#apache kafka developer
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
There are dozens of funny blogs to kill time on Tumblr.
Text
Real-Time Data Streaming: How Apache Kafka is Changing the Game
Introduction
In today’s fast-paced digital world, real-time data streaming has become more essential than ever because businesses now rely on instant data processing to make data-driven and informed decision-making. Apache Kafka, i.e., a distributed streaming platform for handling data in real time, is at the heart of this revolution. Whether you are an Apache Kafka developer or exploring Apache Kafka on AWS, this emerging technology can change the game of managing data streams. Let’s dive deep and understand how exactly Apache Kafka is changing the game.
Rise of Real-Time Data Streaming
The vast amount of data with businesses in the modern world has created a need for systems to process and analyze as it is produced. This amount of data has emerged due to the interconnections of business with other devices like social media, IoT, and cloud computing. Real-time data streaming enables businesses to use that data to unlock vast business opportunities and act accordingly.
However, traditional methods fall short here and are no longer sufficient for organizations that need real-time data insights for data-driven decision-making. Real-time data streaming requires a continuous flow of data from sources to the final destinations, allowing systems to analyze that information in less than milliseconds and generate data-driven patterns. However, building a scalable, reliable, and efficient real-time data streaming system is no small feat. This is where Apache Kafka comes into play.
About Apache Kafka
Apache Kafka is an open-source distributed event streaming platform that can handle large real-time data volumes. It is an open-source platform developed by the Apache Software Foundation. LinkedIn initially introduced the platform; later, in 2011, it became open-source.
Apache Kafka creates data pipelines and systems to manage massive volumes of data. It is designed to manage low-latency, high-throughput data streams. Kafka allows for the injection, processing, and storage of real-time data in a scalable and fault-tolerant way.
Kafka uses a publish-subscribe method in which:
Data (events/messages) are published to Kafka topics by producers.
Consumers read and process data from these subjects.
The servers that oversee Kafka's message dissemination are known as brokers.
ZooKeeper facilitates the management of Kafka's leader election and cluster metadata.
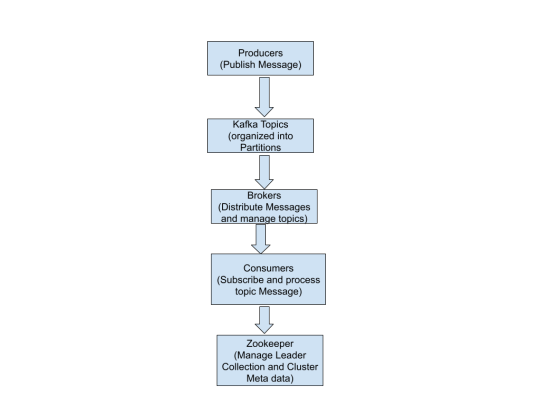
With its distributed architecture, fault tolerance, and scalability, Kafka is a reliable backbone for real-time data streaming and event-driven applications, ensuring seamless data flow across systems.
Why Apache Kafka Is A Game Changer
Real-time data processing helps organizations collect, process, and even deliver the data as it is generated while immediately ensuring the utmost insights and actions. Let’s understand the reasons why Kafka stands out in the competitive business world:
Real-Time Data Processing
Organizations generate vast amounts of data due to their interconnection with social media, IoT, the cloud, and more. This has raised the need for systems and tools that can react instantly and provide timely results. Kafka is a game-changer in this regard. It helps organizations use that data to track user behavior and take action accordingly.
Scalability and Fault Tolerance
Kafka's distributed architecture guarantees data availability and dependability even in the case of network or hardware failures. It is a reliable solution for mission-critical applications because it ensures data durability and recovery through replication and persistent storage.
Easy Integration
Kafka seamlessly connects with a variety of systems, such as databases, analytics platforms, and cloud services. Its ability to integrate effortlessly with these tools makes it an ideal solution for constructing sophisticated data pipelines.
Less Costly Solution
Kafka helps in reducing the cost of data processing and analyzing efficiently and ensures high performance of the businesses. By handling large volumes of data, Kafka also enhances scalability and reliability across distributed systems.
Apache Kafka on AWS: Unlocking Cloud Potential
Using Apache Kafka on ASW has recently become more popular because of the cloud’s advantages, like scalability, flexibility, and cost efficiency. Here, Kafka can be deployed in a number of ways, such as:
Amazon MSK (Managed Streaming for Apache Kafka): A fully managed service helps to make the deployment and management of Kafka very easy. Additionally, it handles infrastructure provisioning, scaling, and even maintenance and allows Apache Kafka developers to focus on building applications.
Self-Managed Kafka on EC2: This is apt for organizations that prefer full control of their Kafka clusters, as AWS EC2 provides the flexibility to deploy and manage Kafka instances.
The benefits of Apache Kafka on ASW are as follows:
Easy scaling of Kafka clusters as per the demand.
Ensures high availability and enables disaster recovery
Less costly because it uses a pay-as-you-go pricing model
The Future of Apache Kafka
Kafka’s role in the technology ecosystem will definitely grow with the increase in the demand for real-time data processing. Innovations like Kafka Streams and Kafka Connect are already expanding the role of Kafka and making real-time processing quite easy. Moreover, integrations with cloud platforms like AWS continuously drive the industry to adopt Kafka within different industries and expand its role.
Conclusion
Apache Kafka is continuously revolutionizing the organizations of modern times that are handling real-time data streaming and changing the actual game of businesses around the world by providing capabilities like flexibility, scalability, and seamless integration. Whether you are deploying Apache Kafka on AWS or working as an Apache Kafka developer, this technology can offer enormous possibilities for innovation in the digitally enabled business landscape.
Do you want to harness the full potential of your Apache Kafka systems? Look no further than Ksolves, where a team of seasoned Apache Kafka experts and developers stands out as a leading Apache Kafka development company with their client-centric approach and a commitment to excellence. With our extensive experience and expertise, we specialize in offering top-notch solutions tailored to your needs.
Do not let your data streams go untapped. Partner with leading partners like Ksolves today!
Visit Ksolves and get started!
#kafka apache#apache kafka on aws#apache kafka developer#apache cassandra consulting#certified developer for apache kafka
0 notes
Text



I try to make a balance between reading the book "Kafka: The Definitive Guide - 2nd Edition," doing Confluent course lab exercises, and a little bit of Udemy projects with Kafka as well. In the middle of the week, I'm making my homepage to showcase some portfolio stuff, which is not my priority at this time, but it involves a lot of coding as well.
Feeling like I can answer any interview questions about Kafka at this point, including the fundamentals, use cases, and examples of writing a pub/sub system in Java.
It's all about studying; it magically changes you inside and out. You're the same person, in the same place, but now capable of creating really good software with refined techniques.
#coding#developer#linux#programmer#programming#software#software development#student#study aesthetic#study blog#studyblr#studynotes#study#software engineering#self improvement#study motivation#university student#studying#student life#study routine#study room#java#apache kafka#softwareengineer#learn#learning#learnsomethingneweveryday#javaprogramming
46 notes
·
View notes
Text
Mastering Real-Time Data Flows: Associative’s Apache Kafka Expertise

The modern business landscape demands real-time data processing capabilities. From monitoring live sensor data to analyzing customer interactions, the ability to handle continuous streams of information has become essential. This is where Apache Kafka, a distributed streaming platform, and Associative’s Kafka development prowess come into play.
Understanding Apache Kafka
Apache Kafka is an open-source platform designed for building real-time data pipelines and streaming applications. Its core features include:
High-Throughput: Kafka can handle millions of messages per second, making it ideal for large-scale data-intensive applications.
Fault-Tolerance: Kafka’s distributed architecture provides resilience against node failures, ensuring your data remains available.
Scalability: Kafka seamlessly scales horizontally, allowing you to add more nodes as data volumes grow.
Publish-Subscribe Model: Kafka uses a pub-sub messaging pattern, enabling flexible communication between data producers and consumers.
The Associative Advantage in Kafka Development
Associative’s team of Apache Kafka specialists helps you harness the platform’s power to drive your business forward:
Real-Time Data Pipelines: We design and build scalable Kafka-powered pipelines for seamless real-time data ingestion, processing, and distribution.
Microservices Integration: We use Kafka to decouple microservices, ensuring reliable communication and fault tolerance in distributed applications.
IoT and Sensor Data: We build Kafka-centric solutions to manage the massive influx of data from IoT devices and sensors, enabling real-time insights.
Event-Driven Architectures: We help you leverage Kafka for event-driven architectures that promote responsiveness and agility across your systems.
Legacy System Modernization: We integrate Kafka to bring real-time capabilities to your legacy systems, bridging the gap between old and new.
Benefits of Partnering with Associative
Tailored Kafka Solutions: We tailor our solutions to your exact business requirements for a perfect fit.
Pune-Based Collaboration: Experience seamless interaction with our team, thanks to our shared time zone.
Focus on Results: We emphasize delivering measurable business outcomes through our Kafka solutions.
Proven Kafka Success
Associative’s portfolio of successful Kafka projects speaks for itself. Our expertise helps you:
Improve Operational Efficiency: Kafka-powered solutions can streamline processes, reducing costs and improving performance.
Enhance Customer Experiences: React to customer behavior in real-time, personalizing offerings and boosting satisfaction.
Enable Data-Driven Decision Making: Extract real-time insights from streaming data to inform strategic decisions.
Ready to Embrace Real-Time Data with Kafka?
Contact Associative today to learn how our Apache Kafka development services can transform how you handle and leverage real-time data. Let’s build a robust, scalable, and responsive data infrastructure for your business.
#Apache Kafka#developer#artificial intelligence#machine learning#ai technology#app development#mobile app development
0 notes
Text
What is Apache Kafka?
Apache Kafka is designed to handle real-time data feeds that provide a high-throughput, resilient, and scalable solution for processing and storing streams of records. The platform ensures durability by replicating data across multiple brokers in a cluster.
Kafka’s exceptional speed is coordinated by two key virtuosos:
Sequential I/O: Kafka addresses the perceived slowness of disks by brilliantly implementing Sequential I/O.
Zero Copy Principle: With this principle, Kafka avoids unnecessary data copies and reduces context switches between user and kernel modes, making it more efficient.
Why Kafka?
High performance: It has the capability to handle millions of messages per second
Non-volatile storage: It stores messages on disk, which enables durability and fault-tolerance
Distributed architecture: It can handle large amounts of data and scale horizontally by adding more machines to the cluster.
Learn more about Apache Kafka read our full blog - https://bit.ly/3urUEWF
#kafka#apache kafka#real time data analysis#real time database#nitor#nitor infotech services#nitor infotech#ascendion#software development#software engineering
0 notes
Text
Can Open Source Integration Services Speed Up Response Time in Legacy Systems?
Legacy systems are still a key part of essential business operations in industries like banking, logistics, telecom, and manufacturing. However, as these systems get older, they become less efficient—slowing down processes, creating isolated data, and driving up maintenance costs. To stay competitive, many companies are looking for ways to modernize without fully replacing their existing systems. One effective solution is open-source integration, which is already delivering clear business results.

Why Faster Response Time Matters
System response time has a direct impact on business performance. According to a 2024 IDC report, improving system response by just 1.5 seconds led to a 22% increase in user productivity and a 16% rise in transaction completion rates. This means increased revenue, customer satisfaction as well as scalability in industries where time is of great essence.
Open-source integration is prominent in this case. It can minimize latency, enhance data flow and make process automation easier by allowing easier communication between legacy systems and more modern applications. This makes the systems more responsive and quick.
Key Business Benefits of Open-Source Integration
Lower Operational Costs
Open-source tools like Apache Camel and Mule eliminate the need for costly software licenses. A 2024 study by Red Hat showed that companies using open-source integration reduced their IT operating costs by up to 30% within the first year.
Real-Time Data Processing
Traditional legacy systems often depend on delayed, batch-processing methods. With open-source platforms using event-driven tools such as Kafka and RabbitMQ, businesses can achieve real-time messaging and decision-making—improving responsiveness in areas like order fulfillment and inventory updates.
Faster Deployment Cycles: Open-source integration supports modular, container-based deployment. The 2025 GitHub Developer Report found that organizations using containerized open-source integrations shortened deployment times by 43% on average. This accelerates updates and allows faster rollout of new services.
Scalable Integration Without Major Overhauls
Open-source frameworks allow businesses to scale specific parts of their integration stack without modifying the core legacy systems. This flexibility enables growth and upgrades without downtime or the cost of a full system rebuild.
Industry Use Cases with High Impact
Banking
Integrating open-source solutions enhances transaction processing speed and improves fraud detection by linking legacy banking systems with modern analytics tools.
Telecom
Customer service becomes more responsive by synchronizing data across CRM, billing, and support systems in real time.
Manufacturing
Real-time integration with ERP platforms improves production tracking and inventory visibility across multiple facilities.
Why Organizations Outsource Open-Source Integration
Most internal IT teams lack skills and do not have sufficient resources to manage open-source integration in a secure and efficient manner. Businesses can also guarantee trouble-free setup and support as well as improved system performance by outsourcing to established providers. Top open-source integration service providers like Suma Soft, Red Hat Integration, Talend, TIBCO (Flogo Project), and Hitachi Vantara offer customized solutions. These help improve system speed, simplify daily operations, and support digital upgrades—without the high cost of replacing existing systems.
2 notes
·
View notes
Text
What is PHP Developer? A Complete Beginner’s Guide
visit the blog : https://penzu.com/public/9aeec77156b814b6
visit for more blogs :
https://dev.to/tpointtechblog/kickstart-your-coding-career-learn-typescript-today-4ogk
https://tpointtechblog.hashnode.dev/from-zero-to-dashboard-power-bi-tutorial-for-absolute-beginners
https://medium.com/@tpointtechblog/what-is-django-used-for-benefits-features-real-world-use-cases-67932cd53a3f
https://www.linkedin.com/pulse/what-apache-kafka-used-benefits-real-world-examples-udhav-khera-4makc
https://sites.google.com/view/what-is-my-sql/home
https://tpointtechblog.blogspot.com/2025/06/the-ultimate-nodejs-tutorial-for.html
0 notes
Text
Architecting for AI- Effective Data Management Strategies in the Cloud
What good is AI if the data feeding it is disorganized, outdated, or locked away in silos?
How can businesses unlock the full potential of AI in the cloud without first mastering the way they handle data?
And for professionals, how can developing Cloud AI skills shape a successful AI cloud career path?
These are some real questions organizations and tech professionals ask every day. As the push toward automation and intelligent systems grows, the spotlight shifts to where it all begins, data. If you’re aiming to become an AI cloud expert, mastering data management in the cloud is non-negotiable.
In this blog, we will explore human-friendly yet powerful strategies for managing data in cloud environments. These are perfect for businesses implementing AI in the cloud and individuals pursuing AI Cloud Certification.
1. Centralize Your Data, But Don’t Sacrifice Control
The first step to architecting effective AI systems is ensuring your data is all in one place, but with rules in place. Cloud AI skills come into play when configuring secure, centralized data lakes using platforms like AWS S3, Azure Data Lake, or Google Cloud Storage.
For instance, Airbnb streamlined its AI pipelines by unifying data into Amazon S3 while applying strict governance with AWS Lake Formation. This helped their teams quickly build and train models for pricing and fraud detection, without dealing with messy, inconsistent data.
Pro Tip-
Centralize your data, but always pair it with metadata tagging, cataloging, and access controls. This is a must-learn in any solid AI cloud automation training program.
2. Design For Scale: Elasticity Over Capacity
AI workloads are not static—they scale unpredictably. Cloud platforms shine when it comes to elasticity, enabling dynamic resource allocation as your needs grow. Knowing how to build scalable pipelines is a core part of AI cloud architecture certification programs.
One such example is Netflix. It handles petabytes of viewing data daily and processes it through Apache Spark on Amazon EMR. With this setup, they dynamically scale compute power depending on the workload, powering AI-based recommendations and content optimization.
Human Insight-
Scalability is not just about performance. It’s about not overspending. Smart scaling = cost-effective AI.
3. Don’t Just Store—Catalog Everything
You can’t trust what you can’t trace. A reliable data catalog and lineage system ensures AI models are trained on trustworthy data. Tools like AWS Glue or Apache Atlas help track data origin, movement, and transformation—a key concept for anyone serious about AI in the cloud.
To give you an example, Capital One uses data lineage tools to manage regulatory compliance for its AI models in credit risk and fraud detection. Every data point can be traced, ensuring trust in both model outputs and audits.
Why it matters-
Lineage builds confidence. Whether you’re a company building AI or a professional on an AI cloud career path, transparency is essential.
4. Build for Real-Time Intelligence
The future of AI is real-time. Whether it’s fraud detection, customer personalization, or predictive maintenance, organizations need pipelines that handle data as it flows in. Streaming platforms like Apache Kafka and AWS Kinesis are core technologies for this.
For example, Uber’s Michelangelo platform processes real-time location and demand data to adjust pricing and ETA predictions dynamically. Their cloud-native streaming architecture supports instant decision-making at scale.
Career Tip-
Mastering stream processing is key if you want to become an AI cloud expert. It’s the difference between reactive and proactive AI.
5. Bake Security and Privacy into Your Data Strategy
When you’re working with personal data, security isn’t optional��it’s foundational. AI architectures in the cloud must comply with GDPR, HIPAA, and other regulations, while also protecting sensitive information using encryption, masking, and access controls.
Salesforce, with its AI-powered Einstein platform, ensures sensitive customer data is encrypted and tightly controlled using AWS Key Management and IAM policies.
Best Practice-
Think “privacy by design.” This is a hot topic covered in depth during any reputable AI Cloud certification.
6. Use Tiered Storage to Optimize Cost and Speed
Not every byte of data is mission-critical. Some data is hot (frequently used), some cold (archived). An effective AI cloud architecture balances cost and speed with a multi-tiered storage strategy.
For instance, Pinterest uses Amazon S3 for high-access data, Glacier for archival, and caching layers for low-latency AI-powered recommendations. This approach keeps costs down while delivering fast, accurate results.
Learning Tip-
This is exactly the kind of cost-smart design covered in AI cloud automation training courses.
7. Support Cross-Cloud and Hybrid Access
Modern enterprises often operate across multiple cloud environments, and data can’t live in isolation. Cloud data architectures should support hybrid and multi-cloud scenarios to avoid vendor lock-in and enable agility.
Johnson & Johnson uses BigQuery Omni to analyze data across AWS and Azure without moving it. This federated approach supports AI use cases in healthcare, ensuring data residency and compliance.
Why it matters?
The future of AI is multi-cloud. Want to stand out? Pursue an AI cloud architecture certification that teaches integration, not just implementation.
Wrapping Up- Your Data Is the AI Foundation
Without well-architected data strategies, AI can’t perform at its best. If you’re leading cloud strategy as a CTO or just starting your journey to become an AI cloud expert, one thing becomes clear early on—solid data management isn’t optional. It’s the foundation that supports everything from smarter models to reliable performance. Without it, even the best AI tools fall short.
Here’s what to focus on-
Centralize data with control
Scale infrastructure on demand
Track data lineage and quality
Enable real-time processing
Secure data end-to-end
Store wisely with tiered solutions
Built for hybrid, cross-cloud access
Ready To Take the Next Step?
If you are looking forward to building smarter systems or your career, now is the time to invest in the future. Consider pursuing an AI Cloud Certification or an AI Cloud Architecture Certification. These credentials not only boost your knowledge but also unlock new opportunities on your AI cloud career path.
Consider checking AI CERTs AI+ Cloud Certification to gain in-demand Cloud AI skills, fast-track your AI cloud career path, and become an AI cloud expert trusted by leading organizations. With the right Cloud AI skills, you won’t just adapt to the future—you’ll shape it.
Enroll today!
0 notes
Link
0 notes
Text
The Data Engineering Evolution: Top Trends to Watch in 2025

Data engineering is the backbone of the data-driven world. It's the critical discipline that builds and maintains the robust pipelines and infrastructure essential for collecting, storing, transforming, and delivering data to data scientists, analysts, and business users. As data volumes explode and the demand for real-time insights intensifies, data engineering is evolving at an unprecedented pace.
As we move further into 2025, here are the top trends that are not just shaping, but fundamentally transforming, the data engineering landscape:
1. The AI/ML Infusion: Automation and Intelligence in Pipelines
Artificial Intelligence and Machine Learning are no longer just consumers of data; they are becoming integral to the data engineering process itself.
AI-Assisted Pipeline Development: Expect more tools leveraging AI to automate repetitive tasks like schema detection, data validation, anomaly detection, and even code generation for transformations. This empowers data engineers to focus on more complex architectural challenges rather than mundane scripting.
Intelligent Data Quality: AI will play a bigger role in real-time data quality monitoring and anomaly detection within pipelines. Instead of just flagging errors, AI systems will predict potential failures and even suggest resolutions.
Generative AI for Data Workflows: Generative AI's ability to understand natural language means it can assist in generating SQL queries, designing data models, and even documenting pipelines, significantly accelerating development cycles.
2. Real-Time Everything: The Demand for Instant Insights
The pace of business demands immediate insights, pushing data engineering towards real-time processing and streaming architectures.
Stream Processing Dominance: Technologies like Apache Kafka, Flink, and Spark Streaming will become even more central, enabling organizations to ingest, process, and analyze data as it's generated.
Edge Computing for Low Latency: As IoT devices proliferate, processing data closer to its source (at the "edge") will be crucial. This reduces latency, saves bandwidth, and enables faster decision-making for use cases like smart factories, autonomous vehicles, and real-time fraud detection.
Zero-ETL Architectures: The movement towards "zero-ETL" aims to minimize or eliminate data movement by enabling direct querying of operational databases or seamless integration with analytical stores, further reducing latency and complexity.
3. Data Mesh and Data Fabric: Decentralization and Interoperability
As data ecosystems grow, centralized data architectures struggle to keep up. Data Mesh and Data Fabric offer compelling alternatives.
Data Mesh: This paradigm promotes decentralized data ownership, treating data as a product owned by domain-specific teams. Data engineers will increasingly work within these domain teams, focusing on building "data products" that are discoverable, addressable, trustworthy, and secure.
Data Fabric: A data fabric acts as an integrated layer of data and analytics services across disparate data sources. It leverages active metadata, knowledge graphs, and AI to automate data discovery, integration, and governance, providing a unified view of data regardless of where it resides. Expect to see increasing synergy between Data Mesh and Data Fabric, with the latter often providing the underlying technical framework for the former.
4. Data Observability and Data Contracts: Building Trust and Reliability
With increased complexity, ensuring data quality and reliability becomes paramount.
Data Observability as a Must-Have: Moving beyond simple monitoring, data observability provides comprehensive insights into the health, quality, and lineage of data throughout its lifecycle. Tools will offer automated anomaly detection, root cause analysis, and proactive alerting to prevent "data downtime."
Data Contracts: Formalizing agreements between data producers and consumers (often referred to as "data contracts") will become a standard practice. These contracts define data schemas, quality expectations, and service level agreements (SLAs), fostering trust and enabling more robust, interconnected data systems.
5. Sustainability and Cost Optimization: Greener and Leaner Data
As data infrastructure scales, the environmental and financial costs become significant concerns.
Green Data Engineering: A growing focus on optimizing data pipelines and infrastructure for energy efficiency. This includes choosing cloud services with strong sustainability commitments, optimizing query performance, and adopting more efficient storage strategies.
FinOps for Data: Data engineers will increasingly be involved in cloud cost management (FinOps), optimizing resource allocation, identifying cost inefficiencies in data pipelines, and leveraging serverless architectures for pay-as-you-go pricing.
The data engineering role is evolving from primarily operational to increasingly strategic. Data engineers are becoming architects of data ecosystems, empowered by AI and automation, focused on delivering real-time, trustworthy, and scalable data solutions. Staying abreast of these trends is crucial for any data professional looking to thrive in the years to come.
0 notes
Text

Currently studying kafka and make my way to the Confluent Certificate Developer Apache Kafka (CCDAK) which is primary use Java and Kafka.
#study aesthetic#studying#study blog#study motivation#studyblr#student#university student#studyblr community#student life#software development#software#developer#software engineering#programmer#programming#coding#brazil#linux#self improvement#self love#selfworth
52 notes
·
View notes
Text
Big Data Analytics Training - Learn Hadoop, Spark

Big Data Analytics Training – Learn Hadoop, Spark & Boost Your Career
Meta Title: Big Data Analytics Training | Learn Hadoop & Spark Online Meta Description: Enroll in Big Data Analytics Training to master Hadoop and Spark. Get hands-on experience, industry certification, and job-ready skills. Start your big data career now!
Introduction: Why Big Data Analytics?
In today’s digital world, data is the new oil. Organizations across the globe are generating vast amounts of data every second. But without proper analysis, this data is meaningless. That’s where Big Data Analytics comes in. By leveraging tools like Hadoop and Apache Spark, businesses can extract powerful insights from large data sets to drive better decisions.
If you want to become a data expert, enrolling in a Big Data Analytics Training course is the first step toward a successful career.
What is Big Data Analytics?
Big Data Analytics refers to the complex process of examining large and varied data sets—known as big data—to uncover hidden patterns, correlations, market trends, and customer preferences. It helps businesses make informed decisions and gain a competitive edge.
Why Learn Hadoop and Spark?
Hadoop: The Backbone of Big Data
Hadoop is an open-source framework that allows distributed processing of large data sets across clusters of computers. It includes:
HDFS (Hadoop Distributed File System) for scalable storage
MapReduce for parallel data processing
Hive, Pig, and Sqoop for data manipulation
Apache Spark: Real-Time Data Engine
Apache Spark is a fast and general-purpose cluster computing system. It performs:
Real-time stream processing
In-memory data computing
Machine learning and graph processing
Together, Hadoop and Spark form the foundation of any robust big data architecture.
What You'll Learn in Big Data Analytics Training
Our expert-designed course covers everything you need to become a certified Big Data professional:
1. Big Data Basics
What is Big Data?
Importance and applications
Hadoop ecosystem overview
2. Hadoop Essentials
Installation and configuration
Working with HDFS and MapReduce
Hive, Pig, Sqoop, and Flume
3. Apache Spark Training
Spark Core and Spark SQL
Spark Streaming
MLlib for machine learning
Integrating Spark with Hadoop
4. Data Processing Tools
Kafka for data ingestion
NoSQL databases (HBase, Cassandra)
Data visualization using tools like Power BI
5. Live Projects & Case Studies
Real-time data analytics projects
End-to-end data pipeline implementation
Domain-specific use cases (finance, healthcare, e-commerce)
Who Should Enroll?
This course is ideal for:
IT professionals and software developers
Data analysts and database administrators
Engineering and computer science students
Anyone aspiring to become a Big Data Engineer
Benefits of Our Big Data Analytics Training
100% hands-on training
Industry-recognized certification
Access to real-time projects
Resume and job interview support
Learn from certified Hadoop and Spark experts
SEO Keywords Targeted
Big Data Analytics Training
Learn Hadoop and Spark
Big Data course online
Hadoop training and certification
Apache Spark training
Big Data online training with certification
Final Thoughts
The demand for Big Data professionals continues to rise as more businesses embrace data-driven strategies. By mastering Hadoop and Spark, you position yourself as a valuable asset in the tech industry. Whether you're looking to switch careers or upskill, Big Data Analytics Training is your pathway to success.
0 notes
Text
Django Tutorial for Beginners: Build Your First Web App
visit the blog: https://tpointtechblog.hashnode.dev/django-tutorial-for-beginners-build-your-first-web-app
visit for more blog: https://dev.to/tpointtechblog/getting-started-with-power-bi-beginners-guide-54ef
https://medium.com/@tpointtechblog/kafka-tutorial-learn-apache-kafka-with-practical-examples-bdd37de7a887
https://velog.io/@tpointtechblog/PHP-Tutorials-for-Web-Developers-Create-Dynamic-and-Interactive-Sites
https://qiita.com/Ronaldo2345/items/9504dd2165c42f388f05
https://www.linkedin.com/pulse/nodejs-tutorial-learn-backend-development-javascript-udhav-khera-gk7rc
https://www.patreon.com/user?u=169347449
0 notes
Text
Empowering Businesses with Advanced Data Engineering Solutions in Toronto – C Data Insights
In a rapidly digitizing world, companies are swimming in data—but only a few truly know how to harness it. At C Data Insights, we bridge that gap by delivering top-tier data engineering solutions in Toronto designed to transform your raw data into actionable insights. From building robust data pipelines to enabling intelligent machine learning applications, we are your trusted partner in the Greater Toronto Area (GTA).
What Is Data Engineering and Why Is It Critical?
Data engineering involves the design, construction, and maintenance of scalable systems for collecting, storing, and analyzing data. In the modern business landscape, it forms the backbone of decision-making, automation, and strategic planning.
Without a solid data infrastructure, businesses struggle with:
Inconsistent or missing data
Delayed analytics reports
Poor data quality impacting AI/ML performance
Increased operational costs
That’s where our data engineering service in GTA helps. We create a seamless flow of clean, usable, and timely data—so you can focus on growth.
Key Features of Our Data Engineering Solutions
As a leading provider of data engineering solutions in Toronto, C Data Insights offers a full suite of services tailored to your business goals:
1. Data Pipeline Development
We build automated, resilient pipelines that efficiently extract, transform, and load (ETL) data from multiple sources—be it APIs, cloud platforms, or on-premise databases.
2. Cloud-Based Architecture
Need scalable infrastructure? We design data systems on AWS, Azure, and Google Cloud, ensuring flexibility, security, and real-time access.
3. Data Warehousing & Lakehouses
Store structured and unstructured data efficiently with modern data warehousing technologies like Snowflake, BigQuery, and Databricks.
4. Batch & Streaming Data Processing
Process large volumes of data in real-time or at scheduled intervals with tools like Apache Kafka, Spark, and Airflow.
Data Engineering and Machine Learning – A Powerful Duo
Data engineering lays the groundwork, and machine learning unlocks its full potential. Our solutions enable you to go beyond dashboards and reports by integrating data engineering and machine learning into your workflow.
We help you:
Build feature stores for ML models
Automate model training with clean data
Deploy models for real-time predictions
Monitor model accuracy and performance
Whether you want to optimize your marketing spend or forecast inventory needs, we ensure your data infrastructure supports accurate, AI-powered decisions.
Serving the Greater Toronto Area with Local Expertise
As a trusted data engineering service in GTA, we take pride in supporting businesses across:
Toronto
Mississauga
Brampton
Markham
Vaughan
Richmond Hill
Scarborough
Our local presence allows us to offer faster response times, better collaboration, and solutions tailored to local business dynamics.
Why Businesses Choose C Data Insights
✔ End-to-End Support: From strategy to execution, we’re with you every step of the way ✔ Industry Experience: Proven success across retail, healthcare, finance, and logistics ✔ Scalable Systems: Our solutions grow with your business needs ✔ Innovation-Focused: We use the latest tools and best practices to keep you ahead of the curve
Take Control of Your Data Today
Don’t let disorganized or inaccessible data hold your business back. Partner with C Data Insights to unlock the full potential of your data. Whether you need help with cloud migration, real-time analytics, or data engineering and machine learning, we’re here to guide you.
📍 Proudly offering data engineering solutions in Toronto and expert data engineering service in GTA.
📞 Contact us today for a free consultation 🌐 https://cdatainsights.com
C Data Insights – Engineering Data for Smart, Scalable, and Successful Businesses
#data engineering solutions in Toronto#data engineering and machine learning#data engineering service in Gta
0 notes
Text
How Modern Data Engineering Powers Scalable, Real-Time Decision-Making
In today's world, driven by technology, businesses have evolved further and do not want to analyze data from the past. Everything from e-commerce websites providing real-time suggestions to banks verifying transactions in under a second, everything is now done in a matter of seconds. Why has this change taken place? The modern age of data engineering involves software development, data architecture, and cloud infrastructure on a scalable level. It empowers organizations to convert massive, fast-moving data streams into real-time insights.
From Batch to Real-Time: A Shift in Data Mindset
Traditional data systems relied on batch processing, in which data was collected and analyzed after certain periods of time. This led to lagging behind in a fast-paced world, as insights would be outdated and accuracy would be questionable. Ultra-fast streaming technologies such as Apache Kafka, Apache Flink, and Spark Streaming now enable engineers to create pipelines that help ingest, clean, and deliver insights in an instant. This modern-day engineering technique shifts the paradigm of outdated processes and is crucial for fast-paced companies in logistics, e-commerce, relevancy, and fintech.
Building Resilient, Scalable Data Pipelines
Modern data engineering focuses on the construction of thoroughly monitored, fault-tolerant data pipelines. These pipelines are capable of scaling effortlessly to higher volumes of data and are built to accommodate schema changes, data anomalies, and unexpected traffic spikes. Cloud-native tools like AWS Glue and Google Cloud Dataflow with Snowflake Data Sharing enable data sharing and integration scaling without limits across platforms. These tools make it possible to create unified data flows that power dashboards, alerts, and machine learning models instantaneously.
Role of Data Engineering in Real-Time Analytics
Here is where these Data Engineering Services make a difference. At this point, companies providing these services possess considerable technical expertise and can assist an organization in designing modern data architectures in modern frameworks aligned with their business objectives. From establishing real-time ETL pipelines to infrastructure handling, these services guarantee that your data stack is efficient and flexible in terms of cost. Companies can now direct their attention to new ideas and creativity rather than the endless cycle of data management patterns.
Data Quality, Observability, and Trust
Real-time decision-making depends on the quality of the data that powers it. Modern data engineering integrates practices like data observability, automated anomaly detection, and lineage tracking. These ensure that data within the systems is clean and consistent and can be traced. With tools like Great Expectations, Monte Carlo, and dbt, engineers can set up proactive alerts and validations to mitigate issues that could affect economic outcomes. This trust in data quality enables timely, precise, and reliable decisions.
The Power of Cloud-Native Architecture
Modern data engineering encompasses AWS, Azure, and Google Cloud. They provide serverless processing, autoscaling, real-time analytics tools, and other services that reduce infrastructure expenditure. Cloud-native services allow companies to perform data processing, as well as querying, on exceptionally large datasets instantly. For example, with Lambda functions, data can be transformed. With BigQuery, it can be analyzed in real-time. This allows rapid innovation, swift implementation, and significant long-term cost savings.
Strategic Impact: Driving Business Growth
Real-time data systems are providing organizations with tangible benefits such as customer engagement, operational efficiency, risk mitigation, and faster innovation cycles. To achieve these objectives, many enterprises now opt for data strategy consulting, which aligns their data initiatives to the broader business objectives. These consulting firms enable organizations to define the right KPIs, select appropriate tools, and develop a long-term roadmap to achieve desired levels of data maturity. By this, organizations can now make smarter, faster, and more confident decisions.
Conclusion
Investing in modern data engineering is more than an upgrade of technology — it's a shift towards a strategic approach of enabling agility in business processes. With the adoption of scalable architectures, stream processing, and expert services, the true value of organizational data can be attained. This ensures that whether it is customer behavior tracking, operational optimization, or trend prediction, data engineering places you a step ahead of changes before they happen, instead of just reacting to changes.
1 note
·
View note