#data coding in qualitative research
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs




Fun Fact
Tumblr was created by web developers David Karp and Marco Arment.
Text
Understanding Content Analysis: A Comprehensive Guide
In the digital era, content is king. From blogs and articles to social media posts and product descriptions, content drives engagement and fuels online conversations. But how do we know if the content we’re creating is effective? This is where content analysis comes into play.
Content analysis is a systematic technique used to analyze and evaluate the content produced for various platforms. It helps to assess how well content is performing, whether it’s meeting objectives, and how it aligns with the target audience’s preferences. In this article, we’ll break down the concept of content analysis, why it’s essential for businesses, and how to conduct one effectively.
What is Content Analysis?
At its core, content analysis is the process of studying and interpreting content — be it text, video, images, or any other form of media. It’s used to identify patterns, trends, and insights that can inform content strategies and improve future content creation.
Content analysis can be both qualitative and quantitative. Qualitative content analysis focuses on interpreting meaning, context, and themes in content. It involves understanding the nuances of language, tone, and the emotional appeal of the content. On the other hand, quantitative content analysis is more about measuring and counting certain elements, such as keywords, hashtags, or engagement metrics (likes, shares, comments, etc.).
In essence, content analysis is about understanding both the “what” and the “how” of the content, and how it impacts its audience.
Why is Content Analysis Important?
Improves Content Strategy Through content analysis, businesses can gain valuable insights into what type of content resonates with their target audience. Whether it’s blog posts, social media updates, or email newsletters, knowing what works allows content creators to focus on producing high-performing content. By tracking trends in user engagement, companies can optimize their content strategy for better results.
Enhances SEO Efforts One of the key aspects of content analysis is keyword analysis. By analyzing the keywords used in the content, businesses can improve their search engine optimization (SEO) strategies. If certain keywords are overused or underused, adjustments can be made to rank higher on search engine results pages (SERPs). Additionally, content analysis can highlight gaps in content that may be affecting SEO performance, helping businesses stay ahead of their competition.
Aligns Content with Business Goals Every piece of content created should serve a purpose. Whether it’s driving traffic to a website, increasing brand awareness, or converting leads into customers, content needs to align with the company’s overall business objectives. Through content analysis, companies can measure how well content is supporting these goals. If it isn’t, adjustments can be made to improve outcomes.
Audience Understanding Content analysis helps businesses understand their audience better. By examining how different segments of the audience interact with the content, marketers can tailor future content to meet their needs. Analyzing metrics such as engagement rates, click-through rates (CTR), and bounce rates can help identify audience preferences, behaviors, and pain points.
Competitive Advantage Keeping track of competitors’ content can provide a huge advantage. Through content analysis, companies can analyze the type of content their competitors are producing, how it’s performing, and where there might be opportunities to differentiate. This gives businesses a clear picture of the market and helps them stay competitive.
How to Conduct Content Analysis?
Now that we understand the importance of content analysis, let’s explore how to carry out an effective content analysis. While the specifics may vary depending on your objectives and tools available, the following steps outline a general approach.
1. Define Your Goals
Before diving into the analysis, you need to know what you want to achieve. Are you trying to improve engagement? Boost SEO? Understand your audience better? Defining clear goals will guide the entire analysis process.
2. Choose Your Content Type
Decide what content you want to analyze. Are you focusing on blogs, social media posts, videos, or product reviews? Different content types may require different analysis techniques, so it’s important to have a clear focus.
3. Select Key Metrics
Choose the metrics you’ll analyze. For qualitative analysis, this could include tone, sentiment, themes, or visual elements. For quantitative analysis, consider metrics like traffic, engagement (likes, shares, comments), CTR, bounce rate, or conversions.
4. Collect Data
Gather all the content you plan to analyze. This could involve using tools like Google Analytics, social media analytics platforms, or specialized software for in-depth content analysis. Make sure you collect enough data for a comprehensive analysis.
5. Analyze the Content
Now, dive into the actual analysis. Start by identifying trends in the content — look for patterns in engagement, language, visual elements, or even sentiment. In quantitative analysis, you’ll be counting occurrences of certain words, hashtags, or engagement types to identify trends.
6. Evaluate Performance
Compare the results to your defined goals. How well is the content meeting your objectives? Are there areas for improvement? This step will guide your next move — whether it’s tweaking your SEO strategy, shifting your content focus, or adjusting your messaging to better connect with your audience.
7. Make Improvements
Based on your findings, make adjustments to your content. If certain topics are performing well, create more content around those themes. If certain keywords are underperforming, adjust your strategy accordingly.
Conclusion
Content analysis is a powerful tool for anyone creating digital content, whether you’re a small business owner, a content marketer, or a blogger. By regularly analyzing your content’s performance, you can ensure it aligns with your business goals, engages your target audience, and drives measurable results. With the right tools and techniques, content analysis becomes an invaluable resource for refining your content strategy, optimizing SEO, and gaining a competitive edge in today’s crowded digital landscape.
So, start digging into your content today — there’s a wealth of insight waiting to be uncovered!
#content analysis#qualitative analysis#data analysis for qualitative#data analysis of a qualitative research#data analysis in qualitative studies#analysis of data qualitative research#qualitative content analysis#content analysis in qualitative research#qualitative analysis methods#qualitative case studies#data coding in qualitative research#need of content analysis#qual data analysis#concept of content analysis#content analysis format
1 note
·
View note
Text
Grounded Theory: Making It Up As You Go Along (But With Integrity)
This week, in a break from stalking the usual parade of sociological ghosts—Marx, Weber, Bourdieu and the like—I thought we’d do something different. Let’s talk about something alive, terrifyingly current, and capable of causing existential dread in postgraduate students across the globe: methodology. More specifically, Grounded Theory. Now, if you’ve never come across Grounded Theory, count…
#Academic Life#coding chaos#data analysis nightmares#Glaser and Strauss#grounded theory#methodology humour#NVivo struggles#postgraduate research#qualitative research#reflexivity#research satire#social science humour#sociological methods#sociology jokes#theoretical saturation
1 note
·
View note
Text
Reference archived on our website
I thought maybe some of y'all would like a qualitative study over a quantitative one. A study of covid disparities in England among PoC and disabled people.
Abstract Background COVID-19 Ethnic Inequalities in Mental health and Multimorbidities (COVEIMM) is a mixed methods study to explore whether COVID-19 exacerbated ethnic health inequalities in adults with serious mental and physical health conditions. We analysed data from electronic health records for England and conducted interviews in Birmingham and Solihull, Manchester, and South London. Sites were selected because they were pilot sites for the Patient and Carer Race Equality Framework being introduced by NHS England to tackle race inequalities in mental health. Prior to the pandemic people in England with severe mental illnesses (SMIs) faced an 11–17-year reduction in life expectancy, mostly due to preventable, long-term, physical health conditions. During the pandemic there was a marked increase in deaths of those living with an SMI.
Aims This qualitative interview study aimed to understand the reasons underlying ethnic inequalities in mortality and service use during the COVID-19 pandemic for adult service users and carers of Black African, Black Caribbean, Indian, Pakistani, and Bangladeshi backgrounds living with serious multiple long-term mental and physical health conditions.
Methods We took a participatory action research approach and qualitative interviews undertaken by experts-by-experience and university researchers Participants were purposively sampled by ethnicity, diagnoses, and comorbidities across three geographically distinct sites in England. Transcriptions were coded inductively and deductively and analysed thematically.
Results Findings indicated multiple points along primary and secondary health pathways for mental and physical health that have the potential to exacerbate the unjust gap in mortality that exists for Black and Asian people with SMIs. Issues such as timely access to care (face-to-face and remote), being treated in a culturally appropriate manner with empathy, dignity and respect, and being able to use services without experiencing undue force, racism or other forms of intersectional discrimination were important themes arising from interviews.
Conclusion These poor experiences create systemic and enduring healthcare harms for racialised groups with SMIs that need to be addressed. Our findings suggest a need to address these, not only in mental health providers, but across the whole health and care system and a need to ensure more equitable healthcare partnerships with service users, carers, and communities from racialised backgrounds who are often excluded.
#race#disability#covidー19#mask up#covid#pandemic#wear a mask#covid 19#public health#coronavirus#sars cov 2#still coviding#wear a respirator#covid conscious#covid is airborne#covid isn't over#covid pandemic#covid19
33 notes
·
View notes
Text
Og content 2
The data I will be collecting is mixed. The qualitative data available on instagram pertaining to each post, so likes, shares, the dates of posts, and comments will be collected. The qualitative is going to be sorting the posts into different categories. I am doing cat accounts so I'll separate them into cute cats, silly cats, and cursed cats. That will be my 'code', I came up with some very specific criteria for each of them to try and make them as useful as possible for my research question, some posts may overlap into multiple categories, but probably not many. I think these will help me to see specifically what kind of cat content these accounts are posting primarily or if they are a mix, etc. and will be good set up for making comparisons across the 3 accounts
2 notes
·
View notes
Text
@girderednerve replied to your post coming out on tumblr as someone whose taught "AI bootcamp" courses to middle school students AMA:
did they like it? what kinds of durable skills did you want them to walk away with? do you feel bullish on "AI"?
It was an extracurricular thing so the students were quite self-selecting and all were already interested in the topic or in doing well in the class. Probably what most interested me about the demographic of students taking the courses (they were online) was the number who were international students outside of the imperial core probably eventually looking to go abroad for college, like watching/participating in the cogs of brain drain.
I'm sure my perspective is influenced because my background is in statistics and not computer science. But I hope that they walked away with a greater understanding and familiarity with data and basic statistical concepts. Things like sample bias, types of data (categorical/quantitative/qualitative), correlation (and correlation not being causation), ways to plot and examine data. Lots of students weren't familiar before we started the course with like, what a csv file is/tabular data in general. I also tried to really emphasize that data doesn't appear in a vacuum and might not represent an "absolute truth" about the world and there are many many ways that data can become biased especially when its on topics where people's existing demographic biases are already influencing reality.
Maybe a bit tangential but there was a part of the course material that was teaching logistic regression using the example of lead pipes in flint, like, can you believe the water in this town was undrinkable until it got Fixed using the power of AI to Predict Where The Lead Pipes Would Be? it was definitely a trip to ask my students if they'd heard of the flint water crisis and none of them had. also obviously it was a trip for the course material to present the flint water crisis as something that got "fixed by AI". added in extra information for my students like, by the way this is actually still happening and was a major protest event especially due to the socioeconomic and racial demographics of flint.
Aside from that, python is a really useful general programming language so if any of the students go on to do any more CS stuff which is probably a decent chunk of them I'd hope that their coding problemsolving skills and familiarity with it would be improved.
do i feel bullish on "AI"? broad question. . . once again remember my disclaimer bias statement on how i have a stats degree but i definitely came away from after teaching classes on it feeling that a lot of machine learning is like if you repackaged statistics and replaced the theoretical/scientific aspects where you confirm that a certain model is appropriate for the data and test to see if it meets your assumptions with computational power via mass guessing and seeing if your mass guessing was accurate or not lol. as i mentioned in my tags i also really don't think things like linear regression which were getting taught as "AI" should be considered "ML" or "AI" anyways, but the larger issue there is that "AI" is a buzzy catchword that can really mean anything. i definitely think relatedly that there will be a bit of an AI bubble in that people are randomly applying AI to tasks that have no business getting done that way and they will eventually reap the pointlessness of these projects.
besides that though, i'm pretty frustrated with a lot of AI hysteria which assumes that anything that is labeled as "AI" must be evil/useless/bad and also which lacks any actual labor-based understanding of the evils of capitalism. . . like AI (as badly formed as I feel the term is) isn't just people writing chatGPT essays or whatever, it's also used for i.e. lots of cutting edge medical research. if insanely we are going to include "linear regression" as an AI thing that's probably half of social science research too. i occasionally use copilot or an LLM for my work which is in public health data affiliated with a university. last week i got driven batty by a post that was like conspiratorially speculating "spotify must have used AI for wrapped this year and thats why its so bad and also why it took a second longer to load, that was the ai generating everything behind the scenes." im saying this as someone who doesnt use spotify, 1) the ship on spotify using algorithms sailed like a decade ago, how do you think your weekly mixes are made? 2) like truly what is the alternative did you think that previously a guy from minnesota was doing your spotify wrapped for you ahead of time by hand like a fucking christmas elf and loading it personally into your account the night before so it would be ready for you? of course it did turned out that spotify had major layoffs so i think the culprit here is really understaffing.
like not to say that AI like can't have a deleterious effect on workers, like i literally know people who were fired through the logic that AI could be used to obviate their jobs. which usually turned out not to be true, but hasn't the goal of stretching more productivity from a single worker whether its effective or not been a central axiom of the capitalist project this whole time? i just don't think that this is spiritually different from retail ceos discovering that they could chronically understaff all of their stores.
2 notes
·
View notes
Text
Addressing discrimination and violence against Lesbian, Gay, Bisexual, Transgender, and Queer (LGBTQ) persons from Brazil: a mobile health intervention

Background
Sexual and gender minorities (SGM) experience higher rates of discrimination and violence when compared to cis, heterosexual peers. However, violent crimes and other hate incidents against SGM persons are consistently not reported and prosecuted because of chronic distrust between the SGM community and police. Brazil is one of the most dangerous countries for SGM persons globally. Herein, we describe the development of a mobile health intervention to address the rampant violence against this population, the Rainbow Resistance—Dandarah app.
Methods
We conducted community-based participatory research (CBPR) between 2019 and 2020. The study started with in-depth interviews (IDIs) and focus group discussions (FGDs) with representatives of the SGM community from Brazil. Descriptive qualitative data analysis included the plotting of a ‘word cloud’, to visually represent word frequency, data coding and analysis of more frequent themes related to app acceptability, usability, and feasibility. A sub-sample of SGM tested the app and suggested improvements, and the final version was launched in December 2019.
Results
Since the app was launched in December 2019, the app recorded 4,114 active SGM users. Most participants are cisgender men (50.9%), self-identified as gay (43.5%), White (47.3%), and aged 29 or less (60.9%). FGDs and IDIs participants discussed the importance of the app in the context of widespread violence toward SGM persons. Study participants perceived this mHealth strategy as an important, effective, and accessible for SGM surviving violence. The CBPR design was highlighted as a key strategy that allowed SGM persons to collaborate in the design of this intervention actively. Some users reported how the panic button saved their lives during violent attacks.
Conclusions
Rainbow Resistance—Dandarah app was endorsed as a powerful tool for enhancing reporting episodes of violence/discrimination against SGM persons and a key strategy to connect users with a safe network of supportive services. Results indicate that the app is an engaging, acceptable, and potentially effective mHealth intervention. Participants reported many advantages of using it, such as being able to report harassment and violence, connect with a safe network and receive immediate support.
Read the paper.
7 notes
·
View notes
Note
Very interested in your thesis 👀
ALRIGHT. putting this under the cut because it's A Lot and i don't wanna clog up your dash. but i'll go ahead and pop in the link to my thesis here! tl;dr - 80 pages of scholarly research that answers the question "why do people use tumblr?"
so, because i'm a grown up with a considerable presence on the web, i'll share some potentially personal info. i don't have any concerns about being doxxed or anything like that lmao this is tumblr dot com.
i completed my masters degree about a year ago at bowling green state university. bgsu is one of the few institutions in this area of the country that has programs for cultural studies, so it was a great fit for me.
my thesis's goal was to use qualitative, humanistic research methods to understand the broad culture of tumblr - that is to say, i wanted to study people and their experiences on the site. basically, my thesis advisor and i sat down and asked, "what the fuck is up with tumblr?" and developed a research methodology to answer this question. my methods were inductive, meaning that i went in and gathered data, took a look at my notes, and generated a conclusion that answered the question.
i did it within the realm of "constructivist grounded theory," which is a specific way to apply inductive reasoning to humanistic research. it focuses on how experiences construct meaning and value; people don't inherently give sites like tumblr value, they use it in a way that creates that for them. the basic steps of the research method are as follows: go over your literature to get an idea for what you're up to, collect your data (in my case, interview users of tumblr), "code" your data (go over the transcripts word by word and look for similarities/draw conclusions), go back into the field and interview MORE people, and then draw a conclusion that answers your question (which is usually "what is up with this thing").
i'm really proud of my thesis and the "theory of tumblr" i came up with (which i'll put in a blockquote at the end of this answer), but there are some things i'd change in the future if i go on to do a phd. i would have liked to go back out into the field to interview more people - i didn't have time for this since i only had two semesters to write my thesis lmao. i also would have liked to get a broader sample size. i was deep into bandom hell, so a lot of my research participants were in that subculture as well. they were all also personal acquaintances and friends - it would have been nice to interview perfect strangers! i guess my theory of tumblr is more "theory of a handful of people in my bubble who are part of a very specific subculture and all have very similar demographic/social backgrounds"
if anyone wants to build off this research, i recommend setting a survey out into the wild on tumblr and THEN doing interviews. give it a nice mix of multiple choice/slider questions as well as some short answer questions. look for overarching themes and similarities in all those responses! and maybe make one of your survey questions "can we reach out to you with further questions?" so you can do interviews that are more in depth. interview a few people at a time, see what they say, and then go out and interview more people and see if they say the same thing. don't be afraid to update your research question or change what themes you focus on. if your findings are different than what you expect, that means you're onto something cutting edge!
also - i TOTALLY recommend doing interview via zoom like i did. if you have a premium subscription, it'll generate a transcript for you in real time, so you don't have to sit down, listen to the audio, and transcribe it chunk by chunk. makes coding WAY easier.
as promised: my academic "theory of tumblr":
Tumblr is a microblogging social media platform that has been turned by users into an emergent space for community development, cultural creation, and identity affirmation. The aspects of the site that prove significant to its construction and userbase include but are not limited to the userbase’s focus on social engagement through shared interests and worldviews, the uniqueness of the site’s design, the prioritization of marginalized and diverse people, and the performance and refinement of user identities. These nuances of Tumblr have made it continuously relevant to users, even when considering both positive and negative personal experiences on the platform, as it helps provide a sense of connectivity and authenticity in an increasingly virtual world.
#frankie.txt#i love infodumping abt my thesis#i'm no longer in academia but i still take pride in it#mayhaps i will start a video essay channel where i do research like this...
2 notes
·
View notes
Text
This introduction to Qualitative Methods course has gone from interesting general discussion of practices to just fucking yeeting us into the deep end and telling us to learn to swim having done 45 FUCKING MINUTES of introduction to a complex system.
Was told Facebook was the most used for research due to ease of access, but we get none of that, and are just told to go collect and then code (categorise) a load of facebook data. You have one week.
This is bullshit and I wish feedback week was this week not last because I have a new arsehole to tear the course organiser.
And whoever wrote the guides to using MaxQDA is gonna get lego glued in all their shoes.
#Will Speaks#Wills life is a joke#Ranting about uni bs because I have no other social media I can#least none away from family eyes
2 notes
·
View notes
Text
Hi! I work in social science research, and wanted to offer a little bit of nuance into the notes of this post. A lot of people seem to be referring to LLMs like ChatGPT/Claude/Deepseek as purely ‘generative AI’ and used to ‘fix’ problems that don’t actually exist and while that is 99% true (hell in my field we’re extremely critical of the use of generative AI in the general public and how it is used), immediately demonizing LLMs as useless overlooks how great of a research tool it is for fields outside of STEM.
Tl;dr for below the cut: even ‘generative AI’ like ChatGPT can be used as an analytical tool in research. In fact, that’s one of the things it’s actually built for.
In social sciences and humanities we deal with a lot of rich qualitative data. It’s great! We capture some really specific and complex phenomena! But there is a drawback to this: it’s bloody hard to get through large amounts of this data.
Imagine you had just spent 12 months studying a particular group or community in the workplace, and as part of that you interviewed different members to gain better insight into the activities/behaviours/norms etc. By the end of this fieldwork stint you have over 20 hours worth of interviews, which transcribed is a metric fuckton of written data (and that’s not even mentioning the field notes or observational data you may have accrued)
The traditional way of handling this was to spend hours and hours and days and days pouring over the data with human eyes, develop a coding scheme, apply codes to sections by hand using programs like Atlas.ti or Nvivo (think Advanced Digital Highlighters), and then generate a new (or validate an existing) theory about People In The Place. This process of ‘coding’ takes a really long fucking time, and a lot of researchers if they have the money outsource it to poor grad students and research assistants to do it for them.
We developed computational methods to handle this somewhat (using natural language processing libraries like NLTK) but these analyse the data on a word-to-word level, which creates limitations in what kind of coding you can apply, and how it can be applied reliably (if at all). NLP like NLTK could recognize a word as a verb, adjective, or nouns, and even identify how ‘related’ words could be to one another (e.g ‘tree’ is more closely related to ‘park’ than it is to ‘concrete’). They couldn’t keep track of a broader context, however. They’re good for telling you whether something is positive or negative in tone (in what we call sentiment analysis) but bad for bad for telling you a phrase might be important when you relate it back to the place or person or circumstance.
LLMs completely change the game in that regard. They’re literally the next step of these Natural Language Processing programs we’ve been using for years, but are much much better at the context level. You can use it to contextualise not just a word, but a whole sentence or phrase against a specific background. This is really helpful when you’re doing what we call deductive coding - when you have a list of codes that relate to a rule or framework or definition that you’re applying to the data. Advanced LLMs like ChatGPT analysis mode can produce a level of reliability that matches human reliability for deductive coding, especially when given adequate context and examples.
But the even crazier thing? It can do inductive coding. Inductive coding is where the codes emerge from the data itself, not from an existing theory or framework. Now this definitely comes with limitations - it’s still the job of the researcher to pull these codes into a coherent and applicable finding, and of course the codes themselves are limited by the biases within the model (so not great for anything that deals with ‘sensitive issues’ or intersectionality).
Some fields like those in metacognition have stacks of historical data from things like protocol studies (people think aloud while doing a task) that were conducted to test individual theories and frameworks, but have never been revisited because the sheer amount of time it would take to hand code them makes the task economically and physically impossible. But now? Researchers are already doing in minutes which historically took them months or years, and the insights they’re gaining are applicable to broader and broader contexts.
People are still doing the necessary work of synthesizing the info that LLMs provide, but now (written) qual data is much more accessibly handled in large amounts - something that qualitative researchers have been trying to achieve for decades.
Midjourney and other generative image programs can still get fucked though.
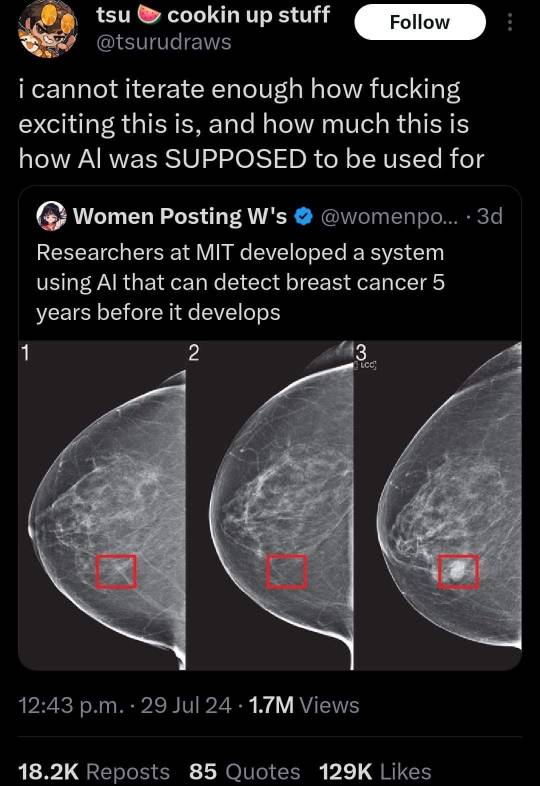
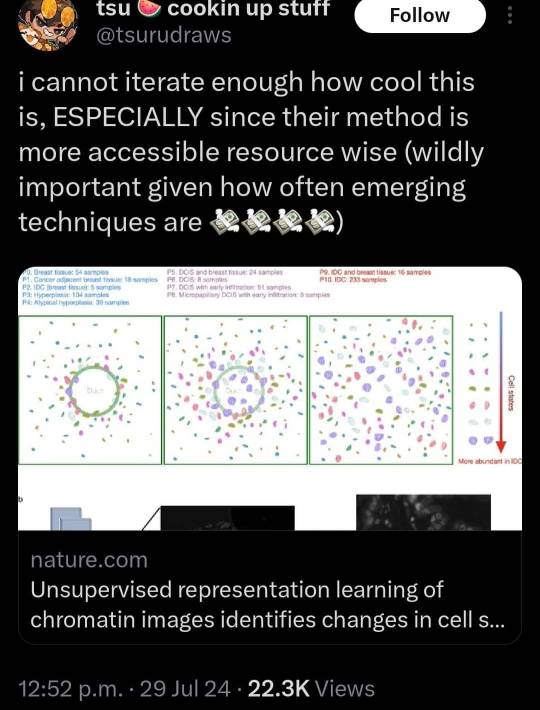

#sorry I don’t normally add to posts and definitely never this much#but I want to offer a slightly different perspective#TO BE CLEAR I HATE HOW CHATGPT IS BEING USED IN THE BROADER WORK SOCIETY#BUT#please please please remember that qual research exists and LLMs like ChatGPT emerged out of the need to analyse this qual data
179K notes
·
View notes
Text
Unlocking New Horizons: 5 Powerful Ways to Use Claude 4

The future of AI is here. Anthropic's highly anticipated Claude 4 models (Opus 4 and Sonnet 4), released in May 2025, have fundamentally shifted the landscape of what large language models are capable of. Moving beyond impressive text generation, Claude 4 represents a significant leap forward in reasoning, coding, autonomous agent capabilities, and deep contextual understanding.
These aren't just incremental upgrades; Claude 4 introduces "extended thinking" and robust tool-use, enabling it to tackle complex, long-running tasks that were previously out of reach for AI. Whether you're a developer, researcher, content creator, or strategist, understanding how to leverage these new powers can unlock unprecedented levels of productivity and insight.
Here are 5 powerful ways you can put Claude 4 to work right now:
1. Revolutionizing Software Development and Debugging
Claude 4 Opus has quickly earned the title of the "world's best coding model," and for good reason. It’s built for the demands of real-world software engineering, moving far beyond simple code snippets.
How it works: Claude 4 can process entire codebases, understand complex multi-file changes, and maintain sustained performance over hours of work. Its "extended thinking" allows it to plan and execute multi-step coding tasks, debug intricate errors by analyzing stack traces, and even refactor large sections of code with precision. Integrations with IDEs like VS Code and JetBrains, and tools like GitHub Actions, make it a true pair programmer.
Why it's powerful: Developers can dramatically reduce time spent on tedious debugging, boilerplate generation, or complex refactoring. Claude 4 enables the automation of entire coding workflows, accelerating development cycles and freeing up engineers for higher-level architectural and design challenges. Its ability to work continuously for several hours on a task is a game-changer for long-running agentic coding projects.
Examples: Asking Claude 4 to update an entire library across multiple files in a complex repository, generating comprehensive unit tests for a new module, or identifying and fixing subtle performance bottlenecks in a large-scale application.
2. Deep Research and Information Synthesis at Scale
The ability to process vast amounts of information has always been a hallmark of advanced LLMs, and Claude 4 pushes this boundary further with its impressive 200K token context window and new "memory files" capability.
How it works: You can feed Claude 4 entire books, dozens of research papers, extensive legal documents, or years of financial reports. It can then not only summarize individual sources but, crucially, synthesize insights across them, identify conflicting data, and draw nuanced conclusions. Its new "memory files" allow it to extract and save key facts over time, building a tacit knowledge base for ongoing projects.
Why it's powerful: This transforms qualitative and quantitative research. Researchers can quickly identify critical patterns, lawyers can analyze massive discovery documents with unprecedented speed, and business analysts can distill actionable insights from overwhelming market data. The memory feature is vital for long-term projects where context retention is key.
Examples: Uploading a collection of scientific papers on a specific disease and asking Claude 4 to identify emerging therapeutic targets and potential side effects across all studies; feeding it competitor annual reports and asking for a comparative SWOT analysis over five years; or using it to build a comprehensive knowledge base about a new regulatory framework.
3. Advanced Document Understanding & Structured Data Extraction
Beyond simple OCR (Optical Character Recognition), Claude 4 excels at Intelligent Document Processing (IDP), understanding complex layouts and extracting structured data even from challenging formats.
How it works: Claude 4 can accurately process PDFs, scanned images, tables, and even mathematical equations. Its advanced vision capabilities combined with its reasoning allow it to not just read text, but to understand the context of information within a document. This makes it highly effective for extracting key-value pairs, table data, and specific entities.
Why it's powerful: This is a boon for automating workflows in industries heavily reliant on documents like finance, healthcare, and legal. It significantly reduces manual data entry, improves accuracy, and speeds up processing times for invoices, contracts, medical records, and more. Its performance on tables and equations makes it particularly valuable for technical and financial data.
Examples: Automatically extracting specific line items and totals from thousands of varied invoices; converting scanned legal contracts into structured data for clause analysis; or digitizing and structuring data from complex scientific papers that include charts and formulas.
4. Building Highly Autonomous AI Agents
The "extended thinking" and parallel tool use capabilities in Claude 4 are specifically designed to power the next generation of AI agents capable of multi-step workflows.
How it works: Claude 4 can plan a series of actions, execute them (e.g., using a web search tool, a code interpreter, or interacting with an API), evaluate the results, and then adjust its strategy – repeating this loop thousands of times if necessary. It can even use multiple tools simultaneously (parallel tool use), accelerating complex processes.
Why it's powerful: This moves AI from a reactive assistant to a proactive collaborator. Claude 4 can manage entire projects, orchestrate cross-functional tasks, conduct in-depth research across the internet, and complete multi-stage assignments with minimal human oversight. It's the beginning of truly "agentic" AI.
Examples: An AI agent powered by Claude 4 autonomously researching a market, generating a business plan, and then outlining a marketing campaign, using web search, data analysis tools, and internal company databases; a customer support agent capable of not just answering questions but also initiating complex troubleshooting steps, accessing internal systems, and escalating issues.
5. Nuanced Content Creation & Strategic Communication
Claude 4's enhanced reasoning and commitment to Constitutional AI allow for the creation of highly nuanced, ethically aligned, and contextually rich content and communications.
How it works: The model's refined understanding allows it to maintain a consistent tone and style over long outputs, adhere strictly to complex brand guidelines, and navigate sensitive topics with greater care. Its "extended thinking" also means it can develop more coherent and logical arguments for strategic documents.
Why it's powerful: This elevates content creation and strategic planning. Businesses can generate high-quality marketing materials, detailed reports, or persuasive proposals that resonate deeply with specific audiences while minimizing the risk of miscommunication or ethical missteps. It's ideal for crafting communications that require significant thought and precision.
Examples: Drafting a comprehensive policy document that balances multiple stakeholder interests and adheres to specific legal and ethical frameworks; generating a multi-channel marketing campaign script that adapts perfectly to different cultural nuances; or crafting a compelling long-form article that synthesizes complex ideas into an engaging narrative.
Claude 4 is more than just a powerful chatbot; it's a versatile foundation for intelligent automation and deeper understanding. By embracing its capabilities in coding, research, document processing, agent building, and content creation, professionals across industries can unlock new levels of efficiency, insight, and innovation. The era of the true AI collaborator has arrived.
0 notes
Text
Unlocking Insights: How Transcription Services Elevate Market Research
Understanding what consumers think, want, and need is at the heart of every successful business strategy. In today’s fast-paced and data-driven world, transcription services for market research have become essential for capturing, organizing, and analyzing the voices that matter most: those of your customers.
Whether you’re conducting focus groups, in-depth interviews, or observational studies, having accurate and timely transcriptions can make or break your research quality. From clear documentation to easier analysis, transcription services are a quiet but powerful force in modern market research.

The Power of the Spoken Word
Market research relies heavily on conversations—authentic, unscripted dialogue that reveals what people truly feel about a product, brand, or service. These conversations are often long and rich in nuance. Recording them is one thing, but turning them into usable text is where the real value begins.
Audio recordings can be time-consuming to review, especially when you’re on a deadline. Transcriptions provide a searchable and scannable format that enables researchers to quickly identify key trends, quotes, and emotional responses. More than convenience, it ensures accuracy when presenting findings to stakeholders.
Why Transcription Services Matter
Transcription services for market research are tailored to handle complex, often jargon-heavy content. They are designed to deliver clean, professional transcripts that are easy to read and analyze. This is especially helpful in group settings where multiple people may be speaking at once.
Professional transcriptionists are trained to differentiate between speakers, maintain context, and preserve essential pauses or reactions. These details matter. A slight hesitation, a laugh, or even a long pause can add layers to your findings.
Also, in both business and academic transcription, data integrity is key. Market researchers often rely on high volumes of qualitative input to create actionable strategies. A professional transcription ensures the raw data is preserved faithfully so nothing is lost in translation.
Making Better Use of Data
Once transcribed, your academic research data transcription or market research sessions become much easier to code, tag, and reference. Analysts can annotate and highlight themes directly within the document. Teams can collaborate without listening through hours of recordings. With digital tools and AI-assisted analysis, transcriptions speed up the entire process and make insights more accessible.
They also make reporting smoother. Pulling direct quotes from transcripts adds authenticity to your presentations and helps decision-makers connect with authentic customer voices. It can also help ensure accurate references back your interpretations.
Who Benefits the Most?
Marketing teams, research agencies, product developers, and customer experience professionals all benefit from transcription services. But it’s not just businesses. In education, scholarly work, business, and academia, transcription services support case studies, thesis interviews, and research publications.
For market research, especially, having clean, timely transcriptions helps companies stay agile and responsive in competitive markets. It saves time and allows researchers to focus more on strategy than note-taking.
The Bottom Line
Accurate and accessible transcripts aren’t just a convenience, they’re a strategic advantage. Transcription services for market research serve as the bridge between raw data and informed decision-making. They help bring consumer voices into the boardroom in a way that’s clear, compelling, and impactful.
So, the next time you’re preparing to gather valuable customer insight, don’t underestimate the importance of transcription. It may just be the most essential tool in your market research toolkit.
0 notes
Text
Global Intelligent Virtual Assistant Market Size, Trends | Report [2025-2033]
Global Intelligent Virtual Assistant Market Market research report provides a complete overview of the market by examining it both qualitatively and statistically, including particular data and in-depth insights from several market segments. While the qualitative analysis of market dynamics, which includes growth drivers, challenges, constraints, and so on, offers in-depth insight into the market's current and potential, the quantitative analysis includes historical and forecast statistics of major market segments . Get Free Request Sample : https://www.globalgrowthinsights.com/enquiry/request-sample-pdf/intelligent-virtual-assistant-market-100044 Who is the Top largest companies (Marketing heads, regional heads) of Intelligent Virtual Assistant Market?Microsoft, Nuance, Samsung Electronics, Alphabet, Apple, Amazon, IBM, Baidu, Blackberry, Inbenta Technologies, Facebook, Cognitive Code, Artificial Solutions, Unified Computer Intelligence, Mycroft AiMarket Segmentations:On the thought of the product, this report displays the assembly, revenue, price, Classifications market share and rate of growth of each type, primarily split intoChatbot, IVA Smart SpeakersOn the thought of the highest users/applications, this report focuses on the status and outlook for major applications/end users, consumption (sales), market share and rate of growth for each application, includingConsumer Electronics, BFSI, Healthcare, Education, RetailKey Drivers of the Intelligent Virtual Assistant Market MarketTechnological Innovation: The pulse of the Intelligent Virtual Assistant Market market is its ongoing technological evolution, enhancing product and service efficiency. Innovations span materials, manufacturing, and digital technologies.Surging Demand: Factors like population growth, urbanization, and shifts in consumer preferences are fueling a rising demand for Intelligent Virtual Assistant Market products and services, propelling market expansion.Regulatory Encouragement: Supportive government measures, including incentives and regulations favoring Intelligent Virtual Assistant Market adoptions, such as renewable energy subsidies and carbon pricing, are catalyzing market growth.Environmental Consciousness: What is the 10-year outlook for the global Intelligent Virtual Assistant Market Market?-What factors are Intelligent Virtual Assistant Market market growth, globally and by region?-Which technologies are poised for the fastest growth by Intelligent Virtual Assistant Market Market and region-How do Intelligent Virtual Assistant Market market opportunities vary by end Market size?-How does Intelligent Virtual Assistant Market break out type, application?What are the influences of COVID-19 and Russia-Ukraine war? View Full Report @: https://www.globalgrowthinsights.com/market-reports/intelligent-virtual-assistant-market-100044 About Us: Global Growth Insights is the credible source for gaining the market reports that will provide you with the lead your business needs. At GlobalGrowthInsights.com, our objective is providing a platform for many top-notch market research firms worldwide to publish their research reports, as well as helping the decision makers in finding most suitable market research solutions under one roof. Our aim is to provide the best solution that matches the exact customer requirements. This drives us to provide you with custom or syndicated research reports.
#Marketsize#Markettrends#growth#Researchreport#trendingreport#Business#Businessgrowth#businessTrends#GGI#Globalgrowthinsights
0 notes
Text
okay i'm diving deeper into the thematic analysis/discursive analysis thing:
thematic analysis:
themes are just patterns of meaning
reflexive thematic analysis can be applied to any epistemology or ontology eg. we can have positivist, contextualist and constructionist versions of TA and analyse the data along that framework
TA can be 1. inductive (bottom-up, rich but not specific) or theoretical (top-down, specific and focused but maybe not as rich as inductive)
TA involves re-reading the dataset, generating initial codes, combining those codes into initial themes, developing the themes more, naming them, and then writing them up.
discourse analysis:
differs from TA in that it looks less at extracting themes from a dataset, and more at looking how 'themes' themselves might be constructed through speech and language -> the ways in which categories of meaning are socially constructed
DA also looks at how language might be used to 'do things' ie. language as performative, having a functional purpose, talk itself is a social action
It focuses on 1. the politics of representation (how reality is represented through speech) and 2. how we construct the world itself through the corpus of talk and text
From there we can define a few things
1. discursive practices - how the speaker constructs their own version of a social reality eg. through reported speech (my doctor friend says 'x' is dangerous, sport is bad for you)
2. discursive resources - the culturally shared discourses that are drawn upon to make an argument 'eg men are strong, women are weak'
3. the rhetorical nature of the talk - eg. 'i'm not racist...but' - essentially pre-emptively defending oneself against an attack re: the discursive practice you're building
other fun stuff:
qual can be combined with quant in a few ways
we can use sequential models: eg. doing a qualitative focus group that helps us to develop some quantitative survey items
we can use parallel models: where we have a central idea but develop slightly different research questions for qual and quant methods
mixed models: where we're answering the same central research question with qual and quant, eg. a healthy combo of open-ended (qual) and close-ended (quant) questions
0 notes
Text
Simplify Complex Data with PhD Data Analysis Services in Dubai and South Africa
Handling research data is one of the most complex tasks during a PhD. At PhD Research Consulting, we offer premium PhD Data Analysis Services in Dubai and South Africa to help scholars decode their findings with accuracy and confidence.
Data Expertise You Can Rely On
Whether your data is quantitative or qualitative, our analysts are proficient in:
SPSS, STATA, R, and Python
NVivo for qualitative research
Advanced Excel and MATLAB
Machine learning models and simulations
Our team works with students in Dubai and South Africa, ensuring they understand and interpret their results clearly, a critical step toward successful thesis submission.
Python Coding and Software Support
We also provide Python Coding Services for PhD in Dubai and India, catering to the growing demand for machine learning and AI-based research. Our coders help with:
Data cleaning and preprocessing
Statistical model implementation
Visualization and interpretation
Looking for technical support in South Africa? Our PhD Software Implementation Services in South Africa are designed for engineering, IT, and data-driven fields.
📈 Get in touch with our consultants today and take your data analysis to the next level.
Follow us on Instagram.
0 notes
Text
Research Paper & Data Analysis Solutions for PhD Scholars in Malaysia and South Africa
Publishing a quality research paper or completing data analysis can be a daunting task for PhD students. Techvidya is here to simplify it for you with our top-rated PhD research paper writing services in Malaysia and South Africa, along with expert phd data analysis solutions tailored to your field.
Research Paper Writing That Gets Published
Our team of experienced writers offers end-to-end research paper writing services in PhD Malaysia and PhD research paper writing services in South Africa. From literature review to result discussion, we follow international formatting and referencing standards (APA, MLA, IEEE, etc.).
Need journal support? We also assist with Journal Manuscript & Publication, helping your work get accepted by reputed journals.
Powerful Data Analysis Services
Data analysis can make or break your thesis. Our experts in phd data analysis solutions in Malaysia and South Africa help you with:
Statistical analysis using SPSS, STATA, R
Qualitative coding with NVivo
Visualization and interpretation of results
We also guide you on integrating analysis into your dissertation or paper.
Quality Editing for Final Touch
Alongside writing and analysis, we offer best manuscript editing services and best paper editing services in South Africa to enhance your academic documents. Our editors refine grammar, coherence, and structure to make your work ready for submission.
When it comes to publishing or analyzing data, trust Techvidya’s professional PhD support.
📧 Get started now with our expert writing and data services in Malaysia and South Africa to take your research to the next level.
Follow us on Instagram.
#phd data analysis services malaysia#phd data analysis services in india#phd literature writing review in india
0 notes
Text
Revolutionizing Primary Research with AI-Powered Augmented Analytics

In the digital age, data plays an important role in organizations' remaining at the forefront of their industry. Hence, understanding consumers, market trends, and business performance is vital. Businesses still conduct primary research like interviews, surveys, and focus groups, but these methods are often costly, tedious, labor-intensive, and time-consuming. To keep up with the pace of the digital world, Primary Market Research Services are adopting AI technology. Combining human intelligence with machine capabilities redefines the standards of accuracy, speed, and relevance in data collection and analysis.
What Is Augmented Analytics?
Augmented analytics uses technologies like AI, machine learning, and natural language processing to automate the preparation of data, its discovery, and the generation of insights. Unlike traditional analytics that depend on human analysis, augmented analytics functions more like a smart assistant that analyzes large datasets, finds patterns, and delivers insights immediately.
In primary research, the use of augmented analytics improves the accuracy of the data, reduces bias, accelerates the pace of decision making, and allows the researcher to focus on making strategies.
The Limitations of Traditional Primary Research
Primary research is the collection of information directly from the source using methods like surveys, interviews, and observational studies. While this method offers direct and tailored insights, it presents the following difficulties:
Time-Intensive: Creating surveys, finding participants, and evaluating responses may take up to weeks or even months.
High Costs: Hiring researchers and buying survey tools come with a hefty price in large-scale research.
Human Error and Bias: Manual data input and analysis processes can lead to blunders, miscalculations, and misinterpretations of data.
Limited Scope: The traditional methods are not able to analyze massive or unstructured data like social media mentions, feedback, or open-ended responses.
How AI-Powered Augmented Analytics Is Transforming Primary Research
1. Automated Data Collection and Cleaning
AI tools efficiently collect data from both organized and unorganized sources. AI can now process numerous data types, including sentiment analysis on open-ended survey responses and voice and video feedback from interviews.
Data cleaning is also automated now. Outlier detection, inconsistency correction, and missing data population are automated through Augmented Analytics Services. They yield more accurate and reliable outcomes in significantly less time for research teams.
2. Natural Language Processing for Deeper Understanding
Previously, in qualitative research, open-ended responses and interview transcripts needed manual coding. NLP can now understand, classify, and summarize text, extracting sentiment, theme, or keywords that human researchers may miss.
Today, AI-powered transcription tools and engines allow researchers to deeply analyze vast amounts of text data and provide real-time insights into consumer sentiment, preference, and behavior.
3. Real-Time Insights and Visualization
The outcomes of traditional research are usually captured in static reports. However, augmented analytics frameworks present information in the form of dashboards and visual data in real time. With these tools, researchers and stakeholders can engage with the data, explore the details, and extract relevant insights immediately.
4. Predictive and Prescriptive Insights
AI not only explains what happened. With the help of machine learning algorithms, augmented analytics can predict future outcomes and even give suggested actions. For example, if a customer survey shows that people are becoming less satisfied with the brand, the platform can determine likely reasons and recommend certain adjustments. This enables companies to act ahead of any issues and take data-driven actions.
5. Enhanced Personalization and Targeting
With AI segmentation, researchers can detect micro-groups in their samples and comprehend unique micro-patterns of behavior. Such granularity allows marketers, product developers, and policy makers to adjust their approaches to meet the needs of specific audiences. Now, companies can take a more personalized approach rather than rely on assumptions and generalizations.
Benefits of AI-Augmented Primary Research
Speed: Research cycles are greatly reduced.
Accuracy: There is less human error and bias.
Cost Efficiency: Operational expenses are reduced with the use of automated systems.
Scalability: Ability to manage large and complex datasets.
Accessibility: Non-technical users can explore data using self-service tools.
Conclusion
AI-augmented analytics is revolutionizing the world of primary research. It allows researchers to make smarter and more accurate decisions by automating repetitive tasks, uncovering deeper insights, and delivering results in real-time. This shift does not mean replacing old methods, but rather, augmenting them. Using AI, qualitative and quantitative research becomes more accessible to all decision makers across the organization and provides greater accuracy.
0 notes