#PDF OCR
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Average visit duration of Tumblr.com is 10 mins and 25 secs.
Note
So the question about books not available on Libby raised another question in my mind. If one of us following you on social media has one of those books that’s unavailable on Libby could we scan it and submit it to you as a PDF somehow so others could access it? I don’t have the several hundred dollar book that was mentioned, and I know this could be dipping my toes into copyright law territory, but it could be beneficial to try and crowd source some of our history, Zine style
ah. okay, love the crowdsource-y punk vibes. however we are NOT in a position to play fast and loose with copyright laws. we can’t even take pdf’s directly from the authors! we have formal non-profit status* and for us, it’s really important that we maintain access nationwide to as many folks as possible, for as many books as we can (and we’re still buying more as fast as our budgets allow - we’re not close to being done yet!)
we’ve got lots of plans to keep growing and expanding our catalogue, but what you’re suggesting is not one of the feasible options for us.
in the meantime, some other great options are to keep requesting queer books from your local public libraries, to use InterLibrary Loan if you (or a friend) has access to a university system, and explore some (legal) Open Access or Public Domain projects that are out there (queer zine archive project, directory of open access books, project gutenberg, etc..)
#*through our fiscal sponsor NOPI -we link on our website#asks#also slightly unrelated but pdfs can be AWFUL for accessibility#like if they dont have OCR (optical character recognition) built in then a screen reader can’t read it#and we also take accessibility pretty seriously around here
85 notes
·
View notes
Note
i hope this doesn't sound patronising if you've already tried that route, but in case you haven't: if this is a text that has been given to you as is and been produced by a general OCR, it might be worth looking into whether ppl have already trained language-specific OCR models for your field of study and using that to transcribe the scanned text again. there's a lot of transcription solutions/software and different fields prefer different ones, and idk the standard for Celtic studies personally, but a site i use often (transkribus) has 2 Irish models whose related projects you might be able to use as a starting point for research at least. best of luck to you either way!
So there are several factors at work with the OCR problems with this text specifically.
The PDF of the text is from Archive. The library copy it was scanned from has various pencil markings and annotations that are interfering with the printed text -- it's not a clean scan. It's also not super high definition, so letters like "h" sometimes get misread as "li", even though they're totally readable to human eyes.
The edition uses frequent italics and brackets to show where abbrevations in the manuscript has been expanded. Individual italicised letters confuse the OCR, as do random square brackets in the middle of words.
It also has a lot of superscript numbers corresponding to manuscirpt variants in the footnotes. Sometimes these are in the middle of a word. This also confuses most OCR systems, even if it can tell that the footnotes are separate from the main text.
The language of the text is late Middle / Early Modern Irish, from two different manuscripts that have their own unique spelling quirks (for example, one of them loves to spell Cú Chulainn's name "Cú Cholain", which is a vibe).
In order to run the text through a more sophisticated OCR system that was equipped to cope with a) annotations, b) weird formatting and punctuation, c) incredibly frequent footnotes (variants), and d) non-standardised spelling (which throws off many language models), I would probably still need to have a reliable, clear, and high-definition scan of the text. Which would require re-digitising it from scratch.
So, the quickest and easiest way to get a version of the text that I personally can use is to sit here and type up 20,000 words into a document. This is 2-4 days' work, depending on how focused I am, and gives me the chance to go through the text in detail and spot things I might miss otherwise, so it's probably a whole lot less effort for more benefit than trying to adapt an entire language model that could read this terrible PDF. Especially as I have no experience of using these programmes so would have a steep learning curve.
Now, somebody absolutely should do that, so we could get proper searchable editions of more things. But honestly, if using transcription tools for medieval/early modern Irish I think there are higher priorities than things already available in printed form, so I doubt it's at the top of anyone's to-do list!
#it's only about 50% the OCR's fault here and it's 50% the PDF just being terrible to start with#which is. a different problem#finn is not doing a phd#answered
16 notes
·
View notes
Text
Kentucky court system needs to fire its web developers.
#are they trying to run ocr/optimization on uploads and then rejecting the filing if the process takes too long or output looks weird#and if not. what are they fucking doing#that requires calls to a paid remote pdf processing api on every fucking upload#this is clearly not a security/virus screening. they don't believe in those. they are the kentucky court system.#the law
8 notes
·
View notes
Text
not only does the (points above my head) blog descriptor always stand. but im also picky about how much dead space people are including in their screenshots of text. if only there was some way we could condense this into just the relevant information that was easily and efficiently displayed on all devices.......
#some shit#also oh my god that was a hand typed image description. BABES! imagetotext.info. remember if u dont have ocr on ur device you can always#📢 GO TO IMAGETOTEXT.INFO#damn tumblr must be the new pdf cause the new epub wouldnt treat me like this
2 notes
·
View notes
Text
Google Chrome: OCR per leggere i pdf scansionati
La nuova versione di Google Chrome integrerà una funzionalità #OCR che consentirà di aprire un file PDF, ottenuto tramite scansione, quindi praticamente un'immagine, e poter utilizzare le funzionalità di copia-incolla, come se quel testo esistesse e fosse stato scritto.
0 notes
Text
احترف تعديل النصوص على الصور المكتوبة بدون برامج

تعديل النصوص المكتوبة على الصور بدون برامج: يعتبر هو أحد أكثر المواضيع بحثًا في وقتنا الحالي، خاصة مع التطور الكبير في أدوات الذكاء الاصطناعي التي أصبحت تتيح إمكانية إزالة النصوص المكتوبة على الصور، أو تعديلها بسهولة ودقة، دون الحاجة إلى تحميل برامج ثقيلة أو معقدة. بالتالي، وسواء كنت تعمل في مجال: التصميم، أو التسويق، أو حتى من مستخدمي وسائل التواصل الاجتماعي، فإنك بالتأكيد تحتاج إلى تعديل النصوص في صورة ما، دون فقدان جودتها أو معناها.
#إزالة النصوص من الصور#الكتابة على الصور بدون برامج#الكتابة على الصور#مسح الكتابة من الصور#تعديل الصور#برنامج تحويل الصور المكتوبة الى النصوص#برنامج تحويل الصور المكتوبة إلى النصوص#مسح الكتابة من الصور بالفوتوشوب#طريقة تحويل الصور الى النصوص#طريقة تحويل الصور إلى النصوص#تعديل الصور دون برامج#الكتابة على الصور بالفوتوشوب#طريقة تحسين ملف pdf بدون برامج#ازالة الكتابة من الصور بالفوتوشوب#تحسين الصور#برنامج نسخ النصوص من الصور ocr#برنامج تحويل النصوص الى الصور#برنامج تحويل النصوص إلى الصور
0 notes
Text
🖼️📃 🔍🔀PDFs come in various forms—standard editable PDFs and scanned image PDFs. Standard PDFs facilitate easy data editing and copy-pasting, whereas scanned image PDFs are not directly editable. But what if you need to extract data from scanned image PDFs? Unlike standard PDFs, you can’t simply copy and paste the information. So, how can you efficiently extract data from scanned image PDFs? In this post, we’ll explore: ✅What is PDF image extraction? ✅The challenges of PDF image extraction ✅The best tools available to streamline the process ✅How AlgoDocs AI simplifies and automates data extraction from scanned PDFs Read our compressive guide to lean more ⬇️ https://www.algodocs.com/pdf-image-extraction-comprehensive-guide-2025/
#ocr#algodocs#ocralgorithms#imagetoexcel#ai tools#dataextraction#pdfconversion#imagetotext#image to text#image recognition#pdf extraction
0 notes
Text
https://www.tvwriting.co.uk/tv_scripts/Collections/Drama/Supernatural/Supernatural_15x18_-_Despair.pdf
NOW you are prepared.
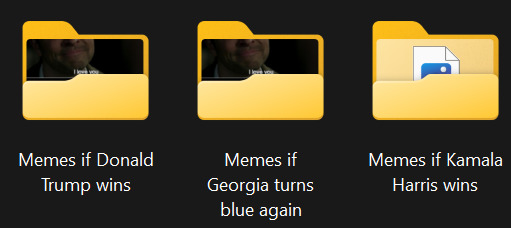
[Image ID: A screenshot of three folders which have been labeled 'memes if Donald Trump wins', 'memes if Georgia turns blue again' and 'memes if Kamala Harris wins' respectively. /End ID]
I am prepared.
#tv writing is where we found our first scripts#only felt right to send pdfs over whenever we got new ones#he usually adds the latest draft and usually one per episode#the scan of 7x17 was too low quality for ocr to work so that's why it's not there#anyway#destiel#remember remember the fifth of november#supernatural
14K notes
·
View notes
Video
youtube
Extract text from PDF(OCR/Image) File using Python / Voter data extraction
0 notes
Text
Putting it out of tags because it's important, but if you ever need to do readings for xyz and you don't do well with text, use a text reader! It's easy to find somewhat good ones for free (if you read in English), like microsoft edge, and even better ones if you can pay.
Do not torture yourself.
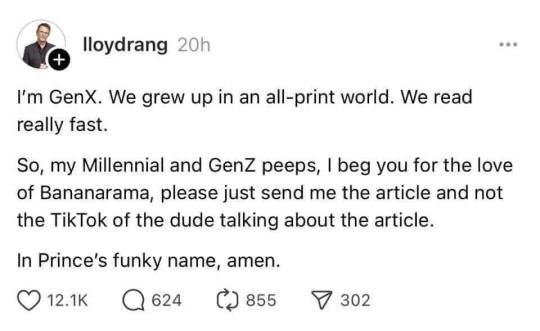
In Prince's funky name, amen.
#I use Natural Reader myself when my brain cannot word#if your pdf does not have OCR#it does it for you
63K notes
·
View notes
Text
0 notes
Text
OCR technology has revolutionized data collection processes, providing many benefits to various industries. By harnessing the power of OCR with AI, businesses can unlock valuable insights from unstructured data, increase operational efficiency, and gain a competitive edge in today's digital landscape. At Globose Technology Solutions, we are committed to leading innovative solutions that empower businesses to thrive in the age of AI.
#OCR Data Collection#Data Collection Compnay#Data Collection#image to text api#pdf ocr ai#ocr and data extraction#data collection company#datasets#ai#machine learning for ai#machine learning
0 notes
Text
#online ocr tool#online pdf ocr tool#free online ocr pdf converting#free online pdf ocr converting#online pdf converting#ocr free online converting
0 notes
Text

Best Free Online OCR Tool
The StarVista Online OCR tool is for converting scanned PDF files that have not been OCR'ed to make them Section 508 Compliant PDFs.
#Best Online OCR Tool#Best Free Online OCR Tool#Free Online OCR#Free Online OCR Tool#Best Free Online OCR Converter#Best Free online pdf image OCR converter#Free online pdf images OCR Tool
0 notes
Text
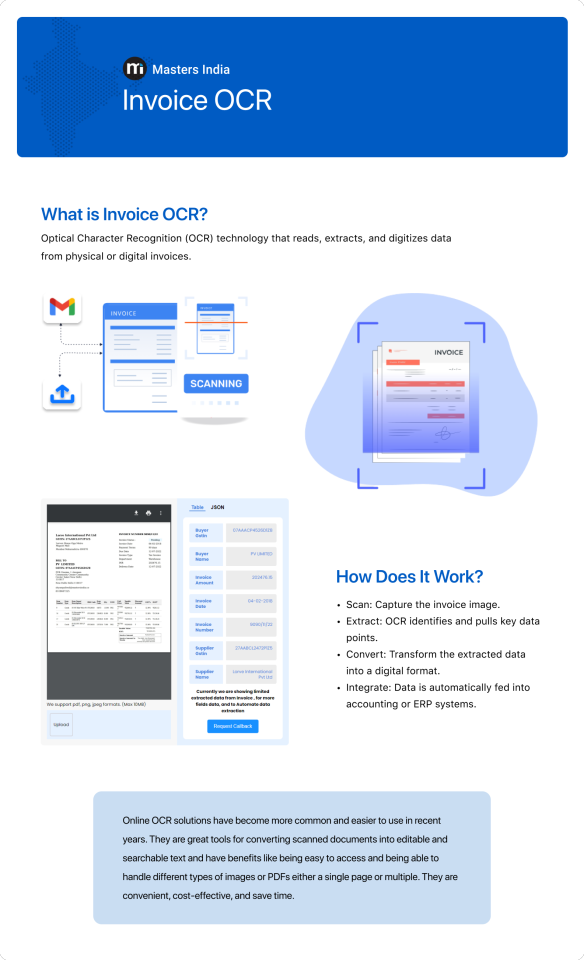
Invoice OCR
The main work of Invoice OCR is to convert the data present in Invoice PDF or Image into machine readable format. Masters India Invoice ocr is Pre-Trained AI & ML Model. It has No template dependency. It is 100% AI. Drag and drop or Upload an Invoices, Receipt, Purchase order, E -invoice Qr code and Bill of entry in PDF, Image or Png and see the OCR in action.
0 notes