#cognito aws react
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has 411 employees.
Text
Amazon Cognito Authentication and Authorization | Cognito User Pool & Identity Pool Explained
Full Video Link https://youtube.com/shorts/plyv476pZmo Hi, a new #video on #aws #apigateway #cloud is published on #codeonedigest #youtube channel. @java #java #awscloud @awscloud #aws @AWSCloudIndia #Cloud #CloudComputing @YouTube #yo
Amazon Cognito is an identity platform for web and mobile apps. Today we will understand important features of Cognito. Userpool – Amazon Cognito user pool is a user directory. With a user pool, your users can sign in to your web or mobile app through Amazon Cognito, or federate through a third-party Identity provider. Amazon Cognito user pool can be a standalone IdP. Amazon Cognito draws from…

View On WordPress
#amazon cognito#amazon web services#aws#aws cloud#aws cognito android#aws cognito authentication java example#aws cognito authentication node js#aws cognito authentication spring boot#aws cognito authorization code grant#aws cognito authorizer#aws cognito custom login page#aws cognito demo#aws cognito otp login#aws cognito react#aws training#aws tutorial#cognito aws react#cognito login#cognito login react#cognito user pool
0 notes
Text
Build A Smarter Security Chatbot With Amazon Bedrock Agents

Use an Amazon Security Lake and Amazon Bedrock chatbot for incident investigation. This post shows how to set up a security chatbot that uses an Amazon Bedrock agent to combine pre-existing playbooks into a serverless backend and GUI to investigate or respond to security incidents. The chatbot presents uniquely created Amazon Bedrock agents to solve security vulnerabilities with natural language input. The solution uses a single graphical user interface (GUI) to directly communicate with the Amazon Bedrock agent to build and run SQL queries or advise internal incident response playbooks for security problems.
User queries are sent via React UI.
Note: This approach does not integrate authentication into React UI. Include authentication capabilities that meet your company's security standards. AWS Amplify UI and Amazon Cognito can add authentication.
Amazon API Gateway REST APIs employ Invoke Agent AWS Lambda to handle user queries.
User queries trigger Lambda function calls to Amazon Bedrock agent.
Amazon Bedrock (using Claude 3 Sonnet from Anthropic) selects between querying Security Lake using Amazon Athena or gathering playbook data after processing the inquiry.
Ask about the playbook knowledge base:
The Amazon Bedrock agent queries the playbooks knowledge base and delivers relevant results.
For Security Lake data enquiries:
The Amazon Bedrock agent takes Security Lake table schemas from the schema knowledge base to produce SQL queries.
When the Amazon Bedrock agent calls the SQL query action from the action group, the SQL query is sent.
Action groups call the Execute SQL on Athena Lambda function to conduct queries on Athena and transmit results to the Amazon Bedrock agent.
After extracting action group or knowledge base findings:
The Amazon Bedrock agent uses the collected data to create and return the final answer to the Invoke Agent Lambda function.
The Lambda function uses an API Gateway WebSocket API to return the response to the client.
API Gateway responds to React UI via WebSocket.
The chat interface displays the agent's reaction.
Requirements
Prior to executing the example solution, complete the following requirements:
Select an administrator account to manage Security Lake configuration for each member account in AWS Organisations. Configure Security Lake with necessary logs: Amazon Route53, Security Hub, CloudTrail, and VPC Flow Logs.
Connect subscriber AWS account to source Security Lake AWS account for subscriber queries.
Approve the subscriber's AWS account resource sharing request in AWS RAM.
Create a database link in AWS Lake Formation in the subscriber AWS account and grant access to the Security Lake Athena tables.
Provide access to Anthropic's Claude v3 model for Amazon Bedrock in the AWS subscriber account where you'll build the solution. Using a model before activating it in your AWS account will result in an error.
When requirements are satisfied, the sample solution design provides these resources:
Amazon S3 powers Amazon CloudFront.
Chatbot UI static website hosted on Amazon S3.
Lambda functions can be invoked using API gateways.
An Amazon Bedrock agent is invoked via a Lambda function.
A knowledge base-equipped Amazon Bedrock agent.
Amazon Bedrock agents' Athena SQL query action group.
Amazon Bedrock has example Athena table schemas for Security Lake. Sample table schemas improve SQL query generation for table fields in Security Lake, even if the Amazon Bedrock agent retrieves data from the Athena database.
A knowledge base on Amazon Bedrock to examine pre-existing incident response playbooks. The Amazon Bedrock agent might propose investigation or reaction based on playbooks allowed by your company.
Cost
Before installing the sample solution and reading this tutorial, understand the AWS service costs. The cost of Amazon Bedrock and Athena to query Security Lake depends on the amount of data.
Security Lake cost depends on AWS log and event data consumption. Security Lake charges separately for other AWS services. Amazon S3, AWS Glue, EventBridge, Lambda, SQS, and SNS include price details.
Amazon Bedrock on-demand pricing depends on input and output tokens and the large language model (LLM). A model learns to understand user input and instructions using tokens, which are a few characters. Amazon Bedrock pricing has additional details.
The SQL queries Amazon Bedrock creates are launched by Athena. Athena's cost depends on how much Security Lake data is scanned for that query. See Athena pricing for details.
Clear up
Clean up if you launched the security chatbot example solution using the Launch Stack button in the console with the CloudFormation template security_genai_chatbot_cfn:
Choose the Security GenAI Chatbot stack in CloudFormation for the account and region where the solution was installed.
Choose “Delete the stack”.
If you deployed the solution using AWS CDK, run cdk destruct –all.
Conclusion
The sample solution illustrates how task-oriented Amazon Bedrock agents and natural language input may increase security and speed up inquiry and analysis. A prototype solution using an Amazon Bedrock agent-driven user interface. This approach may be expanded to incorporate additional task-oriented agents with models, knowledge bases, and instructions. Increased use of AI-powered agents can help your AWS security team perform better across several domains.
The chatbot's backend views data normalised into the Open Cybersecurity Schema Framework (OCSF) by Security Lake.
#securitychatbot#AmazonBedrockagents#graphicaluserinterface#Bedrockagent#chatbot#chatbotsecurity#Technology#TechNews#technologynews#news#govindhtech
0 notes
Text
AWS Project – Building a React App with Amplify, Cognito, and CI/CD with GitHub | AWS Tutorial
In this hands-on tutorial, I’ll show you how to build a simple React app (a quiz app) using AWS Amplify and Cognito. We’ll also see how to set up continuous integration and continuous deployment (CI/CD) using GitHub. By the time you’re done, you’ll have a fully-functioning application you can share with the world, on a real-live Amplify URL. ?? GitHub repo for code and commands:…

View On WordPress
0 notes
Text
Building a Serverless React Application with AWS Amplify

View On WordPress
#ahsan mahmood#Amplify#aoneahsan#AWS#AWS Cognito#AWS Lambda#Deployment#React#React application#Serverless#Serverless architecture#Tutorial#zaions
0 notes
Quote
In this post, we are going to leverage AWS Amplify authentication while still building the UI we want. Prerequisites Seeing as this is a post about AWS and AWS Amplify, you should be set up with both of those. Don't have an AWS account yet? You can set one up here. To interact with AWS Amplify you need to install the CLI via npm. $ yarn global add @aws-amplify/cli Setting up our project Before we can show how to build a custom UI using Amplify, we first need a project to work from. Let's use create-react-app to get a React app going. $ npx create-react-app amplify-demo $ cd amplify-demo With our boilerplate project created we can now add the Amplify libraries we are going to need to it. $ yarn add aws-amplify aws-amplify-react Now we need to initialize Amplify and add authentication to our application. From the root of our new amplify-demo application, run the following commands with the following answers to each question. $ amplify init Note: It is recommended to run this command from the root of your app directory ? Enter a name for the project amplify-demo ? Enter a name for the environment prod ? Choose your default editor: Visual Studio Code ? Choose the type of app that you're building: javascript ? What javascript framework are you using react ? Source Directory Path: src ? Distribution Directory Path: build ? Build Command: npm run-script build ? Start Command: npm run-script start $ amplify add auth Using service: Cognito, provided by: awscloudformation The current configured provider is Amazon Cognito. Do you want to use the default authentication and security configuration? Default configuration Warning: you will not be able to edit these selections. How do you want users to be able to sign in? Username Do you want to configure advanced settings? No, I am done. Successfully added resource amplifydemobc1364f5 locally Now that we have the default authentication via Amplify added to our application we can add the default login. To do that go ahead and update your App component located at src/App.js to have the following code. import React from "react"; import logo from "./logo.svg"; import "./App.css"; import { withAuthenticator } from "aws-amplify-react"; import Amplify from "aws-amplify"; import awsconfig from "./aws-exports"; Amplify.configure(awsconfig); function App() { return ( Internal Application behind Login ); } export default withAuthenticator(App); The default Amplify authentication above leverages the higher-order component, withAuthenticator. We should now be able to see that our App component is behind a login. Go ahead and start the app up in development mode by running yarn start. We should see something like below. Customizing The Amplify Authentication UI Now that we have the default authentication wired up it's time to customize it. In the previous blog post we essentially inherited from the internal Amplify components like SignIn. This allowed us to leverage the functions already defined in that component. But, this felt like the wrong abstraction and a bit of a hack for the long term. It was/is a valid way to get something working. But it required knowing quite a few of the implementation details implemented in the parent component. Things like knowing how handleInputChange and _validAuthStates were getting used in SignIn were critical to making the brute force version below work as expected. import React from "react"; import { SignIn } from "aws-amplify-react"; export class CustomSignIn extends SignIn { constructor(props) { super(props); this._validAuthStates = ["signIn", "signedOut", "signedUp"]; } showComponent(theme) { return ( Username .....omitted..... ); } } But in running with this brute force approach for a bit I was able to form up a better way to customize the Amplify authentication UI. The approach, as we are going to see, boils down to three changes. Instead of using the higher-order component, withAuthenticator. We are going to instead use the component instead. This is the component built into the framework that allows for more customization. We are going to change our App component to make use of an AuthWrapper component that we will write. This is the component that can manage the various states of authentication we can be in. Finally, we will write our own CustomSignIn component to have it's own UI and logic. Let's go ahead and dive in with 1️⃣. Below is what our App component is going to look like now. import React from "react"; import { Authenticator } from "aws-amplify-react"; import "./App.css"; import Amplify from "aws-amplify"; import awsconfig from "./aws-exports"; import AuthWrapper from "./AuthWrapper"; Amplify.configure(awsconfig); function App() { return ( ); } export default App; Notice that our App component is now an entry point into our application. It uses the Authenticator component provided by Amplify instead of the higher-order component. We tell that component to hide all the default authentication UI, we are going to create our own. Then inside of that, we make use of a new component we are going to create called AuthWrapper. This new component is going to act as our router for the different authentication pieces we want to have. For this blog post, we are just going to implement the login workflow. But the idea is transferrable to other things like signing up and forgot password. Here is what AuthWrapper ends up looking like. import React, { Component } from "react"; import { InternalApp } from "./InternalApp"; import { CustomSignIn } from "./SignIn"; class AuthWrapper extends Component { constructor(props) { super(props); this.state = { username: "" }; this.updateUsername = this.updateUsername.bind(this); } updateUsername(newUsername) { this.setState({ username: newUsername }); } render() { return ( ); } } export default AuthWrapper; Here we can see that AuthWrapper is a router for two other components. The first one is CustomSignIn, this is the custom login UI we can build-out. The second one is our InternalApp which is the application UI signed in users can access. Note that both components get the authState passed into them. Internally the components can use this state to determine what they should do. Before taking a look at the CustomSignIn component, let's look at InternalApp to see how authState is leveraged. import React, { Component } from "react"; import logo from "../src/logo.svg"; export class InternalApp extends Component { render() { if (this.props.authState === "signedIn") { return ( Internal Application behind Login ); } else { return null; } } } Notice that we are checking that authState === "signedIn" to determine if we should render the application UI. This is a piece of state that is set by the authentication components defined in AuthWrapper. Now let's see what our customized authentication for the login prompt looks like. Here is what CustomSignIn looks like. import React, { Component } from "react"; import { Auth } from "aws-amplify"; export class CustomSignIn extends Component { constructor(props) { super(props); this._validAuthStates = ["signIn", "signedOut", "signedUp"]; this.signIn = this.signIn.bind(this); this.handleInputChange = this.handleInputChange.bind(this); this.handleFormSubmission = this.handleFormSubmission.bind(this); this.state = {}; } handleFormSubmission(evt) { evt.preventDefault(); this.signIn(); } async signIn() { const username = this.inputs.username; const password = this.inputs.password; try { await Auth.signIn(username, password); this.props.onStateChange("signedIn", {}); } catch (err) { if (err.code === "UserNotConfirmedException") { this.props.updateUsername(username); await Auth.resendSignUp(username); this.props.onStateChange("confirmSignUp", {}); } else if (err.code === "NotAuthorizedException") { // The error happens when the incorrect password is provided this.setState({ error: "Login failed." }); } else if (err.code === "UserNotFoundException") { // The error happens when the supplied username/email does not exist in the Cognito user pool this.setState({ error: "Login failed." }); } else { this.setState({ error: "An error has occurred." }); console.error(err); } } } handleInputChange(evt) { this.inputs = this.inputs || {}; const { name, value, type, checked } = evt.target; const check_type = ["radio", "checkbox"].includes(type); this.inputs[name] = check_type ? checked : value; this.inputs["checkedValue"] = check_type ? value : null; this.setState({ error: "" }); } render() { return ( {this._validAuthStates.includes(this.props.authState) && ( Username Password Login )} ); } } What we have defined up above is a React component that is leveraging the Amplify Authentication API. If we take a look at signIn we see many calls to Auth to sign a user in or resend them a confirmation code. We also see that this._validAuthStates still exists. This internal parameter to determines whether we should show this component inside of the render function. This is a lot cleaner and is not relying on knowing the implementation details of base components provided by Amplify. Making this not only more customizable but a lot less error-prone as well. If you take a look at the class names inside of the markup you'll see that this component is also making use of TailwindCSS. Speaking as a non-designer, Tailwind is a lifesaver. It allows you to build out clean looking interfaces with utility first classes. To add Tailwind into your own React project, complete these steps. Run yarn add tailwindcss --dev in the root of your project. Run ./node_modules/.bin/tailwind init tailwind.js to initialize Tailwind in the root of your project. Create a CSS directory mkdir src/css. Add a tailwind source CSS file at src/css/tailwind.src.css with the following inside of it. @tailwind base; @tailwind components; @tailwind utilities; From there we need to update the scripts in our package.json to build our CSS before anything else. "scripts": { "tailwind:css":"tailwind build src/css/tailwind.src.css -c tailwind.js -o src/css/tailwind.css", "start": "yarn tailwind:css && react-scripts start", "build": "yarn tailwind:css && react-scripts build", "test": "yarn tailwind:css && react-scripts test", "eject": "yarn tailwind:css && react-scripts eject" } Then it is a matter of importing our new Tailwind CSS file, import "./css/tailwind.css"; into the root of our app which is App.js. 💥 We can now make use of Tailwind utility classes inside of our React components. Conclusion AWS Amplify is gaining a lot of traction and it's not hard to see why. They are making it easier and easier to integrate apps into the AWS ecosystem. By abstracting away things like authentication, hosting, etc, folks are able to get apps into AWS at lightning speed. But, with abstractions can come guard rails. Frameworks walk a fine line between providing structure and compressing creativity. They need to provide a solid foundation to build upon. But at the same time, they need to provide avenues for customization. As we saw in this post the default Amplify authentication works fine. But we probably don't want exactly that when it comes to deploying our own applications. With a bit of work and extending the framework into our application, we were able to add that customization.
http://damianfallon.blogspot.com/2020/04/customizing-aws-amplify-authentication.html
1 note
·
View note
Text
Teacode technologies

TEACODE TECHNOLOGIES FULL
TEACODE TECHNOLOGIES REGISTRATION
TEACODE TECHNOLOGIES SOFTWARE
TEACODE TECHNOLOGIES CODE
Its Registered Address and Contact Email are 'A/221 MONALISA RESIDENCY VILLAGE VADODARA VODODARA Vadodara GJ 390011 IN' and respectively.
TEACODE TECHNOLOGIES REGISTRATION
They are: Hiren Buhecha and Alpeshkumar Kanaiyalal Prajapati.Īs per the records of Ministry of Corporate Affairs (MCA), Teacode Technologies Private Limited's last Annual General Meeting (AGM) was held on Oct 30, 2019, and the date of lastest Balance Sheet is Mar 31, 2019.Ĭorporate Identification Number (CIN) of Teacode Technologies Private Limited is U72200GJ2018PTC101974 and its Registration Number is 101974. There are 2 Directors associated with Teacode Technologies Private Limited. It is a Non-govt company with an Authorized Capital of ₹ 50,000 (Fifty Thousand Indian Rupees) and Paid Up Capital of ₹ 50,000 (Fifty Thousand Indian Rupees). It is registered with Registrar of Companies, Ahmedabad on Apr 23, 2018.Ĭurrent Status of Teacode Technologies Private Limited is Active.
TEACODE TECHNOLOGIES CODE
Bartek : As a developer I like to learn every day in my work, in TeaCode I can do it thanks to interesting projects and challenges, but also great code review policy, strong team cooperation and many knowledge sharing events and initiatives.TEACODE TECHNOLOGIES PRIVATE LIMITED is a Private Company limited by Shares.
Thanks to that we create an app not just a separate section. Every person on the project knows what the frontend and backend looks like and how it works.
TEACODE TECHNOLOGIES FULL
Matt : Our great value is that we work on our projects in a full stack way. What did you find most impressive about them They helped me choose the right technology stack and kept very up-to-date with project management tools.
Tech stack : React, React Native, Gatsby, MaterialUI, React Query, React Native Geolocation, AWS (Lambda Functions, DynamoDB, AppSync).
Project 2 : A British app encouraging children to have fun on a fresh air.
Tech stack : React Native, AWS (Amplify : Cognito, S3, Lambda, AppsSync, DynamoDB), Firebase Services, admin panel : Next.
Project 1 : A Californian startup for social media travel industry.
Methodology : Scrum - two week sprints, daily meetings, retro / planning session.
Playwright, Cypress, Jest, TypeScript, React Native Detox, Appium, Testrail, Mocha, K6.
Slack, Github / Gitlab, Asana, Clickup, Jira, Figma, Notion, Confluence, Sentry, Miro, Toggl, Google Workspace.
Node.js, AWS, Amplify, Nest.js, Express, Fastify, MongoDB, Postgresql, TypeScript, Cloudformation, Firebase, Elasticsearch, Serverless.
TypeScript, React (Functional Components, Hooks, Context API), Styled components, Next.js, Redux, Storybook, Webpack, Babel, Prettier, Eslint, GitHub Actions, GitLab, React Native.
technical interview with our developers.
recruitment task - we do our best to make it a real life case.
entry interview with Joanna - our Talent Acquisition Specialist.
What does the recruitment process look like?
last but not least we work together, we party together.
the office full of sweet and spicy snacks but also fresh fruits and vegetables.
table football - we take those gameplays very seriously.
We have monthly meetings that summarise our achievements, allow us to talk in-depth about some of the projects and set our priorities for the upcoming month
active participation in the life of TeaCode - we share our success stories as well as learn from each other's mistakes.
We are looking for experienced developers and freshers also for PHP and who have clear concept of.
workstation equipment (MacBook Pros, additional screen) Teacode Technology is hiring PHP developers with expertise in PHP, Laravel, Codeigniter etc.
technical university degree (preferably IT related faculty).
speaking and writing in English on a very good level (B2).
at least 3 years of experience on both frontend and backend side using React.js and Node.js.
we have clients from all over the world is a Information Technology And Services company and has headquarters in Vadodara, Gujarat, India.
we work on one programming language JavaScript (React.js on the frontend side and Node.js on the backend side).
TEACODE TECHNOLOGIES SOFTWARE
we are a software house based in Warsaw.That will serve as an UI framework with its own database. We are working on an internal tool for a client from the cryptocurrency industry.
0 notes
Photo

Dealing with Enterprises, Startups, and Agencies since 2015, 75way Technologies is a one-stop destination for Web Development, Mobility Solutions, Digital Marketing, UX/UI Consulting, and Software Development.
Collaborate with a team size of 100+ employees specializing in
Node Js, Angular, React Js, PHP, WordPress, Python, Express Js, MEAN Stack, React Native, JavaScript, Magento, MERN Stack, AWS Serverless (Cognito, Amplify, Lambda Functions), and more you can explore at https://75way.com/.
Our key services include-
Mobile Development
Web App Development
UX/UI Design
Digital Marketing
Website Development
Blockchain App Development
CMS
Full Stack Development
Enterprise Solutions
Several clients across the globe-
Alchemex
Chaine
Kingsett
My Medical Dossier
Upped Events
Thor
FindDirt
We meet the client’s needs by providing comprehensive and wide-ranging solutions.
#Top Web development company#Top Mobile app development company#Top Web & Mobile app development company
0 notes
Link
AWS & Typescript Masterclass - CDK, Serverless, React, Code with AWS and Typescript by creating serverless projects with CDK, CloudFormation, Cognito,
0 notes
Text
What Is Amazon Cognito?, Its Use cases & Amazon Cognito FAQ

Introducing Amazon Cognito
What is Amazon Cognito?
In just a few minutes, you can incorporate user sign-up, sign-in, and access management into your web and mobile applications using Amazon Cognito. It is an affordable, developer-focused solution that offers federation options and secure, tenant-based identity stores that can accommodate millions of users. Every month, Amazon Cognito handles over 100 billion authentications, giving your apps customer identity and access management (CIAM).
You can safely manage and synchronize app data for your users across their mobile devices with Amazon Cognito, a straightforward user identification and data synchronization service. With several public login providers (like Amazon, Facebook, and Google), you can give your users distinct identities and allow unauthenticated visitors. App data can be locally stored on users’ devices, enabling your apps to function even when the devices are not connected.
Without building any backend code or maintaining any infrastructure, you can use Amazon Cognito to store any type of data in the AWS Cloud, including game state or app preferences. This means that rather than worrying about developing and maintaining a backend solution to manage identity management, network state, storage, and sync, you can concentrate on making amazing app experiences.
Amazon Cognito benefits
Scalable and safe management of consumer identification and access (CIAM)
Offers enterprise-grade, affordable, and adaptable customer identity and access management that is safe and scalable. supports both passwordless login with WebAuthn passkeys or one-time passwords sent by email and SMS, as well as login with social identity providers. With a well-managed, dependable, and high-performance user directory, grow to millions of users.
Your application can be easily integrated and customized
Gives programmers access to low-code, no-code capabilities that boost efficiency. Create unique sign-up and sign-in processes that are consistent with your brand without the need for a special code. AWS Amplify, React, Next.js, Angular, Vue, Flutter, Java,.NET, C++, PHP, Python, Golang, Ruby, iOS (Swift), and Android are just a few of the many developer frameworks that it works with.
Easy access to resources and services offered by AWS
Allows for role-based access to AWS services, including AWS Lambda, Amazon S3, and Amazon DynamoDB. To enable least privilege access to a service, users can be dynamically assigned to various roles.
Advanced sign-up and sign-in security features
Provides cutting-edge security capabilities to meet your compliance and data residency needs, including risk-based adaptive authentication, compromised credential monitoring, IP geo-velocity tracking, and security metrics.
Applications
Engage clients with personalized, adaptable authentication
With the improved UI editor, you can provide your clients branded customer experiences and safe, password-free access.
Oversee B2B (business-to-business) identities
Make use of a range of multi-tenancy alternatives that offer your company varying degrees of policy and tenant isolation.
Safe authorization of machine-to-machine (M2M)
Create cutting-edge, safe, microservice-based apps and connect them to web services and backend resources more readily.
Gain access to AWS resources and services depending on roles
Get role-based, safe access to AWS services like AWS Lambda, Amazon S3, and Amazon DynamoDB.
In brief
With AWS’s customer identity and access management (CIAM) solution, Amazon Cognito, developers can easily incorporate safe user sign-up and sign-in features into their online and mobile apps. It supports millions of users with scalable, adaptable solutions, connects easily with different developer frameworks, and includes sophisticated security features including risk-based adaptive authentication and multi-factor authentication. Through role-based access management, Cognito enables safe access to other AWS services and resources, supporting a variety of use cases such as M2M and B2B authentication. Up to 10,000 monthly active users can take use of the service’s affordable free tier.
Amazon Cognito FAQ
How does Amazon Cognito support secure authentication practices?
Strong security aspects in Amazon Cognito include:
By dynamically modifying authentication requirements in response to risk variables, risk-based adaptive authentication improves security without sacrificing user experience.
Risk-based Adaptive Authentication: Dynamically controls authentication based on risk indicators to improve security without affecting user experience.
To protect user accounts, continuously monitors for compromised credentials and takes action.
IP Geo-velocity Tracking: Reduces possible risks by identifying suspicious login attempts from odd geographic regions or at odd frequencies.
IP Geo-velocity Tracking: Reduces risks by detecting suspicious login attempts from unusual places or frequencies.
Security and Compliance: Provides comprehensive security metrics and helps meet data residency and security best practices compliance standards.
How do I get started with Amazon Cognito?
Explore these Amazon Cognito resources to get started:
Features Page: Discover Amazon Cognito’s capabilities. Video lessons, workshops, and sample applications help you implement.
Developer Documentation: Find thorough instructions and best practices in developer guides and documentation.
To start Amazon Cognito, use the AWS Free Tier, which offers 10,000 free monthly active users.
What is the AWS Free Tier for Amazon Cognito?
It is free to start using Amazon Cognito with the AWS Free Tier. It offers 10,000 active users each month for free, so you can test out Cognito and see its advantages before deciding to buy a plan. For the testing, development, and deployment of applications with a small user base, this is perfect.
Can I integrate Amazon Cognito with other AWS services?
Yes, you may take use of the power of the AWS ecosystem by using Amazon Cognito’s seamless integration with a variety of AWS services. Role-based access to services such as Amazon S3, Amazon DynamoDB, AWS Lambda, and others can be provided to users through Cognito. For apps working with numerous AWS services, this interface expedites the development process and simplifies authorization.
Read more on govindhtech.com
#AmazonCognito#AmazonCognitoFAQ#AWSCloud#AWSAmplify#AWSLambda#AWSservices#aws#securityfeatures#Applications#technology#technews#adaptableauthentication#news
0 notes
Text
Supercharge your knowledge graph using Amazon Neptune, Amazon Comprehend, and Amazon Lex
Knowledge graph applications are one of the most popular graph use cases being built on Amazon Neptune today. Knowledge graphs consolidate and integrate an organization’s information into a single location by relating data stored from structured systems (e.g., e-commerce, sales records, CRM systems) and unstructured systems (e.g., text documents, email, news articles) together in a way that makes it readily available to users and applications. In reality, data rarely exists in a format that allows us to easily extract and connect relevant elements. In this post we’ll build a full-stack knowledge graph application that demonstrates how to provide structure to unstructured and semi-structured data, and how to expose this structure in a way that’s easy for users to consume. We’ll use Amazon Neptune to store our knowledge graph, Amazon Comprehend to provide structure to semi-structured data from the AWS Database Blog, and Amazon Lex to provide a chatbot interface to answer natural language questions as illustrated below. Deploy the application Let’s discuss the overall architecture and implementation steps used to build this application. If you want to experiment, all the code is available on GitHub. We begin by deploying our application and taking a look at how it works. Our sample solution includes the following: A Neptune cluster Multiple AWS Lambda functions and layers that handle the reading and writing of data to and from our knowledge graph An Amazon API Gateway that our web application uses to fetch data via REST An Amazon Lex chatbot, configured with the appropriate intents, which interacts with via our web application An Amazon Cognito identity pool required for our web application to connect to the chatbot Code that scrapes posts from the AWS Database blog for Neptune, enhances the data, and loads it into our knowledge graph A React-based web application with an AWS Amplify chatbot component Before you deploy our application, make sure you have the following: A machine running Docker, either a laptop or a server, for running our web interface An AWS account with the ability to create resources With these prerequisites satisfied, let’s deploy our application: Launch our solution using the provided AWS CloudFormation template in your desired Region: us-east-1 us-west-2 Costs to run this solution depend on the Neptune instance size chosen with a minimal cost for the other services used. Provide the desired stack name and instance size. Acknowledge the capabilities and choose Create stack. This process may take 10–15 minutes. When it’s complete, the CloudFormation stack’s Outputs tab lists the following values, which you need to run the web front end: ApiGatewayInvokeURL IdentityPoolId Run the following command to create the web interface, providing the appropriate parameters: docker run -td -p 3000:3000 -e IDENTITY_POOL_ID= -e API_GATEWAY_INVOKE_URL= -e REGION= public.ecr.aws/a8u6m715/neptune-chatbot:latest After this container has started, you can access the web application on port 3000 of your Docker server (http://localhost:3000/). If port 3000 is in use on your current server, you can alter the port by changing -p :3000. Use the application With the application started, let’s try out the chatbot integration using the following phrases: Show me all posts by Ian Robinson What has Dave Bechberger written on Amazon Neptune? Have Ian Robinson and Kelvin Lawrence worked together Show me posts by Taylor Rigg (This should prompt for Taylor Riggan; answer “Yes”.) Show me all posts on Amazon Neptune Refreshing the browser clears the canvas and chatbox. Each of these phrases provides a visual representation of the contextually relevant connections with our knowledge graph. Build the application Now that we know what our application is capable of doing, let’s look at how the AWS services are integrated to build a full-stack application. We built this knowledge graph application using a common paradigm for developing these types of applications known as ingest, curate, and discover. This paradigm begins by first ingesting data from one or more sources and creating semi-structured entities from it. In our application, we use Python and Beautiful Soup to scrape the AWS Database blog website to generate and store semi-structured data, which is stored in our Neptune-powered knowledge graph. After we extract these semi-structured entities, we curate and enhance them with additional meaning and connections. We do so using Amazon Comprehend to extract named entities from the blog post text. We connect these extracted entities within our knowledge graph to provide more contextually relevant connections within our blog data. Finally, we create an interface to allow easy discovery of our newly connected information. For our application, we use a React application, powered by Amazon Lex and Amplify, to provide a web-based chatbot interface to provide contextually relevant answers to the questions asked. Putting these aspects together gives the following application architecture. Ingest the AWS Database blog The ingest portion of our application uses Beautiful Soup to scrape the AWS Database blog. We don’t examine it in detail, but knowing the structure of the webpage allows us to create semi-structured data from the unstructured text. We use Beautiful Soup to extract several key pieces of information from each post, such as author, title, tags, and images: { "url": "https://aws.amazon.com/blogs/database/configure-amazon-vpc-for-sparql-1-1-federated-query-with-amazon-neptune/", "img_src": "https://d2908q01vomqb2.cloudfront.net/887309d048beef83ad3eabf2a79a64a389ab1c9f/2020/10/02/VPCforSPARQL1.1.FederatedQueryNeptune2.png", "img_height": "395", "img_width": "800", "title": "Configure Amazon VPC for SPARQL 1.1 Federated Query with Amazon Neptune", "authors": [ { "name": "Charles Ivie", "img_src": "https://d2908q01vomqb2.cloudfront.net/887309d048beef83ad3eabf2a79a64a389ab1c9f/2020/08/06/charles-ivie-100.jpg", "img_height": "132", "img_width": "100" } ], "date": "12 OCT 2020", "tags": [ "Amazon Neptune", "Database" ], "post": "" } After we extract this information for all the posts in the blog, we store it in our knowledge graph. The following figure shows the what this looks like for the first five posts. Although this begins to show connections between the entities in our graph, we can extract more context by examining the data stored within each post. To increase the connectedness of the data in our knowledge graph, let’s look at additional methods to curate this semi-structured data. Curate our semi-structured data To extract additional information from our semi-structured data, we use the DetectEntity functionality in Amazon Comprehend. This feature takes a text input and looks for unique names of real-world items such as people, places, items, or references to measures such as quantities or dates. By default, the types of entities returned are provided a label of COMMERCIAL_ITEM, DATE, EVENT, LOCATION, ORGANIZATION, OTHER, PERSON, QUANTITY, or TITLE. To enhance our data, the input is required to be UTF-encoded strings of up to 5,000-byte chunks. We do this by dividing each post by paragraph and running each paragraph through the batch_detect_entities method in batches of 25. For each entity that’s detected, the score, type, text, as well as begin and end offsets are returned, as in the following example code: { "Score": 0.9177741408348083, "Type": "TITLE", "Text": "SPARQL 1.1", "BeginOffset": 13, "EndOffset": 23 } Associating each of these detected entities with our semi-structured data in our knowledge graph shows even more connections, as seen in a subset in the following graph. When we compare this to our previous graph, we see that a significant number of additional connections have been added. These connections not only link posts together, they allow us to provide additional relevant answers by linking posts based on contextual relevant information stored within the post. This brings us to the final portion of this sample application: creating a web-based chatbot to interact with our new knowledge graph. Discover information in our knowledge graph Creating a web application to discover information in our knowledge graph has two steps: defining our chatbot and integrating the chatbot into a web application. Defining our chatbot Our application’s chatbot is powered by Amazon Lex, which makes it easy to build conversational interfaces for applications. The building block for building any bot with Amazon Lex is an intent. An intent is an action that responds to natural language user input. Our bot has four different intents specified: CoAuthorPosts PostByAuthor PostByAuthorAndTag PostByTag Each intent is identified by defining a variety of short training phrases for that intent, known as utterances. Each utterance is unique and when a user speaks or types that phrase, the associated intent is invoked. The phrases act as training data for the Lex bot to identify user input and map it to the appropriate intent. For example, the PostsByAuthor intent has a few different utterances that can invoke it, as shown in the following screenshot. The best practice is to use 15–20 sample utterances to provide the necessary variations for the model to perform with optimum accuracy. One or more slot values are within each utterance, identified by the curly brackets, which represent input data that is needed for the intent. Each slot value can be required or not, has a slot type associated with it, and has a prompt that used by the chatbot for eliciting the slot value if it’s not present. In addition to configuring the chatbot to prompt the user for missing slot values, you can specify a Lambda function to provide a more thorough validation of the inputs (against values available in the database) or return potential options back to the user to allow them to choose. For our PostsByAuthor intent, we configure a validation check to ensure that the author entered a valid author in our knowledge graph. The final piece is to define the fulfillment action for the intents. This is the action that occurs after the intent is invoked and all required slots are filled or validation checks have occurred. When defining the fulfillment action, you can choose from either invoking a Lambda function or returning the parameters back to the client. After you define the intent, you build and test it on the provided console. Now that the chatbot is functioning as expected, let’s integrate it into our web application. Integrate our chatbot Integration of our chatbot into our React application is relatively straightforward. We use the familiar React paradigms of components and REST calls, so let’s highlight how to configure the integration between React and Amazon Lex. Amazon Lex supports a variety of different deployment options natively, including Facebook, Slack, Twilio, or Amplify. Our application uses Amplify, which is an end-to-end toolkit that allows us to construct full-stack applications powered by AWS. Amplify offers a set of component libraries for a variety of front-end frameworks, including React, which we use in our application. Amplify provides an interaction component that makes it simple to integrate a React front end to our Amazon Lex chatbot. To accomplish this, we need some configuration information, such as the chatbot name and a configured Amazon Cognito identity pool ID. After we provide these configuration values, the component handles the work of wiring up the integration with our chatbot. In addition to the configuration, we need an additional piece of code (available on GitHub) to handle the search parameters returned as the fulfillment action from our Amazon Lex intent: useEffect(() => { const handleChatComplete = (event) => { const { data, err } = event.detail; if (data) { props.setSearchParameter(data["slots"]); } if (err) console.error("Chat failed:", err); }; const chatbotElement = document.querySelector("amplify-chatbot"); chatbotElement.addEventListener("chatCompleted", handleChatComplete); return function cleanup() { chatbotElement.removeEventListener("chatCompleted", handleChatComplete); }; }, [props]); With the search parameters for our intent, we can now call our API Gateway as you would for other REST based calls. Clean up your resources To clean up the resources used in this post, use either the AWS Command Line Interface (AWS CLI) or the AWS Management Console. Delete the CloudFormation template that you used to configure the remaining resources generated as part of this application. Conclusion Knowledge graphs—especially enterprise knowledge graphs—are efficient ways to access vast arrays of information within an organization. However, doing this effectively requires the ability to extract connections from within a large amount of unstructured and semi-structured data. This information then needs to be accessible via a simple and user-friendly interface. NLP and natural language search techniques such as those demonstrated in this post are just one of the many ways that AWS powers an intelligent data extraction and insight platform within organizations. If you have any questions or want a deeper dive into how to leverage Amazon Neptune for your own knowledge graph use case, we suggest looking at our Neptune Workbench notebook (01-Building-a-Knowledge-Graph-Application). This workbook uses the same AWS Database Blog data used here but provides additional details on the methodology, data model, and queries required to build a knowledge graph based search solution. As with other AWS services, we’re always available through your Amazon account manager or via the Amazon Neptune Discussion Forums. About the author Dave Bechberger is a Sr. Graph Architect with the Amazon Neptune team. He used his years of experience working with customers to build graph database-backed applications as inspiration to co-author “Graph Databases in Action” by Manning. https://aws.amazon.com/blogs/database/supercharge-your-knowledge-graph-using-amazon-neptune-amazon-comprehend-and-amazon-lex/
0 notes
Photo

React Native Signin and Signup with AWS Cognito https://buff.ly/2qzkkfV⠀ ⠀ Why AWS Cognito?⠀ AWS Cognito is an Amazon platform that allow us to abstract all the backend of user management process using cloud services and lets you focus on Signin/Signup frontend process of your app. This is perfect for the purpose of this article, that is to demonstrate how to create a basic Authentication using React Native without worrying about the backend. If you are starting learning React Native this article is the perfect fit for you. We will go through how to implement a basic Authentication app using React Native and connecting the backend to it. After you tackle the frontend side of your app and you are comfortable doing it you can build your own backend from scratch.⠀ .⠀ .⠀ .⠀ .⠀ .⠀ .⠀ .⠀ .⠀ .⠀ #ReactNative #CloudServices #reachjs #ProgrammingLanguage #reach #Amazon #apps #frontend #backend #AWS #awscloud #AmazonWebServices #Authentication #Cognito #cloud #google #ciscocloud #googlecloudplatform #Microsoftazure #aws #CloudComputing #AmazonWebServices #growth #amazon #microsoft #azure #alibabacloud #awscloud #gcpcloud #azurecloud (at Brampton, Ontario)
#apps#amazonwebservices#amazon#reachjs#awscloud#cognito#cloud#googlecloudplatform#cloudcomputing#microsoft#growth#programminglanguage#authentication#gcpcloud#aws#reactnative#azurecloud#azure#backend#cloudservices#microsoftazure#ciscocloud#frontend#alibabacloud#google#reach
1 note
·
View note
Link
AWS is just too hard to use, and it's not your fault. Today I'm joining to help AWS build for App Developers, and to grow the Amplify Community with people who Learn AWS in Public.
Muck
When AWS officially relaunched in 2006, Jeff Bezos famously pitched it with eight words: "We Build Muck, So You Don’t Have To". And a lot of Muck was built. The 2006 launch included 3 services (S3 for distributed storage, SQS for message queues, EC2 for virtual servers). As of Jan 2020, there were 283. Today, one can get decision fatigue just trying to decide which of the 7 ways to do async message processing in AWS to choose.
The sheer number of AWS services is a punchline, but is also testament to principled customer obsession. With rare exceptions, AWS builds things customers ask for, never deprecates them (even the failures), and only lowers prices. Do this for two decades, and multiply by the growth of the Internet, and it's frankly amazing there aren't more. But the upshot of this is that everyone understands that they can trust AWS never to "move their cheese". Brand AWS is therefore more valuable than any service, because it cannot be copied, it has to be earned. Almost to a fault, AWS prioritizes stability of their Infrastructure as a Service, and in exchange, businesses know that they can give it their most critical workloads.
The tradeoff was beginner friendliness. The AWS Console has improved by leaps and bounds over the years, but it is virtually impossible to make it fit the diverse usecases and experience levels of over one million customers. This was especially true for app developers. AWS was a godsend for backend/IT budgets, taking relative cost of infrastructure from 70% to 30% and solving underutilization by providing virtual servers and elastic capacity. But there was no net reduction in complexity for developers working at the application level. We simply swapped one set of hardware based computing primitives for an on-demand, cheaper (in terms of TCO), unfamiliar, proprietary set of software-defined computing primitives.
In the spectrum of IaaS vs PaaS, App developers just want an opinionated platform with good primitives to build on, rather than having to build their own platform from scratch:

That is where Cloud Distros come in.
Cloud Distros Recap
I've written before about the concept of Cloud Distros, but I'll recap the main points here:
From inception, AWS was conceived as an "Operating System for the Internet" (an analogy echoed by Dave Cutler and Amitabh Srivasta in creating Azure).
Linux operating systems often ship with user friendly customizations, called "distributions" or "distros" for short.
In the same way, there proved to be good (but ultimately not huge) demand for "Platforms as a Service" - with 2007's Heroku as a PaaS for Rails developers, and 2011's Parse and Firebase as a PaaS for Mobile developers atop AWS and Google respectively.
The PaaS idea proved early rather than wrong – the arrival of Kubernetes and AWS Lambda in 2014 presaged the modern crop of cloud startups, from JAMstack CDNs like Netlify and Vercel, to Cloud IDEs like Repl.it and Glitch, to managed clusters like Render and KintoHub, even to moonshot experiments like Darklang. The wild diversity of these approaches to improving App Developer experience, all built atop of AWS/GCP, lead me to christen these "Cloud Distros" rather than the dated PaaS terminology.
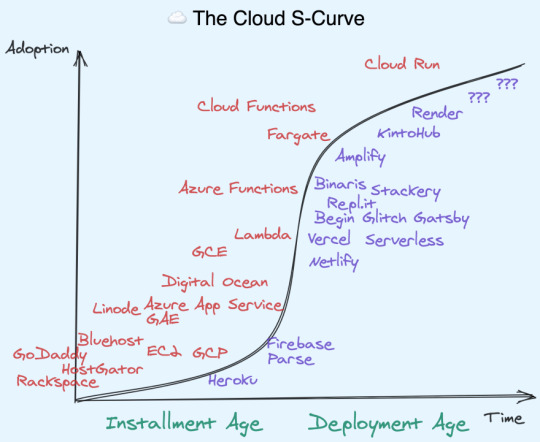
Amplify
Amplify is the first truly first-party "Cloud Distro", if you don't count Google-acquired Firebase. This does not make it automatically superior. Far from it! AWS has a lot of non-negotiable requirements to get started (from requiring a credit card upfront to requiring IAM setup for a basic demo). And let's face it, its UI will never win design awards. That just categorically rules it out for many App Devs. In the battle for developer experience, AWS is not the mighty incumbent, it is the underdog.
But Amplify has at least two killer unique attributes that make it compelling to some, and at least worth considering for most:
It scales like AWS scales. All Amplify features are built atop existing AWS services like S3, DynamoDB, and Cognito. If you want to eject to underlying services, you can. The same isn't true of third party Cloud Distros (Begin is a notable exception). This also means you are paying the theoretical low end of costs, since third party Cloud Distros must either charge cost-plus on their users or subsidize with VC money (unsustainable long term). AWS Scale doesn't just mean raw ability to handle throughput, it also means edge cases, security, compliance, monitoring, and advanced functionality have been fully battle tested by others who came before you.
It has a crack team of AWS insiders. I don't know them well yet, but it stands to reason that working on a Cloud Distro from within offers unfair advantages to working on one from without. (It also offers the standard disadvantages of a bigco vs the agility of a startup) If you were to start a company and needed to hire a platform team, you probably couldn't afford this team. If you fit Amplify's target audience, you get this team for free.
Simplification requires opinionation, and on that Amplify makes its biggest bets of all - curating the "best of" other AWS services. Instead of using one of the myriad ways to setup AWS Lambda and configure API Gateway, you can just type amplify add api and the appropriate GraphQL or REST resources are set up for you, with your infrastructure fully described as code. Storage? amplify add storage. Auth? amplify add auth. There's a half dozen more I haven't even got to yet. But all these dedicated services coming together means you don't need to manage servers to do everything you need in an app.
Amplify enables the "fullstack serverless" future. AWS makes the bulk of its money on providing virtual servers today, but from both internal and external metrics, it is clear the future is serverless. A bet on Amplify is a bet on the future of AWS.
Note: there will forever be a place for traditional VPSes and even on-premises data centers - the serverless movement is additive rather than destructive.
For a company famous for having every team operate as separately moving parts, Amplify runs the opposite direction. It normalizes the workflows of its disparate constituents in a single toolchain, from the hosted Amplify Console, to the CLI on your machine, to the Libraries/SDKs that run on your users' devices. And this works the exact same way whether you are working on an iOS, Android, React Native, or JS (React, Vue, Svelte, etc) Web App.
Lastly, it is just abundantly clear that Amplify represents a different kind of AWS than you or I are used to. Unlike most AWS products, Amplify is fully open source. They write integrations for all popular JS frameworks (React, React Native, Angular, Ionic, and Vue) and Swift for iOS and Java/Kotlin for Android. They do support on GitHub and chat on Discord. They even advertise on podcasts you and I listen to, like ShopTalk Show and Ladybug. In short, they're meeting us where we are.
This is, as far as I know, unprecedented in AWS' approach to App Developers. I think it is paying off. Anecdotally, Amplify is growing three times faster than the rest of AWS.
Note: If you'd like to learn more about Amplify, join the free Virtual Amplify Days event from Jun 10-11th to hear customer stories from people who have put every part of Amplify in production. I'll be right there with you taking this all in!
Personal Note
I am joining AWS Mobile today as a Senior Developer Advocate. AWS Mobile houses Amplify, Amplify Console (One stop CI/CD + CDN + DNS), AWS Device Farm (Run tests on real phones), and AppSync (GraphQL Gateway and Realtime/Offline Syncing), and is closely connected to API Gateway (Public API Endpoints) and Amazon Pinpoint (Analytics & Engagement). AppSync is worth a special mention because it is what first put the idea of joining AWS in my head.
A year ago I wrote Optimistic, Offline-first apps using serverless functions and GraphQL sketching out a set of integrated technologies. They would have the net effect of making apps feel a lot faster and more reliable (because optimistic and offline-first), while making it a lot easier to develop this table-stakes experience (because the GraphQL schema lets us establish an eventually consistent client-server contract).
9 months later, the Amplify DataStore was announced at Re:Invent (which addressed most of the things I wanted). I didn't get everything right, but it was clear that I was thinking on the same wavelength as someone at AWS (it turned out to be Richard Threlkeld, but clearly he was supported by others). AWS believed in this wacky idea enough to resource its development over 2 years. I don't think I've ever worked at a place that could do something like that.
I spoke to a variety of companies, large and small, to explore what I wanted to do and figure out my market value. (As an aside: It is TRICKY for developer advocates to put themselves on the market while still employed!) But far and away the smoothest process where I was "on the same page" with everyone was the ~1 month I spent interviewing with AWS. It helped a lot that I'd known my hiring manager, Nader for ~2yrs at this point so there really wasn't a whole lot he didn't already know about me (a huge benefit of Learning in Public btw) nor I him. The final "super day" on-site was challenging and actually had me worried I failed 1-2 of the interviews. But I was pleasantly surprised to hear that I had received unanimous yeses!
Nader is an industry legend and personal inspiration. When I completed my first solo project at my bootcamp, I made a crappy React Native boilerplate that used the best UI Toolkit I could find, React Native Elements. I didn't know it was Nader's. When I applied for my first conference talk, Nader helped review my CFP. When I decided to get better at CSS, Nader encouraged and retweeted me. He is constantly helping out developers, from sharing invaluable advice on being a prosperous consultant, to helping developers find jobs during this crisis, to using his platform to help others get their start. He doesn't just lift others up, he also puts the "heavy lifting" in "undifferentiated heavy lifting"! I am excited he is leading the team, and nervous how our friendship will change now he is my manager.
With this move, I have just gone from bootcamp grad in 2017 to getting hired at a BigCo L6 level in 3 years. My friends say I don't need the validation, but I gotta tell you, it does feel nice.
The coronavirus shutdowns happened almost immediately after I left Netlify, which caused complications in my visa situation (I am not American). I was supposed to start as a US Remote employee in April; instead I'm starting in Singapore today. It's taken a financial toll - I estimate that this coronavirus delay and change in employment situation will cost me about $70k in foregone earnings. This hurts more because I am now the primary earner for my family of 4. I've been writing a book to make up some of that; but all things considered I'm glad to still have a stable job again.
I have never considered myself a "big company" guy. I value autonomy and flexibility, doing the right thing over the done thing. But AWS is not a typical BigCo - it famously runs on "two pizza teams" (not literally true - Amplify is more like 20 pizzas - but still, not huge). I've quoted Bezos since my second ever meetup talk, and have always admired AWS practices from afar, from the 6-pagers right down to the anecdote told in Steve Yegge's Platforms Rant. Time to see this modern colossus from the inside.
0 notes
Text
AWS Amplify + React Native PubSub
12:06:I’ve been learning React Native by building a Todo app. The backend is maintained by AWS Amplify. Today I’m addng PubSub and calling it programmatically from the API on behalf of the user. The tutorial appears to include a manual CLI step so it’s going to be a learning experience. The below is a real time log of my efforts.
Note: Amplify Auth is best served plain. Aka use Javascript, not Typescript if you want to use the out of the box Auth HOC. It’s written in JS and will fail in a Typescript enabled project.
11:40: Looking at the tutorial here to understand whats happening at a high level: https://docs.amplify.aws/lib/pubsub/getting-started/q/platform/js#aws-iot
11:48: Setting up IoT Core per the instructions: https://console.aws.amazon.com/iot/home?region=us-east-1
Pricing is based on how long a device is connected, which is great:
Connectivity pricing: $0.08 (per million minutes of connection)
For example, in the US East (N. Virginia) region you pay $0.042 per device per year (1 connection * $0.08/1,000,000 minutes of connection * 525,600 minutes/year) for 24/7 connectivity. In order to maintain connectivity, devices may send keep-alive (“Ping”) messages at frequencies ranging from 20 minutes to every 30s, and you do not incur any additional cost for these messages. See additional connectivity pricing details >>
11:55: I think you can use the endpoint that’s configured here:
https://console.aws.amazon.com/iot/home?region=us-east-1#/settings
12:06: Setup an “allow all” IoT Policy since I’m just testing this for now.
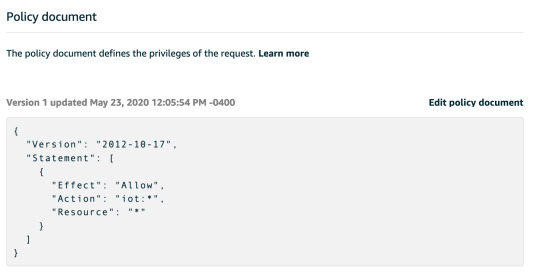
12:13: Added the policy to my user following these instructions:
Allowing your Amazon Cognito Authenticated Role to access IoT Services
For your Cognito Authenticated Role to be able to interact with AWS IoT it may be necessary to update its permissions, if you haven’t done this before. One way of doing this is to log to your AWS Console, select CloudFormation from the available services. Locate the parent stack of your solution: it is usually named <SERVICE-NAME>-<CREATION_TIMESTAMP>. Select the Resources tab and tap on AuthRole Physical ID. The IAM console will be opened in a new tab. Once there, tap on the button Attach Policies, then search AWSIoTDataAccess and AWSIoTConfigAccess, select them and tap on Attach policy.
I got caught up in something else and never finished this. Sorry :(
0 notes
Text
Capbase: Fullstack Javascript Engineer with strong AWS experience (Serverless, Lambda, DynamoDB, CloudFormation)

Headquarters: San Francisco, CA URL: https://www.capbase.com
Capbase is looking to hire a top-end javascript engineer to join our dynamic and growing remote team. Capbase is a digital governance platform for startups and securities transactions. We simplify legal compliance and corporate governance for startups.
We’re a small team, so you’ll have plenty of opportunity to collaborate directly with the founders, and this role in particular will have an architectural scope over our continued development of our AWS based technology stack (Amplify, AppSync, CloudFront, Cognito, DynamoDB, ElasticSearch, and Lambda, among others).
We’re looking for an expert level Javascript programmer who stays up-to-date with the latest code standards (ES2019) and a zeal for testing.
In this role, you will:
Identify opportunities to reduce risk in the codebase and suggest opportunities to improve
Implement new product features and improve existing ones with an emphasis on maintainability, readability and reusability
Propose opportunities to improve our engineering processes, tools and team
Take ownership of key areas related to your responsibilities
A Capbase team member is:
Self motivated and self starting
Has a keen eye open for their work/life balance
Able to express themselves clearly in both written and spoken English
Specific Skills we’d love to bolster within, or add to our team:
Fluency in Javascript (specifically up to and including ES2019 additions, as well as stage 3 TC39 proposals)
Familiarity with developing applications for NodeJS 10/12 for AWS Lambdas
Familiarity with AWS SDKs for various technologies (those listed above and others)
Extensive experience using Jest, Mocha/Chai, or other Javascript testing frameworks
Familiarity with React and/or React Native (our client applications are based on these technologies)
Familiarity with CSS, SASS, SCSS, HTML and front-end templating languages
In addition to a competitive salary and stock benefits, Capbase is proud to offer the following benefits:
25 days annual leave to use for any purpose
$2,500 to purchase any equipment you need to do your job properly
$500 per year for professional development to use however you choose (conferences, books, online classes, etc)
Up to $300/mo in co-working membership allowance (market dependent)
Healthcare benefits fully paid for the employee, plus 75% covered for all dependents (only in countries without national healthcare)
An annual, expenses paid, global meetup of Capbase employees somewhere fun in the world
We are a diverse & distributed team located across several time zones and countries. We are committed to hiring the best talent remotely wherever they live and encourage applicants from all countries to apply.
To apply: [email protected]
from We Work Remotely: Remote jobs in design, programming, marketing and more https://ift.tt/36nw0EM from Work From Home YouTuber Job Board Blog https://ift.tt/2ryjinZ
0 notes
Text
AWS Serverless APIs & Apps - A Complete Introduction

Description
In contrast to in conventional website hosting, the place you spin up servers, configure them after which deploy your code, in serverless functions, you do not handle any servers! As an alternative, you solely present your code and outline when it ought to get executed. Accomplished! With out managing any servers, you sometimes pay approach much less (since you bought no overhead capability), can react significantly better to incoming site visitors spikes and do not have to fret about server safety! What does this course provide then? Particularly, you'll be taught: how one can construct a REST API with out worrying about servers, utilizing AWS API Gateway to arrange your on-demand code by way of AWS Lambda methods to execute that Lambda code at any time when incoming requests attain your outlined REST endpoints how one can retailer information in a database - naturally with out managing any database servers! how one can add consumer authentication to your current frontend apps and how one can then additionally shield your REST API in opposition to unauthenticated entry with ease! how one can simply combine a whole consumer join & check in stream (together with consumer affirmation) into ANY app (internet app, iOS or Android app!) with AWS Cognito methods to deploy your internet app in a serverless method methods to pace up the supply of your static internet app property methods to safe your serverless app the place to dive deeper concerning superior improvement workflows and way more! Is that this course for you? Now that you recognize what this course gives, is it the proper alternative for you? Which expertise do you have to carry? This course is completely the proper alternative for you for those who're focused on offering nice internet functions with out worrying in regards to the provisioning of servers. It is additionally the proper alternative for those who already received expertise as a system administrator however are focused on maintaining with the newest developments and the numerous new prospects serverless computing gives. You will have some fundamental AWS data, or the willingness to dive deeper into AWS alongside taking this course. Moreover, a bank card is required for signing as much as AWS. Lastly, you need to be acquainted with APIs and SPAs (Single-Web page-Functions) and which position they play in at present's internet improvement setting. You need not know methods to create them although. Read the full article
0 notes
Text
AWS Amplify Features For Building Scalable Full-Stack Apps
AWS Amplify features
Build
Summary
Create an app backend using Amplify Studio or Amplify CLI, then connect your app to your backend using Amplify libraries and UI elements.
Verification
With a fully-managed user directory and pre-built sign-up, sign-in, forgot password, and multi-factor auth workflows, you can create smooth onboarding processes. Additionally, Amplify offers fine-grained access management for web and mobile applications and enables login with social providers like Facebook, Google Sign-In, or Login With Amazon. Amazon Cognito is used.
Data Storage
Make use of an on-device persistent storage engine that is multi-platform (iOS, Android, React Native, and Web) and driven by GraphQL to automatically synchronize data between desktop, web, and mobile apps and the cloud. Working with distributed, cross-user data is as easy as working with local-only data thanks to DataStore’s programming style, which leverages shared and distributed data without requiring extra code for offline and online scenarios. Utilizing AWS AppSync.
Analysis
Recognize how your iOS, Android, or online consumers behave. Create unique user traits and in-app analytics, or utilize auto tracking to monitor user sessions and web page data. To increase customer uptake, engagement, and retention, gain access to a real-time data stream, analyze it for customer insights, and develop data-driven marketing plans. Amazon Kinesis and Amazon Pinpoint are the driving forces.
API
To access, modify, and aggregate data from one or more data sources, including Amazon DynamoDB, Amazon Aurora Serverless, and your own custom data sources with AWS Lambda, send secure HTTP queries to GraphQL and REST APIs. Building scalable apps that need local data access for offline situations, real-time updates, and data synchronization with configurable conflict resolution when devices are back online is made simple with Amplify. powered by Amazon API Gateway and AWS AppSync.
Functions
Using the @function directive in the Amplify CLI, you can add a Lambda function to your project that you can use as a datasource in your GraphQL API or in conjunction with a REST API. Using the CLI, you can modify the Lambda execution role policies for your function to gain access to additional resources created and managed by the CLI. You may develop, test, and deploy Lambda functions using the Amplify CLI in a variety of runtimes. After choosing a runtime, you can choose a function template for the runtime to aid in bootstrapping your Lambda function.
GEO
In just a few minutes, incorporate location-aware functionalities like maps and location search into your JavaScript online application. In addition to updating the Amplify Command Line Interface (CLI) tool with support for establishing all necessary cloud location services, Amplify Geo comes with pre-integrated map user interface (UI) components that are based on the well-known MapLibre open-source library. For greater flexibility and sophisticated visualization possibilities, you can select from a variety of community-developed MapLibre plugins or alter embedded maps to fit the theme of your app. Amazon Location Service is the driving force.
Interactions
With only one line of code, create conversational bots that are both interactive and captivating using the same deep learning capabilities that underpin Amazon Alexa. When it comes to duties like automated customer chat support, product information and recommendations, or simplifying routine job chores, chatbots can be used to create fantastic user experiences. Amazon Lex is the engine.
Forecasts
Add AI/ML features to your app to make it better. Use cases such as text translation, speech creation from text, entity recognition in images, text interpretation, and text transcription are all simply accomplished. Amplify makes it easier to orchestrate complex use cases, such as leveraging GraphQL directives to chain numerous AI/ML activities and uploading photos for automatic training. powered by Amazon Sagemaker and other Amazon Machine Learning services.
PubSub
Transmit messages between your app’s backend and instances to create dynamic, real-time experiences. Connectivity to cloud-based message-oriented middleware is made possible by Amplify. Generic MQTT Over WebSocket Providers and AWS IoT services provide the power.
Push alerts
Increase consumer interaction by utilizing analytics and marketing tools. Use consumer analytics to better categorize and target your clientele. You have the ability to customize your content and interact via a variety of channels, such as push alerts, emails, and texts. Pinpoint from Amazon powers this.
Keeping
User-generated content, including images and movies, can be safely stored on a device or in the cloud. A straightforward method for managing user material for your app in public, protected, or private storage buckets is offered by the AWS Amplify Storage module. Utilize cloud-scale storage to make the transition from prototype to production of your application simple. Amazon S3 is the power source.
Ship
Summary
Static web apps can be hosted using the Amplify GUI or CLI.
Amplify Hosting
Fullstack web apps may be deployed and hosted with AWS Amplify’s fully managed service, which includes integrated CI/CD workflows that speed up your application release cycle. A frontend developed with single page application frameworks like React, Angular, Vue, or Gatsby and a backend built with cloud resources like GraphQL or REST APIs, file and data storage, make up a fullstack serverless application. Changes to your frontend and backend are deployed in a single workflow with each code commit when you simply connect your application’s code repository in the Amplify console.
Manage and scale
Summary
To manage app users and content, use Amplify Studio.
Management of users
Authenticated users can be managed with Amplify Studio. Without going through verification procedures, create and modify users and groups, alter user properties, automatically verify signups, and more.
Management of content
Through Amplify Studio, developers may grant testers and content editors access to alter the app data. Admins can render rich text by saving material as markdown.
Override the resources that are created
Change the fine-grained backend resource settings and use CDK to override them. The heavy lifting is done for you by Amplify. Amplify, for instance, can be used to add additional Cognito resources to your backend with default settings. Use amplified override auth to override only the settings you desire.
Personalized AWS resources
In order to add custom AWS resources using CDK or CloudFormation, the Amplify CLI offers escape hatches. By using the “amplify add custom” command in your Amplify project, you can access additional Amplify-generated resources and obtain CDK or CloudFormation placeholders.
Get access to AWS resources
Infrastructure-as-Code, the foundation upon which Amplify is based, distributes resources inside your account. Use Amplify’s Function and Container support to incorporate business logic into your backend. Give your container access to an existing database or give functions access to an SNS topic so they can send an SMS.
Bring in AWS resources
With Amplify Studio, you can incorporate your current resources like your Amazon Cognito user pool and federated identities (identity pool) or storage resources like DynamoDB + S3 into an Amplify project. This will allow your storage (S3), API (GraphQL), and other resources to take advantage of your current authentication system.
Hooks for commands
Custom scripts can be executed using Command Hooks prior to, during, and following Amplify CLI actions (“amplify push,” “amplify api gql-compile,” and more). During deployment, customers can perform credential scans, initiate validation tests, and clear up build artifacts. This enables you to modify Amplify’s best-practice defaults to satisfy the operational and security requirements of your company.
Infrastructure-as-Code Export
Amplify may be integrated into your internal deployment systems or used in conjunction with your current DevOps processes and tools to enforce deployment policies. You may use CDK to export your Amplify project to your favorite toolchain by using Amplify’s export capability. The Amplify CLI build artifacts, such as CloudFormation templates, API resolver code, and client-side code generation, are exported using the “amplify export” command.
Tools
Amplify Libraries
Flutter >> JavaScript >> Swift >> Android >>
To create cloud-powered mobile and web applications, AWS Amplify provides use case-centric open source libraries. Powered by AWS services, Amplify libraries can be used with your current AWS backend or new backends made with Amplify Studio and the Amplify CLI.
Amplify UI components
An open-source UI toolkit called Amplify UI Components has cross-framework UI components that contain cloud-connected workflows. In addition to a style guide for your apps that seamlessly integrate with the cloud services you have configured, AWS Amplify offers drop-in user interface components for authentication, storage, and interactions.
The Amplify Studio
Managing app content and creating app backends are made simple with Amplify Studio. A visual interface for data modeling, authorization, authentication, and user and group management is offered by Amplify Studio. Amplify Studio produces automation templates as you develop backend resources, allowing for smooth integration with the Amplify CLI. This allows you to add more functionality to your app’s backend and establish multiple testing and team collaboration settings. You can give team members without an AWS account access to Amplify Studio so that both developers and non-developers can access the data they require to create and manage apps more effectively.
Amplify CLI toolchain
A toolset for configuring and maintaining your app’s backend from your local desktop is the Amplify Command Line Interface (CLI). Use the CLI’s interactive workflow and user-friendly use cases, such storage, API, and auth, to configure cloud capabilities. Locally test features and set up several environments. Customers can access all specified resources as infrastructure-as-code templates, which facilitates improved teamwork and simple integration with Amplify’s continuous integration and delivery process.
Amplify Hosting
Set up CI/CD on the front end and back end, host your front-end web application, build and delete backend environments, and utilize Amplify Studio to manage users and app content.
Read more on Govindhtech.com
#AWSAmplifyfeatures#GraphQ#iOS#AWSAppSync#AmazonDynamoDB#RESTAPIs#Amplify#deeplearning#AmazonSagemaker#AmazonS3#News#Technews#Technology#technologynews#Technologytrends#govindhtech
0 notes