#Multimodality AI
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
In 2020, Tumblr had 29.4 million users in the US.
Text
Introducing Kreeto: A New AI-Powered Platform Set To Transform Digital Experiences

Kreeto is an advanced AI platform that brings together cutting-edge technologies to provide a comprehensive and efficient solution for various tasks. Equipped with a diverse set of 71 writing tools, Kreeto empowers users to create compelling content, whether it's articles, reports, or creative pieces. With its powerful data mining process called Kreedex, Kreeto utilizes machine learning capabilities to gather relevant information and generate insights. Additionally, Kreeto offers image generation and voice generation features, making it a versatile tool for multimedia content creation. Seamlessly integrating into workflows, Kreeto is designed to enhance productivity and streamline the creative process. Experience the limitless possibilities with Kreeto and unlock your true potential.
Let's dig into deep.
KreeGen: With KreeGen, our cutting-edge image generation model, you have the power to bring your ideas to life visually. Whether you need vibrant illustrations, stunning designs, or realistic renderings, KreeGen is at your service. Simply describe what you envision, and KreeGen will generate high-quality images that align with your creative vision. KryoSynth: When it comes to audio, our advanced KryoSynth technology takes center stage. It allows you to create synthesized voices that capture a range of tones and styles. From natural-sounding narrations to dynamic character voices, KryoSynth empowers you to enhance your projects with captivating audio experiences. CodeKrafter: If coding and programming are on your agenda, look no further than CodeKrafter. This powerful tool assists in generating code snippets to streamline your development process. With CodeKrafter, you can save time and effort by automating repetitive tasks and accessing optimized solutions for various programming languages. KreeStation: For all your creative needs, KreeStation serves as a central hub. It provides seamless access to an array of resources, including writing tools, idea generators, project management features, and more. With KreeStation as your creative command center, you'll find everything you need to fuel your innovative endeavors.
“Pushing boundaries of innovation, we believe Kreeto will change how individuals and industries operate. Our ultimate goal is making technology more accessible, intuitive and efficient,” said a spokesperson from the Kreetoverse team.
The launch of Kreeto marks a significant achievement for technology lovers and industry professionals. Striving towards a more interconnected and intelligent future, Kreeto promises to be a game-changer in the realm of Artificial Intelligence.
#ai#ai art#ai generated#artificial intelligence#machine learning#generative art#generative ai#kreeto#kreeto ai#Multimodality AI#Fine Tuning Model#kreegen#kryosynth#kreestation#kreespace#kreetoverse#ai artwork#technology#ultimate ai#next gen ai
1 note
·
View note
Text
Pegasus 1.2: High-Performance Video Language Model

Pegasus 1.2 revolutionises long-form video AI with high accuracy and low latency. Scalable video querying is supported by this commercial tool.
TwelveLabs and Amazon Web Services (AWS) announced that Amazon Bedrock will soon provide Marengo and Pegasus, TwelveLabs' cutting-edge multimodal foundation models. Amazon Bedrock, a managed service, lets developers access top AI models from leading organisations via a single API. With seamless access to TwelveLabs' comprehensive video comprehension capabilities, developers and companies can revolutionise how they search for, assess, and derive insights from video content using AWS's security, privacy, and performance. TwelveLabs models were initially offered by AWS.
Introducing Pegasus 1.2
Unlike many academic contexts, real-world video applications face two challenges:
Real-world videos might be seconds or hours lengthy.
Proper temporal understanding is needed.
TwelveLabs is announcing Pegasus 1.2, a substantial industry-grade video language model upgrade, to meet commercial demands. Pegasus 1.2 interprets long films at cutting-edge levels. With low latency, low cost, and best-in-class accuracy, model can handle hour-long videos. Their embedded storage ingeniously caches movies, making it faster and cheaper to query the same film repeatedly.
Pegasus 1.2 is a cutting-edge technology that delivers corporate value through its intelligent, focused system architecture and excels in production-grade video processing pipelines.
Superior video language model for extended videos
Business requires handling long films, yet processing time and time-to-value are important concerns. As input films increase longer, a standard video processing/inference system cannot handle orders of magnitude more frames, making it unsuitable for general adoption and commercial use. A commercial system must also answer input prompts and enquiries accurately across larger time periods.
Latency
To evaluate Pegasus 1.2's speed, it compares time-to-first-token (TTFT) for 3–60-minute videos utilising frontier model APIs GPT-4o and Gemini 1.5 Pro. Pegasus 1.2 consistently displays time-to-first-token latency for films up to 15 minutes and responds faster to lengthier material because to its video-focused model design and optimised inference engine.
Performance
Pegasus 1.2 is compared to frontier model APIs using VideoMME-Long, a subset of Video-MME that contains films longer than 30 minutes. Pegasus 1.2 excels above all flagship APIs, displaying cutting-edge performance.
Pricing
Cost Pegasus 1.2 provides best-in-class commercial video processing at low cost. TwelveLabs focusses on long videos and accurate temporal information rather than everything. Its highly optimised system performs well at a competitive price with a focused approach.
Better still, system can generate many video-to-text without costing much. Pegasus 1.2 produces rich video embeddings from indexed movies and saves them in the database for future API queries, allowing clients to build continually at little cost. Google Gemini 1.5 Pro's cache cost is $4.5 per hour of storage, or 1 million tokens, which is around the token count for an hour of video. However, integrated storage costs $0.09 per video hour per month, x36,000 less. Concept benefits customers with large video archives that need to understand everything cheaply.
Model Overview & Limitations
Architecture
Pegasus 1.2's encoder-decoder architecture for video understanding includes a video encoder, tokeniser, and big language model. Though efficient, its design allows for full textual and visual data analysis.
These pieces provide a cohesive system that can understand long-term contextual information and fine-grained specifics. It architecture illustrates that tiny models may interpret video by making careful design decisions and solving fundamental multimodal processing difficulties creatively.
Restrictions
Safety and bias
Pegasus 1.2 contains safety protections, but like any AI model, it might produce objectionable or hazardous material without enough oversight and control. Video foundation model safety and ethics are being studied. It will provide a complete assessment and ethics report after more testing and input.
Hallucinations
Occasionally, Pegasus 1.2 may produce incorrect findings. Despite advances since Pegasus 1.1 to reduce hallucinations, users should be aware of this constraint, especially for precise and factual tasks.
#technology#technews#govindhtech#news#technologynews#AI#artificial intelligence#Pegasus 1.2#TwelveLabs#Amazon Bedrock#Gemini 1.5 Pro#multimodal#API
2 notes
·
View notes






Text
Más allá del chatbot: construyendo agentes reales con IA
Vengo escuchando desde hace un tiempo que un modelo de lenguaje al que, usando ChatGPT o Copilot, le subes archivos y le haces preguntas sobre estos artículos, es un “agente”. A simple vista, parece solo una herramienta que responde preguntas usando texto. Eso no tiene pinta de ser un agente. Pero, ¿lo es?
Tras ver este video sobre los diferentes tipos de agentes de IA que existen, creo que ya sé por qué estamos llamando "agentes" a ese uso concreto de los modelos.
Los 5 tipos de agentes de IA
Según la teoría clásica (ver “Artificial Intelligence: A Modern Approach”, 4th edition, de Stuart Russell y Peter Norvig, sección 2.4, "The Structure of Agents"), los agentes se clasifican así:
Reflexivo simple: responde con reglas fijas.
Basado en modelos: tiene una representación del entorno y memoria.
Basado en objetivos: toma decisiones según metas.
Basado en utilidad: evalúa opciones según preferencia/valor.
De aprendizaje: mejora con la experiencia.
¿Dónde encaja el caso que estamos analizando, ese modelo al que le subimos unos documentos y le hacemos preguntas sobre ellos? Eso que OpenAI llama GPTs y que Microsoft llama "agentes" en el Copilot Studio, ¿con cuál de los anteriores tipos de agentes se corresponde?
Si lo usamos solo para responder una pregunta directa → se parece al reflexivo simple.
Si analiza archivos cargados y extrae conclusiones dispersas → actúa como basado en modelos.
Si le damos tareas claras (resumir, estructurar, comparar) → parece el basado en objetivos.
Si optimiza claridad o formato según instrucciones → podría ser el basado en utilidad.
Si el sistema aprende de nosotros y mejora con el tiempo → sería un agente de aprendizaje.
Por lo tanto, GPT (o el mismo caso hecho en Copilot) por sí mismo no es un agente completo, pero integrado con sistemas (nosotros mismos, por ejemplo) que le dan contexto, metas, memoria y feedback, claramente se convierte en uno.
Entonces, ¿cómo sería un agente “de verdad”? Un agente de verdad es uno que actúa como un sistema autónomo inteligente, no solo uno que responde preguntas.
Para aclarar qué es un agente en términos más prácticos, vamos a intentar comprender la arquitectura MCP (Model Context Processing), propuesta por Anthropic para construir agentes y que está siendo adoptada por la industria.
MCP: Conectando agentes de IA con el mundo real
MCP (Model Context Protocol) es una infraestructura para que modelos de lenguaje puedan interactuar de forma segura y estructurada con herramientas externas, APIs, bases de datos y otros sistemas disponibles dentro de la organización.
Aunque no es una arquitectura cognitiva completa, puede servir como la “capa de integración” que permite a un agente cognitivo acceder a información en tiempo real, ejecutar acciones y trabajar sobre entornos reales. MCP es la “puerta al mundo real” para agentes que necesitan trabajar con datos y sistemas externos.
Ejemplo práctico: Un agente que resuelve problemas en una organización
Imaginemos un asistente corporativo inteligente que:
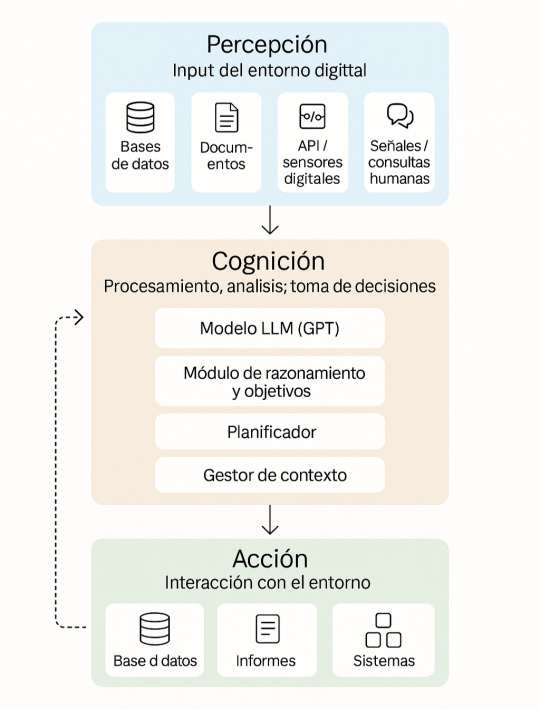
a) hemos diseñado con una arquitectura cognitiva basada en módulos (percepción, cognición, acción) y que, además,
b) se conecta al ecosistema de la empresa mediante el protocolo MCP (Model Context Protocol) de Anthropic.
Veamos qué funciones contendría cada uno de los tres módulos cognitivos que compondrían dicho asistente y cómo interactuaría con el mundo a su alrededor mediante MCP:
1. Percepción
Lee bases de datos, informes, logs, emails, APIs internas.
Recibe consultas humanas o detecta anomalías automáticamente.
2. Cognición
Usa uno o varios GPTs para interpretar texto, combinar datos y razonar.
Planea pasos: “analizar gastos”, “comparar con presupuestos”, “detectar desviaciones”.
Mantiene memoria de su contexto de trabajo, objetivos y estados intermedios.
3. Acción
Consulta sistemas, genera informes, dispara flujos de trabajo.
Toma decisiones o propone acciones con justificación.
Aprende de feedback: mejora sus planes con el tiempo.
Veamos ahora a ese agente en funcionamiento en un caso concreto:
Percibe: detecta aumento de costes en logística.
Razona: analiza contratos, identifica rutas ineficientes, predice impacto.
Actúa: propone cambios, notifica a compras, inicia seguimiento.
¿Por qué queremos construir este tipo de agentes?
Porque van más allá de un chatbot con el que conversamos, como ChatGPT.
Porque automatizan la resolución de problemas reales.
Porque combinan todos los datos de la organización, eliminándose así los silos de información aislados.
Porque actúan con propósito, objetivo. No se limitan a responder preguntas.
La IA no es solo generar texto en respuesta a una pregunta. Es una IA estructurada, autónoma y conectada. Y arquitecturas cognitivas combinadas con protocolos como MCP hacen posible que los agentes realmente trabajen con nosotros —y por nosotros— en contextos organizativos complejos. Es comportamiento estructurado, toma de decisiones, acción. Eso es un agente.

#inteligencia artificial#IA#GPT#agentes inteligentes#machine learning#MCP#Anthropic#arquitectura cognitiva#tecnología empresarial#automatización#datos empresariales#sistemas inteligentes#procesamiento multimodal#LLM#AI agents
0 notes
Text
A New Player in the League of LLMs – Mistral Le Chat | Infographic

Learn about the latest player in the world of LLMs – the Mistral’s Le Chat and understand in this infographic its features, and how it compares with leading players.
Read More: https://shorturl.at/N6pIs
Mistral Le Chat, AI assistant, multimodal AI model, AI models, Machine learning algorithms, AI chatbots, large language models, best AI certifications, AI Engineer, AI skills

0 notes
Text
AI-Driven Content Creation Tools for Smarter Marketing | OneAIChat Boost your brand with AI-driven content creation—generate high-quality, engaging content faster and smarter with advanced artificial intelligence tools.
#ai driven content creation#ai powered content generation#multimodal integration#ai powered content creation
0 notes
Text
Ask A Genius 1353: GPT-5, AI Consciousness, and Crossover Country
Scott Douglas Jacobsen: You have been listening to a country song designed for people who do not usually enjoy country music—not the traditional kind aimed at long-time fans, but rather a version that tries to appeal to outsiders. Rick Rosner: There is crossover country, of course. However, in Albuquerque, I could only find stations playing formulaic country music on the radio. There is…
#AGI without consciousness#AI and nuclear war risk#multimodal AI integration#Rick Rosner#Scott Douglas Jacobsen
0 notes
Text
Meta presenta la nueva versión de su inteligencia artificial: Llama 4
Lanzamiento de Llama 4: La Nueva Versión de la IA de Meta que Revoluciona WhatsApp, Instagram y Más Fecha de publicación: 5 de abril de 2025 Meta, la empresa matriz de Facebook, Instagram y WhatsApp, ha dado un paso gigante en el mundo de la inteligencia artificial con el lanzamiento de Llama 4, su modelo de IA más avanzado hasta la fecha. Anunciado por Mark Zuckerberg el 5 de abril de 2025, este…
#código abierto#Facebook#IA multimodal#innovación digital#Instagram#inteligencia artificial#Llama 4#LlamaCon#Mark Zuckerberg#Messenger#Meta AI#mezcla de expertos#tecnología 2025#WhatsApp
0 notes
Text
Web & Mobile App Development
Tailored development of user-friendly and responsive web and mobile applications to enhance your online presence and user experience.
Cloud and AI-Driven Apps
Implementation of cloud-based and AI-driven solutions to streamline operations, enhance scalability, and leverage predictive analytics for smarter business decisions.
SAAS Solutions
Customized Software as a Service solutions designed to address your unique business needs, providing flexibility, scalability, and efficiency.
PAAS Solutions
Platform as a Service solutions offering a robust framework for application development, deployment, and management, empowering businesses with agility and innovation.
Search Engine Optimization (SEO)
Enhance your website’s visibility and ranking on search engine results pages (SERPs) through strategic optimization techniques, keyword research, content optimization, and technical enhancements, driving organic traffic and improving online presence.
Social Media Optimization (SMO)
Optimize your social media profiles and content to increase visibility, engagement, and brand awareness across various social platforms, leveraging audience insights, targeted messaging, and strategic campaigns for maximum impact and audience reach.
#ui ux design services#ai-based mobile apps#multimodal innovation#Digital Solutions#Web & Mobile App Development#Cloud and AI-Driven Apps#Search Engine Optimization (SEO)
0 notes
Text
SciTech Chronicles. . . . . . . . .Mar 24th, 2025
#genes#chromosome#hippocampus#myelin#Aardvark#multimodal#GFS#democratising#cognitive#assessment#Human-AI#Collaboration#E2A#192Tbit/s#Alcatel#2028#genomics#bioinformatics#antimicrobial
0 notes
Text
Pixtral Large 25.02: Amazon Bedrock Serverless Multimodal AI

AWS releases Pixtral Large 25.02 for serverless Amazon Bedrock.
Amazon Bedrock Pixtral Large
The Pixtral Large 25.02 model is now completely managed and serverless on Amazon Bedrock. AWS was the first major cloud service to provide serverless, fully managed Pixtral Large.
Infrastructure design, specific expertise, and continual optimisation are often needed to manage massive foundation model (FM) computational demands. Many clients must manage complex infrastructures or choose between cost and performance when deploying sophisticated models.
Mistral AI's first multimodal model, Pixtral Large, combines high language understanding with advanced visuals. Its 128K context window makes it ideal for complex visual reasoning. The model performs well on MathVista, DocVQA, and VQAv2, proving its effectiveness in document analysis, chart interpretation, and natural picture understanding.
Pixtral Large excels at multilingualism. Global teams and apps can use English, French, German, Spanish, Italian, Chinese, Japanese, Korean, Portuguese, Dutch, and Polish. Python, Java, C, C++, JavaScript, Bash, Swift, and Fortran are among the 80 languages it can write and read.
Developers will like the model's agent-centric architecture since it integrates with current systems via function calling and JSON output formatting. Its sturdy system fast adherence improves dependability in large context situations and RAG applications.
This complex model is currently available in Amazon Bedrock without infrastructure for Pixtral Large. Serverless allows you to scale usage based on demand without prior commitments or capacity planning. No wasted resources mean you only pay for what you utilise.
Deduction across regions
Pixtral Large is now available in Amazon Bedrock across various AWS Regions due to cross-region inference.
Amazon Bedrock cross-Region inference lets you access a single FM across many regions with high availability and low latency for global applications. A model deployed in both the US and Europe may be accessible via region-specific API endpoints with various prefixes: us.model-id for US and eu.model-id for European.
By confining data processing within defined geographic borders, Amazon Bedrock may comply with laws and save latency by sending inference requests to the user's nearest endpoint. The system automatically manages load balancing and traffic routing across Regional installations to enable seamless scalability and redundancy without your monitoring.
How it works?
I always investigate how new capabilities might solve actual problems as a developer advocate. The Amazon Bedrock Converse API's new multimodal features were perfect for testing when she sought for help with her physics exam.
It struggled to solve these challenges. It realised this was the best usage for the new multimodal characteristics. The Converse API was used to create a rudimentary application that could comprehend photographs of a complex problem sheet with graphs and mathematical symbols. Once the physics test materials were uploaded, ask the model to explain the response process.
The following event impressed them both. Model interpreted schematics, mathematical notation, and French language, and described each difficulty step-by-step. The computer kept context throughout the talk and offered follow-up questions about certain issues to make teaching feel natural.
It was confident and ready for this test, showing how Amazon Bedrock's multimodal capabilities can provide users meaningful experiences.
Start now
The new method is available at US East (Ohio, N. Virginia), US West (Oregon), and Europe (Frankfurt, Ireland, Paris, Stockholm) Regional API endpoints. Regional availability reduces latency, meeting data residency criteria.
Use the AWS CLI, SDK, or Management Console to programmatically access the model using the model ID mistral.pixtral-large-2502-v1:0.
Developers and organisations of all sizes may now employ strong multimodal AI, a major leap. AWS serverless infrastructure with Mistral AI's cutting-edge model let you focus on designing innovative apps without worrying about complexity.
#technology#technews#govindhtech#news#technologynews#AI#artificial intelligence#Pixtral Large#Amazon Bedrock#Mistral AI#Pixtral Large 25.02#Pixtral Large 25.02 model#multimodal model
0 notes
Text
🚀 Exciting news! Google has launched Gemini 2.0 and AI Mode, transforming how we search. Get ready for faster, smarter responses to complex queries! Explore the future of AI in search today! #GoogleAI #Gemini2 #AIMode #SearchInnovation
#accessibility features.#advanced mathematics#advanced reasoning#AI Mode#AI Overviews#AI Premium#AI Technology#AI-driven responses#coding assistance#data sources#digital marketing#fact-checking#Gemini 2.0#Google AI#Google One#image input#information synthesis#Knowledge Graph#multimodal search#Query Fan-Out#response accuracy#search algorithms#search enhancement#search innovation#text interaction#User Engagement#voice interaction
0 notes
Photo

#ai#google-gemini#google#intent-analysis#multimodal-queries#natural-language-processing#nlp#response-generation#search#technology
1 note
·
View note
Text

Microsoft представила новое поколение моделей искусственного интеллекта Phi: Phi-4-multimodal и Phi-4-mini
Эти модели, доступные на Azure AI Foundry и Hugging Face, предназначены для широкого спектра задач. Phi-4-multimodal значительно улучшает возможности распознавания речи, перевода, создания кратких сводок, понимания аудио и анализа изображений. Phi-4-mini, в свою очередь, оптимизирована для работы в условиях, требующих высокой скорости и эффективности. Обе модели предназначены для использования разработчиками на различных устройствах, включая смартфоны, персональные компьютеры и автомобили.
Подписывайтесь на наш канал:
https://t.me/tefidacom
0 notes
Text
https://oneaichat.com/chat
AI Coding Assistant: Transform Text to Code Effortlessly
Boost your coding efficiency with an AI coding assistant for text-to-code conversion. Generate accurate, optimized code from natural language effortlessly!
0 notes
Text
Ask A Genius 1332: ChatGPT, AGI, and the Future of Multimodal AI
Rick Rosner: You had ChatGPT summarize my life using publicly available sources, which it processed into a coherent narrative. There were several minor errors—for example, it claimed I spent ten years in high school. That is inaccurate. I returned to high school a few times over the course of a decade, but I did not attend for ten continuous years. Despite these inaccuracies, the summary…
#AI summary#future of artificial general intelligence#multimodal AI integration#Rick Rosner#Scott Douglas Jacobsen
0 notes