#Data Visualization using Matplotlib
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has 16.74 million mobile monthly users in the US.
Text
the inevitable tension between:
In an effort to demystify programming, which many people still think of as a skill that requires some sort of exceptional intelligence or training, I will always emphasize that basically anyone can do simple programming tasks like creating their own browser extension or simple website, using SQL to query a database, making data visualizations with matplotlib, etc. You can learn to do this in a week. If you're not sure you can for real just ask me (dm here or on Discord). it IS easy and anyone CAN do it! This isn't me saying "learn to code to get a job," which used to be decent advice 5 years ago but isn't any more because of AI and market saturation. More just "if there is something you want to do, at work or as a personal thing, that requires programming skills you think you might not have, I bet you can do it anyway. Do it!"
Okay maybe the reason I think this way is because my dad was teaching me Java when I was literally 8 years old
103 notes
·
View notes
Text
instagram
Learning to code and becoming a data scientist without a background in computer science or mathematics is absolutely possible, but it will require dedication, time, and a structured approach. ✨👌🏻 🖐🏻Here’s a step-by-step guide to help you get started:
1. Start with the Basics:
- Begin by learning the fundamentals of programming. Choose a beginner-friendly programming language like Python, which is widely used in data science.
- Online platforms like Codecademy, Coursera, and Khan Academy offer interactive courses for beginners.
2. Learn Mathematics and Statistics:
- While you don’t need to be a mathematician, a solid understanding of key concepts like algebra, calculus, and statistics is crucial for data science.
- Platforms like Khan Academy and MIT OpenCourseWare provide free resources for learning math.
3. Online Courses and Tutorials:
- Enroll in online data science courses on platforms like Coursera, edX, Udacity, and DataCamp. Look for beginner-level courses that cover data analysis, visualization, and machine learning.
4. Structured Learning Paths:
- Follow structured learning paths offered by online platforms. These paths guide you through various topics in a logical sequence.
5. Practice with Real Data:
- Work on hands-on projects using real-world data. Websites like Kaggle offer datasets and competitions for practicing data analysis and machine learning.
6. Coding Exercises:
- Practice coding regularly to build your skills. Sites like LeetCode and HackerRank offer coding challenges that can help improve your programming proficiency.
7. Learn Data Manipulation and Analysis Libraries:
- Familiarize yourself with Python libraries like NumPy, pandas, and Matplotlib for data manipulation, analysis, and visualization.
For more follow me on instagram.
#studyblr#100 days of productivity#stem academia#women in stem#study space#study motivation#dark academia#classic academia#academic validation#academia#academics#dark acadamia aesthetic#grey academia#light academia#romantic academia#chaotic academia#post grad life#grad student#graduate school#grad school#gradblr#stemblog#stem#stemblr#stem student#engineering college#engineering student#engineering#student life#study
7 notes
·
View notes
Text
Python for Beginners: Launch Your Tech Career with Coding Skills
Are you ready to launch your tech career but don’t know where to start? Learning Python is one of the best ways to break into the world of technology—even if you have zero coding experience.
In this guide, we’ll explore how Python for beginners can be your gateway to a rewarding career in software development, data science, automation, and more.
Why Python Is the Perfect Language for Beginners
Python has become the go-to programming language for beginners and professionals alike—and for good reason:
Simple syntax: Python reads like plain English, making it easy to learn.
High demand: Industries spanning the spectrum are actively seeking Python developers to fuel their technological advancements.
Versatile applications: Python's versatility shines as it powers everything from crafting websites to driving artificial intelligence and dissecting data.
Whether you want to become a software developer, data analyst, or AI engineer, Python lays the foundation.
What Can You Do With Python?
Python is not just a beginner language—it’s a career-building tool. Here are just a few career paths where Python is essential:
Web Development: Frameworks like Django and Flask make it easy to build powerful web applications. You can even enroll in a Python Course in Kochi to gain hands-on experience with real-world web projects.
Data Science & Analytics: For professionals tackling data analysis and visualization, the Python ecosystem, featuring powerhouses like Pandas, NumPy, and Matplotlib, sets the benchmark.
Machine Learning & AI: Spearheading advancements in artificial intelligence development, Python boasts powerful tools such as TensorFlow and scikit-learn.
Automation & Scripting: Simple yet effective Python scripts offer a pathway to amplified efficiency by automating routine workflows.
Cybersecurity & Networking: The application of Python is expanding into crucial domains such as ethical hacking, penetration testing, and the automation of network processes.
How to Get Started with Python
Starting your Python journey doesn't require a computer science degree. Success hinges on a focused commitment combined with a thoughtfully structured educational approach.
Step 1: Install Python
Download and install Python from python.org. It's free and available for all platforms.
Step 2: Choose an IDE
Use beginner-friendly tools like Thonny, PyCharm, or VS Code to write your code.
Step 3: Learn the Basics
Focus on:
Variables and data types
Conditional statements
Loops
Functions
Lists and dictionaries
If you prefer guided learning, a reputable Python Institute in Kochi can offer structured programs and mentorship to help you grasp core concepts efficiently.
Step 4: Build Projects
Learning by doing is key. Start small:
Build a calculator
Automate file organization
Create a to-do list app
As your skills grow, you can tackle more complex projects like data dashboards or web apps.
How Python Skills Can Boost Your Career
Adding Python to your resume instantly opens up new opportunities. Here's how it helps:
Higher employability: Python is one of the top 3 most in-demand programming languages.
Better salaries: Python developers earn competitive salaries across the globe.
Remote job opportunities: Many Python-related jobs are available remotely, offering flexibility.
Even if you're not aiming to be a full-time developer, Python skills can enhance careers in marketing, finance, research, and product management.
If you're serious about starting a career in tech, learning Python is the smartest first step you can take. It’s beginner-friendly, powerful, and widely used across industries.
Whether you're a student, job switcher, or just curious about programming, Python for beginners can unlock countless career opportunities. Invest time in learning today—and start building the future you want in tech.
Globally recognized as a premier educational hub, DataMites Institute delivers in-depth training programs across the pivotal fields of data science, artificial intelligence, and machine learning. They provide expert-led courses designed for both beginners and professionals aiming to boost their careers.
Python Modules Explained - Different Types and Functions - Python Tutorial
youtube
#python course#python training#python#learnpython#pythoncourseinindia#pythoncourseinkochi#pythoninstitute#python for data science#Youtube
3 notes
·
View notes
Note
hi! I love your blog. What programming languages would you recommend learning if you wanted to get into astrophysics? I already know c++, but I heard somewhere that python is better for data analysis?
I'm so sorry anon, I drafted an answer and then completely forgot to post it 😭😭😭
the main programming languages I've seen are c++ and python. there's also julia (new), and fortran (🥴).
so its great you already know c++! personally I've used athena++ code for simulations if you wanted a simulation code to play with.
but python would be good to play around with if you're not familiar, its great for visualization / data analysis! I started by learning the syntax and about packages like numpy, matplotlib, and astropy. "Python for Astronomers" may be helpful if you need a resource for learning, it has a free textbook and some tutorials. part of my undergrad computational astrophysics course could was based on it! another fun package is yt, you can look up "python yt cookbook" or click here. this website also gives you sample data from a simulation run and lots of tutorials.
julia is not as widely used but its supposed to have the intuitiveness of python with the performance/speed of c++. it's a newer language, like 10 years old. I've heard that there is a (very slow) shift to this language in the astrophysics community instead of python. I don't have any resources because I haven't gotten around to learning it yet 😅
fortran is an older language, I can't say I'm familiar with it. I've only encountered it in a skeleton simulation code a postdoc was developing (and I was testing the code) so I just know basic syntax. you'd probably be fine not learning it, unless you want to develop your own simulation code soon
I'm only a couple years into (theoretical) astrophysics research so if anyone else has input, please let me know!!
12 notes
·
View notes
Text
Python Libraries to Learn Before Tackling Data Analysis
To tackle data analysis effectively in Python, it's crucial to become familiar with several libraries that streamline the process of data manipulation, exploration, and visualization. Here's a breakdown of the essential libraries:
1. NumPy
- Purpose: Numerical computing.
- Why Learn It: NumPy provides support for large multi-dimensional arrays and matrices, along with a collection of mathematical functions to operate on these arrays efficiently.
- Key Features:
- Fast array processing.
- Mathematical operations on arrays (e.g., sum, mean, standard deviation).
- Linear algebra operations.
2. Pandas
- Purpose: Data manipulation and analysis.
- Why Learn It: Pandas offers data structures like DataFrames, making it easier to handle and analyze structured data.
- Key Features:
- Reading/writing data from CSV, Excel, SQL databases, and more.
- Handling missing data.
- Powerful group-by operations.
- Data filtering and transformation.
3. Matplotlib
- Purpose: Data visualization.
- Why Learn It: Matplotlib is one of the most widely used plotting libraries in Python, allowing for a wide range of static, animated, and interactive plots.
- Key Features:
- Line plots, bar charts, histograms, scatter plots.
- Customizable charts (labels, colors, legends).
- Integration with Pandas for quick plotting.
4. Seaborn
- Purpose: Statistical data visualization.
- Why Learn It: Built on top of Matplotlib, Seaborn simplifies the creation of attractive and informative statistical graphics.
- Key Features:
- High-level interface for drawing attractive statistical graphics.
- Easier to use for complex visualizations like heatmaps, pair plots, etc.
- Visualizations based on categorical data.
5. SciPy
- Purpose: Scientific and technical computing.
- Why Learn It: SciPy builds on NumPy and provides additional functionality for complex mathematical operations and scientific computing.
- Key Features:
- Optimized algorithms for numerical integration, optimization, and more.
- Statistics, signal processing, and linear algebra modules.
6. Scikit-learn
- Purpose: Machine learning and statistical modeling.
- Why Learn It: Scikit-learn provides simple and efficient tools for data mining, analysis, and machine learning.
- Key Features:
- Classification, regression, and clustering algorithms.
- Dimensionality reduction, model selection, and preprocessing utilities.
7. Statsmodels
- Purpose: Statistical analysis.
- Why Learn It: Statsmodels allows users to explore data, estimate statistical models, and perform tests.
- Key Features:
- Linear regression, logistic regression, time series analysis.
- Statistical tests and models for descriptive statistics.
8. Plotly
- Purpose: Interactive data visualization.
- Why Learn It: Plotly allows for the creation of interactive and web-based visualizations, making it ideal for dashboards and presentations.
- Key Features:
- Interactive plots like scatter, line, bar, and 3D plots.
- Easy integration with web frameworks.
- Dashboards and web applications with Dash.
9. TensorFlow/PyTorch (Optional)
- Purpose: Machine learning and deep learning.
- Why Learn It: If your data analysis involves machine learning, these libraries will help in building, training, and deploying deep learning models.
- Key Features:
- Tensor processing and automatic differentiation.
- Building neural networks.
10. Dask (Optional)
- Purpose: Parallel computing for data analysis.
- Why Learn It: Dask enables scalable data manipulation by parallelizing Pandas operations, making it ideal for big datasets.
- Key Features:
- Works with NumPy, Pandas, and Scikit-learn.
- Handles large data and parallel computations easily.
Focusing on NumPy, Pandas, Matplotlib, and Seaborn will set a strong foundation for basic data analysis.
8 notes
·
View notes
Text
Unlocking the Power of Data: Essential Skills to Become a Data Scientist

In today's data-driven world, the demand for skilled data scientists is skyrocketing. These professionals are the key to transforming raw information into actionable insights, driving innovation and shaping business strategies. But what exactly does it take to become a data scientist? It's a multidisciplinary field, requiring a unique blend of technical prowess and analytical thinking. Let's break down the essential skills you'll need to embark on this exciting career path.
1. Strong Mathematical and Statistical Foundation:
At the heart of data science lies a deep understanding of mathematics and statistics. You'll need to grasp concepts like:
Linear Algebra and Calculus: Essential for understanding machine learning algorithms and optimizing models.
Probability and Statistics: Crucial for data analysis, hypothesis testing, and drawing meaningful conclusions from data.
2. Programming Proficiency (Python and/or R):
Data scientists are fluent in at least one, if not both, of the dominant programming languages in the field:
Python: Known for its readability and extensive libraries like Pandas, NumPy, Scikit-learn, and TensorFlow, making it ideal for data manipulation, analysis, and machine learning.
R: Specifically designed for statistical computing and graphics, R offers a rich ecosystem of packages for statistical modeling and visualization.
3. Data Wrangling and Preprocessing Skills:
Raw data is rarely clean and ready for analysis. A significant portion of a data scientist's time is spent on:
Data Cleaning: Handling missing values, outliers, and inconsistencies.
Data Transformation: Reshaping, merging, and aggregating data.
Feature Engineering: Creating new features from existing data to improve model performance.
4. Expertise in Databases and SQL:
Data often resides in databases. Proficiency in SQL (Structured Query Language) is essential for:
Extracting Data: Querying and retrieving data from various database systems.
Data Manipulation: Filtering, joining, and aggregating data within databases.
5. Machine Learning Mastery:
Machine learning is a core component of data science, enabling you to build models that learn from data and make predictions or classifications. Key areas include:
Supervised Learning: Regression, classification algorithms.
Unsupervised Learning: Clustering, dimensionality reduction.
Model Selection and Evaluation: Choosing the right algorithms and assessing their performance.
6. Data Visualization and Communication Skills:
Being able to effectively communicate your findings is just as important as the analysis itself. You'll need to:
Visualize Data: Create compelling charts and graphs to explore patterns and insights using libraries like Matplotlib, Seaborn (Python), or ggplot2 (R).
Tell Data Stories: Present your findings in a clear and concise manner that resonates with both technical and non-technical audiences.
7. Critical Thinking and Problem-Solving Abilities:
Data scientists are essentially problem solvers. You need to be able to:
Define Business Problems: Translate business challenges into data science questions.
Develop Analytical Frameworks: Structure your approach to solve complex problems.
Interpret Results: Draw meaningful conclusions and translate them into actionable recommendations.
8. Domain Knowledge (Optional but Highly Beneficial):
Having expertise in the specific industry or domain you're working in can give you a significant advantage. It helps you understand the context of the data and formulate more relevant questions.
9. Curiosity and a Growth Mindset:
The field of data science is constantly evolving. A genuine curiosity and a willingness to learn new technologies and techniques are crucial for long-term success.
10. Strong Communication and Collaboration Skills:
Data scientists often work in teams and need to collaborate effectively with engineers, business stakeholders, and other experts.
Kickstart Your Data Science Journey with Xaltius Academy's Data Science and AI Program:
Acquiring these skills can seem like a daunting task, but structured learning programs can provide a clear and effective path. Xaltius Academy's Data Science and AI Program is designed to equip you with the essential knowledge and practical experience to become a successful data scientist.
Key benefits of the program:
Comprehensive Curriculum: Covers all the core skills mentioned above, from foundational mathematics to advanced machine learning techniques.
Hands-on Projects: Provides practical experience working with real-world datasets and building a strong portfolio.
Expert Instructors: Learn from industry professionals with years of experience in data science and AI.
Career Support: Offers guidance and resources to help you launch your data science career.
Becoming a data scientist is a rewarding journey that blends technical expertise with analytical thinking. By focusing on developing these key skills and leveraging resources like Xaltius Academy's program, you can position yourself for a successful and impactful career in this in-demand field. The power of data is waiting to be unlocked – are you ready to take the challenge?
3 notes
·
View notes
Text
Why Python Will Thrive: Future Trends and Applications
Python has already made a significant impact in the tech world, and its trajectory for the future is even more promising. From its simplicity and versatility to its widespread use in cutting-edge technologies, Python is expected to continue thriving in the coming years. Considering the kind support of Python Course in Chennai Whatever your level of experience or reason for switching from another programming language, learning Python gets much more fun.

Let's explore why Python will remain at the forefront of software development and what trends and applications will contribute to its ongoing dominance.
1. Artificial Intelligence and Machine Learning
Python is already the go-to language for AI and machine learning, and its role in these fields is set to expand further. With powerful libraries such as TensorFlow, PyTorch, and Scikit-learn, Python simplifies the development of machine learning models and artificial intelligence applications. As more industries integrate AI for automation, personalization, and predictive analytics, Python will remain a core language for developing intelligent systems.
2. Data Science and Big Data
Data science is one of the most significant areas where Python has excelled. Libraries like Pandas, NumPy, and Matplotlib make data manipulation and visualization simple and efficient. As companies and organizations continue to generate and analyze vast amounts of data, Python’s ability to process, clean, and visualize big data will only become more critical. Additionally, Python’s compatibility with big data platforms like Hadoop and Apache Spark ensures that it will remain a major player in data-driven decision-making.
3. Web Development
Python’s role in web development is growing thanks to frameworks like Django and Flask, which provide robust, scalable, and secure solutions for building web applications. With the increasing demand for interactive websites and APIs, Python is well-positioned to continue serving as a top language for backend development. Its integration with cloud computing platforms will also fuel its growth in building modern web applications that scale efficiently.
4. Automation and Scripting
Automation is another area where Python excels. Developers use Python to automate tasks ranging from system administration to testing and deployment. With the rise of DevOps practices and the growing demand for workflow automation, Python’s role in streamlining repetitive processes will continue to grow. Businesses across industries will rely on Python to boost productivity, reduce errors, and optimize performance. With the aid of Best Online Training & Placement Programs, which offer comprehensive training and job placement support to anyone looking to develop their talents, it’s easier to learn this tool and advance your career.

5. Cybersecurity and Ethical Hacking
With cyber threats becoming increasingly sophisticated, cybersecurity is a critical concern for businesses worldwide. Python is widely used for penetration testing, vulnerability scanning, and threat detection due to its simplicity and effectiveness. Libraries like Scapy and PyCrypto make Python an excellent choice for ethical hacking and security professionals. As the need for robust cybersecurity measures increases, Python’s role in safeguarding digital assets will continue to thrive.
6. Internet of Things (IoT)
Python’s compatibility with microcontrollers and embedded systems makes it a strong contender in the growing field of IoT. Frameworks like MicroPython and CircuitPython enable developers to build IoT applications efficiently, whether for home automation, smart cities, or industrial systems. As the number of connected devices continues to rise, Python will remain a dominant language for creating scalable and reliable IoT solutions.
7. Cloud Computing and Serverless Architectures
The rise of cloud computing and serverless architectures has created new opportunities for Python. Cloud platforms like AWS, Google Cloud, and Microsoft Azure all support Python, allowing developers to build scalable and cost-efficient applications. With its flexibility and integration capabilities, Python is perfectly suited for developing cloud-based applications, serverless functions, and microservices.
8. Gaming and Virtual Reality
Python has long been used in game development, with libraries such as Pygame offering simple tools to create 2D games. However, as gaming and virtual reality (VR) technologies evolve, Python’s role in developing immersive experiences will grow. The language’s ease of use and integration with game engines will make it a popular choice for building gaming platforms, VR applications, and simulations.
9. Expanding Job Market
As Python’s applications continue to grow, so does the demand for Python developers. From startups to tech giants like Google, Facebook, and Amazon, companies across industries are seeking professionals who are proficient in Python. The increasing adoption of Python in various fields, including data science, AI, cybersecurity, and cloud computing, ensures a thriving job market for Python developers in the future.
10. Constant Evolution and Community Support
Python’s open-source nature means that it’s constantly evolving with new libraries, frameworks, and features. Its vibrant community of developers contributes to its growth and ensures that Python stays relevant to emerging trends and technologies. Whether it’s a new tool for AI or a breakthrough in web development, Python’s community is always working to improve the language and make it more efficient for developers.
Conclusion
Python’s future is bright, with its presence continuing to grow in AI, data science, automation, web development, and beyond. As industries become increasingly data-driven, automated, and connected, Python’s simplicity, versatility, and strong community support make it an ideal choice for developers. Whether you are a beginner looking to start your coding journey or a seasoned professional exploring new career opportunities, learning Python offers long-term benefits in a rapidly evolving tech landscape.
#python course#python training#python#technology#tech#python programming#python online training#python online course#python online classes#python certification
2 notes
·
View notes
Text
stream of consciousness about the new animation vs. coding episode, as a python programmer
holy shit, my increasingly exciting reaction as i realized that yellow was writing in PYTHON. i write in python. it's the programming language that i used in school and current use in work.
i was kinda expecting a print("hello world") but that's fine
i think using python to demonstrate coding was a practical choice. it's one of the most commonly used programming languages and it's very human readable.
the episode wasn't able to cram every possible concept in programming, of course, but they got a lot of them!
fun stuff like print() not outputting anything and typecasting between string values and integer values!!
string manipulation
booleans
little things like for-loops and while-loops for iterating over a string or list. and indexing! yay :D
* iterable input :D (the *bomb that got thrown at yellow)
and then they started importing libraries! i've never seen the turtle library but it seems like it draws vectors based on the angle you input into a function
the gun list ran out of "bullets" because it kept removing them from the list gun.pop()
AND THEN THE DATA VISUALIZATION. matplotlib!! numpy!!!! my beloved!!!!!!!! i work in data so this!!!! this!!!!! somehow really validating to me to see my favorite animated web series play with data. i think it's also a nice touch that the blue on the bars appear to be the matplotlib default blue. the plot formatting is accurate too!!!
haven't really used pygame either but making shapes and making them move based on arrow key input makes sense
i recall that yellow isn't the physically strongest, but it's cool to see them move around in space and i'm focusing on how they move and figure out the world.
nuke?!
and back to syntax error and then commenting it out # made it go away
cool nuke text motion graphics too :D (i don't think i make that motion in python, personally)
and then yellow cranks it to 100,000 to make a neural network in pytorch. this gets into nlp (tokenizers and other modeling)
a CLASS? we touch on some object oriented programming here but we just see the __init__ function so not the full concept is demonstrated here.
OH! the "hello world" got broken down into tokens. that's why we see the "hello world" string turn into numbers and then... bits (the 0s and 1s)? the strings are tokenized/turned into values that the model can interpret. it's trying to understand written human language
and then an LSTM?! (long short-term memory)
something something feed-forward neural network
model training (hence the epochs and increasing accuracy)
honestly, the scrolling through the code goes so fast, i had to do a second look through (i'm also not very deeply versed in implementing neural networks but i have learned about them in school)
and all of this to send "hello world" to an AI(?) recreation of the exploded laptop
not too bad for a macbook user lol
i'm just kidding, a major of people used macs in my classes
things i wanna do next since im so hyped
i haven't drawn for the fandom in a long time, but i feel a little motivated to draw my design of yellow again. i don't recall the episode using object oriented programming, but i kinda want to make a very simple example where the code is an initialization of a stick figure object and the instances are each of the color gang.
it wouldn't be full blown AI, but it's just me writing in everyone's personality traits and colors into a function, essentially since each stick figure is an individual program.
#animator vs animation#ava#yellow ava#ava yellow#long post#thank you if you took the time to read lol
5 notes
·
View notes
Text
What Are the Qualifications for a Data Scientist?
In today's data-driven world, the role of a data scientist has become one of the most coveted career paths. With businesses relying on data for decision-making, understanding customer behavior, and improving products, the demand for skilled professionals who can analyze, interpret, and extract value from data is at an all-time high. If you're wondering what qualifications are needed to become a successful data scientist, how DataCouncil can help you get there, and why a data science course in Pune is a great option, this blog has the answers.
The Key Qualifications for a Data Scientist
To succeed as a data scientist, a mix of technical skills, education, and hands-on experience is essential. Here are the core qualifications required:
1. Educational Background
A strong foundation in mathematics, statistics, or computer science is typically expected. Most data scientists hold at least a bachelor’s degree in one of these fields, with many pursuing higher education such as a master's or a Ph.D. A data science course in Pune with DataCouncil can bridge this gap, offering the academic and practical knowledge required for a strong start in the industry.
2. Proficiency in Programming Languages
Programming is at the heart of data science. You need to be comfortable with languages like Python, R, and SQL, which are widely used for data analysis, machine learning, and database management. A comprehensive data science course in Pune will teach these programming skills from scratch, ensuring you become proficient in coding for data science tasks.
3. Understanding of Machine Learning
Data scientists must have a solid grasp of machine learning techniques and algorithms such as regression, clustering, and decision trees. By enrolling in a DataCouncil course, you'll learn how to implement machine learning models to analyze data and make predictions, an essential qualification for landing a data science job.
4. Data Wrangling Skills
Raw data is often messy and unstructured, and a good data scientist needs to be adept at cleaning and processing data before it can be analyzed. DataCouncil's data science course in Pune includes practical training in tools like Pandas and Numpy for effective data wrangling, helping you develop a strong skill set in this critical area.
5. Statistical Knowledge
Statistical analysis forms the backbone of data science. Knowledge of probability, hypothesis testing, and statistical modeling allows data scientists to draw meaningful insights from data. A structured data science course in Pune offers the theoretical and practical aspects of statistics required to excel.
6. Communication and Data Visualization Skills
Being able to explain your findings in a clear and concise manner is crucial. Data scientists often need to communicate with non-technical stakeholders, making tools like Tableau, Power BI, and Matplotlib essential for creating insightful visualizations. DataCouncil’s data science course in Pune includes modules on data visualization, which can help you present data in a way that’s easy to understand.
7. Domain Knowledge
Apart from technical skills, understanding the industry you work in is a major asset. Whether it’s healthcare, finance, or e-commerce, knowing how data applies within your industry will set you apart from the competition. DataCouncil's data science course in Pune is designed to offer case studies from multiple industries, helping students gain domain-specific insights.
Why Choose DataCouncil for a Data Science Course in Pune?
If you're looking to build a successful career as a data scientist, enrolling in a data science course in Pune with DataCouncil can be your first step toward reaching your goals. Here’s why DataCouncil is the ideal choice:
Comprehensive Curriculum: The course covers everything from the basics of data science to advanced machine learning techniques.
Hands-On Projects: You'll work on real-world projects that mimic the challenges faced by data scientists in various industries.
Experienced Faculty: Learn from industry professionals who have years of experience in data science and analytics.
100% Placement Support: DataCouncil provides job assistance to help you land a data science job in Pune or anywhere else, making it a great investment in your future.
Flexible Learning Options: With both weekday and weekend batches, DataCouncil ensures that you can learn at your own pace without compromising your current commitments.
Conclusion
Becoming a data scientist requires a combination of technical expertise, analytical skills, and industry knowledge. By enrolling in a data science course in Pune with DataCouncil, you can gain all the qualifications you need to thrive in this exciting field. Whether you're a fresher looking to start your career or a professional wanting to upskill, this course will equip you with the knowledge, skills, and practical experience to succeed as a data scientist.
Explore DataCouncil’s offerings today and take the first step toward unlocking a rewarding career in data science! Looking for the best data science course in Pune? DataCouncil offers comprehensive data science classes in Pune, designed to equip you with the skills to excel in this booming field. Our data science course in Pune covers everything from data analysis to machine learning, with competitive data science course fees in Pune. We provide job-oriented programs, making us the best institute for data science in Pune with placement support. Explore online data science training in Pune and take your career to new heights!
#In today's data-driven world#the role of a data scientist has become one of the most coveted career paths. With businesses relying on data for decision-making#understanding customer behavior#and improving products#the demand for skilled professionals who can analyze#interpret#and extract value from data is at an all-time high. If you're wondering what qualifications are needed to become a successful data scientis#how DataCouncil can help you get there#and why a data science course in Pune is a great option#this blog has the answers.#The Key Qualifications for a Data Scientist#To succeed as a data scientist#a mix of technical skills#education#and hands-on experience is essential. Here are the core qualifications required:#1. Educational Background#A strong foundation in mathematics#statistics#or computer science is typically expected. Most data scientists hold at least a bachelor’s degree in one of these fields#with many pursuing higher education such as a master's or a Ph.D. A data science course in Pune with DataCouncil can bridge this gap#offering the academic and practical knowledge required for a strong start in the industry.#2. Proficiency in Programming Languages#Programming is at the heart of data science. You need to be comfortable with languages like Python#R#and SQL#which are widely used for data analysis#machine learning#and database management. A comprehensive data science course in Pune will teach these programming skills from scratch#ensuring you become proficient in coding for data science tasks.#3. Understanding of Machine Learning
3 notes
·
View notes
Text
AI Frameworks Help Data Scientists For GenAI Survival

AI Frameworks: Crucial to the Success of GenAI
Develop Your AI Capabilities Now
You play a crucial part in the quickly growing field of generative artificial intelligence (GenAI) as a data scientist. Your proficiency in data analysis, modeling, and interpretation is still essential, even though platforms like Hugging Face and LangChain are at the forefront of AI research.
Although GenAI systems are capable of producing remarkable outcomes, they still mostly depend on clear, organized data and perceptive interpretation areas in which data scientists are highly skilled. You can direct GenAI models to produce more precise, useful predictions by applying your in-depth knowledge of data and statistical techniques. In order to ensure that GenAI systems are based on strong, data-driven foundations and can realize their full potential, your job as a data scientist is crucial. Here’s how to take the lead:
Data Quality Is Crucial
The effectiveness of even the most sophisticated GenAI models depends on the quality of the data they use. By guaranteeing that the data is relevant, AI tools like Pandas and Modin enable you to clean, preprocess, and manipulate large datasets.
Analysis and Interpretation of Exploratory Data
It is essential to comprehend the features and trends of the data before creating the models. Data and model outputs are visualized via a variety of data science frameworks, like Matplotlib and Seaborn, which aid developers in comprehending the data, selecting features, and interpreting the models.
Model Optimization and Evaluation
A variety of algorithms for model construction are offered by AI frameworks like scikit-learn, PyTorch, and TensorFlow. To improve models and their performance, they provide a range of techniques for cross-validation, hyperparameter optimization, and performance evaluation.
Model Deployment and Integration
Tools such as ONNX Runtime and MLflow help with cross-platform deployment and experimentation tracking. By guaranteeing that the models continue to function successfully in production, this helps the developers oversee their projects from start to finish.
Intel’s Optimized AI Frameworks and Tools
The technologies that developers are already familiar with in data analytics, machine learning, and deep learning (such as Modin, NumPy, scikit-learn, and PyTorch) can be used. For the many phases of the AI process, such as data preparation, model training, inference, and deployment, Intel has optimized the current AI tools and AI frameworks, which are based on a single, open, multiarchitecture, multivendor software platform called oneAPI programming model.
Data Engineering and Model Development:
To speed up end-to-end data science pipelines on Intel architecture, use Intel’s AI Tools, which include Python tools and frameworks like Modin, Intel Optimization for TensorFlow Optimizations, PyTorch Optimizations, IntelExtension for Scikit-learn, and XGBoost.
Optimization and Deployment
For CPU or GPU deployment, Intel Neural Compressor speeds up deep learning inference and minimizes model size. Models are optimized and deployed across several hardware platforms including Intel CPUs using the OpenVINO toolbox.
You may improve the performance of your Intel hardware platforms with the aid of these AI tools.
Library of Resources
Discover collection of excellent, professionally created, and thoughtfully selected resources that are centered on the core data science competencies that developers need. Exploring machine and deep learning AI frameworks.
What you will discover:
Use Modin to expedite the extract, transform, and load (ETL) process for enormous DataFrames and analyze massive datasets.
To improve speed on Intel hardware, use Intel’s optimized AI frameworks (such as Intel Optimization for XGBoost, Intel Extension for Scikit-learn, Intel Optimization for PyTorch, and Intel Optimization for TensorFlow).
Use Intel-optimized software on the most recent Intel platforms to implement and deploy AI workloads on Intel Tiber AI Cloud.
How to Begin
Frameworks for Data Engineering and Machine Learning
Step 1: View the Modin, Intel Extension for Scikit-learn, and Intel Optimization for XGBoost videos and read the introductory papers.
Modin: To achieve a quicker turnaround time overall, the video explains when to utilize Modin and how to apply Modin and Pandas judiciously. A quick start guide for Modin is also available for more in-depth information.
Scikit-learn Intel Extension: This tutorial gives you an overview of the extension, walks you through the code step-by-step, and explains how utilizing it might improve performance. A movie on accelerating silhouette machine learning techniques, PCA, and K-means clustering is also available.
Intel Optimization for XGBoost: This straightforward tutorial explains Intel Optimization for XGBoost and how to use Intel optimizations to enhance training and inference performance.
Step 2: Use Intel Tiber AI Cloud to create and develop machine learning workloads.
On Intel Tiber AI Cloud, this tutorial runs machine learning workloads with Modin, scikit-learn, and XGBoost.
Step 3: Use Modin and scikit-learn to create an end-to-end machine learning process using census data.
Run an end-to-end machine learning task using 1970–2010 US census data with this code sample. The code sample uses the Intel Extension for Scikit-learn module to analyze exploratory data using ridge regression and the Intel Distribution of Modin.
Deep Learning Frameworks
Step 4: Begin by watching the videos and reading the introduction papers for Intel’s PyTorch and TensorFlow optimizations.
Intel PyTorch Optimizations: Read the article to learn how to use the Intel Extension for PyTorch to accelerate your workloads for inference and training. Additionally, a brief video demonstrates how to use the addon to run PyTorch inference on an Intel Data Center GPU Flex Series.
Intel’s TensorFlow Optimizations: The article and video provide an overview of the Intel Extension for TensorFlow and demonstrate how to utilize it to accelerate your AI tasks.
Step 5: Use TensorFlow and PyTorch for AI on the Intel Tiber AI Cloud.
In this article, it show how to use PyTorch and TensorFlow on Intel Tiber AI Cloud to create and execute complicated AI workloads.
Step 6: Speed up LSTM text creation with Intel Extension for TensorFlow.
The Intel Extension for TensorFlow can speed up LSTM model training for text production.
Step 7: Use PyTorch and DialoGPT to create an interactive chat-generation model.
Discover how to use Hugging Face’s pretrained DialoGPT model to create an interactive chat model and how to use the Intel Extension for PyTorch to dynamically quantize the model.
Read more on Govindhtech.com
#AI#AIFrameworks#DataScientists#GenAI#PyTorch#GenAISurvival#TensorFlow#CPU#GPU#IntelTiberAICloud#News#Technews#Technology#Technologynews#Technologytrends#govindhtech
2 notes
·
View notes
Text
The Skills I Acquired on My Path to Becoming a Data Scientist
Data science has emerged as one of the most sought-after fields in recent years, and my journey into this exciting discipline has been nothing short of transformative. As someone with a deep curiosity for extracting insights from data, I was naturally drawn to the world of data science. In this blog post, I will share the skills I acquired on my path to becoming a data scientist, highlighting the importance of a diverse skill set in this field.
The Foundation — Mathematics and Statistics
At the core of data science lies a strong foundation in mathematics and statistics. Concepts such as probability, linear algebra, and statistical inference form the building blocks of data analysis and modeling. Understanding these principles is crucial for making informed decisions and drawing meaningful conclusions from data. Throughout my learning journey, I immersed myself in these mathematical concepts, applying them to real-world problems and honing my analytical skills.
Programming Proficiency
Proficiency in programming languages like Python or R is indispensable for a data scientist. These languages provide the tools and frameworks necessary for data manipulation, analysis, and modeling. I embarked on a journey to learn these languages, starting with the basics and gradually advancing to more complex concepts. Writing efficient and elegant code became second nature to me, enabling me to tackle large datasets and build sophisticated models.
Data Handling and Preprocessing
Working with real-world data is often messy and requires careful handling and preprocessing. This involves techniques such as data cleaning, transformation, and feature engineering. I gained valuable experience in navigating the intricacies of data preprocessing, learning how to deal with missing values, outliers, and inconsistent data formats. These skills allowed me to extract valuable insights from raw data and lay the groundwork for subsequent analysis.
Data Visualization and Communication
Data visualization plays a pivotal role in conveying insights to stakeholders and decision-makers. I realized the power of effective visualizations in telling compelling stories and making complex information accessible. I explored various tools and libraries, such as Matplotlib and Tableau, to create visually appealing and informative visualizations. Sharing these visualizations with others enhanced my ability to communicate data-driven insights effectively.

Machine Learning and Predictive Modeling
Machine learning is a cornerstone of data science, enabling us to build predictive models and make data-driven predictions. I delved into the realm of supervised and unsupervised learning, exploring algorithms such as linear regression, decision trees, and clustering techniques. Through hands-on projects, I gained practical experience in building models, fine-tuning their parameters, and evaluating their performance.
Database Management and SQL
Data science often involves working with large datasets stored in databases. Understanding database management and SQL (Structured Query Language) is essential for extracting valuable information from these repositories. I embarked on a journey to learn SQL, mastering the art of querying databases, joining tables, and aggregating data. These skills allowed me to harness the power of databases and efficiently retrieve the data required for analysis.

Domain Knowledge and Specialization
While technical skills are crucial, domain knowledge adds a unique dimension to data science projects. By specializing in specific industries or domains, data scientists can better understand the context and nuances of the problems they are solving. I explored various domains and acquired specialized knowledge, whether it be healthcare, finance, or marketing. This expertise complemented my technical skills, enabling me to provide insights that were not only data-driven but also tailored to the specific industry.
Soft Skills — Communication and Problem-Solving
In addition to technical skills, soft skills play a vital role in the success of a data scientist. Effective communication allows us to articulate complex ideas and findings to non-technical stakeholders, bridging the gap between data science and business. Problem-solving skills help us navigate challenges and find innovative solutions in a rapidly evolving field. Throughout my journey, I honed these skills, collaborating with teams, presenting findings, and adapting my approach to different audiences.
Continuous Learning and Adaptation
Data science is a field that is constantly evolving, with new tools, technologies, and trends emerging regularly. To stay at the forefront of this ever-changing landscape, continuous learning is essential. I dedicated myself to staying updated by following industry blogs, attending conferences, and participating in courses. This commitment to lifelong learning allowed me to adapt to new challenges, acquire new skills, and remain competitive in the field.
In conclusion, the journey to becoming a data scientist is an exciting and dynamic one, requiring a diverse set of skills. From mathematics and programming to data handling and communication, each skill plays a crucial role in unlocking the potential of data. Aspiring data scientists should embrace this multidimensional nature of the field and embark on their own learning journey. If you want to learn more about Data science, I highly recommend that you contact ACTE Technologies because they offer Data Science courses and job placement opportunities. Experienced teachers can help you learn better. You can find these services both online and offline. Take things step by step and consider enrolling in a course if you’re interested. By acquiring these skills and continuously adapting to new developments, they can make a meaningful impact in the world of data science.
#data science#data visualization#education#information#technology#machine learning#database#sql#predictive analytics#r programming#python#big data#statistics
14 notes
·
View notes
Text
How do I learn R, Python and data science?
Learning R, Python, and Data Science: A Comprehensive Guide
Choosing the Right Language
R vs. Python: Both R and Python are very powerful tools for doing data science. R is usually preferred for doing statistical analysis and data visualisations, whereas Python is much more general and currently is very popular for machine learning and general-purpose programming. Your choice of which language to learn should consider your specific goals and preferences.
Building a Strong Foundation
Structured Courses Online Courses and Tutorials: Coursera, edX, and Lejhro offer courses and tutorials in R and Python for data science. Look out for courses that develop theoretical knowledge with practical exercises. Practise your skills with hands-on coding challenges using accompanying datasets, offered on websites like Kaggle and DataCamp.
Books: There are enough books to learn R and Python for data science. You may go through the classical ones: "R for Data Science" by Hadley Wickham, and "Python for Data Analysis" by Wes McKinney.
Learning Data Science Concepts
Statistics: Know basic statistical concepts: probability, distribution, hypothesis testing, and regression analysis.
Cleaning and Preprocessing: Learn how to handle missing data techniques, outliers, and data normalisation.
Data Visualization: Expert libraries to provide informative visualisations, including but not limited to Matplotlib and Seaborn in Python and ggplot2 in R.
Machine Learning: Learn algorithms-Linear Regression, Logistic Regression, Decision Trees, Random Forest, Neural Networks, etc.
Deep Learning: Study deep neural network architecture and how to build and train them using the frameworks TensorFlow and PyTorch.
Practical Experience
Personal Projects: In this, you apply your knowledge to personal projects which help in building a portfolio.
Kaggle Competitions: Participate in Kaggle competitions to solve real-world problems in data science and learn from others.
Contributions to Open-Source Projects: Contribute to some open-source projects for data science in order to gain experience and work with other people.
Other Advice
Join Online Communities: Join online forums or communities such as Stack Overflow and Reddit to ask questions, get help, and connect with other data scientists.
Attend Conferences and Meetups: This is a fantastic way to network with similar working professionals in the field and know the latest trends going on in the industry.
Practice Regularly: For becoming proficient in data science, consistent practice is an indispensable element. Devote some time each day for practising coding challenges or personal projects.
This can be achieved by following the above-mentioned steps and having a little bit of dedication towards learning R, Python, and Data Science.
2 notes
·
View notes
Text
Is it possible to transition to a data scientist from a non-tech background at the age of 28?
Hi,
You can certainly shift to become a data scientist from a nontechnical background at 28. As a matter of fact, very many do. Most data scientists have actually shifted to this field from different academic and professional backgrounds, with some of them having changed careers even in their midlife years.

Build a Strong Foundation:
Devour some of the core knowledge about statistics, programming, and data analysis. Online classes, bootcamps—those are good and many, many convenient resources. Give it a whirl with Coursera and Lejhro for specific courses related to data science, machine learning and programming languages like Python and R.
A data scientist needs to be proficient in at least one or two programming languages. Python is the most used language for data science, for it is simple, and it has many libraries. R is another language that might come in handy for a data scientist, mostly in cases connected with statistical analysis. The study of manipulation libraries for study data and visualization tools includes Pandas for Python and Matplotlib and Seaborn for data, respectively.
Develop Analytical Skills:
The field of data science includes much analytics and statistics. Probability, hypothesis testing, regression analysis would be essential. These skills will help you derive meaningful information out of the data and also allow you to use statistical methods for real-world problems.
Practical experience is very important in the field of data science. In order to gain experience, one might work on personal projects or contribute to open-source projects in the same field. For instance, data analysis on publicly available datasets, machine learning, and creating models to solve particular problems, all these steps help to make the field more aware of skills with one's profile.
Though formal education in data science is by no means a requirement, earning a degree or certification in the discipline you are considering gives you great credibility. Many reputed universities and institutions offer courses on data science, machine learning, and analytics.
Connect with professionals in the same field: try to be part of communities around data science and attend events as well. You would be able to find these opportunities through networking and mentoring on platforms like LinkedIn, Kaggle, and local meetups. This will keep you abreast of the latest developments in this exciting area of research and help you land job opportunities while getting support.
Look out for entry-level job opportunities or internships in the field of data science; this, in effect, would be a great way to exercise your acquired experience so far. Such positions will easily expose one to a real-world problem related to data and allow seizing the occasion to develop practical skills. These might be entry-level positions, such as data analysts or junior data scientists, to begin with.
Stay Current with Industry Trends: Data science keeps on evolving with new techniques, tools, and technologies. Keep up to date with the latest trends and developments in the industry by reading blogs and research papers online and through courses.
Conclusion:
It is definitely possible to move into a data scientist role if one belongs to a non-tech profile and is eyeing this target at the age of 28. Proper approach in building the base of strong, relevant skills, gaining practical experience, and networking with industry professionals helps a lot in being successful in the transition. This is because data science as a field is more about skills and the ability to solve problems, which opens its doors to people from different backgrounds.
#bootcamp#data science course#datascience#python#big data#machinelearning#data analytics#ai#data privacy
3 notes
·
View notes
Text
Essential Skills for Aspiring Data Scientists in 2024

Welcome to another edition of Tech Insights! Today, we're diving into the essential skills that aspiring data scientists need to master in 2024. As the field of data science continues to evolve, staying updated with the latest skills and tools is crucial for success. Here are the key areas to focus on:
1. Programming Proficiency
Proficiency in programming languages like Python and R is foundational. Python, in particular, is widely used for data manipulation, analysis, and building machine learning models thanks to its rich ecosystem of libraries such as Pandas, NumPy, and Scikit-learn.
2. Statistical Analysis
A strong understanding of statistics is essential for data analysis and interpretation. Key concepts include probability distributions, hypothesis testing, and regression analysis, which help in making informed decisions based on data.
3. Machine Learning Mastery
Knowledge of machine learning algorithms and frameworks like TensorFlow, Keras, and PyTorch is critical. Understanding supervised and unsupervised learning, neural networks, and deep learning will set you apart in the field.
4. Data Wrangling Skills
The ability to clean, process, and transform data is crucial. Skills in using libraries like Pandas and tools like SQL for database management are highly valuable for preparing data for analysis.
5. Data Visualization
Effective communication of your findings through data visualization is important. Tools like Tableau, Power BI, and libraries like Matplotlib and Seaborn in Python can help you create impactful visualizations.
6. Big Data Technologies
Familiarity with big data tools like Hadoop, Spark, and NoSQL databases is beneficial, especially for handling large datasets. These tools help in processing and analyzing big data efficiently.
7. Domain Knowledge
Understanding the specific domain you are working in (e.g., finance, healthcare, e-commerce) can significantly enhance your analytical insights and make your solutions more relevant and impactful.
8. Soft Skills
Strong communication skills, problem-solving abilities, and teamwork are essential for collaborating with stakeholders and effectively conveying your findings.
Final Thoughts
The field of data science is ever-changing, and staying ahead requires continuous learning and adaptation. By focusing on these key skills, you'll be well-equipped to navigate the challenges and opportunities that 2024 brings.
If you're looking for more in-depth resources, tips, and articles on data science and machine learning, be sure to follow Tech Insights for regular updates. Let's continue to explore the fascinating world of technology together!
#artificial intelligence#programming#coding#python#success#economy#career#education#employment#opportunity#working#jobs
2 notes
·
View notes
Text
UNLOCKING THE POWER OF AI WITH EASYLIBPAL 2/2

EXPANDED COMPONENTS AND DETAILS OF EASYLIBPAL:
1. Easylibpal Class: The core component of the library, responsible for handling algorithm selection, model fitting, and prediction generation
2. Algorithm Selection and Support:
Supports classic AI algorithms such as Linear Regression, Logistic Regression, Support Vector Machine (SVM), Naive Bayes, and K-Nearest Neighbors (K-NN).
and
- Decision Trees
- Random Forest
- AdaBoost
- Gradient Boosting
3. Integration with Popular Libraries: Seamless integration with essential Python libraries like NumPy, Pandas, Matplotlib, and Scikit-learn for enhanced functionality.
4. Data Handling:
- DataLoader class for importing and preprocessing data from various formats (CSV, JSON, SQL databases).
- DataTransformer class for feature scaling, normalization, and encoding categorical variables.
- Includes functions for loading and preprocessing datasets to prepare them for training and testing.
- `FeatureSelector` class: Provides methods for feature selection and dimensionality reduction.
5. Model Evaluation:
- Evaluator class to assess model performance using metrics like accuracy, precision, recall, F1-score, and ROC-AUC.
- Methods for generating confusion matrices and classification reports.
6. Model Training: Contains methods for fitting the selected algorithm with the training data.
- `fit` method: Trains the selected algorithm on the provided training data.
7. Prediction Generation: Allows users to make predictions using the trained model on new data.
- `predict` method: Makes predictions using the trained model on new data.
- `predict_proba` method: Returns the predicted probabilities for classification tasks.
8. Model Evaluation:
- `Evaluator` class: Assesses model performance using various metrics (e.g., accuracy, precision, recall, F1-score, ROC-AUC).
- `cross_validate` method: Performs cross-validation to evaluate the model's performance.
- `confusion_matrix` method: Generates a confusion matrix for classification tasks.
- `classification_report` method: Provides a detailed classification report.
9. Hyperparameter Tuning:
- Tuner class that uses techniques likes Grid Search and Random Search for hyperparameter optimization.
10. Visualization:
- Integration with Matplotlib and Seaborn for generating plots to analyze model performance and data characteristics.
- Visualization support: Enables users to visualize data, model performance, and predictions using plotting functionalities.
- `Visualizer` class: Integrates with Matplotlib and Seaborn to generate plots for model performance analysis and data visualization.
- `plot_confusion_matrix` method: Visualizes the confusion matrix.
- `plot_roc_curve` method: Plots the Receiver Operating Characteristic (ROC) curve.
- `plot_feature_importance` method: Visualizes feature importance for applicable algorithms.
11. Utility Functions:
- Functions for saving and loading trained models.
- Logging functionalities to track the model training and prediction processes.
- `save_model` method: Saves the trained model to a file.
- `load_model` method: Loads a previously trained model from a file.
- `set_logger` method: Configures logging functionality for tracking model training and prediction processes.
12. User-Friendly Interface: Provides a simplified and intuitive interface for users to interact with and apply classic AI algorithms without extensive knowledge or configuration.
13.. Error Handling: Incorporates mechanisms to handle invalid inputs, errors during training, and other potential issues during algorithm usage.
- Custom exception classes for handling specific errors and providing informative error messages to users.
14. Documentation: Comprehensive documentation to guide users on how to use Easylibpal effectively and efficiently
- Comprehensive documentation explaining the usage and functionality of each component.
- Example scripts demonstrating how to use Easylibpal for various AI tasks and datasets.
15. Testing Suite:
- Unit tests for each component to ensure code reliability and maintainability.
- Integration tests to verify the smooth interaction between different components.
IMPLEMENTATION EXAMPLE WITH ADDITIONAL FEATURES:
Here is an example of how the expanded Easylibpal library could be structured and used:
```python
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from easylibpal import Easylibpal, DataLoader, Evaluator, Tuner
# Example DataLoader
class DataLoader:
def load_data(self, filepath, file_type='csv'):
if file_type == 'csv':
return pd.read_csv(filepath)
else:
raise ValueError("Unsupported file type provided.")
# Example Evaluator
class Evaluator:
def evaluate(self, model, X_test, y_test):
predictions = model.predict(X_test)
accuracy = np.mean(predictions == y_test)
return {'accuracy': accuracy}
# Example usage of Easylibpal with DataLoader and Evaluator
if __name__ == "__main__":
# Load and prepare the data
data_loader = DataLoader()
data = data_loader.load_data('path/to/your/data.csv')
X = data.iloc[:, :-1]
y = data.iloc[:, -1]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Scale features
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# Initialize Easylibpal with the desired algorithm
model = Easylibpal('Random Forest')
model.fit(X_train_scaled, y_train)
# Evaluate the model
evaluator = Evaluator()
results = evaluator.evaluate(model, X_test_scaled, y_test)
print(f"Model Accuracy: {results['accuracy']}")
# Optional: Use Tuner for hyperparameter optimization
tuner = Tuner(model, param_grid={'n_estimators': [100, 200], 'max_depth': [10, 20, 30]})
best_params = tuner.optimize(X_train_scaled, y_train)
print(f"Best Parameters: {best_params}")
```
This example demonstrates the structured approach to using Easylibpal with enhanced data handling, model evaluation, and optional hyperparameter tuning. The library empowers users to handle real-world datasets, apply various machine learning algorithms, and evaluate their performance with ease, making it an invaluable tool for developers and data scientists aiming to implement AI solutions efficiently.
Easylibpal is dedicated to making the latest AI technology accessible to everyone, regardless of their background or expertise. Our platform simplifies the process of selecting and implementing classic AI algorithms, enabling users across various industries to harness the power of artificial intelligence with ease. By democratizing access to AI, we aim to accelerate innovation and empower users to achieve their goals with confidence. Easylibpal's approach involves a democratization framework that reduces entry barriers, lowers the cost of building AI solutions, and speeds up the adoption of AI in both academic and business settings.
Below are examples showcasing how each main component of the Easylibpal library could be implemented and used in practice to provide a user-friendly interface for utilizing classic AI algorithms.
1. Core Components
Easylibpal Class Example:
```python
class Easylibpal:
def __init__(self, algorithm):
self.algorithm = algorithm
self.model = None
def fit(self, X, y):
# Simplified example: Instantiate and train a model based on the selected algorithm
if self.algorithm == 'Linear Regression':
from sklearn.linear_model import LinearRegression
self.model = LinearRegression()
elif self.algorithm == 'Random Forest':
from sklearn.ensemble import RandomForestClassifier
self.model = RandomForestClassifier()
self.model.fit(X, y)
def predict(self, X):
return self.model.predict(X)
```
2. Data Handling
DataLoader Class Example:
```python
class DataLoader:
def load_data(self, filepath, file_type='csv'):
if file_type == 'csv':
import pandas as pd
return pd.read_csv(filepath)
else:
raise ValueError("Unsupported file type provided.")
```
3. Model Evaluation
Evaluator Class Example:
```python
from sklearn.metrics import accuracy_score, classification_report
class Evaluator:
def evaluate(self, model, X_test, y_test):
predictions = model.predict(X_test)
accuracy = accuracy_score(y_test, predictions)
report = classification_report(y_test, predictions)
return {'accuracy': accuracy, 'report': report}
```
4. Hyperparameter Tuning
Tuner Class Example:
```python
from sklearn.model_selection import GridSearchCV
class Tuner:
def __init__(self, model, param_grid):
self.model = model
self.param_grid = param_grid
def optimize(self, X, y):
grid_search = GridSearchCV(self.model, self.param_grid, cv=5)
grid_search.fit(X, y)
return grid_search.best_params_
```
5. Visualization
Visualizer Class Example:
```python
import matplotlib.pyplot as plt
class Visualizer:
def plot_confusion_matrix(self, cm, classes, normalize=False, title='Confusion matrix'):
plt.imshow(cm, interpolation='nearest', cmap=plt.cm.Blues)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45)
plt.yticks(tick_marks, classes)
plt.ylabel('True label')
plt.xlabel('Predicted label')
plt.show()
```
6. Utility Functions
Save and Load Model Example:
```python
import joblib
def save_model(model, filename):
joblib.dump(model, filename)
def load_model(filename):
return joblib.load(filename)
```
7. Example Usage Script
Using Easylibpal in a Script:
```python
# Assuming Easylibpal and other classes have been imported
data_loader = DataLoader()
data = data_loader.load_data('data.csv')
X = data.drop('Target', axis=1)
y = data['Target']
model = Easylibpal('Random Forest')
model.fit(X, y)
evaluator = Evaluator()
results = evaluator.evaluate(model, X, y)
print("Accuracy:", results['accuracy'])
print("Report:", results['report'])
visualizer = Visualizer()
visualizer.plot_confusion_matrix(results['cm'], classes=['Class1', 'Class2'])
save_model(model, 'trained_model.pkl')
loaded_model = load_model('trained_model.pkl')
```
These examples illustrate the practical implementation and use of the Easylibpal library components, aiming to simplify the application of AI algorithms for users with varying levels of expertise in machine learning.
EASYLIBPAL IMPLEMENTATION:
Step 1: Define the Problem
First, we need to define the problem we want to solve. For this POC, let's assume we want to predict house prices based on various features like the number of bedrooms, square footage, and location.
Step 2: Choose an Appropriate Algorithm
Given our problem, a supervised learning algorithm like linear regression would be suitable. We'll use Scikit-learn, a popular library for machine learning in Python, to implement this algorithm.
Step 3: Prepare Your Data
We'll use Pandas to load and prepare our dataset. This involves cleaning the data, handling missing values, and splitting the dataset into training and testing sets.
Step 4: Implement the Algorithm
Now, we'll use Scikit-learn to implement the linear regression algorithm. We'll train the model on our training data and then test its performance on the testing data.
Step 5: Evaluate the Model
Finally, we'll evaluate the performance of our model using metrics like Mean Squared Error (MSE) and R-squared.
Python Code POC
```python
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
# Load the dataset
data = pd.read_csv('house_prices.csv')
# Prepare the data
X = data'bedrooms', 'square_footage', 'location'
y = data['price']
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Create and train the model
model = LinearRegression()
model.fit(X_train, y_train)
# Make predictions
predictions = model.predict(X_test)
# Evaluate the model
mse = mean_squared_error(y_test, predictions)
r2 = r2_score(y_test, predictions)
print(f'Mean Squared Error: {mse}')
print(f'R-squared: {r2}')
```
Below is an implementation, Easylibpal provides a simple interface to instantiate and utilize classic AI algorithms such as Linear Regression, Logistic Regression, SVM, Naive Bayes, and K-NN. Users can easily create an instance of Easylibpal with their desired algorithm, fit the model with training data, and make predictions, all with minimal code and hassle. This demonstrates the power of Easylibpal in simplifying the integration of AI algorithms for various tasks.
```python
# Import necessary libraries
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.naive_bayes import GaussianNB
from sklearn.neighbors import KNeighborsClassifier
class Easylibpal:
def __init__(self, algorithm):
self.algorithm = algorithm
def fit(self, X, y):
if self.algorithm == 'Linear Regression':
self.model = LinearRegression()
elif self.algorithm == 'Logistic Regression':
self.model = LogisticRegression()
elif self.algorithm == 'SVM':
self.model = SVC()
elif self.algorithm == 'Naive Bayes':
self.model = GaussianNB()
elif self.algorithm == 'K-NN':
self.model = KNeighborsClassifier()
else:
raise ValueError("Invalid algorithm specified.")
self.model.fit(X, y)
def predict(self, X):
return self.model.predict(X)
# Example usage:
# Initialize Easylibpal with the desired algorithm
easy_algo = Easylibpal('Linear Regression')
# Generate some sample data
X = np.array([[1], [2], [3], [4]])
y = np.array([2, 4, 6, 8])
# Fit the model
easy_algo.fit(X, y)
# Make predictions
predictions = easy_algo.predict(X)
# Plot the results
plt.scatter(X, y)
plt.plot(X, predictions, color='red')
plt.title('Linear Regression with Easylibpal')
plt.xlabel('X')
plt.ylabel('y')
plt.show()
```
Easylibpal is an innovative Python library designed to simplify the integration and use of classic AI algorithms in a user-friendly manner. It aims to bridge the gap between the complexity of AI libraries and the ease of use, making it accessible for developers and data scientists alike. Easylibpal abstracts the underlying complexity of each algorithm, providing a unified interface that allows users to apply these algorithms with minimal configuration and understanding of the underlying mechanisms.
ENHANCED DATASET HANDLING
Easylibpal should be able to handle datasets more efficiently. This includes loading datasets from various sources (e.g., CSV files, databases), preprocessing data (e.g., normalization, handling missing values), and splitting data into training and testing sets.
```python
import os
from sklearn.model_selection import train_test_split
class Easylibpal:
# Existing code...
def load_dataset(self, filepath):
"""Loads a dataset from a CSV file."""
if not os.path.exists(filepath):
raise FileNotFoundError("Dataset file not found.")
return pd.read_csv(filepath)
def preprocess_data(self, dataset):
"""Preprocesses the dataset."""
# Implement data preprocessing steps here
return dataset
def split_data(self, X, y, test_size=0.2):
"""Splits the dataset into training and testing sets."""
return train_test_split(X, y, test_size=test_size)
```
Additional Algorithms
Easylibpal should support a wider range of algorithms. This includes decision trees, random forests, and gradient boosting machines.
```python
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import GradientBoostingClassifier
class Easylibpal:
# Existing code...
def fit(self, X, y):
# Existing code...
elif self.algorithm == 'Decision Tree':
self.model = DecisionTreeClassifier()
elif self.algorithm == 'Random Forest':
self.model = RandomForestClassifier()
elif self.algorithm == 'Gradient Boosting':
self.model = GradientBoostingClassifier()
# Add more algorithms as needed
```
User-Friendly Features
To make Easylibpal even more user-friendly, consider adding features like:
- Automatic hyperparameter tuning: Implementing a simple interface for hyperparameter tuning using GridSearchCV or RandomizedSearchCV.
- Model evaluation metrics: Providing easy access to common evaluation metrics like accuracy, precision, recall, and F1 score.
- Visualization tools: Adding methods for plotting model performance, confusion matrices, and feature importance.
```python
from sklearn.metrics import accuracy_score, classification_report
from sklearn.model_selection import GridSearchCV
class Easylibpal:
# Existing code...
def evaluate_model(self, X_test, y_test):
"""Evaluates the model using accuracy and classification report."""
y_pred = self.predict(X_test)
print("Accuracy:", accuracy_score(y_test, y_pred))
print(classification_report(y_test, y_pred))
def tune_hyperparameters(self, X, y, param_grid):
"""Tunes the model's hyperparameters using GridSearchCV."""
grid_search = GridSearchCV(self.model, param_grid, cv=5)
grid_search.fit(X, y)
self.model = grid_search.best_estimator_
```
Easylibpal leverages the power of Python and its rich ecosystem of AI and machine learning libraries, such as scikit-learn, to implement the classic algorithms. It provides a high-level API that abstracts the specifics of each algorithm, allowing users to focus on the problem at hand rather than the intricacies of the algorithm.
Python Code Snippets for Easylibpal
Below are Python code snippets demonstrating the use of Easylibpal with classic AI algorithms. Each snippet demonstrates how to use Easylibpal to apply a specific algorithm to a dataset.
# Linear Regression
```python
from Easylibpal import Easylibpal
# Initialize Easylibpal with a dataset
Easylibpal = Easylibpal(dataset='your_dataset.csv')
# Apply Linear Regression
result = Easylibpal.apply_algorithm('linear_regression', target_column='target')
# Print the result
print(result)
```
# Logistic Regression
```python
from Easylibpal import Easylibpal
# Initialize Easylibpal with a dataset
Easylibpal = Easylibpal(dataset='your_dataset.csv')
# Apply Logistic Regression
result = Easylibpal.apply_algorithm('logistic_regression', target_column='target')
# Print the result
print(result)
```
# Support Vector Machines (SVM)
```python
from Easylibpal import Easylibpal
# Initialize Easylibpal with a dataset
Easylibpal = Easylibpal(dataset='your_dataset.csv')
# Apply SVM
result = Easylibpal.apply_algorithm('svm', target_column='target')
# Print the result
print(result)
```
# Naive Bayes
```python
from Easylibpal import Easylibpal
# Initialize Easylibpal with a dataset
Easylibpal = Easylibpal(dataset='your_dataset.csv')
# Apply Naive Bayes
result = Easylibpal.apply_algorithm('naive_bayes', target_column='target')
# Print the result
print(result)
```
# K-Nearest Neighbors (K-NN)
```python
from Easylibpal import Easylibpal
# Initialize Easylibpal with a dataset
Easylibpal = Easylibpal(dataset='your_dataset.csv')
# Apply K-NN
result = Easylibpal.apply_algorithm('knn', target_column='target')
# Print the result
print(result)
```
ABSTRACTION AND ESSENTIAL COMPLEXITY
- Essential Complexity: This refers to the inherent complexity of the problem domain, which cannot be reduced regardless of the programming language or framework used. It includes the logic and algorithm needed to solve the problem. For example, the essential complexity of sorting a list remains the same across different programming languages.
- Accidental Complexity: This is the complexity introduced by the choice of programming language, framework, or libraries. It can be reduced or eliminated through abstraction. For instance, using a high-level API in Python can hide the complexity of lower-level operations, making the code more readable and maintainable.
HOW EASYLIBPAL ABSTRACTS COMPLEXITY
Easylibpal aims to reduce accidental complexity by providing a high-level API that encapsulates the details of each classic AI algorithm. This abstraction allows users to apply these algorithms without needing to understand the underlying mechanisms or the specifics of the algorithm's implementation.
- Simplified Interface: Easylibpal offers a unified interface for applying various algorithms, such as Linear Regression, Logistic Regression, SVM, Naive Bayes, and K-NN. This interface abstracts the complexity of each algorithm, making it easier for users to apply them to their datasets.
- Runtime Fusion: By evaluating sub-expressions and sharing them across multiple terms, Easylibpal can optimize the execution of algorithms. This approach, similar to runtime fusion in abstract algorithms, allows for efficient computation without duplicating work, thereby reducing the computational complexity.
- Focus on Essential Complexity: While Easylibpal abstracts away the accidental complexity; it ensures that the essential complexity of the problem domain remains at the forefront. This means that while the implementation details are hidden, the core logic and algorithmic approach are still accessible and understandable to the user.
To implement Easylibpal, one would need to create a Python class that encapsulates the functionality of each classic AI algorithm. This class would provide methods for loading datasets, preprocessing data, and applying the algorithm with minimal configuration required from the user. The implementation would leverage existing libraries like scikit-learn for the actual algorithmic computations, abstracting away the complexity of these libraries.
Here's a conceptual example of how the Easylibpal class might be structured for applying a Linear Regression algorithm:
```python
class Easylibpal:
def __init__(self, dataset):
self.dataset = dataset
# Load and preprocess the dataset
def apply_linear_regression(self, target_column):
# Abstracted implementation of Linear Regression
# This method would internally use scikit-learn or another library
# to perform the actual computation, abstracting the complexity
pass
# Usage
Easylibpal = Easylibpal(dataset='your_dataset.csv')
result = Easylibpal.apply_linear_regression(target_column='target')
```
This example demonstrates the concept of Easylibpal by abstracting the complexity of applying a Linear Regression algorithm. The actual implementation would need to include the specifics of loading the dataset, preprocessing it, and applying the algorithm using an underlying library like scikit-learn.
Easylibpal abstracts the complexity of classic AI algorithms by providing a simplified interface that hides the intricacies of each algorithm's implementation. This abstraction allows users to apply these algorithms with minimal configuration and understanding of the underlying mechanisms. Here are examples of specific algorithms that Easylibpal abstracts:
To implement Easylibpal, one would need to create a Python class that encapsulates the functionality of each classic AI algorithm. This class would provide methods for loading datasets, preprocessing data, and applying the algorithm with minimal configuration required from the user. The implementation would leverage existing libraries like scikit-learn for the actual algorithmic computations, abstracting away the complexity of these libraries.
Here's a conceptual example of how the Easylibpal class might be structured for applying a Linear Regression algorithm:
```python
class Easylibpal:
def __init__(self, dataset):
self.dataset = dataset
# Load and preprocess the dataset
def apply_linear_regression(self, target_column):
# Abstracted implementation of Linear Regression
# This method would internally use scikit-learn or another library
# to perform the actual computation, abstracting the complexity
pass
# Usage
Easylibpal = Easylibpal(dataset='your_dataset.csv')
result = Easylibpal.apply_linear_regression(target_column='target')
```
This example demonstrates the concept of Easylibpal by abstracting the complexity of applying a Linear Regression algorithm. The actual implementation would need to include the specifics of loading the dataset, preprocessing it, and applying the algorithm using an underlying library like scikit-learn.
Easylibpal abstracts the complexity of feature selection for classic AI algorithms by providing a simplified interface that automates the process of selecting the most relevant features for each algorithm. This abstraction is crucial because feature selection is a critical step in machine learning that can significantly impact the performance of a model. Here's how Easylibpal handles feature selection for the mentioned algorithms:
To implement feature selection in Easylibpal, one could use scikit-learn's `SelectKBest` or `RFE` classes for feature selection based on statistical tests or model coefficients. Here's a conceptual example of how feature selection might be integrated into the Easylibpal class for Linear Regression:
```python
from sklearn.feature_selection import SelectKBest, f_regression
from sklearn.linear_model import LinearRegression
class Easylibpal:
def __init__(self, dataset):
self.dataset = dataset
# Load and preprocess the dataset
def apply_linear_regression(self, target_column):
# Feature selection using SelectKBest
selector = SelectKBest(score_func=f_regression, k=10)
X_new = selector.fit_transform(self.dataset.drop(target_column, axis=1), self.dataset[target_column])
# Train Linear Regression model
model = LinearRegression()
model.fit(X_new, self.dataset[target_column])
# Return the trained model
return model
# Usage
Easylibpal = Easylibpal(dataset='your_dataset.csv')
model = Easylibpal.apply_linear_regression(target_column='target')
```
This example demonstrates how Easylibpal abstracts the complexity of feature selection for Linear Regression by using scikit-learn's `SelectKBest` to select the top 10 features based on their statistical significance in predicting the target variable. The actual implementation would need to adapt this approach for each algorithm, considering the specific characteristics and requirements of each algorithm.
To implement feature selection in Easylibpal, one could use scikit-learn's `SelectKBest`, `RFE`, or other feature selection classes based on the algorithm's requirements. Here's a conceptual example of how feature selection might be integrated into the Easylibpal class for Logistic Regression using RFE:
```python
from sklearn.feature_selection import RFE
from sklearn.linear_model import LogisticRegression
class Easylibpal:
def __init__(self, dataset):
self.dataset = dataset
# Load and preprocess the dataset
def apply_logistic_regression(self, target_column):
# Feature selection using RFE
model = LogisticRegression()
rfe = RFE(model, n_features_to_select=10)
rfe.fit(self.dataset.drop(target_column, axis=1), self.dataset[target_column])
# Train Logistic Regression model
model.fit(self.dataset.drop(target_column, axis=1), self.dataset[target_column])
# Return the trained model
return model
# Usage
Easylibpal = Easylibpal(dataset='your_dataset.csv')
model = Easylibpal.apply_logistic_regression(target_column='target')
```
This example demonstrates how Easylibpal abstracts the complexity of feature selection for Logistic Regression by using scikit-learn's `RFE` to select the top 10 features based on their importance in the model. The actual implementation would need to adapt this approach for each algorithm, considering the specific characteristics and requirements of each algorithm.
EASYLIBPAL HANDLES DIFFERENT TYPES OF DATASETS
Easylibpal handles different types of datasets with varying structures by adopting a flexible and adaptable approach to data preprocessing and transformation. This approach is inspired by the principles of tidy data and the need to ensure data is in a consistent, usable format before applying AI algorithms. Here's how Easylibpal addresses the challenges posed by varying dataset structures:
One Type in Multiple Tables
When datasets contain different variables, the same variables with different names, different file formats, or different conventions for missing values, Easylibpal employs a process similar to tidying data. This involves identifying and standardizing the structure of each dataset, ensuring that each variable is consistently named and formatted across datasets. This process might include renaming columns, converting data types, and handling missing values in a uniform manner. For datasets stored in different file formats, Easylibpal would use appropriate libraries (e.g., pandas for CSV, Excel files, and SQL databases) to load and preprocess the data before applying the algorithms.
Multiple Types in One Table
For datasets that involve values collected at multiple levels or on different types of observational units, Easylibpal applies a normalization process. This involves breaking down the dataset into multiple tables, each representing a distinct type of observational unit. For example, if a dataset contains information about songs and their rankings over time, Easylibpal would separate this into two tables: one for song details and another for rankings. This normalization ensures that each fact is expressed in only one place, reducing inconsistencies and making the data more manageable for analysis.
Data Semantics
Easylibpal ensures that the data is organized in a way that aligns with the principles of data semantics, where every value belongs to a variable and an observation. This organization is crucial for the algorithms to interpret the data correctly. Easylibpal might use functions like `pivot_longer` and `pivot_wider` from the tidyverse or equivalent functions in pandas to reshape the data into a long format, where each row represents a single observation and each column represents a single variable. This format is particularly useful for algorithms that require a consistent structure for input data.
Messy Data
Dealing with messy data, which can include inconsistent data types, missing values, and outliers, is a common challenge in data science. Easylibpal addresses this by implementing robust data cleaning and preprocessing steps. This includes handling missing values (e.g., imputation or deletion), converting data types to ensure consistency, and identifying and removing outliers. These steps are crucial for preparing the data in a format that is suitable for the algorithms, ensuring that the algorithms can effectively learn from the data without being hindered by its inconsistencies.
To implement these principles in Python, Easylibpal would leverage libraries like pandas for data manipulation and preprocessing. Here's a conceptual example of how Easylibpal might handle a dataset with multiple types in one table:
```python
import pandas as pd
# Load the dataset
dataset = pd.read_csv('your_dataset.csv')
# Normalize the dataset by separating it into two tables
song_table = dataset'artist', 'track'.drop_duplicates().reset_index(drop=True)
song_table['song_id'] = range(1, len(song_table) + 1)
ranking_table = dataset'artist', 'track', 'week', 'rank'.drop_duplicates().reset_index(drop=True)
# Now, song_table and ranking_table can be used separately for analysis
```
This example demonstrates how Easylibpal might normalize a dataset with multiple types of observational units into separate tables, ensuring that each type of observational unit is stored in its own table. The actual implementation would need to adapt this approach based on the specific structure and requirements of the dataset being processed.
CLEAN DATA
Easylibpal employs a comprehensive set of data cleaning and preprocessing steps to handle messy data, ensuring that the data is in a suitable format for machine learning algorithms. These steps are crucial for improving the accuracy and reliability of the models, as well as preventing misleading results and conclusions. Here's a detailed look at the specific steps Easylibpal might employ:
1. Remove Irrelevant Data
The first step involves identifying and removing data that is not relevant to the analysis or modeling task at hand. This could include columns or rows that do not contribute to the predictive power of the model or are not necessary for the analysis .
2. Deduplicate Data
Deduplication is the process of removing duplicate entries from the dataset. Duplicates can skew the analysis and lead to incorrect conclusions. Easylibpal would use appropriate methods to identify and remove duplicates, ensuring that each entry in the dataset is unique.
3. Fix Structural Errors
Structural errors in the dataset, such as inconsistent data types, incorrect values, or formatting issues, can significantly impact the performance of machine learning algorithms. Easylibpal would employ data cleaning techniques to correct these errors, ensuring that the data is consistent and correctly formatted.
4. Deal with Missing Data
Handling missing data is a common challenge in data preprocessing. Easylibpal might use techniques such as imputation (filling missing values with statistical estimates like mean, median, or mode) or deletion (removing rows or columns with missing values) to address this issue. The choice of method depends on the nature of the data and the specific requirements of the analysis.
5. Filter Out Data Outliers
Outliers can significantly affect the performance of machine learning models. Easylibpal would use statistical methods to identify and filter out outliers, ensuring that the data is more representative of the population being analyzed.
6. Validate Data
The final step involves validating the cleaned and preprocessed data to ensure its quality and accuracy. This could include checking for consistency, verifying the correctness of the data, and ensuring that the data meets the requirements of the machine learning algorithms. Easylibpal would employ validation techniques to confirm that the data is ready for analysis.
To implement these data cleaning and preprocessing steps in Python, Easylibpal would leverage libraries like pandas and scikit-learn. Here's a conceptual example of how these steps might be integrated into the Easylibpal class:
```python
import pandas as pd
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler
class Easylibpal:
def __init__(self, dataset):
self.dataset = dataset
# Load and preprocess the dataset
def clean_and_preprocess(self):
# Remove irrelevant data
self.dataset = self.dataset.drop(['irrelevant_column'], axis=1)
# Deduplicate data
self.dataset = self.dataset.drop_duplicates()
# Fix structural errors (example: correct data type)
self.dataset['correct_data_type_column'] = self.dataset['correct_data_type_column'].astype(float)
# Deal with missing data (example: imputation)
imputer = SimpleImputer(strategy='mean')
self.dataset['missing_data_column'] = imputer.fit_transform(self.dataset'missing_data_column')
# Filter out data outliers (example: using Z-score)
# This step requires a more detailed implementation based on the specific dataset
# Validate data (example: checking for NaN values)
assert not self.dataset.isnull().values.any(), "Data still contains NaN values"
# Return the cleaned and preprocessed dataset
return self.dataset
# Usage
Easylibpal = Easylibpal(dataset=pd.read_csv('your_dataset.csv'))
cleaned_dataset = Easylibpal.clean_and_preprocess()
```
This example demonstrates a simplified approach to data cleaning and preprocessing within Easylibpal. The actual implementation would need to adapt these steps based on the specific characteristics and requirements of the dataset being processed.
VALUE DATA
Easylibpal determines which data is irrelevant and can be removed through a combination of domain knowledge, data analysis, and automated techniques. The process involves identifying data that does not contribute to the analysis, research, or goals of the project, and removing it to improve the quality, efficiency, and clarity of the data. Here's how Easylibpal might approach this:
Domain Knowledge
Easylibpal leverages domain knowledge to identify data that is not relevant to the specific goals of the analysis or modeling task. This could include data that is out of scope, outdated, duplicated, or erroneous. By understanding the context and objectives of the project, Easylibpal can systematically exclude data that does not add value to the analysis.
Data Analysis
Easylibpal employs data analysis techniques to identify irrelevant data. This involves examining the dataset to understand the relationships between variables, the distribution of data, and the presence of outliers or anomalies. Data that does not have a significant impact on the predictive power of the model or the insights derived from the analysis is considered irrelevant.
Automated Techniques
Easylibpal uses automated tools and methods to remove irrelevant data. This includes filtering techniques to select or exclude certain rows or columns based on criteria or conditions, aggregating data to reduce its complexity, and deduplicating to remove duplicate entries. Tools like Excel, Google Sheets, Tableau, Power BI, OpenRefine, Python, R, Data Linter, Data Cleaner, and Data Wrangler can be employed for these purposes .
Examples of Irrelevant Data
- Personal Identifiable Information (PII): Data such as names, addresses, and phone numbers are irrelevant for most analytical purposes and should be removed to protect privacy and comply with data protection regulations .
- URLs and HTML Tags: These are typically not relevant to the analysis and can be removed to clean up the dataset.
- Boilerplate Text: Excessive blank space or boilerplate text (e.g., in emails) adds noise to the data and can be removed.
- Tracking Codes: These are used for tracking user interactions and do not contribute to the analysis.
To implement these steps in Python, Easylibpal might use pandas for data manipulation and filtering. Here's a conceptual example of how to remove irrelevant data:
```python
import pandas as pd
# Load the dataset
dataset = pd.read_csv('your_dataset.csv')
# Remove irrelevant columns (example: email addresses)
dataset = dataset.drop(['email_address'], axis=1)
# Remove rows with missing values (example: if a column is required for analysis)
dataset = dataset.dropna(subset=['required_column'])
# Deduplicate data
dataset = dataset.drop_duplicates()
# Return the cleaned dataset
cleaned_dataset = dataset
```
This example demonstrates how Easylibpal might remove irrelevant data from a dataset using Python and pandas. The actual implementation would need to adapt these steps based on the specific characteristics and requirements of the dataset being processed.
Detecting Inconsistencies
Easylibpal starts by detecting inconsistencies in the data. This involves identifying discrepancies in data types, missing values, duplicates, and formatting errors. By detecting these inconsistencies, Easylibpal can take targeted actions to address them.
Handling Formatting Errors
Formatting errors, such as inconsistent data types for the same feature, can significantly impact the analysis. Easylibpal uses functions like `astype()` in pandas to convert data types, ensuring uniformity and consistency across the dataset. This step is crucial for preparing the data for analysis, as it ensures that each feature is in the correct format expected by the algorithms.
Handling Missing Values
Missing values are a common issue in datasets. Easylibpal addresses this by consulting with subject matter experts to understand why data might be missing. If the missing data is missing completely at random, Easylibpal might choose to drop it. However, for other cases, Easylibpal might employ imputation techniques to fill in missing values, ensuring that the dataset is complete and ready for analysis.
Handling Duplicates
Duplicate entries can skew the analysis and lead to incorrect conclusions. Easylibpal uses pandas to identify and remove duplicates, ensuring that each entry in the dataset is unique. This step is crucial for maintaining the integrity of the data and ensuring that the analysis is based on distinct observations.
Handling Inconsistent Values
Inconsistent values, such as different representations of the same concept (e.g., "yes" vs. "y" for a binary variable), can also pose challenges. Easylibpal employs data cleaning techniques to standardize these values, ensuring that the data is consistent and can be accurately analyzed.
To implement these steps in Python, Easylibpal would leverage pandas for data manipulation and preprocessing. Here's a conceptual example of how these steps might be integrated into the Easylibpal class:
```python
import pandas as pd
class Easylibpal:
def __init__(self, dataset):
self.dataset = dataset
# Load and preprocess the dataset
def clean_and_preprocess(self):
# Detect inconsistencies (example: check data types)
print(self.dataset.dtypes)
# Handle formatting errors (example: convert data types)
self.dataset['date_column'] = pd.to_datetime(self.dataset['date_column'])
# Handle missing values (example: drop rows with missing values)
self.dataset = self.dataset.dropna(subset=['required_column'])
# Handle duplicates (example: drop duplicates)
self.dataset = self.dataset.drop_duplicates()
# Handle inconsistent values (example: standardize values)
self.dataset['binary_column'] = self.dataset['binary_column'].map({'yes': 1, 'no': 0})
# Return the cleaned and preprocessed dataset
return self.dataset
# Usage
Easylibpal = Easylibpal(dataset=pd.read_csv('your_dataset.csv'))
cleaned_dataset = Easylibpal.clean_and_preprocess()
```
This example demonstrates a simplified approach to handling inconsistent or messy data within Easylibpal. The actual implementation would need to adapt these steps based on the specific characteristics and requirements of the dataset being processed.
Statistical Imputation
Statistical imputation involves replacing missing values with statistical estimates such as the mean, median, or mode of the available data. This method is straightforward and can be effective for numerical data. For categorical data, mode imputation is commonly used. The choice of imputation method depends on the distribution of the data and the nature of the missing values.
Model-Based Imputation
Model-based imputation uses machine learning models to predict missing values. This approach can be more sophisticated and potentially more accurate than statistical imputation, especially for complex datasets. Techniques like K-Nearest Neighbors (KNN) imputation can be used, where the missing values are replaced with the values of the K nearest neighbors in the feature space.
Using SimpleImputer in scikit-learn
The scikit-learn library provides the `SimpleImputer` class, which supports both statistical and model-based imputation. `SimpleImputer` can be used to replace missing values with the mean, median, or most frequent value (mode) of the column. It also supports more advanced imputation methods like KNN imputation.
To implement these imputation techniques in Python, Easylibpal might use the `SimpleImputer` class from scikit-learn. Here's an example of how to use `SimpleImputer` for statistical imputation:
```python
from sklearn.impute import SimpleImputer
import pandas as pd
# Load the dataset
dataset = pd.read_csv('your_dataset.csv')
# Initialize SimpleImputer for numerical columns
num_imputer = SimpleImputer(strategy='mean')
# Fit and transform the numerical columns
dataset'numerical_column1', 'numerical_column2' = num_imputer.fit_transform(dataset'numerical_column1', 'numerical_column2')
# Initialize SimpleImputer for categorical columns
cat_imputer = SimpleImputer(strategy='most_frequent')
# Fit and transform the categorical columns
dataset'categorical_column1', 'categorical_column2' = cat_imputer.fit_transform(dataset'categorical_column1', 'categorical_column2')
# The dataset now has missing values imputed
```
This example demonstrates how to use `SimpleImputer` to fill in missing values in both numerical and categorical columns of a dataset. The actual implementation would need to adapt these steps based on the specific characteristics and requirements of the dataset being processed.
Model-based imputation techniques, such as Multiple Imputation by Chained Equations (MICE), offer powerful ways to handle missing data by using statistical models to predict missing values. However, these techniques come with their own set of limitations and potential drawbacks:
1. Complexity and Computational Cost
Model-based imputation methods can be computationally intensive, especially for large datasets or complex models. This can lead to longer processing times and increased computational resources required for imputation.
2. Overfitting and Convergence Issues
These methods are prone to overfitting, where the imputation model captures noise in the data rather than the underlying pattern. Overfitting can lead to imputed values that are too closely aligned with the observed data, potentially introducing bias into the analysis. Additionally, convergence issues may arise, where the imputation process does not settle on a stable solution.
3. Assumptions About Missing Data
Model-based imputation techniques often assume that the data is missing at random (MAR), which means that the probability of a value being missing is not related to the values of other variables. However, this assumption may not hold true in all cases, leading to biased imputations if the data is missing not at random (MNAR).
4. Need for Suitable Regression Models
For each variable with missing values, a suitable regression model must be chosen. Selecting the wrong model can lead to inaccurate imputations. The choice of model depends on the nature of the data and the relationship between the variable with missing values and other variables.
5. Combining Imputed Datasets
After imputing missing values, there is a challenge in combining the multiple imputed datasets to produce a single, final dataset. This requires careful consideration of how to aggregate the imputed values and can introduce additional complexity and uncertainty into the analysis.
6. Lack of Transparency
The process of model-based imputation can be less transparent than simpler imputation methods, such as mean or median imputation. This can make it harder to justify the imputation process, especially in contexts where the reasons for missing data are important, such as in healthcare research.
Despite these limitations, model-based imputation techniques can be highly effective for handling missing data in datasets where a amusingness is MAR and where the relationships between variables are complex. Careful consideration of the assumptions, the choice of models, and the methods for combining imputed datasets are crucial to mitigate these drawbacks and ensure the validity of the imputation process.
USING EASYLIBPAL FOR AI ALGORITHM INTEGRATION OFFERS SEVERAL SIGNIFICANT BENEFITS, PARTICULARLY IN ENHANCING EVERYDAY LIFE AND REVOLUTIONIZING VARIOUS SECTORS. HERE'S A DETAILED LOOK AT THE ADVANTAGES:
1. Enhanced Communication: AI, through Easylibpal, can significantly improve communication by categorizing messages, prioritizing inboxes, and providing instant customer support through chatbots. This ensures that critical information is not missed and that customer queries are resolved promptly.
2. Creative Endeavors: Beyond mundane tasks, AI can also contribute to creative endeavors. For instance, photo editing applications can use AI algorithms to enhance images, suggesting edits that align with aesthetic preferences. Music composition tools can generate melodies based on user input, inspiring musicians and amateurs alike to explore new artistic horizons. These innovations empower individuals to express themselves creatively with AI as a collaborative partner.
3. Daily Life Enhancement: AI, integrated through Easylibpal, has the potential to enhance daily life exponentially. Smart homes equipped with AI-driven systems can adjust lighting, temperature, and security settings according to user preferences. Autonomous vehicles promise safer and more efficient commuting experiences. Predictive analytics can optimize supply chains, reducing waste and ensuring goods reach users when needed.
4. Paradigm Shift in Technology Interaction: The integration of AI into our daily lives is not just a trend; it's a paradigm shift that's redefining how we interact with technology. By streamlining routine tasks, personalizing experiences, revolutionizing healthcare, enhancing communication, and fueling creativity, AI is opening doors to a more convenient, efficient, and tailored existence.
5. Responsible Benefit Harnessing: As we embrace AI's transformational power, it's essential to approach its integration with a sense of responsibility, ensuring that its benefits are harnessed for the betterment of society as a whole. This approach aligns with the ethical considerations of using AI, emphasizing the importance of using AI in a way that benefits all stakeholders.
In summary, Easylibpal facilitates the integration and use of AI algorithms in a manner that is accessible and beneficial across various domains, from enhancing communication and creative endeavors to revolutionizing daily life and promoting a paradigm shift in technology interaction. This integration not only streamlines the application of AI but also ensures that its benefits are harnessed responsibly for the betterment of society.
USING EASYLIBPAL OVER TRADITIONAL AI LIBRARIES OFFERS SEVERAL BENEFITS, PARTICULARLY IN TERMS OF EASE OF USE, EFFICIENCY, AND THE ABILITY TO APPLY AI ALGORITHMS WITH MINIMAL CONFIGURATION. HERE ARE THE KEY ADVANTAGES:
- Simplified Integration: Easylibpal abstracts the complexity of traditional AI libraries, making it easier for users to integrate classic AI algorithms into their projects. This simplification reduces the learning curve and allows developers and data scientists to focus on their core tasks without getting bogged down by the intricacies of AI implementation.
- User-Friendly Interface: By providing a unified platform for various AI algorithms, Easylibpal offers a user-friendly interface that streamlines the process of selecting and applying algorithms. This interface is designed to be intuitive and accessible, enabling users to experiment with different algorithms with minimal effort.
- Enhanced Productivity: The ability to effortlessly instantiate algorithms, fit models with training data, and make predictions with minimal configuration significantly enhances productivity. This efficiency allows for rapid prototyping and deployment of AI solutions, enabling users to bring their ideas to life more quickly.
- Democratization of AI: Easylibpal democratizes access to classic AI algorithms, making them accessible to a wider range of users, including those with limited programming experience. This democratization empowers users to leverage AI in various domains, fostering innovation and creativity.
- Automation of Repetitive Tasks: By automating the process of applying AI algorithms, Easylibpal helps users save time on repetitive tasks, allowing them to focus on more complex and creative aspects of their projects. This automation is particularly beneficial for users who may not have extensive experience with AI but still wish to incorporate AI capabilities into their work.
- Personalized Learning and Discovery: Easylibpal can be used to enhance personalized learning experiences and discovery mechanisms, similar to the benefits seen in academic libraries. By analyzing user behaviors and preferences, Easylibpal can tailor recommendations and resource suggestions to individual needs, fostering a more engaging and relevant learning journey.
- Data Management and Analysis: Easylibpal aids in managing large datasets efficiently and deriving meaningful insights from data. This capability is crucial in today's data-driven world, where the ability to analyze and interpret large volumes of data can significantly impact research outcomes and decision-making processes.
In summary, Easylibpal offers a simplified, user-friendly approach to applying classic AI algorithms, enhancing productivity, democratizing access to AI, and automating repetitive tasks. These benefits make Easylibpal a valuable tool for developers, data scientists, and users looking to leverage AI in their projects without the complexities associated with traditional AI libraries.
2 notes
·
View notes
Text
Exploring Python: Features and Where It's Used
Python is a versatile programming language that has gained significant popularity in recent times. It's known for its ease of use, readability, and adaptability, making it an excellent choice for both newcomers and experienced programmers. In this article, we'll delve into the specifics of what Python is and explore its various applications.
What is Python?
Python is an interpreted programming language that is high-level and serves multiple purposes. Created by Guido van Rossum and released in 1991, Python is designed to prioritize code readability and simplicity, with a clean and minimalistic syntax. It places emphasis on using proper indentation and whitespace, making it more convenient for programmers to write and comprehend code.
Key Traits of Python :
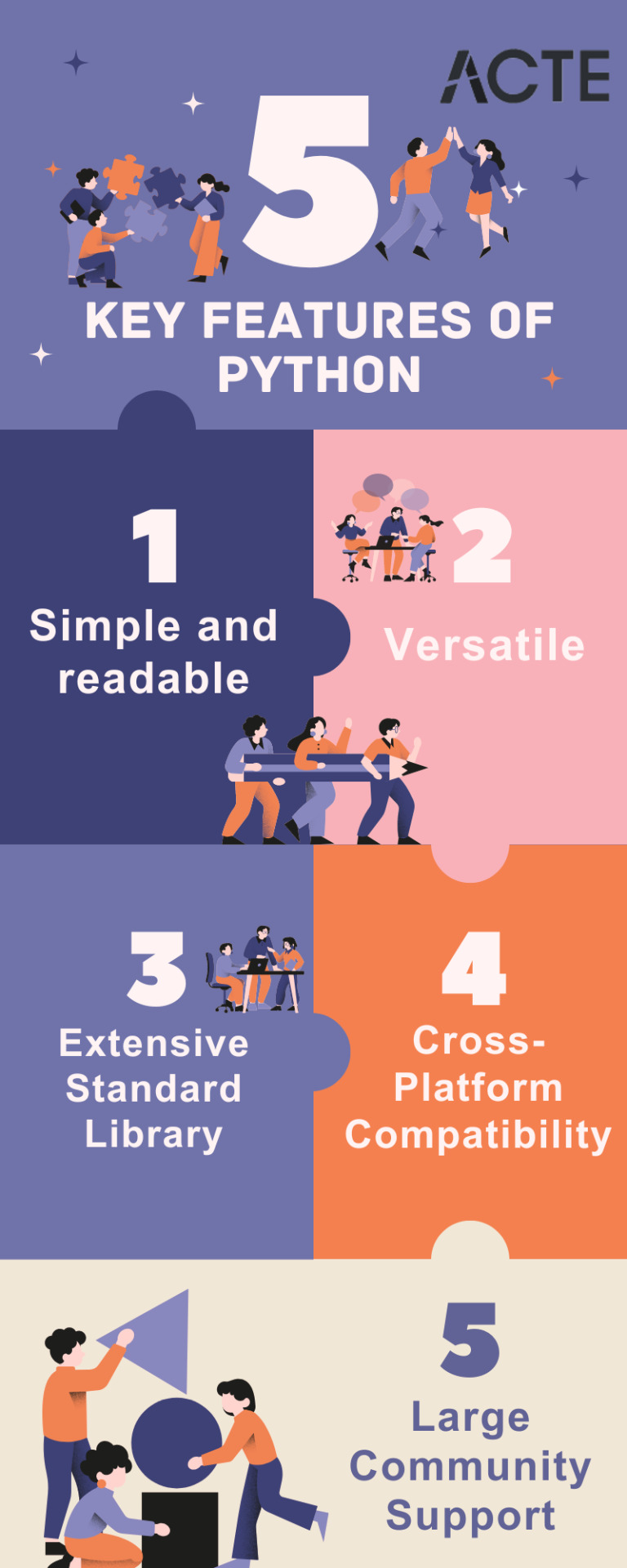
Simplicity and Readability: Python code is structured in a way that's easy to read and understand. This reduces the time and effort required for both creating and maintaining software.
Python code example: print("Hello, World!")
Versatility: Python is applicable across various domains, from web development and scientific computing to data analysis, artificial intelligence, and more.
Python code example: import numpy as np
Extensive Standard Library: Python offers an extensive collection of pre-built libraries and modules. These resources provide developers with ready-made tools and functions to tackle complex tasks efficiently.
Python code example: import matplotlib.pyplot as plt
Compatibility Across Platforms: Python is available on multiple operating systems, including Windows, macOS, and Linux. This allows programmers to create and run code seamlessly across different platforms.
Strong Community Support: Python boasts an active community of developers who contribute to its growth and provide support through online forums, documentation, and open-source contributions. This community support makes Python an excellent choice for developers seeking assistance or collaboration.
Where is Python Utilized?

Due to its versatility, Python is utilized in various domains and industries. Some key areas where Python is widely applied include:
Web Development: Python is highly suitable for web development tasks. It offers powerful frameworks like Django and Flask, simplifying the process of building robust web applications. The simplicity and readability of Python code enable developers to create clean and maintainable web applications efficiently.
Data Science and Machine Learning: Python has become the go-to language for data scientists and machine learning practitioners. Its extensive libraries such as NumPy, Pandas, and SciPy, along with specialized libraries like TensorFlow and PyTorch, facilitate a seamless workflow for data analysis, modeling, and implementing machine learning algorithms.
Scientific Computing: Python is extensively used in scientific computing and research due to its rich scientific libraries and tools. Libraries like SciPy, Matplotlib, and NumPy enable efficient handling of scientific data, visualization, and numerical computations, making Python indispensable for scientists and researchers.
Automation and Scripting: Python's simplicity and versatility make it a preferred language for automating repetitive tasks and writing scripts. Its comprehensive standard library empowers developers to automate various processes within the operating system, network operations, and file manipulation, making it popular among system administrators and DevOps professionals.
Game Development: Python's ease of use and availability of libraries like Pygame make it an excellent choice for game development. Developers can create interactive and engaging games efficiently, and the language's simplicity allows for quick prototyping and development cycles.
Internet of Things (IoT): Python's lightweight nature and compatibility with microcontrollers make it suitable for developing applications for the Internet of Things. Libraries like Circuit Python enable developers to work with sensors, create interactive hardware projects, and connect devices to the internet.
Python's versatility and simplicity have made it one of the most widely used programming languages across diverse domains. Its clean syntax, extensive libraries, and cross-platform compatibility make it a powerful tool for developers. Whether for web development, data science, automation, or game development, Python proves to be an excellent choice for programmers seeking efficiency and user-friendliness. If you're considering learning a programming language or expanding your skills, Python is undoubtedly worth exploring.
9 notes
·
View notes