#DataGeneration
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
US Tumblr user growth rate is estimated to slow down to 4.1%.
Text
Market Growth and Use Cases for Synthetic Data Generation
The global synthetic data generation market size is expected to reach USD 1,788.1 million in 2030 and is projected to grow at a CAGR of 35.3% from 2024 to 2030. Synthetic data has disrupted most industries with the affordability and accessibility of quality training data. Artificial data has gained ground to boost AI and innovation by minimizing data barriers.

Moreover, the exponential growth of smartphones and other smart devices has contributed to the growth of the industry. For instance, customers will receive an uptick from synthetic data to assess the performance of camera modules and decide the optimal camera placement in the car cabin. With the soaring demand for AI systems, synthetic data generation tools will likely gain traction.
Synthetic Data Generation Market Report Highlights
The fully synthetic data segment will grow owing to the need for increased privacy across emerging and advanced economies
Based on end-use, the healthcare & life sciences segment will witness a notable CAGR in the wake of heightened demand for privacy-protecting synthetic data
North America market value will be pronounced on the back of the rising footfall of computer vision and NLP
Geographic expansion may also be noticeable in the coming years. The BFSI, healthcare, manufacturing, and consumer electronics industries continue to rely heavily on synthetic data as a growth enabler and established. Up-and-coming players are expected to strengthen their value propositions
For More Details or Sample Copy please visit link @: Synthetic Data Generation Market Report
It is worth noting that synthetic data is generally used in tandem with real-world data to test and develop AI algorithms. As companies across industry verticals adopt digitization, industry players are poised to emphasize artificial data to bolster strategies. Synthetic data has the innate ability to enhance the performance of computer vision algorithms to develop intelligent assistants in virtual reality and augmented reality and detect hate speech. Social media platforms, such as Meta (Facebook), could exhibit traction for synthetic data.
For instance, in October 2021, Facebook was reported to have acquired AI. Reverie, a synthetic data startup. It is worth mentioning that in July 2020, AI. Reverie was awarded a USD 1.5 million Phase 2 Small Business Innovation Research (SBIR) contract by AFWERX, an innovation arm of the U.S. Air Force. The company was expected to create synthetic images to train the accuracy of navigation vision algorithms.
The IT & telecommunication sector has shown an increased inclination for artificial data for increased security, scalability, and speed. End-users are likely to seek synthetic data to do away with roadblocks of security and privacy protocols. Some factors, such as advanced privacy-preserving, anonymization, and encryption, have encouraged leading companies to inject funds into synthetic data generation tools.
For instance, in October 2021, Türk Telekom announced infusing funds into four AI-based startups, such as Syntonym, B2Metric, QuantWifi, and Optiyol. Notably, Syntonym is a synthetic data anonymization technology developer.
Asia Pacific is expected to provide lucrative growth opportunities in the wake of the rising prominence of computer vision software, predictive analytics, and natural language processing. For instance, the use of artificial data to organize training data for natural language understanding has grown in popularity. China, Australia, Japan, and India could all be searched for prominently synthetic data to streamline privacy compliance and support client-centered goods and services.
With AI, machine learning, and metaverse counting heavily on large datasets to function effectively, the need for data protection could shift attention towards artificial data. Besides, several data scientists are banking on synthetic data to propel their real-world records and garner actionable insights.
List of Key Players in Synthetic Data Generation Market
MOSTLY AI
Synthesis AI
Statice
YData
Ekobit d.o.o. (Span)
Hazy Limited
SAEC / Kinetic Vision, Inc.
kymeralabs
MDClone
Neuromation
Twenty Million Neurons GmbH (Qualcomm Technologies, Inc.)
Anyverse SL
Informatica Inc.
We have segmented the global synthetic data generation market based on data type, modeling type, offering, application, end-use, and region
#SyntheticDataGeneration#SyntheticData#DataGeneration#MachineLearning#BigData#DataPrivacy#DataSecurity#DeepLearning#AI#DigitalTransformation#MarketTrends#DataAnalytics#DataInnovation#FutureOfData#TechTrends#DataDriven#SmartTechnology
0 notes
Text
🏡 Need an Alabama address? Our Random Alabama Address Generator instantly generates random addresses.
0 notes
Text

Woman experiences an Eclipse in 1982.
141 notes
·
View notes
Text
New Preprint: RDFGraphGen: A Synthetic RDF Graph Generator based on SHACL Constraints
In the past year or so, our research team designed, developed and published RDFGraphGen, a general-purpose, domain-independent generator of synthetic RDF knowledge graphs, based on SHACL constraints. Today, we published a preprint detailing its design and implementation: "RDFGraphGen: A Synthetic RDF Graph Generator based on SHACL Constraints".
So, how does RDFGraphGen work, and why was it needed?
The Shapes Constraint Language (SHACL) is a W3C standard which specifies ways to validate data in RDF graphs, by defining constraining shapes. However, even though the main purpose of SHACL is validation of existing RDF data, in order to solve the problem with the lack of available RDF datasets in multiple RDF-based application development processes, we envisioned and implemented a reverse role for SHACL: we use SHACL shape definitions as a starting point to generate synthetic data for an RDF graph. The generation process involves extracting the constraints from the SHACL shapes, converting the specified constraints into rules, and then generating artificial data for a predefined number of RDF entities, based on these rules. The purpose of RDFGraphGen is the generation of small, medium or large RDF knowledge graphs for the purpose of benchmarking, testing, quality control, training and other similar purposes for applications from the RDF, Linked Data and Semantic Web domain.
RDFGraphGen is open-source and is available as a ready-to-use Python package.
Preprint: https://arxiv.org/abs/2407.17941 Authors: Marija Vecovska and Milos Jovanovik RDFGraphGen on GitHub: https://github.com/mveco/RDFGraphGen RDFGraphGen on PyPi: https://pypi.org/project/rdf-graph-gen/

0 notes
Text
kay so it was my first time dealing with tags at all in a datagenerator so
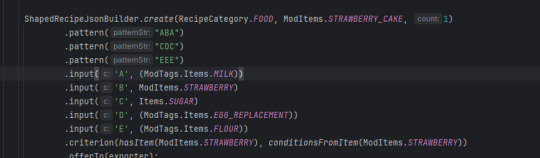
that what it be looking like now time to see if it works
13 notes
·
View notes
Text
Overview
Our client runs a cloud-based platform that turns complex data from sources like firewalls and SIEMs into clear insights for better decision-making. It uses advanced ETL processes to gather and process large volumes of data, making it easy for users to access accurate and real-time information.
Why They Chose Us
As they launched a new app, they needed a testing partner to ensure high performance and reliability. They chose Appzlogic for our expertise in functional and automation testing. We built a custom automation framework tailored to their needs.
Our Testing Strategy
We started with manual testing (sanity, smoke, functional, regression) and later automated key UI and API workflows. Poor data quality and manual ETL testing are major reasons why BI projects fail. We addressed this by ensuring data accuracy and reducing manual work.
Manual Testing Process:
Requirement Analysis: Understood the product and its goals
Scope Definition: Identified what to test
Test Case Design: Created test cases for all scenarios
Execution & Defect Logging: Ran tests and reported issues in JIRA
Automation Testing Results:
We reduced manual effort by 60%. Automated tests were created for data validation across AWS and Azure services. Modular and end-to-end tests boosted efficiency and coverage.
Source Data Flow Overview

These events flowed through the volume controller and were distributed across multiple processing nodes, with one rule node actively handling 1 event. The transformation stage processed 1 event, which was then successfully delivered to the Raw-S3-1 destination. This streamlined flow highlights a well-structured and reliable data processing pipeline.
Centralized Data Operations Briefly

The Data Command Center showcases a well-orchestrated flow of data with 2,724 sources feeding into 3,520 pipelines, resulting in 98.4k events ingested and 21.3 MB of log data processed, all at an average rate of 1 EPS (event per second). Every connected destination received 100% of the expected data with zero loss. Additionally, 51 devices were newly discovered and connected, with no pending actions. This dashboard reflects a highly efficient and reliable data pipeline system in action.
Smooth and Reliable Data Flow

The source TC-DATAGENERATOR-SOURCE-STATUS-1745290102 is working well and is active. It collected 9.36k events and processed 933 KB of data. All events were successfully delivered to the Sandbox with no data loss. The graph shows a steady flow of data over time, proving the system is running smoothly and efficiently.
Tools & Frameworks Used:
Python + Pytest: For unit and functional tests
RequestLibrary: For API testing
Selenium: For UI automation
GitHub + GitHub Actions: For CI/CD
Boto3: To work with AWS
Paramiko: For remote server access
Conclusion
Our testing helped the client build a reliable and scalable platform. With a mix of manual and automated testing, we boosted test accuracy, saved time, and supported their continued growth.
We are The Best IT Service Provider across the globe.
Contact Us today.
0 notes
Text
#ai_act #ai #act .@eu_commission .@eucouncil @euparl_en .@eupa rl_dk @california @texas #keypoint #ai is: the statistical sortin g forth and back along timelines of matching the most a desired or trained pattern is not thinking but itis apowerful sorting tool
#ai_act #ai #act .@eu_commission .@eucouncil @euparl_en .@euparl_dk @california @texas #keypoint #ai is: the statistical sorting forth and back along timelines of matching the most a desired or trained pattern is not thinking but itis apowerful sorting tool //// handle ai strictly as statistical s o r t i n g machinery with (!)datageneration required (!)to s o r t that generated data with ai. it…
View On WordPress
0 notes
Text
Lead Management System in Nodia by IQ Setters - IT Service Provider Company

#IQLMS#iqsetter#iqsetters#LMS#leadgeneration#datageneration#CRM#qualityleads#leaddistribution#leadmanagement#management#businessoperations#leadnotification#leadmanagementsystem#leadreport#salesforceautomation#salestracking
0 notes
Text

When researchers and scientists can't get their hands on it due to privacy or privacy concerns, synthetic data replaces real data. Simply put, synthetic data is the place of real data. Informationsecurity.report provides the best knowledge regarding Data Generation. If you want to know more about this visit their website
0 notes
Photo

Python fibonacci sequence and memoization. One of the more daring data handling procecces in programming is when recursion and automation data generations are involved. Fibonacci sequence is one of the ways data can be generated using certain mathematical patterns. But if it gets slow and big,some mechanism to optimize data loading for such algorithms need to be employed.And that's where memoization come in. In this slide set,I show you just Abit of what fibonacci sequence are and how to use memoization to solve the slow data loads . #python #fibonaccisequence #memoization #datageneration #computerscience #algorithms #datastructures (at Lilongwe, Malawi) https://www.instagram.com/p/CKWoyOCgxEA/?igshid=1gnb4vn71rhoz
0 notes
Text




CoMPuTEr daTa geNErAL d210
53 notes
·
View notes
Photo
1984

Data General-One (DG1) portable computer, circa 1984.
425 notes
·
View notes
Photo

Do I see a dab in Data General’s promotional poster for the microNOVA?
In many ways they could see the future, but not take part in it
https://www.chipsetc.com/data-general.html
0 notes
Text

Data General Dasher D200 terminal (1980)
169 notes
·
View notes
Photo

NOW Increase your #Sales/#Leads for any Campaign/Process Live and Hot leads #sales #leads #liveleads #hotleads #callcentre #callcenter #insurance #finance #loan #mortgage #tax #website #landingpage #leadtechnology #dailyleads #phonecall #mobileapp #leadgeneration #datageneration #data #usa #uk #india #australia #canada @jainstechnology #jts #jainstechnology For further more details or queries you can DM or contact +91 9662212415 (at Jains Technology Solution OPC Private Limited)
#liveleads#callcentre#callcenter#usa#canada#leads#sales#hotleads#dailyleads#landingpage#phonecall#datageneration#leadgeneration#finance#australia#tax#jts#uk#india#mortgage#insurance#loan#jainstechnology#data#website#leadtechnology#mobileapp
0 notes
Photo

Testing Data General ECLIPSE MV-7800xp tape drive @verdebinario #datageneral #dg #eclipse #aosvs #retrocomputer #retrocomputing #datarecovery #tapes #instanerd #computer #circuit #maker #laboratory #programmable #tech #tecnology #projects #vintagecomputer #broadcasting #oldhardware #instatech #electronicscomponents https://ift.tt/2HjhMZE
12 notes
·
View notes