#big data artificial intelligence
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
1,644 Tumblr posts in 1 second.
Text
The almost overnight surge in electricity demand from data centers is now outstripping the available power supply in many parts of the world, according to interviews with data center operators, energy providers and tech executives. That dynamic is leading to years-long waits for businesses to access the grid as well as growing concerns of outages and price increases for those living in the densest data center markets. The dramatic increase in power demands from Silicon Valley’s growth-at-all-costs approach to AI also threatens to upend the energy transition plans of entire nations and the clean energy goals of trillion-dollar tech companies. In some countries, including Saudi Arabia, Ireland and Malaysia, the energy required to run all the data centers they plan to build at full capacity exceeds the available supply of renewable energy, according to a Bloomberg analysis of the latest available data. By one official estimate, Sweden could see power demand from data centers roughly double over the course of this decade — and then double again by 2040. In the UK, AI is expected to suck up 500% more energy over the next decade. And in the US, data centers are projected to use 8% of total power by 2030, up from 3% in 2022, according to Goldman Sachs, which described it as “the kind of electricity growth that hasn’t been seen in a generation.”
21 June 2024
673 notes
·
View notes
Text
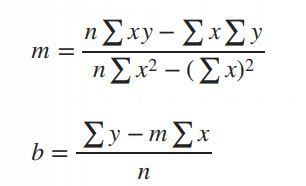
Simple Linear Regression in Data Science and machine learning
Simple linear regression is one of the most important techniques in data science and machine learning. It is the foundation of many statistical and machine learning models. Even though it is simple, its concepts are widely applicable in predicting outcomes and understanding relationships between variables.
This article will help you learn about:
1. What is simple linear regression and why it matters.
2. The step-by-step intuition behind it.
3. The math of finding slope() and intercept().
4. Simple linear regression coding using Python.
5. A practical real-world implementation.
If you are new to data science or machine learning, don’t worry! We will keep things simple so that you can follow along without any problems.
What is simple linear regression?
Simple linear regression is a method to model the relationship between two variables:
1. Independent variable (X): The input, also called the predictor or feature.
2. Dependent Variable (Y): The output or target value we want to predict.
The main purpose of simple linear regression is to find a straight line (called the regression line) that best fits the data. This line minimizes the error between the actual and predicted values.
The mathematical equation for the line is:
Y = mX + b
: The predicted values.
: The slope of the line (how steep it is).
: The intercept (the value of when).
Why use simple linear regression?
click here to read more https://datacienceatoz.blogspot.com/2025/01/simple-linear-regression-in-data.html
#artificial intelligence#bigdata#books#machine learning#machinelearning#programming#python#science#skills#big data#linear algebra#linear b#slope#interception
6 notes
·
View notes
Text

A lot of questions remain unanswered about how much the ever-tightening relationship between private AI and for-profit automated decision making systems will impact much needed transparency and accountability.
Read More: https://thefreethoughtproject.com/news/the-u-s-national-security-state-is-here-to-make-ai-even-less-transparent-and-accountable
#TheFreeThoughtProject
#the free thought project#tftp#police state#AI#big tech#big data#intelligence community#artificial intelligence#news
8 notes
·
View notes
Text
Abathur

At Abathur, we believe technology should empower, not complicate.
Our mission is to provide seamless, scalable, and secure solutions for businesses of all sizes. With a team of experts specializing in various tech domains, we ensure our clients stay ahead in an ever-evolving digital landscape.
Why Choose Us? Expert-Led Innovation – Our team is built on experience and expertise. Security First Approach – Cybersecurity is embedded in all our solutions. Scalable & Future-Proof – We design solutions that grow with you. Client-Centric Focus – Your success is our priority.
#Software Development#Web Development#Mobile App Development#API Integration#Artificial Intelligence#Machine Learning#Predictive Analytics#AI Automation#NLP#Data Analytics#Business Intelligence#Big Data#Cybersecurity#Risk Management#Penetration Testing#Cloud Security#Network Security#Compliance#Networking#IT Support#Cloud Management#AWS#Azure#DevOps#Server Management#Digital Marketing#SEO#Social Media Marketing#Paid Ads#Content Marketing
2 notes
·
View notes
Text

Pickl.AI offers a comprehensive approach to data science education through real-world case studies and practical projects. By working on industry-specific challenges, learners gain exposure to how data analysis, machine learning, and artificial intelligence are applied to solve business problems. The hands-on learning approach helps build technical expertise while developing critical thinking and problem-solving abilities. Pickl.AI’s programs are designed to prepare individuals for successful careers in the evolving data-driven job market, providing both theoretical knowledge and valuable project experience.
#Pickl.AI#data science#data science certification#data science case studies#machine learning#AI#artificial intelligence#data analytics#data science projects#career in data science#online education#real-world data science#data analysis#big data#technology
2 notes
·
View notes
Text
OpenAI counter-sues Elon Musk for attempts to ‘take down’ AI rival
New Post has been published on https://thedigitalinsider.com/openai-counter-sues-elon-musk-for-attempts-to-take-down-ai-rival/
OpenAI counter-sues Elon Musk for attempts to ‘take down’ AI rival
OpenAI has launched a legal counteroffensive against one of its co-founders, Elon Musk, and his competing AI venture, xAI.
In court documents filed yesterday, OpenAI accuses Musk of orchestrating a “relentless” and “malicious” campaign designed to “take down OpenAI” after he left the organisation years ago.
Elon’s nonstop actions against us are just bad-faith tactics to slow down OpenAI and seize control of the leading AI innovations for his personal benefit. Today, we counter-sued to stop him.
— OpenAI Newsroom (@OpenAINewsroom) April 9, 2025
The court filing, submitted to the US District Court for the Northern District of California, alleges Musk could not tolerate OpenAI’s success after he had “abandoned and declared [it] doomed.”
OpenAI is now seeking legal remedies, including an injunction to stop Musk’s alleged “unlawful and unfair action” and compensation for damages already caused.
Origin story of OpenAI and the departure of Elon Musk
The legal documents recount OpenAI’s origins in 2015, stemming from an idea discussed by current CEO Sam Altman and President Greg Brockman to create an AI lab focused on developing artificial general intelligence (AGI) – AI capable of outperforming humans – for the “benefit of all humanity.”
Musk was involved in the launch, serving on the initial non-profit board and pledging $1 billion in donations.
However, the relationship fractured. OpenAI claims that between 2017 and 2018, Musk’s demands for “absolute control” of the enterprise – or its potential absorption into Tesla – were rebuffed by Altman, Brockman, and then-Chief Scientist Ilya Sutskever. The filing quotes Sutskever warning Musk against creating an “AGI dictatorship.”
Following this disagreement, OpenAI alleges Elon Musk quit in February 2018, declaring the venture would fail without him and that he would pursue AGI development at Tesla instead. Critically, OpenAI contends the pledged $1 billion “was never satisfied—not even close”.
Restructuring, success, and Musk’s alleged ‘malicious’ campaign
Facing escalating costs for computing power and talent retention, OpenAI restructured and created a “capped-profit” entity in 2019 to attract investment while remaining controlled by the non-profit board and bound by its mission. This structure, OpenAI states, was announced publicly and Musk was offered equity in the new entity but declined and raised no objection at the time.
OpenAI highlights its subsequent breakthroughs – including GPT-3, ChatGPT, and GPT-4 – achieved massive public adoption and critical acclaim. These successes, OpenAI emphasises, were made after the departure of Elon Musk and allegedly spurred his antagonism.
The filing details a chronology of alleged actions by Elon Musk aimed at harming OpenAI:
Founding xAI: Musk “quietly created” his competitor, xAI, in March 2023.
Moratorium call: Days later, Musk supported a call for a development moratorium on AI more advanced than GPT-4, a move OpenAI claims was intended “to stall OpenAI while all others, most notably Musk, caught up”.
Records demand: Musk allegedly made a “pretextual demand” for confidential OpenAI documents, feigning concern while secretly building xAI.
Public attacks: Using his social media platform X (formerly Twitter), Musk allegedly broadcast “press attacks” and “malicious campaigns” to his vast following, labelling OpenAI a “lie,” “evil,” and a “total scam”.
Legal actions: Musk filed lawsuits, first in state court (later withdrawn) and then the current federal action, based on what OpenAI dismisses as meritless claims of a “Founding Agreement” breach.
Regulatory pressure: Musk allegedly urged state Attorneys General to investigate OpenAI and force an asset auction.
“Sham bid”: In February 2025, a Musk-led consortium made a purported $97.375 billion offer for OpenAI, Inc.’s assets. OpenAI derides this as a “sham bid” and a “stunt” lacking evidence of financing and designed purely to disrupt OpenAI’s operations, potential restructuring, fundraising, and relationships with investors and employees, particularly as OpenAI considers evolving its capped-profit arm into a Public Benefit Corporation (PBC). One investor involved allegedly admitted the bid’s aim was to gain “discovery”.
Based on these allegations, OpenAI asserts two primary counterclaims against both Elon Musk and xAI:
Unfair competition: Alleging the “sham bid” constitutes an unfair and fraudulent business practice under California law, intended to disrupt OpenAI and gain an unfair advantage for xAI.
Tortious interference with prospective economic advantage: Claiming the sham bid intentionally disrupted OpenAI’s existing and potential relationships with investors, employees, and customers.
OpenAI argues Musk’s actions have forced it to divert resources and expend funds, causing harm. They claim his campaign threatens “irreparable harm” to their mission, governance, and crucial business relationships. The filing also touches upon concerns regarding xAI’s own safety record, citing reports of its AI Grok generating harmful content and misinformation.
Elon’s never been about the mission. He’s always had his own agenda. He tried to seize control of OpenAI and merge it with Tesla as a for-profit – his own emails prove it. When he didn’t get his way, he stormed off.
Elon is undoubtedly one of the greatest entrepreneurs of our…
— OpenAI Newsroom (@OpenAINewsroom) April 9, 2025
The counterclaims mark a dramatic escalation in the legal battle between the AI pioneer and its departed co-founder. While Elon Musk initially sued OpenAI alleging a betrayal of its founding non-profit, open-source principles, OpenAI now contends Musk’s actions are a self-serving attempt to undermine a competitor he couldn’t control.
With billions at stake and the future direction of AGI in the balance, this dispute is far from over.
See also: Deep Cogito open LLMs use IDA to outperform same size models
Want to learn more about AI and big data from industry leaders? Check out AI & Big Data Expo taking place in Amsterdam, California, and London. The comprehensive event is co-located with other leading events including Intelligent Automation Conference, BlockX, Digital Transformation Week, and Cyber Security & Cloud Expo.
Explore other upcoming enterprise technology events and webinars powered by TechForge here.
#2023#2025#adoption#AGI#AGI development#agreement#ai#ai & big data expo#amp#arm#artificial#Artificial General Intelligence#Artificial Intelligence#assets#auction#automation#Big Data#billion#board#breach#Building#Business#california#CEO#chatGPT#Cloud#Companies#competition#comprehensive#computing
2 notes
·
View notes
Text
"These "hallucinations" are a stubbornly persistent feature of large language models, because these models only give the illusion of understanding; in reality, they are just sophisticated forms of autocomplete, drawing on huge databases to make shrewd (but reliably fallible) guesses about which word comes next:
Guessing the next word without understanding the meaning of the resulting sentence makes unsupervised LLMs unsuitable for high-stakes tasks. The whole AI bubble is based on convincing investors that one or more of the following is true:
I. There are low-stakes, high-value tasks that will recoup the massive costs of AI training and operation;
II. There are high-stakes, high-value tasks that can be made cheaper by adding an AI to a human operator;
III. Adding more training data to an AI will make it stop hallucinating, so that it can take over high-stakes, high-value tasks without a "human in the loop."
These are dubious propositions. There's a universe of low-stakes, low-value tasks – political disinformation, spam, fraud, academic cheating, nonconsensual porn, dialog for video-game NPCs – but none of them seem likely to generate enough revenue for AI companies to justify the billions spent on models, nor the trillions in valuation attributed to AI companies:
https://locusmag.com/2023/12/commentary-cory-doctorow-what-kind-of-bubble-is-ai/
The proposition that increasing training data will decrease hallucinations is hotly contested among AI practitioners. I confess that I don't know enough about AI to evaluate opposing sides' claims, but even if you stipulate that adding lots of human-generated training data will make the software a better guesser, there's a serious problem. All those low-value, low-stakes applications are flooding the internet with botshit. After all, the one thing AI is unarguably very good at is producing bullshit at scale. As the web becomes an anaerobic lagoon for botshit, the quantum of human-generated "content" in any internet core sample is dwindling to homeopathic levels:
This means that adding another order of magnitude more training data to AI won't just add massive computational expense – the data will be many orders of magnitude more expensive to acquire, even without factoring in the additional liability arising from new legal theories about scraping:
5 notes
·
View notes
Text
From Curious Novice to Data Enthusiast: My Data Science Adventure
I've always been fascinated by data science, a field that seamlessly blends technology, mathematics, and curiosity. In this article, I want to take you on a journey—my journey—from being a curious novice to becoming a passionate data enthusiast. Together, let's explore the thrilling world of data science, and I'll share the steps I took to immerse myself in this captivating realm of knowledge.

The Spark: Discovering the Potential of Data Science
The moment I stumbled upon data science, I felt a spark of inspiration. Witnessing its impact across various industries, from healthcare and finance to marketing and entertainment, I couldn't help but be drawn to this innovative field. The ability to extract critical insights from vast amounts of data and uncover meaningful patterns fascinated me, prompting me to dive deeper into the world of data science.
Laying the Foundation: The Importance of Learning the Basics
To embark on this data science adventure, I quickly realized the importance of building a strong foundation. Learning the basics of statistics, programming, and mathematics became my priority. Understanding statistical concepts and techniques enabled me to make sense of data distributions, correlations, and significance levels. Programming languages like Python and R became essential tools for data manipulation, analysis, and visualization, while a solid grasp of mathematical principles empowered me to create and evaluate predictive models.
The Quest for Knowledge: Exploring Various Data Science Disciplines
A. Machine Learning: Unraveling the Power of Predictive Models
Machine learning, a prominent discipline within data science, captivated me with its ability to unlock the potential of predictive models. I delved into the fundamentals, understanding the underlying algorithms that power these models. Supervised learning, where data with labels is used to train prediction models, and unsupervised learning, which uncovers hidden patterns within unlabeled data, intrigued me. Exploring concepts like regression, classification, clustering, and dimensionality reduction deepened my understanding of this powerful field.
B. Data Visualization: Telling Stories with Data
In my data science journey, I discovered the importance of effectively visualizing data to convey meaningful stories. Navigating through various visualization tools and techniques, such as creating dynamic charts, interactive dashboards, and compelling infographics, allowed me to unlock the hidden narratives within datasets. Visualizations became a medium to communicate complex ideas succinctly, enabling stakeholders to understand insights effortlessly.
C. Big Data: Mastering the Analysis of Vast Amounts of Information
The advent of big data challenged traditional data analysis approaches. To conquer this challenge, I dived into the world of big data, understanding its nuances and exploring techniques for efficient analysis. Uncovering the intricacies of distributed systems, parallel processing, and data storage frameworks empowered me to handle massive volumes of information effectively. With tools like Apache Hadoop and Spark, I was able to mine valuable insights from colossal datasets.
D. Natural Language Processing: Extracting Insights from Textual Data
Textual data surrounds us in the digital age, and the realm of natural language processing fascinated me. I delved into techniques for processing and analyzing unstructured text data, uncovering insights from tweets, customer reviews, news articles, and more. Understanding concepts like sentiment analysis, topic modeling, and named entity recognition allowed me to extract valuable information from written text, revolutionizing industries like sentiment analysis, customer service, and content recommendation systems.
Building the Arsenal: Acquiring Data Science Skills and Tools
Acquiring essential skills and familiarizing myself with relevant tools played a crucial role in my data science journey. Programming languages like Python and R became my companions, enabling me to manipulate, analyze, and model data efficiently. Additionally, I explored popular data science libraries and frameworks such as TensorFlow, Scikit-learn, Pandas, and NumPy, which expedited the development and deployment of machine learning models. The arsenal of skills and tools I accumulated became my assets in the quest for data-driven insights.
The Real-World Challenge: Applying Data Science in Practice
Data science is not just an academic pursuit but rather a practical discipline aimed at solving real-world problems. Throughout my journey, I sought to identify such problems and apply data science methodologies to provide practical solutions. From predicting customer churn to optimizing supply chain logistics, the application of data science proved transformative in various domains. Sharing success stories of leveraging data science in practice inspires others to realize the power of this field.
Cultivating Curiosity: Continuous Learning and Skill Enhancement
Embracing a growth mindset is paramount in the world of data science. The field is rapidly evolving, with new algorithms, techniques, and tools emerging frequently. To stay ahead, it is essential to cultivate curiosity and foster a continuous learning mindset. Keeping abreast of the latest research papers, attending data science conferences, and engaging in data science courses nurtures personal and professional growth. The journey to becoming a data enthusiast is a lifelong pursuit.
Joining the Community: Networking and Collaboration
Being part of the data science community is a catalyst for growth and inspiration. Engaging with like-minded individuals, sharing knowledge, and collaborating on projects enhances the learning experience. Joining online forums, participating in Kaggle competitions, and attending meetups provides opportunities to exchange ideas, solve challenges collectively, and foster invaluable connections within the data science community.
Overcoming Obstacles: Dealing with Common Data Science Challenges
Data science, like any discipline, presents its own set of challenges. From data cleaning and preprocessing to model selection and evaluation, obstacles arise at each stage of the data science pipeline. Strategies and tips to overcome these challenges, such as building reliable pipelines, conducting robust experiments, and leveraging cross-validation techniques, are indispensable in maintaining motivation and achieving success in the data science journey.
Balancing Act: Building a Career in Data Science alongside Other Commitments
For many aspiring data scientists, the pursuit of knowledge and skills must coexist with other commitments, such as full-time jobs and personal responsibilities. Effectively managing time and developing a structured learning plan is crucial in striking a balance. Tips such as identifying pockets of dedicated learning time, breaking down complex concepts into manageable chunks, and seeking mentorships or online communities can empower individuals to navigate the data science journey while juggling other responsibilities.
Ethical Considerations: Navigating the World of Data Responsibly
As data scientists, we must navigate the world of data responsibly, being mindful of the ethical considerations inherent in this field. Safeguarding privacy, addressing bias in algorithms, and ensuring transparency in data-driven decision-making are critical principles. Exploring topics such as algorithmic fairness, data anonymization techniques, and the societal impact of data science encourages responsible and ethical practices in a rapidly evolving digital landscape.
Embarking on a data science adventure from a curious novice to a passionate data enthusiast is an exhilarating and rewarding journey. By laying a foundation of knowledge, exploring various data science disciplines, acquiring essential skills and tools, and engaging in continuous learning, one can conquer challenges, build a successful career, and have a good influence on the data science community. It's a journey that never truly ends, as data continues to evolve and offer exciting opportunities for discovery and innovation. So, join me in your data science adventure, and let the exploration begin!
#data science#data analytics#data visualization#big data#machine learning#artificial intelligence#education#information
17 notes
·
View notes
Text
Hello, you know there are a lot of different AI Tools to make our life easier. I want to share them with. The first one is free AI Animation Tools for 3D Masterpieces. You will find 6 different AI Tools.
Take a look at my blog !.
Ebubekir ATABEY
Data Scientist
2 notes
·
View notes
Text
The latest, AI-dedicated server racks contain 72 specialised chips from manufacturer Nvidia. The largest “hyperscale” data centres, used for AI tasks, would have about 5,000 of these racks. And as anyone using a laptop for any period of time knows, even a single chip warms up in operation. To cool the servers requires water – gallons of it. Put all this together, and a single hyperscale data centre will typically need as much water as a town of 30,000 people – and the equivalent amount of electricity. The Financial Times reports that Microsoft is currently opening one of these behemoths somewhere in the world every three days. Even so, for years, the explosive growth of the digital economy had surprisingly little impact on global energy demand and carbon emissions. Efficiency gains in data centres—the backbone of the internet—kept electricity consumption in check. But the rise of generative AI, turbocharged by the launch of ChatGPT in late 2022, has shattered that equilibrium. AI elevates the demand for data and processing power into the stratosphere. The latest version of OpenAI’s flagship GPT model, GPT-4, is built on 1.3 trillion parameters, with each parameter describing the strength of a connection between different pathways in the model’s software brain. The more novel data that can be pushed into the model for training, the better – so much data that one research paper estimated machine learning models will have used up all the data on the internet by 2028. Today, the insatiable demand for computing power is reshaping national energy systems. Figures from the International Monetary Fund show that data centres worldwide already consume as much electricity as entire countries like France or Germany. It forecasts that by 2030, the worldwide energy demand from data centres will be the same as India’s total electricity consumption.
30 May 2025
81 notes
·
View notes
Text
Understanding Outliers in Machine Learning and Data Science

In machine learning and data science, an outlier is like a misfit in a dataset. It's a data point that stands out significantly from the rest of the data. Sometimes, these outliers are errors, while other times, they reveal something truly interesting about the data. Either way, handling outliers is a crucial step in the data preprocessing stage. If left unchecked, they can skew your analysis and even mess up your machine learning models.
In this article, we will dive into:
1. What outliers are and why they matter.
2. How to detect and remove outliers using the Interquartile Range (IQR) method.
3. Using the Z-score method for outlier detection and removal.
4. How the Percentile Method and Winsorization techniques can help handle outliers.
This guide will explain each method in simple terms with Python code examples so that even beginners can follow along.
1. What Are Outliers?
An outlier is a data point that lies far outside the range of most other values in your dataset. For example, in a list of incomes, most people might earn between $30,000 and $70,000, but someone earning $5,000,000 would be an outlier.
Why Are Outliers Important?
Outliers can be problematic or insightful:
Problematic Outliers: Errors in data entry, sensor faults, or sampling issues.
Insightful Outliers: They might indicate fraud, unusual trends, or new patterns.
Types of Outliers
1. Univariate Outliers: These are extreme values in a single variable.
Example: A temperature of 300°F in a dataset about room temperatures.
2. Multivariate Outliers: These involve unusual combinations of values in multiple variables.
Example: A person with an unusually high income but a very low age.
3. Contextual Outliers: These depend on the context.
Example: A high temperature in winter might be an outlier, but not in summer.
2. Outlier Detection and Removal Using the IQR Method
The Interquartile Range (IQR) method is one of the simplest ways to detect outliers. It works by identifying the middle 50% of your data and marking anything that falls far outside this range as an outlier.
Steps:
1. Calculate the 25th percentile (Q1) and 75th percentile (Q3) of your data.
2. Compute the IQR:
{IQR} = Q3 - Q1
Q1 - 1.5 \times \text{IQR}
Q3 + 1.5 \times \text{IQR} ] 4. Anything below the lower bound or above the upper bound is an outlier.
Python Example:
import pandas as pd
# Sample dataset
data = {'Values': [12, 14, 18, 22, 25, 28, 32, 95, 100]}
df = pd.DataFrame(data)
# Calculate Q1, Q3, and IQR
Q1 = df['Values'].quantile(0.25)
Q3 = df['Values'].quantile(0.75)
IQR = Q3 - Q1
# Define the bounds
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
# Identify and remove outliers
outliers = df[(df['Values'] < lower_bound) | (df['Values'] > upper_bound)]
print("Outliers:\n", outliers)
filtered_data = df[(df['Values'] >= lower_bound) & (df['Values'] <= upper_bound)]
print("Filtered Data:\n", filtered_data)
Key Points:
The IQR method is great for univariate datasets.
It works well when the data isn’t skewed or heavily distributed.
3. Outlier Detection and Removal Using the Z-Score Method
The Z-score method measures how far a data point is from the mean, in terms of standard deviations. If a Z-score is greater than a certain threshold (commonly 3 or -3), it is considered an outlier.
Formula:
Z = \frac{(X - \mu)}{\sigma}
is the data point,
is the mean of the dataset,
is the standard deviation.
Python Example:
import numpy as np
# Sample dataset
data = {'Values': [12, 14, 18, 22, 25, 28, 32, 95, 100]}
df = pd.DataFrame(data)
# Calculate mean and standard deviation
mean = df['Values'].mean()
std_dev = df['Values'].std()
# Compute Z-scores
df['Z-Score'] = (df['Values'] - mean) / std_dev
# Identify and remove outliers
threshold = 3
outliers = df[(df['Z-Score'] > threshold) | (df['Z-Score'] < -threshold)]
print("Outliers:\n", outliers)
filtered_data = df[(df['Z-Score'] <= threshold) & (df['Z-Score'] >= -threshold)]
print("Filtered Data:\n", filtered_data)
Key Points:
The Z-score method assumes the data follows a normal distribution.
It may not work well with skewed datasets.
4. Outlier Detection Using the Percentile Method and Winsorization
Percentile Method:
In the percentile method, we define a lower percentile (e.g., 1st percentile) and an upper percentile (e.g., 99th percentile). Any value outside this range is treated as an outlier.
Winsorization:
Winsorization is a technique where outliers are not removed but replaced with the nearest acceptable value.
Python Example:
from scipy.stats.mstats import winsorize
import numpy as np
Sample data
data = [12, 14, 18, 22, 25, 28, 32, 95, 100]
Calculate percentiles
lower_percentile = np.percentile(data, 1)
upper_percentile = np.percentile(data, 99)
Identify outliers
outliers = [x for x in data if x < lower_percentile or x > upper_percentile]
print("Outliers:", outliers)
# Apply Winsorization
winsorized_data = winsorize(data, limits=[0.01, 0.01])
print("Winsorized Data:", list(winsorized_data))
Key Points:
Percentile and Winsorization methods are useful for skewed data.
Winsorization is preferred when data integrity must be preserved.
Final Thoughts
Outliers can be tricky, but understanding how to detect and handle them is a key skill in machine learning and data science. Whether you use the IQR method, Z-score, or Wins
orization, always tailor your approach to the specific dataset you’re working with.
By mastering these techniques, you’ll be able to clean your data effectively and improve the accuracy of your models.
#science#skills#programming#bigdata#books#machinelearning#artificial intelligence#python#machine learning#data centers#outliers#big data#data analysis#data analytics#data scientist#database#datascience#data
4 notes
·
View notes
Text
In a silicon valley, throw rocks. Welcome to my tech blog.
Antiterf antifascist (which apparently needs stating). This sideblog is open to minors.
Liberation does not come at the expense of autonomy.
* I'm taking a break from tumblr for a while. Feel free to leave me asks or messages for when I return.
Frequent tags:
#tech#tech regulation#technology#big tech#privacy#data harvesting#advertising#technological developments#spyware#artificial intelligence#machine learning#data collection company#data analytics#dataspeaks#data science#data#llm#technews
2 notes
·
View notes
Text
I think this part is truly the most damning:

If it's all pre-rendered mush and it's "too expensive to fully experiment or explore" then such AI is not a valid artistic medium. It's entirely deterministic, like a pseudorandom number generator. The goal here is optimizing the rapid generation of an enormous quantity of low-quality images which fulfill the expectations put forth by The Prompt.
It's the modern technological equivalent of a circus automaton "painting" a canvas to be sold in the gift shop.


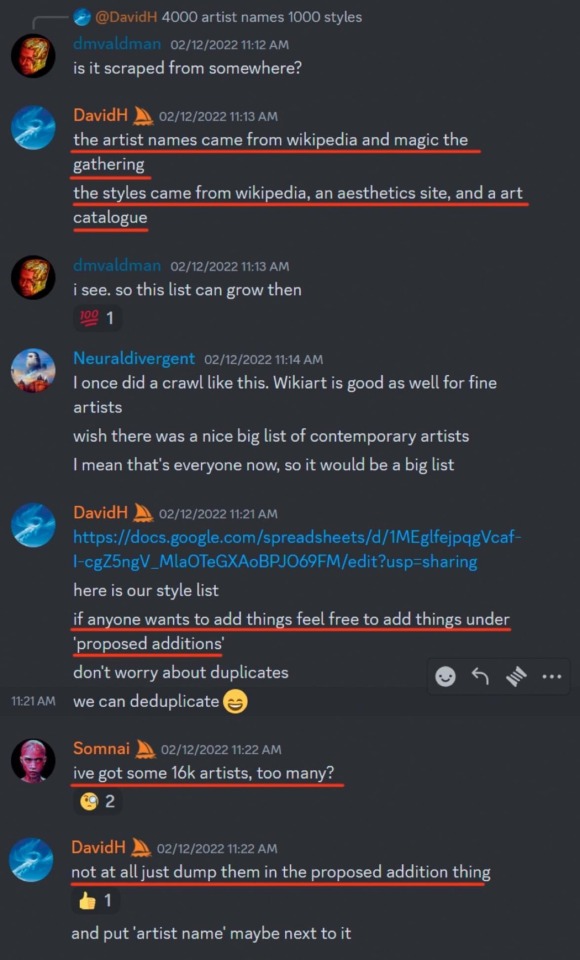
so a huge list of artists that was used to train midjourney’s model got leaked and i’m on it
literally there is no reason to support AI generators, they can’t ethically exist. my art has been used to train every single major one without consent lmfao 🤪
link to the archive
#to be clear AI as a concept has the power to create some truly fantastic images#however when it is subject to the constraints of its purpose as a machine#it is only capable of performing as its puppeteer wills it#and these puppeteers have the intention of stealing#tech#technology#tech regulation#big tech#data harvesting#data#technological developments#artificial intelligence#ai#machine generated content#machine learning#intellectual property#copyright
37K notes
·
View notes
Text
Data Analytics with AI in 2025: Trends, Impact & What’s Next

As we move deeper into 2025, the fusion of Artificial Intelligence (AI) and data analytics has become more than a competitive edge—it's a business necessity. Companies that once viewed AI as experimental are now embedding it into the core of their operations, using it to transform raw data into real-time insights, accurate forecasts, and automated decisions.
In this post, we’ll explore how AI-powered data analytics is evolving in 2025, what trends are shaping the future, and how your organization can harness its full potential.
What Is AI-Driven Data Analytics?
AI-driven data analytics uses intelligent algorithms—such as machine learning (ML), deep learning, and natural language processing—to discover hidden patterns, predict future trends, and automate insights from vast and complex datasets.
Unlike traditional analytics, AI doesn’t just report on what happened; it explains why it happened and suggests what to do next—with unprecedented speed and precision.
Key Trends in 2025
1. Real-Time AI Analytics
Thanks to edge computing and faster cloud processing, AI analytics is now happening in real time. Businesses can react to customer behavior, supply chain issues, and financial trends instantly.
2. AI + Business Intelligence Platforms
Modern BI tools like Tableau, Power BI, and Looker now offer built-in AI features—from auto-generated visual insights to natural language queries (e.g., “Why did sales drop in Q1?”).
3. Predictive + Prescriptive Analytics
AI doesn’t just forecast future outcomes—it now recommends specific actions. For instance, AI can predict customer churn and suggest retention campaigns tailored to individual users.
4. Natural Language Insights
Non-technical users can now interact with data using plain English. Think: “Show me the top 5 products by revenue in the last 90 days.”
5. Ethical AI and Data Governance
With growing concerns about bias and data privacy, 2025 emphasizes explainable AI and strong data governance policies to ensure compliance and transparency.
Use Cases by Industry
Retail & E-commerce: Personalized shopping experiences, dynamic pricing, demand forecasting
Finance: Fraud detection, credit risk analysis, algorithmic trading
Healthcare: Diagnostic analytics, patient risk prediction, treatment optimization
Manufacturing: Predictive maintenance, quality control, supply chain optimization
Marketing: Customer segmentation, sentiment analysis, campaign optimization
Benefits of AI in Data Analytics
Faster Insights: Analyze billions of data points in seconds
Smarter Forecasting: Anticipate trends with high accuracy
Cost Reduction: Automate repetitive analysis and reporting
Enhanced Decision-Making: Make strategic choices based on real-time, AI-enhanced insights
Personalization at Scale: Serve your customers better with hyper-relevant experiences
Challenges to Watch
Data Quality: AI requires clean, consistent, and well-labeled data
Talent Gap: Skilled AI/ML professionals are still in high demand
Ethics & Bias: AI models must be monitored to avoid reinforcing social or business biases
Integration Complexity: Aligning AI tools with legacy systems takes planning and expertise
What’s Next for AI & Analytics?
By late 2025 and beyond, expect:
More autonomous analytics platforms that self-learn and self-correct
Increased use of generative AI to automatically create dashboards, summaries, and even business strategies
Tighter integration between IoT, AI, and analytics for industries like smart cities, healthcare, and logistics
Final Thoughts
In 2025, AI in data analytics is no longer just a tool—it's a strategic partner. Whether you're optimizing operations, enhancing customer experiences, or driving innovation, AI analytics gives you the insights you need to lead with confidence.
📩 Ready to transform your data into business intelligence? Contact us to learn how our AI-powered analytics solutions can help you stay ahead in 2025 and beyond.
#Data Analytics#Artificial Intelligence#AI in Business#Business Intelligence#Predictive Analytics#Big Data#Machine Learning#Data Science#Real-Time Analytics#AI Trends 2025
0 notes
Text
We'd mostly moved away from the term AI within the field. We called it Big Data. Or Machine Learning. Or Data Statistics. Or. Or. Or. We've had a dozen better names than AI.
But then media realized the term AI sold more papers. That the masses couldn't ignore what they didn't understand. Applied Statistics makes too much sense. It doesn't grab the imagination. But AI. Theres room for all sorts of theories with that term. No one will know if what you say is factual or made up. AI is a fantasy anyways so who even cares?
It's not that we made a poor choice of words in 1954. The idea of AI has floated through countless iterations of sci-fi novel, movie, and tv series. The media would have gravitated to it sooner or later. The issue is the need of masses for relief from their labors. The desire to live in a fantasy world. Not a bad desire. But an impactful one.
I mean I desperately want these data models to be real AI. Can you imagine what good true AI could do for the world? The appeal of living in a more just, more equitable, world is higher than ever. People will jump at every chance they get. They're willing to risk looking stupid on the off chance that this one is real. That this time they'll be saved. And the media and corporations are eating it up.
Corporations are more than happy to sell us another AI to ease our troubles for a while. When the novelty of one wears off they'll sell us another. They can churn them out faster now than we can consume them. And the media is just another corporation, happy to steal our information and feed it back to us in the form of a new AI application.
It doesn't matter what data and computer scientists call it. It doesn't matter anymore today than it did in 1954. The problem isn't the words they've chosen to use. The problem is our society and our need to escape it.
"There was an exchange on Twitter a while back where someone said, ‘What is artificial intelligence?' And someone else said, 'A poor choice of words in 1954'," he says. "And, you know, they’re right. I think that if we had chosen a different phrase for it, back in the '50s, we might have avoided a lot of the confusion that we're having now." So if he had to invent a term, what would it be? His answer is instant: applied statistics. "It's genuinely amazing that...these sorts of things can be extracted from a statistical analysis of a large body of text," he says. But, in his view, that doesn't make the tools intelligent. Applied statistics is a far more precise descriptor, "but no one wants to use that term, because it's not as sexy".
'The machines we have now are not conscious', Lunch with the FT, Ted Chiang, by Madhumita Murgia, 3 June/4 June 2023
24K notes
·
View notes
Text
Hire Big Data Architects Today for Scalable Business Success – PearlHire
In today’s data-driven landscape, businesses must build systems that are fast, secure, and scalable. PearlHire makes it simple to hire big data architects who can design and implement powerful architectures that support AI, machine learning, and real-time analytics. These professionals align data infrastructure with your business goals, ensuring long-term success. From integrating Hadoop and Spark to securing sensitive data, PearlHire connects you with experts who understand both innovation and compliance. Whether you’re modernizing legacy systems or planning for future growth, hiring top-tier talent through PearlHire is a strategic move toward building smarter, future-ready digital environments.
0 notes