#Web scraping Twitter data
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has 4 main sources of revenue.
Text
Twitter Data Scraping Services -Twitter Data Collection Services
Scrape data like profile handle, followers count, etc., using our Twitter data scraping services. Our Twitter data collection services are functional across the USA, UK, etc.
know more:
#Twitter Data Scraping Services#Twitter Data Collection Services#Scrape Data from Twitter Social Media App#Web scraping Twitter data#Twitter data scraper#Scrape Tweets data from Twitter
0 notes
Text
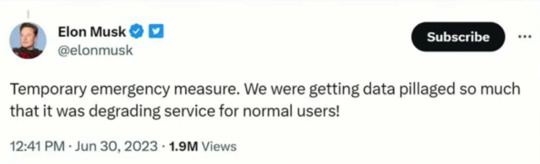
Fascinated that the owners of social media sites see API usage and web scraping as "data pillaging" -- immoral theft! Stealing! and yet, if you or I say that we should be paid for the content we create on social media the idea is laughed out of the room.
Social media is worthless without people and all the things we create do and say.
It's so valuable that these boys are trying to lock it in a vault.
#socail media#data mining#web scraping#twitter#reddit#you are the product#free service#free as in privacy invasion#pay me for that banger tweet you wretched nerd
8 notes
·
View notes
Text
How twitter scraping will help you fuel marketing efforts
Scraping data from relevant Twitter pages like competitors or influencers will help you run sentiment analysis and understand the market better. Twitter scraping will help you analyze market better and boost conversion. Read more
1 note
·
View note
Text
year in review - hockey rpf on ao3

hello!! the annual ao3 year in review had some friends and i thinking - wouldn't it be cool if we had a hockey rpf specific version of that. so i went ahead and collated the data below!!
i start with a broad overview, then dive deeper into the 3 most popular ships this year (with one bonus!)
if any images appear blurry, click on them to expand and they should become clear!
₊˚⊹♡ . ݁₊ ⊹ . ݁˖ . ݁𐙚 ‧₊˚ ⋅. ݁
before we jump in, some key things to highlight: - CREDIT TO: the webscraping part of my code heavily utilized the ao3 wrapped google colab code, as lovingly created by @kyucultures on twitter, as the main skeleton. i tweaked a couple of things but having it as a reference saved me a LOT of time and effort as a first time web scraper!!! thank you stranger <3 - please do NOT, under ANY circumstances, share any part of this collation on any other website. please do not screenshot or repost to twitter, tiktok, or any other public social platform. thank u!!! T_T - but do feel free to send requests to my inbox! if you want more info on a specific ship, tag, or you have a cool idea or wanna see a correlation between two variables, reach out and i should be able to take a look. if you want to take a deeper dive into a specific trope not mentioned here/chapter count/word counts/fic tags/ship tags/ratings/etc, shoot me an ask!
˚ . ˚ . . ✦ ˚ . ★⋆. ࿐࿔
with that all said and done... let's dive into hockey_rpf_2024_wrapped_insanity.ipynb
BIG PICTURE OVERVIEW
i scraped a total of 4266 fanfics that dated themselves as published or finished in the year 2024. of these 4000 odd fanfics, the most popular ships were:

Note: "Minor or Background Relationship(s)" clocked in at #9 with 91 fics, but I removed it as it was always a secondary tag and added no information to the chart. I did not discern between primary ship and secondary ship(s) either!
breaking down the 5 most popular ships over the course of the year, we see:

super interesting to see that HUGE jump for mattdrai in june/july for the stanley cup final. the general lull in the offseason is cool to see as well.
as for the most popular tags in all 2024 hockey rpf fic...

weee like our fluff. and our established relationships. and a little H/C never hurt no one.
i got curious here about which AUs were the most popular, so i filtered down for that. note that i only regex'd for tags that specifically start with "Alternate Universe - ", so A/B/O and some other stuff won't appear here!

idk it was cool to me.
also, here's a quick breakdown of the ratings % for works this year:

and as for the word counts, i pulled up a box plot of the top 20 most popular ships to see how the fic length distribution differed amongst ships:

mattdrai-ers you have some DEDICATION omg. respect
now for the ship by ship break down!!
₊ . ݁ ݁ . ⊹ ࣪ ˖͙͘͡★ ⊹ .
#1 MATTDRAI
most popular ship this year. peaked in june/july with the scf. so what do u people like to write about?

fun fun fun. i love that the scf is tagged there like yes actually she is also a main character
₊ . ݁ ݁ . ⊹ ࣪ ˖͙͘͡★ ⊹ .
#2 SIDGENO
(my babies) top tags for this ship are:

folks, we are a/b/o fiends and we cannot lie. thank you to all the selfless authors for feeding us good a/b/o fic this year. i hope to join your ranks soon.
(also: MPREG. omega sidney crosby. alpha geno. listen, the people have spoken, and like, i am listening.)
₊ . ݁ ݁ . ⊹ ࣪ ˖͙͘͡★ ⊹ .
#3 NICOJACK
top tags!!

it seems nice and cozy over there... room for one more?
₊ . ݁ ݁ . ⊹ ࣪ ˖͙͘͡★ ⊹ .
BONUS: JDTZ.
i wasnt gonna plot this but @marcandreyuri asked me if i could take a look and the results are so compelling i must include it. are yall ok. do u need a hug

top tags being h/c, angst, angst, TRADES, pining, open endings... T_T katie said its a "torture vortex" and i must concurr
₊ . ݁ ݁ . ⊹ ࣪ ˖͙͘͡★ ⊹ .
BONUS BONUS: ALPHA/BETA/OMEGA
as an a/b/o enthusiast myself i got curious as to what the most popular ships were within that tag. if you want me to take a look about this for any other tag lmk, but for a/b/o, as expected, SID GENO ON TOP BABY!:

thats all for now!!! if you have anything else you are interested in seeing the data for, send me an ask and i'll see if i can get it to ya!
#fanfic#sidgeno#evgeni malkin#hockey rpf#sidney crosby/evgeni malkin#hockeyrpf#hrpf fic#sidgeno fic#sidney crosby#hockeyrpf wrapped 2024#leon draisaitl#matthew tkachuk#mattdrai#leon draisaitl/matthew tkachuk#nicojack#nico hischier#nico hischier/jack hughes#jack hughes#jamie drysdale#trevor zegras#jdtz#jamie drysdale/trevor zegras#pittsburgh penguins#edmonton oilers#florida panthers#new jersey devils
473 notes
·
View notes
Note
Wait, I just read you use stable diffusion. I don't condone that, due to it using data scraped from the web to train on. You using the models trained on your own art is fine though.
This is exactly what I do. Installed in my laptop, consuming my own resources and ram. I NEVER agreed nor supported people who uses stolen works to create their “stuff”. If most of you were following me in Twitter for the past years you should know that.
Simply as this.
Btw, our mind is a “custom model” trained with millions of other artists works since we are born. But this is ok? Funny times.
How easy to point what is out of us, and how hard to recognize what we have inside. Isn’t it?👀👍
267 notes
·
View notes
Text
Humans now share the web equally with bots, according to a major new report – as some fear that the internet is dying. In recent months, the so-called “dead internet theory” has gained new popularity. It suggests that much of the content online is in fact automatically generated, and that the number of humans on the web is dwindling in comparison with bot accounts. Now a new report from cyber security company Imperva suggests that it is increasingly becoming true. Nearly half, 49.6 per cent, of all internet traffic came from bots last year, its “Bad Bot Report” indicates. That is up 2 per cent in comparison with last year, and is the highest number ever seen since the report began in 2013. In some countries, the picture is worse. In Ireland, 71 per cent of internet traffic is automated, it said. Some of that rise is the result of the adoption of generative artificial intelligence and large language models. Companies that build those systems use bots scrape the internet and gather data that can then be used to train them. Some of those bots are becoming increasingly sophisticated, Imperva warned. More and more of them come from residential internet connections, which makes them look more legitimate. “Automated bots will soon surpass the proportion of internet traffic coming from humans, changing the way that organizations approach building and protecting their websites and applications,” said Nanhi Singh, general manager for application security at Imperva. “As more AI-enabled tools are introduced, bots will become omnipresent.”
236 notes
·
View notes
Text
NO AI
TL;DR: almost all social platforms are stealing your art and use it to train generative AI (or sell your content to AI developers); please beware and do something. Or don’t, if you’re okay with this.
Which platforms are NOT safe to use for sharing you art:
Facebook, Instagram and all Meta products and platforms (although if you live in the EU, you can forbid Meta to use your content for AI training)
Reddit (sold out all its content to OpenAI)
Twitter
Bluesky (it has no protection from AI scraping and you can’t opt out from 3rd party data / content collection yet)
DeviantArt, Flikr and literally every stock image platform (some didn’t bother to protect their content from scraping, some sold it out to AI developers)
Here’s WHAT YOU CAN DO:
1. Just say no:
Block all 3rd party data collection: you can do this here on Tumblr (here’s how); all other platforms are merely taking suggestions, tbh
Use Cara (they can’t stop illegal scraping yet, but they are currently working with Glaze to built in ‘AI poisoning’, so… fingers crossed)
2. Use art style masking tools:
Glaze: you can a) download the app and run it locally or b) use Glaze’s free web service, all you need to do is register. This one is a fav of mine, ‘cause, unlike all the other tools, it doesn’t require any coding skills (also it is 100% non-commercial and was developed by a bunch of enthusiasts at the University of Chicago)
Anti-DreamBooth: free code; it was originally developed to protect personal photos from being used for forging deepfakes, but it works for art to
Mist: free code for Windows; if you use MacOS or don’t have powerful enough GPU, you can run Mist on Google’s Colab Notebook
(art style masking tools change some pixels in digital images so that AI models can’t process them properly; the changes are almost invisible, so it doesn’t affect your audiences perception)
3. Use ‘AI poisoning’ tools
Nightshade: free code for Windows 10/11 and MacOS; you’ll need GPU/CPU and a bunch of machine learning libraries to use it though.
4. Stay safe and fuck all this corporate shit.
75 notes
·
View notes
Text
I hope the Internet blows up.
I hope that every bit centralized platform chokes on its infinite growth and rent seeking until everyone starts making smaller platforms and site corners again.
I hope discord goes next so everyone migrates to shit like revolt or other small char clients.
I hope bluesky dies in 5 years because it's trying to be the new Twitter and the needs of that will outgrow how much money they can make so quickly under such late stage capitalism.
I hope Tumblr goes after.
I hope everyone learns to make sites again, I hope forums come back, I hope people start pioneering new free video sharing sites that you don't have to pay a fucking subscription to use.
I hope this proto web 3 we exist in dies and we get knocked back to web 2 or 1.5
This shit is a joke. The Internet fucking sucks now. Monoliths of minimalist garbage infinite adspace trackers selling data racist homophobic transphobic moderation content censoring generative content scraping art theft that uses ten billion gallons of water and kills a thousand trees every time someone makes am excuse that they're just too poor off to be an artist and this is the only way they can do it copyright striking bullshit preservation becoming impossible "intellectual property" and monetary incentives
I hope it all blows up and phones that do less come back into style.
Im tired, I'm angry, I barely got to experience the world I grew up in before it was drawn and quartered to be sold like butcher paper wrapped nostalgia.
Fuck this.
8 notes
·
View notes
Text
pulling out a section from this post (a very basic breakdown of generative AI) for easier reading;
AO3 and Generative AI
There are unfortunately some massive misunderstandings in regards to AO3 being included in LLM training datasets. This post was semi-prompted by the ‘Knot in my name’ AO3 tag (for those of you who haven’t heard of it, it’s supposed to be a fandom anti-AI event where AO3 writers help “further pollute” AI with Omegaverse), so let’s take a moment to address AO3 in conjunction with AI. We’ll start with the biggest misconception:
1. AO3 wasn’t used to train generative AI.
Or at least not anymore than any other internet website. AO3 was not deliberately scraped to be used as LLM training data.
The AO3 moderators found traces of the Common Crawl web worm in their servers. The Common Crawl is an open data repository of raw web page data, metadata extracts and text extracts collected from 10+ years of web crawling. Its collective data is measured in petabytes. (As a note, it also only features samples of the available pages on a given domain in its datasets, because its data is freely released under fair use and this is part of how they navigate copyright.) LLM developers use it and similar web crawls like Google’s C4 to bulk up the overall amount of pre-training data.
AO3 is big to an individual user, but it’s actually a small website when it comes to the amount of data used to pre-train LLMs. It’s also just a bad candidate for training data. As a comparison example, Wikipedia is often used as high quality training data because it’s a knowledge corpus and its moderators put a lot of work into maintaining a consistent quality across its web pages. AO3 is just a repository for all fanfic -- it doesn’t have any of that quality maintenance nor any knowledge density. Just in terms of practicality, even if people could get around the copyright issues, the sheer amount of work that would go into curating and labeling AO3’s data (or even a part of it) to make it useful for the fine-tuning stages most likely outstrips any potential usage.
Speaking of copyright, AO3 is a terrible candidate for training data just based on that. Even if people (incorrectly) think fanfic doesn’t hold copyright, there are plenty of books and texts that are public domain that can be found in online libraries that make for much better training data (or rather, there is a higher consistency in quality for them that would make them more appealing than fic for people specifically targeting written story data). And for any scrapers who don’t care about legalities or copyright, they’re going to target published works instead. Meta is in fact currently getting sued for including published books from a shadow library in its training data (note, this case is not in regards to any copyrighted material that might’ve been caught in the Common Crawl data, its regarding a book repository of published books that was scraped specifically to bring in some higher quality data for the first training stage). In a similar case, there’s an anonymous group suing Microsoft, GitHub, and OpenAI for training their LLMs on open source code.
Getting back to my point, AO3 is just not desirable training data. It’s not big enough to be worth scraping for pre-training data, it’s not curated enough to be considered for high quality data, and its data comes with copyright issues to boot. If LLM creators are saying there was no active pursuit in using AO3 to train generative AI, then there was (99% likelihood) no active pursuit in using AO3 to train generative AI.
AO3 has some preventative measures against being included in future Common Crawl datasets, which may or may not work, but there’s no way to remove any previously scraped data from that data corpus. And as a note for anyone locking their AO3 fics: that might potentially help against future AO3 scrapes, but it is rather moot if you post the same fic in full to other platforms like ffn, twitter, tumblr, etc. that have zero preventative measures against data scraping.
2. A/B/O is not polluting generative AI
…I’m going to be real, I have no idea what people expected to prove by asking AI to write Omegaverse fic. At the very least, people know A/B/O fics are not exclusive to AO3, right? The genre isn’t even exclusive to fandom -- it started in fandom, sure, but it expanded to general erotica years ago. It’s all over social media. It has multiple Wikipedia pages.
More to the point though, omegaverse would only be “polluting” AI if LLMs were spewing omegaverse concepts unprompted or like…associated knots with dicks more than rope or something. But people asking AI to write omegaverse and AI then writing omegaverse for them is just AI giving people exactly what they asked for. And…I hate to point this out, but LLMs writing for a niche the LLM trainers didn’t deliberately train the LLMs on is generally considered to be a good thing to the people who develop LLMs. The capability to fill niches developers didn’t even know existed increases LLMs’ marketability. If I were a betting man, what fandom probably saw as a GOTCHA moment, AI people probably saw as a good sign of LLMs’ future potential.
3. Individuals cannot affect LLM training datasets.
So back to the fandom event, with the stated goal of sabotaging AI scrapers via omegaverse fic.
…It’s not going to do anything.
Let’s add some numbers to this to help put things into perspective:
LLaMA’s 65 billion parameter model was trained on 1.4 trillion tokens. Of that 1.4 trillion tokens, about 67% of the training data was from the Common Crawl (roughly ~3 terabytes of data).
3 terabytes is 3,000,000,000 kilobytes.
That’s 3 billion kilobytes.
According to a news article I saw, there has been ~450k words total published for this campaign (*this was while it was going on, that number has probably changed, but you’re about to see why that still doesn’t matter). So, roughly speaking, ~450k of text is ~1012 KB (I’m going off the document size of a plain text doc for a fic whose word count is ~440k).
So 1,012 out of 3,000,000,000.
Aka 0.000034%.
And that 0.000034% of 3 billion kilobytes is only 2/3s of the data for the first stage of training.
And not to beat a dead horse, but 0.000034% is still grossly overestimating the potential impact of posting A/B/O fic. Remember, only parts of AO3 would get scraped for Common Crawl datasets. Which are also huge! The October 2022 Common Crawl dataset is 380 tebibytes. The April 2021 dataset is 320 tebibytes. The 3 terabytes of Common Crawl data used to train LLaMA was randomly selected data that totaled to less than 1% of one full dataset. Not to mention, LLaMA’s training dataset is currently on the (much) larger size as compared to most LLM training datasets.
I also feel the need to point out again that AO3 is trying to prevent any Common Crawl scraping in the future, which would include protection for these new stories (several of which are also locked!).
Omegaverse just isn’t going to do anything to AI. Individual fics are going to do even less. Even if all of AO3 suddenly became omegaverse, it’s just not prominent enough to influence anything in regards to LLMs. You cannot affect training datasets in any meaningful way doing this. And while this might seem really disappointing, this is actually a good thing.
Remember that anything an individual can do to LLMs, the person you hate most can do the same. If it were possible for fandom to corrupt AI with omegaverse, fascists, bigots, and just straight up internet trolls could pollute it with hate speech and worse. AI already carries a lot of biases even while developers are actively trying to flatten that out, it’s good that organized groups can’t corrupt that deliberately.
#generative ai#pulling this out wasnt really prompted by anything specific#so much as heard some repeated misconceptions and just#sighs#nope#incorrect#u got it wrong#sorry#unfortunately for me: no consistent tag to block#sigh#ao3
101 notes
·
View notes
Text
Social Media and Privacy Concerns!!! What You Need to Know???
In a world that is becoming more digital by the day, social media has also become part of our day-to-day lives. From the beginning of sharing personal updates to networking with professionals, social media sites like Facebook, Instagram, and Twitter have changed the way we communicate. However, concerns over privacy have also grown, where users are wondering what happens to their personal information. If you use social media often, it is important to be aware of these privacy risks. In this article, we will outline the main issues and the steps you need to take to protect your online data privacy. (Related: Top 10 Pros and Cons of Social media)

1. How Social Media Platforms Scrape Your Data The majority of social media platforms scrape plenty of user information, including your: ✅ Name, email address, and phone number ✅ Location and web browsing history ✅ Likes, comments, and search history-derived interests. Although this enhances the user experience as well as advertising, it has serious privacy issues. (Read more about social media pros and cons here) 2. Risks of Excessive Sharing Personal Information Many users unknowingly expose themselves to security risks through excessive sharing of personal information. Posting details of your daily routine, location, or personal life can lead to: ⚠️ Identity theft ⚠️Stalking and harassment ⚠️ Cyber fraud

This is why you need to alter your privacy settings and be careful about what you post on the internet. (Read this article to understand how social media affects users.) 3. The Role of Third-Party Apps in Data Breaches Did you register for a site with Google or Facebook? Handy, maybe, but in doing so, you're granting apps access to look at your data, normally more than is necessary. Some high profile privacy scandals, the Cambridge Analytica one being an example, have shown how social media information can be leveraged for in politics and advertising. To minimize danger: 👍Regularly check app permissions 👍Don't sign up multiple accounts where you don't need to 👍Strong passwords and two-factor authentication To get an in-depth overview of social media's impact on security, read this detailed guide. 4. How Social Media Algorithms Follow You You may not realize this, but social media algorithms are tracking you everywhere. From the likes you share to the amount of time you watch a video, sites monitor it all through AI-driven algorithms that learn from behavior and build personalized feeds. Though it can drive user engagement, it also: ⚠️ Forms filter bubbles that limit different perspectives ⚠️ Increases data exposure in case of hacks ⚠️ Increases ethical concerns around online surveillance Understanding the advantages and disadvantages of social media will help you make an informed decision. (Find out more about it here) 5. Maintaining Your Privacy: Real-Life Tips

To protect your personal data on social media: ✅ Update privacy settings to limit sharing of data ✅ Be cautious when accepting friend requests from unknown people ✅ Think before you post—consider anything shared online can be seen by others ✅ Use encrypted messaging apps for sensitive conversations These small habits can take you a long way in protecting your online existence. (For more detailed information, read this article) Final Thoughts Social media is a powerful tool that connects people, companies, and communities. There are privacy concerns, though, and you need to be clever about how your data is being utilized. Being careful about what you share, adjusting privacy settings, and using security best practices can enable you to enjoy the benefits of social media while being safe online. Interested in learning more about how social media influences us? Check out our detailed article on the advantages and disadvantages of social media and the measures to be taken to stay safe on social media.
#social media#online privacy#privacymatters#data privacy#digital privacy#hacking#identity theft#data breach#socialmediaprosandcons#social media safety#cyber security#social security
2 notes
·
View notes
Text
The news of Tumblr getting a massive staff cut inevitably make me expect the worse, so here's a reminder of where to find me:
MAPPAPAPA: my website. Shrines, store, comics, fics, event archives, any and all things that I feel like making or sharing end up here eventually.
Fediverse: on blorbo.social, my chattiest social media. Mostly talk about what I'm playing or watching at the moment, post art and occasionally WIPs.
Twitter: my activity has declined heavily with the news of data scraping for AI, so all art shared here is actually posted to Poipiku.
Other less active haunts are listed on the links page of my site.
This blog is currently my only active gallery for older and current art, so if (when) it goes down I'll be back to square one. I might start building galleries for my site in the near future if I get motivated enough. On the flip side, there's some of my R18 work there that you can't see anywhere else. Thanks for that, modern era corpo-bleached web!
I'll continue to share my art here whenever possible. This is a "just in case" post. Thanks for reading!
20 notes
·
View notes
Text
📊 Unlocking Trading Potential: The Power of Alternative Data 📊
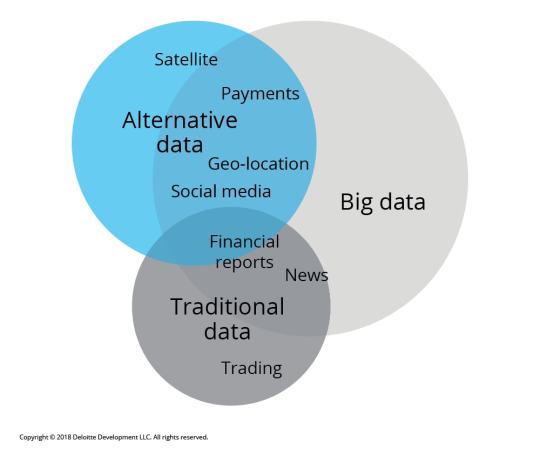
In the fast-paced world of trading, traditional data sources—like financial statements and market reports—are no longer enough. Enter alternative data: a game-changing resource that can provide unique insights and an edge in the market. 🌐
What is Alternative Data? Alternative data refers to non-traditional data sources that can inform trading decisions. These include:
Social Media Sentiment: Analyzing trends and sentiments on platforms like Twitter and Reddit can offer insights into public perception of stocks or market movements. 📈
Satellite Imagery: Observing traffic patterns in retail store parking lots can indicate sales performance before official reports are released. 🛰️
Web Scraping: Gathering data from e-commerce websites to track product availability and pricing trends can highlight shifts in consumer behavior. 🛒
Sensor Data: Utilizing IoT devices to track activity in real-time can give traders insights into manufacturing output and supply chain efficiency. 📡
How GPT Enhances Data Analysis With tools like GPT, traders can sift through vast amounts of alternative data efficiently. Here’s how:
Natural Language Processing (NLP): GPT can analyze news articles, earnings calls, and social media posts to extract key insights and sentiment analysis. This allows traders to react swiftly to market changes.
Predictive Analytics: By training GPT on historical data and alternative data sources, traders can build models to forecast price movements and market trends. 📊
Automated Reporting: GPT can generate concise reports summarizing alternative data findings, saving traders time and enabling faster decision-making.
Why It Matters Incorporating alternative data into trading strategies can lead to more informed decisions, improved risk management, and ultimately, better returns. As the market evolves, staying ahead of the curve with innovative data strategies is essential. 🚀
Join the Conversation! What alternative data sources have you found most valuable in your trading strategy? Share your thoughts in the comments! 💬
#Trading #AlternativeData #GPT #Investing #Finance #DataAnalytics #MarketInsights
2 notes
·
View notes
Text
The open internet once seemed inevitable. Now, as global economic woes mount and interest rates climb, the dream of the 2000s feels like it’s on its last legs. After abruptly blocking access to unregistered users at the end of last month, Elon Musk announced unprecedented caps on the number of tweets—600 for those of us who aren’t paying $8 a month—that users can read per day on Twitter. The move follows the platform’s controversial choice to restrict third-party clients back in January.
This wasn’t a standalone event. Reddit announced in April that it would begin charging third-party developers for API calls this month. The Reddit client Apollo would have to pay more than $20 million a year under new pricing, so it closed down, triggering thousands of subreddits to go dark in protest against Reddit’s new policy. The company went ahead with its plan anyway.
Leaders at both companies have blamed this new restrictiveness on AI companies unfairly benefitting from open access to data. Musk has said that Twitter needs rate limits because AI companies are scraping its data to train large language models. Reddit CEO Steve Huffman has cited similar reasons for the company’s decision to lock down its API ahead of a potential IPO this year.
These statements mark a major shift in the rhetoric and business calculus of Silicon Valley. AI serves as a convenient boogeyman, but it is a distraction from a more fundamental pivot in thinking. Whereas open data and protocols were once seen as the critical cornerstone of successful internet business, technology leaders now see these features as a threat to the continued profitability of their platforms.
It wasn’t always this way. The heady days of Web 2.0 were characterized by a celebration of the web as a channel through which data was abundant and widely available. Making data open through an API or some other means was considered a key way to increase a company’s value. Doing so could also help platforms flourish as developers integrated the data into their own apps, users enriched datasets with their own contributions, and fans shared products widely across the web. The rapid success of sites like Google Maps—which made expensive geospatial data widely available to the public for the first time—heralded an era where companies could profit through free, mass dissemination of information.
“Information Wants To Be Free” became a rallying cry. Publisher Tim O’Reilly would champion the idea that business success in Web 2.0 depended on companies “disagreeing with the consensus” and making data widely accessible rather than keeping it private. Kevin Kelly marveled in WIRED in 2005 that “when a company opens its databases to users … [t]he corporation’s data becomes part of the commons and an invitation to participate. People who take advantage of these capabilities are no longer customers; they’re the company’s developers, vendors, skunk works, and fan base.” Investors also perceived the opportunity to generate vast wealth. Google was “most certainly the standard bearer for Web 2.0,” and its wildly profitable model of monetizing free, open data was deeply influential to a whole generation of entrepreneurs and venture capitalists.
Of course, the ideology of Web 2.0 would not have evolved the way it did were it not for the highly unusual macroeconomic conditions of the 2000s and early 2010s. Thanks to historically low interest rates, spending money on speculative ventures was uniquely possible. Financial institutions had the flexibility on their balance sheets to embrace the idea that the internet reversed the normal laws of commercial gravity: It was possible for a company to give away its most valuable data and still get rich quick. In short, a zero interest-rate policy, or ZIRP, subsidized investor risk-taking on the promise that open data would become the fundamental paradigm of many Google-scale companies, not just a handful.
Web 2.0 ideologies normalized much of what we think of as foundational to the web today. User tagging and sharing features, freely syndicated and embeddable links to content, and an ecosystem of third-party apps all have their roots in the commitments made to build an open web. Indeed, one of the reasons that the recent maneuvers of Musk and Huffman seem so shocking is that we have come to expect data will be widely and freely available, and that platforms will be willing to support people that build on it.
But the marriage between the commercial interests of technology companies and the participatory web has always been one of convenience. The global campaign by central banks to curtail inflation through aggressive interest rate hikes changes the fundamental economics of technology. Rather than facing a landscape of investors willing to buy into a hazy dream of the open web, leaders like Musk and Huffman now confront a world where clear returns need to be seen today if not yesterday.
This presages major changes ahead for the design of the internet and the rights of users. Twitter and Reddit are pioneering an approach to platform management (or mismanagement) that will likely spread elsewhere across the web. It will become increasingly difficult to access content without logging in, verifying an identity, or paying a toll. User data will become less exportable and less shareable, and there will be increasingly fewer expectations that it will be preserved. Third-parties that have relied on the free flow of data online—from app-makers to journalists—will find APIs ever more expensive to access and scraping harder than ever before.
We should not let the open web die a quiet death. No doubt much of the foundational rhetoric of Web 2.0 is cringeworthy in the harsh light of 2023. But it is important to remember that the core project of building a participatory web where data can be shared, improved, critiqued, remixed, and widely disseminated by anyone is still genuinely worthwhile.
The way the global economic landscape is shifting right now creates short-sighted incentives toward closure. In response, the open web ought to be enshrined as a matter of law. New regulations that secure rights around the portability of user data, protect the continued accessibility of crucial APIs to third parties, and clarify the long-ambiguous rules surrounding scraping would all help ensure that the promise of a free, dynamic, competitive internet can be preserved in the coming decade.
For too long, advocates for the open web have implicitly relied on naive beliefs that the network is inherently open, or that web companies would serve as unshakable defenders of their stated values. The opening innings of the post-ZIRP world show how broader economic conditions have actually played the larger role in architecting how the internet looks and feels to this point. Believers in a participatory internet need to reach for stronger tools to mitigate the effects of these deep economic shifts, ensuring that openness can continue to be embedded into the spaces that we inhabit online.
WIRED Opinion publishes articles by outside contributors representing a wide range of viewpoints. Read more opinions here. Submit an op-ed at [email protected].
19 notes
·
View notes
Text
For Artists on Tumble
Because of the stinky stinky AI stuff tumble is adding to our webbed site tm make sure to use either GLAZE AND/OR NIGHTSHADE for anything you upload online to protect it from data scraping (link to the Twitter below)
4 notes
·
View notes
Text
Cakelin Fable over at TikTok scraped the information from Project N95 a few months ago after Project N95 announcing shutting down December 18, 2023 (archived copy of New York Times article) then compiled the data into an Excel spreadsheet [.XLSX, 18.2 MB] with Patrick from PatricktheBioSTEAMist.
You can access the back up files above.
The webpage is archived to Wayback Machine.
The code for the web-scraping project can be found over at GitHub.
Cakelin's social media details:
Website
Beacons
TikTok
Notion
Medium
Substack
X/Twitter
Bluesky
Instagram
Pinterest
GitHub
Redbubble
Cash App
Patrick's social media details:
Linktree
YouTube
TikTok
Notion
Venmo
#Project N95#We Keep Us Safe#COVID-19#SARS-CoV-2#Mask Up#COVID is not over#pandemic is not over#COVID resources#COVID-19 resources#data preservation#web archival#web scraping#SARS-CoV-2 resources#Wear A Mask
2 notes
·
View notes
Text
Beyond the Books: Real-World Coding Projects for Aspiring Developers
One of the best colleges in Jaipur, which is Arya College of Engineering & I.T. They transitioning from theoretical learning to hands-on coding is a crucial step in a computer science education. Real-world projects bridge this gap, enabling students to apply classroom concepts, build portfolios, and develop industry-ready skills. Here are impactful project ideas across various domains that every computer science student should consider:
Web Development
Personal Portfolio Website: Design and deploy a website to showcase your skills, projects, and resume. This project teaches HTML, CSS, JavaScript, and optionally frameworks like React or Bootstrap, and helps you understand web hosting and deployment.
E-Commerce Platform: Build a basic online store with product listings, shopping carts, and payment integration. This project introduces backend development, database management, and user authentication.
Mobile App Development
Recipe Finder App: Develop a mobile app that lets users search for recipes based on ingredients they have. This project covers UI/UX design, API integration, and mobile programming languages like Java (Android) or Swift (iOS).
Personal Finance Tracker: Create an app to help users manage expenses, budgets, and savings, integrating features like OCR for receipt scanning.
Data Science and Analytics
Social Media Trends Analysis Tool: Analyze data from platforms like Twitter or Instagram to identify trends and visualize user behavior. This project involves data scraping, natural language processing, and data visualization.
Stock Market Prediction Tool: Use historical stock data and machine learning algorithms to predict future trends, applying regression, classification, and data visualization techniques.
Artificial Intelligence and Machine Learning
Face Detection System: Implement a system that recognizes faces in images or video streams using OpenCV and Python. This project explores computer vision and deep learning.
Spam Filtering: Build a model to classify messages as spam or not using natural language processing and machine learning.
Cybersecurity
Virtual Private Network (VPN): Develop a simple VPN to understand network protocols and encryption. This project enhances your knowledge of cybersecurity fundamentals and system administration.
Intrusion Detection System (IDS): Create a tool to monitor network traffic and detect suspicious activities, requiring network programming and data analysis skills.
Collaborative and Cloud-Based Applications
Real-Time Collaborative Code Editor: Build a web-based editor where multiple users can code together in real time, using technologies like WebSocket, React, Node.js, and MongoDB. This project demonstrates real-time synchronization and operational transformation.
IoT and Automation
Smart Home Automation System: Design a system to control home devices (lights, thermostats, cameras) remotely, integrating hardware, software, and cloud services.
Attendance System with Facial Recognition: Automate attendance tracking using facial recognition and deploy it with hardware like Raspberry Pi.
Other Noteworthy Projects
Chatbots: Develop conversational agents for customer support or entertainment, leveraging natural language processing and AI.
Weather Forecasting App: Create a user-friendly app displaying real-time weather data and forecasts, using APIs and data visualization.
Game Development: Build a simple 2D or 3D game using Unity or Unreal Engine to combine programming with creativity.
Tips for Maximizing Project Impact
Align With Interests: Choose projects that resonate with your career goals or personal passions for sustained motivation.
Emphasize Teamwork: Collaborate with peers to enhance communication and project management skills.
Focus on Real-World Problems: Address genuine challenges to make your projects more relevant and impressive to employers.
Document and Present: Maintain clear documentation and present your work effectively to demonstrate professionalism and technical depth.
Conclusion
Engaging in real-world projects is the cornerstone of a robust computer science education. These experiences not only reinforce theoretical knowledge but also cultivate practical abilities, creativity, and confidence, preparing students for the demands of the tech industry.
0 notes