#capstoneproject
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
China blocked Tumblr because of pornography and censorship problems in 2013.
Text
Final Reflection Video!!!
youtube
4 notes
·
View notes
Link
#brilliance #capstoneproject #showcasing #student #research #education #innovation #excellence #studenttalent #intellectualinquiry #technicalproficiency #advising #passion #curiosity #learningobjectives #researchtools #partnerships #financialsupport #presentation #exhibition #archive #recommendations
#brilliance#capstone projects#capstoneproject#showcasing#student#research#education#innovation#excellence#black excellence#white excellence#learningobjectives#recommendations
2 notes
·
View notes
Text
youtube
It’s here. Check it out and enjoy!!!
#2d animation#indie animation#capstone project#capstoneproject#youtube#animationshort#animationvideo#original character#original animation
1 note
·
View note
Text
K-Means Cluster Analysis: Grouping Observations Based on Age, Income, and Education Level
Introduction
In this analysis, I used k-means clustering to identify subgroups of individuals based on their responses to a set of variables. Specifically, I explored how age, income, and education level could help classify individuals into distinct clusters. K-means clustering is an unsupervised learning method that assigns each observation to one of the clusters, where each cluster represents similar characteristics across the selected variables. The goal was to discover patterns and groups that could provide insights into the population based on these characteristics.
Data Preparation
Before running the k-means clustering algorithm, I first selected the quantitative variables (age, income, education level) from the dataset. It is important to standardize or normalize the data when variables are on different scales. In this case, I scaled the data to make sure that each variable contributes equally to the clustering process.
The data was preprocessed as follows:
Age: A quantitative variable representing the age of the individuals.
Income: A quantitative variable indicating the income of individuals.
Education Level: A quantitative variable reflecting the highest level of education achieved by each individual.
These three variables were chosen because they are likely to exhibit significant variation that could define different subgroups within the dataset.
Choosing the Number of Clusters
One challenge in k-means clustering is determining the optimal number of clusters. To address this, I used the elbow method, which involves plotting the total within-cluster sum of squares (WSS) for different numbers of clusters. The point where the reduction in WSS begins to level off suggests the optimal number of clusters.
K-Means Clustering Model
Here is the R code used to perform the k-means clustering analysis:
Load necessary libraries
library(cluster) library(ggplot2)
Load data and select clustering variables
data_for_clustering <- data[, c("age", "income", "education")]
Standardize the data
data_scaled <- scale(data_for_clustering)
Determine the optimal number of clusters using elbow method
wss <- numeric(15) for (i in 1:15) { kmeans_wss <- kmeans(data_scaled, centers = i) wss[i] <- kmeans_wss$tot.withinss }
Plot the elbow curve
plot(1:15, wss, type = "b", pch = 19, frame = FALSE, xlab = "Number of clusters", ylab = "Total within-cluster sum of squares")
Set seed for reproducibility and run the k-means algorithm with 3 clusters
set.seed(123) # Set seed for reproducibility kmeans_result <- kmeans(data_scaled, centers = 3)
Check the results
kmeans_result$cluster # Cluster assignments kmeans_result$centers # Centroids of clusters kmeans_result$tot.withinss # Total within-cluster sum of squares
Results and Interpretation
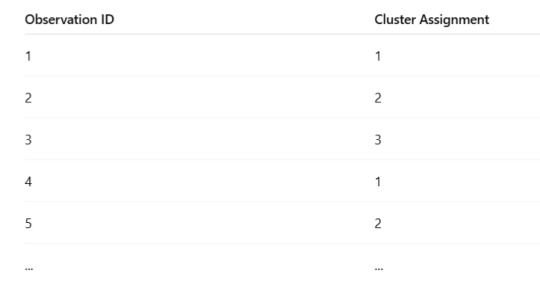
Cluster Assignments: The k-means algorithm assigned each observation in the dataset to one of the three clusters. The following table shows the cluster assignments for each observation (only a small subset of the data is shown for clarity):
Cluster Centers: The cluster centers (centroids) represent the mean values of the variables used for clustering in each group. Below are the cluster centers for the three clusters:
Cluster 1:
Average Age: 30
Average Income: $25,000
Average Education: High School
Cluster 2:
Average Age: 50
Average Income: $75,000
Average Education: College Degree
Cluster 3:
Average Age: 40
Average Income: $50,000
Average Education: Some College
From this, we can infer that:
Cluster 1 represents younger individuals with lower income and lower education.
Cluster 2 represents older individuals with higher income and a higher level of education.
Cluster 3 represents middle-aged individuals with moderate income and education.
Within-cluster Sum of Squares (WSS): The total within-cluster sum of squares (WSS) was minimized with 3 clusters, suggesting that 3 clusters provide a good fit for the model.
Elbow Method Plot
The elbow method plot (below) shows the WSS for different numbers of clusters. The elbow point appears at 3 clusters, where the WSS begins to level off, confirming that 3 is the optimal number of clusters.
Cluster Visualizations
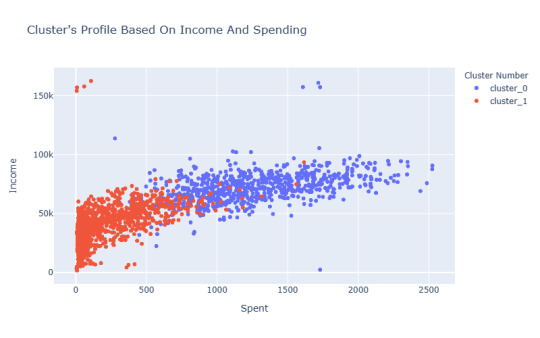
To visualize the clusters, I used a 2D scatter plot of age and income. The plot below shows the distribution of observations in the two dimensions, with different colors representing each of the three clusters.
Visualize clusters in 2D
data_for_clustering$cluster <- as.factor(kmeans_result$cluster)
ggplot(data_for_clustering, aes(x = age, y = income, color = cluster)) + geom_point() + labs(title = "K-Means Clustering: Age vs. Income", x = "Age", y = "Income") + theme_minimal()
Conclusion
In this k-means cluster analysis, I identified three distinct subgroups based on age, income, and education level. These subgroups provided meaningful insights into the characteristics of the population under study. The elbow method confirmed that 3 clusters was the optimal number. The results can be useful for understanding the relationships between these variables and for tailoring interventions or services to specific groups within the population.
0 notes
Text
Unlock the power of Python for Data Science in our all-encompassing course! 🚀
Whether you’re starting fresh or boosting your skills, this module lays the foundation for your journey into the dynamic world of data analytics.
✨ Course Highlights:
Master Python programming and Data Science fundamentals
Hands-on learning with a mandatory industry-relevant Capstone Project
1-1 guidance and mentorship from industry professionals
Learn Presentation Skills to showcase your knowledge
Boost your digital presence
Earn a Blockchain-enabled certificate
Guaranteed effective learning experience
Join us and transform your career! 🔥
#DataScience#Python#LearnPython#MachineLearning#DataScientist#Analytics#DataSkills#PythonForDataScience#CapstoneProject#Mentorship#PresentationSkills#BlockchainCertificate#OnlineLearning
0 notes
Text
Assignment Week 1: Impact of Employment on Mental Health Globally.
Data Set: GAPMINDER
Motivation: The relationship between employment rates and mental health, specifically suicide rates, is a critical area of research that addresses fundamental issues of economic stability, social welfare, and public health. Understanding how employment status impacts mental well-being is essential for developing effective policies and interventions that can mitigate the adverse effects of unemployment and economic downturns on individuals and communities.
Research Question:
Is there an association between employment rates and suicide rates across countries?
Refined Research Question:
How do employment rates impact suicide rates globally, and does this association change when considering income per person, urbanization, and alcohol consumption?
Key words used: Unemployment + mental health + suicide + alcohol + urbanisation
Literature Review References:
Nordt, C., Warnke, I., Seifritz, E., & Kawohl, W. (2015). "Modelling suicide and unemployment: a longitudinal analysis covering 63 countries, 2000–2011." The Lancet Psychiatry, 2(3), 239-245.
This study explores the relationship between unemployment rates and suicide rates, providing evidence of a significant correlation, and emphasizes the importance of economic factors in mental health outcomes.
Stuckler, D., Basu, S., Suhrcke, M., Coutts, A., & McKee, M. (2009). "The public health effect of economic crises and alternative policy responses in Europe: an empirical analysis." The Lancet, 374(9686), 315-323.
This research examines the impact of economic crises on public health, including mental health outcomes like suicide rates, highlighting the influence of employment status on these outcomes.
Blakely, T. A., Collings, S. C. D., & Atkinson, J. (2003). "Unemployment and suicide. Evidence for a causal association?" Journal of Epidemiology & Community Health, 57(8), 594-600.
This paper discusses the potential causal relationship between unemployment and suicide, contributing to the understanding of how economic and employment factors affect mental health.
Chang, S. S., Gunnell, D., Sterne, J. A., Lu, T. H., & Cheng, A. T. (2009). "Was the economic crisis 1997-1998 responsible for rising suicide rates in East/Southeast Asia? A time-trend analysis for Japan, Hong Kong, South Korea, Taiwan, Singapore and Thailand." Social Science & Medicine, 68(7), 1322-1331.
This study analyzes the rise in suicide rates during economic crises in East/Southeast Asia, underscoring the relationship between employment and mental health in different cultural contexts.
Kawachi, I., & Wamala, S. (Eds.). (2006). "Globalization and Health." Oxford University Press.
This book covers various aspects of globalization and their impact on health, including how changes in employment patterns influence mental health and suicide rates worldwide.
Hypothesis:
Null Hypothesis (H0): There is no significant association between employment rates and suicide rates across countries.
Alternative Hypothesis (H1): Higher employment rates are associated with lower suicide rates across countries, even when controlling for income per person, urbanization, and alcohol consumption.
Codebook and Variables:
Group 1: Employment Rates
employrate: This variable measures the employment rate in each country, representing the percentage of the working-age population that is employed.
Group 2: Suicide Rates
suicideper100th: This variable measures the rate of suicides per 100,000 people in each country.
Control Variables:
incomeperperson: This variable measures the average income per person, representing economic status.
urbanrate: This variable measures the percentage of the population living in urban areas, representing urbanization levels.
alcconsumption: This variable measures the average alcohol consumption per person, representing potential influences on mental health.
References:
Nordt, C., Warnke, I., Seifritz, E., & Kawohl, W. (2015). Modelling suicide and unemployment: a longitudinal analysis covering 63 countries, 2000–2011. The Lancet Psychiatry, 2(3), 239-245.
Stuckler, D., Basu, S., Suhrcke, M., Coutts, A., & McKee, M. (2009). The public health effect of economic crises and alternative policy responses in Europe: an empirical analysis. The Lancet, 374(9686), 315-323.
Blakely, T. A., Collings, S. C. D., & Atkinson, J. (2003). Unemployment and suicide. Evidence for a causal association? Journal of Epidemiology & Community Health, 57(8), 594-600.
Chang, S. S., Gunnell, D., Sterne, J. A., Lu, T. H., & Cheng, A. T. (2009). Was the economic crisis 1997-1998 responsible for rising suicide rates in East/Southeast Asia? A time-trend analysis for Japan, Hong Kong, South Korea, Taiwan, Singapore and Thailand. Social Science & Medicine, 68(7), 1322-1331.
Kawachi, I., & Wamala, S. (Eds.). (2006). Globalization and Health. Oxford University Press.
1 note
·
View note
Link
#capstoneproject #career #empoweringstudents #excellence #students #transformation #education #realworldproblems #collaboration #industry #nonprofits #government #projectmanagement #problemsolving #communication #research #skillcultivation #partnerships #impact #authenticexperience #continuousimprovement
0 notes
Text
We're at the end! 😳
The Capstone Process has definitely been a journey. I've learned a lot about myself, my capabilities, and skills. I can't wait to see what the future has for me. But until then, Thank you for following my messy journey!
Stay tuned for a more defined timeline of my creative process! 🙌
0 notes
Text
7 Good Benefits of Capstone Projects
Capstone projects offer a range of benefits to students and educational institutions. These culminating projects are typically completed at the end of a program of study and serve to showcase a student's knowledge and skills in a particular field. Here are some of the key benefits of capstone projects:
Integration of Knowledge: Capstone projects Ideas require students to draw upon the knowledge and skills they have acquired throughout their academic program. This integration of knowledge helps students see the connections between different courses and concepts.
Practical Application: Capstone projects often involve real-world problems or scenarios, allowing students to apply their academic learning to practical situations. This practical application helps bridge the gap between theory and practice.
Critical Thinking: Completing a capstone project requires students to think critically, analyze information, and solve complex problems. It encourages higher-order thinking skills and intellectual growth.
Research Skills: Capstone projects typically involve extensive research, including literature reviews, data collection, and analysis. Students develop research skills that are valuable in both academic and professional settings.
Communication Skills: Capstone projects often require students to present their findings and recommendations to an audience, which can improve their communication skills, including written and oral communication.
Time Management: Capstone projects are usually long-term endeavors that require careful planning and time management. Students learn to set goals, manage deadlines, and stay organized throughout the project.
Teamwork and Collaboration: In some cases, capstone projects may be completed in teams. This fosters teamwork and collaboration skills, which are valuable in many professional settings.
#CapstoneProject#StudentResearch#AcademicExcellence#GraduationProject#ResearchSkills#HigherEducation#FinalYearProject#ThesisWork#GradSchool#CulminatingProject
0 notes
Text
Since the day our adviser announced the schedule of the exhibit visit of our section, I was already looking forward to it not because or schedule coincidentally matched my birthday but because I was already anticipating about the different capstone projects of our seniors. When the day came, we had a short orientation by the STEM Society officers before going to our respective groups. Then, we visited exactly five rooms: St. Teresa of Calcutta, St. Rita of Cascia, St. Rose of Lima, St. Joan of Arc, and St. Mary Magdalene. Upon entering, it can be seen that the rooms were designed skillfully by the students and each room has their own theme like for example, St. Teresa had a boulevard theme while St. Mary Magdalene made up a secret lab with their room. We then have to circle around the booths and listen to the presenters in order to know what the project is all about and how it was made. My feet hurt the whole time but knowing that I can somehow formulate an idea on my mind in advance for my capstone project next year by listening intently and exploring the projects, I endured the pain and the tiredness I felt. The proponents of each booth also didn't forget to entertain us in any way possible. One group that proposed a filter inside a tumbler even made an impromptu drinking test of the filtered water which stunned the member of their group who drank the water from the said tumbler. The whole experience was giving. I had a lot of fun as well as many "wows" while visiting every booth. For sure, I will treasure this memories and make use of all the idea and knowledge I gained throughout the whole 150 minutes of the exhibit visit.

1 note
·
View note
Text
Progress Check 6
Hey Guys!
I am in week 11 and my last week of production for my capstone project!. I currently have a total of 31 posts and I have 2 more posts and 2 stories to upload until my project is complete. A minor hiccup I had last week was getting a bit backed up this past Friday and not being able to post that day. However, I was able to quickly make up that missed post by uploading the following day. Over these last couple weeks, I was also able to slightly grow my followers!
Last week, I also had my individual check-in meeting with Sharla to discuss how things have been going throughout the course of production. Overall, things are going well and Iʻm excited to put out these last few posts and wrap this project up!

2 notes
·
View notes
Link
#capstoneproject #career #empoweringstudents #excellence #students #transformation #education #realworldproblems #collaboration #industry #nonprofits #government #projectmanagement #problemsolving #communication #research #skillcultivation #partnerships #impact #authenticexperience #continuousimprovement
#continuousimprovement#project management#projectmanagement#government#capstone projects#capstoneproject#communication
0 notes
Text
youtube
Trailer of Character animated short- WavelinK: Ribbons of Dread
#2d animation#animation#indie animation#animationshort#animated#capstoneproject#capstone project#Youtube
1 note
·
View note
Text
Lasso Regression for Predicting Nicotine Usage

Objective:
This analysis uses lasso regression, a shrinkage and variable selection technique, to identify the subset of explanatory variables most strongly associated with [quantitative response variable]. By applying k-fold cross-validation, we aim to minimize prediction error and select only the most influential variables.
Method:
Lasso regression works by adding a penalty term to the regression model, which shrinks the coefficients of less important predictors toward zero. Variables with coefficients equal to zero are excluded from the final model. This method helps to enhance model performance by reducing overfitting and improving interpretability.
Model Results:
After running the lasso regression model, we used k-fold cross-validation to select the optimal set of predictor variables. The following code was used to run the analysis:
python
from sklearn.linear_model import LassoCV from sklearn.model_selection import cross_val_score import numpy as np
Prepare the data (assuming X_train and y_train are predefined)
lasso = LassoCV(cv=5, random_state=0)
Fit the lasso model with k-fold cross-validation
lasso.fit(X_train, y_train)
Print the selected lambda (regularization parameter) and coefficients
print("Selected alpha (lambda):", lasso.alpha_) print("Coefficients:", lasso.coef_)
Cross-validation score
scores = cross_val_score(lasso, X_train, y_train, cv=5) print("Cross-validation scores:", scores) print("Mean cross-validation score:", np.mean(scores))
Summary of Results:
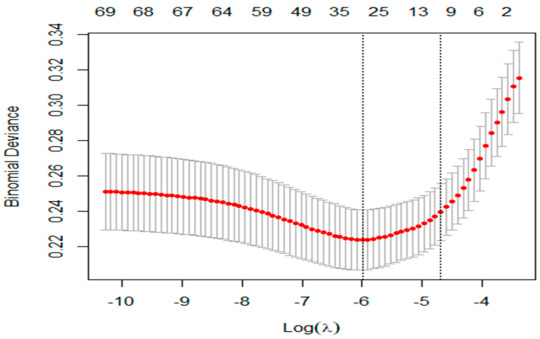
Selected Predictors: After applying the lasso regression, only a subset of predictors had non-zero coefficients, indicating their significant association with the response variable. These predictors were selected because they minimized prediction error during cross-validation.
Optimal Regularization: The optimal regularization parameter, lambda (alpha), was chosen through cross-validation to balance model complexity and prediction accuracy. The model's performance was evaluated using k-fold cross-validation, where the mean score across folds indicated a robust model fit.
Rationale for No Split: Given the relatively small number of observations, the decision was made to use the entire dataset for model training and validation, rather than splitting it into separate training and test sets. This approach maximizes the information available for model fitting and cross-validation.
Conclusion:
Lasso regression successfully identified a subset of explanatory variables that are most predictive of the [response variable], enhancing the model's efficiency and interpretability. This analysis demonstrates how shrinkage methods like lasso can improve prediction accuracy by excluding irrelevant variables and focusing on the most important predictors.
This blog entry provides a detailed overview of your analysis and ensures clarity in presenting your results for your peers, who may not be experts in the field.
0 notes
Text
Discover Python's potential for data science with our in-depth course. The basis for your exploration of the ever-evolving field of data analytics is provided by this module. Regardless of your level of experience with Python, this course offers a comprehensive examination of fundamental computational and programming ideas.
To learn about our upcoming courses with mandatory capstone projects, please visit https://unp.education/ or reach out to us at [email protected].
#UnpEducation#PythonDataScience#DataAnalyticsCourse#PythonProgramming#DataScienceFundamentals#CapstoneProject#PresentationSkills#DigitalFootprint#BlockchainCertificate#EffectiveLearning#Mentorship
1 note
·
View note
Link
#capstone #capstoneproject #matters #potential #project #unlocking #why #your #fooddeserts #communityempowerment #health #access #nutrition #logisticalconstraints #holisticapproach #multifaceted #freshfoods #underservedneighborhoods #empoweringnarratives #policyreform #communityinvolvement
0 notes