#Integrating Python
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr Inc. has $15.1M in annual revenue.
Text
The integration of Python in Excel highlights a significant advancement in data analytics. With the ‘PY’ function integrated within Excel, users can now access the vast libraries of Python. Tasks such as data visualization, advanced analytics, and machine learning are available at the fingertips. All within the familiar boundaries of an Excel spreadsheet. This eliminates the need for separate installations or shifting between platforms. This is a boon for someone who works on both of these platforms.
0 notes
Text
Given three definite integrals and solving for the third is the mathmatical equivalent of fighting the “Tis but a scratch” knight from Monty Python and the Holy Grail. In this essay, I’ll be demonstrating with my dear friend, John…
2 notes
·
View notes
Text


peta.exe upon ye
#peter griffin family guy upon the naysayers#integrating brian griffin into my everyday work tasks so people know im horrible and pretentious#anyways.#i made this for work cos some dude was complaining about how the vscode python integration didnt work in one of my appvols and then everyon#i showed it to got mad at me. justifiably so
4 notes
·
View notes
Text
Fuck. If we want to start looking for work as a dev, probably need to start actually putting shit on github -_- is there like. An alternative repo host that ISN'T owned and mined by Microsoft?
#Basically all our projects have been for work for... 5+ years >.<#Everything else's... NOT something we want tied to our professional identity XD#“Oh yeah here's our fork of buttplug.io's python implementation to integrate a better API for responsiveness with music over bt”#Like yeah that'll be impressive? But one of those devil's sacrament moments
0 notes
Text
0 notes
Text
youtube
Transforming Data Integration: Clarion's Python-Powered Solution
Clarion developed a Python-based reusable library, streamlining data integration and empowering users to configure the system to their unique needs.
0 notes
Text
Neues Python-Framework erleichtert die Entwicklung von KI-Anwendungen
Die Entwicklung von Künstlicher Intelligenz (KI) hat in den letzten Jahren exponentiell zugenommen. Mit dem Aufkommen neuer Technologien und Frameworks wird die Erstellung und Implementierung von KI-Anwendungen immer zugänglicher. Ein neues Python-Framework verspricht nun, diesen Prozess zu revolutionieren, indem es Entwicklern eine benutzerfreundliche und effiziente Plattform bietet, um…
#Algorithmen#Innovation#Integration#Intelligenz#IoT#KI#Python#SEM#Spracherkennung#Wettbewerbsfähigkeit
0 notes
Text
Integrating Django with Elasticsearch: A Comprehensive Guide
Introduction:In modern web applications, search functionality plays a crucial role in enhancing user experience by enabling quick and efficient data retrieval. Elasticsearch, a powerful open-source search and analytics engine, is designed for handling large-scale data and complex queries at lightning speed. Integrating Elasticsearch with Django allows you to build scalable, high-performance…
#Database Indexing#Django#Elasticsearch#Full-Text Search#Python#REST API Integration#Search Engine#web development
0 notes
Text
[Fabric] Dataflows Gen2 destino “archivos” - Opción 2
Continuamos con la problematica de una estructura lakehouse del estilo “medallón” (bronze, silver, gold) con Fabric, en la cual, la herramienta de integración de datos de mayor conectividad, Dataflow gen2, no permite la inserción en este apartado de nuestro sistema de archivos, sino que su destino es un spark catalog. ¿Cómo podemos utilizar la herramienta para armar un flujo limpio que tenga nuestros datos crudos en bronze?
Veamos una opción más pythonesca donde podamos realizar la integración de datos mediante dos contenidos de Fabric
Como repaso de la problemática, veamos un poco la comparativa de las características de las herramientas de integración de Data Factory dentro de Fabric (Feb 2024)
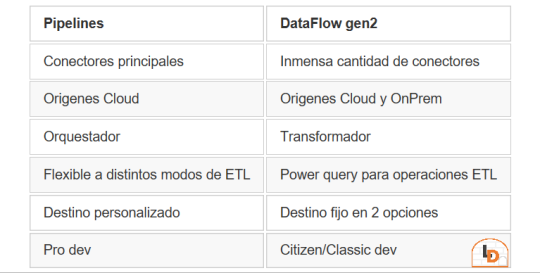
Si nuestro origen solo puede ser leído con Dataflows Gen2 y queremos iniciar nuestro proceso de datos en Raw o Bronze de Archivos de un Lakehouse, no podríamos dado el impedimento de delimitar el destino en la herramienta.
Para solucionarlo planteamos un punto medio de stage y un shortcut en un post anterior. Pueden leerlo para tener más cercanía y contexto con esa alternativa.
Ahora vamos a verlo de otro modo. El planteo bajo el cual llegamos a esta solución fue conociendo en más profundidad la herramienta. Conociendo que Dataflows Gen2 tiene la característica de generar por si mismo un StagingLakehouse, ¿por qué no usarlo?. Si no sabes de que hablo, podes leer todo sobre staging de lakehouse en este post.
Ejemplo práctico. Cree dos dataflows que lean datos con "Enable Staging" activado pero sin destino. Un dataflow tiene dos tablas (InternetSales y Producto) y otro tiene una tabla (Product). De esa forma pensaba aprovechar este stage automático sin necesidad de crear uno. Sin embargo, al conectarme me encontre con lo siguiente:
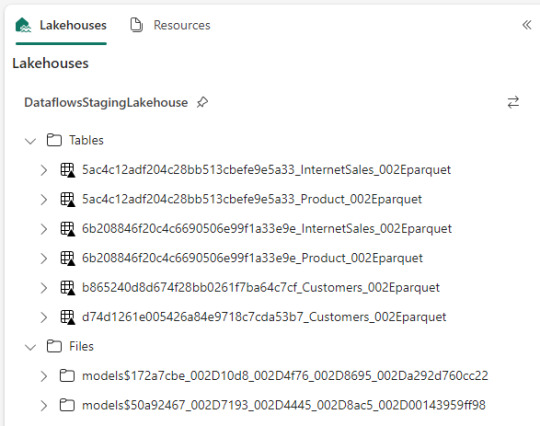
Dataflow gen2 por defecto genera snapshots de cada actualización. Los dataflows corrieron dos veces entonces hay 6 tablas. Por si fuera aún más dificil, ocurre que las tablas no tienen metadata. Sus columnas están expresadas como "column1, column2, column3,...". Si prestamos atención en "Files" tenemos dos models. Cada uno de ellos son jsons con toda la información de cada dataflow.
Muy buena información pero de shortcut difícilmente podríamos solucionarlo. Sin perder la curiosidad hablo con un Data Engineer para preguntarle más en detalle sobre la información que podemos encontrar de Tablas Delta, puesto que Fabric almacena Delta por defecto en "Tables". Ahi me compartió que podemos ver la última fecha de modificación con lo que podríamos conocer cual de esos snapshots es el más reciente para moverlo a Bronze o Raw con un Notebook. El desafío estaba. Leer la tabla delta más reciente, leer su metadata en los json de files y armar un spark dataframe para llevarlo a Bronze de nuestro lakehouse. Algo así:
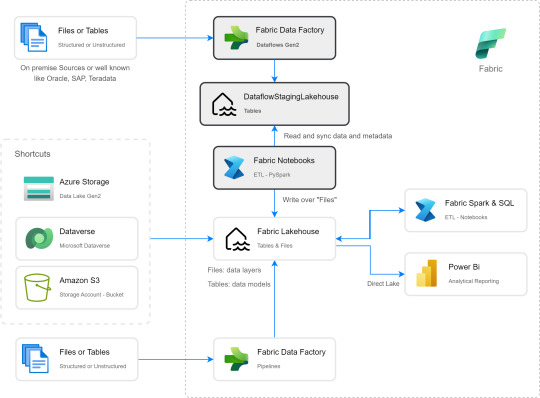
Si apreciamos las cajas con fondo gris, podremos ver el proceso. Primero tomar los datos con Dataflow Gen2 sin configurar destino asegurando tener "Enable Staging" activado. De esa forma llevamos los datos al punto intermedio. Luego construir un Notebook para leerlo, en mi caso el código está preparado para construir un Bronze de todas las tablas de un dataflow, es decir que sería un Notebook por cada Dataflow.
¿Qué encontraremos en el notebook?
Para no ir celda tras celda pegando imágenes, puede abrirlo de mi GitHub y seguir los pasos con el siguiente texto.
Trás importar las librerías haremos los siguientes pasos para conseguir nuestro objetivo.
1- Delimitar parámetros de Onelake origen y Onelake destino. Definir Dataflow a procesar.
Podemos tomar la dirección de los lake viendo las propiedades de carpetas cuando lo exploramos:

La dirección del dataflow esta delimitado en los archivos jsons dentro de la sección Files del StagingLakehouse. El parámetro sería más o menos así:
Files/models$50a92467_002D7193_002D4445_002D8ac5_002D00143959ff98/*.json
2- Armar una lista con nombre de los snapshots de tablas en Tables
3- Construimos una nueva lista con cada Tabla y su última fecha de modificación para conocer cual de los snapshots es el más reciente.
4- Creamos un pandas dataframe que tenga nombre de la tabla delta, el nombre semántico apropiado y la fecha de modificación
5- Buscamos la metadata (nombre de columnas) de cada Tabla puesto que, tal como mencioné antes, en sus logs delta no se encuentran.
6- Recorremos los nombre apropiados de tabla buscando su más reciente fecha para extraer el apropiado nombre del StagingLakehouse con su apropiada metadata y lo escribimos en destino.
Para más detalle cada línea de código esta documentada.
De esta forma llegaríamos a construir la arquitectura planteada arriba. Logramos así construir una integración de datos que nos permita conectarnos a orígenes SAP, Oracle, Teradata u otro onpremise que son clásicos y hoy Pipelines no puede, para continuar el flujo de llevarlos a Bronze/Raw de nuestra arquitectura medallón en un solo tramo. Dejamos así una arquitectura y paso del dato más limpio.
Por supuesto, esta solución tiene mucho potencial de mejora como por ejemplo no tener un notebook por dataflow, sino integrar de algún modo aún más la solución.
#dataflow#data integration#fabric#microsoft fabric#fabric tutorial#fabric tips#fabric training#data engineering#notebooks#python#pyspark#pandas
0 notes
Text
THE FUTURE OF DATA ANALYTICS
INTRODUCTION

In the ever-evolving landscape of technology, data analytics stands as a pivotal force, driving informed decision-making across industries. As we embrace the era of big data, artificial intelligence, and advanced computing, the future of data analytics promises to be both transformative and revolutionary.
Let's embark on a journey into the realms of tomorrow's data analytics, exploring the trends, technologies, and possibilities that will shape the way we derive insights from data.
AI-POWERED ANALYTICS

The integration of artificial intelligence (AI) into data analytics is set to redefine the capabilities of predictive modeling and data interpretation.
Machine learning algorithms will play a crucial role in automating data analysis, uncovering patterns, and providing real-time insights.
AI-driven analytics will enable businesses to make faster, more accurate decisions based on a deeper understanding of their data.
EDGE ANALYTICS

The future of data analytics will witness a shift towards decentralized processing with the rise of edge analytics.
Edge computing allows data analysis to occur closer to the source, reducing latency and enabling real-time decision-making in scenarios such as IoT devices and smart sensors.
This trend will be particularly impactful in industries where instantaneous insights are critical, such as healthcare and manufacturing.
EXPONENTIAL GROWTH OF UNSTRUCTURED DATA

With the proliferation of multimedia, social media, and other unstructured data sources, the future of analytics will grapple with managing and extracting meaningful insights from vast and diverse datasets
Natural Language Processing (NLP) and advanced text analytics will become integral to deciphering the value hidden within unstructured data, providing a more comprehensive understanding of customer sentiments and market trends.
ETHICAL AND RESPONSIBLE DATA ANALYTICS

With increased public awareness about data privacy and ethics, the future of data analytics will prioritize responsible practices.
Ethical considerations in data collection, usage, and storage will become integral, requiring organizations to establish transparent and accountable data analytics frameworks.
AUGMENTED ANALYTICS

The rise of augmented analytics will empower business users with tools that automate data preparation, insight discovery, and sharing, reducing their reliance on data scientists.
Natural language interfaces and automated insights will make data analytics more accessible to a broader audience within organizations.
CONCLUSION

The future of data analytics is an exciting frontier where technological advancements and evolving trends promise to unlock unprecedented possibilities.
As businesses and industries adapt to these changes, the journey towards data-driven decision-making will become more dynamic, intelligent, and ethical.
By staying at the forefront of these developments, organizations can harness the power of data analytics to navigate the complexities of the future and gain a competitive edge in an increasingly data-driven world.
#Integration of AI and ML. ...#Augmented Analytics. ...#Data Governance & Security. ...#Natural Language Processing (NLP) ...#Rising Demand for Data Analysts. ...#Ubiquitous AI. ...#References.#dataanalytics#datascience#data#machinelearning#bigdata#datascientist#datavisualization#artificialintelligence#python#analytics#dataanalysis#ai#technology#deeplearning#programming#database
0 notes
Text
Python, a versatile and powerful programming language, has become the go-to choice for many software development projects. Its simplicity, readability, and extensive libraries make it a valuable tool for various applications. If you're seeking to maximize your software potential, partnering with leading Python developers in Kochi can be the key to success.
Read more:
#accolades integrated#python developers in kochi#python developers in calicut#python developers in kerala#web development companies#web designing companies#website development companies
0 notes
Link
Exploring TA-Lib Integration with Python: A Guide to Installation and Usage
In this informative post, we delve into the installation process of TA-Lib using Python – a robust library in the domain of financial market analysis. The article emphasizes the significance of first installing TA-Lib and then integrating it with Python by installing the appropriate Python wrapper. Through this seamless process, users gain access to the myriad functionalities of TA-Lib conveniently within the Python ecosystem.
The article meticulously guides readers through installation steps across various platforms, including Mac OS X, Windows, and Linux, highlighting crucial considerations and addressing common issues that might arise. A clear and concise example is provided, demonstrating the calculation of technical indicators using TA-Lib within Python.
In essence, this article equips readers with the necessary knowledge to successfully install and utilize TA-Lib, enhancing their ability to conduct advanced financial market analysis efficiently.
#TA-Lib#Financial Market Analysis#Python Integration#Installation Guide#Technical Indicators#Common Problems#Solutions
0 notes
Text
Python is one of the most popular and used programming languages in the data analysis industry. Understand the capabilities of Python and Excel in the field of data analytics.
0 notes
Text
Google Gen AI SDK, Gemini Developer API, and Python 3.13
A Technical Overview and Compatibility Analysis 🧠 TL;DR – Google Gen AI SDK + Gemini API + Python 3.13 Integration 🚀 🔍 Overview Google’s Gen AI SDK and Gemini Developer API provide cutting-edge tools for working with generative AI across text, images, code, audio, and video. The SDK offers a unified interface to interact with Gemini models via both Developer API and Vertex AI 🌐. 🧰 SDK…
#AI development#AI SDK#AI tools#cloud AI#code generation#deep learning#function calling#Gemini API#generative AI#Google AI#Google Gen AI SDK#LLM integration#multimodal AI#Python 3.13#Vertex AI
0 notes
Text
How to Write a Python Script
Python is a high-level programming language that many organizations use. Developers can use it to build sites, analyze data, perform tasks and more. A Python script is a set of commands written in a file that runs similarly to a program, allowing the file to perform a specific function.
The best and easiest way to write code is to use data apps for Python scripts. The right app can save you hours while reducing the risk of error. But even if you use data apps for Python scripts, it pays to know how to write them from scratch.
In this blog, you'll learn how to write a simple Python Script with one of the most famous coding exercises in the world.
Organize Your Scripts
The first step is to create a folder for your Python scripts. Naming conventions are flexible. The key is to choose a folder hierarchy that makes sense to you. For simplicity, consider making a separate folder on your desktop. You can name it "python_workshop."
Creating Your First Script
To start your script, open up Notepad++ and create a new file. Then, click File>Save As.
Save your script in your newly created "python_workshop" folder and name it "exercise_hello_world.py." Pay attention to that file extension!
Write Your Code
On the first line, type out:
# Author: YOUR NAME and email address
Fill out the code with the relevant information to make the script run properly.
On the next line, type:
# This is a script to test that Python is working.
Add an empty line to create your next line of code. It should read:
print("Hello world from YOUR NAME").
Save your file.
Running the Script
Open a new Terminal window. You should see:
C:\Users\YOURNAME>
After you see your name, type in "CD desktop." Hit "Enter," and you can type in the name of your "python_workshop" folder. Hit "Enter" again, and type in the name of the script file you just created.
After hitting "Enter," you should see that little "hello world" message you created in your script.
Read a similar article about chatgpt and spreadsheets here at this page.
#low code sql tool#data apps for python scripts#python integration for enterprise#python for bioinformatics
0 notes