#breadth first search algorithm with example
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
BuzzFeed published a report claiming that Tumblr was utilized as a distribution channel for Russian agents to influence American voting habits during the 2016 presidential election in Feb 2018.
Text
Data Structures and Algorithms: The Building Blocks of Efficient Programming
The world of programming is vast and complex, but at its core, it boils down to solving problems using well-defined instructions. While the specific code varies depending on the language and the task, the fundamental principles of data structures and algorithms underpin every successful application. This blog post delves into these crucial elements, explaining their importance and providing a starting point for understanding and applying them.
What are Data Structures and Algorithms?
Imagine you have a vast collection of books. You could haphazardly pile them, making it nearly impossible to find a specific title. Alternatively, you could organize them by author, genre, or subject, with indexed catalogs, allowing quick retrieval. Data structures are the organizational systems for data. They define how data is stored, accessed, and manipulated.
Algorithms, on the other hand, are the specific instructions—the step-by-step procedures—for performing tasks on the data within the chosen structure. They determine how to find a book, sort the collection, or even search for a particular keyword within all the books.
Essentially, data structures provide the containers, and algorithms provide the methods to work with those containers efficiently.
Fundamental Data Structures:
Arrays: A contiguous block of memory used to store elements of the same data type. Accessing an element is straightforward using its index (position). Arrays are efficient for storing and accessing data, but inserting or deleting elements can be costly. Think of a numbered list of items in a shopping cart.
Linked Lists: A linear data structure where elements are not stored contiguously. Instead, each element (node) contains data and a pointer to the next node. This allows for dynamic insertion and deletion of elements but accessing a specific element requires traversing the list from the beginning. Imagine a chain where each link has a piece of data and points to the next link.
Stacks: A LIFO (Last-In, First-Out) structure. Think of a stack of plates: the last plate placed on top is the first one removed. Stacks are commonly used for function calls, undo/redo operations, and expression evaluation.
Queues: A FIFO (First-In, First-Out) structure. Imagine a queue at a ticket counter—the first person in line is the first one served. Queues are useful for managing tasks, processing requests, and implementing breadth-first search algorithms.
Trees:Hierarchical data structures that resemble a tree with a root, branches, and leaves. Binary trees, where each node has at most two children, are common for searching and sorting. Think of a file system's directory structure, representing files and folders in a hierarchical way.
Graphs: A collection of nodes (vertices) connected by edges. Represent relationships between entities. Examples include social networks, road maps, and dependency diagrams.
Crucial Algorithms:
Sorting Algorithms: Bubble Sort, Insertion Sort, Merge Sort, Quick Sort, Heap Sort—these algorithms arrange data in ascending or descending order. Choosing the right algorithm for a given dataset is critical for efficiency. Large datasets often benefit from algorithms with time complexities better than O(n^2).
Searching Algorithms: Linear Search, Binary Search—finding a specific item in a dataset. Binary search significantly improves efficiency on sorted data compared to linear search.
Graph Traversal Algorithms: Depth-First Search (DFS), Breadth-First Search (BFS)—exploring nodes in a graph. Crucial for finding paths, determining connectivity, and solving various graph-related problems.
Hashing: Hashing functions take input data and produce a hash code used for fast data retrieval. Essential for dictionaries, caches, and hash tables.
Why Data Structures and Algorithms Matter:
Efficiency: Choosing the right data structure and algorithm is crucial for performance. An algorithm's time complexity (e.g., O(n), O(log n), O(n^2)) significantly impacts execution time, particularly with large datasets.
Scalability:Applications need to handle growing amounts of data. Well-designed data structures and algorithms ensure that the application performs efficiently as the data size increases.
Readability and Maintainability: A structured approach to data handling makes code easier to understand, debug, and maintain.
Problem Solving: Understanding data structures and algorithms helps to approach problems systematically, breaking them down into solvable sub-problems and designing efficient solutions.
0 notes
Text
im on my train and im bored so let's do this fully, by that i mean completing the maze with the shortest path
the first step is to isolate the path. bumping the contrast is good enough, but a cleaner way to do this is to do a simple thresholding, this makes the image binary (i.e., black and white) and makes the later processes simpler
i picked the threshold manually (value 200), we just need to make the maze look visible
since we wanna find a path (along the white line) from start to finish, we'd like the line to not be so thick, preferrably just one pixel thick, so we have a clearer path to walk on later. this process is called thinning in computer vision
the thresholding result and the thinning result are the below two images



now we walk from bottom to top (either way is fine). we simply do a breadth-first-search (BFS) to find the shortest path, where the nodes are the white pixels and the edges are the link between the neighbors

when the BFS reaches the other side, we can backtrack and get the result path



the time complexity of the maze solving BFS itself should be roughly O(number of white pixels), and the number of pixels is definitely under 1e8 (100,000,000), by the rule of thumb in comp sci field this program should be done under 1 second and there's really no need for further optimization
the code btw
Also two things to note:
1. There are algorithms to generate a valid maze, the (probably) most famous one is called Eller's algorithm, which basically guarentees that if you bucket fill the path at the start it will fill the whole maze. Thats probably why the original post's method didnt really reduce the search space
2. There are also algorithms to complete a maze with simple rules, for example the also famous hand-on-wall rule, where you just use one hand to touch the wall, keep following the wall until you reach the end. It does need some condition on the maze and almost definitely not the shortest path to solve the maze, but yeah you could try if you run out of options
edit: if you are actually looking at the code, tbh all (x, y) shouldve been written as (r, c) (meaning row & column) instead. oh well, im not gonna edit that now
SOBBING

ok so someone in a server im in sent this maze and told another friend to solve it, and i said i'd solve it my plan was simple, i was just going to use the bucket tool to fill in at least the main path from the start to the end.. there was an issue though

the image wasnt very high res so this anti aliasing made the bucket tool not play nicely. i figured i'd just use a levels adjustment layer to bump up the contrast and that worked well!

and so I covered the start and end with red, then used the bucket tool to fill in the rest. ..the maze had no disconnected parts, and my levels adjustment made the seal and ball at the top and bottom become uhh..

FUCKING. EVIL MAZE. JUMPSCARE
181 notes
·
View notes
Text
Beyond the ChatGPT Hype: Exploring the Diverse Horizons of AI
In the ever-evolving landscape of artificial intelligence (AI), the current buzz predominantly centers around generative AI models like ChatGPT. While these advancements are undoubtedly groundbreaking, it’s essential to recognize that AI’s potential extends far beyond conversational agents. To fully appreciate the breadth of AI’s capabilities, we can draw parallels to a pivotal moment in the history of technology: Google’s introduction of the PageRank algorithm.
A Glimpse into AI’s Early Impact: Google’s PageRank
Recall the first time Google introduced the PageRank algorithm. This innovative approach revolutionized how we navigate the vast expanse of the internet, fundamentally altering our daily lives. PageRank didn’t just improve search results; it transformed information accessibility, setting the stage for the digital age. Almost immediately, we began to understand the profound utility of this algorithm, appreciating its ability to deliver relevant, reliable information swiftly and efficiently.
The Shift to Generative AI: A Singular Focus
Fast forward to today, and we find ourselves amidst a new wave of AI enthusiasm, predominantly focused on generative models like ChatGPT. These models excel at creating human-like text, generating images, composing music, and more, capturing the public’s imagination and driving significant media attention. However, this focus often overshadows the vast array of other AI technologies that are equally, if not more, impactful across various sectors. One such example is Allreno GPT, an innovative tool that leverages generative AI to transform the home renovation industry. By automating complex design processes and enhancing customer interactions, Allreno GPT exemplifies how generative AI can be tailored to specific industries, maximizing its impact.
Expansive Application Areas: AI’s Multifaceted Potential
AI’s applications are as diverse as the industries it serves. In healthcare, AI-driven diagnostics and personalized medicine are transforming patient care. The finance sector leverages AI for fraud detection, algorithmic trading, and risk management. Education benefits from AI through personalized learning experiences and administrative automation. Manufacturing utilizes AI for predictive maintenance, quality control, and supply chain optimization. These examples illustrate that AI’s utility is not confined to generating content but extends to enhancing efficiency, accuracy, and innovation across multiple domains.
Generative AI in Retail: Unlocking New Possibilities
Focusing on the retail industry, generative AI presents a plethora of opportunities to revolutionize operations and customer experiences. Personalized marketing campaigns can be crafted with greater precision, tailoring content to individual consumer preferences. Inventory management can be optimized through predictive analytics, ensuring that products are stocked based on anticipated demand. Virtual assistants powered by generative AI can enhance customer service, providing instant, accurate responses to inquiries. Additionally, generative AI can aid in product design and development, enabling retailers to innovate and stay competitive in a dynamic market.
Embracing the Full Spectrum of AI: A Call to Action
While the allure of generative AI like ChatGPT is undeniable, it is crucial for businesses and professionals to recognize and harness the full spectrum of AI technologies available. Diversifying our focus ensures that we leverage the most appropriate tools for each unique challenge, driving comprehensive growth and innovation.
As Elsa from Disney’s Frozen wisely says, “Let it go.” Let us release our singular focus on generative AI and embrace the entire landscape of artificial intelligence. By doing so, we unlock unprecedented opportunities to transform industries, enhance lives, and shape a future where AI serves as a versatile and powerful ally in our quest for progress.

#ai#bathroom remodeling#bathroom renovation#investors#proptech#interior design#techinnovation#real estate#tech
0 notes
Text
Recitation 9 Graph Algorithms
Objectives What is a Graph? Depth First Search Breadth First Search Exercise Challenge 1 (Silver Badge) Challenge 2 (Gold Badge) In real world, many problems are represented in terms of objects and connections between them. For example, in an airline route map, we might be interested in questions like: “What’s the fastest way to go from Denver to San Francisco” or “What is the cheapest way…

View On WordPress
0 notes
Text
All right. So.
Interesting mapping question.
Suppose you have a map, represented as a graph with coordinates.
And your little robot is told the coordinates of the exit of a maze, but not where any of the obstacles are.
Do you alter your algorithm to make use of this?
I feel like I'd run two algorithms - an "assume-it's-easy" search and then the common breadth-first as a backup.
Assume-It's-Easy Search would be a variant of Depth-First where instead of a standard "NESW" clockwise rotation for deciding what direction to try next on arriving in a given square, it starts by attempting to go toward the correct coordinates. If you're at (1,1) and you know the goal is at (5,5) the first move you TRY should be toward (1,2) or (2,1). It should not be toward (1,0) or (0,1).
This cuts out the usual problem with Depth-First Search - that being that when it doesn't guess the direction correctly on the first try it can spend an inordinate amount of time going the wrong way. After all, "depth first" means going until it hits some form of dead end before trying an alternative.
But in a program like Maps you're not "guessing direction." You have to be careful about city streets that will literally only let you go the right way after going the wrong way for 6 blocks (lookin' at you, Boston), but generally you can determine that you want to go toward [place you said you wanted to go] and prioritize that.
This also answers a curiosity I had during class: Why the hell were we even learning about Depth-First Search? We learned about DFS and BFS at the same time as if they were equal and then were introduced to a bunch of examples where BFS was vastly superior.
But when it comes to applying values to the process of where to search next because you do have information about your target? Depth-First Search is often better! While it's possible to have mazes where going as straight as possible toward the exit you can see is secretly counterproductive, randomly-generated mazes are not going to trend toward that being the case. Usually, the Depth-First will be getting closer to the goal faster, and I'd bet most of the time that will result in enough trimming of the overall problem that it solves it faster than BFS.
The thing is, you can apply this superior information to BFS but it won't help. If you tell a BFS to prioritize "go the right way" it's still only doing that for a single room or intersection. So in the above "go from 1,1 to 5,5" example, it would start by adding 1,2 and 2,1 to the list, yes, but then it would still look at 1,0 and 0,1 before adding 1,3 or 2,2 or 3,1. Because that's what "breadth-first" means. It means assessing all the options attached to a given node before moving on to the next one, and prioritizing what's closest to your start point to make sure you've searched everything and can efficiently return the shortest route.
1 note
·
View note
Text
Is it hard to pass coding interview?
Coding interviews can be challenging, but whether they are "hard" or not depends on various factors, including your level of preparation, the specific interview format, the company's expectations, and your prior coding experience. Here are some factors to consider:
1. Preparation: The Foundation of Success
Adequate preparation is crucial for success in coding interviews. If you've invested time in learning and practicing data structures, algorithms, and problem-solving techniques, you'll be better equipped to tackle interview questions. Regularly practicing coding challenges on platforms like LeetCode, HackerRank, and CodeSignal can enhance your problem-solving skills and prepare you for technical interviews.
It's also beneficial to recognize common problem-solving patterns, such as two pointers, sliding window, depth-first search (DFS), and breadth-first search (BFS). Familiarity with these patterns can help you approach problems more efficiently and effectively.
2. Experience: The Role of Familiarity
Your level of experience in coding and problem-solving plays a significant role in determining how challenging coding interviews feel. If you're already proficient in coding and have experience with algorithms and data structures, coding interviews may be less daunting. Conversely, if you're relatively new to these concepts, the learning curve can make interviews seem more difficult.
Building a strong foundation in computer science fundamentals and gaining practical experience through projects can boost your confidence and performance in interviews. Additionally, participating in coding challenges and hackathons can provide valuable exposure and opportunities to showcase your skills.
3. Interview Format: Varies by Company
The difficulty of coding interviews can vary based on the format. Some companies focus on algorithmic questions, while others emphasize system design, behavioral questions, or coding exercises related to the role. Understanding the specific interview format of the company you're applying to can help you tailor your preparation accordingly.
For instance, companies like Google and Facebook often prioritize algorithmic problem-solving, while companies like Amazon may place more emphasis on system design and behavioral interviews. Researching the company's interview process and reviewing common interview questions can give you a clearer idea of what to expect.
4. Company Expectations: Aligning with Standards
The expectations of the company you're interviewing with can affect the perceived difficulty of the interview. Some companies have rigorous technical assessments, while others may have more lenient requirements. It's essential to align your preparation with the company's standards and expectations.
For example, top-tier tech companies often have high expectations and may require candidates to solve complex problems under time constraints. In contrast, startups may focus more on practical skills and cultural fit. Understanding the company's priorities can help you focus your preparation on the most relevant areas.
5. Nervousness: Managing Interview Anxiety
Interview nerves can make even simple coding questions seem challenging. The pressure to perform well, coupled with the fear of making mistakes, can hinder your ability to think clearly and solve problems effectively. Managing nervousness is a crucial aspect of performing well in coding interviews.
Practicing mock interviews can help alleviate nervousness and improve your performance. Mock interviews simulate real interview conditions, allowing you to become more comfortable with the interview process and receive constructive feedback. Platforms like Pramp and Interviewing.io offer free mock interview services, pairing you with experienced interviewers for practice sessions.
6. Specific Questions: Varying Complexity
The complexity of coding questions can vary widely. Some questions are straightforward and test basic concepts, while others are highly complex and require advanced problem-solving skills. The difficulty of a question can depend on various factors, including its topic, the constraints provided, and the approach required to solve it.
To prepare for a range of question complexities, it's beneficial to practice problems of varying difficulty levels. Start with easy problems to build your confidence, then gradually progress to medium and hard problems to challenge yourself and improve your problem-solving abilities.
7. Real-Time Pressure: Performing Under Constraints
Coding interviews typically have a time constraint, which can add to the pressure. Being able to think clearly and write code efficiently under time pressure is a skill that requires practice. Time management is crucial during coding interviews; allocating appropriate time to understand the problem, devise a solution, implement the code, and test it is essential.
Practicing coding problems under timed conditions can help you develop this skill. Many online platforms allow you to set timers while solving problems, simulating the time constraints of real interviews. Regular practice can help you become more efficient and confident in managing time during interviews.
8. Feedback and Adaptation: Learning from Experience
Some candidates may face initial challenges but learn from feedback and adapt their preparation strategies to improve over time. Constructive feedback from mock interviews or peers can provide valuable insights into areas of improvement and help you refine your problem-solving approach.
Adapting your preparation based on feedback ensures continuous improvement. Focus on areas where you struggle the most, whether it's understanding certain algorithms, optimizing solutions, or communicating your thought process clearly. Over time, consistent practice and adaptation can significantly enhance your performance in coding interviews.
Conclusion: Overcoming the Challenges
Coding interviews can be challenging, but with the right preparation, mindset, and strategies, they become manageable and even rewarding. Remember, the perceived difficulty of coding interviews is not an insurmountable barrier but a hurdle that can be overcome with dedication and practice.
Focus on building a strong foundation in computer science fundamentals, practicing regularly, managing your nerves, and learning from feedback. By doing so, you'll not only improve your chances of success in coding interviews but also gain valuable skills that will benefit you throughout your career.
0 notes
Text
Understanding Binary Search: A Efficient Technique for Finding in Sorted Arrays
Introduction
In the realm of computer science and algorithms, efficiency is a key factor in solving complex problems. Binary search, a fundamental algorithm, stands as a shining example of efficiency when it comes to searching for elements in sorted arrays. This article delves into the concept of What is Binary Search elucidating its working principle, advantages, and scenarios where it shines.
Demystifying Binary Search
Binary search is a search algorithm that operates on sorted arrays, cutting down the search space in half with each iteration. Unlike linear search, which examines each element one by one, binary search exploits the property of sorted arrays to efficiently locate the desired element.
Here's how binary search works:
Initialization: Begin with the entire sorted array.
Comparison: Compare the middle element of the current search space with the target element.
Divide and Conquer: If the middle element matches the target, the search is successful. If the target is smaller,
focus the search on the left half of the array; if it's larger, focus on the right half.
Repeat: Repeat steps 2 and 3 on the chosen sub-array. Continue this process until the target element is found or the search space becomes empty.
Binary search's power lies in its ability to drastically reduce the number of comparisons needed to find an element, making it an optimal choice for large datasets.
Advantages of Binary Search
Efficiency: Binary search operates with a time complexity of O(log n), where n is the number of elements in the array. This is a significant improvement over linear search's O(n) time complexity, especially for large datasets.
Optimal for Sorted Data: Binary search capitalizes on sorted arrays, making it ideal for applications where data is organized. It's frequently used in scenarios like searching in dictionaries, phonebooks, and databases.
Resource Savings: In addition to time efficiency, binary search also requires less memory compared to other algorithms like depth-first search or breadth-first search.
When to Use Binary Search
Binary search is not universally applicable; it shines under specific conditions
Sorted Data: As mentioned earlier, binary search necessitates a sorted dataset. If the data isn't sorted,
preprocessing steps must be undertaken, potentially negating its efficiency advantage.
Static Data: Binary search is most effective when the data remains relatively unchanged. If the data frequently undergoes insertions or deletions, the cost of maintaining the sorted order might outweigh the algorithm's benefits.
Search Intensive Operations: When the search process is repeated multiple times, the initial investment in sorting the data and implementing binary search pays off with each subsequent search.
For more info:-
What is Cocktail Sort
What is Dijkstra Algo
0 notes
Text
Unlocking the Secrets of Keyword Research Trends & Tips
Unlocking the Secrets of Keyword Research Trends & Tips
The internet is a vast and ever-changing landscape, and before businesses can reach new customers online they must understand the language of search engine optimization (SEO) and the importance of keyword research. By understanding keyword research trends and tips, businesses can craft effective SEO campaigns that bring in more customers and more traffic.
Cracking the Code on Keyword Research: Trends & Strategies
The first step towards unlocking the secrets of keyword research is to understand current trends in the industry. Understanding search engine algorithms and what they prioritize helps businesses understand what keywords will be most effective for a given search. Additionally, staying up-to-date on trends in keyword research can help businesses capitalize on changes in internet culture and usage. Another important part of keyword research is developing a strategy for utilizing them. Taking the time to craft an effective strategy can make the difference between a successful SEO campaign and an ineffective one. Understanding the keyword trends and using those insights to formulate an effective strategy is a key component of successful keyword research. Finally, leveraging the right tools is essential to effective keyword research. For example, using keyword tools like Google Keyword Planner and Semrush can provide insights into the most effective keywords in a given industry while giving businesses an idea of the competition for certain keywords.
Finding the Path to Success with Keyword Research Tips & Tricks
Once businesses understand the trends and strategies of keywords, they can break down the process into smaller steps and use tips and tricks to more effectively navigate the industry. For example, targeting long-tail keywords provides a better chance at achieving higher search engine rankings as they offer more specific, niche phrases that are less competitive than shorter keywords. Additionally, analyzing competitors’ keyword use can allow businesses to see which keywords are working and which are not. Another key to successful keyword research is breadth over depth; businesses should aim to have a wide variety of keywords rather than focusing on one or two. Additionally, don’t forget local keywords; more companies are appearing in local searches and having a solid foundation of local keyword phrases can give businesses an advantage. Finally, businesses should focus on updating their content to utilize new and trending keywords. By taking the time to expand upon existing content, businesses can make sure they get the most out of their SEO campaigns and capitalize on any new trends in the industry.
Conclusion
Keyword research is an essential part of successful SEO campaigns, and taking the time to explore the trends & strategies of keyword research and tips & tricks for successful campaigns can pay dividends for businesses. With the right tools and understanding, businesses can unlock the secrets of keyword research and enjoy the rewards of higher search engine rankings and more customers. Read the full article
0 notes
Text
Breadth First Search In Artificial Intelligence
In this article will try to understand what is Breadth First Search In Artificial Intelligence, properties of BFS in AI, Algorithm of BFS, example of BFS & Advantages – Disadvantages of BFS in Artificial Intelligence. Breadth First Search In Artificial Intelligence comes under the Uninformed search technique .In Previous article we have studies about Depth First Search(DFS) which is also types of Uninformed search.
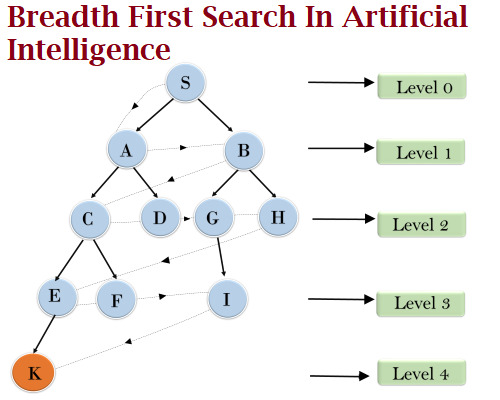
Click here to know more about Breadth First Search In Artificial Intelligence with example
#Algorithm of BFS#artificial intelligence#what is Breadth First Search In Artificial Intelligence#properties of BFS in AI#breadth first search algorithm#breadth first search algorithm in artificial intelligence with example#example of BFS & Advantages - Disadvantages of BFS in Artificial Intelligence
0 notes
Text
Session 1. What is Infocomm Law and How is it Relevant to Society Today
READ: ICTL TEXTBOOK CHAPTER 1
A. TRANSACTIONS - ICTL AND SOCIETY
What is ICTL: What is “information technology” and what is “communications technology”? What is the law relating to ICT?
Different Perspectives of ICTL: According to a leading textbook on the subject, the subject can be studied from two perspectives -
“[As] a set of discrete topics linked solely by virtue of their transient novelty and relationship to information technologies”, or
“[As] a set of topics that raises new political, social, and economic issues, and this requires consideration of appropriate legal and regulatory approaches to tackling them, outside of traditional legal paradigms.” *
What is your opinion on the above perspectives? What are the issues that can arise in relation to transactions and activities using information technology and in relation to electronic forms of communications?
Is it accurate to label an “IT lawyer” a “generalist” in law? Is it fair to make the assertion that “IT Law” is merely a “collection of legal areas that happen to touch upon IT”? *
* Diane Rowland et al, Information Technology Law (Routledge, 4ed, 2011) at p. 3
The Digital Society and Online Community: We live in an age where we do not need to physically leave home in order to interact and transact with one another. We can order food using a food delivery app, work from home through communication devices and functions, read the news and socially interact through social media platforms and be entertained through various streaming platforms. During the pandemic and In the ‘new normal’ of a world with covid-19 as endemic, ICT is becoming even more important as a safe way for human interaction as well as to conduct transactions and do business. However, although the virtual environment provides a lot of benefits and conveniences, the same technology can be abused and can cause negative effects on society and the individual.
Because of the four (or some say five) ‘V’s of Big Data, the way that we interact (communicate) and what and how we do so (information) have fundamentally changed giving rise to problems stemming from the sheer “volume”, “variety” and “velocity” of data that we have to selectively filter and process (or have it done for us), and the type of information and the manner that we consume it and how that affects our thoughts and values. One of the biggest challenges is the “veracity” of data as well as the bias in how it is being received or transmitted to us. Other issues include the increased surveillance and loss of privacy that the Internet of Things have given rise to as well as the trustworthiness and ethics of applying Artificial Intelligence in our lives.
The Evolution of the World Wide Web: Consider the general understanding of Web 1.0 and Web 2.0. What were the fundamental changes and how have the law generally responded? What are the problems of regulating the Internet? What is Web 3.0 and is there a consistent understanding and meaning in the term? How do the buzzwords and catchphrases that have dominated ‘tech-talk’ in recent years (Big Data, Smart Contract, Blockchain, Cryptocurrency, IoT, A.I.) fit into the vision of the future of ICT? What further challenges will it pose to the lawyer and the regulator, and to law itself?
Class Discussion: Consider what areas of law are covered in the study of ICT Law relating to electronic transactions as well as any possible ‘new’ areas of law that have emerged or are emerging as a result of ICT developments. Take into account the socio-economic and cultural contexts and the regulatory aspects of the law as it has developed in response to the evolution of ICT, and in particular the “Internet society”.
Browse only:
Pew Research Internet Project Publications (Browse for a general understanding of the current and overall ICT issues, but note the U.S. slant to reporting; and see e.g., this article on Ethics and A.I. Design)
Lev Grossman, You – Yes, You – Are TIME’s Person of the Year (TIME Magazine, 25 December 2006) (How does this relate to Web 2.0 and what are the issues relating to the empowerment of the individual through the Internet Intermediaries?)
B. INTERMEDIARIES - ICTL AND THE ECONOMY
The Data Economy: What is the “data economy” and how does it relate to disruptions to business models and the development of new industries based on information as the core asset?
Disruptive Technology and the Impact of New Media: What is “disruptive technology” and how has such innovations affected the economic markets of the world? What are the differences and similarities between new markets and new business models in this context? What are the political, social and cultural impact of new media? For example, consider how social media has shaped the new political landscape and developments; how the configuration of search and newsfeed algorithms as well as I2B arrangements can shape the socio-cultural norms and thinking of a new generation; and how the debate over “net neutrality” is relevant to the same inquiry. Finally, what and where is the ‘push back’ from both the public and private sector to an otherwise free market to the development and use of such technologies and the operation of their developers and users?
Digital Economy and the New Dot.com: The digital economy can be compartmentalised into two categories of corporate entities -
The first set are the products and services sector that may pre-exist the Internet and WWW or that may have arisen because of it. These include bricks-and-mortar companies transitioning into online companies as well as new powerhouses performing much of the same function but on a greater scale and breadth, such as Amazon, eBay and Alibaba. It will also cover network access providers that provides the gateway to WWW accessibility, companies that innovate and provide both hardware and software for mobile access such as Apple and Samsung as well as related and often complementary services including app developers.
The second consists of content-non-generators that provide ‘free’ or subscription (or mixed) services tied to the storage and/or organisation of content (including cloud storage services like Dropbox and indexing/search engines like Google). Others include Facebook and Linkedin (social and professional networking platforms), news aggregation services (Google and Yahoo!), electronic mail and text transmission (Gmail and Twitter), Multi-media sharing services (YouTube and P2P), Blogging platforms (e.g. Tumblr) and new forms of B2B, B2C and C2C middlemen like Uber/Grab, AirBnB, Carousel, etc. (also called the “Sharing Economy” and the “Gig Economy”)
Governments and public organisations are increasingly providing public and non-profit services via ICT innovations as well.
The Internet Intermediary: What are “intermediaries” in the true sense of the word and how are intermediaries, which are often themselves organisations/corporations different from other organisations/corporations in the eyes of the law? What is the distinction based on? Why is the study of intermediaries law important? Are these facilitative or disruptive innovations (or both), and depending on whose perspective? What is an ‘owning’ versus a ‘sharing’ economy, or a traditional versus a data economy?
Class Discussion: Categorise “intermediaries” according to a set of factors that you consider relevant. Explain the reason for the categorisation and how, in your opinion, it is important to the issue of legal status and concomitant rights and liabilities. Second, factor in the diverse social, historical and cultural contexts within which these intermediaries operate; now, consider how the context can affect the way these intermediaries operate.
Browse:
OECD Publication: The Economic and Social Role of Internet Intermediaries (2010) [Browse for an idea of a type of categorisation of Internet intermediaries and related issues]
WIPO Studies: Internet Intermediaries and Creative Content [As above, but in the context of Intellectual Property]
Lev Grossman, Person of the Year 2010: Mark Zuckerberg (TIME Magazine, 15 December 2010) [How does this relate to Web 2.0 and what are the current (legal) problems facing Facebook and its ilk?]
Joshua Quittner, Person of the Year 1999: Jeff Bezos (TIME Magazine, 27 December 1999) [Consider the new and alternative business models to Amazon and the rise of Alibaba]
C. ARTIFICIAL INTELLIGENCE - AI AND THE REGULATOR
Artificial Intelligence, Ethics and Frameworks: Critically consider the analysis and recommendations made in the report on Applying Ethical Principles for Artificial Intelligence in Regulatory Reform, SAL Law Reform Committee, July 2020. Evaluate it against the Model AI Governance Framework from the IMDA. Take note of this even as we embark on the ‘tour’ of disparate ICT topics from Session 2 onwards, and its implications for each of those areas of law.
1 note
·
View note
Text
50 Most Important Artificial Intelligence Interview Questions and Answers

Artificial Intelligence is one of the most happening fields today and the demand for AI jobs and professionals with the right skills is huge. Businesses are projected to invest heavily in artificial intelligence and machine learning in the coming years. This will lead to an increased demand for such professionals with AI skills who can help them revolutionize business operations for better productivity and profits. If you are preparing for an AI-related job interview, you can check out these AI interview questions and answers that will give you a good grip on the subject matter.
1. What is Artificial Intelligence?
Artificial intelligence, also known as machine intelligence, focuses on creating machines that can behave like humans. It is one of the wide-ranging branches of computer science which deals with the creation of smart machines that can perform tasks that usually need human intelligence. Google’s search engine is one of the most common examples of artificial intelligence.
2. What are the different domains of Artificial Intelligence?
Artificial intelligence mainly has six different domains. These are neural networks, machine learning, expert systems, robotics, fuzzy logic systems, natural language processing are the different domains of artificial intelligence. Together they help in creating an environment where machines mimic human behavior and do tasks that are usually done by them.
3. What are the different types of Artificial Intelligence?
There are seven different types of artificial intelligence. They are limited memory AI, Reactive Machines AI, Self Aware AI, Theory of Mind AI, Artificial General Intelligence (AGI), Artificial Narrow Intelligence (ANI) and Artificial Superhuman Intelligence (ASI). These different types of artificial intelligence differ in the form of complexities, ranging from basic to the most advanced ones.
4. What are the areas of application of Artificial Intelligence?
Artificial intelligence finds its application across various sectors. Speech recognition, computing, humanoid robots, computer software, bioinformatics, aeronautics and space are some of the areas where artificial intelligence can be used.
5. What is the agent in Artificial Intelligence ?
Agents can involve programs, humans and robots, and are something that perceives the environment through sensors and acts upon it with the help of effectors. Some of the different types of agents are goal-based agents, simple reflex agent, model-based reflex agent, learning agent and utility-based agent.
6. What is Generality in Artificial Intelligence?
It is the simplicity with which the method can be made suitable for different domains of application. It also means how the agent responds to unknown or new data. If it manages to predict a better outcome depending on the environment, it can be termed as a good agent. Likewise, if it does not respond to the unknown or new data, it can be called a bad agent. The more generalized the algorithm is, the better it is.
7. What is the use of semantic analyses in Artificial Intelligence?
Semantic analysis is used for extracting the meaning from the group of sentences in artificial intelligence. The semantic technology classifies the rational arrangement of sentences to recognize the relevant elements and recognize the topic.
8. What is an Artificial Intelligence Neural Network?
An artificial neural network is basically an interconnected group of nodes which takes inspiration from the simplification of neurons in a human brain. They can create models that exactly imitate the working of a biological brain. These models can recognize speech and objects as humans do.
9. What is a Dropout?
It is a tool that prevents a neural network from overfitting. It can further be classified as a regularization technique that is patented by Google to reduce overfitting in neural networks. This is achieved by preventing composite co-adaptations on training data. The word dropout refers to dropping out units in a neural network.
10. How can Tensor Flow run on Hadoop?
The path of the file needs to be changed for reading and writing data for an HDFS path.
11. Where can the Bayes rule be used in Artificial Intelligence?
It can be used to answer probabilistic queries that are conditioned on one piece of evidence. It can easily calculate the subsequent step of the robot when the current executed step is given. Bayes' rule finds its wide application in weather forecasting.
12. How many terms are required for building a Bayes model?
Only three terms are required for building a Bayes model. These three terms include two unconditional probabilities and one conditional probability.
13. What is the result between a node and its predecessors when creating a Bayesian network?
The result is that a node can provisionally remain independent of its precursor. For constructing Bayesian networks, the semantics were led to the consequence to derive this method.
14. How can a Bayesian network be used to solve a query?
The network must be a part of the joint distribution after which it can resolve a query once all the relevant joint entries are added. The Bayesian network presents a holistic model for its variables and their relationships. Due to this, it can easily respond to probabilistic questions about them.
15. What is prolog in Artificial Intelligence?
Prolog is a logic-based programming language in artificial intelligence. It is also a short for programming logic and is widely used in the applications of artificial intelligence, especially expert systems.
17. How are artificial learning and machine learning related to each other?
Machine learning is a subset of artificial learning and involves training machines in a manner by which they behave like humans without being clearly programmed. Artificial intelligence can be considered as a wider concept of machines where they can execute tasks that humans can consider smart. It also considers giving machines the access to information and making them learn on their own.
18. What is the difference between best-first search and breadth-first search?
They are similar strategies in which best-first search involves the expansion of nodes in acceptance with the evaluation function. For the latter, the expansion is in acceptance with the cost function of the parent node. Breadth-first search is always complete and will find solutions if they exist. It will find the best solution based on the available resources.
19. What is a Top-Down Parser?
It is something that hypothesizes a sentence and predicts lower-level constituents until the time when individual pre-terminal symbols are generated. It can be considered as a parsing strategy through which the highest level of the parse tree is looked upon first and it will be worked down with the help of rewriting grammar rules. An example of this could be the LL parsers that use the top-down parsing strategy.
20. On which search method is A* algorithm based?
It is based on the best first search method because it highlights optimization, path and different characteristics. When search algorithms have optimality, they will always find the best possible solution. In this case, it would be about finding the shortest route to the finish state.
21. Which is not a popular property of a logical rule-based system?
Attachment is a property that is not considered desirable in a logical rule-based system in artificial intelligence.
22. When can an algorithm be considered to be complete?
When an algorithm terminates with an answer when one exists, it can be said to be complete. Further, if an algorithm can guarantee a correct answer for any random input, it can be considered complete. If answers do not exist, it should guarantee to return failure.
23. How can different logical expressions look identical?
They can look identical with the help of the unification process. In unification, the lifted inference rules need substitutions through which different logical expressions can look identical. The unify algorithm combines two sentences to return a unifier.
24. How Does Partial order involve?
It involves searching for possible plans rather than possible situations. The primary idea involves generating a plan piece by piece. A partial order can be considered a binary relation that is antisymmetric, reflexive and transitive.
25. What are the two steps involved in constructing a plan ?
The first step is to add an operator, followed by adding an ordering constraint between operators. The planning process in Artificial Intelligence is primarily about decision-making of robots or computer programs to achieve the desired objectives. It will involve choosing actions in a sequence that will work systematically towards solving the given problems.
26. What is the difference between classical AI and statistical AI?
Classical AI is related to deductive thought that is given as constraints, while statistical AI is related to inductive thought that involves a pattern, trend induction, etc. Another major difference is that C++ is the favorite language of statistical AI, while LISP is the favorite language of classical AI. However, for a system to be truly intelligent, it will require the properties of deductive and inductive thought.
27. What does a production rule involve?
It involves a sequence of steps and a set of rules. A production system, also known as a production rule system, is used to provide artificial intelligence. The rules are about behavior and also the mechanism required to follow those rules.
28 .What are FOPL and its role in Artificial Intelligence?
First Order Predicate Logic (FOPL) provides a language that can be used to express assertions. It also provides an inference system to deductive apparatus. It involves quantification over simple variables and they can be seen only inside a predicate. It gives reasoning about functions, relations and world entities.
29 What does FOPL language include?
It includes a set of variables, predicate symbols, constant symbols, function symbols, logical connective, existential quantifier and a universal quantifier. The wffs that are obtained will be according to the FOPL and will represent the factual information of AI studies.
30. What is the role of the third component in the planning system?
Its role is to detect the solutions to problems when they are found. search method is the one that consumes less memory. It is basically a traversal technique due to which less space is occupied in memory. The algorithm is recursive in nature and makes use of backtracking.
31. What are the components of a hybrid Bayesian network?
The hybrid Bayesian network components include continuous and discrete variables. The conditional probability distributions are used as numerical inputs. One of the common examples of the hybrid Bayesian network is the conditional linear Gaussian (CLG) model.
32. How can inductive methods be combined with the power of first-order representations?
Inductive methods can be combined with first-order representations with the help of inductive logic programming.
33. What needs to be satisfied in inductive logic programming?
Inductive logic programming is one of the areas of symbolic artificial intelligence. It makes use of logic programming that is used to represent background knowledge, hypotheses and examples. To satisfy the entailment constraint, the inductive logic programming must prepare a set of sentences for the hypothesis.
34. What is a heuristic function?
Also simply known as heuristic, a heuristic function is a function that helps rank alternatives in search algorithms. This is done at each branching step which is based on the existing information that decides the branch that must be followed. It involves the ranking of alternatives at each step which is based on the information that helps decide which branch must be followed.
35. What are scripts and frames in artificial intelligence?
Scripts are used in natural language systems that help organize a knowledge repository of the situations. It can also be considered a structure through which a set of circumstances can be expected to follow one after the other. It is very similar to a chain of situations or a thought sequence. Frames are a type of semantic networks and are one of the recognized ways of showcasing non-procedural information.
36. How can a logical inference algorithm be solved in Propositional Logic?
Logical inference algorithms can be solved in propositional logic with the help of validity, logical equivalence and satisfying ability.
37. What are the signals used in Speech Recognition?
Speech is regarded as the leading method for communication between human beings and dependable speech recognition between machines. An acoustic signal is used in speech recognition to identify a sequence of words that is uttered by the speaker. Speech recognition develops technologies and methodologies that help the recognition and translation of the human language into text with the help of computers.
38. Which model gives the probability of words in speech recognition?
In speech recognition, the Diagram model gives the probability of each word that will be followed by other words.
39. Which search agent in artificial intelligence operates by interleaving computation and action?
The online search would involve taking the action first and then observing the environment.
40. What are some good programming languages in artificial intelligence?
Prolog, Lisp, C/C++, Java and Python are some of the most common programming languages in artificial intelligence. These languages are highly capable of meeting the various requirements that arise in the designing and development of different software.
41. How can temporal probabilistic reasoning be solved with the help of algorithms?
The Hidden Markov Model can be used for solving temporal probabilistic reasoning. This model observes the sequence of emission and after a careful analysis, it recovers the state of sequence from the data that was observed.
42. What is the Hidden Markov Model used for?
It is a tool that is used for modelling sequence behavior or time-series data in speech recognition systems. A statistical model, the hidden Markov model (HMM) describes the development of events that are dependent on internal factors. Most of the time, these internal factors cannot be directly observed. The hidden states lead to the creation of a Markov chain. The underlying state determines the probability allocation of the observed symbol.
43. What are the possible values of the variables in HMM?
The possible values of the variable in HMM are the “Possible States of the World”.
44. Where is the additional variable added in HMM?
The additional state variables are usually added to a temporal model in HMM.
45 . How many literals are available in top-down inductive learning methods?
Equality and inequality, predicates and arithmetic literals are the three literals available in top-down inductive learning methods.
46. What does compositional semantics mean?
Compositional semantics is a process that determines the meaning of P*Q from P,Q and*. Also simply known as CS, the compositional semantics is also known as the functional dependence of the connotation of an expression or the parts of that expression. Many people might have the question if a set of NL expressions can have any compositional semantics.
47. How can an algorithm be planned through a straightforward approach?
The most straightforward approach is using state-space search as it considers everything that is required to find a solution. The state-space search can be solved in two ways. These include backward from the goal and forward from the initial state.
48. What is Tree Topology?
Tree topology has many connected elements that are arranged in the form of branches of a tree. There is a minimum of three specific levels in the hierarchy. Since any two given nodes can have only one mutual connection, the tree topologies can create a natural hierarchy between parent and child.
If you wish to learn an Artificial Intelligence Course, Great Learning is offering several advanced courses in the subject. An artificial intelligence Certification will provide candidates the AI skills that are required to grab a well-paying job as an AI engineer in the business world. There are several AI Courses that are designed to give candidates extensive hands-on learning experience. Great Learning is offering Machine Learning and Artificial Intelligence courses at great prices. Contact us today for more details. The future of AI is very bright, so get enrolled today to make a dream AI career.
#artificial intelligence#Interview Questions#interview q&a#machine learning#career#ai#learn ai#interview question
4 notes
·
View notes
Text
C Program to implement BFS Algorithm for Connected Graph
BFS Algorithm for Connected Graph Write a C Program to implement BFS Algorithm for Connected Graph. Here’s simple Program for traversing a directed graph through Breadth First Search(BFS), visiting only those vertices that are reachable from start vertex. Breadth First Search (BFS) BFS is a traversing algorithm where you should start traversing from a selected node (source or starting node) and…
View On WordPress
#BFS#bfs algorithm example#bfs algorithm in c#Breadth First Search#breadth first search algorithm#breadth first search algorithm with example#breadth first search connected components#breadth first search connected graph#breadth first search example#breadth first search example for directed graph#breadth first search for directed graph#breadth first search for graph#breadth first search in c#breadth first search in c source code#breadth first search pseudocode#breadth first search strongly connected components#c data structures#c graph programs#connected components of a graph example#strongly connected graph example
0 notes
Text
Learning Exponential Audio Plug-ins for Music Production
Exponential Audio delivers several reverb plug-ins which produce a fantastic addition to any audio manufacturer's toolkit. These plug-ins offer you lush-sounding reverbs and intriguing sound design abilities, able to include lots of personality to a monitor. Additionally, because these plug-ins utilize algorithmic reverb, they could compete with the desire of a convolution reverb without needing just as much CPU. For more in-depth information about soundtracks. I highly recommend this website soundtracks
Being very complicated in design, these plug-ins might appear a bit intimidating at first glance. But, Exponential Audio has comprised a slew of presets with each one of the reverb plug-ins. This makes them user-friendly to people who have not employed the plug-ins earlier as they're too seasoned users.
In this guide, we will examine the capacity of all Exponential Audio plug-ins with presets. To begin with, we will do a comprehensive run-of-the-mill of Nimbus and R4, just two of Exponential Audio's finest plug-ins for audio production functions. With an illustration monitor, we are going to be showcasing presets that function nicely for all sorts of components in both typical reverb and audio design contexts.
Given that Nimbus and R4 every has tens of thousands of presets, we clearly will not be going through all of them.
Exponential Audio would like to remember to locate the precise reverb sound that you're searching for, so they have created the preset selection procedure effortless to navigate.
We can narrow our choices with all the Keyword menu. By choosing a general category such as"Big,""Driven,""Vintage," or"Effect" (to mention a couple ), the accessible preset from the Preset menu will alter. This is a superb way to accelerate the selection procedure.
Inside the Preset menu, now we've got a lot of alternatives to pick from. Each preset has a foundation set, with many also having many variants. Variants such as"Dark" and"Lite" will normally cause unique quantities of high-frequency filtering into the reverb's early reflections, variations like"Bad" and"Nch" will apply group or notch filters into the late and early reflections, and variations like"Narr" and"Broad" will automatically correct the reverb's stereo breadth.
Remember that everyone these parameters could be manually corrected after choosing a preset, so the reverb sound matches your requirements.
For reference, here is what the ironic trail seems just like before including any reverb. Until we begin adding reverb to the vocals, I will be muting the vocals therefore that the reverb on other components is much more perceptible.
As for me, I enjoy adding reverb to each other trap to present some variant. For these examples, we will only be adding reverb to each one the snare hits.
A brief room reverb may add a great deal of personality to a trap sound. In the next example, I have added this little room seems working with the"Tight Snare" preset in Nimbus. I have shortened the reverb decay time a little too to get the sharp slap-back effect which you would expect from a little room.
Here is another area reverb on the trap, now utilizing R4. I have used the"Drum Room" preset located beneath the"Percussion" key word. This preset has a little darker sound than the Nimbus preset over, on account of the extra pliable filtering employed to the reverb tail. Usually, at a comparatively dry trail such as this, a more reverb tail seems somewhat out of place. The simple fact that this monitor is really dry in the event, however, permit you to listen to the reverb sound somewhat more readily. This obviously includes a longer decay time, in addition to a dark personality that I prefer for big rooms in this way. The greater pre-delay worth also will help create the sensation of a massive area.
Exponential Audio delivers several reverb plug-ins which produce a fantastic addition to any audio manufacturer's toolkit. These plug-ins offer you lush-sounding reverbs and intriguing sound design abilities, able to include lots of personality to a monitor.
Additionally, because these plug-ins utilize algorithmic reverb, they could compete with the desire of a convolution reverb without needing just as much CPU.
Being very complicated in design, these plug-ins might appear a bit intimidating at first glance. But, Exponential Audio has comprised a slew of presets with each one of the reverb plug-ins. This makes them user-friendly to people who have not employed the plug-ins earlier as they're too seasoned users.
There are a couple of tools in our small track that may use some reverb. Let us begin with all the chopped, vamping synth that plays in the start.
In the next example, I have processed the synth using all the"Live Room" preset beneath the"Instrumental" key word in Nimbus.
Presets within this class is, obviously, fantastic alternatives for almost any device on your mixture. Notice that this specific preset really has a reverb decay time of 0 sec, and is therefore supposed to just make the effect of an area without including a reverb tail.
I enjoy this preset reinforces the low-mids of the synth.
Now that we have employed a super brief reverb sound let us try a bigger room for your synth. In the next example, I have processed our synth using the"Sophisticated Big Hall (Broad )" present in R4's"Big Hall" class.
I have reduced the reverb decay time to approximately two seconds, so the reverb tail is timed to the most significant gap between notes from the synth performance.
Next, let us try using some reverb presets into the piano which moves at the second half of the monitor.
Since the piano is a classic-sounding tool, my initial instinct was to look at R4's"Vintage" key word for a preset. Both these effects seem characteristically classic, which seems fantastic in an electric piano.
Additionally, I filtered some low frequencies from this input (the piano) until it strikes the reverb. This really helps to reinforce the"classic" sound that we are going for this.
Whenever it is not advised to apply reverb into low-frequency sounds, our bass is an integral component in the monitor and may sound intriguing with a brief or sound-design-esque reverb sound.
We will begin with a brief space for the bass to give it more presence from the surfaces of the stereo field. I opted to utilize the"From the Nursery" preset from Nimbus'"Little" keyword. Having a brief decay period plus pre-delay, this preset assists the bass control a little more space in the mixture. Additionally, I filtered some low frequencies from this input signal to prevent creating muddy reverb sign, which would lead to lots of problems to get nonhuman clarity in the combination.
Conclusion
As you can see, the two Nimbus and R4 are amazingly effective and flexible reverb units. With a lot of high quality presets and an assortment of parameters such as fine-tuning, Exponential Audio plug-ins are invaluable assets to any audio producer.
1 note
·
View note
Text
AI without Machine Learning: Exploring Alternative Approaches
Introduction:
Artificial Intelligence (AI) is a multidisciplinary field that aims to create intelligent systems capable of performing tasks that typically require human intelligence. While Machine Learning (ML) is a prominent subset of AI, it is important to recognize that AI can exist and be implemented without relying solely on ML techniques. This article delves into the concept of AI without Machine Learning, exploring alternative approaches and highlighting their potential applications and limitations.
Understanding AI without Machine Learning:
1. Rule-Based Systems: One approach to AI without Machine Learning involves using rule-based systems, also known as expert systems. These systems rely on a set of predefined rules and logical reasoning to make decisions or perform tasks. Rules are created by human experts in the specific domain and guide the AI system's behavior. Rule-based AI is particularly useful in areas where the knowledge and decision-making processes can be explicitly defined.
2. Symbolic AI: Symbolic AI, also referred to as classical AI, focuses on the manipulation and representation of symbols and knowledge. It employs logic and algorithms to process symbolic information and derive conclusions. Symbolic AI systems excel in areas that require logical reasoning, such as puzzle-solving, planning, and theorem proving. They are based on explicit rules and representations rather than learning from data.
3. Search and Optimization Algorithms: Another approach to AI without Machine Learning involves the use of search and optimization algorithms. These algorithms traverse a problem space, systematically exploring possible solutions to find the optimal or near-optimal result. Examples of such algorithms include depth-first search, breadth-first search, and genetic algorithms. These techniques are widely used in problem-solving domains where finding the best solution is crucial, such as scheduling, routing, and resource allocation.
Applications and Limitations:
1. Expert Systems: Rule-based AI systems have found applications in areas like healthcare diagnostics, customer support, and decision support systems. They excel in domains where there is a clear set of rules and knowledge that can be codified. However, their effectiveness is limited in complex and dynamic environments that require continuous learning and adaptation.
2. Symbolic AI: Symbolic AI techniques are well-suited for domains that demand logical reasoning, such as natural language processing, planning, and theorem proving. They have been used in applications like intelligent tutoring systems, information retrieval, and automated reasoning. However, symbolic AI struggles with handling uncertainty and dealing with large amounts of unstructured data.
3. Search and Optimization Algorithms: Search and optimization algorithms are valuable in optimization problems, including route planning, resource allocation, and scheduling. They are effective when the problem space is well-defined and the objective function can be quantified. However, they may face challenges in highly complex and dynamic environments with large search spaces.
Conclusion:
While Machine Learning has become synonymous with AI, it is essential to recognize that AI can exist and thrive without relying exclusively on ML techniques. Rule-based systems, symbolic AI, and search and optimization algorithms offer alternative approaches to AI, each with its own strengths and limitations. Understanding these different approaches expands the toolbox for developing intelligent systems and allows for tailoring solutions to specific domains and requirements. By exploring diverse AI techniques, we can uncover new avenues for solving complex problems and advancing the field of artificial intelligence.
For more info you can visit to Pusula #Pusulaint #Ai #Machinelearning #Machine #Aitechnology #openai
0 notes
Text
Building Toys
Back in the intro course we had this lesson in abstract; We checked whether our pixel-changing algorithm would alter our pixels properly using a 2x2 grid of pixels, maybe 3x3 if we were feeling spicy, but not a whole screen.
We've seen this over and over, with our professors giving us tiny bite-size examples to make sure our results make sense. If our "dictionary" is just a set of 10 words, we can tell at a glance if our "add a new word to the dictionary" works and puts it in the right place, because we're still only looking through 11 results.
But like the process of testing after every step and designing your program to fit the test itself, this too is how it's done IRL.
The only difference - the one addition to our skill set that we're making in this lesson - is that we make the toy.
You want to know whether you can make an AI that can find its way through a maze? Start with a 2x2 "maze" with only exterior walls, to make sure your robot can find its way from one corner to the other corner. A depth-first search will find the goal in 2 steps (if you start NW and have to go to the SE corner, depth-first with a clockwise search will go (Look N, can't go that way, Look E, go that way. Look N, no, Look E, no, Look S, go that way. Goal). A breadth-first search will look at the two adjacent spaces (the NE and SW corners) before expanding to the goal.
Once you have that version of the problem solved by hand, you can run it through your program and see if it solves it the way you planned. It's actually pretty easy to make your program spit out phrases like "Look [direction]" into the console window when you're running it, so you can get it to write out what it did and then compare with how you wanted it to go about things.
You can also build another toy to test it - for instance a slightly larger shape that allows for an actual wrong way dead end, to test whether your algorithm not only checks for "have I already been here" but properly backing up and testing entire alternate routes when one fails.
This process of making the "toy scenario" program that lets you check your algorithm against a known right answer to see if it's working before you're asking it a question like, "how many times does the letter G appear in these 5 pages of genetic material?" is one you'll need for designing good code.
0 notes
Text
Recitation 9 Graph Algorithms
Objectives What is a Graph? Depth First Search Breadth First Search Exercise Challenge 1 (Silver Badge) Challenge 2 (Gold Badge) In real world, many problems are represented in terms of objects and connections between them. For example, in an airline route map, we might be interested in questions like: “What’s the fastest way to go from Denver to San Francisco” or “What…

View On WordPress
0 notes