#LinkedIn scraper api
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
If you dial 1-866-584-6757, you can leave an audio post for your followers.
Text
Automate LinkedIn Data Collection Using Advanced Scraper APIs and Tools
Data scraping at scale depends on automation, and the LinkedIn scraper api plays a vital role in this process. It allows developers and analysts to pull relevant profiles or company data directly from LinkedIn in structured formats.
0 notes
Link
[ad_1] In this tutorial, we walk you through building an enhanced web scraping tool that leverages BrightData’s powerful proxy network alongside Google’s Gemini API for intelligent data extraction. You’ll see how to structure your Python project, install and import the necessary libraries, and encapsulate scraping logic within a clean, reusable BrightDataScraper class. Whether you’re targeting Amazon product pages, bestseller listings, or LinkedIn profiles, the scraper’s modular methods demonstrate how to configure scraping parameters, handle errors gracefully, and return structured JSON results. An optional React-style AI agent integration also shows you how to combine LLM-driven reasoning with real-time scraping, empowering you to pose natural language queries for on-the-fly data analysis. !pip install langchain-brightdata langchain-google-genai langgraph langchain-core google-generativeai We install all of the key libraries needed for the tutorial in one step: langchain-brightdata for BrightData web scraping, langchain-google-genai and google-generativeai for Google Gemini integration, langgraph for agent orchestration, and langchain-core for the core LangChain framework. import os import json from typing import Dict, Any, Optional from langchain_brightdata import BrightDataWebScraperAPI from langchain_google_genai import ChatGoogleGenerativeAI from langgraph.prebuilt import create_react_agent These imports prepare your environment and core functionality: os and json handle system operations and data serialization, while typing provides structured type hints. You then bring in BrightDataWebScraperAPI for BrightData scraping, ChatGoogleGenerativeAI to interface with Google’s Gemini LLM, and create_react_agent to orchestrate these components in a React-style agent. class BrightDataScraper: """Enhanced web scraper using BrightData API""" def __init__(self, api_key: str, google_api_key: Optional[str] = None): """Initialize scraper with API keys""" self.api_key = api_key self.scraper = BrightDataWebScraperAPI(bright_data_api_key=api_key) if google_api_key: self.llm = ChatGoogleGenerativeAI( model="gemini-2.0-flash", google_api_key=google_api_key ) self.agent = create_react_agent(self.llm, [self.scraper]) def scrape_amazon_product(self, url: str, zipcode: str = "10001") -> Dict[str, Any]: """Scrape Amazon product data""" try: results = self.scraper.invoke( "url": url, "dataset_type": "amazon_product", "zipcode": zipcode ) return "success": True, "data": results except Exception as e: return "success": False, "error": str(e) def scrape_amazon_bestsellers(self, region: str = "in") -> Dict[str, Any]: """Scrape Amazon bestsellers""" try: url = f" results = self.scraper.invoke( "url": url, "dataset_type": "amazon_product" ) return "success": True, "data": results except Exception as e: return "success": False, "error": str(e) def scrape_linkedin_profile(self, url: str) -> Dict[str, Any]: """Scrape LinkedIn profile data""" try: results = self.scraper.invoke( "url": url, "dataset_type": "linkedin_person_profile" ) return "success": True, "data": results except Exception as e: return "success": False, "error": str(e) def run_agent_query(self, query: str) -> None: """Run AI agent with natural language query""" if not hasattr(self, 'agent'): print("Error: Google API key required for agent functionality") return try: for step in self.agent.stream( "messages": query, stream_mode="values" ): step["messages"][-1].pretty_print() except Exception as e: print(f"Agent error: e") def print_results(self, results: Dict[str, Any], title: str = "Results") -> None: """Pretty print results""" print(f"\n'='*50") print(f"title") print(f"'='*50") if results["success"]: print(json.dumps(results["data"], indent=2, ensure_ascii=False)) else: print(f"Error: results['error']") print() The BrightDataScraper class encapsulates all BrightData web-scraping logic and optional Gemini-powered intelligence under a single, reusable interface. Its methods enable you to easily fetch Amazon product details, bestseller lists, and LinkedIn profiles, handling API calls, error handling, and JSON formatting, and even stream natural-language “agent” queries when a Google API key is provided. A convenient print_results helper ensures your output is always cleanly formatted for inspection. def main(): """Main execution function""" BRIGHT_DATA_API_KEY = "Use Your Own API Key" GOOGLE_API_KEY = "Use Your Own API Key" scraper = BrightDataScraper(BRIGHT_DATA_API_KEY, GOOGLE_API_KEY) print("🛍️ Scraping Amazon India Bestsellers...") bestsellers = scraper.scrape_amazon_bestsellers("in") scraper.print_results(bestsellers, "Amazon India Bestsellers") print("📦 Scraping Amazon Product...") product_url = " product_data = scraper.scrape_amazon_product(product_url, "10001") scraper.print_results(product_data, "Amazon Product Data") print("👤 Scraping LinkedIn Profile...") linkedin_url = " linkedin_data = scraper.scrape_linkedin_profile(linkedin_url) scraper.print_results(linkedin_data, "LinkedIn Profile Data") print("🤖 Running AI Agent Query...") agent_query = """ Scrape Amazon product data for in New York (zipcode 10001) and summarize the key product details. """ scraper.run_agent_query(agent_query) The main() function ties everything together by setting your BrightData and Google API keys, instantiating the BrightDataScraper, and then demonstrating each feature: it scrapes Amazon India’s bestsellers, fetches details for a specific product, retrieves a LinkedIn profile, and finally runs a natural-language agent query, printing neatly formatted results after each step. if __name__ == "__main__": print("Installing required packages...") os.system("pip install -q langchain-brightdata langchain-google-genai langgraph") os.environ["BRIGHT_DATA_API_KEY"] = "Use Your Own API Key" main() Finally, this entry-point block ensures that, when run as a standalone script, the required scraping libraries are quietly installed, and the BrightData API key is set in the environment. Then the main function is executed to initiate all scraping and agent workflows. In conclusion, by the end of this tutorial, you’ll have a ready-to-use Python script that automates tedious data collection tasks, abstracts away low-level API details, and optionally taps into generative AI for advanced query handling. You can extend this foundation by adding support for other dataset types, integrating additional LLMs, or deploying the scraper as part of a larger data pipeline or web service. With these building blocks in place, you’re now equipped to gather, analyze, and present web data more efficiently, whether for market research, competitive intelligence, or custom AI-driven applications. Check out the Notebook. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences. [ad_2] Source link
0 notes
Text
Unlock SEO & Automation with Python
In today’s fast-paced digital world, marketers are under constant pressure to deliver faster results, better insights, and smarter strategies. With automation becoming a cornerstone of digital marketing, Python has emerged as one of the most powerful tools for marketers who want to stay ahead of the curve.
Whether you’re tracking SEO performance, automating repetitive tasks, or analyzing large datasets, Python offers unmatched flexibility and speed. If you're still relying solely on traditional marketing platforms, it's time to step up — because Python isn't just for developers anymore.
Why Python Is a Game-Changer for Digital Marketers
Python’s growing popularity lies in its simplicity and versatility. It's easy to learn, open-source, and supports countless libraries that cater directly to marketing needs. From scraping websites for keyword data to automating Google Analytics reports, Python allows marketers to save time and make data-driven decisions faster than ever.
One key benefit is how Python handles SEO tasks. Imagine being able to monitor thousands of keywords, track competitors, and audit websites in minutes — all without manually clicking through endless tools. Libraries like BeautifulSoup, Scrapy, and Pandas allow marketers to extract, clean, and analyze SEO data at scale. This makes it easier to identify opportunities, fix issues, and outrank competitors efficiently.
Automating the Routine, Empowering the Creative
Repetitive tasks eat into a marketer's most valuable resource: time. Python helps eliminate the grunt work. Need to schedule social media posts, generate performance reports, or pull ad data across platforms? With just a few lines of code, Python can automate these tasks while you focus on creativity and strategy.
In Dehradun, a growing hub for tech and education, professionals are recognizing this trend. Enrolling in a Python Course in Dehradun not only boosts your marketing skill set but also opens up new career opportunities in analytics, SEO, and marketing automation. Local training programs often offer real-world marketing projects to ensure you gain hands-on experience with tools like Jupyter, APIs, and web scrapers — critical assets in the digital marketing toolkit.
Real-World Marketing Use Cases
Python's role in marketing isn’t just theoretical — it’s practical. Here are a few real-world scenarios where marketers are already using
Python to their advantage:
Content Optimization: Automate keyword research and content gap analysis to improve your blog and web copy.
Email Campaign Analysis: Analyze open rates, click-throughs, and conversions to fine-tune your email strategies.
Ad Spend Optimization: Pull and compare performance data from Facebook Ads, Google Ads, and LinkedIn to make smarter budget decisions.
Social Listening: Monitor brand mentions or trends across Twitter and Reddit to stay responsive and relevant.
With so many uses, Python is quickly becoming the Swiss army knife for marketers. You don’t need to become a software engineer — even a basic understanding can dramatically improve your workflow.
Getting Started with Python
Whether you're a fresh graduate or a seasoned marketer, investing in the right training can fast-track your career. A quality Python training in Dehradun will teach you how to automate marketing workflows, handle SEO analytics, and visualize campaign performance — all with practical, industry-relevant projects.
Look for courses that include modules on digital marketing integration, data handling, and tool-based assignments. These elements ensure you're not just learning syntax but applying it to real marketing scenarios. With Dehradun's increasing focus on tech education, it's a great place to gain this in-demand skill.
Python is no longer optional for forward-thinking marketers. As SEO becomes more data-driven and automation more essential, mastering Python gives you a clear edge. It simplifies complexity, drives efficiency, and helps you make smarter, faster decisions.
Now is the perfect time to upskill. Whether you're optimizing search rankings or building powerful marketing dashboards, Python is your key to unlocking smarter marketing in 2025 and beyond.
Python vs Ruby, What is the Difference? - Pros & Cons
youtube
#python course#python training#education#python#pythoncourseinindia#pythoninstitute#pythoninstituteinindia#pythondeveloper#Youtube
0 notes
Text
💼💖👉🍀 Hướng dẫn tích hợp Jobs API (LinkedIn, Indeed, Glassdoor...) vào WordPress bằng Rapi dAPI
💼💖👉🍀 Hướng dẫn tích hợp Jobs API (LinkedIn, Indeed, Glassdoor…) vào WordPress bằng RapidAPI 🚀 Cho phép bạn tự động hiển thị danh sách việc làm mới nhất trên trang WordPress từ các nguồn lớn như LinkedIn, Glassdoor, ZipRecruiter… 1️⃣ Tạo tài khoản và lấy API Key trên RapidAPI 🔗 Truy cập: https://rapidapi.com Tìm API: JSearch, LinkedIn Job Scraper, Glassdoor, Job Search… Bấm Subscribe → chọn gói…
0 notes
Text
Learn how to scrape LinkedIn profile data at scale using Scrapingdog’s LinkedIn API and Make.com. Perfect for recruiters, marketers, and data professionals.
0 notes
Text
Un espacio donde desarrolladores, diseñadores y creadores puedan colaborar en proyectos de automatización de marketing, scraping de datos, análisis SEO y desarrollo de contenido con IA.

✅ Desarrolladores interesados en bots, automatización y scraping.
✅ Marketers que buscan mejorar su estrategia digital con IA y datos.
✅ Creadores de contenido que quieran explorar herramientas y scripts útiles.
Estructura del Repositorio
📁 README.md → Presentación del proyecto.
📁 CONTRIBUTING.md → Reglas y cómo contribuir.
📁 .github/PULL_REQUEST_TEMPLATE.md → Guía para Pull Requests.
📁 .github/ISSUE_TEMPLATE.md → Plantilla para reportar errores o sugerencias.
📁 LICENSE → Licencia (MIT para código abierto).
📁 src/ → Código fuente (Ej: scripts de scraping, APIs, etc.).
📁 docs/ → Documentación y tutoriales.
📁 examples/ → Ejemplos de uso.
# 🚀 HormigasAIS Open Lab
¡Bienvenido a **HormigasAIS Open Lab**! 🐜💡
Este es un espacio colaborativo para desarrolladores, marketers y creadores que buscan herramientas innovadoras para **automatización, scraping, análisis SEO y contenido con IA**.
## 🔥 ¿Qué puedes encontrar aquí?
✅ **Scripts y bots** para automatizar tareas de marketing.
✅ **Scrapers** para obtener insights de la web.
✅ **Herramientas SEO** para optimizar contenido.
✅ **IA aplicada al marketing digital**.
## 💡 ¿Cómo contribuir?
1. Explora los [Issues](https://github.com/HormigasAIS-ux/HormigasAIS-OpenLab/issues) y elige uno.
2. Haz un fork del repositorio.
3. Trabaja en tu rama y haz un pull request.
📖 **Consulta** [`CONTRIBUTING.md`](CONTRIBUTING.md) para más detalles.
## 📌 Recursos
- [Guía para colaboradores](CONTRIBUTING.md)
- [Ejemplos y casos de uso](examples/)
- [Documentación](docs/)
🔗 **Únete a la conversación en [LinkedIn](https://www.linkedin.com/in/cristhiam-quiñonez-7b6222325)**
# 🤝 Guía de Contribución
¡Gracias por tu interés en colaborar con **HormigasAIS Community**! 🐜✨
## 📌 Reglas básicas
✔ Sé respetuoso con otros colaboradores.
✔ Sigue las buenas prácticas de código y documentación.
✔ Antes de abrir un Pull Request, revisa los [Issues abiertos](https://github.com/HormigasAIS-ux/HormigasAIS-OpenLab/issues).
## 🚀 Cómo contribuir
1. **Forkea** el repositorio y clónalo en tu máquina.
2. Crea una rama (`git checkout -b feature-nombre`).
3. Trabaja en tu contribución.
4. Asegúrate de que tu código sigue el formato y estilo del proyecto.
5. **Haz un Pull Request** detallando los cambios.
## 📜 Estándares de Código
Usamos [Prettier](https://prettier.io/) para formateo y seguimos la convención de commits de [Conventional Commits](https://www.conventionalcommits.org/).
💡 **Si tienes dudas, revisa el [README](README.md) o abre un Issue.**
## 🚀 Descripción
<!-- Explica brevemente los cambios que hiciste y su propósito. -->
## 📌 Checklist
- [ ] He probado el código y funciona correctamente.
- [ ] He agregado documentación si es necesario.
- [ ] La estructura y estilo siguen los estándares del proyecto.
## 🔗 Referencias
<!-- Si este PR cierra un Issue, colócalo aquí. Ejemplo: Closes #12 -->
## 📌 Descripción del problema o sugerencia
<!-- Explica claramente el error o mejora que propones. -->
## 🔍 Pasos para reproducir (si es un error)
1. Ir a '...'
2. Hacer clic en '...'
3. Ver error '...'
## ✅ Posibles soluciones
<!-- ¿Tienes alguna idea de cómo solucionarlo? Escríbela aquí. -->
## 📷 Capturas de pantalla
<!-- Opcional: adjunta imágenes si es necesario. -->
0 notes
Text

Web Scraper Tools For Marketing
With the accelerated pace of digital transformation, extracting data from numerous online sources has become remarkably essential. Today we have highly sophisticated page scraper tools, such as online data scraper tool, online screen scraper tool, or online web scraper tool free that allow us to effortlessly exfoliate information from the web, granting us access to a plethora of insights that aid in our decision making.
Among the various types of scrapeable data, Google Maps Data, Google Maps Directory, Google Maps Reviews, Google Play Reviews, Google search results, Trustpilot Reviews, Emails & Contacts, Amazon Products, Amazon Reviews, and Onlyfans Profiles are some popular choices.
Web scraping tools are becoming an essential element in today’s digital world, enabling businesses to tap into unstructured data on the web and transform it into structured, valuable information. For instance, you can use a free online URL Scraper tool to scrape website URLs and gain insight into your competitors’ tactics and strategies. Similarly, an email scraper can help you build a mailing list for your marketing initiatives, and an AI website scraper can help you crawl and extract complex data from websites in an efficient manner.
Scraping data using online scrape tools or online web scraper tools can have various applications. Amazon scraper can help you extract product details and reviews to conduct competitor analysis and market research. Google scraper can gather search data for SEO tracking, while LinkedIn scraper can facilitate recruitment process by collecting potential candidates’ data.
If you’re interested in exploring these tools, for more information, visit [here] (https://ad.page/micro ) to learn more about effective web scraping tools. Moreover, to get started with using these tools, register [here]( https://ad.page/app/register ).
Furthermore, you can use SERP scraping API or SERP scraper to routinely check your website’s ranking and performance. If you’re curious about how your site ranks on Google and other search engines, the Advanced SERP Checker is a handy tool that provides you with just that. You can find more about it [here](https://ad.page/serp).
Finally, the Onlyfans-scraper and Instagram scrapper are specific scraping tools popular in the influencer and entertainment industries for identifying potential collaborators, tracking engagement, or monitoring trends. And if you want a simple, accessible tool for your scraping projects, you may want to check free web scraper or free web scraper chrome extension to quickly extract web data directly from your browser.
These are a handful of the numerous tools that can Revolutionize the way we extract and analyse data online. In this digital era, understanding and harnessing the ability to web-scrape using these online scraper tools proves to be an essential skillset, opening doors to copious amounts of vital information that would otherwise be daunting to access. Whether it’s for market research, brand reputation monitoring, or collecting social media data, these tools offer solutions that cater to a wide range of needs.
To wrap up, the online environment is a gold mine of data waiting to be tapped into. With the right tools such as web scraper tool online, ai website scraper, email extractor and more, you can unlock immeasurable value from web data and use it to drive your business decisions and growth.
1 note
·
View note
Text
How to Access LinkedIn API - Step-by-Step Guide
LinkedIn has proven its worth as one of the most authentic professional networking platforms. It offers a wide array of structured data points for talent, marketing, sales, etc. Companies can access this data by using LinkedIn APIs (Application Programming Interface). An API serves as a gateway for integrating LinkedIn data into applications created by businesses.

Visit Here :- https://www.scrapin.io/blog/linkedin-api
0 notes
Link
[ad_1] In this tutorial, we walk you through building an enhanced web scraping tool that leverages BrightData’s powerful proxy network alongside Google’s Gemini API for intelligent data extraction. You’ll see how to structure your Python project, install and import the necessary libraries, and encapsulate scraping logic within a clean, reusable BrightDataScraper class. Whether you’re targeting Amazon product pages, bestseller listings, or LinkedIn profiles, the scraper’s modular methods demonstrate how to configure scraping parameters, handle errors gracefully, and return structured JSON results. An optional React-style AI agent integration also shows you how to combine LLM-driven reasoning with real-time scraping, empowering you to pose natural language queries for on-the-fly data analysis. !pip install langchain-brightdata langchain-google-genai langgraph langchain-core google-generativeai We install all of the key libraries needed for the tutorial in one step: langchain-brightdata for BrightData web scraping, langchain-google-genai and google-generativeai for Google Gemini integration, langgraph for agent orchestration, and langchain-core for the core LangChain framework. import os import json from typing import Dict, Any, Optional from langchain_brightdata import BrightDataWebScraperAPI from langchain_google_genai import ChatGoogleGenerativeAI from langgraph.prebuilt import create_react_agent These imports prepare your environment and core functionality: os and json handle system operations and data serialization, while typing provides structured type hints. You then bring in BrightDataWebScraperAPI for BrightData scraping, ChatGoogleGenerativeAI to interface with Google’s Gemini LLM, and create_react_agent to orchestrate these components in a React-style agent. class BrightDataScraper: """Enhanced web scraper using BrightData API""" def __init__(self, api_key: str, google_api_key: Optional[str] = None): """Initialize scraper with API keys""" self.api_key = api_key self.scraper = BrightDataWebScraperAPI(bright_data_api_key=api_key) if google_api_key: self.llm = ChatGoogleGenerativeAI( model="gemini-2.0-flash", google_api_key=google_api_key ) self.agent = create_react_agent(self.llm, [self.scraper]) def scrape_amazon_product(self, url: str, zipcode: str = "10001") -> Dict[str, Any]: """Scrape Amazon product data""" try: results = self.scraper.invoke( "url": url, "dataset_type": "amazon_product", "zipcode": zipcode ) return "success": True, "data": results except Exception as e: return "success": False, "error": str(e) def scrape_amazon_bestsellers(self, region: str = "in") -> Dict[str, Any]: """Scrape Amazon bestsellers""" try: url = f" results = self.scraper.invoke( "url": url, "dataset_type": "amazon_product" ) return "success": True, "data": results except Exception as e: return "success": False, "error": str(e) def scrape_linkedin_profile(self, url: str) -> Dict[str, Any]: """Scrape LinkedIn profile data""" try: results = self.scraper.invoke( "url": url, "dataset_type": "linkedin_person_profile" ) return "success": True, "data": results except Exception as e: return "success": False, "error": str(e) def run_agent_query(self, query: str) -> None: """Run AI agent with natural language query""" if not hasattr(self, 'agent'): print("Error: Google API key required for agent functionality") return try: for step in self.agent.stream( "messages": query, stream_mode="values" ): step["messages"][-1].pretty_print() except Exception as e: print(f"Agent error: e") def print_results(self, results: Dict[str, Any], title: str = "Results") -> None: """Pretty print results""" print(f"\n'='*50") print(f"title") print(f"'='*50") if results["success"]: print(json.dumps(results["data"], indent=2, ensure_ascii=False)) else: print(f"Error: results['error']") print() The BrightDataScraper class encapsulates all BrightData web-scraping logic and optional Gemini-powered intelligence under a single, reusable interface. Its methods enable you to easily fetch Amazon product details, bestseller lists, and LinkedIn profiles, handling API calls, error handling, and JSON formatting, and even stream natural-language “agent” queries when a Google API key is provided. A convenient print_results helper ensures your output is always cleanly formatted for inspection. def main(): """Main execution function""" BRIGHT_DATA_API_KEY = "Use Your Own API Key" GOOGLE_API_KEY = "Use Your Own API Key" scraper = BrightDataScraper(BRIGHT_DATA_API_KEY, GOOGLE_API_KEY) print("🛍️ Scraping Amazon India Bestsellers...") bestsellers = scraper.scrape_amazon_bestsellers("in") scraper.print_results(bestsellers, "Amazon India Bestsellers") print("📦 Scraping Amazon Product...") product_url = " product_data = scraper.scrape_amazon_product(product_url, "10001") scraper.print_results(product_data, "Amazon Product Data") print("👤 Scraping LinkedIn Profile...") linkedin_url = " linkedin_data = scraper.scrape_linkedin_profile(linkedin_url) scraper.print_results(linkedin_data, "LinkedIn Profile Data") print("🤖 Running AI Agent Query...") agent_query = """ Scrape Amazon product data for in New York (zipcode 10001) and summarize the key product details. """ scraper.run_agent_query(agent_query) The main() function ties everything together by setting your BrightData and Google API keys, instantiating the BrightDataScraper, and then demonstrating each feature: it scrapes Amazon India’s bestsellers, fetches details for a specific product, retrieves a LinkedIn profile, and finally runs a natural-language agent query, printing neatly formatted results after each step. if __name__ == "__main__": print("Installing required packages...") os.system("pip install -q langchain-brightdata langchain-google-genai langgraph") os.environ["BRIGHT_DATA_API_KEY"] = "Use Your Own API Key" main() Finally, this entry-point block ensures that, when run as a standalone script, the required scraping libraries are quietly installed, and the BrightData API key is set in the environment. Then the main function is executed to initiate all scraping and agent workflows. In conclusion, by the end of this tutorial, you’ll have a ready-to-use Python script that automates tedious data collection tasks, abstracts away low-level API details, and optionally taps into generative AI for advanced query handling. You can extend this foundation by adding support for other dataset types, integrating additional LLMs, or deploying the scraper as part of a larger data pipeline or web service. With these building blocks in place, you’re now equipped to gather, analyze, and present web data more efficiently, whether for market research, competitive intelligence, or custom AI-driven applications. Check out the Notebook. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences. [ad_2] Source link
0 notes
Text
In recent months, the signs and portents have been accumulating with increasing speed. Google is trying to kill the 10 blue links. Twitter is being abandoned to bots and blue ticks. There’s the junkification of Amazon and the enshittification of TikTok. Layoffs are gutting online media. A job posting looking for an “AI editor” expects “output of 200 to 250 articles per week.” ChatGPT is being used to generate whole spam sites. Etsy is flooded with “AI-generated junk.” Chatbots cite one another in a misinformation ouroboros. LinkedIn is using AI to stimulate tired users. Snapchat and Instagram hope bots will talk to you when your friends don’t. Redditors are staging blackouts. Stack Overflow mods are on strike. The Internet Archive is fighting off data scrapers, and “AI is tearing Wikipedia apart.” The old web is dying, and the new web struggles to be born.
The web is always dying, of course; it’s been dying for years, killed by apps that divert traffic from websites or algorithms that reward supposedly shortening attention spans. But in 2023, it’s dying again — and, as the litany above suggests, there’s a new catalyst at play: AI.
The problem, in extremely broad strokes, is this. Years ago, the web used to be a place where individuals made things. (..) Then companies decided they could do things better. They created slick and feature-rich platforms and threw their doors open for anyone to join. (..) The companies chased scale, because once enough people gather anywhere, there’s usually a way to make money off them. But AI changes these assumptions.
Given money and compute, AI systems — particularly the generative models currently in vogue — scale effortlessly. (..) Their output can potentially overrun or outcompete the platforms we rely on for news, information, and entertainment. (..). Companies scrape information from the open web and refine it into machine-generated content that’s cheap to generate but less reliable. This product then competes for attention with the platforms and people that came before them. Sites and users are reckoning with these changes, trying to decide how to adapt and if they even can.
In recent months, discussions and experiments at some of the web’s most popular and useful destinations — sites like Reddit, Wikipedia, Stack Overflow, and Google itself — have revealed the strain created by the appearance of AI systems.
Reddit’s moderators are staging blackouts after the company said it would steeply increase charges to access its API, with the company’s execs saying the changes are (in part) a response to AI firms scraping its data. (..) This is not the only factor — Reddit is trying to squeeze more revenue from the platform before a planned IPO later this year — but it shows how such scraping is both a threat and an opportunity to the current web, something that makes companies rethink the openness of their platforms.
Wikipedia is familiar with being scraped in this way. The company’s information has long been repurposed by Google to furnish “knowledge panels,” and in recent years, the search giant has started paying for this information. But Wikipedia’s moderators are debating how to use newly capable AI language models to write articles for the site itself. They’re acutely aware of the problems associated with these systems, which fabricate facts and sources with misleading fluency, but know they offer clear advantages in terms of speed and scope. (..)
Stack Overflow offers a similar but perhaps more extreme case. Like Reddit, its mods are also on strike, and like Wikipedia’s editors, they’re worried about the quality of machine-generated content. When ChatGPT launched last year, Stack Overflow was the first major platform to ban its output. (..)
The site’s management, though, had other plans. The company has since essentially reversed the ban by increasing the burden of evidence needed to stop users from posting AI content, and it announced it wants to instead take advantage of this technology. Like Reddit, Stack Overflow plans to charge firms that scrape its data while building its own AI tools — presumably to compete with them. The fight with its moderators is about the site’s standards and who gets to enforce them. The mods say AI output can’t be trusted, but execs say it’s worth the risk.
All these difficulties, though, pale in significance to changes taking place at Google. Google Search underwrites the economy of the modern web, distributing attention and revenue to much of the internet. Google has been spurred into action by the popularity of Bing AI and ChatGPT as alternative search engines, and it’s experimenting with replacing its traditional 10 blue links with AI-generated summaries. But if the company goes ahead with this plan, then the changes would be seismic.
A writeup of Google’s AI search beta from Avram Piltch, editor-in-chief of tech site Tom’s Hardware, highlights some of the problems. Piltch says Google’s new system is essentially a “plagiarism engine.” Its AI-generated summaries often copy text from websites word-for-word but place this content above source links, starving them of traffic. (..) If this new model of search becomes the norm, it could damage the entire web, writes Piltch. Revenue-strapped sites would likely be pushed out of business and Google itself would run out of human-generated content to repackage.
Again, it’s the dynamics of AI — producing cheap content based on others’ work — that is underwriting this change, and if Google goes ahead with its current AI search experience, the effects would be difficult to predict. Potentially, it would damage whole swathes of the web that most of us find useful — from product reviews to recipe blogs, hobbyist homepages, news outlets, and wikis. Sites could protect themselves by locking down entry and charging for access, but this would also be a huge reordering of the web’s economy. In the end, Google might kill the ecosystem that created its value, or change it so irrevocably that its own existence is threatened.
But what happens if we let AI take the wheel here, and start feeding information to the masses? What difference does it make?
Well, the evidence so far suggests it’ll degrade the quality of the web in general. As Piltch notes in his review, for all AI’s vaunted ability to recombine text, it’s people who ultimately create the underlying data (..). By contrast, the information produced by AI language models and chatbots is often incorrect. The tricky thing is that when it’s wrong, it’s wrong in ways that are difficult to spot.
Here’s an example. Earlier this year, I was researching AI agents — systems that use language models like ChatGPT that connect with web services and act on behalf of the user, ordering groceries or booking flights. In one of the many viral Twitter threads extolling the potential of this tech, the author imagines a scenario in which a waterproof shoe company wants to commission some market research and turns to AutoGPT (a system built on top of OpenAI’s language models) to generate a report on potential competitors. The resulting write-up is basic and predictable. (You can read it here.) It lists five companies, including Columbia, Salomon, and Merrell, along with bullet points that supposedly outline the pros and cons of their products. “Columbia is a well-known and reputable brand for outdoor gear and footwear,” we’re told. “Their waterproof shoes come in various styles” and “their prices are competitive in the market.” You might look at this and think it’s so trite as to be basically useless (and you’d be right), but the information is also subtly wrong.
To check the contents of the report, I ran it by someone I thought would be a reliable source on the topic: a moderator for the r/hiking subreddit named Chris. Chris told me that the report was essentially filler. (..) It doesn’t mention important factors like the difference between men’s and women’s shoes or the types of fabric used. It gets facts wrong and ranks brands with a bigger web presence as more worthy. Overall, says Chris, there’s just no expertise in the information — only guesswork. (..)
This is the same complaint identified by Stack Overflow’s mods: that AI-generated misinformation is insidious because it’s often invisible. It’s fluent but not grounded in real-world experience, and so it takes time and expertise to unpick. If machine-generated content supplants human authorship, it would be hard — impossible, even — to fully map the damage. And yes, people are plentiful sources of misinformation, too, but if AI systems also choke out the platforms where human expertise currently thrives, then there will be less opportunity to remedy our collective errors.
The effects of AI on the web are not simple to summarize. Even in the handful of examples cited above, there are many different mechanisms at play. In some cases, it seems like the perceived threat of AI is being used to justify changes desired for other reasons while in others, AI is a weapon in a struggle between workers who create a site’s value and the people who run it. There are also other domains where AI’s capacity to fill boxes is having different effects — from social networks experimenting with AI engagement to shopping sites where AI-generated junk is competing with other wares.
In each case, there’s something about AI’s ability to scale that changes a platform. Many of the web’s most successful sites are those that leverage scale to their advantage, either by multiplying social connections or product choice, or by sorting the huge conglomeration of information that constitutes the internet itself. But this scale relies on masses of humans to create the underlying value, and humans can’t beat AI when it comes to mass production. (..) There’s a famous essay in the field of machine learning known as “The Bitter Lesson,” which notes that decades of research prove that the best way to improve AI systems is not by trying to engineer intelligence but by simply throwing more computer power and data at the problem. (..)
Does this have to be a bad thing, though? If the web as we know it changes in the face of artificial abundance? Some will say it’s just the way of the world, noting that the web itself killed what came before it, and often for the better. Printed encyclopedias are all but extinct, for example, but I prefer the breadth and accessibility of Wikipedia to the heft and reassurance of Encyclopedia Britannica. And for all the problems associated with AI-generated writing, there are plenty of ways to improve it, too — from improved citation functions to more human oversight. Plus, even if the web is flooded with AI junk, it could prove to be beneficial, spurring the development of better-funded platforms. If Google consistently gives you garbage results in search, for example, you might be more inclined to pay for sources you trust and visit them directly.
Really, the changes AI is currently causing are just the latest in a long struggle in the web’s history. Essentially, this is a battle over information — over who makes it, how you access it, and who gets paid. But just because the fight is familiar doesn’t mean it doesn’t matter, nor does it guarantee the system that follows will be better than what we have now. The new web is struggling to be born, and the decisions we make now will shape how it grows.
0 notes
Text
Hướng dẫn 1️⃣ 📌 API việc làm theo quốc gia trên RapidAPI
🌍💖 Trả lời nhanh cho bạn đây: 1️⃣ 📌 Có tìm việc theo quốc gia không? ✅ CÓ – đa số API việc làm trên RapidAPI như: 🔹 JSearch 🔹 LinkedIn Job Scraper 🔹 Jobs API từ Rapid 🔹 ZipRecruiter API 🎯 Đều hỗ trợ tìm theo quốc gia, thành phố, bang hoặc vùng lãnh thổ bằng tham số như: https://jsearch.p.rapidapi.com/search?query=developer&location=Vietnam Hoặc: 'query' => 'designer', 'location' => 'United…
0 notes
Text
How Do Marketers Get Leads Using LinkedIn?

Without a doubt, LinkedIn is a wonderful platform for collecting valid as well as real data but not because LinkedIn is the most extensively utilized social platform for collecting marketing data. It has many awesome other reasons also and one such reason is finding leads for marketing objectives.
Though, many organizations have stopped using LinkedIn to discover leads because it follows many stringent policies compared to other social media platforms. Although despite that, or might be due to that, LinkedIn continues to be among the finest options to discover as well as generate leads. Having 750 million active users, LinkedIn offers incredible opportunities and a huge client base.
It’s perhaps the largest source of all kinds of companies and professionals around the world because all the companies want to come on LinkedIn searches for getting new orders or hiring the best talent.
Business owners and marketing researchers utilize data from LinkedIn for finding new business opportunities. However, the question is “how the marketers discover and get leads using LinkedIn”? Many freelancers, marketers, as well as programmers, utilize LinkedIn Data Scraper to get and extract leads from LinkedIn because it saves money, time, and effort.
Find and Scrape Leads from LinkedIn with Excel Using LinkedIn Lead Extractor
It is a wonderful way of getting leads from LinkedIn using LinkedIn Lead Finder. Using LinkedIn Data Extraction Tool, it’s quite possible to have a list of experts having a phone number, email, website link, skills, working history, etc. Furthermore, the LinkedIn Data Extractor goes to all LinkedIn profiles as well as looks for extra contact details like social links, emails, and more. This is the most utilized and attractive tool by different marketers to get leads from LinkedIn profiles with no programming knowledge.
Challenges Faced While Generating Leads Manually
Without a doubt, LinkedIn is a wonderful source for generating leads. However, there are many challenges to producing leads manually using LinkedIn. You need to get leads from LinkedIn used for marketing objectives however, you need to scrape those contacts or leads to the excel sheet or CRM for building a list.
You need to manually copy and paste every contact information from any LinkedIn profile to a database. You need to visit different LinkedIn profiles, change through thousands of profiles, copy the contact data and paste them into the database. It needs ample time and effort to get and collect some leads from LinkedIn that swallow the selling time. That is where lead-generating software like LinkedIn Lead Extractor could be useful.
How To Get and Scrape Leads with LinkedIn Using LinkedIn Lead Extractor?
Install LinkedIn Lead Extractor on your PC or laptop to extract leads from LinkedIn.
Open the LinkedIn Profile Extractor as well as insert keywords in its search bar or add LinkedIn profile URLs in bulk in the tool search bar.
You will find many results as per the given data when you click on the “Search” button. Choose particular all results or search results and start scraping.
After the scraping job gets finished, you would get email address, first name, phone number, address, last name, and social media links on the software grid.
You could get all the data in Text, Excel, or CSV files for usage by clicking on the “Export” button.
That’s how you can scrape leads from LinkedIn within minutes.
If you have any specific data extraction requirements that LinkedIn Profile Extractor is unable to fulfill, you can contact 3i Data Scraping and ask for a free quote!
#Linkedin Data Scraping#LinkedIn Scraper API#LinkedIn Data Extraction#LinkedIn Post Scraping#LinkedIn Leads Scraper#3i Data Scraping
0 notes
Text
How Scraping LinkedIn Data Can Give You a Competitive Edge Over Your Competitors?

In the era of digital world, data is an important part in any growing business. Apart from extracting core data for investigation, companies believe in the usefulness of open internet data for competitive benefits. There are various data resources, but we consider LinkedIn as the most advantageous data source.
LinkedIn is the largest social media website for professionals and businesses. Also, it is one of the best sources for social media data and job data. Using LinkedIn web scraping, it becomes easy to fetch the data fields to investigate performance.
LinkedIn holds a large amount of data for both businesses and researchers. Along with finding profile information of companies and businesses, it is also possible to get data for profile details of the employees. LinkedIn is the biggest platform for job posting and searching jobs related information.
LinkedIn does not provide an inclusive API that will allow data analysts to access.
How Valuable is LinkedIn Data?
LinkedIn has registered almost 772 million clients among 200 countries. According 2018 data, there is 70% growth in information workers for the LinkedIn platform among 1.25 billion global workers’ population.
There are about 55 million firms, 14 million disclosed job posts, and 36000 skills are mentioned in LinkedIn platform. Hence, it is proved that web data for LinkedIn is extremely important for Business Intelligence.
Which type of Information Is Extracted From LinkedIn Scraping?
Millions of data items are accessible on the platform. There is some useful information for customers and businesses. Here are several data points commonly utilized by LinkedIn extracting services. According to data facts, LinkedIn registers two or more users every second!
Public data
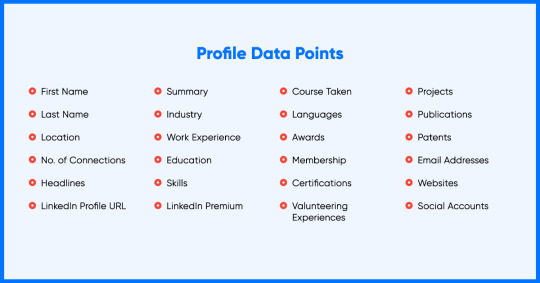
Having 772 million registered user accounts on LinkedIn and increasing, it is not possible to manually tap on the capital of such user information. There are around 100 data opinions available per LinkedIn account. Importantly, LinkedIn’s profile pattern is very reflective where a employer enters entire details of career or study history. Then it possible goes to rebuild an individual’s professional career from their work knowledge in a information.
Below shown is an overview of data points fetched from a personal LinkedIn users.
Company Data
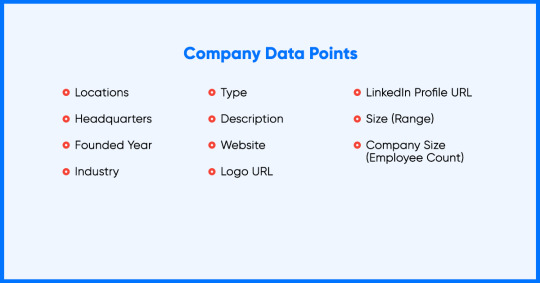
Organizations invest resources for upholding their LinkedIn profile using key firmographic, job data, and public activity. Fetching main firmographic data will enhance companies to remain ahead of the opposite companies and investigate the market site. Firms need to search filters such as industry, business size, and geological location to receive detailed competitive intelligence.
It is possible to scrape company’s data with necessary information as shown below:
Social Listening Information:

Either in research, business discipline, or any other economics, what data a top executive will share on social media platforms is as valuable as statistics with probable business impact. We can capture new market expansion, executive hires, and product failures, M&As, or departures. This is the fact because individuals and companies initiate to be more live on LinkedIn.
The point is to stay updated on those indicators by observing the social actions of the top experts and companies.
One can fetch data from the social actions of LinkedIn by highlighting the below data points.
How Businesses use LinkedIn Data Scraping?

Using all the available data, how will business effectively utilize the data to compete in the market. To learn this, there are few common use cases for information.
Research
Having the capability of rebuilding whole careers for creating a LinkedIn profile, one can only think how broad it is in the research arena.
Research institutions and top academic are initiating to explore the power of information and are even starting to integrate LinkedIn in their publications as a reference.
We can choose an example as fetching all the profiles corporated with company X from 2012 to 2018 and collecting data items such like skills, and interacting to the sales presentation of the company X. It can be assumed that few abilities found in workers would result in an outstanding company.
Human Resources
Human resources are all about people, and LinkedIn is a database record of experts across the globe. One creates a competitive advantage that goes to any recruiter, HR technical SaaS, or any service provider. It is obvious that searching them physically on LinkedIn is not that extensible, but it is valuable when you have all the data with you.
Alternative Information For Finance
Financial organizations are looking forward for data to calculate better investment capability of the company. That is where people’s data play an important role and drives the presentation of the company.
The capability of LinkedIn User information of all the employees cannot be judged. Organizations can utilize this information to monitor business hierarchies, educational backgrounds, functional compositions, and more. Furthermore, gathering the information will provide insights like key departures/ executive hires, talent acquisition policies, and geographical market expansions.
Ways to Extract LinkedIn Data
Looking forward to reader’s advantage, web data scraping for LinkedIn is a method that will use computer programming to enhance data fetching from several sources like sites, digital media platforms, e-commerce, and webpages business platforms. If someone is professional enough to build the scraper, then you can build it. But, extracting LinkedIn information has its challenges with a huge figure of information and social media platform control.
There are various LinkedIn data scraping tools available in the marketplace with distinguishing factors such as data points, data quality, and aggregation scale. Selecting the perfect data partner according to your company’s requirement is quite difficult.
Here at iWeb Scraping, our data collecting methods are continuously evolving in providing LinkedIn extracting service delivering scraping results with well-formatted complete data points, datasets, and even first-class data.
Conclusions
LinkedIn is a far-reaching and filter-after data source from public and company information. This is predictable for more growth as the company continues to utilize more employers. The possibility of using the volume of data is boundless and business firms might start capitalization for this opportunity.
Unless you know the effective methods for scraping, it is better to use LinkedIn scrapers developed by experts. Also, you can ping us for more assistance regarding LinkedIn data web scraping.
https://www.iwebscraping.com/how-scraping-linkedin-data-can-give-you-a-competitive-edge-over-your-competitors.php
6 notes
·
View notes
Text
Leading 10 Internet Scraping Devices For Reliable Data Extraction In 2023
It likewise provides fantastic support help through conversation, e-mail as well as also over a telephone call. Prospects.io provides 2 kinds of prices plans, one is for Beginners and the other is for experts. The strategies can be paid either monthly or yearly however for the expert plan, you require to ask for a demo.
DASSAULT SYSTÈMES PRIVACY POLICY - discover.3ds.com
DASSAULT SYSTÈMES PRIVACY POLICY.
Posted: Wed, 26 Oct 2022 07:00:00 GMT [source]
You can export your information in JSON or CSV styles and also effortlessly incorporate it with NodeJS, Cheerio, Python Selenium, as well as Python Scrapy Combination. Shifter.io is a leading supplier of on-line proxy solutions with among the biggest residential proxy networks available. Additionally, the website offers a banner at the top of the https://public.sitejot.com/gjwhana987.html page that makes it possible for clients to pick in which language they 'd like to view the web site. Even the firm's Products navigation food selection consists of how the item can "Get Your Business Online" and "Market Your Company". Providing a lot valuable, fascinating content free of charge is a superb instance of reliable B2B advertising, which should constantly supply worth prior to it attempts to remove it. Adobe is successful on the application due to the fact that it creates engaging content specifically provided for TikTok's audience.
youtube
Extracting Details From Tables
You can likewise set up crawls or cause them via API, as well as connect to significant storage space platforms. It sustains shows languages such as Node.js, Java, C#, Python, VB, PHP, Ruby, and Perl. Furthermore, it provides customized search specifications, geolocation, time range, safe setting, and other features. The device additionally provides geotargeting with as much as 195 places, rotating proxies, and advanced abilities for avoiding captcha, fingerprinting, and also IP blocking. With easy modification of headers, sticky sessions, and also timeout limitations, it's easy to customize your scraping to your details requirements. Whether you're a beginner or an experienced information expert, our detailed guide will aid you find the very best web scraping tool for your demands.
Increased competitors amongst marketing professionals has actually made it required for services to keep an eye on rival's rates approaches. Customers are continuously trying to find the best services or product at the most affordable rate. All these variables motivate organizations to perform item prices contrast consisting of sales and discount costs, rate history, and also many more. Since manually locating such vast data can be an overwhelming task, executing internet scrapers can automate marketing research to extract accurate information in genuine time. The Byteline no-code internet scraper saves even more time by quickly automating processes across your cloud services.
Select Your Marketing Mix (or The 4 Ps Of Advertising)
You can accomplish this by manually including the addresses to your list or by utilizing a tool that will certainly do it for you. Essence the leads from any type of LinkedIn or Sales Navigator search and also send them directly to possibility listing. The list of Instagram e-mail scrapers is Hunter, Skyrapp.io, SalesQL.com, Kendo, Getprospect.io, and also a lot more. The checklist of e-mail extractors from internet sites is Zoominfo, Skyrapp.io, Octoparse, Hunter.io, Rocket reach, and much more. Sales Navigator is the best technique to fulfill the demands of the modern-day sales associates these days. Whether it is performing sales prospecting or shutting deals with this application both the processes have actually taken one action in the direction of providing a reliable outcome.
Just how do I gather e-mails for associate advertising and marketing?
So, this is definitely an outstanding opportunity to gain some added funds. You can get your repayment after 45 days by means of PayPal after every successful referral conversion. Zyte is result-driven, and also its proxy server is among the most made use of and also reliable web servers when compared across various ranges of API systems. It has a fast, automated, and straightforward data junking and also web combination, which or else verifies to be very pricey as well as ineffective as a result of manual work as well as scaling problems. Closing is an integral part of the email where you can once again link to your target market. An effective closing urges individuals to ask inquiries as well as enter contact.
The Utmost Overview To B2b Advertising In 2023 [+ Brand-new Information] What Is B2b Marketing?
Some websites have them as they are, while others may have them named arbitrarily, in the footer, or behind a picture. We present our CRM monitoring method to increase your efficiency and remain organized. Two various other plans to improve 5,000 leads or 20,000 leads/month are likewise offered at EUR49 and also EUR99/month specifically. Evaboot permits you to discover the contacts of your target straight from LinkedIn and after that import the data received in csv straight right into your Sales Automation options. Lemlist makes it SEO scraping for improved search engine rankings very easy to create HYPER-customized multi-channel Cold Email as well as LinkedIn sequences many thanks to the Liquid language and personalized picture options. Below are the guidelines that would extract general info and all blog post details from ScrapingBee's blog.
Your recipient demands to really feel vital, so ensure your e-mail is custom-tailored to the target market you are especially sending the email to. Fire a message to simply link you to the relevant person, and also they will enjoy to do so. Just make sure that your e-mail trademark states your objective of connecting or you may be disregarded.
Spend more time connecting with your followers with our time-saving collection of social tools.
The video clip asked its audience, Who is a creative TikToker we should know about?
10.1% increase in associate marketing spending in the United States each year; by 2020, that number will certainly get to $6.8 billion.
Import.io is an user-friendly internet scratching tool that simplifies information extraction from any kind of web page as well as exports it to CSV for easy combination right into applications using APIs as well as webhooks.
Several business utilize web scraping to develop substantial databases and also remove industry-specific understandings from them.
There are lots of ways internet scraping services can benefit your advertising initiatives; however, in this specific article, we will certainly speak about what an excellent device information scraping is for associate advertising and marketing. A lot more particularly, we'll check into methods you can make use of e-mail advertising and marketing for affiliate https://www.eater.com/users/ofeithbknd advertising and marketing by leveraging the power of internet scratching. While information removal is an essential process, it can be complicated and also untidy, commonly calling for a considerable quantity of time as well as effort to accomplish. This is where web scrapers can be found in useful, as they can remove structured information and also web content from a web site by examining the underlying HTML code and also information stored in a data source. To help you select the ideal internet scraping tool, we have actually assembled a checklist of the leading 10 ideal web scuffing devices based on their attributes, pricing, as well as ease-of-use. Our listing covers a broad variety of internet scratching devices, from straightforward browser expansions to effective enterprise-level services, so you can pick the one that best suits your requirements.
0 notes
Text
Efficient Data Extraction with LinkedIn Data Scraping Tools
LinkedIn data holds immense potential for businesses. A LinkedIn data extraction tool can help you harness this potential by extracting relevant data efficiently. This data can then be used to enhance various business functions. Additionally, automated tools can reduce manual effort and increase accuracy.
linkedin data extraction tool
0 notes
Link
[ad_1] In this tutorial, we walk you through building an enhanced web scraping tool that leverages BrightData’s powerful proxy network alongside Google’s Gemini API for intelligent data extraction. You’ll see how to structure your Python project, install and import the necessary libraries, and encapsulate scraping logic within a clean, reusable BrightDataScraper class. Whether you’re targeting Amazon product pages, bestseller listings, or LinkedIn profiles, the scraper’s modular methods demonstrate how to configure scraping parameters, handle errors gracefully, and return structured JSON results. An optional React-style AI agent integration also shows you how to combine LLM-driven reasoning with real-time scraping, empowering you to pose natural language queries for on-the-fly data analysis. !pip install langchain-brightdata langchain-google-genai langgraph langchain-core google-generativeai We install all of the key libraries needed for the tutorial in one step: langchain-brightdata for BrightData web scraping, langchain-google-genai and google-generativeai for Google Gemini integration, langgraph for agent orchestration, and langchain-core for the core LangChain framework. import os import json from typing import Dict, Any, Optional from langchain_brightdata import BrightDataWebScraperAPI from langchain_google_genai import ChatGoogleGenerativeAI from langgraph.prebuilt import create_react_agent These imports prepare your environment and core functionality: os and json handle system operations and data serialization, while typing provides structured type hints. You then bring in BrightDataWebScraperAPI for BrightData scraping, ChatGoogleGenerativeAI to interface with Google’s Gemini LLM, and create_react_agent to orchestrate these components in a React-style agent. class BrightDataScraper: """Enhanced web scraper using BrightData API""" def __init__(self, api_key: str, google_api_key: Optional[str] = None): """Initialize scraper with API keys""" self.api_key = api_key self.scraper = BrightDataWebScraperAPI(bright_data_api_key=api_key) if google_api_key: self.llm = ChatGoogleGenerativeAI( model="gemini-2.0-flash", google_api_key=google_api_key ) self.agent = create_react_agent(self.llm, [self.scraper]) def scrape_amazon_product(self, url: str, zipcode: str = "10001") -> Dict[str, Any]: """Scrape Amazon product data""" try: results = self.scraper.invoke( "url": url, "dataset_type": "amazon_product", "zipcode": zipcode ) return "success": True, "data": results except Exception as e: return "success": False, "error": str(e) def scrape_amazon_bestsellers(self, region: str = "in") -> Dict[str, Any]: """Scrape Amazon bestsellers""" try: url = f" results = self.scraper.invoke( "url": url, "dataset_type": "amazon_product" ) return "success": True, "data": results except Exception as e: return "success": False, "error": str(e) def scrape_linkedin_profile(self, url: str) -> Dict[str, Any]: """Scrape LinkedIn profile data""" try: results = self.scraper.invoke( "url": url, "dataset_type": "linkedin_person_profile" ) return "success": True, "data": results except Exception as e: return "success": False, "error": str(e) def run_agent_query(self, query: str) -> None: """Run AI agent with natural language query""" if not hasattr(self, 'agent'): print("Error: Google API key required for agent functionality") return try: for step in self.agent.stream( "messages": query, stream_mode="values" ): step["messages"][-1].pretty_print() except Exception as e: print(f"Agent error: e") def print_results(self, results: Dict[str, Any], title: str = "Results") -> None: """Pretty print results""" print(f"\n'='*50") print(f"title") print(f"'='*50") if results["success"]: print(json.dumps(results["data"], indent=2, ensure_ascii=False)) else: print(f"Error: results['error']") print() The BrightDataScraper class encapsulates all BrightData web-scraping logic and optional Gemini-powered intelligence under a single, reusable interface. Its methods enable you to easily fetch Amazon product details, bestseller lists, and LinkedIn profiles, handling API calls, error handling, and JSON formatting, and even stream natural-language “agent” queries when a Google API key is provided. A convenient print_results helper ensures your output is always cleanly formatted for inspection. def main(): """Main execution function""" BRIGHT_DATA_API_KEY = "Use Your Own API Key" GOOGLE_API_KEY = "Use Your Own API Key" scraper = BrightDataScraper(BRIGHT_DATA_API_KEY, GOOGLE_API_KEY) print("🛍️ Scraping Amazon India Bestsellers...") bestsellers = scraper.scrape_amazon_bestsellers("in") scraper.print_results(bestsellers, "Amazon India Bestsellers") print("📦 Scraping Amazon Product...") product_url = " product_data = scraper.scrape_amazon_product(product_url, "10001") scraper.print_results(product_data, "Amazon Product Data") print("👤 Scraping LinkedIn Profile...") linkedin_url = " linkedin_data = scraper.scrape_linkedin_profile(linkedin_url) scraper.print_results(linkedin_data, "LinkedIn Profile Data") print("🤖 Running AI Agent Query...") agent_query = """ Scrape Amazon product data for in New York (zipcode 10001) and summarize the key product details. """ scraper.run_agent_query(agent_query) The main() function ties everything together by setting your BrightData and Google API keys, instantiating the BrightDataScraper, and then demonstrating each feature: it scrapes Amazon India’s bestsellers, fetches details for a specific product, retrieves a LinkedIn profile, and finally runs a natural-language agent query, printing neatly formatted results after each step. if __name__ == "__main__": print("Installing required packages...") os.system("pip install -q langchain-brightdata langchain-google-genai langgraph") os.environ["BRIGHT_DATA_API_KEY"] = "Use Your Own API Key" main() Finally, this entry-point block ensures that, when run as a standalone script, the required scraping libraries are quietly installed, and the BrightData API key is set in the environment. Then the main function is executed to initiate all scraping and agent workflows. In conclusion, by the end of this tutorial, you’ll have a ready-to-use Python script that automates tedious data collection tasks, abstracts away low-level API details, and optionally taps into generative AI for advanced query handling. You can extend this foundation by adding support for other dataset types, integrating additional LLMs, or deploying the scraper as part of a larger data pipeline or web service. With these building blocks in place, you’re now equipped to gather, analyze, and present web data more efficiently, whether for market research, competitive intelligence, or custom AI-driven applications. Check out the Notebook. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences. [ad_2] Source link
0 notes