#User Basic Software
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
BuzzFeed published a report claiming that Tumblr was utilized as a distribution channel for Russian agents to influence American voting habits during the 2016 presidential election in Feb 2018.
Text
you have no idea the level of restraint required to not ever go on tangents when I see people objectively be wrong about software on the internet especially when I can tell it's because they've read some weird screed from gnu users or something
#computing#sometimes this is also things that are like technically a matter of opinion but basically anyone worth listening to would all agree on#like automatic software updates being a net good because thats the only sure fire way users get things like security fixes installed
2 notes
·
View notes
Text
⭐ So you want to learn pixel art? ⭐
🔹 Part 1 of ??? - The Basics!
Edit: Now available in Google Doc format if you don't have a Tumblr account 🥰
Hello, my name is Tofu and I'm a professional pixel artist. I have been supporting myself with freelance pixel art since 2020, when I was let go from my job during the pandemic.


My progress, from 2017 to 2024. IMO the only thing that really matters is time and effort, not some kind of natural talent for art.
This guide will not be comprehensive, as nobody should be expected to read allat. Instead I will lean heavily on my own experience, and share what worked for me, so take everything with a grain of salt. This is a guide, not a tutorial. Cheers!
🔹 Do I need money?
NO!!! Pixel art is one of the most accessible mediums out there.
I still use a mouse because I prefer it to a tablet! You won't be at any disadvantage here if you can't afford the best hardware or software.
Because our canvases are typically very small, you don't need a good PC to run a good brush engine or anything like that.
✨Did you know? One of the most skilled and beloved pixel artists uses MS PAINT! Wow!!
🔹 What software should I use?
Here are some of the most popular programs I see my friends and peers using. Stars show how much I recommend the software for beginners! ⭐
💰 Paid options:
⭐⭐⭐ Aseprite (for PC) - $19.99
This is what I and many other pixel artists use. You may find when applying to jobs that they require some knowledge of Aseprite. Since it has become so popular, companies like that you can swap raw files between artists.
Aseprite is amazingly customizable, with custom skins, scripts and extensions on Itch.io, both free and paid.
If you have ever used any art software before, it has most of the same features and should feel fairly familiar to use. It features a robust animation suite and a tilemap feature, which have saved me thousands of hours of labour in my work. The software is also being updated all the time, and the developers listen to the users. I really recommend Aseprite!
⭐ Photoshop (for PC) - Monthly $$
A decent option for those who already are used to the PS interface. Requires some setup to get it ready for pixel-perfect art, but there are plenty of tutorials for doing so.
Animation is also much more tedious on PS which you may want to consider before investing time!
⭐⭐ ProMotion NG (for PC) - $19.00
An advanced and powerful software which has many features Aseprite does not, including Colour Cycling and animated tiles.
⭐⭐⭐ Pixquare (for iOS) - $7.99 - $19.99 (30% off with code 'tofu'!!)
Probably the best app available for iPad users, in active development, with new features added all the time.

Look! My buddy Jon recommends it highly, and uses it often.
One cool thing about Pixquare is that it takes Aseprite raw files! Many of my friends use it to work on the same project, both in their office and on the go.
⭐ Procreate (for iOS) - $12.99
If you have access to Procreate already, it's a decent option to get used to doing pixel art. It does however require some setup. Artist Pixebo is famously using Procreate, and they have tutorials of their own if you want to learn.
⭐⭐ ReSprite iOS and Android. (free trial, but:) $19.99 premium or $$ monthly
ReSprite is VERY similar in terms of UI to Aseprite, so I can recommend it. They just launched their Android release!
🆓 Free options:
⭐⭐⭐ Libresprite (for PC)
Libresprite is an alternative to Aseprite. It is very, very similar, to the point where documentation for Aseprite will be helpful to Libresprite users.
⭐⭐ Pixilart (for PC and mobile)
A free in-browser app, and also a mobile app! It is tied to the website Pixilart, where artists upload and share their work. A good option for those also looking to get involved in a community.
⭐⭐ Dotpict (for mobile)
Dotpict is similar to Pixilart, with a mobile app tied to a website, but it's a Japanese service. Did you know that in Japanese, pixel art is called 'Dot Art'? Dotpict can be a great way to connect with a different community of pixel artists! They also have prompts and challenges often.
🔹 So I got my software, now what?
◽Nice! Now it's time for the basics of pixel art.
❗ WAIT ❗ Before this section, I want to add a little disclaimer. All of these rules/guidelines can be broken at will, and some 'no-nos' can look amazing when done intentionally.
The pixel-art fundamentals can be exceedingly helpful to new artists, who may feel lost or overwhelmed by choice. But if you feel they restrict you too harshly, don't force yourself! At the end of the day it's your art, and you shouldn't try to contort yourself into what people think a pixel artist 'should be'. What matters is your own artistic expression. 💕👍
◽Phew! With that out of the way...
🔸"The Rules"
There are few hard 'rules' of pixel art, mostly about scaling and exporting. Some of these things will frequently trip up newbies if they aren't aware, and are easy to overlook.
🔹Scaling method
There are a couple ways of scaling your art. The default in most art programs, and the entire internet, is Bi-linear scaling, which usually works out fine for most purposes. But as pixel artists, we need a different method.


Both are scaled up x10. See the difference?
On the left is scaled using Bilinear, and on the right is using Nearest-Neighbor. We love seeing those pixels stay crisp and clean, so we use nearest-neighbor.
(Most pixel-art programs have nearest-neighbor enabled by default! So this may not apply to you, but it's important to know.)
🔹Mixels
Mixels are when there are different (mixed) pixel sizes in the same image.

Here I have scaled up my art- the left is 200%, and the right is 150%. Yuck!
As we can see, the "pixel" sizes end up different. We generally try to scale our work by multiples of 100 - 200%, 300% etc. rather than 150%. At larger scales however, the minute differences in pixel sizes are hardly noticeable!
Mixels are also sometimes seen when an artist scales up their work, then continues drawing on it with a 1 pixel brush.

Many would say that this is not great looking! This type of pixels can be indicative of a beginner artist. But there are plenty of creative pixel artists out there who mixels intentionally, making something modern and cool.
🔹Saving Your Files
We usually save our still images as .PNGs as they don’t create any JPEG artifacts or loss of quality. It's a little hard to see here, but there are some artifacts, and it looks a little blurry. It also makes the art very hard to work with if we are importing a JPEG.

For animations .GIF is good, but be careful of the 256 colour limit. Try to avoid using too many blending mode layers or gradients when working with animations. If you aren’t careful, your animation could flash afterwards, as the .GIF tries to reduce colours wherever it can. It doesn’t look great!

Here's an old piece from 2021 where I experienced .GIF lossiness, because I used gradients and transparency, resulting in way too many colours.
🔹Pixel Art Fundamentals - Techniques and Jargon
❗❗Confused about Jaggies? Anti-Aliasing? Banding? Dithering? THIS THREAD is for you❗❗ << it's a link, click it!!
As far as I'm concerned, this is THE tutorial of all time for understanding pixel art. These are techniques created and named by the community of people who actually put the list together, some of the best pixel artists alive currently. Please read it!!
🔸How To Learn
Okay, so you have your software, and you're all ready to start. But maybe you need some more guidance? Try these tutorials and resources! It can be helpful to work along with a tutorial until you build your confidence up.
⭐⭐ Pixel Logic (A Digital Book) - $10 A very comprehensive visual guide book by a very skilled and established artist in the industry. I own a copy myself.
⭐⭐⭐ StudioMiniBoss - free A collection of visual tutorials, by the artist that worked on Celeste! When starting out, if I got stuck, I would go and scour his tutorials and see how he did it.
⭐ Lospec Tutorials - free A very large collection of various tutorials from all over the internet. There is a lot to sift through here if you have the time.
⭐⭐⭐ Cyangmou's Tutorials - free (tipping optional) Cyangmou is one of the most respected and accomplished modern pixel artists, and he has amassed a HUGE collection of free and incredibly well-educated visual tutorials. He also hosts an educational stream every week on Twitch called 'pixelart for beginners'.
⭐⭐⭐ Youtube Tutorials - free There are hundreds, if not thousands of tutorials on YouTube, but it can be tricky to find the good ones. My personal recommendations are MortMort, Brandon, and AdamCYounis- these guys really know what they're talking about!
🔸 How to choose a canvas size
When looking at pixel art turorials, we may see people suggest things like 16x16, 32x32 and 64x64. These are standard sizes for pixel art games with tiles. However, if you're just making a drawing, you don't necessarily need to use a standard canvas size like that.
What I like to think about when choosing a canvas size for my illustrations is 'what features do I think it is important to represent?' And make my canvas as small as possible, while still leaving room for my most important elements.
Imagine I have characters in a scene like this:

I made my canvas as small as possible (232 x 314), but just big enough to represent the features and have them be recognizable (it's Good Omens fanart 😤)!! If I had made it any bigger, I would be working on it for ever, due to how much more foliage I would have to render.
If you want to do an illustration and you're not sure, just start at somewhere around 100x100 - 200x200 and go from there.
It's perfectly okay to crop your canvas, or scale it up, or crunch your art down at any point if you think you need a different size. I do it all the time! It only takes a bit of cleanup to get you back to where you were.
🔸Where To Post
Outside of just regular socials, Twitter, Tumblr, Deviantart, Instagram etc, there are a few places that lean more towards pixel art that you might not have heard of.
⭐ Lospec Lospec is a low-res focused art website. Some pieces get given a 'monthly masterpiece' award. Not incredibly active, but I believe there are more features being added often.
⭐⭐ Pixilart Pixilart is a very popular pixel art community, with an app tied to it. The community tends to lean on the young side, so this is a low-pressure place to post with an relaxed vibe.
⭐⭐ Pixeljoint Pixeljoint is one of the big, old-school pixel art websites. You can only upload your art unscaled (1x) because there is a built-in zoom viewer. It has a bit of a reputation for being elitist (back in the 00s it was), but in my experience it's not like that any more. This is a fine place for a pixel artist to post if they are really interested in learning, and the history. The Hall of Fame has some of the most famous / impressive pixel art pieces that paved the way for the work we are doing today.
⭐⭐⭐ Cafe Dot Cafe Dot is my art server so I'm a little biased here. 🍵 It was created during the recent social media turbulence. We wanted a place to post art with no algorithms, and no NFT or AI chuds. We have a heavy no-self-promotion rule, and are more interested in community than skill or exclusivity. The other thing is that we have some kind of verification system- you must apply to be a Creator before you can post in the Art feed, or use voice. This helps combat the people who just want to self-promo and dip, or cause trouble, as well as weed out AI/NFT people. Until then, you are still welcome to post in any of the threads or channels. There is a lot to do in Cafe Dot. I host events weekly, so check the threads!
⭐⭐/r/pixelart The pixel art subreddit is pretty active! I've also heard some of my friends found work through posting here, so it's worth a try if you're looking. However, it is still Reddit- so if you're sensitive to rude people, or criticism you didn't ask for, you may want to avoid this one. Lol
🔸 Where To Find Work
You need money? I got you! As someone who mostly gets scouted on social media, I can share a few tips with you:
Put your email / portfolio in your bio Recruiters don't have all that much time to find artists, make it as easy as possible for someone to find your important information!
Clean up your profile If your profile feed is all full of memes, most people will just tab out rather than sift through. Doesn't apply as much to Tumblr if you have an art tag people can look at.
Post regularly, and repost Activity beats everything in the social media game. It's like rolling the dice, and the more you post the more chances you have. You have to have no shame, it's all business baby
Outside of just posting regularly and hoping people reach out to you, it can be hard to know where to look. Here are a few places you can sign up to and post around on.
/r/INAT INAT (I Need A Team) is a subreddit for finding a team to work with. You can post your portfolio here, or browse for people who need artists.
/r/GameDevClassifieds Same as above, but specifically for game-related projects.
Remote Game Jobs / Work With Indies Like Indeed but for game jobs. Browse them often, or get email notifications.
VGen VGen is a website specifically for commissions. You need a code from another verified artist before you can upgrade your account and sell, so ask around on social media or ask your friends. Once your account is upgraded, you can make a 'menu' of services people can purchase, and they send you an offer which you are able to accept, decline, or counter.
The evil websites of doom: Fiverr and Upwork I don't recommend them!! They take a big cut of your profit, and the sites are teeming with NFT and AI people hoping to make a quick buck. The site is also extremely oversaturated and competitive, resulting in a race to the bottom (the cheapest, the fastest, doing the most for the least). Imagine the kind of clients who go to these websites, looking for the cheapest option. But if you're really desperate...
🔸 Community
I do really recommend getting involved in a community. Finding like-minded friends can help you stay motivated to keep drawing. One day, those friends you met when you were just starting out may become your peers in the industry. Making friends is a game changer!
Discord servers Nowadays, the forums of old are mostly abandoned, and people split off into many different servers. Cafe Dot, Pixel Art Discord (PAD), and if you can stomach scrolling past all the AI slop, you can browse Discord servers here.
Twitch Streams Twitch has kind of a bad reputation for being home to some of the more edgy gamers online, but the pixel art community is extremely welcoming and inclusive. Some of the people I met on Twitch are my friends to this day, and we've even worked together on different projects! Browse pixel art streams here, or follow some I recommend: NickWoz, JDZombi, CupOhJoe, GrayLure, LumpyTouch, FrankiePixelShow, MortMort, Sodor, NateyCakes, NyuraKim, ShinySeabass, I could go on for ever really... There are a lot of good eggs on Pixel Art Twitch.
🔸 Other Helpful Websites
Palettes Lospec has a huge collection of user-made palettes, for any artist who has trouble choosing their colours, or just wants to try something fun. Rejected Palettes is full of palettes that didn't quite make it onto Lospec, ran by people who believe there are no bad colours.
The Spriters Resource TSR is an incredible website where users can upload spritesheets and tilesets from games. You can browse for your favourite childhood game, and see how they made it! This website has helped me so much in understanding how game assets come together in a scene.
VGMaps Similar to the above, except there are entire maps laid out how they would be played. This is incredible if you have to do level design, or for mocking up a scene for fun.
Game UI Database Not pixel-art specific, but UI is a very challenging part of graphics, so this site can be a game-changer for finding good references!
Retronator A digital newspaper for pixel-art lovers! New game releases, tutorials, and artworks!
Itch.io A website where people can upload, games, assets, tools... An amazing hub for game devs and game fans alike. A few of my favourite tools: Tiled, PICO-8, Pixel Composer, Juice FX, Magic Pencil for Aseprite
🔸 The End?
This is just part 1 for now, so please drop me a follow to see any more guides I release in the future. I plan on doing some writeups on how I choose colours, how to practise, and more!
I'm not an expert by any means, but everything I did to get to where I am is outlined in this guide. Pixel art is my passion, my job and my hobby! I want pixel art to be recognized everywhere as an art-form, a medium of its own outside of game-art or computer graphics!

This guide took me a long time, and took a lot of research and experience. Consider following me or supporting me if you are feeling generous.
And good luck to all the fledgling pixel artists, I hope you'll continue and have fun. I hope my guide helped you, and don't hesitate to send me an ask if you have any questions! 💕
My other tutorials (so far): How to draw Simple Grass for a game Hue Shifting
28K notes
·
View notes
Text
i was like. thinking about the software situation with the cryptonloids and i got curious if there was any progress on the non-miku NT banks yet so i went to listen to those vocals they use in that mobile game (if i remember correctly they use beta versions unreleased to the public?) and like. you know. despite how contentious miku nt herself is i think some of the betas for the others sound pretty good, len sounds fantastic and rin sounds about on par with her older banks (although i do miss a bit of her sharpness) and like. i may be killed with hammers for this but i was listening to the heat abnormal cover and i think i like the kaito nt beta sound more than his v3 like he sounds fantastic here. i dont dislike his v3 or anything but the nt bits ive heard has like some of the depth and richness i so sorely miss from his v1 while having the old-yamaha-keyboard-keyboard-key-spring sound that i do enjoy of his v3.... i do wish it had more of the v1 strength tho
#luka i also like the sound of but also i dont think she sounds like luka. but also im really picky about older luka banks anyway#im not usually a huge fan so that might be why i do enjoy her nt sound. but i also understand why someone would be disappointed because lik#she straight up sounds like a diff person LOL its so fucked up like who is that..... who is that....#and meiko nt beta..... im still not sure if i like her or not. she sounds a bit weak.#they keep getting her to sing in these medium high ranges when i prefer her in either a really high range a la nostalogic OR#in a deeper medium range so i dunno. i just dont know orz#but len does sound really REALLY good like i think i might also like his nt a bit more than his v4#rin is not quite as good as her v4 tho. shes pretty good but missing a bit. which is fascinating. how does that happen but not with len LOL#but its also fascinating the whole situation to begin with. am i insane or has miku nt been like. near abandoned#i basically never see people use her covers or originals outside of the game. is she alive. is she alive#i dont think she sounds horrible or anything ive seen some users do some fantastic things with her. she does look hard to use tho#that might be the biggest issue. and in the game songs she sounds really fantastic on occasion but most of the time she sounds...#kinda wack LOL i love her in the from y to y cover. and that stella song. i dunno about the others#part of this i also think is the line distribution tho. i think with these nt vocals u gotta be careful when putting them with real vocals#like thats why i think the heat abnormal one sounds so good. they use kaito as an accent in a way. he mostly sings backing with his solos#being like the end of the chorus for emphasis. and this already is a perfect song for robotic vocals LOL it was made for em#but combining like his deeper formant with the breathy sound of tomorirus character and that one with the low side ponytail#and the stronger medium high voices of the blonde one and the brunette. sorry i dont know their names LOL the game doesnt run on me phooone#its gorgeous tho it adds such richness. i think the from y to y cover also sounds great with the rich breathy vocal of the girl with#the long straight hair with the thin robotic sound of miku nt. like it swells up from mikus vocals like an orchestra its awesome#i think u cant just use the vsynths like any other character voice in line distribution you gotta use it mostly for depth and emphasis#but i also dont play the game so i might be talking nonsense LOL i just like the songs. but i do wonder why its been so like radio silence#on the other nts software wise. len and rin sound near ready for release. at least compared to miku nt HJLKSJD#and i would like that kaito....give him to me... and i think i could fix the meiko. i could fix her. i can fix her.
1 note
·
View note
Text
Nobody is wrong for having bitter feelings abt having been inconvenienced by webp while it WAS not supported by software they were trying to use to edit images they downloaded from websites they expected to be handing them pngs or whatever, is the thing. I get what you're saying + agree with the essence of most of it, but I think you're underestimating the amount of responsibility that Software Knowers & Doers just kind of. have. to make interactions like "new file format is suddenly getting downloaded onto your computer instead of the old one you know about already" not piss people off.
the people involved in this kind of interaction WHO KNOW WHAT IS HAPPENING probably should assume that to avoid problems down the line they either have to make Sure the change goes smoothly for the end user, or explain themselves coherently somewhere the end user is likely to notice and understand the explanation. I recognize that this is easier said than done but this isn't, like. something I personally think Should Be Done for moral reasons or whatever; it's just the only way I can think of to realistically have the webp problem not happen. specifically:
1. the onus is on developers to build support into their shit for formats they consider to be up-and-coming in some way, Before most people need it, if they want to live in a world where bitter intractable end users don't manifest all over the place and then stay there. (+NUANCE JUST IMAGINE THERE IS NUANCE HERE FOR YOUR USE CASE OF CHOICE.)
2. the onus is also on web developers to not be changing images into formats that aren't supported (YET.) by software people are going to want to use to do stuff with those images, or bitter end users Will Manifest. they just will. (imagine slightly less nuance here. I'm The Most mad at whoever typed characters that made webps start happening to my downloads folder instead of pngs.)
3. the reasons these things weren't done don't matter as long as the statement being made is "for a lot of end users, this behavior made webp suck bad"
4.a. there is a third onus, on everyone who knows why webp is good, why it got made to suck bad for end users, and whether when & under what circumstances end users can expect it to STOP sucking bad, to explain those things non-confrontationally in public sometimes, if they would like to get complained in front of less.
4.b. "there's no reason for webp to exist" is an IGNORANT complaint but calling it a "bad" complaint is reductive, imo. you have more of a reason to understand why someone might think webp is pointless than the average Webp Complainer has to know what the whole deal was & is with it.
5. hyperspecific thing: I personally would prefer to live in a world where ESPECIALLY playful, low-effort editing of images downloaded from the internet were frictionless. I believe that a lot of parties' reasons for not prioritizing or considering this when designing software are stupid and suck. my believing this isn't going to like generate change in the world by itself or anything but it seemed relevant to mention. who decides what criteria are important & when !! how much responsibility does Websites Georg have to cater to my sense of whimsy. legally NONE ethically IMPOSSIBLE TO SAY.
& finally 6. I use computers in a way that is annoying and webp still isn't supported by my image editing program of choice or my file browser (thumbnails don't work), which is annoying, and it's also annoying to have to navigate this whole file format conversion issue when I'm working on picky shit like video games or low-effort shit like spur-of-the-moment discord emotes. so I still get hyperspecifically mad about webp on a semi-regular basis, unfortunately.
one piece of Computer Guy contrairianism i can't stand is "webp isn't actually bad, the programs you use just aren't equipped to support it!" okay well. soudns like for all intents and purposes its bad then innit
#for me 'being mad about (literally any computer thing)' is just Tuesday so on the one hand it's whatever. but on the other hand#taking up arms for my fellow mildly inconvenienced people is also Tuesday. and so is running into this really persistent#communication gap btwn Software People (busy + knowledgeable) and annoyed end users (more receptive than theyre given credit for#but only if you take their lack of knowledge into account when explaining shit. which takes a lot of time and effort)#I don't know what we DO about any of this except prioritize that time + effort more consistently.#I dont expect most people to spend as much of their free time hunting down Basically Trivia needles in What The Fuck Does Any#Of This Mean haystacks as I do. it's a weird hobby it's a weird thing to enjoy doing. I'm inefficient and often ineffectual at the end#of the day. but like. telling someone 'no your problem isnt a problem actually it's fine' isn't CONSTRUCTIVE. even I would take#'yeah webp kind of got rolled out sloppy-ways. should be okay now though. what issues have you run into with it lately' a hell of a lot#better than 'it's inevitable though bc it's better than png for (PEOPLE WHO ARE NOT ME)' like I already regard all business entities#with extreme distrust so I really can't not empathize with anyone who heard that one + immediately got More Mad More Permanently#I would love for tech to be more intentional I would love for everyone to chew their fucking food for a little bit longer#to demonstrate this I have taken like an hour and a half to write this post I hope it doesn't suck. I swear to GOD I'm not Hard Arguing#with you or anyone here I'm just like. never not sick to bastard death of the 'devs cant explain shit for fuck' phenomenon. it haunts me.#computer#long post
3K notes
·
View notes
Text
Microsoft made Recall—the feature that automatically tracks everything you do in an attempt at helping you except, you know, that's a massive security risk and data mining source—a dependency for the windows file explorer, meaning even if you forcibly strip Recall out you end up losing basic tools.
This is very much a "learn how to install Linux Mint on your laptop" moment. Richard Stallman et al were entirely correct, your computer will soon have spyware integrated deep into the system internals with no ability to cleanly remove it even for experienced, tech savvy users.
Yes, it sucks, there is no Linux distribution that has to even close to the level of support for software and peripherals that windows has, and even the easier distros like Mint still expect a level of tech savvy that Mac and Windows just don't require. Anyone telling you that Linux is just as easy and just as good is lying to you.
But Linux has never been easier, has never been as well supported as today, and simply doesn't contain egregious spyware (well, besides Ubuntu that one time I guess).
2K notes
·
View notes
Text
So, let me try and put everything together here, because I really do think it needs to be talked about.
Today, Unity announced that it intends to apply a fee to use its software. Then it got worse.
For those not in the know, Unity is the most popular free to use video game development tool, offering a basic version for individuals who want to learn how to create games or create independently alongside paid versions for corporations or people who want more features. It's decent enough at this job, has issues but for the price point I can't complain, and is the idea entry point into creating in this medium, it's a very important piece of software.
But speaking of tools, the CEO is a massive one. When he was the COO of EA, he advocated for using, what out and out sounds like emotional manipulation to coerce players into microtransactions.
"A consumer gets engaged in a property, they might spend 10, 20, 30, 50 hours on the game and then when they're deep into the game they're well invested in it. We're not gouging, but we're charging and at that point in time the commitment can be pretty high."
He also called game developers who don't discuss monetization early in the planning stages of development, quote, "fucking idiots".
So that sets the stage for what might be one of the most bald-faced greediest moves I've seen from a corporation in a minute. Most at least have the sense of self-preservation to hide it.
A few hours ago, Unity posted this announcement on the official blog.
Effective January 1, 2024, we will introduce a new Unity Runtime Fee that’s based on game installs. We will also add cloud-based asset storage, Unity DevOps tools, and AI at runtime at no extra cost to Unity subscription plans this November. We are introducing a Unity Runtime Fee that is based upon each time a qualifying game is downloaded by an end user. We chose this because each time a game is downloaded, the Unity Runtime is also installed. Also we believe that an initial install-based fee allows creators to keep the ongoing financial gains from player engagement, unlike a revenue share.
Now there are a few red flags to note in this pitch immediately.
Unity is planning on charging a fee on all games which use its engine.
This is a flat fee per number of installs.
They are using an always online runtime function to determine whether a game is downloaded.
There is just so many things wrong with this that it's hard to know where to start, not helped by this FAQ which doubled down on a lot of the major issues people had.
I guess let's start with what people noticed first. Because it's using a system baked into the software itself, Unity would not be differentiating between a "purchase" and a "download". If someone uninstalls and reinstalls a game, that's two downloads. If someone gets a new computer or a new console and downloads a game already purchased from their account, that's two download. If someone pirates the game, the studio will be asked to pay for that download.
Q: How are you going to collect installs? A: We leverage our own proprietary data model. We believe it gives an accurate determination of the number of times the runtime is distributed for a given project. Q: Is software made in unity going to be calling home to unity whenever it's ran, even for enterprice licenses? A: We use a composite model for counting runtime installs that collects data from numerous sources. The Unity Runtime Fee will use data in compliance with GDPR and CCPA. The data being requested is aggregated and is being used for billing purposes. Q: If a user reinstalls/redownloads a game / changes their hardware, will that count as multiple installs? A: Yes. The creator will need to pay for all future installs. The reason is that Unity doesn’t receive end-player information, just aggregate data. Q: What's going to stop us being charged for pirated copies of our games? A: We do already have fraud detection practices in our Ads technology which is solving a similar problem, so we will leverage that know-how as a starting point. We recognize that users will have concerns about this and we will make available a process for them to submit their concerns to our fraud compliance team.
This is potentially related to a new system that will require Unity Personal developers to go online at least once every three days.
Starting in November, Unity Personal users will get a new sign-in and online user experience. Users will need to be signed into the Hub with their Unity ID and connect to the internet to use Unity. If the internet connection is lost, users can continue using Unity for up to 3 days while offline. More details to come, when this change takes effect.
It's unclear whether this requirement will be attached to any and all Unity games, though it would explain how they're theoretically able to track "the number of installs", and why the methodology for tracking these installs is so shit, as we'll discuss later.
Unity claims that it will only leverage this fee to games which surpass a certain threshold of downloads and yearly revenue.
Only games that meet the following thresholds qualify for the Unity Runtime Fee: Unity Personal and Unity Plus: Those that have made $200,000 USD or more in the last 12 months AND have at least 200,000 lifetime game installs. Unity Pro and Unity Enterprise: Those that have made $1,000,000 USD or more in the last 12 months AND have at least 1,000,000 lifetime game installs.
They don't say how they're going to collect information on a game's revenue, likely this is just to say that they're only interested in squeezing larger products (games like Genshin Impact and Honkai: Star Rail, Fate Grand Order, Among Us, and Fall Guys) and not every 2 dollar puzzle platformer that drops on Steam. But also, these larger products have the easiest time porting off of Unity and the most incentives to, meaning realistically those heaviest impacted are going to be the ones who just barely meet this threshold, most of them indie developers.
Aggro Crab Games, one of the first to properly break this story, points out that systems like the Xbox Game Pass, which is already pretty predatory towards smaller developers, will quickly inflate their "lifetime game installs" meaning even skimming the threshold of that 200k revenue, will be asked to pay a fee per install, not a percentage on said revenue.

[IMAGE DESCRIPTION: Hey Gamers!
Today, Unity (the engine we use to make our games) announced that they'll soon be taking a fee from developers for every copy of the game installed over a certain threshold - regardless of how that copy was obtained.
Guess who has a somewhat highly anticipated game coming to Xbox Game Pass in 2024? That's right, it's us and a lot of other developers.
That means Another Crab's Treasure will be free to install for the 25 million Game Pass subscribers. If a fraction of those users download our game, Unity could take a fee that puts an enormous dent in our income and threatens the sustainability of our business.
And that's before we even think about sales on other platforms, or pirated installs of our game, or even multiple installs by the same user!!!
This decision puts us and countless other studios in a position where we might not be able to justify using Unity for our future titles. If these changes aren't rolled back, we'll be heavily considering abandoning our wealth of Unity expertise we've accumulated over the years and starting from scratch in a new engine. Which is really something we'd rather not do.
On behalf of the dev community, we're calling on Unity to reverse the latest in a string of shortsighted decisions that seem to prioritize shareholders over their product's actual users.
I fucking hate it here.
-Aggro Crab - END DESCRIPTION]
That fee, by the way, is a flat fee. Not a percentage, not a royalty. This means that any games made in Unity expecting any kind of success are heavily incentivized to cost as much as possible.

[IMAGE DESCRIPTION: A table listing the various fees by number of Installs over the Install Threshold vs. version of Unity used, ranging from $0.01 to $0.20 per install. END DESCRIPTION]
Basic elementary school math tells us that if a game comes out for $1.99, they will be paying, at maximum, 10% of their revenue to Unity, whereas jacking the price up to $59.99 lowers that percentage to something closer to 0.3%. Obviously any company, especially any company in financial desperation, which a sudden anchor on all your revenue is going to create, is going to choose the latter.
Furthermore, and following the trend of "fuck anyone who doesn't ask for money", Unity helpfully defines what an install is on their main site.
While I'm looking at this page as it exists now, it currently says
The installation and initialization of a game or app on an end user’s device as well as distribution via streaming is considered an “install.” Games or apps with substantially similar content may be counted as one project, with installs then aggregated to calculate the Unity Runtime Fee.
However, I saw a screenshot saying something different, and utilizing the Wayback Machine we can see that this phrasing was changed at some point in the few hours since this announcement went up. Instead, it reads:
The installation and initialization of a game or app on an end user’s device as well as distribution via streaming or web browser is considered an “install.” Games or apps with substantially similar content may be counted as one project, with installs then aggregated to calculate the Unity Runtime Fee.
Screenshot for posterity:

That would mean web browser games made in Unity would count towards this install threshold. You could legitimately drive the count up simply by continuously refreshing the page. The FAQ, again, doubles down.
Q: Does this affect WebGL and streamed games? A: Games on all platforms are eligible for the fee but will only incur costs if both the install and revenue thresholds are crossed. Installs - which involves initialization of the runtime on a client device - are counted on all platforms the same way (WebGL and streaming included).
And, what I personally consider to be the most suspect claim in this entire debacle, they claim that "lifetime installs" includes installs prior to this change going into effect.
Will this fee apply to games using Unity Runtime that are already on the market on January 1, 2024? Yes, the fee applies to eligible games currently in market that continue to distribute the runtime. We look at a game's lifetime installs to determine eligibility for the runtime fee. Then we bill the runtime fee based on all new installs that occur after January 1, 2024.
Again, again, doubled down in the FAQ.
Q: Are these fees going to apply to games which have been out for years already? If you met the threshold 2 years ago, you'll start owing for any installs monthly from January, no? (in theory). It says they'll use previous installs to determine threshold eligibility & then you'll start owing them for the new ones. A: Yes, assuming the game is eligible and distributing the Unity Runtime then runtime fees will apply. We look at a game's lifetime installs to determine eligibility for the runtime fee. Then we bill the runtime fee based on all new installs that occur after January 1, 2024.
That would involve billing companies for using their software before telling them of the existence of a bill. Holding their actions to a contract that they performed before the contract existed!
Okay. I think that's everything. So far.
There is one thing that I want to mention before ending this post, unfortunately it's a little conspiratorial, but it's so hard to believe that anyone genuinely thought this was a good idea that it's stuck in my brain as a significant possibility.
A few days ago it was reported that Unity's CEO sold 2,000 shares of his own company.
On September 6, 2023, John Riccitiello, President and CEO of Unity Software Inc (NYSE:U), sold 2,000 shares of the company. This move is part of a larger trend for the insider, who over the past year has sold a total of 50,610 shares and purchased none.
I would not be surprised if this decision gets reversed tomorrow, that it was literally only made for the CEO to short his own goddamn company, because I would sooner believe that this whole thing is some idiotic attempt at committing fraud than a real monetization strategy, even knowing how unfathomably greedy these people can be.
So, with all that said, what do we do now?
Well, in all likelihood you won't need to do anything. As I said, some of the biggest names in the industry would be directly affected by this change, and you can bet your bottom dollar that they're not just going to take it lying down. After all, the only way to stop a greedy CEO is with a greedier CEO, right?
(I fucking hate it here.)
And that's not mentioning the indie devs who are already talking about abandoning the engine.
[Links display tweets from the lead developer of Among Us saying it'd be less costly to hire people to move the game off of Unity and Cult of the Lamb's official twitter saying the game won't be available after January 1st in response to the news.]
That being said, I'm still shaken by all this. The fact that Unity is openly willing to go back and punish its developers for ever having used the engine in the past makes me question my relationship to it.
The news has given rise to the visibility of free, open source alternative Godot, which, if you're interested, is likely a better option than Unity at this point. Mostly, though, I just hope we can get out of this whole, fucking, environment where creatives are treated as an endless mill of free profits that's going to be continuously ratcheted up and up to drive unsustainable infinite corporate growth that our entire economy is based on for some fuckin reason.
Anyways, that's that, I find having these big posts that break everything down to be helpful.
#Unity#Unity3D#Video Games#Game Development#Game Developers#fuckshit#I don't know what to tag news like this
6K notes
·
View notes
Note
whats wrong with ai?? genuinely curious <3
okay let's break it down. i'm an engineer, so i'm going to come at you from a perspective that may be different than someone else's.
i don't hate ai in every aspect. in theory, there are a lot of instances where, in fact, ai can help us do things a lot better without. here's a few examples:
ai detecting cancer
ai sorting recycling
some practical housekeeping that gemini (google ai) can do
all of the above examples are ways in which ai works with humans to do things in parallel with us. it's not overstepping--it's sorting, using pixels at a micro-level to detect abnormalities that we as humans can not, fixing a list. these are all really small, helpful ways that ai can work with us.
everything else about ai works against us. in general, ai is a huge consumer of natural resources. every prompt that you put into character.ai, chatgpt? this wastes water + energy. it's not free. a machine somewhere in the world has to swallow your prompt, call on a model to feed data into it and process more data, and then has to generate an answer for you all in a relatively short amount of time.
that is crazy expensive. someone is paying for that, and if it isn't you with your own money, it's the strain on the power grid, the water that cools the computers, the A/C that cools the data centers. and you aren't the only person using ai. chatgpt alone gets millions of users every single day, with probably thousands of prompts per second, so multiply your personal consumption by millions, and you can start to see how the picture is becoming overwhelming.
that is energy consumption alone. we haven't even talked about how problematic ai is ethically. there is currently no regulation in the united states about how ai should be developed, deployed, or used.
what does this mean for you?
it means that anything you post online is subject to data mining by an ai model (because why would they need to ask if there's no laws to stop them? wtf does it matter what it means to you to some idiot software engineer in the back room of an office making 3x your salary?). oh, that little fic you posted to wattpad that got a lot of attention? well now it's being used to teach ai how to write. oh, that sketch you made using adobe that you want to sell? adobe didn't tell you that anything you save to the cloud is now subject to being used for their ai models, so now your art is being replicated to generate ai images in photoshop, without crediting you (they have since said they don't do this...but privacy policies were never made to be human-readable, and i can't imagine they are the only company to sneakily try this). oh, your apartment just installed a new system that will use facial recognition to let their residents inside? oh, they didn't train their model with anyone but white people, so now all the black people living in that apartment building can't get into their homes. oh, you want to apply for a new job? the ai model that scans resumes learned from historical data that more men work that role than women (so the model basically thinks men are better than women), so now your resume is getting thrown out because you're a woman.
ai learns from data. and data is flawed. data is human. and as humans, we are racist, homophobic, misogynistic, transphobic, divided. so the ai models we train will learn from this. ai learns from people's creative works--their personal and artistic property. and now it's scrambling them all up to spit out generated images and written works that no one would ever want to read (because it's no longer a labor of love), and they're using that to make money. they're profiting off of people, and there's no one to stop them. they're also using generated images as marketing tools, to trick idiots on facebook, to make it so hard to be media literate that we have to question every single thing we see because now we don't know what's real and what's not.
the problem with ai is that it's doing more harm than good. and we as a society aren't doing our due diligence to understand the unintended consequences of it all. we aren't angry enough. we're too scared of stifling innovation that we're letting it regulate itself (aka letting companies decide), which has never been a good idea. we see it do one cool thing, and somehow that makes up for all the rest of the bullshit?
#yeah i could talk about this for years#i could talk about it forever#im so passionate about this lmao#anyways#i also want to point out the examples i listed are ONLY A FEW problems#there's SO MUCH MORE#anywho ai is bleh go away#ask#ask b#🐝's anons#ai
1K notes
·
View notes
Text
A summary of the Chinese AI situation, for the uninitiated.
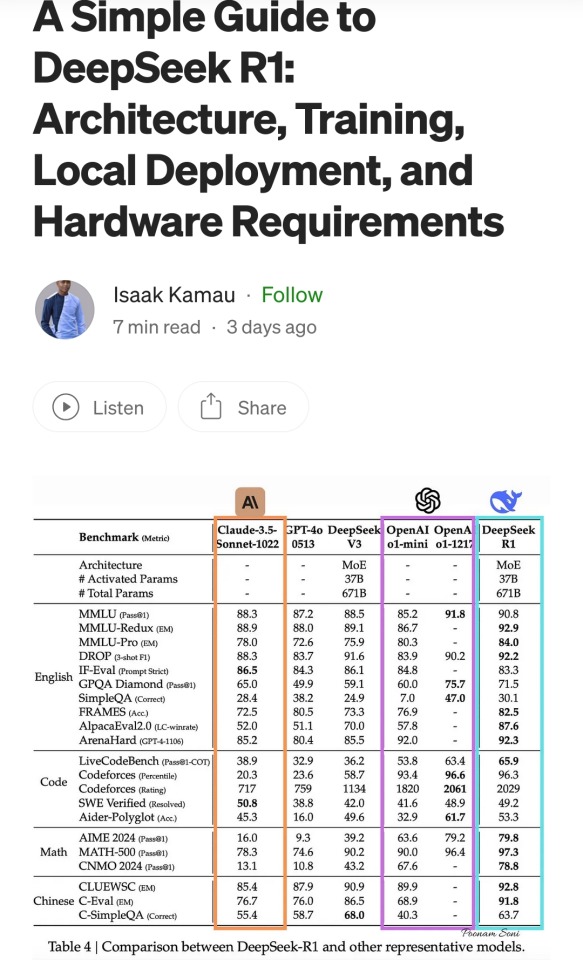
These are scores on different tests that are designed to see how accurate a Large Language Model is in different areas of knowledge. As you know, OpenAI is partners with Microsoft, so these are the scores for ChatGPT and Copilot. DeepSeek is the Chinese model that got released a week ago. The rest are open source models, which means everyone is free to use them as they please, including the average Tumblr user. You can run them from the servers of the companies that made them for a subscription, or you can download them to install locally on your own computer. However, the computer requirements so far are so high that only a few people currently have the machines at home required to run it.
Yes, this is why AI uses so much electricity. As with any technology, the early models are highly inefficient. Think how a Ford T needed a long chimney to get rid of a ton of black smoke, which was unused petrol. Over the next hundred years combustion engines have become much more efficient, but they still waste a lot of energy, which is why we need to move towards renewable electricity and sustainable battery technology. But that's a topic for another day.
As you can see from the scores, are around the same accuracy. These tests are in constant evolution as well: as soon as they start becoming obsolete, new ones are released to adjust for a more complicated benchmark. The new models are trained using different machine learning techniques, and in theory, the goal is to make them faster and more efficient so they can operate with less power, much like modern cars use way less energy and produce far less pollution than the Ford T.
However, computing power requirements kept scaling up, so you're either tied to the subscription or forced to pay for a latest gen PC, which is why NVIDIA, AMD, Intel and all the other chip companies were investing hard on much more powerful GPUs and NPUs. For now all we need to know about those is that they're expensive, use a lot of electricity, and are required to operate the bots at superhuman speed (literally, all those clickbait posts about how AI was secretly 150 Indian men in a trenchcoat were nonsense).
Because the chip companies have been working hard on making big, bulky, powerful chips with massive fans that are up to the task, their stock value was skyrocketing, and because of that, everyone started to use AI as a marketing trend. See, marketing people are not smart, and they don't understand computers. Furthermore, marketing people think you're stupid, and because of their biased frame of reference, they think you're two snores short of brain-dead. The entire point of their existence is to turn tall tales into capital. So they don't know or care about what AI is or what it's useful for. They just saw Number Go Up for the AI companies and decided "AI is a magic cow we can milk forever". Sometimes it's not even AI, they just use old software and rebrand it, much like convection ovens became air fryers.
Well, now we're up to date. So what did DepSeek release that did a 9/11 on NVIDIA stock prices and popped the AI bubble?

Oh, I would not want to be an OpenAI investor right now either. A token is basically one Unicode character (it's more complicated than that but you can google that on your own time). That cost means you could input the entire works of Stephen King for under a dollar. Yes, including electricity costs. DeepSeek has jumped from a Ford T to a Subaru in terms of pollution and water use.
The issue here is not only input cost, though; all that data needs to be available live, in the RAM; this is why you need powerful, expensive chips in order to-

Holy shit.
I'm not going to detail all the numbers but I'm going to focus on the chip required: an RTX 3090. This is a gaming GPU that came out as the top of the line, the stuff South Korean LoL players buy…
Or they did, in September 2020. We're currently two generations ahead, on the RTX 5090.
What this is telling all those people who just sold their high-end gaming rig to be able to afford a machine that can run the latest ChatGPT locally, is that the person who bought it from them can run something basically just as powerful on their old one.
Which means that all those GPUs and NPUs that are being made, and all those deals Microsoft signed to have control of the AI market, have just lost a lot of their pulling power.
Well, I mean, the ChatGPT subscription is 20 bucks a month, surely the Chinese are charging a fortune for-

Oh. So it's free for everyone and you can use it or modify it however you want, no subscription, no unpayable electric bill, no handing Microsoft all of your private data, you can just run it on a relatively inexpensive PC. You could probably even run it on a phone in a couple years.
Oh, if only China had massive phone manufacturers that have a foot in the market everywhere except the US because the president had a tantrum eight years ago.
So… yeah, China just destabilised the global economy with a torrent file.
#valid ai criticism#ai#llms#DeepSeek#ai bubble#ChatGPT#google gemini#claude ai#this is gonna be the dotcom bubble again#hope you don't have stock on anything tech related#computer literacy#tech literacy
433 notes
·
View notes
Text
“Disenshittify or Die”
youtube
I'm coming to BURNING MAN! On TUESDAY (Aug 27) at 1PM, I'm giving a talk called "DISENSHITTIFY OR DIE!" at PALENQUE NORTE (7&E). On WEDNESDAY (Aug 28) at NOON, I'm doing a "Talking Caterpillar" Q&A at LIMINAL LABS (830&C).

Last weekend, I traveled to Las Vegas for Defcon 32, where I had the immense privilege of giving a solo talk on Track 1, entitled "Disenshittify or die! How hackers can seize the means of computation and build a new, good internet that is hardened against our asshole bosses' insatiable horniness for enshittification":
https://info.defcon.org/event/?id=54861
This was a followup to last year's talk, "An Audacious Plan to Halt the Internet's Enshittification," a talk that kicked off a lot of international interest in my analysis of platform decay ("enshittification"):
https://www.youtube.com/watch?v=rimtaSgGz_4
The Defcon organizers have earned a restful week or two, and that means that the video of my talk hasn't yet been posted to Defcon's Youtube channel, so in the meantime, I thought I'd post a lightly edited version of my speech crib. If you're headed to Burning Man, you can hear me reprise this talk at Palenque Norte (7&E); I'm kicking off their lecture series on Tuesday, Aug 27 at 1PM.
==
What the fuck happened to the old, good internet?
I mean, sure, our bosses were a little surveillance-happy, and they were usually up for sharing their data with the NSA, and whenever there was a tossup between user security and growth, it was always YOLO time.
But Google Search used to work. Facebook used to show you posts from people you followed. Uber used to be cheaper than a taxi and pay the driver more than a cabbie made. Amazon used to sell products, not Shein-grade self-destructing dropshipped garbage from all-consonant brands. Apple used to defend your privacy, rather than spying on you with your no-modifications-allowed Iphone.
There was a time when you searching for an album on Spotify would get you that album – not a playlist of insipid AI-generated covers with the same name and art.
Microsoft used to sell you software – sure, it was buggy – but now they just let you access apps in the cloud, so they can watch how you use those apps and strip the features you use the most out of the basic tier and turn them into an upcharge.
What – and I cannot stress this enough – the fuck happened?!
I’m talking about enshittification.
Here’s what enshittification looks like from the outside: First, you see a company that’s being good to its end users. Google puts the best search results at the top; Facebook shows you a feed of posts from people and groups you followl; Uber charges small dollars for a cab; Amazon subsidizes goods and returns and shipping and puts the best match for your product search at the top of the page.
That’s stage one, being good to end users. But there’s another part of this stage, call it stage 1a). That’s figuring out how to lock in those users.
There’s so many ways to lock in users.
If you’re Facebook, the users do it for you. You joined Facebook because there were people there you wanted to hang out with, and other people joined Facebook to hang out with you.
That’s the old “network effects” in action, and with network effects come “the collective action problem." Because you love your friends, but goddamn are they a pain in the ass! You all agree that FB sucks, sure, but can you all agree on when it’s time to leave?
No way.
Can you agree on where to go next?
Hell no.
You’re there because that’s where the support group for your rare disease hangs out, and your bestie is there because that’s where they talk with the people in the country they moved away from, then there’s that friend who coordinates their kid’s little league car pools on FB, and the best dungeon master you know isn’t gonna leave FB because that’s where her customers are.
So you’re stuck, because even though FB use comes at a high cost – your privacy, your dignity and your sanity – that’s still less than the switching cost you’d have to bear if you left: namely, all those friends who have taken you hostage, and whom you are holding hostage
Now, sometimes companies lock you in with money, like Amazon getting you to prepay for a year’s shipping with Prime, or to buy your Audible books on a monthly subscription, which virtually guarantees that every shopping search will start on Amazon, after all, you’ve already paid for it.
Sometimes, they lock you in with DRM, like HP selling you a printer with four ink cartridges filled with fluid that retails for more than $10,000/gallon, and using DRM to stop you from refilling any of those ink carts or using a third-party cartridge. So when one cart runs dry, you have to refill it or throw away your investment in the remaining three cartridges and the printer itself.
Sometimes, it’s a grab bag:
You can’t run your Ios apps without Apple hardware;
you can’t run your Apple music, books and movies on anything except an Ios app;
your iPhone uses parts pairing – DRM handshakes between replacement parts and the main system – so you can’t use third-party parts to fix it; and
every OEM iPhone part has a microscopic Apple logo engraved on it, so Apple can demand that the US Customs and Border Service seize any shipment of refurb Iphone parts as trademark violations.
Think Different, amirite?
Getting you locked in completes phase one of the enshittification cycle and signals the start of phase two: making things worse for you to make things better for business customers.
For example, a platform might poison its search results, like Google selling more and more of its results pages to ads that are identified with lighter and lighter tinier and tinier type.
Or Amazon selling off search results and calling it an “ad” business. They make $38b/year on this scam. The first result for your search is, on average, 29% more expensive than the best match for your search. The first row is 25% more expensive than the best match. On average, the best match for your search is likely to be found seventeen places down on the results page.
Other platforms sell off your feed, like Facebook, which started off showing you the things you asked to see, but now the quantum of content from the people you follow has dwindled to a homeopathic residue, leaving a void that Facebook fills with things that people pay to show you: boosted posts from publishers you haven’t subscribed to, and, of course, ads.
Now at this point you might be thinking ‘sure, if you’re not paying for the product, you’re the product.'
Bullshit!
Bull.
Shit.
The people who buy those Google ads? They pay more every year for worse ad-targeting and more ad-fraud
Those publishers paying to nonconsensually cram their content into your Facebook feed? They have to do that because FB suppresses their ability to reach the people who actually subscribed to them
The Amazon sellers with the best match for your query have to outbid everyone else just to show up on the first page of results. It costs so much to sell on Amazon that between 45-51% of every dollar an independent seller brings in has to be kicked up to Don Bezos and the Amazon crime family. Those sellers don’t have the kind of margins that let them pay 51% They have to raise prices in order to avoid losing money on every sale.
"But wait!" I hear you say!
[Come on, say it!]
"But wait! Things on Amazon aren’t more expensive that things at Target, or Walmart, or at a mom and pop store, or direct from the manufacturer.
"How can sellers be raising prices on Amazon if the price at Amazon is the same as at is everywhere else?"
[Any guesses?!]
That’s right, they charge more everywhere. They have to. Amazon binds its sellers to a policy called “most favored nation status,” which says they can’t charge more on Amazon than they charge elsewhere, including direct from their own factory store.
So every seller that wants to sell on Amazon has to raise their prices everywhere else.
Now, these sellers are Amazon’s best customers. They’re paying for the product, and they’re still getting screwed.
Paying for the product doesn’t fill your vapid boss’s shriveled heart with so much joy that he decides to stop trying to think of ways to fuck you over.
Look at Apple. Remember when Apple offered every Ios user a one-click opt out for app-based surveillance? And 96% of users clicked that box?
(The other four percent were either drunk or Facebook employees or drunk Facebook employees.)
That cost Facebook at least ten billion dollars per year in lost surveillance revenue?
I mean, you love to see it.
But did you know that at the same time Apple started spying on Ios users in the same way that Facebook had been, for surveillance data to use to target users for its competing advertising product?
Your Iphone isn’t an ad-supported gimme. You paid a thousand fucking dollars for that distraction rectangle in your pocket, and you’re still the product. What’s more, Apple has rigged Ios so that you can’t mod the OS to block its spying.
If you’re not not paying for the product, you’re the product, and if you are paying for the product, you’re still the product.
Just ask the farmers who are expected to swap parts into their own busted half-million dollar, mission-critical tractors, but can’t actually use those parts until a technician charges them $200 to drive out to the farm and type a parts pairing unlock code into their console.
John Deere’s not giving away tractors. Give John Deere a half mil for a tractor and you will be the product.
Please, my brothers and sisters in Christ. Please! Stop saying ‘if you’re not paying for the product, you’re the product.’
OK, OK, so that’s phase two of enshittification.
Phase one: be good to users while locking them in.
Phase two: screw the users a little to you can good to business customers while locking them in.
Phase three: screw everybody and take all the value for yourself. Leave behind the absolute bare minimum of utility so that everyone stays locked into your pile of shit.
Enshittification: a tragedy in three acts.
That’s what enshittification looks like from the outside, but what’s going on inside the company? What is the pathological mechanism? What sci-fi entropy ray converts the excellent and useful service into a pile of shit?
That mechanism is called twiddling. Twiddling is when someone alters the back end of a service to change how its business operates, changing prices, costs, search ranking, recommendation criteria and other foundational aspects of the system.
Digital platforms are a twiddler’s utopia. A grocer would need an army of teenagers with pricing guns on rollerblades to reprice everything in the building when someone arrives who’s extra hungry.
Whereas the McDonald’s Investments portfolio company Plexure advertises that it can use surveillance data to predict when an app user has just gotten paid so the seller can tack an extra couple bucks onto the price of their breakfast sandwich.
And of course, as the prophet William Gibson warned us, ‘cyberspace is everting.' With digital shelf tags, grocers can change prices whenever they feel like, like the grocers in Norway, whose e-ink shelf tags change the prices 2,000 times per day.
Every Uber driver is offered a different wage for every job. If a driver has been picky lately, the job pays more. But if the driver has been desperate enough to grab every ride the app offers, the pay goes down, and down, and down.
The law professor Veena Dubal calls this ‘algorithmic wage discrimination.' It’s a prime example of twiddling.
Every youtuber knows what it’s like to be twiddled. You work for weeks or months, spend thousands of dollars to make a video, then the algorithm decides that no one – not your own subscribers, not searchers who type in the exact name of your video – will see it.
Why? Who knows? The algorithm’s rules are not public.
Because content moderation is the last redoubt of security through obscurit: they can’t tell you what the como algorithm is downranking because then you’d cheat.
Youtube is the kind of shitty boss who docks every paycheck for all the rules you’ve broken, but won’t tell you what those rules were, lest you figure out how to break those rules next time without your boss catching you.
Twiddling can also work in some users’ favor, of course. Sometimes platforms twiddle to make things better for end users or business customers.
For example, Emily Baker-White from Forbes revealed the existence of a back-end feature that Tiktok’s management can access they call the “heating tool.”
When a manager applies the heating toll to a performer’s account, that performer’s videos are thrust into the feeds of millions of users, without regard to whether the recommendation algorithm predicts they will enjoy that video.
Why would they do this? Well, here’s an analogy from my boyhood I used to go to this traveling fair that would come to Toronto at the end of every summer, the Canadian National Exhibition. If you’ve been to a fair like the Ex, you know that you can always spot some guy lugging around a comedically huge teddy bear.
Nominally, you win that teddy bear by throwing five balls in a peach-basket, but to a first approximation, no one has ever gotten five balls to stay in that peach-basket.
That guy “won” the teddy bear when a carny on the midway singled him out and said, "fella, I like your face. Tell you what I’m gonna do: You get just one ball in the basket and I’ll give you this keychain, and if you amass two keychains, I’ll let you trade them in for one of these galactic-scale teddy-bears."
That’s how the guy got his teddy bear, which he now has to drag up and down the midway for the rest of the day.
Why the hell did that carny give away the teddy bear? Because it turns the guy into a walking billboard for the midway games. If that dopey-looking Judas Goat can get five balls into a peach basket, then so can you.
Except you can’t.
Tiktok’s heating tool is a way to give away tactical giant teddy bears. When someone in the TikTok brain trust decides they need more sports bros on the platform, they pick one bro out at random and make him king for the day, heating the shit out of his account.
That guy gets a bazillion views and he starts running around on all the sports bro forums trumpeting his success: *I am the Louis Pasteur of sports bro influencers!"
The other sports bros pile in and start retooling to make content that conforms to the idiosyncratic Tiktok format. When they fail to get giant teddy bears of their own, they assume that it’s because they’re doing Tiktok wrong, because they don’t know about the heating tool.
But then comes the day when the TikTok Star Chamber decides they need to lure in more astrologers, so they take the heat off that one lucky sports bro, and start heating up some lucky astrologer.
Giant teddy bears are all over the place: those Uber drivers who were boasting to the NYT ten years ago about earning $50/hour? The Substackers who were rolling in dough? Joe Rogan and his hundred million dollar Spotify payout? Those people are all the proud owners of giant teddy bears, and they’re a steal.
Because every dollar they get from the platform turns into five dollars worth of free labor from suckers who think they just internetting wrong.
Giant teddy bears are just one way of twiddling. Platforms can play games with every part of their business logic, in highly automated ways, that allows them to quickly and efficiently siphon value from end users to business customers and back again, hiding the pea in a shell game conducted at machine speeds, until they’ve got everyone so turned around that they take all the value for themselves.
That’s the how: How the platforms do the trick where they are good to users, then lock users in, then maltreat users to be good to business customers, then lock in those business customers, then take all the value for themselves.
So now we know what is happening, and how it is happening, all that’s left is why it’s happening.
Now, on the one hand, the why is pretty obvious. The less value that end-users and business customers capture, the more value there is left to divide up among the shareholders and the executives.
That’s why, but it doesn’t tell you why now. Companies could have done this shit at any time in the past 20 years, but they didn’t. Or at least, the successful ones didn’t. The ones that turned themselves into piles of shit got treated like piles of shit. We avoided them and they died.
Remember Myspace? Yahoo Search? Livejournal? Sure, they’re still serving some kind of AI slop or programmatic ad junk if you hit those domains, but they’re gone.
And there’s the clue: It used to be that if you enshittified your product, bad things happened to your company. Now, there are no consequences for enshittification, so everyone’s doing it.
Let’s break that down: What stops a company from enshittifying?
There are four forces that discipline tech companies. The first one is, obviously, competition.
If your customers find it easy to leave, then you have to worry about them leaving
Many factors can contribute to how hard or easy it is to depart a platform, like the network effects that Facebook has going for it. But the most important factor is whether there is anywhere to go.
Back in 2012, Facebook bought Insta for a billion dollars. That may seem like chump-change in these days of eleven-digit Big Tech acquisitions, but that was a big sum in those innocent days, and it was an especially big sum to pay for Insta. The company only had 13 employees, and a mere 25 million registered users.
But what mattered to Zuckerberg wasn’t how many users Insta had, it was where those users came from.
[Does anyone know where those Insta users came from?]
That’s right, they left Facebook and joined Insta. They were sick of FB, even though they liked the people there, they hated creepy Zuck, they hated the platform, so they left and they didn’t come back.
So Zuck spent a cool billion to recapture them, A fact he put in writing in a midnight email to CFO David Ebersman, explaining that he was paying over the odds for Insta because his users hated him, and loved Insta. So even if they quit Facebook (the platform), they would still be captured Facebook (the company).
Now, on paper, Zuck’s Instagram acquisition is illegal, but normally, that would be hard to stop, because you’d have to prove that he bought Insta with the intention of curtailing competition.
But in this case, Zuck tripped over his own dick: he put it in writing.
But Obama’s DoJ and FTC just let that one slide, following the pro-monopoly policies of Reagan, Bush I, Clinton and Bush II, and setting an example that Trump would follow, greenlighting gigamergers like the catastrophic, incestuous Warner-Discovery marriage.
Indeed, for 40 years, starting with Carter, and accelerating through Reagan, the US has encouraged monopoly formation, as an official policy, on the grounds that monopolies are “efficient.”
If everyone is using Google Search, that’s something we should celebrate. It means they’ve got the very best search and wouldn’t it be perverse to spend public funds to punish them for making the best product?
But as we all know, Google didn’t maintain search dominance by being best. They did it by paying bribes. More than 20 billion per year to Apple alone to be the default Ios search, plus billions more to Samsung, Mozilla, and anyone else making a product or service with a search-box on it, ensuring that you never stumble on a search engine that’s better than theirs.
Which, in turn, ensured that no one smart invested big in rival search engines, even if they were visibly, obviously superior. Why bother making something better if Google’s buying up all the market oxygen before it can kindle your product to life?
Facebook, Google, Microsoft, Amazon – they’re not “making things” companies, they’re “buying things” companies, taking advantage of official tolerance for anticompetitive acquisitions, predatory pricing, market distorting exclusivity deals and other acts specifically prohibited by existing antitrust law.
Their goal is to become too big to fail, because that makes them too big to jail, and that means they can be too big to care.
Which is why Google Search is a pile of shit and everything on Amazon is dropshipped garbage that instantly disintegrates in a cloud of offgassed volatile organic compounds when you open the box.
Once companies no longer fear losing your business to a competitor, it’s much easier for them to treat you badly, because what’re you gonna do?
Remember Lily Tomlin as Ernestine the AT&T operator in those old SNL sketches? “We don’t care. We don’t have to. We’re the phone company.”
Competition is the first force that serves to discipline companies and the enshittificatory impulses of their leadership, and we just stopped enforcing competition law.
It takes a special kind of smooth-brained asshole – that is, an establishment economist – to insist that the collapse of every industry from eyeglasses to vitamin C into a cartel of five or fewer companies has nothing to do with policies that officially encouraged monopolization.
It’s like we used to put down rat poison and we didn’t have a rat problem. Then these dickheads convinced us that rats were good for us and we stopped putting down rat poison, and now rats are gnawing our faces off and they’re all running around saying, "Who’s to say where all these rats came from? Maybe it was that we stopped putting down poison, but maybe it’s just the Time of the Rats. The Great Forces of History bearing down on this moment to multiply rats beyond all measure!"
Antitrust didn’t slip down that staircase and fall spine-first on that stiletto: they stabbed it in the back and then they pushed it.
And when they killed antitrust, they also killed regulation, the second force that disciplines companies. Regulation is possible, but only when the regulator is more powerful than the regulated entities. When a company is bigger than the government, it gets damned hard to credibly threaten to punish that company, no matter what its sins.
That’s what protected IBM for all those years when it had its boot on the throat of the American tech sector. Do you know, the DOJ fought to break up IBM in the courts from 1970-1982, and that every year, for 12 consecutive years, IBM spent more on lawyers to fight the USG than the DOJ Antitrust Division spent on all the lawyers fighting every antitrust case in the entire USA?
IBM outspent Uncle Sam for 12 years. People called it “Antitrust’s Vietnam.” All that money paid off, because by 1982, the president was Ronald Reagan, a man whose official policy was that monopolies were “efficient." So he dropped the case, and Big Blue wriggled off the hook.
It’s hard to regulate a monopolist, and it’s hard to regulate a cartel. When a sector is composed of hundreds of competing companies, they compete. They genuinely fight with one another, trying to poach each others’ customers and workers. They are at each others’ throats.
It’s hard enough for a couple hundred executives to agree on anything. But when they’re legitimately competing with one another, really obsessing about how to eat each others’ lunches, they can’t agree on anything.
The instant one of them goes to their regulator with some bullshit story, about how it’s impossible to have a decent search engine without fine-grained commercial surveillance; or how it’s impossible to have a secure and easy to use mobile device without a total veto over which software can run on it; or how it’s impossible to administer an ISP’s network unless you can slow down connections to servers whose owners aren’t paying bribes for “premium carriage"; there’s some *other company saying, “That’s bullshit”
“We’ve managed it! Here’s our server logs, our quarterly financials and our customer testimonials to prove it.”
100 companies are a rabble, they're a mob. They can’t agree on a lobbying position. They’re too busy eating each others’ lunch to agree on how to cater a meeting to discuss it.
But let those hundred companies merge to monopoly, absorb one another in an incestuous orgy, turn into five giant companies, so inbred they’ve got a corporate Habsburg jaw, and they become a cartel.
It’s easy for a cartel to agree on what bullshit they’re all going to feed their regulator, and to mobilize some of the excess billions they’ve reaped through consolidation, which freed them from “wasteful competition," sp they can capture their regulators completely.
You know, Congress used to pass federal consumer privacy laws? Not anymore.
The last time Congress managed to pass a federal consumer privacy law was in 1988: The Video Privacy Protection Act. That’s a law that bans video-store clerks from telling newspapers what VHS cassettes you take home. In other words, it regulates three things that have effectively ceased to exist.
The threat of having your video rental history out there in the public eye was not the last or most urgent threat the American public faced, and yet, Congress is deadlocked on passing a privacy law.
Tech companies’ regulatory capture involves a risible and transparent gambit, that is so stupid, it’s an insult to all the good hardworking risible transparent ruses out there.
Namely, they claim that when they violate your consumer, privacy or labor rights, It’s not a crime, because they do it with an app.
Algorithmic wage discrimination isn’t illegal wage theft: we do it with an app.
Spying on you from asshole to appetite isn’t a privacy violation: we do it with an app.
And Amazon’s scam search tool that tricks you into paying 29% more than the best match for your query? Not a ripoff. We do it with an app.
Once we killed competition – stopped putting down rat poison – we got cartels – the rats ate our faces. And the cartels captured their regulators – the rats bought out the poison factory and shut it down.
So companies aren’t constrained by competition or regulation.
But you know what? This is tech, and tech is different.IIt’s different because it’s flexible. Because our computers are Turing-complete universal von Neumann machines. That means that any enshittificatory alteration to a program can be disenshittified with another program.
Every time HP jacks up the price of ink , they invite a competitor to market a refill kit or a compatible cartridge.
When Tesla installs code that says you have to pay an extra monthly fee to use your whole battery, they invite a modder to start selling a kit to jailbreak that battery and charge it all the way up.
Lemme take you through a little example of how that works: Imagine this is a product design meeting for our company’s website, and the guy leading the meeting says “Dudes, you know how our KPI is topline ad-revenue? Well, I’ve calculated that if we make the ads just 20% more invasive and obnoxious, we’ll boost ad rev by 2%”
This is a good pitch. Hit that KPI and everyone gets a fat bonus. We can all take our families on a luxury ski vacation in Switzerland.
But here’s the thing: someone’s gonna stick their arm up – someone who doesn’t give a shit about user well-being, and that person is gonna say, “I love how you think, Elon. But has it occurred to you that if we make the ads 20% more obnoxious, then 40% of our users will go to a search engine and type 'How do I block ads?'"
I mean, what a nightmare! Because once a user does that, the revenue from that user doesn’t rise to 102%. It doesn’t stay at 100% It falls to zero, forever.
[Any guesses why?]
Because no user ever went back to the search engine and typed, 'How do I start seeing ads again?'
Once the user jailbreaks their phone or discovers third party ink, or develops a relationship with an independent Tesla mechanic who’ll unlock all the DLC in their car, that user is gone, forever.
Interoperability – that latent property bequeathed to us courtesy of Herrs Turing and Von Neumann and their infinitely flexible, universal machines – that is a serious check on enshittification.
The fact that Congress hasn’t passed a privacy law since 1988 Is countered, at least in part, by the fact that the majority of web users are now running ad-blockers, which are also tracker-blockers.
But no one’s ever installed a tracker-blocker for an app. Because reverse engineering an app puts in you jeopardy of criminal and civil prosecution under Section 1201 of the Digital Millennium Copyright Act, with penalties of a 5-year prison sentence and a $500k fine for a first offense.
And violating its terms of service puts you in jeopardy under the Computer Fraud and Abuse Act of 1986, which is the law that Ronald Reagan signed in a panic after watching Wargames (seriously!).
Helping other users violate the terms of service can get you hit with a lawsuit for tortious interference with contract. And then there’s trademark, copyright and patent.
All that nonsense we call “IP,” but which Jay Freeman of Cydia calls “Felony Contempt of Business Model."
So if we’re still at that product planning meeting and now it’s time to talk about our app, the guy leading the meeting says, “OK, so we’ll make the ads in the app 20% more obnoxious to pull a 2% increase in topline ad rev?”
And that person who objected to making the website 20% worse? Their hand goes back up. Only this time they say “Why don’t we make the ads 100% more invasive and get a 10% increase in ad rev?"
Because it doesn't matter if a user goes to a search engine and types, “How do I block ads in an app." The answer is: you can't. So YOLO, enshittify away.
“IP” is just a euphemism for “any law that lets me reach outside my company’s walls to exert coercive control over my critics, competitors and customers,” and “app” is just a euphemism for “A web page skinned with the right IP so that protecting your privacy while you use it is a felony.”
Interop used to keep companies from enshittifying. If a company made its client suck, someone would roll out an alternative client, if they ripped a feature out and wanted to sell it back to you as a monthly subscription, someone would make a compatible plugin that restored it for a one-time fee, or for free.
To help people flee Myspace, FB gave them bots that you’d load with your login credentials. It would scrape your waiting Myspace messages and put ‘em in your FB inbox, and login to Myspace and paste your replies into your Myspace outbox. So you didn’t have to choose between the people you loved on Myspace, and Facebook, which launched with a promise never to spy on you. Remember that?!
Thanks to the metastasis of IP, all that is off the table today. Apple owes its very existence to iWork Suite, whose Pages, Numbers and Keynote are file-compatible with Microsoft’s Word, Excel and Powerpoint. But make an IOS runtime that’ll play back the files you bought from Apple’s stores on other platforms, and they’ll nuke you til you glow.
FB wouldn’t have had a hope of breaking Myspace’s grip on social media without that scrape, but scrape FB today in support of an alternative client and their lawyers will bomb you til the rubble bounces.
Google scraped every website in the world to create its search index. Try and scrape Google and they’ll have your head on a pike.
When they did it, it was progress. When you do it to them, that’s piracy. Every pirate wants to be an admiral.
Because this handful of companies has so thoroughly captured their regulators, they can wield the power of the state against you when you try to break their grip on power, even as their own flagrant violations of our rights go unpunished. Because they do them with an app.
Tech lost its fear of competitin it neutralized the threat from regulators, and then put them in harness to attack new startups that might do unto them as they did unto the companies that came before them.
But even so, there was a force that kept our bosses in check That force was us. Tech workers.
Tech workers have historically been in short supply, which gave us power, and our bosses knew it.
To get us to work crazy hours, they came up with a trick. They appealed to our love of technology, and told us that we were heroes of a digital revolution, who would “organize the world’s information and make it useful,” who would “bring the world closer together.”
They brought in expert set-dressers to turn our workplaces into whimsical campuses with free laundry, gourmet cafeterias, massages, and kombucha, and a surgeon on hand to freeze our eggs so that we could work through our fertile years.
They convinced us that we were being pampered, rather than being worked like government mules.
This trick has a name. Fobazi Ettarh, the librarian-theorist, calls it “vocational awe, and Elon Musk calls it being “extremely hardcore.”
This worked very well. Boy did we put in some long-ass hours!
But for our bosses, this trick failed badly. Because if you miss your mother’s funeral and to hit a deadline, and then your boss orders you to enshittify that product, you are gonna experience a profound moral injury, which you are absolutely gonna make your boss share.
Because what are they gonna do? Fire you? They can’t hire someone else to do your job, and you can get a job that’s even better at the shop across the street.
So workers held the line when competition, regulation and interop failed.
But eventually, supply caught up with demand. Tech laid off 260,000 of us last year, and another 100,000 in the first half of this year.
You can’t tell your bosses to go fuck themselves, because they’ll fire your ass and give your job to someone who’ll be only too happy to enshittify that product you built.
That’s why this is all happening right now. Our bosses aren’t different. They didn’t catch a mind-virus that turned them into greedy assholes who don’t care about our users’ wellbeing or the quality of our products.
As far as our bosses have always been concerned, the point of the business was to charge the most, and deliver the least, while sharing as little as possible with suppliers, workers, users and customers. They’re not running charities.
Since day one, our bosses have shown up for work and yanked as hard as they can on the big ENSHITTIFICATION lever behind their desks, only that lever didn’t move much. It was all gummed up by competition, regulation, interop and workers.
As those sources of friction melted away, the enshittification lever started moving very freely.
Which sucks, I know. But think about this for a sec: our bosses, despite being wildly imperfect vessels capable of rationalizing endless greed and cheating, nevertheless oversaw a series of actually great products and services.
Not because they used to be better people, but because they used to be subjected to discipline.
So it follows that if we want to end the enshittocene, dismantle the enshitternet, and build a new, good internet that our bosses can’t wreck, we need to make sure that these constraints are durably installed on that internet, wound around its very roots and nerves. And we have to stand guard over it so that it can’t be dismantled again.
A new, good internet is one that has the positive aspects of the old, good internet: an ethic of technological self-determination, where users of technology (and hackers, tinkerers, startups and others serving as their proxies) can reconfigure and mod the technology they use, so that it does what they need it to do, and so that it can’t be used against them.
But the new, good internet will fix the defects of the old, good internet, the part that made it hard to use for anyone who wasn’t us. And hell yeah we can do that. Tech bosses swear that it’s impossible, that you can’t have a conversation friend without sharing it with Zuck; or search the web without letting Google scrape you down to the viscera; or have a phone that works reliably without giving Apple a veto over the software you install.
They claim that it’s a nonsense to even ponder this kind of thing. It’s like making water that’s not wet. But that’s bullshit. We can have nice things. We can build for the people we love, and give them a place that’s worth of their time and attention.
To do that, we have to install constraints.
The first constraint, remember, is competition. We’re living through a epochal shift in competition policy. After 40 years with antitrust enforcement in an induced coma, a wave of antitrust vigor has swept through governments all over the world. Regulators are stepping in to ban monopolistic practices, open up walled gardens, block anticompetitive mergers, and even unwind corrupt mergers that were undertaken on false pretenses.
Normally this is the place in the speech where I’d list out all the amazing things that have happened over the past four years. The enforcement actions that blocked companies from becoming too big to care, and that scared companies away from even trying.
Like Wiz, which just noped out of the largest acquisition offer in history, turning down Google’s $23b cashout, and deciding to, you know, just be a fucking business that makes money by producing a product that people want and selling it at a competitive price.
Normally, I’d be listing out FTC rulemakings that banned noncompetes nationwid. Or the new merger guidelines the FTC and DOJ cooked up, which – among other things – establish that the agencies should be considering whether a merger will negatively impact privacy.
I had a whole section of this stuff in my notes, a real victory lap, but I deleted it all this week.
[Can anyone guess why?]
That’s right! This week, Judge Amit Mehta, ruling for the DC Circuit of these United States of America, In the docket 20-3010 a case known as United States v. Google LLC, found that “Google is a monopolist, and it has acted as one to maintain its monopoly," and ordered Google and the DOJ to propose a schedule for a remedy, like breaking the company up.
So yeah, that was pretty fucking epic.
Now, this antitrust stuff is pretty esoteric, and I won’t gatekeep you or shame you if you wanna keep a little distance on this subject. Nearly everyone is an antitrust normie, and that's OK. But if you’re a normie, you’re probably only catching little bits and pieces of the narrative, and let me tell you, the monopolists know it and they are flooding the zone.
The Wall Street Journal has published over 100 editorials condemning FTC Chair Lina Khan, saying she’s an ineffectual do-nothing, wasting public funds chasing doomed, quixotic adventures against poor, innocent businesses accomplishing nothing
[Does anyone out there know who owns the Wall Street Journal?]
That’s right, it’s Rupert Murdoch. Do you really think Rupert Murdoch pays his editorial board to write one hundred editorials about someone who’s not getting anything done?
The reality is that in the USA, in the UK, in the EU, in Australia, in Canada, in Japan, in South Korea, even in China, we are seeing more antitrust action over the past four years than over the preceding forty years.
Remember, competition law is actually pretty robust. The problem isn’t the law, It’s the enforcement priorities. Reagan put antitrust in mothballs 40 years ago, but that elegant weapon from a more civilized age is now back in the hands of people who know how to use it, and they’re swinging for the fences.
Next up: regulation.
As the seemingly inescapable power of the tech giants is revealed for the sham it always was, governments and regulators are finally gonna kill the “one weird trick” of violating the law, and saying “It doesn’t count, we did it with an app.”
Like in the EU, they’re rolling out the Digital Markets Act this year. That’s a law requiring dominant platforms to stand up APIs so that third parties can offer interoperable services.
So a co-op, a nonprofit, a hobbyist, a startup, or a local government agency wil eventuallyl be able to offer, say, a social media server that can interconnect with one of the dominant social media silos, and users who switch to that new platform will be able to continue to exchange messages with the users they follow and groups they belong to, so the switching costs will fall to damned near zero.
That’s a very cool rule, but what’s even cooler is how it’s gonna be enforced. Previous EU tech rules were “regulations” as in the GDPR – the General Data Privacy Regulation. EU regs need to be “transposed” into laws in each of the 27 EU member states, so they become national laws that get enforced by national courts.
For Big Tech, that means all previous tech regulations are enforced in Ireland, because Ireland is a tax haven, and all the tech companies fly Irish flags of convenience.
Here’s the thing: every tax haven is also a crime haven. After all, if Google can pretend it’s Irish this week, it can pretend to be Cypriot, or Maltese, or Luxembougeious next week. So Ireland has to keep these footloose criminal enterprises happy, or they’ll up sticks and go somewhere else.
This is why the GDPR is such a goddamned joke in practice. Big tech wipes its ass with the GDPR, and the only way to punish them starts with Ireland’s privacy commissioner, who barely bothers to get out of bed. This is an agency that spends most of its time watching cartoons on TV in its pajamas and eating breakfast cereal. So all of the big GDPR cases go to Ireland and they die there.
This is hardly a secret. The European Commission knows it’s going on. So with the DMA, the Commission has changed things up: The DMA is an “Act,” not a “Regulation.” Meaning it gets enforced in the EU’s federal courts, bypassing the national courts in crime-havens like Ireland.
In other words, the “we violate privacy law, but we do it with an app” gambit that worked on Ireland’s toothless privacy watchdog is now a dead letter, because EU federal judges have no reason to swallow that obvious bullshit.
Here in the US, the dam is breaking on federal consumer privacy law – at last!
Remember, our last privacy law was passed in 1988 to protect the sanctity of VHS rental history. It's been a minute.
And the thing is, there's a lot of people who are angry about stuff that has some nexus with America's piss-poor privacy landscape. Worried that Facebook turned grampy into a Qanon? That Insta made your teen anorexic? That TikTok is brainwashing millennials into quoting Osama Bin Laden? Or that cops are rolling up the identities of everyone at a Black Lives Matter protest or the Jan 6 riots by getting location data from Google? Or that Red State Attorneys General are tracking teen girls to out-of-state abortion clinics? Or that Black people are being discriminated against by online lending or hiring platforms? Or that someone is making AI deepfake porn of you?
A federal privacy law with a private right of action – which means that individuals can sue companies that violate their privacy – would go a long way to rectifying all of these problems
There's a pretty big coalition for that kind of privacy law! Which is why we have seen a procession of imperfect (but steadily improving) privacy laws working their way through Congress.
If you sign up for EFF’s mailing list at eff.org we’ll send you an email when these come up, so you can call your Congressjerk or Senator and talk to them about it. Or better yet, make an appointment to drop by their offices when they’re in their districts, and explain to them that you’re not just a registered voter from their district, you’re the kind of elite tech person who goes to Defcon, and then explain the bill to them. That stuff makes a difference.
What about self-help? How are we doing on making interoperability legal again, so hackers can just fix shit without waiting for Congress or a federal agency to act?
All the action here these day is in the state Right to Repair fight. We’re getting state R2R bills, like the one that passed this year in Oregon that bans parts pairing, where DRM is used to keep a device from using a new part until it gets an authorized technician’s unlock code.
These bills are pushed by a fantastic group of organizations called the Repair Coalition, at Repair.org, and they’ll email you when one of these laws is going through your statehouse, so you can meet with your state reps and explain to the JV squad the same thing you told your federal reps.
Repair.org’s prime mover is Ifixit, who are genuine heroes of the repair revolution, and Ifixit’s founder, Kyle Wiens, is here at the con. When you see him, you can shake his hand and tell him thanks, and that’ll be even better if you tell him that you’ve signed up to get alerts at repair.org!
Now, on to the final way that we reverse enhittification and build that new, good internet: you, the tech labor force.
For years, your bosses tricked you into thinking you were founders in waiting, temporarily embarrassed entrepreneurs who were only momentarily drawing a salary.
You certainly weren’t workers. Your power came from your intrinsic virtue, not like those lazy slobs in unions who have to get their power through that kumbaya solidarity nonsense.
It was a trick. You were scammed. The power you had came from scarcity, and so when the scarcity ended, when the industry started ringing up six-figure annual layoffs, your power went away with it.
The only durable source of power for tech workers is as workers, in a union.
Think about Amazon. Warehouse workers have to piss in bottles and have the highest rate of on-the-job maimings of any competing business. Whereas Amazon coders get to show up for work with facial piercings, green mohawks, and black t-shirts that say things their bosses don’t understand. They can piss whenever they want!
That’s not because Jeff Bezos or Andy Jassy loves you guys. It’s because they’re scared you’ll quit and they don’t know how to replace you.
Time for the second obligatory William Gibson quote: “The future is here, it’s just not evenly distributed.” You know who’s living in the future?. Those Amazon blue-collar workers. They are the bleeding edge.
Drivers whose eyeballs are monitored by AI cameras that do digital phrenology on their faces to figure out whether to dock their pay, warehouse workers whose bodies are ruined in just months.
As tech bosses beef up that reserve army of unemployed, skilled tech workers, then those tech workers – you all – will arrive at the same future as them.
Look, I know that you’ve spent your careers explaining in words so small your boss could understand them that you refuse to enshittify the company’s products, and I thank you for your service.
But if you want to go on fighting for the user, you need power that’s more durable than scarcity. You need a union. Wanna learn how? Check out the Tech Workers Coalition and Tech Solidarity, and get organized.
Enshittification didn’t arise because our bosses changed. They were always that guy.
They were always yankin’ on that enshittification lever in the C-suite.
What changed was the environment, everything that kept that switch from moving.
And that’s good news, in a bankshot way, because it means we can make good services out of imperfect people. As a wildly imperfect person myself, I find this heartening.
The new good internet is in our grasp: an internet that has the technological self-determination of the old, good internet, and the greased-skids simplicity of Web 2.0 that let all our normie friends get in on the fun.
Tech bosses want you to think that good UX and enshittification can’t ever be separated. That’s such a self-serving proposition you can spot it from orbit. We know it, 'cause we built the old good internet, and we’ve been fighting a rear-guard action to preserve it for the past two decades.
It’s time to stop playing defense. It's time to go on the offensive. To restore competition, regulation, interop and tech worker power so that we can create the new, good internet we’ll need to fight fascism, the climate emergency, and genocide.
To build a digital nervous system for a 21st century in which our children can thrive and prosper.

Community voting for SXSW is live! If you wanna hear RIDA QADRI and me talk about how GIG WORKERS can DISENSHITTIFY their jobs with INTEROPERABILITY, VOTE FOR THIS ONE!
If you'd like an essay-formatted version of this post to read or share, here's a link to it on pluralistic.net, my surveillance-free, ad-free, tracker-free blog:
https://pluralistic.net/2024/08/17/hack-the-planet/#how-about-a-nice-game-of-chess
Image: https://twitter.com/igama/status/1822347578094043435/ (cropped)
@[email protected] (cropped)
https://mamot.fr/@[email protected]/112963252835869648
CC BY 4.0 https://creativecommons.org/licenses/by/4.0/deed.pt
#pluralistic#defcon#defcon 32#hackers#enshittification#speeches#transcripts#disenshittify or die#Youtube
926 notes
·
View notes
Text
OK since I haven't seen too many people talk about this since twitter news usually strikes pretty fast over here whenever e'usk does anything ever, let me give ya'll the run down on two things that will go live on NOVEMBER 15TH and why people are mass migrating to Blue Sky once more; and provide resources to help protect your art and make the transition to Blue Sky easier if you so choose:
The Block function no longer blocks people as intended. It now basically acts as a glorified Mute button. Even when you block someone, they can still see your posts, but they can't engage in them. If your account is a Public one and not a Private one, people you blocked will see your posts.

They say because people can easily "share and hide harmful or private information about those they've blocked," they changed it this way for "greater transparency." When in reality, this is an extremely dangerous change, as the whole point of blocking is to cease interaction with people entirely for a plethora of reasons, i.e. stalking, harassment, spam, endangerment, or just plainly annoying and not wanting to see said tweets/accounts. or you know, for 18+ accounts who do not want minors interacting with them or their material at all (There is speculation saying these changes are specifically for Elon himself so he can do his own kind of stalking, and honestly, with the private likes change, it lowkey checks out in my opinion)
Also, this straight up goes against and may violate Apple and Google's app store policies and also is straight up illegal in Canada and probably other countries as well.

If this ACTUALLY goes through, twitter will only be available in select countries, probably exclusively in the US, which would collapse the site with the lost of users and stock, and probably be the last push it needs to kill the site. And if not, will be a very sad and exclusive platform made for specific kinds of people who line up with musk's line of thinking.
2. New policies regarding Grok AI and basically removing the option to opt out of Grok's information gathering to improve their software.

And anything you upload/post on the site is considered "fair game" with "royalty-free licenses" and they can do whatever they please with it. Primarily using any and all posts on twitter to train their Grok AI. A few months ago, there was a setting you can opt out of so they couldn't take anything you post to "improve" Grok, but I guess because so many people were opting out, they decided to make it mandatory as part of the policy change (This is mainly speculation from what I hear).
So this is considered the final straw for a LOT of people, especially artists who have been gripping on to twitter for as long as they can, but the AI nonsense is too much for people now, including myself. Lot's of people are moving to Blue Sky for good reason, and from personal experience, it is literally 10x better than twitter ever was, even before elon took over. There is no algorithm on there, and you can save "feeds" to your timeline to have a catered timelines to hop between if your looking for something specific like furry art or game dev stuff. It's taken them a bit to get off the ground and add much needed features, but it's genuinely so much better now
RESOURCES
Project Glaze & Cara
If you're an artist who's still on twitter or trying to ride it out for as long as you can for whatever reason you have, do yourself a favor and Glaze and/or Nightshade your work. Project Glaze is a free program designed to protect your art work from getting scrapped by AI machines. Glazing basically makes it harder to adapt and copy artwork that AI programs try to scan, while Nightshade basically "poisons" works to make AI libraries much more unstable and generate images completely off the mark. (These are layman's terms I'm using here, but follow the link to get more information)
The only problem with these programs is that they can be resource intensive for computers, and not every pc can run glaze. It's basically like rendering a frame/animation, you gotta let your pc sit there to get it glazed/nightshade, and depending on the intensity and power of your pc, this may take minutes to hours depending on how much you wanna protect your work.
HOWEVER, there are two alternatives, WebGlaze and Cara
WebGlaze is an in browser version of the program, so your pc doesn't have to do the heavy lifting. You do need to have an account with Glaze and be invited to use the program (I have not done so personally so I don't know much about the process.)
Cara is an artist focused site that doubles as both a portfolio site and a general social media platform. They've partnered with Glaze and have their own browser glazing called "Cara Glaze," and highly encourage users to post their work Glazed and are extremely anti-ai. You do get limited uses per day to glaze your work, so if you plan on doing a huge backlog uploading of your art, it may take awhile if your using just Cara Glaze.
Some twitter users have suggested glazing your art, cropping it, and overlaying it with a frame telling people to follow them elsewhere like on Bluesky. Here's a template someone provided if you wanna use this one or make your own.

Blue Sky Resources and Tips
So if your a twitter user and your about to realize the hellish task of refollowing a massive chunk of people you follow, have no fear, there's an extension called Sky Follower Bridge (Firefox & Chrome links). This is a very basic extension that makes it really easy to find people on Bluesky

It sorts them out by trying to find matching usernames, usernames in descriptions, or by screen name. It's not 100% perfect, there's a couple people I already follow on Blue Sky but the extension could not find them on twitter correctly, but I still found a huge chunk of people. Also if your worried that this extension is "iffy," they do have a github open with the source publicly available and the Blue Sky Team themselves have promoted the extension in their recent posts while welcoming new users to the platform.
FEEDS and LABELS
OK SO THE COOLEST PART ABOUT BLUESKY IS THE FEEDS SYSTEM. Basically if you've made a twitter list before, it's like that, but way more customizable and caters to specific types of posts/topics. Consolidating them into a timeline/feed that exclusively filled about those particular topics, or just people in general. There's thousands to pick and choose from!


Here's a couple of mine that I have saved and ready (down below). Some feeds I have saved so I can jump to seeing what my friends and mutuals are up to, and see their posts specifically so it doesn't get lost in reposts or other accounts, and also specialized feeds for browsing artists within the furry community.


The Furry Community feeds I have here were created by people who've built an algorithm to place any #furry or #furryart or other special tags like #Furrystreamer or #furrydev. They even have one for commissions, and yes you can say commissions on a post and not have it destroyed or shadow banned. You are safe.
If you want, and I highly recommend it to get visibility and check out a neat community, follow furryli.st to get added to their list and feeds. Once your on the list, even without a hashtag, you'll still pop up in their specialized feeds as just a member of the community there. There are plenty of other feeds out there besides this one, but I feel like a lot of people could use one like this. They even got ones for OC specific too I remember seeing somewhere.

And in terms of labels, they can be either ways to help label yourself with specific things or have user created accessibility settings to help better control your experience on Blue Sky.



And my personal favorite: Ai Imagery Labeler. Removes any AI stuff or hides it to the best of it's abilities, and it does a pretty good job, I have not seen anything AI related since subscribing to it.
Finally, HASHTAGS WORK & No need to censor yourself!
This is NOT like twitter or any other big named social media site AT ALL, so you don't have to work around words to get your stuff out there and be seen. There are literally feeds built around having commissions getting and art seen! Some people worry about bots and that has been a recent issue since a lot of people are migrating to Blue Sky, but it comes with any social media territory.
ALSO COOL PART,
you can search a hashtag on someone's profile and search exclusively on that profile as well! You can even put the hashtag in bio for easy access if you have a specialize tag like here on tumblr. OR EVEN BUILD YOUR OWN ART FEED FOR YOUR STUFF SPECIFICALLY!

So yeah, there's your quick run down about twitter's current burning building, how to protect your art, and what to do when you move to Blue Sky! Have fun!
#Twitter#Blue Sky#BlueSky#Cara#Project Glaze#Glazed Art#NightShade#Twitter Update#cara artists#art resource#resource#Online resource
717 notes
·
View notes
Note
On that recent Disney Vs Midjourney court thing wrt AI, how strong do you think their case is in a purely legal sense, what do you think MJ's best defenses are, how likely is Disney to win, and how bad would the outcome be if they do win?
Oh sure, ask an easy one.
In a purely legal sense, this case is very questionable.
Scraping as fair use has already been established when it comes to text in legal cases, and infringement is based on publication, not inspiration. There's also the question of if Midjourney would be responsible for their users' creations under safe harbor provisions, or even basic understanding of what an art tool is. Adobe isn't responsible for the many, many illegal images its software is used to make, after all.
The best defense, I would say, is the fair use nature of dataset training and the very nature of transformative work, which is protected, requires the work-to-be-transformed is involved. Disney's basic approach of 'your AI knows who our characters are, so that proves you stole from us' would render fair use impossible.
I don't think its likely for Disney to win, but the problem with civil action is proof isn't needed, just convincing. Bad civil cases happen all the time, and produce case law. Which is what Disney is trying to do here.
If Disney wins, they'll have pulled off a coup of regulatory capture, basically ensuring that large media corporations can replace their staff with robots but that small creators will be limited to underpowered models to compete with them.
Worse, everything that is a 'smoking gun' when it comes to copyright infringement on Midjourney? That's fan art. All that "look how many copyrighted characters they're using-" applies to the frontpage of Deviantart or any given person's Tumblr feed more than to the featured page of Midjourney.
Every single website with user-generated content it chock full of copyright infringement because of fan art and fanfic, and fair use arguments are far harder to pull out for fan-works. The law won't distinguish between a human with a digital art package and a human with an AI art package, and any win Disney makes against MJ is a win against Artstation, Deviantart, Rule34.xxx, AO3, and basically everyone else.
"We get a slice of your cheese if enough of your users post our mouse" is not a rule you want in law.
And the rules won't be enforced by a court 9/10 times. Even if your individual work is plainly fair use, it's not going to matter to whatever image-based version of youtube's copyreich bots gets applied to Artstation and RedBubble to keep the site owners safe.
Even if you're right, you won't have the money to fight.
Heck, Adobe already spies on what you make to report you to the feds if you're doing a naughty, imagine it's internal watchdogs throwing up warnings when it detects you drawing Princess Jasmine and Ariel making out. That may sound nuts, but it's entirely viable.
And that's just one level of possible nightmare. If the judgement is broad enough, it could provide a legal pretext for pursuing copyright lawsuits over style and inspiration. Given how consolidated IP is, this means you're going to have several large cabals that can crush any new work that seems threatening, as there's bound to be something they can draw a connection to.
If you want to see how utterly stupid inspiration=theft is, check out when Harlan Ellison sued James Cameron over Terminator because Cameron was dumb enough to say he was inspired by Demon with a Glass Hand and Soldier from the Outer Limits.
Harlan was wrong on the merits, wrong ethically, and the case shouldn't have been entertained in the first place, but like I said, civil law isn't about facts. Cameron was honest about how two episodes of a show he saw as a kid gave him this completely different idea (the similarities are 'robot that looks like a guy with hand reveal' and 'time traveling soldier goes into a gun store and tries to buy future guns'), and he got unjustly sued for it.
If you ever wonder why writers only talk about their inspirations that are dead, that's why. Anything that strengthens the "what goes in" rather than the "what goes out" approach to IP is good for corps, bad for culture.
146 notes
·
View notes
Text
How I ditched streaming services and learned to love Linux: A step-by-step guide to building your very own personal media streaming server (V2.0: REVISED AND EXPANDED EDITION)
This is a revised, corrected and expanded version of my tutorial on setting up a personal media server that previously appeared on my old blog (donjuan-auxenfers). I expect that that post is still making the rounds (hopefully with my addendum on modifying group share permissions in Ubuntu to circumvent 0x8007003B "Unexpected Network Error" messages in Windows 10/11 when transferring files) but I have no way of checking. Anyway this new revised version of the tutorial corrects one or two small errors I discovered when rereading what I wrote, adds links to all products mentioned and is just more polished generally. I also expanded it a bit, pointing more adventurous users toward programs such as Sonarr/Radarr/Lidarr and Overseerr which can be used for automating user requests and media collection.
So then, what is this tutorial? This is a tutorial on how to build and set up your own personal media server using Ubuntu as an operating system and Plex (or Jellyfin) to not only manage your media, but to also stream that media to your devices both at home and abroad anywhere in the world where you have an internet connection. Its intent is to show you how building a personal media server and stuffing it full of films, TV, and music that you acquired through indiscriminate and voracious media piracy various legal methods will free you to completely ditch paid streaming services. No more will you have to pay for Disney+, Netflix, HBOMAX, Hulu, Amazon Prime, Peacock, CBS All Access, Paramount+, Crave or any other streaming service that is not named Criterion Channel. Instead whenever you want to watch your favourite films and television shows, you’ll have your own personal service that only features things that you want to see, with files that you have control over. And for music fans out there, both Jellyfin and Plex support music streaming, meaning you can even ditch music streaming services. Goodbye Spotify, Youtube Music, Tidal and Apple Music, welcome back unreasonably large MP3 (or FLAC) collections.
On the hardware front, I’m going to offer a few options catered towards different budgets and media library sizes. The cost of getting a media server up and running using this guide will cost you anywhere from $450 CAD/$325 USD at the low end to $1500 CAD/$1100 USD at the high end (it could go higher). My server was priced closer to the higher figure, but I went and got a lot more storage than most people need. If that seems like a little much, consider for a moment, do you have a roommate, a close friend, or a family member who would be willing to chip in a few bucks towards your little project provided they get access? Well that's how I funded my server. It might also be worth thinking about the cost over time, i.e. how much you spend yearly on subscriptions vs. a one time cost of setting up a server. Additionally there's just the joy of being able to scream "fuck you" at all those show cancelling, library deleting, hedge fund vampire CEOs who run the studios through denying them your money. Drive a stake through David Zaslav's heart.
On the software side I will walk you step-by-step through installing Ubuntu as your server's operating system, configuring your storage as a RAIDz array with ZFS, sharing your zpool to Windows with Samba, running a remote connection between your server and your Windows PC, and then a little about started with Plex/Jellyfin. Every terminal command you will need to input will be provided, and I even share a custom #bash script that will make used vs. available drive space on your server display correctly in Windows.
If you have a different preferred flavour of Linux (Arch, Manjaro, Redhat, Fedora, Mint, OpenSUSE, CentOS, Slackware etc. et. al.) and are aching to tell me off for being basic and using Ubuntu, this tutorial is not for you. The sort of person with a preferred Linux distro is the sort of person who can do this sort of thing in their sleep. Also I don't care. This tutorial is intended for the average home computer user. This is also why we’re not using a more exotic home server solution like running everything through Docker Containers and managing it through a dashboard like Homarr or Heimdall. While such solutions are fantastic and can be very easy to maintain once you have it all set up, wrapping your brain around Docker is a whole thing in and of itself. If you do follow this tutorial and had fun putting everything together, then I would encourage you to return in a year’s time, do your research and set up everything with Docker Containers.
Lastly, this is a tutorial aimed at Windows users. Although I was a daily user of OS X for many years (roughly 2008-2023) and I've dabbled quite a bit with various Linux distributions (mostly Ubuntu and Manjaro), my primary OS these days is Windows 11. Many things in this tutorial will still be applicable to Mac users, but others (e.g. setting up shares) you will have to look up for yourself. I doubt it would be difficult to do so.
Nothing in this tutorial will require feats of computing expertise. All you will need is a basic computer literacy (i.e. an understanding of what a filesystem and directory are, and a degree of comfort in the settings menu) and a willingness to learn a thing or two. While this guide may look overwhelming at first glance, it is only because I want to be as thorough as possible. I want you to understand exactly what it is you're doing, I don't want you to just blindly follow steps. If you half-way know what you’re doing, you will be much better prepared if you ever need to troubleshoot.
Honestly, once you have all the hardware ready it shouldn't take more than an afternoon or two to get everything up and running.
(This tutorial is just shy of seven thousand words long so the rest is under the cut.)
Step One: Choosing Your Hardware
Linux is a light weight operating system, depending on the distribution there's close to no bloat. There are recent distributions available at this very moment that will run perfectly fine on a fourteen year old i3 with 4GB of RAM. Moreover, running Plex or Jellyfin isn’t resource intensive in 90% of use cases. All this is to say, we don’t require an expensive or powerful computer. This means that there are several options available: 1) use an old computer you already have sitting around but aren't using 2) buy a used workstation from eBay, or what I believe to be the best option, 3) order an N100 Mini-PC from AliExpress or Amazon.
Note: If you already have an old PC sitting around that you’ve decided to use, fantastic, move on to the next step.
When weighing your options, keep a few things in mind: the number of people you expect to be streaming simultaneously at any one time, the resolution and bitrate of your media library (4k video takes a lot more processing power than 1080p) and most importantly, how many of those clients are going to be transcoding at any one time. Transcoding is what happens when the playback device does not natively support direct playback of the source file. This can happen for a number of reasons, such as the playback device's native resolution being lower than the file's internal resolution, or because the source file was encoded in a video codec unsupported by the playback device.
Ideally we want any transcoding to be performed by hardware. This means we should be looking for a computer with an Intel processor with Quick Sync. Quick Sync is a dedicated core on the CPU die designed specifically for video encoding and decoding. This specialized hardware makes for highly efficient transcoding both in terms of processing overhead and power draw. Without these Quick Sync cores, transcoding must be brute forced through software. This takes up much more of a CPU’s processing power and requires much more energy. But not all Quick Sync cores are created equal and you need to keep this in mind if you've decided either to use an old computer or to shop for a used workstation on eBay
Any Intel processor from second generation Core (Sandy Bridge circa 2011) onward has Quick Sync cores. It's not until 6th gen (Skylake), however, that the cores support the H.265 HEVC codec. Intel’s 10th gen (Comet Lake) processors introduce support for 10bit HEVC and HDR tone mapping. And the recent 12th gen (Alder Lake) processors brought with them hardware AV1 decoding. As an example, while an 8th gen (Kaby Lake) i5-8500 will be able to hardware transcode a H.265 encoded file, it will fall back to software transcoding if given a 10bit H.265 file. If you’ve decided to use that old PC or to look on eBay for an old Dell Optiplex keep this in mind.
Note 1: The price of old workstations varies wildly and fluctuates frequently. If you get lucky and go shopping shortly after a workplace has liquidated a large number of their workstations you can find deals for as low as $100 on a barebones system, but generally an i5-8500 workstation with 16gb RAM will cost you somewhere in the area of $260 CAD/$200 USD.
Note 2: The AMD equivalent to Quick Sync is called Video Core Next, and while it's fine, it's not as efficient and not as mature a technology. It was only introduced with the first generation Ryzen CPUs and it only got decent with their newest CPUs, we want something cheap.
Alternatively you could forgo having to keep track of what generation of CPU is equipped with Quick Sync cores that feature support for which codecs, and just buy an N100 mini-PC. For around the same price or less of a used workstation you can pick up a mini-PC with an Intel N100 processor. The N100 is a four-core processor based on the 12th gen Alder Lake architecture and comes equipped with the latest revision of the Quick Sync cores. These little processors offer astounding hardware transcoding capabilities for their size and power draw. Otherwise they perform equivalent to an i5-6500, which isn't a terrible CPU. A friend of mine uses an N100 machine as a dedicated retro emulation gaming system and it does everything up to 6th generation consoles just fine. The N100 is also a remarkably efficient chip, it sips power. In fact, the difference between running one of these and an old workstation could work out to hundreds of dollars a year in energy bills depending on where you live.
You can find these Mini-PCs all over Amazon or for a little cheaper on AliExpress. They range in price from $170 CAD/$125 USD for a no name N100 with 8GB RAM to $280 CAD/$200 USD for a Beelink S12 Pro with 16GB RAM. The brand doesn't really matter, they're all coming from the same three factories in Shenzen, go for whichever one fits your budget or has features you want. 8GB RAM should be enough, Linux is lightweight and Plex only calls for 2GB RAM. 16GB RAM might result in a slightly snappier experience, especially with ZFS. A 256GB SSD is more than enough for what we need as a boot drive, but going for a bigger drive might allow you to get away with things like creating preview thumbnails for Plex, but it’s up to you and your budget.
The Mini-PC I wound up buying was a Firebat AK2 Plus with 8GB RAM and a 256GB SSD. It looks like this:

Note: Be forewarned that if you decide to order a Mini-PC from AliExpress, note the type of power adapter it ships with. The mini-PC I bought came with an EU power adapter and I had to supply my own North American power supply. Thankfully this is a minor issue as barrel plug 30W/12V/2.5A power adapters are easy to find and can be had for $10.
Step Two: Choosing Your Storage
Storage is the most important part of our build. It is also the most expensive. Thankfully it’s also the most easily upgrade-able down the line.
For people with a smaller media collection (4TB to 8TB), a more limited budget, or who will only ever have two simultaneous streams running, I would say that the most economical course of action would be to buy a USB 3.0 8TB external HDD. Something like this one from Western Digital or this one from Seagate. One of these external drives will cost you in the area of $200 CAD/$140 USD. Down the line you could add a second external drive or replace it with a multi-drive RAIDz set up such as detailed below.
If a single external drive the path for you, move on to step three.
For people with larger media libraries (12TB+), who prefer media in 4k, or care who about data redundancy, the answer is a RAID array featuring multiple HDDs in an enclosure.
Note: If you are using an old PC or used workstatiom as your server and have the room for at least three 3.5" drives, and as many open SATA ports on your mother board you won't need an enclosure, just install the drives into the case. If your old computer is a laptop or doesn’t have room for more internal drives, then I would suggest an enclosure.
The minimum number of drives needed to run a RAIDz array is three, and seeing as RAIDz is what we will be using, you should be looking for an enclosure with three to five bays. I think that four disks makes for a good compromise for a home server. Regardless of whether you go for a three, four, or five bay enclosure, do be aware that in a RAIDz array the space equivalent of one of the drives will be dedicated to parity at a ratio expressed by the equation 1 − 1/n i.e. in a four bay enclosure equipped with four 12TB drives, if we configured our drives in a RAIDz1 array we would be left with a total of 36TB of usable space (48TB raw size). The reason for why we might sacrifice storage space in such a manner will be explained in the next section.
A four bay enclosure will cost somewhere in the area of $200 CDN/$140 USD. You don't need anything fancy, we don't need anything with hardware RAID controls (RAIDz is done entirely in software) or even USB-C. An enclosure with USB 3.0 will perform perfectly fine. Don’t worry too much about USB speed bottlenecks. A mechanical HDD will be limited by the speed of its mechanism long before before it will be limited by the speed of a USB connection. I've seen decent looking enclosures from TerraMaster, Yottamaster, Mediasonic and Sabrent.
When it comes to selecting the drives, as of this writing, the best value (dollar per gigabyte) are those in the range of 12TB to 20TB. I settled on 12TB drives myself. If 12TB to 20TB drives are out of your budget, go with what you can afford, or look into refurbished drives. I'm not sold on the idea of refurbished drives but many people swear by them.
When shopping for harddrives, search for drives designed specifically for NAS use. Drives designed for NAS use typically have better vibration dampening and are designed to be active 24/7. They will also often make use of CMR (conventional magnetic recording) as opposed to SMR (shingled magnetic recording). This nets them a sizable read/write performance bump over typical desktop drives. Seagate Ironwolf and Toshiba NAS are both well regarded brands when it comes to NAS drives. I would avoid Western Digital Red drives at this time. WD Reds were a go to recommendation up until earlier this year when it was revealed that they feature firmware that will throw up false SMART warnings telling you to replace the drive at the three year mark quite often when there is nothing at all wrong with that drive. It will likely even be good for another six, seven, or more years.

Step Three: Installing Linux
For this step you will need a USB thumbdrive of at least 6GB in capacity, an .ISO of Ubuntu, and a way to make that thumbdrive bootable media.
First download a copy of Ubuntu desktop (for best performance we could download the Server release, but for new Linux users I would recommend against the server release. The server release is strictly command line interface only, and having a GUI is very helpful for most people. Not many people are wholly comfortable doing everything through the command line, I'm certainly not one of them, and I grew up with DOS 6.0. 22.04.3 Jammy Jellyfish is the current Long Term Service release, this is the one to get.
Download the .ISO and then download and install balenaEtcher on your Windows PC. BalenaEtcher is an easy to use program for creating bootable media, you simply insert your thumbdrive, select the .ISO you just downloaded, and it will create a bootable installation media for you.
Once you've made a bootable media and you've got your Mini-PC (or you old PC/used workstation) in front of you, hook it directly into your router with an ethernet cable, and then plug in the HDD enclosure, a monitor, a mouse and a keyboard. Now turn that sucker on and hit whatever key gets you into the BIOS (typically ESC, DEL or F2). If you’re using a Mini-PC check to make sure that the P1 and P2 power limits are set correctly, my N100's P1 limit was set at 10W, a full 20W under the chip's power limit. Also make sure that the RAM is running at the advertised speed. My Mini-PC’s RAM was set at 2333Mhz out of the box when it should have been 3200Mhz. Once you’ve done that, key over to the boot order and place the USB drive first in the boot order. Then save the BIOS settings and restart.
After you restart you’ll be greeted by Ubuntu's installation screen. Installing Ubuntu is really straight forward, select the "minimal" installation option, as we won't need anything on this computer except for a browser (Ubuntu comes preinstalled with Firefox) and Plex Media Server/Jellyfin Media Server. Also remember to delete and reformat that Windows partition! We don't need it.
Step Four: Installing ZFS and Setting Up the RAIDz Array
Note: If you opted for just a single external HDD skip this step and move onto setting up a Samba share.
Once Ubuntu is installed it's time to configure our storage by installing ZFS to build our RAIDz array. ZFS is a "next-gen" file system that is both massively flexible and massively complex. It's capable of snapshot backup, self healing error correction, ZFS pools can be configured with drives operating in a supplemental manner alongside the storage vdev (e.g. fast cache, dedicated secondary intent log, hot swap spares etc.). It's also a file system very amenable to fine tuning. Block and sector size are adjustable to use case and you're afforded the option of different methods of inline compression. If you'd like a very detailed overview and explanation of its various features and tips on tuning a ZFS array check out these articles from Ars Technica. For now we're going to ignore all these features and keep it simple, we're going to pull our drives together into a single vdev running in RAIDz which will be the entirety of our zpool, no fancy cache drive or SLOG.
Open up the terminal and type the following commands:
sudo apt update
then
sudo apt install zfsutils-linux
This will install the ZFS utility. Verify that it's installed with the following command:
zfs --version
Now, it's time to check that the HDDs we have in the enclosure are healthy, running, and recognized. We also want to find out their device IDs and take note of them:
sudo fdisk -1
Note: You might be wondering why some of these commands require "sudo" in front of them while others don't. "Sudo" is short for "super user do”. When and where "sudo" is used has to do with the way permissions are set up in Linux. Only the "root" user has the access level to perform certain tasks in Linux. As a matter of security and safety regular user accounts are kept separate from the "root" user. It's not advised (or even possible) to boot into Linux as "root" with most modern distributions. Instead by using "sudo" our regular user account is temporarily given the power to do otherwise forbidden things. Don't worry about it too much at this stage, but if you want to know more check out this introduction.
If everything is working you should get a list of the various drives detected along with their device IDs which will look like this: /dev/sdc. You can also check the device IDs of the drives by opening the disk utility app. Jot these IDs down as we'll need them for our next step, creating our RAIDz array.
RAIDz is similar to RAID-5 in that instead of striping your data over multiple disks, exchanging redundancy for speed and available space (RAID-0), or mirroring your data writing by two copies of every piece (RAID-1), it instead writes parity blocks across the disks in addition to striping, this provides a balance of speed, redundancy and available space. If a single drive fails, the parity blocks on the working drives can be used to reconstruct the entire array as soon as a replacement drive is added.
Additionally, RAIDz improves over some of the common RAID-5 flaws. It's more resilient and capable of self healing, as it is capable of automatically checking for errors against a checksum. It's more forgiving in this way, and it's likely that you'll be able to detect when a drive is dying well before it fails. A RAIDz array can survive the loss of any one drive.
Note: While RAIDz is indeed resilient, if a second drive fails during the rebuild, you're fucked. Always keep backups of things you can't afford to lose. This tutorial, however, is not about proper data safety.
To create the pool, use the following command:
sudo zpool create "zpoolnamehere" raidz "device IDs of drives we're putting in the pool"
For example, let's creatively name our zpool "mypool". This poil will consist of four drives which have the device IDs: sdb, sdc, sdd, and sde. The resulting command will look like this:
sudo zpool create mypool raidz /dev/sdb /dev/sdc /dev/sdd /dev/sde
If as an example you bought five HDDs and decided you wanted more redundancy dedicating two drive to this purpose, we would modify the command to "raidz2" and the command would look something like the following:
sudo zpool create mypool raidz2 /dev/sdb /dev/sdc /dev/sdd /dev/sde /dev/sdf
An array configured like this is known as RAIDz2 and is able to survive two disk failures.
Once the zpool has been created, we can check its status with the command:
zpool status
Or more concisely with:
zpool list
The nice thing about ZFS as a file system is that a pool is ready to go immediately after creation. If we were to set up a traditional RAID-5 array using mbam, we'd have to sit through a potentially hours long process of reformatting and partitioning the drives. Instead we're ready to go right out the gates.
The zpool should be automatically mounted to the filesystem after creation, check on that with the following:
df -hT | grep zfs
Note: If your computer ever loses power suddenly, say in event of a power outage, you may have to re-import your pool. In most cases, ZFS will automatically import and mount your pool, but if it doesn’t and you can't see your array, simply open the terminal and type sudo zpool import -a.
By default a zpool is mounted at /"zpoolname". The pool should be under our ownership but let's make sure with the following command:
sudo chown -R "yourlinuxusername" /"zpoolname"
Note: Changing file and folder ownership with "chown" and file and folder permissions with "chmod" are essential commands for much of the admin work in Linux, but we won't be dealing with them extensively in this guide. If you'd like a deeper tutorial and explanation you can check out these two guides: chown and chmod.
You can access the zpool file system through the GUI by opening the file manager (the Ubuntu default file manager is called Nautilus) and clicking on "Other Locations" on the sidebar, then entering the Ubuntu file system and looking for a folder with your pool's name. Bookmark the folder on the sidebar for easy access.
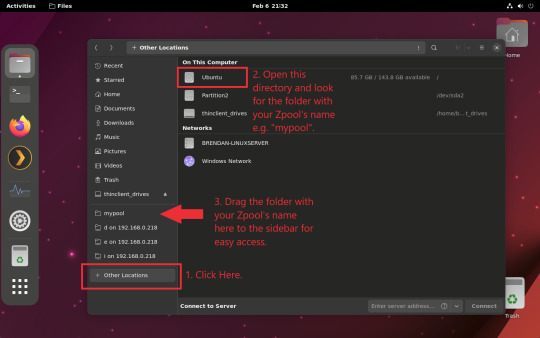
Your storage pool is now ready to go. Assuming that we already have some files on our Windows PC we want to copy to over, we're going to need to install and configure Samba to make the pool accessible in Windows.
Step Five: Setting Up Samba/Sharing
Samba is what's going to let us share the zpool with Windows and allow us to write to it from our Windows machine. First let's install Samba with the following commands:
sudo apt-get update
then
sudo apt-get install samba
Next create a password for Samba.
sudo smbpswd -a "yourlinuxusername"
It will then prompt you to create a password. Just reuse your Ubuntu user password for simplicity's sake.
Note: if you're using just a single external drive replace the zpool location in the following commands with wherever it is your external drive is mounted, for more information see this guide on mounting an external drive in Ubuntu.
After you've created a password we're going to create a shareable folder in our pool with this command
mkdir /"zpoolname"/"foldername"
Now we're going to open the smb.conf file and make that folder shareable. Enter the following command.
sudo nano /etc/samba/smb.conf
This will open the .conf file in nano, the terminal text editor program. Now at the end of smb.conf add the following entry:
["foldername"]
path = /"zpoolname"/"foldername"
available = yes
valid users = "yourlinuxusername"
read only = no
writable = yes
browseable = yes
guest ok = no
Ensure that there are no line breaks between the lines and that there's a space on both sides of the equals sign. Our next step is to allow Samba traffic through the firewall:
sudo ufw allow samba
Finally restart the Samba service:
sudo systemctl restart smbd
At this point we'll be able to access to the pool, browse its contents, and read and write to it from Windows. But there's one more thing left to do, Windows doesn't natively support the ZFS file systems and will read the used/available/total space in the pool incorrectly. Windows will read available space as total drive space, and all used space as null. This leads to Windows only displaying a dwindling amount of "available" space as the drives are filled. We can fix this! Functionally this doesn't actually matter, we can still write and read to and from the disk, it just makes it difficult to tell at a glance the proportion of used/available space, so this is an optional step but one I recommend (this step is also unnecessary if you're just using a single external drive). What we're going to do is write a little shell script in #bash. Open nano with the terminal with the command:
nano
Now insert the following code:
#!/bin/bash CUR_PATH=`pwd` ZFS_CHECK_OUTPUT=$(zfs get type $CUR_PATH 2>&1 > /dev/null) > /dev/null if [[ $ZFS_CHECK_OUTPUT == *not\ a\ ZFS* ]] then IS_ZFS=false else IS_ZFS=true fi if [[ $IS_ZFS = false ]] then df $CUR_PATH | tail -1 | awk '{print $2" "$4}' else USED=$((`zfs get -o value -Hp used $CUR_PATH` / 1024)) > /dev/null AVAIL=$((`zfs get -o value -Hp available $CUR_PATH` / 1024)) > /dev/null TOTAL=$(($USED+$AVAIL)) > /dev/null echo $TOTAL $AVAIL fi
Save the script as "dfree.sh" to /home/"yourlinuxusername" then change the ownership of the file to make it executable with this command:
sudo chmod 774 dfree.sh
Now open smb.conf with sudo again:
sudo nano /etc/samba/smb.conf
Now add this entry to the top of the configuration file to direct Samba to use the results of our script when Windows asks for a reading on the pool's used/available/total drive space:
[global]
dfree command = /home/"yourlinuxusername"/dfree.sh
Save the changes to smb.conf and then restart Samba again with the terminal:
sudo systemctl restart smbd
Now there’s one more thing we need to do to fully set up the Samba share, and that’s to modify a hidden group permission. In the terminal window type the following command:
usermod -a -G sambashare “yourlinuxusername”
Then restart samba again:
sudo systemctl restart smbd
If we don’t do this last step, everything will appear to work fine, and you will even be able to see and map the drive from Windows and even begin transferring files, but you'd soon run into a lot of frustration. As every ten minutes or so a file would fail to transfer and you would get a window announcing “0x8007003B Unexpected Network Error”. This window would require your manual input to continue the transfer with the file next in the queue. And at the end it would reattempt to transfer whichever files failed the first time around. 99% of the time they’ll go through that second try, but this is still all a major pain in the ass. Especially if you’ve got a lot of data to transfer or you want to step away from the computer for a while.
It turns out samba can act a little weirdly with the higher read/write speeds of RAIDz arrays and transfers from Windows, and will intermittently crash and restart itself if this group option isn’t changed. Inputting the above command will prevent you from ever seeing that window.
The last thing we're going to do before switching over to our Windows PC is grab the IP address of our Linux machine. Enter the following command:
hostname -I
This will spit out this computer's IP address on the local network (it will look something like 192.168.0.x), write it down. It might be a good idea once you're done here to go into your router settings and reserving that IP for your Linux system in the DHCP settings. Check the manual for your specific model router on how to access its settings, typically it can be accessed by opening a browser and typing http:\\192.168.0.1 in the address bar, but your router may be different.
Okay we’re done with our Linux computer for now. Get on over to your Windows PC, open File Explorer, right click on Network and click "Map network drive". Select Z: as the drive letter (you don't want to map the network drive to a letter you could conceivably be using for other purposes) and enter the IP of your Linux machine and location of the share like so: \\"LINUXCOMPUTERLOCALIPADDRESSGOESHERE"\"zpoolnamegoeshere"\. Windows will then ask you for your username and password, enter the ones you set earlier in Samba and you're good. If you've done everything right it should look something like this:

You can now start moving media over from Windows to the share folder. It's a good idea to have a hard line running to all machines. Moving files over Wi-Fi is going to be tortuously slow, the only thing that’s going to make the transfer time tolerable (hours instead of days) is a solid wired connection between both machines and your router.
Step Six: Setting Up Remote Desktop Access to Your Server
After the server is up and going, you’ll want to be able to access it remotely from Windows. Barring serious maintenance/updates, this is how you'll access it most of the time. On your Linux system open the terminal and enter:
sudo apt install xrdp
Then:
sudo systemctl enable xrdp
Once it's finished installing, open “Settings” on the sidebar and turn off "automatic login" in the User category. Then log out of your account. Attempting to remotely connect to your Linux computer while you’re logged in will result in a black screen!
Now get back on your Windows PC, open search and look for "RDP". A program called "Remote Desktop Connection" should pop up, open this program as an administrator by right-clicking and selecting “run as an administrator”. You’ll be greeted with a window. In the field marked “Computer” type in the IP address of your Linux computer. Press connect and you'll be greeted with a new window and prompt asking for your username and password. Enter your Ubuntu username and password here.
If everything went right, you’ll be logged into your Linux computer. If the performance is sluggish, adjust the display options. Lowering the resolution and colour depth do a lot to make the interface feel snappier.
Remote access is how we're going to be using our Linux system from now, barring edge cases like needing to get into the BIOS or upgrading to a new version of Ubuntu. Everything else from performing maintenance like a monthly zpool scrub to checking zpool status and updating software can all be done remotely.

This is how my server lives its life now, happily humming and chirping away on the floor next to the couch in a corner of the living room.
Step Seven: Plex Media Server/Jellyfin
Okay we’ve got all the ground work finished and our server is almost up and running. We’ve got Ubuntu up and running, our storage array is primed, we’ve set up remote connections and sharing, and maybe we’ve moved over some of favourite movies and TV shows.
Now we need to decide on the media server software to use which will stream our media to us and organize our library. For most people I’d recommend Plex. It just works 99% of the time. That said, Jellyfin has a lot to recommend it by too, even if it is rougher around the edges. Some people run both simultaneously, it’s not that big of an extra strain. I do recommend doing a little bit of your own research into the features each platform offers, but as a quick run down, consider some of the following points:
Plex is closed source and is funded through PlexPass purchases while Jellyfin is open source and entirely user driven. This means a number of things: for one, Plex requires you to purchase a “PlexPass” (purchased as a one time lifetime fee $159.99 CDN/$120 USD or paid for on a monthly or yearly subscription basis) in order to access to certain features, like hardware transcoding (and we want hardware transcoding) or automated intro/credits detection and skipping, Jellyfin offers some of these features for free through plugins. Plex supports a lot more devices than Jellyfin and updates more frequently. That said, Jellyfin's Android and iOS apps are completely free, while the Plex Android and iOS apps must be activated for a one time cost of $6 CDN/$5 USD. But that $6 fee gets you a mobile app that is much more functional and features a unified UI across platforms, the Plex mobile apps are simply a more polished experience. The Jellyfin apps are a bit of a mess and the iOS and Android versions are very different from each other.
Jellyfin’s actual media player is more fully featured than Plex's, but on the other hand Jellyfin's UI, library customization and automatic media tagging really pale in comparison to Plex. Streaming your music library is free through both Jellyfin and Plex, but Plex offers the PlexAmp app for dedicated music streaming which boasts a number of fantastic features, unfortunately some of those fantastic features require a PlexPass. If your internet is down, Jellyfin can still do local streaming, while Plex can fail to play files unless you've got it set up a certain way. Jellyfin has a slew of neat niche features like support for Comic Book libraries with the .cbz/.cbt file types, but then Plex offers some free ad-supported TV and films, they even have a free channel that plays nothing but Classic Doctor Who.
Ultimately it's up to you, I settled on Plex because although some features are pay-walled, it just works. It's more reliable and easier to use, and a one-time fee is much easier to swallow than a subscription. I had a pretty easy time getting my boomer parents and tech illiterate brother introduced to and using Plex and I don't know if I would've had as easy a time doing that with Jellyfin. I do also need to mention that Jellyfin does take a little extra bit of tinkering to get going in Ubuntu, you’ll have to set up process permissions, so if you're more tolerant to tinkering, Jellyfin might be up your alley and I’ll trust that you can follow their installation and configuration guide. For everyone else, I recommend Plex.
So pick your poison: Plex or Jellyfin.
Note: The easiest way to download and install either of these packages in Ubuntu is through Snap Store.
After you've installed one (or both), opening either app will launch a browser window into the browser version of the app allowing you to set all the options server side.
The process of adding creating media libraries is essentially the same in both Plex and Jellyfin. You create a separate libraries for Television, Movies, and Music and add the folders which contain the respective types of media to their respective libraries. The only difficult or time consuming aspect is ensuring that your files and folders follow the appropriate naming conventions:
Plex naming guide for Movies
Plex naming guide for Television
Jellyfin follows the same naming rules but I find their media scanner to be a lot less accurate and forgiving than Plex. Once you've selected the folders to be scanned the service will scan your files, tagging everything and adding metadata. Although I find do find Plex more accurate, it can still erroneously tag some things and you might have to manually clean up some tags in a large library. (When I initially created my library it tagged the 1963-1989 Doctor Who as some Korean soap opera and I needed to manually select the correct match after which everything was tagged normally.) It can also be a bit testy with anime (especially OVAs) be sure to check TVDB to ensure that you have your files and folders structured and named correctly. If something is not showing up at all, double check the name.
Once that's done, organizing and customizing your library is easy. You can set up collections, grouping items together to fit a theme or collect together all the entries in a franchise. You can make playlists, and add custom artwork to entries. It's fun setting up collections with posters to match, there are even several websites dedicated to help you do this like PosterDB. As an example, below are two collections in my library, one collecting all the entries in a franchise, the other follows a theme.

My Star Trek collection, featuring all eleven television series, and thirteen films.
My Best of the Worst collection, featuring sixty-nine films previously showcased on RedLetterMedia’s Best of the Worst. They’re all absolutely terrible and I love them.
As for settings, ensure you've got Remote Access going, it should work automatically and be sure to set your upload speed after running a speed test. In the library settings set the database cache to 2000MB to ensure a snappier and more responsive browsing experience, and then check that playback quality is set to original/maximum. If you’re severely bandwidth limited on your upload and have remote users, you might want to limit the remote stream bitrate to something more reasonable, just as a note of comparison Netflix’s 1080p bitrate is approximately 5Mbps, although almost anyone watching through a chromium based browser is streaming at 720p and 3mbps. Other than that you should be good to go. For actually playing your files, there's a Plex app for just about every platform imaginable. I mostly watch television and films on my laptop using the Windows Plex app, but I also use the Android app which can broadcast to the chromecast connected to the TV in the office and the Android TV app for our smart TV. Both are fully functional and easy to navigate, and I can also attest to the OS X version being equally functional.
Part Eight: Finding Media
Now, this is not really a piracy tutorial, there are plenty of those out there. But if you’re unaware, BitTorrent is free and pretty easy to use, just pick a client (qBittorrent is the best) and go find some public trackers to peruse. Just know now that all the best trackers are private and invite only, and that they can be exceptionally difficult to get into. I’m already on a few, and even then, some of the best ones are wholly out of my reach.
If you decide to take the left hand path and turn to Usenet you’ll have to pay. First you’ll need to sign up with a provider like Newshosting or EasyNews for access to Usenet itself, and then to actually find anything you’re going to need to sign up with an indexer like NZBGeek or NZBFinder. There are dozens of indexers, and many people cross post between them, but for more obscure media it’s worth checking multiple. You’ll also need a binary downloader like SABnzbd. That caveat aside, Usenet is faster, bigger, older, less traceable than BitTorrent, and altogether slicker. I honestly prefer it, and I'm kicking myself for taking this long to start using it because I was scared off by the price. I’ve found so many things on Usenet that I had sought in vain elsewhere for years, like a 2010 Italian film about a massacre perpetrated by the SS that played the festival circuit but never received a home media release; some absolute hero uploaded a rip of a festival screener DVD to Usenet. Anyway, figure out the rest of this shit on your own and remember to use protection, get yourself behind a VPN, use a SOCKS5 proxy with your BitTorrent client, etc.
On the legal side of things, if you’re around my age, you (or your family) probably have a big pile of DVDs and Blu-Rays sitting around unwatched and half forgotten. Why not do a bit of amateur media preservation, rip them and upload them to your server for easier access? (Your tools for this are going to be Handbrake to do the ripping and AnyDVD to break any encryption.) I went to the trouble of ripping all my SCTV DVDs (five box sets worth) because none of it is on streaming nor could it be found on any pirate source I tried. I’m glad I did, forty years on it’s still one of the funniest shows to ever be on TV.
Part Nine/Epilogue: Sonarr/Radarr/Lidarr and Overseerr
There are a lot of ways to automate your server for better functionality or to add features you and other users might find useful. Sonarr, Radarr, and Lidarr are a part of a suite of “Servarr” services (there’s also Readarr for books and Whisparr for adult content) that allow you to automate the collection of new episodes of TV shows (Sonarr), new movie releases (Radarr) and music releases (Lidarr). They hook in to your BitTorrent client or Usenet binary newsgroup downloader and crawl your preferred Torrent trackers and Usenet indexers, alerting you to new releases and automatically grabbing them. You can also use these services to manually search for new media, and even replace/upgrade your existing media with better quality uploads. They’re really a little tricky to set up on a bare metal Ubuntu install (ideally you should be running them in Docker Containers), and I won’t be providing a step by step on installing and running them, I’m simply making you aware of their existence.
The other bit of kit I want to make you aware of is Overseerr which is a program that scans your Plex media library and will serve recommendations based on what you like. It also allows you and your users to request specific media. It can even be integrated with Sonarr/Radarr/Lidarr so that fulfilling those requests is fully automated.
And you're done. It really wasn't all that hard. Enjoy your media. Enjoy the control you have over that media. And be safe in the knowledge that no hedgefund CEO motherfucker who hates the movies but who is somehow in control of a major studio will be able to disappear anything in your library as a tax write-off.
1K notes
·
View notes
Text
Edit this screenie with me!


This is an unused screenie of Penny Pizzazz and Marcus Flex. Feel free to save the screenshot (Dropbox link below) and follow along with the instructions, or play around with it and do your own thing! I’m going to keep the instructions as simple as possible; hopefully they make sense.
Note: My process is kinda involved, but it’s a relaxing hobby for me. You do not need to do all of these steps! If the process doesn’t bring you joy, don’t bother!
I’m using procreate, but I’m also a photoshop user. You can use any software that has layers and blend modes :)
Instructions and downloads under the cut!
Dropbox link to the screenshot, and overlays!
1. Let’s start with shadows. The first step is to create a new layer. Put the blend mode to “multiply” (this darkens anything you draw on the layer). Then select a soft brush. We’ll start with Penny’s face. Use the eyedropper tool to choose a shadowy color of her skin (hold your finger on the color you want).

2. Decide where the light will be coming from (we’ll be placing it behind them on the top left). Deepen the shadows already made by the game, and add some shadows opposite to where the light will be. Choose a darker color to match each area you’re drawing on (Penny’s hair, her shirt, Marcus’ skin, his sweater).
When you’re finished drawing the shadows, go into your layer and lower the opacity. Less is more!

3. Choose the eraser (set it to soft brush). With a light hand, soften any shaded areas that are too harsh. Basically you want to blend the shadow with the skin using the eraser. You can also use Gaussian blur!

4. Let’s add some background lighting. This will also be our guide as we add bolder highlights in the next steps. Make a new layer and set the blend mode to “add.” Take your soft brush and a yellowy-orange color, and draw some glowy light coming from the top left.
Lower the opacity and take the eraser and erase much of the light on the right side of Marcus, and erase a bit of the light on their skin/ hair/ etc (like we did with the shadows). You can use Gaussian blur here too!
Note about lighting and highlights: experiment with the color of light, because some will look better depending on the environment and the sims skin tones. Because Penny and Marcus have dark skin, a bolder or darker yellow/orange will look much better than a pale yellow.

5. Let’s start adding more highlights! Make another new layer and change the blend mode to “add.” Choose a yellow-orange and paint some highlights on Penny’s hair, her left shoulder, her chest, cheekbone, and the left side of Marcus’ face. I made the image on the left a different color so you can see where I put the highlights.
Lower the opacity, and use the eraser or Gaussian blur to blend.

6. More highlights! Make a new layer and set the blend mode to “overlay.” Overlay lightens while adding color. I use “light pen” for any outlined highlights (the outer left of Penny’s hair, Penny’s shoulder, the left side of Marcus’ face), and I use a soft brush for the rest. Lower with the opacity, and use the eraser to blend.
This is a great time to play around with other highlight colors! I’m sticking with yellows, so I chose a peach color. Note: the red is to show what I drew.

7. We’re going to import a light leak overlay, and set the layer to “screen.” Then take your eraser, and erase any areas where you don’t want there to be too much light (red areas).

Finally, I’ll merge the layers together and bump up the highlights by going to adjustments > curves. Then I’ll add noise, and a vintage dust overlay. Sometimes I do more than this, sometimes less. I also like to draw hair strands and stuff, but that’s a whole second tutorial.
259 notes
·
View notes
Text

Start Me Up: 30 years of Windows 95 - @commodorez and @ms-dos5
Okay, last batch of photos from our exhibit, and I wanted to highlight a few details because so much planning and preparation went into making this the ultimate Windows 95 exhibit. And now you all have to hear about it.
You'll note software boxes from both major versions of Windows 95 RTM (Release To Manufacturing, the original version from August 24, 1995): the standalone version "for PCs without Windows", and the Upgrade version "for users of Windows". We used both versions when setting up the machines you see here to show the variety of install types people performed. My grandpa's original set of install floppies was displayed in a little shadowbox, next to a CD version, and a TI 486DX2-66 microprocessor emblazoned with "Designed for Microsoft Windows 95".

The machines on display, from left to right include:
Chicago Beta 73g on a custom Pentium 1 baby AT tower
Windows 95 RTM on an AST Bravo LC 4/66d desktop
Windows 95 RTM on a (broken) Compaq LTE Elite 4/75cx laptop
Windows 95 OSR 1 on an Intertel Pentium 1 tower
Windows 95 OSR 1 on a VTEL Pentium 1 desktop
Windows 95 OSR 2 on a Toshiba Satellite T1960CT laptop
Windows 95 OSR 2 on a Toshiba Libretto 70CT subnotebook
Windows 95 OSR 2 on an IBM Thinkpad 760E laptop
Windows 95 OSR 2.5 on a custom Pentium II tower (Vega)

That's alot of machines that had to be prepared for the exhibit, so for all of them to work (minus the Compaq) was a relief. Something about the trip to NJ rendered the Compaq unstable, and it refused to boot consistently. I have no idea what happened because it failed in like 5 different steps of the process.
The SMC TigerHub TP6 nestled between the Intertel and VTEL served as the network backbone for the exhibit, allowing 6 machines to be connected over twisted pair with all the multicolored network cables. However, problems with PCMCIA drivers on the Thinkpad, and the Compaq being on the blink meant only 5 machines were networked. Vega was sporting a CanoScan FS2710 film scanner connected via SCSI, which I demonstrated like 9 times over the course of the weekend -- including to LGR!
Game controllers were attached to computers where possible, and everything with a sound card had a set of era-appropriate speakers. We even picked out a slew of mid-90s mouse pads, some of which were specifically Windows 95 themed. We had Zip disks, floppy disks, CDs full of software, and basically no extra room on the tables. Almost every machine had a different screensaver, desktop wallpaper, sound scheme, and UI theme, showing just how much was user customizable.
@ms-dos5 made a point to have a variety of versions of Microsoft Office products on the machines present, meaning we had everything from stand-alone copies of Word 95 and Excel 95, thru complete MS Office 95 packages (standard & professional), MS Office 97 (standard & professional), Publisher, Frontpage, & Encarta.
We brought a bunch of important books about 95 too:
The Windows Interface Guidelines for Software Design
Microsoft Windows 95 Resource Kit
Hardware Design Guide for Windows 95
Inside Windows 95 by Adrian King
Just off to the right, stacked on top of some boxes was an Epson LX-300+II dot matrix printer, which we used to create all of the decorative banners, and the computer description cards next to each machine. Fun fact -- those were designed to mimic the format and style of 95's printer test page! We also printed off drawings for a number of visitors, and ended up having more paper jams with the tractor feed mechanism than we had Blue Screen of Death instances.

In fact, we only had 3 BSOD's total, all weekend, one of which was expected, and another was intentional on the part of an attendee.

We also had one guy install some shovelware/garbageware on the AST, which caused all sorts of errors, that was funny!
Thanks for coming along on this ride, both @ms-dos5 and I appreciate everyone taking the time to enjoy our exhibit.

It's now safe to turn off your computer.
VCF East XX
#vcfexx#vcf east xx#vintage computer festival east xx#commodorez goes to vcfexx#windows 95#microsoft windows 95
210 notes
·
View notes
Text
WIP excerpt for LadyKarma behind the cut, who requested "shenanigans with any version of Kon" and is getting "Superpup". Listen, yes this is technically the start of a "new" WIP but ALSO-technically this WIP tag already existed sooooo . . . (( chrono || non-chrono ))
So apparently Kon is a dog right now.
Worse: Kon is a puppy right now. Couldn't even be a cool badass junkyard bruiser, no; he's all fluffy curly black fur and soft floppy ears and huge blue eyes and tiny clumsy everything.
It is literally fucking mortifying, yes. It is fully fucking mortifying.
Also, it's fully fucking alarming, because it's really, really hard to figure shit out right now. He knows he's not a dog. He knows his name–his names. He's just having a little bit of trouble figuring out much else.
He's having trouble thinking, is what he means. And he's not usually all that great at thinking as it is.
Kon honestly should probably be having a total goddamn freakout, actually, but is mostly still stuck at the “how does having four legs work” stage, because that one is really, really being an issue at the moment. Mostly it’s an issue because, uh, there is absolutely a cackling asshole magic-user tossing fucking fireballs at his stupid fluffy curly ass while he tries very hard to dodge them. He really does not think the asshole magic-user turned him into a Kryptonian-invulnerable puppy, he cannot imagine why they would have, so he definitely, definitely does not wanna get hit by any of those.
Why a fucking puppy, seriously. Who the fuck turns a dude who’s just trying to do his superhero super-duties into a fucking puppy for it? Over a fucking basic-bitch midnight jewelry store robbery, even? Kon was literally just flying back to Smallville from his latest off-planet escapade when he'd randomly caught the sound of shattering glass and screaming just outside Kansas and obviously gone to check it out and make sure nobody was getting murdered, and this is what he gets for that? Turned into a fucking puppy and getting fucking fireballs chucked at him?
Magic is such goddamn bullshit, seriously.
At least the jewelry store clerk got away, he guesses. Like–that’s good. Just it’s less good how bad his fucking brain is working, and he does actually feel pretty damn close to freaking the fuck out, because like–because it’s–
Kon, to his disgust, is pretty sure he’s actually scared right now. Like–the tiny puppy-brain hardware that is currently running his personal software is scared, anyway, because everything’s loud and messy and all smashed-up and broken and whoever the fuck this asshole magic-user is is like–is mean!
Kon is actually even more disgusted over the tiny puppy-brain hardware making him think a wannabe-supervillain doing some barely-above-petty theft is being “mean”. Like seriously, that is just . . . what. What even is that?
Goddamn bullshit, again.
“Fetch!” the asshole magic-user gloats, lobbing another lazy fireball across the scorched-up jewelry store that Kon barely skids to a stop in time to avoid running into the path of, tiny paws scrabbling desperately on the linoleum floor. Which is absolutely just cheap-ass linoleum, because this isn’t even a nice jewelry store, just some shitty chain one in an outdoor mall. How the fuck is a shitty chain jewelry store supposed to be worth traumatizing a clerk and turning a superhero into a fucking dog and trying to fry them? That is way too damn much investment for a shitty chain jewelry store!
“What’s wrong, Superboy, don’t wanna play?!” the asshole magic-user crows, summoning up another pair of wickedly-bright fireballs as Kon dives beneath one of the shelves in stupid puppy-brained panic. Very, very big fireballs. Way bigger than a stupid fluffy floppy-eared puppy, for fucking goddamn sure.
What a fucking prick, Jesus.
“Heeeeere, Superboy,” the asshole calls mockingly, strolling forward across the cheap-ass linoleum and tossing both fireballs up and down in his hands as he does. Kon would like to at least growl at the asshole or, like, bare his teeth or something, but the only damn thing the stupid puppy body and stupid puppy brain manage is to fucking cower under the damn shelf, stomach flat against the floor and tail tucked between his legs.
Maybe he is, actually, having that total goddamn freakout right now.
Fuck. Fuck. Fuck. He needs to think. He needs to think. He’s already bad enough at thinking as it is, though, and this asshole’s so big and scary and being so mean and–a-and–!
Kon thinks, maybe, he’s getting worse at the thinking. The thinking isn’t . . . isn’t working that great, he thinks. He . . . he thinks it’s . . . it’s all . . . s’all slow and weird and stupid and . . . and . . .
“Aw, don’t like strangers, boy?” the asshole magic-user taunts, dropping into a crouch a few feet back and down just low enough to grin viciously under the shelf at him, and the creepy magic fire in his hands lights up his eyes all glowy and sparking and lightning-bright, and his smile is too wide and his teeth are all bared and the jewelry store’s dark and it’s dark outside and dark everywhere and he’s so big and it’s so scary and–!
The fire flares up brighter, and Kon shrieks in terror.
Or–no: Kon howls in terror. Howls high-pitched and panicked and shrill, a noise he didn’t know a dog’s throat could even make. The asshole laughs, because he’s a fucking asshole, and then reaches forward with a hand wrapped in fiery flame-y burny scary scary scaryscaryscary–!
Kon shrieks/howls again, and his stupid stupid stupid dog-sized brain is all fritzed-out with terror and the useless useless useless dog-sized body fucking cowers and flattens completely against the floor and hides its face behind its paws and everything’s burny-bright and hot and he’s so fucking scared and–!
“Jesus FUCK!” the asshole magic-user yells as the light goes out with a crashing sound, and suddenly the whole store is full of booming, echoing snarling.
It’s so scary.
There’s more crashing and snarling and yelling and then–
Then there’s barking.
The stupid puppy-brain Kon’s brain is currently trying to use hears barking, and what’s working of Kon’s brain hears–recognizes–
Kon hears Krypto barking, and the puppy-brain hears another dog–hears a species that can pass for another dog, anyway–and Kon doesn’t know if it’s him or the puppy-sized brain doing it, but one of them wails. The aggressive barking gets a lot more aggressive, and glass shatters and fabric rips, and the magic-user shrieks “Fuck this!”, and magic light spills everywhere as the air makes a tearing sound, and then his voice cuts off and all the light vanishes in a blink, and Krypto stops barking.
“Wuff?” Krypto says into the empty echoing store.
The puppy curls up into a tiny, trembling little ball underneath the shelf and sobs.
157 notes
·
View notes
Text
🌸 Soft Pink Intro Loading Screen Override for SIMS 3
Tired of the boring sims 3 loading screen when you first open your game? Are you looking for a much more girly loading screen? I present to you a coquette inspired intro loading screen override, perfect for those who love a more pastel and girly vibe. More info & download links under the cut!
🍰INFORMATION
♡ This override will replace the default loading screen no matter which pack you installed last.
♡ You can only have ONE intro loading screen at a time
♡ This loading screen might look slightly different depending on your monitor and gshade/reshade. This screenshot was taken without any shaders.
♡ Compatiable with version 1.69.47.024017
♡ Ensure to always read my TOU
♡ Credit has been given to the relevant users/softwares
🍰WHERE TO PUT IT
⚠ MUST BE PUT IN THE OVERRIDES FOLDER ESPECIALLY IF YOU HAVE A UI RECOLOR
Documents > Electronic Arts > The Sims 3 > Mods > Overrides (or anywhere you have your sims 3 mods folder)
🍰DOWNLOAD
🌸Soft Pink Intro Loading Screen
🌸Patreon (alt)
Feel free to tag me if you use this override in your game, I'd love to see it! And if there is any problems don't hesitate to contact me <3
🍰CREDITS
♡ This interface was HEAVILY inspired by the USE YOUR HEART collection by @novabytesims for sims 4!
♡ I used the CLEAN UI LOADING SCREEN by @justmiha97 as the base for this loading screen so it's basically a recolour 🤭
♡ RawPixels for the icons you see in the hearts
♡ Blender 3.6, Photoshop 2021
🍰Terms Of Use (TOU)
♡ PERSONAL USE ONLY: My original cc & overrides are free for personal use in you Sims 3 game. DO NOT redistribute or claim as your own.
♡ CREDIT OF USAGE: If you share my cc in any way, please credit me.
♡ NO PAYWALLS: DO NOT put my cc behind any paywalls or adlinks such as linkvertise.
♡ REDISTRIBUTION POLICY: DO NOT reupload my cc on other sites. Please share my original download links to respect work put into my cc and spread the word.
♡ MODIFICATIONS: If you edit or recolour my cc, and want to share it, please give full credit where it's due.
#cozykhuwa cc#sims 3 cc#sims 3 custom content#sims 3 mods#sims 3 loading screen#ts3#ts3 simblr#ts3 cc#sims3cc#overrides
263 notes
·
View notes