#GPU-powered AI infrastructure
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has a 66 index score for customer satisfaction in the US.
Text
AI Infrastructure Solutions: The Backbone of High-Performance AI Development
Artificial Intelligence is transforming industries across the world, and to accomplish that, it needs a strong foundation in the form of infrastructure support for complex tasks like deep learning, machine learning, and data analysis. Advanced AI infrastructure solutions form the core on which AI models are developed, deployed, and optimized.
What is High-Performance AI Infrastructure?
High-performance AI infrastructure refers to a specific hardware-software combination that caters to intensive computational needs of AI-related tasks, such as deep learning models training, and predictions. Computer systems of conventional type rarely provide the capability for handling such operations; thus, advanced infrastructure is highly reliant.
These comprise of:
- Powerful GPUs:
These are designed with parallel computing in mind so that they can accelerate any AI task far beyond any standard CPU.
- Massive Storage:
AI models require vast amounts of data, requiring scalable and fast storage solutions.
- Efficient Networking:
High-speed communication for smooth data flow during training and inference processes.
This infrastructure allows businesses to complete AI tasks more efficiently, enhancing innovation and accuracy.
Role of AI Workload Optimization
AI workload optimization services are an important way of enhancing the efficiency of processes in AI. The right services would ensure that data processing and model training are all done effectively.
Optimizing AI workloads provides numerous benefits.
- Reduces Processing Time:
Proper infrastructure reduces the time for training models and making predictions.
- Increases Resource Utilization:
Optimized workloads use computing power as much as is available.
- Cost Savings:
Resource consumption management reduces hardware expenditure and energy consumption.
Optimization helps companies harness the full potential of infrastructure with high performance, giving better results and higher efficiency.
Why AI Infrastructure is So Important for Deep Learning
Deep learning needs unique infrastructure to handle massive data as well as computing power used in training complex models. Without proper infrastructure, deep learning projects can become slow, inefficient, and costly.
With the right AI infrastructure, businesses can:
Train complex models: Deep learning models require large datasets and quite a bit of processing power. High-performance infrastructure accelerates the training process.
Scale AI projects: As deep learning models evolve, businesses need infrastructure that can scale with increasing data and computational demands.
GPU-Powered Infrastructure: The Boost for AI Development
GPU-powered AI infrastructure accelerates both the training and inference processes of AI models. GPUs are better suited than CPUs for handling the parallel tasks common in machine learning and deep learning, making them essential for fast, efficient AI development.
Benefits include:
- Faster Training Times: GPUs can process multiple tasks simultaneously, significantly reducing training time.
- Faster Inference Speed: Once the models are trained, they make rapid predictions, a must for real-time applications.
The Future of AI Infrastructure
As AI keeps advancing, the call for powerful infrastructure will go only higher. Whether optimization of workloads, making use of GPU-powered systems, or scaling deep learning models, this requires businesses to invest in the right infrastructure to not get left behind. At Sharon AI, we provide customers with end-to-end solutions of AI infrastructure, whether workload optimization or GPU-powered AI systems, to accelerate business with AI capabilities. Ready to give your AI performance a boost? Explore our AI services today!
#AI Infrastructure Solutions#High-Performance AI Development#workload optimization services#GPU-powered AI infrastructure#AI services#Sharon AI
0 notes
Text
What does AI actually look like?
There has been a lot of talk about the negative externalities of AI, how much power it uses, how much water it uses, but I feel like people often discuss these things like they are abstract concepts, or people discuss AI like it is this intangible thing that exists off in "The cloud" somewhere, but I feel like a lot of people don't know what the infrastructure of AI actually is, and how it uses all that power and water, so I would like to recommend this video from Linus Tech Tips, where he looks at a supercomputer that is used for research in Canada. To be clear I do not have anything against supercomputers in general and they allow important work to be done, but before the AI bubble, you didn't need one, unless you needed it. The recent AI bubble is trying to get this stuff into the hands of way more people than needed them before, which is causing a lot more datacenter build up, which is causing their companies to abandon climate goals. So what does AI actually look like?
First of all, it uses a lot of hardware. It is basically normal computer hardware, there is just a lot of it networked together.

Hundreds of hard drives all spinning constantly

Each one of the blocks in this image is essentially a powerful PC, that you would still be happy to have as your daily driver today even though the video is seven years old. There are 576 of them, and other more powerful compute nodes for bigger datasets.


The GPU section, each one of these drawers contains like four datacenter level graphics cards. People are fitting a lot more of them into servers now than they were then.

Now for the cooling and the water. Each cabinet has a thick door, with a water cooled radiator in it. In summer, they even spray water onto the radiator directly so it can be cooled inside and out.

They are all fed from the pump room, which is the floor above. A bunch of pumps and pipes moving the water around, and it even has cooling towers outside that the water is pumped out into on hot days.

So is this cool? Yes. Is it useful? Also yes. Anyone doing biology, chemistry, physics, simulations, even stuff like social sciences, and even legitimate uses of analytical ai is glad stuff like this exists. It is very useful for analysing huge datasets, but how many people actually do that? Do you? The same kind of stuff is also used for big websites with youtube. But the question is, is it worth building hundreds more datacenters just like this one, so people can automatically generate their emails, have an automatic source of personal attention from a computer, and generate incoherent images for social media clicks? Didn't tech companies have climate targets, once?
110 notes
·
View notes
Text
Companies across the continent – from start-ups in Berlin to manufacturers in Milan – are adopting its capabilities to optimize their processes, analyze their data, and compete with the American and Chinese behemoths.
The Colossus supercomputer, installed in Memphis and powered by 100,000 GPUs (Graphics Processing Units), provides xAI with computing power that Europe, with its aging infrastructures that are crumbling under castrating standards and killer taxes, cannot match.
Banning X would not only deprive Europeans of a platform that is essential to their freedom to inform and express themselves but would also sabotage access to an AI that is a pillar of what remains of their economic competitiveness.
------------------------------------------------------------------------------
The really smart people do NOT run things in the EU. Just like in Canadia.
2 notes
·
View notes
Text
Efficient GPU Management for AI Startups: Exploring the Best Strategies
The rise of AI-driven innovation has made GPUs essential for startups and small businesses. However, efficiently managing GPU resources remains a challenge, particularly with limited budgets, fluctuating workloads, and the need for cutting-edge hardware for R&D and deployment.
Understanding the GPU Challenge for Startups
AI workloads—especially large-scale training and inference—require high-performance GPUs like NVIDIA A100 and H100. While these GPUs deliver exceptional computing power, they also present unique challenges:
High Costs – Premium GPUs are expensive, whether rented via the cloud or purchased outright.
Availability Issues – In-demand GPUs may be limited on cloud platforms, delaying time-sensitive projects.
Dynamic Needs – Startups often experience fluctuating GPU demands, from intensive R&D phases to stable inference workloads.
To optimize costs, performance, and flexibility, startups must carefully evaluate their options. This article explores key GPU management strategies, including cloud services, physical ownership, rentals, and hybrid infrastructures—highlighting their pros, cons, and best use cases.
1. Cloud GPU Services
Cloud GPU services from AWS, Google Cloud, and Azure offer on-demand access to GPUs with flexible pricing models such as pay-as-you-go and reserved instances.
✅ Pros:
✔ Scalability – Easily scale resources up or down based on demand. ✔ No Upfront Costs – Avoid capital expenditures and pay only for usage. ✔ Access to Advanced GPUs – Frequent updates include the latest models like NVIDIA A100 and H100. ✔ Managed Infrastructure – No need for maintenance, cooling, or power management. ✔ Global Reach – Deploy workloads in multiple regions with ease.
❌ Cons:
✖ High Long-Term Costs – Usage-based billing can become expensive for continuous workloads. ✖ Availability Constraints – Popular GPUs may be out of stock during peak demand. ✖ Data Transfer Costs – Moving large datasets in and out of the cloud can be costly. ✖ Vendor Lock-in – Dependency on a single provider limits flexibility.
🔹 Best Use Cases:
Early-stage startups with fluctuating GPU needs.
Short-term R&D projects and proof-of-concept testing.
Workloads requiring rapid scaling or multi-region deployment.
2. Owning Physical GPU Servers
Owning physical GPU servers means purchasing GPUs and supporting hardware, either on-premises or collocated in a data center.
✅ Pros:
✔ Lower Long-Term Costs – Once purchased, ongoing costs are limited to power, maintenance, and hosting fees. ✔ Full Control – Customize hardware configurations and ensure access to specific GPUs. ✔ Resale Value – GPUs retain significant resale value (Sell GPUs), allowing you to recover investment costs when upgrading. ✔ Purchasing Flexibility – Buy GPUs at competitive prices, including through refurbished hardware vendors. ✔ Predictable Expenses – Fixed hardware costs eliminate unpredictable cloud billing. ✔ Guaranteed Availability – Avoid cloud shortages and ensure access to required GPUs.
❌ Cons:
✖ High Upfront Costs – Buying high-performance GPUs like NVIDIA A100 or H100 requires a significant investment. ✖ Complex Maintenance – Managing hardware failures and upgrades requires technical expertise. ✖ Limited Scalability – Expanding capacity requires additional hardware purchases.
🔹 Best Use Cases:
Startups with stable, predictable workloads that need dedicated resources.
Companies conducting large-scale AI training or handling sensitive data.
Organizations seeking long-term cost savings and reduced dependency on cloud providers.
3. Renting Physical GPU Servers
Renting physical GPU servers provides access to high-performance hardware without the need for direct ownership. These servers are often hosted in data centers and offered by third-party providers.
✅ Pros:
✔ Lower Upfront Costs – Avoid large capital investments and opt for periodic rental fees. ✔ Bare-Metal Performance – Gain full access to physical GPUs without virtualization overhead. ✔ Flexibility – Upgrade or switch GPU models more easily compared to ownership. ✔ No Depreciation Risks – Avoid concerns over GPU obsolescence.
❌ Cons:
✖ Rental Premiums – Long-term rental fees can exceed the cost of purchasing hardware. ✖ Operational Complexity – Requires coordination with data center providers for management. ✖ Availability Constraints – Supply shortages may affect access to cutting-edge GPUs.
🔹 Best Use Cases:
Mid-stage startups needing temporary GPU access for specific projects.
Companies transitioning away from cloud dependency but not ready for full ownership.
Organizations with fluctuating GPU workloads looking for cost-effective solutions.
4. Hybrid Infrastructure
Hybrid infrastructure combines owned or rented GPUs with cloud GPU services, ensuring cost efficiency, scalability, and reliable performance.
What is a Hybrid GPU Infrastructure?
A hybrid model integrates: 1️⃣ Owned or Rented GPUs – Dedicated resources for R&D and long-term workloads. 2️⃣ Cloud GPU Services – Scalable, on-demand resources for overflow, production, and deployment.
How Hybrid Infrastructure Benefits Startups
✅ Ensures Control in R&D – Dedicated hardware guarantees access to required GPUs. ✅ Leverages Cloud for Production – Use cloud resources for global scaling and short-term spikes. ✅ Optimizes Costs – Aligns workloads with the most cost-effective resource. ✅ Reduces Risk – Minimizes reliance on a single provider, preventing vendor lock-in.
Expanded Hybrid Workflow for AI Startups
1️⃣ R&D Stage: Use physical GPUs for experimentation and colocate them in data centers. 2️⃣ Model Stabilization: Transition workloads to the cloud for flexible testing. 3️⃣ Deployment & Production: Reserve cloud instances for stable inference and global scaling. 4️⃣ Overflow Management: Use a hybrid approach to scale workloads efficiently.
Conclusion
Efficient GPU resource management is crucial for AI startups balancing innovation with cost efficiency.
Cloud GPUs offer flexibility but become expensive for long-term use.
Owning GPUs provides control and cost savings but requires infrastructure management.
Renting GPUs is a middle-ground solution, offering flexibility without ownership risks.
Hybrid infrastructure combines the best of both, enabling startups to scale cost-effectively.
Platforms like BuySellRam.com help startups optimize their hardware investments by providing cost-effective solutions for buying and selling GPUs, ensuring they stay competitive in the evolving AI landscape.
The original article is here: How to manage GPU resource?
#GPU Management#High Performance Computing#cloud computing#ai hardware#technology#Nvidia#AI Startups#AMD#it management#data center#ai technology#computer
2 notes
·
View notes
Text
What is Artificial Intelligence?? A Beginner's Guide to Understand Artificial Intelligence
1) What is Artificial Intelligence (AI)??
Artificial Intelligence (AI) is a set of technologies that enables computer to perform tasks normally performed by humans. This includes the ability to learn (machine learning) reasoning, decision making and even natural language processing from virtual assistants like Siri and Alexa to prediction algorithms on Netflix and Google Maps.
The foundation of the AI lies in its ability to simulate cognitive tasks. Unlike traditional programming where machines follow clear instructions, AI systems use vast algorithms and datasets to recognize patterns, identify trends and automatically improve over time.
2) Many Artificial Intelligence (AI) faces
Artificial Intelligence (AI) isn't one thing but it is a term that combines many different technologies together. Understanding its ramifications can help you understand its versatility:
Machine Learning (ML): At its core, AI focuses on enabling ML machines to learn from data and make improvements without explicit programming. Applications range from spam detection to personalized shopping recommendations.
Computer Vision: This field enables machines to interpret and analyze image data from facial recognition to medical image diagnosis. Computer Vision is revolutionizing many industries.
Robotics: By combining AI with Engineering Robotics focuses on creating intelligent machines that can perform tasks automatically or with minimal human intervention.
Creative AI: Tools like ChatGPT and DALL-E fail into this category. Create human like text or images and opens the door to creative and innovative possibilities.
3) Why is AI so popular now??
The Artificial Intelligence (AI) explosion may be due to a confluence of technological advances:
Big Data: The digital age creates unprecedented amounts of data. Artificial Intelligence (AI) leverages data and uses it to gain insights and improve decision making.
Improved Algorithms: Innovations in algorithms make Artificial Intelligence (AI) models more efficient and accurate.
Computing Power: The rise of cloud computing and GPUs has provided the necessary infrastructure for processing complex AI models.
Access: The proliferation of publicly available datasets (eg: ImageNet, Common Crawl) has provided the basis for training complex AI Systems. Various Industries also collect a huge amount of proprietary data. This makes it possible to deploy domain specific AI applications.
4) Interesting Topics about Artificial Intelligence (AI)
Real World applications of AI shows that AI is revolutionizing industries such as Healthcare (primary diagnosis and personalized machine), finance (fraud detection and robo advisors), education (adaptive learning platforms) and entertainment (adaptive platforms) how??
The role of AI in "Creativity Explore" on how AI tools like DALL-E and ChatGPT are helping artists, writers and designers create incredible work. Debate whether AI can truly be creative or just enhance human creativity.
AI ethics and Bias are an important part of AI decision making, it is important to address issues such as bias, transparency and accountability. Search deeper into the importance of ethical AI and its impact on society.
AI in everyday life about how little known AI is affecting daily life, from increasing energy efficiency in your smart home to reading the forecast on your smartphone.
The future of AI anticipate upcoming advance services like Quantum AI and their potential to solve humanity's biggest challenges like climate change and pandemics.
5) Conclusion
Artificial Intelligence (AI) isn't just a technological milestone but it is a paradigm shift that continues to redefine our future. As you explore the vast world of AI, think outside the box to find nuances, applications and challenges with well researched and engaging content
Whether unpacking how AI works or discussing its transformative potential, this blog can serve as a beacon for those eager to understand this underground branch.
"As we stand on the brink of an AI-powered future, the real question isn't what AI can do for us, but what we dare to imagine next"
"Get Latest News on www.bloggergaurang.com along with Breaking News and Top Headlines from all around the World !!"
2 notes
·
View notes
Text
A Rising Tide of E-Waste, Worsened by AI, Threatens Our Health, Environment, and Economy

The digital age has ushered in a wave of innovation and convenience, powered in large part by artificial intelligence (AI). From AI-driven virtual assistants to smart home devices, technology has made life easier for millions. But beneath this rapid progress lies a less glamorous truth: a mounting crisis of electronic waste (e-waste).
The global e-waste problem is already enormous, with millions of tons discarded every year. Now, with the rapid growth of AI, this tide of e-waste is swelling even faster. Let’s break this down to understand the full scope of the issue and what can be done to mitigate it.
What Is E-Waste, and Why Should We Care?
E-waste encompasses discarded electronic devices — everything from old mobile phones and laptops to smart home gadgets, electric toothbrushes, and even large appliances like refrigerators. It’s not just junk; it’s an environmental and health hazard in disguise.
Each device contains a cocktail of valuable materials like gold and silver, but also toxic substances like lead, mercury, cadmium, and flame retardants. When improperly disposed of, these toxins leach into the environment, harming ecosystems and human health.
A Problem of Global Proportions
Annual Generation: The world generates over 50 million metric tons of e-waste annually, and this figure is projected to grow by 2 million tons each year.
Recycling Rates: Only 17% of e-waste is formally recycled. The rest? It ends up in landfills, incinerated, or handled by informal recycling sectors in developing nations.

While we’re busy marveling at AI-driven innovations, the discarded byproducts of our tech obsession are quietly poisoning our planet.
The Role of AI in Escalating E-Waste
AI, often lauded as the backbone of modern technology, is inadvertently exacerbating the e-waste crisis. Let’s examine the key ways AI contributes to this issue:
1. Accelerating Product Obsolescence
AI-powered devices are evolving at an astonishing pace. Smartphones with AI-enhanced cameras and processors, smart TVs with AI voice assistants, and wearables with health-tracking AI have become must-haves.
But these devices are often rendered obsolete within a few years due to:
Frequent Software Updates: AI systems improve rapidly, making older hardware incompatible with newer software.
Limited Repairability: Many modern gadgets are designed in a way that discourages repairs — sealed batteries, proprietary parts, and inaccessible interiors push consumers toward replacing rather than fixing.
Consumer Demand for New Features: AI advancements create a “fear of missing out” (FOMO), prompting consumers to upgrade frequently.
2. Proliferation of AI-Specific Hardware
AI-driven technologies require specialized, powerful hardware. Graphics Processing Units (GPUs), Tensor Processing Units (TPUs), and custom AI chips are integral to devices and data centers. Unlike general-purpose electronics, these components are challenging to recycle due to their complexity.
3. Growing Data Center Infrastructure

AI thrives on data, which means a relentless demand for computational power. Data centers, the backbone of AI, are:
Upgrading Constantly: To keep up with AI’s demands, servers are frequently replaced, generating massive amounts of e-waste.
Consuming Energy: Outdated hardware contributes to inefficiency and waste.
The Consequences of the E-Waste Crisis
The consequences of unmanaged e-waste are vast, impacting not only the environment but also human health and economic stability.
Health Hazards
E-waste releases harmful substances, including:
Lead and Cadmium: Found in circuit boards, these cause neurological damage and kidney issues when absorbed by humans.
Mercury: Found in screens and lighting, it can lead to brain damage and developmental issues, especially in children.
Burning Plastics: Informal recycling often involves burning e-waste, releasing carcinogenic dioxins into the air.
These pollutants disproportionately affect workers in informal recycling industries, often in developing countries with lax regulations.
Environmental Devastation
Soil Contamination: Toxic metals seep into the ground, affecting agriculture and entering the food chain.
Water Pollution: E-waste dumped in waterways contaminates drinking water and harms aquatic life.
Air Pollution: Incinerating e-waste produces greenhouse gases, contributing to climate change.
Economic Loss
Ironically, e-waste is a treasure trove of valuable materials like gold, silver, and rare earth elements. In 2019 alone, the value of discarded e-waste was estimated at $62.5 billion — higher than the GDP of many countries. Yet, due to poor recycling infrastructure, most of this wealth is wasted.
Turning the Tide: Solutions to the E-Waste Crisis

For Tech Companies
Design for Longevity: Adopt modular designs that make repairs and upgrades easy. For example, Fairphone and Framework Laptop are already doing this.
Reduce Planned Obsolescence: Commit to longer software support and avoid locking critical components like batteries.
Improve Recycling Systems: Implement take-back programs and closed-loop recycling processes to recover valuable materials.
For Governments
Enforce Right-to-Repair Laws: Legislation that mandates access to repair manuals and spare parts empowers consumers to fix devices instead of discarding them.
Promote Circular Economy Models: Incentivize businesses to design products for reuse, repair, and recycling.
Ban Hazardous E-Waste Exports: Prevent the dumping of e-waste in developing countries, where improper recycling leads to environmental and human rights violations.
For Consumers
Think Before You Upgrade: Do you really need the latest gadget, or can your current one suffice?
Repair Instead of Replace: Support local repair shops or DIY fixes with the help of online resources.
Recycle Responsibly: Look for certified e-waste recycling programs in your area.

Can AI Help Solve the Problem It Created?
Interestingly, AI itself could be part of the solution. Here’s how:
Optimizing Recycling Processes: AI-powered robots can sort e-waste more efficiently, separating valuable materials from toxins.
Predicting E-Waste Trends: AI can analyze data to anticipate where e-waste generation is highest, helping governments and companies prepare better recycling strategies.
Sustainable Product Design: AI can assist engineers in designing eco-friendly devices with recyclable components.
A Call to Action
The e-waste crisis is a ticking time bomb, exacerbated by the rapid rise of AI and our insatiable appetite for new technology. But the solution lies in our hands. By embracing sustainable practices, holding companies accountable, and making conscious choices as consumers, we can ensure that the benefits of AI don’t come at the cost of our planet.
It’s time to act, because a rising tide of e-waste doesn’t just threaten the environment — it threatens our future.
#technology#artificial intelligence#tech news#ai#e waste#economy#environment#nature#beautiful planet
2 notes
·
View notes
Text
A3 Ultra VMs With NVIDIA H200 GPUs Pre-launch This Month

Strong infrastructure advancements for your future that prioritizes AI
To increase customer performance, usability, and cost-effectiveness, Google Cloud implemented improvements throughout the AI Hypercomputer stack this year. Google Cloud at the App Dev & Infrastructure Summit:
Trillium, Google’s sixth-generation TPU, is currently available for preview.
Next month, A3 Ultra VMs with NVIDIA H200 Tensor Core GPUs will be available for preview.
Google’s new, highly scalable clustering system, Hypercompute Cluster, will be accessible beginning with A3 Ultra VMs.
Based on Axion, Google’s proprietary Arm processors, C4A virtual machines (VMs) are now widely accessible
AI workload-focused additions to Titanium, Google Cloud’s host offload capability, and Jupiter, its data center network.
Google Cloud’s AI/ML-focused block storage service, Hyperdisk ML, is widely accessible.
Trillium A new era of TPU performance
Trillium A new era of TPU performance is being ushered in by TPUs, which power Google’s most sophisticated models like Gemini, well-known Google services like Maps, Photos, and Search, as well as scientific innovations like AlphaFold 2, which was just awarded a Nobel Prize! We are happy to inform that Google Cloud users can now preview Trillium, our sixth-generation TPU.
Taking advantage of NVIDIA Accelerated Computing to broaden perspectives
By fusing the best of Google Cloud’s data center, infrastructure, and software skills with the NVIDIA AI platform which is exemplified by A3 and A3 Mega VMs powered by NVIDIA H100 Tensor Core GPUs it also keeps investing in its partnership and capabilities with NVIDIA.
Google Cloud announced that the new A3 Ultra VMs featuring NVIDIA H200 Tensor Core GPUs will be available on Google Cloud starting next month.
Compared to earlier versions, A3 Ultra VMs offer a notable performance improvement. Their foundation is NVIDIA ConnectX-7 network interface cards (NICs) and servers equipped with new Titanium ML network adapter, which is tailored to provide a safe, high-performance cloud experience for AI workloads. A3 Ultra VMs provide non-blocking 3.2 Tbps of GPU-to-GPU traffic using RDMA over Converged Ethernet (RoCE) when paired with our datacenter-wide 4-way rail-aligned network.
In contrast to A3 Mega, A3 Ultra provides:
With the support of Google’s Jupiter data center network and Google Cloud’s Titanium ML network adapter, double the GPU-to-GPU networking bandwidth
With almost twice the memory capacity and 1.4 times the memory bandwidth, LLM inferencing performance can increase by up to 2 times.
Capacity to expand to tens of thousands of GPUs in a dense cluster with performance optimization for heavy workloads in HPC and AI.
Google Kubernetes Engine (GKE), which offers an open, portable, extensible, and highly scalable platform for large-scale training and AI workloads, will also offer A3 Ultra VMs.
Hypercompute Cluster: Simplify and expand clusters of AI accelerators
It’s not just about individual accelerators or virtual machines, though; when dealing with AI and HPC workloads, you have to deploy, maintain, and optimize a huge number of AI accelerators along with the networking and storage that go along with them. This may be difficult and time-consuming. For this reason, Google Cloud is introducing Hypercompute Cluster, which simplifies the provisioning of workloads and infrastructure as well as the continuous operations of AI supercomputers with tens of thousands of accelerators.
Fundamentally, Hypercompute Cluster integrates the most advanced AI infrastructure technologies from Google Cloud, enabling you to install and operate several accelerators as a single, seamless unit. You can run your most demanding AI and HPC workloads with confidence thanks to Hypercompute Cluster’s exceptional performance and resilience, which includes features like targeted workload placement, dense resource co-location with ultra-low latency networking, and sophisticated maintenance controls to reduce workload disruptions.
For dependable and repeatable deployments, you can use pre-configured and validated templates to build up a Hypercompute Cluster with just one API call. This include containerized software with orchestration (e.g., GKE, Slurm), framework and reference implementations (e.g., JAX, PyTorch, MaxText), and well-known open models like Gemma2 and Llama3. As part of the AI Hypercomputer architecture, each pre-configured template is available and has been verified for effectiveness and performance, allowing you to concentrate on business innovation.
A3 Ultra VMs will be the first Hypercompute Cluster to be made available next month.
An early look at the NVIDIA GB200 NVL72
Google Cloud is also awaiting the developments made possible by NVIDIA GB200 NVL72 GPUs, and we’ll be providing more information about this fascinating improvement soon. Here is a preview of the racks Google constructing in the meantime to deliver the NVIDIA Blackwell platform’s performance advantages to Google Cloud’s cutting-edge, environmentally friendly data centers in the early months of next year.
Redefining CPU efficiency and performance with Google Axion Processors
CPUs are a cost-effective solution for a variety of general-purpose workloads, and they are frequently utilized in combination with AI workloads to produce complicated applications, even if TPUs and GPUs are superior at specialized jobs. Google Axion Processors, its first specially made Arm-based CPUs for the data center, at Google Cloud Next ’24. Customers using Google Cloud may now benefit from C4A virtual machines, the first Axion-based VM series, which offer up to 10% better price-performance compared to the newest Arm-based instances offered by other top cloud providers.
Additionally, compared to comparable current-generation x86-based instances, C4A offers up to 60% more energy efficiency and up to 65% better price performance for general-purpose workloads such as media processing, AI inferencing applications, web and app servers, containerized microservices, open-source databases, in-memory caches, and data analytics engines.
Titanium and Jupiter Network: Making AI possible at the speed of light
Titanium, the offload technology system that supports Google’s infrastructure, has been improved to accommodate workloads related to artificial intelligence. Titanium provides greater compute and memory resources for your applications by lowering the host’s processing overhead through a combination of on-host and off-host offloads. Furthermore, although Titanium’s fundamental features can be applied to AI infrastructure, the accelerator-to-accelerator performance needs of AI workloads are distinct.
Google has released a new Titanium ML network adapter to address these demands, which incorporates and expands upon NVIDIA ConnectX-7 NICs to provide further support for virtualization, traffic encryption, and VPCs. The system offers best-in-class security and infrastructure management along with non-blocking 3.2 Tbps of GPU-to-GPU traffic across RoCE when combined with its data center’s 4-way rail-aligned network.
Google’s Jupiter optical circuit switching network fabric and its updated data center network significantly expand Titanium’s capabilities. With native 400 Gb/s link rates and a total bisection bandwidth of 13.1 Pb/s (a practical bandwidth metric that reflects how one half of the network can connect to the other), Jupiter could handle a video conversation for every person on Earth at the same time. In order to meet the increasing demands of AI computation, this enormous scale is essential.
Hyperdisk ML is widely accessible
For computing resources to continue to be effectively utilized, system-level performance maximized, and economical, high-performance storage is essential. Google launched its AI-powered block storage solution, Hyperdisk ML, in April 2024. Now widely accessible, it adds dedicated storage for AI and HPC workloads to the networking and computing advancements.
Hyperdisk ML efficiently speeds up data load times. It drives up to 11.9x faster model load time for inference workloads and up to 4.3x quicker training time for training workloads.
With 1.2 TB/s of aggregate throughput per volume, you may attach 2500 instances to the same volume. This is more than 100 times more than what big block storage competitors are giving.
Reduced accelerator idle time and increased cost efficiency are the results of shorter data load times.
Multi-zone volumes are now automatically created for your data by GKE. In addition to quicker model loading with Hyperdisk ML, this enables you to run across zones for more computing flexibility (such as lowering Spot preemption).
Developing AI’s future
Google Cloud enables companies and researchers to push the limits of AI innovation with these developments in AI infrastructure. It anticipates that this strong foundation will give rise to revolutionary new AI applications.
Read more on Govindhtech.com
#A3UltraVMs#NVIDIAH200#AI#Trillium#HypercomputeCluster#GoogleAxionProcessors#Titanium#News#Technews#Technology#Technologynews#Technologytrends#Govindhtech
2 notes
·
View notes
Text
Lenovo Starts Manufacturing AI Servers in India: A Major Boost for Artificial Intelligence
Lenovo, a global technology giant, has taken a significant step by launching the production of AI servers in India. This decision is ready to give a major boost to the country’s artificial intelligence (AI) ecosystem, helping to meet the growing demand for advanced computing solutions. Lenovo’s move brings innovative Machine learning servers closer to Indian businesses, ensuring faster access, reduced costs, and local expertise in artificial intelligence. In this blog, we’ll explore the benefits of Lenovo’s AI server manufacturing in India and how it aligns with the rising importance of AI, graphic processing units (GPU) and research and development (R&D) in India.
The Rising Importance of AI Servers:
Artificial intelligence is transforming industries worldwide, from IT to healthcare, finance and manufacturing. AI systems process vast amounts of data, analyze it, and help businesses make decisions in real time. However, running these AI applications requires powerful hardware.
Artificial Intelligence servers are essential for companies using AI, machine learning, and big data, offering the power and scalability needed for processing complex algorithms and large datasets efficiently. They enable organizations to process massive datasets, run AI models, and implement real-time solutions. Recognizing the need for these advanced machine learning servers, Lenovo’s decision to start production in South India marks a key moment in supporting local industries’ digital transformation. Lenovo India Private Limited will manufacture around 50,000 Artificial intelligence servers in India and also 2,400 Graphic Processing Units annually.
Benefits of Lenovo’s AI Server Manufacturing in India:
1. Boosting AI Adoption Across Industries:
Lenovo’s machine learning server manufacturing will likely increase the adoption of artificial intelligence across sectors. Their servers with high-quality capabilities will allow more businesses, especially small and medium-sized enterprises, to integrate AI into their operations. This large adoption could revolutionize industries like manufacturing, healthcare, and education in India, enhancing innovation and productivity.
2. Making India’s Technology Ecosystem Strong:
By investing in AI server production and R&D labs, Lenovo India Private Limited is contributing to India’s goal of becoming a global technology hub. The country’s IT infrastructure will build up, helping industries control the power of AI and graphic processing units to optimize processes and deliver innovative solutions. Lenovo’s machine learning servers, equipped with advanced graphic processing units, will serve as the foundation for India’s AI future.
3. Job Creation and Skill Development:
Establishing machine learning manufacturing plants and R&D labs in India will create a wealth of job opportunities, particularly in the tech sector. Engineers, data scientists, and IT professionals will have the chance to work with innovative artificial intelligence and graphic processing unit technologies, building local expertise and advancing skills that agree with global standards.
4. The Role of GPU in AI Servers:
GPU (graphic processing unit) plays an important role in the performance of AI servers. Unlike normal CPU, which excel at performing successive tasks, GPUs are designed for parallel processing, making them ideal for handling the massive workloads involved in artificial intelligence. GPUs enable AI servers to process large datasets efficiently, accelerating deep learning and machine learning models.
Lenovo’s AI servers, equipped with high-performance GPU, provide the analytical power necessary for AI-driven tasks. As the difficulty of AI applications grows, the demand for powerful GPU in AI servers will also increase. By manufacturing AI servers with strong GPU support in India, Lenovo India Private Limited is ensuring that businesses across the country can leverage the best-in-class technology for their AI needs.
Conclusion:
Lenovo’s move to manufacture AI servers in India is a strategic decision that will have a long-running impact on the country’s technology landscape. With increasing dependence on artificial intelligence, the demand for Deep learning servers equipped with advanced graphic processing units is expected to rise sharply. By producing AI servers locally, Lenovo is ensuring that Indian businesses have access to affordable, high-performance computing systems that can support their artificial intelligence operations.
In addition, Lenovo’s investment in R&D labs will play a critical role in shaping the future of AI innovation in India. By promoting collaboration and developing technologies customized to the country’s unique challenges, Lenovo’s deep learning servers will contribute to the digital transformation of industries across the nation. As India moves towards becoming a global leader in artificial intelligence, Lenovo’s AI server manufacturing will support that growth.
2 notes
·
View notes
Text
Data Centers in High Demand: The AI Industry’s Unending Quest for More Capacity

The demand for data centers to support the booming AI industry is at an all-time high. Companies are scrambling to build the necessary infrastructure, but they’re running into significant hurdles. From parts shortages to power constraints, the AI industry’s rapid growth is stretching resources thin and driving innovation in data center construction.
The Parts Shortage Crisis
Data center executives report that the lead time to obtain custom cooling systems has quintupled compared to a few years ago. Additionally, backup generators, which used to be delivered in a month, now take up to two years. This delay is a major bottleneck in the expansion of data centers.
The Hunt for Suitable Real Estate
Finding affordable real estate with adequate power and connectivity is a growing challenge. Builders are scouring the globe and employing creative solutions. For instance, new data centers are planned next to a volcano in El Salvador to harness geothermal energy and inside shipping containers in West Texas and Africa for portability and access to remote power sources.
Case Study: Hydra Host’s Struggle
Earlier this year, data-center operator Hydra Host faced a significant hurdle. They needed 15 megawatts of power for a planned facility with 10,000 AI chips. The search for the right location took them from Phoenix to Houston, Kansas City, New York, and North Carolina. Each potential site had its drawbacks — some had power but lacked adequate cooling systems, while others had cooling but no transformers for additional power. New cooling systems would take six to eight months to arrive, while transformers would take up to a year.
Surge in Demand for Computational Power
The demand for computational power has skyrocketed since late 2022, following the success of OpenAI’s ChatGPT. The surge has overwhelmed existing data centers, particularly those equipped with the latest AI chips, like Nvidia’s GPUs. The need for vast numbers of these chips to create complex AI systems has put enormous strain on data center infrastructure.
Rapid Expansion and Rising Costs
The amount of data center space in the U.S. grew by 26% last year, with a record number of facilities under construction. However, this rapid expansion is not enough to keep up with demand. Prices for available space are rising, and vacancy rates are negligible.
Building Data Centers: A Lengthy Process
Jon Lin, the general manager of data-center services at Equinix, explains that constructing a large data facility typically takes one and a half to two years. The planning and supply-chain management involved make it challenging to quickly scale up capacity in response to sudden demand spikes.
Major Investments by Tech Giants

Supply Chain and Labor Challenges
The rush to build data centers has extended the time required to acquire essential components. Transceivers and cables now take months longer to arrive, and there’s a shortage of construction workers skilled in building these specialized facilities. AI chips, particularly Nvidia GPUs, are also in short supply, with lead times extending to several months at the height of demand.
Innovative Solutions to Power Needs

Portable Data Centers and Geothermal Energy
Startups like Armada are building data centers inside shipping containers, which can be deployed near cheap power sources like gas wells in remote Texas or Africa. In El Salvador, AI data centers may soon be powered by geothermal energy from volcanoes, thanks to the country’s efforts to create a more business-friendly environment.
Conclusion: Meeting the Unending Demand
The AI industry’s insatiable demand for data centers shows no signs of slowing down. While the challenges are significant — ranging from parts shortages to power constraints — companies are responding with creativity and innovation. As the industry continues to grow, the quest to build the necessary infrastructure will likely become even more intense and resourceful.
FAQs
1. Why is there such a high demand for data centers in the AI industry?
The rapid growth of AI technologies, which require significant computational power, has driven the demand for data centers.
2. What are the main challenges in building new data centers?
The primary challenges include shortages of critical components, suitable real estate, and sufficient power supply.
3. How long does it take to build a new data center?
It typically takes one and a half to two years to construct a large data facility due to the extensive planning and supply-chain management required.
4. What innovative solutions are companies using to meet power needs for data centers?
Companies are exploring options like modular nuclear reactors, geothermal energy, and portable data centers inside shipping containers.
5. How are tech giants like Amazon, Microsoft, and Google responding to the demand for data centers?
They are investing billions of dollars in new data centers to expand their capacity and meet the growing demand for AI computational power.
Muhammad Hussnain Facebook | Instagram | Twitter | Linkedin | Youtube
3 notes
·
View notes
Text
So this is all just... entirely false?
'AI' doesn't use a huge amount of water. What uses a huge amount of water are the giant datacenters that are required to process billions of queries a second. In truth, you can do everything that ChatGPT and DallE and Midjourney can do on your home system.
To put it in perspective: I can run Stable Diffusion on my home PC, using an Nvidia 1080. My entire system has a 750 watt power supply. Even if I spent 24 hours a day generating things, which no one does, the amount of power it would take would not in fact change my electric bill (which is around $50-70 a month and that's with appliances and a roommate with his own gaming pcs).
In fact, you can generate images with a gpu that has as little as 4gb vram, and maybe lower. Which means you could do it, entirely on your home system, without actually using much power.
That goes for training things as well. Training models and the like is usually a question of time, not power. More power makes it faster, but in general you don't need anything beyond what you would get from a normal gaming PC.
Now, text generation is a bit different. Text generation requires around 12-16gb vram, but that's because it's more complex than image generation. Furthermore, the big issue with text generation is that by and large it's a bullshit generator, devoid of context. But even still, it doesn't require massive amounts of power to do it.
What takes power is running millions of queries from all over the world, because in order to have say, Google, use chatgpt, you need to have that plugged into the Google datacenters. But saying that it's generative AI that makes internet datacenters use power is is a bit like saying that it's your muffler that makes car exhaust.
The thing about the internet is that it requires enormous amounts of power to function. People think of the internet like it's still 1995, but in reality the thing that needs all that power is the ability for you to check the internet on your phone from anywhere on earth. Because in order for that to happen, there needs to be infrastructure and that takes power.
Unlike crypto, which involves turning a hundred gpus into a supercomputer to solve massive equations for no conceivable purpose, generative AI is not actually doing anything that amazing or powerful under the hood, and doesn't require that much power. In fact, you can probably run stable diffusion locally on your average tablet these days.
TLDR: dall-e is not consuming massive amounts of power. The infrastructure required to connect to a sprawling network and then predict things based on that network does. In other words, google searching. The more you want computers to do for you, the more power it's going to take. It doesn't SEEM like it would take that much more power to go from looking at web pages yourself to having chatgpt look at them and then guess what it should say instead, but it does. But that's not because the tech is consuming it itself.
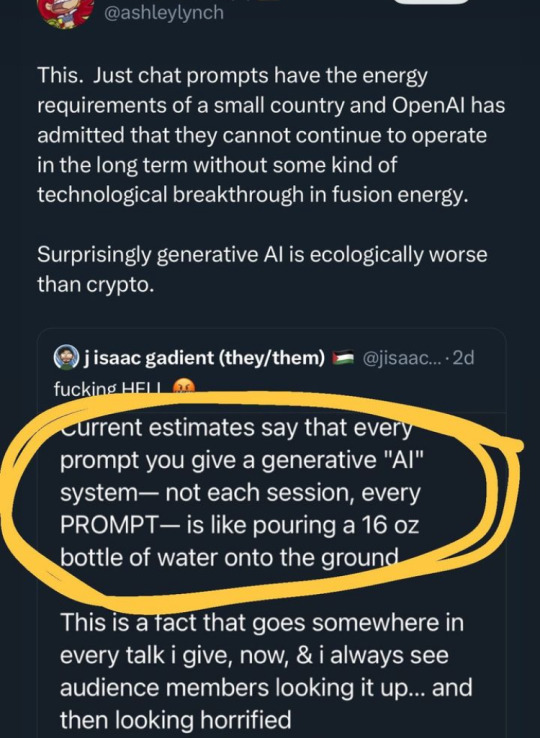
63K notes
·
View notes
Text
Optimized AI infrastructure for training and inference workloads

AI Infrastructure Solutions: The Nerve Centre of State-of-the-Art AI Development
Artificial Intelligence (AI) is fast-changing today. To keep abreast, businesses and researchers require solid and effective systems that will support models in AI, especially for deep learning, machine learning, and data analysis. Such a system comes in the form of advanced AI infrastructure solutions.
AI infrastructure refers to the underlying hardware and software stack that is the foundation upon which AI workloads can be deployed and optimized. Indeed, be it deep-learning model training or inference work, proper infrastructure will be a determinant.
In this blog post, we'll walk you through the importance of high-performance AI infrastructure and how to optimize your AI workloads with the right setup. From GPU-powered solutions to deep learning-focused infrastructure, we will outline the essentials you need to know.
What is High-Performance AI Infrastructure?
High-performance AI infrastructure refers to the combination of advanced hardware and software optimized for handling intensive AI tasks. These tasks, such as training deep learning models, require immense computational power. Traditional computer systems often struggle with these demands, so specialized infrastructure is needed.
Key components of high-performance AI infrastructure include:
- Powerful GPUs:
These are built to support the parallel computation requirements of AI tasks and are much faster than a traditional CPU.
- Massive Storage:
AI models generate and process vast amounts of data, so they need fast and scalable storage solutions.
- Networking and Communication:
High-speed connections between AI systems are necessary to ensure data flows efficiently during training and inference processes.
By utilizing high-performance infrastructure, AI tasks can be completed much faster, enabling businesses to innovate more quickly and accurately.
How Can AI Workload Optimization Services Help Your Business?
AI workload optimization services are essential for improving the efficiency and effectiveness of AI processes. These services ensure that AI workloads—like data processing, model training, and inference—are managed in the most optimized manner possible.
Through AI workload optimization, businesses can:
- Reduce Processing Time:
The right infrastructure and effective management of workloads help reduce the time taken to train AI models and make predictions.
- Improve Resource Utilization:
Optimized AI workloads ensure that every bit of computing power is used effectively, thereby minimizing waste and improving overall performance.
- Cost Savings:
Through the adjustment of the performance and resource consumption of AI systems, firms reduce unutilized hardware expenses and power consumption.
Optimization of workloads, for example, becomes even more efficient in utilizing high-performance AI infrastructure to its full extent since it offers companies the possibility of reaping maximum rewards from advanced computing systems.
Why Is AI Infrastructure Necessary For Deep Learning?
Deep learning, as the name suggests, falls under machine learning and utilizes the training of models on extensive datasets by multiple layers of processing. Because deep learning models are huge and complex in their infrastructure, they require proper infrastructure.
The AI infrastructure in deep learning is made of powerful high-performance servers, containing ample storage for huge data and processing heavy computational processes. In the absence of this infrastructure, deep learning projects get slow and inefficient, becoming cost-prohibitive as well.
With AI infrastructure specifically built for deep learning, businesses can train:
- More Complex Models:
Deep learning models - neural networks and their analogs - require big amounts of data and computing power for the real training process. Such infrastructures ensure the proper design and refinement of models with appropriate speed.
- Scalable AI Projects:
Deep learning models are always changing and demand more computing power and storage. Scalable infrastructure will make it easy for companies to scale their capabilities to match increasing demands.
GPU-Powered AI Infrastructure: Accelerating Your AI Capabilities
The training and deployment of AI models will be sped up with the help of GPU-powered infrastructure. The parallel processing algorithms that are required in machine learning and deep learning work better on GPUs than on CPUs due to the efficiency that results from their design.
Add GPU-powered infrastructure to boost the development of AI.
These will give you:
- Faster Training Times:
With the ability to run multiple tasks in parallel, GPUs can reduce the time required to train complex models by orders of magnitude.
- Faster Inference Speed:
Once the models are trained, GPUs ensure that the inference (or prediction) phase is also fast, which is critical for real-time applications such as autonomous driving or predictive analytics.
Using GPU-powered AI infrastructure, businesses can enhance their AI applications, reduce time to market, and improve overall performance.
AI Infrastructure with NVIDIA GPUs: The Future of AI Development
NVIDIA GPUs stand for excellence in performance among most applications involving AI or deep learning. By using optimized hardware and software, NVIDIA has revolutionized itself to be more valuable than the competition and can help companies scale their business more easily with AI operation development.
Optimized AI Infrastructure for Training and Inference Workloads
Optimized AI infrastructure is both critical for training and inference workloads. Training is the phase when the model learns from the data, while inference is the process by which the trained model makes predictions. Both stages are resource-intensive and demand high-performance infrastructure to function efficiently.
Conclusion: The Future of AI Infrastructure
AI infrastructure is no longer a luxury but a necessity. As AI keeps growing, the demand for high-performance AI infrastructure will keep on increasing. Whether it's to optimize workloads, utilize GPU-powered systems, or scale deep learning models, getting the right infrastructure is important.
At Sharon AI, we provide end-to-end AI infrastructure solutions that fit your business needs. Our services include AI workload optimization, AI infrastructure for deep learning, and GPU-powered AI infrastructure to optimize performance. Ready to accelerate your AI capabilities? Explore our AI services today!
#Advanced AI Infrastructure Services#Inference & Training Workloads#AI infrastructure solutions#High-performance AI infrastructure#AI workload optimization services#AI infrastructure for deep learning#GPU-powered AI infrastructure#AI infrastructure with NVIDIA GPUs
0 notes
Text
Data Center Accelerator Market Set to Transform AI Infrastructure Landscape by 2031

The global data center accelerator market is poised for exponential growth, projected to rise from USD 14.4 Bn in 2022 to a staggering USD 89.8 Bn by 2031, advancing at a CAGR of 22.5% during the forecast period from 2023 to 2031. Rapid adoption of Artificial Intelligence (AI), Machine Learning (ML), and High-Performance Computing (HPC) is the primary catalyst driving this expansion.
Market Overview: Data center accelerators are specialized hardware components that improve computing performance by efficiently handling intensive workloads. These include Graphics Processing Units (GPUs), Tensor Processing Units (TPUs), Field Programmable Gate Arrays (FPGAs), and Application-Specific Integrated Circuits (ASICs), which complement CPUs by expediting data processing.
Accelerators enable data centers to process massive datasets more efficiently, reduce reliance on servers, and optimize costs a significant advantage in a data-driven world.
Market Drivers & Trends
Rising Demand for High-performance Computing (HPC): The proliferation of data-intensive applications across industries such as healthcare, autonomous driving, financial modeling, and weather forecasting is fueling demand for robust computing resources.
Boom in AI and ML Technologies: The computational requirements of AI and ML are driving the need for accelerators that can handle parallel operations and manage extensive datasets efficiently.
Cloud Computing Expansion: Major players like AWS, Azure, and Google Cloud are investing in infrastructure that leverages accelerators to deliver faster AI-as-a-service platforms.
Latest Market Trends
GPU Dominance: GPUs continue to dominate the market, especially in AI training and inference workloads, due to their capability to handle parallel computations.
Custom Chip Development: Tech giants are increasingly developing custom chips (e.g., Meta’s MTIA and Google's TPUs) tailored to their specific AI processing needs.
Energy Efficiency Focus: Companies are prioritizing the design of accelerators that deliver high computational power with reduced energy consumption, aligning with green data center initiatives.
Key Players and Industry Leaders
Prominent companies shaping the data center accelerator landscape include:
NVIDIA Corporation – A global leader in GPUs powering AI, gaming, and cloud computing.
Intel Corporation – Investing heavily in FPGA and ASIC-based accelerators.
Advanced Micro Devices (AMD) – Recently expanded its EPYC CPU lineup for data centers.
Meta Inc. – Introduced Meta Training and Inference Accelerator (MTIA) chips for internal AI applications.
Google (Alphabet Inc.) – Continues deploying TPUs across its cloud platforms.
Other notable players include Huawei Technologies, Cisco Systems, Dell Inc., Fujitsu, Enflame Technology, Graphcore, and SambaNova Systems.
Recent Developments
March 2023 – NVIDIA introduced a comprehensive Data Center Platform strategy at GTC 2023 to address diverse computational requirements.
June 2023 – AMD launched new EPYC CPUs designed to complement GPU-powered accelerator frameworks.
2023 – Meta Inc. revealed the MTIA chip to improve performance for internal AI workloads.
2023 – Intel announced a four-year roadmap for data center innovation focused on Infrastructure Processing Units (IPUs).
Gain an understanding of key findings from our Report in this sample - https://www.transparencymarketresearch.com/sample/sample.php?flag=S&rep_id=82760
Market Opportunities
Edge Data Center Integration: As computing shifts closer to the edge, opportunities arise for compact and energy-efficient accelerators in edge data centers for real-time analytics and decision-making.
AI in Healthcare and Automotive: As AI adoption grows in precision medicine and autonomous vehicles, demand for accelerators tuned for domain-specific processing will soar.
Emerging Markets: Rising digitization in emerging economies presents substantial opportunities for data center expansion and accelerator deployment.
Future Outlook
With AI, ML, and analytics forming the foundation of next-generation applications, the demand for enhanced computational capabilities will continue to climb. By 2031, the data center accelerator market will likely transform into a foundational element of global IT infrastructure.
Analysts anticipate increasing collaboration between hardware manufacturers and AI software developers to optimize performance across the board. As digital transformation accelerates, companies investing in custom accelerator architectures will gain significant competitive advantages.
Market Segmentation
By Type:
Central Processing Unit (CPU)
Graphics Processing Unit (GPU)
Application-Specific Integrated Circuit (ASIC)
Field-Programmable Gate Array (FPGA)
Others
By Application:
Advanced Data Analytics
AI/ML Training and Inference
Computing
Security and Encryption
Network Functions
Others
Regional Insights
Asia Pacific dominates the global market due to explosive digital content consumption and rapid infrastructure development in countries such as China, India, Japan, and South Korea.
North America holds a significant share due to the presence of major cloud providers, AI startups, and heavy investment in advanced infrastructure. The U.S. remains a critical hub for data center deployment and innovation.
Europe is steadily adopting AI and cloud computing technologies, contributing to increased demand for accelerators in enterprise data centers.
Why Buy This Report?
Comprehensive insights into market drivers, restraints, trends, and opportunities
In-depth analysis of the competitive landscape
Region-wise segmentation with revenue forecasts
Includes strategic developments and key product innovations
Covers historical data from 2017 and forecast till 2031
Delivered in convenient PDF and Excel formats
Frequently Asked Questions (FAQs)
1. What was the size of the global data center accelerator market in 2022? The market was valued at US$ 14.4 Bn in 2022.
2. What is the projected market value by 2031? It is projected to reach US$ 89.8 Bn by the end of 2031.
3. What is the key factor driving market growth? The surge in demand for AI/ML processing and high-performance computing is the major driver.
4. Which region holds the largest market share? Asia Pacific is expected to dominate the global data center accelerator market from 2023 to 2031.
5. Who are the leading companies in the market? Top players include NVIDIA, Intel, AMD, Meta, Google, Huawei, Dell, and Cisco.
6. What type of accelerator dominates the market? GPUs currently dominate the market due to their parallel processing efficiency and widespread adoption in AI/ML applications.
7. What applications are fueling growth? Applications like AI/ML training, advanced analytics, and network security are major contributors to the market's growth.
Explore Latest Research Reports by Transparency Market Research: Tactile Switches Market: https://www.transparencymarketresearch.com/tactile-switches-market.html
GaN Epitaxial Wafers Market: https://www.transparencymarketresearch.com/gan-epitaxial-wafers-market.html
Silicon Carbide MOSFETs Market: https://www.transparencymarketresearch.com/silicon-carbide-mosfets-market.html
Chip Metal Oxide Varistor (MOV) Market: https://www.transparencymarketresearch.com/chip-metal-oxide-varistor-mov-market.html
About Transparency Market Research Transparency Market Research, a global market research company registered at Wilmington, Delaware, United States, provides custom research and consulting services. Our exclusive blend of quantitative forecasting and trends analysis provides forward-looking insights for thousands of decision makers. Our experienced team of Analysts, Researchers, and Consultants use proprietary data sources and various tools & techniques to gather and analyses information. Our data repository is continuously updated and revised by a team of research experts, so that it always reflects the latest trends and information. With a broad research and analysis capability, Transparency Market Research employs rigorous primary and secondary research techniques in developing distinctive data sets and research material for business reports. Contact: Transparency Market Research Inc. CORPORATE HEADQUARTER DOWNTOWN, 1000 N. West Street, Suite 1200, Wilmington, Delaware 19801 USA Tel: +1-518-618-1030 USA - Canada Toll Free: 866-552-3453 Website: https://www.transparencymarketresearch.com Email: [email protected] of Form
Bottom of Form
0 notes
Text
Point of Load Power Chip Market: Opportunities in Commercial and Residential Sectors

MARKET INSIGHTS
The global Point of Load Power Chip Market size was valued at US$ 1,340 million in 2024 and is projected to reach US$ 2,450 million by 2032, at a CAGR of 9.27% during the forecast period 2025-2032. This growth trajectory follows a broader semiconductor industry trend, where the worldwide market reached USD 580 billion in 2022 despite macroeconomic headwinds.
Point-of-load (PoL) power chips are voltage regulator ICs designed for localized power conversion near high-performance processors, FPGAs, and ASICs. These compact solutions provide precise voltage regulation, improved transient response, and higher efficiency compared to centralized power architectures. Key variants include single-channel (dominant with 65% market share) and multi-channel configurations, deployed across industrial (32% share), automotive (25%), and aerospace (18%) applications.
The market expansion is driven by escalating power demands in 5G infrastructure, AI servers, and electric vehicles—each requiring advanced power management solutions. Recent innovations like Infineon’s 12V/48V multi-phase controllers and TI’s buck-boost converters demonstrate how PoL technology addresses modern efficiency challenges. However, supply chain constraints and geopolitical factors caused Asia-Pacific revenues to dip 2% in 2022, even as Americas grew 17%.
MARKET DYNAMICS
MARKET DRIVERS
Expanding Demand for Energy-Efficient Electronics to Accelerate Market Growth
The global push toward energy efficiency is creating substantial demand for point-of-load (POL) power chips across multiple industries. These components play a critical role in reducing power consumption by delivering optimized voltage regulation directly to processors and other sensitive ICs rather than relying on centralized power supplies. Current market analysis reveals that POL solutions can improve overall system efficiency by 15-30% compared to traditional power architectures, making them indispensable for modern electronics. The rapid proliferation of IoT devices, 5G infrastructure, and AI-driven applications further amplifies this demand, as these technologies require precise power management at minimal energy loss.
Automotive Electrification Trends to Fuel Adoption Rates
Automakers worldwide are accelerating their transition to electric vehicles (EVs) and advanced driver-assistance systems (ADAS), creating unprecedented opportunities for POL power chips. These components are essential for managing power distribution to onboard computing modules, sensors, and infotainment systems with minimal electromagnetic interference. Industry projections estimate that automotive applications will account for over 25% of the total POL power chip market by 2027, driven by increasing semiconductor content per vehicle. Recent advancements in autonomous driving technology particularly benefit from the high current density and fast transient response offered by next-generation POL regulators.
Data Center Infrastructure Modernization to Sustain Market Expansion
Hyperscale data centers are undergoing significant architectural changes to support AI workloads and edge computing, with POL power delivery emerging as a critical enabling technology. Modern server designs increasingly adopt distributed power architectures to meet the stringent efficiency requirements of advanced CPUs, GPUs, and memory modules. This shift comes amid forecasts predicting global data center power consumption will reach 8% of worldwide electricity usage by 2030, making efficiency improvements economically imperative. Leading chip manufacturers have responded with innovative POL solutions featuring digital interfaces for real-time voltage scaling and load monitoring capabilities.
MARKET RESTRAINTS
Supply Chain Disruptions and Material Shortages to Constrain Market Potential
While demand for POL power chips continues growing, the semiconductor industry faces persistent challenges in securing stable supply chains for critical materials. Specialty substrates, such as silicon carbide (SiC) and gallium nitride (GaN), which enable high-efficiency POL designs, remain subject to allocation due to fabrication capacity limitations. Market intelligence suggests lead times for certain power semiconductors exceeded 52 weeks during recent supply crunches, creating bottlenecks for electronics manufacturers. These constraints particularly impact automotive and industrial sectors where component qualification processes limit rapid supplier substitutions.
Thermal Management Challenges to Limit Design Flexibility
As POL regulators push toward higher current densities in smaller form factors, thermal dissipation becomes a significant constraint for system designers. Contemporary applications often require POL solutions to deliver upwards of 30A from packages smaller than 5mm x 5mm, creating localized hot spots that challenge traditional cooling approaches. This thermal limitation forces compromises between power density, efficiency, and reliability—particularly in space-constrained applications like smartphones or wearable devices. Manufacturers continue investing in advanced packaging technologies to address these limitations, but thermal considerations remain a key factor in POL architecture decisions.
MARKET OPPORTUNITIES
Integration of AI-Based Power Optimization to Create New Value Propositions
Emerging artificial intelligence applications in power management present transformative opportunities for the POL chip market. Adaptive voltage scaling algorithms powered by machine learning can dynamically optimize power delivery based on workload patterns and environmental conditions. Early implementations in data centers demonstrate potential energy savings of 10-15% through AI-driven POL adjustments, with similar techniques now being adapted for mobile and embedded applications. This technological convergence enables POL regulators to evolve from static components into intelligent power nodes within larger system architectures.
Medical Electronics Miniaturization to Open New Application Verticals
The healthcare sector’s accelerating adoption of portable and implantable medical devices creates substantial growth potential for compact POL solutions. Modern diagnostic equipment and therapeutic devices increasingly incorporate multiple voltage domains that must operate reliably within strict safety parameters. POL power chips meeting medical safety standards (IEC 60601) currently represent less than 15% of the total market, signaling significant expansion capacity as device manufacturers transition from linear regulators to more efficient switching architectures. This transition aligns with broader healthcare industry trends toward battery-powered and wireless solutions.
MARKET CHALLENGES
Design Complexity and Verification Costs to Impact Time-to-Market
Implementing advanced POL architectures requires sophisticated power integrity analysis and system-level verification—processes that significantly extend development cycles. Power delivery networks incorporating multiple POL regulators demand extensive simulation to ensure stability across all operating conditions, with analysis suggesting power subsystem design now consumes 30-40% of total PCB development effort for complex electronics. These challenges are compounded by the need to comply with evolving efficiency standards and electromagnetic compatibility requirements across different geographic markets.
Intense Price Competition to Pressure Profit Margins
The POL power chip market faces ongoing pricing pressures as the technology matures and experiences broader adoption. While premium applications like servers and telecom infrastructure tolerate higher component costs, consumer electronics and IoT devices demonstrate extreme price sensitivity. Market analysis indicates that average selling prices for basic POL regulators have declined by 7-12% annually over the past three years, forcing manufacturers to achieve economies of scale through architectural innovations and process technology advancements. This relentless pricing pressure creates significant challenges for sustaining research and development investments.
POINT OF LOAD POWER CHIP MARKET TRENDS
Rising Demand for Efficient Power Management in Electronic Devices
The global Point of Load (PoL) power chip market is experiencing robust growth, driven by the increasing complexity of electronic devices requiring localized voltage regulation. As modern integrated circuits (ICs) operate at progressively lower voltages with higher current demands, PoL solutions have become critical for minimizing power loss and optimizing efficiency. The automotive sector alone accounts for over 30% of the market demand, as electric vehicles incorporate dozens of PoL regulators for advanced driver assistance systems (ADAS) and infotainment. Meanwhile, 5G infrastructure deployment is accelerating adoption in telecommunications, where base stations require precise voltage regulation for RF power amplifiers.
Other Trends
Miniaturization and Integration Advancements
Manufacturers are pushing the boundaries of semiconductor packaging technologies to develop smaller, more integrated PoL solutions. Stacked die configurations and wafer-level packaging now allow complete power management ICs (PMICs) to occupy less than 10mm² board space. This miniaturization is particularly crucial for portable medical devices and wearable technologies, where space constraints demand high power density. Recent innovations in gallium nitride (GaN) and silicon carbide (SiC) technologies are further enhancing power conversion efficiency, with some PoL converters now achieving over 95% efficiency even at load currents exceeding 50A.
Industry 4.0 and Smart Manufacturing Adoption
The fourth industrial revolution is driving significant demand for industrial-grade PoL solutions as factories deploy more IoT-enabled equipment and robotics. Unlike commercial-grade components, these industrial PoL converters feature extended temperature ranges (-40°C to +125°C operation) and enhanced reliability metrics. Market analysis indicates industrial applications will grow at a CAGR exceeding 8% through 2030, as manufacturers increasingly adopt predictive maintenance systems requiring robust power delivery. Furthermore, the aerospace sector’s shift toward more electric aircraft (MEA) architectures is creating specialized demand for radiation-hardened PoL regulators capable of withstanding harsh environmental conditions.
COMPETITIVE LANDSCAPE
Key Industry Players
Semiconductor Giants Compete Through Innovation and Strategic Expansions
The global Point of Load (PoL) power chip market features a highly competitive landscape dominated by established semiconductor manufacturers, with Analog Devices and Texas Instruments collectively holding over 35% market share in 2024. These companies maintain leadership through continuous R&D investment – Analog Devices alone allocated approximately 20% of its annual revenue to product development last year.
While traditional power management leaders maintain strong positions, emerging players like Infineon Technologies are gaining traction through specialized automotive-grade solutions. The Germany-based company reported 18% year-over-year growth in its power segment during 2023, fueled by increasing electric vehicle adoption.
Market dynamics show regional variations in competitive strategies. Renesas Electronics and ROHM Semiconductor dominate the Asia-Pacific sector with cost-optimized solutions, whereas North American firms focus on high-efficiency chips for data center applications. This regional specialization creates multiple growth avenues across market segments.
Recent years have seen accelerated consolidation, with NXP Semiconductors acquiring three smaller power IC developers since 2022 to expand its PoL portfolio. Such strategic moves, combined with ongoing technological advancements in wide-bandgap semiconductors, are reshaping competitive positioning across the value chain.
List of Key Point of Load Power Chip Manufacturers
Analog Devices, Inc. (U.S.)
Infineon Technologies AG (Germany)
Texas Instruments Incorporated (U.S.)
NXP Semiconductors N.V. (Netherlands)
STMicroelectronics N.V. (Switzerland)
Renesas Electronics Corporation (Japan)
ROHM Semiconductor (Japan)
Dialog Semiconductor (Germany)
Microchip Technology Inc. (U.S.)
Segment Analysis:
By Type
Multi-channel Segment Dominates Due to Growing Demand for Higher Efficiency Power Management
The market is segmented based on type into:
Single Channel
Subtypes: Non-isolated, Isolated
Multi-channel
Subtypes: Dual-output, Triple-output, Quad-output
By Application
Automotive Segment Leads Owing to Increasing Electronic Content in Vehicles
The market is segmented based on application into:
Industrial
Aerospace
Automotive
Medical
Others
By Form Factor
Surface-Mount Devices Gaining Traction Due to Miniaturization Trends
The market is segmented based on form factor into:
Through-hole
Surface-mount
By Voltage Rating
Low Voltage Segment Prevails in Consumer Electronics Applications
The market is segmented based on voltage rating into:
Low Voltage (Below 5V)
Medium Voltage (5V-24V)
High Voltage (Above 24V)
Regional Analysis: Point of Load Power Chip Market
North America The North American Point of Load (PoL) power chip market is driven by strong demand from automotive, industrial, and aerospace applications, particularly in the U.S. and Canada. The region benefits from advanced semiconductor manufacturing infrastructure and high investments in next-generation power management solutions. With automotive electrification trends accelerating—such as the shift toward electric vehicles (EVs) and ADAS (Advanced Driver Assistance Systems)—demand for efficient PoL power chips is rising. Additionally, data center expansions and 5G infrastructure deployments are fueling growth. The U.S. holds the majority share, supported by key players like Texas Instruments and Analog Devices, as well as increasing government-backed semiconductor investments such as the CHIPS and Science Act.
Europe Europe’s PoL power chip market is shaped by stringent energy efficiency regulations and strong industrial automation adoption, particularly in Germany and France. The automotive sector remains a key driver, with European OEMs integrating advanced power management solutions to comply with emissions regulations and enhance EV performance. The presence of leading semiconductor firms like Infineon Technologies and STMicroelectronics strengthens innovation, focusing on miniaturization and high-efficiency chips. Challenges include economic uncertainties and supply chain disruptions, but demand remains resilient in medical and renewable energy applications, where precise power distribution is critical.
Asia-Pacific Asia-Pacific dominates the global PoL power chip market, led by China, Japan, and South Korea, which account for a majority of semiconductor production and consumption. China’s rapid industrialization, coupled with its aggressive investments in EVs and consumer electronics, fuels demand for multi-channel PoL solutions. Meanwhile, Japan’s automotive and robotics sectors rely on high-reliability power chips, while India’s expanding telecom and renewable energy infrastructure presents new opportunities. Despite supply chain vulnerabilities and export restrictions impacting the region, local players like Renesas Electronics and ROHM Semiconductor continue to advance technologically.
South America South America’s PoL power chip market is still in a nascent stage, with Brazil and Argentina showing gradual growth in industrial and automotive applications. Local infrastructure limitations and heavy reliance on imports hinder market expansion, but rising investments in automotive manufacturing and renewable energy projects could spur future demand. Political and economic instability remains a barrier; however, increasing digitization in sectors like telecommunications and smart grid development provides a foundation for long-term PoL adoption.
Middle East & Africa The Middle East & Africa’s PoL power chip market is emerging but constrained by limited semiconductor infrastructure. Gulf nations like Saudi Arabia and the UAE are investing in smart city projects, data centers, and industrial automation, driving demand for efficient power management solutions. Africa’s market is more fragmented, though increasing mobile penetration and renewable energy initiatives present growth avenues. Regional adoption is slower due to lower local manufacturing capabilities, but partnerships with global semiconductor suppliers could accelerate market penetration.
Report Scope
This market research report provides a comprehensive analysis of the Global Point of Load Power Chip market, covering the forecast period 2025–2032. It offers detailed insights into market dynamics, technological advancements, competitive landscape, and key trends shaping the industry.
Key focus areas of the report include:
Market Size & Forecast: Historical data and future projections for revenue, unit shipments, and market value across major regions and segments. The Global Point of Load Power Chip market was valued at USD 1.2 billion in 2024 and is projected to reach USD 2.8 billion by 2032, growing at a CAGR of 11.3%.
Segmentation Analysis: Detailed breakdown by product type (Single Channel, Multi-channel), application (Industrial, Aerospace, Automotive, Medical, Others), and end-user industry to identify high-growth segments and investment opportunities.
Regional Outlook: Insights into market performance across North America, Europe, Asia-Pacific, Latin America, and the Middle East & Africa. Asia-Pacific currently dominates with 42% market share due to strong semiconductor manufacturing presence.
Competitive Landscape: Profiles of leading market participants including Analog Devices, Texas Instruments, and Infineon Technologies, including their product offerings, R&D focus (notably in automotive and industrial applications), and recent developments.
Technology Trends & Innovation: Assessment of emerging technologies including integration with IoT devices, advanced power management solutions, and miniaturization trends in semiconductor design.
Market Drivers & Restraints: Evaluation of factors driving market growth (increasing demand for energy-efficient devices, growth in automotive electronics) along with challenges (supply chain constraints, semiconductor shortages).
Stakeholder Analysis: Insights for component suppliers, OEMs, system integrators, and investors regarding strategic opportunities in evolving power management solutions.
Related Reports:https://semiconductorblogs21.blogspot.com/2025/06/laser-diode-cover-glass-market-valued.htmlhttps://semiconductorblogs21.blogspot.com/2025/06/q-switches-for-industrial-market-key.htmlhttps://semiconductorblogs21.blogspot.com/2025/06/ntc-smd-thermistor-market-emerging_19.htmlhttps://semiconductorblogs21.blogspot.com/2025/06/lightning-rod-for-building-market.htmlhttps://semiconductorblogs21.blogspot.com/2025/06/cpe-chip-market-analysis-cagr-of-121.htmlhttps://semiconductorblogs21.blogspot.com/2025/06/line-array-detector-market-key-players.htmlhttps://semiconductorblogs21.blogspot.com/2025/06/tape-heaters-market-industry-size-share.htmlhttps://semiconductorblogs21.blogspot.com/2025/06/wavelength-division-multiplexing-module.htmlhttps://semiconductorblogs21.blogspot.com/2025/06/electronic-spacer-market-report.htmlhttps://semiconductorblogs21.blogspot.com/2025/06/5g-iot-chip-market-technology-trends.htmlhttps://semiconductorblogs21.blogspot.com/2025/06/polarization-beam-combiner-market.htmlhttps://semiconductorblogs21.blogspot.com/2025/06/amorphous-selenium-detector-market-key.htmlhttps://semiconductorblogs21.blogspot.com/2025/06/output-mode-cleaners-market-industry.htmlhttps://semiconductorblogs21.blogspot.com/2025/06/digitally-controlled-attenuators-market.htmlhttps://semiconductorblogs21.blogspot.com/2025/06/thin-double-sided-fpc-market-key.html
0 notes
Text
Developing and Deploying AI/ML Applications on Red Hat OpenShift AI (AI268)
As AI and Machine Learning continue to reshape industries, the need for scalable, secure, and efficient platforms to build and deploy these workloads is more critical than ever. That’s where Red Hat OpenShift AI comes in—a powerful solution designed to operationalize AI/ML at scale across hybrid and multicloud environments.
With the AI268 course – Developing and Deploying AI/ML Applications on Red Hat OpenShift AI – developers, data scientists, and IT professionals can learn to build intelligent applications using enterprise-grade tools and MLOps practices on a container-based platform.
🌟 What is Red Hat OpenShift AI?
Red Hat OpenShift AI (formerly Red Hat OpenShift Data Science) is a comprehensive, Kubernetes-native platform tailored for developing, training, testing, and deploying machine learning models in a consistent and governed way. It provides tools like:
Jupyter Notebooks
TensorFlow, PyTorch, Scikit-learn
Apache Spark
KServe & OpenVINO for inference
Pipelines & GitOps for MLOps
The platform ensures seamless collaboration between data scientists, ML engineers, and developers—without the overhead of managing infrastructure.
📘 Course Overview: What You’ll Learn in AI268
AI268 focuses on equipping learners with hands-on skills in designing, developing, and deploying AI/ML workloads on Red Hat OpenShift AI. Here’s a quick snapshot of the course outcomes:
✅ 1. Explore OpenShift AI Components
Understand the ecosystem—JupyterHub, Pipelines, Model Serving, GPU support, and the OperatorHub.
✅ 2. Data Science Workspaces
Set up and manage development environments using Jupyter notebooks integrated with OpenShift’s security and scalability features.
✅ 3. Training and Managing Models
Use libraries like PyTorch or Scikit-learn to train models. Learn to leverage pipelines for versioning and reproducibility.
✅ 4. MLOps Integration
Implement CI/CD for ML using OpenShift Pipelines and GitOps to manage lifecycle workflows across environments.
✅ 5. Model Deployment and Inference
Serve models using tools like KServe, automate inference pipelines, and monitor performance in real-time.
🧠 Why Take This Course?
Whether you're a data scientist looking to deploy models into production or a developer aiming to integrate AI into your apps, AI268 bridges the gap between experimentation and scalable delivery. The course is ideal for:
Data Scientists exploring enterprise deployment techniques
DevOps/MLOps Engineers automating AI pipelines
Developers integrating ML models into cloud-native applications
Architects designing AI-first enterprise solutions
🎯 Final Thoughts
AI/ML is no longer confined to research labs—it’s at the core of digital transformation across sectors. With Red Hat OpenShift AI, you get an enterprise-ready MLOps platform that lets you go from notebook to production with confidence.
If you're looking to modernize your AI/ML strategy and unlock true operational value, AI268 is your launchpad.
👉 Ready to build and deploy smarter, faster, and at scale? Join the AI268 course and start your journey into Enterprise AI with Red Hat OpenShift.
For more details www.hawkstack.com
0 notes
Text
NVIDIA AI Blueprints For Build Visual AI Data In Any Sector

NVIDIA AI Blueprints
Businesses and government agencies worldwide are creating AI agents to improve the skills of workers who depend on visual data from an increasing number of devices, such as cameras, Internet of Things sensors, and automobiles.
Developers in almost any industry will be able to create visual AI agents that analyze image and video information with the help of a new NVIDIA AI Blueprints for video search and summarization. These agents are able to provide summaries, respond to customer inquiries, and activate alerts for particular situations.
The blueprint is a configurable workflow that integrates NVIDIA computer vision and generative AI technologies and is a component of NVIDIA Metropolis, a suite of developer tools for creating vision AI applications.
The NVIDIA AI Blueprints for visual search and summarization is being brought to businesses and cities around the world by global systems integrators and technology solutions providers like Accenture, Dell Technologies, and Lenovo. This is launching the next wave of AI applications that can be used to increase productivity and safety in factories, warehouses, shops, airports, traffic intersections, and more.
The NVIDIA AI Blueprint, which was unveiled prior to the Smart City Expo World Congress, provides visual computing developers with a comprehensive set of optimized tools for creating and implementing generative AI-powered agents that are capable of consuming and comprehending enormous amounts of data archives or live video feeds.
Deploying virtual assistants across sectors and smart city applications is made easier by the fact that users can modify these visual AI agents using natural language prompts rather than strict software code.
NVIDIA AI Blueprint Harnesses Vision Language Models
Vision language models (VLMs), a subclass of generative AI models, enable visual AI agents to perceive the physical world and carry out reasoning tasks by fusing language comprehension and computer vision.
NVIDIA NIM microservices for VLMs like NVIDIA VILA, LLMs like Meta’s Llama 3.1 405B, and AI models for GPU-accelerated question answering and context-aware retrieval-augmented generation may all be used to configure the NVIDIA AI Blueprint for video search and summarization. The NVIDIA NeMo platform makes it simple for developers to modify other VLMs, LLMs, and graph databases to suit their particular use cases and settings.
By using the NVIDIA AI Blueprints, developers may be able to avoid spending months researching and refining generative AI models for use in smart city applications. It can significantly speed up the process of searching through video archives to find important moments when installed on NVIDIA GPUs at the edge, on-site, or in the cloud.
An AI agent developed using this methodology could notify employees in a warehouse setting if safety procedures are broken. An AI bot could detect traffic accidents at busy crossroads and provide reports to support emergency response activities. Additionally, to promote preventative maintenance in the realm of public infrastructure, maintenance personnel could request AI agents to analyze overhead imagery and spot deteriorating roads, train tracks, or bridges.
In addition to smart places, visual AI agents could be used to automatically create video summaries for visually impaired individuals, classify large visual datasets for training other AI models, and summarize videos for those with visual impairments.
The workflow for video search and summarization is part of a set of NVIDIA AI blueprints that facilitate the creation of digital avatars driven by AI, the development of virtual assistants for individualized customer support, and the extraction of enterprise insights from PDF data.
With NVIDIA AI Enterprise, an end-to-end software platform that speeds up data science pipelines and simplifies the development and deployment of generative AI, developers can test and download NVIDIA AI Blueprints for free. These blueprints can then be implemented in production across accelerated data centers and clouds.
AI Agents to Deliver Insights From Warehouses to World Capitals
With the assistance of NVIDIA’s partner ecosystem, enterprise and public sector clients can also utilize the entire library of NVIDIA AI Blueprints.
With its Accenture AI Refinery, which is based on NVIDIA AI Foundry and allows clients to create custom AI models trained on enterprise data, the multinational professional services firm Accenture has integrated NVIDIA AI Blueprints.
For smart city and intelligent transportation applications, global systems integrators in Southeast Asia, such as ITMAX in Malaysia and FPT in Vietnam, are developing AI agents based on the NVIDIA AI Blueprint for video search and summarization.
Using computing, networking, and software from international server manufacturers, developers can also create and implement NVIDIA AI Blueprints on NVIDIA AI systems.
In order to improve current edge AI applications and develop new edge AI-enabled capabilities, Dell will combine VLM and agent techniques with its NativeEdge platform. VLM capabilities in specialized AI workflows for data center, edge, and on-premises multimodal corporate use cases will be supported by the NVIDIA AI Blueprint for video search and summarization and the Dell Reference Designs for the Dell AI Factory with NVIDIA.
Lenovo Hybrid AI solutions powered by NVIDIA also utilize NVIDIA AI blueprints.
The new NVIDIA AI Blueprint will be used by businesses such as K2K, a smart city application supplier in the NVIDIA Metropolis ecosystem, to create AI agents that can evaluate real-time traffic camera data. City officials will be able to inquire about street activities and get suggestions on how to make things better with to this. Additionally, the company is utilizing NIM microservices and NVIDIA AI blueprints to deploy visual AI agents in collaboration with city traffic management in Palermo, Italy.
NVIDIA booth at the Smart Cities Expo World Congress, which is being held in Barcelona until November 7, to learn more about the NVIDIA AI Blueprints for video search and summarization.
Read more on Govindhtech.com
#NVIDIAAI#AIBlueprints#AI#VisualAI#VisualAIData#Blueprints#generativeAI#VisionLanguageModels#AImodels#News#Technews#Technology#Technologynews#Technologytrends#govindhtech
2 notes
·
View notes
Text
🧠 AI Infrastructure in Europe: Inside Nvidia’s GPU Cloud Expansion in Germany
AI infrastructure in Europe is evolving fast with Nvidia’s GPU cloud expansion in Germany, strengthening Europe’s digital and AI future. The future of AI infrastructure in Europe is unfolding rapidly as Nvidia’s powerful GPU cloud centers take root in Germany. This major expansion aligns with Europe’s broader mission to strengthen digital sovereignty, reduce reliance on external platforms, and…
#AIinEurope#AIInfrastructure#DigitalEurope#DigitalTransformation#EuropeanTech#EuropeCloudComputing#NvidiaGermany#NvidiaGPUCloud
0 notes