#JSON To Type Definitions Code
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Post activity is at the highest at 4:00 pm EDT; notes peak at 10:00 pm EDT.
Text
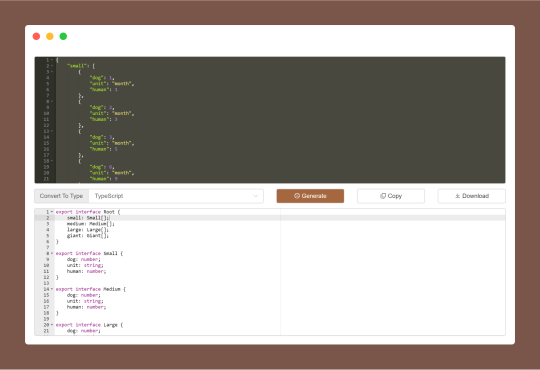
JSON To Type Generator is a code convert tool for generating types from JSON data for Golang, Rust, Kotlin and TypeScript. I.e. you just give it some JSON data, and it gives you the type definitions necessary to use that JSON in a program.
#JSON To Type Generator#JSON To TypeScript Interfaces#JSON To Golang Structs#JSON To Rust Structs#JSON to JSON Schema#JSON To Type Definitions Code#free online tools#online tools#web tools#online web tools#free web tools#online tool
0 notes
Text
Master Data Like a Pro: Enroll in the 2025 R Programming Bootcamp for Absolute Beginners!!

Are you curious about how companies turn numbers into real-world decisions? Have you ever looked at graphs or reports and wondered how people make sense of so much data?
If that sounds like you, then you’re about to discover something that could completely change the way you think about numbers — and your career. Introducing the 2025 R Programming Bootcamp for Absolute Beginners: your all-in-one launchpad into the exciting world of data science and analytics.
This isn’t just another course. It’s a bootcamp built from the ground up to help beginners like you master R programming — the language trusted by data scientists, statisticians, and analysts across the world.
Let’s break it down and see what makes this course the go-to starting point for your R journey in 2025.
Why Learn R Programming in 2025?
Before we dive into the bootcamp itself, let’s answer the big question: Why R?
Here’s what makes R worth learning in 2025:
Data is the new oil — and R is your refinery.
It’s free and open-source, meaning no costly software licenses.
R is purpose-built for data analysis, unlike general-purpose languages.
It’s widely used in academia, government, and corporate settings.
With the rise of AI, data literacy is no longer optional — it’s essential.
In short: R is not going anywhere. In fact, it’s only growing in demand.
Whether you want to become a data scientist, automate your reports, analyze customer trends, or even enter into machine learning, R is one of the best tools you can have under your belt.
What Makes This R Bootcamp a Perfect Fit for Beginners?
There are plenty of R programming tutorials out there. So why should you choose the 2025 R Programming Bootcamp for Absolute Beginners?
Because this bootcamp is built with you in mind — the total beginner.
✅ No coding experience? No problem. This course assumes zero background in programming. It starts from the very basics and gradually builds your skills.
✅ Hands-on learning. You won’t just be watching videos. You’ll be coding along with real exercises and practical projects.
✅ Step-by-step explanations. Every topic is broken down into easy-to-understand segments so you’re never lost or overwhelmed.
✅ Real-world applications. From day one, you’ll work with real data and solve meaningful problems — just like a real data analyst would.
✅ Lifetime access & updates. Once you enroll, you get lifetime access to the course, including any future updates or new content added in 2025 and beyond.
Here's What You'll Learn in This R Bootcamp
Let’s take a sneak peek at what you’ll walk away with:
1. The Foundations of R
Installing R and RStudio
Understanding variables, data types, and basic operators
Writing your first R script
2. Data Structures in R
Vectors, matrices, lists, and data frames
Indexing and subsetting data
Data importing and exporting (CSV, Excel, JSON, etc.)
3. Data Manipulation Made Easy
Using dplyr to filter, select, arrange, and group data
Transforming messy datasets into clean, analysis-ready formats
4. Data Visualization with ggplot2
Creating stunning bar plots, line charts, histograms, and more
Customizing themes, labels, and layouts
Communicating insights visually
5. Exploratory Data Analysis (EDA)
Finding patterns and trends
Generating summary statistics
Building intuition from data
6. Basic Statistics & Data Modeling
Mean, median, standard deviation, correlation
Simple linear regression
Introduction to classification models
7. Bonus Projects
Build dashboards
Analyze customer behavior
Create a mini machine-learning pipeline
And don’t worry — everything is taught in plain English with real-world examples and analogies. This is not just learning to code; it’s learning to think like a data professional.
Who Should Take This Course?
If you’re still wondering whether this bootcamp is right for you, let’s settle that.
You should definitely sign up if you are:
✅ A student looking to boost your resume with data skills ✅ A career switcher wanting to break into analytics or data science ✅ A marketer or business professional aiming to make data-driven decisions ✅ A freelancer wanting to add analytics to your skill set ✅ Or just someone who loves to learn and try something new
In short: if you’re a curious beginner who wants to learn R the right way — this course was made for you.
Real Success Stories from Learners Like You
Don’t just take our word for it. Thousands of beginners just like you have taken this course and found incredible value.
"I had zero background in programming or data analysis, but this course made everything click. The instructor was clear, patient, and made even the complicated stuff feel simple. Highly recommend!" — ★★★★★ "I used this bootcamp to prepare for my first data internship, and guess what? I landed the role! The hands-on projects made all the difference." — ★★★★★
How R Programming Can Transform Your Career in 2025
Here’s where things get really exciting.
With R under your belt, here are just a few of the opportunities that open up for you:
Data Analyst (average salary: $65K–$85K)
Business Intelligence Analyst
Market Researcher
Healthcare Data Specialist
Machine Learning Assistant or Intern
And here’s the kicker: even if you don’t want a full-time data job, just knowing how to work with data makes you more valuable in almost any field.
In 2025 and beyond, data skills are the new power skills.
Why Choose This Bootcamp Over Others?
It’s easy to get lost in a sea of online courses. But the 2025 R Programming Bootcamp for Absolute Beginners stands out for a few key reasons:
Updated content for 2025 standards and tools
Beginner-first mindset — no jargon, no skipping steps
Interactive practice with feedback
Community support and Q&A access
Certificate of completion to boost your resume or LinkedIn profile
This isn’t just a video series — it’s a true bootcamp experience, minus the high cost.
Common Myths About Learning R (and Why They’re Wrong)
Let’s bust some myths, shall we?
Myth #1: R is too hard for beginners. Truth: This bootcamp breaks everything down step by step. If you can use Excel, you can learn R.
Myth #2: You need a math background. Truth: While math helps, the course teaches everything you need to know without expecting you to be a math whiz.
Myth #3: It takes months to learn R. Truth: With the right structure (like this bootcamp), you can go from beginner to confident in just a few weeks of part-time study.
Myth #4: Python is better than R. Truth: R excels in statistics, visualization, and reporting — especially in academia and research.
Learning on Your Own Terms
Another great thing about this course?
You can learn at your own pace.
Pause, rewind, or skip ahead — it’s your journey.
No deadlines, no pressure.
Plus, you’ll gain access to downloadable resources, cheat sheets, and quizzes to reinforce your learning.
Whether you have 20 minutes a day or 2 hours, the course fits into your schedule — not the other way around.
Final Thoughts: The Best Time to Start Is Now
If you’ve been waiting for a sign to start learning data skills — this is it.
The 2025 R Programming Bootcamp for Absolute Beginners is not just a course. It’s a launchpad for your data journey, your career, and your confidence.
You don’t need a background in coding. You don’t need to be a math genius. You just need curiosity, commitment, and a little bit of time.
So go ahead — take that first step. Because in a world where data rules everything, learning R might just be the smartest move you make this year.
0 notes
Text
JS2TS tool and TypeScript Best Practices: Writing Clean and Scalable Code
Introduction
Working with TypeScript, we have to write clean and scalable code; that is crucial for any development project. TypeScript provides a structure and type safety guarantee to JavaScript, which makes the code easier to maintain and debug. But type definitions across large projects are not easy to ensure consistency.
JS2TS tool makes this process much easier by automatically translating JSON data into hard TypeScript interface. The JS2TS tool allows developers to, instead of manual type definition, just define their types and generate structured and reusable type definitions automatically. But it not only saves time, it reduces the amount of rubbish code out in the open (bad code is spoken of by many as ‘the thing’). It produces cleaner, more maintainable, and more scalable code.
About JS2TS tool
The JS2TS tool is a very good tool to convert JSON data to very exact TypeScript interfaces. We know that JSON is extremely popular for APIs, databases, and configuring files; thus, in order to define it in a TypeScript format, this can become very time-consuming and prone to errors.
The JS2TS tool automates that by creating nicely formatted TypeScript interfaces in a couple of seconds. The JS2TS tool helps developers get rid of inconsistencies in type definitions, minimize human errors, and keep up coding standards in projects.
About TypeScript
TypeScript is a superset of JavaScript that will add reliability and scalability. Along with static typing, interfaces, and strict type checks they also introduce to us, which catch errors early and write more predictable code.
Type definitions enforce a structured format for functions, variables, and objects in order to ensure that they follow. Both patterns and it allow code bases to scale well in large projects with many developers, better debugging, and maintainability.
Importance of Clean and Scalable TypeScript Code
The clean and scalable code is necessary for developing efficient, maintainable, and error-free applications. Maintaining well-organized type definitions is very important in a TypeScript codebase so that the code can remain readable and changeable as the project grows.
Automatically defining type structures on teams reduces the chances of introducing bugs due to inconsistency, the amount of redundant code, and confusion during collaboration. Similarly, they improve code reusability, make the program more performant, and are easier to debug.
Developers, through the best practices and the aid of automated tools like the JS2TS, ensure that their TypeScript code remains consistent, sustainable, and due to standards of industry.
How does the JS2TS tool ensure consistency in type definitions?
Maintaining the consistent type definitions across the whole project is considered one of the biggest challenges in TypeScript development. Types defined by hand require consistent efforts, redundant interfaces, and bugs that are harder to understand.
The JS2TS tool solves these problems by converting this automatically, so all the type definitions are in standardized format. In other words, each developer on the team has the same, well-structured interfaces to work with and thus better code organization, fewer conflicts, and better collaboration.
Using the JS2TS tool, teams enforce one source of truth for data structures, less duplication, and also a more reliable codebase.
Best Practices for using JS2TS tool in Large Projects
It is important to keep modular and reusable type definitions for large-scale applications. The JS2TS tool enables developers to do this by creating accurate and reusable interfaces that can be stored in separate files and used across the whole project.
In addition, developers can generate type definitions with the JS2TS tool from API responses to minimize differences in data structure between frontend and backend teams. It helps in collaboration, reduces the miscommunication, and increases the speed of the development.
Also Read: How to Convert JSON to TypeScript Made Easy?
One of the best practices is to include integration of the JS2TS tool into the development workflow. The JS2TS tool allows developers to simply define new interfaces upon changing an API, allowing the code to auto-update without disintegrating into production delivery errors.
How does the JS2TS tool align with TypeScript best practices?
Type safety, reusability, and maintainability are emphasized as the best practices of TypeScript. The JS2TS tool can help the developer follow these principles by automating the creation of the structured, reusable, and precise type definition.
The JS2TS tool is creating interfaces from given JSON data, thus reducing the chance of missing or wrong type definitions, which assures that TypeScript code is strict about type checkups. It reduces the number of runtime errors, helps save the code from being broken, and makes long-term maintainability better.
Also Read: Convert Object to JSON in a Snap
As with most of the services mentioned on this page, integrating the JS2TS tool into a workflow helps enable developers to manage types better, ensure the correct coding standards and create TypeScript code that will easily scale.
Conclusion
Writing clean, structured, and scallable TypeScript code is a JS2TS tool. It kills manual error, increases consistency, and makes sure the best coding practices are implemented by automating type definition generation.
The JS2TS tool makes its life much easier for developers and teams working on TypeScript projects and more reliably maintains and defines types. JS2TS tool can be used when building small applications or a large system and is the key to writing better TypeScript code with minimum effort.
JS2TS offers you JS2TS tool, your purely effort solution today to type in TypeScript type definitions!
0 notes
Text
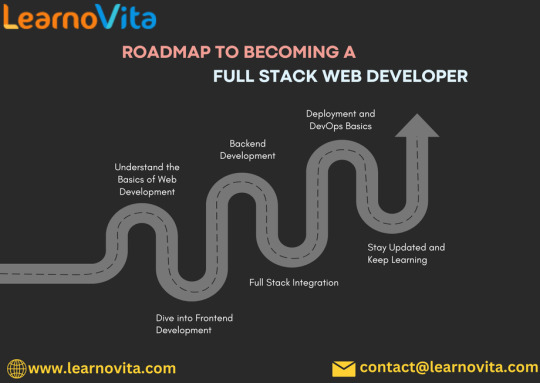
The Definitive Blueprint for Aspiring Full Stack Web Developers
Embarking on a career as a full stack web developer is an exciting journey filled with endless possibilities. Full stack developers are equipped to handle both the frontend and backend aspects of web applications, making them invaluable in the tech industry. This blog serves as your definitive blueprint, guiding you through the essential skills and steps needed to achieve success in this field.
For those looking to enhance their skills, Full Stack Developer Course Online programs offer comprehensive education and job placement assistance, making it easier to master this tool and advance your career.

Step 1: Lay the Groundwork
Master HTML & CSS
Start by learning the foundational technologies of the web:
HTML (HyperText Markup Language): Understand how to structure web content using various elements and tags. Familiarize yourself with semantic HTML to improve accessibility and SEO.
CSS (Cascading Style Sheets): Learn to style your web pages effectively. Focus on layout techniques, color schemes, typography, and responsive design principles.
Get Comfortable with JavaScript
JavaScript: This powerful scripting language is essential for adding interactivity to your web applications. Concentrate on:
Variables, data types, and operators
Control structures (if statements, loops)
Functions, scope, and DOM manipulation for dynamic content
Step 2: Strengthen Your Frontend Skills
Deepen Your JavaScript Knowledge
ES6 and Modern Features: Become proficient in newer JavaScript features such as arrow functions, destructuring, template literals, and modules.
Explore Frontend Frameworks
React: Dive into this popular library for building user interfaces. Understand components, state management, and hooks.
Alternative Frameworks: Consider learning Vue.js or Angular to broaden your perspective on frontend development.
Responsive Design Practices
Learn how to create mobile-friendly applications using responsive design techniques. Frameworks like Bootstrap or Tailwind CSS can expedite your design process.
Version Control with Git
Git: Familiarize yourself with version control systems. Learn to track changes in your code and collaborate using platforms like GitHub.
Step 3: Transition to Backend Development
Learn Server-Side Technologies
Node.js: Get to know this JavaScript runtime for server-side programming. Understand its architecture and how to build scalable applications.
Express.js: Learn this framework for Node.js that simplifies the creation of robust APIs and web applications.
Database Management
SQL Databases: Start with relational databases like PostgreSQL or MySQL. Learn how to write queries and manage data effectively.
NoSQL Databases: Explore MongoDB for handling unstructured data, and understand when to use NoSQL versus SQL.
API Development
Master the principles of RESTful API design. Learn to create and consume APIs using HTTP methods and status codes.
With the aid of Best Online Training & Placement programs, which offer comprehensive training and job placement support to anyone looking to develop their talents, it’s easier to learn this tool and advance your career.
Step 4: Full Stack Integration
Build Complete Applications
Combine your frontend and backend skills to create full stack projects. Ideas include:
A personal blog or portfolio site
A task management application
An e-commerce store
Implement User Authentication
Learn to secure your applications by implementing user authentication and authorization. Explore techniques such as JWT (JSON Web Tokens) and OAuth.
With the aid of Best Online Training & Placement programs, which offer comprehensive training and job placement support to anyone looking to develop their talents, it’s easier to learn this tool and advance your career.
Step 5: Deployment and DevOps Fundamentals
Deploy Your Applications
Understand the deployment process using platforms like Heroku, Vercel, or AWS. Learn how to configure your applications for production environments.
Basic DevOps Knowledge
Familiarize yourself with key DevOps practices, including Continuous Integration/Continuous Deployment (CI/CD) and containerization with Docker.
Step 6: Engage with the Community and Continuous Learning
Join Online Developer Communities
Connect with fellow developers through forums such as Stack Overflow, Reddit, or Discord. Engaging with a community can provide support, resources, and networking opportunities.
Stay Current
Follow blogs, podcasts, and YouTube channels dedicated to web development. Continuous learning is vital in this fast-paced industry.
Create a Professional Portfolio
Build a portfolio showcasing your projects, skills, and experiences. Highlight your best work to attract potential employers and clients.
Conclusion
The path to becoming a full stack web developer is filled with challenges and opportunities for growth. By following this definitive blueprint, you can equip yourself with the skills and knowledge needed to thrive in this dynamic field. Embrace the learning journey, stay curious, and enjoy the process of becoming a skilled developer
0 notes
Text
What is the Person Schema & How to Implement?
Person Schema is a type of structured data specifically aimed at providing information about individuals. It encapsulates a variety of details about a person such as their name, job position, employer, and contact info. Leveraging this schema helps search engines better understand the content relating to people on your web pages, thereby optimizing your site for better search results and enhanced SEO performance.
Understanding Person Schema Definition of Person Schema Person Schema is a form of structured data markup from Schema.org that allows you to furnish detailed information about someone. Whether you’re illuminating details about yourself on a personal blog, showcasing team members on a business site, or detailing a character in a book, Person Schema helps you clearly define attributes such as name, photograph, professional title, and social media accounts. This markup is implemented using several formats, most commonly, JSON-LD, and integrates within your site’s HTML code to communicate to search engines meticulous aspects about the person featured.
Importance of Schema in SEO Schema in SEO acts as a powerful catalyst, heightening your website’s communication with search engines. By delivering precise, structured data, schemas allow you insightfully to articulate the context and content of your webpages to search crawlers, optimizing their understanding and matching search intent with the information you provide. This comprehensive clarity not only boosts the potential to enhance your page rankings but also strategizes how your data is indexed and presented in Search Engine Results Pages (SERPs), presenting a direct impact on your digital visibility and traffic.
How Person Schema Differs from Other Schema Types Person Schema is distinct from other schema types—it’s tailored to represent individual people, whether they are real or fictional. This contrasts with, for instance, Organization Schema which describes businesses or groups, or Event Schema which details events. Person Schema encapsulates details about a person’s life and work, such as biographical information and achievements, while other schemas might focus on product specifics or geographical locations. The focused data provided by Person Schema helps to shape a clearer identity for individuals within the vast digital landscape where context can often become obscured.
Benefits of Implementing Person Schema Enhancing Search Engine Visibility Implementing the Person Schema can substantially boost your search engine visibility. Search engines, equipped with detailed structured data about a person, can elevate pertinent content within their search results, enhancing the probability of your profile appearing to users. This can be particularly beneficial for professionals looking to amplify their online presence or businesses hoping to spotlight team members. By texting search algorithms in their language, you interpret your website’s content with greater clarity, ensuring accurate indexing which, in turn, can translate into a stronger online presence.
Improving Click-Through Rates (CTR) Employing the Person Schema can lead to richer search results that captivate potential visitors, thus improving Click-Through Rates (CTR). When personal information is displayed as a rich snippet in search results—complete with a photo, job title, or social profile—it can stand out against plain text counterparts and invite more clicks. This visual prominence combined with relevant, appealing details tends to encourage users to choose your link over others, escalating CTR and driving more traffic to your site.
Enriching Search Results with Rich Snippets Rich snippets, born from well-structured Person Schema markup, serve as attractive hooks in search results. These snippets can display photos, names, job titles, and other personal attributes, enriching the search experience and providing a snapshot of who the individual is at a glance. This enriched display differentiates and elevates a search result, enhancing the informativeness and attractiveness of your listing. Visitors are supplied with engaging, targeted information even before they click through, setting a precedent for quality and relevance.
0 notes
Text
What are the top 10 Java SpringBoot interview questions?

Here’s a list of the Top 10 Java Spring Boot Interview Questions with detailed answers. At the end, I’ll include a promotion for Spring Online Training to help learners dive deeper into this popular framework.
1. What is Spring Boot, and how does it differ from the Spring Framework?
Answer: Spring Boot is an extension of the Spring Framework, designed to simplify the setup and development of new Spring applications by providing an opinionated approach and avoiding complex configuration. It comes with embedded servers, auto-configuration, and production-ready features, making it faster to get started with a project compared to traditional Spring Framework projects, which require more manual setup and configuration.
2. How does Spring Boot handle dependency management?
Answer: Spring Boot simplifies dependency management using Spring Boot Starters — pre-defined dependencies that bundle commonly used libraries and configurations. For instance, spring-boot-starter-web includes dependencies for building a web application, including embedded Tomcat, Spring MVC, etc. Spring Boot also supports dependency versions automatically via its parent pom.xml, ensuring compatibility.
3. What is the purpose of the @SpringBootApplication annotation?
Answer: The @SpringBootApplication annotation is a convenience annotation that combines:
@Configuration��- Marks the class as a source of bean definitions.
@EnableAutoConfiguration - Enables Spring Boot’s auto-configuration feature.
@ComponentScan - Scans for components in the package.
This annotation is usually placed on the main class to bootstrap the application.
4. Explain the role of the application.properties or application.yml file in Spring Boot.
Answer: application.properties or application.yml files are used to configure the application's settings, including database configurations, server port, logging levels, and more. Spring Boot reads these files on startup, allowing developers to manage configuration without hardcoding them in code. The .yml format is more readable and hierarchical compared to .properties.
5. How does Spring Boot handle exception management?
Answer: Spring Boot provides a global exception handling mechanism via the @ControllerAdvice annotation, which allows you to define a centralized exception handler across the application. With @ExceptionHandler within a @ControllerAdvice, you can customize error responses based on the exception type.
6. What is Spring Boot Actuator, and what are its benefits?
Answer: Spring Boot Actuator provides a set of endpoints to monitor and manage a Spring Boot application, such as /health, /metrics, /info, and more. It helps with application diagnostics and monitoring, offering insights into application health, runtime metrics, environment properties, and request tracing, making it easier to monitor in production environments.
7. What is the difference between @RestController and @Controller?
Answer: @RestController is a specialized version of @Controller in Spring MVC. It is used for RESTful web services, combining @Controller and @ResponseBody annotations. This means that every method in a @RestController will return data (usually in JSON format) directly, rather than resolving to a view template. @Controller is used when views (e.g., JSP, Thymeleaf) are involved in rendering the response.
8. How does Spring Boot handle database connectivity and configuration?
Answer: Spring Boot simplifies database connectivity by providing auto-configuration for supported databases (e.g., MySQL, PostgreSQL). Using the spring.datasource.* properties in application.properties, developers can configure data source properties. For in-memory databases like H2, Spring Boot can automatically create and initialize a database using SQL scripts if placed in src/main/resources.
9. What are Profiles in Spring Boot, and how are they used?
Answer: Spring Boot Profiles allow applications to define different configurations for different environments (e.g., development, testing, production). Profiles can be set using spring.profiles.active=<profile> in application.properties or with environment-specific configuration files like application-dev.properties. Profiles enable smooth switching between configurations without changing the codebase.
10. What is the role of embedded servers in Spring Boot, and how can you configure them?
Answer: Spring Boot includes embedded servers like Tomcat, Jetty, and Undertow, enabling applications to be run independently without external deployment. This setup is useful for microservices. You can configure the embedded server (e.g., server port, SSL settings) via application.properties with properties like server.port, server.ssl.*, etc. This helps create stand-alone applications that are easy to deploy.
Promote Spring Online Training
Mastering Spring Boot and Spring Framework is essential for building efficient, scalable applications. Naresh I Technologies offers comprehensive Spring Online Training designed for aspiring developers and professionals. Our training covers essential Spring concepts, hands-on projects, real-world case studies, and guidance from industry experts. Sign up to boost your career and become a skilled Spring developer with the most in-demand skills. Join our Spring Online Training and take the first step toward becoming a proficient Spring Boot developer!
For Spring Interview Question Visit :- 35 Easy Spring Framework Interview Questions and Answers
Top Spring Interview Questions and Answers (2024)
#programming#100daysofcode#software#web development#angulardeveloper#coding#backend frameworks#backenddevelopment
0 notes
Text
Unleashing Python's Potential: A Comprehensive Exploration
Python, renowned as one of the most adaptable programming languages, presents a multitude of learning avenues, spanning from fundamental principles to avant-garde applications across various domains. Immerse yourself in the realm of Python and embark on an odyssey of enlightenment with our extensive Python Course in Hyderabad, meticulously crafted to unleash your full capabilities and kindle your career aspirations.

Navigating Python: A Pathway to Proficiency
Embark on a journey into Python's depths and unearth a trove of knowledge awaiting discovery. Here’s an intricate guide detailing the spectrum of insights Python offers:
Grasping Basic Programming Concepts
Syntax and Semantics: Acquaint yourself with Python's fundamental framework and syntax regulations governing code structure, encompassing essential elements like indentation, statement formation, and expression evaluation.
Data Types and Variables: Master the manipulation of diverse data types - integers, floats, strings, lists, tuples, dictionaries, and sets - refining your expertise in data management and manipulation.
Control Structures: Harness the potency of loops (for, while) and conditional statements (if, else, elif) to govern program flow, facilitating efficient execution and logical decision-making.
Functions: Immerse yourself in the intricacies of function definition and invocation, grasp the subtleties of parameters and return values, and explore concepts such as scope and recursion for heightened code organization and efficiency.
Error Handling: Equip yourself with adept tools to proficiently manage errors and exceptions, ensuring the resilience and robustness of your Python programs amidst unforeseen challenges.

Exploring Advanced Programming Concepts
Object-Oriented Programming (OOP): Unlock the prowess of OOP principles as you delve into class and object creation and manipulation, unraveling concepts like inheritance, polymorphism, encapsulation, and abstraction. Enroll in our Python Online Course to delve deeper into Object-Oriented Programming (OOP) concepts and broaden your horizons.
Modules and Packages: Harness Python's expansive library ecosystem by mastering the importation and utilization of standard libraries and third-party packages, seamlessly augmenting your application’s functionality.
File Handling: Navigate the complexities of file I/O operations, learning to read from and write to files while adeptly managing various file formats like text, CSV, and JSON for efficient data handling.
Decorators and Generators: Elevate your coding prowess with advanced features such as decorators and generators, empowering you to optimize and streamline your code for enhanced performance and functionality.
Concurrency: Embrace the realm of concurrent programming as you delve into threading and asynchronous programming techniques, mastering the art of handling parallel operations with finesse.
Unlocking Your Potential with Python
Python transcends boundaries, catering to an array of interests and career trajectories. Whether you’re a fledgling enthusiast embarking on your coding odyssey or a seasoned professional seeking to expand your skill set, Python serves as a gateway to success across diverse domains such as data science, web development, automation, software engineering, game development, networking, cybersecurity, and IoT.
Its innate simplicity and readability render it accessible to novices, while its robustness and versatility make it indispensable for seasoned professionals. Embrace the power of Python, unlock your potential, and embark on a journey towards unparalleled success in the dynamic realm of technology and innovation.
0 notes
Text
Databases
What are databases?
First, what are databases for?
Storing data in your application (in memory) has the obvious shortcoming that, whatever the technology you’re using, your data dies when your server stops. Some programming languages and/or frameworks take it even further by being stateless, which, in the case of an HTTP server, means your data dies at the end of an HTTP request. Whether the technology you’re using is stateless or stateful, you will need to persist your data somewhere. That’s what databases are for.
Then, why not store your data in flat files, as you did in the “Relational databases, done wrong” project? A solid database is expected to be acid, which means it guarantees:
Atomicity: transactions are atomic, which means if a transaction fails, the result will be like it never happened.
Consistency: you can define rules for your data, and expect that the data abides by the rules, or else the transaction fails.
Isolation: run two operations at the same time, and you can expect that the result is as though they were ran one after the other. That’s not the case with the JSON file storage you built: if 2 insert operations are done at the same time, the later one will fetch an outdated collection of users because the earlier one is not finished yet, and therefore overwrite the file without the change that the earlier operation made, totally ignoring that it ever happened.
Durability: unplug your server at any time, boot it back up, and it didn’t lose any data.
Also, a solid database will provide strong performance (because I/O is your bottleneck and databases are I/O, so their performance makes a whole lot more of a difference than the performance of your application’s code) and scalability (inserting one user in a collection of 5 users should take about the same time as inserting one user in a collection of 5 billion users).
ACID is a cool acronym! CRUD is another cool one
You will definitely run into the concept of “CRUD” operations. It’s just a fancy way to refer to the 4 operations that can be performed on the data itself:
Create some data;
Read some data;
Update some data;
Destroy some data.
Obviously, a database should allow all four. Yes, that’s it.
2+ kinds of databases
When people talk about databases, they’re usually referring to relational databases (such as PostgreSQL, MySQL, Oracle, …); but there are many other kinds of databases used in the industry, which are globally referred to as “NoSQL” databases, even though they can be very different from each other, and serve very various purposes. Also, the name “NoSQL” comes from SQL, which is the name of the syntax used to give orders (CRUD operations, creating and deleting tables, …) to a relational databases; however, some non-relational databases, which are referred to as “NoSQL” give the option to use the SQL syntax. Therefore, the term “NoSQL” is quite controversial to refer to non-relational databases, but it is still widely used.
“NoSQL” (non-relational) databases have known a boost in popularity, over the last decade or so, so much that there was a point, a few years ago, where people were wondering if they were to replace relational databases entirely. But years later, the market has now solidified, NoSQL databases’ market share doesn’t progress much anymore and is now quite steady. The result: many NoSQL databases have made it into solid maturity, and are used in some very ambitious projects (as well as small ones), but relational databases are still by far the most used in projects, and are not going anywhere after all.
Therefore: it is crucial for a software engineer to know very well how relational databases work, because the odds are very strong that you will encounter them in your career; but it is also very important to get acquainted with the most popular types of NoSQL databases, because the odds that you run into them, however kinda smaller, are pretty strong too.
SQL
In order to work with relational databases, you will need to get familiar with SQL syntax. A lot of developers will acknowledge that they find the SQL syntax unpleasantly hard to use, which has some outcomes:
Engineers that are comfortable with SQL are very respected in the industry, even more so in this age where data has gotten so valuable. To be honest, the fact that I aced the SQL challenge on my Apple interview is probably a huge reason for me to have gotten the job; it turns out the initial role was a lot about manipulating data.
The fear of SQL explains a lot why non-relational databases got called “NoSQL”, a bit like if it was a statement, a complain. Non-relational databases push a lot the button of not having to use SQL.
Modern full-fledged frameworks contain tools that are called ORMs, and one of their roles is to abstract away SQL queries (which is good for day-to-day ease of use, but can turn out very dangerous). We’ll cover ORMs more later, but it’s worth noting that you do find back-end engineers in the industry who work with relational databases, but never write a line of SQL, which makes them a lot less valuable on a project.
For a beginner, keep in mind that SQL’s syntax is a bit hard to wrap your head around, so maybe you should follow a tutorial first. Please don’t try to memorize the SQL syntax. I’ve used SQL extensively in very advanced cases, on systems with hundreds of millions of records, and I still go on Google each time I need to compose a SQL query.
Some terminology around relational databases
One good thing about relational databases is that whether they’re PostgreSQL, MySQL, Oracle, or other, they’ve managed to be pretty consistent across brands. Therefore, not only are their versions of SQL pretty decently similar (at least for CRUD operations), but the terminology they’re using are mostly the same.
Say you need to store users. To do that, you create a table that is called “users”.
Your users have 3 pieces of information to store: their ���id”, their “login”, and their “password”. Those are called columns, and they all have types, like integer for the “id”, varchar(32) for “login” (a string of variable length, but maximum 32), and char(32) (a string of exactly 32 characters, which is the case for all text encrypted with the md5 algorithm, for instance). The available types may vary heavily from one database “brand” to the other.
Now, let’s add a user in the database with SQL:
INSERT INTO users (login, password) VALUES ('rudy', '01234567890123456789012345678901');
This adds a row in the table (sometimes also refered to as a record, or more rarely, a tuple).
Why are they called “relational” databases?
Historically, the initial reason was that tables used to be called “relations” (they gather a lot of datas that are “related” to each other, since they follow the same structure). However, tables are now tables, and the term “relation” has now been recycled for another use.
A relation as used today is something that ties two records together, most often across different tables. For instance, say you have a blog, and you have 2 tables:
posts, with the fields id, title and body
comments, with the fields id and body
In both tables, the “id” fields are primary keys, because they uniquely identify the row that they belong to (if you say “give me the post of id 4”, you’re sure to be getting only one post).
But how do you know that a given comment is attached to a given post. Well, you add a postid field to the comments table, containing the id of the post you with to attach it to. The postid field is called a foreign key, uniquely identifying another’s table primary key.
Now that you have that, you can easily identify, from a comment, which post it is attached to; but you can also easily identify, from a post, which comments are attached to it. Just fetch the comments whose post_id field contain the id of the post you had in mind. The fact that you can do that is what is called a relation.
Once you have your relation, you can do pretty advanced things. For instance, you can join tables together while querying them, which will allow you to search for “the comments whose posts were published within the last month”, for instance (well, provided the posts table has a published_at column of type date, for instance).
Note: you can have a relation between rows of the same table, for instance, a user that is the “sponsor” of another one, a comment that is a “reply” of another one, …
Some more terminology around relational databases
Indexes
Say you want to get all of the comments that are attached to the post of ID 12:
SELECT * FROM comments WHERE post_id=12;
If you have millions or billions of comments, having your database extract the comments that match this condition can be amazingly time-consuming. Therefore, you can add an index on the comments table, that applies to the post_id column. This will “precompute” every possible SELECT query with WHERE conditions on this column, which will update themselves every time you modify data, so that those calls are ready to respond very quickly.
Let’s complicate things a bit, and say you want to optimize this query:
SELECT * FROM comments WHERE post_id=12 AND published=1;
Your index on the post_id column might not help much on that query. However, for that query, you can absolutely define an index on multiple column (in this case, the columns post_id and published).
Setting indexes properly is a known quick win to improve performance of relational databases on queries that are performed very often and take a long time to respond (so-called slow queries). I can quote at least a dozen occurrences in my career where setting up an index properly boosted a database’s performance with minimal effort, the most notable of which allowed us to boost a data migration that was taking ~48 hours, to suddenly complete in about 3 hours.
Joins
You can join tables together that have relations between each other, so that you can operate on data across those tables. For instance, I want the titles of all posts that have published comments.
SELECT posts.title FROM posts JOIN comments ON posts.id = comments.post_id WHERE comments.published=1;
(Note: each post on that query will appear as many times as it has comments, but let’s focus on the join for now.)
Performance is dramatically better if you manage to get the database to do most of the work, as opposed to your application, because the database knows most about your data and how to handle it most efficiently. Joins are amazing wins for that, because the other way to get it done is to perform many separate SQL queries, and manipulate that data in your code, which is very inefficient.
Note: you can join tables together across many relations. The largest join in my career was 7-fold, in a database at Apple that contained information about localization projects.
A NoSQL kind of database: document-based databases
One particularly popular type of NoSQL database is document-oriented databases, such as MongoDB or CouchDB. One reason they’re popular is because their learning curve is very smooth, and they feel natural to use: you just send them JSON documents, much like we’ve done in the “Relational databases done wrong” project, and they make it right when you need to fetch them back. You don’t need your JSON documents to have specific fields of specific types, just send whatever JSON you want; the technical word for this is that they are schemaless.
One caveat is that they’re much, much harder to scale than relational databases (the data being more “formatted” in relational databases makes it easier and faster to work with).
Another caveat is that there is some comfort in having the database enforcing a schema (proper columns of proper types, …); if the database doesn’t do it, you can expect that some JSON documents in the collection are not of the schema you expect, and then you have to enforce schema in your code, which means more work. As a result, some document-based databases offer ways to enforce some schema, but I don’t believe many developers use it, because it defeats the purpose of having schemaless storage.
Just as relational databases, document-based databases offer a variety of extra features to tune your usage of the data: indexes, joins, … sometimes even relations!
Document-based databases will be covered towards the end of year 1.
Another NoSQL kind of database: key-value stores
Some applications may need very large key-value storage, which you may think of as the persistence of a single huge “dictionary” structure (the same structure that Ruby calls “hash”, Python calls “dict”, PHP calls “associative array”, Objective C and Swift calls “dictionary”, …). An obvious need for that is around caching (if you don’t understand why, we’ll cover this when we talk about caching). Cassandre, memcached and Redis are popular key-value stores.
As your collection of key-values grows, you may need pretty advanced ways to organize them (and expire them, for instance), so, obviously, each key-value storage solution comes with more advanced tools than just the usual CRUD operations.
At the intersection of NoSQL and relational
As mentioned before, NoSQL databases sometimes get closer to relational databases by allowing to be queried using the SQL syntax (like Cassandra and Hypertable); but databases are getting closer also the other way around, as relational databases themselves have started offering some document-based storage.
A mature example of that is PostgreSQL’s “hstore” type, which allows to store JSON data in PostgreSQL, in a way that is queriable. Most recently, this has allowed PostgreSQL to have a certain leg up against their competition of open-source relational databases, because MySQL hasn’t been able to ship a similar feature yet, although they’re expected too (MySQL development has dramatically slowed down now that they belong to Oracle, which is a direct closed-source competitor; a few years ago, most MySQL contributors went ahead to create another open-source database called MariaDB, which never really became mainstream, so maybe there won’t ever be document-based storage in MySQL, actually).
What NoSQL storage do I need?
NoSQL databases address all kinds of requirements, and therefore the ways they work are dramatically different. Here’s a really accurate map of the various solutions: http://kkovacs.eu/cassandra-vs-mongodb-vs-couchdb-vs-redis
Note: in year 1, your main project must be done using a relational database, and we’ll cover document-oriented databases (probably MongoDB) and key-value stores (probably Redis) towards the end of the year.
0 notes
Text
REST API vs GraphQL API: Choosing an API Which You Need

REST API vs. GraphQL APIs: A Developer Showdown
APIs power modern online services by connecting software components and transferring data across the internet. API technologies like SOAP, REST, and GraphQL facilitate software development by integrating third-party data and services. APIs allow firms to securely communicate data and provide services to workers, business partners, and users.
Recent disputes have focused on REST (representational state transfer) and GraphQL, despite the various APIs. Both have several advantages and are used in networking projects worldwide. Data traffic management differs greatly between them. IBM compare REST and GraphQL APIs and explain how corporations may optimise their networks.
Explain REST and GraphQL APIs Comparing REST and GraphQL APIs requires knowledge of each.
REST The early 2000s-developed REST architecture paradigm for networked hypermedia applications uses a stateless, client/server, cacheable communication protocol. RESTful APIs drive REST designs.
REST APIs address resources using URIs. REST APIs use endpoints to execute CRUD (“create,” “read,” “update,” and “delete”) network resource activities. They shape and size client resources based on a media type or MIME type. Most formats are JSON and XML (occasionally HTML or plain text).
The server handles client requests for resources and returns all related data. HTTP response codes include “200 OK” for successful REST queries and “404 Not Found” for missing resources.
GraphQL In 2012, Facebook created GraphQL, a query language and API runtime that became open source in 2015.
API schema published in GraphQL schema definition language defines GraphQL. Each schema lists data types and associations the user may query or alter. The resolver backs each schema field. The resolver converts GraphQL queries, modifications, and subscriptions into data and fetches it from databases, cloud services, and other sources. Resolvers specify data formats and let the system combine data from several sources.
Instead of utilising several endpoints to acquire data and conduct network operations like REST, GraphQL exposes data models by using a single endpoint for all GraphQL queries. Using resource attributes and resource references, the API gets the client all the data they need from a single query to the GraphQL server.
GraphQL and REST APIs are resource-based data exchanges that employ HTTP methods like PUT and GET to limit client actions. However, important contrasts explain why GraphQL has grown and why RESTful systems have endured.
REST API vs GraphQL API GraphQL APIs are typically considered an enhancement over RESTful settings due to their ability to promote front-end-back-end team cooperation. An organization’s API journey should continue with GraphQL, which solves REST difficulties.
REST was the norm for API designs, and many developers and architects still use RESTful settings to manage IT networks. Understanding the differences is crucial to any IT management plan.
REST and GraphQL APIs handle differently:
Data retrieval REST uses many endpoints and stateless interactions to handle each API request as a new query, so clients obtain all resource data. Over-fetching occurs when a client only wants a portion of the data. To make up for under-fetching, a RESTful system frequently requires clients query each resource individually if they need data from numerous resources. Single-endpoint GraphQL APIs eliminate over- and under-fetching by providing clients with an accurate, full data response in one round trip from a single request.
Versioning Teams must version APIs to adjust data structures and avoid end-user errors and service outages in a REST architecture. Developers must establish a new endpoint for every update, producing several API versions and complicating maintenance. GraphQL eliminates versioning since clients may express data needs via queries. Clients without need for new server fields are unaffected. Clients may request deprecated fields until queries are updated.
Error handling HTTP status codes indicate request success or failure in REST APIs. Each status code has a purpose. A successful HTTP request returns 200, whereas a client error returns 400 and a server error returns 500.
This status reporting method sounds simpler, however HTTP status codes are typically more valuable to online users than APIs, particularly for mistakes. REST does not specify errors, therefore API failures may display as transport problems or not at all with the status code. This may compel staff to study status documentation to understand faults and how infrastructure communicates failures.
Because HTTP status codes don’t transmit problems (excluding transport faults), GraphQL APIs return 200 OK for every request. The system sends faults in the response body with the data, so clients must interpret it to determine whether the request was successful.
However, GraphQL specifies errors, making API problems easier to identify from transport failures. The response body’s “errors” item describes errors, making GraphQL APIs easier to develop upon.
REST lacks built-in functionality for real-time data changes. Long-polling and server-sent events are required for real-time functionality, which might complicate a programme.
Subscriptions provide real-time changes in GraphQL. Subscriptions enable the server to notify clients when events occur by maintaining a continuous connection.
Environment and tools Developers have several tools, libraries, and frameworks in the REST environment. Teams must browse several endpoints and learn each API’s norms and practices while using REST APIs.
GraphQL APIs are young, but the ecosystem has evolved greatly since their inception, with several server and client development tools and modules. GraphiQL and GraphQL Playground are powerful in-browser IDEs for discovering and testing GraphQL APIs. GraphQL also supports code generation, simplifying client-side development.
Caching REST APIs use eTags and last-modified headers to cache API requests. While effective, some caching solutions are difficult to implement and may not be suited for all use situations.
Dynamic queries make GraphQL APIs harder to cache. Persisted queries, response caching, and server-side caching may alleviate these issues and simplify GraphQL caching.
When to utilise GraphQL and REST APIs REST and GraphQL APIs are distinct tools for various goals, not better.
For public-facing e-commerce sites like Shopify and GitHub, REST is easy to deploy and provides a simple, cacheable communication protocol with strict access constraints. Due to under- and over-fetching issues, REST APIs are ideal for:
Businesses with simpler data profiles and smaller applications Businesses without complicated data queries Businesses where most customers utilise data and processes similarly GraphQL APIs increase system efficiency and developer ease-of-use by providing flexible, fast data fetching. This makes GraphQL ideal for APIs in complicated setups with quickly changing front-end needs. This includes:
Business with limited bandwidth wants to restrict calls and answers Companies who seek to aggregate data at one endpoint Businesses with diverse client requirements Though they employ distinct methods, GraphQL and REST APIs may improve network scalability and server speed.
Control your API environment using IBM API Connect Whether you use REST or GraphQL APIs or a mix of both your business can benefit from a wide range of applications, including JavaScript implementations and integration with microservices and serverless architectures. Use both API types to optimise your IT infrastructure with IBM API Connect.
IBM API Connect lets you establish, manage, protect, socialise, and monetise APIs and encourage digital transformation in data centres and clouds. This lets organisations and consumers power digital applications and innovate in real time.
API Connect helps organisations stay ahead in API management, which will be crucial in a computing ecosystem that will get bigger, more complicated, and more competitive.
Read more on Govindhtech.com
0 notes
Text
Mastering TypeScript Faster: How the JS2TS tool Can Help New Learners?
Introduction
When starting out with TypeScript, beginners can easily find it to be overwhelming learning about types, interfaces, etc. together with themselves working on complex data structures. In contrast to JavaScript, one of its main differences is that TypeScript forces the developer to define data types, meaning that at first it can be confused. It is frustrating for new learners to understand how to properly define types and progress slowly.
This makes the learning process much easier by automatically converting JSON data into accurate TypeScript type definitions using the JS2TS tool. Instead of having to manually determine the correct type structure for beginners, the JS2TS tool provides a way to show how TypeScript handles various data structures in real time. This makes it easier for new developers to learn TypeScript faster and create errors, and it increases their confidence in their coding skills.
About JS2TS tool
The JS2TS tool is an online tool to transpose JSON data into TypeScript type definition in a single click. JSON, or JavaScript Object Notation, is a common data format used for APIs and applications, but it becomes difficult to define its structure for TypeScript as a beginner.
The JS2TS tool lets learners take JSON data and paste it in the tool and within seconds they get a well-structured TypeScript interface. This eliminates the need to guess and gives the beginners a chance to focus on learning how TypeScript works instead of dealing with type definitions.
About TypeScript
It is a type-based javascript programming language with added syntax and static typing to javascript. Typescript does that, meaning you can’t store everything in JavaScript variables but must specify its type every time. Contrary to JavaScript, this makes your code more controlled so you don’t get bugs you thought you would not get and, yes, this does mean that TypeScript allows you to write more elegant and, in some sense, safer code.
TypeScript is a hard language for beginners due to the need for careful attention to type definitions, interfaces, and strict coding rules. How is that such a useful tool can sound scary? Well, it’s because too many newcomers use TypeScript when that’s simply not the case.
How does the JS2TS Tool help beginners understand TypeScript types?
Defining types correctly is one of the hardest things one needs to learn first with TypeScript. For new developers, interfaces, type annotations, and handling complex nested structures are the problem.
Auto-typing JSON data into TypeScript with the JS2TS tool makes it an excellent resource for new learners. It helps the learners to look at real-world types of data to understand how types of data in TypeScript are structured without writing the type definitions manally. Using the JS2TS tool, it is easy for a beginner to understand how TypeScript interfaces work and to be able to write their own type definitions.
Rather than spending hours researching the appropriate type structures, learners can play around with the JS2TS tool brainlessly and see on the fly how TypeScript translates different types of data. That makes learning TypeScript faster and easier because it is added.
How does using the JS2TS tool reduce frustration for new developers?
In fighting the errors and debugging problems while learning a new programming language, this is a real issue. TypeScript evaluates strict rules and if the type definition is wrong, it may cause confusion and slow down the progress.
The JS2TS tool reduces much of this frustration by automating the type definition process. The JS2TS tool allows beginners to not have to write interfaces and deal with errors and instead to generate correct type definitions instantly. It helps them not waste their time trying to solve syntax errors but rather focus on the TypeScript concepts.
The JS2TS tool simplifies the type definitions, which helps new developers learn to write TypeScript code with more confidence. It gives them to play around with different JSON structures, play with how TypeScript handles those, and incrementally enhances their grasp of TypeScript’s type system.
Why is the JS2TS tool the perfect learning companion?
The JS2TS tool is a helpful guide to anyone new to TypeScript; it provides clear, ready-to-use type definitions. This helps reduce the learning time by letting the developers easily see the real examples of how TypeScript works without the headache of manually converting the code.
The JS2TS tool is also good for self-study. TypeScript defines different JSON data structures, which beginners can paste into the tool and observe how they are defined. With this interactive approach, learning is more engaging and learners learn better about TypeScript’s type system.
Also Read: How to Convert JSON to TypeScript Made Easy?
The JS2TS tool generates precise and standardized TypeScript interfaces, so beginners also get good practices from the start. This also prepares them for the real projects in real-world TypeScript projects where they already have a solid base for writing clean and well-structured code.
Conclusion
Learning TypeScript is not an insurmountable task. JS2TS tool lets you skip the frustration of requiring to define types yourself and learn how TypeScript works. The JS2TS tool allows for immediate transformation of the JSON data into the TypeScript interface, making it faster for fresh developers to learn concepts of TypeScript and avoiding standard mistakes at the same time.
Also Read: Convert Object to JSON in a Snap
The JS2TS tool is a must-use tool for anyone who is starting their TypeScript journey; it makes it smooth, efficient, and error-free. JS2TS offers you to try it and start mastering TypeScript with absolutely no effort!
0 notes
Text
Codecademy Badges
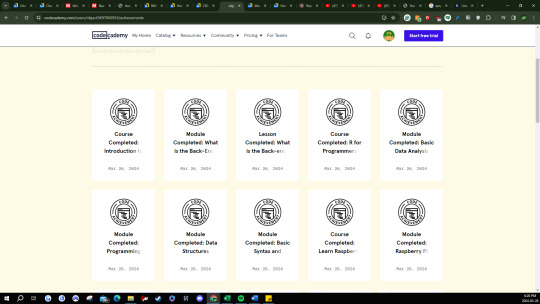
I was able to successfully utilize Codecademy.com to learn more about different programming languages to improve my skills. The courses I chose to complete were "R for Programmers", "Getting Started Off-Platform for Data Science", Learn CSS: Browser Compatibility", "Learn to Code with Blockly", and "Introduction to Back-End Programming". For the R programming course, I was able to learn about basic syntax in R and different variable types as well. I've also taken the beginner data science course and learned command line interface setups and how to use Jupyter Notebook as well as SQL for the first time. These courses will benefit me in my workplace as I am currently interning for a data analyst position which requires me to leverage R programming to analyze data. I've also taken the Introduction to back-end programming course because one of my good friends is a back-end programmer and I was curious to learn more. Here I learned about the basics of what back-end means and what JSON coding is. Finally, I have also completed the "Learn to Code with Blockly" which is a beginner-friendly programming course. In this course I learned how to use variables, functions, loops, if statements, and lists.
Codecademy is a great free website to learn more about programming languages for employment. I can definitely see myself using Codecademy more to prepare me for interviews or learn a new skill for my role as a data analyst.
0 notes
Text
How Chrome Extensions Can Scrape Hidden Information From Network Requests By Overriding XMLHttpRequest

Chrome extensions offer a versatile way to enhance browsing experiences by adding extra functionality to the Chrome browser. They serve various purposes, like augmenting product pages with additional information on e-commerce sites, scraping data from social media platforms such as LinkedIn or Twitter for analysis or future use, and even facilitating content scraping services for retrieving specific data from websites.
Scraping data from web pages typically involves injecting a content script to parse HTML or traverse the DOM tree using CSS selectors and XPaths. However, modern web applications built with frameworks like React or Vue pose challenges to this traditional scraping method due to their reactive nature.
When visiting a tweet on Twitter, essential details like author information, likes, retweets, and replies aren't readily available in the DOM. However, by inspecting the network tab, one can find API calls containing this hidden data, inaccessible through traditional DOM scraping. It's indeed possible to scrape this information from API calls, bypassing the limitations posed by the DOM.
A secondary method for scraping data involves intercepting API calls by overriding XMLHttpRequest. This entails replacing the native definition of XMLHttpRequest with a modified version via a content script injection. By doing so, developers gain the ability to monitor events within their modified XMLHttpRequest object while still maintaining the functionality of the original XMLHttpRequest object, allowing for seamless traffic monitoring without disrupting the user experience on third-party websites.
Step-by-Step Guide to Overriding XMLHttpRequest
Create a Script.js
This is an immediately invoked function expression (IIFE). It creates a private scope for the code inside, preventing variables from polluting the global scope.
XHR Prototype Modification: These lines save references to the original send and open methods of the XMLHttpRequest prototype.
Override Open Method: This code overrides the open method of XMLHttpRequest. When we create an XMLHttpRequest, this modification stores the request URL in the URL property of the XHR object.
Override Send Method: This code overrides the send method of XMLHttpRequest. It adds an event listener for the 'load' event. If the URL contains the specified string ("UserByScreenName"), it executes code to handle the response. After that, it calls the original send method.
Handling the Response: If the URL includes "UserByScreenName," it creates a new div element, sets its innerText to the intercepted response, and appends it to the document body.
Let's explore how we can override XMLHttpRequest!
Creating a Script Element: This code creates a new script element, sets its type to "text/javascript," specifies the source URL using Chrome.runtime.getURL("script.js"), and then appends it to the head of the document since it is a common way to inject a script into a web page.
Checking for DOM Elements: The checkForDOM function checks if the document's body and head elements are present. If they are, it calls the interceptData function. If not, it schedules another call to checkForDOM using requestIdleCallback to ensure the script waits until the necessary DOM elements are available.
Scraping Data from Profile: The scrapeDataProfile function looks for an element with the ID "__interceptedData." If found, it parses the JSON content of that element and logs it to the console as the API response. If not found, it schedules another call to scrapeDataProfile using requestIdleCallback.
Initiating the Process: These lines initiate the process by calling requestIdleCallback on checkForDOM and scrapeDataProfile. This ensures that the script begins by checking for the existence of the necessary DOM elements and then proceeds to scrape data when the "__interceptedData" element is available.
Pros
You can obtain substantial information from the server response and store details not in the user interface.
Cons
The server response may change after a certain period.
Here's a valuable tip
By simulating Twitter's internal API calls, you can retrieve additional information that wouldn't typically be displayed. For instance, you can access user details who liked tweets by invoking the API responsible for fetching this data, which is triggered when viewing the list of users who liked a tweet. However, it's important to keep these API calls straightforward, as overly frequent or unusual calls may trigger bot protection measures. This caution is crucial, as platforms like LinkedIn often use such strategies to detect scrapers, potentially leading to account restrictions or bans.
Conclusion
To conclude the entire situation, one must grasp the specific use case. Sometimes, extracting data from the user interface can be challenging due to its scattered placement. Therefore, opting to listen to API calls and retrieve data in a unified manner is more straightforward, especially for a browser extension development company aiming to streamline data extraction processes. Many websites utilize APIs to fetch collections of entities from the backend, subsequently binding them to the UI; this is precisely why intercepting API calls becomes essential.
#Content Scraping Services#Innovative Scrapping Techniques#Advanced Information Scraping Methods#browser extension development services
0 notes
Text
What is Schema Data?
Unlock the potential of structured information and watch your SEO soar to new heights. Structured information, powered by schema data, acts as a bridge between your content and search engines.
By providing a clear roadmap that search engines can easily follow, you enhance your content’s visibility and user experience. Imagine your web pages being presented with rich snippets in major search engines’ results—complete with ratings, reviews, and more.
Structured information is the key to standing out in a cluttered digital landscape and driving SEO success that’s both measurable and impactful.
The Power of Structured Information for SEO Success
Website schema structured data refers to a specialised code, often written in JSON-LD format, that is added to a webpage’s HTML to provide explicit information about the content on that page.
This structured data helps search engines better understand the context and meaning of the content, enabling them to display rich snippets in search results.
These snippets can include additional details such as:
Ratings
Reviews
Event dates
Local business
Services
and more
Enhancing the visibility and attractiveness of the search result listings. Website schema structured data plays a crucial role in improving search engine rankings, user experience, and the overall visibility of a webpage in search results.
Example JSON-LD Schema code
<html> <head> <title>Apple Pie by Grandma</title> <script type="application/ld+json"> "@context": "https://schema.org/", "@type": "Recipe", "name": "Apple Pie by Grandma", "author": "Elaine Smith", "image": "https://images.edge-generalmills.com/56459281-6fe6-4d9d-984f-385c9488d824.jpg", "description": "A classic apple pie.", "aggregateRating": "@type": "AggregateRating", "ratingValue": "4.8", "reviewCount": "7462", "bestRating": "5", "worstRating": "1" , "prepTime": "PT30M", "totalTime": "PT1H30M", "recipeYield": "8", "nutrition": "@type": "NutritionInformation", "calories": "512 calories" , "recipeIngredient": [ "1 box refrigerated pie crusts, softened as directed on box", "6 cups thinly sliced, peeled apples (6 medium)" ] </script> </head> <body> </body> </html>
How the Example Schema Displays in the Search Results
Unlocking SEO Potential with Schema Data
Imagine your website soaring high in search rankings, effortlessly attracting the right audience, and standing out in the vast digital landscape. This isn’t just a dream; it’s a reality you can achieve with the magic of schema data.
If you’re wondering what schema data is and how it can transform your online presence, you’ve come to the right place. In this article, we’ll demystify the world of schema data, explain its importance, and show you how to harness its power for your website’s SEO success.
Understanding Schema Data: Making Sense of Structured Data for Your Website
Schema data might sound like a complex term, but at its core, it’s all about structured information that speaks the language of search engines. It’s like giving your website a secret code that search engines can easily decipher, leading to better visibility and improved user experience. Here’s the breakdown:
Structured Data Definition: Schema data is organised and labelled information presented in a specific format single schema that helps search engines recognise and understand your content better.
Why It Matters: When search engines like Google understand your content, they can intelligently display relevant content around it in a more appealing way, known as rich snippets, which can significantly boost your click-through rates.
The Building Blocks: Database, Schema Markup, and More
Dive deeper into the world of schema data with these essential building blocks:
Database: Think of a database as your organised vault of information. It stores data in tables, or database objects, making it easy to retrieve and manage. Different types of databases suit various needs, from relational databases to NoSQL options.
Relational Database: This type of database organises data in tables with relationships between them, a primary key to ensuring data integrity and efficient management.
In DBMS: A Database Management System (DBMS) is a database instance the software that helps you manage databases efficiently. You can use SQL to communicate with databases and perform tasks like searching and updating.
Schema Markup: This is where the magic happens. Schema markup is code you add to the markup typesof your website to provide extra context to search engines. It’s like giving search engines a backstage pass to your content.
Physical database schema
A schema describes the shape of the data and how it relates to other models, tables and databases. In this scenario, a database entry is an instance of the database schema, containing all the properties described in the schema.
A database schema is (generally) broadly divided into two categories: physical and relational database management systems schema that defines how the data-like files are actually stored; and logical database schema, which describes all the logical constraints including integrity, tables and views applied on the stored data.
Some common database schema examples include the following: star schema snowflake schema.
What is Star Schema?
youtube
A star schema is a way of organising data in a special way to help people analyse and understand it better. It’s like a star with a centre and many points around it. The centre is called the fact table, and it holds the database tables of important numbers or measurements, like sales or revenue.
The points around the centre are called dimension tables, and they give more information about the facts. For example, they have data items that might tell you when and where the sales happened, or what products were sold. These dimension tables help give context and make the facts more meaningful.
The star schema makes it easier to ask questions and find answers from the data. It’s like having everything you need in one place, so you can quickly find the information you’re looking for. It also helps with calculations and comparing data from different angles.
People use star schemas in special databases called data warehouses, database systems where they store lots of data from different sources. By using a star schema, they can analyse the data more easily and make better decisions based on what they find.
In summary, a star schema is a way of organising data to make it easier to understand and analyse. It’s like a star with a centre of important numbers and points around it that give more information. It helps people ask questions, find answers, and make better decisions.
What is Snowflake Schema?
A snowflake schema is an expanded version of a star schema, which is used for organising multi-dimensional data. In the snowflake schema, dimension tables are further divided into subdimensions, creating a more intricate structure to add schema.
This schema type finds frequent application in business intelligence, reporting data modelling, and analysis within OLAP data warehouses, relational databases, and data marts.
Understanding Schema Data: Unveiling the Magic Behind Enhanced Web Pages
In the vast digital landscape, web pages are the vibrant canvases where online communication unfolds. Each web page acts as a window to your content, connecting you with your audience across the globe. From informative articles to captivating visuals, web pages hold the power to engage and inform.
However, the challenge lies in making your web pages not just appealing, but also intelligible to search engines. This is where the schema data steps in.
By imbuing your web pages with structured information, schema data transforms them into interactive and informative entities that stand out in search results. Let’s dive deeper into the world of schema data and how it influences your web pages’ impact.
1. Web Page: The Canvas of Digital Communication
At its core, a web page is a digital space where information, creativity, and interaction converge. It’s where you showcase your products, share your thoughts, and engage with your audience. Every web page represents a unique opportunity to make a lasting impression.
Whether it’s a blog post, a product page, or a contact form, web pages are essential elements of your online presence. Ensuring that your web pages effectively communicate with both humans and search engines is crucial. This is where schema data becomes a powerful tool.
2. Description: Decoding Schema Data’s Purpose
Schema data plays a vital role in making your web pages more than just blocks of text and images. It provides a deeper layer of meaning that search engines can understand. Consider schema data as a translator between your web content and search engines.
It deciphers the context, structure, and relationships within your content, transforming it into information that search engines can easily interpret.
This enhanced understanding leads to the creation of rich snippets—those informative snippets of text, images, meta description, and even ratings that you often see in search results. These snippets are more than eye-catching; they’re the result of a strategic schema data implementation.
3. Structure: The Blueprint for Organised Information
Imagine walking into a well-organised library, each book neatly placed on its shelf, and categories clearly marked. Similarly, web pages with structured information are like well-arranged libraries for search engines.
Schema data defines the layout and structure of your content, ensuring that search engines can navigate through your information effortlessly.
This organisation not only enhances search engine understanding but also guides users through your content logically. As a result, users find what they’re looking for faster, and search engines reward you with improved visibility.
4. XML: The Language Behind Schema Data
Underneath the surface of schema data lies XML, or Extensible Markup Language. XML serves as the backbone, enabling schema data to represent intricate relationships and hierarchies. It’s the language that gives structure to your structured data.
XML is a versatile tool, allowing you to add schema markup to create custom data structures that match the uniqueness of your content.
By speaking the language of XML, schema data communicates complex information to search engines in a clear and organised manner, enhancing the potential for your web pages to be highlighted in search results.
5. Hyperlink: Bridging Schema Data to Interactive Experiences
Hyperlinks are the digital bridges that connect one piece of information to another, enriching the user experience by allowing easy navigation between related content. Schema data can play a role in enhancing hyperlinks as well.
For instance, imagine a product hyperlink that not only takes you to a product page but also displays its price, availability, and even reviews directly in the search results.
This enhanced hyperlink experience is made possible through various types of schema data, making your web pages more interactive and enticing for users to explore further.
Elevating Web Pages with Schema Data Mastery
In the ever-evolving world of online communication, the impact of schema data cannot be overstated. By embracing schema data, you transform your web pages into dynamic, informative, and engaging entities that capture both human and search engine attention.
Your web pages become not only visually appealing but also strategically crafted to convey meaning. Remember, every pixel and snippet of content counts.
As you master the art of incorporating schema data, you’re not only enhancing your web pages; you’re elevating your online presence and making a significant mark in the digital landscape.
Ready to take the next step in optimising your web pages with schema data? Contact Red Kite SEO today and let us guide you toward web page excellence!
Transforming Your Website: The Benefits of Schema Data
It’s time to reap the rewards of schema data:
Enhanced Search Results: Imagine your product’s reviews, recipe ratings, and event details showing up directly in search results, capturing users’ attention instantly.
Better User Experience: Schema data helps search engines understand your content’s purpose, delivering more accurate results to users’ queries.
Improved Click-Through Rates: Rich snippets created by schema data make your listings stand out, enticing users to click and explore.
Putting Theory into Practise Your Action Plan
Feeling excited? Here’s a simple action plan to unleash schema data’s potential on your website:
1. Identify Opportunities: Find content on your website that could benefit from enhanced search results, like product pages, reviews, events, or recipes.
2. Choose Schema Types: Select the appropriate schema and data and markup types for your content. Google’s Structured Data Markup Helper can assist in generating schema markup code.
3. Implement Schema Markup: Add the generated schema markup code to your webpage’s HTML. Ensure accuracy by adding schema markup and testing it using Google’s Structured Data Testing Tool.
4. Monitor and Optimise: Keep an eye on how your enhanced search results perform. Make adjustments as needed to achieve optimal results.
How to Leverage Schema Data: A Quick Step-by-Step Guide
How to Create JSON-LD Schema for Your Website
Crafting a JSON-LD schema might sound daunting, but with the right guidance, it’s a straightforward process. Here’s how:
1. Identify Schema Type: Determine the type of content you want to mark up—whether it’s:
Webpage
Product
Article
Event
Person
Organization
Local Business
or something else.
Visit Schema.org for all schema types.
2. Choose a Generator: Use online schema generators to simplify the process. Fill in the relevant details about your content, and the generator will produce the JSON-LD code for you.
Try some of these Schema Generators listed below:
3. Customise the Code: Review the generated code and ensure it accurately reflects your content. You can modify it to match your specific needs.
4. Embed in Your Web Page: Paste the JSON-LD code within the `<script>` tags of your web page’s HTML. Place it within the `<head>` section for optimal results.
5. Validate Your Schema: Utilise Google’s Structured Data Testing Tool to validate your schema. This step ensures that your schema is error-free and ready for implementation.
Using Schema.org for Website Schema: Elevating Content Visibility
When it comes to enhancing your website’s presence and boosting its discoverability, Schema.org serves as an invaluable resource. Schema.org provides a comprehensive collection of structured data types and properties that can be incorporated into your website’s HTML code.
By referencing Schema.org, you’re tapping into a universal language that search engines understand, enabling you to communicate the precise context of your content. Whether you’re marking up product details, articles, events, or reviews, Schema.org offers a standardised way to present your information.
Embracing Schema.org ensures that your website’s schema data is recognised across various search engines, leading to enriched search results that captivate users and amplify your online impact.
Example: Schema Markup for a Local Business
Let’s consider an example of a local bakery, “Sweet Delights Bakery,” and how schema data from Schema.org can be utilised to enhance its online presence.
<script type="application/ld+json"> "@context": "http://schema.org", "@type": "LocalBusiness", "name": "Sweet Delights Bakery", "description": "A cozy bakery offering freshly baked goods and delightful treats.", "address": "@type": "PostalAddress", "streetAddress": "123 Main Street", "addressLocality": "Cityville", "addressRegion": "State", "postalCode": "12345" , "telephone": "(123) 456-7890", "openingHours": "Mo-Fr 08:00-18:00, Sa 09:00-17:00", "image": "https://example.com/images/bakery.jpg", "priceRange": "$", "url": "https://sweetdelightsbakery.com" </script>
In this example, the JSON-LD code defines the schema markup for “Sweet Delights Bakery” as a `LocalBusiness`.
The code includes essential details such as the bakery’s name, description, address, contact information, opening hours, image, price range, and website URL.
By incorporating this schema markup, search engines can display rich snippets in search results, showcasing key bakery information directly to potential customers.
This not only increases the bakery’s visibility but also entices users to engage with the listing.
Embracing Schema.org standardised schema markup empowers businesses like “Sweet Delights Bakery” to stand out in local search results and provide users with valuable information at a glance.
How to Place Schema on Your WordPress Website
Integrating schema data into your WordPress website is a breeze. Follow these steps:
1. Choose a Plugin: Select a schema plugin like “Schema Pro” or “All In One Schema Rich Snippets” (there are lots to choose from, some paid and some free) from the WordPress Plugin Repository.
2. Configure Settings: Install and activate the chosen plugin. Configure its settings to match the content you want to mark up.
3. Create Schema: For each piece of content, such as a product or article, navigate to the editor, where you’ll find schema-specific fields to input relevant information.
4. Review and Publish: Verify the schema details and publish your content. The plugin will automatically generate and embed the necessary schema markup.
5. Validate Schema: After publishing, use the Structured Data Testing Tool to ensure your schema is implemented correctly.
Here is a list of popular schema plugins for WordPress:
Schema Pro: Schema Pro is a plugin that helps you add special tags to your WordPress website, making it easier for search engines to understand and display your content. It offers various types of tags to enhance your search results.
All in One Schema Rich Snippets: This plugin adds special tags to your posts, pages, and other content on your WordPress site. These tags improve how your website appears in search results, making it more attractive to users.
WP SEO Structured Data Schema: This plugin adds special tags to your website, helping search engines better understand your content. It may also improve your search rankings.
Schema App Structured Data: This plugin provides an easy way to add special tags to your WordPress site. These tags help search engines categorise and display your content more effectively.
WPSSO Schema JSON-LD Markup: This plugin generates special tags in a format called JSON-LD, which helps search engines understand your content. It improves how your website is presented in search results.
Schema & Structured Data for WP & AMP: This plugin allows you to add special tags to your WordPress site and AMP pages. These tags ensure that search engines can properly interpret your content and display it accurately.
Remember to review the ratings, reviews, and compatibility of these plugins with your WordPress version before choosing one for your website.
It’s vital to understand, that using custom crafted schema and node referencing, beats a standard plugin for box standard schema code.
However, if your competitor isn’t using schema on their website and you are, you will reap the website SEO rewards in better online visibility.
How to Place Schema on Your HTML Website
For websites built with HTML, adding schema data requires manual implementation. Here’s how:
1. Craft the Schema: Follow the steps mentioned earlier to create JSON-LD schema for your content.
2. Embed in HTML: Within your HTML code, insert the JSON-LD schema using the `<script>` tags. Place it within the `<head>` section of the web page.
3. Test and Validate: After embedding the schema, use the Structured Data Testing Tool to validate your implementation and catch any errors.
4. Regularly Update: As your content evolves, remember to update your schema accordingly to maintain accuracy.
By following these quick guides, you’ll harness the power of schema data to optimise your website, drive better search visibility, and provide enhanced experiences for both users and search engines.
Conclusion: Elevate Your Web Presence with Schema Mastery
Integrating schema data into your website is an investment in your online success. Whether you’re using JSON-LD, WordPress plugins, or a manual HTML implementation, each step you take brings you closer to improved search results, higher click-through rates, and a more engaged audience.
With the right schema data strategy in place, you’re not just marking up content—you’re marking your spot in the digital world.
Red Kite SEO: Your Partner in Website SEO Excellence!
At Red Kite SEO, we’re not just SEO experts; we’re your guides to SEO success. Our commitment to empowering website owners like you with the knowledge and tools you need sets us apart. We believe in harnessing the power of schema data to elevate your online presence, and we’re here to help you every step of the way.
Ranking Higher with Schema Data
In a world of digital dominance, staying ahead requires innovation. Schema data isn’t just a trend; it’s a game-changer.
By implementing schema markup and unlocking the potential of structured data, you’re not only boosting your website’s visibility but also providing a seamless experience for your users. So, what are you waiting for?
Take your website to new heights with the magic of schema data and Red Kite SEO by your side.
Ready to supercharge your SEO journey? Contact Red Kite SEO today and let’s get started together!
Read more here https://redkiteseo.co.uk/what-is-schema-data/
0 notes
Text
What is Schema Data?
Unlock the potential of structured information and watch your SEO soar to new heights. Structured information, powered by schema data, acts as a bridge between your content and search engines.
By providing a clear roadmap that search engines can easily follow, you enhance your content’s visibility and user experience. Imagine your web pages being presented with rich snippets in major search engines’ results—complete with ratings, reviews, and more.
Structured information is the key to standing out in a cluttered digital landscape and driving SEO success that’s both measurable and impactful.
The Power of Structured Information for SEO Success
Website schema structured data refers to a specialised code, often written in JSON-LD format, that is added to a webpage’s HTML to provide explicit information about the content on that page.
This structured data helps search engines better understand the context and meaning of the content, enabling them to display rich snippets in search results.
These snippets can include additional details such as:
Ratings
Reviews
Event dates
Local business
Services
and more
Enhancing the visibility and attractiveness of the search result listings. Website schema structured data plays a crucial role in improving search engine rankings, user experience, and the overall visibility of a webpage in search results.
Example JSON-LD Schema code
<html> <head> <title>Apple Pie by Grandma</title> <script type="application/ld+json"> "@context": "https://schema.org/", "@type": "Recipe", "name": "Apple Pie by Grandma", "author": "Elaine Smith", "image": "https://images.edge-generalmills.com/56459281-6fe6-4d9d-984f-385c9488d824.jpg", "description": "A classic apple pie.", "aggregateRating": "@type": "AggregateRating", "ratingValue": "4.8", "reviewCount": "7462", "bestRating": "5", "worstRating": "1" , "prepTime": "PT30M", "totalTime": "PT1H30M", "recipeYield": "8", "nutrition": "@type": "NutritionInformation", "calories": "512 calories" , "recipeIngredient": [ "1 box refrigerated pie crusts, softened as directed on box", "6 cups thinly sliced, peeled apples (6 medium)" ] </script> </head> <body> </body> </html>
How the Example Schema Displays in the Search Results
Unlocking SEO Potential with Schema Data
Imagine your website soaring high in search rankings, effortlessly attracting the right audience, and standing out in the vast digital landscape. This isn’t just a dream; it’s a reality you can achieve with the magic of schema data.
If you’re wondering what schema data is and how it can transform your online presence, you’ve come to the right place. In this article, we’ll demystify the world of schema data, explain its importance, and show you how to harness its power for your website’s SEO success.
Understanding Schema Data: Making Sense of Structured Data for Your Website
Schema data might sound like a complex term, but at its core, it’s all about structured information that speaks the language of search engines. It’s like giving your website a secret code that search engines can easily decipher, leading to better visibility and improved user experience. Here’s the breakdown:
Structured Data Definition: Schema data is organised and labelled information presented in a specific format single schema that helps search engines recognise and understand your content better.
Why It Matters: When search engines like Google understand your content, they can intelligently display relevant content around it in a more appealing way, known as rich snippets, which can significantly boost your click-through rates.
The Building Blocks: Database, Schema Markup, and More
Dive deeper into the world of schema data with these essential building blocks:
Database: Think of a database as your organised vault of information. It stores data in tables, or database objects, making it easy to retrieve and manage. Different types of databases suit various needs, from relational databases to NoSQL options.
Relational Database: This type of database organises data in tables with relationships between them, a primary key to ensuring data integrity and efficient management.
In DBMS: A Database Management System (DBMS) is a database instance the software that helps you manage databases efficiently. You can use SQL to communicate with databases and perform tasks like searching and updating.
Schema Markup: This is where the magic happens. Schema markup is code you add to the markup typesof your website to provide extra context to search engines. It’s like giving search engines a backstage pass to your content.
Physical database schema
A schema describes the shape of the data and how it relates to other models, tables and databases. In this scenario, a database entry is an instance of the database schema, containing all the properties described in the schema.
A database schema is (generally) broadly divided into two categories: physical and relational database management systems schema that defines how the data-like files are actually stored; and logical database schema, which describes all the logical constraints including integrity, tables and views applied on the stored data.
Some common database schema examples include the following: star schema snowflake schema.
What is Star Schema?
youtube
A star schema is a way of organising data in a special way to help people analyse and understand it better. It’s like a star with a centre and many points around it. The centre is called the fact table, and it holds the database tables of important numbers or measurements, like sales or revenue.
The points around the centre are called dimension tables, and they give more information about the facts. For example, they have data items that might tell you when and where the sales happened, or what products were sold. These dimension tables help give context and make the facts more meaningful.
The star schema makes it easier to ask questions and find answers from the data. It’s like having everything you need in one place, so you can quickly find the information you’re looking for. It also helps with calculations and comparing data from different angles.
People use star schemas in special databases called data warehouses, database systems where they store lots of data from different sources. By using a star schema, they can analyse the data more easily and make better decisions based on what they find.
In summary, a star schema is a way of organising data to make it easier to understand and analyse. It’s like a star with a centre of important numbers and points around it that give more information. It helps people ask questions, find answers, and make better decisions.
What is Snowflake Schema?
A snowflake schema is an expanded version of a star schema, which is used for organising multi-dimensional data. In the snowflake schema, dimension tables are further divided into subdimensions, creating a more intricate structure to add schema.
This schema type finds frequent application in business intelligence, reporting data modelling, and analysis within OLAP data warehouses, relational databases, and data marts.
Understanding Schema Data: Unveiling the Magic Behind Enhanced Web Pages
In the vast digital landscape, web pages are the vibrant canvases where online communication unfolds. Each web page acts as a window to your content, connecting you with your audience across the globe. From informative articles to captivating visuals, web pages hold the power to engage and inform.
However, the challenge lies in making your web pages not just appealing, but also intelligible to search engines. This is where the schema data steps in.
By imbuing your web pages with structured information, schema data transforms them into interactive and informative entities that stand out in search results. Let’s dive deeper into the world of schema data and how it influences your web pages’ impact.
1. Web Page: The Canvas of Digital Communication
At its core, a web page is a digital space where information, creativity, and interaction converge. It’s where you showcase your products, share your thoughts, and engage with your audience. Every web page represents a unique opportunity to make a lasting impression.
Whether it’s a blog post, a product page, or a contact form, web pages are essential elements of your online presence. Ensuring that your web pages effectively communicate with both humans and search engines is crucial. This is where schema data becomes a powerful tool.
2. Description: Decoding Schema Data’s Purpose
Schema data plays a vital role in making your web pages more than just blocks of text and images. It provides a deeper layer of meaning that search engines can understand. Consider schema data as a translator between your web content and search engines.
It deciphers the context, structure, and relationships within your content, transforming it into information that search engines can easily interpret.
This enhanced understanding leads to the creation of rich snippets—those informative snippets of text, images, meta description, and even ratings that you often see in search results. These snippets are more than eye-catching; they’re the result of a strategic schema data implementation.
3. Structure: The Blueprint for Organised Information
Imagine walking into a well-organised library, each book neatly placed on its shelf, and categories clearly marked. Similarly, web pages with structured information are like well-arranged libraries for search engines.
Schema data defines the layout and structure of your content, ensuring that search engines can navigate through your information effortlessly.
This organisation not only enhances search engine understanding but also guides users through your content logically. As a result, users find what they’re looking for faster, and search engines reward you with improved visibility.
4. XML: The Language Behind Schema Data
Underneath the surface of schema data lies XML, or Extensible Markup Language. XML serves as the backbone, enabling schema data to represent intricate relationships and hierarchies. It’s the language that gives structure to your structured data.
XML is a versatile tool, allowing you to add schema markup to create custom data structures that match the uniqueness of your content.
By speaking the language of XML, schema data communicates complex information to search engines in a clear and organised manner, enhancing the potential for your web pages to be highlighted in search results.
5. Hyperlink: Bridging Schema Data to Interactive Experiences
Hyperlinks are the digital bridges that connect one piece of information to another, enriching the user experience by allowing easy navigation between related content. Schema data can play a role in enhancing hyperlinks as well.
For instance, imagine a product hyperlink that not only takes you to a product page but also displays its price, availability, and even reviews directly in the search results.
This enhanced hyperlink experience is made possible through various types of schema data, making your web pages more interactive and enticing for users to explore further.
Elevating Web Pages with Schema Data Mastery
In the ever-evolving world of online communication, the impact of schema data cannot be overstated. By embracing schema data, you transform your web pages into dynamic, informative, and engaging entities that capture both human and search engine attention.
Your web pages become not only visually appealing but also strategically crafted to convey meaning. Remember, every pixel and snippet of content counts.
As you master the art of incorporating schema data, you’re not only enhancing your web pages; you’re elevating your online presence and making a significant mark in the digital landscape.
Ready to take the next step in optimising your web pages with schema data? Contact Red Kite SEO today and let us guide you toward web page excellence!
Transforming Your Website: The Benefits of Schema Data
It’s time to reap the rewards of schema data:
Enhanced Search Results: Imagine your product’s reviews, recipe ratings, and event details showing up directly in search results, capturing users’ attention instantly.
Better User Experience: Schema data helps search engines understand your content’s purpose, delivering more accurate results to users’ queries.
Improved Click-Through Rates: Rich snippets created by schema data make your listings stand out, enticing users to click and explore.
Putting Theory into Practise Your Action Plan
Feeling excited? Here’s a simple action plan to unleash schema data’s potential on your website:
1. Identify Opportunities: Find content on your website that could benefit from enhanced search results, like product pages, reviews, events, or recipes.
2. Choose Schema Types: Select the appropriate schema and data and markup types for your content. Google’s Structured Data Markup Helper can assist in generating schema markup code.
3. Implement Schema Markup: Add the generated schema markup code to your webpage’s HTML. Ensure accuracy by adding schema markup and testing it using Google’s Structured Data Testing Tool.
4. Monitor and Optimise: Keep an eye on how your enhanced search results perform. Make adjustments as needed to achieve optimal results.
How to Leverage Schema Data: A Quick Step-by-Step Guide
How to Create JSON-LD Schema for Your Website
Crafting a JSON-LD schema might sound daunting, but with the right guidance, it’s a straightforward process. Here’s how:
1. Identify Schema Type: Determine the type of content you want to mark up—whether it’s:
Webpage
Product
Article
Event
Person
Organization
Local Business
or something else.
Visit Schema.org for all schema types.
2. Choose a Generator: Use online schema generators to simplify the process. Fill in the relevant details about your content, and the generator will produce the JSON-LD code for you.
Try some of these Schema Generators listed below:
3. Customise the Code: Review the generated code and ensure it accurately reflects your content. You can modify it to match your specific needs.
4. Embed in Your Web Page: Paste the JSON-LD code within the `<script>` tags of your web page’s HTML. Place it within the `<head>` section for optimal results.
5. Validate Your Schema: Utilise Google’s Structured Data Testing Tool to validate your schema. This step ensures that your schema is error-free and ready for implementation.
Using Schema.org for Website Schema: Elevating Content Visibility
When it comes to enhancing your website’s presence and boosting its discoverability, Schema.org serves as an invaluable resource. Schema.org provides a comprehensive collection of structured data types and properties that can be incorporated into your website’s HTML code.
By referencing Schema.org, you’re tapping into a universal language that search engines understand, enabling you to communicate the precise context of your content. Whether you’re marking up product details, articles, events, or reviews, Schema.org offers a standardised way to present your information.
Embracing Schema.org ensures that your website’s schema data is recognised across various search engines, leading to enriched search results that captivate users and amplify your online impact.
Example: Schema Markup for a Local Business
Let’s consider an example of a local bakery, “Sweet Delights Bakery,” and how schema data from Schema.org can be utilised to enhance its online presence.
<script type="application/ld+json"> "@context": "http://schema.org", "@type": "LocalBusiness", "name": "Sweet Delights Bakery", "description": "A cozy bakery offering freshly baked goods and delightful treats.", "address": "@type": "PostalAddress", "streetAddress": "123 Main Street", "addressLocality": "Cityville", "addressRegion": "State", "postalCode": "12345" , "telephone": "(123) 456-7890", "openingHours": "Mo-Fr 08:00-18:00, Sa 09:00-17:00", "image": "https://example.com/images/bakery.jpg", "priceRange": "$", "url": "https://sweetdelightsbakery.com" </script>
In this example, the JSON-LD code defines the schema markup for “Sweet Delights Bakery” as a `LocalBusiness`.
The code includes essential details such as the bakery’s name, description, address, contact information, opening hours, image, price range, and website URL.
By incorporating this schema markup, search engines can display rich snippets in search results, showcasing key bakery information directly to potential customers.
This not only increases the bakery’s visibility but also entices users to engage with the listing.
Embracing Schema.org standardised schema markup empowers businesses like “Sweet Delights Bakery” to stand out in local search results and provide users with valuable information at a glance.
How to Place Schema on Your WordPress Website
Integrating schema data into your WordPress website is a breeze. Follow these steps:
1. Choose a Plugin: Select a schema plugin like “Schema Pro” or “All In One Schema Rich Snippets” (there are lots to choose from, some paid and some free) from the WordPress Plugin Repository.
2. Configure Settings: Install and activate the chosen plugin. Configure its settings to match the content you want to mark up.
3. Create Schema: For each piece of content, such as a product or article, navigate to the editor, where you’ll find schema-specific fields to input relevant information.
4. Review and Publish: Verify the schema details and publish your content. The plugin will automatically generate and embed the necessary schema markup.
5. Validate Schema: After publishing, use the Structured Data Testing Tool to ensure your schema is implemented correctly.
Here is a list of popular schema plugins for WordPress:
Schema Pro: Schema Pro is a plugin that helps you add special tags to your WordPress website, making it easier for search engines to understand and display your content. It offers various types of tags to enhance your search results.
All in One Schema Rich Snippets: This plugin adds special tags to your posts, pages, and other content on your WordPress site. These tags improve how your website appears in search results, making it more attractive to users.
WP SEO Structured Data Schema: This plugin adds special tags to your website, helping search engines better understand your content. It may also improve your search rankings.
Schema App Structured Data: This plugin provides an easy way to add special tags to your WordPress site. These tags help search engines categorise and display your content more effectively.
WPSSO Schema JSON-LD Markup: This plugin generates special tags in a format called JSON-LD, which helps search engines understand your content. It improves how your website is presented in search results.
Schema & Structured Data for WP & AMP: This plugin allows you to add special tags to your WordPress site and AMP pages. These tags ensure that search engines can properly interpret your content and display it accurately.
Remember to review the ratings, reviews, and compatibility of these plugins with your WordPress version before choosing one for your website.
It’s vital to understand, that using custom crafted schema and node referencing, beats a standard plugin for box standard schema code.
However, if your competitor isn’t using schema on their website and you are, you will reap the website SEO rewards in better online visibility.
How to Place Schema on Your HTML Website
For websites built with HTML, adding schema data requires manual implementation. Here’s how:
1. Craft the Schema: Follow the steps mentioned earlier to create JSON-LD schema for your content.
2. Embed in HTML: Within your HTML code, insert the JSON-LD schema using the `<script>` tags. Place it within the `<head>` section of the web page.
3. Test and Validate: After embedding the schema, use the Structured Data Testing Tool to validate your implementation and catch any errors.
4. Regularly Update: As your content evolves, remember to update your schema accordingly to maintain accuracy.
By following these quick guides, you’ll harness the power of schema data to optimise your website, drive better search visibility, and provide enhanced experiences for both users and search engines.
Conclusion: Elevate Your Web Presence with Schema Mastery
Integrating schema data into your website is an investment in your online success. Whether you’re using JSON-LD, WordPress plugins, or a manual HTML implementation, each step you take brings you closer to improved search results, higher click-through rates, and a more engaged audience.
With the right schema data strategy in place, you’re not just marking up content—you’re marking your spot in the digital world.
Red Kite SEO: Your Partner in Website SEO Excellence!
At Red Kite SEO, we’re not just SEO experts; we’re your guides to SEO success. Our commitment to empowering website owners like you with the knowledge and tools you need sets us apart. We believe in harnessing the power of schema data to elevate your online presence, and we’re here to help you every step of the way.
Ranking Higher with Schema Data
In a world of digital dominance, staying ahead requires innovation. Schema data isn’t just a trend; it’s a game-changer.
By implementing schema markup and unlocking the potential of structured data, you’re not only boosting your website’s visibility but also providing a seamless experience for your users. So, what are you waiting for?
Take your website to new heights with the magic of schema data and Red Kite SEO by your side.
Ready to supercharge your SEO journey? Contact Red Kite SEO today and let’s get started together!
Read more here https://redkiteseo.co.uk/what-is-schema-data/
0 notes