#Databricks training
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The most popular pages on Tumblr are about Minecraft, GIFs, and David J. Peterson.
Text

Databricks Training
Master Databricks with AccentFuture! Learn data engineering, machine learning, and analytics using Apache Spark. Gain hands-on experience with labs, real-world projects, and expert guidance to accelerate your journey to data mastery.
0 notes
Text

Master data analytics with our Databricks Training and become proficient in big data, Apache Spark, and machine learning. Join our Databricks Online Training for hands-on projects, expert guidance, and flexible learning ideal for beginners and professionals alike.
0 notes
Text
Navigating the Data Landscape: A Deep Dive into ScholarNest's Corporate Training

In the ever-evolving realm of data, mastering the intricacies of data engineering and PySpark is paramount for professionals seeking a competitive edge. ScholarNest's Corporate Training offers an immersive experience, providing a deep dive into the dynamic world of data engineering and PySpark.
Unlocking Data Engineering Excellence
Embark on a journey to become a proficient data engineer with ScholarNest's specialized courses. Our Data Engineering Certification program is meticulously crafted to equip you with the skills needed to design, build, and maintain scalable data systems. From understanding data architecture to implementing robust solutions, our curriculum covers the entire spectrum of data engineering.
Pioneering PySpark Proficiency
Navigate the complexities of data processing with PySpark, a powerful Apache Spark library. ScholarNest's PySpark course, hailed as one of the best online, caters to both beginners and advanced learners. Explore the full potential of PySpark through hands-on projects, gaining practical insights that can be applied directly in real-world scenarios.
Azure Databricks Mastery
As part of our commitment to offering the best, our courses delve into Azure Databricks learning. Azure Databricks, seamlessly integrated with Azure services, is a pivotal tool in the modern data landscape. ScholarNest ensures that you not only understand its functionalities but also leverage it effectively to solve complex data challenges.
Tailored for Corporate Success
ScholarNest's Corporate Training goes beyond generic courses. We tailor our programs to meet the specific needs of corporate environments, ensuring that the skills acquired align with industry demands. Whether you are aiming for data engineering excellence or mastering PySpark, our courses provide a roadmap for success.
Why Choose ScholarNest?
Best PySpark Course Online: Our PySpark courses are recognized for their quality and depth.
Expert Instructors: Learn from industry professionals with hands-on experience.
Comprehensive Curriculum: Covering everything from fundamentals to advanced techniques.
Real-world Application: Practical projects and case studies for hands-on experience.
Flexibility: Choose courses that suit your level, from beginner to advanced.
Navigate the data landscape with confidence through ScholarNest's Corporate Training. Enrol now to embark on a learning journey that not only enhances your skills but also propels your career forward in the rapidly evolving field of data engineering and PySpark.
#data engineering#pyspark#databricks#azure data engineer training#apache spark#databricks cloud#big data#dataanalytics#data engineer#pyspark course#databricks course training#pyspark training
3 notes
·
View notes
Text

Join our latest AWS Data Engineering demo and take your career to the next level!
Attend Online #FREEDEMO from Visualpath on # AWSDataEngineering by Mr.Chandra (Best Industry Expert).
Join Link: https://meet.goto.com/248120661
Free Demo on: 01/02/2025 @9:00AM IST
Contact us: +91 9989971070
Trainer Name: Mr Chandra
WhatsApp: https://www.whatsapp.com/catalog/919989971070/
Visit Blog: https://awsdataengineering1.blogspot.com/
Visit: https://www.visualpath.in/online-aws-data-engineering-course.html
#azuredataengineer#Visualpath#elearning#TechEducation#online#training#students#softwaredevelopment#trainingcourse#handsonlearning#DataFactory#DataBricks#DataLake#software#dataengineering#SynapseAnalytics#ApacheSpark#synapse#NewTechnology#TechSkills#ITSkills#ade#Azure#careergrowth
0 notes
Text

Quiz Time: Which framework does azure data bricks use?. comment your answer below!
To know more about frameworks and other topics in #azureadmin, #azuredevops, #azuredataengineer join in azure trainings
For more details contact
Phone:+91 9882498844
website: https://azuretrainings.in/
Email: [email protected]
0 notes
Text
[Fabric] Leer y escribir storage con Databricks
Muchos lanzamientos y herramientas dentro de una sola plataforma haciendo participar tanto usuarios técnicos (data engineers, data scientists o data analysts) como usuarios finales. Fabric trajo una unión de involucrados en un único espacio. Ahora bien, eso no significa que tengamos que usar todas pero todas pero todas las herramientas que nos presenta.
Si ya disponemos de un excelente proceso de limpieza, transformación o procesamiento de datos con el gran popular Databricks, podemos seguir usándolo.
En posts anteriores hemos hablado que Fabric nos viene a traer un alamacenamiento de lake de última generación con open data format. Esto significa que nos permite utilizar los más populares archivos de datos para almacenar y que su sistema de archivos trabaja con las convencionales estructuras open source. En otras palabras podemos conectarnos a nuestro storage desde herramientas que puedan leerlo. También hemos mostrado un poco de Fabric notebooks y como nos facilita la experiencia de desarrollo.
En este sencillo tip vamos a ver como leer y escribir, desde databricks, nuestro Fabric Lakehouse.
Para poder comunicarnos entre databricks y Fabric lo primero es crear un recurso AzureDatabricks Premium Tier. Lo segundo, asegurarnos de dos cosas en nuestro cluster:
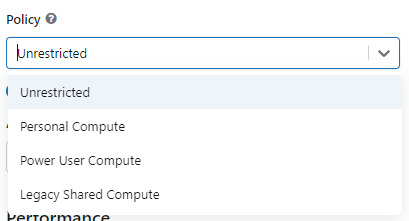
Utilizar un policy "unrestricted" o "power user compute"
2. Asegurarse que databricks podría pasar nuestras credenciales por spark. Eso podemos activarlo en las opciones avanzadas
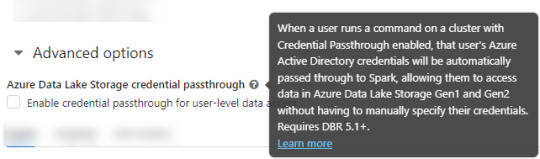
NOTA: No voy a entrar en más detalles de creación de cluster. El resto de las opciones de procesamiento les dejo que investiguen o estimo que ya conocen si están leyendo este post.
Ya creado nuestro cluster vamos a crear un notebook y comenzar a leer data en Fabric. Esto lo vamos a conseguir con el ABFS (Azure Bllob Fyle System) que es una dirección de formato abierto cuyo driver está incluido en Azure Databricks.
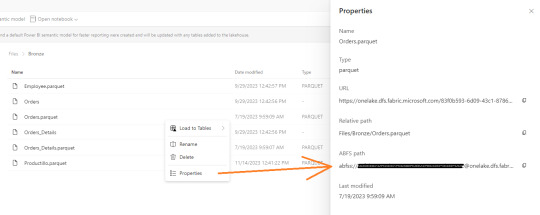
La dirección debe componerse de algo similar a la siguiente cadena:
oneLakePath = 'abfss://[email protected]/myLakehouse.lakehouse/Files/'
Conociendo dicha dirección ya podemos comenzar a trabajar como siempre. Veamos un simple notebook que para leer un archivo parquet en Lakehouse Fabric
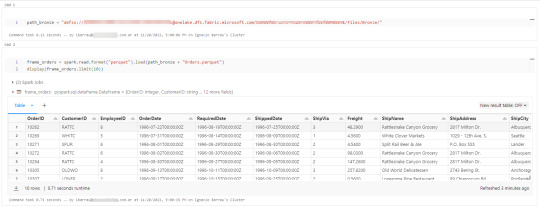
Gracias a la configuración del cluster, los procesos son tan simples como spark.read
Así de simple también será escribir.

Iniciando con una limpieza de columnas innecesarias y con un sencillo [frame].write ya tendremos la tabla en silver limpia.
Nos vamos a Fabric y podremos encontrarla en nuestro Lakehouse
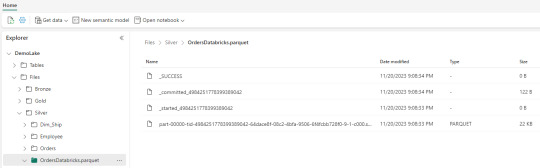
Así concluye nuestro procesamiento de databricks en lakehouse de Fabric, pero no el artículo. Todavía no hablamos sobre el otro tipo de almacenamiento en el blog pero vamos a mencionar lo que pertine a ésta lectura.
Los Warehouses en Fabric también están constituidos con una estructura tradicional de lake de última generación. Su principal diferencia consiste en brindar una experiencia de usuario 100% basada en SQL como si estuvieramos trabajando en una base de datos. Sin embargo, por detras, podrémos encontrar delta como un spark catalog o metastore.
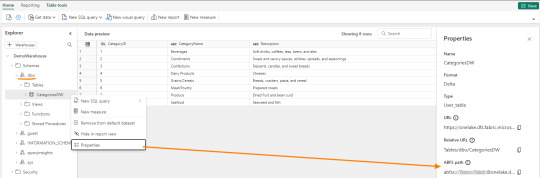
El path debería verse similar a esto:
path_dw = "abfss://[email protected]/WarehouseName.Datawarehouse/Tables/dbo/"
Teniendo en cuenta que Fabric busca tener contenido delta en su Spark Catalog de Lakehouse (tables) y en su Warehouse, vamos a leer como muestra el siguiente ejemplo
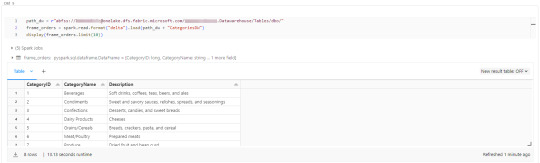
Ahora si concluye nuestro artículo mostrando como podemos utilizar Databricks para trabajar con los almacenamientos de Fabric.
#fabric#microsoftfabric#fabric cordoba#fabric jujuy#fabric argentina#fabric tips#fabric tutorial#fabric training#fabric databricks#databricks#azure databricks#pyspark
0 notes
Text


Skillup Yourself with #Azure #Power BI and #SQL
#azuretraining#azure data engineer course#azure data engineer training#azuredatafactory#azure data engineer online training#sqlschool#sql school training#azure databricks training#azure data engineer projects
0 notes
Text

Boost your career with AccentFuture's Databricks online training. Learn from industry experts, master real-time data analytics, and get hands-on experience with Databricks tools. Flexible learning, job-ready skills, and certification support included.
#course training#databricks online training#databricks training#databricks training course#learn databricks
0 notes
Text
#Apache Spark Databricks tutorial#Best data engineering tools 2025#Data engineering with Databricks#Databricks certification course#Databricks training#learn databricks in 2025#Learn Databricks online
0 notes
Text
From Beginner to Pro: The Best PySpark Courses Online from ScholarNest Technologies

Are you ready to embark on a journey from a PySpark novice to a seasoned pro? Look no further! ScholarNest Technologies brings you a comprehensive array of PySpark courses designed to cater to every skill level. Let's delve into the key aspects that make these courses stand out:
1. What is PySpark?
Gain a fundamental understanding of PySpark, the powerful Python library for Apache Spark. Uncover the architecture and explore its diverse applications in the world of big data.
2. Learning PySpark by Example:
Experience is the best teacher! Our courses focus on hands-on examples, allowing you to apply your theoretical knowledge to real-world scenarios. Learn by doing and enhance your problem-solving skills.
3. PySpark Certification:
Elevate your career with our PySpark certification programs. Validate your expertise and showcase your proficiency in handling big data tasks using PySpark.
4. Structured Learning Paths:
Whether you're a beginner or seeking advanced concepts, our courses offer structured learning paths. Progress at your own pace, mastering each skill before moving on to the next level.
5. Specialization in Big Data Engineering:
Our certification course on big data engineering with PySpark provides in-depth insights into the intricacies of handling vast datasets. Acquire the skills needed for a successful career in big data.
6. Integration with Databricks:
Explore the integration of PySpark with Databricks, a cloud-based big data platform. Understand how these technologies synergize to provide scalable and efficient solutions.
7. Expert Instruction:
Learn from the best! Our courses are crafted by top-rated data science instructors, ensuring that you receive expert guidance throughout your learning journey.
8. Online Convenience:
Enroll in our online PySpark courses and access a wealth of knowledge from the comfort of your home. Flexible schedules and convenient online platforms make learning a breeze.
Whether you're a data science enthusiast, a budding analyst, or an experienced professional looking to upskill, ScholarNest's PySpark courses offer a pathway to success. Master the skills, earn certifications, and unlock new opportunities in the world of big data engineering!
#big data#data engineering#data engineering certification#data engineering course#databricks data engineer certification#pyspark course#databricks courses online#best pyspark course online#pyspark online course#databricks learning#data engineering courses in bangalore#data engineering courses in india#azure databricks learning#pyspark training course#pyspark certification course
1 note
·
View note
Text
What EDAV does:
Connects people with data faster. It does this in a few ways. EDAV:
Hosts tools that support the analytics work of over 3,500 people.
Stores data on a common platform that is accessible to CDC's data scientists and partners.
Simplifies complex data analysis steps.
Automates repeatable tasks, such as dashboard updates, freeing up staff time and resources.
Keeps data secure. Data represent people, and the privacy of people's information is critically important to CDC. EDAV is hosted on CDC's Cloud to ensure data are shared securely and that privacy is protected.
Saves time and money. EDAV services can quickly and easily scale up to meet surges in demand for data science and engineering tools, such as during a disease outbreak. The services can also scale down quickly, saving funds when demand decreases or an outbreak ends.
Trains CDC's staff on new tools. EDAV hosts a Data Academy that offers training designed to help our workforce build their data science skills, including self-paced courses in Power BI, R, Socrata, Tableau, Databricks, Azure Data Factory, and more.
Changes how CDC works. For the first time, EDAV offers CDC's experts a common set of tools that can be used for any disease or condition. It's ready to handle "big data," can bring in entirely new sources of data like social media feeds, and enables CDC's scientists to create interactive dashboards and apply technologies like artificial intelligence for deeper analysis.
4 notes
·
View notes
Text
Google Cloud’s BigQuery Autonomous Data To AI Platform

BigQuery automates data analysis, transformation, and insight generation using AI. AI and natural language interaction simplify difficult operations.
The fast-paced world needs data access and a real-time data activation flywheel. Artificial intelligence that integrates directly into the data environment and works with intelligent agents is emerging. These catalysts open doors and enable self-directed, rapid action, which is vital for success. This flywheel uses Google's Data & AI Cloud to activate data in real time. BigQuery has five times more organisations than the two leading cloud providers that just offer data science and data warehousing solutions due to this emphasis.
Examples of top companies:
With BigQuery, Radisson Hotel Group enhanced campaign productivity by 50% and revenue by over 20% by fine-tuning the Gemini model.
By connecting over 170 data sources with BigQuery, Gordon Food Service established a scalable, modern, AI-ready data architecture. This improved real-time response to critical business demands, enabled complete analytics, boosted client usage of their ordering systems, and offered staff rapid insights while cutting costs and boosting market share.
J.B. Hunt is revolutionising logistics for shippers and carriers by integrating Databricks into BigQuery.
General Mills saves over $100 million using BigQuery and Vertex AI to give workers secure access to LLMs for structured and unstructured data searches.
Google Cloud is unveiling many new features with its autonomous data to AI platform powered by BigQuery and Looker, a unified, trustworthy, and conversational BI platform:
New assistive and agentic experiences based on your trusted data and available through BigQuery and Looker will make data scientists, data engineers, analysts, and business users' jobs simpler and faster.
Advanced analytics and data science acceleration: Along with seamless integration with real-time and open-source technologies, BigQuery AI-assisted notebooks improve data science workflows and BigQuery AI Query Engine provides fresh insights.
Autonomous data foundation: BigQuery can collect, manage, and orchestrate any data with its new autonomous features, which include native support for unstructured data processing and open data formats like Iceberg.
Look at each change in detail.
User-specific agents
It believes everyone should have AI. BigQuery and Looker made AI-powered helpful experiences generally available, but Google Cloud now offers specialised agents for all data chores, such as:
Data engineering agents integrated with BigQuery pipelines help create data pipelines, convert and enhance data, discover anomalies, and automate metadata development. These agents provide trustworthy data and replace time-consuming and repetitive tasks, enhancing data team productivity. Data engineers traditionally spend hours cleaning, processing, and confirming data.
The data science agent in Google's Colab notebook enables model development at every step. Scalable training, intelligent model selection, automated feature engineering, and faster iteration are possible. This agent lets data science teams focus on complex methods rather than data and infrastructure.
Looker conversational analytics lets everyone utilise natural language with data. Expanded capabilities provided with DeepMind let all users understand the agent's actions and easily resolve misconceptions by undertaking advanced analysis and explaining its logic. Looker's semantic layer boosts accuracy by two-thirds. The agent understands business language like “revenue” and “segments” and can compute metrics in real time, ensuring trustworthy, accurate, and relevant results. An API for conversational analytics is also being introduced to help developers integrate it into processes and apps.
In the BigQuery autonomous data to AI platform, Google Cloud introduced the BigQuery knowledge engine to power assistive and agentic experiences. It models data associations, suggests business vocabulary words, and creates metadata instantaneously using Gemini's table descriptions, query histories, and schema connections. This knowledge engine grounds AI and agents in business context, enabling semantic search across BigQuery and AI-powered data insights.
All customers may access Gemini-powered agentic and assistive experiences in BigQuery and Looker without add-ons in the existing price model tiers!
Accelerating data science and advanced analytics
BigQuery autonomous data to AI platform is revolutionising data science and analytics by enabling new AI-driven data science experiences and engines to manage complex data and provide real-time analytics.
First, AI improves BigQuery notebooks. It adds intelligent SQL cells to your notebook that can merge data sources, comprehend data context, and make code-writing suggestions. It also uses native exploratory analysis and visualisation capabilities for data exploration and peer collaboration. Data scientists can also schedule analyses and update insights. Google Cloud also lets you construct laptop-driven, dynamic, user-friendly, interactive data apps to share insights across the organisation.
This enhanced notebook experience is complemented by the BigQuery AI query engine for AI-driven analytics. This engine lets data scientists easily manage organised and unstructured data and add real-world context—not simply retrieve it. BigQuery AI co-processes SQL and Gemini, adding runtime verbal comprehension, reasoning skills, and real-world knowledge. Their new engine processes unstructured photographs and matches them to your product catalogue. This engine supports several use cases, including model enhancement, sophisticated segmentation, and new insights.
Additionally, it provides users with the most cloud-optimized open-source environment. Google Cloud for Apache Kafka enables real-time data pipelines for event sourcing, model scoring, communications, and analytics in BigQuery for serverless Apache Spark execution. Customers have almost doubled their serverless Spark use in the last year, and Google Cloud has upgraded this engine to handle data 2.7 times faster.
BigQuery lets data scientists utilise SQL, Spark, or foundation models on Google's serverless and scalable architecture to innovate faster without the challenges of traditional infrastructure.
An independent data foundation throughout data lifetime
An independent data foundation created for modern data complexity supports its advanced analytics engines and specialised agents. BigQuery is transforming the environment by making unstructured data first-class citizens. New platform features, such as orchestration for a variety of data workloads, autonomous and invisible governance, and open formats for flexibility, ensure that your data is always ready for data science or artificial intelligence issues. It does this while giving the best cost and decreasing operational overhead.
For many companies, unstructured data is their biggest untapped potential. Even while structured data provides analytical avenues, unique ideas in text, audio, video, and photographs are often underutilised and discovered in siloed systems. BigQuery instantly tackles this issue by making unstructured data a first-class citizen using multimodal tables (preview), which integrate structured data with rich, complex data types for unified querying and storage.
Google Cloud's expanded BigQuery governance enables data stewards and professionals a single perspective to manage discovery, classification, curation, quality, usage, and sharing, including automatic cataloguing and metadata production, to efficiently manage this large data estate. BigQuery continuous queries use SQL to analyse and act on streaming data regardless of format, ensuring timely insights from all your data streams.
Customers utilise Google's AI models in BigQuery for multimodal analysis 16 times more than last year, driven by advanced support for structured and unstructured multimodal data. BigQuery with Vertex AI are 8–16 times cheaper than independent data warehouse and AI solutions.
Google Cloud maintains open ecology. BigQuery tables for Apache Iceberg combine BigQuery's performance and integrated capabilities with the flexibility of an open data lakehouse to link Iceberg data to SQL, Spark, AI, and third-party engines in an open and interoperable fashion. This service provides adaptive and autonomous table management, high-performance streaming, auto-AI-generated insights, practically infinite serverless scalability, and improved governance. Cloud storage enables fail-safe features and centralised fine-grained access control management in their managed solution.
Finaly, AI platform autonomous data optimises. Scaling resources, managing workloads, and ensuring cost-effectiveness are its competencies. The new BigQuery spend commit unifies spending throughout BigQuery platform and allows flexibility in shifting spend across streaming, governance, data processing engines, and more, making purchase easier.
Start your data and AI adventure with BigQuery data migration. Google Cloud wants to know how you innovate with data.
#technology#technews#govindhtech#news#technologynews#BigQuery autonomous data to AI platform#BigQuery#autonomous data to AI platform#BigQuery platform#autonomous data#BigQuery AI Query Engine
2 notes
·
View notes
Text
Master Big Data with a Comprehensive Databricks Course
A Databricks Course is the perfect way to master big data analytics and Apache Spark. Whether you are a beginner or an experienced professional, this course helps you build expertise in data engineering, AI-driven analytics, and cloud-based collaboration. You will learn how to work with Spark SQL, Delta Lake, and MLflow to process large datasets and create smart data solutions.
This Databricks Course provides hands-on training with real-world projects, allowing you to apply your knowledge effectively. Learn from industry experts who will guide you through data transformation, real-time streaming, and optimizing data workflows. The course also covers managing both structured and unstructured data, helping you make better data-driven decisions.
By enrolling in this Databricks Course, you will gain valuable skills that are highly sought after in the tech industry. Engage with specialists and improve your ability to handle big data analytics at scale. Whether you want to advance your career or stay ahead in the fast-growing data industry, this course equips you with the right tools.
🚀 Enroll now and start your journey toward mastering big data analytics with Databricks!
2 notes
·
View notes
Text
Azure Data Factory Training In Hyderabad
Key Features:
Hybrid Data Integration: Azure Data Factory supports hybrid data integration, allowing users to connect and integrate data from on-premises sources, cloud-based services, and various data stores. This flexibility is crucial for organizations with diverse data ecosystems.
Intuitive Visual Interface: The platform offers a user-friendly, visual interface for designing and managing data pipelines. Users can leverage a drag-and-drop interface to effortlessly create, monitor, and manage complex data workflows without the need for extensive coding expertise.

Data Movement and Transformation: Data movement is streamlined with Azure Data Factory, enabling the efficient transfer of data between various sources and destinations. Additionally, the platform provides a range of data transformation activities, such as cleansing, aggregation, and enrichment, ensuring that data is prepared and optimized for analysis.
Data Orchestration: Organizations can orchestrate complex workflows by chaining together multiple data pipelines, activities, and dependencies. This orchestration capability ensures that data processes are executed in a logical and efficient sequence, meeting business requirements and compliance standards.
Integration with Azure Services: Azure Data Factory seamlessly integrates with other Azure services, including Azure Synapse Analytics, Azure Databricks, Azure Machine Learning, and more. This integration enhances the platform's capabilities, allowing users to leverage additional tools and services to derive deeper insights from their data.
Monitoring and Management: Robust monitoring and management capabilities provide real-time insights into the performance and health of data pipelines. Users can track execution details, diagnose issues, and optimize workflows to enhance overall efficiency.
Security and Compliance: Azure Data Factory prioritizes security and compliance, implementing features such as Azure Active Directory integration, encryption at rest and in transit, and role-based access control. This ensures that sensitive data is handled securely and in accordance with regulatory requirements.
Scalability and Reliability: The platform is designed to scale horizontally, accommodating the growing needs of organizations as their data volumes increase. With built-in reliability features, Azure Data Factory ensures that data processes are executed consistently and without disruptions.
2 notes
·
View notes
Text
DOGE "engineers" are:
Akash Bobba: "investment engineering intern at the Bridgewater Associates hedge fund as of last spring, and previously an intern at both Meta and Palantir"
Edward Coristine: "appears to have recently graduated from high school and to have been enrolled at Northeastern University. According to a copy of his resume obtained by WIRED, he spent three months at Neuralink, Musk’s brain-computer interface company, last summer."
Luke Farritor: "former intern at SpaceX and currently a Thiel Fellow after, according to his LinkedIn, dropping out of the University of Nebraska-Lincoln. While in school, he was part of an award-winning team that deciphered portions of an ancient Greek scroll."
Gautier Cole Killian: "attended UC Berkeley until 2020; most recently, according to his LinkedIn, he worked for the AI company Databricks." Has a Substack.
Gavin Kliger: volunteer with DOGE, "attended McGill University through at least 2021 and graduated high school in 2019," former engineer at Jump Training.
Ethan Shaotran: "told Business Insider in September that he was a senior at Harvard studying computer science, and also the founder of an OpenAI-backed startup, Energize AI. Shaotran was the runner-up in a hackathon held by xAI, Musk’s AI company."

(BSky Post)
“WIRED has identified six young men—all apparently between the ages of 19 and 24, according to public databases, their online presences, and other records—who have little to no government experience and are now playing critical roles in Musk’s so-called Department of Government Efficiency (DOGE) project, tasked by executive order with “modernizing Federal technology and software to maximize governmental efficiency and productivity.” The engineers all hold nebulous job titles within DOGE, and at least one appears to be working as a volunteer. The engineers are Akash Bobba, Edward Coristine, Luke Farritor, Gautier Cole Killian, Gavin Kliger, and Ethan Shaotran. None have responded to requests for comment from WIRED. Representatives from OPM, GSA, and DOGE did not respond to requests for comment.”
—
The Young, Inexperienced Engineers Aiding Elon Musk’s Government Takeover
This is insane. These children can’t even rent a car.
Why aren’t Democrats at Defcon 1? Honestly. I don’t understand why this is happening and there isn’t a loud and forceful response from the opposition. Schumer is droning on about the price of tomatoes, while these unvetted kids are installing root kits, for fuck’s sake.
4K notes
·
View notes
Text
Master the Future: Become a Databricks Certified Generative AI Engineer

What if we told you that one certification could position you at the crossroads of AI innovation, high-paying job opportunities, and technical leadership?
That’s exactly what the Databricks Certified Generative AI Engineer certification does. As generative AI explodes across industries, skilled professionals who can bridge the gap between AI theory and real-world data solutions are in high demand. Databricks, a company at the forefront of data and AI, now offers a credential designed for those who want to lead the next wave of innovation.
If you're someone looking to validate your AI engineering skills with an in-demand, globally respected certification, keep reading. This blog will guide you through what the certification is, why it’s valuable, how to prepare effectively, and how it can launch or elevate your tech career.
Why the Databricks Certified Generative AI Engineer Certification Matters
Let’s start with the basics: why should you care about this certification?
Databricks has become synonymous with large-scale data processing, AI model deployment, and seamless ML integration across platforms. As AI continues to evolve into Generative AI, the need for professionals who can implement real-world solutions—using tools like Databricks Unity Catalog, MLflow, Apache Spark, and Lakehouse architecture—is only going to grow.
This certification tells employers that:
You can design and implement generative AI models.
You understand the complexities of data management in modern AI systems.
You know how to use Databricks tools to scale and deploy these models effectively.
For tech professionals, data scientists, ML engineers, and cloud developers, this isn't just a badge—it's a career accelerator.
Who Should Pursue This Certification?
The Databricks Certified Generative AI Engineer path is for:
Data Scientists & Machine Learning Engineers who want to shift into more cutting-edge roles.
Cloud Developers working with AI pipelines in enterprise environments.
AI Enthusiasts and Researchers ready to demonstrate their applied knowledge.
Professionals preparing for AI roles at companies using Databricks, Azure, AWS, or Google Cloud.
If you’re familiar with Python, machine learning fundamentals, and basic model deployment workflows, you’re ready to get started.
What You'll Learn: Core Skills Covered
The exam and its preparation cover a broad but practical set of topics:
🧠 1. Foundation of Generative AI
What is generative AI?
How do models like GPT, DALL·E, and Stable Diffusion actually work?
Introduction to transformer architectures and tokenization.
📊 2. Databricks Ecosystem
Using Databricks notebooks and workflows
Unity Catalog for data governance and model security
Integrating MLflow for reproducibility and experiment tracking
���� 3. Model Training & Tuning
Fine-tuning foundation models on your data
Optimizing training with distributed computing
Managing costs and resource allocation
⚙️ 4. Deployment & Monitoring
Creating real-time endpoints
Model versioning and rollback strategies
Using MLflow’s model registry for lifecycle tracking
🔐 5. Responsible AI & Ethics
Bias detection and mitigation
Privacy-preserving machine learning
Explainability and fairness
Each of these topics is deeply embedded in the exam and reflects current best practices in the industry.
Why Databricks Is Leading the AI Charge
Databricks isn’t just a platform—it’s a movement. With its Lakehouse architecture, the company bridges the gap between data warehouses and data lakes, providing a unified platform to manage and deploy AI solutions.
Databricks is already trusted by organizations like:
Comcast
Shell
HSBC
Regeneron Pharmaceuticals
So, when you add a Databricks Certified Generative AI Engineer credential to your profile, you’re aligning yourself with the tools and platforms that Fortune 500 companies rely on.
What’s the Exam Format?
Here’s what to expect:
Multiple choice and scenario-based questions
90 minutes total
Around 60 questions
Online proctored format
You’ll be tested on:
Generative AI fundamentals
Databricks-specific tools
Model development, deployment, and monitoring
Data handling in an AI lifecycle
How to Prepare: Your Study Blueprint
Passing this certification isn’t about memorizing definitions. It’s about understanding workflows, being able to apply best practices, and showing proficiency in a Databricks-native AI environment.
Step 1: Enroll in a Solid Practice Course
The most effective way to prepare is to take mock tests and get hands-on experience. We recommend enrolling in the Databricks Certified Generative AI Engineer practice test course, which gives you access to realistic exam-style questions, explanations, and performance feedback.
Step 2: Set Up a Databricks Workspace
If you don’t already have one, create a free Databricks Community Edition workspace. Explore notebooks, work with data in Delta Lake, and train a simple model using MLflow.
Step 3: Focus on the Databricks Stack
Make sure you’re confident using:
Databricks Notebooks
MLflow
Unity Catalog
Model Serving
Feature Store
Step 4: Review Key AI Concepts
Brush up on:
Transformer models and attention mechanisms
Fine-tuning vs. prompt engineering
Transfer learning
Generative model evaluation metrics (BLEU, ROUGE, etc.)
What Makes This Certification Unique?
Unlike many AI certifications that stay theoretical, this one is deeply practical. You’ll not only learn what generative AI is but also how to build and manage it in production.
Here are three reasons this stands out:
✅ 1. Real-world Integration
You’ll learn deployment, version control, and monitoring—which is what companies care about most.
✅ 2. Based on Industry-Proven Tools
Everything is built on top of Databricks, Apache Spark, and MLflow, used by data teams globally.
✅ 3. Focus on Modern AI Workflows
This certification keeps pace with the rapid evolution of AI—especially around LLMs (Large Language Models), prompt engineering, and GenAI use cases.
How It Benefits Your Career
Once certified, you’ll be well-positioned to:
Land roles like AI Engineer, ML Engineer, or Data Scientist in leading tech firms.
Negotiate a higher salary thanks to your verified skills.
Work on cutting-edge projects in AI, including enterprise chatbots, text summarization, image generation, and more.
Stand out in competitive job markets with a Databricks-backed credential on your LinkedIn.
According to recent industry trends, professionals with AI certifications earn an average of 20-30% more than those without.
Use Cases You’ll Be Ready to Tackle
After completing the course and passing the exam, you’ll be able to confidently work on:
Enterprise chatbots using foundation models
Real-time content moderation
AI-driven customer service agents
Medical imaging enhancement
Financial fraud detection using pattern generation
The scope is broad—and the possibilities are endless.
Don’t Just Study—Practice
It’s tempting to dive into study guides or YouTube videos, but what really works is practice. The Databricks Certified Generative AI Engineer practice course offers exam-style challenges that simulate the pressure and format of the real exam.
You’ll learn by doing—and that makes all the difference.
Final Thoughts: The Time to Act Is Now
Generative AI isn’t the future anymore—it’s the present. Companies across every sector are racing to integrate it. The question is:
Will you be ready to lead that charge?
If your goal is to become an in-demand AI expert with practical, validated skills, earning the Databricks Certified Generative AI Engineer credential is the move to make.
Start today. Equip yourself with the skills the industry is hungry for. Stand out. Level up.
👉 Enroll in the Databricks Certified Generative AI Engineer practice course now and take control of your AI journey.
🔍 Keyword Optimiz
0 notes