#JSOUP
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Premium Tumblr themes are available from anywhere between $9 to $49.
Note
Before puck drop on the conference finals… group chat wellness check? Especially the Oilers and Maple Leafs. I don’t think there are any Bruins in the gc but watching them hug Bergeron as they left the ice was rough
YOU COME HERE? INTO MY HOUSE BLOG and ask me about the FEELINGS OF THE BRUINS????
No fr fr tho I did see that handshake line and it was very sad.
BUT a wellness check... and a couple of lil spoilers for upcoming gc
Gabe's in surgery - he's recovering, poor Baberiel.
EJ's down in Cali with Paul, holed up and trying not to think about the future.
JT is feeling like the WORLDS WORST CAPTAIN because obviously if he were a BETTER CAPTAIN the leafs would have made it further (he's wrong. It wasn't on him)
Freddie is stressed. Because he NEEDS to prove that he can make it in the postseason but he's not getting as many starts as he WANTS, but also he's won way more games than he's lost. So overall. He's ok
Auston is in carolina, hiding in Fred's apartment. Being his biggest cheerleader and being secretly grateful that they never had to play 5OT
Jacky is mourning the loss of his tooth. Also playoffs are HARD why did nobody tell him that playoff hockey was hard? I mean, obviously he figured it out pretty quickly, but yeah, that's so fucking different to regular season hockey... why did nobody mention it? (spoiler alert, they did)
JSoup is very happy about Jacky's lil tooth gap which he thinks is the cutest thing ever. He lowkey doesn't care about not making it any further because honestly, he wasn't getting the starts and he wasn't expecting the starts and he never knows where he's gonna be, maybe it'll be a cup contender, maybe it won't, he's just along for the ride.
Leon and Connor are fighting, because one of them thinks that they should head down to Florida to support Matthew even though they've only just been kicked out of the playoffs themselves, and the other one thinks they should give themselves a couple of weeks together to lick their metaphorical wounds and just be with each other. It is not the way round we expect.
Jeff is cheering on Carolina like he's never cheered any team on before and if you ask him he'll say it's just because they're his old teammates but truly it's because he just wants the panthers to lose...
Sid and Nate had a brief moment of "should we just go to worlds?" and then decided they were far too old and are on holiday in the sunshine working on their golf
Dylan and Alex are in Toronto chilling with the fam and generally enjoying the off season
Tyler is playing his lil socks off
Matthew is....... Matthew is pretty convinced he's walking around in a dream because none of this actually feels REAL right now. Oh, and also he learnt to advocate for himself a little bit, with some help from his boyfriend
Ritter - is in florida, enjoying "the sun" ;)
Willy and Latts are holed up in their cabin
Jeff and Richie are holed up in THEIR cabin
Danny and Claude would LOVE to be holed up in the cabin, except, well... there are children to look after and they're working hard to give Ryanne a break
Cale is... struggling. Because OK he could feel the team was different from last year but, but, they were the fucking reigning champs, and they lost? In the first round? And he needs to TALK about it, but... he doesn't feel he can talk to Carter because, well, it's a bit shitty to COMPLAIN about losing IN THE PLAYOFFS to someone who's not MADE the playoffs for the past few years
Bobby Lu is having the time of his life
Kaner is sulking. This year did NOT go to plan. Also he's now a UFA... what's with that, he could play ANYWHERE? That's not how hockey's supposed to work... he's a hockey GOD... he's supposed to STILL BE IN THE PLAYOFFS and also he'd very much like to stay in NY please, but he doesn't think that's likely to happen and he really REALLY wants to blame Vladi Tarasenko, if only the fucker wasn't so nice....
Jonny is... dealing with Sulky Peeks. And Baby Pat. And he's still sick, because chronic illness doesn't just Go Away and he's having to make tough decisions and if Peeks could stop trying to make himself the centre of the universe for just one minute... you'd think he'd be used to that by now
Key is having Big Confusing Feelings... nothing new there then. He's in his research era. We stan a man with footnotes.
9 notes
·
View notes
Text
蜘蛛池需要哪些编程语言?
蜘蛛池,也被称为爬虫池或爬虫集群,是用于自动化网络数据抓取和处理的工具。它通过模拟浏览器行为,自动访问网页并提取所���信息。在构建和维护蜘蛛池时,选择合适的编程语言至关重要。不同的编程语言各有优势,适用于不同场景下的需求。本文将探讨几种常用的编程语言,并分析它们在蜘蛛池开发中的应用。
Python
Python 是目前最流行的爬虫开发语言之一。它的语法简洁明了,易于学习,拥有丰富的第三方库支持,如 Scrapy、BeautifulSoup 和 Selenium 等,这些库大大简化了网络爬虫的开发过程。此外,Python 社区活跃,遇到问题时可以轻松找到解决方案。
JavaScript
JavaScript 通常与 Node.js 结合使用,非常适合处理异步操作和事件驱动的编程模型。Node.js 提供了非阻塞 I/O 模型,使得它在处理大量并发请求时表现优异。对于需要实时抓取动态内容的蜘蛛池来说,JavaScript 是一个不错的选择。
Java
Java 是一种面向对象的编程语言,以其平台无关性和稳定性著称。Spring Boot 和 Jsoup 等框架为 Java 开发者提供了强大的工具来构建高效的爬虫系统。虽然 Java 的学习曲线较陡峭,但一旦掌握,其性能和可扩展性都非常出色。
Go
Go 语言(又称 Golang)是一种编译型语言,设计初衷是为了提高开发效率和代码质量。Go 支持并发编程,内置的 Goroutines 和 Channels 机制使得编写高并发程序变得简单。对于需要处理大规模数据抓取任务的蜘蛛池而言,Go 是一个值得考虑的选择。
总结
选择哪种编程语言取决于具体的需求和团队的技术栈。Python 因其易用性和强大的社区支持而成为入门首选;JavaScript 和 Node.js 在处理异步和实时数据方面表现出色;Java 则以稳定性和高性能见长;Go 适合那些对并发处理有较高要求的项目。无论选择哪种语言,关键在于理解每种语言的特点,并根据项目需求做出最佳决策。
讨论点
你认为在构建蜘蛛池时,除了上述提到的语言之外,还有哪些编程语言值得关注?请在评论区分享你的观点!
加飞机@yuantou2048

谷歌快排
SEO优化
0 notes
Text
Web Scraping in Java: A Powerful Approach to Data Extraction
Web Scraping in Java enables developers to collect and process web data efficiently. With libraries like JSoup and Selenium, Java simplifies handling HTML parsing, automating browsers, and extracting real-time information. Java offers a scalable and reliable scraping solution for market research, SEO, or analytics.
#serphouse#seo#google serp api#serpdata#java#web scraping#serpapi#serp scraping api#api#google search api#google#bing#data scraping
1 note
·
View note
Text
Kotlin for Web Scraping: Using Jsoup and Selenium
Introduction Kotlin for Web Scraping: Using Jsoup and Selenium is a powerful combination that allows developers to extract data from websites using Kotlin programming language. This tutorial will guide you through the process of using Kotlin to scrape websites using Jsoup and Selenium. In this tutorial, you will learn how to use Kotlin to extract data from websites, handle different types of web…
0 notes
Text
How to Build a Web Scraping API Looking for an easy guide to scraping web data? Learn how to create a Web Scraping API using Java, Spring Boot, and Jsoup! Perfect for developers at any level.
0 notes
Text

Smart Web Crawler - Mar 2023 – Apr 2023
(Data Structures, Algorithms, Java, Spring Boot, React, JavaScript, REST API)
Engineered efficient DFS and BFS web crawling algorithms using Jsoup and Spring Boot, achieving optimal time (O(V+E)) and space (O(V)) complexities.
Created custom data structures in Java to minimize redundant processing (20% reduction) and ensured efficient URL management through constant-time comparisons (O(1) with hashing).
Enhanced user search time (90%) with interactive data visualization (React graph, JavaScript) & URL sorting (O(n log n)).
0 notes
Text
Exporting AEM Experience Fragment/Page Content for A/B Testing and External Systems without HTML Tags
Problem Statement: How to export experience fragment or page content from author to: Adobe Target or any other application similar to Target without HTML Head/Body tags just component content for A/B Testing or targeting etc. Salesforce Marketing Cloud or Adobe Campaign system without HTML Head/Body tags Non-AEM sister sites are to be used as an iframe content. Introduction: If you are…
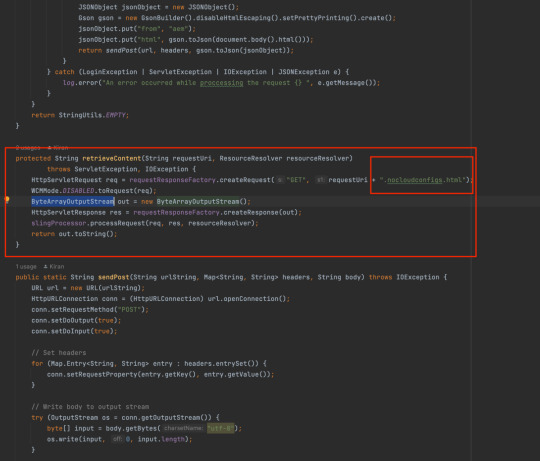
View On WordPress
#A/B Testing#Adobe Campaign#Adobe Target#AEM#Experience Fragment#GSON Type Registry#GsonBuilder#HTML Tags#HTTP Client factory#HTTP Post Request#JSOUP#OOTB Editor Tags#Page Content#Salesforce Marketing Cloud#SlingRequestProcessor
0 notes
Photo

Happy Madness day 2019! you are now gay.
(real serious madness day drawings to come this afternoon~)
#madness combat#madness day 2019#hank#hank j wimbleton#pinky#pinkhank#minty plays with crayons#shitpost#i just have to wait till jsoup posts his trailer so I can release the stuff!
88 notes
·
View notes
Text
i found the page with all of schlatt’s aliases (the bolded ones are my favorites)
i’m so sorry
Schlatt
Jchlatt the Bi-Guy
My Drug Dealer
Schlagg
The Man of Steel
Logan from Big Time Rush
The PVP God
Schlatticus
Schlatticus Maximus
Jaylor Schwift
Jamaica Schlattville
Jay Scott
Big Hot Man
J Money
Jschlitt
Schlitt
Jshroud
JenocideSchlatt
Ladical
Parkinsons
NutSchlack
Schlurp
Jschlattos Basculus
Jslapmynuts
Work Guy
Wheels
Chrome Guy
Flying Man
Flight Man
Pence Man
Jack Frost
The Winner
Sun Rise Guy
Mr. Fortnite
Monitor Man
Mr. Goop
A p p l e man
Dropper Dude
Button Man
Ladder Man
Blades
Build Boy
Build Man
Build Bob
Mr Windex
Jstal
jschloot
Water Man
Mr SMP Live
King of Tekkit
Tekkit Man
GaySchlatt
Jschlong
The Cuck Shed Man
Jslat
Homewrecker
Jshmuck
Flap-Schlatt
The Lawnmower
Gay
Gayshat
The Parkour God
Funny Mic
The Parkour Prince
Mr Cobble
Schlett (British accent)
Mr Cobblestone
Eagle Eyes
Bladez
Breaker of Chains
Jesus H Christ
Gay Shart
The Bread Man
One half of the Hexxit Hebrew
Hackerman
Fifty Mick
Mr Minecraft
Mr Business
Greek Philosopher
Nice Catch 2
Twisty Neck
Sch
Slut
Gay Slut
Sack Schlatt
Sweatyballs
Wilbur's Pretty Princess
Wilbur Schlatt From Schlatt House
Bukowski
Islam
Nice Shot
Adolf Schlattler
Jason Schlatum
Mr Skid
Schlattdoesminecraft
Nacho Libre
SchlittleStick
FatSchlatt
JizzSlurp
Pokiman
JFK
Jacob Schlatt
Jgorsh
Nostalgia Critic
Cosby
Justin Trudeau
JMcChill
Schlattbama
Chuck
ProJschlatt
Joseph Stalin
Sea Cock
Schlattorious
Shlunk
Jamie Hyneman
Jefferey Epstein
Wilbur
Carson
Joko
Fitz
The Misschlatts
AntVenom
Technoblade
Alinity
ConnorEatsPants
ConarEatPant
Joebunga
Precum
Asianschlatt
Cumschlatt
Joe Jonas
Johnny Sins
Dad
Jay Hatt
Pewdiepie
Roll Man
Sea Salt
Semen
The Amazing Grapist
A Homo-Sexual
JUULSchlatt
2 Scoops
Smokestack
70 Nic (previously known as 50 Nic)
Jondar Shit
Wall Man
Mail Man
The Man with a Plan
Yes Papa
Furry
Jebediah
Jebediah Schlatt
Word Smith
Texas Instruments
Beethoven
Metronome
Colonel Sanders
Logan paul
JFLAT
JSOUP
No Plan Andy
Nice Catch
Yes
Jackie Robinson's Golden Boy
Wordsmith
Shit
Jshit
Jshat
Scat, Baby
Cat-Flap
VOICEOVERPETEACE
SwaggerSouls
James Charles
Schlonic the Hedgehog
Uh Oh
Noob Pooper
Terraria Man
Big Guy
New Guy
Counter Strike Man
Mr. Moustache Man
Mr. Rabbid
The Age of Empires
Jschalf
Man
Hot Gay Man
Sinus Infection
One Tablet Twice a Day
Hospital
Little girl
Your Man
POOPOOMAN
Dan Schneider
Jschlutt
The Sword Man
Jonathan Schlatt
Tiny Dick Man
Tiny Dick Boy
Nintey Thousand Dollars In Debt
The Horned Cuck
SheepBitch
WilberSoot
Traves
God
Mr Health and Safety
Jeff Bezos
El Presidente
Man of Steel
The Inventor of Loud = Funny
Secretary of Steel
Bilingual
Jimmy Neutron
Magic Fingers
Two in a Row
Two Piece
Floyd Mayweather
Addict
Dyin' Bryan
Mr. 8 Ball
Double Time
Doctor Shakey Jones
Shakey Bones
Shakey
Issac Newton
the Pool Boy
House Man
The Man Behind The Slaughter
Sword Man
The Fruit Ninja
Master Oogway
Gayass
Tony Hawk
The Hole In One Man
Larry the Lobster
Pablo Picasso
Power Plant
Power Point
Mr. Minecraft
Mr. Serotonin
Mr. Twitch
The Blade Runner
Lightning McQueen
Gongaga
Misfits
The Ebay Man
an eboy
Hook Line and Sinker
The Fisherman
The Hook Man
The Pacifier (starring Vin Diesel)
Renaissance Man
Inspector Gadget
Katniss Everdeen
Balls of Fury
The Night Owl
The North Tower
WordHunt
Luigi
Beyblade
Mr.Mutton Chops
Captain Price
The Deity
The Curator
The Steel Toe
The Foot Man
The Shit and Cum Man
Warrior
The God of Yoga
The Human Hula Hoop
The God of Wii Fit
Scott Slanders
'J for Joe Rogan' Schlatt
Mr Hands
Misfits Schlatt
Dick and Balls Man
SpaceX
Spitshine
Ricardo
S c h l a t t
Swiss Army Knife
Rbx
Scat Man
Manny from Cloudy with a Chance of Meatballs (so true)
Nice Catch
Gerund Gerald
The Rollercoaster Man
Mr. Cock and Penis
JFK (The J stands for Jschlatt)
The Hooker
Sunrise Guy
The Cat Whisperer
Trump
The Dicktator
The President o7
White boy
Gay boy
Flat
JFK’s Sister
Piss Boy
Bill Boy
Jerk Off
Thee Dick Cock Sucking Lover Boy
Thee Dick Cock Sucking Lover Man
Sunrise man
GaySchlatt
Mr. President
Jebediah Schlatt
Cripple
Bisexual
rammy (bad, very bad)
Hot
Schlattina
rort
me
verified guy
unverified guy
Jschlatt le stroke
Locker room dick sucker
Everyone’s fave white boy
Mr i hide in drug vans
Drunkschlatt
goatschlatt
the official goat
unverified goat man
verified goat man
goaty
supreme drug overlord
depressed </3
upload on theweeklyslap you cunt
cotton looking ass drug dealer
man in my window
cardiac arrest
foot cream lickere
hot garbage on my ceiling
the
inbred missisipi schlatt
Darth Schlagg
Schluddle
Relief
Schlurt
Schlong
#i copied and pasted this directly from the lunch club wiki so#jschlatt#schlatt#lunch club#dream smp#mcyt
110 notes
·
View notes
Text
[Media] jsoup
jsoup The Java HTML parser, built for HTML editing, cleaning, scraping, and XSS safety. jsoup is a Java library for working with real-world HTML. It provides a very convenient API for fetching URLs and extracting and manipulating data, using the best of HTML5 DOM methods and CSS selectors. https://github.com/jhy/jsoup

0 notes
Text
蜘蛛池源码定制:打造专属的爬虫利器
在当今大数据时代,信息的获取与处理变得尤为重要。无论是企业还是个人,都需要从海量的信息中提取有价值的数据。而���蛛池(Spider Pool)作为一种高效的网络爬虫解决方案,正逐渐成为数据采集领域的热门工具。本文将深入探讨蜘蛛池源码定制的相关内容,帮助你了解如何根据自身需求打造专属的爬虫利器。
什么是蜘蛛池?
蜘蛛池是一种用于自动化网络数据抓取的技术框架。它通过模拟多个浏览器或用户行为,高效地从目标网站上抓取所需信息。相较于传统的单线程爬虫,蜘蛛池能够实现多线程并发操作,大大提高了数据采集的效率和稳定性。
为什么需要定制蜘蛛池源码?
1. 个性化需求:不同的应用场景对爬虫的需求各不相同。例如,电商网站的商品信息抓取、新闻网站的文章更新监控等,都需要特定的功能模块来支持。
2. 安全性提升:定制化的蜘蛛池可以更好地规避反爬机制,降低被封禁的风险。
3. 性能优化:根据实际使用场景进行代码优化,可以显著提高爬虫的运行效率和稳定性。
如何进行蜘蛛池源码定制?
1. 需求分析:首先明确你的具体需求,包括要抓取的目标网站、数据类型、抓取频率等。
2. 技术选型:选择合适的编程语言和技术栈。常见的选择有Python(Scrapy框架)、Java(Jsoup库)等。
3. 开发与测试:编写代码并进行初步测试,确保功能正常且稳定。
4. 优化与部署:根据测试结果进行代码优化,并部署到服务器上。
结语
蜘蛛池源码定制是一项复杂但极具价值的工作。通过定制化开发,你可以获得一个高度契合自身需求的爬虫系统,从而在数据采集领域占据优势。希望本文能为你提供一些启示,欢迎在评论区分享你的想法和经验!
以上是关于蜘蛛池源码定制的公众号文章示例。希望对你有所帮助!
加飞机@yuantou2048

SEO优化
谷歌快排
0 notes
Text
Building a Web Scraper with Kotlin and Jsoup
Introduction Building a Web Scraper with Kotlin and Jsoup is a powerful tool for extracting data from websites. This tutorial will guide you through the process of creating a web scraper using Kotlin and Jsoup, a popular JavaScript library for parsing HTML and XML documents. In this tutorial, you will learn how to build a web scraper, understand its technical background, and implement it using…
0 notes
Text
HTML Parsing in FLUTTER for Android / iOS Development

The HTML parser is the structured markup processing tool defining the HTML Parser class. It is often accessed to parse HTML files. Parsing is to resolve into component parts and then describe their syntactic roles.
In general, parsing analyzes the String of the symbols in computer or natural languages. When speaking about HTML parsing, it takes the HTML code and extracts the relevant information, such as the page’s title, headings, paragraphs, links, bold text, and much more.
Keep reading this article to learn much about HTML parsing in Flutter for android or iOS platforms! If you need professional assistance, do not hesitate to contact the reputable and trustworthy Flutter app development company.
Introduction to flutter HTML
Flutter is an open-source, cross-platform mobile app development framework. It is highly compatible with the present web rendering technologies such as HTML, JavaScript, and CSS.
Therefore, it is a perfect platform for web and mobile app development. With the help of Flutter developers, you can compile the existing code into the client experience, implant it into the browser and finally deploy it to any web server.
When you build the application with Flutter and need to render some HTML content, you can do it easily by accessing the plugin flutter_html. You can add flutter_html and its latest version to the dependencies section in pubspec.yaml file using the command “flutter pub add flutter_html.” Then, you have to use “flutter pub get” to execute the command.
How to do HTML parsing in Flutter
Android developers use the Jsoup library to parse HTML text and code. But, developers new to the flutter mobile app development do not know the existence of such a library to parse HTML text and code from the website in Flutter.
So, are you thinking about the right way to perform HTML parsing in Flutter for Android or iOS development? Well! Here are the two different solutions to meet your demands.
Solution: 1
You can now parse the HTML string in this way.
import ‘package:html/parser.dart’;
//here goes the function
String _parseHtmlString(String htmlString) {
var document = parse(htmlString);
String parsedString = parse(document.body.text).documentElement.text;
return parsedString;
}
Solution: 2
Next, you have to fetch data using http.get(url) to the user parser, and then you can parse whatever you want. Follow the below-mentioned code properly.
Fetch HTML page:
Future<string> fetchHTML(String url) async {
final response = await http.get(url);
if (response.statusCode == 200)
return response.body;
else throw Exception(‘Failed’);
}</string>
After that, you should call FutureBuilder()
FutureBuilder< String>(
future: fetchHTML(‘http://your_page.ru/page.html'),
builder: (context, snapshot){
if (snapshot.hasData) {
//Your downloaded page
_temp = snapshot.data;
print(snapshot.data);
return Text(‘Finished’);
}
else if (snapshot.hasError)
return Text(‘ERROR’);
return Text(‘LOADING’);
},
),
Now, you can parse it:
parse(_temp);
Other ways to parse HTML in FlutterMethod: 1
Are you accessing Flutter? Do you wish to parse HTML using parser.dart? If yes, then run the following code.
<div class=”weather-item now”>
<span class=”time”>Now</span>
<div class=”temp”>19.8<span>℃</span>
<small>(23℃)</small>
</div>
<table>
<tbody><tr>
<th><i class=”icon01" aria-label=”true”></i></th>
<td>93%</td>
</tr>
<tr>
<th><i class=”icon02" aria-label=”true”></i></th>
<td>south 2.2km/h</td>
</tr>
<tr>
<th><i class=”icon03" aria-label=”true”></i></th>
<td>-</td>
</tr>
</tbody></table>
</div>
You may have to use the following command to get this data.
import ‘package:html/parser dart’;
output:
19.8,23,93%,south 2.2km/h
Method: 2
Since you access the HTML package, you can obtain the desired data by accessing some HTML parsing and string processing whenever needed. Here is the dart sample where you can utilize the parse data function in your flutter application.
main.dart
import ‘package:html/parser.dart’ show parse;
main(List<string> args) {
parseData();
}
parseData(){
var document = parse(“””
<div class=”weather-item now”>
<span class=”time”>Now</span>
<div class=”temp”>19.8<span>℃</span>
<small>(23℃)</small>
</div>
<table>
<tbody><tr>
<th><i class=”icon01" aria-label=”true”></i></th>
<td>93%</td>
</tr>
<tr>
<th><i class=”icon02" aria-label=”true”></i></th>
<td>south 2.2km/h</td>
</tr>
<tr>
<th><i class=”icon03" aria-label=”true”></i></th>
<td>-</td>
</tr>
</tbody></table>
</div>
“””);
//declaring a list of String to hold all the data.
List<string> data = []
data.add(document.getElementsByClassName(“time”)[0].innerHtml);
//declaring a variable for temp since you use it in multiple places
var temp = document.getElementsByClassName(“temp”)[0];
data.add(temp.innerHtml.substring(0, temp.innerHtml.indexOf(“<span>”)));
data.add(temp.getElementsByTagName(“small”)[0].innerHtml.replaceAll(RegExp(“[(|)|℃]”), “”));
//You can also do document.getElementsByTagName(“td”) but it is more specific here.
var rows = document.getElementsByTagName(“table”)[0].getElementsByTagName(“td”);
//Map element to its innerHtml,
because we’re gonna need it.
//Iterate over the table-data and then store it safely in the data list
rows.map((e) => e.innerHtml).forEach((element) {
if(element != “-”){
data.add(element);
}
});
//print the data to console.
print(data);
}</span></string></string>
Output

How to parse HTML tags in Flutter
Do you need to parse HTML tags in your flutter project? Well! You can follow the steps mentioned here to meet your needs instantly.
At first, you should create the flutter application.
Then, you must add the required plugins in pubspec.yaml file as mentioned below.
dev_dependencies:
flutter_test:
sdk: Flutter
html: ^0.15.0
http: ^0.13.3
flutter_html: ^2.1.0
Now, you have to read the HTML file from the URL. Once you mention the site, it reads the data online. Use the http:package to read the data you have accessed and get the http class.
var response=await http.Client().get(Uri.parse(widget.url));
Now, you have HTML data fetched from the URL by accessing the HTTP package. So, it is the right time to parse the fetched content. You can use the below code to parse the HTML tags.
var chapters = document.getElementsByClassName(“chapters”);
chapters.forEach((element) {
var inner = element.innerHtml.toString();
if (inner.contains(“href”)) {
parse(inner).getElementsByTagName(“li”).forEach((element) {
var list = element.innerHtml;
if (list.contains(“href”)) {
//
indexlist_local.add(list.substring(list.indexOf(“href=”)+6,list.indexOf(“>”)-1));
indexlist_local.add(IndexContent(title: element.text,
path: list.substring(
list.indexOf(“href=”) + 6, list.indexOf(“>”) — 1)));
}
});
}
});
This code is written for fetching the data from the indexed tutorial page “chapters.” According to the URL you choose, you can change the index tag.
Finally, you can run the application successfully.
Conclusion
So, you will now be aware of the HTML parsing in Flutter for android/iOS development. If you do not get the desired result even after trying all the possible ways, you should seek professional assistance. Hire Flutter developer to get assistance in HTML parsing and complete your flutter project without hassle.
Source: https://flutteragency.com/html-parsing-flutter-android-ios-development/
0 notes
Text
How to Build a Web Scraping API using Java, Spring Boot, and Jsoup?

Overview
At 3i Data Scraping, we will create an API for scraping data from a couple of vehicle selling sites as well as extract the ads depending on vehicle models that we pass for an API. This type of API could be used from the UI as well as show different ads from various websites in one place.
Web Scraping
IntelliJ as IDE of option
Maven 3.0+ as a building tool
JDK 1.8+
Getting Started
Initially, we require to initialize the project using a spring initializer
It can be done by visiting http://start.spring.io/
Ensure to choose the given dependencies also:
Lombok: Java library, which makes a code cleaner as well as discards boilerplate codes.
Spring WEB: It is a product of the Spring community, with a focus on making document-driven web services.
After starting the project, we would be utilizing two-third party libraries JSOUP as well as Apache commons. The dependencies could be added in the pom.xml file.
<dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <!-- https://mvnrepository.com/artifact/org.jsoup/jsoup --> <dependency> <groupId>org.jsoup</groupId> <artifactId>jsoup</artifactId> <version>1.13.1</version> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.commons/commons-lang3 --> <dependency> <groupId>org.apache.commons</groupId> <artifactId>commons-lang3</artifactId> <version>3.11</version> </dependency> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <optional>true</optional> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency> </dependencies>
Analyze HTML to Extract Data
Before starting the implementation of API, we need to visit https://riyasewana.com/ and https://ikman.lk/ to locate data, which we need to extract from these sites.
We can perform that by launching the given sites on the browser as well as inspecting HTML code with Dev tools.
If you are using Chrome, just right-click on the page as well as choose inspect.
Its result will look like this:
After opening different websites we need to navigate through HTML for identifying a DOM where the ad list is positioned. These identified elements would be utilized in the spring boot project for getting relevant data.
From navigating through ikman.lk HTML, it’s easy to see a list of ads are positioned under a class name’s list — 3NxGO.
After that, we need to perform the same with Riyasewana.com where ad data is positioned under a div with id content.
After recognizing all the data, let’s create our API for scraping the data!!!.
Implementation
Initially, we need to define website URLs in the file called application.yml/application.properties
website: urls: https://ikman.lk/en/ads/sri-lanka/vehicles?sort=relevance&buy_now=0&urgent=0&query=,https://riyasewana.com/search/
After that, create an easy model class for mapping data using HTML.
package com.scraper.api.model; import lombok.Data; @Data public class ResponseDTO { String title; String url; }
In the given code, we utilize Data annotation generation setters and getters for attributes.
After that, it’s time to create a service layer as well as scrape data from these websites.
package com.scraper.api.service; import com.scraper.api.model.ResponseDTO; import org.apache.commons.lang3.StringUtils; import org.jsoup.Jsoup; import org.jsoup.nodes.Document; import org.jsoup.nodes.Element; import org.jsoup.select.Elements; import org.springframework.beans.factory.annotation.Value; import org.springframework.stereotype.Service; import java.io.IOException; import java.util.HashSet; import java.util.List; import java.util.Set; @Service public class ScraperServiceImpl implements ScraperService { //Reading data from property file to a list @Value("#{'${website.urls}'.split(',')}") List<String> urls; @Override public Set<ResponseDTO> getVehicleByModel(String vehicleModel) { //Using a set here to only store unique elements Set<ResponseDTO> responseDTOS = new HashSet<>(); //Traversing through the urls for (String url: urls) { if (url.contains("ikman")) { //method to extract data from Ikman.lk extractDataFromIkman(responseDTOS, url + vehicleModel); } else if (url.contains("riyasewana")) { //method to extract Data from riyasewana.com extractDataFromRiyasewana(responseDTOS, url + vehicleModel); } } return responseDTOS; } private void extractDataFromRiyasewana(Set<ResponseDTO> responseDTOS, String url) { try { //loading the HTML to a Document Object Document document = Jsoup.connect(url).get(); //Selecting the element which contains the ad list Element element = document.getElementById("content"); //getting all the <a> tag elements inside the content div tag Elements elements = element.getElementsByTag("a"); //traversing through the elements for (Element ads: elements) { ResponseDTO responseDTO = new ResponseDTO(); if (!StringUtils.isEmpty(ads.attr("title")) ) { //mapping data to the model class responseDTO.setTitle(ads.attr("title")); responseDTO.setUrl(ads.attr("href")); } if (responseDTO.getUrl() != null) responseDTOS.add(responseDTO); } } catch (IOException ex) { ex.printStackTrace(); } } private void extractDataFromIkman(Set<ResponseDTO> responseDTOS, String url) { try { //loading the HTML to a Document Object Document document = Jsoup.connect(url).get(); //Selecting the element which contains the ad list Element element = document.getElementsByClass("list--3NxGO").first(); //getting all the <a> tag elements inside the list- -3NxGO class Elements elements = element.getElementsByTag("a"); for (Element ads: elements) { ResponseDTO responseDTO = new ResponseDTO(); if (StringUtils.isNotEmpty(ads.attr("href"))) { //mapping data to our model class responseDTO.setTitle(ads.attr("title")); responseDTO.setUrl("https://ikman.lk"+ ads.attr("href")); } if (responseDTO.getUrl() != null) responseDTOS.add(responseDTO); } } catch (IOException ex) { ex.printStackTrace(); } } }
After writing the scraping logic for a service layer, we can now implement the RestController for fetching data from these websites.
package com.scraper.api.controller; import com.scraper.api.model.ResponseDTO; import com.scraper.api.service.ScraperService; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.web.bind.annotation.GetMapping; import org.springframework.web.bind.annotation.PathVariable; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.RestController; import java.util.Set; @RestController @RequestMapping(path = "/") public class ScraperController { @Autowired ScraperService scraperService; @GetMapping(path = "/{vehicleModel}") public Set<ResponseDTO> getVehicleByModel(@PathVariable String vehicleModel) { return scraperService.getVehicleByModel(vehicleModel); } }
When everything is completed. We need to Run this Project as well as a test this API!
Go to the RestClient as well as call API through offering a vehicle model.
For example http://localhost:8080/axio
Here, you can observe that you have all the ad URLs as well as titles associated to given vehicle models from both these websites.
Conclusion
In this blog, you have learned about how to manipulate the HTML document using jsoup as well as spring boot to extract data from these two websites. The next step will be:
Improving this API to help pagination in these websites.
Implementing the UI for consuming the API
For more information on building web scraping API with Java, Spring Boot, or Jsoup, you can contact 3i Data Scraping or ask for a free quote!
0 notes
Text
Gabe's in surgery - he's recovering, poor Baberiel. EJ's down in Cali with Paul, holed up and trying not to think about the future. JT is feeling like the WORLDS WORST CAPTAIN because obviously if he were a BETTER CAPTAIN the leafs would have made it further (he's wrong. It wasn't on him) Mitchy is trying to convince his boyfriend that a. he doesn't carry an entire hockey team on his shoulders and b. He's not too old. They can win a cup together and the world won't fall apart without Spezz and Dubey Freddie is stressed. Because he NEEDS to prove that he can make it in the postseason but he's not getting as many starts as he WANTS, but also he's won way more games than he's lost. So overall. He's ok Auston is in carolina, hiding in Fred's apartment. Being his biggest cheerleader and being secretly grateful that they never had to play 5OT Jacky is mourning the loss of his tooth. Also playoffs are HARD why did nobody tell him that playoff hockey was hard? I mean, obviously he figured it out pretty quickly, but yeah, that's so fucking different to regular season hockey... why did nobody mention it? (spoiler alert, they did) JSoup is very happy about Jacky's lil tooth gap which he thinks is the cutest thing ever. He lowkey doesn't care about not making it any further because honestly, he wasn't getting the starts and he wasn't expecting the starts and he never knows where he's gonna be, maybe it'll be a cup contender, maybe it won't, he's just along for the ride. Leon and Connor are fighting, because one of them thinks that they should head down to Florida to support Matthew even though they've only just been kicked out of the playoffs themselves, and the other one thinks they should give themselves a couple of weeks together to lick their metaphorical wounds and just be with each other. It is not the way round we expect. Jeff is cheering on Carolina like he's never cheered any team on before and if you ask him he'll say it's just because they're his old teammates but truly it's because he just wants the panthers to lose...
Anonymous asked:
Before puck drop on the conference finals… group chat wellness check? Especially the Oilers and Maple Leafs. I don’t think there are any Bruins in the gc but watching them hug Bergeron as they left the ice was rough
YOU COME HERE? INTO MY HOUSE BLOG and ask me about the FEELINGS OF THE BRUINS???? No fr fr tho I did see that handshake line and it was very sad. BUT a wellness check... and a couple of lil spoilers for upcoming gc
(except tumblr hates me. so uh, gonna post this in sections?)
12 notes
·
View notes
Photo

A.A.M.O.
the second piece I did for Jsoull’s upcoming MAXIFICATION 2: Commencement!
Watch the intro here!
happy madness day (for real!)
and thank you mister jsoup for ur patronage~
46 notes
·
View notes