, obviously, is untrue.
or is it?
....sadly I can personally confirm that having breasts does not prevent spontaneous pneumothorax, but that's another story lmao
This brings us to another big problem with AI in medicine –

If you are collecting your dataset from, say, a wealthy hospital in a suburban, majority white neighbourhood in America, then you will have those same demographics represented within that dataset. If we build a blind spot into the neural network, and it will discriminate based on that.
That’s an important thing to remember: the goal here is to create a generalisable tool for diagnosis. The algorithm will only ever be as generalisable as its dataset.
But there are plenty of huge free datasets online which have been specifically developed for training AI. What if we had hundreds of chest images, from a diverse population range, split between those which show pneumothoraxes, and those which don’t?
If we had a much larger dataset, the algorithm would be able to study the labelled ‘abnormal’ and ‘normal’ images, and come to far more accurate conclusions about what separates a pneumothorax from a normal chest in radiography. So, let’s pretend we’re the neural network, and pop in four characteristics that the algorithm might use to differentiate ‘normal’ from ‘abnormal’.
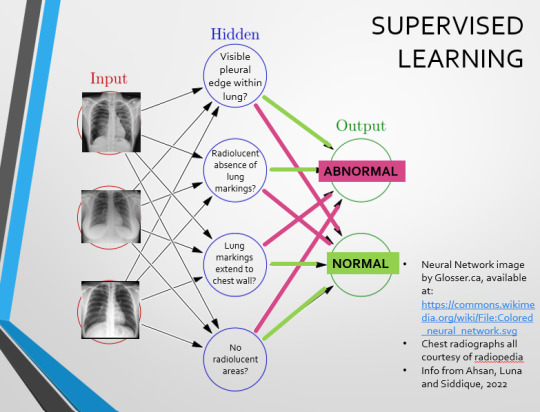
We can distinguish a pneumothorax by the appearance of a pleural edge where lung tissue has pulled away from the chest wall, and the radiolucent absence of peripheral lung markings around this area. So, let’s make those our first two nodes. Our last set of nodes are ‘do the lung markings extend to the chest wall?’ and ‘Are there no radiolucent areas?’
Now, red lines mean the answer is ‘no’ and green means the answer is ‘yes’. If the answer to the first two nodes is yes and the answer to the last two nodes is no, this is indicative of a pneumothorax – and vice versa.
Right. So, who can see the problem with this?
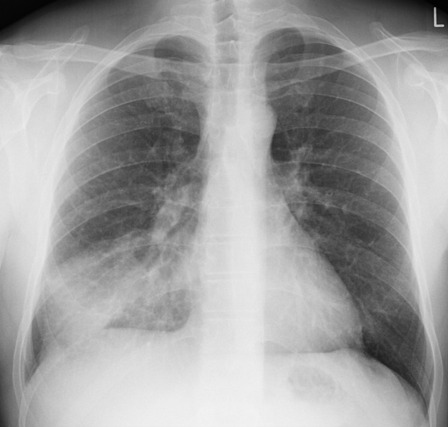
(image courtesy of radiopaedia)
This chest radiograph demonstrates alveolar patterns and air bronchograms within the right lung, indicative of a pneumonia. But if we fed it into our neural network...
The lung markings extend all the way to the chest wall. Therefore, this image might well be classified as ‘normal’ – a false negative.
Now we start to see why Neural Networks become deep and convolutional, and can get incredibly complex. In order to accurately differentiate a ‘normal’ from an ‘abnormal’ chest, you need a lot of nodes, and layers of nodes. This is also where unsupervised learning can come in.
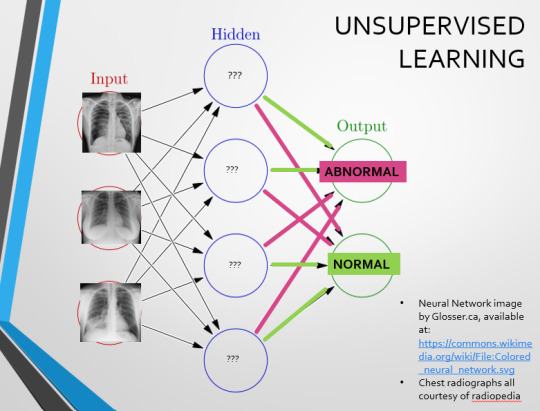
Originally, Supervised Learning was used on Analytical AI, and Unsupervised Learning was used on Generative AI, allowing for more creativity in picture generation, for instance. However, more and more, Unsupervised learning is being incorporated into Analytical areas like Computer-Aided Diagnosis!
Unsupervised Learning involves feeding a neural network a large databank and giving it no information about which of the input images are ‘normal’ or ‘abnormal’. This saves massively on money and time, as no one has to go through and label the images first. It is also surprisingly very effective. The algorithm is told only to sort and classify the images into distinct categories, grouping images together and coming up with its own parameters about what separates one image from another. This sort of learning allows an algorithm to teach itself to find very small deviations from its discovered definition of ‘normal’.
BUT this is not to say that CAD is without its issues.
Let's take a look at some of the ethical and practical considerations involved in implementing this technology within clinical practice!

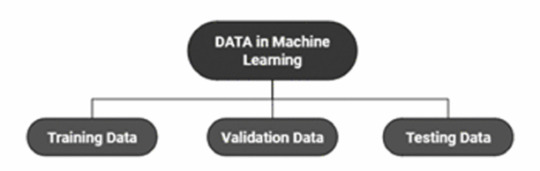
(Image from Agrawal et al., 2020)
Training Data does what it says on the tin – these are the initial images you feed your algorithm. What is key here is volume, variety - with especial attention paid to minimising bias – and veracity. The training data has to be ‘real’ – you cannot mislabel images or supply non-diagnostic images that obscure pathology, or your algorithm is useless.
Validation data evaluates the algorithm and improves on it. This involves tweaking the nodes within a neural network by altering the ‘weights’, or the intensity of the connection between various nodes. By altering these weights, a neural network can send an image that clearly fits our diagnostic criteria for a pneumothorax directly to the relevant output, whereas images that do not have these features must be put through another layer of nodes to rule out a different pathology.
Finally, testing data is the data that the finished algorithm will be tested on to prove its sensitivity and specificity, before any potential clinical use.
However, if algorithms require this much data to train, this introduces a lot of ethical questions.
Where does this data come from?
Is it ‘grey data’ (data of untraceable origin)? Is this good (protects anonymity) or bad (could have been acquired unethically)?
Could generative AI provide a workaround, in the form of producing synthetic radiographs? Or is it risky to train CAD algorithms on simulated data when the algorithms will then be used on real people?
If we are solely using CAD to make diagnoses, who holds legal responsibility for a misdiagnosis that costs lives? Is it the company that created the algorithm or the hospital employing it?
And finally – is it worth sinking so much time, money, and literal energy into AI – especially given concerns about the environment – when public opinion on AI in healthcare is mixed at best? This is a serious topic – we’re talking diagnoses making the difference between life and death. Do you trust a machine more than you trust a doctor? According to Rojahn et al., 2023, there is a strong public dislike of computer-aided diagnosis.
So, it's fair to ask...
why are we wasting so much time and money on something that our service users don't actually want?
Then we get to the other biggie.

There are also a variety of concerns to do with the sensitivity and specificity of Computer-Aided Diagnosis.
We’ve talked a little already about bias, and how training sets can inadvertently ‘poison’ the algorithm, so to speak, introducing dangerous elements that mimic biases and problems in society.
But do we even want completely accurate computer-aided diagnosis?
The name is computer-aided diagnosis, not computer-led diagnosis. As noted by Rajahn et al, the general public STRONGLY prefer diagnosis to be made by human professionals, and their desires should arguably be taken into account – as well as the fact that CAD algorithms tend to be incredibly expensive and highly specialised. For instance, you cannot put MRI images depicting CNS lesions through a chest reporting algorithm and expect coherent results – whereas a radiologist can be trained to diagnose across two or more specialties.
For this reason, there is an argument that rather than focusing on sensitivity and specificity, we should just focus on producing highly sensitive algorithms that will pick up on any abnormality, and output some false positives, but will produce NO false negatives.
(Sensitivity = a test's ability to identify sick people with a disease)
(Specificity = a test's ability to identify that healthy people do not have this disease)
This means we are working towards developing algorithms that OVERESTIMATE rather than UNDERESTIMATE disease prevalence. This makes CAD a useful tool for triage rather than providing its own diagnoses – if a CAD algorithm weighted towards high sensitivity and low specificity does not pick up on any abnormalities, it’s highly unlikely that there are any.
Finally, we have to question whether CAD is even all that accurate to begin with. 10 years ago, according to Lehmen et al., CAD in mammography demonstrated negligible improvements to accuracy. In 1989, Sutton noted that accuracy was under 60%. Nowadays, however, AI has been proven to exceed the abilities of radiologists when detecting cancers (that’s from Guetari et al., 2023). This suggests that there is a common upwards trajectory, and AI might become a suitable alternative to traditional radiology one day. But, due to the many potential problems with this field, that day is unlikely to be soon...

That's all, folks! Have some references~
#medblr#artificial intelligence#radiography#radiology#diagnosis#medicine#studyblr#radioactiveradley#radley irradiates people#long post
16 notes
·
View notes
Text
AI helps distinguish dark matter from cosmic noise
Dark matter is the invisible force holding the universe together – or so we think. It makes up around 85% of all matter and around 27% of the universe’s contents, but since we can’t see it directly, we have to study its gravitational effects on galaxies and other cosmic structures. Despite decades of research, the true nature of dark matter remains one of science’s most elusive questions.
According to a leading theory, dark matter might be a type of particle that barely interacts with anything else, except through gravity. But some scientists believe these particles could occasionally interact with each other, a phenomenon known as self-interaction. Detecting such interactions would offer crucial clues about dark matter’s properties.
However, distinguishing the subtle signs of dark matter self-interactions from other cosmic effects, like those caused by active galactic nuclei (AGN) – the supermassive black holes at the centers of galaxies – has been a major challenge. AGN feedback can push matter around in ways that are similar to the effects of dark matter, making it difficult to tell the two apart.
In a significant step forward, astronomer David Harvey at EPFL’s Laboratory of Astrophysics has developed a deep-learning algorithm that can untangle these complex signals. Their AI-based method is designed to differentiate between the effects of dark matter self-interactions and those of AGN feedback by analyzing images of galaxy clusters – vast collections of galaxies bound together by gravity. The innovation promises to greatly enhance the precision of dark matter studies.
Harvey trained a Convolutional Neural Network (CNN) – a type of AI that is particularly good at recognizing patterns in images – with images from the BAHAMAS-SIDM project, which models galaxy clusters under different dark matter and AGN feedback scenarios. By being fed thousands of simulated galaxy cluster images, the CNN learned to distinguish between the signals caused by dark matter self-interactions and those caused by AGN feedback.
Among the various CNN architectures tested, the most complex - dubbed “Inception” – proved to also be the most accurate. The AI was trained on two primary dark matter scenarios, featuring different levels of self-interaction, and validated on additional models, including a more complex, velocity-dependent dark matter model.
Inceptionachieved an impressive accuracy of 80% under ideal conditions, effectively identifying whether galaxy clusters were influenced by self-interacting dark matter or AGN feedback. It maintained is high performance even when the researchers introduced realistic observational noise that mimics the kind of data we expect from future telescopes like Euclid.
What this means is that Inception – and the AI approach more generally – could prove incredibly useful for analyzing the massive amounts of data we collect from space. Moreover, the AI’s ability to handle unseen data indicates that it’s adaptable and reliable, making it a promising tool for future dark matter research.
AI-based approaches like Inception could significantly impact our understanding of what dark matter actually is. As new telescopes gather unprecedented amounts of data, this method will help scientists sift through it quickly and accurately, potentially revealing the true nature of dark matter.
10 notes
·
View notes
Text
youtube
A new scientific paper has been published in the research journal Frontiers in Remote Sensing titled ‘Automatic detection of unidentified fish sounds: a comparison of traditional deep learning with machine learning” authored by Xavier Mouy et al, which analyzed week-long hydrophone recordings of the Coral City Camera site at PortMiami in order to detect fish sounds.
The researchers found that using a Convolutional Neural Network (CNN) enabled detection of fish sounds that both human analysts and traditional spectrogram data analysis otherwise could not detect. The CNN was trained using hydrophone recordings made in British Columbia, but proved accurate in the novel environment at PortMiami, even despite significant background noises from boats. The software developed for this study is open-source and available to other researchers.
Stay tuned in the coming months as we prepare to connect a hydrophone to the Coral City Camera and provide an audio channel to the YouTube livestream. If possible, we aim to incorporate real-time analysis of the underwater sounds to help monitor and track fish activity.
Click to read ‘Automatic detection of unidentified fish sounds: a comparison of traditional deep learning with machine learning'.
8 notes
·
View notes
Text
AI-powered convolutional neural network achieves high accuracy in detecting biliary malignancies
A groundbreaking AI model utilizing a convolutional neural network (CNN) has demonstrated exceptional accuracy in distinguishing between malignant and benign biliary strictures. According to a new transatlantic study published on 14 February, the CNN was trained on over 90,000 endoscopic images. These images were collected from three leading medical centers in Portugal, Spain, and the United…
4 notes
·
View notes
Text
The Building Blocks of AI : Neural Networks Explained by Julio Herrera Velutini
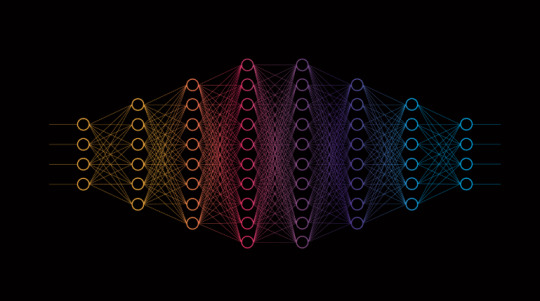
What is a Neural Network?
A neural network is a computational model inspired by the human brain’s structure and function. It is a key component of artificial intelligence (AI) and machine learning, designed to recognize patterns and make decisions based on data. Neural networks are used in a wide range of applications, including image and speech recognition, natural language processing, and even autonomous systems like self-driving cars.
Structure of a Neural Network
A neural network consists of layers of interconnected nodes, known as neurons. These layers include:
Input Layer: Receives raw data and passes it into the network.
Hidden Layers: Perform complex calculations and transformations on the data.
Output Layer: Produces the final result or prediction.
Each neuron in a layer is connected to neurons in the next layer through weighted connections. These weights determine the importance of input signals, and they are adjusted during training to improve the model’s accuracy.
How Neural Networks Work?
Neural networks learn by processing data through forward propagation and adjusting their weights using backpropagation. This learning process involves:
Forward Propagation: Data moves from the input layer through the hidden layers to the output layer, generating predictions.
Loss Calculation: The difference between predicted and actual values is measured using a loss function.
Backpropagation: The network adjusts weights based on the loss to minimize errors, improving performance over time.
Types of Neural Networks-
Several types of neural networks exist, each suited for specific tasks:
Feedforward Neural Networks (FNN): The simplest type, where data moves in one direction.
Convolutional Neural Networks (CNN): Used for image processing and pattern recognition.
Recurrent Neural Networks (RNN): Designed for sequential data like time-series analysis and language processing.
Generative Adversarial Networks (GANs): Used for generating synthetic data, such as deepfake images.
Conclusion-
Neural networks have revolutionized AI by enabling machines to learn from data and improve performance over time. Their applications continue to expand across industries, making them a fundamental tool in modern technology and innovation.
3 notes
·
View notes
Text

The Mathematical Foundations of Machine Learning
In the world of artificial intelligence, machine learning is a crucial component that enables computers to learn from data and improve their performance over time. However, the math behind machine learning is often shrouded in mystery, even for those who work with it every day. Anil Ananthaswami, author of the book "Why Machines Learn," sheds light on the elegant mathematics that underlies modern AI, and his journey is a fascinating one.
Ananthaswami's interest in machine learning began when he started writing about it as a science journalist. His software engineering background sparked a desire to understand the technology from the ground up, leading him to teach himself coding and build simple machine learning systems. This exploration eventually led him to appreciate the mathematical principles that underlie modern AI. As Ananthaswami notes, "I was amazed by the beauty and elegance of the math behind machine learning."
Ananthaswami highlights the elegance of machine learning mathematics, which goes beyond the commonly known subfields of calculus, linear algebra, probability, and statistics. He points to specific theorems and proofs, such as the 1959 proof related to artificial neural networks, as examples of the beauty and elegance of machine learning mathematics. For instance, the concept of gradient descent, a fundamental algorithm used in machine learning, is a powerful example of how math can be used to optimize model parameters.
Ananthaswami emphasizes the need for a broader understanding of machine learning among non-experts, including science communicators, journalists, policymakers, and users of the technology. He believes that only when we understand the math behind machine learning can we critically evaluate its capabilities and limitations. This is crucial in today's world, where AI is increasingly being used in various applications, from healthcare to finance.
A deeper understanding of machine learning mathematics has significant implications for society. It can help us to evaluate AI systems more effectively, develop more transparent and explainable AI systems, and address AI bias and ensure fairness in decision-making. As Ananthaswami notes, "The math behind machine learning is not just a tool, but a way of thinking that can help us create more intelligent and more human-like machines."
The Elegant Math Behind Machine Learning (Machine Learning Street Talk, November 2024)
youtube
Matrices are used to organize and process complex data, such as images, text, and user interactions, making them a cornerstone in applications like Deep Learning (e.g., neural networks), Computer Vision (e.g., image recognition), Natural Language Processing (e.g., language translation), and Recommendation Systems (e.g., personalized suggestions). To leverage matrices effectively, AI relies on key mathematical concepts like Matrix Factorization (for dimension reduction), Eigendecomposition (for stability analysis), Orthogonality (for efficient transformations), and Sparse Matrices (for optimized computation).
The Applications of Matrices - What I wish my teachers told me way earlier (Zach Star, October 2019)
youtube
Transformers are a type of neural network architecture introduced in 2017 by Vaswani et al. in the paper “Attention Is All You Need”. They revolutionized the field of NLP by outperforming traditional recurrent neural network (RNN) and convolutional neural network (CNN) architectures in sequence-to-sequence tasks. The primary innovation of transformers is the self-attention mechanism, which allows the model to weigh the importance of different words in the input data irrespective of their positions in the sentence. This is particularly useful for capturing long-range dependencies in text, which was a challenge for RNNs due to vanishing gradients. Transformers have become the standard for machine translation tasks, offering state-of-the-art results in translating between languages. They are used for both abstractive and extractive summarization, generating concise summaries of long documents. Transformers help in understanding the context of questions and identifying relevant answers from a given text. By analyzing the context and nuances of language, transformers can accurately determine the sentiment behind text. While initially designed for sequential data, variants of transformers (e.g., Vision Transformers, ViT) have been successfully applied to image recognition tasks, treating images as sequences of patches. Transformers are used to improve the accuracy of speech-to-text systems by better modeling the sequential nature of audio data. The self-attention mechanism can be beneficial for understanding patterns in time series data, leading to more accurate forecasts.
Attention is all you need (Umar Hamil, May 2023)
youtube
Geometric deep learning is a subfield of deep learning that focuses on the study of geometric structures and their representation in data. This field has gained significant attention in recent years.
Michael Bronstein: Geometric Deep Learning (MLSS Kraków, December 2023)
youtube
Traditional Geometric Deep Learning, while powerful, often relies on the assumption of smooth geometric structures. However, real-world data frequently resides in non-manifold spaces where such assumptions are violated. Topology, with its focus on the preservation of proximity and connectivity, offers a more robust framework for analyzing these complex spaces. The inherent robustness of topological properties against noise further solidifies the rationale for integrating topology into deep learning paradigms.
Cristian Bodnar: Topological Message Passing (Michael Bronstein, August 2022)
youtube
Sunday, November 3, 2024
#machine learning#artificial intelligence#mathematics#computer science#deep learning#neural networks#algorithms#data science#statistics#programming#interview#ai assisted writing#machine art#Youtube#lecture
4 notes
·
View notes
Text
HyperTransformer: A Example of a Self-Attention Mechanism For Supervised Learning
Subscribe .t9ce7d96b-e3c9-448d-b1fd-97f643ade4ab { color: #fff; background: #222; border: 1px solid transparent; border-radius: undefinedpx; padding: 8px 21px; } .t9ce7d96b-e3c9-448d-b1fd-97f643ade4ab.place-top { margin-top: -10px; } .t9ce7d96b-e3c9-448d-b1fd-97f643ade4ab.place-top::before { content: “”; background-color: inherit; position: absolute; z-index: 2; width: 20px; height: 12px; }…

View On WordPress
#conventional-machine-learning#convolutional-neural-network#few-shot-learning#hypertransformer#parametric-model#small-target-cnn-architectures#supervised-model-generation#task-independent-embedding
0 notes
Text
Mastering Neural Networks: A Deep Dive into Combining Technologies
How Can Two Trained Neural Networks Be Combined?
Introduction
In the ever-evolving world of artificial intelligence (AI), neural networks have emerged as a cornerstone technology, driving advancements across various fields. But have you ever wondered how combining two trained neural networks can enhance their performance and capabilities? Let’s dive deep into the fascinating world of neural networks and explore how combining them can open new horizons in AI.
Basics of Neural Networks
What is a Neural Network?
Neural networks, inspired by the human brain, consist of interconnected nodes or "neurons" that work together to process and analyze data. These networks can identify patterns, recognize images, understand speech, and even generate human-like text. Think of them as a complex web of connections where each neuron contributes to the overall decision-making process.
How Neural Networks Work
Neural networks function by receiving inputs, processing them through hidden layers, and producing outputs. They learn from data by adjusting the weights of connections between neurons, thus improving their ability to predict or classify new data. Imagine a neural network as a black box that continuously refines its understanding based on the information it processes.
Types of Neural Networks
From simple feedforward networks to complex convolutional and recurrent networks, neural networks come in various forms, each designed for specific tasks. Feedforward networks are great for straightforward tasks, while convolutional neural networks (CNNs) excel in image recognition, and recurrent neural networks (RNNs) are ideal for sequential data like text or speech.
Why Combine Neural Networks?
Advantages of Combining Neural Networks
Combining neural networks can significantly enhance their performance, accuracy, and generalization capabilities. By leveraging the strengths of different networks, we can create a more robust and versatile model. Think of it as assembling a team where each member brings unique skills to tackle complex problems.
Applications in Real-World Scenarios
In real-world applications, combining neural networks can lead to breakthroughs in fields like healthcare, finance, and autonomous systems. For example, in medical diagnostics, combining networks can improve the accuracy of disease detection, while in finance, it can enhance the prediction of stock market trends.
Methods of Combining Neural Networks
Ensemble Learning
Ensemble learning involves training multiple neural networks and combining their predictions to improve accuracy. This approach reduces the risk of overfitting and enhances the model's generalization capabilities.
Bagging
Bagging, or Bootstrap Aggregating, trains multiple versions of a model on different subsets of the data and combines their predictions. This method is simple yet effective in reducing variance and improving model stability.
Boosting
Boosting focuses on training sequential models, where each model attempts to correct the errors of its predecessor. This iterative process leads to a powerful combined model that performs well even on difficult tasks.
Stacking
Stacking involves training multiple models and using a "meta-learner" to combine their outputs. This technique leverages the strengths of different models, resulting in superior overall performance.
Transfer Learning
Transfer learning is a method where a pre-trained neural network is fine-tuned on a new task. This approach is particularly useful when data is scarce, allowing us to leverage the knowledge acquired from previous tasks.
Concept of Transfer Learning
In transfer learning, a model trained on a large dataset is adapted to a smaller, related task. For instance, a model trained on millions of images can be fine-tuned to recognize specific objects in a new dataset.
How to Implement Transfer Learning
To implement transfer learning, we start with a pretrained model, freeze some layers to retain their knowledge, and fine-tune the remaining layers on the new task. This method saves time and computational resources while achieving impressive results.
Advantages of Transfer Learning
Transfer learning enables quicker training times and improved performance, especially when dealing with limited data. It’s like standing on the shoulders of giants, leveraging the vast knowledge accumulated from previous tasks.
Neural Network Fusion
Neural network fusion involves merging multiple networks into a single, unified model. This method combines the strengths of different architectures to create a more powerful and versatile network.
Definition of Neural Network Fusion
Neural network fusion integrates different networks at various stages, such as combining their outputs or merging their internal layers. This approach can enhance the model's ability to handle diverse tasks and data types.
Types of Neural Network Fusion
There are several types of neural network fusion, including early fusion, where networks are combined at the input level, and late fusion, where their outputs are merged. Each type has its own advantages depending on the task at hand.
Implementing Fusion Techniques
To implement neural network fusion, we can combine the outputs of different networks using techniques like averaging, weighted voting, or more sophisticated methods like learning a fusion model. The choice of technique depends on the specific requirements of the task.
Cascade Network
Cascade networks involve feeding the output of one neural network as input to another. This approach creates a layered structure where each network focuses on different aspects of the task.
What is a Cascade Network?
A cascade network is a hierarchical structure where multiple networks are connected in series. Each network refines the outputs of the previous one, leading to progressively better performance.
Advantages and Applications of Cascade Networks
Cascade networks are particularly useful in complex tasks where different stages of processing are required. For example, in image processing, a cascade network can progressively enhance image quality, leading to more accurate recognition.
Practical Examples
Image Recognition
In image recognition, combining CNNs with ensemble methods can improve accuracy and robustness. For instance, a network trained on general image data can be combined with a network fine-tuned for specific object recognition, leading to superior performance.
Natural Language Processing
In natural language processing (NLP), combining RNNs with transfer learning can enhance the understanding of text. A pre-trained language model can be fine-tuned for specific tasks like sentiment analysis or text generation, resulting in more accurate and nuanced outputs.
Predictive Analytics
In predictive analytics, combining different types of networks can improve the accuracy of predictions. For example, a network trained on historical data can be combined with a network that analyzes real-time data, leading to more accurate forecasts.
Challenges and Solutions
Technical Challenges
Combining neural networks can be technically challenging, requiring careful tuning and integration. Ensuring compatibility between different networks and avoiding overfitting are critical considerations.
Data Challenges
Data-related challenges include ensuring the availability of diverse and high-quality data for training. Managing data complexity and avoiding biases are essential for achieving accurate and reliable results.
Possible Solutions
To overcome these challenges, it’s crucial to adopt a systematic approach to model integration, including careful preprocessing of data and rigorous validation of models. Utilizing advanced tools and frameworks can also facilitate the process.
Tools and Frameworks
Popular Tools for Combining Neural Networks
Tools like TensorFlow, PyTorch, and Keras provide extensive support for combining neural networks. These platforms offer a wide range of functionalities and ease of use, making them ideal for both beginners and experts.
Frameworks to Use
Frameworks like Scikit-learn, Apache MXNet, and Microsoft Cognitive Toolkit offer specialized support for ensemble learning, transfer learning, and neural network fusion. These frameworks provide robust tools for developing and deploying combined neural network models.
Future of Combining Neural Networks
Emerging Trends
Emerging trends in combining neural networks include the use of advanced ensemble techniques, the integration of neural networks with other AI models, and the development of more sophisticated fusion methods.
Potential Developments
Future developments may include the creation of more powerful and efficient neural network architectures, enhanced transfer learning techniques, and the integration of neural networks with other technologies like quantum computing.
Case Studies
Successful Examples in Industry
In healthcare, combining neural networks has led to significant improvements in disease diagnosis and treatment recommendations. For example, combining CNNs with RNNs has enhanced the accuracy of medical image analysis and patient monitoring.
Lessons Learned from Case Studies
Key lessons from successful case studies include the importance of data quality, the need for careful model tuning, and the benefits of leveraging diverse neural network architectures to address complex problems.
Online Course
I have came across over many online courses. But finally found something very great platform to save your time and money.
1.Prag Robotics_ TBridge
2.Coursera
Best Practices
Strategies for Effective Combination
Effective strategies for combining neural networks include using ensemble methods to enhance performance, leveraging transfer learning to save time and resources, and adopting a systematic approach to model integration.
Avoiding Common Pitfalls
Common pitfalls to avoid include overfitting, ignoring data quality, and underestimating the complexity of model integration. By being aware of these challenges, we can develop more robust and effective combined neural network models.
Conclusion
Combining two trained neural networks can significantly enhance their capabilities, leading to more accurate and versatile AI models. Whether through ensemble learning, transfer learning, or neural network fusion, the potential benefits are immense. By adopting the right strategies and tools, we can unlock new possibilities in AI and drive advancements across various fields.
FAQs
What is the easiest method to combine neural networks?
The easiest method is ensemble learning, where multiple models are combined to improve performance and accuracy.
Can different types of neural networks be combined?
Yes, different types of neural networks, such as CNNs and RNNs, can be combined to leverage their unique strengths.
What are the typical challenges in combining neural networks?
Challenges include technical integration, data quality, and avoiding overfitting. Careful planning and validation are essential.
How does combining neural networks enhance performance?
Combining neural networks enhances performance by leveraging diverse models, reducing errors, and improving generalization.
Is combining neural networks beneficial for small datasets?
Yes, combining neural networks can be beneficial for small datasets, especially when using techniques like transfer learning to leverage knowledge from larger datasets.
#artificialintelligence#coding#raspberrypi#iot#stem#programming#science#arduinoproject#engineer#electricalengineering#robotic#robotica#machinelearning#electrical#diy#arduinouno#education#manufacturing#stemeducation#robotics#robot#technology#engineering#robots#arduino#electronics#automation#tech#innovation#ai
4 notes
·
View notes
Text
3rd July 2024
Goals:
Watch all Andrej Karpathy's videos
Watch AWS Dump videos
Watch 11-hour NLP video
Complete Microsoft GenAI course
GitHub practice
Topics:
1. Andrej Karpathy's Videos
Deep Learning Basics: Understanding neural networks, backpropagation, and optimization.
Advanced Neural Networks: Convolutional neural networks (CNNs), recurrent neural networks (RNNs), and LSTMs.
Training Techniques: Tips and tricks for training deep learning models effectively.
Applications: Real-world applications of deep learning in various domains.
2. AWS Dump Videos
AWS Fundamentals: Overview of AWS services and architecture.
Compute Services: EC2, Lambda, and auto-scaling.
Storage Services: S3, EBS, and Glacier.
Networking: VPC, Route 53, and CloudFront.
Security and Identity: IAM, KMS, and security best practices.
3. 11-hour NLP Video
NLP Basics: Introduction to natural language processing, text preprocessing, and tokenization.
Word Embeddings: Word2Vec, GloVe, and fastText.
Sequence Models: RNNs, LSTMs, and GRUs for text data.
Transformers: Introduction to the transformer architecture and BERT.
Applications: Sentiment analysis, text classification, and named entity recognition.
4. Microsoft GenAI Course
Generative AI Fundamentals: Basics of generative AI and its applications.
Model Architectures: Overview of GANs, VAEs, and other generative models.
Training Generative Models: Techniques and challenges in training generative models.
Applications: Real-world use cases such as image generation, text generation, and more.
5. GitHub Practice
Version Control Basics: Introduction to Git, repositories, and version control principles.
GitHub Workflow: Creating and managing repositories, branches, and pull requests.
Collaboration: Forking repositories, submitting pull requests, and collaborating with others.
Advanced Features: GitHub Actions, managing issues, and project boards.
Detailed Schedule:
Wednesday:
2:00 PM - 4:00 PM: Andrej Karpathy's videos
4:00 PM - 6:00 PM: Break/Dinner
6:00 PM - 8:00 PM: Andrej Karpathy's videos
8:00 PM - 9:00 PM: GitHub practice
Thursday:
9:00 AM - 11:00 AM: AWS Dump videos
11:00 AM - 1:00 PM: Break/Lunch
1:00 PM - 3:00 PM: AWS Dump videos
3:00 PM - 5:00 PM: Break
5:00 PM - 7:00 PM: 11-hour NLP video
7:00 PM - 8:00 PM: Dinner
8:00 PM - 9:00 PM: GitHub practice
Friday:
9:00 AM - 11:00 AM: Microsoft GenAI course
11:00 AM - 1:00 PM: Break/Lunch
1:00 PM - 3:00 PM: Microsoft GenAI course
3:00 PM - 5:00 PM: Break
5:00 PM - 7:00 PM: 11-hour NLP video
7:00 PM - 8:00 PM: Dinner
8:00 PM - 9:00 PM: GitHub practice
Saturday:
9:00 AM - 11:00 AM: Andrej Karpathy's videos
11:00 AM - 1:00 PM: Break/Lunch
1:00 PM - 3:00 PM: 11-hour NLP video
3:00 PM - 5:00 PM: Break
5:00 PM - 7:00 PM: AWS Dump videos
7:00 PM - 8:00 PM: Dinner
8:00 PM - 9:00 PM: GitHub practice
Sunday:
9:00 AM - 12:00 PM: Complete Microsoft GenAI course
12:00 PM - 1:00 PM: Break/Lunch
1:00 PM - 3:00 PM: Finish any remaining content from Andrej Karpathy's videos or AWS Dump videos
3:00 PM - 5:00 PM: Break
5:00 PM - 7:00 PM: Wrap up remaining 11-hour NLP video
7:00 PM - 8:00 PM: Dinner
8:00 PM - 9:00 PM: Final GitHub practice and review
4 notes
·
View notes
Text
youtube
Discover how to build a CNN model for skin melanoma classification using over 20,000 images of skin lesions
We'll begin by diving into data preparation, where we will organize, clean, and prepare the data form the classification model.
Next, we will walk you through the process of build and train convolutional neural network (CNN) model. We'll explain how to build the layers, and optimize the model.
Finally, we will test the model on a new fresh image and challenge our model.
Check out our tutorial here : https://youtu.be/RDgDVdLrmcs
Enjoy
Eran
#Python #Cnn #TensorFlow #deeplearning #neuralnetworks #imageclassification #convolutionalneuralnetworks #SkinMelanoma #melonomaclassification
#artificial intelligence#convolutional neural network#deep learning#python#tensorflow#machine learning#Youtube
3 notes
·
View notes
Text
Exploring the Depths: A Comprehensive Guide to Deep Neural Network Architectures
In the ever-evolving landscape of artificial intelligence, deep neural networks (DNNs) stand as one of the most significant advancements. These networks, which mimic the functioning of the human brain to a certain extent, have revolutionized how machines learn and interpret complex data. This guide aims to demystify the various architectures of deep neural networks and explore their unique capabilities and applications.
1. Introduction to Deep Neural Networks
Deep Neural Networks are a subset of machine learning algorithms that use multiple layers of processing to extract and interpret data features. Each layer of a DNN processes an aspect of the input data, refines it, and passes it to the next layer for further processing. The 'deep' in DNNs refers to the number of these layers, which can range from a few to several hundreds. Visit https://schneppat.com/deep-neural-networks-dnns.html
2. Fundamental Architectures
There are several fundamental architectures in DNNs, each designed for specific types of data and tasks:
Convolutional Neural Networks (CNNs): Ideal for processing image data, CNNs use convolutional layers to filter and pool data, effectively capturing spatial hierarchies.
Recurrent Neural Networks (RNNs): Designed for sequential data like time series or natural language, RNNs have the unique ability to retain information from previous inputs using their internal memory.
Autoencoders: These networks are used for unsupervised learning tasks like feature extraction and dimensionality reduction. They learn to encode input data into a lower-dimensional representation and then decode it back to the original form.
Generative Adversarial Networks (GANs): Comprising two networks, a generator and a discriminator, GANs are used for generating new data samples that resemble the training data.
3. Advanced Architectures
As the field progresses, more advanced DNN architectures have emerged:
Transformer Networks: Revolutionizing the field of natural language processing, transformers use attention mechanisms to improve the model's focus on relevant parts of the input data.
Capsule Networks: These networks aim to overcome some limitations of CNNs by preserving hierarchical spatial relationships in image data.
Neural Architecture Search (NAS): NAS employs machine learning to automate the design of neural network architectures, potentially creating more efficient models than those designed by humans.
4. Training Deep Neural Networks
Training DNNs involves feeding large amounts of data through the network and adjusting the weights using algorithms like backpropagation. Challenges in training include overfitting, where a model learns the training data too well but fails to generalize to new data, and the vanishing/exploding gradient problem, which affects the network's ability to learn.
5. Applications and Impact
The applications of DNNs are vast and span multiple industries:
Image and Speech Recognition: DNNs have drastically improved the accuracy of image and speech recognition systems.
Natural Language Processing: From translation to sentiment analysis, DNNs have enhanced the understanding of human language by machines.
Healthcare: In medical diagnostics, DNNs assist in the analysis of complex medical data for early disease detection.
Autonomous Vehicles: DNNs are crucial in enabling vehicles to interpret sensory data and make informed decisions.
6. Ethical Considerations and Future Directions
As with any powerful technology, DNNs raise ethical questions related to privacy, data security, and the potential for misuse. Ensuring the responsible use of DNNs is paramount as the technology continues to advance.
In conclusion, deep neural networks are a cornerstone of modern AI. Their varied architectures and growing applications are not only fascinating from a technological standpoint but also hold immense potential for solving complex problems across different domains. As research progresses, we can expect DNNs to become even more sophisticated, pushing the boundaries of what machines can learn and achieve.
3 notes
·
View notes