#Real Estate Web Scraping
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr’s reach among the 26-to-35-year-olds in the US is 11%.
Text

Real Estate Web Scraping helps gather vast property listings, prices, and market trends efficiently from various sources. By scraping real estate data, you can collect critical insights like property details, agent information, and pricing comparisons. This automated process empowers businesses to stay ahead, analyze trends, and make data-driven decisions in the competitive real estate market.
#Real Estate Web Scraping#Scrape Real Estate Data#extract data from real estate#Real Estate Data Scraping
0 notes
Text
Unlock Data-Driven Insights in Real Estate Using Web Scraping

In real estate, timely access to property trends and market data is crucial for staying competitive. Web scraping is the key tool for unlocking a wealth of real estate data. This blog will cover Real Estate Web Scraping techniques, ethical practices, and gathering real-time trends to transform your approach from spreadsheets.
The real estate market is always changing. Web scraping allows you to gather a large amount of data for analyzing trends including market direction, property values, and ideal buying/selling times. With this information, investors can select properties with higher potential return on investment (ROI), real estate agents can create targeted marketing campaigns and competitively price properties, and home buyers/sellers can find the best deals and negotiate effectively. Web scraping also helps in building real estate aggregators and identifying customer needs for developers and builders aiming to construct properties that will sell quickly.
You can scrape various types of real estate data from websites, including property details such as basic information and descriptions, listing details like price and status, market data such as sales and rental information, and other data points like public records and demographic data.
Read More: Real Estate Web Scraping
0 notes
Text
Real Estate Web Scraping | Scrape Data From Real Estate Website
In the digital age, data is king, and nowhere is this more evident than in the real estate industry. With vast amounts of information available online, web scraping has emerged as a powerful tool for extracting valuable data from real estate websites. Whether you're an investor looking to gain insights into market trends, a real estate agent seeking to expand your property listings, or a developer building a property analysis tool, web scraping can provide you with the data you need. In this blog, we'll explore the fundamentals of web scraping in real estate, its benefits, and how to get started.
What is Web Scraping? Web scraping is the automated process of extracting data from websites. It involves using software to navigate web pages and collect specific pieces of information. This data can include anything from property prices and descriptions to images and location details. The scraped data can then be analyzed or used to populate databases, allowing for a comprehensive view of the real estate landscape.
Benefits of Web Scraping in Real Estate Market Analysis: Web scraping allows investors and analysts to gather up-to-date data on property prices, rental rates, and market trends. By collecting and analyzing this information, you can make informed decisions about where to buy, sell, or invest.
Competitive Intelligence: Real estate agents and brokers can use web scraping to monitor competitors' listings. This helps in understanding the competitive landscape and adjusting marketing strategies accordingly.
Property Aggregation: For websites and apps that aggregate property listings, web scraping is essential. It enables them to pull data from multiple sources and provide users with a wide selection of properties to choose from.
Automated Updates: Web scraping can be used to keep databases and listings up-to-date automatically. This is particularly useful for platforms that need to provide users with the latest information on available properties.
Detailed Insights: By scraping detailed property information such as square footage, amenities, and neighborhood details, developers and analysts can provide more nuanced insights and improve their decision-making processes.
Getting Started with Real Estate Web Scraping Step 1: Identify the Target Website Start by choosing the real estate websites you want to scrape. Popular choices include Zillow, Realtor.com, and Redfin. Each website has its own structure, so understanding how data is presented is crucial. Look for listings pages, property details pages, and any relevant metadata.
Step 2: Understand the Legal and Ethical Considerations Before diving into web scraping, it's important to understand the legal and ethical implications. Many websites have terms of service that prohibit scraping, and violating these can lead to legal consequences. Always check the website’s robots.txt file, which provides guidance on what is permissible. Consider using APIs provided by the websites as an alternative when available.
Step 3: Choose Your Tools Web scraping can be performed using various tools and programming languages. Popular choices include:
BeautifulSoup: A Python library for parsing HTML and XML documents. It’s great for beginners due to its ease of use. Scrapy: An open-source Python framework specifically for web scraping. It's powerful and suitable for more complex scraping tasks. Selenium: A tool for automating web browsers. It’s useful when you need to scrape dynamic content that requires interaction with the webpage. Step 4: Develop Your Scraping Script Once you have your tools ready, the next step is to write a script that will perform the scraping. Here’s a basic outline of what this script might do:
Send a Request: Use a tool like requests in Python to send an HTTP request to the target website and retrieve the page content. Parse the HTML: Use BeautifulSoup or another parser to extract specific data from the HTML. This might include property prices, addresses, descriptions, and images. Store the Data: Save the extracted data in a structured format such as CSV or a database for further analysis. Step 5: Handle Dynamic Content and Pagination Many modern websites load content dynamically using JavaScript, or they may paginate their listings across multiple pages. This requires handling JavaScript-rendered content and iterating through multiple pages to collect all relevant data.
For Dynamic Content: Use Selenium or a headless browser like Puppeteer to render the page and extract the dynamic content. For Pagination: Identify the pattern in the URL for paginated pages or look for pagination controls within the HTML. Write a loop in your script to navigate through all pages and scrape the data. Step 6: Clean and Analyze the Data After collecting the data, it’s essential to clean and normalize it. Remove duplicates, handle missing values, and ensure consistency in the data format. Tools like pandas in Python can be incredibly helpful for this step. Once the data is clean, you can begin analyzing it to uncover trends, insights, and opportunities.
0 notes
Text
#real estate data scraping services#Zillow scraper#extract property details#track competitor pricing strategies#mobile app scraping#web scraping#instant data scraper
0 notes
Text
Abode Enterprise
Abode Enterprise is a reliable provider of data solutions and business services, with over 15 years of experience, serving clients in the USA, UK, and Australia. We offer a variety of services, including data collection, web scraping, data processing, mining, and management. We also provide data enrichment, annotation, business process automation, and eCommerce product catalog management. Additionally, we specialize in image editing and real estate photo editing services.
With more than 15 years of experience, our goal is to help businesses grow and become more efficient through customized solutions. At Abode Enterprise, we focus on quality and innovation, helping organizations make the most of their data and improve their operations. Whether you need useful data insights, smoother business processes, or better visuals, we’re here to deliver great results.

#Data Collection Services#Web Scraping Services#Data Processing Service#Data Mining Services#Data Management Services#Data Enrichment Services#Business Process Automation Services#Data Annotation Services#Real Estate Photo Editing Services#eCommerce Product Catalog Management Services#Image Editing service
1 note
·
View note
Text
🏠 Revolutionize Real Estate Data Collection with the Realtor Agents Scraper!
Looking to extract reliable real estate agent data without the hassle? The Realtor Agents Scraper by Dainty Screw is here to save your time and boost your productivity.
✨ What Can This Scraper Do?
• 🏢 Extract agent names, phone numbers, and email addresses.
• 🌐 Scrape agent websites and company details.
• 📍 Gather location-specific agent data.
• 🚀 Automate data collection from Realtor.com effortlessly.
💡 Perfect For:
• Real estate agencies building agent directories.
• Marketers looking to expand their leads.
• Developers building real estate tools.
• Researchers analyzing agent trends.
🚀 Why Choose This Scraper?
• Accurate Data: Extracts up-to-date information effortlessly.
• Customizable Filters: Scrape data for specific regions or categories.
• Time-Saving Automation: No more manual data collection.
• Ideal for Scaling: Handle large datasets efficiently.
🔗 Get Started Now:
Simplify your real estate data extraction with one click: Realtor Agents Scraper
🙌 Whether you’re looking for leads, building tools, or conducting research, this scraper is your all-in-one solution. Start automating today!
Tags: #RealEstate #RealtorScraper #WebScraping #DataAutomation #RealEstateAgents #LeadGeneration #Apify #DataExtraction
#real estate#100 days of productivity#data scraping#lead generation#realtor scraper#realtor agents extractor#data automation#real estate agents#apify#web scraping
0 notes
Text
Discover the Transformative Potential of Web Scraping for Real Estate Businesses
youtube
#Web Scraping for Real Estate#Real Estate Data Scraping#Scrape Real Estate Data#Real Estate Data Collection#Real Estate Data Extractor#Youtube
0 notes
Text
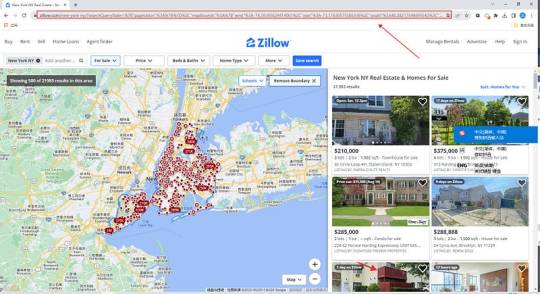
Easy way to get real estate data from Zillow
Zillow is one of the largest online real estate marketplaces in the United States, dedicated to providing a wide range of real estate information and services to help people make informed decisions about buying, selling, renting and managing properties.
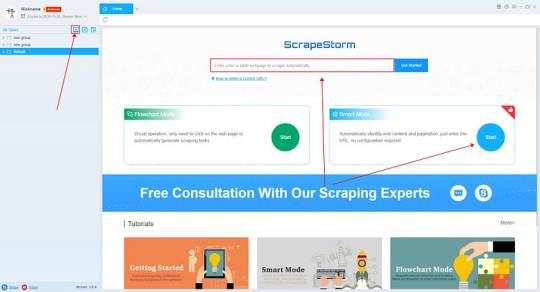
Introduction to the scraping tool
ScrapeStorm is a new generation of Web Scraping Tool based on artificial intelligence technology. It is the first scraper to support both Windows, Mac and Linux operating systems.
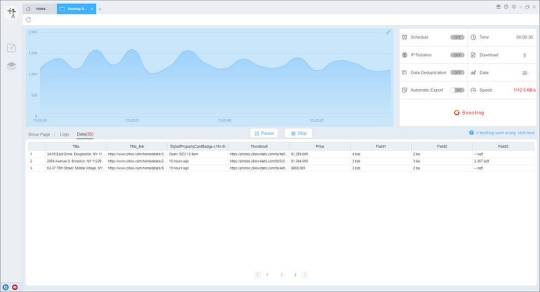
Preview of the scraped result
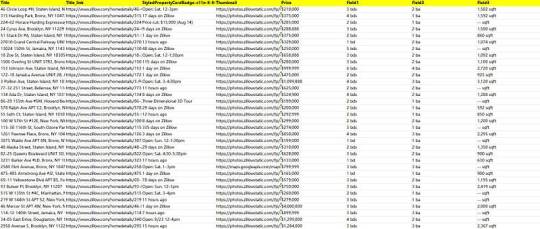
1. Create a task
(2) Create a new smart mode task
You can create a new scraping task directly on the software, or you can create a task by importing rules.
How to create a smart mode task
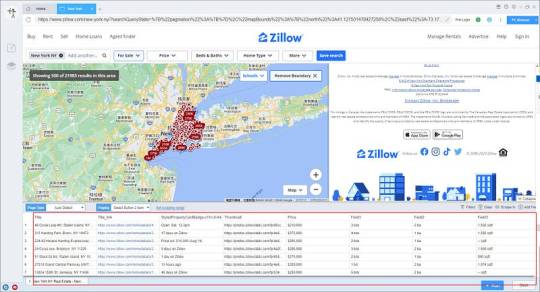
2. Configure the scraping rules
Smart mode automatically detects the fields on the page. You can right-click the field to rename the name, add or delete fields, modify data, and so on.
3. Set up and start the scraping task
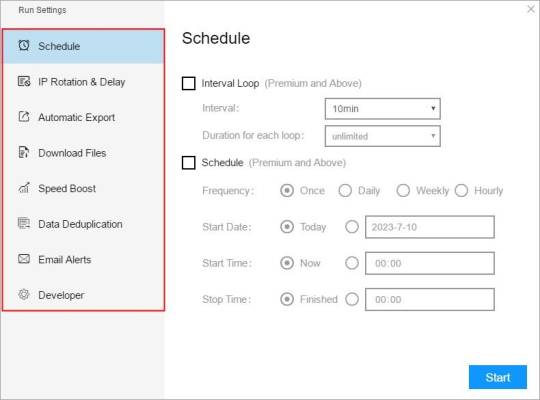
(1) Run settings
Choose your own needs, you can set Schedule, IP Rotation&Delay, Automatic Export, Download Images, Speed Boost, Data Deduplication and Developer.
4. Export and view data
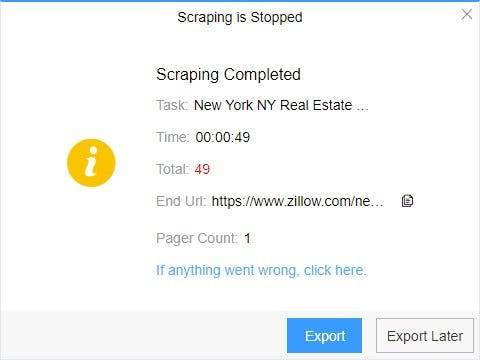
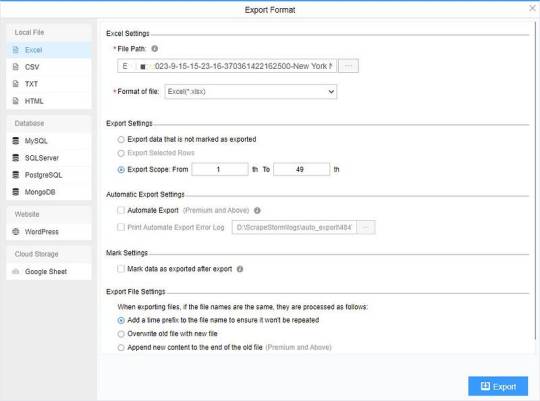
(2) Choose the format to export according to your needs.
ScrapeStorm provides a variety of export methods to export locally, such as excel, csv, html, txt or database. Professional Plan and above users can also post directly to wordpress.
How to view data and clear data
0 notes
Text
0 notes
Text
Lensnure Solutions is a passionate web scraping and data extraction company that makes every possible effort to add value to their customer and make the process easy and quick. The company has been acknowledged as a prime web crawler for its quality services in various top industries such as Travel, eCommerce, Real Estate, Finance, Business, social media, and many more.
We wish to deliver the best to our customers as that is the priority. we are always ready to take on challenges and grab the right opportunity.
3 notes
·
View notes
Text
Zillow Scraping Mastery: Advanced Techniques Revealed

In the ever-evolving landscape of data acquisition, Zillow stands tall as a treasure trove of valuable real estate information. From property prices to market trends, Zillow's extensive database holds a wealth of insights for investors, analysts, and researchers alike. However, accessing this data at scale requires more than just a basic understanding of web scraping techniques. It demands mastery of advanced methods tailored specifically for Zillow's unique structure and policies. In this comprehensive guide, we delve into the intricacies of Zillow scraping, unveiling advanced techniques to empower data enthusiasts in their quest for valuable insights.
Understanding the Zillow Scraper Landscape
Before diving into advanced techniques, it's crucial to grasp the landscape of zillow scraper. As a leading real estate marketplace, Zillow is equipped with robust anti-scraping measures to protect its data and ensure fair usage. These measures include rate limiting, CAPTCHA challenges, and dynamic page rendering, making traditional scraping approaches ineffective. To navigate this landscape successfully, aspiring scrapers must employ sophisticated strategies tailored to bypass these obstacles seamlessly.
Advanced Techniques Unveiled
User-Agent Rotation: One of the most effective ways to evade detection is by rotating User-Agent strings. Zillow's anti-scraping mechanisms often target commonly used User-Agent identifiers associated with popular scraping libraries. By rotating through a diverse pool of User-Agent strings mimicking legitimate browser traffic, scrapers can significantly reduce the risk of detection and maintain uninterrupted data access.
IP Rotation and Proxies: Zillow closely monitors IP addresses to identify and block suspicious scraping activities. To counter this, employing a robust proxy rotation system becomes indispensable. By routing requests through a pool of diverse IP addresses, scrapers can distribute traffic evenly and mitigate the risk of IP bans. Additionally, utilizing residential proxies offers the added advantage of mimicking genuine user behavior, further enhancing scraping stealth.
Session Persistence: Zillow employs session-based authentication to track user interactions and identify potential scrapers. Implementing session persistence techniques, such as maintaining persistent cookies and managing session tokens, allows scrapers to simulate continuous user engagement. By emulating authentic browsing patterns, scrapers can evade detection more effectively and ensure prolonged data access.
JavaScript Rendering: Zillow's dynamic web pages rely heavily on client-side JavaScript to render content dynamically. Traditional scraping approaches often fail to capture dynamically generated data, leading to incomplete or inaccurate results. Leveraging headless browser automation frameworks, such as Selenium or Puppeteer, enables scrapers to execute JavaScript code dynamically and extract fully rendered content accurately. This advanced technique ensures comprehensive data coverage across Zillow's dynamic pages, empowering scrapers with unparalleled insights.
Data Parsing and Extraction: Once data is retrieved from Zillow's servers, efficient parsing and extraction techniques are essential to transform raw HTML content into structured data formats. Utilizing robust parsing libraries, such as BeautifulSoup or Scrapy, facilitates seamless extraction of relevant information from complex web page structures. Advanced XPath or CSS selectors further streamline the extraction process, enabling scrapers to target specific elements with precision and extract valuable insights efficiently.
Ethical Considerations and Compliance
While advanced scraping techniques offer unparalleled access to valuable data, it's essential to uphold ethical standards and comply with Zillow's terms of service. Scrapers must exercise restraint and avoid overloading Zillow's servers with excessive requests, as this may disrupt service for genuine users and violate platform policies. Additionally, respecting robots.txt directives and adhering to rate limits demonstrates integrity and fosters a sustainable scraping ecosystem beneficial to all stakeholders.
Conclusion
In the realm of data acquisition, mastering advanced scraping techniques is paramount for unlocking the full potential of platforms like Zillow. By employing sophisticated strategies tailored to bypass anti-scraping measures seamlessly, data enthusiasts can harness the wealth of insights hidden within Zillow's vast repository of real estate data. However, it's imperative to approach scraping ethically and responsibly, ensuring compliance with platform policies and fostering a mutually beneficial scraping ecosystem. With these advanced techniques at their disposal, aspiring scrapers can embark on a journey of exploration and discovery, unraveling valuable insights to inform strategic decisions and drive innovation in the real estate industry.
2 notes
·
View notes
Text
We provide the Best Real Estate Web Scraping Services in USA, Australia, UAE, to scrape or extract Real Estate Property listing Data from the Zillow, Realtor, Trulia, MLS Webiste using api.
For More Information:-
0 notes
Text
Enhance Data Extraction with AI for Smarter Insights
In today’s data-driven world, businesses need efficient ways to gather and process vast amounts of information. Traditional data extraction methods can be time-consuming and prone to errors, making AI-powered solutions a game-changer. By integrating artificial intelligence, companies can enhance data extraction with AI, leading to faster, more accurate, and scalable data collection processes.

The Power of AI in Data Extraction
Artificial intelligence is transforming how data is collected and analyzed. Unlike conventional scraping techniques, AI-powered extraction adapts to changes in website structures, understands unstructured data, and ensures high accuracy. Businesses leveraging AI can:
Automate Data Collection: Reduce manual efforts and speed up data processing.
Improve Accuracy: AI algorithms minimize errors by intelligently recognizing patterns.
Scale Efficiently: Handle large datasets with ease, making data extraction more reliable.
To explore how AI enhances web scraping, check out our detailed insights on web scraping with AI.
Why Businesses Need AI-Driven Data Extraction
Industries across various sectors rely on high-quality data for decision-making. Whether tracking competitor prices, monitoring customer sentiment, or extracting market trends, AI-powered data extraction offers unmatched efficiency. Here are some use cases:
1. E-commerce and Retail
Companies can extract real-time promotions data to stay ahead of market trends and offer competitive pricing. Learn more about how AI can help businesses extract real-time promotions data.
2. Real Estate Market Insights
AI-driven tools streamline real estate data scraping services, helping businesses gather property listings, pricing trends, and investment opportunities. Find out how our real estate data scraping services provide valuable insights.
3. Grocery and Retail Analytics
AI-powered scraping solutions can track grocery sales trends and consumer behavior. Check out how we analyze the Blinkit sales dataset for deeper business insights.
How Professional Web Scraping Enhances AI Integration
A key aspect of AI-driven data extraction is leveraging professional web scraping solutions. These services ensure seamless data retrieval, improved data quality, and real-time analytics, enabling businesses to make data-backed decisions efficiently.
Conclusion
Enhancing data extraction with AI is no longer a luxury but a necessity for businesses looking to stay competitive. AI-powered solutions offer automation, accuracy, and scalability, transforming raw data into actionable insights. Ready to leverage AI for your data needs? Explore our web scraping solutions today!
#web scraping with AI#extract real-time promotions data#real estate data scraping services#Blinkit sales dataset#professional web scraping
0 notes
Text
Data Scraping Made Simple: What It Really Means
Data Scraping Made Simple: What It Really Means
In the digital world, data scraping is a powerful way to collect information from websites automatically. But what exactly does that mean—and why is it important?
Let’s break it down in simple terms.
What Is Data Scraping?
Data scraping (also called web scraping) is the process of using bots or scripts to extract data from websites. Instead of copying and pasting information manually, scraping tools do the job automatically—much faster and more efficiently.
You can scrape product prices, news headlines, job listings, real estate data, weather reports, and more.
Imagine visiting a website with hundreds of items. Now imagine a tool that can read all that content and save it in a spreadsheet in seconds. That’s what data scraping does.
Why Is It So Useful?
Businesses, researchers, and marketers use data scraping to:
Track competitors' prices
Monitor customer reviews
Gather contact info for leads
Collect news for trend analysis
Keep up with changing market data
In short, data scraping helps people get useful information without wasting time.
Is Data Scraping Legal?
It depends. Public data (like product prices or news articles) is usually okay to scrape, but private or copyrighted content is not. Always check a website’s terms of service before scraping it.
Tools for Data Scraping
There are many tools that make data scraping easy:
Beautiful Soup (for Python developers)
Octoparse (no coding needed)
Scrapy (for advanced scraping tasks)
SERPHouse APIs (for SEO and search engine data)
Some are code-based, others are point-and-click tools. Choose what suits your need and skill level.
Final Thoughts
What is data scraping? It’s the smart way to extract website content for business, research, or insights. With the right tools, it saves time, increases productivity, and opens up access to valuable online data.
Just remember: scrape responsibly.
#serphouse#google serp api#serp scraping api#google search api#seo#api#google#bing#data scraping#web scraping
0 notes
Text
Web Scraping 101: Everything You Need to Know in 2025

🕸️ What Is Web Scraping? An Introduction
Web scraping—also referred to as web data extraction—is the process of collecting structured information from websites using automated scripts or tools. Initially driven by simple scripts, it has now evolved into a core component of modern data strategies for competitive research, price monitoring, SEO, market intelligence, and more.
If you’re wondering “What is the introduction of web scraping?” — it’s this: the ability to turn unstructured web content into organized datasets businesses can use to make smarter, faster decisions.
💡 What Is Web Scraping Used For?
Businesses and developers alike use web scraping to:
Monitor competitors’ pricing and SEO rankings
Extract leads from directories or online marketplaces
Track product listings, reviews, and inventory
Aggregate news, blogs, and social content for trend analysis
Fuel AI models with large datasets from the open web
Whether it’s web scraping using Python, browser-based tools, or cloud APIs, the use cases are growing fast across marketing, research, and automation.
🔍 Examples of Web Scraping in Action
What is an example of web scraping?
A real estate firm scrapes listing data (price, location, features) from property websites to build a market dashboard.
An eCommerce brand scrapes competitor prices daily to adjust its own pricing in real time.
A SaaS company uses BeautifulSoup in Python to extract product reviews and social proof for sentiment analysis.
For many, web scraping is the first step in automating decision-making and building data pipelines for BI platforms.
⚖️ Is Web Scraping Legal?
Yes—if done ethically and responsibly. While scraping public data is legal in many jurisdictions, scraping private, gated, or copyrighted content can lead to violations.
To stay compliant:
Respect robots.txt rules
Avoid scraping personal or sensitive data
Prefer API access where possible
Follow website terms of service
If you’re wondering “Is web scraping legal?”—the answer lies in how you scrape and what you scrape.
🧠 Web Scraping with Python: Tools & Libraries
What is web scraping in Python? Python is the most popular language for scraping because of its ease of use and strong ecosystem.
Popular Python libraries for web scraping include:
BeautifulSoup – simple and effective for HTML parsing
Requests – handles HTTP requests
Selenium – ideal for dynamic JavaScript-heavy pages
Scrapy – robust framework for large-scale scraping projects
Puppeteer (via Node.js) – for advanced browser emulation
These tools are often used in tutorials like “Web scraping using Python BeautifulSoup” or “Python web scraping library for beginners.”
⚙️ DIY vs. Managed Web Scraping
You can choose between:
DIY scraping: Full control, requires dev resources
Managed scraping: Outsourced to experts, ideal for scale or non-technical teams
Use managed scraping services for large-scale needs, or build Python-based scrapers for targeted projects using frameworks and libraries mentioned above.
🚧 Challenges in Web Scraping (and How to Overcome Them)
Modern websites often include:
JavaScript rendering
CAPTCHA protection
Rate limiting and dynamic loading
To solve this:
Use rotating proxies
Implement headless browsers like Selenium
Leverage AI-powered scraping for content variation and structure detection
Deploy scrapers on cloud platforms using containers (e.g., Docker + AWS)
🔐 Ethical and Legal Best Practices
Scraping must balance business innovation with user privacy and legal integrity. Ethical scraping includes:
Minimal server load
Clear attribution
Honoring opt-out mechanisms
This ensures long-term scalability and compliance for enterprise-grade web scraping systems.
🔮 The Future of Web Scraping
As demand for real-time analytics and AI training data grows, scraping is becoming:
Smarter (AI-enhanced)
Faster (real-time extraction)
Scalable (cloud-native deployments)
From developers using BeautifulSoup or Scrapy, to businesses leveraging API-fed dashboards, web scraping is central to turning online information into strategic insights.
📘 Summary: Web Scraping 101 in 2025
Web scraping in 2025 is the automated collection of website data, widely used for SEO monitoring, price tracking, lead generation, and competitive research. It relies on powerful tools like BeautifulSoup, Selenium, and Scrapy, especially within Python environments. While scraping publicly available data is generally legal, it's crucial to follow website terms of service and ethical guidelines to avoid compliance issues. Despite challenges like dynamic content and anti-scraping defenses, the use of AI and cloud-based infrastructure is making web scraping smarter, faster, and more scalable than ever—transforming it into a cornerstone of modern data strategies.
🔗 Want to Build or Scale Your AI-Powered Scraping Strategy?
Whether you're exploring AI-driven tools, training models on web data, or integrating smart automation into your data workflows—AI is transforming how web scraping works at scale.
👉 Find AI Agencies specialized in intelligent web scraping on Catch Experts,
📲 Stay connected for the latest in AI, data automation, and scraping innovation:
💼 LinkedIn
🐦 Twitter
📸 Instagram
👍 Facebook
▶️ YouTube
#web scraping#what is web scraping#web scraping examples#AI-powered scraping#Python web scraping#web scraping tools#BeautifulSoup Python#web scraping using Python#ethical web scraping#web scraping 101#is web scraping legal#web scraping in 2025#web scraping libraries#data scraping for business#automated data extraction#AI and web scraping#cloud scraping solutions#scalable web scraping#managed scraping services#web scraping with AI
0 notes
Text

🏠 How to Scrape Japanese Real Estate Data for Market Insights in 2025?
Want to explore trends in Japan’s property market? Web scraping helps hashtag#ExtractReal-time listings, hashtag#property prices, hashtag#RentalRates, hashtag#LocationData, and amenities from top Japanese real estate portals—empowering smarter hashtag#Investment, hashtag#Planning, and hashtag#CompetitiveAnalysis.
✅ Key Benefits of Japanese Real Estate Data Scraping:
🔹 Track Property Prices – Monitor trends across cities & property types
🔹 Analyze Rental Yields – Compare short-term and long-term rental rates
🔹 Extract Listing Details – Gather size, type, location & amenities
🔹 Identify Market Opportunities – Spot rising locations & buyer patterns
🔹 Support Investment Decisions – Use data for valuation & forecasting
📌 Gain a competitive edge with structured real estate data from Japan’s top platforms.
1 note
·
View note