#Machine Learning OCR
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr was acquired by Yahoo for $1.1B in 2013.
Text
youtube
Receipt OCR
The best receipt OCR model is that found in the Tabscanner API. Their advanced AI machine learning and deep learning have made Tabscanner the fastest, most accurate and cheapest receipt OCR API. Supporting all languages in all countries, it is the best option, especially with the recent free option added.
2 notes
·
View notes
Text
Intelligent Document Processing (IDP) is a cutting-edge technology that leverages AI, machine learning, and OCR to automate the extraction, processing, and analysis of data from documents. From invoices and contracts to customer forms and emails, IDP transforms unstructured and semi-structured data into actionable insights, reducing manual effort and errors. Its applications span industries such as finance, healthcare, logistics, and legal, enabling organizations to streamline workflows, enhance accuracy, and improve operational efficiency. Explore the transformative potential of IDP and its role in driving digital transformation.
#IDP#Intelligent Document Processing#AI#machine learning#OCR#document automation#data extraction#workflow automation#digital transformation.
1 note
·
View note
Text
#AWS#Amazon Bedrock#Anthropic#Claude 3.5 Sonnet#Claude#Amazon Textract#Optical Character Recognition#OCR#Generative AI#AI#Machine Learning
0 notes
Text
Revolutionizing Document Management: Document AI Solutions with Piazza Consulting Group
Discover how Piazza Consulting Group is leveraging PCG's cutting-edge Document AI Solutions to transform the landscape of document management. This comprehensive guide explores the intricacies and benefits of implementing AI-driven technologies in streamlining document processing tasks. With a deep dive into the capabilities of Document AI, we will show you how it enhances accuracy, increases efficiency, and reduces operational costs. Learn about real-world applications, client success stories, and the technical underpinnings that make PCG's solutions a game-changer in various industries. Join us in understanding how these innovative technologies are not just reshaping data handling but are also setting new standards for business intelligence and compliance in the digital age. This 1000-word exploration provides insights into the future of document management, powered by artificial intelligence.

Explore the future of document management with "Revolutionizing Document Management: PCG's Document AI Solutions with Piazza Consulting Group." This detailed 1000-word article delves into how Piazza Consulting Group is harnessing the power of PCG's advanced Document AI technologies to redefine traditional document handling processes across various sectors.
In this blog, we'll unpack the sophisticated features of Document AI, such as optical character recognition (OCR), natural language processing (NLP), and machine learning algorithms that enable businesses to extract, process, and analyze data from documents with unprecedented precision and speed. Understand how these technologies are eliminating human error, automating repetitive tasks, and facilitating faster decision-making processes.
We'll showcase real-life case studies demonstrating the transformative impacts of Document AI in industries like finance, healthcare, and legal, where accuracy and efficiency are paramount. From automating data entry and enhancing security protocols to providing actionable insights and improving compliance, the applications are vast and varied.
Additionally, this blog will cover the strategic partnership between PCG and Piazza Consulting Group, highlighting how their collaborative approach has led to the development and implementation of customized solutions that cater specifically to the unique needs of their clients.
Discover the competitive advantages businesses gain by adopting these AI solutions, including cost reductions, improved customer experiences, and enhanced scalability. We'll also touch upon the ethical considerations and challenges of implementing AI in document management, ensuring a balanced view.
Join us to learn how PCG's Document AI Solutions are not just revolutionizing document management but also driving the digital transformation of enterprises worldwide, making them smarter, faster, and more connected. This is your ultimate guide to understanding the role of artificial intelligence in shaping the future of document interactions.
#Document AI Solutions#PCG Document Management#AI in Business#Piazza Consulting AI Technology#AI Document Processing#Intelligent Document Solutions#Machine Learning in Documents#AI OCR Technology#Business Automation AI#AI Compliance and Security
0 notes
Text
USING OCR AND AI TO CHECK AND EVALUATE ANSWER SHEETS
As a 16-year-old student who recently appeared for the CBSE Class 10 board exams, I've witnessed firsthand the stress and anticipation that accompany the exam season. However, beyond the anxiety of sitting for the exams lies another concern – the accuracy and fairness of the evaluation process. While our answer sheets are scrutinized by real human teachers, the inherent subjectivity and potential for errors in manual evaluation raise valid concerns. In this blog post, I propose an innovative solution: leveraging artificial intelligence (AI) and Optical Character Recognition (OCR) technology to enhance the evaluation process, ensuring fairness and accuracy for all students.

The traditional method of evaluating exam answer sheets relies heavily on human teachers, who manually assess each response and assign marks based on their judgment. However, this subjective approach can lead to inconsistencies and errors, potentially affecting students' grades. Moreover, the sheer volume of answer sheets to be evaluated poses a logistical challenge, increasing the likelihood of oversight and discrepancies in grading. And the teachers are affected by some emotional religious factors and maybe even the handwriting of the students often lead them to cut unnecessary marks even if the content/answer written is correct.
The Solution:
As a solution I would propose an AI-powered OCR technology – a game-changer in the realm of exam evaluation. By digitizing answer sheets and employing machine learning algorithms, this innovative solution can automatically process and analyze students' responses with unprecedented speed and accuracy. Unlike human teachers, AI systems are not susceptible to fatigue, bias, or variations in judgment, thereby minimizing the risk of errors and ensuring consistent evaluation standards.

The AI-powered evaluation system begins by converting handwritten or printed text on answer sheets into digital format using OCR technology. Next, a machine learning algorithms analyze the content of each response, identifying key concepts, grammar, and mathematical accuracy. Based on predefined criteria and scoring rubrics, the system assigns marks to each answer, taking into account factors such as correctness, relevance, and clarity. The entire process is automated and transparent, providing instant feedback to both students and educators.
Benefits of AI in Exam Evaluation:
Accuracy: AI systems can analyze answer sheets with unparalleled precision, significantly reducing errors and inconsistencies in grading.
Fairness: By applying standardized criteria and scoring criteria, AI ensures equitable evaluation for all students, regardless of individual biases or preferences.
Efficiency: The speed and efficiency of AI-powered evaluation streamline the grading process, enabling faster turnaround times and timely feedback for students.
Scalability: AI systems can handle large volumes of answer sheets with ease, making them ideal for high-stakes exams such as board examinations.
Transparency: Unlike manual evaluation, AI-driven grading offers transparency and accountability, allowing students to understand how their marks are determined.
Challenges and Considerations:
While AI holds immense potential to revolutionize exam evaluation, its implementation comes with certain challenges and considerations. These include ensuring the reliability and accuracy of OCR technology and providing adequate training and support for educators transitioning to AI-driven evaluation methods.
The Road Ahead:
As we look to the future of exam evaluation, embracing AI and OCR technology represents a promising path forward. By harnessing the power of machine learning and automation, we can enhance the fairness, accuracy, and efficiency of grading processes, ultimately benefiting students, educators, and educational institutions alike. Together, let's embrace this transformative shift towards a more equitable and transparent approach to evaluating student performance.
As a student who has experienced the anxieties and uncertainties of exam season, I am excited by the potential of AI to revolutionize the evaluation process. By leveraging OCR technology and machine learning algorithms, we can ensure that every student receives fair and accurate assessment of their knowledge and skills. Let's embrace this opportunity to harness the power of AI in education and pave the way for a brighter future for students everywhere.
1 note
·
View note
Text
OCR technology has revolutionized data collection processes, providing many benefits to various industries. By harnessing the power of OCR with AI, businesses can unlock valuable insights from unstructured data, increase operational efficiency, and gain a competitive edge in today's digital landscape. At Globose Technology Solutions, we are committed to leading innovative solutions that empower businesses to thrive in the age of AI.
#OCR Data Collection#Data Collection Compnay#Data Collection#image to text api#pdf ocr ai#ocr and data extraction#data collection company#datasets#ai#machine learning for ai#machine learning
0 notes
Text
Embark on a journey with our new article that delves into the intricacies of MoAI, an innovative Mixture of Experts approach in an open-source Large Language and Vision Model (LLVM). Learn how MoAI leveraging auxiliary visual information and multiple intelligences to revolutionize the field. Discover how this model aligns and condenses outputs from external CV models, efficiently using relevant information for vision language tasks. Understand the unique blend of visual features, auxiliary features from external CV models, and language features that MoAI brings together.
#artificial intelligence#ai#open source#machine learning#machinelearning#nlp#MoAI#VisionLanguageModels#AI#ArtificialIntelligence#MachineLearning#DeepLearning#NLP#ComputerVision#FutureOfAI#TechNews#AIResearch#LLVM#OCR#OpenSource#DataScience#NeuralNetworks#KAIST#MixtureOfExperts#VisionLanguageTasks
0 notes
Text
New Notes from Nature publication: Humans in the loop
Happy New Year! We’re kicking 2024 off on a high note with the year’s first publication! “Humans in the loop: Community science and machine learning synergies for overcoming herbarium digitization bottlenecks” is a new publication from the Notes from Nature and Zooniverse teams. It includes details about the collaborative work we’ve carried out as part of an NSF-funded project called Leaping the…
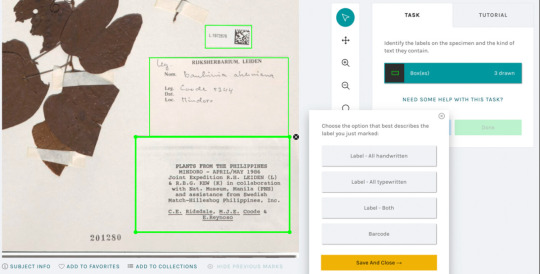
View On WordPress
0 notes
Note
それをもう問うたかもしれないが、日本語話せるの?
("I may have already asked this one, but do you speak Japanese"?) No, not really! Like of course I do know a bunch of Japanese, so my level is "some", sure, but I do my translation work through a hybrid machine-assisted approach and couldn't do it without at any speed. I spelled this out elsewhere a while ago (and have a note on my blog about it so anyone using my translations is aware of the limitations) but obviously no one would keep track of that - I have a multi-model LLM set-up where I OCR document text and run them through the disparate models that are tuned differently, and then give the text a quick check myself. If all the models agree with each other, and nothing red flags, then I more-or-less accept the translation as is - when they disagree I go in by hand and manually translate them to resolve it. (I also manually translate anything I directly quote, versus just reading for learning/research purposes.)
Doing all of that has had me develop a kind of funny skillset where I know a lot of Japanese grammatical rules and the like, because that is something you need to know for that task. But memorizing kanji outside of topic-specific niche vocab is nearly useless because lookup for kanji is trivial (due to Japan's lack of spacing and such kana can be trickier so you need to know more). And meanwhile you will have jargon for certain topics so I have studied a lot of say anime industry vocabulary and such. This leaves me with a weird skillset! Plus, If I am doing a "deep" translation I typically have to do a bunch of spot research to figure say what specific 90's culture reference this or that word is pointing to, which is it's own skill.
When experimenting with set-ups I did blind tests between the LLM-mixed methods and my own or fluent-speakers results and they passed with flying colors; the technology has progressed dramatically, and even since I have been doing this kind of work the need for corrections has gone down notably. We aren't at the point where you can simply throw out single-source translations with no corrections too reliably if you want anything quotable, but if you want to read a document yourself and get a 90% accurate read of it with no language knowledge at all, I think we are there now. I don't like to pretend I am uniquely skilled - I am instead simply putting in the work. Others can too, and I definitely encourage it - never before has global culture & history been more accessible than it is today.
26 notes
·
View notes
Text
What are Optimal Character Recognition (OCR) Services?
OCR Outsourcing Services

Optical Character Recognition is a technology and resource that converts various types of documents—such as scanned and printed paper documents and sheets, PDFs, or images and physical documents captured and scanned by a digital camera or device—into editable and searchable data of information. OCR Outsourcing refers to hiring third-party experts to handle these processes, making data management more efficient and cost-effective for businesses.
How Do OCR Services Work?
OCR technology scans printed or handwritten text and translates it into digital characters using pattern recognition and machine learning. Once the data is converted, it can be edited, searched, and stored electronically. This is especially useful and beneficial for the businesses that manage and hold a high volume of paper records or image-based files as raw source data.
Key Benefits of OCR Outsourcing -
Faster Data Processing:
By outsourcing OCR services, businesses can process large volumes of data significantly faster than they can do in-house. Professional experts leverage tools and advanced resources and employ trained professionals to assure the prompt turnaround times and processing for faster data proceedings and operations.
Improved Accuracy:
High-quality OCR Outsourcing providers use AI-driven tools and resources that minimize and lower down the errors. As this guarantees that the captured data is examined up to as precise as possible, lowering the demand for manual corrections and errors.
Cost Efficiency:
Maintaining and leveraging in-house source OCR setup can be expensive and costly. As the outsourcing eliminates the demand for costly software and system, infrastructure, and specialized staff, offering a more affordable option for ongoing needs and business demands.
Better Data Organization:
OCR Outsourcing makes it easier to store and retrieve data as scanned documents become searchable. While this is quite helpful and considerable for industries such as healthcare, law, finance, and logistics.
Scalability:
Whether you need to process a few documents or thousands, outsourcing partners can scale their services to match your demand without affecting quality or delivery speed. Companies and professional experts such as Suma Soft, IBM, Cyntexa, and Cignex are known for offering reliable OCR Outsourcing services. They aid businesses to simplify the data capture process, lower down the workload, and improve the operational efficiency by handling document digitization with precision and care. Choosing a trusted partner ensures high-quality results and seamless data management. They combine technology, skilled teams, and secure processes to deliver high-quality OCR results tailored and personalized as per the settings of different industries and business sizes.
#itsolutions#techsolutions#it services#technology#saas#saas development company#software#saas technology#digital transformation
2 notes
·
View notes
Text
The most annoying part of techbros just slapping the term "AI" onto everything from machine learning to OCR to basic recognition algorithms is that it makes it that much harder to avoid actual AI garbage and normalizes this shit with people who aren't paying attention.
Like. i don't actually think investobros and their cohort have any intent to muddy the waters by calling the oven and dryer temperature sensors that have existed for 20 years "AI" or make people forget both the human and environmental costs AI slop incurs; i don't don't think they have any thoughts being "AI makes line go up" actually but i still hate it for the knock on effects.
3 notes
·
View notes
Text
we all agree that ocr is good right. we arent demonizing all machine learning. right. we are recognizing that the problem with machine learning as a field is things like coercively and nonconsensually obtained and organized datasets which are biased in curation leading to bias in the alogrithms. right. right?
11 notes
·
View notes
Note
Hello! I understand that you may not know Japanese well, but I know that you know the Legend of Arslan well. What do you think Tanaka said here about Farangis and Giwa? Did he also talk there about “16 wings” and about the fact that “Each of them knows his own body completely”? What? Unclear. I would like to know what you think, as well as perhaps those who know Japanese. Here is the link:
https://www.youtube.com/watch?v=0XJxgAD7R-s
(For reference, the video link is the final Wright Staff interview with Tanaka where he discussed the relationship between Gieve and Farangis.)
I'm gonna go right ahead and say I really don't know Japanese at all, I've never studied it and without OCR/machine translation etc I can only really pick out the odd word! The automatic closed caption translation on this video wasn't clear at all, though I had slightly better luck extracting the Japanese captions and looking at those. Just be aware that I may make some errors!
Regarding what Tanaka had to say about Gieve and Farangis, after teasing us with the title of the video he didn't really say anything new about their relationship. Essentially, he said that he left the nature of their relationship ambiguous, and left it for readers to decide for themselves. Some people may think that the two of them were never together right up to the end, while others may think there was actually something between them.
As far as I can tell, the line about the 16 generals refers to the fact that other than Farangis and Gieve, the rest of them are well known (in terms of their origins, history etc, whereas for Gieve and Farangis there's a bit of mystery about their lives before meeting Arslan, though we do learn a little bit about Farangis's backstory later).
The most interesting (and kinda sad) tidbit of information that came out of this video was the fact that Tanaka said Arslan longed for love (アルスラーンなんかのはもう子供の恋愛時代に憧れてるようなそういう for anyone who wants to translate that bit, looks like Tanaka said that someone like Arslan already seemed to long for love/romance in childhood).
#arslan senki#the heroic legend of arslan#arslan senki novel spoilers#just in case#gieve#farangis#arslan
37 notes
·
View notes
Text
#AWS#Amazon Textract#AI#Machine Learning#API#AWS SDK#Extraction#Detection#Optical Character Recognition#OCR#Textract
0 notes
Text
Tools I use for learning languages
Since the core concept of how I learn languages is by understanding "messages", there's really only one tool that I actually need: a translator. Well maybe two if you count search engine or chatgpt for looking for some explanation on grammar points. That said, I use several tools (usually in the form of chrome extensions), basically to streamline the process, to make the process easier and faster so that I have more time to actually learn the language, not wasting my time on, for example, going back and forth between my learning materials and a translation website and copying and pasting sentences every time.
1. Mouse Tooltip Translator

This is my main tool that if I can only have 1 chrome extension I'll probably choose this. What it does is actually really simple, I wonder why there's nothing like this anywhere else: it gives you a popup translation of a word that you're hovering on. That's it.
But I think what makes it even more powerful is that you can tweak some settings. Like you can, instead of a word, translate a sentence at a time. You still want to look up word by word but sometimes phrase by phrase, sentence by sentence, even a whole paragraph? Just turn on selection translation. That way, when you're hovering on a word, it will translate by word, but when you're selecting some text, it will give you the translation of whatever you're selecting. It uses external translation machine like Google Translate, Deepl etc so it basically works the same way, what you select or hover is just like what you copy and paste into the translator. Pretty neat to me.
It also has several extra features, like Youtube dual subs etc but I personally don't use everything because I prefer 'one tool one function' tools so that it's not so overwhelming and easier to keep track if one malfunctions.
Speaking of malfunctions, lately the tools often experience errors and not showing you the translation, even though the translation machine websites are all okay. So that's why I use some backup tools just in case this one is not working right.
2. Edge Translate
I used this one before I found the Mouse Tooltip one. It basically works the same way like Mouse Tooltip, but it doesn't have the translate-on-hover feature, so you have to at least select the texts you want to translate. But other things that I used this for is translating PDF. I tried to use some other popup translation extensions, but none of them can actually translate a PDF that I'm opening with chrome. I don't know the technical details but it seems that when you're opening a PDF with chrome it's like a different kind of chrome that doesn't have all your extensions. So what this Edge Translate does is it acts as a PDF reader so that you can use the translator as well (Mouse Tooltip actually also has this function so it easily replaces Edge Translate)
I haven't used this tool for quite a while and it seems they're closing soon?
3. asbplayer

I use asbplayer when I'm learning with Youtube (they can also be used on Netflix but I'm not learning with Netflix right now). Some of its features are, it allows you to use dual subtitles, to use external subtitles for Youtube and Netflix, and it makes the workflow of making Anki cards easier. However what I personally use it for is only to make Youtube subtitles selectable so I can make use of the Mouse Tooltip Translator 😂
And I think that's basically all the tools that I use. I'm not including the tools or websites that I use to get contents that I actually use in my learning, maybe I will make a post about it too in the future. In the meantime, chau~
4 notes
·
View notes
Text
How can AI models handle complex and diverse documents?Check out our new article on JPMorgan’s DocLLM, a new AI model that excels in visually rich form understanding tasks.It incorporates spatial layout into language generation.This novel AI model can extends large language models with disentangled spatial attention. Learn more about DocLLM, its features, its architecture, its performance and more and share your thoughts with us.
#artificial intelligence#ai#open source#machine learning#machinelearning#DocLLM#JPMorgan#AI#DocumentIntelligence#Multimodal#SpatialLayout#OCR#jp morgan#programming
0 notes