#Elasticsearch Developers
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has a 66 index score for customer satisfaction in the US.
Text
Hire Expert Elasticsearch Developers to Accelerate Search Performance & Business Insights
Looking to enhance your application’s search capabilities and scale with confidence? Hire expert Elasticsearch developers from Prosperasoft to power smarter, faster, and more secure search solutions across your digital platforms.
Our seasoned Elasticsearch team brings deep technical expertise across E-commerce, Fintech, Healthcare, SaaS, and more. From seamless cloud migrations to performance optimization, we ensure your search engine is fast, scalable, and secure.
Why Prosperasoft? ✅ 100+ customized Elasticsearch solutions delivered ✅ Trusted by 50+ global startups & enterprises ✅ Lightning-fast onboarding & flexible contracts ✅ 24/7 production support and emergency response ✅ Enterprise-grade consulting with strict NDA protection
We go beyond basic implementation. Our experts help you unlock real-time business insights and enhance search relevance with advanced ELK stack integration, cloud migration, and version upgrades.
Get started today and transform your user search experience with confidence. 🔎 Hire expert Elasticsearch developers now
#Hire Expert Elasticsearch Developers#Expert Elasticsearch Developers#Elasticsearch Developers#elasticsearch consulting#hire elasticsearch developer#elasticsearch developer for hire
0 notes
Text
Elasticsearch with Ruby on Rails: Enhanced Search Capabilities
Integrating Elasticsearch with Ruby on Rails can significantly boost your application's search capabilities, providing fast and scalable search functionality. By leveraging Elasticsearch, you can enhance the user experience with real-time, advanced query options, allowing users to quickly and efficiently find the information they need. This integration not only improves search performance but also offers a robust solution for handling large volumes of data, making your application more responsive and user-friendly.

#Elasticsearch with Ruby on Rails#ruby on rails development#ruby on rails development company#ruby on rails company#ruby on rails development services#offshore ruby on rails development#ruby on rails development agency#ruby on rails development india#ruby on rails development firm#custom ruby on rails development services#ruby on rails development company usa#ruby on rails development company in india#ruby on rails development company india#hire ruby on rails development company#offshore ruby on rails development company#ruby on rails development new york#hire ruby on rails development companies#top ruby on rails development company#ruby on rails development companies in india#rails development companies#rails development company#ruby development company#rails company#rails development#ruby development#ruby on rails development companies#ruby on rails companies#ruby on rails web development#best ruby on rails companies#ruby on rails agency
0 notes
Text
Integrating Django with Elasticsearch: A Comprehensive Guide
Introduction:In modern web applications, search functionality plays a crucial role in enhancing user experience by enabling quick and efficient data retrieval. Elasticsearch, a powerful open-source search and analytics engine, is designed for handling large-scale data and complex queries at lightning speed. Integrating Elasticsearch with Django allows you to build scalable, high-performance…
#Database Indexing#Django#Elasticsearch#Full-Text Search#Python#REST API Integration#Search Engine#web development
0 notes
Text
Unnecessarily compiling sensitive information can be as damaging as actively trying to steal it. For example, the Cybernews research team discovered a plethora of supermassive datasets, housing billions upon billions of login credentials. From social media and corporate platforms to VPNs and developer portals, no stone was left unturned.
Our team has been closely monitoring the web since the beginning of the year. So far, they’ve discovered 30 exposed datasets containing from tens of millions to over 3.5 billion records each. In total, the researchers uncovered an unimaginable 16 billion records.
None of the exposed datasets were reported previously, bar one: in late May, Wired magazine reported a security researcher discovering a “mysterious database” with 184 million records. It barely scratches the top 20 of what the team discovered. Most worryingly, researchers claim new massive datasets emerge every few weeks, signaling how prevalent infostealer malware truly is.
“This is not just a leak – it’s a blueprint for mass exploitation. With over 16 billion login records exposed, cybercriminals now have unprecedented access to personal credentials that can be used for account takeover, identity theft, and highly targeted phishing. What’s especially concerning is the structure and recency of these datasets ��� these aren’t just old breaches being recycled. This is fresh, weaponizable intelligence at scale,” researchers said.
The only silver lining here is that all of the datasets were exposed only briefly: long enough for researchers to uncover them, but not long enough to find who was controlling vast amounts of data. Most of the datasets were temporarily accessible through unsecured Elasticsearch or object storage instances.
What do the billions of exposed records contain?
Researchers claim that most of the data in the leaked datasets is a mix of details from stealer malware, credential stuffing sets, and repackaged leaks.
There was no way to effectively compare the data between different datasets, but it’s safe to say overlapping records are definitely present. In other words, it’s impossible to tell how many people or accounts were actually exposed.
However, the information that the team managed to gather revealed that most of the information followed a clear structure: URL, followed by login details and a password. Most modern infostealers – malicious software stealing sensitive information – collect data in exactly this way.
Information in the leaked datasets opens the doors to pretty much any online service imaginable, from Apple, Facebook, and Google, to GitHub, Telegram, and various government services. It’s hard to miss something when 16 billion records are on the table.
According to the researchers, credential leaks at this scale are fuel for phishing campaigns, account takeovers, ransomware intrusions, and business email compromise (BEC) attacks.
“The inclusion of both old and recent infostealer logs – often with tokens, cookies, and metadata – makes this data particularly dangerous for organizations lacking multi-factor authentication or credential hygiene practices,” the team said.
What dataset exposed billions of credentials?
The datasets that the team uncovered differ widely. For example, the smallest, named after malicious software, had over 16 million records. Meanwhile, the largest one, most likely related to the Portuguese-speaking population, had over 3.5 billion records. On average, one dataset with exposed credentials had 550 million records.
Some of the datasets were named generically, such as “logins,” “credentials,” and similar terms, preventing the team from getting a better understanding of what’s inside. Others, however, hinted at the services they’re related to.
For example, one dataset with over 455 million records was named to indicate its origins in the Russian Federation. Another dataset, with over 60 million records, was named after Telegram, a cloud-based instant messaging platform.
“The inclusion of both old and recent infostealer logs – often with tokens, cookies, and metadata – makes this data particularly dangerous for organizations lacking multi-factor authentication or credential hygiene practices,”
While naming is not the best way to deduce where the data comes from, it seems some of the information relates to cloud services, business-oriented data, and even locked files. Some dataset names likely point to a form of malware that was used to collect the data.
It is unclear who owns the leaked data. While it could be security researchers that compile data to check and monitor data leaks, it’s virtually guaranteed that some of the leaked datasets were owned by cybercriminals. Cybercriminals love massive datasets as aggregated collections allow them to scale up various types of attacks, such as identity theft, phishing schemes, and unauthorized access.
A success rate of less than a percent can open doors to millions of individuals, who can be tricked into revealing more sensitive details, such as financial accounts. Worryingly, since it's unclear who owns the exposed datasets, there’s little impact users can do to protect themselves.
However, basic cyber hygiene is essential. Using a password manager to generate strong, unique passwords, and updating them regularly, can be the difference between a safe account and stolen details. Users should also review their systems for infostealers, to avoid losing their data to attackers.
No, Facebook, Google, and Apple passwords weren’t leaked. Or were they?
With a dataset containing 16 billion passwords, that’s equivalent to two leaked accounts for every person on the planet.
We don’t really know how many duplicate records there are, as the leak comes from multiple datasets. However, some reporting by other media outlets can be quite misleading. Some claim that Facebook, Google, and Apple credentials were leaked. While we can’t completely dismiss such claims, we feel this is somewhat inaccurate.
Bob Diachenko, a Cybernews contributor, cybersecurity researcher, and owner of SecurityDiscovery.com, is behind this recent major discovery.
16-billion-record data breach signals a shift in the underground world
According to Cybernews researcher Aras Nazarovas, this discovery might signal that criminals are abandoning previously popular methods of obtaining stolen data.
"The increased number of exposed infostealer datasets in the form of centralized, traditional databases, like the ones found be the Cybernews research team, may be a sign, that cybercriminals are actively shifting from previously popular alternatives such as Telegram groups, which were previously the go-to place for obtaining data collected by infostealer malware," Nazarovas said.
He regularly works with exposed datasets, ensuring that defenders secure them before threat actors can access them.
Here’s what Nazarovas suggests you should do to protect yourself.
"Some of the exposed datasets included information such as cookies and session tokens, which makes the mitigation of such exposure more difficult. These cookies can often be used to bypass 2FA methods, and not all services reset these cookies after changing the account password. Best bet in this case is to change your passwords, enable 2FA, if it is not yet enabled, closely monitor your accounts, and contact customer support if suspicious activity is detected."
Billions of records exposed online: recent leaks involve WeChat, Alipay
Major data leaks, with billions of exposed records, have become nearly ubiquitous. Last week, Cybernews wrote about what is likely the biggest data leak to ever hit China, billions of documents with financial data, WeChat and Alipay details, as well as other sensitive personal data.
Last summer, the largest password compilation with nearly ten billion unique passwords, RockYou2024, was leaked on a popular hacking forum. In 2021, a similar compilation with over 8 billion records was leaked online.
In early 2024, the Cybernews research team discovered what is likely still the largest data leak ever: the Mother of All Breaches (MOAB), with a mind-boggling 26 billion records.
16 billion passwords exposed: how to protect yourself
Huge datasets of passwords spill onto the dark web all the time, highlighting the need to change them regularly. This also demonstrates just how weak our passwords still are.
Last year, someone leaked the largest password compilation ever, with nearly ten billion unique passwords published online. Such leaks pose severe threats to people who are prone to reusing passwords.
Even if you think you are immune to this or other leaks, go and reset your passwords just in case.
Select strong, unique passwords that are not reused across multiple platforms
Enable multi-factor authentication (MFA) wherever possible
Closely monitor your accounts
Contact customer support in case of any suspicious activity
3 notes
·
View notes
Text
🚀 Exploring Kafka: Scenario-Based Questions 📊
Dear community, As Kafka continues to shape modern data architectures, it's crucial for professionals to delve into scenario-based questions to deepen their understanding and application. Whether you're a seasoned Kafka developer or just starting out, here are some key scenarios to ponder: 1️⃣ **Scaling Challenges**: How would you design a Kafka cluster to handle a sudden surge in incoming data without compromising latency? 2️⃣ **Fault Tolerance**: Describe the steps you would take to ensure high availability in a Kafka setup, considering both hardware and software failures. 3️⃣ **Performance Tuning**: What metrics would you monitor to optimize Kafka producer and consumer performance in a high-throughput environment? 4️⃣ **Security Measures**: How do you secure Kafka clusters against unauthorized access and data breaches? What are some best practices? 5️⃣ **Integration with Ecosystem**: Discuss a real-world scenario where Kafka is integrated with other technologies like Spark, Hadoop, or Elasticsearch. What challenges did you face and how did you overcome them? Follow : https://algo2ace.com/kafka-stream-scenario-based-interview-questions/
#Kafka #BigData #DataEngineering #TechQuestions #ApacheKafka #BigData #Interview
2 notes
·
View notes
Text
Navigating the DevOps Landscape: Opportunities and Roles
DevOps has become a game-changer in the quick-moving world of technology. This dynamic process, whose name is a combination of "Development" and "Operations," is revolutionising the way software is created, tested, and deployed. DevOps is a cultural shift that encourages cooperation, automation, and integration between development and IT operations teams, not merely a set of practises. The outcome? greater software delivery speed, dependability, and effectiveness.

In this comprehensive guide, we'll delve into the essence of DevOps, explore the key technologies that underpin its success, and uncover the vast array of job opportunities it offers. Whether you're an aspiring IT professional looking to enter the world of DevOps or an experienced practitioner seeking to enhance your skills, this blog will serve as your roadmap to mastering DevOps. So, let's embark on this enlightening journey into the realm of DevOps.
Key Technologies for DevOps:
Version Control Systems: DevOps teams rely heavily on robust version control systems such as Git and SVN. These systems are instrumental in managing and tracking changes in code and configurations, promoting collaboration and ensuring the integrity of the software development process.
Continuous Integration/Continuous Deployment (CI/CD): The heart of DevOps, CI/CD tools like Jenkins, Travis CI, and CircleCI drive the automation of critical processes. They orchestrate the building, testing, and deployment of code changes, enabling rapid, reliable, and consistent software releases.
Configuration Management: Tools like Ansible, Puppet, and Chef are the architects of automation in the DevOps landscape. They facilitate the automated provisioning and management of infrastructure and application configurations, ensuring consistency and efficiency.
Containerization: Docker and Kubernetes, the cornerstones of containerization, are pivotal in the DevOps toolkit. They empower the creation, deployment, and management of containers that encapsulate applications and their dependencies, simplifying deployment and scaling.
Orchestration: Docker Swarm and Amazon ECS take center stage in orchestrating and managing containerized applications at scale. They provide the control and coordination required to maintain the efficiency and reliability of containerized systems.
Monitoring and Logging: The observability of applications and systems is essential in the DevOps workflow. Monitoring and logging tools like the ELK Stack (Elasticsearch, Logstash, Kibana) and Prometheus are the eyes and ears of DevOps professionals, tracking performance, identifying issues, and optimizing system behavior.
Cloud Computing Platforms: AWS, Azure, and Google Cloud are the foundational pillars of cloud infrastructure in DevOps. They offer the infrastructure and services essential for creating and scaling cloud-based applications, facilitating the agility and flexibility required in modern software development.
Scripting and Coding: Proficiency in scripting languages such as Shell, Python, Ruby, and coding skills are invaluable assets for DevOps professionals. They empower the creation of automation scripts and tools, enabling customization and extensibility in the DevOps pipeline.
Collaboration and Communication Tools: Collaboration tools like Slack and Microsoft Teams enhance the communication and coordination among DevOps team members. They foster efficient collaboration and facilitate the exchange of ideas and information.
Infrastructure as Code (IaC): The concept of Infrastructure as Code, represented by tools like Terraform and AWS CloudFormation, is a pivotal practice in DevOps. It allows the definition and management of infrastructure using code, ensuring consistency and reproducibility, and enabling the rapid provisioning of resources.

Job Opportunities in DevOps:
DevOps Engineer: DevOps engineers are the architects of continuous integration and continuous deployment (CI/CD) pipelines. They meticulously design and maintain these pipelines to automate the deployment process, ensuring the rapid, reliable, and consistent release of software. Their responsibilities extend to optimizing the system's reliability, making them the backbone of seamless software delivery.
Release Manager: Release managers play a pivotal role in orchestrating the software release process. They carefully plan and schedule software releases, coordinating activities between development and IT teams. Their keen oversight ensures the smooth transition of software from development to production, enabling timely and successful releases.
Automation Architect: Automation architects are the visionaries behind the design and development of automation frameworks. These frameworks streamline deployment and monitoring processes, leveraging automation to enhance efficiency and reliability. They are the engineers of innovation, transforming manual tasks into automated wonders.
Cloud Engineer: Cloud engineers are the custodians of cloud infrastructure. They adeptly manage cloud resources, optimizing their performance and ensuring scalability. Their expertise lies in harnessing the power of cloud platforms like AWS, Azure, or Google Cloud to provide robust, flexible, and cost-effective solutions.
Site Reliability Engineer (SRE): SREs are the sentinels of system reliability. They focus on maintaining the system's resilience through efficient practices, continuous monitoring, and rapid incident response. Their vigilance ensures that applications and systems remain stable and performant, even in the face of challenges.
Security Engineer: Security engineers are the guardians of the DevOps pipeline. They integrate security measures seamlessly into the software development process, safeguarding it from potential threats and vulnerabilities. Their role is crucial in an era where security is paramount, ensuring that DevOps practices are fortified against breaches.
As DevOps continues to redefine the landscape of software development and deployment, gaining expertise in its core principles and technologies is a strategic career move. ACTE Technologies offers comprehensive DevOps training programs, led by industry experts who provide invaluable insights, real-world examples, and hands-on guidance. ACTE Technologies's DevOps training covers a wide range of essential concepts, practical exercises, and real-world applications. With a strong focus on certification preparation, ACTE Technologies ensures that you're well-prepared to excel in the world of DevOps. With their guidance, you can gain mastery over DevOps practices, enhance your skill set, and propel your career to new heights.
11 notes
·
View notes
Text
Interactive and Conversational Search with Google Cloud and Elasticsearch

These days, where we have such a lot of online information, it’s truly essential to find what you really want rapidly and precisely. That is the very thing that this blog post is about. We will discuss a better approach for looking and searching online, utilizing something many refer to as interactive and conversational search.
This method makes searching more like having a chat, and it uses some cool tools from Google Cloud and Elasticsearch. We’ll take a gander at how these better approaches for looking are unique in relation to the old ones, and how Google Cloud’s most recent tech improves looking through even. We’re likewise going to look at Elasticsearch, which is a search engine web index, and perceive how it cooperates with Google Cloud to make your searches fast and simple.
What is Interactive and Conversational Search?
A flow method for looking for information that goes beyond the usual practice of inputting keywords into a search engine is interactive and conversational search. All things being equal, it empowers clients to communicate with the search system in a more normal and conversational manner, using text or voice.
This technology utilizes progress in artificial intelligence, especially in natural language processing and machine learning, to comprehend, interpret, and answer client inquiries in a way like that of a human. The objective is to further develop the search experience by making it more automatic, productive, and easy to understand.
Users can get clarification on pressing issues or make demands in natural language, and the system is intended to comprehend the context and intent behind these searches, resulting in more accurate and relevant replies.
This technology is particularly helpful in applications requiring fast and exact information retrieval, such as customer service bots, personal digital assistants, and sophisticated data analysis tools.
Google Cloud – Powering Advanced Search Capabilities
What is Google Cloud?
Google Cloud is a Google cloud computing service that provides a variety of server and computation choices for web applications. It offers computing, storage, and Application Development Services that are provided on Google hardware, allowing developers and organizations to develop, test, and roll out applications on Google’s highly scalable and dependable infrastructure.
Let’s discuss various aspects of Google Cloud
The AI and Machine Learning Edge of Google Cloud
At its core, Google Cloud uses the force of power of artificial intelligence (AI) and machine learning (ML) to offer extraordinary abilities in information handling and analytics. These technologies are significant in understanding and interpreting the vast amount of data generated day to day. Google Cloud’s sAI and ML services are intended to be available and adaptable, making them reasonable for organizations, all things considered.
The strength of Google Cloud lies in its complex calculations and neural networks, which are continually learning and evolving. This consistent improvement considers more precise expectations and insights, essential for making a proficient and intelligent search experience.
Enhancing Search Functionalities with Google Cloud
Google Cloud significantly enhances search functionalities in several ways, most notably through natural language processing (NLP). NLP is a branch of AI that focuses on the interaction between computers and human language. It enables machines to understand, interpret, and respond to human language in a useful and meaningful way.
One of the key applications of NLP in search is understanding the context and intent behind user queries. Traditional search engines might struggle with complex or conversational queries, but with Google Cloud’s NLP capabilities, search engines can interpret these queries more effectively. This means users can ask questions in natural, conversational language and receive more accurate and relevant results.
For example, if a user searches for “best strategies for online marketing in 2023,” Google Cloud’s NLP tools can analyze the query to understand the specific intent – in this case, looking for recent and effective online marketing strategies. The search engine can then prioritize content that is not only relevant to online marketing but also current and strategy-focused.
Real-World Applications and Future Potential
The applications of Google Cloud’s search capabilities are vast and varied. From powering sophisticated recommendation engines in e-commerce platforms to enabling efficient document search in large corporate databases, the potential is limitless. The real power lies in its adaptability and how businesses can leverage these tools to meet their specific needs.
As we look to the future, the integration of AI and ML in search is only set to deepen. With advancements in AI and machine learning, particularly in areas like deep learning and predictive analytics, Google Cloud is well-positioned to lead this charge. The potential for creating even more personalized, intuitive, and intelligent search experiences is immense, paving the way for a new era in digital information access and management.
Elasticsearch – The Backbone of Search Engines
Elasticsearch stands out as a pivotal technology. Originally released in 2010, it has rapidly grown to become a key player in the search engine landscape, renowned for its speed, scalability, and robust set of features.
What is Elasticsearch?
Elasticsearch is an open-source, distributed search and analytics engine, designed for horizontal scalability, reliability, and easy management. It is built on top of Apache Lucene, a high-performance, full-text search engine library. This foundation enables Elasticsearch to not only perform complex searches but also to handle large volumes of data in real time.
Also Read: Explore Elasticsearch and Why It’s Worth Using?
Core Features of Elasticsearch
Full-Text Search: At its core, Elasticsearch excels in full-text search. It breaks down texts into individual terms or phrases and allows for complex query types including fuzzy matching, wildcard searches, and synonym handling. This makes it extremely powerful for searching through large volumes of text-heavy data.
Scalability: One of the most amazing elements of Elasticsearch is its capacity to scale. It can deal with petabytes of structured and unstructured information, and its appropriate nature implies that it can develop with your necessities. Whether you’re a little startup or a huge endeavor, Elasticsearch adjusts to your data requirements without compromising on performance.
Real-Time Data and Analytics: Elasticsearch works progressively. As soon as a document is indexed, it’s searchable. This feature is critical for applications that require immediate insights from their data, like monitoring tools, financial analysis, and e-commerce platforms.
Distributed Architecture: Its distributed architecture ensures that your data is always available and accessible. Elasticsearch automatically replicates data to ensure resilience and high availability, meaning that even in the case of hardware failure, your search system remains operational.
Powerful API and Ecosystem: Elasticsearch comes with a rich set of APIs that allow for seamless integration with numerous languages such as Java, Python, PHP, JavaScript, and more. The Elastic Stack, which includes Kibana for data visualization and Logstash for data processing, complements Elasticsearch to provide a comprehensive search and data analysis solution.
Applications of Elasticsearch
Elasticsearch is used across various industries for different purposes:
E-commerce: For product searches and personalized recommendations.
Logging and Monitoring: For analyzing and visualizing logs in real-time.
Security Information and Event Management (SIEM): For threat hunting and security analytics.
Search Applications: As the underlying engine for custom search applications across websites and enterprise systems.
Integrating Google Cloud with Elasticsearch
Integrating Google Cloud with Elasticsearch represents a significant advancement in search and data analysis. This integration combines Google Cloud’s cutting-edge artificial intelligence and machine learning capabilities with Elasticsearch’s robust, scalable search engine framework.
The result is a powerful synergy that enhances search functionalities, enabling more intuitive, accurate, and real-time responses to complex queries. Businesses can leverage this integration to analyze large datasets, gain actionable insights, and provide users with an unmatched search experience.
Whether it’s processing natural language queries, delivering personalized search results, or offering predictive analytics, the combination of Google Cloud and Elasticsearch paves the way for innovative and efficient data-driven solutions.
Use Cases and Applications
The integration of Google Cloud and Elasticsearch significantly enhances search capabilities across various sectors. In e-commerce, it improves product discovery through natural language queries, enhancing both user experience and sales.
Customer service benefits from AI-powered conversational bots that can handle complex inquiries efficiently. In healthcare, it streamlines access to patient records and medical information, aiding in faster decision-making.
Additionally, for data analytics, this combination simplifies extracting insights from large datasets, making the process more intuitive and efficient. This synergy of Google Cloud’s AI and Elasticsearch’s search functionality marks a leap in creating more user-friendly, intelligent search experiences across diverse industries.
Conclusion
The integration of Google Cloud and Elasticsearch marks a transformative step in search technology. More than a technical feat, it’s a portal to a future where search engines evolve into intelligent partners, adept in processing natural language and delivering precise, efficient results.
This synergy heralds a new wave of innovation across sectors, making our interactions with the digital world more intuitive, responsive, and centered around user needs. As we advance, this blend of Google Cloud’s AI and Elasticsearch’s search prowess promises to redefine not just how we search, but also how we experience the digital landscape. The future of search is conversational, intelligent, and here to revolutionize our digital interactions.
Originally published by: Interactive and Conversational Search with Google Cloud and Elasticsearch
2 notes
·
View notes
Text
How To Setup Elasticsearch 6.4 On RHEL/CentOS 6/7?

What is Elasticsearch? Elasticsearch is a search engine based on Lucene. It is useful in a distributed environment and helps in a multitenant-capable full-text search engine. While you query something from Elasticsearch it will provide you with an HTTP web interface and schema-free JSON documents. it provides the ability for full-text search. Elasticsearch is developed in Java and is released as open-source under the terms of the Apache 2 license. Scenario: 1. Server IP: 192.168.56.101 2. Elasticsearch: Version 6.4 3. OS: CentOS 7.5 4. RAM: 4 GB Note: If you are a SUDO user then prefix every command with sudo, like #sudo ifconfig With the help of this guide, you will be able to set up Elasticsearch single-node clusters on CentOS, Red Hat, and Fedora systems. Step 1: Install and Verify Java Java is the primary requirement for installing Elasticsearch. So, make sure you have Java installed on your system. # java -version openjdk version "1.8.0_181" OpenJDK Runtime Environment (build 1.8.0_181-b13) OpenJDK 64-Bit Server VM (build 25.181-b13, mixed mode) If you don’t have Java installed on your system, then run the below command # yum install java-1.8.0-openjdk Step 2: Setup Elasticsearch For this guide, I am downloading the latest Elasticsearch tar from its official website so follow the below step # wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.4.2.tar.gz # tar -xzf elasticsearch-6.4.2.tar.gz # tar -xzf elasticsearch-6.4.2.tar.gz # mv elasticsearch-6.4.2 /usr/local/elasticsearch Step 5: Permission and User We need a user for running elasticsearch (root is not recommended). # useradd elasticsearch # chown -R elasticsearch.elasticsearch /usr/local/elasticsearch/ Step 6: Setup Ulimits Now to get a Running system we need to make some changes of ulimits else we will get an error like “max number of threads for user is too low, increase to at least ” so to overcome this issue make below changes you should run. # ulimit -n 65536 # ulimit -u 2048 Or you may edit the file to make changes permanent # vim /etc/security/limits.conf elasticsearch - nofile 65536 elasticsearch soft nofile 64000 elasticsearch hard nofile 64000 elasticsearch hard nproc 4096 elasticsearch soft nproc 4096 Save files using :wq Step 7: Configure Elasticsearch Now make some configuration changes like cluster name or node name to make our single node cluster live. # cd /usr/local/elasticsearch/ Now, look for the below keywords in the file and change according to you need # vim conf/elasticsearch.yml cluster.name: kapendra-cluster-1 node.name: kapendra-node-1 http.port: 9200 to set this value to your IP or make it 0.0.0.0 ID needs to be accessible from anywhere from the network. Else put your IP of localhost network.host: 0.0.0.0 There is one more thing if you have any dedicated mount pint for data then change the value for #path.data: /path/to/data to your mount point.
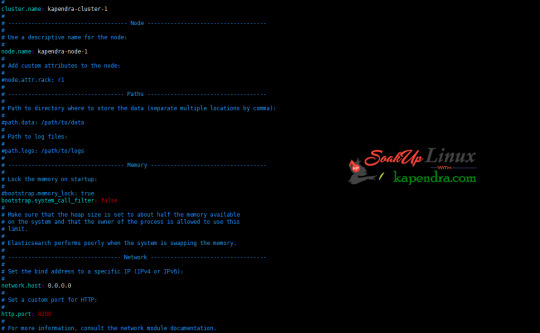
Your configuration should look like the above. Step 8: Starting Elasticsearch Cluster As the Elasticsearch setup is completed. Let the start Elasticsearch cluster with elastic search user so first switch to elastic search user and then run the cluster # su - elasticsearch $ /usr/local/elasticsearch/bin/elasticsearch 22278 Step 9: Verify Setup You have all done it, just need to verify the setup. Elasticsearch works on port default port 9200, open your browser to point your server on port 9200, You will find something like the below output http://localhost:9200 or http://192.168.56.101:9200 at the end of this article, you have successfully set up Elasticsearch single node cluster. In the next few articles, we will try to cover a few commands and their setup in the docker container for development environments on local machines. Read the full article
2 notes
·
View notes
Text
What is Solr – Comparing Apache Solr vs. Elasticsearch

In the world of search engines and data retrieval systems, Apache Solr and Elasticsearch are two prominent contenders, each with its strengths and unique capabilities. These open-source, distributed search platforms play a crucial role in empowering organizations to harness the power of big data and deliver relevant search results efficiently. In this blog, we will delve into the fundamentals of Solr and Elasticsearch, highlighting their key features and comparing their functionalities. Whether you're a developer, data analyst, or IT professional, understanding the differences between Solr and Elasticsearch will help you make informed decisions to meet your specific search and data management needs.
Overview of Apache Solr
Apache Solr is a search platform built on top of the Apache Lucene library, known for its robust indexing and full-text search capabilities. It is written in Java and designed to handle large-scale search and data retrieval tasks. Solr follows a RESTful API approach, making it easy to integrate with different programming languages and frameworks. It offers a rich set of features, including faceted search, hit highlighting, spell checking, and geospatial search, making it a versatile solution for various use cases.
Overview of Elasticsearch
Elasticsearch, also based on Apache Lucene, is a distributed search engine that stands out for its real-time data indexing and analytics capabilities. It is known for its scalability and speed, making it an ideal choice for applications that require near-instantaneous search results. Elasticsearch provides a simple RESTful API, enabling developers to perform complex searches effortlessly. Moreover, it offers support for data visualization through its integration with Kibana, making it a popular choice for log analysis, application monitoring, and other data-driven use cases.
Comparing Solr and Elasticsearch
Data Handling and Indexing
Both Solr and Elasticsearch are proficient at handling large volumes of data and offer excellent indexing capabilities. Solr uses XML and JSON formats for data indexing, while Elasticsearch relies on JSON, which is generally considered more human-readable and easier to work with. Elasticsearch's dynamic mapping feature allows it to automatically infer data types during indexing, streamlining the process further.
Querying and Searching
Both platforms support complex search queries, but Elasticsearch is often regarded as more developer-friendly due to its clean and straightforward API. Elasticsearch's support for nested queries and aggregations simplifies the process of retrieving and analyzing data. On the other hand, Solr provides a range of query parsers, allowing developers to choose between traditional and advanced syntax options based on their preference and familiarity.
Scalability and Performance
Elasticsearch is designed with scalability in mind from the ground up, making it relatively easier to scale horizontally by adding more nodes to the cluster. It excels in real-time search and analytics scenarios, making it a top choice for applications with dynamic data streams. Solr, while also scalable, may require more effort for horizontal scaling compared to Elasticsearch.
Community and Ecosystem
Both Solr and Elasticsearch boast active and vibrant open-source communities. Solr has been around longer and, therefore, has a more extensive user base and established ecosystem. Elasticsearch, however, has gained significant momentum over the years, supported by the Elastic Stack, which includes Kibana for data visualization and Beats for data shipping.
Document-Based vs. Schema-Free
Solr follows a document-based approach, where data is organized into fields and requires a predefined schema. While this provides better control over data, it may become restrictive when dealing with dynamic or constantly evolving data structures. Elasticsearch, being schema-free, allows for more flexible data handling, making it more suitable for projects with varying data structures.
Conclusion
In summary, Apache Solr and Elasticsearch are both powerful search platforms, each excelling in specific scenarios. Solr's robustness and established ecosystem make it a reliable choice for traditional search applications, while Elasticsearch's real-time capabilities and seamless integration with the Elastic Stack are perfect for modern data-driven projects. Choosing between the two depends on your specific requirements, data complexity, and preferred development style. Regardless of your decision, both Solr and Elasticsearch can supercharge your search and analytics endeavors, bringing efficiency and relevance to your data retrieval processes.
Whether you opt for Solr, Elasticsearch, or a combination of both, the future of search and data exploration remains bright, with technology continually evolving to meet the needs of next-generation applications.
2 notes
·
View notes
Text
Built-in Logging with Serilog: How EasyLaunchpad Keeps Debugging Clean and Insightful

Debugging shouldn’t be a scavenger hunt.
When things break in production or behave unexpectedly in development, you don’t have time to dig through vague error messages or guess what went wrong. That’s why logging is one of the most critical — but often neglected — parts of building robust applications.
With EasyLaunchpad, logging is not an afterthought.
We’ve integrated Serilog, a powerful and structured logging framework for .NET, directly into the boilerplate so developers can monitor, debug, and optimize their apps from day one.
In this post, we’ll explain how Serilog is implemented inside EasyLaunchpad, why it’s a developer favorite, and how it helps you launch smarter and maintain easier.
🧠 Why Logging Matters (Especially in Startups)
Whether you’re launching a SaaS MVP or maintaining a production application, logs are your eyes and ears:
Track user behavior
Monitor background job status
Catch and analyze errors
Identify bottlenecks or API failures
Verify security rules and access patterns
With traditional boilerplates, you often need to configure and wire this up yourself. But EasyLaunchpad comes preloaded with structured, scalable logging using Serilog, so you’re ready to go from the first line of code.
🔧 What Is Serilog?
Serilog is one of the most popular logging libraries for .NET Core. Unlike basic logging tools that write unstructured plain-text logs, Serilog generates structured logs — which are easier to search, filter, and analyze in any environment.
It supports:
JSON log output
File, Console, or external sinks (like Seq, Elasticsearch, Datadog)
Custom formats and enrichers
Log levels: Information, Warning, Error, Fatal, and more
Serilog is lightweight, flexible, and production-proven — ideal for modern web apps like those built with EasyLaunchpad.
🚀 How Serilog Is Integrated in EasyLaunchpad

When you start your EasyLaunchpad-based project, Serilog is already:
Installed via NuGet
Configured via appsettings.json
Injected into the middleware pipeline
Wired into all key services (auth, jobs, payments, etc.)
🔁 Configuration Example (appsettings.json):
“Serilog”: {
“MinimumLevel”: {
“Default”: “Information”,
“Override”: {
“Microsoft”: “Warning”,
“System”: “Warning”
}
},
“WriteTo”: [
{ “Name”: “Console” },
{
“Name”: “File”,
“Args”: {
“path”: “Logs/log-.txt”,
“rollingInterval”: “Day”
}
}
}
}
This setup gives you daily rotating log files, plus real-time console logs for development mode.
🛠 How It Helps Developers
✅ 1. Real-Time Debugging
During development, logs are streamed to the console. You’ll see:
Request details
Controller actions triggered
Background job execution
Custom messages from your services
This means you can debug without hitting breakpoints or printing Console.WriteLine().
✅ 2. Structured Production Logs
In production, logs are saved to disk in a structured format. You can:
Tail them from the server
Upload them to a logging platform (Seq, Datadog, ELK stack)
Automatically parse fields like timestamp, level, message, exception, etc.
This gives predictable, machine-readable logging — critical for scalable monitoring.
✅ 3. Easy Integration with Background Jobs
EasyLaunchpad uses Hangfire for background job scheduling. Serilog is integrated into:
Job execution logging
Retry and failure logs
Email queue status
Error capturing
No more “silent fails” in background processes — every action is traceable.
✅ 4. Enhanced API Logging (Optional Extension)
You can easily extend the logging to:
Log request/response for APIs
Add correlation IDs
Track user activity (e.g., login attempts, failed validations)
The modular architecture allows you to inject loggers into any service or controller via constructor injection.
🔍 Sample Log Output
Here’s a typical log entry generated by Serilog in EasyLaunchpad:
{
“Timestamp”: “2024–07–10T08:33:21.123Z”,
“Level”: “Information”,
“Message”: “User {UserId} logged in successfully.”,
“UserId”: “5dc95f1f-2cc2–4f8a-ae1b-1d29f2aa387a”
}
This is not just human-readable — it’s machine-queryable.
You can filter logs by UserId, Level, or Timestamp using modern logging dashboards or scripts.
🧱 A Developer-Friendly Logging Foundation
Unlike minimal templates, where you have to integrate logging yourself, EasyLaunchpad is:
Ready-to-use from first launch
Customizable for your own needs
Extendable with any Serilog sink (e.g., database, cloud services, Elasticsearch)
This means you spend less time configuring and more time building and scaling.
🧩 Built-In + Extendable
You can add additional log sinks in minutes:
Log.Logger = new LoggerConfiguration()
.WriteTo.Console()
.WriteTo.File(“Logs/log.txt”)
.WriteTo.Seq(“http://localhost:5341")
.CreateLogger();
Want to log in to:
Azure App Insights?
AWS CloudWatch?
A custom microservice?
Serilog makes it possible, and EasyLaunchpad makes it easy to start.
💼 Real-World Scenarios
Here are some real ways logging helps EasyLaunchpad-based apps:
Use Case and the Benefit
Login attempts — Audit user activity and failed attempts
Payment errors- Track Stripe/Paddle API errors
Email queue- Debug failed or delayed emails
Role assignment- Log admin actions for compliance
Cron jobs- Monitor background jobs in real-time
🧠 Final Thoughts
You can’t fix what you can’t see.
Whether you’re launching an MVP or running a growing SaaS platform, structured logging gives you visibility, traceability, and peace of mind.
EasyLaunchpad integrates Serilog from day one — so you’re never flying blind. You get a clean, scalable logging system with zero setup required.
No more guesswork. Just clarity.
👉 Start building with confidence. Check out EasyLaunchpad at https://easylaunchpad.com and see how production-ready logging fits into your stack.
#Serilog .NET logging#structured logs .NET Core#developer-friendly logging in boilerplate#.net development#saas starter kit#saas development company#app development#.net boilerplate
1 note
·
View note
Text
Building a Scalable News Website with Headless CMS
In the digital age, news consumption is rapid, constant, and highly competitive. Users expect instant access to updates, seamless performance, and engaging design—whether on a smartphone, tablet, or desktop. To keep up with this demand, building a scalable news website is not optional—it’s essential.
In this blog, we’ll explore the key strategies, technologies, and features needed to create a modern news platform that can handle growing traffic, frequent content updates, and a diverse audience base without compromising performance.
Why Scalability Matters for News Platforms
News websites experience unpredictable traffic spikes—especially during breaking news, elections, or viral events. A scalable site ensures:
Zero downtime during peak loads
Consistent performance for global readers
Future growth without major overhauls
Must-Have Features for a Scalable News Platform
Dynamic Content Management Use a CMS (like WordPress, Drupal, or Headless CMS) that supports:
Custom post types (news, opinions, videos)
Real-time updates
Editorial workflows
Advanced Search & Filtering Allow users to easily find stories by keyword, category, date, or location. Consider integrating ElasticSearch or Algolia.
Responsive Design Ensure your layout is mobile-friendly and adapts to all screen sizes. Over 60% of news is now consumed on mobile devices.
User Roles & Permissions Separate responsibilities for reporters, editors, and admins with secure login systems and access control.
Content Delivery via API Enable easy syndication and sharing of content through REST or GraphQL APIs. This supports mobile apps, partner feeds, or even smart devices.
Conclusion
Building a scalable news website goes beyond great design—it’s about delivering reliable, real-time content to millions without interruption. Whether you're a local news agency or a national media house, laying the right technical foundation ensures long-term growth, trust, and engagement.
Let Qtriangle Infotech help you design, develop, and launch a future-ready news website that delivers performance, power, and speed. Contact us today!
0 notes
Link
0 notes
Text
Where Can I Find DevOps Training with Placement Near Me?
Introduction: Unlock Your Tech Career with DevOps Training
In today’s digital world, companies are moving faster than ever. Continuous delivery, automation, and rapid deployment have become the new norm. That’s where DevOps comes in a powerful blend of development and operations that fuels speed and reliability in software delivery.
Have you ever wondered how companies like Amazon, Netflix, or Facebook release features so quickly without downtime? The secret lies in DevOps an industry-demanded approach that integrates development and operations to streamline software delivery. Today, DevOps skills are not just desirable they’re essential. If you’re asking, “Where can I find DevOps training with placement near me?”, this guide will walk you through everything you need to know to find the right training and land the job you deserve.

Understanding DevOps: Why It Matters
DevOps is more than a buzzword it’s a cultural and technical shift that transforms how software teams build, test, and deploy applications. It focuses on collaboration, automation, continuous integration (CI), continuous delivery (CD), and feedback loops.
Professionals trained in DevOps can expect roles like:
DevOps Engineer
Site Reliability Engineer
Cloud Infrastructure Engineer
Release Manager
The growing reliance on cloud services and rapid deployment pipelines has placed DevOps engineers in high demand. A recent report by Global Knowledge ranks DevOps as one of the highest-paying tech roles in North America.
Why DevOps Training with Placement Is Crucial
Many learners begin with self-study or unstructured tutorials, but that only scratches the surface. A comprehensive DevOps training and placement program ensures:
Structured learning of core and advanced DevOps concepts
Hands-on experience with DevOps automation tools
Resume building, interview preparation, and career support
Real-world project exposure to simulate a professional environment
Direct pathways to job interviews and job offers
If you’re looking for DevOps training with placement “near me,” remember that “location” today is no longer just geographic—it’s also digital. The right DevOps online training can provide the accessibility and support you need, no matter your zip code.
Core Components of a DevOps Course Online
When choosing a DevOps course online, ensure it covers the following modules in-depth:
1. Introduction to DevOps Culture and Principles
Evolution of DevOps
Agile and Lean practices
Collaboration and communication strategies
2. Version Control with Git and GitHub
Branching and merging strategies
Pull requests and code reviews
Git workflows in real-world projects
3. Continuous Integration (CI) Tools
Jenkins setup and pipelines
GitHub Actions
Code quality checks and automated builds
4. Configuration Management
Tools like Ansible, Chef, or Puppet
Managing infrastructure as code (IaC)
Role-based access control
5. Containerization and Orchestration
Docker fundamentals
Kubernetes (K8s) clusters, deployments, and services
Helm charts and autoscaling strategies
6. Monitoring and Logging
Prometheus and Grafana
ELK Stack (Elasticsearch, Logstash, Kibana)
Incident alerting systems
7. Cloud Infrastructure and DevOps Automation Tools
AWS, Azure, or GCP fundamentals
Terraform for IaC
CI/CD pipelines integrated with cloud services
Real-World Applications: Why Hands-On Learning Matters
A key feature of any top-tier DevOps training online is its practical approach. Without hands-on labs or real projects, theory can only take you so far.
Here’s an example project structure:
Project: Deploying a Multi-Tier Application with Kubernetes
Such projects help learners not only understand tools but also simulate real DevOps scenarios, building confidence and clarity.
DevOps Training and Certification: What You Should Know
Certifications validate your knowledge and can significantly improve your job prospects. A solid DevOps training and certification program should prepare you for globally recognized exams like:
DevOps Foundation Certification
Certified Kubernetes Administrator (CKA)
AWS Certified DevOps Engineer
Docker Certified Associate
While certifications are valuable, employers prioritize candidates who demonstrate both theoretical knowledge and applied skills. This is why combining training with placement offers the best return on investment.
What to Look for in a DevOps Online Course
If you’re on the hunt for the best DevOps training online, here are key features to consider:
Structured Curriculum
It should cover everything from fundamentals to advanced automation practices.
Expert Trainers
Trainers should have real industry experience, not just academic knowledge.
Hands-On Projects
Project-based assessments help bridge the gap between theory and application.
Flexible Learning
A good DevOps online course offers recordings, live sessions, and self-paced materials.
Placement Support
Look for programs that offer:
Resume writing and LinkedIn profile optimization
Mock interviews with real-time feedback
Access to a network of hiring partners
Benefits of Enrolling in DevOps Bootcamp Online
A DevOps bootcamp online fast-tracks your learning process. These are intensive, short-duration programs designed for focused outcomes. Key benefits include:
Rapid skill acquisition
Industry-aligned curriculum
Peer collaboration and group projects
Career coaching and mock interviews
Job referrals and hiring events
Such bootcamps are ideal for professionals looking to upskill, switch careers, or secure a DevOps role without spending years in academia.
DevOps Automation Tools You Must Learn
Git & GitHub Git is the backbone of version control in DevOps, allowing teams to track changes, collaborate on code, and manage development history. GitHub enhances this by offering cloud-based repositories, pull requests, and code review tools—making it a must-know for every DevOps professional.
Jenkins Jenkins is the most popular open-source automation server used to build and manage continuous integration and continuous delivery (CI/CD) pipelines. It integrates with almost every DevOps tool and helps automate testing, deployment, and release cycles efficiently.
Docker Docker is a game-changer in DevOps. It enables you to containerize applications, ensuring consistency across environments. With Docker, developers can package software with all its dependencies, leading to faster development and more reliable deployments.
Kubernetes Once applications are containerized, Kubernetes helps manage and orchestrate them at scale. It automates deployment, scaling, and load balancing of containerized applications—making it essential for managing modern cloud-native infrastructures.
Ansible Ansible simplifies configuration management and infrastructure automation. Its agentless architecture and easy-to-write YAML playbooks allow you to automate repetitive tasks across servers and maintain consistency in deployments.
Terraform Terraform enables Infrastructure as Code (IaC), allowing teams to provision and manage cloud resources using simple, declarative code. It supports multi-cloud environments and ensures consistent infrastructure with minimal manual effort.
Prometheus & Grafana For monitoring and alerting, Prometheus collects metrics in real-time, while Grafana visualizes them beautifully. Together, they help track application performance and system health essential for proactive operations.
ELK Stack (Elasticsearch, Logstash, Kibana) The ELK stack is widely used for centralized logging. Elasticsearch stores logs, Logstash processes them, and Kibana provides powerful visualizations, helping teams troubleshoot issues quickly.
Mastering these tools gives you a competitive edge in the DevOps job market and empowers you to build reliable, scalable, and efficient software systems.
Job Market Outlook for DevOps Professionals
According to the U.S. Bureau of Labor Statistics, software development roles are expected to grow 25% by 2032—faster than most other industries. DevOps roles are a large part of this trend. Companies need professionals who can automate pipelines, manage scalable systems, and deliver software efficiently.
Average salaries in the U.S. for DevOps engineers range between $95,000 to $145,000, depending on experience, certifications, and location.
Companies across industries—from banking and healthcare to retail and tech—are hiring DevOps professionals for critical digital transformation roles.
Is DevOps for You?
If you relate to any of the following, a DevOps course online might be the perfect next step:
You're from an IT background looking to transition into automation roles
You enjoy scripting, problem-solving, and system management
You're a software developer interested in faster and reliable deployments
You're a system admin looking to expand into cloud and DevOps roles
You want a structured, placement-supported training program to start your career
How to Get Started with DevOps Training and Placement
Step 1: Enroll in a Comprehensive Program
Choose a program that covers both foundational and advanced concepts and includes real-time projects.
Step 2: Master the Tools
Practice using popular DevOps automation tools like Docker, Jenkins, and Kubernetes.
Step 3: Work on Live Projects
Gain experience working on CI/CD pipelines, cloud deployment, and infrastructure management.
Step 4: Prepare for Interviews
Use mock sessions, Q&A banks, and technical case studies to strengthen your readiness.
Step 5: Land the Job
Leverage placement services, interview support, and resume assistance to get hired.
Key Takeaways
DevOps training provides the automation and deployment skills demanded in modern software environments.
Placement support is crucial to transitioning from learning to earning.
Look for comprehensive online courses that offer hands-on experience and job assistance.
DevOps is not just a skill it’s a mindset of collaboration, speed, and innovation.
Ready to launch your DevOps career? Join H2K Infosys today for hands-on learning and job placement support. Start your transformation into a DevOps professional now.
#devops training#DevOps course#devops training online#devops online training#devops training and certification#devops certification training#devops training with placement#devops online courses#best devops training online#online DevOps course#advanced devops course#devops training and placement#devops course online#devops real time training#DevOps automation tools
0 notes
Text
DevOps: Bridging Development & Operations

In the whirlwind environment of software development, getting code quickly and reliably from concept to launch is considered fast work. There has usually been a wall between the "Development" (Dev) and the "Operations" (Ops) teams that has usually resulted in slow deployments, conflicts, and inefficiencies. The DevOps culture and practices have been created as tools to close this gap in a constructive manner by fostering collaboration, automation, and continuous delivery.
DevOps is not really about methodology; it's more of a philosophy whereby developers and operations teams are brought together to collaborate and increase productivity by automation of infrastructure and workflows and continuous assessment of application's performance. Today, it is imperative for any tech-savvy person to have the basic know-how of DevOps methodologies-adopting them-and especially in fast-developing IT corridors like Ahmedabad.
Why DevOps is Crucial in Today's Tech Landscape
It is very clear that the benefits of DevOps have led to its adoption worldwide across industries:
Offering Faster Time-to-Market: DevOps has automated steps, placing even more importance on collaboration, manuals, to finish testing, and to deploy applications very fast.
Ensuring Better Quality and Reliability: With continuous testing, integration, and deployment, we get fewer bugs and more stable applications.
Fostering Collaboration: It removes traditional silos between teams, thus promoting shared responsibility and communication.
Operational Efficiency and Cost-Saving: It automates repetitive tasks, eliminates manual efforts, and reduces errors.
Building Scalability and Resilience: DevOps practices assist in constructing scalable systems and resilient systems that can handle grow-thrust of users.
Key Pillars of DevOps
A few of the essential practices and tools on which DevOps rests:
Continuous Integration (CI): Developers merge their code changes into a main repository on a daily basis, in which automated builds and tests are run to detect integration errors early. Tools: Jenkins, GitLab CI, Azure DevOps.
Continuous Delivery / Deployment: Builds upon CI to automatically build, test, and prepare code changes for release to production. Continuous Deployment then deploys every valid change to production automatically. Tools: Jenkins, Spinnaker, Argo CD.
Infrastructure as Code (IaC): Managing and provisioning infrastructure through code instead of through manual processes. Manual processes can lead to inconsistent setups and are not easily repeatable. Tools: Terraform, Ansible, Chef, Puppet.
Monitoring & Logging: Monitor the performance of applications as well as the health of infrastructure and record logs to troubleshoot and detect issues in the shortest possible time. Tools: Prometheus, Grafana, ELK Stack (Elasticsearch, Logstash, Kibana).
Collaboration and Communication: On the other hand, it is a cultural change towards open communication, working jointly, and feedback loops.
Essential Skills for a DevOps Professional
If you want to become a DevOps Engineer or start incorporating DevOps methodologies into your day-to-day work, these are some skills to consider:
Linux Basics: A good understanding of Linux OS is almost a prerequisite, as most servers run on Linux.
Scripting Languages: Having a working understanding of one or another scripting language (like Python, Bash, or PowerShell) comes in handy in automation.
Cloud Platforms: Working knowledge of cloud providers like AWS, Microsoft Azure, or Google Cloud Platform, given cloud infrastructure is an integral part of deployments nowadays.
Containerization: These include skills on containerization using Docker and orchestration using Kubernetes for application deployment and scaling.
CI/CD Tools: Good use of established CI/CD pipeline tools (Jenkins, GitLab CI, Azure DevOps, etc.).
Version Control: Proficiency in Git through the life of the collaborative code change.
Networking Basics: Understanding of networking protocols and configurations.
Your Path to a DevOps Career
The demand for DevOps talent in India is rapidly increasing.. Since the times are changing, a lot of computer institutes in Ahmedabad are offering special DevOps courses which cover these essential tools and practices. It is advisable to search for programs with lab sessions, simulated real-world projects, and guidance on industry-best practices.
Adopting DevOps is more than just learning new tools; it is a mindset that values efficiency and trust in automation as well as seamless collaboration. With such vital skills, you can act as a critical enabler between development and operations to ensure the rapid release of reliable software, thereby guaranteeing your position as one of the most sought-after professionals in the tech world.
At TCCI, we don't just teach computers — we build careers. Join us and take the first step toward a brighter future.
Location: Bopal & Iskcon-Ambli in Ahmedabad, Gujarat
Call now on +91 9825618292
Visit Our Website: http://tccicomputercoaching.com/
0 notes
Text
Pluto AI: A New Internal AI Platform For Enterprise Growth

Pluto AI
Magyar Telekom, Deutsche Telekom's Hungarian business, launched Pluto AI, a cutting-edge internal AI platform, to capitalise on AI's revolutionary potential. This project is a key step towards the company's objective of incorporating AI into all business operations and empowering all employees to use AI's huge potential.
After realising that AI competence is no longer a luxury but a necessary for future success, Magyar Telekom faced comparable issues, such as staff with varying AI comprehension and a lack of readily available tools for testing and practical implementation. To address this, the company created a scalable system that could serve many use cases and adapt to changing AI demands, democratising AI knowledge and promoting innovation.
Pluto AI was founded to provide business teams with a simple prompting tool for safe and lawful generative AI deployment. Generative AI and its applications were taught to business teams. This strategy led to the company's adoption of generative AI, allowing the platform to quickly serve more use cases without the core platform staff having to comprehend every new application.
Pluto AI development
Google Cloud Consulting and Magyar Telekom's AI Team built Pluto AI. This relationship was essential to the platform's compliance with telecom sector security and compliance regulations and best practices.
Pluto AI's modular design lets teams swiftly integrate, change, and update AI models, tools, and architectural patterns. Its architecture allows the platform to serve many use cases and grow swiftly with Magyar Telekom's AI goal. Pluto AI includes Retrieval Augmented Generation (RAG), which combines LLMs with internal knowledge sources, including multimodal content, to provide grounded responses with evidence, API access to allow other parts of the organisation to integrate AI into their solutions, Large Language Models (LLMs) for natural language understanding and generation, and code generation and assistance to increase developer productivity.
The platform also lets users develop AI companions for specific business needs.
Pluto AI employs virtual machines and Compute Engine for scalability and reliability. It uses foundation models from the Model Garden on Vertex AI, including Anthropic's Claude 3.5 Sonnet and Google's Gemini, Imagen, and Veo. RAG procedures use Google Cloud ElasticSearch for knowledge bases. Other Google Cloud services like Cloud Logging, Pub/Sub, Storage, Firestore, and Looker help create production-ready apps.
The user interface and experience were prioritised during development. Pluto AI's user-friendly interface lets employees of any technical ability level use AI without a steep learning curve.
With hundreds of daily active users from various departments, the platform has high adoption rates. Its versatility and usability have earned the platform high praise from employees. Pluto AI has enabled knowledge management, software development, legal and compliance, and customer service chatbots.
Pluto AI's impact is quantified. The platform records tens of thousands of API requests and hundreds of thousands of unique users daily. A 15% decrease in coding errors and a 20% reduction in legal paper review time are expected.
Pluto AI vision and roadmap
Pluto AI is part of Magyar Telekom's long-term AI plan. Plans call for adding departments, business divisions, and markets to the platform. The company is also considering offering Pluto AI to other Deutsche Telekom markets.
A multilingual language selection, an enhanced UI for managing RAG solutions and tracking usage, and agent-based AI technologies for automating complex tasks are envisaged. Monitoring and optimising cloud resource utilisation and costs is another priority.
Pluto AI has made AI usable, approachable, and impactful at Magyar Telekom. Pluto AI sets a new standard for internal AI adoption by enabling experimentation and delivering business advantages.
#PlutoAI#generativeAI#googlecloudPlutoAI#DevelpoingPlutoAI#MagyarTelekom#PlutoAIRoadmap#technology#technews#technologynews#news#govindhtech
0 notes