#Data Engineering Bootcamp
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr.com rank in the US is 25.
Text

How to Prepare for a Data Engineering Bootcamp: Skills and Knowledge Primer
Preparing for a data engineering bootcamp involves strengthening foundational skills in programming, especially in Python or Java, and understanding basic database concepts. Familiarize yourself with SQL and NoSQL databases, practice data structure and algorithms, and explore introductory topics in big data technologies like Hadoop and Spark. Additionally, brushing up on statistics and data visualization can provide a well-rounded skill set, setting the stage for a successful bootcamp experience.
For more information visit: https://www.webagesolutions.com/courses/WA3020-data-engineering-bootcamp-training-using-python-and-pyspark
0 notes
Text
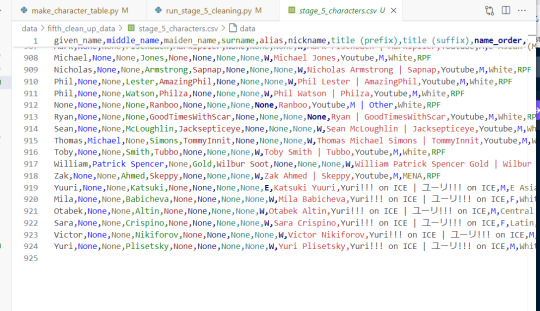
*laughs in still 923 characters in my data set after cleaning up all the duplicate names* 🙃 (down from 975 (unique) old names)
#ship stats#coding#I love csv files they're so satisfying to look at#I'm like THIS 🤏 close to visualising this first version aaaah#I've assigned and completed/corrected (as much as possible) the demographic data#(you need to understand the amount of wikis I had to manually look through for this cleaning process)#now turning everything into csv files again so I can LOOK AT EM BETTER#and then need to look into vis softwares to use o.o#we had bootcamp graduation today also!! 🎉 I am officially a trained data engineer#what will I do with my time now until I have hunted myself a job? hoPEFULLY FINALLY EDIT MY REMAINING MATRIARCHY VIDEOS Q.Q
3 notes
·
View notes
Text
The Future of Full Stack Java Development

Full-stack developers, also known as “jack of all trades,” are in high demand in India. They are capable of carrying out the duties of numerous professionals. They earn good money and have many job opportunities with rewarding experiences because of their diverse skills. Full-stack Java programming has a bright future because its popularity is growing and will continue to grow in the coming years.
It’s well known that full-stack developers are proficient in both server-side and client-side programming. They are the professionals who carry out the responsibilities of backend and frontend developers. Despite not always being regarded as specialists, their abilities enable them to handle development tasks with ease. All firms look forward to having a brilliant full-stack developer as a future developer for a number of reasons. They handle a variety of technologies, which enables them to manage more project facets than the typical coder.
An experienced web developer who primarily works with Java programming is known as a Java full-stack developer. The front end, back end, and database layer are the three levels of code that these web developers build. The web development teams are frequently led by full-stack Java engineers, who also assist in updating and designing new websites. Because there is a great demand for Java full-stack developers. Many institutions have seized the opportunity by providing well-thought-out Java full-stack developer courses. You may study full-stack development quickly and become an expert in the area with the aid of these courses.
Java Full Stack Development by Datavalley
100% Placement Assistance
Duration: 3 Months (500+ hours)
Mode: Online/Offline
Let’s look into the future opportunities for full-stack Java professionals in India.
4 things that will Expand the Future Purpose of Java Full-Stack Developers
The Role of a Full-Stack Developer
Full-stack developers work on numerous tasks at once. They need to be extremely talented and knowledgeable in both front-end and back-end programming languages for this. JavaScript, CSS, HTML, and other frontend programming languages are essential. When creating new websites or modifying old ones, Java is a key programming language used by Java full-stack developers. However, backend programming languages consist of .Net, PHP, and Python depending on the projects. The full stack developers are distinguished from other developers by their proficiency and understanding of programming languages. With the availability of the finest Java full stack developer training, students may now easily master a frontend programming language like Java. The full-stack developer is more valuable and in demand when they are knowledgeable in multiple programming languages.
Responsibilities of a Full-Stack Developer
Functional databases are developed by full-stack developers. It creates aesthetically pleasing frontend designs that improve user experience and support the backend. The entire web-to-web architecture is under the control of these full-stack developers. They are also in charge of consistently maintaining and updating the software as needed. The full-stack developers bear the responsibility of overseeing a software project from its inception to its finalized product.
In the end, these full-stack developers also satisfy client and technical needs. Therefore, having a single, adaptable person do many tasks puts them in high demand and increases their potential for success in the technology field. Through extensively developed modules that expand their future scope, the Java full-stack developer course equips students with the skills necessary to take on these tasks.
The full-stack developer salary range
Full-stack developers are among the highest-paid workers in the software industry. In India, the average salary for a full-stack developer is 9.5 lakhs per annum. The elements that determine income typically include experience, location of the position, company strength, and other considerations. A highly skilled and adaptable full-stack developer makes between 16 and 20 lakhs per annum. Full-stack engineers get paid a lot because of their extensive skills, they can handle the tasks of two or three other developers at once.
By fostering the growth of small teams, preventing misunderstandings, and cutting the brand’s operating expenses, these full-stack developers perform remarkable work. Students who take the Java full-stack developer course are better equipped to become versatile full-stack developers, which will increase their demand currently as well as in the future in the industry.
Job Opportunities of Java Full Stack Developers
The full-stack developers are knowledgeable professionals with a wide range of technological skills. These competent workers are conversant with numerous stacks, including MEAN and LAMP, and are capable of handling more tasks than a typical developer. They are skilled experts with a wealth of opportunities due to their extensive understanding of several programming languages.
Full-stack developers are in high demand because they can work on a variety of projects and meet the needs of many companies. The full-stack Java developer course helps students build this adaptability so they can eventually become the first choice for brands searching for high-end developers.
As a result, these are a few key factors improving the future prospects of Java Full Stack developers in India. They are vibrant professionals who are in high demand due to their diverse skill set and experience, and they are growing steadily. The Java full stack developer course can help students hone their knowledge and abilities to succeed in this industry.
Datavalley’s Full Stack Java Developer course can help you start a promising career in full stack development. Enroll today to gain the expertise and knowledge you need to succeed.
Attend Free Bootcamps
Looking to supercharge your Java skills and become a full-stack Java developer? Look no further than Datavalley’s Java Full Stack Developer bootcamp. This is your chance to take your career to the next level by enhancing your expertise.
Key points about Bootcamps:
It is completely free, and there is no obligation to complete the entire course.
20 hours total, two hours daily for two weeks.
Gain hands-on experience with tools and projects.
Explore and decide if the field or career is right for you.
Complete a mini-project.
Earn a certificate to show on your profile.
No commitment is required after bootcamp.
Take another bootcamp if you are unsure about your track.

#dataexperts#datavalley#data engineering#data analytics#dataexcellence#business intelligence#data science#power bi#data analytics course#data science course#java developers#java full stack bootcamp#java full stack training#java full stack course#java full stack developer
2 notes
·
View notes
Text
Data Science vs Data Engineering: What’s the Difference?

The Short Answer: Builders vs Explorers
Think of data engineers as the people who build the roads, and data scientists as the people who drive on them looking for treasure. A data engineer creates the systems and pipelines that collect, clean, and organize raw data. A data scientist, on the other hand, takes that cleaned-up data and analyzes it to uncover insights, patterns, and predictions.
You can’t have one without the other. If data engineers didn’t build the infrastructure, data scientists would be stuck cleaning messy spreadsheets all day. And without data scientists, all that clean, beautiful data would just sit there doing nothing — like a shiny sports car in a garage.
So if you’re asking “Data Science vs Data Engineering: What’s the Difference?”, it really comes down to what part of the data journey excites you more.
What Does a Data Engineer Do?
Data engineers are the behind-the-scenes heroes who make sure data is usable, accessible, and fast. They design databases, write code to move data from one place to another, and make sure everything is running smoothly.
You’ll find them working with tools like Apache Spark, Kafka, SQL, and ETL pipelines. Their job is technical, logical, and kind of like building Lego structures — but instead of bricks, they’re stacking code and cloud platforms.
They may not always be the ones doing the fancy machine learning, but without them, machine learning wouldn’t even be possible. They’re like the stage crew in a big play — quietly making everything work behind the scenes so the stars can shine.
What Does a Data Scientist Do?
Data scientists are the curious minds asking big questions like “Why are sales dropping?” or “Can we predict what customers want next?” They take the data that engineers prepare and run experiments, visualizations, and models to uncover trends and make smart decisions.
Their toolbox includes Python, R, Pandas, Matplotlib, scikit-learn, and plenty of Jupyter notebooks. They often use machine learning algorithms to make predictions and identify patterns. If data engineering is about getting the data ready, data science is about making sense of it.
They’re creative, analytical, and a little bit detective. So if you love puzzles and want to tell stories with numbers, data science might be your jam.
How Do They Work Together?
In most modern data teams, data scientists and engineers are like teammates on the same mission. The engineer prepares the data pipeline and builds systems to handle huge amounts of information. The scientist uses those systems to run models and generate business insights.
The magic really happens when they collaborate well. The better the pipeline, the faster the insights. The better the insights, the more valuable the data becomes. It’s a team sport — and when done right, it leads to smarter decisions, better products, and happy stakeholders.
Which One Is Right for You?
If you love solving technical problems and enjoy working with infrastructure and systems, data engineering could be a great fit. If you’re more into statistics, analytics, and asking “why” all the time, data science might be the path for you.
Both careers are in demand, both pay well, and both are at the heart of every data-driven company. You just need to decide which role gets you more excited.
And if you’re still unsure, try building a mini project! Play with a dataset, clean it, analyze it, and see which part you enjoyed more.
Final Thoughts
So now you know the answer to that confusing question: Data Science vs Data Engineering — what’s the difference? One builds the systems, the other finds the insights. Both are crucial. And hey, if you learn a little of both, you’ll be even more unstoppable in your data career.
At Coding Brushup, we make it easy to explore both paths with hands-on resources, real-world projects, and simplified learning tools. Whether you’re cleaning data or building pipelines, Coding Brushup helps you sharpen your skills and stay ahead in the ever-growing world of data.
1 note
·
View note
Text

📣 New Python Batch Alert!
🔗 Register here: https://tr.ee/Chl7PS
🧠 Learn: Python, Django, HTML, JS, Bootstrap, Angular, Database
🗓️ Start Date: April 9th, 2025 🕢 Time: 7:30 AM IST 👨🏫 Trainer: Mr. Mahesh 💻 Mode: Classroom & Online
📍 KPHB (Beside Metro Station) 🌐 Webex ID: 2513 181 6287 | Pass: 112233
. #PythonTraining #FullStackDeveloper #CodingBootcamp #NareshIT #DevJourney
https://tr.ee/Chl7PS
#python training#full stack developer#Coding Bootcamp#django#development#course#training#angular#bootstrap#java#coding#software developers#programming#software engineering#python#data science#data scientist
0 notes
Text

Data Engineer Training & Python Coding Certification Prepzee Learning Solutions offers comprehensive Data Engineer Training and an intensive Data Engineer Bootcamp to help professionals master data pipelines and big data technologies. Our Python Coding Certification ensures hands-on learning in programming and data processing, equipping learners with industry-relevant skills. Boost your expertise with Prepzee Learning today!
0 notes
Text
How to Choose the Right Machine Learning Course for Your Career

As the demand for machine learning professionals continues to surge, choosing the right machine learning course has become crucial for anyone looking to build a successful career in this field. With countless options available, from free online courses to intensive boot camps and advanced degrees, making the right choice can be overwhelming.
#machine learning course#data scientist#AI engineer#machine learning researcher#eginner machine learning course#advanced machine learning course#Python programming#data analysis#machine learning curriculum#supervised learning#unsupervised learning#deep learning#natural language processing#reinforcement learning#online machine learning course#in-person machine learning course#flexible learning#machine learning certification#Coursera machine learning#edX machine learning#Udacity machine learning#machine learning instructor#course reviews#student testimonials#career support#job placement#networking opportunities#alumni network#machine learning bootcamp#degree program
0 notes
Text
How does feature engineering impact the performance of machine learning models?
Hi,
Here some information about How Feature Engineering Impacts Machine Learning Model Performance.
Feature engineering is all about creating and modifying features to improve the performance of your machine learning models.
1. Enhances Model Accuracy:
Impact: Well-engineered features can help the model better capture important patterns and relationships in the data.
Example: Adding a feature that represents the age of a car can help a model better predict its resale value compared to just using the car’s make and model alone.
2. Simplifies the Model:
Impact: Creating useful features can reduce the need for complex models by making the data more understandable for the model.
Example: Combining individual date components into a single “day of the week” feature can simplify the model’s task of identifying patterns related to different days.
3. Improves Feature Relevance:
Impact: Feature engineering helps in focusing the model on the most relevant aspects of the data, leading to better performance.
Example: Creating interaction terms between features (like combining income and education level) can highlight relationships that were not obvious in the original features.
4. Reduces Overfitting:
Impact: By creating meaningful features, you can reduce the complexity of the model and make it less likely to overfit the training data.
Example: Instead of using raw data with many irrelevant features, feature engineering helps in selecting the most important ones, improving the model’s generalization to new data.
5. Helps Handle Missing Data:
Impact: Feature engineering can include methods to handle missing data, improving the robustness of your model.
Example: Creating a binary feature that indicates whether data is missing can help the model make better predictions even when some values are missing.
In Summary: Feature engineering impacts model performance by improving accuracy, simplifying models, making features more relevant, reducing overfitting, and handling missing data better. By carefully designing and selecting features, you help your machine learning model work more effectively and make better predictions.
0 notes
Text
📝 Guest Post: Local Agentic RAG with LangGraph and Llama 3*
New Post has been published on https://thedigitalinsider.com/guest-post-local-agentic-rag-with-langgraph-and-llama-3/
📝 Guest Post: Local Agentic RAG with LangGraph and Llama 3*
In this guest post, Stephen Batifol from Zilliz discusses how to build agents capable of tool-calling using LangGraph with Llama 3 and Milvus. Let’s dive in.
LLM agents use planning, memory, and tools to accomplish tasks. Here, we show how to build agents capable of tool-calling using LangGraph with Llama 3 and Milvus.
Agents can empower Llama 3 with important new capabilities. In particular, we will show how to give Llama 3 the ability to perform a web search, call custom user-defined functions
Tool-calling agents with LangGraph use two nodes: an LLM node decides which tool to invoke based on the user input. It outputs the tool name and tool arguments based on the input. The tool name and arguments are passed to a tool node, which calls the tool with the specified arguments and returns the result to the LLM.
Milvus Lite allows you to use Milvus locally without using Docker or Kubernetes. It will store the vectors you generate from the different websites we will navigate to.
Introduction to Agentic RAG
Language models can’t take actions themselves—they just output text. Agents are systems that use LLMs as reasoning engines to determine which actions to take and the inputs to pass them. After executing actions, the results can be transmitted back into the LLM to determine whether more actions are needed or if it is okay to finish.
They can be used to perform actions such as Searching the web, browsing your emails, correcting RAG to add self-reflection or self-grading on retrieved documents, and many more.
Setting things up
LangGraph – An extension of Langchain aimed at building robust and stateful multi-actor applications with LLMs by modeling steps as edges and nodes in a graph.
Ollama & Llama 3 – With Ollama you can run open-source large language models locally, such as Llama 3. This allows you to work with these models on your own terms, without the need for constant internet connectivity or reliance on external servers.
Milvus Lite – Local version of Milvus that can run on your laptop, Jupyter Notebook or Google Colab. Use this vector database we use to store and retrieve your data efficiently.
Using LangGraph and Milvus
We use LangGraph to build a custom local Llama 3-powered RAG agent that uses different approaches:
We implement each approach as a control flow in LangGraph:
Routing (Adaptive RAG) – Allows the agent to intelligently route user queries to the most suitable retrieval method based on the question itself. The LLM node analyzes the query, and based on keywords or question structure, it can route it to specific retrieval nodes.
Example 1: Questions requiring factual answers might be routed to a document retrieval node searching a pre-indexed knowledge base (powered by Milvus).
Example 2: Open-ended, creative prompts might be directed to the LLM for generation tasks.
Fallback (Corrective RAG) – Ensures the agent has a backup plan if its initial retrieval methods fail to provide relevant results. Suppose the initial retrieval nodes (e.g., document retrieval from the knowledge base) don’t return satisfactory answers (based on relevance score or confidence thresholds). In that case, the agent falls back to a web search node.
The web search node can utilize external search APIs.
Self-correction (Self-RAG) – Enables the agent to identify and fix its own errors or misleading outputs. The LLM node generates an answer, and then it’s routed to another node for evaluation. This evaluation node can use various techniques:
Reflection: The agent can check its answer against the original query to see if it addresses all aspects.
Confidence Score Analysis: The LLM can assign a confidence score to its answer. If the score is below a certain threshold, the answer is routed back to the LLM for revision.
General ideas for Agents
Reflection – The self-correction mechanism is a form of reflection where the LangGraph agent reflects on its retrieval and generations. It loops information back for evaluation and allows the agent to exhibit a form of rudimentary reflection, improving its output quality over time.
Planning – The control flow laid out in the graph is a form of planning, the agent doesn’t just react to the query; it lays out a step-by-step process to retrieve or generate the best answer.
Tool use – The LangGraph agent’s control flow incorporates specific nodes for various tools. These can include retrieval nodes for the knowledge base (e.g., Milvus), demonstrating its ability to tap into a vast pool of information, and web search nodes for external information.
Examples of Agents
To showcase the capabilities of our LLM agents, let’s look into two key components: the Hallucination Grader and the Answer Grader. While the full code is available at the bottom of this post, these snippets will provide a better understanding of how these agents work within the LangChain framework.
Hallucination Grader
The Hallucination Grader tries to fix a common challenge with LLMs: hallucinations, where the model generates answers that sound plausible but lack factual grounding. This agent acts as a fact-checker, assessing if the LLM’s answer aligns with a provided set of documents retrieved from Milvus.
```
### Hallucination Grader
# LLM
llm = ChatOllama(model=local_llm, format="json", temperature=0)
# Prompt
prompt = PromptTemplate(
template="""You are a grader assessing whether
an answer is grounded in / supported by a set of facts. Give a binary score 'yes' or 'no' score to indicate
whether the answer is grounded in / supported by a set of facts. Provide the binary score as a JSON with a
single key 'score' and no preamble or explanation.
Here are the facts:
documents
Here is the answer:
generation
""",
input_variables=["generation", "documents"],
)
hallucination_grader = prompt | llm | JsonOutputParser()
hallucination_grader.invoke("documents": docs, "generation": generation)
```
Answer Grader
Following the Hallucination Grader, another agent steps in. This agent checks another crucial aspect: ensuring the LLM’s answer directly addresses the user’s original question. It utilizes the same LLM but with a different prompt, specifically designed to evaluate the answer’s relevance to the question.
```
def grade_generation_v_documents_and_question(state):
"""
Determines whether the generation is grounded in the document and answers questions.
Args:
state (dict): The current graph state
Returns:
str: Decision for next node to call
"""
print("---CHECK HALLUCINATIONS---")
question = state["question"]
documents = state["documents"]
generation = state["generation"]
score = hallucination_grader.invoke("documents": documents, "generation": generation)
grade = score['score']
# Check hallucination
if grade == "yes":
print("---DECISION: GENERATION IS GROUNDED IN DOCUMENTS---")
# Check question-answering
print("---GRADE GENERATION vs QUESTION---")
score = answer_grader.invoke("question": question,"generation": generation)
grade = score['score']
if grade == "yes":
print("---DECISION: GENERATION ADDRESSES QUESTION---")
return "useful"
else:
print("---DECISION: GENERATION DOES NOT ADDRESS QUESTION---")
return "not useful"
else:
pprint("---DECISION: GENERATION IS NOT GROUNDED IN DOCUMENTS, RE-TRY---")
return "not supported"
```
You can see in the code above that we are checking the predictions by the LLM that we use as a classifier.
Compiling the LangGraph graph.
This will compile all the agents that we defined and will make it possible to use different tools for your RAG system.
```
# Compile
app = workflow.compile()
# Test
from pprint import pprint
inputs = "question": "Who are the Bears expected to draft first in the NFL draft?"
for output in app.stream(inputs):
for key, value in output.items():
pprint(f"Finished running: key:")
pprint(value["generation"])
```
Conclusion
In this blog post, we showed how to build a RAG system using agents with LangChain/ LangGraph, Llama 3, and Milvus. These agents make it possible for LLMs to have planning, memory, and different tool use capabilities, which can lead to more robust and informative responses.
Feel free to check out the code available in the Milvus Bootcamp repository.
If you enjoyed this blog post, consider giving us a star on Github, and share your experiences with the community by joining our Discord.
This is inspired by the Github Repository from Meta with recipes for using Llama 3
*This post was written by Stephen Batifol and originally published on Zilliz.com here. We thank Zilliz for their insights and ongoing support of TheSequence.
#ADD#agent#agents#amp#Analysis#APIs#app#applications#approach#backup#bears#binary#Blog#bootcamp#Building#challenge#code#CoLab#Community#connectivity#data#Database#Docker#emails#engines#explanation#extension#Facts#form#framework
0 notes
Text
#data engineering#industry data#classroom#school#dataanalytics#dataspeaks#the next generation#bootcamp
0 notes
Photo

(via GIPHY) Takeo Boorcamp
#giphy#transparent#tech#bootcamp#programmer#data scientist#full stack developer#java developer#data engineering#frontend developer#aws python developer
1 note
·
View note
Text
Data Engineering Bootcamp Training – Featuring Everything You Need to Accelerate Growth
If you want your team to master data engineering skills, you should explore the potential of data engineering bootcamp training focusing on Python and PySpark. That will provide your team with extensive knowledge and practical experience in data engineering. Here is a closer look at the details of how data engineering bootcamps can help your team grow.
Big Data Concepts and Systems Overview for Data Engineers
This foundational data engineering boot camp module offers a comprehensive understanding of big data concepts, systems, and architectures. The topics covered in this module include emerging technologies such as Apache Spark, distributed computing, and Hadoop Ecosystem components. The topics discussed in this module equip teams to manage complex data engineering challenges in real-world settings.
Translating Data into Operational and Business Insights
Unlike what most people assume, data engineering is a whole lot more than just processing data. It also involves extracting actionable insights to drive business decisions. Data engineering bootcamps course emphasize translating raw data into actionable and operational business insights. Learners are equipped with techniques to transform, aggregate, and analyze data so that they can deliver meaningful insights to stakeholders.
Data Processing Phases
Efficient data engineering requires a deep understanding of the data processing life cycle. With data engineering bootcamps, teams will be introduced to various phases of data processing, such as data storage, processing, ingestion, and visualization. Employees will also gain practical experience in designing and deploying data processing pathways using Python and PySpark. This translates into improved efficiency and reliability in data workflow.
Running Python Programs, Control Statements, and Data Collections
Python is one of the most popular programming languages and is widely used for data engineering purposes. For this reason, data engineering bootcamps offer an introduction to Python programming and cover basic concepts such as running Python programs, common data collections, and control statements. Additionally, teams learn how to create efficient and secure Python code to process and manipulate data efficiently.
Functions and Modules
Effective data engineering workflow demands creating modular and reusable code. Consequently, this module is necessary to understand data engineering work processes comprehensively. The module focuses on functions and modules in Python, enabling teams to transform logic into functions and manage code as a reusable module. The course introduces participants to optimal code organization, thereby improving productivity and sustainability in data engineering projects.
Data Visualization in Python
Clarity in data visualization is vital to communicating key insights and findings to stakeholders. This Data engineering bootcamp module on data visualization emphasizes techniques that utilize libraries such as Seaborn and Matplotlib in Python. During the course, teams learn how to design informative and visually striking charts, plots, and dashboards to communicate complex data relationships effectively.
Final word
To sum up, data engineering bootcamp training using Python and PySpark provides a gateway for teams to venture into the rapidly growing realm of data engineering. The training endows them with a solid foundation in big data concepts, practical experience in Python, and hands-on skills in data processing and visualization. Ensure that you choose an established course provider to enjoy the maximum benefits of data engineering courses.
For more information visit: https://www.webagesolutions.com/courses/WA3020-data-engineering-bootcamp-training-using-python-and-pyspark
0 notes
Text
Beyond Technical Skills
Baru-baru ini, World Economic Forum (WEF) merilis Future of Jobs Report 2030. Laporan ini mengungkapkan prediksi menarik: 92 juta pekerjaan akan hilang, tapi 170 juta pekerjaan baru bakal muncul!
92 juta pekerjaan yang bakal hilang ini kebanyakan pekerjaan administratif yang bakal digantikan otomatisasi. Misalnya kasir, penjaga tiket, bahkan akuntan sama auditor. Sementara 170 juta lowongan baru ini lebih ke arah teknologi dan energi terbarukan - kayak big data specialist, software engineers, sama UX designer (wohoo!).
McKinsey pun punya prediksi serupa: sampai 2030, 75-375 juta orang bakal perlu belajar skill baru dan ganti profesi. Sebenernya tren ini udah predictable sih, gak terlalu mengejutkan.
Tapi munculnya generative AI (gen AI) bikin saya was-was. Rasanya AI ini malah mempercepat prediksi yang udah ada. Awalnya saya skeptis, berpikir AI gak bakal bisa sepintar itu menggantikan manusia di bidang kreatif. Nyatanya? AI udah bisa bikin video, gambar, musik, tulisan - hal-hal yang kita pikir cuma bisa dilakukan manusia!
Di bidang saya sendiri, saya udah liat AI bisa bikin deliverables kayak sitemap dan wireframe. Tinggal nunggu waktu sampe AI bisa bikin desain web sama aplikasi yang high fidelity.
Yang bikin saya khawatir bukan soal bakal digantikan, tapi generasi saya dan generasi di bawah saya yang kayaknya belum sadar ada "pergeseran tektonik" gara-gara AI, khususnya gen AI.
Di era tech spring Indonesia (2012-2021), lowongan kerja banyak banget tapi yang qualified dikit. Sekarang dengan gen AI, gap antara industri sama pendidikan bakal makin melebar. Lowongan kerja bakal makin selektif, makin butuh skill tinggi, sementara talenta yang bener-bener siap cuma segelintir.
Contohnya, desainer yang cuma "jualan" kemampuan merancang desain bakal rentan digantikan AI yang bisa generate website dalam hitungan detik. Tapi desainer yang punya critical thinking, empati, berpikir sistematis, sama bisa bangun relasi - mereka bakal fokus ke aspek strategis yang belum bisa disentuh AI.
Skill-skill dasar ini penting, tapi gak semenawan bootcamp atau ebook yang janjiin gaji gede. Padahal skill foundational kayak critical thinking, problem solving, interpersonal skills, mental flexibility, systems thinking, self awareness, sama literasi teknologi itu yang bener-bener valuable - tak lekang waktu dan bisa dipake di berbagai industri.
Di era AI ini, kita gak bisa cuma jadi penonton. Kita harus jadi pemain. Belajar, adaptasi, sama terus-terusan upgrade skill. Bukan soal kalah atau menang sama AI, tapi bagaimana kita bisa naik level dengan menggunakan teknologi baru ini.
Stay curious, stay hungry!
71 notes
·
View notes
Note
Hey! This is very random, but I saw that you work in cyber security right now. I work in data science, but I'm really interested in cyber security and considering making a switch. I was wondering what kind of cybersecurity work you do, and what has been the most helpful for you to learn what you need for your job!
Hi! Cybersecurity is a really broad field, and you can do a lot of different things depending on what your interests are.
My work is mostly focused around automating things for security, since my background is in programming. Automation is really helpful for speeding up boring, monotonous tasks that need to get done, but don't necessarily need a human involved. A good example is automated phishing analysis, since phishing reports are a big chunk of the cases that security analysts have to deal with, and an analyst usually follows the same few steps at the beginning. Rather than someone having to manually check the reputation of the sender domain, check the reputation of any links, and all of that every single time, we can build tools to automatically scan for things like that and then present the info to the analyst. The whole idea here is to automate the boring data retrieval stuff, since computers are good at that, and give the analyst more time for decision-making and analysis, since humans are good at that.
If you're coming from data science, you might be interested in detection engineering. Cybersecurity is essentially a data problem - we have a ton of logs from a ton of different sources (internal logs, threat intelligence feeds, etc.) - how do we sort through that data to highlight things that we want to pay attention to, and how can we correlate events from different sources? If you're into software development or want to stay more on the data science side, maybe you could also look into roles for software development at companies that have SIEM (Security Information and Event Management) products - these are essentially the big log repositories that organizations rely on for correlation and alerting.
As for starting to learn security, my general go-to recommendation is to start looking through the material for the Security+ certification. For better or worse, certifications are pretty big in security, much more so than other tech fields (to my knowledge). I'm a bit more hesitant to recommend the Security+ now, since CompTIA (the company that offers it) was bought by a private equity company last year. Everyone is kind of expecting the prices to go up and the quality to go down. (The Security+ exam costs $404 USD as of writing this, and I think I took mine for like $135ish with a student discount in 2022). However, the Security+ is still the most well-known and comprehensive entry-level certification that I'm aware of. You can (and should) study for it completely for free - check out Professor Messer's training videos on YouTube. There are also plenty of books out there if that's more of your thing. I'd say to treat the Security+ as a way to get a broad overview of security and figure out what you don't know. (It's certainly not a magic ticket to a job, no matter what those expensive bootcamps will tell you.)
If you aren't familiar with networking, it's worth checking out Professor Messer's Network+ training videos as well. You don't need to know everything on there, but having an understanding of ports, protocols, and network components and design is super useful. I hear a lot that the best security folks are often the ones who come from IT or networking or similar and have a really solid understanding of the fundamentals and then get into security. Don't neglect the basics!
One thing that I'll also add, based on conversations I've had with folks in my network… getting a job in cybersecurity is harder now than it used to be, at least in the US (where I am). There are a ton of very well-qualified people who have been laid off who are now competing with people trying to get into the field in the first place, and with the wrecking ball that Elon is taking to the federal government (and by extension, government contractors) right now… it's hard. There's still a need for skilled folks in cyber, but you're going to run into a lot of those "5 years of experience required for this entry-level job" kind of job postings.
On a slightly happier note, another thing you should do if you want to get into cyber is to stay up to date with what's happening in the industry! I have a masterpost that has a section with some of my favorite news sources. The SANS Stormcast is a good place to start - it's a 5 minute podcast every weekday morning that covers most of the big things. Black Hills Infosec also does a weekly news livestream on YouTube that's similar (but longer and with more banter). Also, a lot of infosec folks hang out on Mastodon & in the wider fediverse. Let me know if you want some recs for folks to follow over there.
The nice thing about cybersecurity (and computer-related fields in general, I find) is that there are a ton of free resources out there to help you learn. Sometimes it's harder to find the higher-quality ones, but let me know if there are any topics you're interested in & I'll see what I can find. I have a few posts in my cybersecurity tag on here that might help.
Thank you for your patience, I know you sent this in over a week ago lol but life has been busy. Feel free to send any follow-up questions if you have any!
10 notes
·
View notes
Text
"From Passion to Profession: Steps to Enter the Tech Industry"
How to Break into the Tech World: Your Comprehensive Guide
In today’s fast-paced digital landscape, the tech industry is thriving and full of opportunities. Whether you’re a student, a career changer, or someone passionate about technology, you may be wondering, “How do I get into the tech world?” This guide will provide you with actionable steps, resources, and insights to help you successfully navigate your journey.
Understanding the Tech Landscape
Before you start, it's essential to understand the various sectors within the tech industry. Key areas include:
Software Development: Designing and building applications and systems.
Data Science: Analyzing data to support decision-making.
Cybersecurity: Safeguarding systems and networks from digital threats.
Product Management: Overseeing the development and delivery of tech products.
User Experience (UX) Design: Focusing on the usability and overall experience of tech products.
Identifying your interests will help you choose the right path.
Step 1: Assess Your Interests and Skills
Begin your journey by evaluating your interests and existing skills. Consider the following questions:
What areas of technology excite me the most?
Do I prefer coding, data analysis, design, or project management?
What transferable skills do I already possess?
This self-assessment will help clarify your direction in the tech field.
Step 2: Gain Relevant Education and Skills
Formal Education
While a degree isn’t always necessary, it can be beneficial, especially for roles in software engineering or data science. Options include:
Computer Science Degree: Provides a strong foundation in programming and system design.
Coding Bootcamps: Intensive programs that teach practical skills quickly.
Online Courses: Platforms like Coursera, edX, and Udacity offer courses in various tech fields.
Self-Learning and Online Resources
The tech industry evolves rapidly, making self-learning crucial. Explore resources like:
FreeCodeCamp: Offers free coding tutorials and projects.
Kaggle: A platform for data science practice and competitions.
YouTube: Channels dedicated to tutorials on coding, design, and more.
Certifications
Certifications can enhance your credentials. Consider options like:
AWS Certified Solutions Architect: Valuable for cloud computing roles.
Certified Information Systems Security Professional (CISSP): Great for cybersecurity.
Google Analytics Certification: Useful for data-driven positions.
Step 3: Build a Portfolio
A strong portfolio showcases your skills and projects. Here’s how to create one:
For Developers
GitHub: Share your code and contributions to open-source projects.
Personal Website: Create a site to display your projects, skills, and resume.
For Designers
Design Portfolio: Use platforms like Behance or Dribbble to showcase your work.
Case Studies: Document your design process and outcomes.
For Data Professionals
Data Projects: Analyze public datasets and share your findings.
Blogging: Write about your data analysis and insights on a personal blog.
Step 4: Network in the Tech Community
Networking is vital for success in tech. Here are some strategies:
Attend Meetups and Conferences
Search for local tech meetups or conferences. Websites like Meetup.com and Eventbrite can help you find relevant events, providing opportunities to meet professionals and learn from experts.
Join Online Communities
Engage in online forums and communities. Use platforms like:
LinkedIn: Connect with industry professionals and share insights.
Twitter: Follow tech influencers and participate in discussions.
Reddit: Subreddits like r/learnprogramming and r/datascience offer valuable advice and support.
Seek Mentorship
Finding a mentor can greatly benefit your journey. Reach out to experienced professionals in your field and ask for guidance.
Step 5: Gain Practical Experience
Hands-on experience is often more valuable than formal education. Here’s how to gain it:
Internships
Apply for internships, even if they are unpaid. They offer exposure to real-world projects and networking opportunities.
Freelancing
Consider freelancing to build your portfolio and gain experience. Platforms like Upwork and Fiverr can connect you with clients.
Contribute to Open Source
Engaging in open-source projects can enhance your skills and visibility. Many projects on GitHub are looking for contributors.
Step 6: Prepare for Job Applications
Crafting Your Resume
Tailor your resume to highlight relevant skills and experiences. Align it with the job description for each application.
Writing a Cover Letter
A compelling cover letter can set you apart. Highlight your passion for technology and what you can contribute.
Practice Interviewing
Prepare for technical interviews by practicing coding challenges on platforms like LeetCode or HackerRank. For non-technical roles, rehearse common behavioral questions.
Step 7: Stay Updated and Keep Learning
The tech world is ever-evolving, making it crucial to stay current. Subscribe to industry newsletters, follow tech blogs, and continue learning through online courses.
Follow Industry Trends
Stay informed about emerging technologies and trends in your field. Resources like TechCrunch, Wired, and industry-specific blogs can provide valuable insights.
Continuous Learning
Dedicate time each week for learning. Whether through new courses, reading, or personal projects, ongoing education is essential for long-term success.
Conclusion
Breaking into the tech world may seem daunting, but with the right approach and commitment, it’s entirely possible. By assessing your interests, acquiring relevant skills, building a portfolio, networking, gaining practical experience, preparing for job applications, and committing to lifelong learning, you’ll be well on your way to a rewarding career in technology.
Embrace the journey, stay curious, and connect with the tech community. The tech world is vast and filled with possibilities, and your adventure is just beginning. Take that first step today and unlock the doors to your future in technology!
contact Infoemation wensite: https://agileseen.com/how-to-get-to-tech-world/ Phone: 01722-326809 Email: [email protected]
#tech career#how to get into tech#technology jobs#software development#data science#cybersecurity#product management#UX design#tech education#networking in tech#internships#freelancing#open source contribution#tech skills#continuous learning#job application tips
9 notes
·
View notes
Note
Hi! I saw your post about being a programmer and previously working in a warehouse. How did you make the switch? Im trying to get into tech as a 2nd career as well. Thinking about data analytics as it applies to healthcare (I’m a nurse). Did you do a bootcamp? What did you do to change careers? Thanks!
I actually got a Bachelor's in Electrical Engineering in 2012 but never got a job doing that because everyone wanted experience and because the process of getting a job is not designed with autistic people in mind.
The warehouse job was supposed to be a temporary job while I looked for a job as an Electrical Engineer, but because I never got one, I stayed at the warehouse for 8 years until the pandemic caused them to close.
I decided that I'd have a better chance as a programmer because I could start off making my own apps. Even if I didn't make much money from my own apps, they could be mentioned on a resume or talked about in an interview in order to give me an edge over others with no experience.
So I taught myself how to make Android apps and made some of my own. I then took an online boot camp in order to learn the best practices and specific skills that are more relevant to a career.
I tried every method of job hunting I could think of. I tried applying on job boards. I tried writing a cover letter. I tried a professional resume writing service. I tried responding to calls from telemarketers.
I tried using a staffing agency that wrote a bogus resume filled with lies in order to make it seem like I had 10 years of experience with many different tasks. This got me several interviews a week. This didn't get me a job, but it gave me practice for when I finally got an interview for real. I wouldn't recommend this, but I didn't know their tactics until an interviewer showed me the resume that was being used.
I eventually got a job from a telemarketer. But to prevent them from wasting my time, I told every telemarketer upfront that I have no experience and no interest in relocating. Once they got me an interview, it was very easy to answer their questions after all the bogus interviews that I did.
10 notes
·
View notes