#kafka apache
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The Tumblr office adopted Tommy, an 11-year-old Pomeranian.
Text
Real-Time Data Streaming: How Apache Kafka is Changing the Game
Introduction
In today’s fast-paced digital world, real-time data streaming has become more essential than ever because businesses now rely on instant data processing to make data-driven and informed decision-making. Apache Kafka, i.e., a distributed streaming platform for handling data in real time, is at the heart of this revolution. Whether you are an Apache Kafka developer or exploring Apache Kafka on AWS, this emerging technology can change the game of managing data streams. Let’s dive deep and understand how exactly Apache Kafka is changing the game.
Rise of Real-Time Data Streaming
The vast amount of data with businesses in the modern world has created a need for systems to process and analyze as it is produced. This amount of data has emerged due to the interconnections of business with other devices like social media, IoT, and cloud computing. Real-time data streaming enables businesses to use that data to unlock vast business opportunities and act accordingly.
However, traditional methods fall short here and are no longer sufficient for organizations that need real-time data insights for data-driven decision-making. Real-time data streaming requires a continuous flow of data from sources to the final destinations, allowing systems to analyze that information in less than milliseconds and generate data-driven patterns. However, building a scalable, reliable, and efficient real-time data streaming system is no small feat. This is where Apache Kafka comes into play.
About Apache Kafka
Apache Kafka is an open-source distributed event streaming platform that can handle large real-time data volumes. It is an open-source platform developed by the Apache Software Foundation. LinkedIn initially introduced the platform; later, in 2011, it became open-source.
Apache Kafka creates data pipelines and systems to manage massive volumes of data. It is designed to manage low-latency, high-throughput data streams. Kafka allows for the injection, processing, and storage of real-time data in a scalable and fault-tolerant way.
Kafka uses a publish-subscribe method in which:
Data (events/messages) are published to Kafka topics by producers.
Consumers read and process data from these subjects.
The servers that oversee Kafka's message dissemination are known as brokers.
ZooKeeper facilitates the management of Kafka's leader election and cluster metadata.
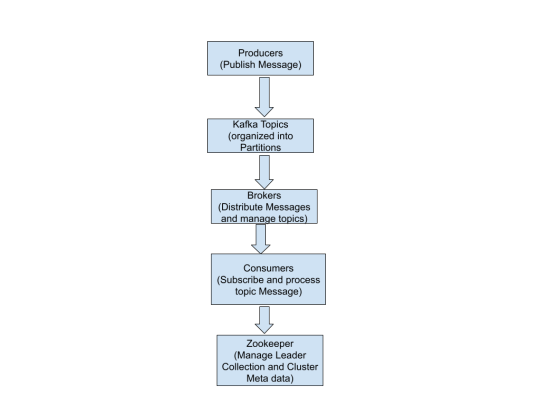
With its distributed architecture, fault tolerance, and scalability, Kafka is a reliable backbone for real-time data streaming and event-driven applications, ensuring seamless data flow across systems.
Why Apache Kafka Is A Game Changer
Real-time data processing helps organizations collect, process, and even deliver the data as it is generated while immediately ensuring the utmost insights and actions. Let’s understand the reasons why Kafka stands out in the competitive business world:
Real-Time Data Processing
Organizations generate vast amounts of data due to their interconnection with social media, IoT, the cloud, and more. This has raised the need for systems and tools that can react instantly and provide timely results. Kafka is a game-changer in this regard. It helps organizations use that data to track user behavior and take action accordingly.
Scalability and Fault Tolerance
Kafka's distributed architecture guarantees data availability and dependability even in the case of network or hardware failures. It is a reliable solution for mission-critical applications because it ensures data durability and recovery through replication and persistent storage.
Easy Integration
Kafka seamlessly connects with a variety of systems, such as databases, analytics platforms, and cloud services. Its ability to integrate effortlessly with these tools makes it an ideal solution for constructing sophisticated data pipelines.
Less Costly Solution
Kafka helps in reducing the cost of data processing and analyzing efficiently and ensures high performance of the businesses. By handling large volumes of data, Kafka also enhances scalability and reliability across distributed systems.
Apache Kafka on AWS: Unlocking Cloud Potential
Using Apache Kafka on ASW has recently become more popular because of the cloud’s advantages, like scalability, flexibility, and cost efficiency. Here, Kafka can be deployed in a number of ways, such as:
Amazon MSK (Managed Streaming for Apache Kafka): A fully managed service helps to make the deployment and management of Kafka very easy. Additionally, it handles infrastructure provisioning, scaling, and even maintenance and allows Apache Kafka developers to focus on building applications.
Self-Managed Kafka on EC2: This is apt for organizations that prefer full control of their Kafka clusters, as AWS EC2 provides the flexibility to deploy and manage Kafka instances.
The benefits of Apache Kafka on ASW are as follows:
Easy scaling of Kafka clusters as per the demand.
Ensures high availability and enables disaster recovery
Less costly because it uses a pay-as-you-go pricing model
The Future of Apache Kafka
Kafka’s role in the technology ecosystem will definitely grow with the increase in the demand for real-time data processing. Innovations like Kafka Streams and Kafka Connect are already expanding the role of Kafka and making real-time processing quite easy. Moreover, integrations with cloud platforms like AWS continuously drive the industry to adopt Kafka within different industries and expand its role.
Conclusion
Apache Kafka is continuously revolutionizing the organizations of modern times that are handling real-time data streaming and changing the actual game of businesses around the world by providing capabilities like flexibility, scalability, and seamless integration. Whether you are deploying Apache Kafka on AWS or working as an Apache Kafka developer, this technology can offer enormous possibilities for innovation in the digitally enabled business landscape.
Do you want to harness the full potential of your Apache Kafka systems? Look no further than Ksolves, where a team of seasoned Apache Kafka experts and developers stands out as a leading Apache Kafka development company with their client-centric approach and a commitment to excellence. With our extensive experience and expertise, we specialize in offering top-notch solutions tailored to your needs.
Do not let your data streams go untapped. Partner with leading partners like Ksolves today!
Visit Ksolves and get started!
#kafka apache#apache kafka on aws#apache kafka developer#apache cassandra consulting#certified developer for apache kafka
0 notes
Text



I try to make a balance between reading the book "Kafka: The Definitive Guide - 2nd Edition," doing Confluent course lab exercises, and a little bit of Udemy projects with Kafka as well. In the middle of the week, I'm making my homepage to showcase some portfolio stuff, which is not my priority at this time, but it involves a lot of coding as well.
Feeling like I can answer any interview questions about Kafka at this point, including the fundamentals, use cases, and examples of writing a pub/sub system in Java.
It's all about studying; it magically changes you inside and out. You're the same person, in the same place, but now capable of creating really good software with refined techniques.
#coding#developer#linux#programmer#programming#software#software development#student#study aesthetic#study blog#studyblr#studynotes#study#software engineering#self improvement#study motivation#university student#studying#student life#study routine#study room#java#apache kafka#softwareengineer#learn#learning#learnsomethingneweveryday#javaprogramming
46 notes
·
View notes
Text
#Change Data Capture (CDC)#Real-time data synchronization#CDC with Apache Kafka#CDC integration with Apache Spark#Apache Kafka for data streaming#Spotify
0 notes
Text
Understanding Apache Kafka: The Backbone of Real-Time Data
visit the blog: https://velog.io/@tpointtechblog/Understanding-Apache-Kafka-The-Backbone-of-Real-Time-Data
Visit more blog:
https://themediumblog.com/read-blog/167042https://tpointtechblog.blogspot.com/2025/05/what-is-mysql-and-why-should-you-learn.htmlhttps://sites.google.com/view/learnjavaprogramminglanguage/home
https://dev.to/tpointtechblog/power-bi-for-beginners-complete-introduction-dashboard-creation-2khehttps://medium.com/@tpointtechblog/understanding-django-pythons-most-powerful-web-framework-2b969e7319f0
0 notes
Text
Bigtable SQL Introduces Native Support for Real-Time Queries

Upgrades to Bigtable SQL offer scalable, fast data processing for contemporary analytics. Simplify procedures and accelerate business decision-making.
Businesses have battled for decades to use data for real-time operations. Bigtable, Google Cloud's revolutionary NoSQL database, powers global, low-latency apps. It was built to solve real-time application issues and is now a crucial part of Google's infrastructure, along with YouTube and Ads.
Continuous materialised views, an enhancement of Bigtable's SQL capabilities, were announced at Google Cloud Next this week. Maintaining Bigtable's flexible schema in real-time applications requires well-known SQL syntax and specialised skills. Fully managed, real-time application backends are possible with Bigtable SQL and continuous materialised views.
Bigtable has gotten simpler and more powerful, whether you're creating streaming apps, real-time aggregations, or global AI research on a data stream.
The Bigtable SQL interface is now generally available.
SQL capabilities, now generally available in Bigtable, has transformed the developer experience. With SQL support, Bigtable helps development teams work faster.
Bigtable SQL enhances accessibility and application development by speeding data analysis and debugging. This allows KNN similarity search for improved product search and distributed counting for real-time dashboards and metric retrieval. Bigtable SQL's promise to expand developers' access to Bigtable's capabilities excites many clients, from AI startups to financial institutions.
Imagine AI developing and understanding your whole codebase. AI development platform Augment Code gives context for each feature. Scalability and robustness allow Bigtable to handle large code repositories. This user-friendliness allowed it to design security mechanisms that protect clients' valuable intellectual property. Bigtable SQL will help onboard new developers as the company grows. These engineers can immediately use Bigtable's SQL interface to access structured, semi-structured, and unstructured data.
Equifax uses Bigtable to store financial journals efficiently in its data fabric. The data pipeline team found Bigtable's SQL interface handy for direct access to corporate data assets and easier for SQL-savvy teams to use. Since more team members can use Bigtable, it expects higher productivity and integration.
Bigtable SQL also facilitates the transition between distributed key-value systems and SQL-based query languages like HBase with Apache Phoenix and Cassandra.
Pega develops real-time decisioning apps with minimal query latency to provide clients with real-time data to help their business. As it seeks database alternatives, Bigtable's new SQL interface seems promising.
Bigtable is also previewing structured row keys, GROUP BYs, aggregations, and a UNPACK transform for timestamped data in its SQL language this week.
Continuously materialising views in preview
Bigtable SQL works with Bigtable's new continuous materialised views (preview) to eliminate data staleness and maintenance complexity. This allows real-time data aggregation and analysis in social networking, advertising, e-commerce, video streaming, and industrial monitoring.
Bigtable views update gradually without impacting user queries and are fully controllable. Bigtable materialised views accept a full SQL language with functions and aggregations.
Bigtable's Materialised Views have enabled low-latency use cases for Google Cloud's Customer Data Platform customers. It eliminates ETL complexity and delay in time series use cases by setting SQL-based aggregations/transformations upon intake. Google Cloud uses data transformations during import to give AI applications well prepared data with reduced latency.
Ecosystem integration
Real-time analytics often require low-latency data from several sources. Bigtable's SQL interface and ecosystem compatibility are expanding, making end-to-end solutions using SQL and basic connections easier.
Open-source Apache Large Table Washbasin Kafka
Companies utilise Google Cloud Managed Service for Apache Kafka to build pipelines for Bigtable and other analytics platforms. The Bigtable team released a new Apache Kafka Bigtable Sink to help clients build high-performance data pipelines. This sends Kafka data to Bigtable in milliseconds.
Open-source Apache Flink Connector for Bigtable
Apache Flink allows real-time data modification via stream processing. The new Apache Flink to Bigtable Connector lets you design a pipeline that modifies streaming data and publishes it to Bigtable using the more granular Datastream APIs and the high-level Apache Flink Table API.
BigQuery Continuous Queries are commonly available
BigQuery continuous queries run SQL statements continuously and export output data to Bigtable. This widely available capability can let you create a real-time analytics database using Bigtable and BigQuery.
Python developers may create fully-managed jobs that synchronise offline BigQuery datasets with online Bigtable datasets using BigQuery's Python frameworks' bigrames streaming API.
Cassandra-compatible Bigtable CQL Client Bigtable is previewed.
Apache Cassandra uses CQL. Bigtable CQL Client enables developers utilise CQL on enterprise-grade, high-performance Bigtable without code modifications as they migrate programs. Bigtable supports Cassandra's data migration tools, which reduce downtime and operational costs, and ecosystem utilities like the CQL shell.
Use migrating tools and Bigtable CQL Client here.
Using SQL power via NoSQL. This blog addressed a key feature that lets developers use SQL with Bigtable. Bigtable Studio lets you use SQL from any Bigtable cluster and create materialised views on Flink and Kafka data streams.
#technology#technews#govindhtech#news#technologynews#cloud computing#Bigtable SQL#Continuous Queries#Apache Flink#BigQuery Continuous Queries#Bigtable#Bigtable CQL Client#Open-source Kafka#Apache Kafka
0 notes
Text
Integrating ColdFusion with Apache Kafka for Streaming Data
#Integrating ColdFusion with Apache Kafka for Streaming Data#Integrating ColdFusion with Apache Kafka#ColdFusion with Apache Kafka for Streaming Data#ColdFusion with Apache Kafka
0 notes
Text
0 notes
Text
An example of how to run Kafka with Zookeeper via docker compose.
0 notes
Text

Apache Kafka is a powerful distributed platform used for building real-time data pipelines and streaming applications. This Kafka tutorial is designed for beginners who want to understand how Kafka works, including its core components like producers, consumers, brokers, and topics. Learn how data flows in real time, how to set up a basic Kafka environment, and how to avoid common mistakes. Whether you're a developer or data engineer, this guide will help you get started with confidence in event-driven architecture.
For more information and interview questions, you can also visit Tpoint Tech, where you can find many related topics.
Contact Information:
��Address : G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
Mobile: +91-9599086977
Email: [email protected]
Website: https://www.tpointtech.com/apache-kafka
0 notes
Text
AWS MSK Create & List Topics
Problem I needed to created topics in Amazon Web Services(AWS) Managed Streaming for Apache Kafka(MSK) and I wanted to list out the topics after they were created to verify. Solution This solution is written in python using the confluent-kafka package. It connects to the Kafka cluster and adds the new topics. Then it prints out all of the topics for verification This file contains…

View On WordPress
#amazon web services#apache kafka#aws#confluent-kafka#create#kafka#kafka topic#list#managed streaming for apache kafka#msk#python#topic
0 notes
Text
Mastering Real-Time Data Flows: Associative’s Apache Kafka Expertise

The modern business landscape demands real-time data processing capabilities. From monitoring live sensor data to analyzing customer interactions, the ability to handle continuous streams of information has become essential. This is where Apache Kafka, a distributed streaming platform, and Associative’s Kafka development prowess come into play.
Understanding Apache Kafka
Apache Kafka is an open-source platform designed for building real-time data pipelines and streaming applications. Its core features include:
High-Throughput: Kafka can handle millions of messages per second, making it ideal for large-scale data-intensive applications.
Fault-Tolerance: Kafka’s distributed architecture provides resilience against node failures, ensuring your data remains available.
Scalability: Kafka seamlessly scales horizontally, allowing you to add more nodes as data volumes grow.
Publish-Subscribe Model: Kafka uses a pub-sub messaging pattern, enabling flexible communication between data producers and consumers.
The Associative Advantage in Kafka Development
Associative’s team of Apache Kafka specialists helps you harness the platform’s power to drive your business forward:
Real-Time Data Pipelines: We design and build scalable Kafka-powered pipelines for seamless real-time data ingestion, processing, and distribution.
Microservices Integration: We use Kafka to decouple microservices, ensuring reliable communication and fault tolerance in distributed applications.
IoT and Sensor Data: We build Kafka-centric solutions to manage the massive influx of data from IoT devices and sensors, enabling real-time insights.
Event-Driven Architectures: We help you leverage Kafka for event-driven architectures that promote responsiveness and agility across your systems.
Legacy System Modernization: We integrate Kafka to bring real-time capabilities to your legacy systems, bridging the gap between old and new.
Benefits of Partnering with Associative
Tailored Kafka Solutions: We tailor our solutions to your exact business requirements for a perfect fit.
Pune-Based Collaboration: Experience seamless interaction with our team, thanks to our shared time zone.
Focus on Results: We emphasize delivering measurable business outcomes through our Kafka solutions.
Proven Kafka Success
Associative’s portfolio of successful Kafka projects speaks for itself. Our expertise helps you:
Improve Operational Efficiency: Kafka-powered solutions can streamline processes, reducing costs and improving performance.
Enhance Customer Experiences: React to customer behavior in real-time, personalizing offerings and boosting satisfaction.
Enable Data-Driven Decision Making: Extract real-time insights from streaming data to inform strategic decisions.
Ready to Embrace Real-Time Data with Kafka?
Contact Associative today to learn how our Apache Kafka development services can transform how you handle and leverage real-time data. Let’s build a robust, scalable, and responsive data infrastructure for your business.
#Apache Kafka#developer#artificial intelligence#machine learning#ai technology#app development#mobile app development
0 notes
Text
What is Apache Kafka?
Apache Kafka is designed to handle real-time data feeds that provide a high-throughput, resilient, and scalable solution for processing and storing streams of records. The platform ensures durability by replicating data across multiple brokers in a cluster.
Kafka’s exceptional speed is coordinated by two key virtuosos:
Sequential I/O: Kafka addresses the perceived slowness of disks by brilliantly implementing Sequential I/O.
Zero Copy Principle: With this principle, Kafka avoids unnecessary data copies and reduces context switches between user and kernel modes, making it more efficient.
Why Kafka?
High performance: It has the capability to handle millions of messages per second
Non-volatile storage: It stores messages on disk, which enables durability and fault-tolerance
Distributed architecture: It can handle large amounts of data and scale horizontally by adding more machines to the cluster.
Learn more about Apache Kafka read our full blog - https://bit.ly/3urUEWF
#kafka#apache kafka#real time data analysis#real time database#nitor#nitor infotech services#nitor infotech#ascendion#software development#software engineering
0 notes
Text
Apache Kafka vs Apache Pulsar - Which one to choose?
In today’s data-driven world, the ability to process and analyze real-time data streams is crucial for businesses. Two open-source platforms, Apache Kafka and Apache Pulsar, have emerged as leaders in this space. But which one is right for you? Market Share and Community: Apache Kafka: Commands a dominant 70% market share, boasting a vast user base and extensive ecosystem of tools and…

View On WordPress
0 notes